kmkolasinski / deep-learning-notes Goto Github PK
View Code? Open in Web Editor NEWExperiments with Deep Learning
Experiments with Deep Learning

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")


































































































































































I am trying to run and understand 2.Demo_optimize_bullet_trajectory.ipynb in seminars/2019-03-Neural-Ordinary-Differential-Equations but when I arrive at the line where you want to import a few things from the module "neural_ode" my python install doesn't seem to be able to find it. I tried searching for the module but to no avail. My installed python version is 3.6.8 my tensorflow version is 2.1.0 with cuda version 10.1 and cuDNN 7.6.5
In Neural_ode.py, we're using the tf automatic differentiation API for calculating the differential, so do we use the adjoint method to calculate the gradient? Sorry but getting a little mixed up here. Thank you.
Thanks for sharing your amazing notes! In /seminars/2018-10-Normalizing-Flows-NICE-RealNVP-GLOW/2018.10.10_Normalizing_Flows_NICE_RealNVP_GLOW.pdf page 9, the expression for the normalizing flow has a typo in the numerator of the Jacobian:

z should be f, as in the original paper by Rezende (2016):

**Hi, I want to use your solver in CIFAR10 training with ResNet-32. I used the tensorflow official code (https://github.com/tensorflow/models/tree/master/official/resnet).
I only changed one line of code in https://github.com/tensorflow/models/blob/master/official/resnet/resnet_run_loop.py**
#optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate, momentum=momentum) optimizer = tf_opt.AdaptiveNormalizedSGD(lr=0.1, norm_type='std')
but I got the following errors:
Traceback (most recent call last):
File "cifar10_main.py", line 260, in
absl_app.run(main)
File "/home/user/tensorflow3/lib/python3.5/site-packages/absl/app.py", line 274, in run
_run_main(main, argv)
File "/home/user/tensorflow3/lib/python3.5/site-packages/absl/app.py", line 238, in _run_main
sys.exit(main(argv))
File "cifar10_main.py", line 254, in main
run_cifar(flags.FLAGS)
File "/usr/lib/python3.5/contextlib.py", line 77, in exit
self.gen.throw(type, value, traceback)
File "/home/user/models_base/models/official/utils/logs/logger.py", line 100, in benchmark_context
yield
File "cifar10_main.py", line 254, in main
run_cifar(flags.FLAGS)
File "cifar10_main.py", line 249, in run_cifar
shape=[_HEIGHT, _WIDTH, _NUM_CHANNELS])
File "/home/user/models_base/models/official/resnet/resnet_run_loop.py", line 415, in resnet_main
max_steps=flags_obj.max_train_steps)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/estimator/estimator.py", line 363, in train
loss = self._train_model(input_fn, hooks, saving_listeners)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/estimator/estimator.py", line 841, in _train_model
return self._train_model_distributed(input_fn, hooks, saving_listeners)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/estimator/estimator.py", line 977, in _train_model_distributed
saving_listeners)
File "/usr/lib/python3.5/contextlib.py", line 77, in exit
self.gen.throw(type, value, traceback)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/framework/ops.py", line 5265, in get_controller
yield g
File "/usr/lib/python3.5/contextlib.py", line 77, in exit
self.gen.throw(type, value, traceback)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/framework/ops.py", line 5060, in get_controller
yield default
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/framework/ops.py", line 5265, in get_controller
yield g
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/estimator/estimator.py", line 977, in _train_model_distributed
saving_listeners)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/training/distribute.py", line 304, in exit
self._var_creator_scope.exit(exception_type, exception_value, traceback)
File "/usr/lib/python3.5/contextlib.py", line 77, in exit
self.gen.throw(type, value, traceback)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/ops/variable_scope.py", line 2283, in variable_creator_scope
yield
File "/usr/lib/python3.5/contextlib.py", line 77, in exit
self.gen.throw(type, value, traceback)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/framework/ops.py", line 2939, in _variable_creator_scope
yield
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/ops/variable_scope.py", line 2283, in variable_creator_scope
yield
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/estimator/estimator.py", line 884, in _train_model_distributed
self.config)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/training/distribute.py", line 756, in call_for_each_tower
