->Original rentrys (news) https://rentry.org/sdupdates3 (non-news) https://rentry.org/sdgoldmine<- ->Old stuff here https://rentry.org/sdupdates2 and here https://rentry.org/sdupdates<-
!!! danger Warnings:
1. Ckpts/hypernetworks/embeddings are ==not== interently safe as of right now. They can be pickled/contain malicious code. Use your common sense and protect yourself as you would with any random download link you would see on the internet.
2. Monitor your GPU temps and increase cooling and/or undervolt them if you need to. There have been claims of GPU issues due to high temps.
3. Extensions can change code when they're ran. Be careful Check the news for more information
!!! info There is now a github for this rentry: https://github.com/questianon/sdupdates. This should allow you to see changes across the different updates
!!! note Changelog: everything except discord and reddit
All rentry links are ended with a '.org' here and can be changed to a '.co'. Also, use incognito/private browsing when opening google links, else you lose your anonymity / someone may dox you
If you have information/files (e.g. embed) not on this list, have questions, or want to help, please contact me with details
Socials: Trip: questianon !!YbTGdICxQOw Discord: malt#6065 Reddit: u/questianon Github: https://github.com/questianon Twitter: https://twitter.com/questianon)
!!! note Don't forget to git pull to get a lot of new optimizations + updates, if SD breaks go backward in commits until it starts working again
Instructions:
* If on Windows:
1. navigate to the webui directory through command prompt or git bash
a. Git bash: right click > git bash here
b. Command prompt: click the spot in the "url" between the folder and the down arrow and type "command prompt".
c. If you don't know how to do this, open command prompt, type "cd [path to stable-diffusion-webui]" (you can get this by right clicking the folder in the "url" or holding shift + right clicking the stable-diffusion-webui folder)
2. git pull
3. pip install -r requirements.txt
* If on Linux:
1. go to the webui directory
2. source ./venv/bin/activate
a. if this doesn't work, run python -m venv venv beforehand
3. git pull
4. pip install -r requirements.txt
11/13+11/14
- Watermark for img2img released?: https://github.com/MadryLab/photoguard
- Seems similar to https://github.com/ShieldMnt/invisible-watermark
- Self-signed TLS/HHTPS extension (not sure if it covers the system cert store for windows/linux/mac): https://github.com/papuSpartan/stable-diffusion-webui-auto-tls-https
- Cool demonstration of Stable Diffusion + production company (?): https://www.youtube.com/watch?v=QBWVHCYZ_Zs
- (Old but not implemented yet) Stabilize the sampling of DPM Solver++ 2M with a stabilizing trick: crowsonkb/k-diffusion#43 (comment)
- Edit to make: https://rentry.org/wf7pv
- Repo to train stable diffusion model with Diffusers, Hivemind and Pytorch Lightning released (according to anon: finetune NAI models with their blog mentioned enhancements): https://github.com/Mikubill/naifu-diffusion
11/11+11/12
- Open source SD model based on chinese text and images released: https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1
- To allow it to work with AUTOMATIC1111's webui (I think): https://github.com/IDEA-CCNL/stable-diffusion-webui/commit/61ece0cec1097ab8f5e2b52c8d340ca203c5917b
- Explicit padding in prompt (slightly old): AUTOMATIC1111/stable-diffusion-webui#2642
- Related, might help with prompting: AUTOMATIC1111/stable-diffusion-webui#2305
- DeviantArt released an AI image generator: https://twitter.com/DeviantArt/status/1591113199218487300
- Costs money for premium and is probably not as good as webui
- Immediately gets nerfed: https://www.deviantart.com/team/journal/UPDATE-All-Deviations-Are-Opted-Out-of-AI-Datasets-934500371
- Stable Diffusion with ColossalAI for training: https://github.com/hpcaitech/ColossalAI/tree/main/examples/images/diffusion
- 6.5x faster training and pretraining cost saving, the hardware cost of fine-tuning can be almost 7X cheaper (from RTX3090/4090 24GB to RTX3050/2070 8GB)
- Animating generated face test: https://www.reddit.com/r/StableDiffusion/comments/ys434h/animating_generated_face_test/
- Waifu Diffusion 1.4 Tagger (next iteration of deepdanbooru?): https://mega.nz/file/ptA2jSSB#G4INKHQG2x2pGAVQBn-yd_U5dMgevGF8YYM9CR_R1SY
- Waifu Diffusion dev (SD training labs server): https://discord.com/channels/1038249716149928046/1038249717001359402/1041160494150594671
- DreamArtist extension changes ui.py code in the modules directory
- Extension: https://github.com/7eu7d7/DreamArtist-sd-webui-extension
- Relevant code: https://github.com/7eu7d7/DreamArtist-sd-webui-extension/blob/9f65d05127a551e5dcf044ed6340510f3ba082f4/install.py#L15-L28
- Breaks itself and normal textual inversion until all the files in the repo are replaced with fresh copies
- Webui doesn't start after disabling the extension, because of the addition 'dream_artist_trigger'
- So far, it's not in the wiki extensions list and must be downloaded via repo url. If you want to download it, do it at your own risk
- To fix your install, do a
git stashandgit pull
- Automatically adjust hypernetwork learning rates based on how different the preview image is from the learning data (automate what trainers already do): AUTOMATIC1111/stable-diffusion-webui#4509
- Diffusion attentive attribution maps for interpreting Stable Diffusion (aka heat maps for what your prompt does): https://github.com/castorini/daam
- DeepDanbooru broken (not sure if fixed yet): AUTOMATIC1111/stable-diffusion-webui#4458
- macOS Finder right-click menu extension released: https://github.com/anastasiuspernat/UnderPillow
11/10
- WD 1.4 information:
- New Deepdanbooru for better tagging (prerelease right now)
- much better hands - look at 'Cafe Unofficial Instagram TEST Model Release' for a sample of what it can do in an unfinished model
- Trained off SD 1.5
- Creator: "In terms of general flexibility of being able to prompt a wide range of things, wd1.4 should be better than everything" (planned to supercede all current models, including NAI and anything.ckpt, to the point where you don't need to merge)
- Creator: "we may create our own version of hypernetworks and create fine tunes for anime and realistic styles"
- Creator: the instagram model training includes improvements such as:
- dynamic image aspect training (as in we trained images with ZERO cropping, the entire image is fed into SD all at once, even if it's landscape or portrait)
- unconditional training such that the model can somewhat self improve
- higher resolutions during training (640x640 max)
- much faster training code (6-8x performance increase)
- better training hyperparameters
- automated blip captioning of all images
- Dataset and associated tags will be public
- Haru and Cafe came up with a temporary plan that may be able to drastically improve the performance of clip without having to retrain clip from scratch, though it'll have to happen after wd1.4
- to prevent bleed from the images, each source will have a tag associated with it in the caption data when fed into SD
- Intel Arc (A770) can get ~5.2 it/s right now with unoptimized SD, fp16: https://github.com/rahulunair/stable_diffusion_arc
- NovelAI releases their Furry (Beta V1.2) model: https://twitter.com/novelaiofficial/status/1590814613201117184
- PR for inpainting with color: AUTOMATIC1111/stable-diffusion-webui#3865
- Models trained on synthetic data can be more accurate than other models in some cases, which could eliminate some privacy, copyright, and ethical concerns from using real data: https://news.mit.edu/2022/synthetic-data-ai-improvements-1103
- Japanese text to speech (sounds pretty good, can probably use for a VN): https://huggingface.co/spaces/skytnt/moe-tts
- VAE selector fixes: AUTOMATIC1111/stable-diffusion-webui#4214
- xformers collection of issues: AUTOMATIC1111/stable-diffusion-webui#2958 (comment)
- Berkeley working on a cheap way to train on the scale of SD using something like a 2070 (easy, efficient, and scalable distributed training): https://github.com/hpcaitech/ColossalAI
Google Docs with a prompt list/ranking/general info for waifu creation: https://docs.google.com/document/d/1Vw-OCUKNJHKZi7chUtjpDEIus112XBVSYHIATKi1q7s/edit?usp=sharing Ranked and calssibied danbooru tags, sorted by amount of pictures, and ranked by type and quality (WD): https://cdn.discordapp.com/attachments/1029235713989951578/1038585908934483999/Kopi_af_WAIFU_MASTER_PROMPT_DANBOORU_LIST.pdf Anon's prompt collection: https://mega.nz/folder/VHwF1Yga#sJhxeTuPKODgpN5h1ALTQg Tag effects on img: https://pastebin.com/GurXf9a4 Clothing comparison: https://files.catbox.moe/z3n66e.jpg
- Anon says that "8k, 4k, (highres:1.1), best quality, (masterpiece:1.3)" leads to nice details
Chinese scroll collection: https://note.com/sa1p/ Scroll 1: https://docs.qq.com/doc/DWHl3am5Zb05QbGVs
- Site: https://aiguidebook.top/
- Backup: https://www105.zippyshare.com/v/lUYn1pXB/file.html
- translated + download: https://mega.nz/folder/MssgiRoT#enJklumlGk1KDEY_2o-ViA
- another backup? https://note.com/sa1p/n/ne71c846326ac
- another another backup: https://files.catbox.moe/tmvjd7.zip
Scroll 2: https://docs.qq.com/doc/DWGh4QnZBVlJYRkly Scroll 3 (spooky): https://docs.qq.com/doc/DWEpNdERNbnBRZWNL Tome: https://docs.qq.com/doc/DSHBGRmRUUURjVmNM Tome 2 (missing link) Japanese Scroll: https://p1atdev.notion.site/021f27001f37435aacf3c84f2bc093b5?p=f9d8c61c4ed8471a9ca0d701d80f9e28
- author: https://twitter.com/p1atdev_art/ Japenese wiki: https://seesaawiki.jp/nai_ch/d/
Using emoticons and emojis can be really good: https://docs.google.com/spreadsheets/d/1aTYr4723NSPZul6AVYOX56CVA0YP3qPos8rg4RwVIzA/edit#gid=1453378351 🕊💥😱😲😶🙄 leads to https://files.catbox.moe/biy755.png 🌷🕊🗓👋😛👋 leads to https://files.catbox.moe/7khxe0.png spoken squiggle: https://twitter.com/AI_Illust_000/status/1588838369593032706 Anon: The emoji performs well in terms of semantic accuracy because it is only one character.
Database of prompts: https://publicprompts.art/
Hololive prompts: https://rentry.org/3y56t Hololive 2: https://rentry.org/q8x5y
Big negative: https://pastes.io/x9crpin0pq Fat negative: https://www.reddit.com/r/WaifuDiffusion/comments/yrpovu/img2img_from_my_own_loose_sketch/
Krea AI prompt database: https://github.com/krea-ai/open-prompts Prompt search: https://www.ptsearch.info/home/ Another search: http://novelai.io/ 4chan prompt search: https://desuarchive.org/g/search/text/masterpiece%20high%20quality/ Prompt book: https://openart.ai/promptbook Prompt word/phrase collection: https://huggingface.co/spaces/Gustavosta/MagicPrompt-Stable-Diffusion/raw/main/ideas.txt
Dynamic prompts: https://github.com/adieyal/sd-dynamic-prompts
- guide: https://www.reddit.com/r/StableDiffusion/comments/ynztiz/how_to_turbocharge_your_prompts_using/
Japanese prompt generator: https://magic-generator.herokuapp.com/ Build your prompt (chinese): https://tags.novelai.dev/ NAI Prompts: https://seesaawiki.jp/nai_ch/d/%c8%c7%b8%a2%a5%ad%a5%e3%a5%e9%ba%c6%b8%bd/%a5%a2%a5%cb%a5%e1%b7%cf
Japanese wiki: https://seesaawiki.jp/nai_ch/
- Apparently a good subwiki: https://seesaawiki.jp/nai_ch/d/%c7%ed%a4%ae%a5%b3%a5%e9%a5%c6%a5%af
Korean wiki: https://arca.live/b/aiart/60392904 Korean wiki 2: https://arca.live/b/aiart/60466181
Multilingual study: https://jalonso.notion.site/Stable-Diffusion-Language-Comprehension-5209abc77a4f4f999ec6c9b4a48a9ca2
Aesthetic value (imgs used to train SD): https://laion-aesthetic.datasette.io/laion-aesthetic-6pls
NAI to webui translator (not 100% accurate): https://seesaawiki.jp/nai_ch/d/%a5%d7%a5%ed%a5%f3%a5%d7%a5%c8%ca%d1%b4%b9
Prompt editing parts of image but without using img2img/inpaint/prompt editing guide by anon: https://files.catbox.moe/fglywg.JPG
Tip Dump: https://rentry.org/robs-novel-ai-tips Tips: https://github.com/TravelingRobot/NAI_Community_Research/wiki/NAI-Diffusion:-Various-Tips-&-Tricks Info dump of tips: https://rentry.org/Learnings Outdated guide: https://rentry.co/8vaaa Tip for more photorealism: https://www.reddit.com/r/StableDiffusion/comments/yhn6xx/comment/iuf1uxl/
- TLDR: add noise to your img before img2img
NAI prompt tips: https://docs.novelai.net/image/promptmixing.html NAI tips 2: https://docs.novelai.net/image/uifunctionalities.html
Masterpiece vs no masterpiece: https://desuarchive.org/g/thread/89714899#89715160
SD 1.4 vs 1.5: https://postimg.cc/gallery/mhvWsnx NAI vs Anything: https://www.bilibili.com/read/cv19603218 Model merge comparisons: https://files.catbox.moe/rcxqsi.png Model merge: https://files.catbox.moe/vgv44j.jpg Some sampler comparisons: https://www.reddit.com/r/StableDiffusion/comments/xmwcrx/a_comparison_between_8_samplers_for_5_different/ More comparisons: https://files.catbox.moe/csrjt5.jpg More: https://i.redd.it/o440iq04ocy91.jpg (https://www.reddit.com/r/StableDiffusion/comments/ynt7ap/another_new_sampler_steps_comparison/) More: https://i.redd.it/ck4ujoz2k6y91.jpg (https://www.reddit.com/r/StableDiffusion/comments/yn2yp2/automatic1111_added_more_samplers_so_heres_a/) Every sampler comparison: https://files.catbox.moe/u2d6mf.png
Prompt: 1girl, pointy ears, white hair, medium hair, ahoge, hair between eyes, green eyes, medium:small breasts, cyberpunk, hair strand, dynamic angle, cute, wide hips, blush, sharp eyes, ear piercing, happy, hair highlights, multicoloured hair, cybersuit, cyber gas mask, spaceship computers, ai core, spaceship interior Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, animal ears, panties
Original image: Steps: 50, Sampler: DDIM, CFG scale: 11, Seed: 3563250880, Size: 1024x1024, Model hash: cc024d46, Denoising strength: 0.57, Clip skip: 2, ENSD: 31337, First pass size: 512x512 NAI/SD mix at 0.25
New samplers: AUTOMATIC1111/stable-diffusion-webui#4363 New vs. DDIM: https://files.catbox.moe/5hfl9h.png
f222 comparisons: https://desuarchive.org/g/search/text/f222/filter/text/start/2022-11-01/
Deep Danbooru: https://github.com/KichangKim/DeepDanbooru Demo: https://huggingface.co/spaces/hysts/DeepDanbooru
Embedding tester: https://huggingface.co/spaces/sd-concepts-library/stable-diffusion-conceptualizer
Collection of Aesthetic Gradients: https://github.com/vicgalle/stable-diffusion-aesthetic-gradients/tree/main/aesthetic_embeddings
Euler vs. Euler A: AUTOMATIC1111/stable-diffusion-webui#2017 (comment)
- Euler: https://cdn.discordapp.com/attachments/1036718343140409354/1036719238607540296/euler.gif
- Euler A: https://cdn.discordapp.com/attachments/1036718343140409354/1036719239018590249/euler_a.gif
According to anon: DPM++ should converge to result much much faster than Euler does. It should still converge to the same result though.
Seed hunting:
- By nai speedrun asuka imgur anon:
made something that might help the highres seed/prompt hunters out there. this mimics the "0x0" firstpass calculation and suggests lowres dimensions based on target higheres size. it also shows data about firstpass cropping as well. it's a single file so you can download and use offline. picrel. https://preyx.github.io/sd-scale-calc/ view code and download from https://files.catbox.moe/8ml5et.html for example you can run "firstpass" lowres batches for seed/prompt hunting, then use them in firstpass size to preserve composition when making highres.
Script for tagging (like in NAI) in AUTOMATIC's webui: https://github.com/DominikDoom/a1111-sd-webui-tagcomplete Danbooru Tag Exporter: https://sleazyfork.org/en/scripts/452976-danbooru-tags-select-to-export Another: https://sleazyfork.org/en/scripts/453380-danbooru-tags-select-to-export-edited Tags (latest vers): https://sleazyfork.org/en/scripts/453304-get-booru-tags-edited Basic gelbooru scraper: https://pastebin.com/0yB9s338 UMI AI: https://www.patreon.com/klokinator
- Discord: https://discord.gg/9K7j7DTfG2
- Author is looking for help filling out and improving wildcards
- Ex: https://cdn.discordapp.com/attachments/1032201089929453578/1034546970179674122/Popular_Female_Characters.txt
- Author: Klokinator#0278
- Looking for wildcards with traits and tags of characters
- Code: https://github.com/Klokinator/UnivAICharGen/
Random Prompts: https://rentry.org/randomprompts Python script of generating random NSFW prompts: https://rentry.org/nsfw-random-prompt-gen Prompt randomizer: https://github.com/adieyal/sd-dynamic-prompting Prompt generator: https://github.com/h-a-te/prompt_generator
- apparently UMI uses these?
http://dalle2-prompt-generator.s3-website-us-west-2.amazonaws.com/ https://randomwordgenerator.com/ funny prompt gen that surprisingly works: https://www.grc.com/passwords.htm Unprompted extension released: https://github.com/ThereforeGames/unprompted
- HAS ADS
StylePile: https://github.com/some9000/StylePile script that pulls prompt from Krea.ai and Lexica.art based on search terms: https://github.com/Vetchems/sd-lexikrea randomize generation params for txt2img, works with other extensions: https://github.com/stysmmaker/stable-diffusion-webui-randomize
Ideas for when you have none: https://pentoprint.org/first-line-generator/ Colors: http://colorcode.is/search?q=pantone
- Image editor for SD for inpainting/outpainting/txt2img/img2img: https://github.com/BlinkDL/Hua
- https://www.painthua.com/ - New GUI focusing on Inpainting and Outpainting
- https://www.reddit.com/r/StableDiffusion/comments/ygp0iv/painthuacom_new_gui_focusing_on_inpainting_and/
- To use it with webui add this to webui-user.bat: --api --cors-allow-origins=https://www.painthua.com
- Vid: https://www.bilibili.com/video/BV16e4y1a7ne/
I didn't check the safety of these plugins, but they're open source, so you can check them yourself Photoshop/Krita plugin (free): https://internationaltd.github.io/defuser/ (kinda new and currently only 2 stars on github)
Photoshop: https://github.com/Invary/IvyPhotoshopDiffusion Photoshop plugin (paid, not open source): https://www.flyingdog.de/sd/ Krita plugins (free):
- https://github.com/sddebz/stable-diffusion-krita-plugin (listed in the OP, outdated? dead?)
