一直以来,工程师都有一个观念:“性能为王”,以前是,现在是,以后更是。
根据《Data Never Sleeps 5.0》调查研究,世界上每天产生2.5万亿字节的数据,并且保持着每年25%的速度递增。在我们如今的社会生活中,信息产生的来源越来越多,信息交换的速度越来越快,推动了对更快软件(SW)和更快硬件(HW)的需求。简而言之,数据增长不仅对计算能力提出了更高的需求,而且对存储和网络系统也提出了更高需求。
在PC时代,开发人员通常直接在操作系统之上编程,有时候还不可避免的需要直接参与控制硬件。随着世界进入云时代,软件堆栈变得更深更复杂。通过对底层硬件的高度抽象,大多数开发人员往往无需对于实际硬件的把控,直接基于分布式、虚拟化、微服务以及更高层次的开发环境进行开发,效率极大提高的同时,却也带来了消极的一面,导致现代应用程序对于硬件的亲和性逐渐降低。
还有,幸亏于摩尔定律的有效性,软件程序员这几十年来一直“轻松愉快”。过去,一些软件供应商更愿意等待新一代硬件来加快应用程序的速度,而不花费人力资源来改进代码。但是,花无百日红,如今摩尔定律正在逐渐失效,通过查看图1,我们可以看到单线程性能增长正在放缓,想要再通过简单的ScalUp的方式提高性能,收益越来越小。

因此当硬件性能提升不再提供显著的收益时,我们必须开始更多地关注代码运行的速度,分析软硬件运行方式,提高协同能力,并且对软件进行优化。
“Software today is massively inefficient; it’s become prime time again for software programmers to get really good at optimization.” - Marc Andreessen, the US entrepreneur and investor (a16z Podcast, 2020)
作者经验:在英特尔工作期间,我经常听到这样的故事:当英特尔客户应用程序运行性能不达标时,他们会立即下意识地开始指责英特尔的CPU性能不足。但是,当英特尔派遣我们的性能优化专家与他们合作并帮助他们改进应用程序时,客户的程序性能立刻提高5到10倍
笔者经验:笔者曾经也处理过类似的案例,在华为鲲鹏处理器上运行的一个加密货币的业务,仅仅因为优化了一下软件的算法指令,性能直接提升20倍以上。由此可见,很多时候,并非处理器性能不达标,而是软硬协同能力不足,并没有充分发挥处理器的能力
优化应用性能是一件具有挑战性的工作,通常需要大量的努力,但希望这本书能够给你提供一定的帮助!
为什么需要性能优化
现代CPU核心数量逐年递增。从2019年底开始,市场上已经有了高达100个核心的处理器(目前估计可以到200个核心以上了),这是非常令人兴奋的,但这并不意味着我们不必再关心性能了,甚至我们更需要关注性能,因为更多的核心有可能导致应用性能反而出现下降的可能。
