I'm Dan, a PhD student in ML at UC Berkeley.
See my webpage for my research.
See below for my code.
The Combined Anomalous Object Segmentation (CAOS) Benchmark
License: MIT License
I'm Dan, a PhD student in ML at UC Berkeley.
See my webpage for my research.
See below for my code.










































































































In your paper, you mention that the BatchNorm is frozen, but I notice that your implementation doesn't freeze the BN. So I want to know if there are any mistakes or my misunderstanding.
Hello, dear author, why do I get an empty validation.odgt file after running create_bdd_dataset.py?
Hi,
Thanks for making all the codes public, which is very helpful. Yet, I'm just having difficulty preparing the BDD100K data.
Lines 152 to 155 in c7cdd0a
Specifically, in create_dataset.py, I don't see what is the seg folder in line 153, and also couldn't find where to download train_labels. More clearly, I downloaded the 100K Images and Segmentation files from the BDD100K website, unzipped them, and now I have a folder whose structure is as follows:
bdd100k
├── images
│ ├── 100k
│ │ ├── test
│ │ ├── train
│ │ ├── val
├── labels
│ ├── sem_seg
│ │ ├── colormaps
│ │ ├── masks
│ │ ├── polygons
As you can see, no subfolders correspond to train_labels/train. I would appreciate it if more clear instructions can be given, e.g., what is the expected folder structure, or exactly where should I download the train_labels?
Thanks!
Thanks for your excellent work! I'm working on OOD detection and plan to conduct experiments on your ImageNet vs. Species benchmark, but when I use Linux commands to download the Species folder to my server, there is an error "two many users have viewed or downloaded this file recently." I'm still able to access the link in the browser, but the files are too large for directly downloading on my PC. Could you please consider updating the sharing link to facilitate the evaluation on your novel benchmark? Thanks very much.
Hi,
i would like to ask what the reason is for not sharing the reproduction code for Section "3. Multi-Class Prediction for OOD Detection" in the paper. If it would be possible to get this code it would be very nice. If that is not possible the exact test setting would be helpful:
Thanks in advance! Any support is much appreciated :)
Hello authors,
Thank you for your hard work! My question is that what's the training hyper parameters for BDD dataset? Is it the same as Street Hazards?
Thanks,
Yingda
Hello, thank you for your work, where can i get the BDD-Anomaly dataset?
Does the code work on google colab ?
I have this error "KeyError: Caught KeyError in DataLoader worker process 0." when calling train(segmentation_module, iterator_train, optimizers, history, epoch+1, cfg) after running the command python3 train.py --gpu 1 ...
Could you please share your pretrained segmentation model on BDD100K? I found your released model in Google Drive is the one for StreetHzards.
Hello, thanks for your hard work! I want to do some experiments with the StreetHazards and BDD-anomaly dataset,but I have some confusion during the experiment. In your《Scaling Out-of-Distribution Detection for Real-World Settings》paper, for StreetHazards dataset, it is stated that there are 12 classes used for training, but the dataset label shows that there are a total of 14 classes(label:1-14). Except for the anomaly class, the training set includes another 13 classes. Is there any class that does not participate in training and testing during the experiment? For BDD-anomaly dataset, in your paper, it is stated that there are 18 original classes, but the dataset label shows that there are a total of 20 classes (label:0-18,255). Is there any class that does not participate in training and testing during the experiment? Could you give me some help so that I can better understand the benchmark? Thank you very much and looking forward to your reply.
Hello!
I have a little question about the resnet arch implemented by yourself. I notice that there are two more stages before resnet layer_1 compared to the official code released in torchvision.
I wanna know why there are two more stages😂
Thanks for your time!
Hello,
The color encoding followed for the visualizations of the semantic maps for the street hazards dataset is unclear. Could you please help me identify the encoding followed?