- https://github.com/Interpause/auto-sd-paint-ext
- https://github.com/Interpause/auto-sd-krita (a fork from above, more improvement)
- https://www.flyingdog.de/sd/en/ (https://github.com/imperator-maximus/stable-diffusion-krita)
GIMP: https://github.com/blueturtleai/gimp-stable-diffusion
Blender: https://github.com/carson-katri/dream-textures https://github.com/benrugg/AI-Render
External masking: https://github.com/dfaker/stable-diffusion-webui-cv2-external-masking-script anon: theres a commanda rg for adding basic painting, its '--gradio-img2img-tool'
Script collection: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Custom-Scripts Prompt matrix tutorial: https://gigazine.net/gsc_news/en/20220909-automatic1111-stable-diffusion-webui-prompt-matrix/ Animation Script: https://github.com/amotile/stable-diffusion-studio Animation script 2: https://github.com/Animator-Anon/Animator Video Script: https://github.com/memes-forever/Stable-diffusion-webui-video Masking Script: https://github.com/dfaker/stable-diffusion-webui-cv2-external-masking-script XYZ Grid Script: https://github.com/xrpgame/xyz_plot_script Vector Graphics: https://github.com/GeorgLegato/Txt2Vectorgraphics/blob/main/txt2vectorgfx.py Txt2mask: https://github.com/ThereforeGames/txt2mask Prompt changing scripts:
- https://github.com/yownas/seed_travel
- https://github.com/feffy380/prompt-morph
- https://github.com/EugeoSynthesisThirtyTwo/prompt-interpolation-script-for-sd-webui
- https://github.com/some9000/StylePile
Interpolation script (img2img + txt2img mix): https://github.com/DiceOwl/StableDiffusionStuff
img2tiles script: https://github.com/arcanite24/img2tiles Script for outpainting: https://github.com/TKoestlerx/sdexperiments Img2img animation script: https://github.com/Animator-Anon/Animator/blob/main/animation_v6.py
- Can use in txt2img mode and combine with https://film-net.github.io/ for content aware interpolation
Google's interpolation script: https://github.com/google-research/frame-interpolation
Animation Guide: https://rentry.org/AnimAnon#introduction Rotoscope guide: https://rentry.org/AnimAnon-Rotoscope Chroma key after SD (fully prompted?): https://files.catbox.moe/d27xdl.gif
- Cool mmd vid (20 frames, I think it uses chroma key): https://files.catbox.moe/jtp14x.mp4
More animation guide: https://www.reddit.com/r/StableDiffusion/comments/ymwk53/better_frame_consistency/ Animation guide + example for face: https://www.reddit.com/r/StableDiffusion/comments/ys434h/animating_generated_face_test/ Something for aninmation: https://github.com/nicolai256/Few-Shot-Patch-Based-Training
Animating faces by anon:
- https://github.com/yoyo-nb/Thin-Plate-Spline-Motion-Model
- How to Animate faces from Stable Diffusion!
workflow looks like this:
>generate square portrait (i use 1024 for this example)
>create or find driving video
>crop driving video to square with ffmpeg, making sure to match the general distance from camera and face position(it does not do well with panning/zooming video or too much head movement)
>run thin-plate-spline-motion-model
>take result.mp4 and put it into Video2x (Waifu2x Caffe)
>put into flowframes for 60fps and webm
>if you don't care about upscaling it makes 256x256 pretty easily
>an extension for webui could probably be made by someone smarter than me, its a bit tedious right now with so many terminals
here is a pastebin of useful commands for my workflow
https://pastebin.com/6Y6ZK8PNAnother person who used it: https://www.reddit.com/r/StableDiffusion/comments/ynejta/stable_diffusion_animated_with_thinplate_spline/
Img2img megalist + implementations: AUTOMATIC1111/stable-diffusion-webui#2940
Runway inpaint model: https://huggingface.co/runwayml/stable-diffusion-inpainting
- Tutorial from their github: https://github.com/runwayml/stable-diffusion#inpainting-with-stable-diffusion
Inpainting Tips: https://www.pixiv.net/en/artworks/102083584 Rentry version: https://rentry.org/inpainting-guide-SD
Extensions: Artist inspiration: https://github.com/yfszzx/stable-diffusion-webui-inspiration
- https://huggingface.co/datasets/yfszzx/inspiration
- delete the 0 bytes folders from their dataset zip or you might get an error extracting it
History: https://github.com/yfszzx/stable-diffusion-webui-images-browser Collection + Info: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Extensions Deforum (video animation): https://github.com/deforum-art/deforum-for-automatic1111-webui
- Math: https://docs.google.com/document/d/1pfW1PwbDIuW0cv-dnuyYj1UzPqe23BlSLTJsqazffXM/edit
- Blender camera animations to deforum: https://github.com/micwalk/blender-export-diffusion
- Tutorial: https://www.youtube.com/watch?v=lztn6qLc9UE
- Diffusion_cadence variation value comparison: https://www.reddit.com/r/StableDiffusion/comments/yh3dno/diffusion_cadence_variation_testing_values_to/
Auto-SD-Krita: https://github.com/Interpause/auto-sd-paint-ext
ddetailer (object detection and auto-mask, helpful in fixing faces without manually masking): https://github.com/dustysys/ddetailer Aesthetic Gradients: https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients Aesthetic Scorer: https://github.com/tsngo/stable-diffusion-webui-aesthetic-image-scorer Autocomplete Tags: https://github.com/DominikDoom/a1111-sd-webui-tagcomplete Prompt Randomizer: https://github.com/adieyal/sd-dynamic-prompting Wildcards: https://github.com/AUTOMATIC1111/stable-diffusion-webui-wildcards/ Wildcard script + collection of wildcards: https://app.radicle.xyz/seeds/pine.radicle.garden/rad:git:hnrkcfpnw9hd5jb45b6qsqbr97eqcffjm7sby Symmetric image script (latent mirroring): https://github.com/dfaker/SD-latent-mirroring
- Comparisons:
- No mirroring - https://files.catbox.moe/blbnwt.png (embed)
- Alternate Steps - Roll Channels - fraction 0.2 - https://files.catbox.moe/dprlxr.png (embed)
- Alternate Steps - Roll Channels - fraction 0.3 - https://files.catbox.moe/7az24b.png
macOS Finder right-click menu extension: https://github.com/anastasiuspernat/UnderPillow
Clip interrogator: https://colab.research.google.com/github/pharmapsychotic/clip-interrogator/blob/main/clip_interrogator.ipynb 2 (apparently better than AUTO webui's interrogate): https://huggingface.co/spaces/pharma/CLIP-Interrogator, https://github.com/pharmapsychotic/clip-interrogator
Enchancement Workflow by anon: https://pastebin.com/8WVyDxt9
Inpainting a face by anon:
send the picture to inpaint modify the prompt to remove anything related to the background add (face) to the prompt slap a masking blob over the whole face mask blur 10-16 (may have to adjust after), masked content: original, inpaint at full resolution checked, full resolution padding 0, sampling steps ~40-50, sampling method DDIM, width and height set to your original picture's full res denoising strength .4-.5 if you want minor adjustments, .6-.7 if you want to really regenerate the entire masked area let it rip
- AUTOMATIC1111 webui modification that "compensates for the natural heavy-headedness of sd by adding a line from 0 -> sqrt(2) over the 0 -> 74 token range (anon)" (evens out the token weights with a linear model, helps with the weight reset at 75 tokens (?))
VAEs
Tutorial + how to use on ALL models (applies for the NAI vae too): https://www.reddit.com/r/StableDiffusion/comments/yaknek/you_can_use_the_new_vae_on_old_models_as_well_for/
- SD 1.4 Anime styled: https://huggingface.co/hakurei/waifu-diffusion-v1-4/blob/main/vae/kl-f8-anime.ckpt
- Stability AI's VAE: https://huggingface.co/stabilityai
- Comparisons: https://huggingface.co/stabilityai/sd-vae-ft-mse-original
- an anon recommended vae-ft-mse-840k-ema-pruned: https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.ckpt, https://huggingface.co/stabilityai/sd-vae-ft-mse-original/tree/main
Booru tag scraping:
- https://sleazyfork.org/en/scripts/451098-get-booru-tags
- script to run in browser, hover over pic in Danbooru and Gelbooru
- https://rentry.org/owmmt
- another script
- https://pastecode.io/s/jexs5p9c
- another script, maybe pickle
- press tilde on dan, gel, e621
- https://textedit.tools/
- if you want an online alternative
- https://github.com/onusai/grab-booru-tags
- works with e621, dev will try to get it to work with rule34.xxx
- https://pastecode.io/s/jexs5p9c
- https://pastecode.io/s/61owr7mz
- Press ] on the page you want the tags from
- Another script: https://pastecode.io/s/q6fpoa8k
- Another: https://pastecode.io/s/t7qg2z67
- Github for scraper: https://github.com/onusai/grab-booru-tags
- Tag copier: https://greasyfork.org/en/scripts/453443-danbooru-tag-copier
Wildcards:
-
Danbooru tags: https://danbooru.donmai.us/wiki_pages/tag_groups
-
Artist tags: https://danbooru.donmai.us/artists
-
Guide (ish): https://is2.4chan.org/h/1665343016289442.png
-
A few wildcards: https://cdn.lewd.host/EtbKpD8C.zip
-
https://github.com/Lopyter/stable-soup-prompts/tree/main/wildcards
-
https://github.com/Lopyter/sd-artists-wildcards
- Allows you to split up the artists.csv from Automatic by category
-
Another wildcard script: https://raw.githubusercontent.com/adieyal/sd-dynamic-prompting/main/dynamic_prompting.py
-
wildcardNames.txt generation script: https://files.catbox.moe/c1c4rx.py
-
Another script: https://files.catbox.moe/hvly0p.rar
-
Script: https://gist.github.com/h-a-te/30f4a51afff2564b0cfbdf1e490e9187
-
UMI AI: https://www.patreon.com/posts/umi-ai-official-73544634
- Check the presets folder for a lot of dumps
-
Dump:
- faces https://rentry.org/pu8z5
- focus https://rentry.org/rc3dp
- poses https://rentry.org/hkuuk
- times https://rentry.org/izc4u
- views https://rentry.org/pv72o
- Clothing: https://pastebin.com/EyghiB2F
-
Another dump: https://github.com/jtkelm2/stable-diffusion-webui-1/tree/master/scripts/wildcards
-
Big NAI Wildcard List: https://rentry.org/NAIwildcards
-
316 colors list: https://pastebin.com/s4tqKB8r
-
82 colors list: https://pastebin.com/kiSEViGA
-
Backgrounds: https://pastebin.com/FCybuqYW
-
More clothing: https://pastebin.com/DrkG1MRw
-
Dump: https://www.dropbox.com/s/oa451lozzgo7sbl/wildcards.zip?dl=1
-
483 txt files, huge dump (for Danbooru trained models): https://files.catbox.moe/ipqljx.zip
- old 329 version: https://files.catbox.moe/qy6vaf.zip
- old 314 version: https://files.catbox.moe/11s1tn.zip
-
Styles: https://pastebin.com/71HTfsML
-
Word list (small): https://cdn.lewd.host/EtbKpD8C.zip
-
Emotions/expressions: https://pastebin.com/VVnH2b83
-
Clothing: https://pastebin.com/cXxN1fJw
-
More clothing: https://files.catbox.moe/88s7bf.zip
-
Dump: https://www.mediafire.com/file/iceamfawqhn5kvu/wildcards.zip/file
-
Locations: https://pastebin.com/R6ugwd2m
-
Clothing/outfits: https://pastebin.com/Xhhnyfvj
-
Locations: https://pastebin.com/uyDJMnvC
-
Clothes: https://pastebin.com/HaL3rW3j
-
Color (has nouns): https://pastebin.com/GTAaLLnm
-
Artists: https://pastebin.com/1HpNRRJU
-
Animals: https://pastebin.com/aM4PJ2YY
-
Characters: https://files.catbox.moe/xe9qj7.txt
-
Backgrounds: https://pastebin.com/gVue2q8g
-
WIP random h-manga scene generator: https://files.catbox.moe/ukah7u.jpg
-
Collection from https://rentry.org/NAIwildcards: https://files.catbox.moe/s7expb.7z
-
Outfits: https://files.catbox.moe/y75qda.txt
-
Collection: https://cdn.lewd.host/4Ql5bhQD.7z
-
Settings + Minerals: https://pastebin.com/9iznuYvQ
-
Hairstyles: https://pastebin.com/X39Kzxh7
-
Hairstyles 2: https://pastebin.com/bRWu1Xvv
-
subject filewords: https://pastebin.com/XRFhwXj8
-
subject filewords but less emphasis on filewords: https://pastebin.com/LxZGkzj1
-
subject filewords v3: https://pastebin.com/hL4nzEDW
-
Danbooru Poses: https://pastebin.com/RgerA8Ry
-
Character training text template: https://files.catbox.moe/wbat5x.txt
-
Outfits: https://pastebin.com/Z9aHVpEy
-
Danbooru tag group wildcard dump organized into folders: https://files.catbox.moe/hz5mom.zip
- by uploader anon: "I recommend using Dynamic Prompting rather than the normal Wildcards extension. It does everything the Wildcards extension does and then some, * being a thing is especially great and so is |"
-
Poses: https://rentry.org/m9dz6
-
Clothes: https://pastebin.com/4a0BscGr
-
sex positions: https://files.catbox.moe/tzibuf.txt
-
Angles: https://pastebin.com/T8w8HEED
-
Hairstyles: https://pastebin.com/GguTseaR
-
Actresses: https://raw.githubusercontent.com/Mylakovich/SD-wildcards/main/wildcards/actress.txt
Wildcard extension: https://github.com/AUTOMATIC1111/stable-diffusion-webui-wildcards/
Someone's prompt using a lot of wildcards: Positive Prompt: (masterpiece:1.4), (best quality:1.4), [[nsfw]], highres, large breasts, 1girl, detailed clothing, skimpy clothing, haircolor, haircut, hairlength, eyecolor, cum, ((fetish)), lingerie, lingeriestate, ((sexacts)), sexposition,
Artist Comparisons (may or may not work with NAI):
-
SD 1.5 artists (might lag your pc): https://docs.google.com/spreadsheets/d/1SRqJ7F_6yHVSOeCi3U82aA448TqEGrUlRrLLZ51abLg/htmlview#
-
pre-modern art: https://www.artrenewal.org/Museum/Search#/
-
SD 1.4 artists: https://rentry.org/artists_sd-v1-4
-
Link list: https://pastebin.com/HD7D6pnh
-
Artist comparison grids: https://files.catbox.moe/y6bff0.rar
-
Artist Comparison: https://reddit.com/r/NovelAi/comments/y879x1/i_made_an_experiment_with_different_artists_here/
-
Site: https://sdartists.app/
-
Comparison: https://imgur.com/a/hTEUmd9
-
Comparison: https://proximacentaurib.notion.site/e28a4f8d97724f14a784a538b8589e7d?v=ab624266c6a44413b42a6c57a41d828c
-
Comparison: https://imgur.com/a/ADPHh9q
-
Extension: https://github.com/yfszzx/stable-diffusion-webui-inspiration
-
Huge comparison of artists (3gb, 90x90 different artist combinations on untampered WD v1.3.)
-
Huge tested list: https://proximacentaurib.notion.site/e28a4f8d97724f14a784a538b8589e7d?v=42948fd8f45c4d47a0edfc4b78937474
-
artists and themes: https://dict.latentspace.observer/
-
SD 1.5 artist study: https://docs.google.com/spreadsheets/d/1SRqJ7F_6yHVSOeCi3U82aA448TqEGrUlRrLLZ51abLg/edit#gid=2005893444
-
Artist comparisons for NAI: https://www.reddit.com/r/NovelAi/comments/y879x1/i_made_an_experiment_with_different_artists_here/
-
Artist rankings: https://www.urania.ai/top-sd-artists
-
Some comparisons:
-
Artists To Study: https://artiststostudy.pages.dev/
-
Big compilation of artists: https://sgreens.notion.site/4ca6f4e229e24da6845b6d49e6b08ae7?v=fdf861d1c65d456e98904fe3f3670bd3
-
Comparison of using and not using "by artist [first name] [last name]": https://www.reddit.com/r/StableDiffusion/comments/yiny15/by_artist_firstname_lastname_really_does_makes_a/
-
414 artists comparison using BerryMix: https://mega.nz/file/MX00jb6I#sWbvlt8AhH0B2CZTJJVmfz-LTZIB9O0sLYqjoWbvwN0
-
558 artists comparison: https://decentralizedcreator.com/list-of-artists-supported-by-stable-diffusion/
-
NAI artist comparison + some extra information: https://zele.st/NovelAI/?Artists
-
Arist comparison from https://rentry.org/artists_sd-v1-4: https://rentry.org/oadb5
Some comparisons of 421 different artists in different models.
-
Berry Mix: https://mega.nz/file/8OlUkapK#4XpOm4kOcw3LOJZeSuSZbO89tRrAuRO_RSfmu_RqzWA
-
SD v1.5 (CLIP 1): https://mega.nz/file/dDU2WB5B#wFsVS0RUX6YK2IJiOtQ5nI7sMMrWEqZg2r3fZrCQ4OI
-
SD v1.5 (CLIP 2): https://mega.nz/file/lS1iyQCT#zJhV6URsT01QJpYdqbf3Jubhyi09rXn8FFT-HaXvgd0
Anon's list of comparisons:
- Stable Diffusion v1.5, Waifu Diffusion v1.3, Trinart it4
- Berry Mix, CLIP 2:
- Berry Mix, CLIP 1:
- Artist + Artist, WD v1.3 (incomplete):
https://mega.nz/file/ACtigCpD#f9zP9h1AU_0_4DPsBnvdhnUYdQmIJMb4pyc6PJ4J-FU
Creating fake animes:
-
Prompt tag comparisons: https://i.4cdn.org/h/1668114368781212.jpg, https://i.4cdn.org/h/1668119420557795.jpg, https://i.4cdn.org/h/1668126729971806.jpg
Some observations by anon:
- Removing the spaces after the commas changed nothing
- Using "best_quality" instead of "best_quality" did change the image. masterpiece,best_quality,akai haato but she is a spider,blonde hair,blue eyes
- Changing all of the spaces into underscores changed the image somewhat substantially.
- Replacing those commas with spaces changed the image again.
Reduce bias of dreambooth models: https://www.reddit.com/r/StableDiffusion/comments/ygyq2j/a_simple_method_explained_in_the_comments_to/?utm_source=share&utm_medium=web2x&context=3
Landscape tutorial: https://www.reddit.com/r/StableDiffusion/comments/yivokx/landscape_matte_painting_with_stable_diffusion/
Anon's process:
- Start with a prompt to get the general scenario you have in mind, here I was just looking to seggs the rrat so I used the embed here >>36743515 and described some of her character features to help steer the AI (in this case hair details, sharp teeth, her mouse ears and tail) as well as making her be naked and having vaginal sex
- Generate images at a default resolution size (512 by X pixels) at a relative standard number of steps (30 in this case) and keep going until I find an image thats in a position I like (in this case seed 1920052602 gave me a very nice one to work with, as you can see here https://files.catbox.moe/8z2mua.png (embed))
- Copy the seed of the image and paste it into the Seed field on the Web UI, which will maintain the composition of the image. I then double the resolution I was working with (so here I went from 512 by 768 to 1024 by 1536) and checkmark the "Hires fix option" underneath the width and height sliders. Hires fix is the secret sauce on the Web UI that helps maintain the detail of the image when you are upscaling the resolution of the image, and combined with that Upscale latent space option I mentioned earlier it really enhances the detail. With that done you can generate the upscaled image.
- Play around with the weights of the prompt tags and add things to the negatives to fix little things like hair being too red, tummy too chubby, etc. You have to be careful with adding new tags because that can drastically change the image
Anon's booba process: >you can generate a perfect barbie doll anatomy but more accurate chuba in curated >then switch to full, img2img it on the same seed after blotching nipples on it like a caveman, and hit generate
Boooba v2:
- Generate whatever NSFW proompt you were thinking of using the CURATED model, yes, I know that sounds ridiculous https://files.catbox.moe/b6k6i4.png (embed)
- Inpaint the naughty bits back in. You REALLY don't have to do a good job of this: https://files.catbox.moe/yegjrw.png (embed)
- Switch to Full after clicking "Save", set Strength to 0.69, Noise to 0.17, and make sure you copy/paste the same seed # back in. Hit Generate: https://files.catbox.moe/8dag88.png (embed) Compare that with what you'd get trying to generate the same exact proompt using the Full model purely txt2img on the same seed: https://files.catbox.moe/ytfdv3.png (embed)
Img2img rotoscoping tutorial by anon:
1. extract image sequence from video
2. testing prompt by using the 1st photo from the batch
3. find the suitable prompt that you want, the pose/sexual acts should be the same as the original to prevent weirdness
4. CFG Scale and Denoising Strength is very important
> Low CFG Scale will make your image less follow your prompt and make it more blurry and messy (i use 9-13)
> Denoising Strength determines the mix between your prompt and your image: 0 = Original input 1 = Only Prompt, nothing resemble of the input except the colors.
the interesting thing that i've noticed from Denoising strength is not linear, its behave more exponential ( my speculation is 0-0.6 = still reminds of the original 0.61-0.76 = starting to change 0.77-1 = change a lot )
5. sampler:
> Euler-a is quite nice, but lack of consistency between the step, adding/lower 1 step can change the entire photo
> Euler is better than euler-a in terms of consistency but requires more steps = longer generation time between each image
> DPM++ 2S a Karras is the best in quality (for me) but it is very slow, good for generate single image
> DDIM is the fastest and very useful for this case, 20-30 steps can produces a nice quality anime image.
