ibm / aihwkit Goto Github PK
View Code? Open in Web Editor NEWIBM Analog Hardware Acceleration Kit
Home Page: https://aihwkit.readthedocs.io
License: Apache License 2.0
IBM Analog Hardware Acceleration Kit
Home Page: https://aihwkit.readthedocs.io
License: Apache License 2.0
As we have a number of examples since 0.2.0, it would be nice to have a summary in the examples/ for being able to navigate through them a bit more easily (and pave the way for additional examples as well).
As part of the next round of features, we should enable hardware-aware training (albeit in a basic form that can be expanded in later iterations).
Provide an interface for applying during forward pass:
During some tests using the CUDA-compiled version of the library, the following error is displayed:
TypeError: forward_indexed(): incompatible function arguments. The following argument types are supported:
It seems the forward_indexed for the rpu_base_tiles_cuda.cpp binding needs to be revised in order to match its CPU counterpart.
Currently, the build system has not been checked and adjusted in order to support Windows-based systems. While in theory cmake should help us in the process, it has not been tested and it is likely lacking some Windows-specific adjustments. We should revise the build system in order to allow easy compilation on Windows machines as well, as well as updating the documentation accordingly if needed.
Travis Windows support can help in automating and verifying the changes.
As part of the next round of features, we should add the ability to perform inference using PCM statistical models.
Currently, it is not possible to use the BUILD_TEST_ON flag during compilation, as it results in linking errors. The culprit seems to be that the googletest library is compiled using a different libstdc++ ABI (old vs new) than pytorch on most of the distributions and systems.
Compiling with -DBUILD_TEST=ON.
As a workaround, compiling manually googletest in order to use the right ABI should reenable compilation of the tests.
There is a test that seems to be failing occasionally:
tests/test_inference_tiles.py:160: in test_post_forward_modifier_types
self.assertNotAlmostEqualTensor(x_output, x_output_post)
tests/helpers/testcases.py:36: in assertNotAlmostEqualTensor
assert_raises(AssertionError, self.assertTensorAlmostEqual, tensor_a, tensor_b)
E AssertionError: AssertionError not raised by assertTensorAlmostEqual
Check the test and update it as needed - it seems an issue with the test rather than with the code.
I tried to run the py files under tests/ and examples/ but it will return an error: ImportError: cannot import name 'AnalogSGD' from 'aihwkit.optim'
python tests/test_utils.py
Follow the installation guide and python version is 3.7.3
Currently there are some aspects of using decay_weights in AnalogSGD that are a bit different from the standard SGD. It would be great if we could refine the remaining aspects and revise the current documentation in order to highlight the differences and potential pitfalls to users, and streamline a bit its usage.
This is meant to be a small, "refinement" issue - not meaning to include bigger changes to the optimizer.
While using the family of RPUConfig devices and adjust their parameters manually offers a great deal of flexibility, for some use cases being able to start with a set of pre-defined interesting configurations would be useful. This would help the users being familiar with the different options, serve as a basis for exploring the toolkit, and allow using "well-known" configurations off the shelf for a number of purposes.
Add a number of curated analog device presets to the package, representing devices in existing literature or other specific configurations that seem relevant or interesting.
Add the possibility to drift the weights during training with a power-law (similar to decay weights).
Hello, from my last comment about the jupyter notebook in a few previous issues ago I said I would post about the Jupyter notebook error with aihwkit. Please see the attached output below.