一般来说,通用多线程应用程序的性能并不总是随我们分配给任务的CPU核心数量线性扩展。了解发生这种情况的原因以及修复这种情况的可能方法对于产品性能的未来增长至关重要。如果不对应用进行适当的性能分析和优化,这将会导致大量的性能和资金浪费,并扼杀项目产品。
根据paper《There’s plenty of room at the Top: What will drive computer performance after Moore’s law?》研究表明,至少在短期内,大多数应用程序的性能提升将来自软件栈的优化。但是遗憾的是,应用程序默认条件下很难无法获得最佳性能。该paper还提供了一个很好的示例,说明了在源代码级别上进行性能优化潜力极大。如下表1显示了各种优化方案的性能提升的比例,该测试程序是两个4096×4096矩阵进行相乘,通过应用多种优化手段,最终结果是程序运行速度相较原始程序快了60,000倍以上。提供这个例子的原因并不是为了挑Python或Java(它们是伟大的语言)毛病,而是为了打破软件默认具有“足够好”性能的信念。
一般情况下,以下因素会对应用软件的性能造成比较大的影响:
-
软件限制,有人可能会问,“为什么处理器不能解决所有的问题?”, 现代CPU的处理速度如此之快,甚至每一代都有一定的提升,但是CPU仍然执行的是人们告诉它的程序,换句话说,程序员给定的程序是什么样的,它就按照什么样执行。比如程序员给定的是冒泡排序,它不会自动的选择更快的快速排序方案。它还是会盲目地执行它被告知要做的任何事情,这就导致了如果程序员给定的一个傻白甜的程序块,CPU也只能傻乎乎的执行,从而影响了整体应用的性能。有兴趣的同学可以看看这个新闻:打开游戏要运行 19.8 亿次 if 语句?黑客嘲讽 RockStar 游戏代码太烂了
-
编译器限制,诚然,如今的编译器越来越智能,可以主动进行非常多的优化,因此很多开发人员也意识不到编译器做的事情,但是尽管如此,在一些涉及到更复杂的决策时,还是无法完美的达到最佳情况。这是由于编译器第一性要求是保证程序的正确性,在一些场景下,由于无法确定程序员的真实意图,编译器也无法激进的进行优化,不得不倾向于更保守的编译选择,因此在某些场景下,编译器也提供了一些特定的指令或选项,让开发人员指定优化方案,已达到更佳的性能。
-
经验算法限制,开发人员有时候往往痴迷于算法的复杂性,默认觉得O(N log N)的算法一定比O( )性能要强,比如考虑InsertionSort以及QuickSort,大负债工作量下,QuickSort是相对于InsertionSort具有一定的优势,但是假如工作负载较小时,InsertionSort性能反而优于QuickSort。在没有测试目标工作负载的情况下盲目相信 Big O 表示法,可能会导致开发人员走上错误的道路。所以,即使是最知名的算法,对于所有的可能的输入,性能不一定是实践中最高的。
