A collaborative project to build an ETL pipeline using Python, Pandas, and PostgreSQL for extracting, transforming, and loading crowdfunding data from Excel files into a relational database.
ETL (Extract, Transform and Load) data processing is an automated procedure that extracts relevant information from raw data, converts it into a format that fulfills business requirements and loads it into a target system.
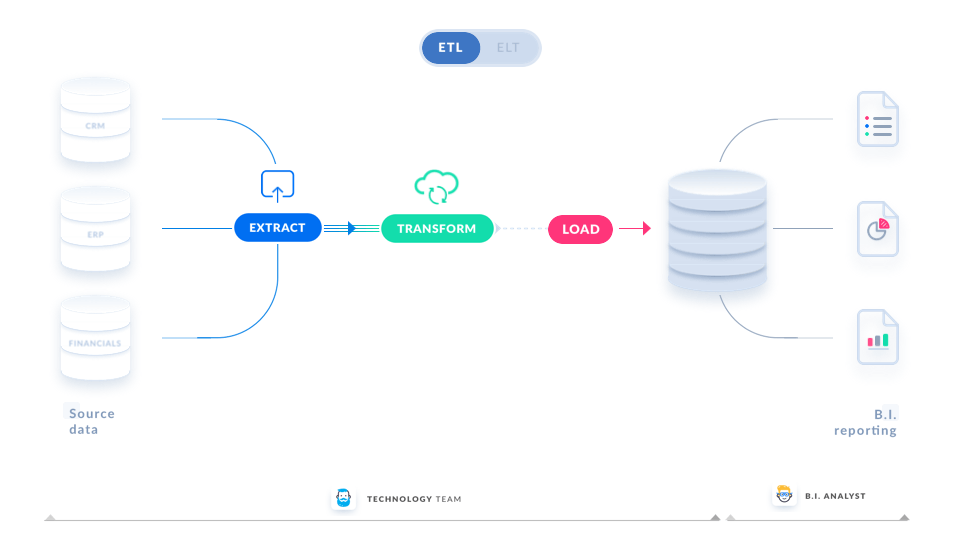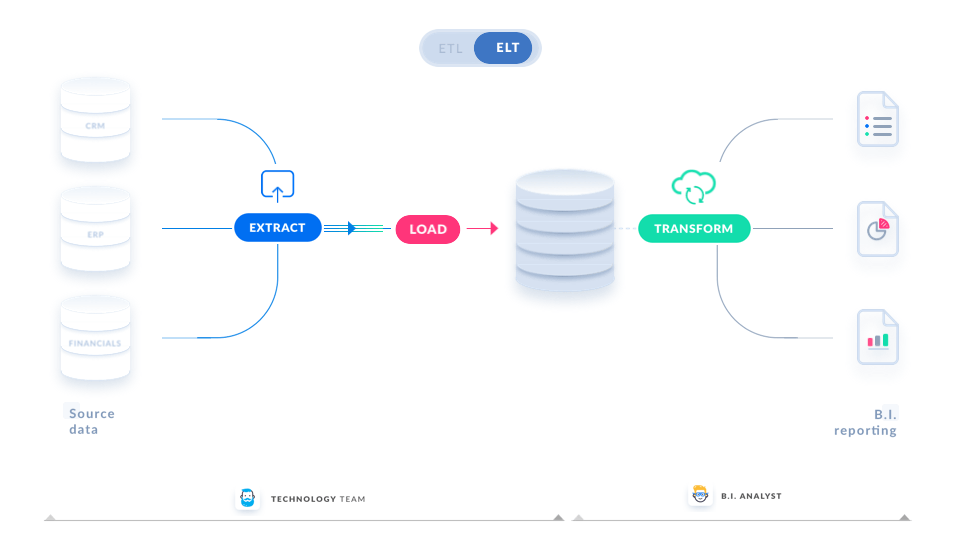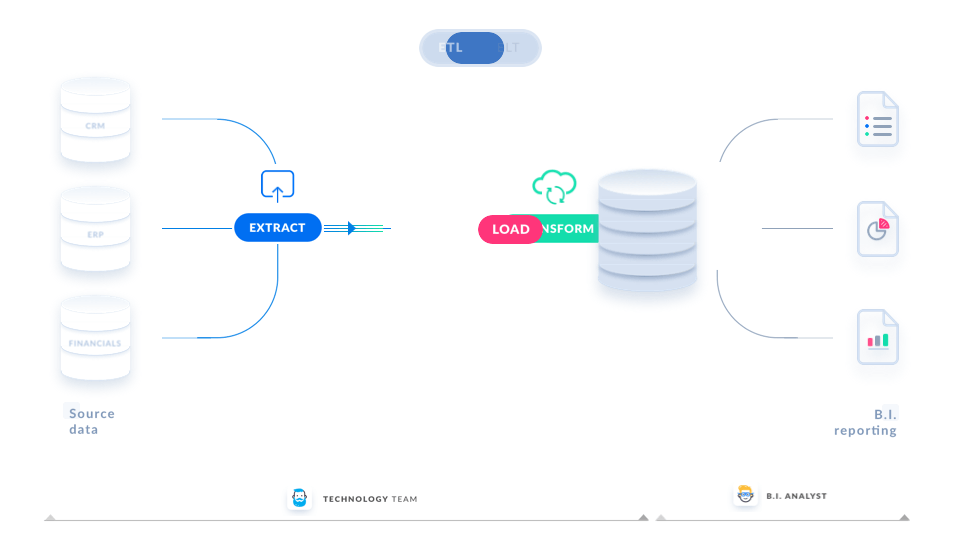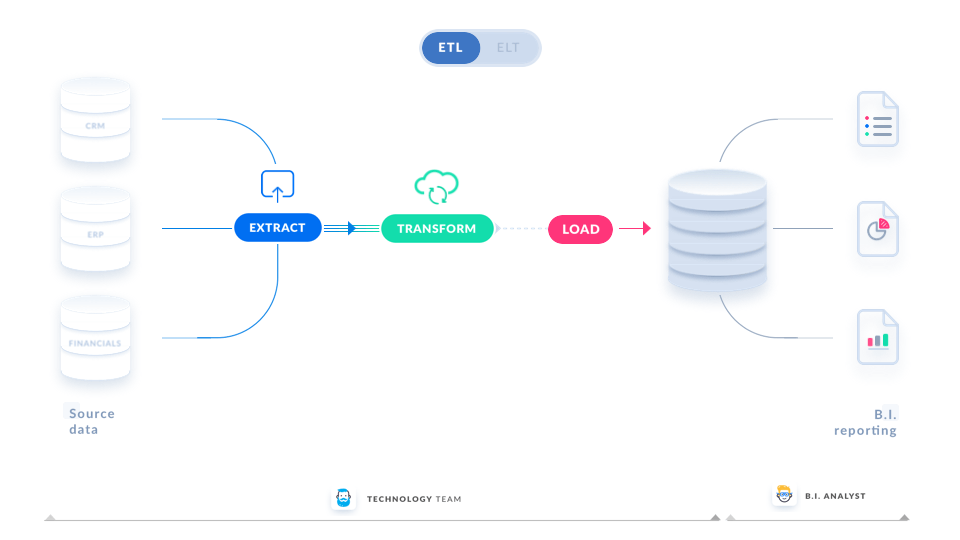
The instructions for this mini project are divided into the following subsections:
- Create the Category and Subcategory DataFrames
- Create the Campaign DataFrame
- Create the Contacts DataFrame
- Create the Crowdfunding Database
- Utilize Python and Pandas in order to:
- Extract and transform crowdfunding and contact data from Excel files
- Create and export Category, Subcategory, Campaign, and Contact DataFrames as CSV files
- Utilize PostgreSQL in order to:
- Design an ERD and table schema for the database
- Create and populate PostgreSQL database tables
-
For our analysis, we have extracted and transformed data from the following datasets available in the
Resourcesfolder.- contacts.xlsx
- crowdfunding.xlsx
-
Then, we loaded our transformed data into
crowdfunding_dbPostgreSQL database.- category.csv
- subcategory.csv
- contacts.csv
- campaign.csv
-
Clone the repository.
-
