joecao.github.io's People
Contributors

Stargazers




































































































Watchers















































































Forkers
stormblader datatraveler00 ehowwonga c-lins xdcs100 demonphp ivywan issac1413 fanghongbiao oeohomos chenange scanry beiyexertz satcon jackzhanghai linving xiaopohaizadan1 mf1389004071 kintondo johnmyqin tianshizanghuawy dyb10101 joseone qiusheng2011 codering lun130220 ppayaoxing fanwentao-felix xhhw fxwhu bradley-db lyw1129 zhangchao123 mav787 zh605929205 yl0625 hubin19871220 412537896 ccczone huangjiasingle privatecollections geek-kai liuyang0919 monical1 ldhqqzs bobobobo666 1923982924 enrique8191 hackfengjam bewalter foamfish glory-lee yimmmm aitmac13cj rzs840707 songchao168 hehuilei gyc567 laphilee pumzx bae0107 hszjs liuchengqiao mingsc tapate yangtaoxf jyh5215joecao.github.io's Issues
厉害
架构的话得根据业务来,我觉得技术很厉害的不代表能当架构师,只有将技术和实际业务结合起来才能设计出nice的软件
多研究些架构,少谈些框架(2)-- 微服务和充血模型
多研究些架构,少谈些框架(1) -- 论微服务架构的核心概念
多研究些架构,少谈些框架(2)-- 微服务和充血模型
多研究些架构,少谈些框架(3)-- 微服务和事件驱动
多研究些架构,少谈些框架(2)-- 微服务和充血模型
2017-6-12 曹祖鹏
上篇我们聊了微服务的DDD之间的关系,很多人还是觉得很虚幻,DDD那么复杂的理论,聚合根、值对象、事件溯源,到底我们该怎么入手呢?
实际上DDD和面向对象设计、设计模式等等理论有千丝万缕的联系,如果不熟悉OOA、OOD,DDD也是使用不好的。不过学习这些OO理论的时候,大家往往感觉到无用武之地,因为大部分的Java程序员开发生涯是从学习J2EE经典的分层理论开始的(Action、Service、Dao),在这种分层理论中,我们基本没有啥机会使用那些所谓的“行为型”的设计模式,这里的核心原因,就是J2EE经典分层的开发方式是“贫血模型”。
Martin Fowler在他的《企业应用架构模式》这本书中提出了两种开发方式“事务脚本”和“领域模型”,这两种开发分别对应了“贫血模型”和“充血模型”。
事务脚本开发模式
- 事务脚本的核心是过程,可以认为大部分的业务处理都是一条条的SQL,事务脚本把单个SQL组织成为一段业务逻辑,在逻辑执行的时候,使用事务来保证逻辑的ACID。最典型的就是存储过程。当然我们在平时J2EE经典分层架构中,经常在Service层使用事务脚本。

使用这种开发方式,对象只用于在各层之间传输数据用,这里的对象就是“贫血模型”,只有数据字段和Get/Set方法,没有逻辑在对象中。
我们以一个库存扣减的场景来举例:
- 业务场景
首先谈一下业务场景,一个下订单扣减库存(锁库存),这个很简单
先判断库存是否足够,然后扣减可销售库存,增加订单占用库存,然后再记录一个库存变动记录日志(作为凭证) - 贫血模型的设计
首先设计一个库存表 Stock,有如下字段

设计一个Stock对象(Getter和Setter省略)
public class Stock {
private String spuId;
private String skuId;
private int stockNum;
private int orderStockNum;
}- Service入口
设计一个StockService,在其中的lock方法中写逻辑
入参为(spuId, skuId, num)
实现伪代码
count = select stocknum from stock where spuId=xx and skuid=xx
if count>num {
update stock set stocknum=stocknum-num, orderstocknum=orderstocknum+num where skuId=xx and spuId=xx
} else {
//库存不足,扣减失败
}
insert stock_log set xx=xx, date= new Date()-
ok,打完收工,如果做的好一些,可以把update和select count合一,这样可以利用一条语句完成自旋,解决并发问题(高手)。
小结一下:
有没有发现,在这个业务领域非常重要的核心逻辑 -- 下订单扣减库存中操作过程中,Stock对象根本不用出现,全部是数据库操作SQL,所谓的业务逻辑就是由多条SQL构成。Stock只是CRUD的数据对象而已,没逻辑可言。 -
马丁福勒定义的“贫血模型”是反模式,面对简单的小系统用事务脚本方式开发没问题,业务逻辑复杂了,业务逻辑、各种状态散布在大量的函数中,维护扩展的成本一下子就上来,贫血模型没有实施微服务的基础。
-
虽然我们用Java这样的面向对象语言来开发,但是其实和过程型语言是一样的,所以很多情况下大家用数据库的存储过程来替代Java写逻辑反而效果会更好,(ps:用了Spring boot也不是微服务),
领域模型的开发模式
- 领域模型是将数据和行为封装在一起,并与现实世界的业务对象相映射。各类具备明确的职责划分,使得逻辑分散到合适对象中。这样的对象就是“充血模型” 。
- 在具体实践中,我们需要明确一个概念,就是领域模型是有状态的,他代表一个实际存在的事物。还是接着上面的例子,我们设计Stock对象需要代表一种商品的实际库存,并在这个对象上面加上业务逻辑的方法
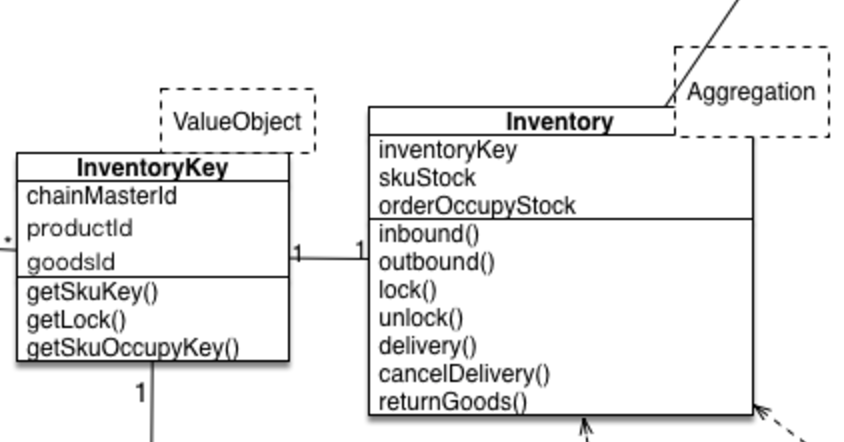
这样做下单锁库存业务逻辑的时候,每次必须先从Repository根据主键load还原Inventory这个对象,然后执行对应的lock(num)方法改变这个Inventory对象的状态(属性也是状态的一种),然后再通过Repository的save方法把这个对象持久化到存储去。
完成上述一系列操作的是Application,Application对外提供了这种集成操作的接口

领域模型开发方法最重要的是把扣减造成的状态变化的细节放到了Inventory对象执行,这就是对业务逻辑的封装。
Application对象的lock方法可以和事务脚本方法的StockService的lock来做个对比,StockService是完全掌握所有细节,一旦有了变化(比如库存为0也可以扣减),Service方法要跟着变;而Application这种方式不需要变化,只要在Inventory对象内部计算就可以了。代码放到了合适的地方,计算在合适层次,一切都很合理。这种设计可以充分利用各种OOD、OOP的理论把业务逻辑实现的很漂亮。
- 充血模型的缺点
从上面的例子,在Repository的load 到执行业务方法,再到save回去,这是需要耗费一定时间的,但是这个过程中如果多个线程同时请求对Inventory库存的锁定,那就会导致状态的不一致,麻烦的是针对库存的并发不仅难处理而且很常见。
贫血模型完全依靠数据库对并发的支撑,实现可以简化很多,但充血模型就得自己实现了,不管是在内存中通过锁对象,还是使用Redis的远程锁机制,都比贫血模型复杂而且可靠性下降,这是充血模型带来的挑战。更好的办法是可以通过事件驱动的架构来取消并发。
领域模型和微服务的关系
上面讲了领域模型的实现,但是他和微服务是什么关系呢?在实践中,这个Inventory是一个限界上下文的聚合根,我们可以认为一个限界上下文是一个微服务进程。
不过问题又来了,一个库存的Inventory一定和商品信息是有关联的,仅仅靠Inventory中的冗余那点商品ID是不够的,商品的上下架状态等等都是业务逻辑需要的,那不是又把商品Sku这样的重型对象引入了这个微服务?两个重型的对象在一个服务中?这样的微服务拆不开啊,还是必须依靠商品库?!
请参考下一篇,通过事件驱动架构来完成领域间的松耦合。
版权说明
本文采用 CC BY 3.0 CN协议 进行许可。 可自由转载、引用,但需署名作者且注明文章出处。如转载至微信公众号,请在文末添加作者公众号二维码。
关注我
微信公众号

微服务之构建容错&自动降级的系统
微服务之构建容错&自动降级的系统
微服务是什么
MicroService主要是针对以前的Monolithic(单体)服务来说的,类似优步打车(Uber)这样的应用,如果使用Monolithic来架构,可能是这样的