6. test prompting into a batch of 4-6 to choosing a seed
7. Batch img2img
8. Assembling the generated images into video, i don't want to use eveyframes so i rendered into 2 frame steps and half the frame rate
9. Use Flowframes to interpolate the inbetween frame to match the original video frame rate.Ex: https://files.catbox.moe/e30szo.mp4
- Open source SD model based on chinese text and images: https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1
!!! Downloads listed as "sus" or "might be pickled" generally mean there were 0 replies and not enough "information" (like training info). or, the replies indicated they were suspicious. I don't think any of the embeds/hypernets have had their code checked so they could all be malicious, but as far as I know no one has gotten pickled yet
!!! All files in this section (ckpt, vae, pt, hypernetwork, embedding, etc) can be malicious: https://docs.python.org/3/library/pickle.html, https://huggingface.co/docs/hub/security-pickle. Make sure to check them for pickles using a tool like https://github.com/zxix/stable-diffusion-pickle-scanner
Collection of potentially dangerous models: https://bt4g.org/search/.ckpt/1 Collection?: https://civitai.com/ Huggingface collection: https://huggingface.co/models?pipeline_tag=text-to-image&sort=downloads
- anything.ckpt (v3 6569e224; v2.1 619c23f0), a Chinese finetune/training continuation of NAI, is released: https://www.bilibili.com/read/cv19603218
- Huggingface, might be pickled: https://huggingface.co/Linaqruf/anything-v3.0/tree/main
- Uploader pruned one of the 3.0 models down to 4gb
- Torrent: https://rentry.org/sdmodels#anything-v30-38c1ebe3-1a7df6b8-6569e224
- Supposed ddl, I didn't check these for pickles: https://rentry.org/NAI-Anything_v3_0_n_v2_1
- instructions to download from Baidu from outside China and without SMS or an account and with speeds more than 100KBps:
Download a download manager that allows for a custom user-agent (e.g. IDM) >If you need IDM, contact me Go here: https://udown.vip/#/ In the "在线解析" section, put 'https://pan.baidu.com/s/1gsk77KWljqPBYRYnuzVfvQ' into the first prompt box and 'hheg' in the second (remove the ') Click the first blue button In the bottom box area, click the folder icon next to NovelAI Open your dl manager and add 'netdisk;11.33.3;' into the user-agent section (remove the ') Click the paperclip icon next to the item you want to download in the bottom box and put it into your download manager
To get anything v3 and v2.1: first box:https://pan.baidu.com/s/1r--2XuWV--MVoKKmTftM-g, second box:ANYN * another link that has 1 letter changed that could mean it's pickled: https://pan.baidu.com/s/1r--2XuWV--MVoKKmTfyM-g
- seems to be better (e.g. provide more detailed backgrounds and characters) than NAI, but can overfry some stuff. Try lowering the cfg if that happens
- Passes AUTOMATIC's pickle tester and https://github.com/zxix/stable-diffusion-pickle-scanner, but there's no guarantee on pickle safety, so it still might be ccp spyware
- Use the vae or else your outputs will have a grey filter
- Windows Defender might mark this as a virus, it should be a false positive
- Supposed torrent from anon on /g/ (don't know if safe)
- Huggingface, might be pickled: https://huggingface.co/Linaqruf/anything-v3.0/tree/main
potential magnet that someone gave me
magnet:?xt=urn:btih:689c0fe075ab4c7b6c08a6f1e633491d41186860&dn=Anything-V3.0.ckpt&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337%2fannounce&tr=udp%3a%2f%2f9.rarbg.com%3a2810%2fannounce&tr=udp%3a%2f%2ftracker.openbittorrent.com%3a6969%2fannounce&tr=udp%3a%2f%2fopentracker.i2p.rocks%3a6969%2fannounce&tr=https%3a%2f%2fopentracker.i2p.rocks%3a443%2fannounce&tr=udp%3a%2f%2ftracker.torrent.eu.org%3a451%2fannounce&tr=udp%3a%2f%2fopen.stealth.si%3a80%2fannounce&tr=http%3a%2f%2ftracker.openbittorrent.com%3a80%2fannounce&tr=udp%3a%2f%2fvibe.sleepyinternetfun.xyz%3a1738%2fannounce&tr=udp%3a%2f%2ftracker1.bt.moack.co.kr%3a80%2fannounce&tr=udp%3a%2f%2ftracker.zerobytes.xyz%3a1337%2fannounce&tr=udp%3a%2f%2ftracker.tiny-vps.com%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.theoks.net%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.swateam.org.uk%3a2710%2fannounce&tr=udp%3a%2f%2ftracker.publictracker.xyz%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.monitorit4.me%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.moeking.me%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.encrypted-data.xyz%3a1337%2fannounce&tr=udp%3a%2f%2ftracker.dler.org%3a6969%2fannounce&tr=udp%3a%2f%2ftracker.army%3a6969%2fannounce&tr=http%3a%2f%2ftracker.bt4g.com%3a2095%2fannounceMag2
Little update, here's the link with all including VAE (second one)
magnet:?xt=urn:btih:689C0FE075AB4C7B6C08A6F1E633491D41186860&dn=Anything-V3.0.ckpt&tr=udp%3a%2f%2ftracker.openbittorrent.com%3a80%2fannounce&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337%2fannounce
magnet:?xt=urn:btih:E87B1537A4B5B5F2E23236C55F2F2F0A0BB6EA4A&dn=NAI-Anything&tr=udp%3a%2f%2ftracker.openbittorrent.com%3a80%2fannounce&tr=udp%3a%2f%2ftracker.opentrackr.org%3a1337%2fannounceMag3
magnet:?xt=urn:btih:689c0fe075ab4c7b6c08a6f1e633491d41186860&dn=Anything-V3.0.ckpt&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=udp%3A%2F%2F9.rarbg.com%3A2810%2Fannounce&tr=udp%3A%2F%2Fopentracker.i2p.rocks%3A6969%2Fannounce&tr=https%3A%2F%2Fopentracker.i2p.rocks%3A443%2Fannounce&tr=udp%3A%2F%2Ftracker.torrent.eu.org%3A451%2Fannounce&tr=udp%3A%2F%2Fopen.stealth.si%3A80%2Fannounce&tr=http%3A%2F%2Ftracker.openbittorrent.com%3A80%2Fannounce&tr=udp%3A%2F%2Fvibe.sleepyinternetfun.xyz%3A1738%2Fannounce&tr=udp%3A%2F%2Ftracker1.bt.moack.co.kr%3A80%2Fannounce&tr=udp%3A%2F%2Ftracker.zerobytes.xyz%3A1337%2Fannounce&tr=udp%3A%2F%2Ftracker.tiny-vps.com%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.theoks.net%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.swateam.org.uk%3A2710%2Fannounce&tr=udp%3A%2F%2Ftracker.publictracker.xyz%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.monitorit4.me%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.moeking.me%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.encrypted-data.xyz%3A1337%2Fannounce&tr=udp%3A%2F%2Ftracker.dler.org%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.army%3A6969%2Fannounce&tr=udp%3A%2F%2Ftracker.altrosky.nl%3A6969%2Fannounce&tr=http%3A%2F%2Ftracker.bt4g.com%3A2095%2Fannouncefrom: https://bt4g.org/magnet/689c0fe075ab4c7b6c08a6f1e633491d41186860
another magnet on https://rentry.org/sdmodels from the author
-
Mixed SFW/NSFW Pony/Furry V2 from AstraliteHeart: https://mega.nz/file/Va0Q0B4L#QAkbI2v0CnPkjMkK9IIJb2RZTegooQ8s6EpSm1S4CDk
-
Mega mixing guide (has a different berry mix): https://rentry.org/lftbl
- Model showcases from lftbl: https://rentry.co/LFTBL-showcase
-
Cafe Unofficial Instagram TEST Model Release
- Trained on ~140k 640x640 Instagram images made up of primarily Japanese accounts (mix of cosplay, model, and personal accounts)
- Note: While the model can create some realistic (Japanese) Instagram-esque images on its own, for full potential, it is recommended that it be merged with another model (such as berry or anything)
- Note: Use CLIP 2 and resolutions greater than 640x640
Raspberry mix download by anon (not sure if safe): https://pixeldrain.com/u/F2mkQEYp Strawberry Mix (anon, safety caution): https://pixeldrain.com/u/z5vNbVYc
magnet:?xt=urn:btih:eb085b3e22310a338e6ea00172cb887c10c54cbc&dn=cafe-instagram-unofficial-test-epoch-9-140k-images-fp32.ckpt&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A80&tr=udp%3A%2F%2Fopentor.org%3A2710&tr=udp%3A%2F%2Ftracker.ccc.de%3A80&tr=udp%3A%2F%2Ftracker.blackunicorn.xyz%3A6969&tr=udp%3A%2F%2Ftracker.coppersurfer.tk%3A6969&tr=udp%3A%2F%2Ftracker.leechers-paradise.org%3A6969ThisModel:
- (Weighted Sum 0.05) Anything3 + SD1.5 = Temp1
- (Add Difference 1.0) Temp1 + F222 + SD1.5 = Temp2
- (Weighted Sum 0.2) Temp2 + TrinArt2_115000 = ThisModel
Anon's model for vampires(?):
My steps
Step 1:
>A : Anything-V3.0
>B : trinart2_step115000.ckpt [f1c7e952]
>C : stable-diffusion-v-1-4-original
A from https://huggingface.co/Linaqruf/anything-v3.0/blob/main/Anything-V3.0-pruned.ckpt
B from https://rentry.org/sdmodels#trinart2_step115000ckpt-f1c7e952
C from https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/blob/main/sd-v1-4.ckpt
and I "Add Difference" at 0.45, and name as part1.ckpt
Step 2:
>A : part1.ckpt (What I made in Step 1)
>B: Cafe Unofficial Instagram TEST Model [50b987ae]
B is from https://rentry.org/sdmodels#cafe-unofficial-instagram-test-model-50b987ae
and I "Weighted Sum" at 0.5, and name it TrinArtMix.ckpt!!! All files in this section (ckpt, vae, pt, hypernetwork, embedding, etc) can be malicious: https://docs.python.org/3/library/pickle.html, https://huggingface.co/docs/hub/security-pickle. Make sure to check them for pickles using a tool like https://github.com/zxix/stable-diffusion-pickle-scanner
Download + info + prompt templates: https://github.com/victorchall/EveryDream-trainer
-
by anon: allows you to train multiple subjects quickly via labelling file names but it requires a normalization training set of random labelled images in order to preserve model integrity
-
Made in Abyss: https://drive.google.com/drive/u/0/folders/1FxFitSdqMmR-fNrULmTpaQwKEefi4UGI
!!! All files in this section (ckpt, vae, pt, hypernetwork, embedding, etc) can be malicious: https://docs.python.org/3/library/pickle.html, https://huggingface.co/docs/hub/security-pickle. Make sure to check them for pickles using a tool like https://github.com/zxix/stable-diffusion-pickle-scanner
Links:
-
https://huggingface.co/jinofcoolnes
- For preview pics/descriptions:
-
Toolkit anon: https://huggingface.co/demibit/
-
Big collection: https://publicprompts.art/
-
Big collection of sex models (Might be a large pickle, so be careful): https://rentry.org/kwai
-
Collection: https://cyberes.github.io/stable-diffusion-dreambooth-library/
-
/vt/ collection: https://mega.nz/folder/L2hhmRja#CCydQIW7rBcQIFaJl8r6sg/folder/L6RUURqJ
-
Big collection: https://publicprompts.art/
-
Nami: https://mega.nz/file/VlQk0IzC#8MEhKER_IjoS8zj8POFDm3ZVLHddNG5woOcGdz4bNLc
-
https://huggingface.co/IShallRiseAgain/StudioGhibli/tree/main
-
Jinx: https://huggingface.co/jinofcoolnes/sksjinxmerge/tree/main
-
Arcane Vi: https://huggingface.co/jinofcoolnes/VImodel/tree/main
-
Lucy (Edgerunners): https://huggingface.co/jinofcoolnes/Lucymodel/tree/main
-
Gundam (full ema, non pruned): https://huggingface.co/Gazoche/stable-diffusion-gundam
-
Starsector Portraits: https://huggingface.co/Severian-Void/Starsector-Portraits
-
Evangelion style: https://huggingface.co/crumb/eva-fusion-v2
-
Robo Diffusion: https://huggingface.co/nousr/robo-diffusion/tree/main/models
-
Arcane Diffusion: https://huggingface.co/nitrosocke/Arcane-Diffusion
-
Wikihow style: https://huggingface.co/jvkape/WikiHowSDModel
- 60 Images. 2500 Steps. Embedding Aesthetics + 40 Image Embedding options
- Their patreon: https://www.patreon.com/user?u=81570187
-
Lain girl: https://mega.nz/file/VK0U0ALD#YDfGgOu8rquuR5FbFxmzKD5hzxO1iF0YQafN0ipw-Ck
-
Wikiart: https://huggingface.co/valhalla/sd-wikiart-v2/tree/main/unet
- diffusion_pytorch_model.bin, just rename to whatever.ckpt
-
Megaman zero: https://huggingface.co/jinofcoolnes/Zeromodel/tree/main
-
Cyberware: https://huggingface.co/Eppinette/Cyberware/tree/main
-
taffy (keyword: champi): https://drive.google.com/file/d/1ZKBf63fV1Zm5_-a0bZzYsvwhnO16N6j6/view?usp=sharing
-
Disney (3d?): https://huggingface.co/nitrosocke/modern-disney-diffusion/
-
El Risitas (KEK guy): https://huggingface.co/Fictiverse/ElRisitas
-
Cyberpunk Anime Diffusion: https://huggingface.co/DGSpitzer/Cyberpunk-Anime-Diffusion
-
Kurzgesagt (called with "kurzgesagt! style"): https://drive.google.com/file/d/1-LRNSU-msR7W1HgjWf8g1UhgD_NfQjJ4/view?usp=sharing
- SHA-256: d47168677d75045ae1a3efb8ba911f87cfcde4fba38d5c601ef9e008ccc6086a
-
Robodiffusion (good outputs for "meh" prompting): https://huggingface.co/nousr/robo-diffusion
-
2D Illustration style: https://huggingface.co/ogkalu/hollie-mengert-artstyle
-
Rebecca (edgerunners, by booru anon, info is in link): https://huggingface.co/demibit/rebecca
-
Kiwi (by booru anon): https://huggingface.co/demibit/kiwi
-
Ranni (Elden Ring): https://huggingface.co/bitspirit3/SD-Ranni-dreambooth-finetune
-
Modern Disney style (modi, mo-di): https://huggingface.co/nitrosocke/mo-di-diffusion/
-
Silco: https://huggingface.co/jinofcoolnes/silcomodel/tree/main
-
Lara: https://huggingface.co/jinofcoolnes/Oglaramodel/tree/main
-
theofficialpit bimbo (26 pics for 2600 steps, Use "thepit bimbo" in prompt for more effect): https://mega.nz/file/wSdigRxJ#WrF8cw85SDebO8EK35gIjYIl7HYAz6WqOxcA-pWJ_X8
-
DCAU (Batman_the_animated_series): https://huggingface.co/IShallRiseAgain/DCAU/blob/main/DCAUV1.ckpt
- https://www.reddit.com/r/StableDiffusion/comments/yf2qz0/initial_version_of_dcau_model_im_making/
- hand captioning 782 screencap, 44,000 steps, training set for the regularization images
-
NSFW: https://megaupload.nz/N7m7S4E7yf/Magnum_Opus_alpha_22500_steps_mini_version_ckpt
-
Hardcore: https://pixeldrain.com/u/Stk98vyH
- Trained on 3498 images and around 250K steps
- porn, sex acts of all sorts: anal sex, anilingus, ass, ass fingering, ball sucking, blowjob, cumshot, cunnilingus, dick, dildo, double penetration, exposed pussy, female masturbation, fingering, full nelson, handjob, large ass, large tits, lesbian kissing, massive ass, massive tits, o-face, sixty-nine, spread pussy, tentacle sex (try also oral/anal tentacle sex and tentacle dp), tit fucking, tit sucking, underboob, vaginal sex, long tongue, tits
- Example grid from training (single shot batch): https://cdn.discordapp.com/attachments/1010982959525929010/1035236689850941440/samples_gs-995960_e-000046_b000000.png
- Trained on 3498 images and around 250K steps
-
disney 2d (classic) animation style: https://huggingface.co/nitrosocke/classic-anim-diffusion
-
Kim Jung Gi: https://drive.google.com/drive/folders/1uL-oUUhuHL-g97ydqpDpHRC1m3HVcqBt
-
Pyro's Blowjob Model: https://rentry.org/pyros-sd-model
-
Pixel Art Sprite Sheet (stardew valley): https://huggingface.co/Onodofthenorth/SD_PixelArt_SpriteSheet_Generator
- 4 different angles
- Examples + Reddit post: https://www.reddit.com/r/StableDiffusion/comments/yj1kbi/ive_trained_a_new_model_to_output_pixel_art/
-
corporate memphis A.I model (infographics): https://huggingface.co/jinofcoolnes/corporate_memphis/tree/main
-
Tron: https://huggingface.co/dallinmackay/Tron-Legacy-diffusion
-
Superhero: https://huggingface.co/ogkalu/Superhero-Diffusion
-
Chicken (trained on images from r/chickens): https://huggingface.co/fake4325634/chkn
-
1.5 based model created from the Spede images (not too sure if this is Dreambooth): https://mega.nz/file/mdcVARhL#FUq5TL2xp7FuzzgMS4B20sOYYnPZsyPMw93sPMHeQ78
-
Redshift Diffusion (High quality 3D renders): https://huggingface.co/nitrosocke/redshift-diffusion
-
Cats: https://huggingface.co/dallinmackay/Cats-Musical-diffusion
-
Van Gogh: https://huggingface.co/dallinmackay/Van-Gogh-diffusion
-
Rouge the Bat (44 SFW images of Rouge the Bat for 1600 or 2400 steps, keyword: 'rkugasebz'): https://huggingface.co/ChanseyIsForeverAI/Rouge-the-bat-dreambooth
-
Made in Abyss (MIA 1-6 V2): https://drive.google.com/drive/folders/1FxFitSdqMmR-fNrULmTpaQwKEefi4UGI?usp=sharing
- Uploader note: I was hesitant to share this one because I have been having a lot of problems with the new captioning format. With the new format essentially we have much better multiple character flexibility and outfits. You can generate 2 characters in completely separate outfits with a high percentage of no blending. However, my new captioning was causing everything to train significantly slower, so some side characters don't look as good as they did in the original 1-6 model. There is also a strict captioning format I used, so I also uploaded a prompt readme to the folder which contains all the information needed to best use this model
-
Gyokai/onono imoko/@_himehajime: https://mega.nz/folder/HzYT1T7L#H9TWVVYowA0cX8Eh6x_H3g
- use term 'gyokai' under class '1girl' e.g 'illustration of gyokai 1girl' + optionally 'multicolored hair, halftone, polka dot'
- Img: https://i.4cdn.org/h/1667881224238388.jpg
-
Midjourney: https://huggingface.co/prompthero/midjourney-v4-diffusion
-
Borderlands (training info in reddit): https://www.reddit.com/r/StableDiffusion/comments/yong77/borderlands_model_works_for/
-
Pixel art model: https://publicprompts.art/all-in-one-pixel-art-dreambooth-model/
-
Satania (has two iterations of the model, 500 step has more flexibility but 1k can look nicer if you want base Satania, link will expire soon): https://i.mmaker.moe/sd/mmkr-greatmosu-satania.7z
-
Pokemon: https://huggingface.co/justinpinkney/pokemon-stable-diffusion
-
final fantasy tactics: https://huggingface.co/jinofcoolnes/FinalfantasyTactics/tree/main
-
smthdssmth: https://huggingface.co/Marre-Barre/smthdssmth
-
A model I found on /vt/, not too sure what it is of: https://drive.google.com/file/d/1iR9wVI1wm4M6ZTJgJR_i3TZPAQBDB0Bk/view?usp=share_link
-
Anmi: https://drive.google.com/drive/folders/1YFzJKQNVhCRgu0EnkVYgSQ5v63i_LBa4
-
Samdoesart (merged model using the original, chewtoy's model, and Chris(orginalcode)'s model): https://huggingface.co/jinofcoolnes/sammod/tree/main
- Uploader note: all training credit goes to the 3 model maker this merge made from, thank you to them!
-
CopeSeetheMald (samdoesart) (Both were trained with the same dataset. 204 images @ 20.4k steps, 1e-6 learning rate. It's just the base model that differs):
- berry-based model: https://mega.nz/folder/1a1xkQQK#4atlB1cJqI35InXxlxyA7A
- blossom-based model: https://mega.nz/folder/ZG0UnRBJ#jykESWBUCr7hjOoNVTXwLw
- Comparison: https://i.4cdn.org/g/1668068841516679.png
-
CopeSeetheMald v2 (10k CHINAI (anything.ckpt)): https://mega.nz/file/xT9jVToK#Sj1S76kl-PC-zCRwJ2FWen6DS0NHY0IXFFAkXhm03eo
-
SOVLFUL original Xbox/PS2/2006 PC era (jaggy92500): https://mega.nz/file/0SER2YpC#_MRc6p_sG9cSWqihpt33jpOWyMR8bCZrUaVkh4z5kGE
-
Midna (wip): https://mega.nz/folder/E18R2SwC#jHBFsK7zCSuVemOsU4UZ9Q
- dreambooth midna training config: https://pastebin.com/5EWnMJEz
- Tagging tool in "Datasets:" section
-
Pepe (word: pepestyle): https://mega.nz/file/NbUShTDR#bZpcYFlv--VqpqUfgDnU95duQlr3wFhRZ4m26WK-Qts
-
Pepe continued: https://huggingface.co/SpiteAnon/Pepestyle
-
Gigachad: https://huggingface.co/SpiteAnon/gigachad-diffusion
-
y2k (by JF#8026): https://mega.nz/file/hT0mgTqR#d8g133APl30UtDwsNmzV73_ZESi_kTa5pmQgJoxomn0
- ykgl.ckpt. It does cgi girls from the y2k era. Trained for 40k steps.
- You call on them with (ykgl cgi_girl), or (ykgl cgi_girls), or just (ykgl girl), and then maybe with , cgi_artstyle.