Line 17-33 of create_dataset.py, provides a list of colors used for street hazards, but they don't really match the colors on the semantic map generated nor the ground truth labels.
I believe the color encoding from ADE is not being used here.
Where can I find the exact color-coding that is being used?
Regards,
Shravanthi
Dear xksteven:
Thank you so much for your work.
I still confuse about detecting the anomalous class. As you said that we can evaluate how confident the model is on the predictions for the anomalous class or classes during testing (@xksteven in #17), which can evalue the performance according to the evaluation metrics auroc, aupr. However, auroc, aupr calculated by adjusting the threshold of confidence score.
If we want to visualze the final anomaly segmentation result like 'Figure 4, prediction result', we should define a certain threshold (for example, 0.5 for binary classification), is it means calculate the threshold value in test and use the same value for prediction ?
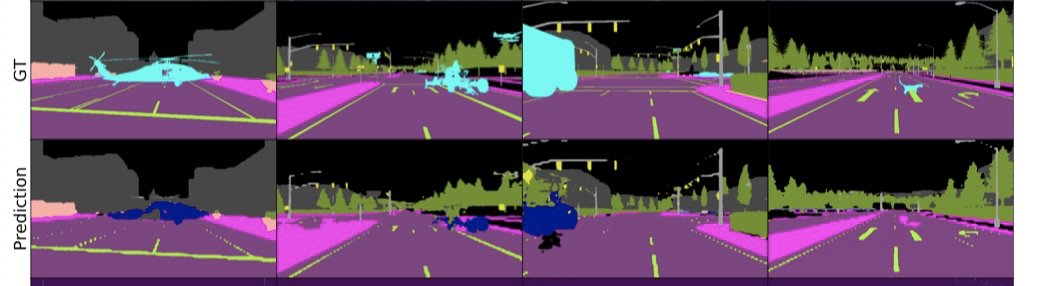
Also, if we select the threshold Θ to split normal/anomaly, how to classify classes in in-distribution class ? Argmax ?
@xksteven in #20 , because model only train in in-distribution classes, so line 174 only visualize the mask(RGB) in in_distribution classes, how to visualize the out-distribtuion classes ? and 'MaxLogit' probability image (heatmap, anomaly score) drawed by conf?

Look forward to your reply, have a nice day, ^_^, thank you so much.
As the TrainDataset output in dataset.py , I got seg_label as
[[ 0, 9, 9, ..., 9, 9, -1],
[ 9, 9, 9, ..., 9, 9, -1],
[ 9, 9, 0, ..., 9, 9, -1],
...,
[ 0, 0, 0, ..., 7, 7, -1],
[ 0, 0, 0, ..., 7, 7, -1],
[ 0, 0, 0, ..., 7, 7, -1]],
[[ 1, 1, 1, ..., 1, 1, -1],
[ 1, 1, 1, ..., 1, 1, -1],
[ 1, 1, 1, ..., 1, 1, -1],
...,
[ 7, 7, 7, ..., 7, 7, -1],
[ 7, 7, 7, ..., 7, 7, -1],
[ 7, 7, 7, ..., 7, 7, -1]]])}]`
But the true label range in your paper 0-12 for training and 0-13 for testing. So what is the meaning of "-1" label?
[[[Hey so you can use the script below to undo the conversion from uint back to colors. The main difference that I had forgotten was that the counter starts at 1. The semantic segmentation pytorch code ignores the index 0 and this was our hack to get the code to learn the background class. I attached one of the examples below to demonstrate it working in converting back to the original colors.
