kosinkadink / comfyui-animatediff-evolved Goto Github PK
View Code? Open in Web Editor NEWImproved AnimateDiff for ComfyUI and Advanced Sampling Support
License: Apache License 2.0
Improved AnimateDiff for ComfyUI and Advanced Sampling Support
License: Apache License 2.0






































































































































comfyui-animatediff-evolved gives error while installed via comfyui-manager. also gives same error with " git " manuel installation.
all helps wellcomes.
manjaro-linux (uptodate with al rocm drivers etc.) AMDGPU, comfyui fresh install yesterday did some generations and so on.
i just stuck at installing animatediff.
how about a new update? The error is already displayed for me and he can't recognize it with the new model.
got prompt
3
[AnimateDiff] - INFO - Loading motion module mm_sd_v15_v2.ckpt
[AnimateDiff] - INFO - Using fp16, converting motion module to fp16
!!! Exception during processing !!!
Traceback (most recent call last):
File "/content/comfyui/execution.py", line 152, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
File "/content/comfyui/execution.py", line 82, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
File "/content/comfyui/execution.py", line 75, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
File "/content/comfyui/custom_nodes/comfyui-animatediff/animatediff/nodes.py", line 334, in inject_motion_modules
motion_modules[model_name] = load_motion_module(model_name)
File "/content/comfyui/custom_nodes/comfyui-animatediff/animatediff/nodes.py", line 140, in load_motion_module
motion_module.load_state_dict(mm_state_dict)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 2041, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for MotionWrapper:
Unexpected key(s) in state_dict: "mid_block.motion_modules.0.temporal_transformer.norm.weight", "mid_block.motion_modules.0.temporal_transformer.norm.bias", "mid_block.motion_modules.0.temporal_transformer.proj_in.weight", "mid_block.motion_modules.0.temporal_transformer.proj_in.bias", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.0.to_q.weight", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.0.to_k.weight", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.0.to_v.weight", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.0.to_out.0.weight", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.0.to_out.0.bias", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.1.to_q.weight", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.1.to_k.weight", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.1.to_v.weight", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.1.to_out.0.weight", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.1.to_out.0.bias", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.norms.0.weight", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.norms.0.bias", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.norms.1.weight", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.norms.1.bias", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.ff.net.0.proj.weight", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.ff.net.0.proj.bias", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.ff.net.2.weight", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.ff.net.2.bias", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.ff_norm.weight", "mid_block.motion_modules.0.temporal_transformer.transformer_blocks.0.ff_norm.bias", "mid_block.motion_modules.0.temporal_transformer.proj_out.weight", "mid_block.motion_modules.0.temporal_transformer.proj_out.bias".
size mismatch for down_blocks.0.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 320]) from checkpoint, the shape in current model is torch.Size([1, 24, 320]).
size mismatch for down_blocks.0.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 320]) from checkpoint, the shape in current model is torch.Size([1, 24, 320]).
size mismatch for down_blocks.0.motion_modules.1.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 320]) from checkpoint, the shape in current model is torch.Size([1, 24, 320]).
size mismatch for down_blocks.0.motion_modules.1.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 320]) from checkpoint, the shape in current model is torch.Size([1, 24, 320]).
size mismatch for down_blocks.1.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 640]) from checkpoint, the shape in current model is torch.Size([1, 24, 640]).
size mismatch for down_blocks.1.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 640]) from checkpoint, the shape in current model is torch.Size([1, 24, 640]).
size mismatch for down_blocks.1.motion_modules.1.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 640]) from checkpoint, the shape in current model is torch.Size([1, 24, 640]).
size mismatch for down_blocks.1.motion_modules.1.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 640]) from checkpoint, the shape in current model is torch.Size([1, 24, 640]).
size mismatch for down_blocks.2.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for down_blocks.2.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for down_blocks.2.motion_modules.1.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for down_blocks.2.motion_modules.1.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for down_blocks.3.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for down_blocks.3.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for down_blocks.3.motion_modules.1.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for down_blocks.3.motion_modules.1.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for up_blocks.0.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for up_blocks.0.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for up_blocks.0.motion_modules.1.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for up_blocks.0.motion_modules.1.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for up_blocks.0.motion_modules.2.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for up_blocks.0.motion_modules.2.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for up_blocks.1.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for up_blocks.1.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for up_blocks.1.motion_modules.1.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for up_blocks.1.motion_modules.1.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for up_blocks.1.motion_modules.2.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for up_blocks.1.motion_modules.2.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 1280]) from checkpoint, the shape in current model is torch.Size([1, 24, 1280]).
size mismatch for up_blocks.2.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 640]) from checkpoint, the shape in current model is torch.Size([1, 24, 640]).
size mismatch for up_blocks.2.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 640]) from checkpoint, the shape in current model is torch.Size([1, 24, 640]).
size mismatch for up_blocks.2.motion_modules.1.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 640]) from checkpoint, the shape in current model is torch.Size([1, 24, 640]).
size mismatch for up_blocks.2.motion_modules.1.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 640]) from checkpoint, the shape in current model is torch.Size([1, 24, 640]).
size mismatch for up_blocks.2.motion_modules.2.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 640]) from checkpoint, the shape in current model is torch.Size([1, 24, 640]).
size mismatch for up_blocks.2.motion_modules.2.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 640]) from checkpoint, the shape in current model is torch.Size([1, 24, 640]).
size mismatch for up_blocks.3.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 320]) from checkpoint, the shape in current model is torch.Size([1, 24, 320]).
size mismatch for up_blocks.3.motion_modules.0.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 320]) from checkpoint, the shape in current model is torch.Size([1, 24, 320]).
size mismatch for up_blocks.3.motion_modules.1.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 320]) from checkpoint, the shape in current model is torch.Size([1, 24, 320]).
size mismatch for up_blocks.3.motion_modules.1.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 320]) from checkpoint, the shape in current model is torch.Size([1, 24, 320]).
size mismatch for up_blocks.3.motion_modules.2.temporal_transformer.transformer_blocks.0.attention_blocks.0.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 320]) from checkpoint, the shape in current model is torch.Size([1, 24, 320]).
size mismatch for up_blocks.3.motion_modules.2.temporal_transformer.transformer_blocks.0.attention_blocks.1.pos_encoder.pe: copying a param with shape torch.Size([1, 32, 320]) from checkpoint, the shape in current model is torch.Size([1, 24, 320]).
Greetings @Kosinkadink
I've been trying to get this node to work but have been running into an error I do not particular understand. The following error occurs when I try and run the workflow you provided here but I keep running into the following error. Everything appears to be installed correctly and the KSampler works fine for image generation so I'm not sure what's going on. Let me know if you can provide any additional info. I'm running comfyui via a docker container in wsl2(https://github.com/AbdBarho/stable-diffusion-webui-docker).
Error occurred when executing KSampler:
cat() received an invalid combination of arguments - got (Tensor, int), but expected one of:
* (tuple of Tensors tensors, int dim, *, Tensor out)
* (tuple of Tensors tensors, name dim, *, Tensor out)
File "/stable-diffusion/execution.py", line 151, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
File "/stable-diffusion/execution.py", line 81, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
File "/stable-diffusion/execution.py", line 74, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
File "/stable-diffusion/nodes.py", line 1211, in sample
return common_ksampler(model, seed, steps, cfg, sampler_name, scheduler, positive, negative, latent_image, denoise=denoise)
File "/stable-diffusion/nodes.py", line 1181, in common_ksampler
samples = comfy.sample.sample(model, noise, steps, cfg, sampler_name, scheduler, positive, negative, latent_image,
File "/stable-diffusion/custom_nodes/ComfyUI-AnimateDiff-Evolved/animatediff/sampling.py", line 161, in animatediff_sample
return wrap_function_to_inject_xformers_bug_info(orig_comfy_sample)(model, *args, **kwargs)
File "/stable-diffusion/custom_nodes/ComfyUI-AnimateDiff-Evolved/animatediff/model_utils.py", line 144, in wrapped_function
return function_to_wrap(*args, **kwargs)
File "/stable-diffusion/comfy/sample.py", line 95, in sample
samples = sampler.sample(noise, positive_copy, negative_copy, cfg=cfg, latent_image=latent_image, start_step=start_step, last_step=last_step, force_full_denoise=force_full_denoise, denoise_mask=noise_mask, sigmas=sigmas, callback=callback, disable_pbar=disable_pbar, seed=seed)
File "/stable-diffusion/comfy/samplers.py", line 733, in sample
samples = getattr(k_diffusion_sampling, "sample_{}".format(self.sampler))(self.model_k, noise, sigmas, extra_args=extra_args, callback=k_callback, disable=disable_pbar)
File "/opt/conda/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/stable-diffusion/comfy/k_diffusion/sampling.py", line 137, in sample_euler
denoised = model(x, sigma_hat * s_in, **extra_args)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/stable-diffusion/comfy/samplers.py", line 323, in forward
out = self.inner_model(x, sigma, cond=cond, uncond=uncond, cond_scale=cond_scale, cond_concat=cond_concat, model_options=model_options, seed=seed)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/stable-diffusion/comfy/k_diffusion/external.py", line 125, in forward
eps = self.get_eps(input * c_in, self.sigma_to_t(sigma), **kwargs)
File "/stable-diffusion/comfy/k_diffusion/external.py", line 151, in get_eps
return self.inner_model.apply_model(*args, **kwargs)
File "/stable-diffusion/comfy/samplers.py", line 311, in apply_model
out = sampling_function(self.inner_model.apply_model, x, timestep, uncond, cond, cond_scale, cond_concat, model_options=model_options, seed=seed)
File "/stable-diffusion/custom_nodes/ComfyUI-AnimateDiff-Evolved/animatediff/sampling.py", line 527, in sliding_sampling_function
cond, uncond = calc_cond_uncond_batch(model_function, cond, uncond, x, timestep, max_total_area, cond_concat, model_options)
File "/stable-diffusion/custom_nodes/ComfyUI-AnimateDiff-Evolved/animatediff/sampling.py", line 427, in calc_cond_uncond_batch
output = model_function(input_x, timestep_, **c).chunk(batch_chunks)
File "/stable-diffusion/comfy/model_base.py", line 56, in apply_model
context = torch.cat(c_crossattn, 1)
ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\model_utils.py", line 45, in
folder_names_and_paths[Folders.MODELS] = ([MODEL_DIR], folder_paths.supported_ckpt_extensions)
AttributeError: module 'folder_paths' has no attribute 'supported_ckpt_extensions'
[This is a note for future me and devs.]
Currently, context schedulers must produce windows with the length of context_length. Unlike 'uniform', 'uniform v2' has the potential to produce non-16-length windows, such as with a latent count of 48, context_length 16, context_stride 1, context_overlap 4, and closed_loop false. One of the context windows ends up being length '12', which is not the required length '16', and since the motion module loaded up this way expects 16 frames, the math does not math and either it crashes, or produces very undesirable results when the context_length is a factor of the erroneous context window.
Will look into eliminating non-16 length context windows from the 'uniform v2' scheduler. 'uniform' scheduler is unaffected.
When xformers==0.0.21:
Successfully installed MarkupSafe-2.1.3 cmake-3.27.4.1 filelock-3.12.3 jinja2-3.1.2 lit-16.0.6 mpmath-1.3.0 networkx-3.1 numpy-1.25.2 nvidia-cublas-cu11-11.10.3.66 nvidia-cuda-cupti-cu11-11.7.101 nvidia-cuda-nvrtc-cu11-11.7.99 nvidia-cuda-runtime-cu11-11.7.99 nvidia-cudnn-cu11-8.5.0.96 nvidia-cufft-cu11-10.9.0.58 nvidia-curand-cu11-10.2.10.91 nvidia-cusolver-cu11-11.4.0.1 nvidia-cusparse-cu11-11.7.4.91 nvidia-nccl-cu11-2.14.3 nvidia-nvtx-cu11-11.7.91 setuptools-68.2.0 sympy-1.12 torch-2.0.1 triton-2.0.0 typing-extensions-4.7.1 wheel-0.41.2 xformers-0.0.21
The following results appear:
got prompt
2
3
[AnimateDiff] - INFO - Motion module already injected, only injecting params.
[AnimateDiff] - INFO - Hacking torch.nn.GroupNorm forward function.
loading new
0%| | 0/20 [00:00<?, ?it/s]
!!! Exception during processing !!!
Traceback (most recent call last):
File "/mnt/workspace/ComfyUI/execution.py", line 152, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
File "/mnt/workspace/ComfyUI/execution.py", line 82, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
File "/mnt/workspace/ComfyUI/execution.py", line 75, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
File "/mnt/workspace/ComfyUI/nodes.py", line 1236, in sample
return common_ksampler(model, seed, steps, cfg, sampler_name, scheduler, positive, negative, latent_image, denoise=denoise)
File "/mnt/workspace/ComfyUI/nodes.py", line 1206, in common_ksampler
samples = comfy.sample.sample(model, noise, steps, cfg, sampler_name, scheduler, positive, negative, latent_image,
File "/mnt/workspace/ComfyUI/custom_nodes/ComfyUI-AnimateDiff/animatediff/nodes.py", line 101, in sample_wrapper
return orig_comfy_sample(model, *args, **kwargs)
File "/mnt/workspace/ComfyUI/custom_nodes/ComfyUI-Impact-Pack/modules/impact/hacky.py", line 22, in informative_sample
raise e
File "/mnt/workspace/ComfyUI/custom_nodes/ComfyUI-Impact-Pack/modules/impact/hacky.py", line 9, in informative_sample
return original_sample(*args, **kwargs)
File "/mnt/workspace/ComfyUI/comfy/sample.py", line 93, in sample
samples = sampler.sample(noise, positive_copy, negative_copy, cfg=cfg, latent_image=latent_image, start_step=start_step, last_step=last_step, force_full_denoise=force_full_denoise, denoise_mask=noise_mask, sigmas=sigmas, callback=callback, disable_pbar=disable_pbar, seed=seed)
File "/mnt/workspace/ComfyUI/comfy/samplers.py", line 740, in sample
samples = getattr(k_diffusion_sampling, "sample_{}".format(self.sampler))(self.model_k, noise, sigmas, extra_args=extra_args, callback=k_callback, disable=disable_pbar)
File "/opt/conda/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/mnt/workspace/ComfyUI/comfy/k_diffusion/sampling.py", line 137, in sample_euler
denoised = model(x, sigma_hat * s_in, **extra_args)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/mnt/workspace/ComfyUI/comfy/samplers.py", line 321, in forward
out = self.inner_model(x, sigma, cond=cond, uncond=uncond, cond_scale=cond_scale, cond_concat=cond_concat, model_options=model_options, seed=seed)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in call_impl
return forward_call(*args, **kwargs)
File "/mnt/workspace/ComfyUI/comfy/k_diffusion/external.py", line 125, in forward
eps = self.get_eps(input * c_in, self.sigma_to_t(sigma), **kwargs)
File "/mnt/workspace/ComfyUI/comfy/k_diffusion/external.py", line 151, in get_eps
return self.inner_model.apply_model(*args, **kwargs)
File "/mnt/workspace/ComfyUI/comfy/samplers.py", line 309, in apply_model
out = sampling_function(self.inner_model.apply_model, x, timestep, uncond, cond, cond_scale, cond_concat, model_options=model_options, seed=seed)
File "/mnt/workspace/ComfyUI/comfy/samplers.py", line 287, in sampling_function
cond, uncond = calc_cond_uncond_batch(model_function, cond, uncond, x, timestep, max_total_area, cond_concat, model_options)
File "/mnt/workspace/ComfyUI/comfy/samplers.py", line 263, in calc_cond_uncond_batch
output = model_function(input_x, timestep, **c).chunk(batch_chunks)
File "/mnt/workspace/ComfyUI/comfy/model_base.py", line 63, in apply_model
return self.diffusion_model(xc, t, context=context, y=c_adm, control=control, transformer_options=transformer_options).float()
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/mnt/workspace/ComfyUI/comfy/ldm/modules/diffusionmodules/openaimodel.py", line 626, in forward
h = forward_timestep_embed(module, h, emb, context, transformer_options)
File "/mnt/workspace/ComfyUI/custom_nodes/ComfyUI-AnimateDiff/animatediff/nodes.py", line 59, in forward_timestep_embed
x = layer(x, context)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/mnt/workspace/ComfyUI/custom_nodes/ComfyUI-AnimateDiff/animatediff/motion_module.py", line 128, in forward
return self.temporal_transformer(input_tensor, encoder_hidden_states, attention_mask)
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/mnt/workspace/ComfyUI/custom_nodes/ComfyUI-AnimateDiff/animatediff/motion_module.py", line 200, in forward
hidden_states = block(
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/mnt/workspace/ComfyUI/custom_nodes/ComfyUI-AnimateDiff/animatediff/motion_module.py", line 280, in forward
attention_block(
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/mnt/workspace/ComfyUI/custom_nodes/ComfyUI-AnimateDiff/animatediff/motion_module.py", line 367, in forward
hidden_states = super().forward(
File "/mnt/workspace/ComfyUI/comfy/ldm/modules/attention.py", line 438, in forward
out = xformers.ops.memory_efficient_attention(q, k, v, attn_bias=None, op=self.attention_op)
File "/opt/conda/lib/python3.10/site-packages/xformers/ops/fmha/init.py", line 193, in memory_efficient_attention
return _memory_efficient_attention(
File "/opt/conda/lib/python3.10/site-packages/xformers/ops/fmha/init.py", line 291, in _memory_efficient_attention
return _memory_efficient_attention_forward(
File "/opt/conda/lib/python3.10/site-packages/xformers/ops/fmha/init.py", line 311, in memory_efficient_attention_forward
out, * = op.apply(inp, needs_gradient=False)
File "/opt/conda/lib/python3.10/site-packages/xformers/ops/fmha/flash.py", line 251, in apply
out, softmax_lse, rng_state = cls.OPERATOR(
File "/opt/conda/lib/python3.10/site-packages/torch/_ops.py", line 502, in call
return self._op(*args, **kwargs or {})
File "/opt/conda/lib/python3.10/site-packages/xformers/ops/fmha/flash.py", line 79, in _flash_fwd
) = _C_flashattention.varlen_fwd(
RuntimeError: CUDA error: invalid configuration argument
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
When xformers==0.0.20:
Installing collected packages: xformers
Attempting uninstall: xformers
Found existing installation: xformers 0.0.21
Uninstalling xformers-0.0.21:
Successfully uninstalled xformers-0.0.21
Successfully installed xformers-0.0.2
Everything works fine
I've been trying to generate videos but after 2 successful generations I get the following error in the console:
!!! Exception during processing !!!
Traceback (most recent call last):
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\execution.py", line 152, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\execution.py", line 82, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\execution.py", line 75, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\nodes.py", line 1236, in sample
return common_ksampler(model, seed, steps, cfg, sampler_name, scheduler, positive, negative, latent_image, denoise=denoise)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\nodes.py", line 1206, in common_ksampler
samples = comfy.sample.sample(model, noise, steps, cfg, sampler_name, scheduler, positive, negative, latent_image,
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 161, in animatediff_sample
return wrap_function_to_inject_xformers_bug_info(orig_comfy_sample)(model, *args, **kwargs)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\model_utils.py", line 144, in wrapped_function
return function_to_wrap(*args, **kwargs)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\comfy\sample.py", line 93, in sample
samples = sampler.sample(noise, positive_copy, negative_copy, cfg=cfg, latent_image=latent_image, start_step=start_step, last_step=last_step, force_full_denoise=force_full_denoise, denoise_mask=noise_mask, sigmas=sigmas, callback=callback, disable_pbar=disable_pbar, seed=seed)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 741, in sample
samples = getattr(k_diffusion_sampling, "sample_{}".format(self.sampler))(self.model_k, noise, sigmas, extra_args=extra_args, callback=k_callback, disable=disable_pbar)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\utils\_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\comfy\k_diffusion\sampling.py", line 137, in sample_euler
denoised = model(x, sigma_hat * s_in, **extra_args)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 322, in forward
out = self.inner_model(x, sigma, cond=cond, uncond=uncond, cond_scale=cond_scale, cond_concat=cond_concat, model_options=model_options, seed=seed)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\comfy\k_diffusion\external.py", line 125, in forward
eps = self.get_eps(input * c_in, self.sigma_to_t(sigma), **kwargs)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\comfy\k_diffusion\external.py", line 151, in get_eps
return self.inner_model.apply_model(*args, **kwargs)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 310, in apply_model
out = sampling_function(self.inner_model.apply_model, x, timestep, uncond, cond, cond_scale, cond_concat, model_options=model_options, seed=seed)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 527, in sliding_sampling_function
cond, uncond = calc_cond_uncond_batch(model_function, cond, uncond, x, timestep, max_total_area, cond_concat, model_options)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 427, in calc_cond_uncond_batch
output = model_function(input_x, timestep_, **c).chunk(batch_chunks)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\comfy\model_base.py", line 63, in apply_model
return self.diffusion_model(xc, t, context=context, y=c_adm, control=control, transformer_options=transformer_options).float()
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\comfy\ldm\modules\diffusionmodules\openaimodel.py", line 633, in forward
h = forward_timestep_embed(self.middle_block, h, emb, context, transformer_options)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 71, in forward_timestep_embed
x = layer(x, context)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\motion_module.py", line 398, in forward
return self.temporal_transformer(input_tensor, encoder_hidden_states, attention_mask)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\motion_module.py", line 461, in forward
hidden_states = self.norm(hidden_states)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 160, in new_forward
args, kwargs = module._hf_hook.pre_forward(module, *args, **kwargs)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 104, in pre_forward
args, kwargs = hook.pre_forward(module, *args, **kwargs)
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 286, in pre_forward
set_module_tensor_to_device(
File "D:\apps\AI\COMFYUI2\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\utils\modeling.py", line 298, in set_module_tensor_to_device
new_value = value.to(device)
NotImplementedError: Cannot copy out of meta tensor; no data!
This is the first time I've tried AnimateDiff so I'm not sure if it's something I did wrong on my end or if it's greater than that. I'm running this on Windows 11 with a GTX 1660 6GB, 16GB RAM and a Ryzen 5600X with the latest ComfyUI.
I've also never opened a GitHub issue before so if there's anything you need please do tell me.
Here's the workflow I'm using (i have 256x256 latent image size so that i could quickly generate while i was trying to figure out what was going on):