-
dbmai (model by 火柴人之父L): https://rentry.org/3en6a
-
Vulcan (from Star Trek): https://huggingface.co/mitchtech/vulcan-diffusion
-
Complex Lineart: https://huggingface.co/Conflictx/Complex-Lineart
-
More Abmayo (has model and imgs): https://mega.nz/folder/l5NxwTKa#9fA_tn_OZxWm3kHjdA9TPg
-
Yuzuki Yukari: https://mega.nz/folder/8hNEiSSC#fYPUNzazZQ04dSizcjmhcg
-
Samdoesartv2: https://huggingface.co/kijaw/samdoesarts_v2
-
Nadanainone (created and trained on their own art, 1076 images (including flipped copies), 10k steps, 1e-6 learning rate): https://huggingface.co/nadanainone/istolemyownart
-
Pop n Music: https://huggingface.co/nadanainone/popnm
-
Heaven burns red artstyle: https://gofile.io/d/3q5WO3
- use hbrs as a prompt
- highly recommand to use 1girl and portrait as those were trained on those the most
!!! info If an embedding is >80mb, I mislabeled it and it's a hypernetwork
!!! info Use a download manager to download these. It saves a lot of time + good download managers will tell you if you have already downloaded one
!!! All files in this section (ckpt, vae, pt, hypernetwork, embedding, etc) can be malicious: https://docs.python.org/3/library/pickle.html, https://huggingface.co/docs/hub/security-pickle. Make sure to check them for pickles using a tool like https://github.com/zxix/stable-diffusion-pickle-scanner
You can check .pts here for their training info using a text editor
- Text Tutorial: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Textual-Inversion
- Make sure to use pictures of your subject in varied areas, it gives more for the AI to work with
- Tutorial 2: https://rentry.org/textard
- Another tutorial: https://imgur.com/a/kXOZeHj
- Test embeddings: https://huggingface.co/spaces/sd-concepts-library/stable-diffusion-conceptualizer
- Collection: https://huggingface.co/sd-concepts-library
- Collection 2: https://mega.nz/folder/fVhXRLCK#4vRO9xVuME0FGg3N56joMA
- Collection 3: https://cyberes.github.io/stable-diffusion-textual-inversion-models/
- Korean megacollection:
- https://arca.live/b/hypernetworks?category=%EA%B3%B5%EC%9C%A0
- Link scrape: https://pastebin.com/p0F4k98y
- (includes mega compilation of artists): https://arca.live/b/hypernetworks/60940948
- Original: https://arca.live/b/hypernetworks/60930993
- Large collection of stuff from korean megacollection: https://mega.nz/folder/sSACBAgC#kNiPVzRwnuzs8JClovS1Tw
- https://arca.live/b/hypernetworks?category=%EA%B3%B5%EC%9C%A0
- Large Vtuber collection dump (not sure if pickled, even linker anon said to be careful, but a big list anyway): https://rentry.org/EmbedList
- Waifu Diffusion collection: https://gitlab.com/cattoroboto/waifu-diffusion-embeds
- Collection of curated embeds that aren't random junk/test ones from HF's Stable Diffusion Concept library (Updated to Nov 10): https://mega.nz/file/58tRlZDQ#Xbs7kYRC-bot1FIDdkJcz_chJpVrdghrGYMO9POPq9U
- contains two folders, one for the top liked list and one for the entire library (excluding top liked)
Found on 4chan:
-
Embeddings + Artists: https://rentry.org/anime_and_titties (https://mega.nz/folder/7k0R2arB#5_u6PYfdn-ZS7sRdoecD2A)
-
Random embedding I found: https://ufile.io/c3s5xrel
-
Embeddings: https://rentry.org/embeddings
-
Anon's collection of embeddings: https://mega.nz/folder/7k0R2arB#5_u6PYfdn-ZS7sRdoecD2A
-
Collection: https://gitgud.io/ZeroMun/stable-diffusion-tis/-/tree/master/embedding
-
Collection: https://gitgud.io/sn33d/stable-diffusion-embeddings
-
Collection from anon's "friend" (might be malicious): https://files.catbox.moe/ilej0r.7z
-
Collection from anon: https://files.catbox.moe/22rncc.7z
-
Collection: https://gitlab.com/rakurettocorp/stable-diffusion-embeddings/-/tree/main/
-
Collection: https://gitlab.com/mwlp/sd
-
Senri Gan: https://files.catbox.moe/8sqmeh.rar
-
Collection: https://gitgud.io/viper1/stable-diffusion-embeddings
-
Repo for some: https://git.evulid.cc/wasted-raincoat/Textual-Inversion-Embeds/src/branch/master/simonstalenhag
-
automatic's secret embedding list: https://gitlab.com/16777216c/stable-diffusion-embeddings
-
Collection of /vt/ embeds in 0-Embeds folder: https://mega.nz/folder/23oAxTLD#vNH9tPQkiP1KCp72d2qINQ
-
Henreader embedding, all 311 imgs on gelbooru, trained on NAI: https://files.catbox.moe/gr3hu7.pt
-
Henreader (a different one, made for SD 1.4 or WD 1.2 with a small dataset): https://mega.nz/folder/7k0R2arB#5_u6PYfdn-ZS7sRdoecD2A/folder/Go9CRRoC
-
Kantoku (NAI, 12 vectors, WD 1.3): https://files.catbox.moe/j4acm4.pt
-
Asanagi (NAI): https://files.catbox.moe/xks8j7.pt
- Asanagi trained on 135 images augmented to 502 for 150296 steps on NAI Anime Full Pruned with 16 vectors per token with init word as voluptuous
- training imgs: https://litter.catbox.moe/2flguc.7z
-
DEAD LINK Asanagi (another one): https://litter.catbox.moe/g9nbpx.pt
-
Imp midna (NAI, 80k steps): mega.nz/folder/QV9lERIY#Z9FXQIbtXXFX5SjGf1Ba1Q
-
imp midna 2 (NAI_80K): mega.nz/file/1UkgWRrD#2-DMrwM0Ph3Ebg-M8Ceoam_YUWhlQWsyo1rcBtuKTcU
-
inverted nipples: https://anonfiles.com/300areCby8/invertedNipples-13000_zip (reupload)
- Dead link: https://litter.catbox.moe/wh0tkl.pt
-
Takeda Hiromitsu Embedding 130k steps: https://litter.catbox.moe/a2cpai.pt
-
Takeda embedding at 120000 steps: https://filebin.net/caggim3ldjvu56vn
-
Nenechi (momosuzu nene) embedding: https://mega.nz/folder/E0lmSCrb#Eaf3wr4ZdhI2oettRW4jtQ
-
Touhou Fumo embedding (57 epochs): https://birchlabs.co.uk/share/textual-inversion/fumo.cpu.pt
-
Abigail from Great Pretender (24k steps): https://workupload.com/file/z6dQQC8hWzr
-
Naoki Ikushima (40k steps): https://files.catbox.moe/u88qu5.pt
-
Gigachad: https://easyupload.io/nlha2m
-
Kusada Souta (95k steps): https://files.catbox.moe/k78y65.pt
-
Yohan1754: https://files.catbox.moe/3vkg2o.pt
-
Kaneko Kazuma (Kazuma Kaneko): https://litter.catbox.moe/6glsh1.pt
-
Senran Kagura (850 CGs, deepdanbooru tags, 0.005 learning rate, 768x768, 3000 iterations): https://files.catbox.moe/jwiy8u.zip
-
Abmayo (miku) (14.7k): https://www.mediafire.com/folder/trxo3wot10j41/abmono
-
Aroma Sensei (86k, "aroma"): https://files.catbox.moe/wlylr6.pt
-
Zun (75:25 weighted sum NAI full:WD): https://www.fluffyboys.moe/sd/zunstyle.pt
-
Kurisu Mario (20k): https://files.catbox.moe/r7puqx.pt
- creator anon: "I suggest using him for the first 40% of steps so that the AI draws the body in his style, but it's up to you. Also, put speech_bubble in the negative prompt, since the training data had them"
-
ATDAN (33k): https://files.catbox.moe/8qoag3.pt
-
Valorant (25k): https://files.catbox.moe/n7i9lq.pt
-
Takifumi (40k, 153 imgs, NAI): https://freeufopictures.com/ai/embeddings/takafumi/
- for competition swimsuit lovers
-
40hara (228 imgs, 70k, 421 after processing): https://freeufopictures.com/ai/embeddings/40hara/
-
Tsurai (160k, NAI): https://mega.nz/file/bBYjjRoY#88o-WcBXOidEwp-QperGzEr1qb8J2UFLHbAAY7bkg4I
-
jtveemo (150k): https://a.pomf.cat/kqeogh.pt
- Creator anon: "I didn't crop out any of the @jtveemo stuff so put twitter username in the negatives."
- 150k steps, 0.005 LR, art from exhentai collection and processed with mirror and autocrop, deepdanbooru
-
Nahida (Genshin Impact): https://files.catbox.moe/nwqx5b.zip
-
Arcane (SD 1.4): https://files.catbox.moe/z49k24.pt
- People say this triggered the pickle warning, so it might be pickled.
-
Gothica: https://litter.catbox.moe/yzp91q.pt
-
Mordred: https://a.pomf.cat/ytyrvk.pt
-
100k steps tenako (mugu77): https://www.mediafire.com/file/1afk5fm4f33uqoa/tenako-mugu77-100000.pt/file
-
erere-26k (fuckass(?)): https://litter.catbox.moe/cxmll4.pt
-
Great Mosu (44k): https://files.catbox.moe/6hca0u.pt
-
no idea what this embedding is, apparently it's an artist?: https://files.catbox.moe/2733ce.pt
-
Dohna Dohna, Rance remakes (305 images (all VN-style full-body standing character CGs). 12000 steps): https://files.catbox.moe/gv9col.pt
- trained only on dohna dohna's VN sprites
- Onono imoko
-
Senri Gan: https://files.catbox.moe/8sqmeh.rar
- 2 hypernetworks and 5 TI
- Anon: "For the best results I think using hyper + TI is the way. I'm using TI-6000 and Hyper-8000. It was trained on CLIP 1 Vae off with those rates 5e-5:100, 5e-6:1500, 5e-7:10000, 5e-8:20000."
-
om_(n2007): https://files.catbox.moe/gntkmf.zip
-
Kenkou Cross: https://mega.nz/folder/ZYAx3ITR#pxjhWOEw0IF-hZjNA8SWoQ
-
Baffu (~47500 steps): https://files.catbox.moe/l8hrip.pt
- Biased toward brown-haired OC girl (Hitoyo)
-
Danganronpa: https://files.catbox.moe/3qh6jb.pt
-
Hifumi Takimoto: https://files.catbox.moe/wiucep.png
- 18500 steps, prompt tag is takimoto_hifumi. Trained on NAI + Trinart2 80/20, but works fine using just NAI
-
Power (WIP): https://files.catbox.moe/bzdnzw.7z
-
shiki_(psychedelic_g2): https://files.catbox.moe/smeilx.rar
-
Embeddings using the old version of TI
-
Takeda Hiromitsu reupload: https://www.mediafire.com/file/ljemvmmtz0dqy0y/takeda_hiromitsu.pt/file
-
Takeda Hiromitsu (another reupload): https://a.pomf.cat/eabxqt.pt
-
Pochi: https://files.catbox.moe/7vegvg.rar
- Author's notes: Smut version was trained on a lot of doujins and it looks more like her old style from the start of smut version of Ane doujin (compare to chapter 1 and you can see that it worked). 200k version is looking a bit more like her recent style but I can see it isn't going to work the way I hoped.
- By accident I started with 70 pics where half of them were doujins to give reference for smut. Complete data is 200 with again those same 35 doujins for smut. I realized that I used half smut instead of full set so I went back to around 40k steps and then gave it complete 200 picture set hoping it would course correct since non smut is more recent art style. Now it looks like it didn't course correct and will never do that. On the other hand recent iterations are less horny.
-
Power (Chainsaw Man): https://files.catbox.moe/c1rf8w.pt
-
ooyari:
- 70k (last training): https://litter.catbox.moe/gndvee.pt
- 20k (last stable loss trend): https://litter.catbox.moe/i7nh3x.pt
- 60k (lowest loss rate state in trending graph): https://litter.catbox.moe/8wot9a.pt
-
Kunaboto (195 images. 16 vectors per token, default learning rate of 0.005): https://files.catbox.moe/uk964z.pt
-
Erika (Shadowverse): https://files.catbox.moe/y9cgr0.pt
-
Luna (Shadowverse): https://files.catbox.moe/zwq5jz.pt
-
Fujisaka Lyric: https://files.catbox.moe/8j6ith.pt
-
Hitoyo (maybe WIP?): https://files.catbox.moe/srg90p.pt
-
Hitoyo (58k): https://files.catbox.moe/btjsfg.pt
-
kunaboto v2 (Same dataset, just a different training rate of 0.005:25000,0.0005:75000,0.00005:-1, 70k): https://files.catbox.moe/v9j3bz.pt
-
Hitoyo (another, final vers?) (100k steps, bonnie-esque): https://files.catbox.moe/l9j1f4.pt
-
Fatamoru: https://litter.catbox.moe/pn9xep.pt
- Dead link: https://litter.catbox.moe/xd2ht9.pt
-
Zip of Fatamoru, Morgana, and Kaneko Kazuma: https://litter.catbox.moe/9bf77l.zip
-
Tekuho (NAI model, Clip Skip 2, VAE unloaded, Learning rate 0.002:2000, 0.0005:5000, 0.0001:9000): https://mega.nz/folder/VB5XyByY#HLvKyIJ6U5nMXx6i3M__VQ
- manually cropped about 150 images, making sure that all of them have a full body shot, a shot from torso and up, and if applicable a closeup on the face
- Images not from Danbooru
- Best results around 4000 steps
-
Embed of a girl anon liked (2500 steps, keyword "jma"): https://files.catbox.moe/1qlhjf.pt
-
Carpet Crawler: https://anonfiles.com/i3a2o0E5y0/carpetcrawlerv2-12500_pt
- Embedding trained on nai-final-pruned at 8 vectors up to 20k steps. Turned into ugly overtrained garbage over 125000 steps so this is the one I'm releasing. Not good for much other than eldritch abominations.
- https://www.deviantart.com/carpet-crawler/gallery
- recommend using it in combination with other horror artist embeddings for best results.
-
nora higuma (Fuckass, 0.0038, 24k, 1000+ dataset, might be pickle): https://litter.catbox.moe/tkj61z.pt
- dead link: https://litter.catbox.moe/25n10h.pt
-
mdf an (Bitchass train: 0.0038, steps: 48k, loss rate trend: 0.095, dataset: 500+, issue: nsfw majority, will darken sfw images): https://litter.catbox.moe/lxsnyi.pt
- dead link: https://litter.catbox.moe/4liook.p
-
subachi (shitass, train: 0.0038, steps: 48k, loss rate trend: 0.118, dataset: 500+, issue: due to artist's style, it's on sigma male mode; respecting woman is not an option with this embedding): https://litter.catbox.moe/6nykny.pt
- dead link: https://litter.catbox.moe/idskrg.pt
-
DEAD LINK Omaru-polka: https://litter.catbox.moe/qfchu1.pt
-
Embed for "veemo" (?), used to make this picture (https://s1.alice.al/vt/image/1665/54/1665544747543.png): https://files.catbox.moe/18bgla.pt
-
Reine:
- 39,5k steps, pretty high vectors per token: https://files.catbox.moe/s2s5qg.pt
- smaller clip skip and less steps, trained it to 13k: https://files.catbox.moe/nq126i.pt
-
Big reine collection: https://files.catbox.moe/xe139m.zip
-
Ilulu (64k steps with a learning rate of 0.001): https://files.catbox.moe/8acmvo.pt
-
random embed from furry thread (6500 steps, 10 vectors, 1 placeholder_string, init_word "girl" these four images used): https://files.catbox.moe/4qiy0k.pt
-
Cookie (from furry thread, apprently good with inpainting): https://files.catbox.moe/9iq7hh.pt
-
Cutie (cyclops, from furry thread, 8k steps): https://files.catbox.moe/aqs3x3.pt
-
Felino's artstyle (from furry thread, 7 images): https://files.catbox.moe/vp21w4.pt
-
Yakov (from mlp thread): https://i.4cdn.org/mlp/1666224881260593.png
-
Rebecca (by booru anon, info is in link): https://huggingface.co/demibit/rebecca
-
eastern artists combinination: https://mega.nz/file/SlQVmRxR#nLBxMj7_Zstv4XqfuEcF-pgza3T1NPlejCm1KGBbw70
-
Elana (Shadowverse): https://files.catbox.moe/vbpo7m.pt
-
Info by anon: I just grab all the good images I can find, tag with BLIP and Deepdanbooru in the preprocessing, and pick a number of vectors based on how many images I have (16 here since not a lot). Other than that, I trained 6500 steps at 1 batch size under the schedule:
0.02:200, 0.01:1000, 0.005:2000, 0.002:3000, 0.0005:4000, 0.00005
-
-
Power (60k): https://files.catbox.moe/72dfvc.pt
-
Takeda, Mogudan Fourchanbal (?, from KR site): https://files.catbox.moe/430rus.pt
-
Mikan (30 tokens, 36 images (before flipping/splitting), 5700steps, 5e-02:2000, 5e-03:4000): https://files.catbox.moe/xwdohx.pt
- creator: I've been getting best results with these tags: (orange hair and (hair tubes:1.2), (dog ears and dog tail and (huge ahoge:1.2):1.2)), green eyes
- apparently it's not very effective. a hypernetwork is WIP
-
Fuurin Rei (6000, 5.5k most): https://files.catbox.moe/s19ub3.7z
-
Mutsuki (Blue Archive) embedding (10k step,150 image, no clip skip [set the "stop at last layers of clip model" option at 1 to get good results], 0.02:300, 0.01:1000, 0.005:2000, 0.002:3000, 0.0005:4000, 0.0005, vae disabled by renaming): https://files.catbox.moe/6yklfl.pt
-
as109 (trained with 1000+ dataset, 0.003 learning rate, 0.12 loss rate trend, 25k step snapshot): https://litter.catbox.moe/5iwbi5.pt
-
sasamori tomoe (0.92 loss trend, 60k+ steps, 0.003 learning rate. 500+ dataset, pruned pre 2015 images. biased to doujin, weak to certain positions (mostly side)): https://litter.catbox.moe/mybrvu.pt
-
egami(500+ dataset, 0.03 learning rate, 0.13 loss trend, 40k steps): https://litter.catbox.moe/dpqp1k.pt
-
pink doragon (20k+ steps, 0.0031 learning rate, 0.113 loss trend, 800+ dataset): https://litter.catbox.moe/mml9b9.pt
- kind of failure: fancy recent artworks are ignored due to dataset bias - will train with 2018+ data.
- leaning to BIG ASS and BIG TIDDIES.
-
Kiwi (by booru anon): https://huggingface.co/demibit/kiwi
-
Labiata (8 vectors/token): https://files.catbox.moe/0kri2d.pt
-
Akari (another, one I missed): https://files.catbox.moe/dghjhh.pt
-
Arona from Blue Archive (I'm pretty sure): https://files.catbox.moe/4cp6rl.pt
-
Emma (arcane, 50 vector embedding trained on ~250 pics for ~13500 steps): https://files.catbox.moe/2cd7s3.pt
-
blade4649 embedding (10k steps, 352 images,16 vectors,learning rate at 0.005): https://files.catbox.moe/5evrpn.pt
-
fechtbuch of Mair: https://files.catbox.moe/vcisig.pt
-
Longsword (mainly for img2img): https://files.catbox.moe/r442ma.pt
-
Le Malin (listless Lapin skin, 10k steps with 712 inputs): https://files.catbox.moe/3rhbvq.pt
-
minakata hizuru (summertime girl): https://files.catbox.moe/9igh8t.pt
-
Roon (Azur Lane) (NAI model, 10k steps but with 83 different inputs): https://files.catbox.moe/9b77mp.pt
-
arcane-32500: https://files.catbox.moe/nxe9qr.pt
-
mashu003 (https://mashu003.tumblr.com/) (all danbooru images used as dataset): https://files.catbox.moe/kk7v9w.pt
-
Takimoto Hifumi (18500 steps, prompt tag is takimoto_hifumi. Trained on NAI + Trinart2 80/20, but works fine using just NAI): https://files.catbox.moe/wiucep.png
-
momosuzu nene: https://mega.nz/folder/s8UXSJoZ#2Beh1O4aroLaRbjx2YuAPg
-
Harada Takehito (disgaea artist) (78k steps with 150 images): https://files.catbox.moe/e2iatm.pt
-
Mda (1700 images and trained for 20k): https://files.catbox.moe/tz37dj.pt
-
Polka (NAI, 16 vectors, 5500 steps): https://files.catbox.moe/pmzyhi.png
-
Ghislaine Dedoldia ("dark-skinned female" init word, 12 vectors per token, 0.02:200, 0.01:1000, 0.005:2000, 0.002:3000, 0.0005:4000, 0.00005 LR, 10k steps 75 image crop data set) https://mega.nz/folder/JPVSVLbQ#SqGZb7OVKe_UNRvI0R8U8A
- Notes by uploader: Here is a terrible Ghislaine Dedoldia embedding I made while testing sd-tagging-helper and the new webui dataset tag editor extension. She has no tail because the crops were shit and I only trained on crops made using the helper. Sometimes the eye patch is on the wrong side because of two images where it was on the wrong eye. Stomach scar is sometimes there sort of but probably needed more time in the oven. She doesn't have dark skin because the AI is racist and probably because it was only tagged on half the images.
- Uploader: Use "dark-skinned female" in your prompt or she will be pale
-
Mizuryu-Kei (Mizuryu Kei): https://files.catbox.moe/bcy7vx.pt
-
kidmo: https://litter.catbox.moe/44e28e.pt
- dataset:kidmo
- dataset:no filter
- 10 tokens
- 26k steps
- 0.129 loss trend
- 90-ish dataset
- 0.0028 learning rate
- issue: generic as shit, irradiated with kpop, potato gaming (you'll know when you try to use this shit with i2i)
-
asanugget-16: https://litter.catbox.moe/9r0ixj.pt
- dataset: asanagi
- dataset: no pre-2010 artworks
- 16 tokens
- 22k steps
- 0.114 loss trend
- 500+ dataset (w/ auto focalpoint)
- 0.0028 learning rate
-
Ohisashimono (20k to 144k): https://www.mediafire.com/folder/eslki3wzlmesj/ohi
-
Shadman: https://files.catbox.moe/fhwn7m.png
-
ratatatat74: https://mega.nz/folder/PfhRUbST#6oXUaNjk_B6nhJzjc_M0UA
- Uploader: Because the source images were prominently lewd in some shape or form, it really likes to give half-naked people.
- In combination with Puuzaki Puuna, it certainly brings out some interesting humanoid Nanachis.
-
WLOP: https://mega.nz/folder/PfhRUbST#6oXUaNjk_B6nhJzjc_M0UA/folder/KWJUSR7T
- This embedding has 24 vectors, has been trained by a rate of 0.00005 and was completed at the steps of around 35000.
- The embedding was trained on NovelAI (final-pruned.ckpt).
- Uploader's Note: This embedding has a HUGE problem in keeping the signature out - feel free to crop out the signature if you wish to redo the embedding. If you do find a way to remove it without recreating the whole embedding - feel free to post it in 4chan/g/ and I may stumble upon it.
- Note 2: Use inpainting on the face in img2img to create some beautiful faces if they come out distorted initially.