return self._call_for_each_tower(fn, *args, **kwargs)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/contrib/distribute/python/one_device_strategy.py", line 78, in _call_for_each_tower
return fn(*args, **kwargs)
File "/usr/lib/python3.5/contextlib.py", line 77, in exit
self.gen.throw(type, value, traceback)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/framework/ops.py", line 4338, in device
yield
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/contrib/distribute/python/one_device_strategy.py", line 78, in _call_for_each_tower
return fn(*args, **kwargs)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/estimator/estimator.py", line 831, in _call_model_fn
model_fn_results = self._model_fn(features=features, **kwargs)
File "cifar10_main.py", line 224, in cifar10_model_fn
dtype=params['dtype']
File "/home/user/models_base/models/official/resnet/resnet_run_loop.py", line 296, in resnet_model_fn
minimize_op = optimizer.minimize(loss, global_step)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/training/optimizer.py", line 424, in minimize
name=name)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/training/optimizer.py", line 572, in apply_gradients
self._distributed_apply, grads_and_vars, global_step, name)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/training/distribute.py", line 1045, in merge_call
return self._merge_call(merge_fn, *args, **kwargs)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/training/distribute.py", line 1052, in _merge_call
return merge_fn(self._distribution_strategy, *args, **kwargs)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/training/optimizer.py", line 729, in _distributed_apply
return apply_updates
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/framework/ops.py", line 5991, in exit
self._name_scope.exit(type_arg, value_arg, traceback_arg)
File "/usr/lib/python3.5/contextlib.py", line 77, in exit
self.gen.throw(type, value, traceback)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/framework/ops.py", line 4115, in name_scope
yield "" if new_stack is None else new_stack + "/"
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/training/optimizer.py", line 702, in _distributed_apply
for grad, var in grads_and_vars
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/training/optimizer.py", line 703, in
for op in distribution.unwrap(distribution.update(var, update, grad))
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/training/distribute.py", line 838, in update
return self._update(var, fn, *args, **kwargs)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/contrib/distribute/python/one_device_strategy.py", line 99, in _update
return fn(var, *args, **kwargs)
File "/usr/lib/python3.5/contextlib.py", line 77, in exit
self.gen.throw(type, value, traceback)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/framework/ops.py", line 4338, in device
yield
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/contrib/distribute/python/one_device_strategy.py", line 99, in _update
return fn(var, *args, **kwargs)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/training/optimizer.py", line 695, in update
return p.update_op(self, g)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/framework/ops.py", line 5991, in exit
self._name_scope.exit(type_arg, value_arg, traceback_arg)
File "/usr/lib/python3.5/contextlib.py", line 77, in exit
self.gen.throw(type, value, traceback)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/framework/ops.py", line 4115, in name_scope
yield "" if new_stack is None else new_stack + "/"
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/training/optimizer.py", line 695, in update
return p.update_op(self, g)
File "/usr/lib/python3.5/contextlib.py", line 77, in exit
self.gen.throw(type, value, traceback)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/eager/context.py", line 514, in device_policy
yield
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/training/optimizer.py", line 695, in update
return p.update_op(self, g)
File "/home/user/tensorflow3/lib/python3.5/site-packages/tensorflow/python/training/optimizer.py", line 165, in update_op
update_op = optimizer._resource_apply_dense(g, self._v)
File "/home/user/deep-learning-notes/max-normed-optimizer/src/tf_optimizer.py", line 350, in _resource_apply_dense
raise NotImplementedError("Resource apply dense not implemented.")
NotImplementedError: Resource apply dense not implemented.
Hi,
I am just getting my feet wet with this material so I apologize if this is a naive question.
The spiral problem you showed for NeuralODE has two outputs, one input (time), and unknown matrix coefficients. How would one implement an ODE in the same fashion with multiple time-dependent features, in addition to time itself?