注:
STRIPE是支付服务
SENDGRID是邮件推送服务
TWILIO是语音、消息的云服务
大部分的项目都是由Monolithic起步的。刚开始最合适不过了,开发简单直接(直接在一个IDE里面就可以调试)、部署方便(搞个war包扔到tomcat里面就能跑)。
但是随着时间的增长,单体应用的缺陷暴露出来了。
- 首先是代码量大大增加
从几千行到几十万行,接手的程序员已经无法搞清楚里面模块交互逻辑和依赖关系了。大家都在小心翼翼的加代码,避免触碰以前的旧代码。至于单元测试,这种怪兽级别的应用,能不能拆分出来单元啊? - 不可避免的超长启动时间
3分钟以内的都算是快的。启动后,程序员抽支烟再回来的不在少数。大量的时间在等待,使得程序员越来越不愿意测试自己的功能,写完了之后直接扔给测试就完事了。测试轮次一次又一次,时间不可避免的浪费。 - 部署扩展困难
各个模块对服务器的性能要求不同,有的占用CPU高,有的需要大量的IO,有的需要更多的内存。部署在一个服务器内相互影响,扩容的话,无法针对性的扩展。 - 单个的bug会损坏整个服务
可能一个模块的内存泄露,会使得整个服务都crash down。 - 对于一些新技术尝试有限制
比如想换个新框架试试,但是要换就全部得换,风险太大。
服务化的改造
解决方案就是服务化,进行下图的Y轴方向的功能拆解。

最终可能的情况类似下图

MicroService不是银弹
- 服务之间的通讯机制RPC开销大
- 需要考虑分布式情况下的服务失效恢复等等问题
- 数据库分布带来的分布式事务困扰,还有分布式数据结果Join的问题
- 如何管理这么多服务之间的依赖关系,出了问题如何定位?
- 部署服务变得复杂。包括配置、部署、扩容、监控,都是需要专门的工具链支持。
微服务和SOA
虽然微服务很火,但是仅仅把微服务和Monolithic服务做对比,然后搞个大新闻把Monolithic批判一番,我认为是很不公平的。
一般稍具规模企业都在前几年完成了SOA的演化,那么微服务和SOA的区别?SOA在十年前就提出了服务化的概念,那微服务到底是新的理论突破,还是新瓶装旧酒换了一个概念出来忽悠?
总结了微服务应该具备的特点:
- 小, 且专注于做⼀件事情
- 独立的进程
- 松耦合、独立部署
- 轻量级的通信机制
- 有边界:
服务间边界清晰、灵活选择语言和技术(这个是有争议的) - 松耦合:
服务无状态、容错性、故障隔离、自动恢复、弹性伸缩、服务间独立部署,发布、升级、降级互不影响 - 面向服务架构(SOA) :
服务化、服务分层
我个人理解SOA和MicroService理论是同源,但是实施方案上面有轻量和重量解决方案的区别,类似当年EJB和Spring之争。
基于ESB、SOAP、WSDL等重型解决方案,演化出来SOA。
利用Dubbo、zookeeper、http/rest、consul、Eureka这些框架的轻量解决方案,也就是现在流行的MicroService。
微服务之后,前端(Web、App)怎么开发?
以电商APP为例,需要购物车、物流服务、库存服务、推荐服务、订单服务、评价服务、商品类目服务....

如果我们让APP分别去调用这些服务会带来什么后果?
- 后端代码必须改造,因为APP调不了Dubbo协议(二进制的比较复杂),我们得给每个服务都架设一个HTTP代理,也无法利用MicroService的服务发现机制(暴露Zookeeper到公网,非常不安全),必须通过额外的nginx做负载均衡
- 客户端的代码极其冗余,因为业务数据是需要融合的,很多页面需要发送多次请求才能返回给用户一个完成的View,再加上UI 的Callback hell,特别酸爽
- 将内部的逻辑放到了客户端,一旦服务有拆分、融合之类的操作,APP也必须升级
适配移动化的BFF架构
在微服务和APP之间建立一个沟通的桥梁,一个网关(Gateway),我们称之为Backend for Frontier,一个专为前端准备的后端(绕口令中)

BFF职责是路由、聚合、协议转换。
每个请求BFF都可能会调用后面多个微服务的Dubbo接口,将结果聚合后返回给前台。BFF需要给前端更粗颗粒的接口,避免APP的多次调用降低效率。比如/products/{productId}这样的接口会将商品标题、规格、图片、详情页面、评价一股脑的返回给前台。
优缺点
优点:提供了一站式的接口,隐藏内部逻辑,对前端开发友好
缺点:对高可用的架构来说,这个单点的职责较重。
微服务后,中心应该如何开发?
以商品中心为例:一个大的商品中心服务可以被拆为类目、商品、价格、库存四个微服务。这样每个服务的职责专注,接口单一。每个服务可以有自己的存储,甚至可以用不同的存储,比如商品适合Elasticsearch的搜索引擎,库存就适合Redis这样的内存数据库。这样系统的性能提升。
问题又出现了,服务拆开,本来一个接口能返回的数据,必须通过分别调用不同服务的接口来完成。更糟糕的是,不同的服务使用不同的存储引擎,以前一个sql join能解决的事情,变得非常的复杂。
如何解决?
- 得益于现在技术的提升,我们可以在BFF侧使用zip、join这类的函数式写法替代原来的多层循环来更高效聚合数据。
- 可以使用最新的思路在客户端缓存数据,相当于在app、js侧做了一个数据拷贝的子集(mongodb?),通过diff之类的算法和后端不断同步数据。(类似firebase,野狗的思路)
- 使用类似物化视图的概念,在业务侧生成他需要的视图数据。加快查询速度。

以上方案视情况采用
Backend for Frontier和SOA配合的烦恼
一旦涉及到调用多个后台SOA的接口,SOA接口之间有一定关联关系,需要将结果组合,这组调用的危险性就很大。
以我们常见的商品列表的接口举例,该接口不仅仅是调用了商品中心商品信息接口,还调用了定价服务的用户级别价格接口,然后组合(zip)成为一个商品完整信息返回。
在某些情况下价格服务失效,或者是返回时长波动,那么整个商品列表就一直会阻塞,直到超时也不会返回结果,用户在前台看到的是一个空白的转圈的页面。 用户只会认为整个系统都挂了,他可不管你里面发生了什么。
微服务架构成规模后,任何一个我们认为的微不足道的服务的故障,都会导致整个业务的不可用。而在SOA模式下面数千个服务,可能有一定的几率某几个服务是失效的,这种minor的失效导致整个系统不可用的失败,是SOA的一大硬伤。

在后端服务失效这种情况下,我们希望API网关能做到
- 快速响应用户的请求
- 给用户一些详尽的错误提示,安抚客户
- 如果有可能,降级到某个缓存或者备用服务上
- 快速的跟踪到错误位置
- 防止失效扩散到整个集群
- 如果服务正常了,前端API网关能够自动恢复

Hystrix 是什么?
Hystrix是Netflix开发的一个库,能够实现
- 调用外部API能够设置超时时间(默认1000ms)
- 限制外部系统的并发调用(默认10个)
- Circuit Breaker可以在一定错误率后不再调用API(默认50%)
- Circuit Breaker启动后,每隔五秒可以再次尝试调用API
- 可以监控实时的调用情况,Hystrix甚至提供了一个可视化的监控面板
Hystrix适用场景
Hystrix用在BFF侧,包装外部系统API的调用是最合适的。当然不仅仅是外部系统API调用,即使是内部进程内的调用,也可以用Hystrix的Semaphore模式进行并发限制和监控
Hystrix提供了贴心的Fallback(回落、降级,怎么称呼好呢?)功能,在我们设置的条件满足后,就会转到Fallback方法上,替代原来的接口的返回。
有两个场景,不适合Hystrix的Fallback:
- 如果接口是write操作
-- 这里的write包括append,update、delete等等操作,这些操作会改变外部系统状态,使用Hystrix是不合适的。因为Hystrix只是在客户端做了限制和监控,Hystrix判定的超时,和外部系统判定的标准并不同步,这就会导致数据不一致。 - 批量操作或者是离线操作
-- 如果是导出一个订单列表或者统计一个报表之类的操作,就不要Fallback了,让他异步执行吧,没有必要降级。
CircuitBreaker模式
Martin Flower 曾经总结了一个CircuitBreaker的模式,就是在服务故障的情况下,迅速做出反应,不让故障扩散

在图中看到,在可能出现超时的调用中,保护性的调用启动了两个线程,一个线程去实际调用,一个线程监控,如果超过设定的阈值,监控线程会返回一个默认值或者直接抛出异常给客户端,就不等那个真正的远调用线程的返回了
当然这种对超时的控制,一般的RPC都会有(比如Dubbo做了mock的功能)。但是CircuitBreaker的高效之处在于过了一段时间后,可以检测接口的状况,如果接口正常了,自动恢复。
在这里Martin Flower设计了一个“half open”半开的状态