)性能要强,比如考虑InsertionSort以及QuickSort,大负债工作量下,QuickSort是相对于InsertionSort具有一定的优势,但是假如工作负载较小时,InsertionSort性能反而优于QuickSort。在没有测试目标工作负载的情况下盲目相信 Big O 表示法,可能会导致开发人员走上错误的道路。所以,即使是最知名的算法,对于所有的可能的输入,性能不一定是实践中最高的。
笔者经验: 在性能优化中,往往这一块经常犯经验性的错误,比如在一个数据库性能优化中,我们往往觉得更快的存储设备性能越佳,但是在特定场景中,NVME盘的性能甚至比不过一个简单的SSD盘的性能
上述限制为我们的优化软件的性能留下了充足的空间。 从广义上讲,软件堆栈包括许多层,例如,固件、BIOS、操作系统、
库和应用程序的源代码。 但由于大多数较低的 SW 层不是在我们的直接控制下,因此我们优化的主要重点将放在应用可控的源代码上。 另一个重要的点是我们将经常接触的软件是编译器,通过编译器进行优化,获得性能的提升是非常有可能的,在本书中可以找到许多这样的例子。
作者经验: 即使不是编译器相关的专家也可以通过编译器对应用程序进行优化,并且根据我的经验,至少 90% 的优化可以在源代码级别完成,无需深入研究编译器源代码。 虽然,了解编译器的工作原理以及知道如何让它做你想做的事情在与性能相关的工作中总是有好处的。
笔者经验: 在实际优化的项目中,往往分析的第一顺序是应用程序源码本身,其次是编译器,库,操作系统以及更加底层的驱动,硬件优化等等,同时依次优化的难度递增,优化带来的收益相对而言也越小(这个不完全一定,笔者也遇到过硬件的一个配置直接极大的提升了整体软件的性能,比如打开硬件的预取等)。
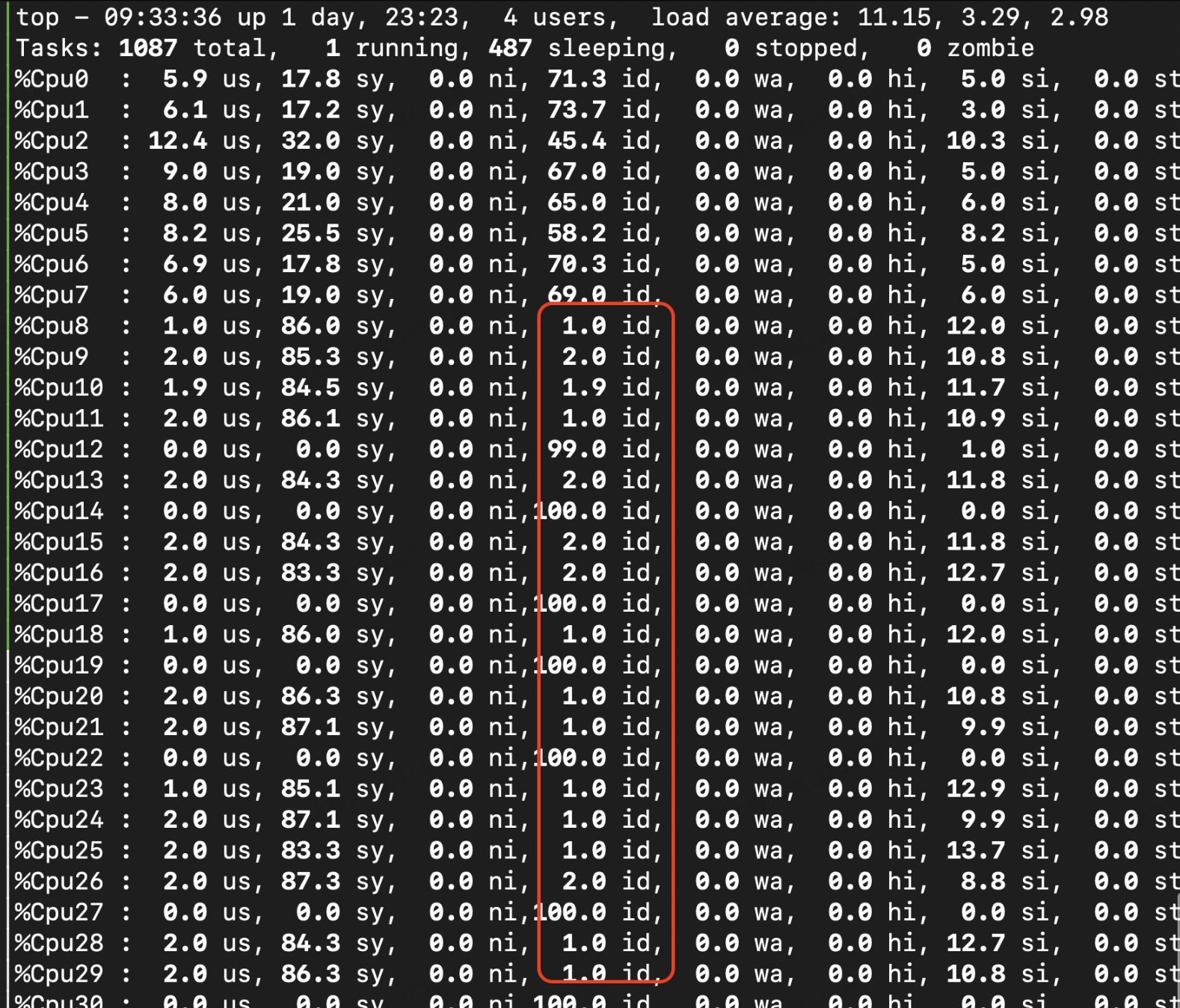
此外,由于现代处理器多核多线程的原因,应用程序分布在多核之间并行运行,也会给应用程序带来通信相关的消耗以及资源竞争相关的问题。
值得一提的是,性能提升不仅来自优化软件。根据 paper《There’s plenty of room at the Top: What will drive computer performance after Moore’s law?》研究表明,算法(特别是对于机器学习等新问题领域)和效率更高的流水线硬件设计也可以带来较大的性能提升。 算法显然在应用程序的性能中起着重要作用,但我们不会在本书中讨论这个主题。 我们也不会讨论新的硬件设计架构,因为大多数时候,软件开发人员更多的是面向当前已有的处理器进行软件开发。但是,了解现代 CPU架构设计对于优化应用程序非常重要。
- 笔者经验: 在很多CPU公司都需要有懂处理器设计的软件性能优化人员,并且多多益善,笔者曾经在华为为鲲鹏处理器招聘这方面的人才,相对硬件设计来说,既懂软件又懂硬件的人才实在太少了, 大家可以看看如下Intel的招聘要求:
在后摩尔时代,代码优化能力的重要性越来越高,特别是需要根据运行它的硬件进行软硬协同优化,这一点对于工程师的要求也越来越高,也是区分码农与码神的关键因素。
