continuum
Lambda Architecture is not enough! Continuum is more fundamental
What is Lambda Architecture?
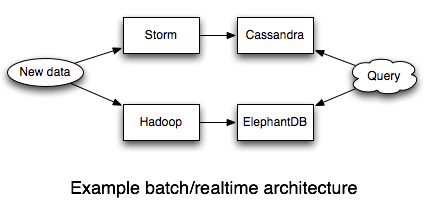
Long long ago, creator of Apache Storm, Nathan Marz, talked about Lambda Architecture in his article [How to beat the CAP theorem] (http://nathanmarz.com/blog/how-to-beat-the-cap-theorem.html). His idea was to combine a 'batch compute' with a 'stream/realtime compute' to combine the goodness of the two - provide better reliability and consistency respectively.
But??
The blog presents Lambda Arch as a solution to balance availability vs consistency trade-offs. Practically, data systems need to make freshness vs correctness trade-offs (because storage and compute capacities are finite). Freshness is defined as "how realtime are the results of the computation". Correctness is defined as "how accurate and complete the results of a computation are". The freshness and correctness are fundamental properties of data systems whereas 'availability' and 'consistency' are properties of the solution's architecture.
Now, data can arrive unordered and late. A recent, but a small window of data cannot portray the 'complete' reality. As such, a realtime system's accuracy is limited by the availability of 'complete data' within its smaller operating window. Using a similar reason, a batch system is more accurate (and less fresh) because it operates on a larger window of data.

Lambda Architecture makes a discreet choices for freshness and correctness; infact it picks up 2 points to balance the freshness and correctness. There are problems with above choice:
- Most often the stream and batch are 2 different stacks and hence 2 definitions of the same processing. This leads to maintenance and operational overheads.
- The 2 pipelines have to be tuned/configured to ensure that each event is processed at-least once as and when it is received by the respective pipeline. Example, assume that we need to join 2 streams of events e1 and e2. Suppose e1 stream stops for arbitrary amount of time. In such a case we cannot process events from stream e2 and have to wait for batch systems to pick up the processing. If e1 stream has not recovered by that time, then we would miss processing of events from e1 stream entirely. (This is depicted in above figure by regions D1 and D2; if D1 < D2, then any event that arrives after D1 duration, might not be processed by stream pipeline)
- Re-runs are a big issue as one need to manually figure out which pipeline is required to be re-run based on the duration and the age of the data.
- The entire system needs to be reconfigured if we need to change W1, W2 parameters for stream and batch pipelines respectively. More generically, since the system is designed to be pivoted on 2 distinct points, it cannot tolerate presence of more pipelines working at different parameters (W and S) - which might be the case if we have resource crunch. We can engineer the Query system to merge results from more than 2 pipelines; but we still need to manage an entirely new data pipeline as and when they are introduced.
Introducing...
Continuum. Instead of solving the 'freshness' and 'correctness' problem by 2 different systems, we take it as a tradeoff technology needs to make all the time. Continuum is designed to be a technology solution rather than an architecture reference. The design of continuum should solve for following problems:
Problem with Message Queues/Relays
Most queues have solve the problems of scale, but have largely ignored the solutions for failure recovery. Message pile up in case of consumer failure is one of the classic problems. It is essential that we recover the newest changes first when recovering from failure and either drop older changes or process the older changes in background. As such time become one of the dimension to track in message queues (along with message offsets).
Heisenberg Data
In Lambda architecture, data can be present in the storage layer of either or both pipelines - but one cannot be sure. Data storage tech used in stream and batch pipelines are very different and there is no metadata to maintain relationship between them. Effectively, we want a tenured data storage where stream data storage (eg: Kafka) contains fresh data and batch data storage (eg: HDFS) contains old data. This calls for fine tuning stream and batch data store retentions such that data is available on at least one storage in case of failures.
Processing Abstraction
Keeping 2 or more versions of the same processing logic in multiple languages is tough. Not a critical problem, though, as there solutions like summingbird.
Stateful processing - Joins
Lambda architecture doesn't talk about joins. The solution to join problem can look different in Stream and Batch pipelines. For starters, we need to find solution that provides visibility into incomplete joins and ability to join incrementally as the data arrive.