从图上可以看到,在客户端调用次数到了一定的阈值的时候,CircuitBreaker进入了Open状态,在Open状态启动定时器,到了时间会转入Half Open,再次尝试一下接口调用,如果正常了,就恢复。如果还是错误,那就回到Open状态,继续等着吧。
如何集成到我们的SpringBoot的框架
很简单,就是几个Jar包的引入和annotation的使用
请参考例子
http://git.dev.qianmi.com/commons/micro-service-frontend-sample.git
@Service
public class PricingApi implements PricingProvider {
@Reference(timeout = 15000, check = false)
PricingProvider pricingProvider;
/**
* 默认在500毫秒内就需要返回结果,否则回落到default的值中
*
* @param itemids
* @return
*/
@Override
@HystrixCommand(fallbackMethod = "defaultPrice", commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "500"),
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10")})
public List<ItemPrice> getPrice(String... itemids) {
return pricingProvider.getPrice(itemids);
}
/**如果回落到此方法,使用-1代替价格返回**/
public List<ItemPrice> defaultPrice(String... itemids) {
List<ItemPrice> prices = new ArrayList<>();
for (String itemId : itemids) {
ItemPrice itemPrice = new ItemPrice(itemId, -1.0);
prices.add(itemPrice);
}
return prices;
}
}
只需要通过注解的方式将Dubbo的远程调用包住即可
如果没用Spring boot框架,可以参考这篇文章
https://ahus1.github.io/hystrix-examples/manual.html
最佳实践
几个重要的参数说明
-
execution.isolation.thread.timeoutInMilliseconds
这个用于设置超时时间,默认是1000ms -
execution.isolation.strategy
这里有两个选择,一个是thread 一个semaphore,thread会启动线程池,默认为10个,主要用于控制外部系统的API调用。semaphore是控制内部的API调用,本机调用(顺便说一下其实Hystrix不仅仅用于RPC场景)

-
circuitBreaker.requestVolumeThreshold
这个参数决定了,有规定时间内(一般是10s),有多少个错误请求,会触发circuit breaker open。默认20个 -
circuitBreaker.sleepWindowInMilliseconds
该参数决定了,在circuit break 进入到open状态后,多少时间会再次尝试进入
如何设置线程池的大小

打个比方,经过统计,一个远程接口的返回时间
Median: 40ms
99th: 200ms
99.5th: 300ms
-
线程池的计算公式
requests per second at peak when healthy × 99th percentile latency in seconds + some breathing room
99%的请求都会在200ms内返回,一个高峰期并发30个每秒
那么thread pool size = 30 rps * 0.2 seconds = 6 + breathing room(冗余量) =10 threads
99%的请求都会在200ms之内返回,考虑到在失败时,设置一次retry,那么大概就是240ms左右,这样的话设置执行线程的超时时间为300ms。
如果设置得当,一般来说,线程池的Active Thread只会有1-2个,大部分的40ms内的请求会很快的处理掉。 -
Thread pool设置
@HystrixCommand(commandProperties = { @HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "500") }, threadPoolProperties = { @HystrixProperty(name = "coreSize", value = "30"), @HystrixProperty(name = "maxQueueSize", value = "101"), @HystrixProperty(name = "keepAliveTimeMinutes", value = "2"), @HystrixProperty(name = "queueSizeRejectionThreshold", value = "15"), @HystrixProperty(name = "metrics.rollingStats.numBuckets", value = "12"), @HystrixProperty(name = "metrics.rollingStats.timeInMilliseconds", value = "1440") }) public User getUserById(String id) { return userResource.getUserById(id); }
版权说明
本文采用 CC BY 3.0 CN协议 进行许可。 可自由转载、引用,但需署名作者且注明文章出处。如转载至微信公众号,请在文末添加作者公众号二维码。
关注我
微信公众号

多研究些架构,少谈些框架(3)-- 微服务和事件驱动
多研究些架构,少谈些框架(1) -- 论微服务架构的核心概念
多研究些架构,少谈些框架(2)-- 微服务和充血模型
多研究些架构,少谈些框架(3)-- 微服务和事件驱动
2017-6-16 曹祖鹏
接上篇,我们采用了领域驱动的开发方式,使用了充血模型,享受了他的好处,但是也不得不面对他带来的弊端。这个弊端在分布式的微服务架构下面又被放大。
事务一致性
事务一致性的问题在Monolithic下面不是大问题,在微服务下面却是很致命,我们回顾一下所谓的ACID原则
- Atomicity - 原子性,改变数据状态要么是一起完成,要么一起失败
- Consistency - 一致性,数据的状态是完整一致的
- Isolation - 隔离线,即使有并发事务,互相之间也不影响
- Durability - 持久性, 一旦事务提交,不可撤销
在单体服务和关系型数据库的时候,我们很容易通过数据库的特性去完成ACID。但是一旦你按照DDD拆分聚合根-微服务架构,他们的数据库就已经分离开了,你就要独立面对分布式事务,要在自己的代码里面满足ACID。
对于分布式事务,大家一般会想到以前的JTA标准,2PC两段式提交。我记得当年在Dubbo群里面,基本每周都会有人询问Dubbo啥时候支撑分布式事务。实际上根据分布式系统中CAP原则,当P(分区容忍)发生的时候,强行追求C(一致性),会导致(A)可用性、吞吐量下降,此时我们一般用最终一致性来保证我们系统的AP能力。当然不是说放弃C,而是在一般情况下CAP都能保证,在发生分区的情况下,我们可以通过最终一致性来保证数据一致。
例:
在电商业务的下订单冻结库存场景。需要根据库存情况确定订单是否成交。
假设你已经采用了分布式系统,这里订单模块和库存模块是两个服务,分别拥有自己的存储(关系型数据库),

在一个数据库的时候,一个事务就能搞定两张表的修改,但是微服务中,就没法这么做了。
在DDD理念中,一次事务只能改变一个聚合内部的状态,如果多个聚合之间需要状态一致,那么就要通过最终一致性。订单和库存明显是分属于两个不同的限界上下文的聚合,这里需要实现最终一致性,就需要使用事件驱动的架构。
事件驱动实现最终一致性
事件驱动架构在领域对象之间通过异步的消息来同步状态,有些消息也可以同时发布给多个服务,在消息引起了一个服务的同步后可能会引起另外消息,事件会扩散开。严格意义上的事件驱动是没有同步调用的。
例子:
在订单服务新增订单后,订单的状态是“已开启”,然后发布一个Order Created事件到消息队列上

库存服务在接收到Order Created 事件后,将库存表格中的某sku减掉可销售库存,增加订单占用库存,然后再发送一个Inventory Locked事件给消息队列

订单服务接收到Inventory Locked事件,将订单的状态改为“已确认”

有人问,如果库存不足,锁定不成功怎么办? 简单,库存服务发送一个Lock Fail事件, 订单服务接收后,把订单置为“已取消”。
好消息,我们可以不用锁!事件驱动有个很大的优势就是取消了并发,所有请求都是排队进来,这对我们实施充血模型有很大帮助,我们可以不需要自己来管理内存中的锁了。取消锁,队列处理效率很高,事件驱动可以用在高并发场景下,比如抢购。
是的,用户体验有改变,用了这个事件驱动,用户的体验有可能会有改变,比如原来同步架构的时候没有库存,就马上告诉你条件不满足无法下单,不会生成订单;但是改了事件机制,订单是立即生成的,很可能过了一会系统通知你订单被取消掉。 就像抢购“小米手机”一样,几十万人在排队,排了很久告诉你没货了,明天再来吧。如果希望用户立即得到结果,可以在前端想办法,在BFF(Backend For Frontend)使用CountDownLatch这样的锁把后端的异步转成前端同步,当然这样BFF消耗比较大。
没办法,产品经理不接受,产品经理说用户的体验必须是没有库存就不会生成订单,这个方案会不断的生成取消的订单,他不能接受,怎么办?那就在订单列表查询的时候,略过这些cancel状态的订单吧,也许需要一个额外的视图来做。我并不是一个理想主义者,解决当前的问题是我首先要考虑的,我们设计微服务的目的是本想是解决业务并发量。而现在面临的却是用户体验的问题,所以架构设计也是需要妥协的:( 但是至少分析完了,我知道我妥协在什么地方,为什么妥协,未来还有可能改变。
多个领域多表Join查询
- 我个人认为聚合根这样的模式对修改状态是特别合适,但是对搜索数据的确是不方便,比如筛选出一批符合条件的订单这样的需求,本身聚合根对象不能承担批量的查询任务,因为这不是他的职责。那就必须依赖“领域服务(Domain Service)”这种设施。
当一个方法不便放在实体或者值对象上,使用领域服务便是最佳的解决方法,请确保领域服务是无状态的。
-
我们的查询任务往往很复杂,比如查询商品列表,要求按照上个月的销售额进行排序; 要按照商品的退货率排序等等。但是在微服务和DDD之后,我们的存储模型已经被拆离开,上述的查询都是要涉及订单、用户、商品多个领域的数据。如何搞? 此时我们要引入一个视图的概念。比如下面的,查询用户名下订单的操作,直接调用两个服务自己在内存中join效率无疑是很低的,再加上一些filter条件、分页,没法做了。于是我们将事件广播出去,由一个单独的视图服务来接收这些事件,并形成一个物化视图(materialized view),这些数据已经join过,处理过,放在一个单独的查询库中,等待查询,这是一个典型的以空间换时间的处理方式。
-
经过分析,除了简单的根据主键Find或者没有太多关联的List查询,我们大部分的查询任务可以放到单独的查询库中,这个查询库可以是关系数据库的ReadOnly库,也可以是NoSQL的数据库,实际上我们在项目中使用了ElasticSearch作为专门的查询视图,效果很不错

