

Karpor is Intelligence for Kubernetes. It brings advanced Search, Insight and AI to Kubernetes. It is essentially a Kubernetes Visualization Tool. With Karpor, you can gain crucial visibility into your Kubernetes clusters across any clouds.
We hope to become a small and beautiful, vendor-neutral, developer-friendly, community-driven open-source project!
Current Status: We are iterating v0.5.0 Milestone, welcome to join the discussion.
demo.mp4
|
Automatic Syncing Automatically synchronize your resources across any clusters managed by the multi-cloud platform. Powerful, flexible queries Effectively retrieve and locate resources across multi clusters that you are looking for in a quick and easy way. |

|
|
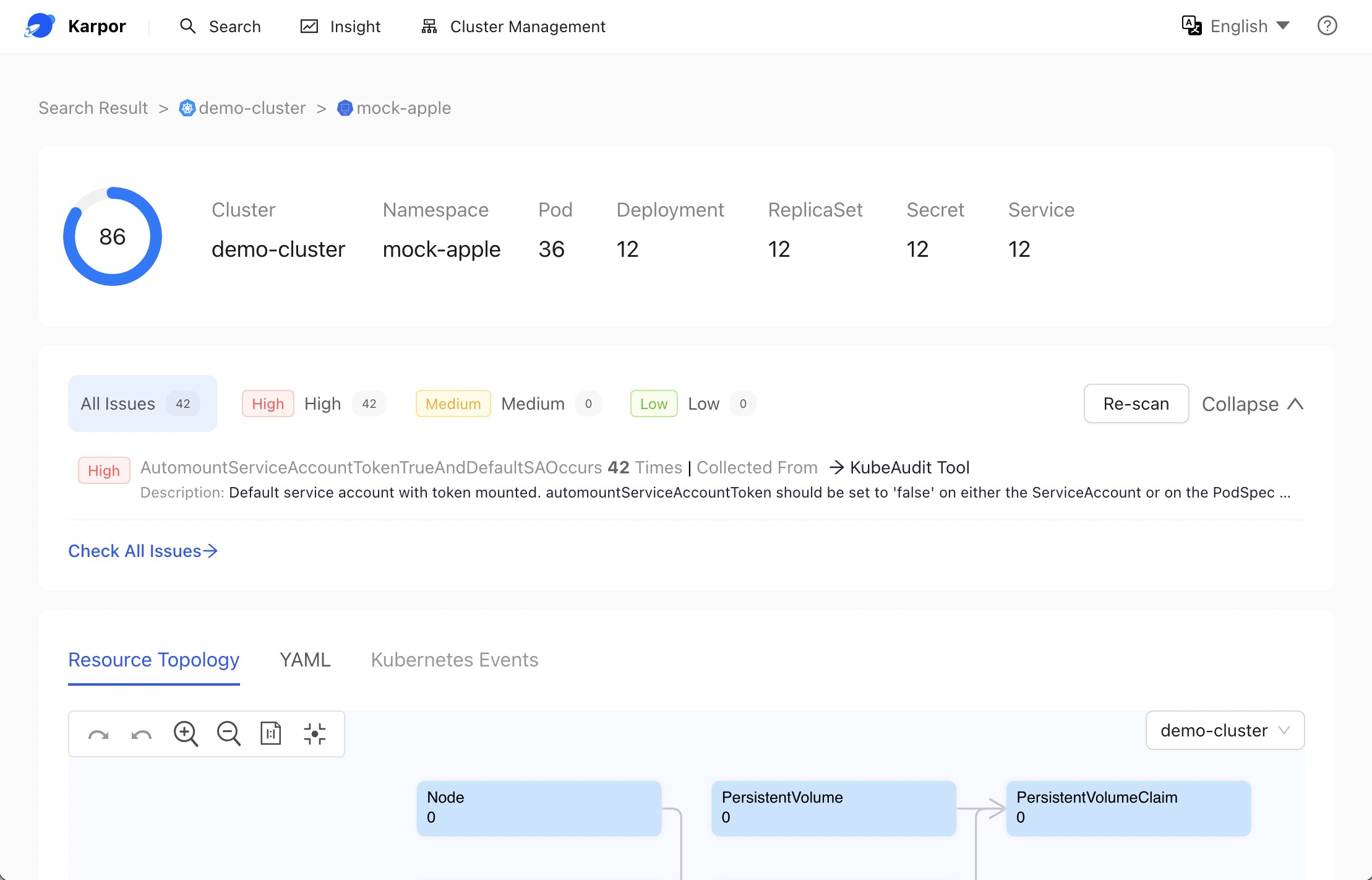
Compliance Governance Understand your compliance status across multiple clusters and compliance standards. Resource Topology Logical and topological views of relevant resources within their operational context. Cost Optimization Coming soon. |
|
Natural Language Operations Interact with Kubernetes using plain language for more intuitive operations. Contextual AI Responses Get smart, contextual assistance that understands your needs. AIOps for Kubernetes Automate and optimize Kubernetes management with AI-powered insights. |

