The stuff below might be incorrect. I am anything but an expert on PID calibration and none of the below has been checked by the PIDCalib group. It reflects the status of my mind, and I hope it will be helpful, but please read with caution.
We are using the PID variables to describe how much the particle in a track behaves like a certain particle type. They tell us things like: "This particle looks much more like a Kaon than a Muon". If we then select for particles that look very much like Kaons, we get a sample where most of the particles are actually, in fact, true Kaons. This is obviously very useful. To give an example, let's say that particle_PIDp is a measure for how much the particle looks like a proton. The higher the value, the more the algorithm thinks it is a proton.
The PID information is calculated by an algorithm that takes into account various features of the event. The problem is that in our simulated data ("Monte Carlo"), we are currently still unable to simulate all of these features precisely enough. That means that the PID information we calculated on simulated data is incorrect. We are usually a bit to good in recognizing the particle: For a particle that is simulated to be a proton ("true proton"), the proton_PIDp tends to be too high.
This means that if we try to measure the efficieny of, for example, a cut on the proton_PIDp on Monte Carlo, we are getting it wrong. And if we use the PID as an input for a multivariate classifier, we are getting an incorrect response.
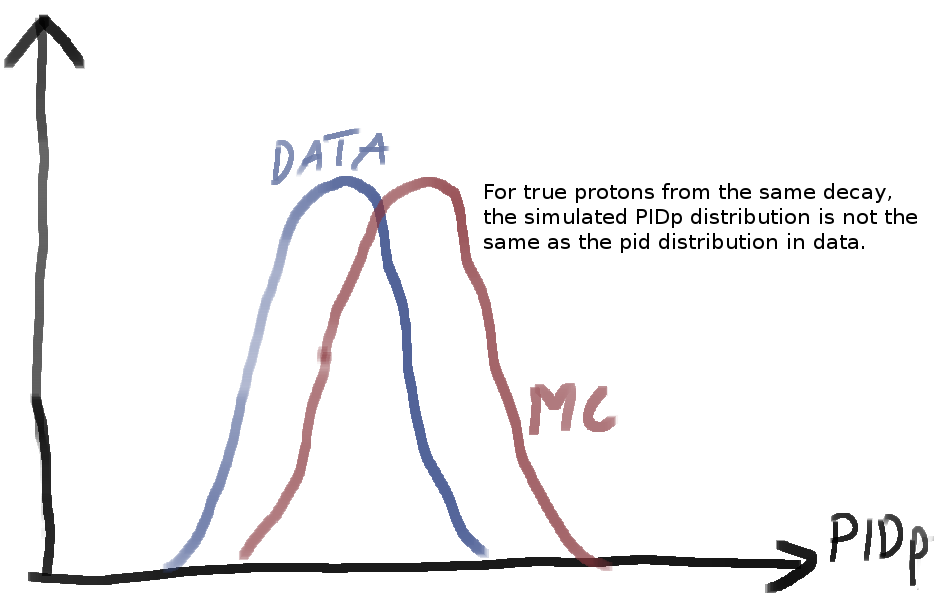
It turns out that, the probability distribution of the PID response (particle_PIDp,particle_PIDK, ...) is approximately a function of
- The true particle type
- The particle momentum
- The event multiplicity (how many charged tracks are in the event)
- The pseudo rapidity of the particle
This functional dependency is (approximately) independent of the decay.
(The above holds for the DLL - typle PID. For the ProbNN - variables, which give PID information using neural networks, this procedure has not yet been established!)
Another way of saying this would be: For a sample of tracks of a given true particle, the distribution of the PID response in a bin of P, ETA and nTracks is the same among different decays. The good thing is that we know the true particle type in Monte Carlo (because that's how we simulated it) and the other 3 variables are reasonably well simulated as well.

In order to obtain the true distribution of the PID variables in bins of P, ETA, nTracks, we need a "clean" data sample where we have all particles correctly identified. (Without cutting on the PID). In this data sample, all particles reconstruced as, say, Kaon, must actually be true Kaons. It is the task of the PIDCalib group to provide these data samples.
The trick is to throw away the PID variables in our Monte Carlo samples (only there) and create new ones. (That's why it is called "PID resampling", not "PID reweighting".)
First we take a clean data sample for the particle type who's PID we want to resample and bin it in bins of P, ETA and nTracks of the corresponding particle.
Then we can resample. For each event and track in Monte Carlo:
- We look at the
P,ETAandnTracksvariable of the concerned track in the MC event. - In the clean data sample for the track type, we find all events that are in the corresponding bin of
P,ETAandnTracks. - From multi-dimensional distribution of the PID variables in this bin, we draw an event (or point in a histogram) and take its PID values as the PID values for the corresponding event in MC.
There are multiple scripts in LHCb who are designed to do this. I participated in writing lhcb_pid_resample which attempts to be especially transparent and user-friendly.
(Somebody please confirm the following)
- Use it to get a feel for the PID response in your signal channel
- Use it to quickly optimize your preselection.
- Use it (if you're confident) to train a multivariate classifier (no warranty).
- Don't use it to calculate the efficiency of a single orthogonal cut. For reasons listed below, is more precise to direcly measure the efficiency on data for each kinematic bin.