-
Asutora style embedding (mainly reflected in coloring and shading, since his faces are very inconsistent): https://mega.nz/folder/nZoECZyI#vkuZJoQyBZN8p66n4DP62A
- uploader: satisfactory results over 20k steps
- Comparisons: https://i.4cdn.org/g/1667701438177228.jpg
-
y'shtola: https://files.catbox.moe/5hefsb.pt
- Uploader: You may need to use square brackets to lower it's impact. Also it likes making cencored pics unless you add penis to the input prompt
-
Selentoxx (nai, 16v, 10k): https://files.catbox.moe/0j7ugy.png
-
Aki (Goodboy, nai, 16v, 10k): https://files.catbox.moe/1p14ra.png
-
Sana (nai, 15v):
- 10k: https://files.catbox.moe/g112gm.png
- 100k: https://files.catbox.moe/3ndubu.png
- In case these aren't good, use:
- 10k: https://files.catbox.moe/r5ciho.pt
- 25k: https://files.catbox.moe/e6aurx.pt
- 50k: https://files.catbox.moe/lz016k.pt
- 75k: https://files.catbox.moe/jhdjc9.pt
- 100k: https://files.catbox.moe/2lvv2z.pt
- Uploader note: don't use more than 0.8 weighting or else it gets deep fried
-
delutaya: https://files.catbox.moe/r6pylz.pt
-
Delutaya (another unrelated, 16v, 10k, nai): https://files.catbox.moe/kv2hdd.png
-
mano-aloe-v1q (nai, manoaloe,mano aloe): https://files.catbox.moe/0i5qfl.pt
-
Fauna (16v, 10k, nai): https://files.catbox.moe/zizgrw.png
-
wawa (15v, 10k, nai): https://files.catbox.moe/2vpyi2.png
-
Wagashi: https://mega.nz/file/exM21aTT#eawWbqsmajzs-TUCWfrVHvsG2HBEZ3HcYR5cy1AxFPw
-
Deadflow: https://mega.nz/file/y41WHIgC#pXtCly7bzjDNJ7RZl7685_Nj1LTliIif_f_1BWMhHSE
-
Elira (16v, 3k, nai sfw): https://litter.catbox.moe/4ylbez.png
-
Rratatat (NAI, 16v, 10k): https://files.catbox.moe/nrekhk.png
- Uploader: Works better with "red hair, multicolored hair, twintails"
-
WLOP (reupload, retrained WITHOUT signatures - 24 vectors, 0.00005 learning rate, around 19000 steps: https://mega.nz/folder/PfhRUbST#6oXUaNjk_B6nhJzjc_M0UA
-
ratatatat74 (reupload, retrained WITHOUT VAE - 24 vectors, 0.00005 learning rate, 13500 steps): https://mega.nz/folder/PfhRUbST#6oXUaNjk_B6nhJzjc_M0UA
-
Wiwa embed steps pre deep frying: https://files.catbox.moe/6lu6od.zip
-
Nilou (by anon, not sure if safe or of any training info, NOTE TO MYSELF SEARCH FOR THIS EMBED's DISCORD): https://cdn.discordapp.com/attachments/1019446913268973689/1039909937884713070/nilou.pt
-
Makima (500s, 4v, NAI): https://i.4cdn.org/h/1668023713496532.png
-
Fauna (updated, NAI, 8v, 10k): https://files.catbox.moe/dmu00i.png
-
New rrat (8v, 10k, NAI): https://files.catbox.moe/fyqxjf.png
-
Weine (8v, 10k, nai): https://files.catbox.moe/b9cn4z.png
-
Moona (10k, 8v, nai): https://files.catbox.moe/tuh4nj.png
- Comparison with Moona 2: https://i.4cdn.org/vt/1668038525258037s.jpg
-
Aki (another, Goodboy, nai, 8v, 10k, nai): https://files.catbox.moe/k2cgxj.png
-
Delu (another, notaloe, 8v, 10k, nai): https://files.catbox.moe/cvykdm.png
-
Moona 2 (another anon, nai, moonmoon, nai, 8v, 10k): https://files.catbox.moe/yh8ora.png
- Comparison with the Moona 4 links up: https://i.4cdn.org/vt/1668038525258037s.jpg
-
Kobogaki (nai, 8v, 10k): https://files.catbox.moe/0r3a8o.png
-
Yopi (nai, 8v, 10k): https://files.catbox.moe/hoh865.png
-
FreeStyle/Yohan TI by andite#8484 (trained on ALL of his artwork, not only skin): https://cdn.discordapp.com/attachments/1019446913268973689/1038423463314075658/yohanstyle.pt
-
Matchach TI by methane#3131: https://cdn.discordapp.com/attachments/1019446913268973689/1040271410217635920/matcha-20000.pt
- Might need to add cat ears to negative prompt because for some reason it appears
-
Elira (8v, 10k, nai): https://files.catbox.moe/ldeg3v.png
- Linked comparison (Elira default-5500 16v 5500 steps, Wiwa 4v 10000 steps, Elira t8 8v 10000 steps): https://i.4cdn.org/vt/1668135849025419s.jpg
-
Reine (35v, 39500s, nai90sd10): https://files.catbox.moe/m0he7i.png
-
Kobo (kbknr, 10k, 16v, NAI): https://files.catbox.moe/kphjec.png
-
Kaela (Kovalski) (NAI, 4500k, 8v): https://files.catbox.moe/nxp368.png
- Uploader: Try, eyewear on head, blonde hair, red eyes, fur trim, jacket, white dress, red ribbon behind hair,
- Dataset?: https://files.catbox.moe/sqci4d.PNG
-
Luna (LunaHime, NAI, 8v, 10k): https://files.catbox.moe/45fe4m.png
- needs heterochromia to force the two eye colors
-
Zeta (Zetanism, 8v, 10k, nai): https://files.catbox.moe/z1u5py.png
-
Aki (Goodboy) (NAI, 8v, 10k): https://litter.catbox.moe/vfd9fw.png
-
Kobo (KoboGaki) (NAI, 8v, 10k): https://litter.catbox.moe/7hssgl.png
-
Delu(?) (NotAloe) (NAI, 8v, 10k): https://litter.catbox.moe/9gdr5t.png
-
Yopi (NAI, 8v, 10k): https://litter.catbox.moe/bhd01v.png
-
AChan (NAI, 8v, 10k): https://i.4cdn.org/vt/1668274461405432.png
-
Wiwa's alt hair (Elira, NAI, 8v, 10k): https://files.catbox.moe/vxz1yo.png
-
miata8674 (45k training steps (4 Colab rounds)): https://mega.nz/folder/nZoECZyI#vkuZJoQyBZN8p66n4DP62A
- Focuses on faces, the defining features of the style are general sketchiness and the eyes. Strengthened by the mention of eyelashes and eyeshadow
-
Asagi Igawa, Edjit, and Rouge the Bat (RealYiffingFar#4510): https://mega.nz/folder/5nIAnJaA#YMClwO8r7tR1zdJJeTfegA
- Has training info and a tutorial
-
NIXEU: https://mega.nz/folder/PfhRUbST#6oXUaNjk_B6nhJzjc_M0UA
- By uploader: 24 vectors, 0.00005 training rate, around 16500 steps and 48 reference images with NovelAI (final-prune.ckpt)
- From the testings that I have done, it is able to replicate the artstyle quite well with one exception - the primary problem being the eyes - they seem to be slightly overbaked. My suggestion is to use img2img to circumvent that problem.
- Regardless: I recommend a CFG of around 8.5 and prompts such as 'soft lighting' which would underline the style. Requires a bit of fine tuning regarding prompts seeing that it is rather delicate to the touch,
-
frank franzetta: https://huggingface.co/sd-concepts-library/frank-frazetta
-
meme50 (WIP, 0.004 LR, 20k): https://litter.catbox.moe/e9v33j.pt
-
Anya (probably a reupload from a collection, v8, 8500s, NAI): https://files.catbox.moe/b8ghxx.png
-
Amelia Watson (amedoko, 8v, 10k, NAI): https://files.catbox.moe/qc3qt2.png
- Produces yellow eyes, prompt for blue eyes
-
Kiara (kiarer, 10k, 5v, NAI): https://files.catbox.moe/87hdj3.png
- op: tried to get a nice spread of quality images from different outfits and artists. It probably won't get any of her outfits right, but the girl in the output is very clearly a wawa
-
NecoArc: https://mega.nz/folder/ToFEARJa#yvSV_Cb5c6KxjM3wXR2_ZA
- Another anon uploaded a mirror (not sure if safe): https://gofile.io/d/fvz1Tl
-
Trixie Lulamoon (100k, 16v, anything 3.0 pruned fp16): https://files.catbox.moe/8ek5o0.png
- For blue/purple witches
- The embedding associated the right blue tone with "aqua", as well as the correct purple tone with "purple". It tends to add long eyelashes and eyeshadow, but those can be enhanced with prompts.
- The correct hairstyle comes from "hair over shoulder" and "asymmetrical hair", but "asymmetrical bangs" helps achieve it.
- It dislikes clothes and will try to cheat them right off your prompts.
- As far as I can tell it works decently well on any Nai-based model and at varying Clip Skip levels, but it was trained on Anything v3 with Clip Skip on 1. Going over 1.2 weight on clip skip 1 looks weird sometimes
- Reupload by anon (not sure if safe): anonfiles.com/1ev4m8Hey1/trixie_lulamoon_pt
NOTE TO MYSELF, ADD THAT PONY EMBEDDING THAT I DOWNLOADING 2 WEEKS AGO
Found on Discord:
- Nahida v2: https://cdn.discordapp.com/attachments/1019446913268973689/1031321278713446540/nahida_v2.zip
- Nahida (50k, very experimental, not enough images): https://files.catbox.moe/2794ea.pt
Found on Reddit:
- look at the 2nd and 3rd images: https://www.reddit.com/gallery/y4tmzo
!!! info If a hypernetwork is <80mb, I mislabeled it and it's an embedding
!!! info Use a download manager to download these. It saves a lot of time + good download managers will tell you if you have already downloaded one
!!! All files in this section (ckpt, vae, pt, hypernetwork, embedding, etc) can be malicious: https://docs.python.org/3/library/pickle.html, https://huggingface.co/docs/hub/security-pickle. Make sure to check them for pickles using a tool like https://github.com/zxix/stable-diffusion-pickle-scanner
- anon: "Requires extremely low learning rate, 0.000005 or 0.0000005" Good Rentry: https://rentry.co/naihypernetworks Hypernetwork Dump: https://gitgud.io/necoma/sd-database Collection: https://gitlab.com/mwlp/sd Another collection: https://www.mediafire.com/folder/bu42ajptjgrsj/hn Senri Gan: https://files.catbox.moe/8sqmeh.rar Big dumpy of a lot of hypernets (has slime too): https://mega.nz/folder/kPdBkT5a#5iOXPnrSfVNU7F2puaOx0w Collection of asanuggy + maybe some more: https://mega.nz/folder/Uf1jFTiT#TZe4d41knlvkO1yg4MYL2A Collection: https://mega.nz/folder/fVhXRLCK#4vRO9xVuME0FGg3N56joMA Mogudan, Mumumu (Three Emu), Satou Shouji + constant updates (thanks mogubro): https://mega.nz/folder/hlZAwara#wgLPMSb4lbo7TKyCI1TGvQ
- Korean megacollection:
- https://arca.live/b/hypernetworks?category=%EA%B3%B5%EC%9C%A0
- Link scrape: https://pastebin.com/p0F4k98y
- (includes mega compilation of artists): https://arca.live/b/hypernetworks/60940948
- Original: https://arca.live/b/hypernetworks/60930993
- Large collection of stuff from korean megacollection: https://mega.nz/folder/sSACBAgC#kNiPVzRwnuzs8JClovS1Tw
- https://arca.live/b/hypernetworks?category=%EA%B3%B5%EC%9C%A0
Chinese telegram (uploaded by telegram anon): magnet:?xt=urn:btih:8cea1f404acfa11b5996d1f1a4af9e3ef2946be0&dn=ChatExport%5F2022-10-30&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce
I've made a full export of the Chinese Telegram channel.
It's 37 GB (~160 hypernetworks and a bunch of full models). If you don't want all that, I would recommend downloading everything but the 'files' folder first (like 26 MB), then opening the html file to decide what you want.
-
Dead link: https://t.me/+H4EGgSS-WH8wYzBl
-
Big collection: https://drive.google.com/drive/folders/1-itk7b_UTrxVdWJcp6D0h4ak6kFDKsce?usp=sharing
-
https://arca.live/b/hypernetworks/60927228?category=%EA%B3%B5%EC%9C%A0&p=2
-
NAIHypernetwork collection: https://rentry.org/naihypernetworks
Found on 4chan:
-
bigrbear: https://files.catbox.moe/wbt30i.pt
-
Senran Kagura v3 (850 images, 0.000005 learn rate, 20000 steps, 768x768): https://files.catbox.moe/m6jynp.pt
- CGs from the Senran Kagura mobile game (NAI model): https://files.catbox.moe/vyjmgw.pt
- Ran for 19,000 steps with a learning rate of 0.0000005. Source images were 768x576. It seems to only reproduce the art style well if you specify senran kagura, illustration, game cg, in your prompt.
- Old version (19k steps, learning rate of 0.0000005. Source images were 768x576. NAI model. 850 CGs): https://files.catbox.moe/di476p.pt
- Senran Kagura again (850, deepdanbooru, 0.000006, 768x576, 7k steps): https://files.catbox.moe/f40el4.pt
- CGs from the Senran Kagura mobile game (NAI model): https://files.catbox.moe/vyjmgw.pt
-
Danganronpa: https://files.catbox.moe/9o5w64.pt
- Trained on 100 images, up to 12k with 0.000025 rate, then up to 18.5k with 0.000005
- Also seed 448840911 seems to be great quality for char showcase with just name + base NAI prompts.
-
Alexi-trained hypernetwork (22000 steps): https://files.catbox.moe/ukzwlp.pt
- Reupload by anon: https://files.catbox.moe/slbk3m.pt
- works best with oppai loli tag
- https://files.catbox.moe/xgozyz.zip
-
Etrian Odyssey Shading hypernetwork (20k steps, WIP, WD 1.3)
-
colored drawings by Hass Chagaev (6k steps, NAI): https://files.catbox.moe/3jh1kk.pt
-
Morgana: https://litter.catbox.moe/3holmx.pt
-
EOa2Nai: https://files.catbox.moe/ex7yow.7z
-
EO (WD 1.3): https://files.catbox.moe/h5phfo.7z
-
Taran Jobu (oppai loli, WIP, apparently it's kobu not jobu)
-
Higurashi (NAI:SD 50:50): https://litter.catbox.moe/lfg6ik.pt
- by op anon: "1girl, [your tags here], looking at viewer, solo, art by higurashi", cfg 7, steps about 40"
-
Tatata (15 imgs, 10k steps): https://files.catbox.moe/7hp2es.pt
-
Zankuro (0.75 NAI:WD, 51 imgs, 25k+ steps): https://files.catbox.moe/tlurbe.pt
- Training info + hypernetwork: https://files.catbox.moe/4do43z.zip
-
Test Hypernetwork (350 imgs where half are flipped, danooru tags, 0.00001 learning rate for 3000 steps, 0.000004 until step 7500): https://files.catbox.moe/coux0u.pt
-
Kyokucho (40k steps, good at 10-15k, NAI:WD1.2): https://workupload.com/file/TFRuGpdGZZn
-
Final Ixy (more detail in discord section): https://mega.nz/folder/yspgEBhQ#GLo7mBc1EH7RK7tQbtC68A
- Old Ixy (more data, more increments): https://mega.nz/file/z8AyDYSS#zbZFo9YLeJHd8tWcvWiRlYwLz2n4QXTKk04-cKMmlrg
- Old Ixy (less increments, no training data): https://mega.nz/file/ixxzkR5T#cxxSNxPF1KmszJDqiP4K4Ou8tbl1SFKL6DdQC58k6zE
-
Grandblue Fantasy character art (836 images, 5e-5:100, 5e-6:1500, 5e-7:10000, 5e-8:20000 learn rate, 20000 steps, 1024x1024): https://files.catbox.moe/2uiyd4.pt
-
Bombergirl (Stats: 178 images, 5e-8 learn rate continuing from old Bombergirl, 20000 steps, 768x768): https://files.catbox.moe/9bgew0.pt
- Old Bombergirl (178 imgs, 0.000005 learning rate, 10k, 768x768): https://files.catbox.moe/4d3df4.pt
-
Aki99 (200 images , 512x512, 0.00005, 19K steps, NAI): https://files.catbox.moe/bwff89.pt
-
Aki99 (200 images , 512x512, 0.0000005, 112K steps, learning prompt: [filewords], NAI): https://www.mediafire.com/file/sud6u1vb0gvqswu/aki99-112000.7z/filehttps://files.catbox.moe/6hca0u.pt
-
Great Mosu: https://files.catbox.moe/mc1l37.pt
-
mda starou: https://a.pomf.cat/xcygvk.pt
-
Mogudan (12 vectors per token, 221 image dataset, preprocessing: split oversize, flipped mirrors, deepdanbooru auto-tag, 0.00005 learning rate, 62,500 steps): https://mega.nz/file/UtAz1CZK#Y5OSHPkD38untOPSEkNttAVi2tdRLBFEsKVkYCFFaHo
-
Onono Imoko: https://files.catbox.moe/amfy2x.pt
- Dataset: https://files.catbox.moe/dkn85w.zip
-
Etrian Odyssey (training rate 5e-5:100, 5e-6:1500, 5e-7:10000, 5e-8:20000,20k steps, 512 x 512 pics): https://files.catbox.moe/94qm83.7z
-
Jesterwii: https://files.catbox.moe/hlylo4.zip
-
jtveemo (v1): https://mega.nz/folder/ctUXmYzR#_Kscs6m8ccIzYzgbCSupWA
- 35k max steps, 0.000005 learning rate, 180 images, ran through deepbooru and manually cleaned up the txt files for incorrect/redundant tags.
- Recommended the 13500.pt, or something near it
- Recommended: https://files.catbox.moe/zijpip.pt
-
Artsyle based on Yuugen (HBR) (Stats: 103 images, 5e-5:100, 5e-6:1500, 5e-7:10000, 5e-8:20000 learn rate, 20000 steps, 1024x1024,Trained on NAI model): https://files.catbox.moe/bi2ts0.7z
-
Alexi: https://files.catbox.moe/3yj2lz.pt (70000 steps)
- as usual, works best with oppai loli tag. chibi helps as well
- changes from original one i noticed during testing: -hair shading is more subtle now -nipple color transition is also more subtle -eyelashes not as thick as before, probably because i used more pre-2022 pictures. actually bit sad about it, but w/e -eyes in general look better, i recommend generating on 768×768 with highres fix -blonde hair got a pink gradient for some reason -tends to hide dicks between the breasts more often, but does it noticeably better -likes to add backgrounds, i think i overcooked it a bit so those look more like artifacts, perhaps with other prompts it will look better -less hags -from my test prompts, it looked like it breaks anatomy less often now, but i mostly tested pov paizuri -became kinda worse at non-paizuri pictures, less sharpness. because of that, i'm also including 60000 steps version, which is slightly better at that, but in the end, it's a matter of preference, whether to use newer version or not: https://files.catbox.moe/1zt65u.pt
-
Ishikei: https://www.mediafire.com/folder/obbbwkkvt7uhk/ishikemono
-
Curss style (slime girls): https://files.catbox.moe/0sixyq.pt
-
WIP Collection of hypernets: https://litter.catbox.moe/xxys2d.7z
-
DEAD LINK Mumumu's art: https://mega.nz/folder/tgpikL6C#Mj0sHUnr-O6u4MOMDRTiMQ
-
Senri Gan: https://files.catbox.moe/8sqmeh.rar
- 2 hypernetworks and 5 TI
- Anon: "For the best results I think using hyper + TI is the way. I'm using TI-6000 and Hyper-8000. It was trained on CLIP 1 Vae off with those rates 5e-5:100, 5e-6:1500, 5e-7:10000, 5e-8:20000."
-
akisora: https://files.catbox.moe/gfdidn.pt
-
lilandy: https://files.catbox.moe/spzm60.pt
-
shadman: https://files.catbox.moe/kc850y.pt
- anon: "if anyone else wants to try training, can recommend - 0.00005:2000, 0.000005:4000, 0.0000005:6000 learning rate setup (6k steps total with 250~1000 images in dataset)"
-
not sure what this is, probably a style: https://files.catbox.moe/lnxwks.pt
-
ndc hypernet, muscle milfs: https://files.catbox.moe/hsx4ml.pt
-
Asanuggy: https://mega.nz/folder/Uf1jFTiT#TZe4d41knlvkO1yg4MYL2A
-
Tomubobu: https://files.catbox.moe/bzotb7.pt
- Works best with jaggy lines, oekaki, and clothed sex tags.
-
satanichia kurumizawa macdowell (around 552 pics in total with 44.5k steps, most of the datasets are fanarts but some of them are from the anime, tagged with deepdanbooru, flipped and manually cropped): https://files.catbox.moe/g519cu.pt
-
Imazon v1: https://files.catbox.moe/0e43tq.pt
-
Imazon v2: https://files.catbox.moe/86pkaq.pt
-
WIP Baffu: https://gofile.io/d/4SNmm5
-
Ilulu (74k steps at 0.0005 learning rate, full NAI, init word "art by Ilulu"): https://files.catbox.moe/18ad25.pt
-
belko paizuri (86k swish + normalization): https://www.mediafire.com/folder/urirter91ect0/belkomono
- WIP: training/0.000005/swish/normalization
-
Pinvise (Suzutsuki Kirara) (NAI-Full with 5e-6 for 8000 steps and 5e-7 until 12000 steps on 200 (400 with flipped) images): https://litter.catbox.moe/glk7ni.zip
-
Another batch of artists hypernetworks (some are with 1221 structure, so bigger size)
- https://files.catbox.moe/srhrn6.pt - diathorn
- https://files.catbox.moe/dytn06.pt - gozaru
- https://files.catbox.moe/69t1im.pt - Sunahara Wataru
-
kunaboto (new swish activation function + dropout using a learning rate of 5e-6:12000, 5e-7:30000): https://files.catbox.moe/lynmxm.pt
- aesthetic: https://files.catbox.moe/qrka4m.pt
-
Om (nk2007):
- 250 images (augmented to 380), learning rate: 5e-5:380,5e-6:10000,5e-7:20000, template: [filewords]
- 10k step : https://files.catbox.moe/8kqb4c.pt
- 16k step : https://files.catbox.moe/7vtcgt.pt
- 20k step (omHyper): https://files.catbox.moe/f8xiz1.pt
-
Spacezin: https://mega.nz/folder/Os5iBQDY#42xOYeZq08ZG0j8ds4uL2Q
- excels at his massive tits, covered nipples, body form, sharp eyes, all that nice stuff
- no cbt data
- using the new swish activation method +dropout, works very well, trained at 5e-6 to 14000
- data it was trained on and cfg test grid included in the folder
- Hypernetwork trained on 13 handpicked images from spacezin
- recommend using spacezin in the prompt, using 14000 step hypernetwork, lesser steps are included for testing
- Aesthetic gradient embedding included
-
amagami artstyle (30k,5e-6:12000, 5e-7:30000,swish+dropout): https://files.catbox.moe/3a2cll.7z
-
Ken Sugimori (pokemon gen1 and gen2) art: https://files.catbox.moe/uifwt7.pt
-
mikozin: https://mega.nz/folder/a0wxgQrR#OnJ0dK_F6_7WZiWscfb5hg
- Trained a hypernetwork on mikozin's art, using nai full pruned, swish activation method+dropout
- placing mikozin in the prompt will make it have a stronger effect, as all the training prompts include the [name] at the end.
- has a number of influences on your output, but mostly gives a very soft, painted style to the output image
- Aesthetic gradient embedding also included, but not necessary
- check the training data rar to read the filewords to see if you want to call anything it was specifically trained on
- Found on Discord (copied from SD Training Labs discord, so grammar mistakes may be present):
-
Pippa (trained on NAI 70%full-30%sfw): https://files.catbox.moe/uw1y8g.pt
-
reine (WIP): https://files.catbox.moe/od4609.pt
-
WiseSpeak/RubbishFox (updated): https://files.catbox.moe/pzix7f.pt
- Info: Uses 176 Fanbox images that were preprocessed with splitting, flipping and mild touchup to remove text in Paint on about 1/4th of the images. I removed images from the Preprocess folder that did not have discernable character traits. Most images are of Tamamo since that is his waifu. Total images after split, flip, and corrections was 636. Took 13 hours at 0.000005 Rate at 512x512. Seems maybe a bit more touchy than the 61.5K file, but I believe that when body horror isn't present you can match the RubbishFox's style better.