import numpy as np
from PIL import Image as image
import os
root = "annotations/test/t5/"
test_images = os.listdir(root)
#StreetHazards colors
colors = np.array([[ 0, 0, 0], # // unlabeled = 0,
[ 70, 70, 70], # // building = 1,
[190, 153, 153], # // fence = 2,
[250, 170, 160], # // other = 3,
[220, 20, 60], # // pedestrian = 4,
[153, 153, 153], # // pole = 5,
[157, 234, 50], # // road line = 6,
[128, 64, 128], # // road = 7,
[244, 35, 232], # // sidewalk = 8,
[107, 142, 35], # // vegetation = 9,
[ 0, 0, 142], # // car = 10,
[102, 102, 156], # // wall = 11,
[220, 220, 0], # // traffic sign = 12,
[ 60, 250, 240], # // anomaly = 13,
])
for im_path in test_images:
im = image.open(root+im_path)
pic = np.array(im)
new_img = np.zeros((720, 1280, 3))
for index, color in enumerate(colors):
new_img[pic==(index+1)] = colors[index]
new_img = image.fromarray(new_img.astype('uint8'), 'RGB')
new_img.save(root+"rgb_"+str(im_path))
Example 300 converted back into standard RGB colors.

Hope you find the dataset helpful :)
_Originally posted by @xksteven in https://github.com/hendrycks/anomaly-seg/issues/15#issuecomment-890300278_](https://github.com/hendrycks/anomaly-seg/issues/15#issuecomment-890300278)](https://github.com/hendrycks/anomaly-seg/issues/15#issuecomment-890300278)](https://github.com/hendrycks/anomaly-seg/issues/15#issuecomment-890300278)
Hi, @xksteven
I don't know where to run this code. Can you tell me.
Thank you. I appreciate it.
Jacky
I'm sorry I don't know how to reopen again, so I created another issue.
Thank you for your answer, but I still have some points to confirm.
1.For StreetHazards dataset, there are a total of 14 classes(0:unlabeled,1:building,2:fence,3:other,...13:anomaly).The label in the label file is from 1 to 14, minus 1 corresponds to 0-13 here. Unlabeled Corresponding background.Use 0-12 for training(a total of 13 categories), including 0(0:unlabeled) and 3(3:other), and use 0-13 for testing(a total of 14 categories), right?
2.For BDD-anomaly dataset, there are a total of 20 classes (0:road,1:sidewalk,...18:bicycle,255:other). Use 0-15 and 255(other) for training(a total of 17 categories), only does not contain 16-18, and use 0-18 and 255 for testing(a total of 20 categories), right?
Thank you very much and looking forward to your reply.
Hello Sir,
When start training, I met some error.
[2020-06-12 00:14:23,603 INFO train.py line 242 9980] Loaded configuration file config/ade20k-resnet50dilated-ppm_deepsup.yaml
[2020-06-12 00:14:23,603 INFO train.py line 243 9980] Running with config:
DATASET:
imgMaxSize: 1000
imgSizes: (300, 375, 450, 525, 600)
list_train: ./data/training.odgt
list_val: ./data/validation.odgt
num_class: 150
padding_constant: 8
random_flip: True
root_dataset: ./data/
segm_downsampling_rate: 8
DIR: ckpt/ade20k-resnet50dilated-ppm_deepsup
MODEL:
arch_decoder: ppm_deepsup
arch_encoder: resnet50dilated
fc_dim: 2048
weights_decoder:
weights_encoder:
OOD:
exclude_back: False
ood: msp
out_labels: 13
TEST:
batch_size: 1
checkpoint: epoch_20.pth
result: ./
TRAIN:
batch_size_per_gpu: 2
beta1: 0.9
deep_sup_scale: 0.4
disp_iter: 20
epoch_iters: 5000
fix_bn: False
lr_decoder: 0.02
lr_encoder: 0.02
lr_pow: 0.9
num_epoch: 20
optim: SGD
seed: 304
start_epoch: 0
weight_decay: 0.0001
workers: 16
VAL:
batch_size: 1
checkpoint: epoch_20.pth
visualize: False
[2020-06-12 00:14:23,603 INFO train.py line 248 9980] Outputing checkpoints to: ckpt/ade20k-resnet50dilated-ppm_deepsup
# samples: 4
1 Epoch = 5000 iters
Traceback (most recent call last):
File "train.py", line 275, in <module>
main(cfg, gpus)
File "train.py", line 202, in main
train(segmentation_module, iterator_train, optimizers, history, epoch+1, cfg)
File "train.py", line 32, in train
batch_data = next(iterator)
File "/home/itsme/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 345, in __next__
data = self._next_data()
File "/home/itsme/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 385, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/home/itsme/anaconda3/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/itsme/anaconda3/lib/python3.7/site-packages/torch/utils/data/_utils/fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/data2/itsme/TESTBOARD/additional_networks/AnomalyDetection/anomaly-seg_hendrycks/semantic-segmentation-pytorch/dataset.py", line 114, in __getitem__
np.random.shuffle(self.list_sample)
File "mtrand.pyx", line 4859, in mtrand.RandomState.shuffle
File "mtrand.pyx", line 4862, in mtrand.RandomState.shuffle
KeyError: 0For solve this status, what I should do??
