
En el presente trabajo se utilizó un dataset proporcionado por Henry dentro del bootcamp de Data Science, como parte del módulo de proyectos prácticos individuales.
El dataset consta de 45,466 registros estructurados en 24 columnas relacionadas con información filmográfica de películas, como su nombre, descripción, puntuación, género, productora, entre otras.
El objetivo de este proyecto es tomar la base de datos proporcionada y pasarla por diferentes etapas de limpieza y extracción necesarias para disponibilizar los datos en una API y generar un modelo de recomendación de películas basado en Machine Learning.
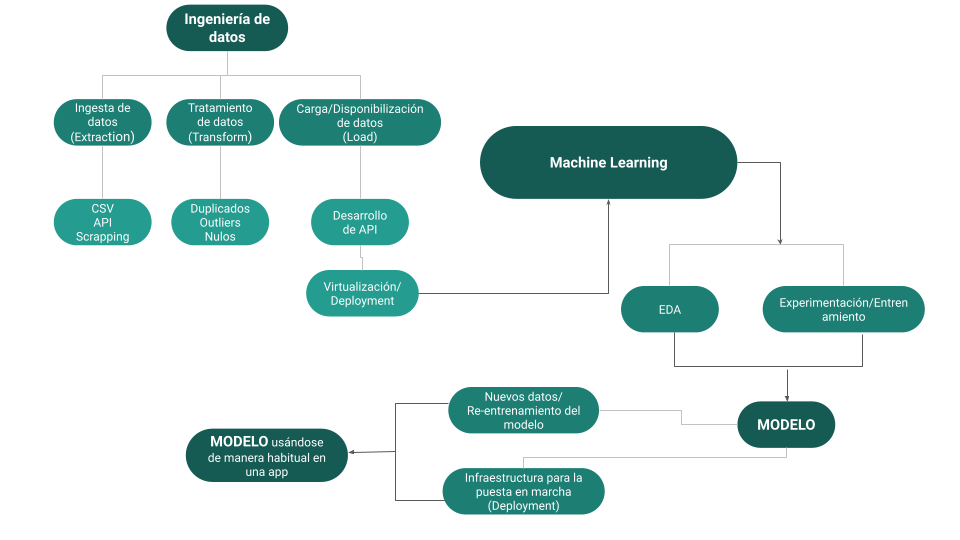
Para la ejecución del proyecto, se realizaron las siguientes transformaciones en la base de datos:
- Desanidar los datos que se encuentran en formato de listas de diccionarios para poder unirlos nuevamente a la base de datos de manera separada.
- Rellenar con 0 los registros con valores nulos en las columnas "revenue" y "budget".
- Eliminar los registros que contengan valores nulos en la columna "release date".
- Asegurarse de que la columna "release_year" esté en formato AAAA-MM-DD y generar una nueva columna que contenga solo el año de estreno.
- Crear una nueva columna "return" que extraiga el retorno de inversión de cada registro, dividiendo la columna "revenue" entre la columna "budget".
- Eliminar las columnas innecesarias para el desarrollo de la API, como "video", "imdb_id", "adult", "original_title", "vote_count", "poster_path" y "homepage".
- Crear una función que muestre la cantidad de películas lanzadas por mes.
- Crear una función que muestre la cantidad de películas lanzadas por día.
- Crear una función que muestre la cantidad de películas de una franquicia, junto con sus ganancias totales y promedio.
- Crear una función que muestre la cantidad de películas lanzadas por país.
- Crear una función que muestre la cantidad de películas lanzadas por productora.
- Crear una función que muestre los ingresos, retorno de inversión, ganancia y año de lanzamiento de una película en particular.
- Disponibilizar los datos de las funciones a través del framework FastAPI.
- Explorar los datos limpios para establecer correlaciones entre las variables.
- Generar un sistema de recomendación de películas basado en Machine Learning.
- Disponibilizar el sistema de recomendación a través del framework FastAPI.
En este repositorio, encontrarás los siguientes archivos:
- _ pycache_: Carpeta donde se almacenan los datos cache de Python para mejorar su proceso de ejecución.
- github_files: Carpeta que almacena los archivos complementarios, como el diccionario de datos e imágenes.
- .gitattributes: Archivo de configuración utilizado en Git para especificar cómo se deben tratar ciertos archivos y tipos de archivos en el repositorio.
- main.py: Archivo donde se almacenan las funciones que se ejecutarán en la API.
- movies_machine_learning.csv: Base de datos suministrada para realizar el proyecto.
- movies_dataset - movies_dataset.csv: Base de datos filtrada para la optimización del modelo de machine learning.
- movies_ok_1.csv: Base de datos filtrada para alimentar las funciones de API no relacionadas con el sistema de recomendación con machine learning.
- requirements.txt: Librerías necesarias para la adecuada ejecución de los documentos.
- API_proyecto_1_Final.ipynb: Documento en formato notebook donde se encuentra el código de limpieza de la base de datos y el desarrollo de las funciones incluidas en la API.
- EDA_&_ML - Final.ipynb: Documento en formato notebook donde se encuentra el código en el que se desarrolla el EDA y se realizan las transformaciones pertinentes para el desarrollo del sistema de recomendación de películas.
Durante el proceso de limpieza de datos, se llevaron a cabo las siguientes acciones:
- Se identificaron los valores sin significado para el análisis y se eliminaron.
- Se desanidaron las columnas que contenían valores en formato de listas de diccionarios.
- Se identificaron y eliminaron registros duplicados.
- Se identificaron y eliminaron registros con valores nulos, considerando la relevancia de los nulos por columna.
- Se identificaron registros con valores faltantes, con la excepción de la columna "belongs_to_collection" debido a su alta cantidad de registros faltantes.
- Se realizaron identificaciones de outliers, pero no se procedió a su eliminación debido a que estos outliers tenían sentido en el contexto histórico de los datos.
Una vez finalizada la limpieza de datos, se descargó la base de datos con las transformaciones realizadas, la cual se utilizó para generar las funciones de consulta que serían empleadas en la API. Dichas funciones se incluyeron en el archivo "main.py" para su uso en la API.
Base de datos transformada para las funciones de consulta
Además, se desarrolló un archivo separado para llevar a cabo el EDA (Exploratory Data Analysis). Durante este análisis se generaron gráficos para explorar las variables y sus relaciones. Posteriormente, se realizó una limpieza adicional en la base de datos, conservando únicamente las variables relevantes para el desarrollo del modelo de recomendación. Debido al tamaño extenso de la base de datos y las limitaciones computacionales, se seleccionó una muestra de 10,000 registros para el desarrollo del modelo.
Una vez se transformaron los datos y se prepararon para alimentar el modelo de recomendación, se descargó la nueva base de datos y se generó una función que utiliza dicha base de datos y el modelo desarrollado utilizando el algoritmo de vecinos cercanos. Este algoritmo ofreció mejores resultados para la implementación en la API.
Base de datos transformada para la función de recomendación
Se probaron dos algoritmos proporcionados por la librería sklearn para el desarrollo del modelo de recomendación. El primer algoritmo utilizado fue la similitud del coseno, el cual ofreció resultados satisfactorios. Sin embargo, surgieron dificultades al implementar este modelo en la API. Por lo tanto, se optó por probar un segundo algoritmo, el de vecinos cercanos. Este algoritmo presentó un rendimiento similar al primero, pero resultó más adecuado para la implementación en la API.