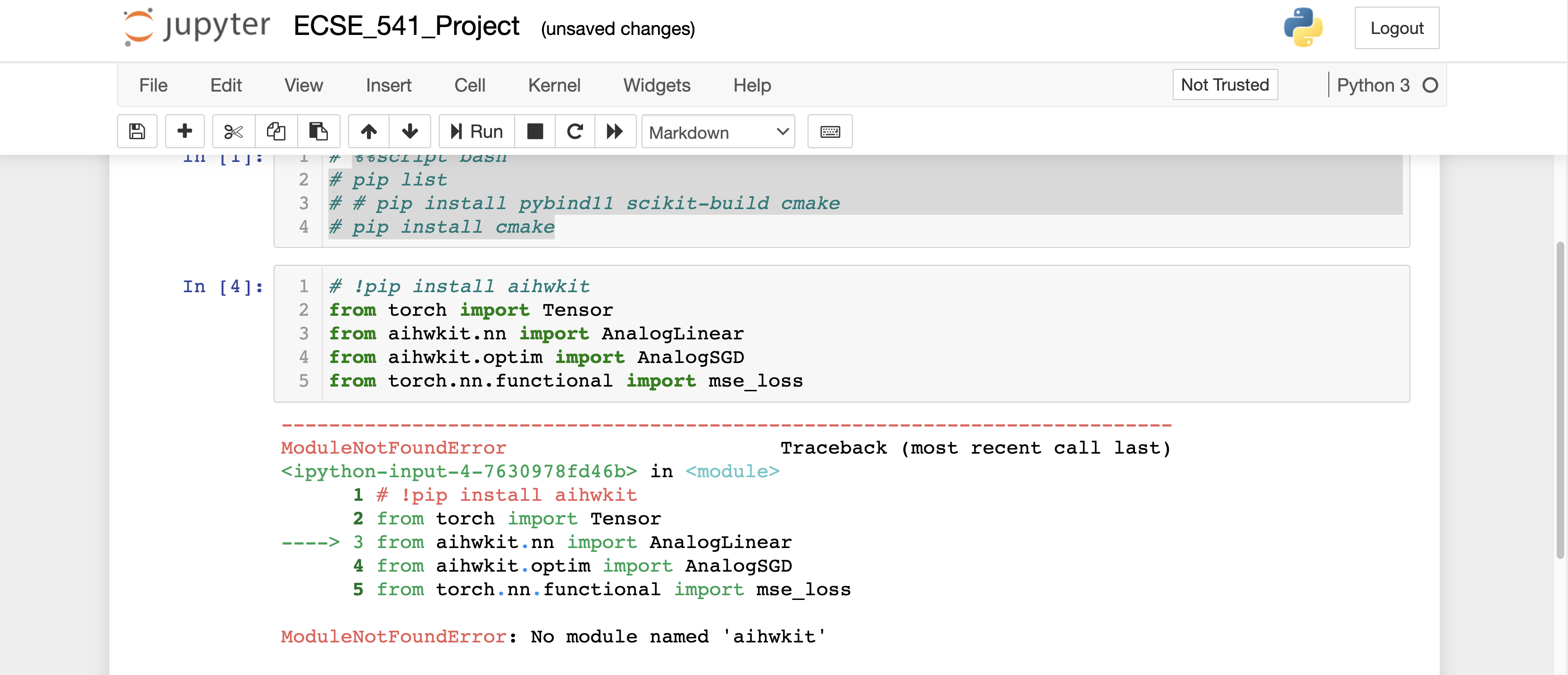
So basically, I've followed the advanced and development guides in starting the virtual environment for building aihwkit from scratch and that works (with conda managing the dependencies). But now I would like to run the example codes in Jupyter Notebook but now I'm getting an aihwkit import error (Symbol not found).
python3 -m venv aihwkit_env
cd aihwkit_env/
source bin/activate
cd aihwkit
git clone https://github.com/IBM/aihwkit.git
*** So after I've done the above steps and installed the dependencies with conda (conda activated also) and build the aihwkit with setup.py I started a Jupyter Notebook and put that notebook inside the "aihwkit" folder (where the python venv and conda environment are). Then after trying to run the example code I get the import error.
Note: I have both conda activated and python venv activated within this folder (aihwkit_env)
Is there a path I'd have to set for the Jupyter Notebook?
The expected behavior is that Is should be able to run the code with no problem as I have already built the project from scratch with setup.py
As part of improving the documentation and describing the usage of the different features, it would be ideal to include more examples in the examples/ directory.
Under recents version of osx/xcode, a couple of warnings are emitted during compilation. While they seem harmless, it would be nice to tackle them in an effort to keep the output readable and not hide other (future) warnings.
Revise the output of compilation in osx, and update the C++ sources to fix the warnings.
As part of widening the scope of the library, it would be great to include more analog optimizers that can be used in different context and use cases. One of the likely first candidates would be one of the Adam variations due its popularity.