Title. Is something similar to this reddit workflow doable?
(Sorry for asking this, not on topic but ) is there an example for using different controlnets for different frames? I assume that's what the Advanced Controlnet nodes is for? Example: frame 1-4 openpose, frame 5-8 depth, frame 9-12 both, ...
Thanks for your work.
After doing a clean install of my Comfyui, a new venv with Python 3.9, everything clean and disabling all the other custom node I can't advance. Now way to make it work on my Mac M1. Any solutions? Any other info you need?

/Users/XXXXXXX/ComfyUI/venv/lib/python3.9/site-packages/urllib3/init.py:34: NotOpenSSLWarning: urllib3 v2.0 only supports OpenSSL 1.1.1+, currently the 'ssl' module is compiled with 'LibreSSL 2.8.3'. See: urllib3/urllib3#3020
warnings.warn(
Set vram state to: SHARED
Device: mps
VAE dtype: torch.float32
Using sub quadratic optimization for cross attention, if you have memory or speed issues try using: --use-split-cross-attention
Traceback (most recent call last):
File "/Users/michaelroulier/ComfyUI/nodes.py", line 1725, in load_custom_node
module_spec.loader.exec_module(module)
File "", line 850, in exec_module
File "", line 228, in _call_with_frames_removed
File "/Users/michaelroulier/ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved/init.py", line 2, in
from .animatediff.nodes import NODE_CLASS_MAPPINGS, NODE_DISPLAY_NAME_MAPPINGS
File "/Users/XXXXXXXX/ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved/animatediff/nodes.py", line 29, in
from .sliding_context_sampling import sliding_common_ksampler
File "/Users/XXXXXXXX/ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved/animatediff/sliding_context_sampling.py", line 19, in
from .context import get_context_scheduler
File "/Users/XXXXXXXXX/ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved/animatediff/context.py", line 147
match name:
^
SyntaxError: invalid syntax
Cannot import /Users/XXXXXXXXX/ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved module for custom nodes: invalid syntax (context.py, line 147)
Import times for custom nodes:
0.0 seconds (IMPORT FAILED): /Users/XXXXXXXXX/ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved
Starting server
To see the GUI go to: http://127.0.0.1:8188
Hello, first thanks for you work, it look very beautiful.
I try to install the plugin from the manager with the last version of comfyUI
then I save some image example from the read me and load the workflow by drag and drop the picture on the UI
Then I got this

