Lindz's blog -- 喜欢的话请点 star,想订阅点 watch
关注 Javascript, ES6, React, Vue, Node, 性能优化等
我的知乎专栏: 敲代码,学编程
部分源码放在 /code 目录下,你可以:
git clone https://github.com/happylindz/blog.git
cd code/xxxx/
Lindz's blog -- 喜欢的话请点 star,想订阅点 watch
Lindz's blog -- 喜欢的话请点 star,想订阅点 watch
关注 Javascript, ES6, React, Vue, Node, 性能优化等
我的知乎专栏: 敲代码,学编程
部分源码放在 /code 目录下,你可以:
git clone https://github.com/happylindz/blog.git
cd code/xxxx/







































































































































































































我们在使用 webpack 打包构建 moment 库的时候,moment 默认会将所有语言包全部引入,这样就会导致打包后的 JS 体积增大,通过 webpack-bundle-analyzer 分析工具可以看到,如果将所有的 moment 语言包引入的话,所占 JS 体积是相当庞大的。gzip 之后也要占据 65kb 的文件大小。
所以如果应用没有国际化背景的需求下,我们一般都会通过 webpack.IgnorePlugin(/^\.\/locale$/, /moment$/) 将所有语言包进行剔除,不进行打包,这样打包后的 moment 体积就只有 16kb。
正常的业务诉求到这里结束了,但是我们阿里巴巴国际站需要支持 14 种语言的切换(即在站点内支持语种的切换),如果像下面这这样 14 语言包一起引入的话也会造成体积上的浪费。
import moment from 'moment';
import 'moment/locale/zh-cn';
// ...other language file
import 'moment/locale/zh-tw';
moment.locale(window.currentLocale);所以本节的重点在于讲讲如何在像 React/Vue 这样单页应用或者其它多页面应用中实现对 moment 语言包的动态引入,其它库引入语言包的**也可以借鉴。
首先需要编写不同语种的脚本文件入口,比如:
// ./locale-zh_cn.js
import moment from 'moment';
import 'moment/locale/zh-cn';
moment.locale('zh-cn');
// ./locale-zh_tw.js
import moment from 'moment';
import 'moment/locale/zh-tw';
moment.locale('zh-tw');在页面打开的时候通过服务端渲染在 html 中注入变量来告诉页面当前的语种脚本。
<script src="/js/locale-${currentLocale}.js"></script>
<script src="/js/main.js"></script>这样做就可以让用户在站点中切换语种是可以保证引入当前语种所需语种包的最小集。
当时这里就产生新的问题,熟悉 webpack 打包机制的同学应该知道 (如果不熟悉可以看我之前写的 深入理解 webpack 文件打包机制 )
在多入口文件的时候,会有不同的 __wepback_require__ 和 installModules,这就导致了你在不同入口文件中使用 moment 库时,其实实例了两个不同的 moment 对象(即 main.js 和 locale-xxx.js 中使用的 moment 其实不是同一个实例,main 入口就无法使用 locale.js 中注入的语种包),针对这样的问题,那么有什么办法能让不同的入口使用同一个 moment 实例?
通过在 webpack 配置文件 externals 属性,让 moment 指向 window.moment 并且在页面中额外引入不带语种包的 moment CDN 库。
{
// ...
externals: {
"moment": "moment",
"../moment": "moment"
},
}不难理解,通过这种方式打包后 webpack 在遇到 import moment from 'moment'时候会直接使用 window.moment,值得一提的是,因为在 moment 内置语种包中通过 .../moment 来调用 moment 的方法,所以我们也将这个设置为外置引用 window.moment。
// node_modules/moment/locale/zh-cn.js
;(function (global, factory) {
typeof exports === 'object' && typeof module !== 'undefined'
&& typeof require === 'function' ? factory(require('../moment')) :
typeof define === 'function' && define.amd ? define(['../moment'], factory) :
factory(global.moment)
}(this, (function (moment) { 'use strict';
var zhCn = moment.defineLocale('zh-cn', {
// ...
}
}这样做有三个好处:
这样做解决了多页应用或单页面应用在第一次打开时的语种问题,如果用户在单页应用切换语种的话就比较简单,直接使用动态 import 即可。
import moment from 'moment';
// 此时已经引入 locale-zh_cn;
console.log(moment(new Date()).format('ALT'));
console.log(moment(new Date()).format('A'));
setTimeout(() => {
import('./locale-zh_tw').then(() => {
console.log(moment(new Date()).format('A'));
})
}, 200);最近在团队分享一些 webpack 技巧,于是便准备梳理出一篇博文总结一下,不过由于讲的内容太多了,无法描述的很详细,更多地是提供一个思路,希望读者感兴趣可以动手去实践实践。
配置多份 webpack 配置,通过 webpack-merge 进行合并,
├── common.js
├── dll.config.js
├── webpack.base.config.js
├── webpack.dev.config.js
├── webpack.prod.config.js
// etc 同构配置,node middleware 等等
然后通过 npm scripts 执行 webpack 命令:
{
"scripts": {
"dev": "webpack-dev-server --config ./webpack.dev.config.js",
"build": "webpack --config ./webpack.prod.config.js",
"start": "npm run dev",
"pre": "webpack --config ./dll.config.js"
},
}node_modules/.bin/webpack-dev-server,npm scripts 会自动把 node_modules/.bin/ 下的指令添加到环境中。想开启热更新,首先需要在入口文件进行配置:
// 入口文件
if(module.hot) {
module.hot.accept(['./App'], () => {
render(<App />, document.getElementById('app'))
})
}模块热更新机制:
最简单的方式:
直接在命令里面加上 webpack-dev-server --hot 即可开启热更新。
该参数相当于是做了:
const HotModuleReplacementPlugin = require('webpack/lib/HotModuleReplacementPlugin');
module.exports = {
plugins: [
new HotModuleReplacementPlugin(),
],
devServer:{
hot: true,
}
};当然如果你想要更加定制化的控制,你需要在 webpack 配置进行额外配置:
const HotModuleReplacementPlugin = require('webpack/lib/HotModuleReplacementPlugin');
module.exports = webpackMerge(baseConfig, {
plugins: [
new HotModuleReplacementPlugin(),
],
devServer: {
// 每次构建时候自动打开浏览器并访问网址
open: true,
// 开启热更新
hot: true,
// 设置静态资源地址如:/public,从这获取你想要的一些外链资源,图片。
contentBase: DIST_PATH,
// 设置端口号
port: 9000,
// 将热更新代码注入到模块中
inline: true,
// 如果你希望服务器外部可访问
host: "0.0.0.0",
// 设置 proxy 代理
proxy: {
context: ['/api'],
target: "//www.proxy.com",
pathRewrite: {"^/api" : ""}
},
// 设置 https
https: true
}
});关于 webpack 热更新原理我就不说了,感兴趣可以看下面两篇文章:
module.exports = {
devtool: 'source-map',
}方便调试源代码
在大型应用减少每次构建的时间十分重要,动不动几十秒的编译时间令人发指,我在经过一些实践,总结下面一些方式,至少可以让你的编译速度快 1-2 倍。
首先第一点:缩小 Babel 的编译范围,并使用 webpack cache 缓存模块。
module.exports = {
// 减小模块的查找范围
resolve: {
modules: [path.resolve(__dirname, 'node_modules')],
},
module: {
rules: [
{
test: /\.js?$/,
use: [{
loader: 'babel-loader',
query: {
// 将 babel 编译过的模块缓存在 webpack_cache 目录下,下次优先复用
cacheDirectory: './webpack_cache/',
},
}],
// 减少 babel 编译范围,忘记设置会让 webpack 编译慢上好几倍
include: path.resolve(__dirname, 'src'),
},
]
},
}通过这步可以快上好几秒,另外你可以使用 DLLPlugin 预先打包好第三方库,避免每次都要去编译。开启 DLLPlugin 需要你额外配置一份 webpack 配置。
// dll.config.js
const webpack = require('webpack');
const path = require('path');
const DllPlugin = require('webpack/lib/DllPlugin')
const vendors = [
'react',
'react-dom',
'react-router',
'redux',
'react-redux',
'jquery',
'antd',
'lodash',
]
module.exports = {
entry: {
'dll': vendors,
},
output: {
filename: '[name].js',
path: path.resolve(__dirname, 'public'),
library: '__[name]__lib',
},
plugins: [
new DllPlugin({
name: '__[name]__lib',
path: path.join(__dirname, 'build', '[name].manifest.json'),
}),
]
}运行则会在 public 目录下得到 dll.js 和 dll.manifest.json 文件,然后需要在开发配置文件中关联。
const webpack = require('webpack');
module.exports = webpackMerge(baseConfig, {
plugins: [
new DllReferencePlugin({
manifest: require('./public/dll.manifest.json'),
}),
]
});另外需要在你的 html 模板里面引入 dll.js,webpack 不会自动帮你引入,用好这一步编译速度应该能快一倍左右的时间。
第三点就是使用 happypack 开启多核构建,webpack 之所以慢,是因为由于有大量文件需要解析和处理,构建是文件读写和计算密集型的操作,特别是当文件数量变多后,webpack 构建慢的问题会显得严重。 也就是说 Webpack 需要处理的任务需要一件件挨着做,不能多个事情一起做。
在整个 webpack 构建流程中,最耗时的流程可能就是 loader 对文件的转换操作了,因为要转换的文件数据巨多,而且这些转换操作都只能一个个挨着处理。 Happypack 的核心原理就是把这部分任务分解到多个进程去并行处理,从而减少了总的构建时间。
需要配置哪些 loader 使用 Happypack 就要改写那些配置,比如你想要修改 babel 为多核编译:
module.exports = {
module: {
rules: [
{
test: /\.js?$/,
use: ['happypack/loader?id=babel'],
include: path.resolve(__dirname, 'src'),
},
]
},
plugins: [
new HappyPack({
id: 'babel',
loaders: [{
loader: 'babel-loader',
query: {
cacheDirectory: './webpack_cache/',
},
}],
})
],
};设置 id=babel,webpack 会去找 plugins 中的 id 为 babel 的插件进行处理。配置其它的 loader 的方式也是类似,不过需要注意的是有的 loader 不支持多核编译。通过这一步应该至少能让你的编译速度快 1/3。
最后一点是不要使用 webpack 里 css 模块化方案,我这里指的模块化指的是 css-loader 提供的模块化方式,我们先来看下它是怎么做的,首先它需要在你的 loader 中进行额外配置。
module.exports = webpackMerge(baseConfig, {
module: {
rules: [
{
test: /\.css/,
use: [
'style-loader',
{
loader: 'css-loader',
options: {
// 开启 css 模块
modules: true,
// 设置命名格式
localIdentName: '[name]__[hash:base64:5]'
}
}
]
},
]
},
} 如果通过这种 css 模块化的方式,意味着你在写 React 组件的时候,需要这样去设置:
import styles from './index.css';
class Index extends React.Component {
render() {
return (
<div className={ styles.recursive }>
xxxx
<h1 className={ styles.header }></h1>
</div>
);
}
}
export default Index;它相当于是在输出 css 文件的时候做了一层原名称到新名称的一次转化来保证 css 模块化的特性,输出的值就像这样:
Object {
recursive: 'recursive__abc53xxxx',
xxxxx: 'xxxxx__def884xxx',
}
这样做不好的点在哪:
所以如果想要使用 css 模块化的可以尽量选择其它方案,比如 styledComponents 或者自己添加命名空间等等。
在发布上线的时候就需要考虑到很多性能优化的因素,比如如何有效地去利用浏览器的缓存,如何减少打包文件的体积等等这些因素都值得去优化。
关于如何高效地利用浏览器缓存,之前写过一篇文章详细描述了 webpack 持久化缓存实践,感兴趣可以看看。
我这里做个总结,我认为 webpack 在浏览器缓存需要做到以下几点:
那么我们要怎样通过 webpack 来完成上面的步骤呢?
首先不建议线上发布直接全部使用 DLLPlugin 插件来开启浏览器缓存,DLLPlugin 本身有几个缺点:
我认为的正确的姿势是:
具体如何拆分模块,我在 webpack 持久化缓存实践 已经说明,这里不再赘述。
想要减少打包后的体积,就需要使用到 webpack2 提供的 tree shaking 功能和 webpack3 提供的 scope hoisting 功能。
想要 tree shaking 生效,下面四点值得注意:
首先,模块引入要基于 ES6 模块机制,不再使用 commonjs 规范,因为 es6 模块的依赖关系是确定的,和运行时的状态无关,可以进行可靠的静态分析,然后清除没用的代码。而 commonjs 的依赖关系是要到运行时候才能确定下来的。
另外对于引用第三方模块使用 tree shaking 功能,可以设置 mainFields 用于配置采用哪个字段作为模块的入口描述。 为了让 tree shaking 对 es6 生效,需要配置 webpack 的文件寻找规则为如下:
module.exports = {
resolve: {
// 针对 npm 中的第三方模块优先采用 jsnext:main 中指向的 ES6 模块化语法的文件
mainFields: ['jsnext:main', 'browser', 'main']
},
};对于一些死代码,就像下面这样:其大致原理是借助环境变量去判断执行哪个分支。
if (process.env.NODE_ENV === 'production') {
console.log('你正在线上环境');
} else {
console.log('你正在使用开发环境');
}通过 shell 脚本的方式去定义的环境变量,例如 NODE_ENV=production webpack,webpack 是不认识的,对 webpack 需要处理的代码中的环境区分语句是没有作用的。
在构建线上环境代码时,需要给当前运行环境设置环境变量 NODE_ENV = 'production',webpack 相关配置如下:
const DefinePlugin = require('webpack/lib/DefinePlugin');
module.exports = {
plugins: [
new DefinePlugin({
'process.env': {
NODE_ENV: JSON.stringify('production')
}
}),
],
};这样设置后 tree shaking 能有效清除跟生产环境无关的代码。
最后需要强调,webpack 只是指出了哪些函数用上了哪些没用上,要剔除用不上的代码还得经过 UglifyJS 去处理一遍。 需要开启代码压缩, tree shaking 才能真正将无用的代码消除。
如果想要开启 Scope hoisting,需要在额外配置 ModuleConcatenationPlugin 插件,并且 Scope hoisting 对下面的情况不生效:
这些我在 深入理解 webpack 文件打包机制 都有详细阐述,这里不多说了。
压缩代码可以使用 UglifyJsPlugin 这个插件对代码进行压缩,不过用过 UglifyJsPlugin 的你一定会发现在构建用于开发环境的代码时很快就能完成,但在构建用于线上的代码时构建一直卡在一个时间点迟迟没有反应,其实卡住的这个时候就是在进行代码压缩。
由于压缩 JavaScript 代码需要先把代码解析成用 Object 抽象表示的 AST 语法树,再去应用各种规则分析和处理 AST,导致这个过程计算量巨大,耗时非常多。
遇到这种情况可以改用 ParallelUglifyPlugin 插件,当 webpack 有多个 JS 文件需要输出和压缩时,原本会使用 UglifyJsPlugin 去一个个挨着压缩再输出, 但是 ParallelUglifyPlugin 则会开启多个子进程,把对多个文件的压缩工作分配给多个子进程去完成,每个子进程其实还是通过 UglifyJsPlugin 去压缩代码,但是变成了并行执行。 所以 ParallelUglifyPlugin 能更快的完成对多个文件的压缩工作。
压缩 CSS 代码的话,因为使用到 extract-text-webpack-plugin 插件将代码从 js 中分离出来,可以通过 optimize-css-assets-webpack-plugin 插件进行压缩,详细的配置项可以看:optimize-css-assets-webpack-plugin
上面讲了很多优化方式,但是无法面面俱到,对此你需要对打包输出结果做分析,以确认下一步的优化思路。这里推荐两个打包分析工具:
简单地介绍下第二种方式,接入方式很简单:
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
module.exports = {
plugins: [
new BundleAnalyzerPlugin()
]
}当你启动 webpack 时候,会唤起浏览器弹出 treemap,通过分析图可以清楚地看到:

本文更多地介绍一些思路,详细的优化步骤可以自己去尝试,你肯定会有更多的收获的!
参考链接:
最近在使用 CSS3 动画的时候遇到一个 DOM 层叠的问题,故此重新学习了一下 z-index,感觉这个 CSS 属性还是挺复杂的,希望本文可以帮助你重新认识 z-index 的魅力。
事情的经过是这样的(背景有点长),最近在写下面这样的列表页:
然后给每个产品项添加一个 CSS3 动画,动画效果大概像这样: demo 地址
实现后的效果大概是这样的(截图有点糊,建议点 demo 地址查看):
在 Chrome 上显示正常,但是从 Safari 打开,就发现不得了了,动画十分卡顿:
在切换不同的产品项的时候会发现页面动画明显卡顿,想到这,其实这难不倒我,于是我就给每个产品项添加 3D 动画硬件加速,方法也十分简单,就像下面这样。
.item {
transform: translateZ(0); /* 或者 will-change: transform; */
}这是一种常见的硬件加速的优化方式, 如果不懂的话可以看这个:用CSS开启硬件加速来提高网站性能
之后打开 Safari 后发现页面动画十分流畅,硬件加速的优化成功,但是随之而来又出现新的问题,也就是本文所说的 DOM 元素层叠问题。
虽然动画效果卡顿修复了,但是页面 DOM 元素层叠却出现问题:也就是下面的产品项会覆盖上面产品项右下角的入口弹框,而我们希望的正常的效果应该是这样:

遇到这样的问题,第一反应:那我将弹框的 z-index 调大不就好了,小菜一碟,但是无论我怎么调整 z-index 的值,弹框始终被下方的产品项所覆盖,一开始我也百思不得其解。
最后通过看了一些资料学习梳理,最终找到解决的办法,废话不多说,下面我就开始梳理整个 z-index 相关知识,并在最后提交上述问题的解决方案。(下文讲解会附带很多的用例,我将代码全部贴在 jsfiddle 方便查阅,读者可以点击 demo 地址查看例子)
首先介绍一下 z-index,z-index 属性是用来调整元素及子元素在 z 轴上的顺序,当元素发生覆盖的时候,哪个元素在上面,哪个元素在下面。通常来说,z-index 值较大的元素会覆盖较低的元素。
z-index 的默认值为 auto,可以设置正整数,也可以设置为负整数,如果不考虑 CSS3,只有定位元素(position:relative/absolute/fixed)的 z-index 才有作用,如果你的 z-index 作用于一个非定位元素(一些 CSS3 也会生效),是不起任何作用的。比如: demo 地址