本书中的方法主要是榨干程序的最后一点性能提升空间。通常这类方法的优化提升的空间不大,一般情况下不超过 10%,例如上表1中的第6/7行。但是,不要低估 10% 提升的重要性,它特别适用于在云环境中运行的大型分布式应用程序。根据google研究分析显示,2018年,谷歌在电力和冷却基础设施上的消耗几乎与其购买的一系列服务器的花费相当,而提升软件的性能就能够直接改善能源消耗,带来相应的收益显而易见。
“At such scale, understanding performance characteristics becomes critical – even small improvements in performance or utilization can translate into immense cost savings.” Kanev et al., 2015
谁需要性能优化
在高性能计算(HPC)、云服务、高频交易(HFT)、游戏开发和其它高速领域,性能至关重要,例如,谷歌报告说,搜索速度每慢2%,每个用户的搜索量就减少2%。又比如雅虎,页面加载速度每加快400毫秒,流量就增加了5-9%。在大部分游戏中,小的改进就可以产生重大的影响。这些例子证明,服务性能得越差,使用它的人就越少。
除了上述领域之外,如今的通用服务应用也需要它。例如,集成到Microsoft Visual Studio IDE中的Visual C++ IntelliSense11功能就有非常苛刻的性能要求。要使IntelliSense自动完成工作,他们必须在以毫秒为单位的时间内完成对整个源代码解析。如果需要几秒钟的时间来构建,估计没有人会使用这个功能。这样的功能必须及时响应用户的请求,并在用户键入新代码时提供有效的反应。只有在设计软件时就考虑了完整的性能需求,并贯彻到架构中,才能实现类似的功能。
- 笔者经验: 没有性能的架构连玩具都不如 (某大型IC设计公司军规)*
相反的是,如果一个工具具有优良的性能,那么就会在非常多的领域或项目里面用到,比如像Unreal13和Unity14这样的游戏引擎被广泛用于建筑、3d可视化、电影制作和其他领域。它们的性能非常好,所以它们是需要进行2d和3d渲染、物理引擎、碰撞检测、声音、动画等的应用程序的不二选择。
“Fast tools don’t just allow users to accomplish tasks faster; they allow users to accomplish entirely new types of tasks, in entirely new ways.” - Nelson Elhage wrote in article15on his blog (2020).
不言而喻,人们本能的讨厌性能缓慢的软件。性能优良的特性可能成为产品的绝佳竞争优势,甚至是唯一因素!