and this

When I rework the flow to remove the missing node the de custom node work.
My question is how to install the missing node ?
I have the control net custom node installed too. But it look that some special controlnet are missed.
Are those missing nodes part of another custom node repos ?
This was working earlier today. I upgraded ConmfyUI & all custom nodes & now I get this when it hits the KSampler
VanillaTemporalModule.forward() missing 1 required positional argument: 'encoder_hidden_states'
Entire error:
[AnimateDiffEvo] - INFO - Removing motion module adStabilizedMotion_stabilizedHigh.pt from cache
!!! Exception during processing !!!
Traceback (most recent call last):
File "E:\ComfyUI\execution.py", line 152, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
File "E:\ComfyUI\execution.py", line 82, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
File "E:\ComfyUI\execution.py", line 75, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
File "E:\ComfyUI\nodes.py", line 1270, in sample
return common_ksampler(model, noise_seed, steps, cfg, sampler_name, scheduler, positive, negative, latent_image, denoise=denoise, disable_noise=disable_noise, start_step=start_at_step, last_step=end_at_step, force_full_denoise=force_full_denoise)
File "E:\ComfyUI\nodes.py", line 1206, in common_ksampler
samples = comfy.sample.sample(model, noise, steps, cfg, sampler_name, scheduler, positive, negative, latent_image,
File "E:\ComfyUI\custom_nodes\ComfyUI-Impact-Pack\modules\impact\sample_error_enhancer.py", line 9, in informative_sample
return original_sample(*args, **kwargs)
File "E:\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 161, in animatediff_sample
return wrap_function_to_inject_xformers_bug_info(orig_comfy_sample)(model, *args, **kwargs)
File "E:\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\model_utils.py", line 162, in wrapped_function
return function_to_wrap(*args, **kwargs)
File "E:\ComfyUI\comfy\sample.py", line 97, in sample
samples = sampler.sample(noise, positive_copy, negative_copy, cfg=cfg, latent_image=latent_image, start_step=start_step, last_step=last_step, force_full_denoise=force_full_denoise, denoise_mask=noise_mask, sigmas=sigmas, callback=callback, disable_pbar=disable_pbar, seed=seed)
File "E:\ComfyUI\comfy\samplers.py", line 785, in sample
return sample(self.model, noise, positive, negative, cfg, self.device, sampler(), sigmas, self.model_options, latent_image=latent_image, denoise_mask=denoise_mask, callback=callback, disable_pbar=disable_pbar, seed=seed)
File "E:\ComfyUI\comfy\samplers.py", line 690, in sample
samples = sampler.sample(model_wrap, sigmas, extra_args, callback, noise, latent_image, denoise_mask, disable_pbar)
File "E:\ComfyUI\comfy\samplers.py", line 630, in sample
samples = getattr(k_diffusion_sampling, "sample_{}".format(sampler_name))(model_k, noise, sigmas, extra_args=extra_args, callback=k_callback, disable=disable_pbar, **extra_options)
File "D:\Python\Python310\lib\site-packages\torch\utils_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "E:\ComfyUI\comfy\k_diffusion\sampling.py", line 137, in sample_euler
denoised = model(x, sigma_hat * s_in, **extra_args)
File "D:\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "E:\ComfyUI\comfy\samplers.py", line 323, in forward
out = self.inner_model(x, sigma, cond=cond, uncond=uncond, cond_scale=cond_scale, cond_concat=cond_concat, model_options=model_options, seed=seed)
File "D:\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 1501, in call_impl
return forward_call(*args, **kwargs)
File "E:\ComfyUI\comfy\k_diffusion\external.py", line 125, in forward
eps = self.get_eps(input * c_in, self.sigma_to_t(sigma), **kwargs)
File "E:\ComfyUI\comfy\k_diffusion\external.py", line 151, in get_eps
return self.inner_model.apply_model(*args, **kwargs)
File "E:\ComfyUI\comfy\samplers.py", line 311, in apply_model
out = sampling_function(self.inner_model.apply_model, x, timestep, uncond, cond, cond_scale, cond_concat, model_options=model_options, seed=seed)
File "E:\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 535, in sliding_sampling_function
cond, uncond = calc_cond_uncond_batch(model_function, cond, uncond, x, timestep, max_total_area, cond_concat, model_options)
File "E:\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 431, in calc_cond_uncond_batch
output = model_function(input_x, timestep, **c).chunk(batch_chunks)
File "E:\ComfyUI\comfy\model_base.py", line 63, in apply_model
return self.diffusion_model(xc, t, context=context, y=c_adm, control=control, transformer_options=transformer_options).float()
File "D:\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "E:\ComfyUI\custom_nodes\FreeU_Advanced\nodes.py", line 173, in __temp__forward
h = forward_timestep_embed(module, h, emb, context, transformer_options)
File "E:\ComfyUI\comfy\ldm\modules\diffusionmodules\openaimodel.py", line 61, in forward_timestep_embed
x = layer(x)
File "D:\Python\Python310\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
TypeError: VanillaTemporalModule.forward() missing 1 required positional argument: 'encoder_hidden_states'
Windows 11
RTX 3090 24GB
I saw on your reddit comment here, that the VRAM usage shouldn't change as you increase batch size.
I loaded this PNG from the README: https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved#txt2img---48-frame-animation-with-16-frame-window
Test Results only changing Batch Size:
Batch Size: 16 - Maxes at 11.8 VRAM
Batch Size: 32 - Maxes at 18.4 VRAM
Batch Size 48 - Maxes the 24 VRAM
I've run into issues after the recent updates were pushed, resulting in either an error or a complete lack of coherence from frame to frame as if just generating a batch.
I've tried: all modules and schedulers, the standard and included empty latent image node, with and without the new context options, the recent workflow examples and custom workflows, and even a fresh install of comfy without other extensions.
Error received from example txt2img workflow:
Error occurred when executing ADE_AnimateDiffLoaderWithContext:
expected str, bytes or os.PathLike object, not NoneType
File "/home/b/SD/ComfyUI/execution.py", line 152, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/b/SD/ComfyUI/execution.py", line 82, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/b/SD/ComfyUI/execution.py", line 75, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/b/SD/ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved/animatediff/nodes.py", line 62, in load_mm_and_inject_params
load_motion_module(model_name)
File "/home/b/SD/ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved/animatediff/motion_module.py", line 51, in load_motion_module
model_hash = calculate_file_hash(model_path)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/b/SD/ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved/animatediff/model_utils.py", line 194, in calculate_file_hash
with open(filename, 'rb', buffering=0) as f:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Queue size: 0
Extra options
I don't receive the error from a nearly identical workflow that functioned before, but as stated previously it doesn't seem to use the motion modules.
Here's the workflow that functions without error, and the output:


Using python venv
OS: Arch Linux
Will investigate and update this issue with easy ways to reproduce the bug.
Hi, I am enjoying so very much your work, and now, like in the awful fairytale, I would like to get even more from you! Would it be possible for you to add some batch functionality for prompts, so that I could sketch out a full story and have it rendered through the night? This would be ever so helpful and fun!
Hi,
currently there is a big missing hole in ComfyUI for a suite of quality nodes revolving around working with videos. That means loading videos, previewing it like we do with images, frame extraction, etc. We want to avoid a situation where users end up with 4 different nodes that essentially do the same thing because every plugin reimplements. It's already happening with other things and it's crucial that we act fast before another mess is created.
Sxela has been porting his Warp Fusion as well to ComfyUI, I don't know if he paused or where he's at but I know he has created nodes as well for working with video, so please contact him as well.
Thanks!
I got a lovely collection of 750 educational photos of the best car crashes from 1949 till 1980 "Unfallbild der Woche", which the Swiss police department created for safer driving. Now I would love to reverse engineer these final stories and to create AI movies of what took place before this final shot. So perhaps this might be described as some kind of mov 2 image ? Could you imagine that something like this would be achievable? That I start the movie with a prompt of "happy kids with some bottles drive through the night" and end at the photo scene?
Would be great to have a lens node that allows to set typical qualities: Aperture, Depth of field
Would be perfect if this could be done together with a camera(wo)man, who knows the standards of classic prime cine lenses.
First of all, I want to express my sincere appreciation for your hard work and dedication to animatediffusion. I'm here to ask for your advice. Sometimes, all generated GIFs are looped, and the start frame and the end frame tend to assimilate themselves. And there's when this doesn't occur. If I can, I want to control it, but I can't figure out the mechanisms behind this discrepancy. Could you please help me understand the mechanisms behind this?
Also, I'm really curious about the role and functions of certain sliders such as 'context stride' 'context overlap' 'closed loop' .
Can you inform me where can I find discriptions of those?
Again, thanks for your awesome contribution!
Can't load Animatediff v1.5V2
err.txt
HI, I followed all the steps and on following this workflow all the images are just showing up black. There are no errors in the terminal either. Any idea how to troubleshoot this? Thanks.

Recently my system got crashed when running your "txt2img - 48 frame animation with 16 context_length (uniform)," workflow but succedded run two of your beggining shared workflows! I had tried to disable xformers but still not solved this problem. Any workaround will be appreciated!
CheckpointLoaderSimpleWithNoiseSelect node is not loading with any workflow. Using the latest version of Comfy and ComfyUI-AnimateDiff.

On the lastest version,"AnimateDiffLoader" node delete "latents" import & output, "Empty Latent Image" node direct to Ksampler ,why?
AnimateDiff model isn't participate in building Empty Latent Image? I'm confused
Is the image mask supposed to work with the animateDiff extension ?
When I add a video mask (same frame number as the original video) the video remains the same after the sampling (as if the mask has been applied to the entire image).