限界上下文(Bounded Context)和数据耦合
除了多领域join的问题,我们在业务中还会经常碰到一些场景,比如电商中的商品信息是基础信息,属于单独的BC,而其他BC,不管是营销服务、价格服务、购物车服务、订单服务都是需要引用这个商品信息的。但是需要的商品信息只是全部的一小部分而已,营销服务需要商品的id和名称、上下架状态;订单服务需要商品id、名称、目录、价格等等。这比起商品中心定义一个商品(商品id、名称、规格、规格值、详情等等)只是一个很小的子集。这说明不同的限界上下文的同样的术语,但是所指的概念不一样。 这样的问题映射到我们的实现中,每次在订单、营销模块中直接查询商品模块,肯定是不合适,因为
- 商品中心需要适配每个服务需要的数据,提供不同的接口
- 并发量必然很大
- 服务之间的耦合严重,一旦宕机、升级影响的范围很大。
特别是最后一条,严重限制了我们获得微服务提供的优势“松耦合、每个服务自己可以频繁升级不影响其他模块”。这就需要我们通过事件驱动方法,适当冗余一些数据到不同的BC去,把这种耦合拆解开。这种耦合有时候是通过Value Object嵌入到实体中的方式,在生成实体的时候就冗余,比如订单在生成的时候就冗余了商品的信息;有时候是通过额外的Value Object列表方式,营销中心冗余一部分相关的商品列表数据,并随时关注监听商品的上下级状态,同步替换掉本限界上下文的商品列表。
下图一个下单场景分析,在电商系统中,我们可以认为会员和商品是所有业务的基础数据,他们的变更应该是通过广播的方式发布到各个领域,每个领域保留自己需要的信息。

保证最终一致性
最终一致性成功依赖很多条件
- 依赖消息传递的可靠性,可能A系统变更了状态,消息发到B系统的时候丢失了,导致AB的状态不一致
- 依赖服务的可靠性,如果A系统变更了自己的状态,但是还没来得及发送消息就挂了。也会导致状态不一致
我记得JavaEE规范中的JMS中有针对这两种问题的处理要求,一个是JMS通过各种确认消息(Client Acknowledge等)来保证消息的投递可靠性,另外是JMS的消息投递操作可以加入到数据库的事务中-即没有发送消息,会引起数据库的回滚(没有查资料,不是很准确的描述,请专家指正)。不过现在符合JMS规范的MQ没几个,特别是保一致性需要降低性能,现在标榜高吞吐量的MQ都把问题抛给了我们自己的应用解决。所以这里介绍几个常见的方法,来提升最终一致性的效果。
使用本地事务
还是以上面的订单扣取信用的例子
- 订单服务开启本地事务,首先新增订单;
- 然后将Order Created事件插入一张专门Event表,事务提交;
- 有一个单独的定时任务线程,定期扫描Event表,扫出来需要发送的就丢到MQ,同时把Event设置为“已发送”。

方案的优势是使用了本地数据库的事务,如果Event没有插入成功,那么订单也不会被创建;线程扫描后把event置为已发送,也确保了消息不会被漏发(我们的目标是宁可重发,也不要漏发,因为Event处理会被设计为幂等)。
缺点是需要单独处理Event发布在业务逻辑中,繁琐容易忘记;Event发送有些滞后;定时扫描性能消耗大,而且会产生数据库高水位隐患;
我们稍作改进,使用数据库特有的MySQL Binlog跟踪(阿里的Canal)或者Oracle的GoldenGate技术可以获得数据库的Event表的变更通知,这样就可以避免通过定时任务来扫描了