当你为 DOM 元素设置了定位后,该元素的 z-index 就会生效,默认为 auto,你可以简单将它等同于 z-index: 0,比如:demo 地址,也就是说,z-index 生效的前提条件是必须要设置定位属性(或者一些 CSS3 属性),才能够生效
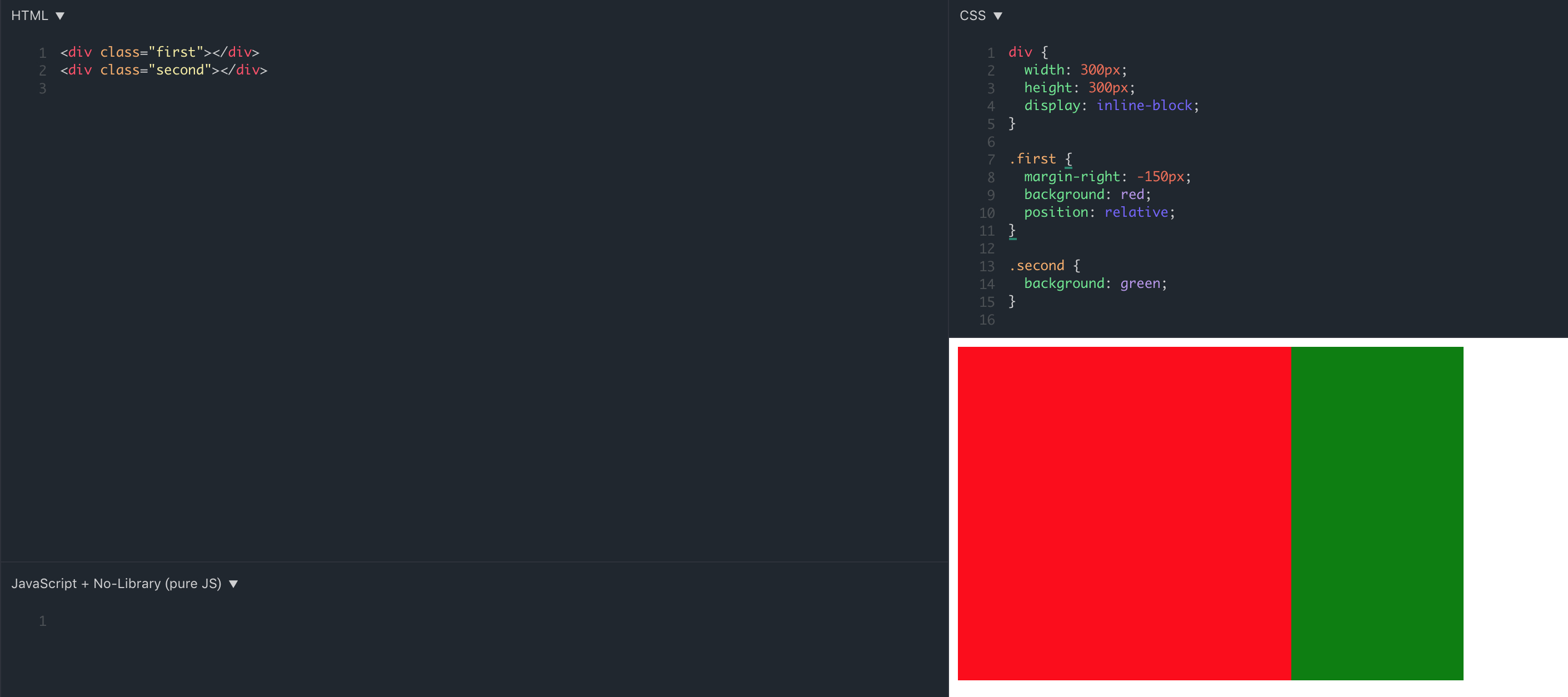
看完 demo 你可能会觉得纳闷,为啥我单单只设置了一个 position 属性,没设置 z-index 值,为啥红色方格会覆盖蓝色方格,这里就涉及到了 z-index 层叠水平的知识。
一个 DOM 元素,在不考虑层叠上下文的情况下,会按照层叠水平决定元素在 z 轴上的显示顺序,通俗易懂地讲,不同的 DOM 元素组合在一起发生重叠的时候,它们的的显示顺序会遵循层叠水平的规则,而 z-index 是用来调整某个元素显示顺序,使该元素能够上浮下沉。
那么层叠水平是什么样的呢?下面就是著名的 7 阶层叠水平(stacking level)
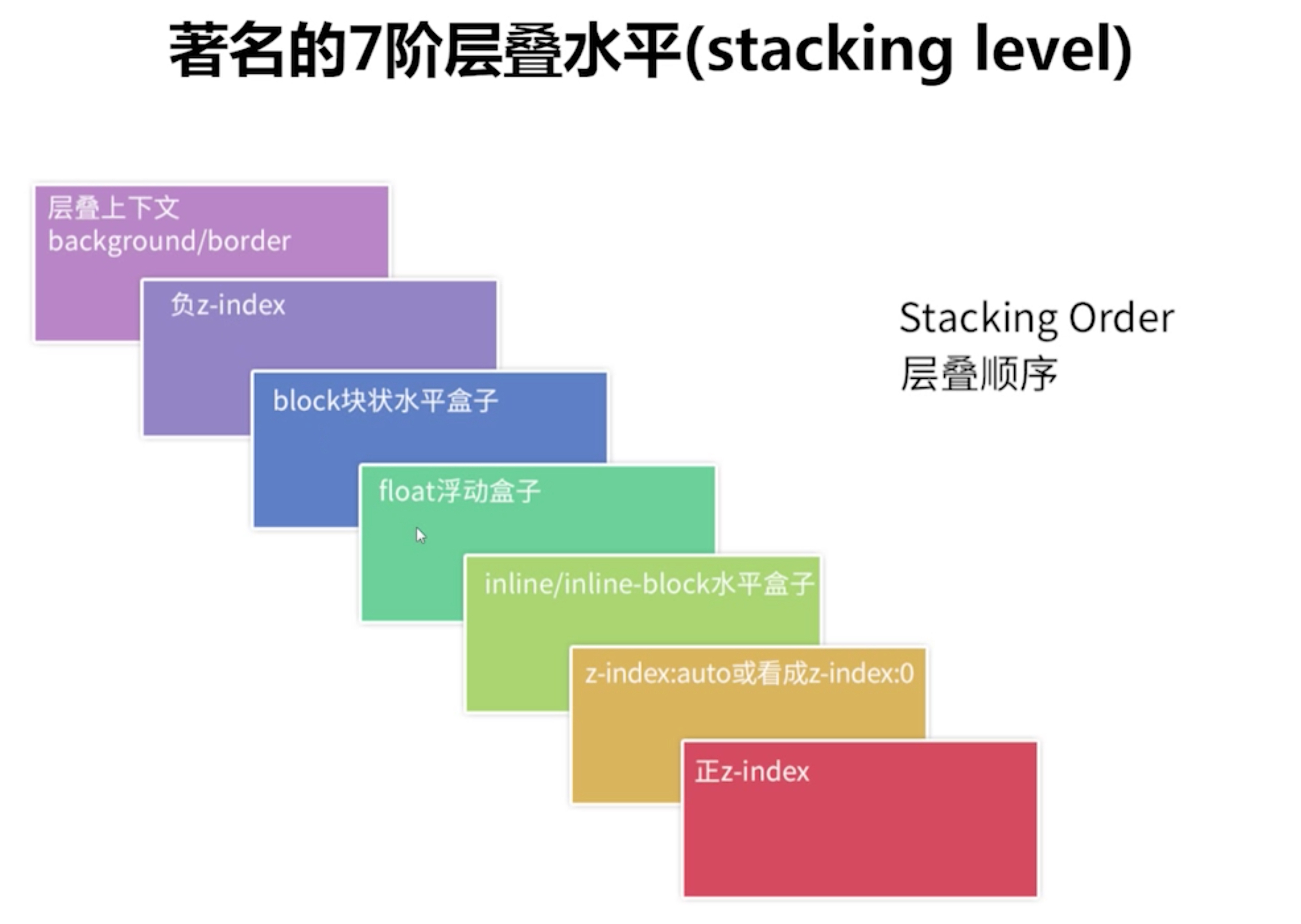
可以看出,层叠水平规范了元素重叠时候的呈现规则,有了这个规则,我们也就不难解释为何之前例子中红色方格会覆盖蓝色方格。因为当你设置了 position: relative 属性后,元素 z-index:auto 生效导致层叠水平提升,比普通内联元素来的高,所以红色方格会显示在上方。
知道了层叠水平的规则后,下面我就举几个例子来说明:
首先是 inline/inline-block 元素高于浮动元素,demo 地址
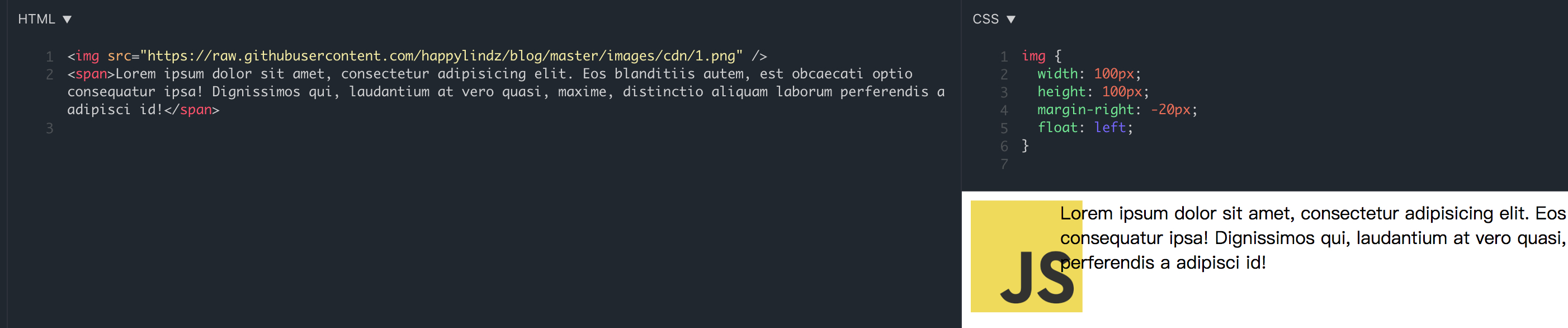
可以很清晰的看出文字(inline元素)覆盖了图片(浮动元素).
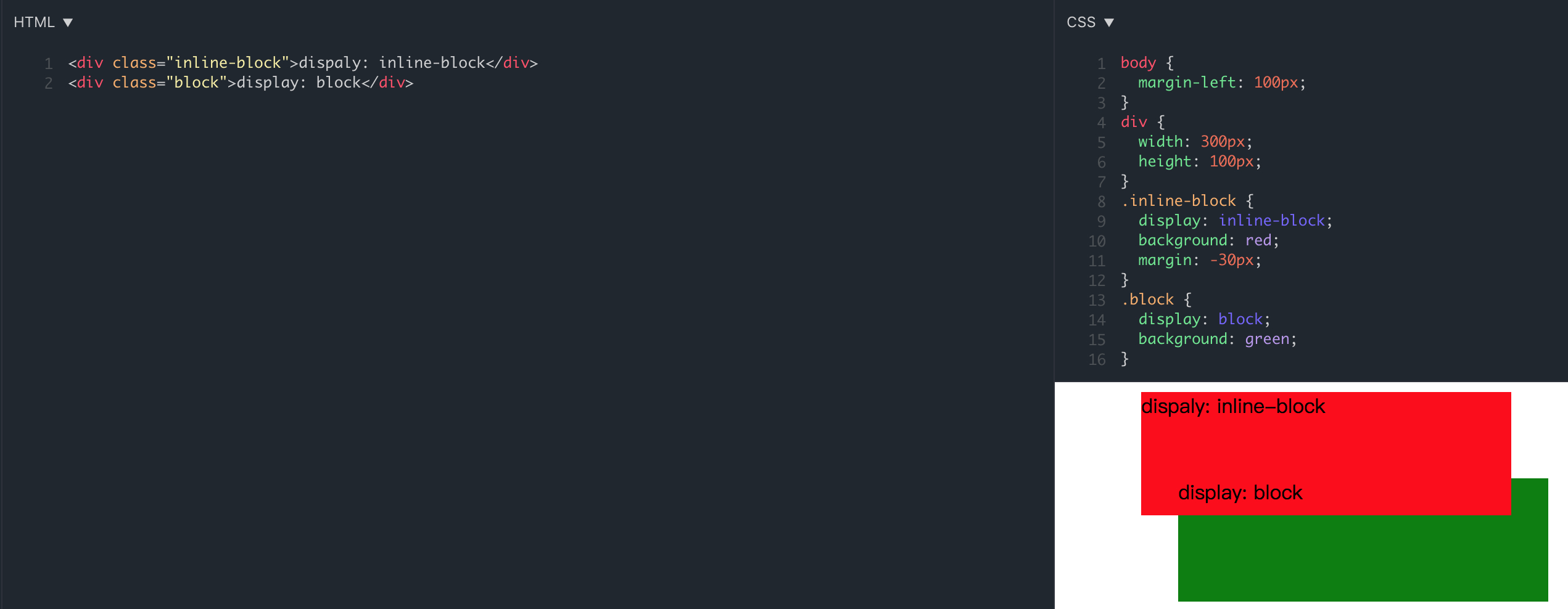
红色方格(inline-block)覆盖绿色方格(block),但是由于文字(display:block)属于 inline 水平,与红色方格(inline-block) 同级,遵循后来居上(接下来会解释)原则,没有被 inline-block 元素覆盖。
那么当两个元素层叠水平相同的时候,这时候就要遵循下面两个准则:
后来居上准则就是说,当元素层叠水平相同的时候后面的 DOM 会覆盖前面的 DOM 元素。这个很好理解,不过多解释了。这也就是我们经常会看到为什么后面的元素会覆盖前面的元素。正如前面看到的那个例子,由于文字(display:block)属于 inline 水平,与红色方格(inline-block) 同级,遵循后来居上(接下来会解释)原则,没有被 inline-block 元素覆盖,这里我就不另外贴例子来说明了。
因为 z-index 的存在,导致元素在相同的层叠上下文中的顺序是可以调整的,那么在 z-index 负值和正值的范围内,在这两个区间内的话 DOM 元素的 z-index 值越大,显示顺序就会越靠前。
知道了层叠水平之后,基本上只要元素在同一个层叠上下文中的显示顺序就确定了,但是如果是在不同的层叠上下文中呢,又是如何显示的呢?这个层叠上下文又是什么意思?别急,接着往下看。
层叠上下文,你可以理解为 JS 中的作用域,一个页面中往往不仅仅只有一个层叠上下文(因为有很多种方式可以生成层叠上下文,只是你没有意识到而已),在一个层叠上下文内,我们按照层叠水平的规则来堆叠元素。
介绍完层叠上下文的概念,我们先来看看哪些方式可以创建层叠上下文?
正常情况下,一共有三种大的类型创建层叠上下文:
默认创建层叠上下文,只有 HTML 根元素,这里你可以理解为 body 标签。它属于根层叠上下文元素,不需要任何 CSS 属性来触发。
依赖 z-index 值创建层叠上下文的情况:
这两种情况下,需要设置具体的 z-index 值,不能设置 z-index 为 auto,这也就是 z-index: auto 和 z-index: 0 的一点细微差别。
前面我们提到,设置 position: relative 的时候 z-index 的值为 auto 会生效,但是这时候并没有创建层叠上下文,当设置 z-index 不为 auto,哪怕设置 z-index: 0 也会触发元素创建层叠上下文。
这种情况下,基本上都是由 CSS3 中新增的属性来触发的,常见的有:
介绍完如何创建层叠上下文概念以及创建方式后,需要说明的是,创建了层叠上下文的元素可以理解局部层叠上下文,它只影响其子孙代元素,它自身的层叠水平是由它的父层叠上下文所决定的。
接下来就来总结一下如何比较两个 DOM 元素的显示顺序呢?
千言万语浓缩于这两句话中,但是里面注意的点有很多,我们先来看第一点:
如果是在相同的层叠上下文,按照层叠水平的规则来显示元素,这个之前在介绍层叠水平的时候就已经介绍了,值得注意的是,父子关系的元素很可能在相同的层叠上下文,这种情况下元素的层级比较也是按照层叠水平的规则来显示。
举个例子:demo 地址
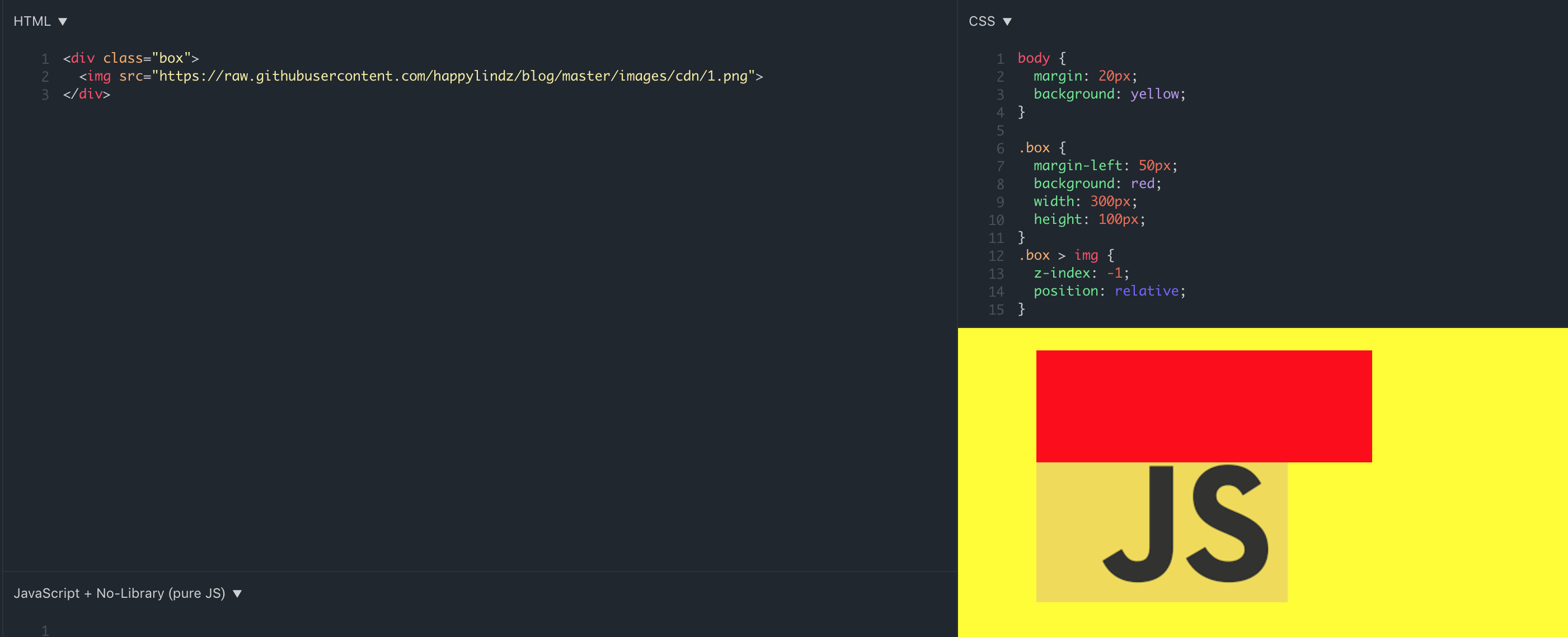
.box 元素和其子元素 img 的比较:因为 img 和 .box 属于相同的层叠上下文中,因为 img z-index 为 -1,所以下沉到父元素的下面,父元素覆盖了图片,但是 img 还是在 body 的背景色之上,因为遵循 7 阶层叠水平,最底下一定会是层叠上下文(body 元素)的 background 或者 border。
但是如果我们让 .box 元素创建局部层叠上下文的时候就不一样了,.box 元素和 img 元素的也是同处于相同层叠上下文,只不过上下文切换为 .box 创建的局部层叠上下文。
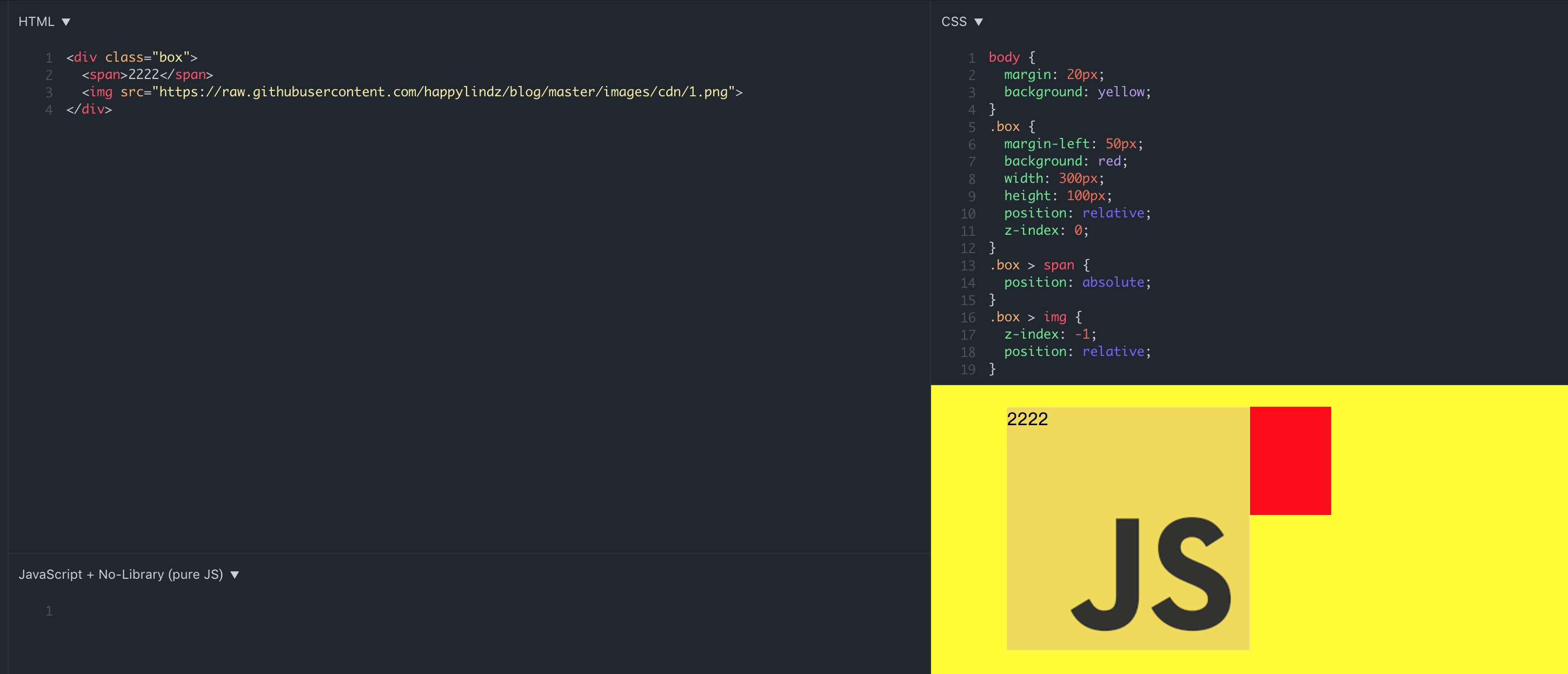
你会发现:img 元素覆盖了 .box 的背景色,因为层叠上下文的背景色永远是在最低下,层叠上下文由 body 元素变为了 .box 元素,但是如果是 .box 下的 span 元素和 img 元素的比较,inline 元素高于 z-index 为负值的元素,所以 2222 显示在图片之上。
通过这个例子是想说明,父子元素的层叠比较有可能父元素是局部层叠上下文,也可能不是局部层叠上下文,那么就需要去寻找共同的层叠上下文。
这个就比较复杂了,可以总结成一句话:打狗还得看主人,下面让我先画了草图来说明一下:
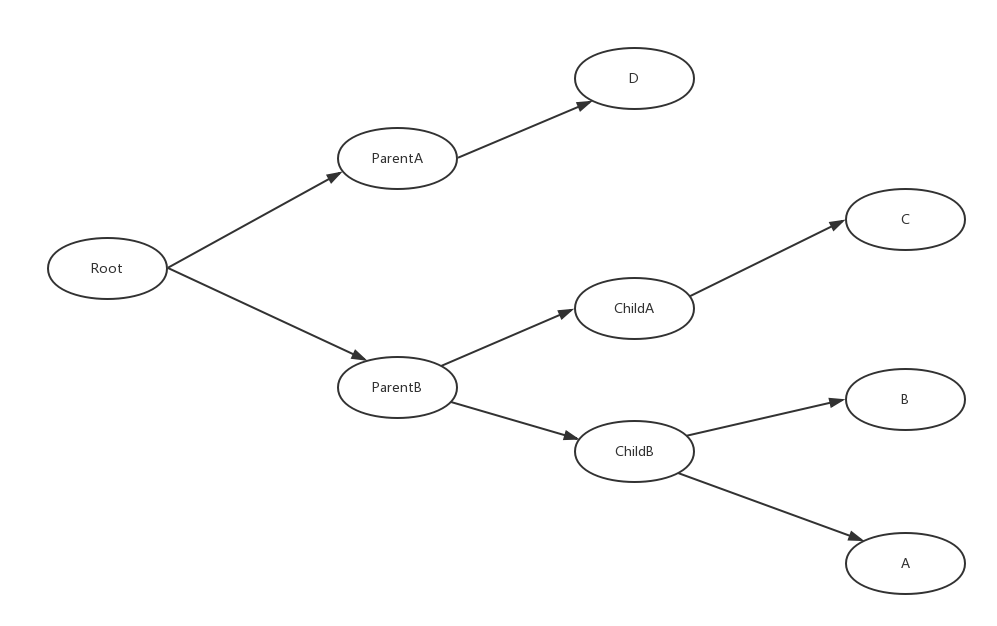
页面中常见的 DOM 树大概是长这样:这里 Root、ParentX、ChildX 均为层叠上下文元素,并非一定是 ABCD 的父元素
是不是很简单,下面再通过两个简单的小示例来说明一下:
示例一:demo 地址
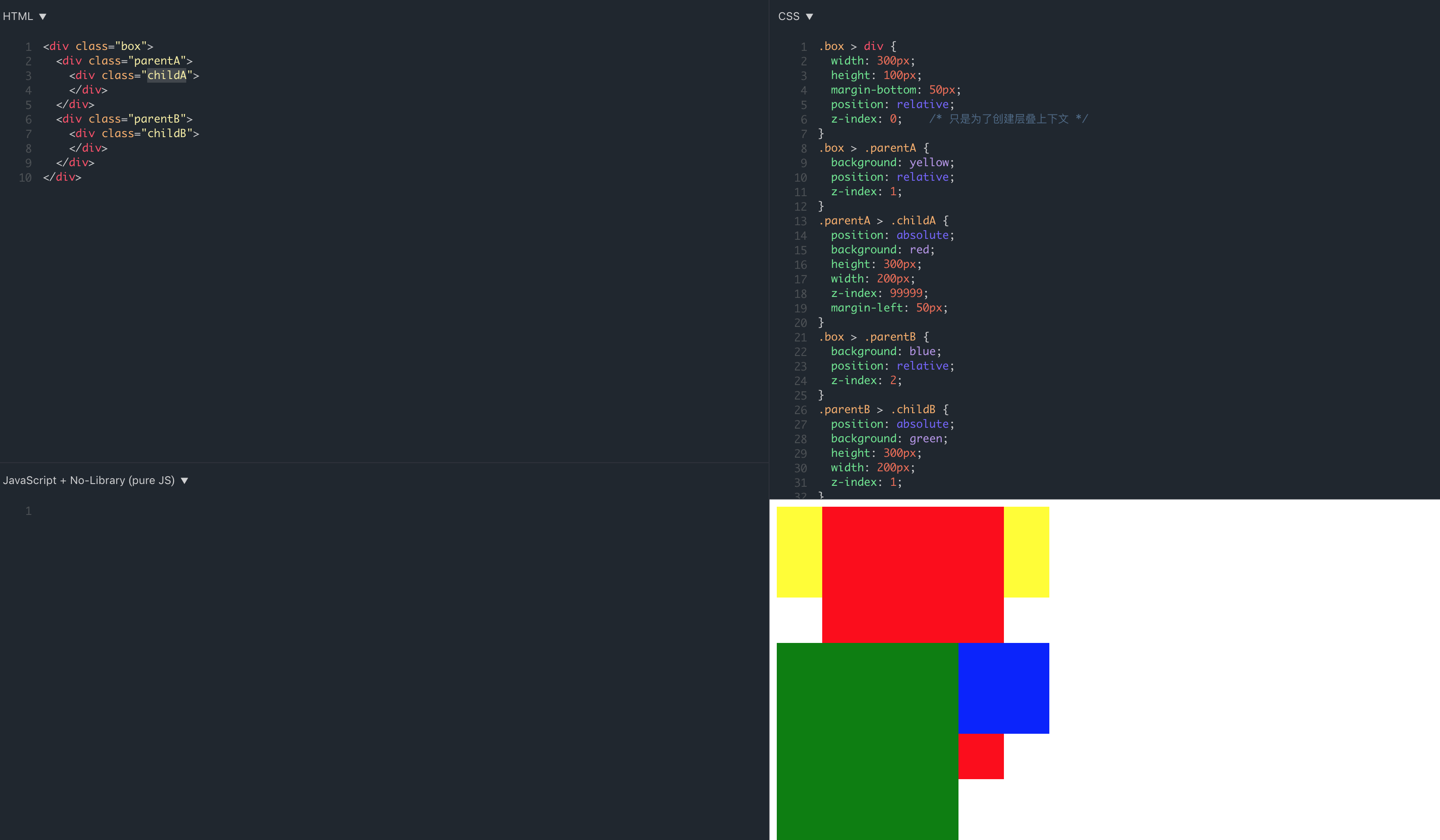
虽然 childA 的 z-index: 9999 非常大,但是在跟 parentB 或者 childB 比较的时候,它没资格去比,只能让它的老大 parentA 去比较,parentA 跟 parentB 一比较,才发现:妈呀,原来你的 z-index 为 2 比我还大,失敬失敬,所以 childA 和 parentA 只好乖乖呆在 parentB 底下。
如果我们将例子稍微改下,让 parentA 不再创建新的层叠上下文元素:demo 地址
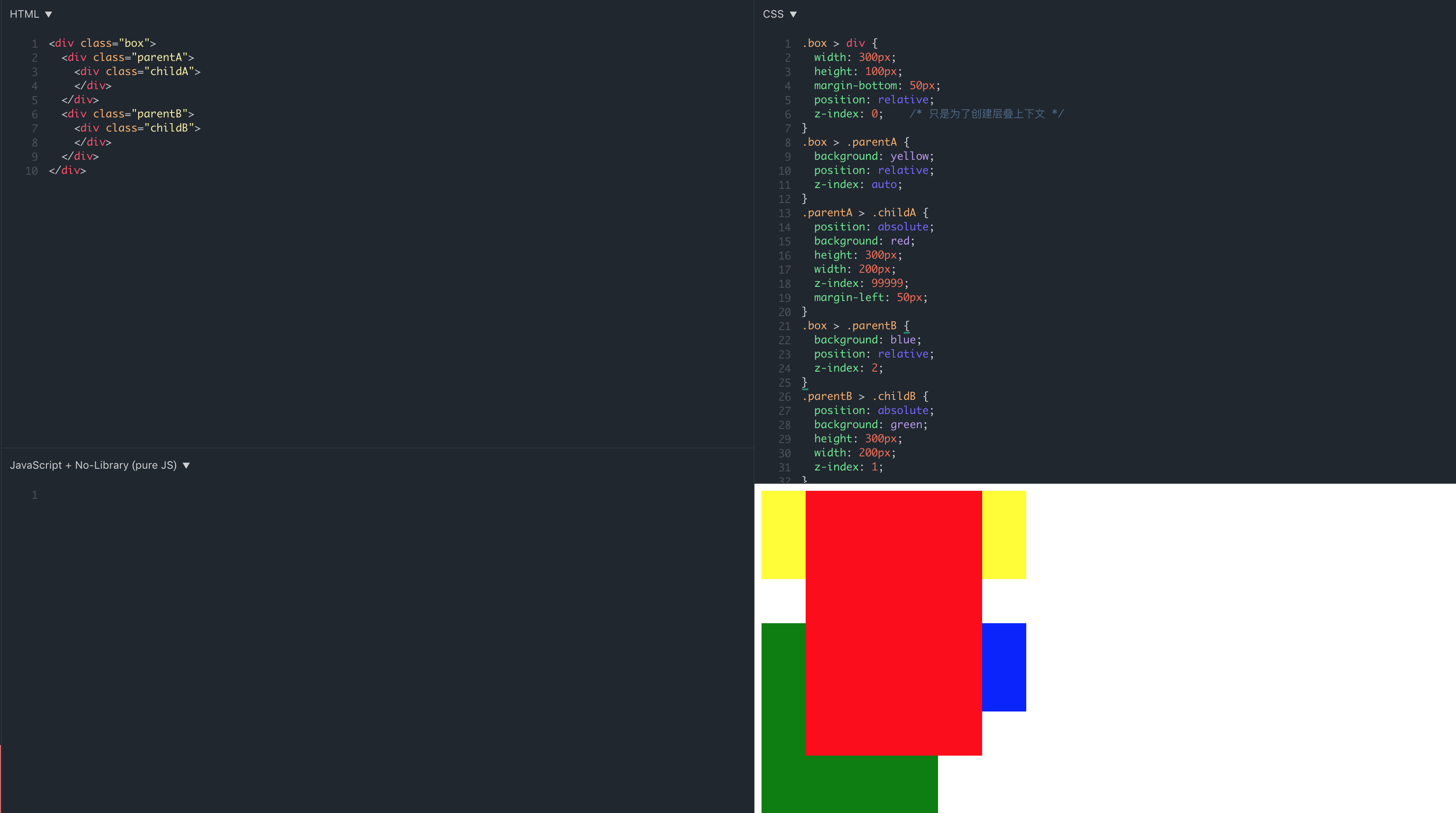
当 parentA 不再创建层叠上下文之后,childA 想跟 childB 比较,就不再受限于 parentA,而是直接跟 parentB 直接比较(因为 childA 和 parentB 在同一个层叠上下文),显然 childA 在最上方,这也就是 childA 覆盖 parentB 的原因。
理论知识已经介绍完了,如果你理解了上面的理论,这个问题应该是小菜一碟,下面就来说说一开始问题的解决方案:
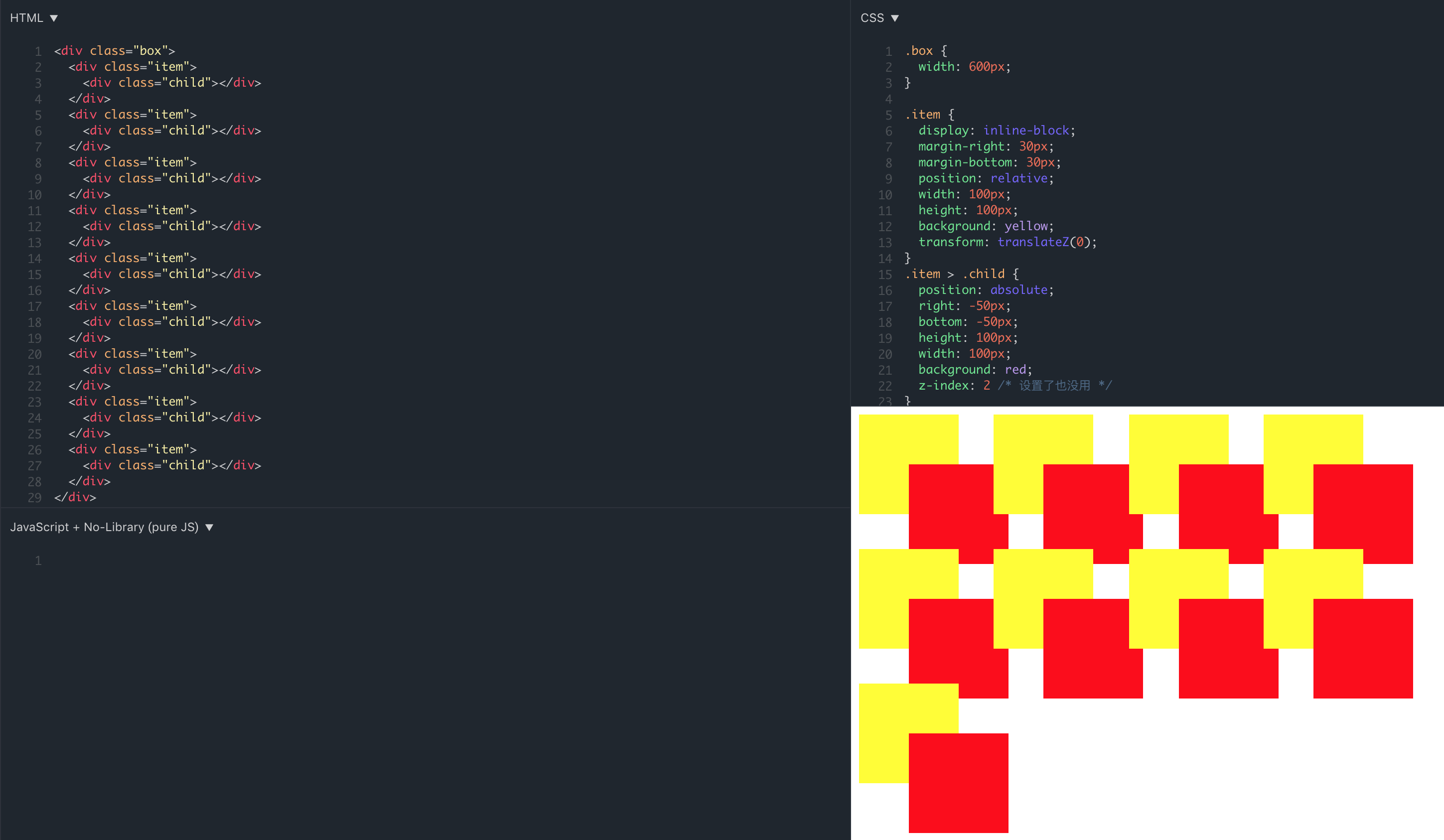
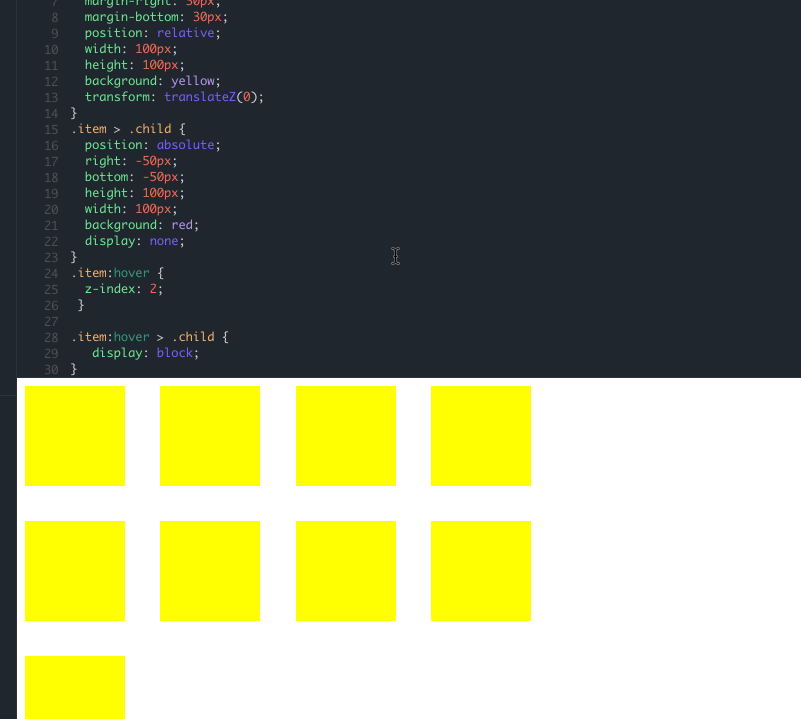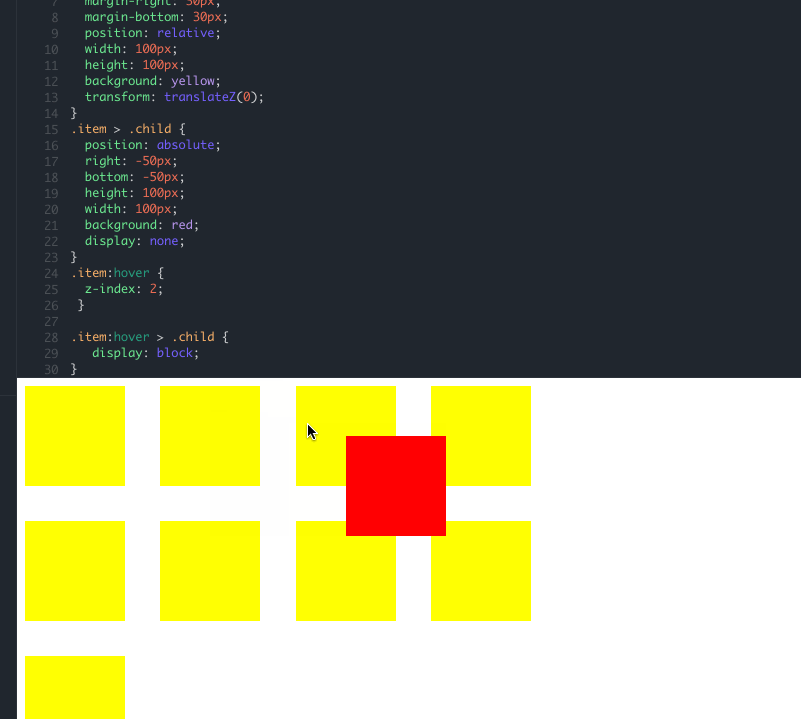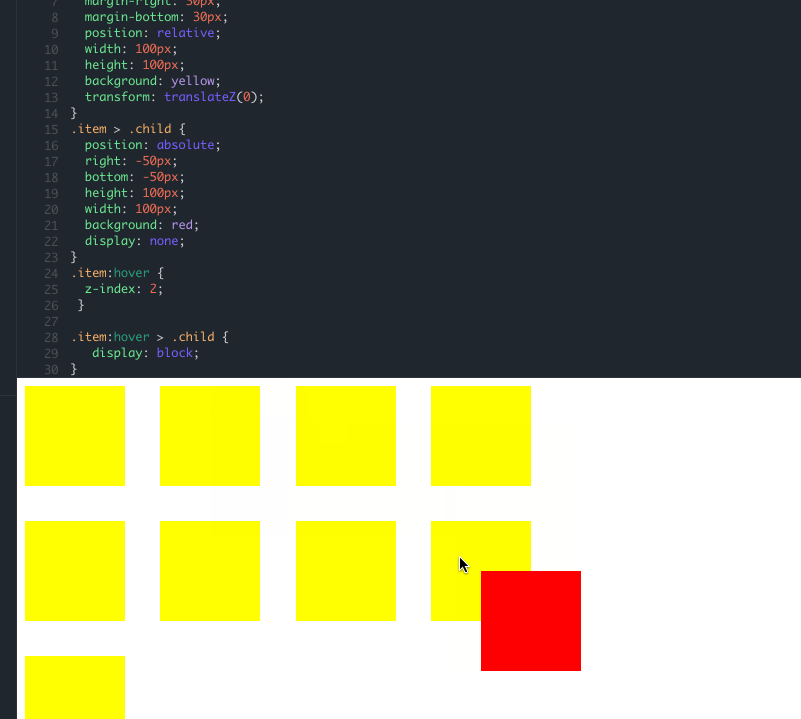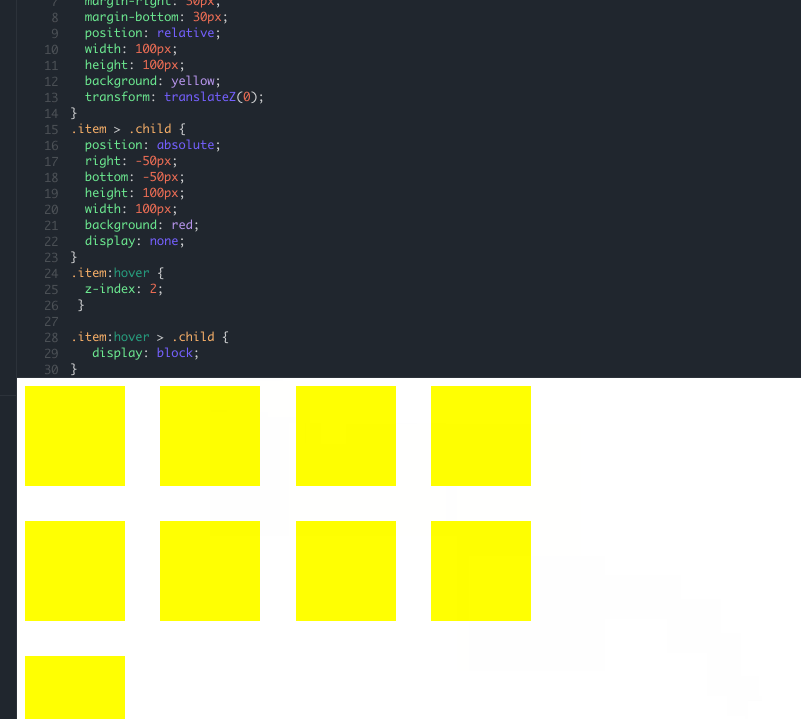
因为在每个产品项上添加了 transform: translateZ(0) 导致每一个产品项都创建了一个层叠上下文,根据前面提到规则,每个产品项里面的 DOM 元素的都是相互独立的,取决于每个产品项(每个局部层叠上下文),又由于这些产品项的层叠水平一致(与 z-index: auto 相同),遵循后来居上原则,这才导致了后面的元素会去覆盖前面的元素。举个简单的例子: demo 地址
就像这样,即使你在 child 上添加多大的 z-index 属性都不会改变它的层叠水平,唯一的办法就是改变 item 的 z-index 数值,由于我们覆盖的部分比较特殊,仅仅只是弹框部分,而弹框部分默认是不显示的,只有当鼠标悬浮到入口的时候才会显示,最简单的方式就是,当鼠标 hover 到 item 上的时候,将其 z-index 值变大即可,破坏后来居上的特性: demo 地址
最终简化效果:
说到这其实可以结束了,我在学习的过程中,看了张鑫旭大佬之前录的视频,他提出了一些最佳实践,我觉得挺不错的,这里也简单地介绍一下:
对于非浮层元素,不要过多地去运用 z-index 去调整显示顺序,要灵活地去运用层叠水平和后来居上的准则去让元素获得正确的显示,如果是在要设置 z-index 去调整,不建议非浮层元素 z-index 数值超过 2,对于 DOM 元素,-1, 0, 1, 2 足够让元素有正确的显示顺序。
对于浮层元素,往往是第三方组件开发,当你无法确认你的浮层是否会百分百覆盖在 DOM 树上的时候,你可以去动态获取页面 body 元素下所有子元素 z-index 的最大值,在此基础加一作为浮层元素 z-index 值,用于保证该浮层元素能够显示在最上方。
最后的最后,本篇深入 z-index 属性已经就完结了,感觉 CSS 属性有许许多多的彩蛋,接下来有时间多接触,多总结,有时间会继续分享出来。
最近在给我的博客网站 PWA 升级,顺便就记录下 React 同构应用在使用 PWA 时遇到的问题,这里不会从头开始介绍什么是 PWA,如果你想学习 PWA 相关知识,可以看下下面我收藏的一些文章:
PWA 不是单纯的某项技术,而是一堆技术的集合,比如:Service Worker,manifest 添加到桌面,push、notification api 等。
而就在前不久时间,IOS 11.3 刚刚支持 Service worker 和类似 manifest 添加到桌面的特性,所以这次 PWA 改造主要还是实现这两部分功能,至于其它的特性,等 iphone 支持了再升级吧。
service worker 在我看来,类似于一个跑在浏览器后台的线程,页面第一次加载的时候会加载这个线程,在线程激活之后,通过对 fetch 事件,可以对每个获取的资源进行控制缓存等。
那么在开始使用 service worker 之前,首先需要清楚哪些资源需要被缓存?
首先是像 CSS、JS 这些静态资源,因为我的博客里引用的脚本样式都是通过 hash 做持久化缓存,类似于:main.ac62dexx.js 这样,然后开启强缓存,这样下次用户下次再访问我的网站的时候就不用重新请求资源。直接从浏览器缓存中读取。对于这部分资源,service worker 没必要再去处理,直接放行让它去读取浏览器缓存即可。
我认为如果你的站点加载静态资源的时候本身没有开启强缓存,并且你只想通过前端去实现缓存,而不需要后端在介入进行调整,那可以使用 service worker 来缓存静态资源,否则就有点画蛇添足了。
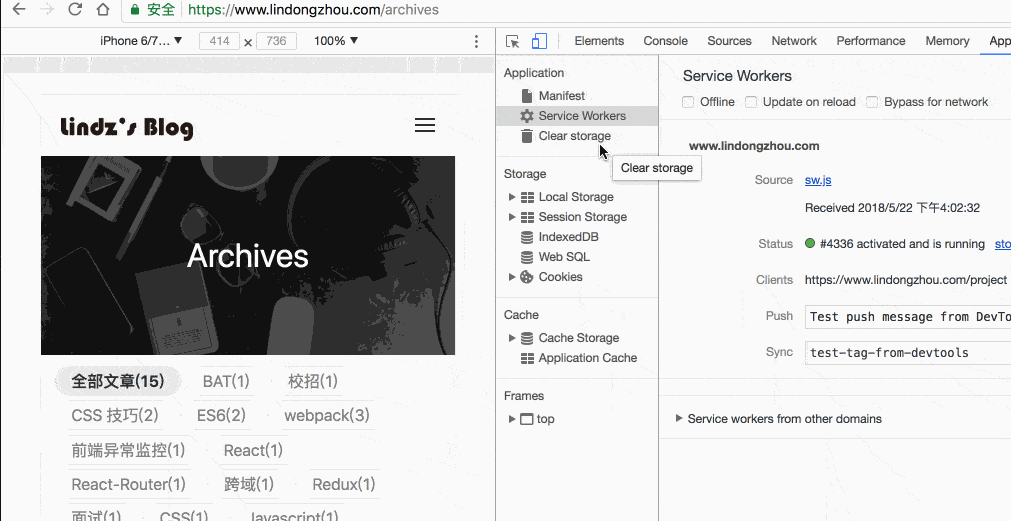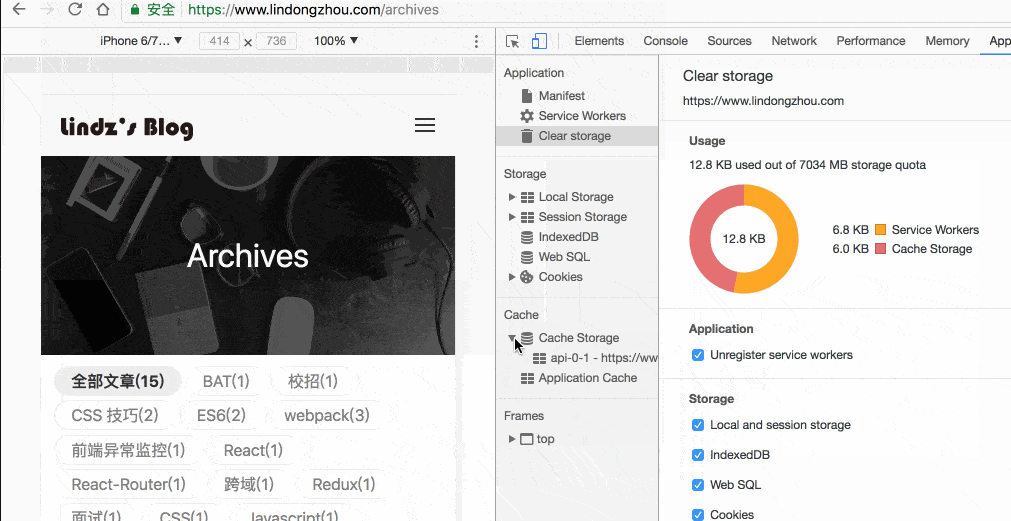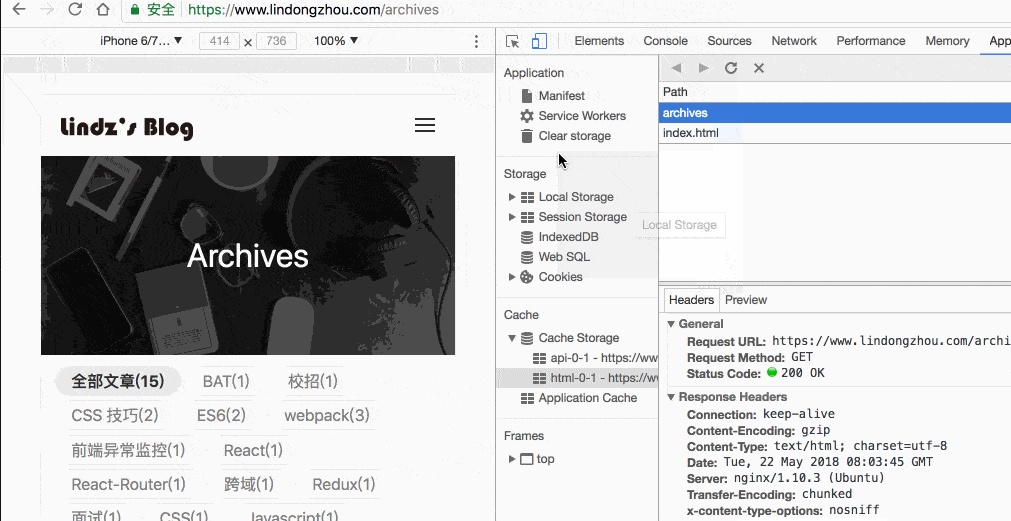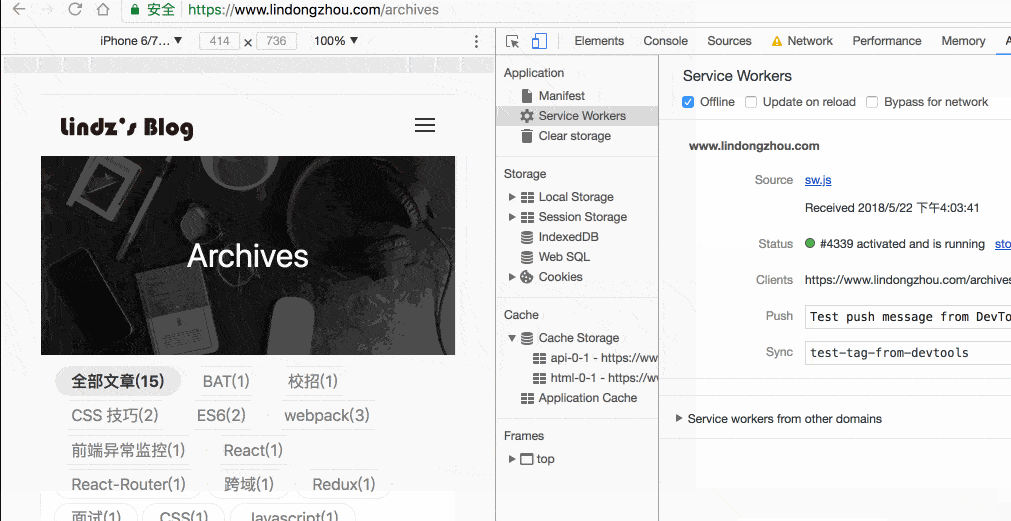
缓存页面显然是必要的,这是最核心的部分,当你在离线的状态下加载页面会之后出现:

究其原因就是因为你在离线状态下没办法加载页面,现在有了 service worker,即使你在没网络的情况下,也可以加载之前缓存好的页面了。
缓存接口数据是需要的,但也不是必须通过 service worker 来实现,前端存放数据的地方有很多,比如通过 localstorage,indexeddb 来进行存储。这里我也是通过 service worker 来实现缓存接口数据的,如果想通过其它方式来实现,只需要注意好 url 路径与数据对应的映射关系即可。
明确了哪些资源需要被缓存后,接下来就要谈谈缓存策略了。
因为是 React 单页同构应用,每次加载页面的时候数据都是动态的,所以我采取的是:
/index.html 默认首页// sw.js
self.addEventListener('fetch', (e) => {
console.log('现在正在请求:' + e.request.url);
const currentUrl = e.request.url;
// 匹配上页面路径
if (matchHtml(currentUrl)) {
const requestToCache = e.request.clone();
e.respondWith(
// 加载网络上的资源
fetch(requestToCache).then((response) => {
// 加载失败
if (!response || response.status !== 200) {
throw Error('response error');
}
// 加载成功,更新缓存
const responseToCache = response.clone();
caches.open(cacheName).then((cache) => {
cache.put(requestToCache, responseToCache);
});
console.log(response);
return response;
}).catch(function() {
// 获取对应缓存中的数据,获取不到则退化到获取默认首页
return caches.match(e.request).then((response) => {
return response || caches.match('/index.html');
});
})
);
}
});为什么存在命中不了缓存页面的情况?
结合上面三点,我的方法是:第一次加载的时候会缓存 /index.html 这个资源,并且缓存页面上的数据,如果用户立刻离线加载的话,这时候并没有缓存对应的路径,比如 /archives 资源访问不到,这返回 /index.html 走异步加载页面的逻辑。
在 install 事件缓存 /index.html,保证了 service worker 第一次加载的时候缓存默认页面,留下退路。
import constants from './constants';
const cacheName = constants.cacheName;
const apiCacheName = constants.apiCacheName;
const cacheFileList = ['/index.html'];
self.addEventListener('install', (e) => {
console.log('Service Worker 状态: install');
const cacheOpenPromise = caches.open(cacheName).then((cache) => {
return cache.addAll(cacheFileList);
});
e.waitUntil(cacheOpenPromise);
});在页面加载完后,在 React 组件中立刻缓存数据:
// cache.js
import constants from '../constants';
const apiCacheName = constants.apiCacheName;
export const saveAPIData = (url, data) => {
if ('caches' in window) {
// 伪造 request/response 数据
caches.open(apiCacheName).then((cache) => {
cache.put(url, new Response(JSON.stringify(data), { status: 200 }));
});
}
};
// React 组件
import constants from '../constants';
export default class extends PureComponent {
componentDidMount() {
const { state, data } = this.props;
// 异步加载数据
if (state === constants.INITIAL_STATE || state === constants.FAILURE_STATE) {
this.props.fetchData();
} else {
// 服务端渲染成功,保存页面数据
saveAPIData(url, data);
}
}
}这样就保证了用户第一次加载页面,立刻离线访问站点后,虽然无法像第一次一样能够服务端渲染数据,但是之后能通过获取页面,异步加载数据的方式构建离线应用。
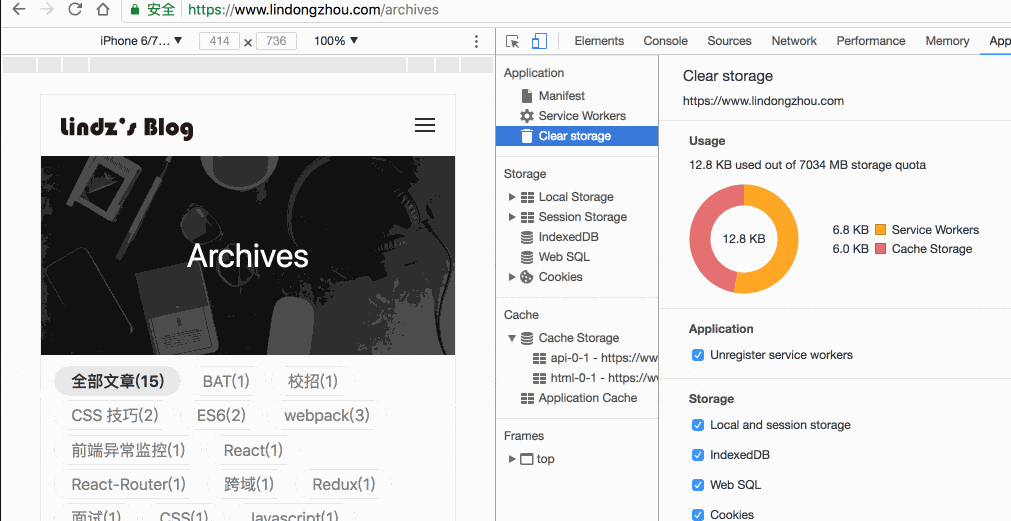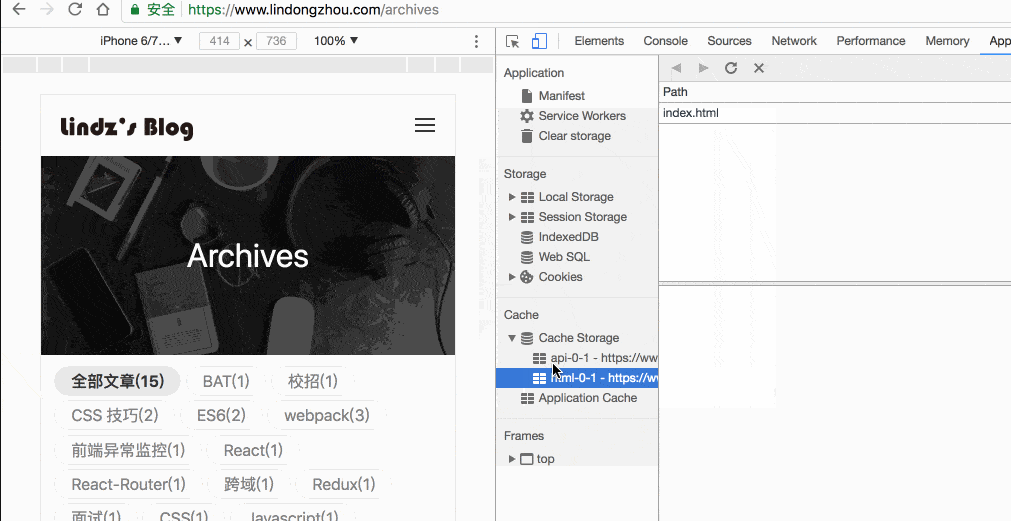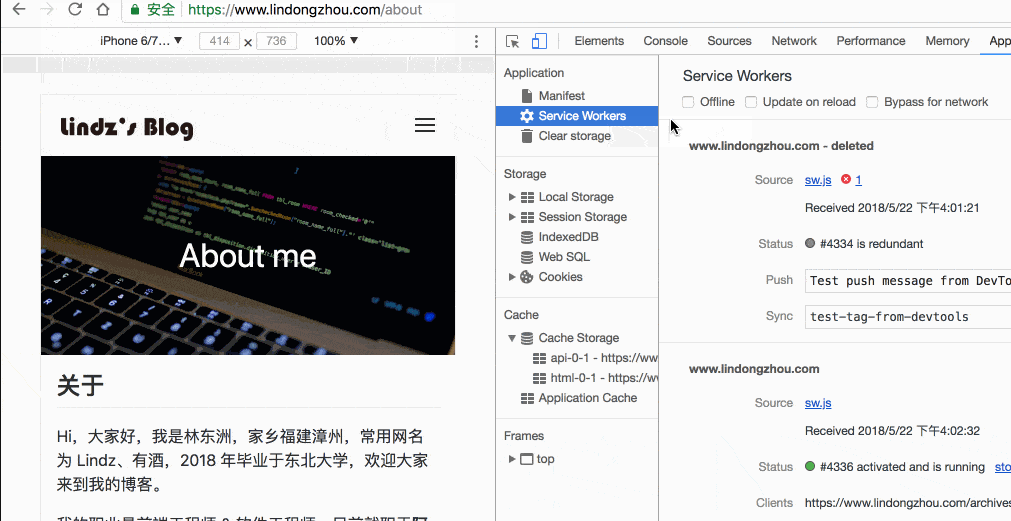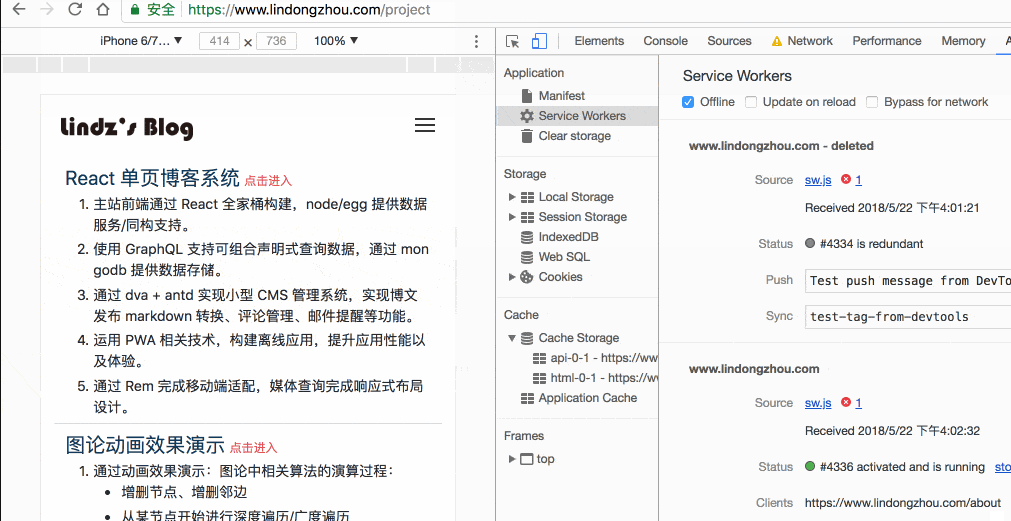
用户第一次访问站点,如果在不刷新页面的情况切换路由到其他页面,则会异步获取到的数据,当下次访问对应的路由的时候,则退化到异步获取数据。
当用户第二次加载页面的时候,因为 service worker 已经控制了站点,已经具备了缓存页面的能力,之后在访问的页面都将会被缓存或者更新缓存,当用户离线访问的的时候,也能访问到服务端渲染的页面了。
谈完页面缓存,再来讲讲接口缓存,接口缓存就跟页面缓存很类似了,唯一的不同在于:页面第一次加载的时候不一定有缓存,但是会有接口缓存的存在(因为伪造了 cache 中的数据),所以缓存策略跟页面缓存类似:
所以代码就像这样(代码类似,不再赘述):
self.addEventListener('fetch', (e) => {
console.log('现在正在请求:' + e.request.url);
const currentUrl = e.request.url;
if (matchHtml(currentUrl)) {
// ...
} else if (matchApi(currentUrl)) {
const requestToCache = e.request.clone();
e.respondWith(
fetch(requestToCache).then((response) => {
if (!response || response.status !== 200) {
return response;
}
const responseToCache = response.clone();
caches.open(apiCacheName).then((cache) => {
cache.put(requestToCache, responseToCache);
});
return response;
}).catch(function() {
return caches.match(e.request);
})
);
}
});这里其实可以再进行优化的,比如在获取数据接口的时候,可以先读取缓存中的接口数据进行渲染,当真正的网络接口数据返回之后再进行替换,这样也能有效减少用户的首屏渲染时间。当然这可能会发生页面闪烁的效果,可以添加一些动画来进行过渡。
到现在为止,已经基本上可以实现 service worker 离线缓存应用的效果了,但是还有仍然存在一些问题:
默认情况下,页面的请求(fetch)不会通过 sw,除非它本身是通过 sw 获取的,也就是说,在安装 sw 之后,需要刷新页面才能有效果。sw 在安装成功并激活之前,不会响应 fetch或push等事件。
因为站点是单页面应用,这就导致了你在切换路由(没有刷新页面)的时候没有缓存接口数据,因为这时候 service worker 还没有开始工作,所以在加载 service worker 的时候需要快速地激活它。代码如下:
self.addEventListener('activate', (e) => {
console.log('Service Worker 状态: activate');
const cachePromise = caches.keys().then((keys) => {
return Promise.all(keys.map((key) => {
if (key !== cacheName && key !== apiCacheName) {
return caches.delete(key);
}
return null;
}));
});
e.waitUntil(cachePromise);
// 快速激活 sw,使其能够响应 fetch 事件
return self.clients.claim();
});有的文章说还需要在 install 事件中添加 self.skipWaiting(); 来跳过等待时间,但是我在实践中发现即使不添加也可以正常激活 service worker,原因不详,有读者知道的话可以交流下。
现在当你第一次加载页面,跳转路由,立刻离线访问的页面,也可以顺利地加载页面了。
用户每次访问页面的时候都会去重新获取 sw.js,根据文件内容跟之前的版本是否一致来判断 service worker 是否有更新。所以如果你对 sw.js 开启强缓存的话,就将陷入死循环,因为每次页面获取到的 sw.js 都是一样,这样就无法升级你的 service worker。
另外对 sw.js 开启强缓存也是没有必要的:
在 sw 中这么做是“最差实践”,要在原地址上修改 sw。
举个例子来说明为什么:
如果你像上面那么做,用户永远也拿不到 sw-v2.js,因为 index.html 在 sw-v1.js 缓存中,这样的话,如果你想更新为 sw-v2.js,还需要更改原来的 sw-v1.js。
自此,我们已经完成了使用 service worker 对页面进行离线缓存的功能,如果想体验功能的话,访问我的博客:https://lindongzhou.com
随意浏览任意的页面,然后关掉网络,再次访问,之前你浏览过的页面都可以在离线的状态下进行访问了。
IOS 需要 11.3 的版本才支持,使用 Safari 进行访问,Android 请选择支持 service worker 的浏览器
前面讲完了如何使用 service worker 来离线缓存你的同构应用,但是 PWA 不仅限于此,你还可以使用设置 manifest 文件来将你的站点添加到移动端的桌面上,从而达到趋近于原生应用的体验。
我的博客站点是通过 webpack 来构建前端代码的,所以我在社区里找到 webpack-pwa-manifest 插件用来生成 manifest.json。
首先安装好 webpack-pwa-manifest 插件,然后在你的 webpack 配置文件中添加:
// webpack.config.prod.js
const WebpackPwaManifest = require('webpack-pwa-manifest');
module.exports = webpackMerge(baseConfig, {
plugins: [
new WebpackPwaManifest({
name: 'Lindz\'s Blog',
short_name: 'Blog',
description: 'An isomorphic progressive web blog built by React & Node',
background_color: '#333',
theme_color: '#333',
filename: 'manifest.[hash:8].json',
publicPath: '/',
icons: [
{
src: path.resolve(constants.publicPath, 'icon.png'),
sizes: [96, 128, 192, 256, 384, 512], // multiple sizes
destination: path.join('icons')
}
],
ios: {
'apple-mobile-web-app-title': 'Lindz\'s Blog',
'apple-mobile-web-app-status-bar-style': '#000',
'apple-mobile-web-app-capable': 'yes',
'apple-touch-icon': '//xxx.com/icon.png',
},
})
]
})简单地阐述下配置信息:
设置完之后,webpack 会在构建过程中生成相应的 manifest 文件,并在 html 文件中引用,下面就是生成 manifest 文件:
{
"icons": [
{
"src": "/icons/icon_512x512.79ddc5874efb8b481d9a3d06133b6213.png",
"sizes": "512x512",
"type": "image/png"
},
{
"src": "/icons/icon_384x384.09826bd1a5d143e05062571f0e0e86e7.png",
"sizes": "384x384",
"type": "image/png"
},
{
"src": "/icons/icon_256x256.d641a3644ce20c06855db39cfb2f7b40.png",
"sizes": "256x256",
"type": "image/png"
},
{
"src": "/icons/icon_192x192.8f11e077242cccd9c42c0cbbecd5149c.png",
"sizes": "192x192",
"type": "image/png"
},
{
"src": "/icons/icon_128x128.cc0714ab18fa6ee6de42ef3d5ca8fd09.png",
"sizes": "128x128",
"type": "image/png"
},
{
"src": "/icons/icon_96x96.dbfccb1a5cef8093a77c079f761b2d63.png",
"sizes": "96x96",
"type": "image/png"
}
],
"name": "Lindz's Blog",
"short_name": "Blog",
"orientation": "portrait",
"display": "standalone",
"start_url": ".",
"description": "An isomorphic progressive web blog built by React & Node",
"background_color": "#333",
"theme_color": "#333"
}html 中会引用这个文件,并且加上对 ios 添加桌面应用的支持,就像这样。
<!DOCTYPE html>
<html lang=en>
<head>
<meta name=apple-mobile-web-app-title content="Lindz's Blog">
<meta name=apple-mobile-web-app-capable content=yes>
<meta name=apple-mobile-web-app-status-bar-style content=#838a88>
<link rel=apple-touch-icon href=xxxxx>
<link rel=manifest href=/manifest.21d63735.json>
</head>
</html>就这么简单,你就可以使用 webpack 来添加你的桌面应用了。
添加完之后你可以通过 chrome 开发者工具 Application - Manifest 来查看你的 mainfest 文件是否生效:

这样说明你的配置生效了,安卓机会自动识别你的配置文件,并询问用户是否添加。
讲到这差不多就完了,等以后 IOS 支持 PWA 的其它功能的时候,到时候我也会相应地去实践其它 PWA 的特性的。现在 IOS 11.3 也仅仅支持 PWA 中的 service worker 和 app manifest 的功能,但是相信在不久的将来,其它的功能也会相应得到支持,到时候相信 PWA 将会在移动端绽放异彩的。
最近有幸受老师邀请,总结一篇关于应届生校招求职的文章,我将它分享出来,希望可以帮助到跟我曾经一样找工作迷茫的同学。
首先介绍一下个人情况,我是某双一流大学的学生,专业是软件工程,在大学期间一直学习从事 Web 前端相关的工作,大三暑期曾在深圳腾讯实习三个月,秋招非常荣幸先后收获阿里、腾讯、头条、美团等企业 offer,最终选择到阿里工作,接下来我就从一名前端工程师的角度来谈谈一名应届生应该如何去获得大公司的校招 offer。
大公司面试无论是实习还是校招,普遍存在面试轮次多,面试周期长的特点,就拿腾讯来说,如果你想成为暑期实习生,大概需要四到五轮面试,3-4 轮技术面+一轮 HR 面试,每次面试时间大概在 0.5-1 小时之间,推荐对自己能力没有把握或者缺少工作经验的同学尽可能在大三下学期找找实习,去自己想去的公司实习,因为大三的暑期实习既可以丰富你的履历,并且实习期间好好表现都是可以相对容易地通过转正,拿到校招 offer。
在申请实习或者校招 offer 的时候,尽可能多找人帮忙内推(ps: 实在找不到人的话可以找我),因为大公司部门比较多,你如果直接从官网上网申的话,简历不容易被人查看,找认识的师兄师姐帮忙内推的优势在于:
内推或者网申(可能有笔试)完之后,就等待面试官打电话给你,一般他们会跟你通过电话或者短信确认现在是否方便或者约个时间进行面试,面试的方式也分为电话面试,视频面试,现场面试等等。
无论是哪种类型的面试,内容大致上都是一致的(除了现场面试可能要求你手写代码外),我将专业技能面试分为以下几个部分:
首先是自我介绍,面试前最好能够准备一段不少于 30 秒的自我介绍并对着镜子反复练习,可以介绍介绍你的名字,学校,专业,对你投递岗位的理解等等,在面试过程中尽可能流利地叙述,而不是介绍时磕磕碰碰,给面试官留下不好的印象。
第二部分是计算机基础知识,对于应届生来说,面试官无非喜欢考察计算机网络,操作系统,数据结构与算法这三大类。当然根据你应聘的岗位有所不同,如果你是应聘一名前端工程师,考察网络的知识相对较多,对于操作系统、数据结构和算法的考察会相对较少,如果你是应聘一个后端工程师的话,那么涉及到操作系统的知识肯定会相对更多。同理算法工程师就会涉及到更多数据结构和算法的知识。
面试网络知识的话,可以多准备 HTTP/TCP 相关的知识,比如我就常被问到:
第三大块也就是你应聘的岗位相关的知识内容了,比如拿前端来说,一般前端知识可以分为三大块:语言基础,框架以及实践。
语言基础一般会考察你对 JS 语言本身的理解,比如说:闭包,继承,作用域,this 用法,ES6 语法等等,也会问你关于 HTML/CSS 的基础知识。
框架的话不仅仅是局限于考察对框架的用法,一般是结合你的简历内容来进行提问,比如你在简历上写你熟悉 React,面试官可能就会问你 virtual-dom 是怎么实现的,Redux 设计**等等,如果你简历上写熟悉 Vue,那可能就会问你数据双向绑定是怎么实现的等等。
还有就是你的实践部分,这部分面试官会结合你的简历提到的一些经历,比如你有什么实习经历阿,或者在学校做过什么项目来进行提问。可能会像这样问你:
一般面试结束后面试官都会问你,还有什么问题想问我,这时候你可以就你感兴趣的内容进行提问,比如我一般就会问下面类型的问题:
这就是标准的面试过程,面试结束后如果你通过面试的话,一般一周内会给答复或者进行下一轮面试。
最后需要强调的是,公司面试周期一般都会比较长,可能你从二月底开始面试,到了四月份你才会收到 offer,所以你应该多投投几家公司,不要在一棵树上吊死,不要抱着非 xxx 公司不去的心态,因为面试这种东西其实是很玄学的,七分实力,三分运气,可能你觉得良好,但是面试官却把你 pass 掉了,所以放平常心,多试试几家公司,说不定会有意外的收获。
前面介绍了面试流程中的一些注意事项,下面就来说说如何去做面试前的准备。我将面试准备分为三个部分:
我看很多人写的简历,发现他们写的都很啰嗦,让人一眼看过去抓不住重点,我建议最好把简历精简一下,控制在 1-2 页,写的经历和项目跟你应聘的岗位有强相关,无关的经历就不要写了,写了反而显得啰嗦。像我百用不烂的的模板就像下图这样:
另外还有三点需要注意:
简历是你获得面试的第一步,简历的好坏需要自己用心准备,希望同学们提前认真地准备好一份觉得让自己满意的简历,以免到时候太仓促。
这部分内容肯定是需要通过自己的不断积累的,不可能说你看了两天 JS 语法就跑来面试,学了两天 Java 就来面试后端工程师。
我们经常会通过网上文章学习内容,我的建议:善于使用浏览器的书签帮助你自己整体知识。
网路上学习技术的途径也很多:
每个岗位都有自己不同的知识体系,在其它领域我也不是专业的,就不班门弄斧了,我就拿前端工程师角度来看,作为一名应届前端工程师,至少要对整体知识体系有自己的理解(如果不是从事前端开发的可以跳过):
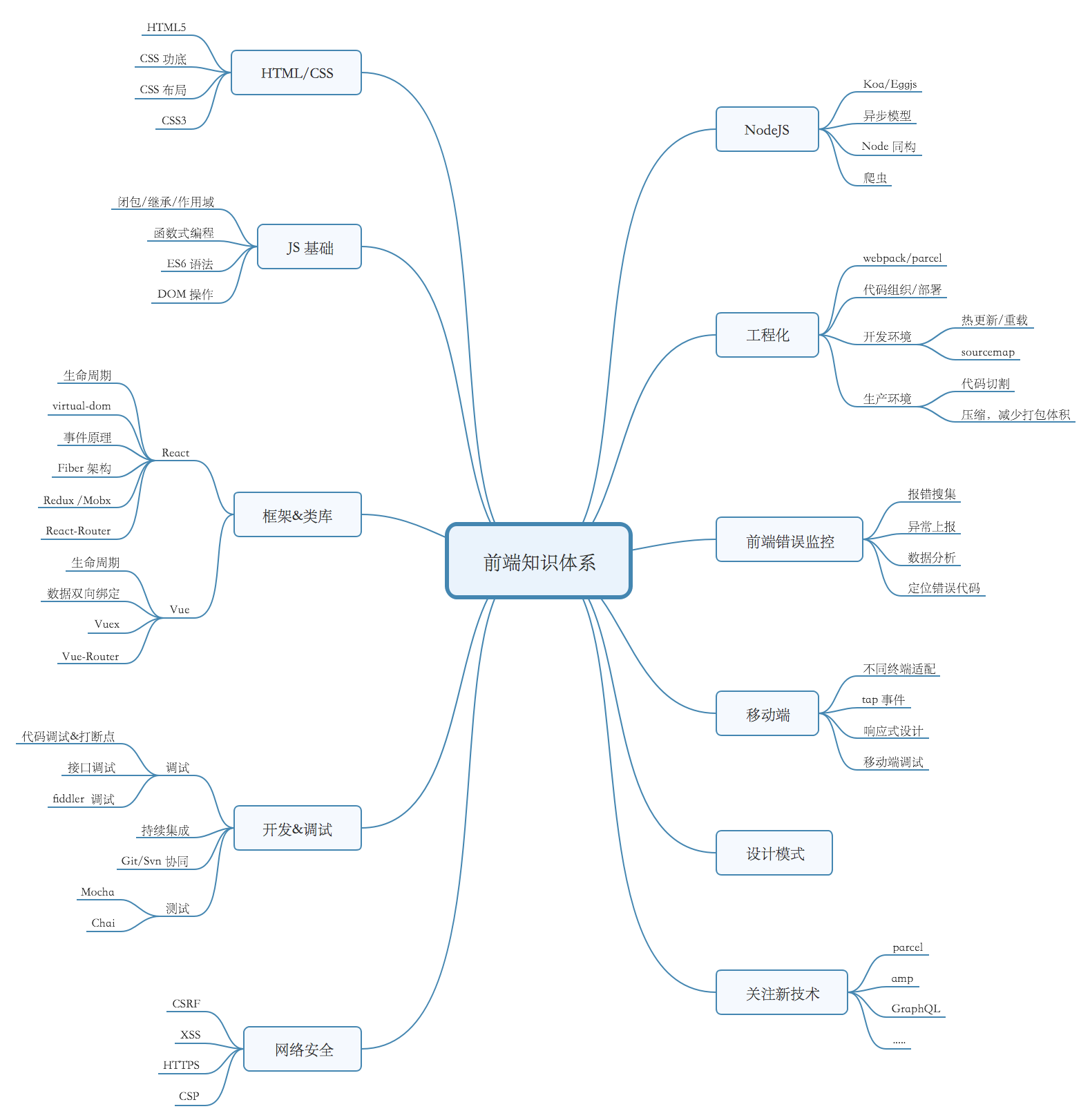
每个岗位都有对应的知识体系,我这里提供一个思路,不管是你在准备面试还是平时技术积累,通过对自己领域的知识梳理,知道自己不足的地方,对自己不熟悉的知识进行查缺补漏。(如果你对整个前端知识体系也不是特别了解,也可以照着我整体的知识体系来进行准备)
面试其实很多情况下都是很类似的,有的时候一面和二面的面试官都会问到相同的问题,所以在面试结束可以总结总结刚才面试中遇到的问题,为什么答不上来,如果是之前没准备的知识,可以去复习复习,这样下次再碰到类似的题目,你就可以对答如流了。
最近在看 webpack 如何做持久化缓存的内容,发现其中还是有一些坑点的,正好有时间就将它们整理总结一下,读完本文你大致能够明白:
首先我们需要去解释一下,什么是持久化缓存,在现在前后端分离的应用大行其道的背景下,前端 html,css,js 往往是以一种静态资源文件的形式存在于服务器,通过接口来获取数据来展示动态内容。这就涉及到公司如何去部署前端代码的问题,所以就涉及到一个更新部署的问题,是先部署页面,还是先部署资源?
所以我们需要一种部署策略来保证在更新我们线上的代码的时候,线上用户也能平滑地过渡并且正确打开我们的网站。
推荐先看这个回答:大公司里怎样开发和部署前端代码?
当你读完上面的回答,大致就会明白,现在比较成熟的持久化缓存方案就是在静态资源的名字后面加 hash 值,因为每次修改文件生成的 hash 值不一样,这样做的好处在于增量式发布文件,避免覆盖掉之前文件从而导致线上的用户访问失效。
因为只要做到每次发布的静态资源(css, js, img)的名称都是独一无二的,那么我就可以:
上面大致介绍了下主流的前端持久化缓存方案,那么我们为什么需要做持久化缓存呢?
上面简单介绍完持久化缓存,下面这个才是重点,那么我们应该如何在 webpack 中进行持久化缓存的呢,我们需要做到以下两点:
hash 文件名是实现持久化缓存的第一步,目前 webpack 有两种计算 hash 的方式([hash] 和 [chunkhash])
所以如果你只是单纯地将所有内容打包成同一个文件,那么 hash 就能够满足你了,如果你的项目涉及到拆包,分模块进行加载等等,那么你需要用 chunkhash,来保证每次更新之后只有相关的文件 hash 值发生改变。
所以我们在一份具有持久化缓存的 webpack 配置应该长这样:
module.exports = {
entry: __dirname + '/src/index.js',
output: {
path: __dirname + '/dist',
filename: '[name].[chunkhash:8].js',
}
}上面代码的含义就是:以 index.js 为入口,将所有的代码全部打包成一个文件取名为 index.xxxx.js 并放到 dist 目录下,现在我们可以在每次更新项目的时候做到生成新命名的文件了。
如果是应付简单的场景,这样做就够了,但是在大型多页面应用中,我们往往需要对页面进行性能优化:
那么如何进行拆包,分模块进行加载,这就需要 webpack 内置插件:CommonsChunkPlugin,下面我将通过一个例子,来诠释 webpack 该如何进行配置。
本文的代码放在我的 Github 上,有兴趣的可以下载来看看:
git clone https://github.com/happylindz/blog.git
cd blog/code/multiple-page-webpack-demo
npm install阅读下面的内容之前我强烈建议你看下我之前的文章:深入理解 webpack 文件打包机制,理解 webpack 文件的打包的机制有助于你更好地实现持久化缓存。
例子大概是这样描述的:它由两个页面组成 pageA 和 pageB
// src/pageA.js
import componentA from './common/componentA';
// 使用到 jquery 第三方库,需要抽离,避免业务打包文件过大
import $ from 'jquery';
// 加载 css 文件,一部分为公共样式,一部分为独有样式,需要抽离
import './css/common.css'
import './css/pageA.css';
console.log(componentA);
console.log($.trim(' do something '));
// src/pageB.js
// 页面 A 和 B 都用到了公共模块 componentA,需要抽离,避免重复加载
import componentA from './common/componentA';
import componentB from './common/componentB';
import './css/common.css'
import './css/pageB.css';
console.log(componentA);
console.log(componentB);
// 用到异步加载模块 asyncComponent,需要抽离,加载首屏速度
document.getElementById('xxxxx').addEventListener('click', () => {
import( /* webpackChunkName: "async" */
'./common/asyncComponent.js').then((async) => {
async();
})
})
// 公共模块基本长这样
export default "component X";上面的页面内容基本简单涉及到了我们拆分模块的三种模式:拆分公共库,按需加载和拆分公共模块。那么接下来要来配置 webpack:
const path = require('path');
const webpack = require('webpack');
const ExtractTextPlugin = require('extract-text-webpack-plugin');
module.exports = {
entry: {
pageA: [path.resolve(__dirname, './src/pageA.js')],
pageB: path.resolve(__dirname, './src/pageB.js'),
},
output: {
path: path.resolve(__dirname, './dist'),
filename: 'js/[name].[chunkhash:8].js',
chunkFilename: 'js/[name].[chunkhash:8].js'
},
module: {
rules: [
{
// 用正则去匹配要用该 loader 转换的 CSS 文件
test: /\.css$/,
use: ExtractTextPlugin.extract({
fallback: "style-loader",
use: ["css-loader"]
})
}
]
},
plugins: [
new webpack.optimize.CommonsChunkPlugin({
name: 'common',
minChunks: 2,
}),
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
minChunks: ({ resource }) => (
resource && resource.indexOf('node_modules') >= 0 && resource.match(/\.js$/)
)
}),
new ExtractTextPlugin({
filename: `css/[name].[chunkhash:8].css`,
}),
]
}第一个 CommonsChunkPlugin 用于抽离公共模块,相当于是说 webpack 大佬,如果你看到某个模块被加载两次即以上,那么请你帮我移到 common chunk 里面,这里 minChunks 为 2,粒度拆解最细,你可以根据自己的实际情况,看选择是用多少次模块才将它们抽离。
第二个 CommonsChunkPlugin 用来提取第三方代码,将它们进行抽离,判断资源是否来自 node_modules,如果是,则说明是第三方模块,那就将它们抽离。相当于是告诉 webpack 大佬,如果你看见某些模块是来自 node_modules 目录的,并且名字是 .js 结尾的话,麻烦把他们都移到 vendor chunk 里去,如果 vendor chunk 不存在的话,就创建一个新的。
这样配置有什么好处,随着业务的增长,我们依赖的第三方库代码很可能会越来越多,如果我们专门配置一个入口来存放第三方代码,这时候我们的 webpack.config.js 就会变成:
// 不利于拓展
module.exports = {
entry: {
app: './src/main.js',
vendor: [
'vue',
'axio',
'vue-router',
'vuex',
// more
],
},
}第三个 ExtractTextPlugin 插件用于将 css 从打包好的 js 文件中抽离,生成独立的 css 文件,想象一下,当你只是修改了下样式,并没有修改页面的功能逻辑,你肯定不希望你的 js 文件 hash 值变化,你肯定是希望 css 和 js 能够相互分开,且互不影响。
运行 webpack 后可以看到打包之后的效果:
├── css
│ ├── common.2beb7387.css
│ ├── pageA.d178426d.css
│ └── pageB.33931188.css
└── js
├── async.03f28faf.js
├── common.2beb7387.js
├── pageA.d178426d.js
├── pageB.33931188.js
└── vendor.22a1d956.js
可以看出 css 和 js 已经分离,并且我们对模块进行了拆分,保证了模块 chunk 的唯一性,当你每次更新代码的时候,会生成不一样的 hash 值。
唯一性有了,那么我们需要保证 hash 值的稳定性,试想下这样的场景,你肯定不希望你修改某部分的代码(模块,css)导致了文件的 hash 值全变了,那么显然是不明智的,那么我们去做到 hash 值变化最小化呢?
换句话说,我们就要找出 webpack 编译中会导致缓存失效的因素,想办法去解决或优化它?
影响 chunkhash 值变化主要由以下四个部分引起的:
这四部分只要有任意部分发生变化,生成的分块文件就不一样了,缓存也就会失效,下面就从四个部分一一介绍:
显然不用多说,缓存必须要刷新,不然就有问题了
看过我之前的文章:深入理解 webpack 文件打包机制 就会知道,在 webpack 启动的时候需要执行一些启动代码。
(function(modules) {
window["webpackJsonp"] = function webpackJsonpCallback(chunkIds, moreModules) {
// ...
};
function __webpack_require__(moduleId) {
// ...
}
__webpack_require__.e = function requireEnsure(chunkId, callback) {
// ...
script.src = __webpack_require__.p + "" + chunkId + "." + ({"0":"pageA","1":"pageB","3":"vendor"}[chunkId]||chunkId) + "." + {"0":"e72ce7d4","1":"69f6bbe3","2":"9adbbaa0","3":"53fa02a7"}[chunkId] + ".js";
};
})([]);大致内容像上面这样,它们是 webpack 的一些启动代码,它们是一些函数,告诉浏览器如何加载 webpack 定义的模块。
其中有一行代码每次更新都会改变的,因为启动代码需要清楚地知道 chunkid 和 chunkhash 值得对应关系,这样在异步加载的时候才能正确地拼接出异步 js 文件的路径。
那么这部分代码最终放在哪个文件呢?因为我们刚才配置的时候最后生成的 common chunk 模块,那么这部分运行时代码会被直接内置在里面,这就导致了,我们每次更新我们业务代码(pageA, pageB, 模块)的时候, common chunkhash 会一直变化,但是这显然不符合我们的设想,因为我们只是要用 common chunk 用来存放公共模块(这里指的是 componentA),那么我 componentA 都没去修改,凭啥 chunkhash 需要变了。
所以我们需要将这部分 runtime 代码抽离成单独文件。
module.exports = {
// ...
plugins: [
// ...
// 放到其他的 CommonsChunkPlugin 后面
new webpack.optimize.CommonsChunkPlugin({
name: 'runtime',
minChunks: Infinity,
}),
]
}这相当于是告诉 webpack 帮我把运行时代码抽离,放到单独的文件中。
├── css
│ ├── common.4cc08e4d.css
│ ├── pageA.d178426d.css
│ └── pageB.33931188.css
└── js
├── async.03f28faf.js
├── common.4cc08e4d.js
├── pageA.d178426d.js
├── pageB.33931188.js
├── runtime.8c79fdcd.js
└── vendor.cef44292.js
多生成了一个 runtime.xxxx.js,以后你在改动业务代码的时候,common chunk 的 hash 值就不会变了,取而代之的是 runtime chunk hash 值会变,既然这部分代码是动态的,可以通过 chunk-manifest-webpack-plugin 将他们 inline 到 html 中,减少一次网络请求。
在 webpack2 中默认加载 OccurrenceOrderPlugin 这个插件,OccurrenceOrderPlugin 插件会按引入次数最多的模块进行排序,引入次数的模块的 moduleId 越小,但是这仍然是不稳定的,随着你代码量的增加,虽然代码引用次数的模块 moduleId 越小,越不容易变化,但是难免还是不确定的。
默认情况下,模块的 id 是这个模块在模块数组中的索引。OccurenceOrderPlugin 会将引用次数多的模块放在前面,在每次编译时模块的顺序都是一致的,如果你修改代码时新增或删除了一些模块,这将可能会影响到所有模块的 id。
最佳实践方案是通过 HashedModuleIdsPlugin 这个插件,这个插件会根据模块的相对路径生成一个长度只有四位的字符串作为模块的 id,既隐藏了模块的路径信息,又减少了模块 id 的长度。
这样一来,改变 moduleId 的方式就只有文件路径的改变了,只要你的文件路径值不变,生成四位的字符串就不变,hash 值也不变。增加或删除业务代码模块不会对 moduleid 产生任何影响。
module.exports = {
plugins: [
new webpack.HashedModuleIdsPlugin(),
// 放在最前面
// ...
]
}实际情况中分块的个数的顺序在多次编译之间大多都是固定的, 不太容易发生变化。
这里涉及的只是比较基础的模块拆分,还有一些其它情况没有考虑到,比如异步加载组件中包含公共模块,可以再次将公共模块进行抽离。形成异步公共 chunk 模块。有想深入学习的可以看这篇文章:Webpack 大法之 Code Splitting
ExtractTextPlugin 有个比较严重的问题,那就是它生成文件名所用的[chunkhash]是直接取自于引用该 css 代码段的 js chunk ;换句话说,如果我只是修改 css 代码段,而不动 js 代码,那么最后生成出来的 css 文件名依然没有变化。
所以我们需要将 ExtractTextPlugin 中的 chunkhash 改为 contenthash,顾名思义,contenthash 代表的是文本文件内容的 hash 值,也就是只有 style 文件的 hash 值。这样编译出来的 js 和 css 文件就有独立的 hash 值了。
module.exports = {
plugins: [
// ...
new ExtractTextPlugin({
filename: `css/[name].[contenthash:8].css`,
}),
]
}如果你使用的是 webpack2,webpack3,那么恭喜你,这样就足够了,js 文件和 css 文件修改都不会影响到相互的 hash 值。那如果你使用的是 webpack1,那么就会出现问题。
具体来讲就是 webpack1 和 webpack 在计算 chunkhash 值得不同:
webpack1 在涉及的时候并没有考虑像 ExtractTextPlugin 会将模块内容抽离的问题,所以它在计算 chunkhash 的时候是通过打包之前模块内容去计算的,也就是说在计算的时候 css 内容也包含在内,之后才将 css 内容抽离成单独的文件,
那么就会出现:如果只修改了 css 文件,未修改引用的 js 文件,那么编译输出的 js 文件的 hash 值也会改变。
对此,webpack2 做了改进,它是基于打包后文件内容来计算 hash 值的,所以是在 ExtractTextPlugin 抽离 css 代码之后,所以就不存在上述这样的问题。如果不幸的你还在使用 webpack1,那么推荐你使用 md5-hash-webpack-plugin 插件来改变 webpack 计算 hash 的策略。
为什么这么说呢?因为最近有朋友来问我,他们 leader 不让在线上用 DllPlugin 插件,来问我为什么?
DllPlugin 本身有几个缺点:
虽然你可以打包成 dll 文件,然后让浏览器去读取缓存,这样下次就不用再去请求,比如你用 lodash 其中一个函数,而你用dll会将整个 lodash 文件打进去,这就会导致你加载无用代码过多,不利于首屏渲染时间。
我认为的正确的姿势是:
好了,感觉我又扯了很多,最近在看 webpack 确实收获不少,希望大家能从文章中也能有所收获。另外推荐再次推荐一下我之前写的文章,能够更好地帮你理解文件缓存机制:深入理解 webpack 文件打包机制
盒子的高宽是由盒子的内容区仅由 width, height 决定的,不包含边框,内外边距。
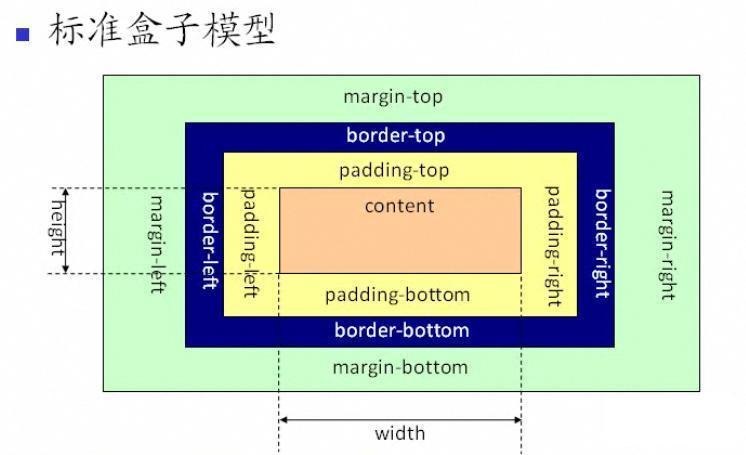