-
Style from furry thread: https://files.catbox.moe/vgojsa.pt
-
2bofkatt (from furry thread): https://files.catbox.moe/cw30m8.pt
-
Hypernetwork trained on all 126 cards from the first YGO set in North America, 'Legend Of The Blue Eyes White Dragon' released on 03/08/2002: https://mega.nz/folder/ILkwRZLb#UJ03LDIfcMiFTn6-pyNyXQ
-
WiseSpeak (Rubbish Fox on Twitter): https://files.catbox.moe/kyllcc.pt
- Info: Uses 176 images that were preprocessed with splitting, flipping and mild touchup to remove text in Paint on about 1/4th of the images. I removed images from the Preprocess folder that did not have discernable character traits. Most images are of Tamamo since that is his waifu. Total images after split, flip, and corrections was 636. Took 8 hours at 0.000005 Rate at 512x512
- 93k, less overtrained: https://files.catbox.moe/fluegz.pt
-
Large collection of stuff from korean megacollection: https://mega.nz/folder/sSACBAgC#kNiPVzRwnuzs8JClovS1Tw
-
Crunchy: https://files.catbox.moe/tv1zf4.pt
-
Obui styled hypernetwork (125k steps): https://files.catbox.moe/6huecu.pt
-
KurosugatariAI (2 hypernets, 1 embed, embedding is light at 17 token weight. at 24 or higher creator anon thinks the effect would be better): https://mega.nz/folder/TAggRTYT#fbxf3Ru8PkXz_edIkD2Ttg
-
Amagami (Layer structure 1, 1.5 1.5 1; mish; xaviernormal; No layer normalization; Dropout O (appling only at 2nd layer due to bug); LR 8e-06 fixed; 20k done): https://files.catbox.moe/ucziks.7z
-
Reine (from VTuber dump, might be pickled): https://files.catbox.moe/uf09mp.pt
-
Onono imoko: https://mega.nz/file/67AUDQ4K#8n4bzcxGGUgaAVy7wLXvVib0jhVjt2wPS-jsoCxcCus
- Info moved to discord section
-
Sironora:
-
minakata hizuru (summertime girl): https://files.catbox.moe/gmbnnr.pt
-
a1 (4.5k): https://files.catbox.moe/x6zt6u.pt
-
焦茶 / cogecha hypernetwork, trained against NAI (DEAD LINK): https://mega.nz/folder/BLtkVIjC#RO6zQaAYCOIii8GnfT92dw
-
山北東 / northeast_mountain hypernetwork, trained against NAI (DEAD LINK): https://mega.nz/folder/RflGBS7R#88znRpu7YC1J1JYa9N-6_A
-
emoting mokou (cursed): https://mega.nz/folder/oPUTQaoR#yAmxD_yqeGqyIGfOYCR4PQ
-
Cutesexyrobutts and gram: https://files.catbox.moe/silh2p.7z
-
zunart (NAI, steps from 20000 to 50000): https://mega.nz/file/T9RmlbCQ#_JPkZqY5f0aaNxVc8MnU3WQHW4bv_yCWzJqOwL8Uz1U
-
HBRv3D aka Heaven Burns Red (yuugen) retrained on new dataset of 142 mixed images: https://files.catbox.moe/urjkbm.7z
- Setting was 1,2,1 relu ,Learning rate: 5e-6:12000, 5e-7:30000
-
momosuzu nene: https://mega.nz/folder/s8UXSJoZ#2Beh1O4aroLaRbjx2YuAPg
-
TATATA and Alkemanubis: https://mega.nz/folder/zYph3LgT#oP3QYKmwqurwc9ievrl9dQ
- Tatata: Contains dataset, hypernetworks for steps 10000-19000 with a 1000 steps step, as well as full res sfw and nsfw comparisons.
- It was created before layer structure option, so it parameters are 1, 2, 1 layer structure, linear activation function.
- Alkemanubis: Alkemanubis is with elu activation function and normalisation, Alkemanubis4 is with swish and dropout, Alkemanubis5 is with linear and dropout. All have 1, 2, 4, 2, 1 layer structure.
- dataset and more fullres preview grid are inside too.
-
HKSW (wrong eye color because of dataset): https://files.catbox.moe/dykyab.pt
-
Nanachi and Puuzaki Puuna (retrained, 4700 steps, sketches are good, VAE turned off): https://mega.nz/folder/PfhRUbST#6oXUaNjk_B6nhJzjc_M0UA
-
HiRyS: https://mega.nz/file/Mk8jTZ4I#TdlF5Bxwz_gAuQeR0PWa_YUZotcQkA34d6m49I6eUMc
- Dead link, I think this is the same hypernetwork: https://litter.catbox.moe/rx8uv0.pt
-
4k, 3d, highres images: 4k, 3d, highres images: https://mega.nz/file/UAEHkbhK#R-zdpiIz6Ig2-laa-M9_Hmtq6xgLNJZ0ZwVOiXt3OSc
- It has a preference for 3d design, large breasts and curves. It also has a preference for applying backgrounds,if none suggested. usually parks, beaches, indoors or cityscapes
- Comparison: https://i.4cdn.org/h/1667278030582788.png
-
Okegom (Funamusea / Deep Sea Prisoner): https://mega.nz/file/XYQF3YoZ#BAvBQduEx-tnUKvyJQ3mH-zOa_cKUKxpc58YpO8h2jc
- Crashed after 5.3k steps, continued training after when hypernetwork training resuming is broken. Apprently it got better
- Uploader: Alright, it's done. Maybe it's the small training data or the mediocre tagging but sometimes you get stuff that doesn't resemble their art style. Still releasing the three models I liked though, they work nicely with img2img.
-
Funamusea/Okegom/Mogeko (12500 steps): https://mega.nz/file/SBg0zBIa#BU1KkBY1vMvLXpfkDci1RZYi5f8P0yN5oyQzGYXF8q0
- Notes by uploader:
Most results (at least with img2img) will have a chibi style regardless of your prompt. 30 steps recommended. Does very well with white skin/pale characters, this is because the hypernetwork is trained mainly on white characters. Not because I wanted to but because it's what she tends to draw the most. Hypernetwork has most of her NSFW art in its data including a fanart which looks like it was drawn by her, just so the AI has a reference. So, yes, it can generate nudity and porn in her style, although I'm not sure about penetration stuff because I haven't tried. "outline" tag is recommended in prompt to have the same thick outlines she often uses in her artwork.
-
Sakimichan: https://mega.nz/file/TBJwFDLI#H_bgih8qbWe-EN4ntL_7ur6Ylr2qbcxhDwlC2AfWpnc
-
arnest (109 images, 12000 steps): https://mega.nz/file/HNIhlZ7B#o1hpR04PxBDWTEHDfxLfbRi_9K56HVJ58YgCwDUeRMw
- uploader: Hypernetwork trained on 109 total images dating from 2015 to 2022, including his deleted NSFW commissions and Fanbox content. Also trained on like two or three pre-2015 images just because why not. Should be able to do Touhou characters (especially Alice and Patchouli) extremely well.
- I recommend using the white pupils tag for the eyes to look like picrel.
-
Zanamaoria (20k steps, 47 imgs, mostly dark-skinned elves, and paizuri/huge tits): https://files.catbox.moe/10iasp.pt
- 18500 steps: https://files.catbox.moe/xgf1ho.pt
-
Pinvise (30k steps, 5e-6 for 8k steps and 5e-7 for the rest): https://files.catbox.moe/dec3h3.pt
-
Black Souls II (V2 wasn't uploaded because it was "disappointing"):
- V1 (Image: 181 augmented to 362,Learning Rate 5e-5:362,5e-6:14000,5e-7:20000, steps: 10k): https://files.catbox.moe/fdoyt9.pt
- V3 (Image:164 augmented to 328, Learning Rate 5e-5:328,5e-6:14000,5e-7:20000, steps: 10k): https://files.catbox.moe/1r36tp.pt
- uploader: Unlike V1, I manually edited almost all tags generated with deepdanbooru with the dataset tag editor
- Uncensored X/Y plots:
- V3 (strength: 1) : https://files.catbox.moe/tse4kr.png, https://files.catbox.moe/8y91f0.png (no 'sketch')
- V1 (strength: 0.7): https://files.catbox.moe/pml06i.png ('sketch'), https://files.catbox.moe/18993y.png (without "sketch")
- Uploader: Those two hypernetwork seem to be more accurate if we put "sketch" in the prompt. V1 break if we set hypernetwork strength to 1 (or anything over 0.8) and 0.7 seem to be the sweet spot. V3 does not seem to have the same problem.
-
Hataraki Ari (30k, 50k, and 100k steps): https://mega.nz/folder/TZ5jXYrb#-NXJo8wlmanr8ebbJ5GBBQ
- Training Info:
Modules: 768, 320, 640, 1280 Hypernetwork layer structure: 1, 2, 1 Activation function: swish + dropout Layer weights initialization / normalization: none 115 images, size 512x512, manually selected from patreon gallery on sadpanda Watermarks + text manually removed or cropped out Deepbooru used for captions Hypernetwork learning rate: 5e-6:12000, 5e-7:30000, 2.5e-7:50000, 1e-7:100000
- Uploader note: Works best with huge or gigantic breasts. Occasionally has some problems with extra limbs or nipples. Tags like tall female, muscular female or abs may lead to small heads or weirdly proportioned bodies, so I recommend lowering the weighting on those.
-
IRyS (not sure if this is a reupload of a previous one): https://files.catbox.moe/qnery5.pt
-
Nanachi (reupload, re-retrained WITHOUT sneaky VAE - 0.000005 learning rate, around 16000 steps, around 13000 steps): https://mega.nz/folder/PfhRUbST#6oXUaNjk_B6nhJzjc_M0UA
-
Puuzaki Puuna (reupload, re-retrained WITHOUT sneaky VAE - 0.000005 learning rate): https://mega.nz/folder/PfhRUbST#6oXUaNjk_B6nhJzjc_M0UA
-
Sayori (trained on mostly nsfw CGs (30 out of 40 images were nsfw) from nekopara, koikuma + fandisc, and tropical liquor, trained on NAI pruned): https://mega.nz/file/LegFzJxa#Q1Se9fByKcjuXA2DNWt0gCaV3rCP8U-voBKgFjOevF8
-
Mogudan (final update), Mumumu (Three Emu wip), Satou Shouji: https://mega.nz/folder/hlZAwara#wgLPMSb4lbo7TKyCI1TGvQ
- Has training info, dataset, comparison, and hypernetworks
- Creator likes 111500s the best
- Training info:
155 image dataset, split oversized (threshold 0.75, overlap ratio 0.1), deepdanbooru tagging (score threshold 0.75) layer structure: 1, 2, 1 activation function: linear weight initialization: normal learning rate: 0.0000005
The image count after splitting them ended up being 291, and I manually pruned some of the deepdanbooru tags out of the busier images, the AI was autotagging shit that I absolutely didn't want it to learn, like background details or fabric prints.
I tried mish and softsign, using xaviernormal, with and without normalization/dropout, different layer structures. For some reason, only this combination was able to nail Mogudan's art style, the others only managed to learn his coloring and shading.
Meanwhile, the Mumumu one worked really well with mish, and the WIP Satou Shouji one appears to work really good with softsign (so far).
-
Olga Discordia (35k): https://www.dropbox.com/s/fc8bg0ti7uy8qxz/olgadiscordiav6-35000.pt?dl=0
- make sure you have these prompt to activate her: yellow eyes, intricate eyes, (symmetrical face), (mature female:1.2), pointy ears, elf, earrings, hair over one eye, jewelry, dark elf, breasts, black hair, long hair, dark skin, parted lips, thighhighs, gloves, 1girl, solo,
- final-pruned model. mixberry gives good results too. clip set at 2. vae is optional
- More info by creator: can use final-pruned, berrymix and v3 without any problem. i do not recommend vae with it. clip set at 1 for higher detail. 2 for whatever. to get the prompt working, make sure to included dark elf, dark skinned female, and pointy ears.
-
Henreader: https://files.catbox.moe/q6t6vw.pt
- 104 imgs, mostly from Loli no Himo and some of his recent art, used a grabber to download with gelbooru tags
- Training settings:
- layer: 1, 2, 1
- activation function: linear
- initialization: Normal
- Images: 104 (208 with flipped images)
- dataset: https://files.catbox.moe/e0e3nk.7z (NSFW + loli)
- resolution: 512x512
- Learning rate: 5e-5:832,5e-6:14000,5e-7:2000
- steps: 10000
- Template: [filewords]
-
Sakimichan (not sure if it's a reupload): https://cdn.discordapp.com/attachments/1041563266041794580/1041563947528093746/sakimichan.pt
Found on Discord:
-
Art style of Rumiko Takahashi
Base: Novel AI's Final Pruned [126 images, 40000 steps, 0.00005 rate] Tips: "by Rumiko Takahashi" or "Shampoo from Ranma" etc.
-
Amamiya Kokoro (天宮こころ) a Vtuber from Njiisanji [NSFW / SFW] (Work on WD / NAI)
(Training set: 36 Input images, 21500 Steps, 0.000005 Learning rate. Training model: NAI-Full-Prunced Start with nijisanji-kokoro to get a good result. Recommend Hypernetwork Strength rate: 0.6 to 1.0
-
Haru Urara (ハルウララ) from Umamusume ウマ娘 [NSFW / SFW] (Work on WD / NAI)
Training set: 42 Input images, 21500 Steps, 0.000005 Learning rate. Training model: NAI-Full-Prunced Start with uma-urara to get a good result. Recommend Hypernetwork Strength rate: 0.6 to 1.0
-
Genshin Impact [SFW]
992 images, official art including some game assets 15k steps trained on nai use "character name genshin impact" or "genshin impact)" for best results
-
45k step version: https://files.catbox.moe/newhp6.pt
-
Ajitani Hifumi (阿慈谷 ヒフミ) from Blue Archive [NSFW / SFW] (Work on WD / NAI)
Training set: 41 Input images, 20055 Steps, 0.000005 Learning rate. Model: NAI-Full-Prunced Start with ba-hifumi to get a good result. Recommend Hypernetwork Strength rate: 0.6 to 1.0 1.0 Is a little bit overkill I thought about. If you want to go different costume like swimsuit or casual, I think 0.4 to 0.7 is the best ideal rate.
-
Higurashi no Nako Koro ni // ryukishi07's artstyle
Trained on Higurashi's original VN sprites. Might do Umineko's sprites next, or mix the two together. 8k steps, 15k steps, 18k steps included.
-
Trained Koharu of Blue Archive. I'm not very good at English, so it's painful to read this describe.
Training set: 41 images, 20000 steps, 0.000005 learning rate. Model: WD1.3 merged NAI (3/7 - Sigmoid)
-
queencomplexstyle (no training info): https://files.catbox.moe/32s6yb.pt
-
Shiroko of Blue Archive. Training set: 14 images at 20000 steps 0.000005 learning rate. The tag is 'ba-shiroko'
-
Queen Complex
(https://queencomplex.net/gallery/?avia-element-paging=2) [NSFW] "It's a cool style, and it has nice results. Don't need to special reference anything, seems to work fine regardless of prompt." Base Model: Novel AI Training set: 52 images at 4300 steps 0.00005 learning rate (images sourced from link above and cropped)
-
Raichiyo33 style hypernetwork. Not perfect but seems good enough.
Trained with captions from booru tags for compability with model + art by raichiyo33 in the beginning over NAI model. Use "art by raichiyo33" in the begining of prompt to triggering. Some useful tips:
- with tag "traditional media" produce more beautiful results
- try to avoid too much negativ promts. I use only "bad anatomy, bad hands, lowres, worst quality, low quality, blurry, bad quality" even that seems too much. With many UC tags (especially with full NAI set of uc) it will produce almost generic NAI result.
- Use CLIP -2 (because its trained over NAI, ofc)
-
Genshin Impact [SFW]
992 images, official art including some game assets 15k steps trained on nai use "character name genshin impact" or "genshin impact)" for best results
-
Gyokai-ZEN (aliases: Gyokai / Onono Imoko / shunin) [NSFW / SFW] (For NAI)
Includes training images Training set: 329 Input images, Various steps included. Main model is 21,000 steps. Training model: NAI-Full-Pruned. Recommend Hypernetwork Strength rate: 0.6 to 1.0. Lower strength is good for the overtrained model. Emphasise the hypernet by using the prompt words "gyokai" or "art by gyokai".
Note: the prompt words "color halftone" or "halftone" can be good at adding the little patterns in the shading often seen in onono imoko's style. HOWEVER: This often results in a noise/grain which often can be fixed if you render at a resolution higher than 768x768 (with hi-res fix) Omit these options from your prompt if the noise is too much in the image. Your outputs will be sharper and cleaner, but unfortunately less in the style.
gyokai-zen-1.0 is 16k steps at 0.000005, then up to 21k steps at 0.0000005 gyokai-zen-1.0-16000 is a bit less trained (16k steps) and sometimes outputs cleaner at full strength. gyokai-zen-1.0-overtrain is at 22k steps all at 0.000005. It can sometimes be a bit baked in.
-
yapo (ヤポ) Art Style [NSFW / SFW] (Work on WD / NAI)
Training set: 51 Input images, 8000 Steps, 0.0000005 Learning rate. Training model: NAI-Full-Prunced Start with in style of yapo / yapo to get a good result. Recommend Hypernetwork Strength rate: 0.4 to 0.8
- Preview Link: https://imgur.com/a/r2sOV41
- Download Link: https://anonfiles.com/N6B4d4D7y9/yapo_pt
-
Lycoris recoil chisato
Training set: 100 Input images, 21500 Steps, 0.000005 Learning rate. Training model: NAI-Full-Prunced Start with "cr-chisato" Recommend Hypernetwork Strength rate: 0.4 to 0.8. clip skip : 1 Euler
-
Liang Xing styled
Artstation: https://www.artstation.com/liangxing 20,000 steps at varying learning rates down to 0.000005, 449 training images. Novel AI base. Requires that you mention Liang Xing in some form as that was what I used in the training document. "in the style of Liang Xing" as an example.
-
アーニャ(anya)(SPY×FAMILY) [NSFW / SFW] (Work on WD / NAI)
Training set: 46 Input images, 20500 Steps, 0.00000005 Learning rate. Training model: NAI-Full-Prunced Start with Anya to get a good result. Recommend Hypernetwork Strength rate: 0.6 to 0.9
- Preview Link: https://imgur.com/a/ZbmIVRe
- Download Link: https://anonfiles.com/ZdKej8D5ya/Anya_pt
-
cp-lucy
Training set: 67 Input images, 21500 Steps, 0.000005 Learning rate. Training model: NAI-Full-Prunced Start with "cp-lucy" / clip skip : 1 Recommend Hypernetwork Strength rate: 0.6 to 0.9
-
バッチ (azur bache) (アズールレーン) [NSFW / SFW] (Work on WD / NAI)
Training set: 55 Input images, 20050 Steps, 0.00000005 Learning rate. Training model: NAI-Full-Prunced Start with azur-bache to get a good result. Recommend Hypernetwork Strength rate: 0.6 to 1.0
-
Ixy (by ixyanon):
Hypernetwork trained on ixy's style from 100 handpicked images from them, using split oversized images. Trained in Nai-full-pruned recommend using white pupils in the prompt, ixy for a greater effect of their style Uses: will generally make your output more flat in shading, very good at frilly stuff, and white pupils of course Grid examples located in the folder.
-
Blue Archives Azusa
Training set: 28 Input images, 20000 Steps, 5e-6:12000, 5e-7:30000 Learning rate. Training model: NAI-Full-Prunced Start with ba-azusa to get a good result. Recommend Hypernetwork Strength rate: 0.6 to 1.0 clip skip : 1
-
Makoto Shinkai HN
trained on a roughly ~150 images, 1,2,2,1 for 30,000 steps on NAI model, use "art by makotoshinkaiv2" to trigger it (experimental, it might not be that much different from base model but I have noticed that it improved composition when paired with the aesthetic gradient) 1007 frames from the entire 5 Centimeter Per Second (Byousoku 5 Centimeter) (2007) animovie by Makoto Shinkai
- Dataset (for the aesthetic gradient and for general hypernetwork training/finetuning of a model if anyone else wants to attempt to get this style down.):
- 1: https://cdn.discordapp.com/attachments/1022209206146838599/1033198526714363954/5_Centimeters_Per_Second.7z.001
- 2: https://cdn.discordapp.com/attachments/1022209206146838599/1033198659321475184/5_Centimeters_Per_Second.7z.002
- 3: https://cdn.discordapp.com/attachments/1022209206146838599/1033198735657803806/5_Centimeters_Per_Second.7z.003
- Link: https://cdn.discordapp.com/attachments/1032726084149583965/1033200762085453874/makotoshinkaiv2.pt
- Aesthetic Gradient: https://cdn.discordapp.com/attachments/1033147620966801609/1033196207478161488/makoto_shinkai.pt
- Dataset (for the aesthetic gradient and for general hypernetwork training/finetuning of a model if anyone else wants to attempt to get this style down.):
-
Hypernetwork based on the following prompts:
- cervix, urethra, puffy pussy, fat_mons, spread_pussy, gaping_anus, prolapse, gape, gaping
This hypernetwork was made by me (IWillRemember) (IWillRemember#1912 on discord) if you have any questions you can find me here on discord!
This hyper network was trained for 2000 steps at different learning rates on different batches of images (usually 25 images each batch)
I suggest using an HYPERNETWORK STRENGTH OF 0,5 or maybe up to 0,8 since it's really strong ; it is compatible with almost all anime like models and it performs great even with semi realistic ones.
The examples are made using the Nai model , but it works with ally , and any other anime based model if strength is adjusted acccordingly , also it COULD work with f111 and other models with the right prompts , to get really fat labia majora/minora , and/or gaping
- Link: https://mega.nz/file/pSN3mYoS#Q7e8tJWPSYGxdsyJMwhhtE5Jj8-A5e-sYZHhzbi3QAg
- Examples: https://cdn.discordapp.com/attachments/1018623945739616346/1033541564603039845/unknown.png, https://cdn.discordapp.com/attachments/1018623945739616346/1033542053444988938/unknown.png, https://cdn.discordapp.com/attachments/1018623945739616346/1033544232310411284/unknown.png, https://cdn.discordapp.com/attachments/1018623945739616346/1033550933151469688/unknown.png
-
(reupload from the 4chan section) Hypernetwork trained on spacezin's art, 13 handpicked images flipped and used oversized crop, data is the rar in the link
by ixyanon Trained in Nai-full-pruned, using swish activation method with dropout, 5e-6 training rate recommend using spacezin in the prompt, lesser steps are included for testing and usage if 20k is too much Uses: booba with covered nipples, sharp eyes and all that stuff you'd expect from him. Aesthetic gradient embedding included, helps a lot to use, nails the style significantly further if you can find good settings...