Thanks,
edward, cho
Thank you for your hard work.
I have some questions.
In the training procedure, does the data and segmentation map are downsampled?
According to the code, I think the model uses the downsampled images and segmentation maps.
Is it for efficient training?
In the validation procedure, is interpolation operation added after the trained model to just matching the segmentation size?
Thanks
Hello,
I could train the PSPnet with a single GPU. However, I am having issues with the evaluation of the model on the out-of-distribution test set.
python3 eval_ood.py --cfg ./config/ade20k-resnet50dilated-ppm_deepsup.yaml --gpu 0 --ood msp
Here is the error:
Traceback (most recent call last):
File "eval_ood.py", line 274, in
cfg.merge_from_list(ood)
File "/home/spati12s/anaconda3/envs/anomaly-seg/lib/python3.6/site-packages/yacs/config.py", line 239, in merge_from_list
subkey in d, "Non-existent key: {}".format(full_key)
File "/home/spati12s/anaconda3/envs/anomaly-seg/lib/python3.6/site-packages/yacs/config.py", line 521, in _assert_with_logging
assert cond, msg
AssertionError: Non-existent key: OOD.exclude_back
/var/spool/slurmd/job362065/slurm_script: line 21: /home/spati12s: Is a directory
~
Hello Sir,
I saw annotation files in test-folder.
What is the purpose of this file??
(When training, Is this file used??)
Thanks.
Edward Cho.
Hello,
thanks for your work. I wanted to ask some simple questions about the models you trained for the CAOS benchmark.
Thanks.
Hi,
Congrats on the great paper.
I checked your evaluation method and found that the results based on the mean of fprs over all images are better than the results based on flattened scores and labels of the entire dataset. Why do you use image-wise results instead of the entire dataset to calculate the fpr.
Thanks.
Hello Sir,
Still, I couldn't solve my error.
I am using your code and config/ade20k-resnet50dilated-ppm_deepsup.yaml, streethazards_train.tar.
When training was started,
[2022-01-04 04:41:01,710 INFO train.py line 249 15579] Outputing checkpoints to: ckpt/ade20k-resnet50dilated-ppm_deepsup
# samples: 5125
1 Epoch = 5000 iters
Traceback (most recent call last):
File "/data/TESTBOARD/additional_networks/anomaly_detection/anomaly-seg/semantic-segmentation-pytorch/train.py", line 276, in <module>
main(cfg, gpus)
File "/data/TESTBOARD/additional_networks/anomaly_detection/anomaly-seg/semantic-segmentation-pytorch/train.py", line 202, in main
train(segmentation_module, iterator_train, optimizers, history, epoch+1, cfg)
File "/data/TESTBOARD/additional_networks/anomaly_detection/anomaly-seg/semantic-segmentation-pytorch/train.py", line 41, in train
loss, acc = segmentation_module(batch_data)
File "/home/mirero/anaconda3/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1102, in _call_impl
return forward_call(*input, **kwargs)
File "/data/TESTBOARD/additional_networks/anomaly_detection/anomaly-seg/semantic-segmentation-pytorch/models/models.py", line 34, in forward
(pred, pred_deepsup) = self.decoder(self.encoder(feed_dict['img_data'], return_feature_maps=True))
TypeError: list indices must be integers or slices, not strI wonder what is my fault??