Hi,
I was analyzing you results in this notebook and I found some bugs/incorrect approach:
validation acc and loss, in fact, you plot training data. This is why momentum method is so low.Check my runs, I think that I trained models correctly and displayed charts also.
https://gist.github.com/melgor/e106ff0e712534d267a2a1851b6fc299
Also, I've made some other experiments regarding Normalization of gradient in Resnet18 in CIFAR-10. And currently I'm not able to match results of SGD + Momentum (I use my own implementation in PyTorch, I did use L2, L1 and Max normalization, STD normalization still on my list)
Hi Krzysztof,
I’m interested in using your codes for my project.
Do you have a license guideline? (Or could you upload a LICENSE file?)
Best,
Ed
Hi, I just learned your oversampling example, it's help me a lot. And I want to know where the sampling method come from in your example? Can you give me the specific paper name of the sampling method?
Thanks!
Hi Krzysztof,
I'm studying Glow with your code and being confused about y and z, please let me ask some questions.
Q.1
My understanding is as follows:
So eventually, when we take the latent representation for a particular x, it should be concate([z,y]), am I correct?
Q.2
I want to know well about the below that is from your slide:
For p(y),
- we want to y keep the information about the image
For p(z),
- we want to p(z) keep the noise,
It means that y will be input to the next flow, so p(y) is possibly still a flexible form, i.e., not Gaussianized yet. The form of non-Gaussian can be interpreted as "keep the information about the image". Am I correct?
In addition, regarding the bellow:
For p(z),
- we could train model with different penalties for p(y) and p(z)
What does it mean? Specifically, which line in the code does correspond to that?
I'm afraid of asking many questions, but I'm looking forward to hearing from you.
Hi Krzysztof,
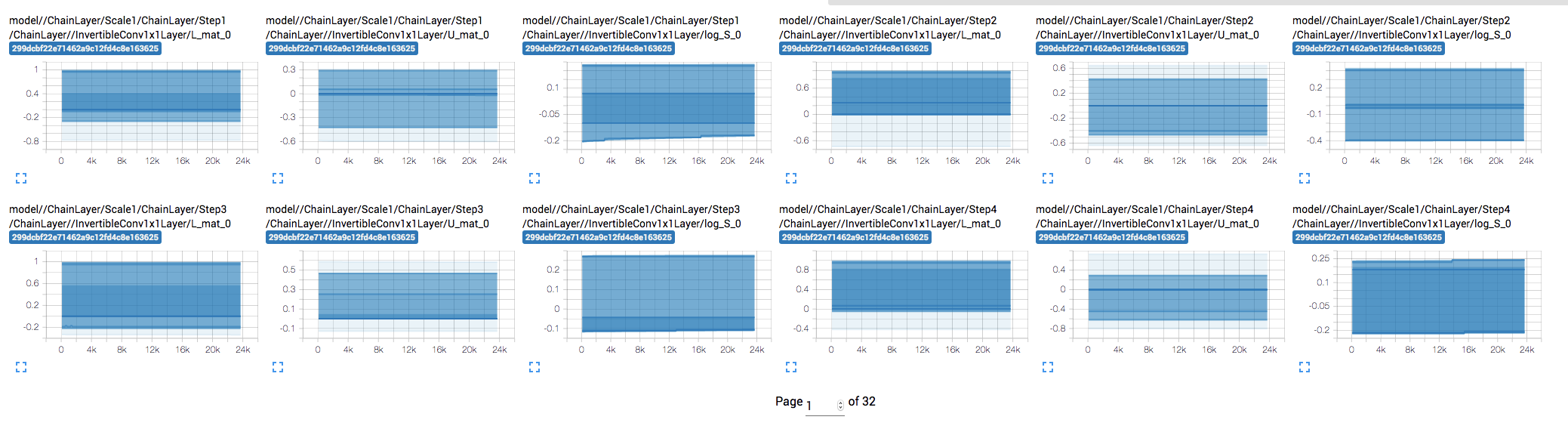
When visualizing the distribution of weights and gradients of each tensor over training, I noticed that some the weights don't seem to be updating. E.g. InvertibleConv1x1Layer's U_mat, L_mat, and log_S.