性能优化是非常重要的和有价值的工作,但它可能非常耗时耗力。事实上,性能优化也是一个永无止境的游戏,总会发现有一些东西需要优化。但是不可避免的是,这也是一个边际效益递减的事情,项目或应用获得的收益在一定程度上也会逐渐降低。在这种情况下,进一步的优化将以非常高的工程成本来进行,这也是性能优化工作需要tradeoff的地方,需要在成本与优化收益之间取得一定的平衡。
在开始性能优化工作之前,我们需要明确这样做的必要性以及目标,避免盲目的进行性能优化,如果仅仅为了优化而进行的优化并不能为您的产品增加价值。正确的开始性能优化工作是需要树立一个明确的性能目标,并且说明为什么要这样做,这样做的收益是什么,明确衡量性能目标的指标数据,同学们可以在这两个paper 《Systems Performance: Enterprise and the Cloud》, 《Pro .NET Benchmarking. Apress》中阅读关于更多关于设定性能目标相关的知识。
此外,为了练习和掌握性能分析和优化的技能而拿起这本书的同学,欢迎你继续阅读。
什么是性能分析
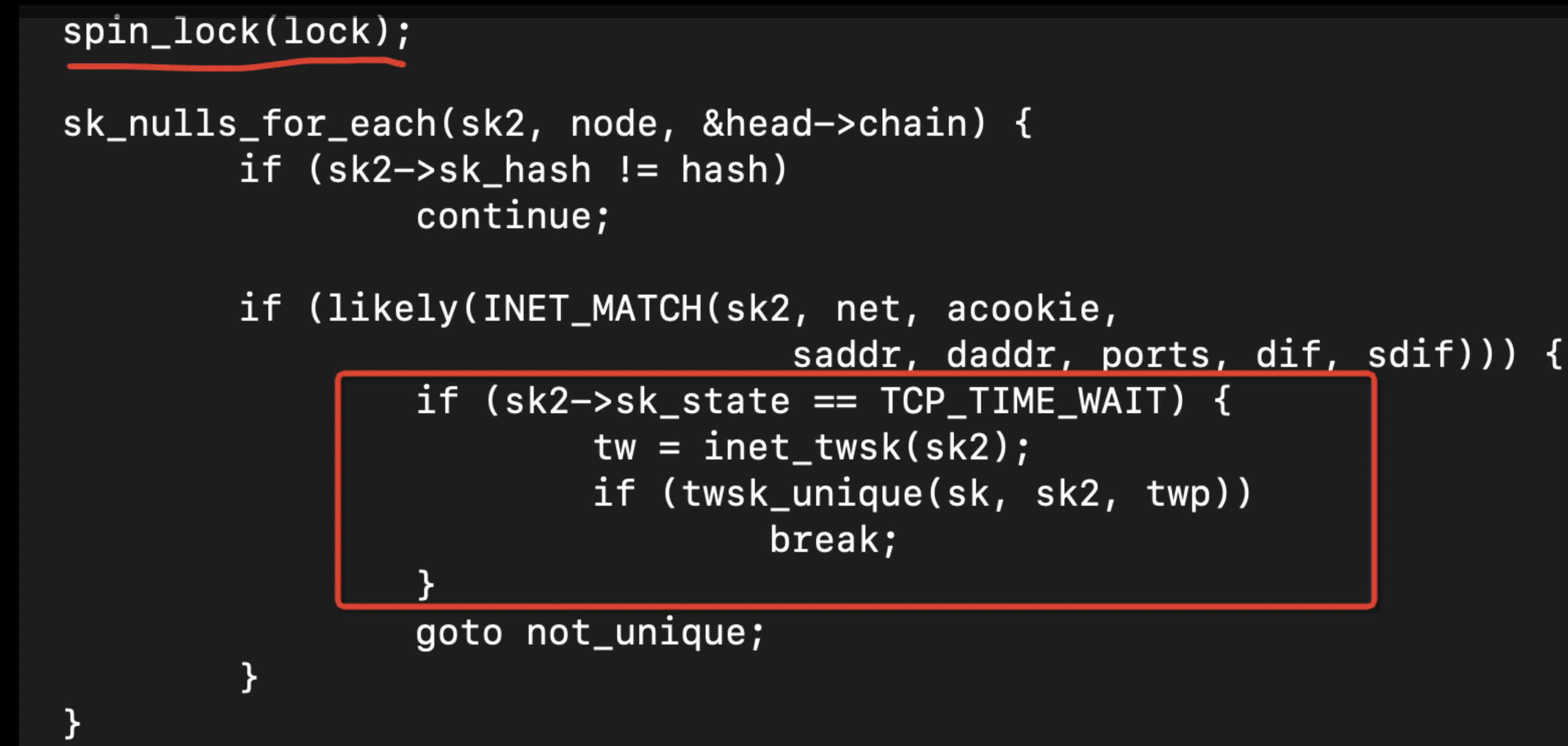
是否有过这样的场景,你跟同事在争论某段代码的性能高低? 但是却缺乏非常有利的手段或者证据证明哪段代码确实性能更优。由于现在处理器的相关特性组件非常多,即使对代码小的调整也会引发显著的性能变化。这也是为什么本书中的第一个建议是: 测试为王 。 talk is cheap , show me the measure result.