Thanks,
Edward Cho.
Hi, @xksteven
I am confuse about the metrics of CAOS benchmark.
Are AUPR, AUROC and FPR95 pixel-level metrics?
Thank you
Jacky
Hello, there are 250 anomaly types in this dataset introduced by your paper. What are these anomaly types specifically?
Does the code works with single GPU.
I manage to make it work with multiple GPU, but each time I try with just one single GPU I have an issue:
self.run()
File "/usr/lib/python3.6/threading.py", line 864, in run
self._target(*self._args, **self._kwargs)
File "/home/user/venv_pytorch1/lib/python3.6/site-packages/torch/utils/data/_utils/pin_memory.py", line 21, in _pin_memory_loop
r = in_queue.get(timeout=MP_STATUS_CHECK_INTERVAL)
File "/usr/lib/python3.6/multiprocessing/queues.py", line 113, in get
return _ForkingPickler.loads(res)
File "/home/user/venv_pytorch1/lib/python3.6/site-packages/torch/multiprocessing/reductions.py", line 284, in rebuild_storage_fd
fd = df.detach()
segm_downsampling_rate: 8
Exception in thread Thread-1:
Traceback (most recent call last):
File "/usr/lib/python3.6/threading.py", line 916, in _bootstrap_inner
self.run()
File "/usr/lib/python3.6/threading.py", line 864, in run
self._target(*self._args, **self._kwargs)
File "/home/user/venv_pytorch1/lib/python3.6/site-packages/torch/utils/data/_utils/pin_memory.py", line 21, in _pin_memory_loop
r = in_queue.get(timeout=MP_STATUS_CHECK_INTERVAL)
File "/usr/lib/python3.6/multiprocessing/queues.py", line 113, in get
return _ForkingPickler.loads(res)
File "/home/user/venv_pytorch1/lib/python3.6/site-packages/torch/multiprocessing/reductions.py", line 284, in rebuild_storage_fd
fd = df.detach()
File "/usr/lib/python3.6/multiprocessing/resource_sharer.py", line 57, in detach
with _resource_sharer.get_connection(self._id) as conn:
File "/usr/lib/python3.6/multiprocessing/resource_sharer.py", line 87, in get_connection
c = Client(address, authkey=process.current_process().authkey)
File "/usr/lib/python3.6/multiprocessing/connection.py", line 493, in Client
answer_challenge(c, authkey)
File "/usr/lib/python3.6/multiprocessing/connection.py", line 732, in answer_challenge
message = connection.recv_bytes(256) # reject large message
File "/usr/lib/python3.6/multiprocessing/connection.py", line 216, in recv_bytes
buf = self._recv_bytes(maxlength)
File "/usr/lib/python3.6/multiprocessing/connection.py", line 407, in _recv_bytes
buf = self._recv(4)
File "/usr/lib/python3.6/multiprocessing/connection.py", line 379, in _recv
chunk = read(handle, remaining)
ConnectionResetError: [Errno 104] Connection reset by peer
Hi,
I was wondering if there is any specific consideration for training the model based on a new dataset with different types of classes?
I want to apply your code on an agricultural dataset and I got 100% accuracy with the basic configuration on my dataset. But the test result shows nothing special. I guess the reason might be caused by the definition of the classes.
Do you have any suggestions?

Hi everyone,
thanks for your work. I'm interested in downloading the datasets for academic purposes. However, github points to a non-existing page when clicking on the link of the BDD-Anomaly dataset. Where can I find the train/val/test images?
Thank you.
there are 17 class defined in defaults.py and the anomaly class is 13,
the comment in create_dataset.py has defined 13 class, but found some color in image which under in folder seg/color_labels, but not in create_dataset.py's comment
so how about the 17 class names and their color defines?
does the anomaly class data existed in training stage?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.