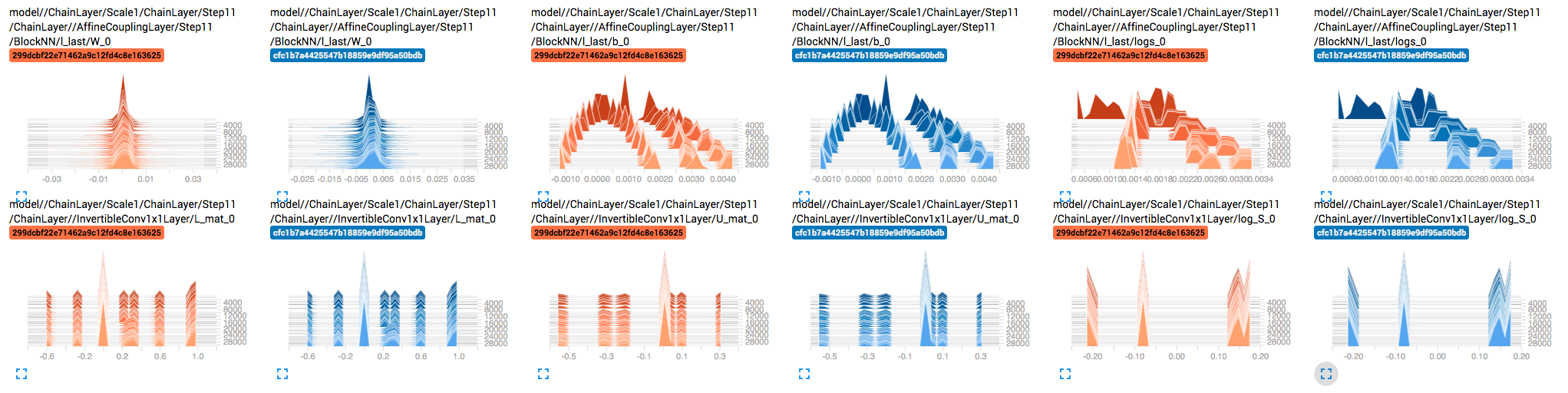
My first thought was that maybe the gradients are too small, but it doesn't look like that's the case:
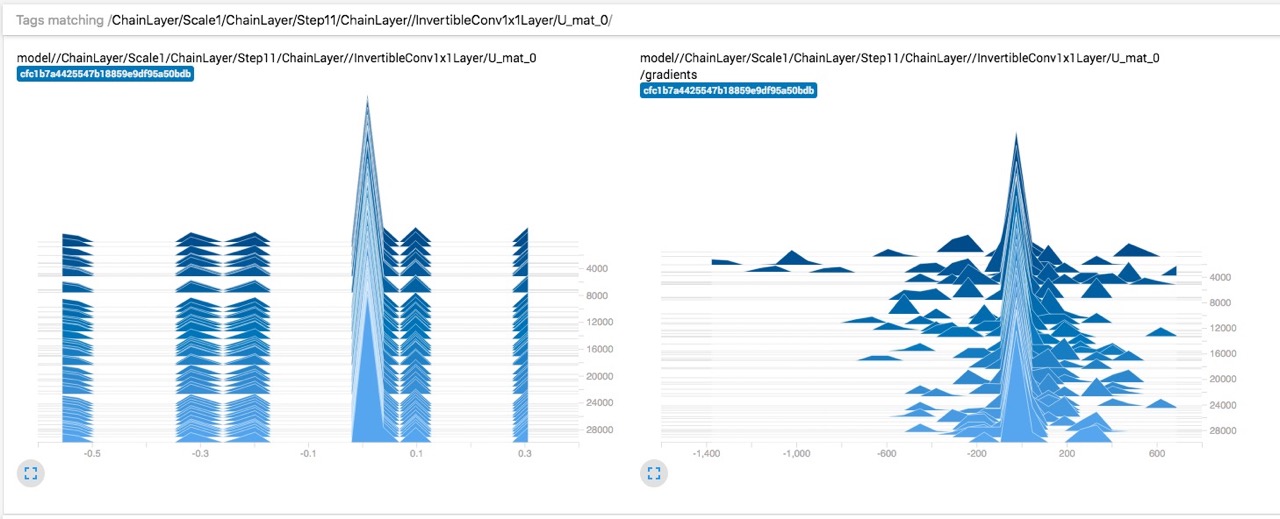
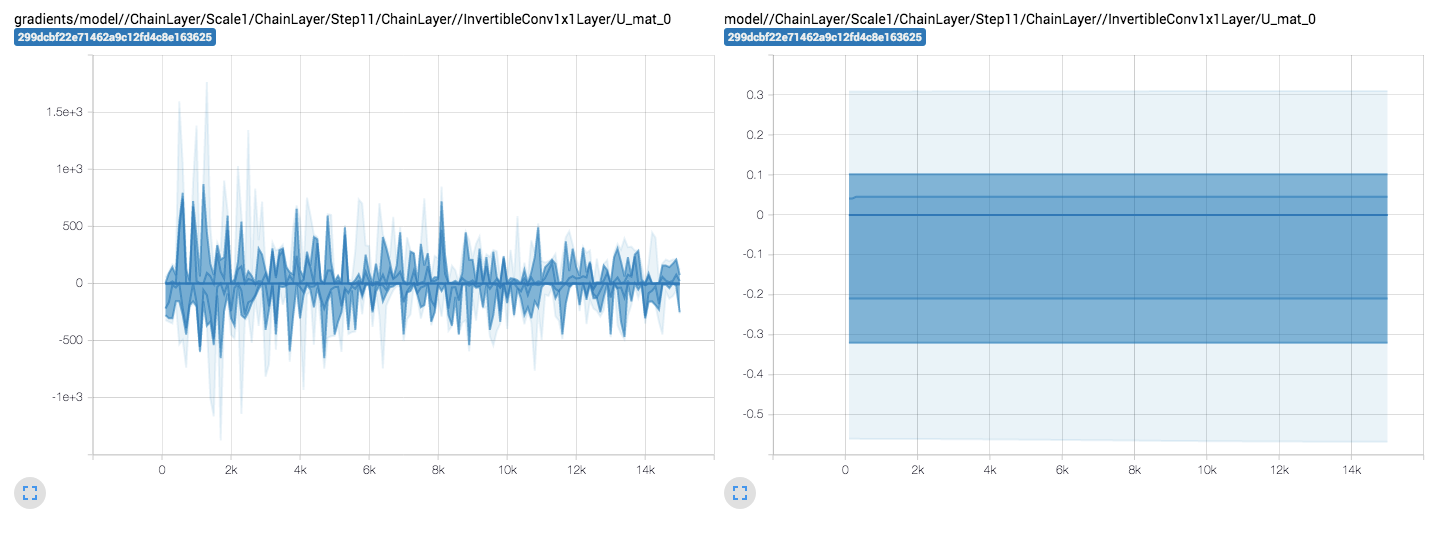
Weights remain mostly constant:
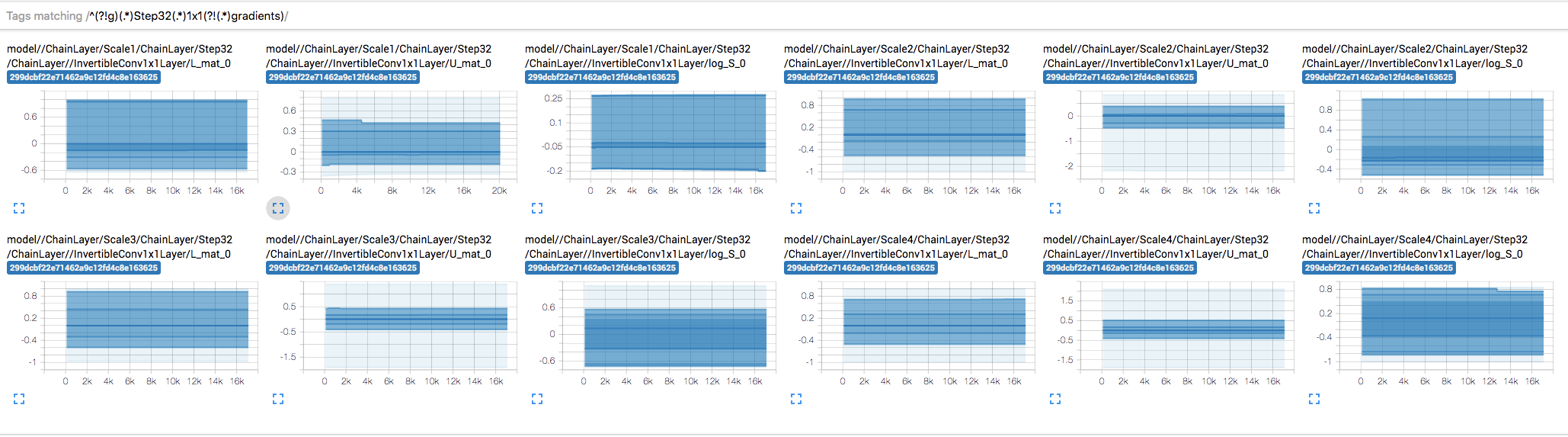
But gradients are... pretty explosive 😔
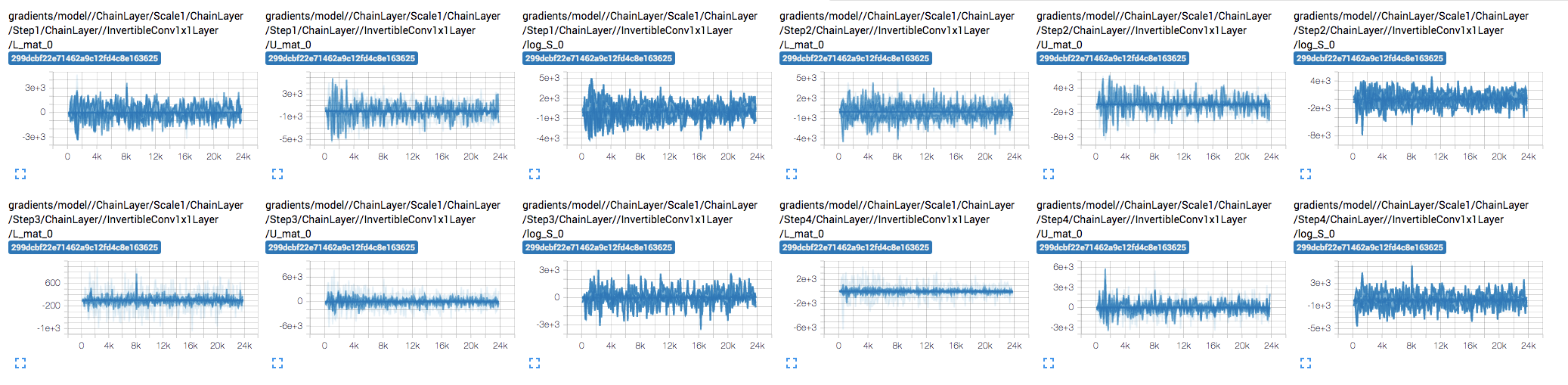
I didn't change the core code and used the high-level API, but trained it on a different task and it is plugged into a larger model.
I will try running the original example you provided and report back with that, but in the meantime I was wondering if you (or anyone else) had any early ideas about this. Thanks!
Hey,
I may be way out of line here, but I stumbled across your talk "Poincaré Embeddings for