|
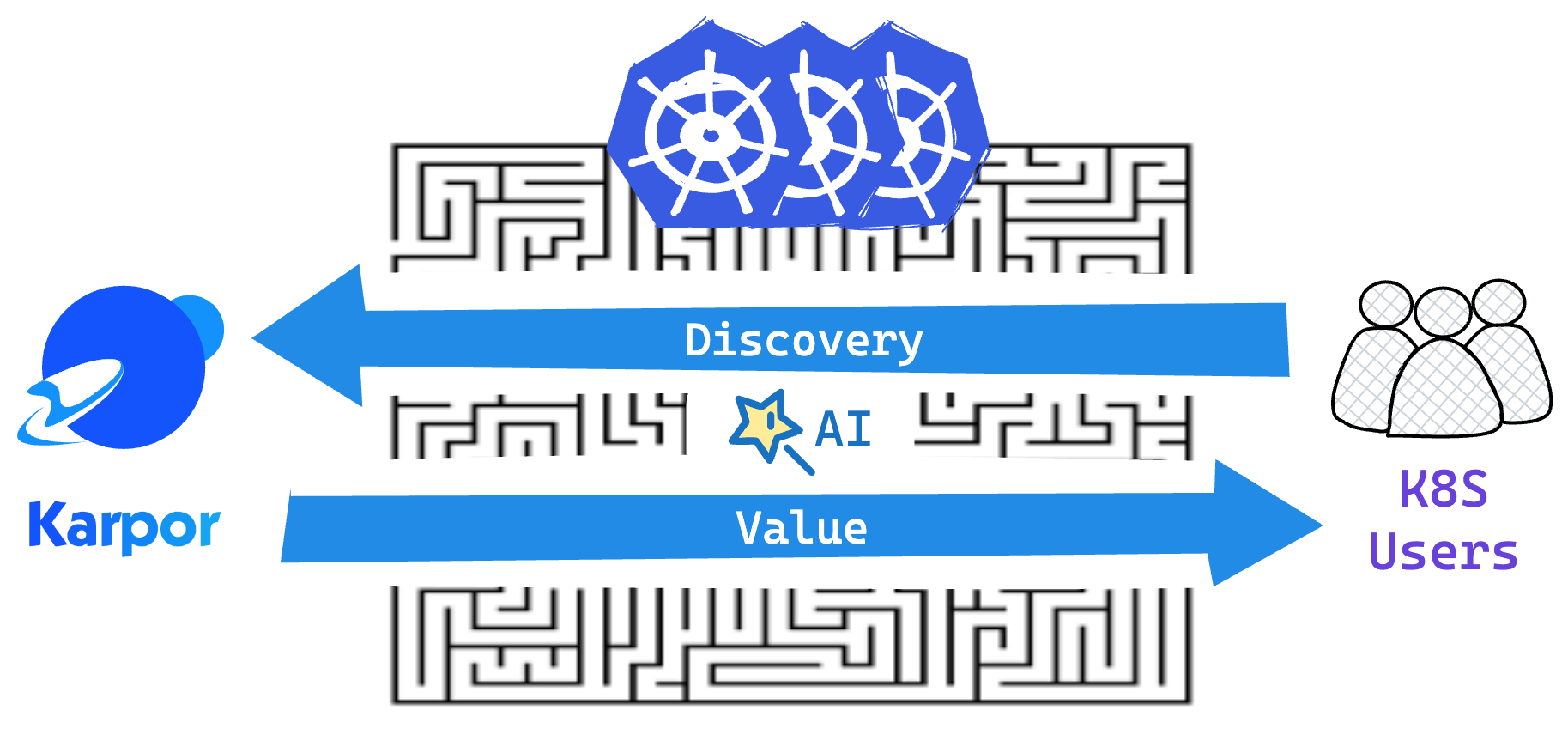
The increasing complexity of the kubernetes ecosystem is an undeniable trend that is becoming more and more difficult to manage. This complexity not only entails a heavier burden on operations and maintenance but also slows down the adoption of new technologies by users, limiting their ability to fully leverage the potential of kubernetes.
In general, we wish Karpor to focus on search, insights, and AI, to break through the increasingly complex maze of kubernetes, achieving the following value proposition:
Karpor can be simply installed by helm v3.5+, which is a simple command-line tool and you can get it from here.
If you are interested, you can also directly view the Karpor Chart Repo.
$ helm repo add kusionstack https://kusionstack.github.io/charts
$ helm repo update
$ helm install karpor kusionstack/karporFor more information about installation, please check the Installation Guide on official website.
Detailed documentation is available at Karpor Website.
Karpor is still in the initial stage, and there are many capabilities that need to be made up, so we welcome everyone to participate in construction with us.
- If you don't know how to start contributing, you can read the Contribution Guide, you will know all the details.
- If you don’t know what issues start, we have prepared a Community tasks | 新手任务清单 🎖︎, you can choose the issue you like.
- If you have any questions, please Submit the Issue or Post on the discussions, we will answer as soon as possible.
Thanks to these wonderful people! Come and join us!























If you have any questions, feel free to reach out to us in the following ways:
-
DingTalk Group:
42753001(Chinese) -
WeChat Group (Chinese): Add the WeChat assistant to bring you into the user group.

![allcontributors[bot] avatar](https://avatars.githubusercontent.com/in/23186?v=4 "allcontributors[bot]")


![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")

























































































