-
Hypernetwork trained on mikozin's art (reupload from 4chan section)
Trained in Nai-full-pruned, using swish activation method with dropout, 5e-6 training rate placing mikozin in the prompt will make it have a stronger effect has a number of effects, but mostly gives a very soft, painted style to the output image Aesthetic gradient embedding included, not necessary but could be neat! Data it was trained on included in the mega link, if you want something specific from the data it was trained on it'll help looking at the fileword txts
-
yabuki_kentarou(1,1_relu_5e-5)-8750
Source image count: 75 (white-bg, hi-res, and hi-qual) Dataset image count: 154 (split, 512x512) Dataset stress test: excellent (LR 0.0005, 2000 steps) Model: NAI [925997e9] Layer: 1, 1 Learning rate: 0.00005 Steps: 8750
-
namori(1,1_relu_5e-5)-9000.pt
Source image count: 50 (white-bg, hi-res, and hi-qual) Dataset image count: 98 (split, 512x512) Dataset stress test: excellent (LR 0.0005, 2000 steps) Model: NAI [925997e9] Layer: 1, 1 Learning rate: 0.00005 Steps: 9000 Preview: https://i.imgur.com/MEmvDCS.jpg Download: https://anonfiles.com/n2W8rdF7y5/namori_1_1_relu_5e-5_-9000_pt
-
Yordles:
Hey everyone , these hypernetworks were released by me (IWillRemember) (IWillRemember#1912 on discord) if you have any questions you can find me on discord!
These hyper networks were trained for roughly 30000 steps at different learning rates on 80 images
Yordles = to be use with an HYPERNETWORK STRENGHT OF 0,7 Yordles-FullSTR = to be useed with an HYPERNETWORK STRENGHT OF 1
I suggest experimenting alot with prompts since they both give roughly the same results but i included both since some people might like the stronger version better.
They were trained with NAI but they work best with Arena's Gape60 (i highly suggest using it)
They are trained on the following tags: Yordle, tristana, lulu_(league_oflegends), poppy(league_oflegends), vex(league_oflegends), shortstack I don't know why but discord modifies the tags for lulu, vex and poppy so read the readme txt !!
I highly suggest building around a specific character but you can make your own yordles too! try using different prompts to amplify the chances of getting a specific character .
Example for Poppy : masterpiece, highest quality, digital art, colored skin, blue skin, white skin, 1girl, (yordle:1.1), purple eyes, (poppy(league_of_legends):1.1), shortstack, twintails, fang, red scarf, white armor, thighs, sitting, night, gradient background , grass , blonde hair , on back, :d
I suggest not using negative prompts or use only the conditional ones like : monochrome, letterbox, ecc ecc
Thank you for reading ! and happy yordle prompting !
https://mega.nz/file/FCdiSIbI#ekOnlvox0ksEe1zzOQCFXgMJPkClEFPJFfGaAXv4rYc
Examples: https://cdn.discordapp.com/attachments/1023082871822503966/1037513553386684527/poppy.png https://cdn.discordapp.com/attachments/1023082871822503966/1037513571355066448/lulu.png I don't know why but discord modifies the tags for lulu, vex and poppy so read the readme txt !!
Colored eyes:
>Hey everyone , this hypernetwork was released by me (IWillRemember) (IWillRemember#1912 on discord) if you have any questions you can find me on discord!
>
>Did the Hn as a commission for a friend 😄
>
>I'm releasing an Hn to do better animation like glowing eyes, and a more slender face/upper body.
>
>The tags are :
>detailed eyes,
>(color) eyes = ex: white eyes, blue eyes, etc etc
>collarbone
>
>Trained for 12k steps on a 80 ish images dataset
>
>You can use the Hn with a str of 1 without any problem.
>
>Happy prompting!
>
>Example: https://media.discordapp.net/attachments/1023082871822503966/1038115846222008392/00162-3940698197-masterpiece_highest_quality_digital_art_1girl_on_back_detailed_eyes_perfect_face_detailed_face_breasts_white_hair_yell.png?width=648&height=702
>
>https://mega.nz/file/dHFwmaxS#NQhMPjT4TElPXX_YAZhTsFrQ36PDJhpWFm9BcHU_BO4
Collection of Aesthetic Gradients: https://github.com/vicgalle/stable-diffusion-aesthetic-gradients/tree/main/aesthetic_embeddings
- Scat (??): https://files.catbox.moe/8hklc5.pt
- Horse (?): https://files.catbox.moe/idm0vf.pt
- MLP nsfw f16 f32 (might be pickled): https://drive.google.com/drive/folders/14JyQE36wYABH-0TSV_HBEsBJ3r8ZITrS?usp=sharing
If you have one of these, please get it to me
Apparently there's a Google drive collection of downloads? (might be the korean site but mistyped)
Dreambooth:
- Anya Taylor-Joy: https://drive.google.com/drive/mobile/folders/1f0FI2Vtr0dNfxyCzsNkNau20JT9Kmgn-
- Fujimoto: https://huggingface.co/demibit/fujimoto_temp/tree/main
Embed:
- Omaru-polka: https://litter.catbox.moe/qfchu1.pt
- Sakimichan: https://mega.nz/file/eE8QDKrI#y7kdyWgPUjI4ZkY8PSq89F28eU_Vz_0EgTbG6yAowH8
- Deadflow (190k, "bitchass"(?)): https://litter.catbox.moe/03lqr6.pt
- Wagashi (12k, shitass(?)), no associated pic or replies so might be pickled: https://litter.catbox.moe/ktch8r.pt
- ex-penis-50000.pt and ex-penis-35000.pt
- Elira default-5500 16v 5500 steps
- Wiwa 4v 10000 steps
Hypernetworks:
-
Chinese telegram (dead link): https://t.me/+H4EGgSS-WH8wYzBl
-
Huge training from KR site: https://mega.nz/folder/wKVAybab#oh42CNeYpnqr2s8IsUFtuQ
-
焦茶 / cogecha hypernetwork, trained against NAI: https://mega.nz/folder/BLtkVIjC#RO6zQaAYCOIii8GnfT92dw
-
山北東 / northeast_mountain hypernetwork, trained against NAI: https://mega.nz/folder/RflGBS7R#88znRpu7YC1J1JYa9N-6_A
-
not sure if this is a hypernet: https://mega.nz/file/l9tAHJBD#xdXMf7vulY4GBigxegFVLSOULONnk4o86qKHYoBZmc
- probably a mis copy paste of Eula Lawrence: https://mega.nz/file/l9tAHJBD#xdXMf7vulY4GJBigxegFVLSOULONnk4o86qKHYoBZmc
Datasets:
- expanded ie_(raarami) dataset: https://litter.catbox.moe/j4mpde.zip
- Toplessness: https://litter.catbox.moe/mttar5.zip
- https://gofile.io/d/R74OtT
- Onono imoko (NSFW + SFW, 300 cropped images): https://files.catbox.moe/dkn85w.zip
- thanukiart (colored): https://www.dropbox.com/sh/mtf094lb5o61uvu/AABb2A83y4ws4-Rlc0lbbyHSa?dl=0
- Moona: https://files.catbox.moe/mmrf0v.rar
- Au'ra, a playable race from Final Fantasy (~100 imgs): https://mega.nz/folder/ZWcXCYpB#Zo-dHbp_u30iIz-LxLUGyA
Training dataset with aesthetic ratings: https://github.com/JD-P/simulacra-aesthetic-captions
- Training guide for textual inversion/embedding and hypernetworks: https://pastebin.com/dqHZBpyA
- Hypernetwork Training by ixynetworkanon: https://rentry.org/hypernetwork4dumdums
- Training with e621 content: https://rentry.org/sd-e621-textual-inversion
- Informal Model Training Guide: https://rentry.org/informal-training-guide
- Anon's guide: https://rentry.org/stmam
- Anon2's guide: https://rentry.org/983k3
- Full Textual Inversion folder: https://files.catbox.moe/c6502c.7z
- Wiki: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Textual-Inversion
- Wiki 2: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#textual-inversion
Use pics where:
- Character doesn't blend with background and isn't overlapped by random stuff
- Character is in different poses, angles, and backgrounds
- Resolution is 512x512 (crop if it's not)
- Manually tagging the pictures allows for faster convergence than auto-tagging. More work is needed to see if deepdanbooru autotagging helps convergence
- Dreambooth on 8gb: https://github.com/huggingface/diffusers/tree/main/examples/dreambooth#training-on-a-8-gb-gpu
- Finetune diffusion: https://github.com/YaYaB/finetune-diffusion
- Can train models locally
- Training guide: https://pastebin.com/xcFpp9Mr
- Reddit guide: https://www.reddit.com/r/StableDiffusion/comments/xzbc2h/guide_for_dreambooth_with_8gb_vram_under_windows/
- Reddit guide (2): https://www.reddit.com/r/StableDiffusion/comments/y389a5/how_do_you_train_dreambooth_locally/
- Dreambooth (8gb of vram if you have 25gb+ of ram and Windows 11): https://pastebin.com/0NHA5YTP
- Another 8gb Dreambooth: https://github.com/Ttl/diffusers/tree/dreambooth_deepspeed/examples/dreambooth#training-on-a-8-gb-gpu
- Dreambooth: https://rentry.org/dreambooth-shitguide
- Dreambooth: https://rentry.org/simple-db-elinas
- Dreambooth (Reddit): https://www.reddit.com/r/StableDiffusion/comments/ybxv7h/good_dreambooth_formula/
- Very in depth Hypernetworks guide: AUTOMATIC1111/stable-diffusion-webui#2670
- Runpod guide: https://rentry.org/runpod4dumdums
- Small guide written on hypernetwork activation functions.: AUTOMATIC1111/stable-diffusion-webui#2670 (comment)
- Dataset tag manager that can also load loss.: https://github.com/starik222/BooruDatasetTagManager
- Tips on hypernetwork layer structure: AUTOMATIC1111/stable-diffusion-webui#2670 (comment)
- Prompt template + info: https://github.com/victorchall/EveryDream-trainer
- by anon: allows you to train multiple subjects quickly via labelling file names but it requires a normalization training set of random labelled images in order to preserve model integrity
- github + some documentation: https://github.com/cafeai/stable-textual-inversion-cafe
- Documentation: https://www.reddit.com/r/StableDiffusion/comments/wvzr7s/tutorial_fine_tuning_stable_diffusion_using_only/
- Guide on dreambooth training in comments: https://www.reddit.com/r/StableDiffusion/comments/yo05gy/cyberpunk_character_concepts/
- Dreambooth on 12gb no WSL: https://gist.github.com/geocine/e51fcc8511c91e4e3b257a0ebee938d0
- Very good beginner Twitter tutorial (read replies): https://twitter.com/divamgupta/status/1587452063721693185
- Japanese finetuning guide (?): https://note.com/kohya_ss/n/nbf7ce8d80f29
- Guide: https://github.com/nitrosocke/dreambooth-training-guide
- TI Guide: https://bennycheung.github.io/stable-diffusion-training-for-embeddings
- Faunanon guide: https://files.catbox.moe/vv8gwa.png
- Discussion about editing the training scripts for Hypernetworks: https://archived.moe/h/thread/6984678/#6984825
- Good training info: AUTOMATIC1111/stable-diffusion-webui#2670 (comment)
Train stable diffusion model with Diffusers, Hivemind and Pytorch Lightning: https://github.com/Mikubill/naifu-diffusion
- Site where you can train: https://www.astria.ai/
- Colab: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb
- Colab 2: https://colab.research.google.com/github/ShivamShrirao/diffusers/blob/main/examples/dreambooth/DreamBooth_Stable_Diffusion.ipynb
- Colab 3: https://github.com/XavierXiao/Dreambooth-Stable-Diffusion
- Colab 4 (fast): https://github.com/TheLastBen/fast-stable-diffusion
- colab 5: https://colab.research.google.com/drive/1Iy-xW9t1-OQWhb0hNxueGij8phCyluOh
- site?: drawanyone.com
Dreambooth colab with custom model (old, so might be outdated): https://desuarchive.org/g/thread/89140837/#89140895
GPU seems to determine training results (--low/med vram arg too)
Extension: https://github.com/d8ahazard/sd_dreambooth_extension
-
Based on https://github.com/ShivamShrirao/diffusers/tree/main/examples/dreambooth
-
Original dreambooth: https://github.com/JoePenna/Dreambooth-Stable-Diffusion
-
Dreambooth gui: https://github.com/smy20011/dreambooth-gui
- the app automatically chooses the best settings for your current VRAM
-
GUI helper for manual tagging and cropping: https://github.com/arenatemp/sd-tagging-helper/
-
Waifu Diffusion 1.4 Tagger: https://mega.nz/file/ptA2jSSB#G4INKHQG2x2pGAVQBn-yd_U5dMgevGF8YYM9CR_R1SY
Image tagger helper: https://github.com/nub2927/image_tagger/
-
Training on multiple people at once comparison: https://www.reddit.com/r/StableDiffusion/comments/yjd5y5/more_dreambooth_experiments_training_on_several/
-
Extract keyframes from a video to use for training: https://github.com/Maurdekye/training-picker
-
Huge collection of regularization images: https://huggingface.co/datasets/ProGamerGov/StableDiffusion-v1-5-Regularization-Images
-
Embed vector, clip skip, and vae comparison: https://desuarchive.org/g/thread/89392239#89392432
-
Hypernet comparison discussion: AUTOMATIC1111/stable-diffusion-webui#2284
-
Comparison of linear vs relu activation function on a number of different prompts, 12K steps at 5e-6.
-
Clip skip comparison: https://files.catbox.moe/f94fhe.jpg
-
Hypernetwork comparison: https://files.catbox.moe/q8h8o3.png
anything.ckpt comparisons Old final-pruned: https://files.catbox.moe/i2zu0b.png (embed) v3-pruned-fp16: https://files.catbox.moe/k1tvgy.png (embed) v3-pruned-fp32: https://files.catbox.moe/cfmpu3.png (embed) v3 full or whatever: https://files.catbox.moe/t9jn7y.png (embed)
-
Image Scraper: https://github.com/mikf/gallery-dl
-
Img scraper 2: https://github.com/Bionus/imgbrd-grabber
-
Bulk resizer: https://www.birme.net/?target_width=512&target_height=512
-
Model merging math: https://github.com/AUTOMATIC1111/stable-diffusion-webui/commit/c250cb289c97fe303cef69064bf45899406f6a40#comments
-
Old model merging: https://github.com/eyriewow/merge-models/
-
Can use ckpt_merge script from https://github.com/bmaltais/dehydrate
- python3 merge.py <path to model 1> --alpha <value between 0.0 and 1.0> --output From anon: For sigmoid/inverse sigmoid interpolation between modesl, add this code starting with line 38 of merge.py:
for key in tqdm(theta_0.keys(), desc="Stage 1/2"):
if "model" in key and key in theta_1:
# sigmoid
alpha = alpha * alpha * (3 - (2 * alpha))
theta_0[key] = theta_0[key] + ((theta_1[key] - theta_0[key]) * alpha)
# inverse sigmoid
#alpha = 0.5 - math.sin(math.asin(1.0 - 2.0 * alpha) / 3.0)
#theta_0[key] = theta_0[key] + ((theta_1[key] - theta_0[key]) * alpha)
# Weighted sum
#theta_0[key] = ((1 - alpha) * theta_0[key]) + (alpha * theta_1[key])- Model merge guide: https://rentry.org/lftbl
- anon: The Checkpoint Merger tab in webui works well. It uses standard RAM not VRAM. As a general guide, you need 2x as much RAM as the total combined size of the models you need to load.
- Supposedly empty ckpt to help with memory issues, might be pickled: https://easyupload.io/ggfxvc
- batch checkpoint merger: https://github.com/lodimasq/batch-checkpoint-merger
Supposedly how to append model data without merging by anon:
x = (Final Dreambooth Model) - (Original Model) filter x for x >= (Some Threshold) out = (Model You Want To Merge It With) * (1 - M) + x * M
Model merging method that preserves weights: https://github.com/samuela/git-re-basin
-
Aesthetic Gradients: https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients
-
Image aesthetic rating (?): https://github.com/waifu-diffusion/aesthetic
-
1 img TI: https://huggingface.co/lambdalabs/sd-image-variations-diffusers
-
You can set a learning rate of "0.1:500, 0.01:1000, 0.001:10000" in textual inversion and it will follow the schedule
-
Tip: combining natural language sentences and tags can create a better training
-
Dreambooth on 2080ti 11GB (anon's guide): https://rentry.org/tfp6h
-
Training a TI on 6gb (not sure if safe or even works, instructions by uploader anon): https://pastebin.com/iFwvy5Gy
- Have xformers enabled.
This diff does 2 things.
- enables cross attention optimizations during TI training. Voldy disabled the optimizations during training because he said it gave him bad results. However, if you use the InvokeAI optimization or xformers after the xformers fix it does not give you bad results anymore. This saves around 1.5GB vram with xformers
>2. unloads vae from VRAM during training. This is done in hypernetworks, and idk why it wasn't in the code for TI. It doesn't break anything and doesn't make anything worse.
>This saves around .2 GB VRAM
>
>After you apply this, turn on Move VAE and CLIP to RAM and Use cross attention optimizations while training
- By anon:
No idea if someone else will have a use for this but I needed to make it for myself since I can't get a hypernetwork trained regardless of what I do.
https://mega.nz/file/LDwi1bab#xrGkqJ9m-IsqsTQNixVkeWrGw2HvmAr_fx9FxNhrrbY
That link above is a spreadsheet where you paste the hypernetwork_loss.csv data into A1 cell (A2 is where numbers should start). Then you can use M1 to set how many epochs of the most recent data you want to use for the red trendline (green is the same length but starting before red). Outlayer % is if you want to filter out extreme points 100% means all points are considered for trendline 95% filters out top and bottom 5 etc. Basically you can use this to see where the training started fucking up.
- Anon's best:
Creation: 1,2,1 Normalized Layers Dropout Enabled Swish XavierNormal (Not sure yet on this one. Normal or XavierUniform might be better)
Training:
Rate: 5e-5:1000, 5e-6:5000, 5e-7:20000, 5e-8:100000 Max Steps: 100,000
- Anon's Guide: https://rentry.org/zcspm
Vector guide by anon: https://rentry.org/dah4f
-
Another training guide: https://www.reddit.com/r/stablediffusion/comments/y91luo
-
Super simple embed guide by anon: Grab the high quality images, run them through the processor. Create an embedding called
art by {artist}. Then train that same embedding with your processed images and set the learning rate to the following:0.1:500,0.05:1000,0.025:1500,0.001:2000,1e-5` Run it for 10k steps and you'll be good. No need for an entire hypernetwork. -
Has training info and a tutorial for Asagi Igawa, Edjit, and Rouge the Bat embeds (RealYiffingFar#4510): https://mega.nz/folder/5nIAnJaA#YMClwO8r7tR1zdJJeTfegA
- ie_(raarami): https://mega.nz/folder/4GkVQCpL#Bg0wAxqXtHThtNDaz2c90w
- Expanded (DEAD LINK): https://litter.catbox.moe/j4mpde.zip
- Toplessness: https://litter.catbox.moe/mttar5.zip
- Reine: https://files.catbox.moe/zv6n6q.zip
- Power: https://files.catbox.moe/wcpcbu.7z
- Baffu: https://files.catbox.moe/ejh5sg.7z
- tatsuki fujimoto: https://litter.catbox.moe/k09588.zip
- Butcha-U and Hypnosis: https://files.catbox.moe/9dv0cy.7z
- (By midnanon) tagged data sets with minimal effort and you're comfortable with C# (not sure if safe): https://pastebin.com/JmZFWCUK
- Take whatever that produces and throw it into a duplicate detector.
- Take whatever remains, filter out stuff you don't like or otherwise deviates too much.
- I built up the midna dataset in about 10 minutes or so end to end.
- You can customise tags on line 248.
- Anya: https://litter.catbox.moe/o5efml.zip
- Amelia Watson: https://files.catbox.moe/vrr2sl.zip
- Henreader (NSFW + loli): https://files.catbox.moe/e0e3nk.7z
Check out https://rentry.org/sdupdates and https://rentry.org/sdupdates2 for other questions https://rentry.org/sdg_FAQ
What's all the new stuff?
Check here to see if your question is answered:
- https://scribe.froth.zone/m/global-identity?redirectUrl=https%3A%2F%2Fblog.novelai.net%2Fnovelai-improvements-on-stable-diffusion-e10d38db82ac
- https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac
- https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki
- https://www.reddit.com/r/StableDiffusion
- https://github.com/AUTOMATIC1111/stable-diffusion-webui/search
How do I set this up?
Refer to https://rentry.org/nai-speedrun (has the "Asuka test") Easy guide: https://rentry.org/3okso Standard guide: https://rentry.org/voldy Detailed guide: AUTOMATIC1111/stable-diffusion-webui#2017 Paperspace: https://rentry.org/865dy
AMD Guide: https://rentry.org/sdamd
- After setting stuff up using this guide, refer back to https://rentry.org/nai-speedrun for settings
What's the "Hello Asuka" test?
It's a basic test to see if you're able to get a 1:1 recreation with NAI and have everything set up properly. Coined after asuka anon and his efforts to recreate 1:1 NAI before all the updates.
Refer to
- AUTOMATIC1111/stable-diffusion-webui#2017
- Very easy Asuka 1:1 Euler A: https://boards.4chan.org/h/thread/6893903#p6894236
- Asuka Euler guide + trpin;esjpptomg: https://imgur.com/a/DCYJCSX
- Asuka Euler a guide + troubleshooting: https://imgur.com/a/s3llTE5
What is pickling/getting pickled?
ckpt files and python files can execute code. Getting pickled is when these files execute malicious code that infect your computer with malware. It's a memey/funny way of saying you got hacked.
