Compared with original hadoop-1.2.0, this version can
-
Output detailed logs. The detailed logs contain:
- concrete processing steps
- Volume of input and output data after user code finishes
- Current dataflow counters when user code starts
For example,
Mapper 22:57:44 INFO [map() starts] 23:00:13 INFO [map() ends] <Input: records = 6128490, bytes = 362377587> <Output: records = 6128490, bytes = 503316368> 23:00:37 INFO [Start combine() in spill 1][partition 1] <currentInputRecords = 0, currentOutputRecords = 0> 23:00:51 INFO [Start combine() in spill 1][partition 2] <currentInputRecords = 8582, currentOutputRecords = 68> Reducer 17:33:57 INFO [Shuffling] Segment (id = 9, bytes = 104523972) into RAM from mapper-9 17:33:57 INFO [Shuffling] Segment (id = 7, bytes = 104585760) into RAM from mapper-7 17:34:00 INFO [combine() in shuffle starts] SegmentIds(5, 4, 9, 0, 1) <currentCombineInputRecords = 0, currentCombineOutputRecords = 0> 17:34:05 INFO [combine() in shuffle ends] <Input: records = 10917050, bytes = 731980261> <Output: records = 513020, bytes = 34387617> 17:34:46 INFO [reduce() starts] <Input: Bytes(in-memory segments) = 0, Bytes(on-disk segments) = 1254859834> -
Display real-time memory usage in task's JVM.
Users only need to specify a configuration 'child.monitor.jstat.seconds = 2'
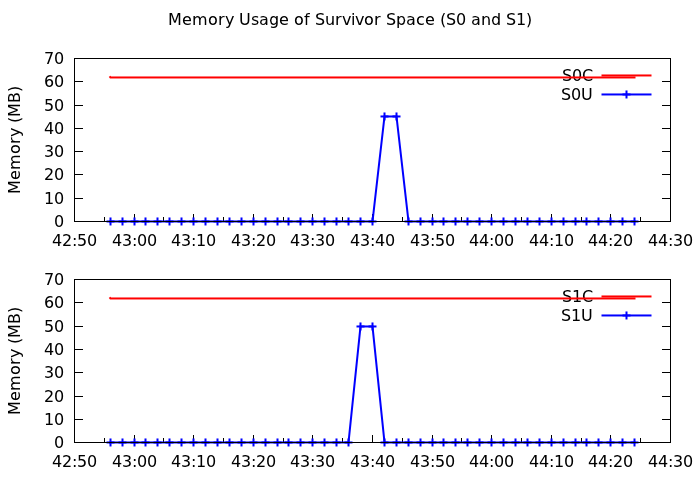
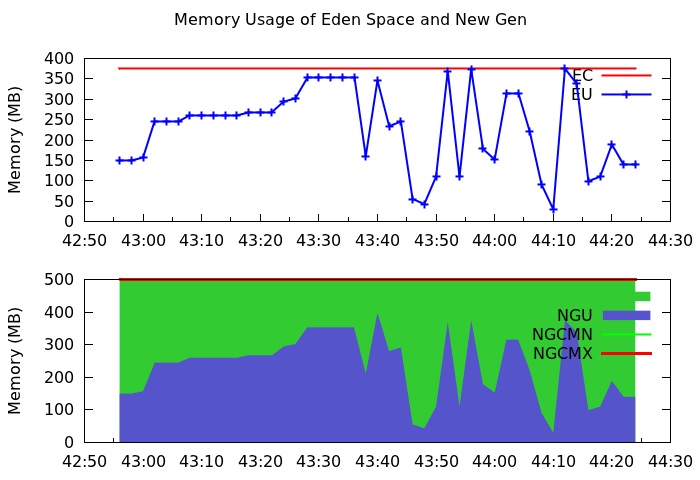
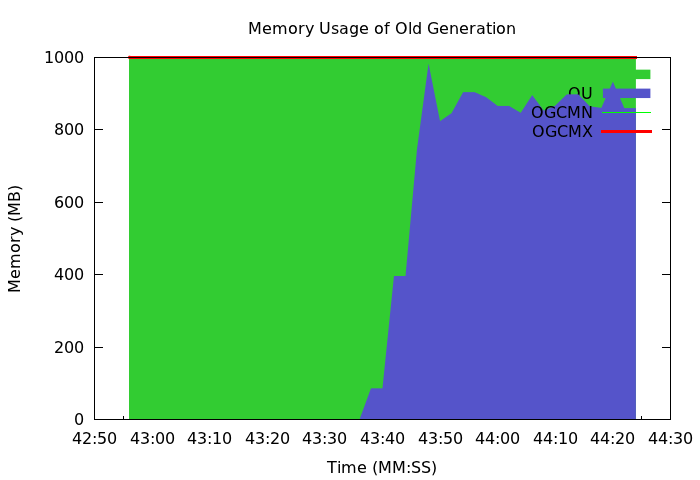
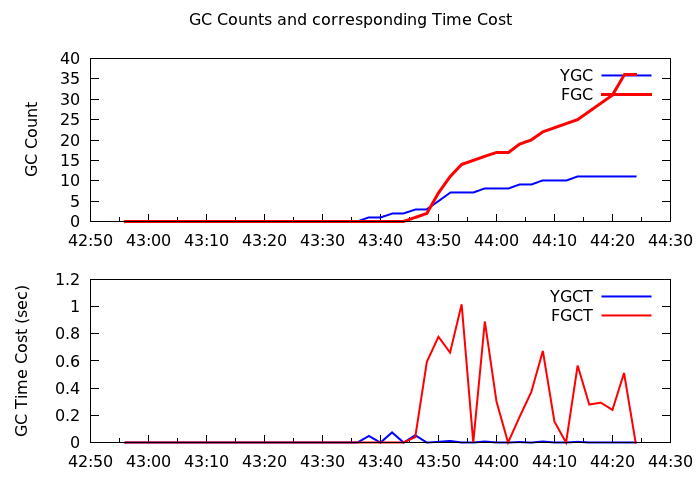
For example, the real-time memory usage of a reducer is as follows.
Eden space
 New generation
New generation
 Old generation
Old generation
 GC counts
GC counts
-