不过用了这些数据库日志的工具,会和具体的数据库实现(甚至是特定的版本)绑定,决策的时候请慎重。
使用Event Sourcing 事件溯源
事件溯源对我们来说是一个特别的思路,他并不持久化Entity对象,而是只把初始状态和每次变更的Event记录下来,并在内存中根据Event还原Entity对象的最新状态,具体实现很类似数据库的Redolog的实现,只是他把这种机制放到了应用层来。
虽然事件溯源有很多宣称的优势,引入这种技术要特别小心,首先他不一定适合大部分的业务场景,一旦变更很多的情况下,效率的确是个大问题;另外一些查询的问题也是困扰。
我们仅仅在个别的业务上探索性的使用Event Souring和AxonFramework,由于实现起来比较复杂,具体的情况还需要等到实践一段时间后再来总结,也许需要额外的一篇文章来详细描述
以上是对事件驱动在微服务架构中一些我的理解,文章部分借鉴了Chris Richardson的Blog,https://www.nginx.com/blog/event-driven-data-management-microservices/ 在此我向他表示致谢 。
版权说明
本文采用 CC BY 3.0 CN协议 进行许可。 可自由转载、引用,但需署名作者且注明文章出处。如转载至微信公众号,请在文末添加作者公众号二维码。
关注我
微信公众号
多研究些架构,少谈些框架(1) -- 论微服务架构的核心概念
多研究些架构,少谈些框架(1) -- 论微服务架构的核心概念
多研究些架构,少谈些框架(2)-- 微服务和充血模型
多研究些架构,少谈些框架(3)-- 微服务和事件驱动
多研究些架构,少谈些框架(1) -- 论微服务架构的核心概念
2017-6-9 曹祖鹏
微服务架构和SOA区别
微服务现在辣么火,业界流行的对比的却都是所谓的Monolithic单体应用,而大量的系统在十几年前都是已经是分布式系统了,那么微服务作为新的理念和原来的分布式系统,或者说SOA(面向服务架构)是什么区别呢?
我们先看相同点:
- 需要Registry,实现动态的服务注册发现机制;
- 需要考虑分布式下面的事务一致性,CAP原则下,两段式提交不能保证性能,事务补偿机制需要考虑;
- 同步调用还是异步消息传递,如何保证消息可靠性?SOA由ESB来集成所有的消息;
- 都需要统一的Gateway来汇聚、编排接口,实现统一认证机制,对外提供APP使用的RESTful接口;
- 同样的要关注如何再分布式下定位系统问题,如何做日志跟踪,就像我们电信领域做了十几年的信令跟踪的功能;
那么差别在哪?
- 是持续集成、持续部署?对于CI、CD(持续集成、持续部署),这本身和敏捷、DevOps是交织在一起的,我认为这更倾向于软件工程的领域而不是微服务技术本身;
- 使用不同的通讯协议是不是区别?微服务的标杆通讯协议是RESTful,而传统的SOA一般是SOAP,不过目前来说采用轻量级的RPC框架Dubbo、Thrift、gRPC非常多,在Spring Cloud中也有Feign框架将标准RESTful转为代码的API这种仿RPC的行为,这些通讯协议不应该是区分微服务架构和SOA的核心差别;
- 是流行的基于容器框架还是虚拟机为主?Docker和虚拟机还是物理机都是架构实现的一种方式,不是核心区别;
微服务架构的精髓在切分
- 服务的切分上有比较大的区别,SOA原本是以一种“集成”技术出现的,很多技术方案是将原有企业内部服务封装为一个独立进程,这样新的业务开发就可重用这些服务,这些服务很可能是类似供应链、CRM这样的非常大的颗粒;而微服务这个“微”,就说明了他在切分上有讲究,不妥协。无数的案例证明,如果你的切分是错误的,那么你得不到微服务承诺的“低耦合、升级不影响、可靠性高”之类的优势,而会比使用Monolithic有更多的麻烦。
- 不拆分存储的微服务是伪服务:在实践中,我们常常见到一种架构,后端存储是全部和在一个数据库中,仅仅把前端的业务逻辑拆分到不同的服务进程中,本质上和一个Monolithic一样,只是把模块之间的进程内调用改为进程间调用,这种切分不可取,违反了分布式第一原则,模块耦合没有解决,性能却受到了影响。
分布式设计第一原则 -- “不要分布你的对象”
- 微服务的“Micro”这个词并不是越小越好,而是相对SOA那种粗粒度的服务,我们需要更小更合适的粒度,这种Micro不是无限制的小。
如果我们将两路(同步)通信与小/微服务结合使用,并根据比如“1个类=1个服务”的原则,那么我们实际上回到了使用Corba、J2EE和分布式对象的20世纪90年代。遗憾的是,新生代的开发人员没有使用分布式对象的经验,因此也就没有认识到这个主意多么糟糕,他们正试图重复历史,只是这次使用了新技术,比如用HTTP取代了RMI或IIOP。
微服务和Domain Driven Design
一个简单的图书管理系统肯定无需微服务架构。既然采用了微服务架构,那么面对的问题空间必然是比较宏大,比如整个电商、CRM。
如何拆解服务呢?
使用什么样的方法拆解服务?业界流行1个类=1个服务、1个方法=1个服务、2 Pizza团队、2周能重写完成等方法,但是这些都缺乏实施基础。我们必须从一些软件设计方法中寻找,面向对象和设计模式适用的问题空间是一个模块,而函数式编程的理念更多的是在代码层面的微观上起作用。
Eric Evans 的《领域驱动设计》这本书对微服务架构有很大借鉴意义,这本书提出了一个能将一个大问题空间拆解分为领域和实体之间的关系和行为的技术。目前来说,这是一个最合理的解决拆分问题的方案,透过限界上下文(Bounded Context,下文简称为BC)这个概念,我们能将实现细节封装起来,让BC都能够实现SRP(单一职责)原则。而每个微服务正是BC在实际世界的物理映射,符合BC思路的微服务互相独立松耦合。
微服务架构是一件好事,逼着大家关注设计软件的合理性,如果原来在Monolithic中领域分析、面向对象设计做不好,换微服务会把这个问题成倍的放大
以电商中的订单和商品两个领域举例,按照DDD拆解,他们应该是两个独立的限界上下文,但是订单中肯定是包含商品的,如果贸然拆为两个BC,查询、调用关系就耦合在一起了,甚至有了麻烦的分布式事务的问题,这个关联如何拆解?BC理论认为在不同的BC中,即使是一个术语,他的关注点也不一样,在商品BC中,关注的是属性、规格、详情等等(实际上商品BC这个领域有价格、库存、促销等等,把他作为单独一个BC也是不合理的,这里为了简化例子,大家先认为商品BC就是商品基础信息), 而在订单BC中更关注商品的库存、价格。所以在实际编码设计中,订单服务往往将关注的商品名称、价格等等属性冗余在订单中,这个设计解脱了和商品BC的强关联,两个BC可以独立提供服务,独立数据存储
小结
微服务架构首先要关注的不是RPC/ServiceDiscovery/Circuit Breaker这些概念,也不是Eureka/Docker/SpringCloud/Zipkin这些技术框架,而是服务的边界、职责划分,划分错误就会陷入大量的服务间的相互调用和分布式事务中,这种情况微服务带来的不是便利而是麻烦。
DDD给我们带来了合理的划分手段,但是DDD的概念众多,晦涩难以理解,如何抓住重点,合理的运用到微服务架构中呢?
我认为如下的几个架构**是重中之重
-
充血模型
-
事件驱动
下面两篇将为大家详细介绍这两个设计思路
版权说明
本文采用 CC BY 3.0 CN协议 进行许可。 可自由转载、引用,但需署名作者且注明文章出处。如转载至微信公众号,请在文末添加作者公众号二维码。
关注我
微信公众号
实在是厌烦Github Pages了,各种麻烦,我还是直接在issues中发布blog吧
Jekyll太麻烦
手工调整模板太累
没有动态的留言互动
Github的Markdown语法和其他的有区别
多研究些架构,少谈些框架(4)-- 架构师是技术的使用者而不是信徒
多研究些架构,少谈些框架(1) -- 论微服务架构的核心概念
多研究些架构,少谈些框架(2)-- 微服务和充血模型
多研究些架构,少谈些框架(3)-- 事件驱动架构
多研究些架构,少谈些框架(4)-- 架构师是技术的使用者而不是信徒
多研究些架构,少谈些主义(4)-- 架构师是技术的使用者而不是信徒
2017-6-9 曹祖鹏
架构师是技术的使用者而不是信徒
我承认我是标题党, 为什么要写这篇充满争议的文章?目前架构师这个职位特别火热,程序员的目标都是成为一个令人尊敬的架构师。但是我们真的理解架构师应该做些什么?很多人把架构师和框架师等同起来,认为研究框架多的才是架构师
下面说的情况请勿对号入座。
-
盲目的追新:
技术人员的喜好往往是什么技术流行就追什么技术。现在的技术发展快,前后端不断涌现各种框架,我们恨不得把这些框架都用在自己的项目里才行,要不然怎么好意思和别人打招呼啊。
我亲身经历,有个技术人员一定要把原来单元测试框架的xml初始数据改为json,他的原话是”json看的更舒服”,但是改完后,我们的单元测试反而难落地了,原因是原来的单元测试框架有个工具是可以将表中的数据自动生成xml的,而改成json后,我们必须手写json数据了。 他的喜好不包括给大家更好用的工具。 -
按技术站队,以结果反推:
很多人把手段当成了目的,成为了框架的信徒。用了Java开发,你的设计就一定是面向对象的?用了Spring boot就是微服务了吗?这些荒唐的事情却在技术圈不断发生,技术人员甚至会按照语言、框架形成不同的圈子,各种技术圈互相鄙视,互相踩,真相此时无法越辩越明,反而把技术方向带歪了。
技术要和实际场景结合
架构师也要深入了解掌握技术,但是更多的是了解技术的优劣和使用场景,而不是简单的生搬硬套。以现在流行的微服务架构来说,Netflix使用RESTful接口作为通讯,我们是不是要把公司的用了n年的基于TCP的RPC换成RESTful接口,因为根据Netflix的实践,RESTful可以更好的解耦、更强的伸缩性等优点,还能支持多种语言开发,互通性好。但是我们需要对RESTful彻底的理解清楚:
- RESTful接口不简单是是http+json,Richardson成熟度模型中哪个层级更合适我们的内网API通讯,HATEOAS是否需要?
- RESTful的核心是资源,如何在微服务中抽象资源概念,如何将基于过程的RPC调用平滑的迁移到RESTful上?
- 多语言开发是快,但是后续维护如何找到稳定的Go、Scala、xxx语言程序员来源?
以上的问题应该是架构师在考虑引入新技术的时候的重点,其中对技术优劣和架构思路是核心
版权说明
本文采用 CC BY 3.0 CN协议 进行许可。 可自由转载、引用,但需署名作者且注明文章出处。如转载至微信公众号,请在文末添加作者公众号二维码。
关注我
微信公众号
领域驱动设计和Spring(翻译)
领域驱动设计和Spring(翻译)
原文 http://static.olivergierke.de/lectures/ddd-and-spring/
1、介绍
这篇文章是的介绍一下领域驱动设计的基础构件、概念和Java的web应用(主要是基于Spring框架)之间的关系和区别。
这篇文章的第二部分讲了怎么把实体、聚合根、仓储映射到使用Spring框架的Java应用中
2、领域驱动设计
Eric Evans的《领域驱动设计》无疑是软件设计领域最重要的几本书之一。
这本书主要集中在软件开发中如何处理领域和软件的映射关系— 开始强调领域通用语言(domain ubiquitous language),通过语言来提取模型,最终映射到一个可工作的软件上。
我们已经对软件设计模式比较熟悉了,他是用于描述和提炼Class和Class关系的技术语言。而DDD是一种用于程序员和业务沟通的更通用的语言,使用DDD可以最终将代码映射到模型上。
2.1 基础构件
构件是DDD中的一些专有名词,让我们看一下图

2.1.1 限界上下文(Bounded Context)
当进行领域建模的时候,任何将其作为一个整体进行建模的尝试注定会失败。因为各类利益相关者和他们对领域的看法可能完全不同,试图建立一个单一的、独特的模型来满足所有需求是完全不可能的,会把系统搞得极为复杂。
让我们看一个示例图,这个图描述了销售领域已经识别出的模型

我们把模型元素稍加区分,成为分离的模型,就可以看出客户和订单的,他们是不同上下文的核心的概念。

在这里,我们确定了系统战略层面的核心部分,这些部分可能都涉及客户或订单的概念,但通常不同限界上下文对它们的属性感兴趣的部分并不相同。比如 Accounting上下文通常对客户的计费信息和不同的支付选项感兴趣,而Shipping上下文的对客户的唯一目标是运送地址,然后跟踪订单。 Order上下文可能通过客户的订单项了解商品信息,但实际上只涉及商品类目基本的内容(译者注:商品规格、商品详情这些信息Order上下文并不关注)。