-
Automatic1111's webui should unpickle the files for you, but that is only 1 line of defense: https://github.com/AUTOMATIC1111/stable-diffusion-webui/search?q=pickle&type=commits
-
anon: there are checks but they can be disabled and you can still bypass with nested things
-
https://docs.python.org/3/library/pickle.html, https://huggingface.co/docs/hub/security-pickle
-
anon: pickle is a format that can load code objects originally the objects weren't sanitized, so remote code could run
by implementing reduce in a class which instances we are going to pickle, we can give the pickling process a callable plus some arguments to run now reduce is restricted (anything not NN related), the joke lives on as a meme
I want to run this, but my computer is too bad. Is there any other way? Check out one of these (I did not used most of these, so they might be unsafe to use):
-
(used and safe) Free online browser SD: https://huggingface.co/spaces/stabilityai/stable-diffusion
-
(used and safe) https://github.com/TheLastBen/fast-stable-diffusion
-
(used and safe) https://github.com/ShivamShrirao/diffusers/blob/main/examples/dreambooth/DreamBooth_Stable_Diffusion.ipynb
-
visualise.ai
- Account required
- Free unlimited 512x512/64 step runs
-
img2img with stable horde: https://tinybots.net/artbot
-
Free, GPU-less, powered by Stable Horde: https://dbzer0.itch.io/lucid-creations
-
Free crowdsourced distributed cluster for Stable Diffusion (not sure how safe this is because of p2p): https://stablehorde.net/
-
Artificy.com
-
- DALL·E mini
-
HF demo list: https://pastebin.com/9X1BPf8S
-
Automatic1111 webui on SageMaker Studio Lab (free): https://github.com/Miraculix200/StableDiffusionUI_SageMakerSL/blob/main/StableDiffusionUI_SageMakerSL.ipynb
-
notebook for running Dreambooth on SageMaker Studio Lab: https://github.com/Miraculix200/diffusers/blob/main/examples/dreambooth/DreamBooth_Stable_Diffusion_SageMakerSL.ipynb
-
anything.ckpt: https://colab.research.google.com/drive/1CkIPJrtXa3hlRsVk4NgpM637gmE3Ly5v
-
Google Colab webui with 1.5/1.5 inpainting/VAE/waifu division (?): https://colab.research.google.com/drive/1VYmKX7eayuI8iTaCFKVHw9uxSkLo8Mde
-
Site (didn't test): https://ai-images.net/
-
SD 1.5: https://colab.research.google.com/drive/1kw3egmSn-KgWsikYvOMjJkVDsPLjEMzl
-
Anything v3 + Gigachad models: https://colab.research.google.com/github/Miraculix200/StableDiffusionUI_Colab/blob/main/StableDiffusionUI_Colab.ipynb#scrollTo=R-xAdMA5wxXd
-
Some gpu rental sites:
How do I directly check AUTOMATIC1111's webui updates?
For a complete list of updates, go here: https://github.com/AUTOMATIC1111/stable-diffusion-webui/commits/master
What do I do if a new updates bricks/breaks my AUTOMATIC1111 webui installation?
Go to https://github.com/AUTOMATIC1111/stable-diffusion-webui/commits/master See when the change happened that broke your install Get the blue number on the right before the change Open a command line/git bash to where you usually git pull (the root of your install) 'git checkout ' to reset your install, use 'git checkout master'
What is...?
What is a VAE? Variational autoencoder, basically a "compressor" that can turn images into a smaller representation and then "decompress" them back to their original size. This is needed so you don't need tons of VRAM and processing power since the "diffusion" part is done in the smaller representation (I think). The newer SD 1.5 VAEs have been trained more and they can recreate some smaller details better. What is pruning? Removing unnecessary data (anything that isn't needed for image generation) from the model so that it takes less disk space and fits more easily into your VRAM What is a pickle, not referring to the python file format? What is the meme surrounding this? When the NAI model leaked people were scared that it might contain malicious code that could be executed when the model is loaded. People started making pickle memes because of the file format. Why is some stuff tagged as being 'dangerous', and why does the StableDiffusion WebUI have a 'safe-unpickle' flag? -- I'm stuck on pytorch 1.11 so I have to disable this Safe unpickling checks the pickle's code library imports against an approved list. If it tried to import something that isn't on the list it won't load it. This doesn't necessarily mean it's dangerous but you should be cautious. Some stuff might be able to slip through and execute arbitrary code on your computer. Is the rentry stuff all written by one person or many? There are many people maintaining different rentries.
Why are some of my prompts outputting black images?
Add " --no-half-vae " (remove the quotations) to your commandline args in webui-user.bat
What's the difference between embeds, hypernetworks, and dreambooths? What should I train? Anon:
I've tested a lot of the model modifications and here are my thoughts on them: embeds: these are tiny files which find the best representation of whatever you're training them on in the base model. By far the most flexible option and will have very good results if the goal is to group or emphasize things the model already understands hypernetworks: there are like instructions that slightly modify the result of the base model after each sampling step. They are quite powerful and work decently for everything I've tried (subjects, styles, compositions). The cons are they can't be easily combined like embeds. They are also harder to train because good parameters seem to vary wildly so a lot of experimentation is needed each time dreambooth: modifies part of the model itself and is the only method which actually teaches it something new. Fast and accurate results but the weights for generating adjacent stuff will get trashed. These are gigantic and have the same cons as embeds
Info:
- Detailed 1:1 setup NAI + current news: AUTOMATIC1111/stable-diffusion-webui#2017
- Very easy Asuka 1:1 Euler A: https://boards.4chan.org/h/thread/6893903#p6894236
- Asuka Euler guide: https://imgur.com/a/DCYJCSX
- Asuka Euler a guide: https://imgur.com/a/s3llTE5
- Beginner's Guide: https://rentry.org/nai-speedrun
- SD NAI FAQ: https://rentry.org/sdg_FAQ
- general wiki: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki
- general wiki 2: https://wiki.installgentoo.com/wiki/Stable_Diffusion
- general wiki 3: https://github.com/Maks-s/sd-akashic
- general wiki 4: https://github.com/awesome-stable-diffusion/awesome-stable-diffusion
- setup guide: https://rentry.org/voldy
- Easy to setup Standard Diffusion: https://nmkd.itch.io/t2i-gui
- Another easy to setup SD: https://github.com/cmdr2/stable-diffusion-ui
- Models: https://rentry.org/sdmodels
- Japanese 4chan: https://may.2chan.net/b/
- Example thread: https://may.2chan.net/b/res/1033557742.htm
- Japanese 4chan 2: https://find.5ch.net/search?q=JNVA%E9%83%A8
- Japanese 4chan 3: http://nozomi.2ch.sc/test/read.cgi/liveuranus/1666357371/355-
- General info: https://rentry.org/sd-nativeisekaitoo
- Guide: https://github.com/Engineer-of-Stuff/stable-diffusion-paperspace/blob/main/docs/archives/VOLDEMORT'S%20GUI%20GUIDE%20FOR%20THE%20MENTALLY%20DEFICIENT.pdf
- NAI info: https://pastebin.com/cExyWkgy
- GPU buying guide: https://rentry.org/stablediffgpubuy
- Clip Studio Paint (CSP) SD: https://github.com/mika-f/nekodraw
- Link collection: https://github.com/pomee4/SD-LinkList
- debug guide: https://rentry.org/pf98i
- Info dump: https://rentry.org/sdhassan
- Massive dumpy dump: https://rentry.org/RentrySD
- Miraheze: https://stablediffusion.miraheze.org/wiki/Main_Page
- Japanese guide(?): https://rentry.co/zk4u5
Boorus:
- Danbooru: danbooru.donmai.us/
- Gelbooru: https://gelbooru.com/
- AIBooru: https://aibooru.online/
- Booru Site: https://infinibooru.moe/
- Local (classic): hydrusnetwork.github.io/
- AI art here: https://e-hentai.org/g/2343153/b4ce2a4b0b
- Easy to setup booru/image gallery by anon, highly recommended: https://github.com/demibit/stable-toolkit
- Simple: https://www.irfanview.com
- SFW: https://nastyprompts.com/
- Infinibooru: https://infinibooru.moe/posts
- Betabooru: https://betabooru.donmai.us
- Japanese pixiv for ai art: https://www.chichi-pui.com/
- discord anon (allows for generation?, runs NovelAI model): https://pixai.art/
- nsfw: https://pornpen.ai/
- /vt/ collection, updated: https://mega.nz/folder/j2AgSB6Y#3Kcq-xms0fWU4na-aaTFhA/folder/unw2EIBI
- AI porn: https://pornpen.ai/
- Booru + generator, anime focused: https://pixai.art/
- /vt/ huge image collection: https://mega.nz/folder/23oAxTLD#vNH9tPQkiP1KCp72d2qINQ
- yodayo: https://yodayo.com/explore/?key=&type=posts&sort=recent
- japanese: https://ai-image-posting-service.com/artworks/
- https://dreamlike.art/
- Pixiv-like: https://aivy.run/
Upscalers:
- Big list: https://upscale.wiki/wiki/Model_Database
- 4xAnimeSharp (NCNN, ONNX) (uploaded by anon, not sure if safe): https://mega.nz/folder/rdpkjZzC#eUXPed_vntJKLrB0wpeJ-w
- Examples: https://imgur.com/a/Loq5290
Resizing: https://www.birme.net/?target_width=512&target_height=512&quality_jpeg=100&quality_webp=100
Simple png editor: https://entropymine.com/jason/tweakpng/
Install Stable Diffusion on an AMD GPU PC running Ubuntu 20.04: https://gist.github.com/geerlingguy/ff3c3cbcf4416be2c0c1e0f836a8183d
How to run https://huggingface.co/spaces/skytnt/moe-tts locally (read through the replies): https://desuarchive.org/g/thread/89714899#89715329
lol: https://desuarchive.org/g/thread/89719598#89719734
Twitter anons: https://twitter.com/AICoomer https://twitter.com/BluMeino https://twitter.com/ElfBreasts https://twitter.com/Elf_Anon https://twitter.com/ElfieAi https://twitter.com/EyeAI_ https://twitter.com/FEDERALOFFICER https://twitter.com/FizzleDorf https://twitter.com/Headstacker https://twitter.com/KLaknatullah https://twitter.com/Kw0337 https://twitter.com/Lisandra_brave https://twitter.com/Merkurial_Mika https://twitter.com/PorchedArt https://twitter.com/Rahmeljackson https://twitter.com/RaincoatWasted https://twitter.com/S37030315 https://twitter.com/YoucefN30829772 https://twitter.com/ai_sneed https://twitter.com/dproompter https://twitter.com/epitaphtoadog https://twitter.com/mommyartfactory https://twitter.com/nadanainone https://twitter.com/spee321
https://mobile.twitter.com/spee321 https://mobile.twitter.com/ElfieAi https://mobile.twitter.com/Headstacker https://mobile.twitter.com/ai_sneed https://mobile.twitter.com/Rahmeljackson https://twitter.com/SpiteAnon
Aggressively clear cache: https://desuarchive.org/g/thread/89718344/#q89722878
diff --git a/modules/sd_hijack_optimizations.py b/modules/sd_hijack_optimizations.py
index 98123fb..0f5f327 100644
--- a/modules/sd_hijack_optimizations.py
+++ b/modules/sd_hijack_optimizations.py
@@ -99,11 +100,14 @@ def split_cross_attention_forward(self, x, context=None, mask=None):
raise RuntimeError(f'Not enough memory, use lower resolution (max approx. {max_res}x{max_res}). '
f'Need: {mem_required / 64 / gb:0.1f}GB free, Have:{mem_free_total / gb:0.1f}GB free')
+ torch.cuda.empty_cache()
slice_size = q.shape[1] // steps if (q.shape[1] % steps) == 0 else q.shape[1]
for i in range(0, q.shape[1], slice_size):
end = i + slice_size
s1 = einsum('b i d, b j d -> b i j', q[:, i:end], k)Something about training? old: https://www.bdhammel.com/learning-rates/
Koikatsu game cards: https://illusioncards.booru.org/index.php?page=post&s=list&tags=card_frame&pid=0
Faunanon's pixiv: https://www.pixiv.net/en/users/87884328
- Funny Twitter post with funny comments: https://twitter.com/PuccaNoodles/status/1591896706509336576
Depickler?: https://github.com/trailofbits/fickling
watermark lol: AUTOMATIC1111/stable-diffusion-webui#2803, https://github.com/AUTOMATIC1111/stable-diffusion-webui/search?q=do_not_add_watermark
Fairseq demse 13B (text model for nsfw?): https://huggingface.co/KoboldAI/fairseq-dense-13B-Shinen?text=My+name+is+Julien+and+I+like+to
Link collection: https://rentry.org/p5pk2
Japanese discussion of images from 4chan: http://yaraon-blog.com/archives/225884 *According to anon: nothing new there, it's the infamous clickbait (アフィカス, stand for site that consists of no content or only reprints from another site for the purpose of advertising revenue)

{kind=link}
{kind=link}
{kind=link}
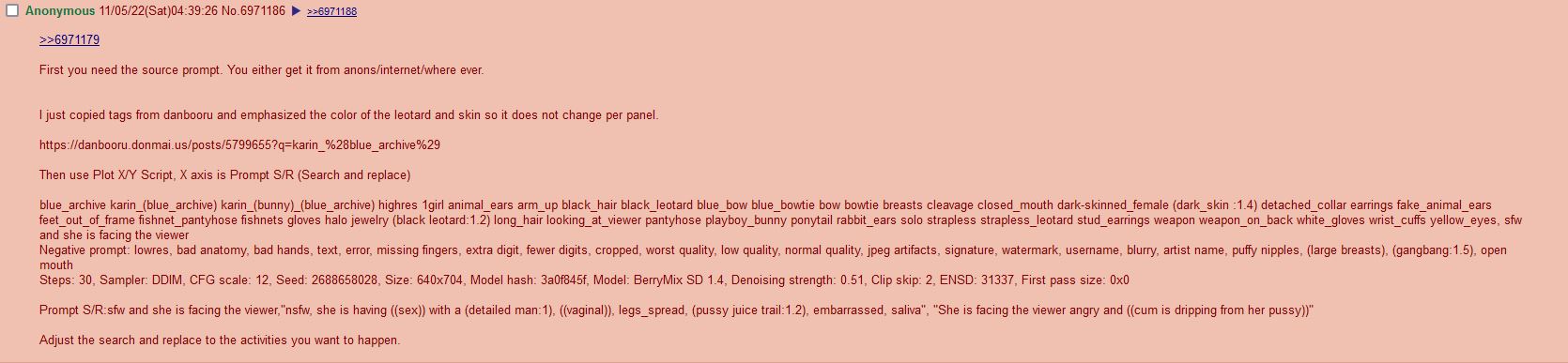{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
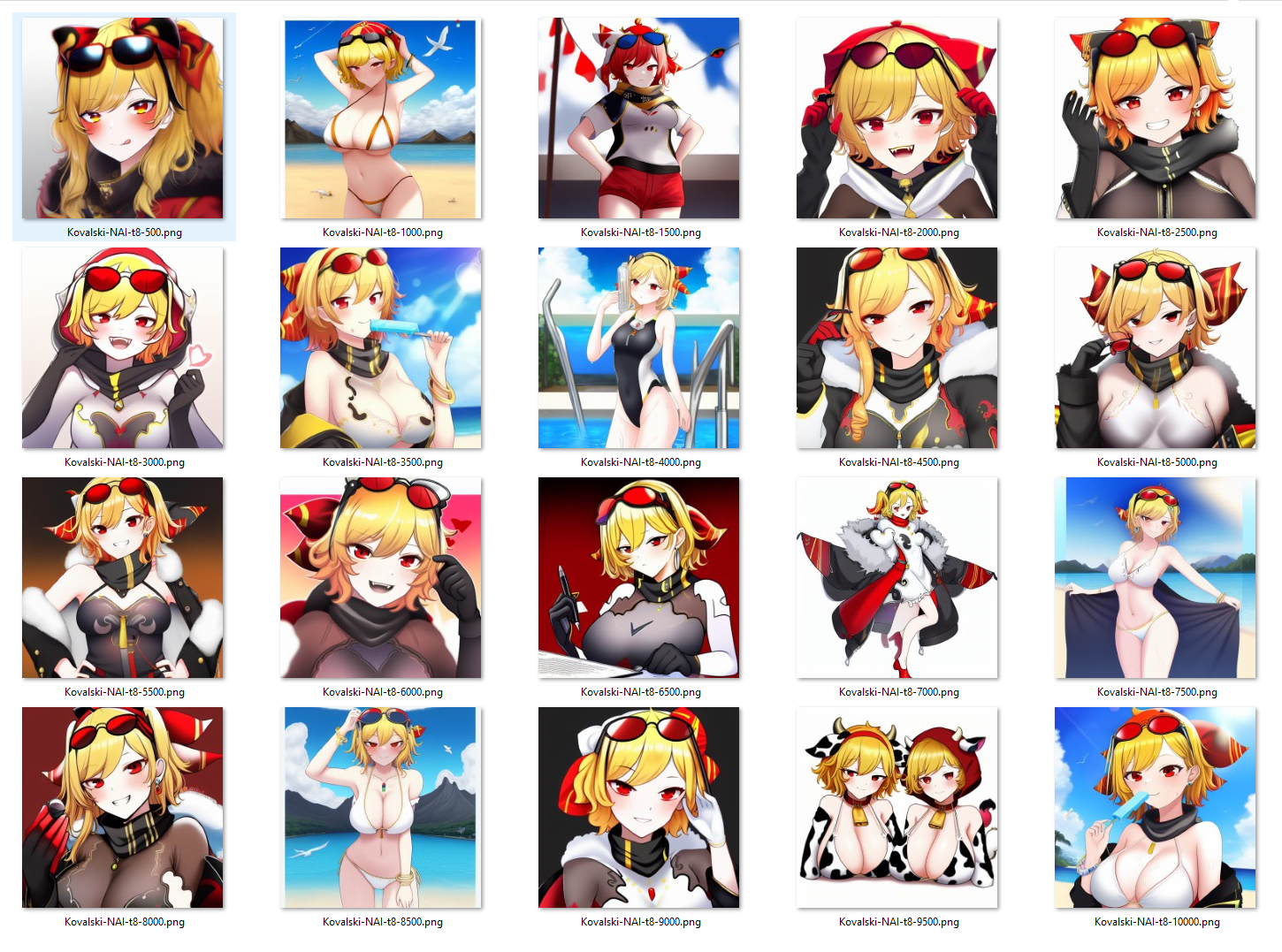{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
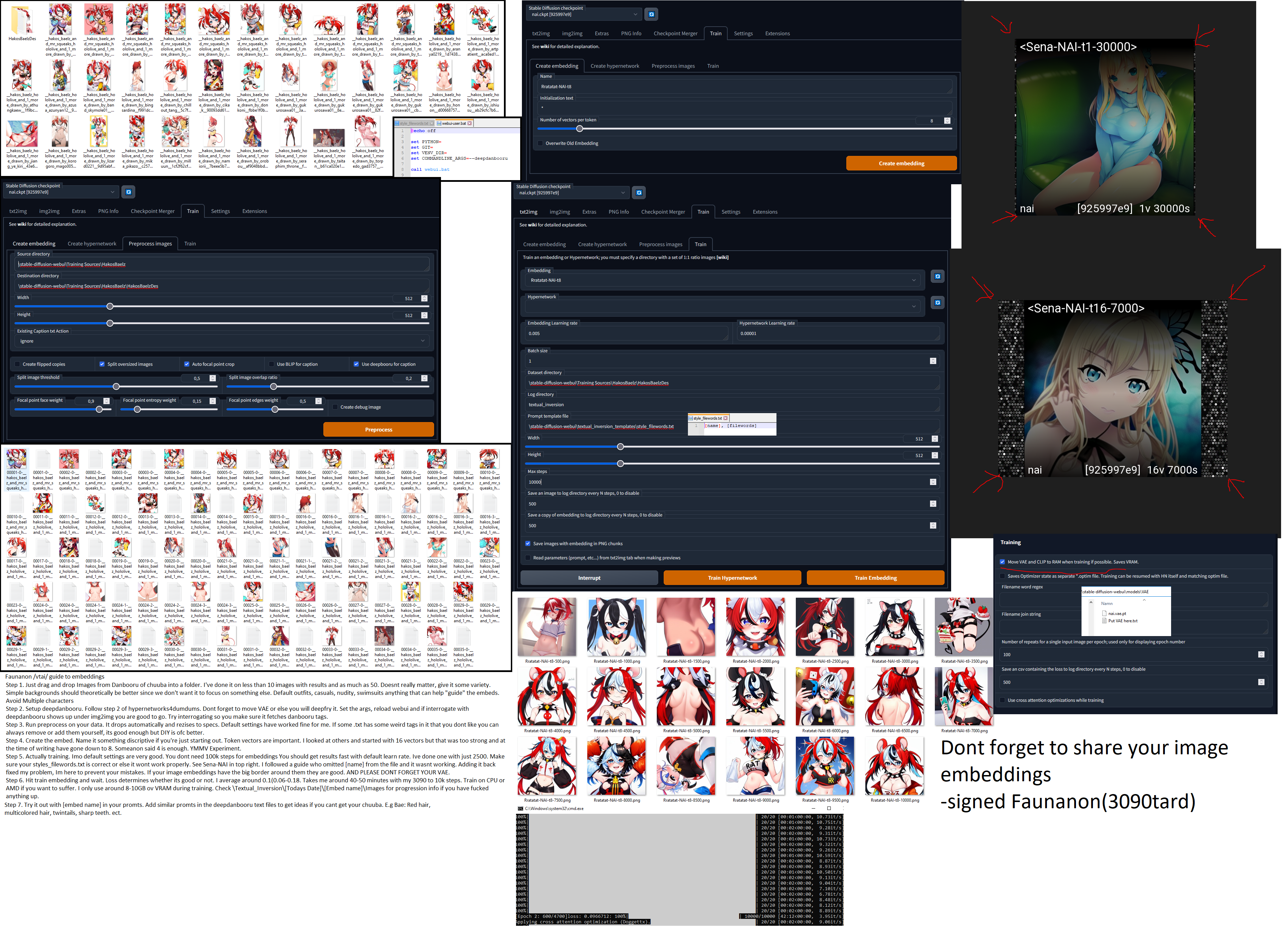{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}