In a similar way to AnalogSGD, create a new subclass of the chosen torch optimizer, customizing its behavior when passing through the analog layers.
regroup_param_groups() seems like a good candidate for a generic function to be shared by all analog optimizers through a base class or similar means.In a relatively large number of cases, we have tests that perform the same check but vary in regards to the tile or device that they test. Currently, each test file handles the variation in a "similar but not quite identical" way, mostly relying on TestCase inheritance and mixins.
For maintainability, it seems we could extract the functionality they have in common and streamline it a bit, making it easier to add new tests and update existing ones. This will become specially relevant as the number of tiles/devices/layer types evolve, for example during #6 .
There are several approaches that can be combined:
get_tile variations into a factory-like methodWhile working on #115 , it seems the documentation for some functions in the bindings might have fallen out of sync since the latest updates. It would be nice to double-check that the documentation is accurate, as for the bindings we cannot take advantage of pylint and the tooling.
Check that the docstrings blocks match the current function signatures (latest updates have been #102
and #115), and update them accordingly.
It would be nice to add a small visualization module that provides convenient plotting functions, which would help users exploring the different RPU configurations and other core entities.
Add plotting functions as part of a module, which would also serve as starting an "utilities" sub-package aimed at providing convenient tools and helpers on top of the core functionality.
As Python 3.9 has been released for some reasonable amount of time, we should ensure that the package is fully compatible with it and update the tooling (travis, etc) and other meta-information.
Test 3.9 compatibility and provide fixes as needed.
Line 29 in f6b140c
I got an error message "UnicodeDecodeError: 'cp949' codec can't decode byte 0xe2 in position 3855: illegal multibyte sequence." This case is solved by adding encoding="UTF-8" when opening file.
(i.e., open(version_path, encoding="UTF8"))
Same as issues occurred at line#37.
Currently, if a model makes use of analog layers as children layers, it seems serialization is not handled properly:
load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for Model:
Unexpected key(s) in state_dict: "analog_tile_state"
Attempt to load the state dict of a model that has analog children layers.
It seems the issue is related to the way the custom analog_tile_state is being used in the state dicts, causing it to be appended always to the top-level instead of respecting the prefix applied to the children layers.
Currently, the .to() method of analog layers is not fully functional. At the moment the recommended way of moving layers to GPU is via .cuda() directly. Ideally, we should support:
cpu.to() with both devicesThe .apply() and ._apply() methods used internally in torch for that purposes are likely to make the implementation tricky, as they are meant to recursively operate only on the layer Parameters and Buffers only. We should evaluate whether it is feasible to fully tackle it without resorting to turning the Tile into a Tensor-like structure (which is likely desirable, but longer term) - as a first stage, focusing on AnalogSequential, where we have more control over the recursion, can be an option.
While we have a manageable number of build dependencies and we list the required versions in the docs, for some of them we don't explicitly check during the cmake build, which can lead to obscure and not easy to debug problems during compilation.
By checking the versions at compile time we would be able to troubleshoot quicker, and overall provide a smoother experience when building. One particularly tricky case is pybind11, which is lagging behind a bit on some distributions and might go unnoticed until the final stages of the compilation.
Make use of cmake commands for defining the minimal versions, or other means that allow failing the build early if unsupported versions are detected.
During the initial stages of the toolkit, a numpy-based tile was created, as an intermediate step for using numpy as the preferred format for the structures that are used between the layers. As it has been a while since the tile is strictly needed and both rpucuda and the upper layers have been centered around torch tensors, it is a good time for finally removing the tile.
Remove the numpy tiles and its tests.
As part of widening the scope of the library, it would be great to include more analog layers that can be used in different context and use cases. One of the likely first candidates would be additional convolution layers, taking advantage of the fact that we currently already have the AnalogConv2d layer implemented and that they would share quite some functionality.
Using AnalogConv2d as a reference, implement other types of convolution layers. Note that torch actually uses a _ConvNd internal module as the basis for the convolution layers: it seems likely that the same approach would help us avoid some duplication and streamline the new layers.
As pytorch 1.7 was released yesterday, we should check the compatibility with the newer version.
At a glance:
As the functionality grows, it would be a good time to introduce a small number of custom Exceptions, in order to allow users finer-grained control over unexpected behavior and for us to have room to expand in a controlled way.
Introduce a aihwkit.exceptions module with a minimal number of useful base exceptions.