这里的模型元素可能看起来会以不同的方式反映在系统的不同层面中(译者:指的是Product和Customer对象会存在多个领域中,但是不同的概念)。现代的软件架构甚至更进一步,积极的通过冗余和最终一致性降低单个系统的复杂度,提升系统弹性,并提高整体的开发生产力(译者:CQRS和事件驱动架构)
2.1.2 值对象
代表了领域对象中的概念 — 值 (和他的名字一样),值对象没有主键没有生命周期。而且他是不可变的,以确保可以在多个消费者之间完整的共享。在Java中,String对象是符合这些特性的一个很好的例子,不过这不太合适领域设计的例子,因为他太抽象了。一般来说,信用卡号码、电子邮箱地都可以很好的被构建为值对象。值对象常常是实体的属性。将领域元素实现为值对象可以大大增强代码的可读性,正如Dan Bergh Johnsson在他的DDD中的Power Use of Value Objects所展示的。
由于需要实现Getter、equals()、hashCode()方法,纯Java实现值对象相当麻烦(译者:特别是没有Builder方法)。所以很多人不愿意做,值对象往往被遗忘。现在你可以用Lombok这个工具来方便的构造处理值对象。
2.1.3 实体类
和值对象相比,实体的核心特征就是他是有主键。两个都叫Michael Muller的客户可能不是一个实例,我们通常会引入一个专用的属性来识别他们。另外一个特征是实体类在问题域中有自己的生命周期。他们被创建,由领域事件驱动,经历各种状态的变化,最终到达一个结束的状态(即可能被删除,但是不一定是物理删除)。实体类通常涉及其他的实体,并包含值对象或者基本类型(类似Java中的int boolean double 等)
实体类 vs 值对象
一个领域概念到底是实体还是值对象?这个要看上下文。而且事实上,一个概念在不同的上下文中他的类型是不一样的。比如一个地址可能是一个商店的属性,一个值对象。但是当他们是一个客户的配送和计费地址的时候,他们就是实体类了,因为这些地址有了生命周期,可以被创建、修改、删除。
2.1.4 聚合根
有一些实体在系统中扮演了很特殊的角色。举例,一个由订单项构成的订单,订单实体可以通过遍历内部的订单项单价,计算出一个总价,如果总价高于某个设定最小值,该订单才会生效。这种实体通常我们把它上升为聚合根,聚合根有如下的含义
1、聚合根对聚合的整体状态负责,对聚合的状态的修改会导致聚合迁移到一个状态或者触发一个异常
2、为了保证这个职责,仓储(Repository)只能访问聚合根。非聚合根的实体类的状态变更,必须通过聚合根触发。(译者:仓储针对聚合根和他的属性对象是整存整取,比如获取一辆车的轮子,我们Repository只能有获取车辆的方法,轮子是通过车辆的属性访问,不能直接访问轮子对象)
3、聚合形成一个自然的一致性边界,对其他聚合的应用需要通过by-id的方式实现。
2.1.5 仓储
从概念上讲,仓库模拟聚合根的集合,并允许访问聚合的子集或者单个属性。他们通常由某种持久化机制支撑,但是不应该把他们暴露给客户端。仓储可以引用实体,但是反过来不行。
2.1.6 领域服务
领域服务是实现那种无法唯一的分配到实体或者值对象方法的服务,同时他还承担了实体值对象和仓储之间的功能逻辑(译者:领域服务通常承担领域对象间的方法,领域服务是无状态的,比如两个账号之间的转账)。虽然有领域服务,但是业务逻辑尽量的多在实体类和值对象中实现。因为他们可以更容易的被测试。
2.2 在Spring 应用中的领域驱动设计
领域的概念和DDD概念的映射方法极大的影响了这些概念到代码的映射。想要有效的编写基于Spring的Java应用,必须区分newables和injectables这两类对象。
正如名字所暗示的那样,这个区别就在开发者在获取特定领域元素的方式中。一个newable的对象是可以通过操作符实例化,当然这种实例化必须限制在尽可能少的地方,如果能使用工厂模式会比较好,实体和值对象是newable的。而injectable往往是一个spring的组件,这意味着spring将控制其生命周期,创建实例并销毁它们。这将允许Spring容器为服务的实例提供事务和安全的基础设施。客户端通过依赖注入的方式获取实例,Repository和Service都是需要注入的。
这两组内的区别定义在依赖方向从injectables到newables。 一般来说
- 值对象Value Object - JPA @embeddable 注解 +对应的equals(…)和 hashCode()方法 (Lombok的@value可以有效的帮助生成)
- 实体类Entity - JPA @entity 注解 +对应的equals(…)和 hashCode()方法
- 仓储Repository - Spring的组件,通常用Spring的Repository的接口。
- 领域服务Domain Service - 通常是Spring的组件,使用@component注解。如果这个服务不需要事务或者安全的支撑,也可以直接new。
不是Spring中所有的对象都可以映射到DDD的分类中。剩下的一般分为两组:
应用配置Application configuration - 对象或者配置模块
技术适配器Technical adapter - 用于将Spring的逻辑层通过一种远程访问技术发布给客户端。在web应用中,远程技术指的是HTTP、HTML和JavaScript。在Spring MVC中,Controller对象将负责翻译远程的对象(比如request、request parameter、payload、response等) 为本地的领域概念,并调用Service、实体类、值对象等等。
3 深入阅读
检查Guestbook和Videoshop确保您了解了哪些类实现哪些DDD的概念
区别您了解这些概念(实体类的主键、值对象的不变性、服务的依赖注入)的不同特性是如何实现的。
Appendix
Appendix A: Bibliography
-
[ddd] - Eric Evans — Domain-Driven Design: Tackling Complexity in the Heart of Software- Addison Wesley. 2003.
-
[ddd-quickly] - Abel Avram, Floyd Marinescu — Domain-Driven Design Quickly. InfoQ. 2006.
-
[power-of-value-objects] - Dan Bergh Johnsson — Power Use of Value Objects in DDD. InfoQ. 2009.
版权说明
本文采用 CC BY 3.0 CN协议 进行许可。 可自由转载、引用,但需署名作者且注明文章出处。如转载至微信公众号,请在文末添加作者公众号二维码。
关注我
微信公众号
比特币UTXO和去中心化系统的设计
title: 比特币UTXO和去中心化系统的设计
date: 2018-01-26 18:00:00
比特币UTXO和去中心化系统的设计
2018-01-26 曹祖鹏
起因
刚进2018年,区块链突然大火,程序员们可能莫名其妙,不就是一个分布式系统么,怎么突然就要改变互联网了?趁着这个东风,我们了解一些区块链基础知识。看看是否可以改变世界。
UTXO是什么
UTXO是Unspent Transaction Output(未消费交易输出)简写。这绝对是比特币的非常特殊的地方,理解UTXO也就理解了比特币去中心化的含义。
说起UTXO必须先要介绍交易模型。以我们平时对交易的理解,我给张三转账了一笔100块钱,那就是我的账上的钱少了100,张三账上的钱多了100。我们再把问题稍微复杂一些,我和张三合起来买一个李四的一个商品390块钱。我的账户支付100,张三账户支付300,李四的帐户获得390,支付宝账户获得了10块钱的转账手续费。那么对这比交易的记录应该是这样的:

这种记账方式常用在财务记账上。不过作为一个去中心化的系统,是没有一个中心化银行管理你的开户、销户、余额的。没有余额,怎么判断你的账上有100块钱?

此时用户C必须将前面几次交易的比特币输出作为下一个关联交易的输入,具体见下图的no 321笔交易,用户C将前面获得的两次输出,作为输入放在了交易中,然后给自己输出1个比特币的找零(如果不给自己输出找零,那么这个差额就被矿工当成小费了,切记切记)。比特币的程序会判定,如果两个UTXO加在一起不够支付,则交易不成功。