Thank you again for this fantastic extension !
Error occurred when executing KSampler:
An xformers bug was encountered in AnimateDiff - this is unexpected, report this to Kosinkadink/ComfyUI-AnimateDiff-Evolved repo as an issue, and a workaround for now is to run ComfyUI with the --disable-xformers argument.
File "E:@ai\tools\ComfyUI_windows_portable\ComfyUI\execution.py", line 152, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
File "E:@ai\tools\ComfyUI_windows_portable\ComfyUI\execution.py", line 82, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
File "E:@ai\tools\ComfyUI_windows_portable\ComfyUI\execution.py", line 75, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
File "E:@ai\tools\ComfyUI_windows_portable\ComfyUI\nodes.py", line 1236, in sample
return common_ksampler(model, seed, steps, cfg, sampler_name, scheduler, positive, negative, latent_image, denoise=denoise)
File "E:@ai\tools\ComfyUI_windows_portable\ComfyUI\nodes.py", line 1206, in common_ksampler
samples = comfy.sample.sample(model, noise, steps, cfg, sampler_name, scheduler, positive, negative, latent_image,
File "E:@ai\tools\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 161, in animatediff_sample
return wrap_function_to_inject_xformers_bug_info(orig_comfy_sample)(model, *args, **kwargs)
File "E:@ai\tools\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\model_utils.py", line 165, in wrapped_function
raise RuntimeError(f"An xformers bug was encountered in AnimateDiff - this is unexpected, \

Error occurred when executing AnimateDiffLoaderV1:
index 10 is out of range
File "D:\ComfyUI_windows_portable\ComfyUI\execution.py", line 151, in recursive_execute
File "D:\ComfyUI_windows_portable\ComfyUI\execution.py", line 81, in get_output_data
uis = []
File "D:\ComfyUI_windows_portable\ComfyUI\execution.py", line 74, in map_node_over_list
nodes.before_node_execution()
File "D:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\nodes.py", line 390, in inject_motion_modules
injectors[self.version](unet, motion_module, injection_params)
File "D:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\nodes.py", line 193, in inject_motion_module_to_unet
unet.input_blocks[unet_idx].append(
File "D:\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\container.py", line 295, in getitem
return self._modules[self._get_abs_string_index(idx)]
File "D:\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\container.py", line 285, in _get_abs_string_index
raise IndexError('index {} is out of range'.format(idx))
Newly released motion lora's here: https://huggingface.co/guoyww/animatediff
Zoom In | Zoom Out | Zoom Pan Left | Zoom Pan Right | Pan Up | Pan Down | Rolling Anti-Clockwise | Rolling Clockwise
Error When executed this workflow https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved#txt2img-w-initial-controlnet-input-using-openpose-images--latent-upscale-w-full-denoise-48-frame-animation-with-16-context_length-uniform.
Error occurred when executing KSampler:
CUDA error: the launch timed out and was terminated
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
File "C:\ComfyUI_windows_portable\ComfyUI\execution.py", line 152, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
File "C:\ComfyUI_windows_portable\ComfyUI\execution.py", line 82, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
File "C:\ComfyUI_windows_portable\ComfyUI\execution.py", line 75, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
File "C:\ComfyUI_windows_portable\ComfyUI\nodes.py", line 1236, in sample
return common_ksampler(model, seed, steps, cfg, sampler_name, scheduler, positive, negative, latent_image, denoise=denoise)
File "C:\ComfyUI_windows_portable\ComfyUI\nodes.py", line 1206, in common_ksampler
samples = comfy.sample.sample(model, noise, steps, cfg, sampler_name, scheduler, positive, negative, latent_image,
File "C:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 161, in animatediff_sample
return wrap_function_to_inject_xformers_bug_info(orig_comfy_sample)(model, *args, **kwargs)
File "C:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\model_utils.py", line 162, in wrapped_function
return function_to_wrap(*args, **kwargs)
File "C:\ComfyUI_windows_portable\ComfyUI\comfy\sample.py", line 97, in sample
samples = sampler.sample(noise, positive_copy, negative_copy, cfg=cfg, latent_image=latent_image, start_step=start_step, last_step=last_step, force_full_denoise=force_full_denoise, denoise_mask=noise_mask, sigmas=sigmas, callback=callback, disable_pbar=disable_pbar, seed=seed)
File "C:\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 785, in sample
return sample(self.model, noise, positive, negative, cfg, self.device, sampler(), sigmas, self.model_options, latent_image=latent_image, denoise_mask=denoise_mask, callback=callback, disable_pbar=disable_pbar, seed=seed)
File "C:\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 690, in sample
samples = sampler.sample(model_wrap, sigmas, extra_args, callback, noise, latent_image, denoise_mask, disable_pbar)
File "C:\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 630, in sample
samples = getattr(k_diffusion_sampling, "sample_{}".format(sampler_name))(model_k, noise, sigmas, extra_args=extra_args, callback=k_callback, disable=disable_pbar, **extra_options)
File "C:\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\utils_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "C:\ComfyUI_windows_portable\ComfyUI\comfy\k_diffusion\sampling.py", line 137, in sample_euler
denoised = model(x, sigma_hat * s_in, **extra_args)
File "C:\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 323, in forward
out = self.inner_model(x, sigma, cond=cond, uncond=uncond, cond_scale=cond_scale, cond_concat=cond_concat, model_options=model_options, seed=seed)
File "C:\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in call_impl
return forward_call(*args, **kwargs)
File "C:\ComfyUI_windows_portable\ComfyUI\comfy\k_diffusion\external.py", line 125, in forward
eps = self.get_eps(input * c_in, self.sigma_to_t(sigma), **kwargs)
File "C:\ComfyUI_windows_portable\ComfyUI\comfy\k_diffusion\external.py", line 151, in get_eps
return self.inner_model.apply_model(*args, **kwargs)
File "C:\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 311, in apply_model
out = sampling_function(self.inner_model.apply_model, x, timestep, uncond, cond, cond_scale, cond_concat, model_options=model_options, seed=seed)
File "C:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 537, in sliding_sampling_function
cond, uncond = sliding_calc_cond_uncond_batch(model_function, cond, uncond, x, timestep, max_total_area, cond_concat, model_options)
File "C:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 519, in sliding_calc_cond_uncond_batch
sub_cond_out, sub_uncond_out = calc_cond_uncond_batch(model_function, sub_cond, sub_uncond, sub_x, sub_timestep, max_total_area, sub_cond_concat, model_options)
File "C:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 408, in calc_cond_uncond_batch
c['control'] = control.get_control(input_x, timestep, c, len(cond_or_uncond))
File "C:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-Advanced-ControlNet\control.py", line 180, in get_control
return self.sliding_get_control(x_noisy, t, cond, batched_number)
File "C:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-Advanced-ControlNet\control.py", line 215, in sliding_get_control
control = self.control_model(x=x_noisy.to(self.control_model.dtype), hint=self.cond_hint, timesteps=t, context=context.to(self.control_model.dtype), y=y)
File "C:\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "C:\ComfyUI_windows_portable\ComfyUI\comfy\cldm\cldm.py", line 302, in forward
outs.append(zero_conv(h, emb, context))
File "C:\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\ComfyUI_windows_portable\ComfyUI\comfy\ldm\modules\diffusionmodules\openaimodel.py", line 47, in forward
x = layer(x)
File "C:\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 160, in new_forward
args, kwargs = module._hf_hook.pre_forward(module, *args, **kwargs)
File "C:\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 286, in pre_forward
set_module_tensor_to_device(
File "C:\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\utils\modeling.py", line 317, in set_module_tensor_to_device
new_value = value.to(device)
it error asking for "timestep_keyframe"
but is no point link for "timestep_keyframe" in ControlNet Model (diff Advanced) node
it can only link for ControlNet Weights but if you do that it will give 'control_net_weights' error
i'm too dump this i miss some point?
https://huggingface.co/Kosinkadink/HotShot-XL-MotionModels
How can this be used with the nodes?
i have i got black noises output i use txt2img, img2img, open pose, i tried different models same issue
also i got out of memory error so i use --disable-xformers,
my gpu 2060 6gb
64 ram
ryzen 5950x