- 作者经验: 我看到很多人在尝试优化应用程序时都依赖直觉。但是通常,这样的优化对于应用很难起到正向的作用
没有经验的开发人员经常会根据直觉对源代码进行优化,希望能提高程序的性能。比如假定前一个i值没有使用的情况下,在代码中使用++i替换i++。但是通常情况下,此更改不会对生成的代码产生任何影响,因为只要有优化能力的编译器都会认识到i的前一个值没有被使用,因此也不会产生冗余的副本,从而影响性能。
许多很早流传在各个优化手册中的代码优化tips在很早以前是有效的,但是目前的编译器已经完全能够自动识别并且优化。此外,有些人倾向于过度使用传统的优化技巧,并奉为圭臬。比如是使用基于XOR的交换语句(XOR_swap_algorithm),但是实际上,简单的std::swap就可以产生更快的代码。这种优化可能不会提高应用程序的性能。依靠仔细的性能分析以及测试验证找到正确的修复位置,而不是靠直接和猜测,这样的优化才是有效的。
本书中的性能分析方式是基于收集有关程序如何执行的某些信息以及如何反应在CPU的特定事件统计上来引导分析的,并且最终在程序源代码中进行的任何更改都可以通过分析和解释收集的数据来体现。
定位出性能瓶颈的确切原因只是工程师工作的一半,就像门诊看病确定病因。而下半场确实要给它开具苦口良药。有时候,只是需要仅仅更改程序源代码中的一行代码就可以产生大幅的性能提升, 而性能分析优化就是为了找到这个关键的位置!
总结:
- 性能分析不是主观臆测,而是通过数据的收集分析以及合理的测试得到的有效的结论
- 有效的测试能够极大的帮助性能分析,而错误的测试却能导致分析南辕北辙
这本书主要讨论什么
这本书的编写是为了帮助开发人员更好地了解他们的应用程序的性能,学习如何发现低效率的代码块并消除它们。解决日常疑惑:为什么我的存档程序的性能比传统的慢两倍?为什么我的函数更改会导致性能下降两倍?客户抱怨我的应用程序太慢,我不知道从何说起?我是否优化了程序,使其充分发挥潜力?如何处理所有缓存未命中和分支错误预测?,希望在这本书的结尾,你能得到这些问题的答案。
以下是这本书的大纲:
- 第二章讨论了如何进行正确的进行性能评估并分析其结果。其中介绍了性能测试和评估结果的最佳实践
- 第三章和第四章提供了CPU微体系架构的基本知识和性能分析中的术语;如果您已经知道这一点,请随时跳过
- 第五章探讨了几种最流行的性能分析方法及工具。它解释了分析性能分析工具的工作原理以及这些工具可以收集哪些数据
- 第六章介绍了有关现代CPU为增强性能分析能力而提供的功能,详细介绍了这些特性是如何工作的,以及它们可以解决什么样的问题
- 第七-九章包含典型性能问题的示例。可与自顶向下的微体系结构分析(见第6.1节)一起使用,结合阅读,这是本书最重要的概念之一
- 第十章包含了前三章中涵盖的性能问题类别以外的一些优化主题,并且仍然比较重要,建议阅读
- 第十一章讨论分析了多线程优化技术。它概述了优化多线程应用程序性能所面临的一些重要的问题,以及可用于分析多线程应用程序性能的工具。这个主题本身相当复杂,所以本章只关注硬件相关的问题,比如“false share”。
本书中提供的示例主要基于如下开源软件:
- linux操作系统
- 基于LLVM的Clang编译器(用于C和C++语言)
- Linux perf(作为分析工具)
选择使用这些软件或者工具的原因不仅是因为提到的技术的流行,而且是因为它们的源代码是开放的,这可以让我们能够更好地了解其工作机制。这对于学习本书中提出的概念特别有用。我们有时还会将展示在性能优化这个领域中“大公司”的专有工具,例如英特尔®VTune TM Profiler。