比特币UTXO使用有点像古代的银锭
- 五两的银锭付给别人二两,需要通过夹剪将一整块银锭剪成两块,二两的给别人,三两的留给自己。对比:比特币在输出中重新创建一个新的UTXO作为给自己的找零
- 要付给别人五两,手上有几块碎银子单都不足五两,则需要将碎银子一起付给对方。对比:比特币在输入中同时引用多个输出UTXO。
这样的做法很繁琐,所以银两在古代并不是一个很普遍的支付方式(别被武侠片给骗了,大部分还是用铜钱)。
比特币采用UTXO并不能很直观的去理解,但是为什么要用呢?
使用UTXO的动机
那么我们站在系统设计的角度猜测一下为什么中本聪会考虑使用UTXO。
- 比特币是没有开户的过程的,一个本地计算生成公私钥就能构成一个合法的帐户,甚至有些用户为了一些“靓号”帐户,通过暴力运算生成天量的再也不会使用的帐户。去中心化系统无法跟踪每个账户的生成和销毁,这样的系统里面的帐户数量远大于未消费的输出数量,所以以UTXO来替代跟踪帐户交易的方式,消耗的系统资源会比较少 ;
- 比特币有个比较好的特性是匿名性,很多人每次交易就换一对公私钥,交易输出的给自己的找零往往输出到一个另外的帐户下去,UTXO迎合了这种需求。而使用帐户就没那么灵活了。
- 如果我使用余额系统,那么在生成一笔交易的时候,我首先要考虑的就是“幂等”问题,因为发出去的交易是给某个帐户加减钱,如果交易因为网络等原因重新发送,变成两笔交易重复扣钱,我就要哭了,这是在区块链里面著名的“重放攻击”。所以交易必须设计一个唯一的标识id让服务器知道这是同一笔交易。但是在去中心化系统中没有一个超级服务器统一分配交易ID,只能本地生成,而且跟踪这些交易ID的状态,也是一个很大的负担,因为我需要将区块链从创世块到现在所有的交易都遍历一遍,才能确定是是否是重复交易。如果用UTXO就可以避免这个问题,UTXO相比交易数少了不止一个数量级,而且UTXO只有两个状态—未消费、被消费,比特币只能有一个操作— 将为消费的UTXO变为已消费状态。不管我发送多少次交易,都会得到一个结果。
- 在中本聪倡导每个cpu都是一票的去中心化社区,让每个节点都有能力去做计算是需要特别重视的,否则单个节点的计算能力要求过高,整个系统将向着“中心化”趋势滑下去。
在比特币的实现中,是把所有的UTXO保存在一个单独的UTXOSet缓存中,截止2017年9月,这个缓存大概2.7Gb,与之对应,整个区块链的交易数据达到140Gb,UTXO缓存像是一个只保存了最终一个状态的git,整体的消耗负担小了很多很多。
但是中本聪没想到,很多人现在把交易输出的脚本玩出花来了,导致很多UTXO创建出来就是不为消费用的,永远不会被消费掉,节点的负担越来越重。这才有了后续的BIP改进以及以太坊的账户模型。那又是一个很长的故事了...
DDD中充血模型的贴身职责如何理解
如何体现贴身职责,这里有个例子
敏捷开发中,有个功能是将一个BackLog Item提交到某个Sprint中,我们要用代码体现出来这个行为
public class BacklogItem extends Entity {
private String sprintId; //标识backlog item属于哪个sprint
private BacklogItemStatusType status; //标识当前backlog状态,是已经加入sprint,还是在待制品中,还是完成了
...
public void setSprintId(String sprintId) {
this.sprintId = sprintId
}
public void setStatus(BacklogItemStatusType status) {
this.status = status
}
}按照平常的习惯,客户端发起将backlog加入sprint,会把spintId填入,然后修改backlog item的状态为committed。
backlogitem.setSprintId(sprintId)
backlogitem.setStatus(BacklogItemStatusType.COMMITTED)但是这样的写法完全是把内部逻辑暴露到客户端了,后续接手的人也搞不清楚commit到sprint的动作,是需要填写一个id,再改一个状态的
如果该backlog已经被提交到一个sprint了,还需要检查是否已经被提交过?
万一客户端忘了改状态怎么办?
万一后面还要增加改一个backlog的type属性怎么办?
最好的办法是把commit操作丢给backlog自己实现
public class BacklogItem extends Entity {
private String sprintId; //标识backlog item属于哪个sprint
private BacklogItemStatusType status; //标识当前backlog状态,是已经加入sprint,还是在待制品中,还是完成了
public void commitTo(Sprint aSprint) {
if (!this.isScheduledForRelease()) {
throw new IllegalStateException(“Must be scheduled for release to commit to sprint.”);
}
if (this.isCommittedToSprint()) {
if (!aSprint.getSprintId().equals(this.sprintId)) {
this.uncommitFromSprint();
}
}
this.elevateStatusWith(BacklogItemStatus.COMMITED);
this.setSprintId(aSprint.getSprintId());
//下面该发布Event了,代码略
}
}这样的话客户端的代码是
backlogitem.commitTo(sprint);这个代码就完全体现了领域行为,将backlog提交到sprint中
版权说明
本文采用 CC BY 3.0 CN协议 进行许可。 可自由转载、引用,但需署名作者且注明文章出处。如转载至微信公众号,请在文末添加作者公众号二维码。
关注我
微信公众号
Python、Go、Java-从一个方法的归属问题引出的思考
Python、Go、Java-从一个方法的归属问题引出的思考
今天在讨论原有API系统重构的时候引出来一个问题,Java中有个ItemForm对象,是用于展示商品信息,和界面传递消息交互的。这个Form需要有个方法,要通过对应实体的类变量把Elasticsearch存储它的url地址拼接出来。

public class ItemForm {
private String itemId;
private String itemName;
private String tenantId;
public String toEsUrl() {
StringBuilder s = new StringBuilder();
s.append("tenant:").append(tenantId).append(",")
.append("itemId:").append(itemId);
return s.toString();
}
}大家在讨论,这个方法是放到Form对象本身作为类方法存在,还是放到一个单独的工具类中。
这个问题挺有趣的,首先他和toString()方法不一样,只是给某个特定系统(搜索引擎)使用;但是又要访问Form对象内部的状态。如果能从多种语言设计习惯来分析分析,对我们理解各类语言设计哲学很有帮助
Java
从纯洁面向对象的设计来看,和对象属性相关的方法当然要归到类方法中,但是因为只是为了ElasticSearch使用,为了职责划分明确,单独设计一个ESAdapter的对象,为了方便属性的重用,这个ESAdapter需要继承原来的Form对象,再加上这个拼接ES地址的方法,为了这种设计理念,我们还经常使用对象拷贝的工具在多个对象之间赋值。
public class ESAdapter extends ItemForm {
public String toEsUrl() {
StringBuilder s = new StringBuilder();
s.append("tenant:").append(getTenantId()).append(",")
.append("itemId:").append(getItemId());
return s.toString();
}
}这样设计导致复杂的继承关系,实在让人有点头大。Java的设计哲学就是这样的,值对象就是值对象,领域对象就是领域对象,严丝合缝,不能混用。
现在都推荐不用继承用组合了, OK
public class ESAdapter {
private ItemForm itemForm;
public ESAdapter(ItemForm form) {
this.itemForm = form;
}
public String toEsUrl() {
StringBuilder s = new StringBuilder();
s.append("tenant:").append(itemForm.getTenantId()).append(",")
.append("itemId:").append(itemForm.getItemId());
return s.toString();
}
}虽然减少了继承,但是凭空多出来的一个ESAdapter对象,让人如鲠在喉。Java程序往往一大堆细小对象,逻辑在里面分散的开来。想设计一个内聚的逻辑不容易。
Python
同样的功能,如果放到Python Django之类的涨血模型(Rich Domain Object)设计的框架中,那自然毫无疑问的使用类方法中(非static方法),管你那么多设计原则呢,我都可以直接把Domain对象抛到页面去显示,Quick and Dirty用起来再说。
class ItemForm(forms.Form):
item_id = forms.CharField(label=u'商品编码')
item_name = forms.CharField(label=u'商品名称')
tenant_id = forms.CharField(lable=u'租户编码')
def to_esurl(self):
return "itemId:{0},tenantId:{1}".format(self.item_id, self.tenant_id)c语言
如果是C语言,因为C语言里面没有对象,只有struct结构体,我们习惯单独设计一个工具方法Func做这个事情,数据和行为分离在不同的代码段中,后续接手的人,恐怕想不起来这个功能还有一个单独的方法处理,肯定自己又搞套新的方法去了,重复代码就这样产生。
当然有很多高手已经尝试过在C语言中实现继承和封装这样的OO机制,具体的我不熟悉,不敢乱说。
Go
最近的Go语言,他的设计哲学正好可以适配这样的场景的的,值对象就是struct,没有任何逻辑。所有的逻辑通过单独定义的func+receiver的方式附加到struct上面,同样实现了面向对象的设计,但是有免去了对象继承的麻烦。据说早期的面向对象设计就是将调用一个类方法称为**“向一个对象发送消息” **
type ItemForm struct {
ItemId string
ItemName string
TenantId string
}
func (form ItemForm) ToESUrl() string {
return fmt.Sprintf("tenant:%s,itemId:%s", form.TenantId, form.ItemId)
}所以说,Go是专门为工程设计的语言,这句话是没错的,从设计哲学上就是实用派,但又坚持自己的原则。这点上看把Go称为Better C是挺有道理的。
思路和语言实现细节
虽然有人说,语言不重要,解决问题的**最重要。但是对脚本语言/编译型语言、面向对象/函数式这些编程范式不相同的语言来说,差别就大了,甚至同样是面向对象,不同语言的细节也是不一样的。每一门语言是有他的特殊的设计理念的,如果不能掌握这理念,写出来代码没法发挥这门语言的优势,**很重要,但是掌握语言的设计细节也很重要。
这篇文章是我在初学Go的时候的一点小小思考,我喜欢通过这样对比异同点的方式将新知识纳入我自己的知识体系中,个人觉得这种学习方法很有效,推荐给大家。不过示例代码都是随手写的,没有编译,不保证通过 :)。
版权说明
本文采用 CC BY 3.0 CN协议 进行许可。 可自由转载、引用,但需署名作者且注明文章出处。如转载至微信公众号,请在文末添加作者公众号二维码。
关注我
微信公众号
CQRS初探
title: CQRS初探
date: 2017-08-26
CQRS初探
背景
我们惯常开发的概念中,一直以CRUD为主(Create、Retrieve、Update、Delete),默认我们读操作(Retrieve)的对象模型和写操作(Create、Update、Delete)是同一个对象、同一张表,这对简单的业务逻辑来说,比较合适,但是在复杂的业务逻辑下,CRUD就有点力不从心了。