Hi, can we use different controlnet before first pass and another different one for uspcale pass?
Im finding some errors while trying that. Thanks!
It stops at loader.
Error occurred when executing AnimateDiffLoaderV1:
index 10 is out of range
File "G:\ComfyUI_windows_portable\ComfyUI\execution.py", line 151, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
File "G:\ComfyUI_windows_portable\ComfyUI\execution.py", line 81, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
File "G:\ComfyUI_windows_portable\ComfyUI\execution.py", line 74, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
File "G:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff\animatediff\nodes.py", line 369, in inject_motion_modules
injectors[self.version](unet, motion_module, injection_params)
File "G:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff\animatediff\nodes.py", line 185, in inject_motion_module_to_unet
unet.input_blocks[unet_idx].append(
File "G:\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\container.py", line 295, in getitem
return self._modules[self._get_abs_string_index(idx)]
File "G:\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\container.py", line 285, in _get_abs_string_index
raise IndexError('index {} is out of range'.format(idx))
Now that I have installed Python 10 in a new venv, everything looks normal and Comfyui UI load the nodes correctly. The default preset (the simplest one) works....until a batch of 8 frames max... That is already great! But as soon as the batch number is above 10, I can see the KSampler starting to calculate tthe first frame, but it immediately goes black and the generated frames are all black.
If I start again with 8 frames, everything back to normal.
I put back 10 frames and over and the frames come out black.
Spended all day trying to make it work. Cleaned installed Comfyui and new dependencies, VenV with Python 10, unistalled et installed again Animatediffevolution many times. Nothing works. What can I try now?
Nothing special in the console, no error, just that I am missing FFmpeg. I guess it has nothing to do with it as that only concerns the last node.
I Tried all the different presets provided. Another bug is that on another more complex preset (with two Ksamplers) as soon as it goes to second sampler, Comfyui breaks and i have to relaunch the terminal.
Here is the terminal messages with only one custom node...ComfyUI-AnimateDiff-Evolved:
Last login: Sat Sep 23 19:19:16 on ttys000
michaelroulier@Mac-Studio-de-Michael ~ % cd Comfyui
michaelroulier@Mac-Studio-de-Michael Comfyui % source venv/bin/activate
(venv) michaelroulier@Mac-Studio-de-Michael Comfyui % ./venv/bin/python main.py
Total VRAM 131072 MB, total RAM 131072 MB
xformers version: 0.0.20
Set vram state to: SHARED
Device: mps
VAE dtype: torch.float32
Using sub quadratic optimization for cross attention, if you have memory or speed issues try using: --use-split-cross-attention
Using sub quadratic optimization for cross attention, if you have memory or speed issues try using: --use-split-cross-attention
Import times for custom nodes:
0.0 seconds: /Users/michaelroulier/ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved
Starting server
To see the GUI go to: http://127.0.0.1:8188
[AnimateDiffEvo] - WARNING - ffmpeg could not be found. Outputs that require it have been disabled
got prompt
[AnimateDiffEvo] - WARNING - ffmpeg could not be found. Outputs that require it have been disabled
model_type EPS
adm 0
making attention of type 'vanilla' with 512 in_channels
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
making attention of type 'vanilla' with 512 in_channels
missing {'cond_stage_model.text_projection', 'cond_stage_model.logit_scale'}
left over keys: dict_keys(['alphas_cumprod', 'alphas_cumprod_prev', 'betas', 'log_one_minus_alphas_cumprod', 'posterior_log_variance_clipped', 'posterior_mean_coef1', 'posterior_mean_coef2', 'posterior_variance', 'sqrt_alphas_cumprod', 'sqrt_one_minus_alphas_cumprod', 'sqrt_recip_alphas_cumprod', 'sqrt_recipm1_alphas_cumprod'])
[AnimateDiffEvo] - INFO - Loading motion module mm-Stabilized_high.pth
loading new
[AnimateDiffEvo] - INFO - Regular AnimateDiff activated - latents passed in (12) less or equal to context_length 16.
[AnimateDiffEvo] - INFO - Injecting motion module mm-Stabilized_high.pth version v1.
loading new
100%|██████████████████████████████████████████████████████████| 20/20 [01:31<00:00, 4.59s/it]
[AnimateDiffEvo] - INFO - Ejecting motion module mm-Stabilized_high.pth version v1.
[AnimateDiffEvo] - INFO - Cleaning motion module from unet.
/Users/michaelroulier/ComfyUI/comfy/model_base.py:47: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
self.register_buffer('betas', torch.tensor(betas, dtype=torch.float32))
/Users/michaelroulier/ComfyUI/comfy/model_base.py:48: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
self.register_buffer('alphas_cumprod', torch.tensor(alphas_cumprod, dtype=torch.float32))
making attention of type 'vanilla' with 512 in_channels
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
making attention of type 'vanilla' with 512 in_channels
[AnimateDiffEvo] - WARNING - ffmpeg could not be found. Outputs that require it have been disabled
Prompt executed in 98.54 seconds
hi.
Since today, il get this error :
VanillaTemporalModule.forward() missing 1 required positional argument: 'encoder_hidden_states'
i'm loading the basic json examples you provided, it worked fine 2 days ago (i updated comfyui yesterday)
Do you know could be the issue ?
Thanks !
Figured out why it happens, xformers attention code currently has a limit for the size of the first dimension of the tensor passed in. I am working on a refactor of the motion module code to adhere to ComfyUI latent dim standards instead of animatediff's original implementation with a different latent setup. Will close this issue once fix is pushed to main.
Until then, current workaround if this issue pops up for you is to run ComfyUI with the "--disable-xformers" arg
Update: trying to refactor the motion module code and the model itself to get around the issue is impractical, currently waiting on a fix within the xformers repo: facebookresearch/xformers#845
Update 2: No xformers fix yet, but I've updated the attention code in AD to use the next-best optimized cross attn code instead of xformers; the --disable-xformers argument is no longer required to avoid the bug. Once xformers bug is fixed, I will update code to use it in AD if available.
Error occurred when executing KSampler:
mixed dtype (CPU): all inputs must share same datatype.
File "D:\ComfyUI_windows_portable\ComfyUI\execution.py", line 152, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\execution.py", line 82, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\execution.py", line 75, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\nodes.py", line 1236, in sample
return common_ksampler(model, seed, steps, cfg, sampler_name, scheduler, positive, negative, latent_image, denoise=denoise)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\nodes.py", line 1206, in common_ksampler
samples = comfy.sample.sample(model, noise, steps, cfg, sampler_name, scheduler, positive, negative, latent_image,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 163, in animatediff_sample
return wrap_function_to_inject_xformers_bug_info(orig_comfy_sample)(model, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\model_utils.py", line 185, in wrapped_function
return function_to_wrap(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\comfy\sample.py", line 97, in sample
samples = sampler.sample(noise, positive_copy, negative_copy, cfg=cfg, latent_image=latent_image, start_step=start_step, last_step=last_step, force_full_denoise=force_full_denoise, denoise_mask=noise_mask, sigmas=sigmas, callback=callback, disable_pbar=disable_pbar, seed=seed)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 785, in sample
return sample(self.model, noise, positive, negative, cfg, self.device, sampler(), sigmas, self.model_options, latent_image=latent_image, denoise_mask=denoise_mask, callback=callback, disable_pbar=disable_pbar, seed=seed)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 690, in sample
samples = sampler.sample(model_wrap, sigmas, extra_args, callback, noise, latent_image, denoise_mask, disable_pbar)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 630, in sample
samples = getattr(k_diffusion_sampling, "sample_{}".format(sampler_name))(model_k, noise, sigmas, extra_args=extra_args, callback=k_callback, disable=disable_pbar, **extra_options)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\utils_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\comfy\k_diffusion\sampling.py", line 137, in sample_euler
denoised = model(x, sigma_hat * s_in, **extra_args)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py", line 1518, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py", line 1527, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 323, in forward
out = self.inner_model(x, sigma, cond=cond, uncond=uncond, cond_scale=cond_scale, cond_concat=cond_concat, model_options=model_options, seed=seed)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py", line 1518, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py", line 1527, in call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\comfy\k_diffusion\external.py", line 125, in forward
eps = self.get_eps(input * c_in, self.sigma_to_t(sigma), **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\comfy\k_diffusion\external.py", line 151, in get_eps
return self.inner_model.apply_model(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 311, in apply_model
out = sampling_function(self.inner_model.apply_model, x, timestep, uncond, cond, cond_scale, cond_concat, model_options=model_options, seed=seed)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 539, in sliding_sampling_function
cond, uncond = sliding_calc_cond_uncond_batch(model_function, cond, uncond, x, timestep, max_total_area, cond_concat, model_options)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 521, in sliding_calc_cond_uncond_batch
sub_cond_out, sub_uncond_out = calc_cond_uncond_batch(model_function, sub_cond, sub_uncond, sub_x, sub_timestep, max_total_area, sub_cond_concat, model_options)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 433, in calc_cond_uncond_batch
output = model_function(input_x, timestep, **c).chunk(batch_chunks)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\comfy\model_base.py", line 63, in apply_model
return self.diffusion_model(xc, t, context=context, y=c_adm, control=control, transformer_options=transformer_options).float()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py", line 1518, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py", line 1527, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\comfy\ldm\modules\diffusionmodules\openaimodel.py", line 627, in forward
h = forward_timestep_embed(module, h, emb, context, transformer_options)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 73, in forward_timestep_embed
x = layer(x, context)
^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py", line 1518, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py", line 1527, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\motion_module_ad.py", line 136, in forward
return self.temporal_transformer(input_tensor, encoder_hidden_states, attention_mask)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py", line 1518, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py", line 1527, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\motion_module_ad.py", line 199, in forward
hidden_states = self.norm(hidden_states)
^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py", line 1518, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\modules\module.py", line 1527, in _call_impl
return forward_call(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 97, in groupnorm_mm_forward
input = group_norm(input, self.num_groups, self.weight, self.bias, self.eps)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\ComfyUI_windows_portable\python_embeded\Lib\site-packages\torch\nn\functional.py", line 2558, in group_norm
return torch.group_norm(input, num_groups, weight, bias, eps, torch.backends.cudnn.enabled)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
a lot of the nodes are showing as deprecated. where have they moved? any input on what's happening?