这本书不包括什么
系统性能取决于不同的组件:CPU、操作系统、内存、I/O设备等。应用程序可以从调整系统的各种组件中受益。一般来说,工程师应该分析整个系统的性能。然而,影响系统性能的最大因素是它的CPU核心。这就是为什么本书主要侧重于从CPU的角度进行性能分析,当然偶尔也会涉及操作系统和内存子系统。
本书的描述的硬件架构并不会超出单个CPU结构,因此我们将不讨论分布式、NUMA和异构系统的优化技术。本书不讨论使用OpenCL和openMP等解决方案将计算卸载到加速器(GPU、FPGA等)相关的方案。
- 笔者赘述: 但是实际上在真实世界的优化,这一部分优化的难度以及复杂性远远超过单颗cpu领域内的问题,后续笔者会根据实际情况在附录中补充一些关于numa,IO协同以及分布式的一些优化的案例*
本书围绕Intel x86 CPU架构展开的,暂不提供基于AMD、ARM或RISC-V芯片的具体调优方案。尽管如此,在其他章节中讨论的许多方法也能很好地适用于这些处理器。此外,Linux是本书的首选操作系统,但对于本书中的大多数示例,这并不重要,因为同样的技术在Windows和Mac操作系统上依然可以很好的使用。
本书中的所有代码片段都是用C、C++或x86汇编语言编写的,然而在很大程度上,本书中的技术或者想法依然可以应用于其他编程语言,如Rust、Go甚至Fortran。但是值得一提的是,本书对于JVM环境上的java类应用的优化,并不涉及。
- 笔者赘述: 关于java类优化其实也非常重要,比如如今的微服务以及很多的中间件 kafka/zookeeper等都是基于java进行开发的,笔者在后续也会在章节中增加一些java相关的优化技术*
最后,作者假设读者可以拥有完全控制他们开发的软件的权限,包括他们选择使用的库和编译器。因此,本书并不包含关于如何优化商业程序,例如,优化SQL数据库查询等。(事实上这些技术依然可以使用在商业软件的技术分析上,只不过无法基于源代码级别进行优化)
章节概要
- CPU在单线程性能上并没有像过去几年那样提升的那么多。这就是为什么性能优化比过去40年变得更加重要的原因。计算行业现在的变化比90年代以来的任何时候都要快得多。
- 根据paper 《There’s plenty of room at the Top: What will drive computer performance after Moore’s law?》表明,将来性能提升的关键因素就是进行软件性能优化。性能优化的重要性不应该被低估。对于大型分布式应用程序,每一个小的性能提升都会带来巨大的成本节约。
- 通常情况下,软件没有所谓的最佳性能。总会存在某些限制,阻止应用程序达到其全部性能潜力,包括硬件或者软件环境。CPU无法神奇地加速奇葩的慢算法,编译器也不能为每个程序生成最佳代码,并且由于硬件的特殊性,即使针对某个问题的最著名的算法也并不总是性能最高的,所有这些都为优化应用程序的性能留下了空间。
- 对于某些类型的应用程序,高性能不仅仅表现的是一项优良特性,在某些方面,它使用户能够以一种新的方式解决新的问题。
- 软件优化应以强大的业务需求为后盾。开发人员应设定可量化的目标和指标,这些目标和指标必须可以用于衡量优化进展情况。
- 预测某段代码的性能几乎是不可能的,因为影响性能的因素太多了。在进行软件优化时,开发人员不应依赖直觉,而应使用仔细的进行性能分析,大胆揣测,小心求证。