Command(写)操作
我们对写操作的定义是会改变对象状态的一种操作,状态指的是广义上的,包含了对象所有属性的修改的一种操作,增删改属于写操作。
在我熟悉的电商业务中,写逻辑是比较复杂的,在写之前需要校验很多状态,拿常见的订单创建场景来说,我们需要检查库存的情况,校验用户价格是否正确,校验匹配的优惠活动,校验用户的积分使用情况.....
在退货的场景下面,需要检查双方达成的退款协议,检验货品是否已经处于发货路上,上述任意条件不达成,就不能退货,然后还要有退还积分、优惠劵等一系列的写操作。
从上面的例子可以看出,完成Command主要有三种情况
- 校验,一系列业务逻辑校验
- 变更,变更领域对象中的属性
- 派生,通知相关领域的变更
业务越重,写操作的逻辑复杂性越高,我们的领域驱动设计中的充血模型为什么要强调将数据和操作统一在一个对象中,就是为了解决写操作的复杂逻辑不要散布到其他地方,在领域模型中完成 — 高内聚。
Query(读)操作
读操作就是查询数据返回,相比写操作,比较简单一些。我们往往认为相对Command操作,Query没啥业务逻辑,就是把数据展示出来好了,这里并不涉及领域模型的事情。
不过我们的产品经理常常在数据读取显示上给程序员出难题,
比如
- 在采购商品列表界面要显示这个商品上一次的采购价格和平均采购价格;
- 要求显示用户的同时显示最新的一条朋友圈状态等等
- 要求客户经理查询订单时,只能看到自己名下客户的订单,不能看到全部的订单
这里面就涉及到了一系列表的join查询,甚至sum、avg等等函数运算,但是请注意这里的查询已经涉及到了业务逻辑,查询程序需要了解领域对象之间的关联原则,用户的角色包含关系,有权限判断的要求。
这给我们的领域模型带来了不小的困惑,我们的领域模型都是按照写模型设计的,一旦查询涉及业务逻辑甚至多个领域的规则,就会力不从心了。比如只能查询自己名下客户的订单,按照DDD设计订单模型本来没有包含权限的部分,这是两个不同的限界上下文,实现方式只能先查询订单,再到权限模块接口上一个个去验证是否可以显示给界面,这样做不仅效率极低,而且没法实现分页的功能。
于是我们需要尝试新的架构风格,将查询和命令分开,使用不同的模型,也就是CQRS模式。
CQRS(Command Query Responsibility Seperation)
这里我们使用了API网关也就是BFF来区分读、写操作,发送到不同的模块执行,其中对Command Model的修改将通过event和消息队列交给Updater模块去更新查询视图

有个需要注意的地方是,我们的查询指令就不通过任何的服务提供查询接口了,由API网关直接去查询对应的视图数据库。这样做有两个原因
1、 我认为数据库提供的SQL或者ElasticSearch提供的查询DSL已经足够强大了,我们不需要自己再封装一层查询接口,浪费工作量而且用起来很别扭。
2、我希望Query是不含有业务逻辑的,直接查询视图就能得到产品想要的数据,不要在查询中进行逻辑运算。我们应该还是尽量的把逻辑隐藏到领域对象内部。
那么上面说的产品经理的变态查询需求如何解决呢?这里Martin Flower给出了一个思路 Eager Read Derivation
这是一种空间换时间的思路,也就是说,在View Updater的时候,就将内在逻辑连接起来,形成一个物化视图
比如要在采购列表中显示商品的上次采购价格和平均采购价格,这个不在查询的时候完成,而是在商品查询视图中冗余两个价格项(上次价格、平均价格)。 每次采购完成的时候,就去更新这两个项,由消息队列和Updater异步完成,利用了异步消息驱动机制,查询变得简化,对原有领域逻辑没有破坏,看起来是个很完美的解决方案。
要解决权限问题,就在视图上增加权限的标识,甚至为每个不同的角色生成不同的视图。这样困扰我们在权限查询时候的分页问题也可以很好的解决了。
CQRS的缺陷
CQRS在解决复杂业务逻辑的时候很有帮助,但是也有很多问题
-
因为两个模型使用不同的数据库,所以消耗增加了一倍以上
-
需要通过消息机制进行数据同步,消息机制的可靠性和及时性对CQRS举足轻重,我们在使用了CQRS后,甚至在新增跳转页面的时候增加了200ms的延时,为的就是避免数据不一致的情况发生。在开发过程中的负担较重,简单的功能变得复杂了。
所以在简单逻辑的时候,使用CQRS就是多此一举,还是CRUD最方便。
附录:查询命令分离原则 Command-query separation principle
CQS是针对方法的经典oo设计原则,该原则指出,任何方法都可能是如下情况之一;
1- 执行动作(更新,调整。。。。)的命令方法,这种方法通常具有改变对象状态等副作用。并且是void的,没有返回值。
2向调用者返回数据的查询,这种方法没有副作用,不会永久性地改变任何对象的状态。
关键是,一个方法不应该同时属于以上2个类型。
写操作按照严格定义是没有返回值(void),我常常见到那种写操作返回最新对象的方法
User changeName(User user)这样实际上是将写操作和读操作合在一块了,违反了CQS原则。
版权说明
本文采用 CC BY 3.0 CN协议 进行许可。 可自由转载、引用,但需署名作者且注明文章出处。如转载至微信公众号,请在文末添加作者公众号二维码。
关注我
微信公众号
Java未来也许不再是电商的首选开发语言
title: Java未来也许不再是电商的首选开发语言
date: 2017-12-06 18:00:00
2017-12-06 曹祖鹏
好久没更新博客了,很多人催促我更新,最近因为公司的事情一直是忙(其实是懒病发作),特别是被推广了一波后,再不更对不起读者了。
上周我参加了在南京举办的IAS的架构师峰会,和很多同行沟通,特别是和当当网的首席架构师张亮做了一个结对的分享 —《技术架构演变全景图—从单体式到云原生》,分享的形式很特殊,采用了一问一答的方式,我作为提问题的,不断“刁难”张亮,张亮一一解答问题,一番“交锋”后,听众有反馈效果不错,我自己也收获了不少。
最重要的一点体会是Java未来也许不再是一个电商首选语言了。当然在互联网其他领域,Java早就不是首选了,开发繁琐,包体积大、运行时开销大等等,都不适合互联网创业。但是对于互联网电商来说,前面有阿里、京东全线转型Java技术栈的案例,后面像饿了么这样的新兴电商也慢慢的从Python转向Java,示范作用很强。以至于我们这样的电商软件提供商,把整体是Java架构当做卖点之一。
我认为Java的卖点主要是JVM运行时强大、工具链成熟,以Spring为首的庞大的生态提供了完善的开发体验。特别是在满足电商的双十一高并发、大容量场景下,有dubbo、Spring Cloud这样的服务治理框架,不管是Go、Python、Php,都没有类似的框架可以对比,其他开发语言想追上这样的生态环境不是一件简单的事情, 可以说对于目前电商公司来看,Java技术栈是不二的选择。但是正像三体中的降维打击概念,打败你的人不是你同维度的,而是来自其他的领域。Service Mesh(服务网格),这个来自底层云平台基础设施正在向上入侵原有的开发框架的领域。
说起来Service Mesh不是新概念了,在之前就有运维维护nginx的配置,做服务之间的调用代理,但是这个是很原始的状态。目前随着k8s在运维层面一统江山,基于k8s的linkerd、envoy、Istio一系列Service Mesh解决方案发展非常迅速,Willian Morgan(linkerd的CEO)给出Service Mesh定义:
— 服务网格是一个基础设施层,用于处理服务间通讯。云原生应用有着复杂的服务拓扑,服务网格负责在这些拓扑中实现请求的可靠传递。在实践中,服务网格同程实现为一组轻量级的网络代理,它们于应用程序部署在一起,而对应用程序透明
对应用程序透明这几个字要画重点,说明以后再也不需要在开发层面关注负载均衡、路由、熔断、限流、服务注册发现、分布式跟踪等等一系列的服务治理内容了,这些都由我们的运行底层设施来完成了。类似网络七层OSI架构定义,我们做上层开发的不需要了解TCP、HTTP具体的协议,而聚焦到我关注的业务逻辑本身,这种情况很快会在微服务领域再次发生。下图预测了在2018年,哪些技术栈可能由于Service Mesh的发展而被抛弃掉。

在这种情况下Java以引为傲的框架都无用武之地了,虽然Java的开发体验依然不错,但是未来的标准不一定是开发者引导的,运维可能会制定所谓的Cloud Native标准,要求满足标准的,才能上平台进行运行和调度。多语言在Service Mesh中一视同仁,我们很可能用Go来开发网络服务,用Php来做Web,用Node来做网关API,用Java做业务逻辑,服务之间的通讯就交给Service Mesh来统一处理,而整个庞大的微服务体系交由k8s这样的平台来调度和编排。
好一幅蓝图,也许我们还觉得可能有点遥远--Istio才0.3版本,等它到了1.0再说,不过互联网技术迭代极快,而且Istio系出名门,发展势头不可小视,大有席卷天下的感觉。

这样的变革对新兴的语言Go之类的是极大的利好,但是对Java并不是好事。特别对于我这样2003年接触Java的老程序员说,对Java是有特殊感情的,难道我们真的要见证一个时代的结束了么?
我觉得Java要发展下去,还是有机会的:
- 在开发体验、工程化方面要继续强化。Java8+Spring boot+Lombok使用体验经常让我感觉不到在写繁琐的Java。
- 微服务的领域驱动设计特别重要,而在领域驱动设计实现中Java是主流,目前还没有太好的替代语言。
- 强化目前的JVM上的语言生态,包括Kotlin、Scala等,也许会有下一个杀手应用出现,抓住类似AI这样的风口机会。
未来怎么样,我们拭目以待。
版权说明
本文采用 CC BY 3.0 CN协议 进行许可。 可自由转载、引用,但需署名作者且注明文章出处。如转载至微信公众号,请在文末添加作者公众号二维码。
关注我
微信公众号
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.