Currently we are modifying CMAKE_CXX_FLAGS directly for setting compilation flags:
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall -Wno-narrowing -Wno-strict-overflow")
set(CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} -O3 -ftree-vectorize")
It would be nice to use add_compile_options instead. It seems to support generator expressions that can be used for differentiating between release and debug, although the main blocker is that the flags end up being passed to the cuda compiler directly, which might result in an error (there seems to be a $<COMPILE_LANGUAGE:lang> that can be used in the generator expression)
Hi! I'm trying to modify the values of specific weights in nn.AnalogLinear layer.
I'm currently using MLP (784-256-128-10) and each layer is made up of nn.AnalogLinear
I know how to access each weight values and initialize, but what I want to do is not only to modify the values but to fix the values for the entire training process, without effecting the gradients.
Would there be any way of doing this using AnalogLinear?
(Sorry for not properly adding the label 'question', that I'm so new to this github system..!)
It seems that CUB is included along the CUDA Toolkit since version 11, which can cause issues during build (thanks @chaeunl for the valuable feedback and troubleshooting!):
$ python setup.py install -DUSE_CUDA=ON -DRPU_CUDA_ARCHITECTURES="80"
[ 14%] Built target cub
[ 50%] Built target RPU_CPU
[ 51%] Building CUDA object CMakeFiles/RPU_GPU.dir/src/rpucuda/cuda/bit_line_maker.cu.o
In file included from /usr/local/cuda-11.1/targets/x86_64-linux/include/thrust/system/cuda/detail/execution_policy.h:33:0,
from /usr/local/cuda-11.1/targets/x86_64-linux/include/thrust/iterator/detail/device_system_tag.h:23,
from /usr/local/cuda-11.1/targets/x86_64-linux/include/thrust/iterator/detail/iterator_facade_category.h:22,
from /usr/local/cuda-11.1/targets/x86_64-linux/include/thrust/iterator/iterator_facade.h:37,
from /.../aihwkit/_skbuild/linux-x86_64-3.8/cmake-build/cub-prefix/src/cub/cub/iterator/arg_index_input_iterator.cuh:48,
from /.../aihwkit/_skbuild/linux-x86_64-3.8/cmake-build/cub-prefix/src/cub/cub/device/device_reduce.cuh:41,
from /.../aihwkit/_skbuild/linux-x86_64-3.8/cmake-build/cub-prefix/src/cub/cub/cub.cuh:53,
from /.../aihwkit/src/rpucuda/cuda/bit_line_maker.cu:24:
/usr/local/cuda-11.1/targets/x86_64-linux/include/thrust/system/cuda/config.h:78:2: error: #error The version of CUB in your include path is not compatible with this release of Thrust. CUB is now included in the CUDA Toolkit, so you no longer need to use your own checkout of CUB. Define THRUST_IGNORE_CUB_VERSION_CHECK to ignore this.
#error The version of CUB in your include path is not compatible with this release of Thrust. CUB is now included in the CUDA Toolkit, so you no longer need to use your own checkout of CUB. Define THRUST_IGNORE_CUB_VERSION_CHECK to ignore this.
We should revise the using of CUB in the build system. Currently, we make an attempt to find it, and if not possible, we automatically download and include the package. This might just not be needed entirely for cuda 11 (as it might be included in the default cuda header paths), or the THRUST_IGNORE_CUB_VERSION_CHECK flag might allow for bypass the check and use the downloaded version (which might not be ideal, though).
Currently, the build system and documentation assume that the package will be installed in a pure-python environment. However, some of the steps could be simplified for conda users, taking advantage of some of the pre-packaged dependencies.
Revise the install instructions, and the cmake configuration.
The underlying C++ simulator has a number of has a number of resistive device types that have not yet been exposed in the Python layers, in particular:
Making them available would facilitate using the simulator and experimenting with its features.
Expose the remaining types of resistive devices, taking as basis the way ConstantStep has been exposed through the different layers.
Thank you for you guys to give detailed replies for any issues.
I am now composing a neural network which consists of AnalogLinear modules. But, when I am trying to specify the device, I have to specify each AnalogLinear module to run on cuda, using .cuda(). As you know, PyTorch modules are automatically run on cuda when users specify the network to run on cuda. But, with AnalogLayer or AnalogConv2d, without specifying each layer to use cuda, the error message occurs.