Install PostgresSQL
-
Install required Python packages:
pandas,numpyandopenpyxl. -
In order to run our analysis, first select
Python Environment (Python 3.9.13)in Jupyter Notebook. -
Select "Run All" in
ETL_Mini_Project.ipynbfile, which will Extract, Transform data, and Create CSV files.- All CSV files will be located in Resources folder.
-
Set up a PostgreSQL server to create a new database called
crowdfunding_db. -
In
Crowdfunding DB folder, use providedcrowdfunding_db_schema.sqlfile to create tables in PostgreSQLcrowdfunding_dbdatabase.- Import each CSV file into its corresponding SQL table in the following order: category, subcategory, contacts, and campaign.
- Query the database to verify the data has been loaded correctly, by running a
SELECTstatement for each.

In this project, we have demonstrated the ETL pipeline utilizing Python, Pandas, and a combination of both Python dictionary and regular expression techniques for data extraction and transformation. We were able to successfully generate four CSV files, and use the data in these files to design an ERD as well as table schema, then loaded the data into PostgresSQL database from the CSV files via dataframes.
| Programming Languages | Database | Libraries | Software | Modules |
|---|---|---|---|---|
| Python |
PostgreSQL |
Pandas |
QuickDBD |
datetime as dt |
| numpy |
Jupyter Notebook |
pprint | ||
| json |
Helena Fedorenko
Jason Barbagallo
Xing Ying Chen
Nancy Santiago
Anthony Parry