Getting this error when attempting to use sliding context. Doesn't seem to be a memory issue.

Doesn't matter if using the new or deprecated sliding context options:

!!! Exception during processing !!!
Traceback (most recent call last):
File "E:\SDXL\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\execution.py", line 152, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
File "E:\SDXL\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\execution.py", line 82, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
File "E:\SDXL\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\execution.py", line 75, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
File "E:\SDXL\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\nodes.py", line 62, in load_mm_and_inject_params
load_motion_module(model_name)
File "E:\SDXL\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\motion_module.py", line 57, in load_motion_module
mm_state_dict = load_torch_file(model_path)
File "E:\SDXL\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\ComfyUI\comfy\utils.py", line 22, in load_torch_file
pl_sd = torch.load(ckpt, map_location=device, pickle_module=comfy.checkpoint_pickle)
File "E:\SDXL\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\serialization.py", line 815, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "E:\SDXL\ComfyUI_windows_portable_nvidia_cu118_or_cpu\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\serialization.py", line 1033, in _legacy_load
magic_number = pickle_module.load(f, **pickle_load_args)
_pickle.UnpicklingError: invalid load key, '<'.
i get an error with freeu-advance(encoder_hidden_states) so i update this node
freeu-advance error fix but i can't work with same workflow that work just fine bofore
it keep saying out of memory
this my workflow i use ipadapter an 2 controlnet work just fine

now if i want same image size i have to use only ipadapter or controlnet cant use both
if i wan to use both ii must reduce image size very low from normal workflow
this is error image

otherthing i notice that it saying
Currently allocated : 7.02 GiB(or 6.8-6.9)
when my GPU
Device limit is 8.00 GiB
when i use only controlnet or ipadapter it will use full 7.9-8 GiB vram is just so weird
i check ipadapter and controlnet node it not update for a week
only 2 node that i update today it this node and freeu-advance
but i delete freeu-advance still get dame error
not so sure if it about new freeu integrated into diffusion or not.
It really bug me out so much i cant work with same workflow i cant rollback either so sad.
This custom node is awesome, thank you so much for making it. It helped me solve a problem that has been bothering me for a long time, but there are still some problems that cannot be solved well.
How to apply different values to each latent in a batch. For example, there is a batch size of 16, and its denoise increases from 0.4 to 0.8. Then the first 8 prompt words include (from behind), and the last 8 prompt words do not contain (from behind)
Hey there, I love this! I could not find the workflow for the last example on the readme. I tried to recreate it but I do not have the option to specify frame_number in the current AnimateDiff Loader. This seems to prevent me from making animations using an existing image as a base.
If this is still possible, can you direct me on how to do it? If not, please let me know if/when this functionality will be available again!
Very interesting
source: https://x.com/c0nsumption_/status/1709787088571277352?s=20
From the terminal, I got this after pressing queue prompt:

Also, how can I "put weight under ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved/models"?

And I also get what #50 gets after 1 generation but apparently, It doesn't show up when It's my first generation basically when I generate for the first time (after loading ComfyUI) there is no problem, but when I do it a second time I get the same error as the guy.
I am on ComfyUI windows portable , Windows 10, and I installed it from ComfyUI Manager.
This is my workflow