I am not sure that this improvement requires efforts. It would be convenient if each module automatically run on cuda by specifying it on the network level.
As the toolkit evolves, there are some cases where it would be good to have a system of emitting information of several levels, in order to help debugging and allow users to chose the granularity of displaying that information.
Start a convention for logging and making use of the logging module sparingly, identifying some cases where producing output would be useful.
Continuing the approach of adding new analog layers to the library that was recently tackled in #47 , it would be interesting to include an analog LSTM layer.
Follow the same approach used by the previous layer, by adding a new class that sticks to the interface of the existing pytorch digital counterpart, and making use of AnalogModuleBase for the setting up of the tile and rest of analog-specific tweaks.
This issue also implies revising if other parts of the library need to be adjusted in order to support LSTM.
Currently, we recommend installing pybind11 from the package manager (or compile it manually), mostly as the pip-versions did not include the .cmake files. It seems the latest release finally includes them in the pip-package, which would simplify quite a bit the instructions and setting up of pybind for the build.
Test the new version and update the cmake and documentation accordingly.
aihwkit/src/rpucuda/rpu_difference_device.cpp
Line 119 in 670a314
To make use of reference devices which correspond to the value "0" of weights, pulse updates should be controlled for each device. The behavior of reference devices is described at the paper, [1]. It would be convenient for users to have the following options:
In addition, it is recommended for every devices inherited from "aihwkit.simulator.configs.devices.PulsedDevice" base to have the reference device. So, I think that it would be better for you to modify the code at the level of device class, "rpu_pulsed.h" and "rpu_pulsed.cpp"
[1] Kim, Hyungjun, Malte Rasch, Tayfun Gokmen, Takashi Ando, Hiroyuki Miyazoe, Jae-Joon Kim, John Rozen, and Seyoung Kim. "Zero-shifting Technique for Deep Neural Network Training on Resistive Cross-point Arrays." arXiv preprint arXiv:1907.10228 (2019).
In the same way we provide pip wheels, it would be great to also provide conda packages for each release, for convenience to end users. This continues the work in #21 and might be able to help closing #58 (as in ironing out and testing further).
Currently depend on two packages that are not in the main anaconda channel (pytorch and scikit-build). We should find out if it is possible to contribute to conda-forge and follow its procedures, which is incidentally the channel where scikit-build is available (and it seems that there is also a pytorch recipe, although lagging behind the official channel quite a bit).
If depending on channels outside conda-forge is not an option, an alternative might be to register our own channel, although that might be a bit too far fetched. Another alternative would be including a base meta.yaml in this repository along with instructions on how to build the package manually.
Hello,
For several reasons, I am trying to update my CUDA toolkit and NVIDIA driver. As PyTorch only supports CUDA 11.0 version, I installed PyTorch 1.8.0 by wheel. But, during installation of aihwkit, I got an error message saying that:
-- The CUDA compiler identification is unknown
-- Check for working CUDA compiler: /usr/bin/nvcc
CMake Error in /home/chaeunl/aihwkit/_skbuild/linux-x86_64-3.8/cmake-build/CMakeFiles/CMakeTmp/CMakeLists.txt:
CUDA_ARCHITECTURES is empty for target "cmTC_6aef9".
A few months ago, I also tried with PyTorch 1.8.0 and it was successful. The differences are CUDA/cuDNN/NVIDIA driver version (previously, CUDA=11.1, cuDNN=8.0.4, NVIDIA driver=455.xx). Also, I tried with the same cmd: python setup.py install -DUSE_CUDA=ON -DRPU_CUDA_ARCHITECTURES="80"
I confirmed that cmake, pybind11, blas, and scikit-build satisfy the conditions described in installation page. Could you let me know how to fix it?
There are two issues on the weight initialization:
From [1], . For instance,
aihwkit.nn.AnalogLinear has 256 fan-ins and 128 fan-outs, then the range of weight should be -0.12 to 0.12. But, as you can see underneath, the range does not match (instead, half of the max/min value).

So, I think it would be better to modify the allowed range of weights or you can also support various type of initialization methods.