In order to remove the remaining background in the clean data samples, the PIDCalib group calculates s-weights (can somebody point me to a good reference for this) for each event. This "weights away" the remaining background from the PID distributions. However, because S-weights can be negative and because the conditions for a successful S-weighting can not always be fulfilled, it can happen that in some bins of P, ETA , nTracks, a PID distribution may look like this:
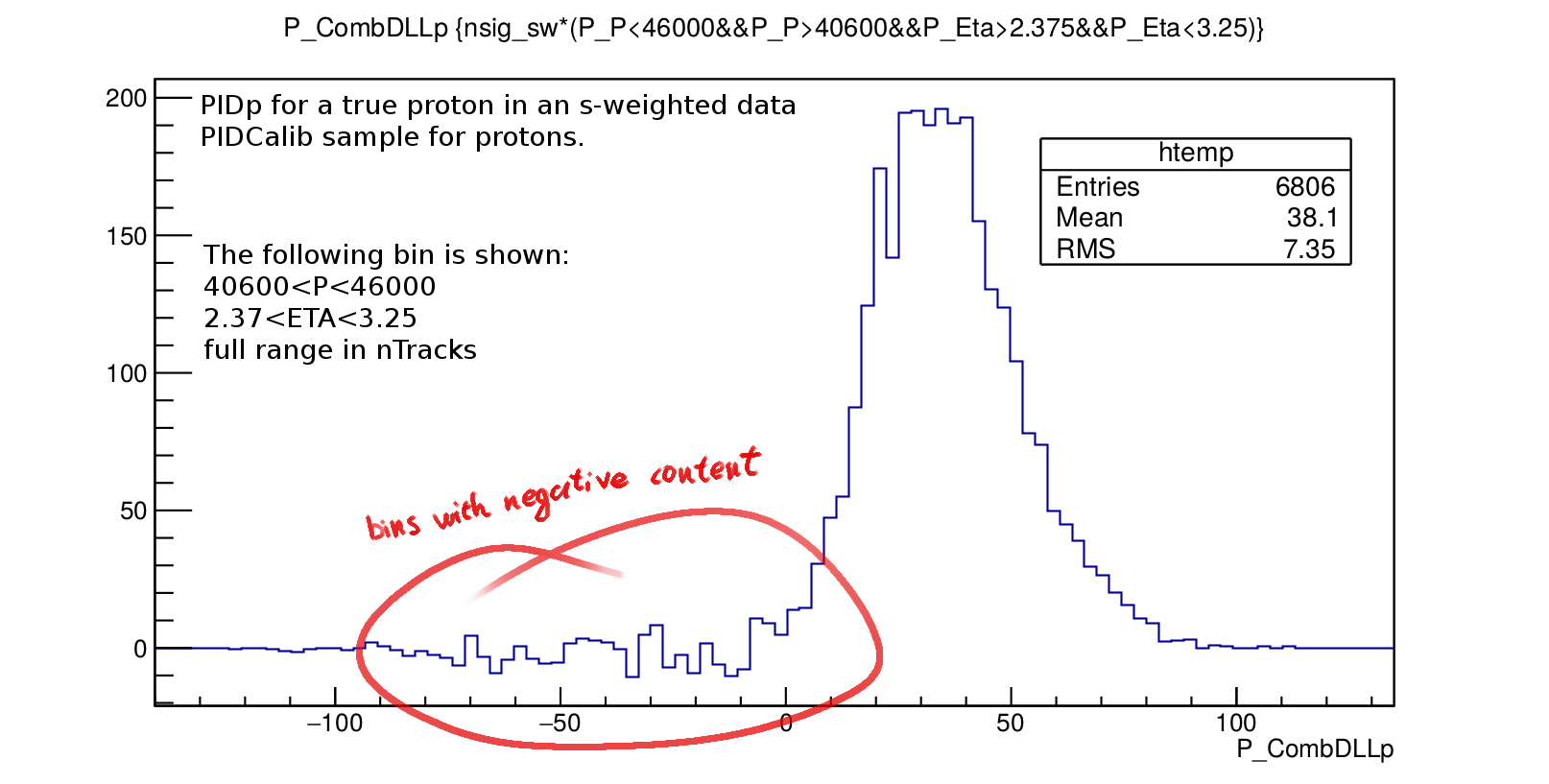
There are quite a few negative bins in the above plot, and choosing a coarser binning likely won't fix it. In order to randomly draw from this distribution when resampling, one has no other choice (?) than to set these negative bins to zero. Are those fluctuations where the s-weights can't do their job due to low statistics or is it caused by an incorrect mass fit? No matter what, we must assume that in other kinematic bins there were equivalent upward fluctuations in the PID bins which are here negative. In total one creates a bias where the resampled distribution has to many events in the affected area.
This effect can be reduced if we just want to know the efficiency of a cut. In this case we integrate the s-weighted number of events up to the cut point and divide by the full norm. I don't understand s-weights enought to make qualified statements about this, but while I think it doesn't fully resolve the underlying issue, it does certainly mitigate it to a certain degree. There is a function in the PIDCalib Package, MakePerfHistsRunRange.py which seems to do exactly this, though I haven't tested it yet.