Learning Hierarchical Representations" and I was wondering if you could shed some light on a related problem. I've described it in more detail here https://datascience.stackexchange.com/questions/56889/hyperbolic-coordinates-poincar%c3%a9-embeddings-as-the-output-of-a-neural-network
But basically I have an encoder (for some some sentences) and an output on a Poincaré ball that was pretrained using the Gensim implementation. I have supervised training data for that mapping. The goal is to use the encoder to predict points on the ball, basically it's an entity linking task. So an encoded fragment like "the river bank" would map to the "river bank" point in a hyperbolically embedded ontology (like WordNet). However I can't seem to get it to work, would really love to hear your ideas on this :-)
Hi Krzysztof,
Is there a bibtex for citation of your Glow code?
If not, I would like to refer to this github url, don’t you mind?
Let's say I have a system that I'd like to describe as x_dot = x+u and given information about when and for how long u was applied; I wish to predict the evolution of x_t+k given x_t and u_t. Ideally, I want the model to be able to generalize for any value of u. For example, a cartpole with initial conditions x and theta, and an input force F.
Can the neural ODE framework deal with x_dot being f(x, u)? How do I go about including this input parameterization in the neural ODE framework? My first thought was to just augment the input state with the time dependent value of u when passing it to the neural network, under the hope that the NN will resolve the relationship between the x_t and u_t when predicting x_t+1, but I haven't had much success with that yet.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.