The underneath figure shows the response curve of a aihwkit.simulator.configs.devices.LinearStepDevice whose slope_up and slope_down are 0.0083.

As you might expect, if the number of neurons increases, then the allowed range of a device would be match the range of initial weights. Although it is rare, somebody will also report this issue in the future. I don't have concrete ideas to this issue, but it is a good alternative if people can modify the initial weights easily.
[1] Kaiming He, et al. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification, 2015.
As a follow-up to #90, it would be nice to revise test_post_forward_modifier_types in order to be able to run each test independently.
I am trying to change the learning rate of an analog tile using nn.AnalogLinear.analog_tile.set_learning_rate(). However, for the case of TransferCompound, I think there is no way to change the learning rate for each devices defined in TranferCompound. For instance, if I define a TransferCompound having two devices, A and C (supposing that each device is defined in different tiles), then there are no way to adjust learning rate of each tile of A or C, respectively.
dw_min of the device. I want to know that is there any specific reason to set the learning rate to be equal to dw_min?It would be great for us if a tile is defined with TransferCompound device, it has multiple learning rates for each device or the device is defined with multiple tiles.
In the docs, I think it is not clear which device is "transferred" or "transferring" Following the paper [1], there are two types of array: A for accumulation of gradients and C for weights of neural network. When defining devices by the parameters, unit_cell_devices, we have no idea about which index of the device corresponds to A and C. As I looked over the C++ source code, 0-th index of unit_cell_devices corresponds to A and 1-st index to C.
I hope you to describe the details at the usage of unit_cell_device.
[1] Tayfun Gokmen and Wilfried Hanesch, Algorithm for Training Neural Networks on Resistive Device Arrays, Frontiers in Neuroscience, 2020.
Hi again!
It feels like I question too much, but I'm now in my way of actively exploring this nice toolkit :3
I'm trying to buy a new pc with AMD EPYC 7002 CPU, but little worried that it might not compatible with aihwkit.
So before I buy, I just want to check if aihwkit works okay with AMD processor.
Would there be any issues if I use AMD CPU for aihwkit?
For the initial 0.1.0 release, the pre-packaged wheels are compiled without GPU support. This requires the users to explicitly compile the library enabling CUDA during the compilation, which can be a non-trivial process - while we have some documentation in place, distributing GPU-enabled wheels in upcoming releases would be more convenient.
Update the wheel build process in order to enable the USE_CUDA (-DUSE_CUDA=ON) flag.
Currently, aihwkit.simulator.rpu_base is not properly displayed in the API reference. This is due to not being able to compile the simulator in the readthedocs build environment, as it does not allow the same flexibility when installing external packages (and at the moment the bindings need to be compiled in order to produce its documentation correctly).
It would be great to have online documentation for that module as well, in the same way as the rest of the modules.
We might have some luck using .pyi stubs - even if they seem not fully supported yet in sphinx (sphinx-doc/sphinx#4824), there are pointers for other options such as https://github.com/readthedocs/sphinx-autoapi.
Traceback (most recent call last):
File "examples/1_simple_layer.py", line 25, in
from aihwkit.optim import AnalogSGD
ImportError: cannot import name 'AnalogSGD'
I tried both
python examples/1_simple_layer.py
python3 examples/1_simple_layer.py
/home/zzzzzz/venv/aihwkit_env/git/aihwkit
Segmentation fault (core dumped) during rebuilding a neural network model.
This is sample code:
def create_model(k):
model = AnalogSequential(AnalogLinear(784, k), nn.Sigmoid, AnalogLinear(k,10)).cuda()
return model
x = [100,200,300]
for i in x:
...
model = create_model(i)
...When I run the above code, after the first iteration, I got the message, "segmentation fault (core dumped)".
If I replace AnalogSequential with nn.Sequential and AnalogLinear with nn.Linear, it works. So, I think PyTorch and cuda are not the cause of this issue. In addition, if I run without cuda(), it also works.
The analog convolution layers (AnalogConv1d, AnalogConv2d and AnalogConv3d) share quite a good chunk of functionality. As we now have enough of them, it would be a good time to generalize their shared pieces, in order to avoid code repetition.
The digital Conv classes already share a common ancestor in PyTorch with some interesting reusing. It can serve as inspiration or taken into account for coming up with the generalization.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.