Generate 'heap dump@record(i)' if one or some following configurations are specified.
Heap dump configurations.
Configuration Description The modified code heapdump.path where the dump will be generated (by default, /tmp) heapdump.map.file.bytes.read external bytes read Task.java heapdump.map.input.records map input records Mapper.java & MapRunner.java heapdump.map.combine.input.records combine input records in mapper ReduceContext.java & Task.java heapdump.reduce.combine.input.records combine input records in reducer ReduceContext.java & Task.java heapdump.reduce.input.group reduce input groups Reducer.java & ReduceTask.java heapdump.reduce.input.records reduce input records ReduceTask.java & ReduceContext.java heapdump.reduce.file.bytes.read external bytes read Task.java task.reporter.update.ms 3000 Task.java For example, if users specify
conf.set("heapdump.map.input.records", "9425[5]")Mapper will dump the heap when it encounter the i-th specified record (1885th, 3769th, 5653rd, 7537th, 9425th)
2014-04-27 21:03:38,797 INFO org.apache.hadoop.mapreduce.Mapper: [map() begins] 2014-04-27 21:03:54,368 INFO org.apache.hadoop.mapred.Utils: [HeapDump] generate /tmp/mapInRecords-1885-out-0-pid-26746.hprof 2014-04-27 21:04:10,118 INFO org.apache.hadoop.mapred.Utils: [HeapDump] generate /tmp/mapInRecords-3769-out-0-pid-26746.hprof 2014-04-27 21:04:33,437 INFO org.apache.hadoop.mapred.Utils: [HeapDump] generate /tmp/mapInRecords-5653-out-0-pid-26746.hprof 2014-04-27 21:04:57,338 INFO org.apache.hadoop.mapred.Utils: [HeapDump] generate /tmp/mapInRecords-7537-out-0-pid-26746.hprof 2014-04-27 21:05:08,634 INFO org.apache.hadoop.mapred.Utils: [HeapDump] generate /tmp/mapInRecords-9425-out-0-pid-26746.hprof