Error occurred when executing KSampler:
Cannot copy out of meta tensor; no data!
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\execution.py", line 152, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\execution.py", line 82, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\execution.py", line 75, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\nodes.py", line 1236, in sample
return common_ksampler(model, seed, steps, cfg, sampler_name, scheduler, positive, negative, latent_image, denoise=denoise)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\nodes.py", line 1206, in common_ksampler
samples = comfy.sample.sample(model, noise, steps, cfg, sampler_name, scheduler, positive, negative, latent_image,
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-Impact-Pack\modules\impact\sample_error_enhancer.py", line 22, in informative_sample
raise e
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-Impact-Pack\modules\impact\sample_error_enhancer.py", line 9, in informative_sample
return original_sample(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 161, in animatediff_sample
return wrap_function_to_inject_xformers_bug_info(orig_comfy_sample)(model, *args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\model_utils.py", line 144, in wrapped_function
return function_to_wrap(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\sample.py", line 93, in sample
samples = sampler.sample(noise, positive_copy, negative_copy, cfg=cfg, latent_image=latent_image, start_step=start_step, last_step=last_step, force_full_denoise=force_full_denoise, denoise_mask=noise_mask, sigmas=sigmas, callback=callback, disable_pbar=disable_pbar, seed=seed)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 742, in sample
samples = getattr(k_diffusion_sampling, "sample_{}".format(self.sampler))(self.model_k, noise, sigmas, extra_args=extra_args, callback=k_callback, disable=disable_pbar)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\utils\_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\k_diffusion\sampling.py", line 137, in sample_euler
denoised = model(x, sigma_hat * s_in, **extra_args)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 323, in forward
out = self.inner_model(x, sigma, cond=cond, uncond=uncond, cond_scale=cond_scale, cond_concat=cond_concat, model_options=model_options, seed=seed)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\k_diffusion\external.py", line 125, in forward
eps = self.get_eps(input * c_in, self.sigma_to_t(sigma), **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\k_diffusion\external.py", line 151, in get_eps
return self.inner_model.apply_model(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 311, in apply_model
out = sampling_function(self.inner_model.apply_model, x, timestep, uncond, cond, cond_scale, cond_concat, model_options=model_options, seed=seed)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 527, in sliding_sampling_function
cond, uncond = calc_cond_uncond_batch(model_function, cond, uncond, x, timestep, max_total_area, cond_concat, model_options)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 427, in calc_cond_uncond_batch
output = model_function(input_x, timestep_, **c).chunk(batch_chunks)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\model_base.py", line 63, in apply_model
return self.diffusion_model(xc, t, context=context, y=c_adm, control=control, transformer_options=transformer_options).float()
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\SeargeSDXL\modules\custom_sdxl_ksampler.py", line 70, in new_unet_forward
x0 = old_unet_forward(self, x, timesteps, context, y, control, transformer_options, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\ldm\modules\diffusionmodules\openaimodel.py", line 659, in forward
h = forward_timestep_embed(module, h, emb, context, transformer_options, output_shape)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 71, in forward_timestep_embed
x = layer(x, context)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\motion_module.py", line 398, in forward
return self.temporal_transformer(input_tensor, encoder_hidden_states, attention_mask)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\motion_module.py", line 461, in forward
hidden_states = self.norm(hidden_states)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 160, in new_forward
args, kwargs = module._hf_hook.pre_forward(module, *args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 104, in pre_forward
args, kwargs = hook.pre_forward(module, *args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 286, in pre_forward
set_module_tensor_to_device(
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\utils\modeling.py", line 298, in set_module_tensor_to_device
new_value = value.to(device)!!! Exception during processing !!!
Traceback (most recent call last):
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\execution.py", line 152, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\execution.py", line 82, in get_output_data
return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\execution.py", line 75, in map_node_over_list
results.append(getattr(obj, func)(**slice_dict(input_data_all, i)))
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\nodes.py", line 1236, in sample
return common_ksampler(model, seed, steps, cfg, sampler_name, scheduler, positive, negative, latent_image, denoise=denoise)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\nodes.py", line 1206, in common_ksampler
samples = comfy.sample.sample(model, noise, steps, cfg, sampler_name, scheduler, positive, negative, latent_image,
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-Impact-Pack\modules\impact\sample_error_enhancer.py", line 22, in informative_sample
raise e
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-Impact-Pack\modules\impact\sample_error_enhancer.py", line 9, in informative_sample
return original_sample(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 161, in animatediff_sample
return wrap_function_to_inject_xformers_bug_info(orig_comfy_sample)(model, *args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\model_utils.py", line 144, in wrapped_function
return function_to_wrap(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\sample.py", line 93, in sample
samples = sampler.sample(noise, positive_copy, negative_copy, cfg=cfg, latent_image=latent_image, start_step=start_step, last_step=last_step, force_full_denoise=force_full_denoise, denoise_mask=noise_mask, sigmas=sigmas, callback=callback, disable_pbar=disable_pbar, seed=seed)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 742, in sample
samples = getattr(k_diffusion_sampling, "sample_{}".format(self.sampler))(self.model_k, noise, sigmas, extra_args=extra_args, callback=k_callback, disable=disable_pbar)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\utils\_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\k_diffusion\sampling.py", line 137, in sample_euler
denoised = model(x, sigma_hat * s_in, **extra_args)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 323, in forward
out = self.inner_model(x, sigma, cond=cond, uncond=uncond, cond_scale=cond_scale, cond_concat=cond_concat, model_options=model_options, seed=seed)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\k_diffusion\external.py", line 125, in forward
eps = self.get_eps(input * c_in, self.sigma_to_t(sigma), **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\k_diffusion\external.py", line 151, in get_eps
return self.inner_model.apply_model(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\samplers.py", line 311, in apply_model
out = sampling_function(self.inner_model.apply_model, x, timestep, uncond, cond, cond_scale, cond_concat, model_options=model_options, seed=seed)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 527, in sliding_sampling_function
cond, uncond = calc_cond_uncond_batch(model_function, cond, uncond, x, timestep, max_total_area, cond_concat, model_options)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 427, in calc_cond_uncond_batch
output = model_function(input_x, timestep_, **c).chunk(batch_chunks)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\model_base.py", line 63, in apply_model
return self.diffusion_model(xc, t, context=context, y=c_adm, control=control, transformer_options=transformer_options).float()
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\SeargeSDXL\modules\custom_sdxl_ksampler.py", line 70, in new_unet_forward
x0 = old_unet_forward(self, x, timesteps, context, y, control, transformer_options, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\comfy\ldm\modules\diffusionmodules\openaimodel.py", line 659, in forward
h = forward_timestep_embed(module, h, emb, context, transformer_options, output_shape)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\sampling.py", line 71, in forward_timestep_embed
x = layer(x, context)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\motion_module.py", line 398, in forward
return self.temporal_transformer(input_tensor, encoder_hidden_states, attention_mask)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\motion_module.py", line 461, in forward
hidden_states = self.norm(hidden_states)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 160, in new_forward
args, kwargs = module._hf_hook.pre_forward(module, *args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 104, in pre_forward
args, kwargs = hook.pre_forward(module, *args, **kwargs)
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\hooks.py", line 286, in pre_forward
set_module_tensor_to_device(
File "F:\Stable_diffusion\ComfyUI_windows_portable\python_embeded\lib\site-packages\accelerate\utils\modeling.py", line 298, in set_module_tensor_to_device
new_value = value.to(device)
NotImplementedError: Cannot copy out of meta tensor; no data!Hi, I heard about you nodes on discord and am really interested in trying them out, but for some reason, the Animate Diff loader is misbehaving. When I first load it the model name reads "null," when I click on again it changes to "undefined" but it won't let me load the model. . . I have downloaded the model that is suggested but it won't let me lod it, or anything for that matter. . .Several devs have done major updates in the last week, I wonder if one of them broke you nodes. . .
Who can tell me What's new main features between with ArtVentureX's AnimateDiff ? Thank you!
This looks amazing. I have gotten the automatic1111 version to work on 8gb vram but it takes over 6 minutes to generate a 2 second gif. When I had a 4090 it took about 20 seconds.
Now that I only this 8GB VRAM laptop, do you think this version would work before I install everything? Thanks!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
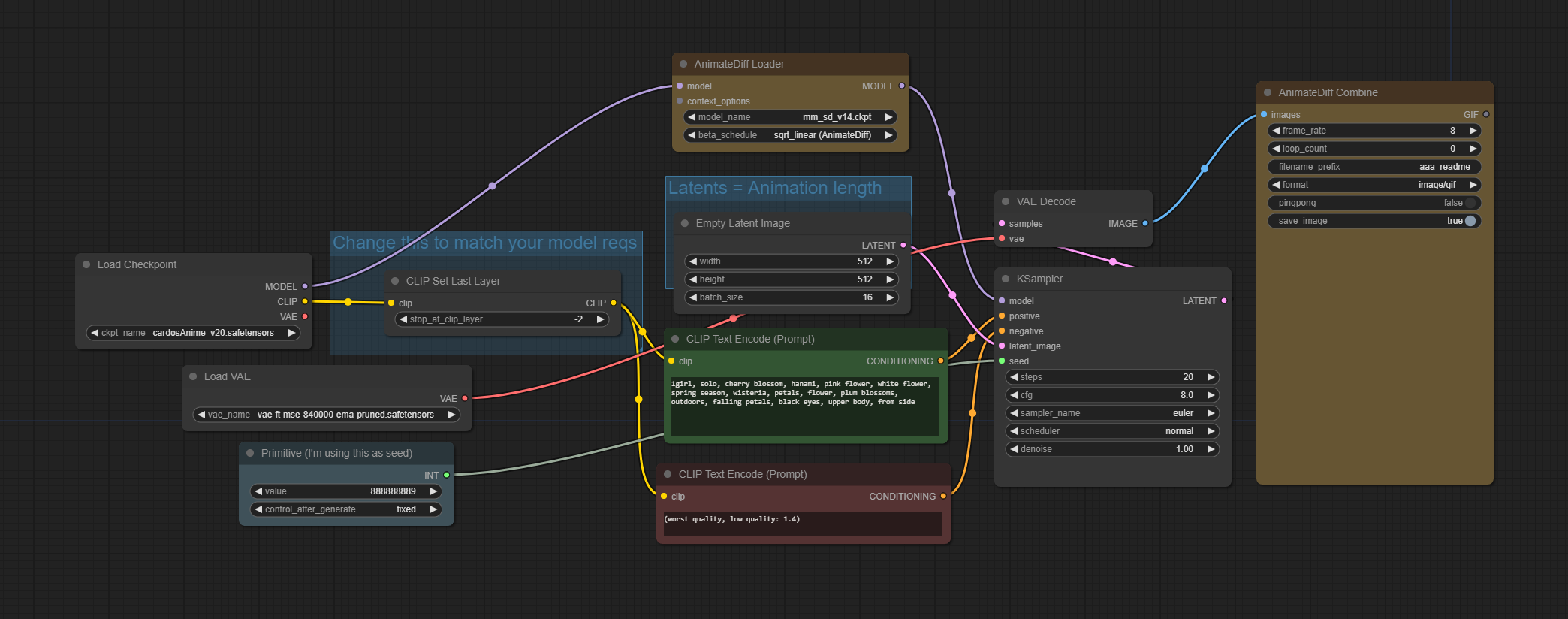{kind=link}
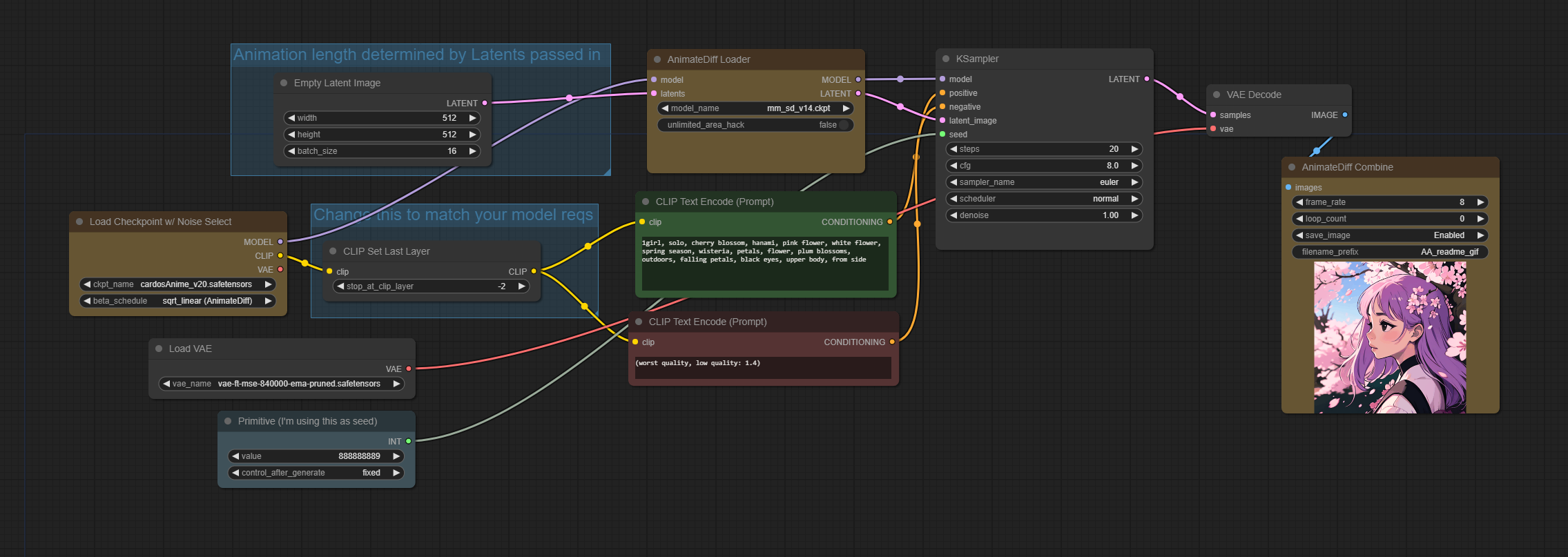{kind=link}