在 IE 盒模型中,盒子宽高不仅包含了元素的宽高,而且包含了元素的边框以及内边距。
所以在同样的设置下,IE 下的元素会看起来相对于标准盒子来的小,如果你想要标准盒子变为像 IE 盒模型,可以对元素样式进行设置:
.item {
box-sizing: border-box; //IE 盒模型效果
box-sizing: content-box; //默认值,标准盒模型效果
}根据该问题下的答案 querySelectorAll 方法相比 getElementsBy 系列方法有什么区别?,我简单地总结一下:
// Demo 1
var ul = document.querySelectorAll('ul')[0],
lis = ul.querySelectorAll("li");
for(var i = 0; i < lis.length ; i++){
ul.appendChild(document.createElement("li"));
}
// Demo 2
var ul = document.getElementsByTagName('ul')[0],
lis = ul.getElementsByTagName("li");
for(var i = 0; i < lis.length ; i++){
ul.appendChild(document.createElement("li"));
}因为 Demo 2 中的 lis 是一个动态的结点列表, 每一次调用 lis 都会重新对文档进行查询,导致无限循环的问题。
而 Demo 1 中的 lis 是一个静态的结点列表,是一个 li 集合的快照,对文档的任何操作都不会对其产生影响。
var foo = 1;
function static() {
console.log(foo);
}
(function() {
var foo = 2;
static();
}());JS 的变量是遵循静态作用域的,在上述代码中会打印出 1 而非 2,因为 static 函数在作用域创建的时候,记录的 foo 是 1,如果是动态作用域的话,那么它应该打印出 2。
静态作用域是产生闭包的关键,即它在代码写好之后就被静态决定它的作用域了。
在 JS 中,关于 this 的执行是基于动态域查询的,下面这段代码打印出 1,如果按静态作用域的话应该会打印出 2
var foo = 1;
var obj = {
foo: 2,
bar: function() {
console.log(this.foo);
}
};
var bar = obj.bar;
bar();常见的返回值就不说了,需要注意的是下面的几种情况:
console.log(typeof NaN); //number
console.log(typeof typeof typeof function(){}) //string
var str = 'abc';
console.log(typeof str++); //number
console.log(typeof ('abc' + 1)); //string
console.log(typeof null); //object
console.log(typeof /\d/g); //object
console.log(typeof []); //object
console.log(typeof new Date()); //object
console.log(typeof Date()); //string
console.log(typeof Date); //functionvar str1 = 'abc';
var str2 = new String('abc');
console.log(str1 instanceof String); //false
console.log(str2 instanceof String); //true
console.log(false instanceof Boolean); //false
console.log(new Boolean(false) instanceof Boolean) //true判断基本类型还是用 typeof 吧,instanceof 不适合。
function Foo(){}
var foo = new Foo();
console.log(foo instanceof Foo) //truefunction Parent() {}
function Child() {}
Child.prototype = new Parent();
Child.prototype.constructor = Child;
var child = new Child();
console.log(child instanceof Child); //true
console.log(child instanceof Parent); //true
console.log(child instanceof Object); //true
console.log(Child instanceof Function); //true
console.log(Function instanceof Object); //true
console.log(Child instanceof Child); //false如果你对上面输出的结果感到困惑,那建议你看下这面这篇文章:深入理解javascript原型和闭包(5)--instanceof - 王福朋 - 博客园
console.log((1).constructor === Number); //true
console.log("a".constructor === String); //true
console.log([].constructor === Array); //true
console.log({}.constructor === Object); //true检测功能还是挺全面的,不过也有它的局限性:如果我们把类的原型进行重写了,在重写的过程中,很有可能把之前 constructor 给覆盖掉,这样检测出的结果就不准确了。
function Fn() {}
Fn.prototype = new Array();
var f = new Fn();
console.log(f.constructor === Array); // true并且 constructor 检测不出 null,undefined 的类型,所以判断类型用 constructor 也不太好用
Object.prototype.toStrong.call() 是检测数据类型最准确最常用的方式,
function toString(data) {
return Object.prototype.toString.call(data).slice(8, -1);
}
console.log(toString('abc') === 'String');
console.log(toString(1) === 'Number');
console.log(toString(false) === 'Boolean');
console.log(toString(null) === 'Null');
console.log(toString(undefined) === 'Undefined');
console.log(toString([]) === 'Array');
console.log(toString({}) === 'Object');
console.log(toString(function(){}) === 'Function')首先函数是一种对象:
var fn = function() {}
console.log(fn instanceof Object); //true对,函数是一种对象,但是函数却不像数组那样 ---- 你可以说数组是对象的一种,因为数组就像对象的一个子集一样,但是函数与对象之间,却不仅仅是包含和被包含的关系。
对象可以由函数创建:
function Fn() {
this.name = "Lindz";
this.year = 1995;
}
var fn1 = new Fn(); // {name: "Lindz", year: 1995}上面的例子很简单,它说明了对象可以通过函数重建,但是其实对象都是通过函数创建的,有人可能会反驳,他认为:
var obj = { a: 10, b: 20 };
var arr = [5, true, "aa"];但是这些都是编程中的语法糖,实际上编译器帮我们做了下面这些事:
var obj = new Object();
obj.a = 10;
obj.b = 20;
var arr = new Array();
arr[0] = 5;
arr[1] = true;
arr[2] = "aa";
console.log(typeof (Object)); // function
console.log(typeof (Array)); // function第一种方式:通过 instanceof 判断
function Person() {
if(this instanceof arguments.callee) {
console.log('new 调用');
}else {
console.log('普通调用');
}
}
let p1 = new Person(); // new 调用
let p2 = Person(); // 函数调用 第二种方式:通过 constructor
function Person() {
if(this.constructor === arguments.callee) {
console.log('new 调用');
}else {
console.log('普通调用');
}
}
let p1 = new Person(); // new 调用
let p2 = Person(); // 函数调用 在 React 的世界中,有容器组件和 UI 组件之分,在 React Hooks 出现之前,UI 组件我们可以使用函数,无状态组件来展示 UI,而对于容器组件,函数组件就显得无能为力,我们依赖于类组件来获取数据,处理数据,并向下传递参数给 UI 组件进行渲染。在我看来,使用 React Hooks 相比于从前的类组件有以下几点好处:
React 在 v16.8 的版本中推出了 React Hooks 新特性,虽然社区还没有最佳实践如何基于 React Hooks 来打造复杂应用(至少我还没有),凭借着阅读社区中大量的关于这方面的文章,下面我将通过十个案例来帮助你认识理解并可以熟练运用 React Hooks 大部分特性。
在类组件中,我们使用 this.state 来保存组件状态,并对其修改触发组件重新渲染。比如下面这个简单的计数器组件,很好诠释了类组件如何运行:在线 Demo
import React from "react";
class App extends React.Component {
constructor(props) {
super(props);
this.state = {
count: 0,
name: "alife"
};
}
render() {
const { count } = this.state;
return (
<div>
Count: {count}
<button onClick={() => this.setState({ count: count + 1 })}>+</button>
<button onClick={() => this.setState({ count: count - 1 })}>-</button>
</div>
);
}
}一个简单的计数器组件就完成了,而在函数组件中,由于没有 this 这个黑魔法,React 通过 useState 来帮我们保存组件的状态。在线 Demo
import React, { useState } from "react";
function App() {
const [obj, setObject] = useState({
count: 0,
name: "alife"
});
return (
<div className="App">
Count: {obj.count}
<button onClick={() => setObject({ ...obj, count: obj.count + 1 })}>+</button>
<button onClick={() => setObject({ ...obj, count: obj.count - 1 })}>-</button>
</div>
);
}通过传入 useState 参数后返回一个带有默认状态和改变状态函数的数组。通过传入新状态给函数来改变原本的状态值。值得注意的是 useState 不帮助你处理状态,相较于 setState 非覆盖式更新状态,useState 覆盖式更新状态,需要开发者自己处理逻辑。(代码如上)
似乎有个 useState 后,函数组件也可以拥有自己的状态了,但仅仅是这样完全不够。
函数组件能保存状态,但是对于异步请求,副作用的操作还是无能为力,所以 React 提供了 useEffect 来帮助开发者处理函数组件的副作用,在介绍新 API 之前,我们先来看看类组件是怎么做的:在线 Demo
import React, { Component } from "react";
class App extends Component {
state = {
count: 1
};
componentDidMount() {
const { count } = this.state;
document.title = "componentDidMount" + count;
this.timer = setInterval(() => {
this.setState(({ count }) => ({
count: count + 1
}));
}, 1000);
}
componentDidUpdate() {
const { count } = this.state;
document.title = "componentDidMount" + count;
}
componentWillUnmount() {
document.title = "componentWillUnmount";
clearInterval(this.timer);
}
render() {
const { count } = this.state;
return (
<div>
Count:{count}
<button onClick={() => clearInterval(this.timer)}>clear</button>
</div>
);
}
}在例子中,组件每隔一秒更新组件状态,并且每次触发更新都会触发 document.title 的更新(副作用),而在组件卸载时修改 document.title(类似于清除)
从例子中可以看到,一些重复的功能开发者需要在 componentDidMount 和 componentDidUpdate 重复编写,而如果使用 useEffect 则完全不一样。在线 Demo
import React, { useState, useEffect } from "react";
let timer = null;
function App() {
const [count, setCount] = useState(0);
useEffect(() => {
document.title = "componentDidMount" + count;
},[count]);
useEffect(() => {
timer = setInterval(() => {
setCount(prevCount => prevCount + 1);
}, 1000);
return () => {
document.title = "componentWillUnmount";
clearInterval(timer);
};
}, []);
return (
<div>
Count: {count}
<button onClick={() => clearInterval(timer)}>clear</button>
</div>
);
}我们使用 useEffect 重写了上面的例子,useEffect 第一个参数传递函数,可以用来做一些副作用比如异步请求,修改外部参数等行为,而第二个参数是个数组,如果数组中的值才会触发 useEffect 第一个参数中的函数。返回值(如果有)则在组件销毁或者调用函数前调用。
基于这个强大 Hooks,我们可以模拟封装出其他生命周期函数,比如 componentDidUpdate 代码十分简单
function useUpdate(fn) {
// useRef 创建一个引用
const mounting = useRef(true);
useEffect(() => {
if (mounting.current) {
mounting.current = false;
} else {
fn();
}
});
}现在我们有了 useState 管理状态,useEffect 处理副作用,异步逻辑,学会这两招足以应对大部分类组件的使用场景。
上面介绍了 useState、useEffect 这两个最基本的 API,接下来介绍的 useContext 是 React 帮你封装好的,用来处理多层级传递数据的方式,在以前组件树种,跨层级祖先组件想要给孙子组件传递数据的时候,除了一层层 props 往下透传之外,我们还可以使用 React Context API 来帮我们做这件事,举个简单的例子:在线 Demo
const { Provider, Consumer } = React.createContext(null);
function Bar() {
return <Consumer>{color => <div>{color}</div>}</Consumer>;
}
function Foo() {
return <Bar />;
}
function App() {
return (
<Provider value={"grey"}>
<Foo />
</Provider>
);
}通过 React createContext 的语法,在 APP 组件中可以跨过 Foo 组件给 Bar 传递数据。而在 React Hooks 中,我们可以使用 useContext 进行改造。在线 Demo
const colorContext = React.createContext("gray");
function Bar() {
const color = useContext(colorContext);
return <div>{color}</div>;
}
function Foo() {
return <Bar />;
}
function App() {
return (
<colorContext.Provider value={"red"}>
<Foo />
</colorContext.Provider>
);
}传递给 useContext 的是 context 而不是 consumer,返回值即是想要透传的数据了。用法很简单,使用 useContext 可以解决 Consumer 多状态嵌套的问题。参考例子
function HeaderBar() {
return (
<CurrentUser.Consumer>
{user =>
<Notifications.Consumer>
{notifications =>
<header>
Welcome back, {user.name}!
You have {notifications.length} notifications.
</header>
}
}
</CurrentUser.Consumer>
);
}而使用 useContext 则变得十分简洁,可读性更强且不会增加组件树深度。
function HeaderBar() {
const user = useContext(CurrentUser);
const notifications = useContext(Notifications);
return (
<header>
Welcome back, {user.name}!
You have {notifications.length} notifications.
</header>
);
}useReducer 这个 Hooks 在使用上几乎跟 Redux/React-Redux 一模一样,唯一缺少的就是无法使用 redux 提供的中间件。我们将上述的计时器组件改写为 useReducer,在线 Demo
import React, { useReducer } from "react";
const initialState = {
count: 0
};
function reducer(state, action) {
switch (action.type) {
case "increment":
return { count: state.count + action.payload };
case "decrement":
return { count: state.count - action.payload };
default:
throw new Error();
}
}
function App() {
const [state, dispatch] = useReducer(reducer, initialState);
return (
<>
Count: {state.count}
<button onClick={() => dispatch({ type: "increment", payload: 5 })}>
+
</button>
<button onClick={() => dispatch({ type: "decrement", payload: 5 })}>
-
</button>
</>
);
}用法跟 Redux 基本上是一致的,用法也很简单,算是提供一个 mini 的 Redux 版本。
在类组件中,我们经常犯下面这样的错误:
class App {
render() {
return <div>
<SomeComponent style={{ fontSize: 14 }} doSomething={ () => { console.log('do something'); }} />
</div>;
}
}这样写有什么坏处呢?一旦 App 组件的 props 或者状态改变了就会触发重渲染,即使跟 SomeComponent 组件不相关,由于每次 render 都会产生新的 style 和 doSomething,所以会导致 SomeComponent 重新渲染,倘若 SomeComponent 是一个大型的组件树,这样的 Virtual Dom 的比较显然是很浪费的,解决的办法也很简单,将参数抽离成变量。
const fontSizeStyle = { fontSize: 14 };
class App {
doSomething = () => {
console.log('do something');
}
render() {
return <div>
<SomeComponent style={fontSizeStyle} doSomething={ this.doSomething } />
</div>;
}
}在类组件中,我们还可以通过 this 这个对象来存储函数,而在函数组件中没办法进行挂载了。所以函数组件在每次渲染的时候如果有传递函数的话都会重渲染子组件。
function App() {
const handleClick = () => {
console.log('Click happened');
}
return <SomeComponent onClick={handleClick}>Click Me</SomeComponent>;
}而有了 useCallback 就不一样了,你可以通过 useCallback 获得一个记忆后的函数。
function App() {
const memoizedHandleClick = useCallback(() => {
console.log('Click happened')
}, []); // 空数组代表无论什么情况下该函数都不会发生改变
return <SomeComponent onClick={memoizedHandleClick}>Click Me</SomeComponent>;
}老规矩,第二个参数传入一个数组,数组中的每一项一旦值或者引用发生改变,useCallback 就会重新返回一个新的记忆函数提供给后面进行渲染。
这样只要子组件继承了 PureComponent 或者使用 React.memo 就可以有效避免不必要的 VDOM 渲染。
useCallback 的功能完全可以由 useMemo 所取代,如果你想通过使用 useMemo 返回一个记忆函数也是完全可以的。
useCallback(fn, inputs) is equivalent to useMemo(() => fn, inputs).
所以前面使用 useCallback 的例子可以使用 useMemo 进行改写:
function App() {
const memoizedHandleClick = useMemo(() => () => {
console.log('Click happened')
}, []); // 空数组代表无论什么情况下该函数都不会发生改变
return <SomeComponent onClick={memoizedHandleClick}>Click Me</SomeComponent>;
}唯一的区别是:**useCallback 不会执行第一个参数函数,而是将它返回给你,而 useMemo 会执行第一个函数并且将函数执行结果返回给你。**所以在前面的例子中,可以返回 handleClick 来达到存储函数的目的。
所以 useCallback 常用记忆事件函数,生成记忆后的事件函数并传递给子组件使用。而 useMemo 更适合经过函数计算得到一个确定的值,比如记忆组件。
function Parent({ a, b }) {
// Only re-rendered if `a` changes:
const child1 = useMemo(() => <Child1 a={a} />, [a]);
// Only re-rendered if `b` changes:
const child2 = useMemo(() => <Child2 b={b} />, [b]);
return (
<>
{child1}
{child2}
</>
)
}当 a/b 改变时,child1/child2 才会重新渲染。从例子可以看出来,只有在第二个参数数组的值发生变化时,才会触发子组件的更新。
useRef 跟 createRef 类似,都可以用来生成对 DOM 对象的引用,看个简单的例子:在线 Demo
import React, { useState, useRef } from "react";
function App() {
let [name, setName] = useState("Nate");
let nameRef = useRef();
const submitButton = () => {
setName(nameRef.current.value);
};
return (
<div className="App">
<p>{name}</p>
<div>
<input ref={nameRef} type="text" />
<button type="button" onClick={submitButton}>
Submit
</button>
</div>
</div>
);
}useRef 返回的值传递给组件或者 DOM 的 ref 属性,就可以通过 ref.current 值访问组件或真实的 DOM 节点,从而可以对 DOM 进行一些操作,比如监听事件等等。
当然 useRef 远比你想象中的功能更加强大,useRef 的功能有点像类属性,或者说您想要在组件中记录一些值,并且这些值在稍后可以更改。
利用 useRef 就可以绕过 Capture Value 的特性。可以认为 ref 在所有 Render 过程中保持着唯一引用,因此所有对 ref 的赋值或取值,拿到的都只有一个最终状态,而不会在每个 Render 间存在隔离。参考例子:精读《Function VS Class 组件》
React Hooks 中存在 Capture Value 的特性:在线 Demo
function MessageThread() {
const [message, setMessage] = useState("");
const showMessage = () => {
alert("You said: " + message);
};
const handleSendClick = () => {
setTimeout(showMessage, 3000);
};
const handleMessageChange = e => {
setMessage(e.target.value);
};
return (
<>
<input value={message} onChange={handleMessageChange} />
<button onClick={handleSendClick}>Send</button>
</>
);
}在点击 Send 按钮后,再次修改输入框的值,3 秒后的输出依然是点击前输入框的值。这就是所谓的 capture value 的特性。而在类组件中 3 秒后输出的就是修改后的值,因为这时候 message 是挂载在 this 变量上,它保留的是一个引用值,对 this 属性的访问都会获取到最新的值。讲到这里你应该就明白了,useRef 创建一个引用,就可以有效规避 React Hooks 中 Capture Value 特性。
function MessageThread() {
const latestMessage = useRef("");
const showMessage = () => {
alert("You said: " + latestMessage.current);
};
const handleSendClick = () => {
setTimeout(showMessage, 3000);
};
const handleMessageChange = e => {
latestMessage.current = e.target.value;
};
}只要将赋值与取值的对象变成 useRef,而不是 useState,就可以躲过 capture value 特性,在 3 秒后得到最新的值。
通过 useImperativeHandle 用于让父组件获取子组件内的索引 在线 Demo
import React, { useRef, useEffect, useImperativeHandle, forwardRef } from "react";
function ChildInputComponent(props, ref) {
const inputRef = useRef(null);
useImperativeHandle(ref, () => inputRef.current);
return <input type="text" name="child input" ref={inputRef} />;
}
const ChildInput = forwardRef(ChildInputComponent);
function App() {
const inputRef = useRef(null);
useEffect(() => {
inputRef.current.focus();
}, []);
return (
<div>
<ChildInput ref={inputRef} />
</div>
);
}通过这种方式,App 组件可以获得子组件的 input 的 DOM 节点。
大部分情况下,使用 useEffect 就可以帮我们处理组件的副作用,但是如果想要同步调用一些副作用,比如对 DOM 的操作,就需要使用 useLayoutEffect,useLayoutEffect 中的副作用会在 DOM 更新之后同步执行。在线 Demo
function App() {
const [width, setWidth] = useState(0);
useLayoutEffect(() => {
const title = document.querySelector("#title");
const titleWidth = title.getBoundingClientRect().width;
console.log("useLayoutEffect");
if (width !== titleWidth) {
setWidth(titleWidth);
}
});
useEffect(() => {
console.log("useEffect");
});
return (
<div>
<h1 id="title">hello</h1>
<h2>{width}</h2>
</div>
);
}在上面的例子中,useLayoutEffect 会在 render,DOM 更新之后同步触发函数,会优于 useEffect 异步触发函数。
尽管我们通过上面的例子看到 React Hooks 的强大之处,似乎类组件完全都可以使用 React Hooks 重写。但是当下 v16.8 的版本中,还无法实现 getSnapshotBeforeUpdate 和 componentDidCatch 这两个在类组件中的生命周期函数。官方也计划在不久的将来在 React Hooks 进行实现。
阅读本文之前,希望你对 Redux 有个清晰的认知,如果不熟悉的话可以看这篇文章:揭秘 React 状态管理
如果觉得本文有帮助,可以点 star 鼓励下,本文所有代码都可以从 github 仓库下载,读者可以按照下述打开:
git clone https://github.com/happylindz/blog.git
cd blog/code/asynchronousAction/
cd xxx/
yarn
yarn start
我们知道,在 Redux 的世界中,Redux action 返回一个 JS 对象,被 Reducer 接收处理后返回新的 State,这一切看似十分美好。整个过程可以看作是:
view -> actionCreator -> action -> reducer -> newState ->(map) container component
但是真实业务开发我们需要处理异步请求,比如:请求后台数据,延迟执行某个效果,setTimout, setInterval 等等,所以当 Redux 遇到异步操作的时候,又该如何处理呢?
首先我们围绕一个简单的例子展开,然后通过各种方式将它实现出来,基本效果如下:

这里我使用的是 CNode 官网的 API,获取首页的文章标题,并将他们全部展示出来,并且右边有个 X 按钮,点击 X 按钮可以将该标题删除。异步请求我们使用封装好的 axios 库,你可以这样发起异步请求:
const response = await axios.get('/api/v1/topics')然后在你的 package.json 文件中加上代理字段
{
"proxy": "https://cnodejs.org",
//...
}
这样当你访问 localhost:3000/api/v1/topics Node 后台会自动帮你转发请求到 CNode,然后将获取到的结果返回给你,这个过程对你来说是透明的,这样能有效避免跨域的问题。
cd asynchronous_without_redux_middleware/
yarn
yarn start
老规矩,我们先来看看项目结构:
├── actionCreator
│ └── index.js
├── actionTypes
│ └── index.js
├── constants
│ └── index.js
├── index.js
├── reducers
│ └── index.js
├── store
│ └── index.js
└── views
├── newsItem.css
├── newsItem.js
└── newsList.js
我们在异步请求时候一共有三种 actionTypes,分别为 FETCH_START, FETCH_SUCCESS, FETCH_FAILURE,这样对应着视图就有四种状态 (constants):INITIAL_STATE, LOADING_STATE, SUCCESS_STATE, FAILURE_STATE。
actionCreator 对 actionTypes 多一层封装,返回的都还是同步 action,主要的逻辑由视图组件来完成。
// views/newsList.js
const mapDispatchToProps = (dispatch, ownProps) => {
return {
fetchNewsTitle: async() => {
dispatch(actionCreator.fetchStart())
try {
const response = await axios.get('/api/v1/topics')
if(response.status === 200) {
dispatch(actionCreator.fetchSuccess(response.data))
}else {
throw new Error('fetch failure')
}
} catch(e) {
dispatch(actionCreator.fetchFailure())
}
}
}
}我们可以看出,在发起异步请求之前,我们先发起 FETCH_START action,然后开始发起异步请求,当请求成功之后发起 FETCH_SUCCESS action 并传递数据,当请求失败时发起 FETCH_FAILURE action。
在上面的例子,我们没有破坏同步 action 这个特性,而是将异步请求封装在了具体的业务代码中,这种直观的写法存在着一些问题:
通过分析,我们得出需要提取这些逻辑到一个公共的部分,然后简单调用,后续操作自动完成,就像:
const mapDispatchToProps = (dispatch, ownProps) => {
return {
fetchNewsTitle:() => {
xxx.fetchStart()
}
}
}一种思路是将这些异步调用独立抽出到一个公共通用异步操作的文件夹,每个需要调用异步操作的组件就到这个目录下获取需要的函数,但是这样就存在一个问题,因为需要发起 action 请求,那么就需要 dispatch 字段,这就意味着每次调用时候必须显式地传入 dispatch 变量,即:
const mapDispatchToProps = (dispatch, ownProps) => {
return {
fetchNewsTitle:() => {
xxx.fetchStart(dispatch)
}
}
}这样写不够优雅,不过也不失为一种解决方案,可以进行尝试,这里就不展开了。
此前介绍的都是同步的 action 请求,接下来介绍一下异步的 action,我们希望在异步请求的时候,action 能够这样处理:
view -> asyncAction -> wait -> action -> reducer -> newState -> container component
这里 action 不再是同步的,而是具有异步功能,当然因为依赖于异步 IO,也会产生副作用。这里就会存在一个问题,我们需要发起两次 action 请求,这好像我们又得将 dispatch 对象传入函数中,显得不够优雅。同步和异步的调用方式截然不同:
好在我们有 Redux 中间件机制能够帮助我们处理异步 action,让 action 不再仅仅处理同步的请求。
Redux 本身只能处理同步的 action,但可以通过中间件来拦截处理其它类型的 action,比如函数(thunk),再用回调触发普通 action,从而实现异步处理,在这点上所有 Redux 的异步方案都是类似的。
首先我们通过 redux-thunk 来改写我们之前的例子
cd asynchronous_with_redux_thunk/
yarn
yarn start
首先需要在 store 里注入中间件 redux-thunk。
import { createStore, applyMiddleware } from 'redux'
import reducer from '../reducers'
import thunk from 'redux-thunk'
// ...
export default createStore(reducer, initValue, applyMiddleware(thunk))这样 redux-thunk 中间件就能够在 action 传递给 reducer 前进行处理。
我们改写我们 actionCreator 对象,再需要那么多同步的 action,只需一个方法即可搞定。
// actionCreator/index.js
import * as actionTypes from '../actionTypes'
import axios from 'axios'
export default {
fetchNewsTitle: () => {
return async (dispatch, getState) => {
dispatch({
type: actionTypes.FETCH_START,
})
try {
const response = await axios.get('https://cnodejs.org/api/v1/topics')
if(response.status === 200) {
dispatch({
type: actionTypes.FETCH_SUCCESS,
news: response.data.data.map(news => news.title),
})
}else {
throw new Error('fetch failure')
}
} catch(e) {
dispatch({
type: actionTypes.FETCH_FAILURE
})
}
}
},
// ...
}这次 fecthNewsTitle 不再简单返回一个 JS 对象,而是返回一个函数,在函数内可以获得当前 state 以及 dispatch,然后之前的异步操作全部封装在这里。是 redux-thunk 中间让 dispatch 不仅能够处理 JS 对象,也能够处理一个函数。
之后我们在业务代码只需调用:
// views/App.js
const mapDispatchToProps = (dispatch, ownProps) => {
return {
fetchNewsTitle: () => {
dispatch(actionCreator.fetchNewsTitle())
}
}
}自此当以后 redux 需要处理异步操作的时候,只需将 actionCreator 设为函数,然后在函数里编写你的异步逻辑。
redux-thunk 是一个通用的解决方案,其核心**是让 action 可以变为一个 thunk ,这样的话:
redux-thunk 看似做了很多工作,实现起来却是相当简单:
function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
if (typeof action === 'function') {
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
const thunk = createThunkMiddleware();
thunk.withExtraArgument = createThunkMiddleware;
export default thunk;乍一看有有很多层箭头函数链式调用,这其实跟中间件的机制有关,我们只需要关心,当 action 传递到中间件的时候,它会判断该 action 是不是一个函数,如果函数,则拦截当前的 action,因为在当前的闭包中存在 dispatch 和 getState 变量,将两个变量传递到函数中并执行,这就是我们在 actionCreator 返回函数时候能够用到 dispatch 和 getState 的关键原因。redux-thunk 看到传递的 action 是个函数的时候就将其拦截并且执行,这时候这个 action 的返回值已经不再关心,因为它根本没有被继续传递下去,不是函数的话它就放过这个 action,让下个中间件去处理它(next(action))
所以我们前面的例子可以理解为:
view -> 函数 action -> redux-thunk 拦截 -> 执行函数并丢弃函数 action -> 一系列 action 操作 -> reducer -> newState -> container component
不难理解我们将原本放在公共目录下的异步操作封装在了一个 action,通过中间件的机制让 action 内部能够拿到 dispatch 值,从而在 action 中能够产生更多的同步 action 对象。
redux-thunk 这种方案对于小型的应用来说足够日常使用,然而对于大型应用来说,你可能会发现一些不方便的地方,对于组合多 action,取消 action,竞态判断的处理就显然有点儿力不从心,这些东西我们也会在后面进行谈到。
redux-thunk **很棒,但是其实代码是有一定的相似,比如其实整个代码都是针对请求、成功、失败三部分来处理的,这让我们自然联想到 Promise,同样也是分为 pending、fulfilled、rejected 三种状态。
Promise 代表一种承诺,本用来解决异步回调地狱问题,首先我们先来看看 redux-promise 中间件的源码:
import { isFSA } from 'flux-standard-action';
function isPromise(val) {
return val && typeof val.then === 'function';
}
export default function promiseMiddleware({ dispatch }) {
return next => action => {
if (!isFSA(action)) {
return isPromise(action)
? action.then(dispatch)
: next(action);
}
return isPromise(action.payload)
? action.payload.then(
result => dispatch({ ...action, payload: result }),
error => {
dispatch({ ...action, payload: error, error: true });
return Promise.reject(error);
}
)
: next(action);
};
}和 redux-thunk 一样,我们抛开复杂的链式箭头函数调用,该中间件做的一件事就是判断 action 或 action.payload 是不是一个 Promise 对象,如果是的话,同样地拦截等待 Promise 对象 resolve 返回数据之后再调用 dispatch,同样的,这个 Promise action 也不会被传递给 reducer 进行处理,如果不是 Promise 对象就不处理。
所以一个异步 action 流程就变成了这样:
view -> Promise action -> redux-promise 拦截 -> 等待 promise resolve -> 将 promise resolve 返回的新的 action(普通) 对象 dispatch -> reducer -> newState -> container component
通过 redux-promise 中间件我们可以在编写 promise action,我们对之前的例子进行修改:
cd asynchronous_with_redux_promise/
yarn
yarn start
我们修改一下 actionCreator:
// actionCreator/index.js
export default {
fetchNewsTitle: () => {
return axios.get('/api/v1/topics').then(response => ({
type: actionTypes.FETCH_SUCCESS,
news: response.data,
})).catch(err => ({
type: actionTypes.FETCH_FAILURE,
}))
},
}修改 store 中间件 redux-promise
// store/index.js
import { createStore, applyMiddleware } from 'redux'
import reducer from '../reducers'
import reduxPromise from 'redux-promise'
export default createStore(reducer, initValue, applyMiddleware(reduxPromise))效果:没有 Loading 这个中间状态

但是如果使用 redux-promise 的话相当于是延后执行了 action,等获取到结果之后再重新 dispatch action。这么写其实有个问题,就是无法发起 FETCH_START action,因为actionCreator 中没有 dispatch 这个字段,redux-promise 虽然赋予了 action 延后执行的能力,但是没有能力发起多 action 请求。
严格上来说,我们完全可以写一个中间件,通过判断 action 对象上的某个字段或者什么其他字段,代码如下:
const thunk = ({ dispatch, getState }) => next => action => {
if(typeof action.async === 'function') {
return action.async(dispatch, getState);
}
return next(action);
}如果能够这样理解 action 对象,那么我们也没有要求 Promise 中间件处理的异步 action 对象是 Promise 对象,只需要 action 对象谋改革字段是 Promise 字段就行,而 action 对象可以拥有其他字段来包含更多信息。所以我们可以自己编写一个中间件:
// myPromiseMiddleware
const isPromise = (obj) => {
return obj && typeof obj.then === 'function';
}
export default ({ dispatch }) => (next) => (action) => {
const { types, async, ...rest } = action
if(!isPromise(async) || !(action.types && action.types.length === 3)) {
return next(action)
}
const [PENDING, SUCCESS, FAILURE] = types
dispatch({
...rest,
type: PENDING,
})
return action.async.then(
(result) => dispatch({ ...rest, ...result, type: SUCCESS }),
(error) => dispatch({ ...rest, ...error, type: FAILURE })
)
}不难理解,中间件接受同样接收一个 action JS 对象,这个对象需要满足 async 字段是 Promise 对象并且 types 字段长度为 3,否则这不是我们需要的处理的 action 对象,我们传入的 types 字段是个数组,分别为 FETCH_START,FETCH_SUCCESS,FETCH_FAILURE,相当于是我们做个一层约定,让中间件内部去帮我们消化这样的异步 action,当 async promise 对象返回之后调用 FETCH_SUCCESS,FETCH_FAILURE action。
我们改写 actionCreator
// actionCreator/index.js
export default {
myFetchNewsTitle: () => {
return {
async: axios.get('/api/v1/topics').then(response => ({
news: response.data,
})),
types: [ actionTypes.FETCH_START, actionTypes.FETCH_SUCCESS, actionTypes.FETCH_FAILURE ]
}
},
}这样写相当于是我们约定好了格式,然后让相应地中间件去处理就可以了。但是扩展性较差,适合小型团队共同开发约定好具体的异步格式。
redux-saga 也是解决 redux 异步 action 的一个中间件,不过它与前面的解决方案思路有所不同,它另辟新径:
让异步行为成为架构中独立的一层(称为 saga),既不在 action creator 中,也不和 reducer 沾边。
它的出发点是把副作用 (Side effect,异步行为就是典型的副作用) 看成"线程",可以通过普通的 action 去触发它,当副作用完成时也会触发 action 作为输出。
详细的文档说明可以看: Redux-saga Beginner Tutorial
接下来我也会举很多例子来说明 redux-saga 的优点。
我们老规矩先来改写我们之前的例子:
cd asynchronous_with_redux_saga/
yarn
yarn start
首先先来看 actionCreator:
import * as actionTypes from '../actionTypes'
export default {
fetchNewsTitle: () => {
return {
type: actionTypes.FETCH_START
}
},
// ...
}是不是变得很干净,因为处理异步的逻辑已经在 creator 里面了,转移到 saga 中,我们来看一下 saga 是怎么写的。
// sagas/index.js
import { put, takeEvery } from 'redux-saga/effects'
import * as actionTypes from '../actionTypes'
import axios from 'axios'
function* fetchNewsTitle() {
try {
const response = yield axios.get('/api/v1/topics')
if(response.status === 200) {
yield put({
type: actionTypes.FETCH_SUCCESS,
news: response.data,
})
}else {
throw new Error('fetch failure')
}
} catch(e) {
yield put({
type: actionTypes.FETCH_FAILURE
})
}
}
export default function* fecthData () {
yield takeEvery(actionTypes.FETCH_START, fetchNewsTitle)
}可以发现这里写的跟之前写的异步操作基本上是一模一样,上面的代码不理解,takeEvery 监听所有的 action,每当发现 action.type === FETCH_START 时执行 fetchNewsTitle 这个函数,注意这里只是做监听 action 的动作,并不会拦截 action,这说明 FETCH_START action 仍然会经过 reducer 去处理,剩下 fetchNewsTitle 函数就很好理解,就是执行所谓的异步操作,这里的 put 相当于 dispatch。
最后我们需要在 store 里面使用 saga 中间件
// store/index.js
import createSagaMiddleware from 'redux-saga'
import mySaga from '../sagas'
const sagaMiddleware = createSagaMiddleware()
// ...
export default createStore(reducer, initValue, applyMiddleware(sagaMiddleware))
sagaMiddleware.run(mySaga)通过注册 saga 中间件并且 run 监听 saga 任务,也就是前面提到的 fecthData。
基于这么一个简单的例子,我们可以看到 saga 将所有的带副作用的操作与 actionCreator 和 reducer 进行分离,通过监听 action 来做自动处理,相比 async action creator 的方案,它可以保证组件触发的 action 是纯对象。
参考回答:redux-saga 实践总结
它与 redux-thunk 编写异步的方式有着它各自的应用场景,没有优劣之分,所谓存在即合理。redux-saga 相对于这种方式,具有以下的特点:
在我看来:redux-thunk + async/await 的方式学习成本低,比较适合不太复杂的异步交互场景。对于竞态判断,多重 action 组合,取消异步等场景下使用则显得乏力,redux-saga 在异步交互复杂的场景下仍能够让你清晰直观地编写代码,不过学习成本相对较高。
以上我们介绍了三种 redux 异步方案,其实关于 redux 异步方案还有很多,比如:redux-observale,通过 rxjs 的方式来书写异步请求,也有像 redux-loop 这样的方式通过在 reducer 上做文章来达到异步效果。其实方案千千万万,各成一派,每种方案都有其适合的场景,结合自己实际的需求来选择你所使用的 redux 异步方案才最可贵。
对于前面获取异步的例子,还没有结束,它仍存在着一些问题:
下面我们将重新改写一个例子,分别用 redux-thunk 和 redux-saga 对其进行处理上述的问题,并进行比较。
我们要做的例子效果如下:

cd race_with_redux_thunk/
yarn
yarn start
查看 actionCreator:
// actions/index.js
import * as actionTypes from '../actionTypes'
let nextId = 0
let prev = 0
export const updateData = (ms) => {
return (dispatch) => {
let id = ++nextId
let now = + new Date()
if(now - prev < 1000) {
return;
}
prev = now;
const checkLast = (action) => {
if(id === nextId) {
dispatch(action)
}
}
setTimeout(() => {
checkLast({
type: actionTypes.UPDATE_DATA,
payload: ms,
})
}, ms)
}
}如果是 redux-saga 重写这个例子,那么又是什么效果呢?
cd race_with_redux_saga/
yarn
yarn start
首先 reducer 就不用那么麻烦,它只要给一个信号就可以了
// actions/index.js
import * as actionTypes from '../actionTypes'
export const updateData = (ms) => {
return {
type: actionTypes.INITIAL,
ms
}
}重点是监听 INITIAL 的 saga 任务
// sagas/index.js
import { put, call, take, fork, cancel } from 'redux-saga/effects'
import * as actionTypes from '../actionTypes'
const delay = (ms) => new Promise(resolve => setTimeout(resolve, ms))
function* asyncAction({ ms }) {
let promise = new Promise((resolve) => {
setTimeout(() => {
resolve(ms)
}, ms)
})
let payload = yield promise
yield put({
type: actionTypes.UPDATE_DATA,
payload: payload
})
}
export default function* watchAsyncAction() {
let task
while(true) {
const action = yield take(actionTypes.INITIAL)
if(task) {
yield cancel(task)
}
task = yield fork(asyncAction, action)
yield call(delay, 1000)
}
}watchAsyncAction 用于监听传递过来的 action 类型,虽然通过 while(true) 来写,不过因为是生成器并不具备执行完代码的能力,它代表会一直重复循环地监听每次 action。
take 监听 INITIAL 类型的 action,首先判断之前有没有任务未执行完毕,如果有,则取消该任务,从而保证竞态判断,然后通过 fork 非阻塞调用,最后停顿一秒,call 代表阻塞调用,在这段时间内,该 saga 任务不再处理新进来的 action,所以在这段时间所有的 INITIAL action 都将会被忽略,从而进行防抖处理,put 相当于 dispatch 操作。
通过这个简单例子的对比,我们可以看出,redux-saga 更加灵活,写起来比较优雅,代码可读性更强,你可以比较清晰地理解代码的行为,当然相应地你也要熟悉更多的基本概念,学习成本较高。
另外值得一提的是因为 redux-saga 基于 ES6 的生成器,可以执行和归还函数的控制权,所以其可以处理更加复杂的业务场景,具有强大的异步流程控制。
最后我们再通过一个例子来对比 thunk 和 saga 在书写上的差异,例子效果如下:

点击按钮可以每秒增加 1,可以再次点击进行取消增加计数器,也可以通过 5s 后自动取消增加计数器。
我们先来看看 redux-thunk 要如何处理:
cd cancellable_counter_with_redux_thunk/
yarn
yarn start
在 action creator 中,我们需要创建两个定时器用来触发两个数字的更新。
import {
INCREMENT,
COUNTDOWN,
COUNTDOWN_CANCEL,
COUNTDOWN_TERMIMATED
} from '../actionTypes'
let incrementTimer
let countdownTimer
const action = type => ({ type })
export const increment = () => action(INCREMENT)
export const terminateCountDown = () => (dispatch) => {
clearInterval(incrementTimer)
clearInterval(countdownTimer)
dispatch(action(COUNTDOWN_TERMIMATED))
}
export const cancelCountDown = () => (dispatch) => {
clearInterval(incrementTimer)
clearInterval(countdownTimer)
dispatch(action(COUNTDOWN_CANCEL))
}
export const incrementAsync = (time) => (dispatch) => {
incrementTimer = setInterval(() => {
dispatch(increment())
}, 1000)
dispatch({
value: time,
type: COUNTDOWN,
})
countdownTimer = setInterval(() => {
time--
if(time <= 0) {
dispatch(cancelCountDown())
}else {
dispatch({
value: time,
type: COUNTDOWN,
})
}
}, 1000)
}incrementAsync 开启两个计时器,用于增加计数器和倒计时,terminateCountDown 为人工触发按钮导致两个定时器被清除,而在 countdownTimer 定时器内部,随着时间流逝,当 time 小于 0 时触发 cancelCountDown,取消所有定时器。
我们可以看出,redux-thunk 在处理这类异步流程控制时候有点力不从心,需要创建多个定时器来并行地改变数据,当场景更加复杂的时候代码就显得有点乱,可读性较差。
再用 redux-saga 改写刚才的例子:
cd cancellable_counter_with_redux_saga/
yarn
yarn start
// sagas/index.js
import {
INCREMENT_ASYNC,
INCREMENT,
COUNTDOWN,
COUNTDOWN_TERMIMATED,
COUNTDOWN_CANCEL,
} from '../actionTypes'
import { take, put, cancelled, call, race, cancel, fork } from 'redux-saga/effects'
import { delay } from 'redux-saga'
const action = type => ({ type })
function* incrementAsync() {
while(true) {
yield call(delay, 1000)
yield put(action(INCREMENT))
}
}
function* countdown({ ms }) {
let task = yield fork(incrementAsync)
try {
while(true) {
yield put({
type: COUNTDOWN,
value: ms--,
})
yield call(delay, 1000)
if(ms <= 0) {
break;
}
}
} finally {
if(!(yield cancelled())) {
yield put(action(COUNTDOWN_CANCEL))
}
yield cancel(task)
}
}
export default function* watchIncrementAsync() {
while(true) {
const action = yield take(INCREMENT_ASYNC)
yield race([
call(countdown, action),
take(COUNTDOWN_TERMIMATED)
])
}
}关于 Redux 异步控制就讲到这里,希望大家有所收获!
这篇文章是之前写的,我重新整理了下,阅读本文前,希望你有一定的 JS/Node 基础,这里不另外介绍如何使用 Ajax 做异步请求,如果不了解,可以先看:
最近在面试的时候常被问到如何解决跨域的问题,看了网上的一些文章后,许多文章并没有介绍清楚,经常使读者(我)感到困惑,所以今天我整理一下常用的跨域技巧,写这篇关于跨域的文章目的在于:
如果觉得本文有帮助,可以点 star 鼓励下,本文所有代码都可以从 github 仓库下载,读者可以按照下述打开:
git clone https://github.com/happylindz/blog.git
cd blog/code/crossOrigin/
yarn 建议你 clone 下来,方便你阅读代码,跟我一起测试。
使用过 Ajax 的同学都知道其便利性,可以在不向服务端提交完整页面的情况下,实现局部刷新,在当今 SPA 应用普遍使用,但是浏览器处于对安全方面的考虑,不允许跨域调用其它页面的对象,这对于我们在注入 iframe 或是 ajax 应用上带来不少麻烦。
简单来说,只有当协议,域名,端口号相同的时候才算是同一个域名,否则,均认为需要做跨域处理。
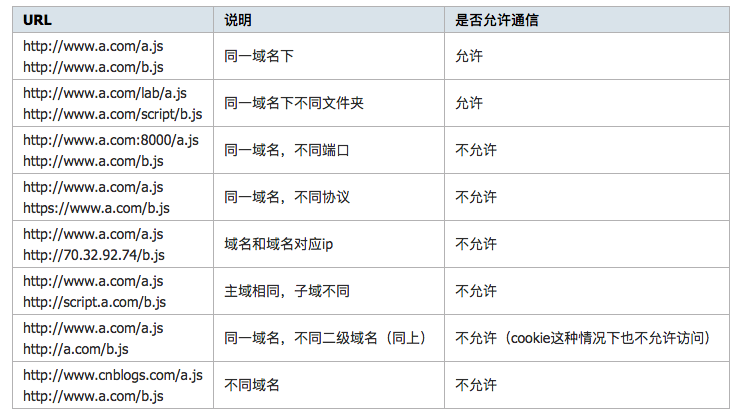
今天一共介绍七种常用的跨域技巧,关于跨域技巧大致可以分为 iframe 跨域和 API 跨域请求。
下面就先介绍三种 API 跨域的方法:
只要说到跨域,就必须聊到 JSONP,JSONP 全称为:JSON with padding,可用于解决老版本浏览器的跨域数据访问问题。
由于 web 页面上调用 js 文件不受浏览器同源策略的影响,所以通过 script 标签可以进行跨域请求:
jsonp 之所以能够跨域的关键在于页面调用 JS 脚本是不受同源策略的影响,相当于向后端发起一条 http 请求,跟后端约定好函数名,后端拿到函数名,动态计算出返回结果并返回给前端执行 JS 脚本,相当于是一种 "动态 JS 脚本"
接下来我们通过一个实例来尝试:
后端逻辑:
// jsonp/server.js
const url = require('url');
require('http').createServer((req, res) => {
const data = {
x: 10
};
// 拿到回调函数名
const callback = url.parse(req.url, true).query.callback;
console.log(callback);
res.writeHead(200);
res.end(`${callback}(${JSON.stringify(data)})`);
}).listen(3000, '127.0.0.1');
console.log('启动服务,监听 127.0.0.1:3000');前端逻辑:
// jsonp/index.html
<script>
function jsonpCallback(data) {
alert('获得 X 数据:' + data.x);
}
</script>
<script src="http://127.0.0.1:3000?callback=jsonpCallback"></script>然后在终端开启服务:
之所以能用脚本指令,是因为我在 package.json 里面设置好了脚本命令:
{
// 输入 yarn jsonp 等于 "node ./jsonp/server.js & http-server ./jsonp"
"scripts": {
"jsonp": "node ./jsonp/server.js & http-server ./jsonp",
"cors": "node ./cors/server.js & http-server ./cors",
"proxy": "node ./serverProxy/server.js",
"hash": "http-server ./hash/client/ -p 8080 & http-server ./hash/server/ -p 8081",
"name": "http-server ./name/client/ -p 8080 & http-server ./name/server/ -p 8081",
"postMessage": "http-server ./postMessage/client/ -p 8080 & http-server ./postMessage/server/ -p 8081",
"domain": "http-server ./domain/client/ -p 8080 & http-server ./domain/server/ -p 8081"
},
// ...
}
yarn jsonp
// 因为端口 3000 和 8080 分别属于不同域名下
// 在 localhost:3000 查看效果,即可收到后台返回的数据 10打开浏览器访问 localhost:8080 即可看到获取到的数据。

至此,通过 JSONP 跨域获取数据已经成功了,但是通过这种方式也存在着一定的优缺点:
优点:
缺点:
CORS 是一个 W3C 标准,全称是"跨域资源共享"(Cross-origin resource sharing)它允许浏览器向跨源服务器,发出 XMLHttpRequest 请求,从而克服了 ajax 只能同源使用的限制。
CORS 需要浏览器和服务器同时支持才可以生效,对于开发者来说,CORS 通信与同源的 ajax 通信没有差别,代码完全一样。浏览器一旦发现 ajax 请求跨源,就会自动添加一些附加的头信息,有时还会多出一次附加的请求,但用户不会有感觉。
因此,实现 CORS 通信的关键是服务器。只要服务器实现了 CORS 接口,就可以跨域通信。
前端逻辑很简单,只要正常发起 ajax 请求即可:
// cors/index.html
<script>
const xhr = new XMLHttpRequest();
xhr.open('GET', 'http://127.0.0.1:3000', true);
xhr.onreadystatechange = function() {
if(xhr.readyState === 4 && xhr.status === 200) {
alert(xhr.responseText);
}
}
xhr.send(null);
</script>这似乎跟一次正常的异步 ajax 请求没有什么区别,关键是在服务端收到请求后的处理:
// cors/server.js
require('http').createServer((req, res) => {
res.writeHead(200, {
'Access-Control-Allow-Origin': 'http://localhost:8080',
'Content-Type': 'text/html;charset=utf-8',
});
res.end('这是你要的数据:1111');
}).listen(3000, '127.0.0.1');
console.log('启动服务,监听 127.0.0.1:3000');关键是在于设置相应头中的 Access-Control-Allow-Origin,该值要与请求头中 Origin 一致才能生效,否则将跨域失败。
然后我们执行命令:yarn cors 打开浏览器访问 localhost:3000 即可看到效果:
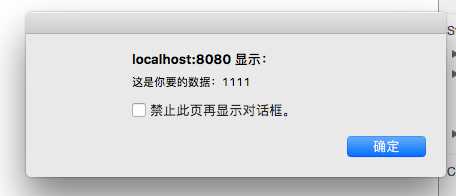
成功的关键在于 Access-Control-Allow-Origin 是否包含请求页面的域名,如果不包含的话,浏览器将认为这是一次失败的异步请求,将会调用 xhr.onerror 中的函数。
CORS 的优缺点:
这里只是对 CORS 做一个简单的介绍,如果想更详细地了解其原理的话,可以看看下面这篇文章:
服务器代理,顾名思义,当你需要有跨域的请求操作时发送请求给后端,让后端帮你代为请求,然后最后将获取的结果发送给你。
假设有这样的一个场景,你的页面需要获取 CNode:Node.js专业中文社区 论坛上一些数据,如通过 https://cnodejs.org/api/v1/topics,当时因为不同域,所以你可以将请求后端,让其对该请求代为转发。
代码如下:
// serverProxy/server.js
const url = require('url');
const http = require('http');
const https = require('https');
const server = http.createServer((req, res) => {
const path = url.parse(req.url).path.slice(1);
if(path === 'topics') {
https.get('https://cnodejs.org/api/v1/topics', (resp) => {
let data = "";
resp.on('data', chunk => {
data += chunk;
});
resp.on('end', () => {
res.writeHead(200, {
'Content-Type': 'application/json; charset=utf-8'
});
res.end(data);
});
})
}
}).listen(3000, '127.0.0.1');
console.log('启动服务,监听 127.0.0.1:3000');通过代码你可以看出,当你访问 http://127.0.0.1:3000/topics 的时候,服务器收到请求,会代你发送请求 https://cnodejs.org/api/v1/topics 最后将获取到的数据发送给浏览器。
启动服务 yarn proxy 并访问 http://localhost:3000/topics 即可看到效果:

跨域请求成功。纯粹的获取跨域获取后端数据的请求的方式已经介绍完了,另外介绍四种通过 iframe 跨域与其它页面通信的方式。
在 url 中,http://www.baidu.com#helloworld 的 "#helloworld" 就是 location.hash,改变 hash 值不会导致页面刷新,所以可以利用 hash 值来进行数据的传递,当然数据量是有限的。
假设 localhost:8080 下有文件 index.html 要和 localhost:8081 下的 data.html 传递消息,index.html 首先创建一个隐藏的 iframe,iframe 的 src 指向 localhost:8081/data.html,这时的 hash 值就可以做参数传递。
// hash/client/index.html 对应 localhost:8080/index.html
<script>
let ifr = document.createElement('iframe');
ifr.style.display = 'none';
ifr.src = "http://localhost:8081/data.html#data";
document.body.appendChild(ifr);
function checkHash() {
try {
let data = location.hash ? location.hash.substring(1) : '';
console.log('获得到的数据是:', data);
}catch(e) {
}
}
window.addEventListener('hashchange', function(e) {
console.log('获得的数据是:', location.hash.substring(1));
});
</script>data.html 收到消息后通过 parent.location.hash 值来修改 index.html 的 hash 值,从而达到数据传递。
// hash/server/data.html 对应 localhost:8081/data.html
<script>
switch(location.hash) {
case "#data":
callback();
break;
}
function callback() {
const data = "data.html 的数据"
try {
parent.location.hash = data;
}catch(e) {
// ie, chrome 下的安全机制无法修改 parent.location.hash
// 所以要利用一个中间的代理 iframe
var ifrproxy = document.createElement('iframe');
ifrproxy.style.display = 'none';
ifrproxy.src = 'http://localhost:8080/proxy.html#' + data; // 该文件在 client 域名的域下
document.body.appendChild(ifrproxy);
}
}
</script>由于两个页面不在同一个域下 IE、Chrome 不允许修改 parent.location.hash 的值,所以要借助于 localhost:8080 域名下的一个代理 iframe 的 proxy.html 页面
// hash/client/proxy.html 对应 localhost:8080/proxy.html
<script>
parent.parent.location.hash = self.location.hash.substring(1);
</script>之后启动服务 yarn hash,即可在 localhost:8080 下观察到:

当然这种方法存在着诸多的缺点:
window.name(一般在 js 代码里出现)的值不是一个普通的全局变量,而是当前窗口的名字,这里要注意的是每个 iframe 都有包裹它的 window,而这个 window 是 top window 的子窗口,而它自然也有 window.name 的属性,window.name 属性的神奇之处在于 name 值在不同的页面(甚至不同域名)加载后依旧存在(如果没修改则值不会变化),并且可以支持非常长的 name 值(2MB)。
举个简单的例子:
你在某个页面的控制台输入:
window.name = "Hello World"
window.location = "http://www.baidu.com"页面跳转到了百度首页,但是 window.name 却被保存了下来,还是 Hello World,跨域解决方案似乎可以呼之欲出了:
前端逻辑:
// name/client/index.html 对应 localhost:8080/index.html
<script>
let data = '';
const ifr = document.createElement('iframe');
ifr.src = "http://localhost:8081/data.html";
ifr.style.display = 'none';
document.body.appendChild(ifr);
ifr.onload = function() {
ifr.onload = function() {
data = ifr.contentWindow.name;
console.log('收到数据:', data);
}
ifr.src = "http://localhost:8080/proxy.html";
}
</script>数据页面:
// name/server/data.html 对应 localhost:8081/data.html
<script>
window.name = "data.html 的数据!";
</script>localhost:8080index.html 在请求数据端 localhost:8081/data.html 时,我们可以在该页面新建一个 iframe,该 iframe 的 src 指向数据端地址(利用 iframe 标签的跨域能力),数据端文件设置好 window.name 的值。
但是由于 index.html 页面与该页面 iframe 的 src 如果不同源的话,则无法操作 iframe 里的任何东西,所以就取不到 iframe 的 name 值,所以我们需要在 data.html 加载完后重新换个 src 去指向一个同源的 html 文件,或者设置成 'about:blank;' 都行,这时候我只要在 index.html 相同目录下新建一个 proxy.html 的空页面即可。如果不重新指向 src 的话直接获取的 window.name 的话会报错:

之后运行 yarn name 即可看到效果:
postMessage 是 HTML5 新增加的一项功能,跨文档消息传输(Cross Document Messaging),目前:Chrome 2.0+、Internet Explorer 8.0+, Firefox 3.0+, Opera 9.6+, 和 Safari 4.0+ 都支持这项功能,使用起来也特别简单。
前端逻辑:
// postMessage/client/index.html 对应 localhost:8080/index.html
<iframe src="http://localhost:8081/data.html" style='display: none;'></iframe>
<script>
window.onload = function() {
let targetOrigin = 'http://localhost:8081';
window.frames[0].postMessage('index.html 的 data!', targetOrigin);
}
window.addEventListener('message', function(e) {
console.log('index.html 接收到的消息:', e.data);
});
</script>创建一个 iframe,使用 iframe 的一个方法 postMessage 可以想 http://localhost:8081/data.html 发送消息,然后监听 message,可以获得其文档发来的消息。
数据端逻辑:
// postMessage/server/data.html 对应 localhost:8081/data.html
<script>
window.addEventListener('message', function(e) {
if(e.source != window.parent) {
return;
}
let data = e.data;
console.log('data.html 接收到的消息:', data);
parent.postMessage('data.html 的 data!', e.origin);
});
</script>启动服务:yarn postMessage 并打开浏览器访问:
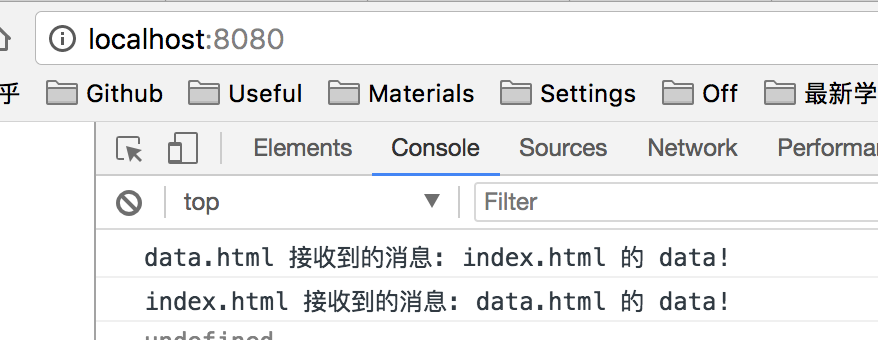
对 postMessage 感兴趣的详细内容可以看看教程:
PostMessage_百度百科
Window.postMessage()
对于主域相同而子域不同的情况下,可以通过设置 document.domain 的办法来解决,具体做法是可以在 http://www.example.com/index.html 和 http://sub.example.com/data.html 两个文件分别加上 document.domain = "example.com" 然后通过 index.html 文件创建一个 iframe,去控制 iframe 的 window,从而进行交互,当然这种方法只能解决主域相同而二级域名不同的情况,如果你异想天开的把 script.example.com 的 domain 设为 qq.com 显然是没用的,那么如何测试呢?
测试的方式稍微复杂点,需要安装 nginx 做域名映射,如果你电脑没有安装 nginx,请先去安装一下: nginx
前端逻辑:
// domain/client/index.html 对应 sub1.example.com/index.html
<script>
document.domain = 'example.com';
let ifr = document.createElement('iframe');
ifr.src = 'http://sub2.example.com/data.html';
ifr.style.display = 'none';
document.body.append(ifr);
ifr.onload = function() {
let win = ifr.contentWindow;
alert(win.data);
}
</script>数据端逻辑:
// domain/server/data 对应 sub2.example.com/data.html
<script>
document.domain = 'example.com';
window.data = 'data.html 的数据!';
</script>打开操作系统下的 hosts 文件:mac 是位于 /etc/hosts 文件,并添加:
127.0.0.1 sub1.example.com
127.0.0.1 sub2.example.com之后打开 nginx 的配置文件:/usr/local/etc/nginx/nginx.conf,并在 http 模块里添加,记得输入 nginx 启动 nginx 服务:
/usr/local/etc/nginx/nginx.conf
http {
// ...
server {
listen 80;
server_name sub1.example.com;
location / {
proxy_pass http://127.0.0.1:8080/;
}
}
server {
listen 80;
server_name sub2.example.com;
location / {
proxy_pass http://127.0.0.1:8081/;
}
}
// ...
}
相当于是讲 sub1.example.com 和 sub2.example.com 这些域名地址指向本地 127.0.0.1:80,然后用 nginx 做反向代理分别映射到 8080 和 8081 端口。
这样访问 sub1(2).example.com 等于访问 127.0.0.1:8080(1)
启动服务 yarn domain 访问浏览器即可看到效果:
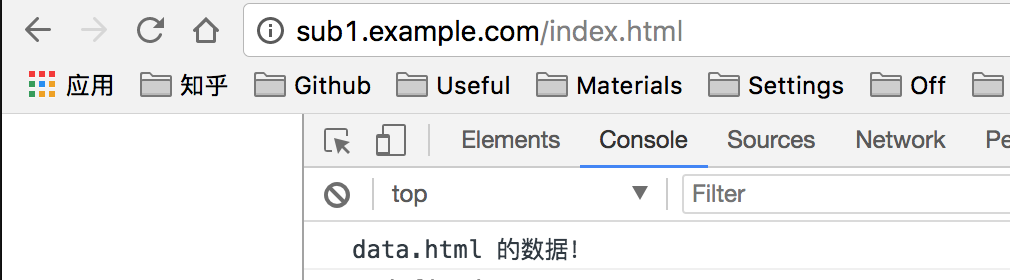
前面七种跨域方式我已经全部讲完,其实讲道理,常用的也就是前三种方式,后面四种更多时候是一些小技巧,虽然在工作中不一定会用到,但是如果你在面试过程中能够提到这些跨域的技巧,无疑在面试官的心中是一个加分项。
上面阐述方法的时候可能有些讲的不明白,希望在阅读的过程中建议你跟着我敲代码,当你打开浏览器看到结果的时候,你也就能掌握到这种方法。
这里不会介绍关于 Promise 相关的基础知识,如果你想学习 Promise 的话,建议看这篇文章 Promise 对象 - ECMAScript 6入门
无论是 resolve, reject,都会将函数剩余的代码执行完
const promise = new Promise((resolve, reject) => {
console.log('mark 1');
resolve('hello world'); // reject('hello world');
console.log('mark 2');
});
promise.then(result => {
console.log(result);
}).catch(err => {
console.log(err);
});相当于:
const promise = new Promise((resolve, reject) => {
console.log('mark 1');
console.log('mark 2');
resolve('hello world'); // reject('hello world');
});
promise.then(result => {
console.log(result);
}).catch(err => {
console.log(err);
});如果你不想在 resolve 或 reject 后执行剩下的代码段,可以在 resolve 后将其返回
const promise = new Promise((resolve, reject) => {
console.log('mark 1');
return resolve('hello world'); // reject('hello world');
console.log('mark 2'); // never be here
});
promise.then(result => {
console.log(result);
}).catch(err => {
console.log(err);
});并行执行很好解决,在 Promise中有 all 这个函数支持, Promise.all 方法用于将多个 Promise 实例,包装成一个新的 Promise 实例。当多个 Promise 实例执行完后才去执行最后新的 Promise 实例。
const datum = [];
for(let i = 0; i < 10; i++) {
datum.push(i);
}
Promise.all(datum.map(i => {
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log(i * 200 + " ms 后执行结束");
resolve("第 " + (i + 1) + " 个 Promise 执行结束");
}, i * 200);
})
})).then((data) => {
console.log(data);
});如果不使用 Promise.all 这个方法的话,你也可以使用像 ES7 的 async/await
const asyncFun = async () => {
const datum = []
for(let i = 0; i < 10; i++) {
datum.push(new Promise((resolve, reject) => {
setTimeout(() => {
console.log(i * 200 + 'ms 后执行结束')
resolve('第 ' + (i + 1) + ' 个 Promise 执行结束')
}, i * 200)
}))
}
const result = []
for(let promise of datum) {
result.push(await promise)
}
console.log(result)
}
asyncFun()串行执行:这里提供两种方式
const datum = [];
for(let i = 0; i < 10; i++) {
datum.push(i);
}
let serial = Promise.resolve();
for(let i of datum) {
serial = serial.then(data => {
console.log(data);
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log(i * 200 + " ms 后执行结束");
resolve("第 " + (i + 1) + " 个 Promise 执行结束");
}, i * 200);
})
});
}另外可以使用 reduce 来串行:
const datum = [];
for(let i = 0; i < 10; i++) {
datum.push(i);
}
datum.reduce((prev, cur) => {
return prev.then(data => {
console.log(data);
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log(cur * 200 + " ms 后执行结束");
resolve("第 " + (cur + 1) + " 个 Promise 执行结束");
}, cur * 200);
})
})
}, Promise.resolve(true));let promise = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('Hello World!');
}, 1000)
});
promise.then('呵呵哒').then((data) => {
console.log(data); // Hello World
})这是一种值穿透的情况,一般有下面两种情况:
promise 已经是 FULFILLED/REJECTED 时,通过 return this 实现的值穿透:
let promise = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('Hello World!');
}, 1000)
});
promise.then(() => {
promise.then().then(null).then('呵呵哒').then((res) => {
console.log(res)
})
promise.catch().catch(null).then('呵呵哒').then((res) => {
console.log(res)
})
})promise 是 PENDING 时,通过生成新的 promise 加入到父 promise 的 queue,父 promise 有值时调用 callFulfilled->doResolve 或 callRejected->doReject(因为 then/catch 传入的参数不是函数)设置子 promise 的状态和值为父 promise 的状态和值。如:
let promise = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('Hello World!');
}, 1000)
});
let a = promise.then('呵呵哒');
a.then(res => {
console.log(res);
});
let b = promise.catch('呵呵哒');
b.then(res => {
console.log(res);
})总而言之,当你给 then() 传递一个非函数(比如一个 promise )值的时候,它实际上会解释为 then(null) ,这会导致之前的 promise 的结果丢失。例如:
Promise.resolve('First Value').then(Promise.resolve('Second Value')).then(null).then((value) => {
console.log(value) // First Value
})不仅 reject,抛出的异常也会被作为拒绝状态被 Promise 捕获
let promise = new Promise((resolve, reject) => {
reject('This is an error');
});
promise.then(result => {
console.log(result);
}).catch(error => {
console.log('handle error: ', error); //handle error: Error: This is an error
}) 但是,永远不要在回调队列中抛出异常,因为回调队列脱离了运行上下文环境,异常无法被当前作用域捕获。
let promise = new Promise((resolve, reject) => {
setTimeout(() => {
throw Error('This is an error');
});
});
promise.then(result => {
console.log(result);
}).catch(error => {
console.log('handle error: ', error); // Error: This is an error
});简单说来,回调队列指的是 JS 事件循环中的 macrotask 队列,比如 setTimeout setInterval 会插入到 macrotask 中。
如果要在回调函数中捕获异常,请使用 reject,永远不要使用 Error。
上述的代码应改成:
let promise = new Promise((resolve, reject) => {
setTimeout(() => {
reject('This is an error');
});
});
promise.then(result => {
console.log(result);
}).catch(error => {
console.log('handle error: ', error); // Error: This is an error
});我们都知道 then 的第二参数跟 catch 用法很像,都是用来进行错误处理的,比如下面这段代码:
let promise1 = new Promise((resolve, reject) => {
reject('this is an error');
});
promise1.then(data => {
console.log(data);
}, err => {
console.log('handle err:', err); // handle err: this is an error
});
let promise2 = new Promise((resolve, reject) => {
reject('this is an error');
});
promise2.then(data => {
console.log(data);
}).catch(err => {
console.log('handle err:', err); // handle err: this is an error
});当时这两者还是区别的,区别于 then 的第二参数无法处理第一参数函数中的错误。
let promise1 = Promise.resolve();
promise1.then(() => {
throw Error('this is a error'); //UnhandledPromiseRejectionWarning: Unhandled promise rejection
}, err => {
console.log(err);
})
let promise2 = Promise.resolve();
promise2.then(() => {
throw Error('this is a error');
}).catch(err => {
console.log('handle err:', err); //handle err: Error: this is a error
})当你使用then( resolveHandler, rejectHandler)格式,如果 resolveHandler 自己抛出一个错误 rejectHandler 并不能捕获。
第一个 Promise 对象无法处理同级 then 中的函数抛出的异常,所以在一般情况下,最后直接使用 catch 来进行异常捕获比较保险。
一般我们用 catch 来捕捉前面抛出的异常,但是如果试想一下如果最后一个 catch 函数也抛出了异常,应该怎么处理呢?
let promise = new Promise((resolve, reject) => {
reject('Hello World')
});
promise.catch((err) => {
throw('Unexpected Error'); // Uncaught (in promise) Unexpected Error
})面对这样的错误,不管以 then 方法或 catch 方法结尾,要是最后一个方法抛出错误,都有可能无法捕捉到(因为 Promise 内部的错误不会冒泡到全局)这里提供两种思路:
window.onerror = (err) => {
console.log(err);
}
Promise.prototype.done = function (onFulfilled, onRejected) {
this.then(onFulfilled, onRejected)
.catch(function (reason) {
// 抛出一个全局错误
setTimeout(() => { throw reason }, 0);
});
};
let promise = new Promise((resolve, reject) => {
reject('Hello World')
});
promise.catch((err) => {
throw('Unexpected Error'); // Uncaught Unexpected Error
}).done()window.addEventListener("unhandledrejection", (e) =>{
console.log(e.reason)
})
let promise = new Promise((resolve, reject) => {
reject('Hello World')
});
promise.catch((err) => {
throw('Unexpected Error'); // Unexpected Error
})let promise = new Promise((resolve, reject) => [
reject('Hello world')
]).then(() => {
console.log('resolve')
})
setTimeout(() => {
promise.catch((e) => {
console.log(e)
}).then(() => {
console.log('catch resolve')
})
}, 1000)let i = 0;
Promise.resolve('resolved promise').then(() => {
i += 2
})
console.log(i) // 0即使是 resolve 的 Promise 调用 then 方法也是异步执行。
const timeout = (ms) => {
return new Promise((resolve) => {
setTimeout(() => {
resolve(ms + ' passed')
}, ms)
})
}
const asyncFunc = async () => {
const value1 = await timeout(2000)
console.log(value1)
const value2 = await timeout(2000)
console.log(value2)
}
asyncFunc()
console.log('now')let promise1 = new Promise((resolve) => {
resolve('Hello world')
})
let promise2 = promise1.then()
console.log(promise1 === promise2) // false
console.log(promise1 instanceof Promise) // true
console.log(promise2 instanceof Promise) // true每次调用 then 方法后都会返回一个新的 Promise 对象,并不是返回原本的 Promise 对象。
在英文或者中文的网站,我们习惯的阅读方式都是从左往右的,所以你在访问国内外的网站的时候会发现,不管是文字还是布局,都是从左往右进行排版,而我们也熟悉和适应了这种阅读习惯,但是在中东地区,有很多国家,诸如像阿拉伯语、希伯来语,他们的阅读习惯却是从右到左的,恰好跟我们是相反的,我也查阅了大量阿拉伯语的网站的设计,感兴趣也可以点击下面的网站看看:
通过上面的网站,可以很直观地看出像阿拉伯语,典型 RTL 布局网站的特点:
知道了 RTL 布局的特点,我们在使用场景上需要考虑:
所以本文探究的是在假定语言文案,图片等信息正确的情况下,如何使用一套代码,不仅可以支持像英文,中文等 LTR 布局的网站,也可以支持像阿拉伯,希伯来语等 RTL 布局的网站。
在做 RTL 布局的时候,我们自然而然就会想到 direction 这个 CSS 属性,它与在 html 标签上直接添加 dir="rtl" 的作用一样,可以改变我们网站的布局特点,CSS 手册中对 direction 属性是这样描述的:该属性指定了块的基本书写方向,以及针对 Unicode 双向算法的嵌入和覆盖方向。
讲的很绕口,看的云里雾里的,通俗点讲,它改变了部分元素的书写特点:
direction:rtl 的元素,如果没有预先定义过 text-align,那么这个元素的 text-align 的值就变成了 right,如果设置了 left/center 则无效通过下面几个简单例子就可以理解:
<style>
span {
display: inline-block;
}
</style>
<div style="direction: rtl;">1 2 3 4 5 6</div>
<div style="text-align:left;">1 2 3 4 5 6</div>
<div style="text-align:right;">1 2 3 4 5 6</div>
<div style="direction: rtl;"><span>This is </span><span>my blog</span></div>
<div style="direction: rtl;">这是我的博客。</div>
<div style="text-align:right;">这是我的博客。</div>
<div style="direction: rtl;">هذا هو بلدي بلوق.</div>
<div style="text-align:right;">هذا هو بلدي بلوق.</div>展示效果:
上面介绍了一些 direction 的基本用法,那是不是就可以认为只要使用 direction: rtl 之后网站就可以做到兼容阿拉伯语/希伯来语等排版从右往左的网站了呢?答案是否定的。 direction 的功能并没有你想象中那么强大。
在 PC 网页上,页面布局是千变万化的,比如我们常使用的布局有:flex,内联,浮动,绝对定位等布局方式。
我也对一些常用的布局方式进行测试:
通过上述的测试可以发现 direction 只能改变 display: flex/inline-block 元素的书写方向,对于 float/绝对定位布局就无能为力,更别谈复杂的页面布局,比如 BFC 布局、双飞翼、圣杯布局等等。
另外 direction 无法改变 margin, padding, border 的水平方向,也就是说除非你的元素是居中的,否则当你的元素是不对称的话,即使你改变了元素的书写方向和顺序,margin-left 还是指向左边的,它并不会留出右边的空白。从下面的图对比就可以看出:在左右间距不对称的时候,直接使用 direction 会对我们本来设计的布局产生效果上的偏差。
在知道了 direction 的特点和不足之后,那么如何围绕 direction 打造一套通用的布局方案呢?
从上面的分析,对于布局/间距翻转能力的缺失,我们可以对 CSS 进行后处理来达到我们需要的效果,举个例子,可以在 Github 上搜 rtlcss 这个模块,它的原理就是对 CSS 文件进行处理,比如将 CSS 属性中的 left 改为 right,right 改为 left。
通过这种能力,无论是 float/绝对定位布局,还是 margin/padding 间距,都可以很好地改变书写方向。举个简单例子:
.test {
direction: ltr;
float: left;
position: relative;
left: 20px;
margin-left: 100px;
padding-right: 30px;
}通过 rtlcss 模块处理后的 CSS 将变成:
.test {
direction: rtl;
float: right;
position: relative;
right: 20px;
margin-right: 100px;
padding-left: 30px;
}通过这样的处理,大部分场景下的布局都可以都可以得到很好的处理,比如简单对比像绝对定位这样的布局:
经过 rtlcss 处理后的页面效果:
上面是基于 direction 布局方案原理,当然它也有一些能力上的不足和值得去思考的地方:
首先这是针对 CSS 的,也就是页面的初始化展示效果,但是涉及到 JS 就无能为力了,比如在轮播图中,通过 JS 去控制图片的下一帧,在不同的 LTR、RTL 布局中就产生额外的兼容代码。
其次,它无法处理 html 中内嵌在标签中的样式,比如我们在写 React 组件中可以能会写出这样的代码:
function SomeComponent({ isSomething }) {
return <div style={{ marginLeft: isSomething ? 20 : 10 }} ></div>;
}像这样书写的方式以后就要改成基于 class 切换:
function SomeComponent({ isSomething }) {
const cls = classNames({
marginLeft20: isSometing,
marginLeft10: !isSometing
})
return <div className={cls}></div>;
}这部分内容可以通过规范去避免写内联样式,也可以通过正则去修改替换修改样式。
第三点需要考虑的是图标库,上面的问题解决了布局,文字排版的问题,但是对于图标来说仅仅只是布局上的移动,根据 Google 的 Material Design在双向性一章 的内容可以看出,有些图标是需要翻转的,有些图标不用,再比如左右箭头,在不同布局中的意义也是不一样的,所以针对 RTL 的布局,我们需要重新设计一套字体库用于 RTL 布局,真正给使用诸如像阿拉伯语、希伯来语的用户带来本地化的体验。
第四点是需要有更加细粒度的控制,因为在 RTL 布局中,不是所有的内容都一定是从右到左进行排版的,我们需要在整体 RTL 的页面中忽视掉某些模块,使其仍然是以从左往右顺序的能力。
这部分怎么做呢?可以给不需要翻转的模块的 CSS 文件中添加像 /* rtl:ignore */,然后让像 rtlcss 在处理的时候可以忽略掉对该模块的处理,从而让该模块在 RTL 布局中保持已有的展示效果。
在真正实现的过程中,肯定还会遇到其它更多的问题,比如像:CSS 的命名规则(直接加 -rtl 或其它来保证非覆盖发布),还是说如何进行 CDN 部署发布等等一系列的工程实践问题,相信在不久的将来,经过实践上线后会产出基于 direction 通用布局的最佳工程实践方案。
上面介绍完基于 direction 的布局方案,最后通过一套代码编译成一套 html,多套 css,一套 js 文件,区分国家用户来进行访问。那么有没有可能通过一套代码,生成一套 html,css,js 文件供用户去访问呢?请听下文分解。
想必前端工程师都使用过 CSS3 的 transform 属性,通过 transform: scaleX(-1) 可以使页面沿着中轴进行水平翻转(关于 transform scaleX/rotateY 水平翻转用法可以看 CSS垂直翻转/水平翻转提高web页面资源重用性
通过水平翻转,原本 LTR 的布局页面:
经过水平翻转之后就变成 RTL 布局页面:
并且这种方式在布局上具有良好的兼容性,跟 direction 改变方向不同,你根本无需考虑你的布局:flex/浮动/绝对定位等等,都可以很好地从 LTR 布局变成 RTL 布局。
解决了布局问题,但是也引入的新的问题,就是文字,图片等等信息全部都翻转了,所以我们在文字部分需要将文字再翻转回来,比如说在文字的容器上加上 transform: scaleX(-1),这样就可以保持内容的正确书写顺序。
基于这样的思路,一种通过 transform 镜像翻转来实现 RTL 布局的方案设计就应运而生。
通过 transform 的镜像翻转,可以很好地解决了布局翻转的问题,基于 transform 设计通用布局我的思路是这样的:
首先编写一个 npm 模块,它是一个 React 组件,使用它的时候需要引入它的 CSS 文件和 JS 组件。
如果页面需要支持,在阿拉伯语页面上添加上全局翻转:
// xxxxx/index.css
html[lang="ar"] {
transform: scaleX(-1);
}接下来只需要考虑页面上不需要翻转的内容,比如:文字,部分图片,一些图标等等元素。
对于这些元素,可以通过 React 组件进行包裹,用法如下:
import{ NoFlipOver } from 'xxxxx';
function SomeComp({ title, imgUrl }) {
const comp1 = <NoFlipOver>
{ title }
</NoFlipOver>;
const comp2 = <NoFlipOver>
<Icon type="clock" />
</NoFlipOver>;
const comp3 = <NoFlipOver>
<img src={ imgUrl } />
</NoFlipOver>;
const comp4 = <NoFlipOver>
<SomethingYouDontKnow />
</NoFlipOver>;
}通过这种轻量级的入侵代码,开发者无需关心具体的翻转逻辑,只需要将页面中不需要翻转的内容进行包裹即可。而我们需要做的是如何编写一个通用的不翻转 React 组件,举个例子,如果接受到的内容是一段文字,就可以像这样进行处理:
// xxxxx/index.js
const NoFlipOver = function({ children, ...props }) {
if(typeof children === 'string') {
return <span { ...props } className="no-flip-over">{ children }</span>;
}
}// xxxxx/index.css
html[lang="ar"] .no-flip-over {
transform: scaleX(-1);
}对文字的处理比较简单,只需要通过 span 标签进行包裹(保证文字向右对齐,如果原本是左对齐的话)这样简单的文字处理组件就完成,当然这里只是举一个简单的例子,在设计通用布局 React 容器组件的时候肯定需要考虑到各个方面,这里需要等我具体实践之后才能产出更多的经验。
基于这样的思路,可以很好,更加细粒度地去控制页面模块的展示形态,需要翻转的内容,无需处理,不需要的翻转的内容,需要用一个 React 容器组件进行包裹,从而达到页面自适应 LTR/RTL 布局效果。
前面介绍了基于 direction/transform 镜像翻转来实现通用布局方案,下面我就对比来谈谈 transform 镜像翻转方案相对于 direction 方案具有哪些优势呢?
首先它不只是针对 CSS 展示效果,因为是将整个页面沿中轴进行翻转,margin-left 在浏览器理解上是属于向右的,所以 transform 方案是兼容 JS 逻辑的,也就是说无需修改 JS 逻辑,而 direction 方案只是针对 CSS,JS 逻辑需要调整兼容。
**第二点,它可以直接使用一套图标库,一套图片即可,需要翻转的无需处理,不需翻转的就使用 NoFlipOver 进行包裹。**比如说像下面这样一个图文分离的 banner:
经过镜像翻转之后,就变成了:
如果是通过 direction 方案的话就需要准备两张图片了(当然如果是图文不分离的话也是需要老老实实准备两套图片)
第三点,它不需要考虑 CSS 命名,CDN 部署等一系列工程问题,因为它是划分 CSS 作用域的方式,针对 LTR/RTL 布局进行隔离适配。
第四点,内嵌样式 transform 方案也可以很好地做到兼容,而 direction 方案是针对 CSS 文件的,如果要针对 html 文件则需要另外额外的工作。
说了一些 transform 方案对比与 direction 方案的优势,下面就讲讲其缺点:
第一,它需要对我们已有的业务场景进行改造,入侵业务代码,也就是说,如果你的场景相对比较分散,公用模块复用率较低,那么在使用 transform 方案的时候就需要对每个场景单独进行修改适配,当然如果你的场景公用组件多,对公共模块修改可以很好在各个场景中复用,这样一次性的成本就相对比较容易。
第二点,对于一些页面滚动组件需要做额外的兼容操作,经过我的实践发现,滚动组件在经过翻转之后存在着一些问题,初步认为是因为翻转之后带来一些高度属性值的变化,具体原因需要等兼容适配时候才清楚。
本文通过对 direction/transform 属性使用和剖析,设计了两款不同思路的 LTR/RTL 通用布局方案,两套方案各有千秋,有优势,也有自身不足的地方。
在动手准备改造之前,最好先跟 UED 确认好 RTL 布局的设计规范,避免因为主观认知导致错误的视觉偏差,这样可以给中东地区的用户提供更加本地化的体验,这里也有关于页面布局双向性的设计规范,感兴趣的可以看一看:MATERIAL DESIGN - Bidirectionality
最后针对不同的业务场景选择,运用合适的通用布局方案,才能有效地降低开发和维护成本。
最近在给团队对 webpack 中的 sideEffects 字段用途进行微分享,于是乎,我最后就整理成一篇文章,希望帮助更多的人理解 sideEffects 的作用。
sideEffects 是什么呢?我用一句话来概括就是:让 webpack 去除 tree shaking 带来副作用的代码。
听起来有点绕口,让我们划出重点:tree shaking/用法/副作用
tree shaking 是一种代码优化技术,它能够将无用的代码进行去除,下面举个简单的例子:
// a.js
export const a = 'a';
export const b = 'b'; // 不导出,删除
export const c = 'c'; // 导出不引用,删除
// index.js
import { a, c } from './a.js';
console.log(a);
if(false) { // 不会执行的代码,删除
console.log('去除我');
}可以从上面简单的例子看出:在 webpack 编译阶段 tree shaking 会将未被使用的代码删除,简单总结一下:
想使用 sideEffects,你的 webpack 的版本号要大于等于 4。那具体应该怎么用呢,如果你在写一个第三方的 npm 模块,sideEffects 支持下面两种写法:
// package.json
{
"sideEffects": false
}
// antd package.json
{
"sideEffects": [
"dist/*",
"es/**/style/*",
"lib/**/style/*"
]
}如果你想要对你的业务代码生效,那你可以再 module.rules 里面添加,比如:
module.exports = {
module: {
rules: [
{
test: /\.jsx?$/,
exclude: /(node_modules|bower_components)/,
use: {
loader: 'babel-loader',
},
sideEffects: false || []
}
]
},
}sideEffects 支持两种写法,一种是 false,一种是数组
webpack 在编译就会去读取这个 sideEffects 字段,如果有的话,它就会将所有引用这个包的副作用代码或者自身具有副作用的业务代码给去除掉。
说了这么多,那什么是有副作用的代码呢?简单说来就是 JS 引用类型属性读/写所带来的副作用,看完下面这个简单的例子你就明白了。
var x = {};
Object.defineProperty(x, "a", {
get: function(val) {
window.x = 'a';
return val;
}
});
function getA ( x ) {
return x.a
}
getA(x);
console.log(window.x); // ax 在获取 a 属性的同时在 window 对象上挂载了 x 字段,跟属性 setter 同理,JS 引用属性的 getter 和 setter 其实是不透明的,webpack 身为保守派,对于这类的代码就会选择保留。
这也是为什么 webpack 对于 ES6 class 类型处理糟糕的原因,在 babel 转义 class 类的时候会有很多 setter 的操作:
class Person {
constructor ({ name, age, sex }) {
this.className = 'Person'
this.name = name
this.age = age
this.sex = sex
}
getName () {
return this.name
}
}
// 分割线
function _classCallCheck(instance, Constructor) { if (!(instance instanceof Constructor)) { throw new TypeError("Cannot call a class as a function"); } }
var _createClass = function() {
function defineProperties(target, props) {
for (var i = 0; i < props.length; i++) {
var descriptor = props[i];
descriptor.enumerable = descriptor.enumerable || !1, descriptor.configurable = !0,
"value" in descriptor && (descriptor.writable = !0), Object.defineProperty(target, descriptor.key, descriptor);
}
}
return function(Constructor, protoProps, staticProps) {
return protoProps && defineProperties(Constructor.prototype, protoProps), staticProps && defineProperties(Constructor, staticProps),
Constructor;
};
}()
var Person = function () {
function Person(_ref) {
var name = _ref.name, age = _ref.age, sex = _ref.sex;
_classCallCheck(this, Person);
this.className = 'Person';
this.name = name;
this.age = age;
this.sex = sex;
}
_createClass(Person, [{
key: 'getName',
value: function getName() {
return this.name;
}
}]);
return Person;
}();在一个简单的 class 中,会有一个立即执行函数,里面对对象属性进行 set 操作。
举个很常见的例子,一般我们在项目里写代码的时候会区分开发环境和生产环境,比如开发阶段会引入一些调试工具包,如:
import DevTools from 'mobx-react-devtools';
class MyApp extends React.Component {
render() {
return (
<div>
...
{ process.env.NODE_ENV === 'production' ? null : <DevTools /> }
</div>
);
}
}乍一看,还以为如果生产环境下 mobx-react-devtools 就完全不会被引入了,但其实如果没有 sideEffects 的话 mobx-react-devtools 并没有被完全移除,里面的副作用代码仍然是会被引入的。
什么时候应该加上?我也不确定自己写的 npm 模块到底有没有副作用?
我们基本能确保这个包是否会对包以外的对象产生影响,比如是否修改了 window 上的属性,是否复写了原生对象 Array, Object 方法。如果我们能保证这一点,其实我们就能知道整个包是否能设置 sideEffects: false 了
webpack 的 tree shaking 依赖于 babel编译 + UglifyJS 压缩,这个过程是没有完善的程序流分析,UglifyJS 没有完善的程序流分析。它可以简单的判断变量后续是否被引用、修改,但是不能判断一个变量完整的修改过程,不知道它是否已经指向了外部变量,所以很多有可能会产生副作用的代码,都只能保守的不删除。
tree shaking 处理代码的类型:
在 webpack4 发布之前,tree shaking 在处理第三方 npm 模块时候一般是这么做的:
// antd package.json
{
"name": "my-package",
"main": "dist/my-package.umd.js",
"module": "dist/my-package.esm.js"
}
// webpack.config.jss
module.exports = {
resolve: {
mainFields: ['browser', 'module', 'main'], // 设置主入口
},
};这样 webpack 在引用 antd 组件的时候就会优先去加载 es 的入口文件,
// antd 入口
export Button from './es/button';
export Message from './es/message';
export Row from './es/row';
// index.js
import { Row } from 'antd';但是这么做的话虽然 webpack 可以找到 Row 对应的入口模块,然后不打包其它组件(Button,Message)等,其它组件虽然没被打包,但是它们产生的副作用的代码却被保留下来了,所以有个 hack 的方法就是通过引入 babel-plugin-import 将模块路径进行替换。
import { Button, Message } form 'antd';
// 转换
import Button from 'antd/lib/button';
import Message from 'antd/lib/button';这样其它没被引用的组件,因为不经过 antd 主入口组件映射,其它组件带来的副作用代码就没被引入了。当然你引入的组件文件里面可能存在一些副作用代码,那就会被保留了。
现在有了 webpack4 事情就变得很简单了,直接在第三方模块里面加上 sideEffects: false,webpack 在读取到 es 入口的时候,没被引用到的文件就完完全全不会被引入了,不用使用 babel-plugin-import 进行 hack 了。
最近在做响应式系统设计的时候遇到需要对标题进行多行文字截取的效果,如下图:
看似十分简单的标题截断效果,但是竟然没有一个统一 CSS 属性实现标准,需要用到一些奇淫妙计来实现,一般来说,在做这样文字截断效果时我们更多是希望:
基于上述的准则,下面我就讲介绍各种技巧实现截断效果,并根据上述的评判标准得出最优解。(代码我都传到 jsfiddle 平台,可点击 demo 地址查看)
文本溢出我们经常用到的应该就是 text-overflow: ellipsis 了,相信大家也很熟悉,只需轻松几行代码就可以实现单行文本截断。
div {
white-space: nowrap;
overflow: hidden;
text-overflow: ellipsis;
}实现效果:demo 地址

属性浏览器原生支持,各大浏览器兼容性好,缺点就是只支持单行文本截断,并不支持多行文本截取。
适用场景:单行文字截断最简单实现,效果最好,放心使用。
如果是多行文字截取效果,实现起来就没有那么轻松。
先介绍第一种方式,就是通过 -webkit-line-clamp 属性实现。具体的方式如下:
div {
display: -webkit-box;
overflow: hidden;
-webkit-line-clamp: 2;
-webkit-box-orient: vertical;
}它需要和 display、-webkit-box-orient 和 overflow 结合使用:
实现效果:demo 地址

从效果上来看,它的优点有:
但是缺点也是很直接,因为 -webkit-line-clamp 是一个不规范的属性,它没有出现在 CSS 规范草案中。也就是说只有 webkit 内核的浏览器才支持这个属性,像 Firefox, IE 浏览器统统都不支持这个属性,浏览器兼容性不好。
使用场景:多用于移动端页面,因为移动设备浏览器更多是基于 webkit 内核,除了兼容性不好,实现截断的效果不错。
另外还有一种靠谱简单的做法就是设置相对定位的容器高度,用包含省略号(…)的元素模拟实现,实现方式如下:
p {
position: relative;
line-height: 18px;
height: 36px;
overflow: hidden;
}
p::after {
content:"...";
font-weight:bold;
position:absolute;
bottom:0;
right:0;
padding:0 20px 1px 45px;
/* 为了展示效果更好 */
background: -webkit-gradient(linear, left top, right top, from(rgba(255, 255, 255, 0)), to(white), color-stop(50%, white));
background: -moz-linear-gradient(to right, rgba(255, 255, 255, 0), white 50%, white);
background: -o-linear-gradient(to right, rgba(255, 255, 255, 0), white 50%, white);
background: -ms-linear-gradient(to right, rgba(255, 255, 255, 0), white 50%, white);
background: linear-gradient(to right, rgba(255, 255, 255, 0), white 50%, white);
}实现原理很好理解,就是通过伪元素绝对定位到行尾并遮住文字,再通过 overflow: hidden 隐藏多余文字。
实现效果:demo 地址

从实现效果来看,它所具备的优点:
但是它无法识别文字的长短,即文本超出范围才显示省略号,否则不显示省略号。还有因为是我们人为地在文字末尾添加一个省略号效果,就会导致它跟文字其实没有贴合的很紧密,遇到这种情况可以通过添加 word-break: break-all; 使一个单词能够在换行时进行拆分。

适合场景:文字内容较多,确定文字内容一定会超过容器的,那么选择这种方式不错。
回到一开始我要做的内容是多行标题文字截取效果,显然是无法控制标题的长度的,显然是无法使用上述的方式。回到事情的本质来看:我们希望 CSS 能够有一种属性,能够在文字溢出的情况下显示省略号,不溢出时不显示省略号。(两种形式,两种效果)
正当我以为 CSS 已经无能为力,只能通过 JS 去实现的时候,后来看到了一个方法非常巧妙,而且能够满足上述提到的所有准则,下面我就介绍如何通过 float 特性实现多行文本截断效果。
基本原理:

有个三个盒子 div,粉色盒子左浮动,浅蓝色盒子和黄色盒子右浮动,
好了,这样两种状态的两种展示形式已经区分开了,那么我们可以将黄色盒子进行相对定位,将内容溢出的黄色盒子移动到文本内容右下角,而未溢出的则会被移到外太空去了,只要我们使用 overflow: hidden 就可以隐藏掉。

基本原理就是这样,我们可以将浅蓝色区域想象成标题,黄色区域想象为省略号效果。那么你可能会觉得粉色盒子占了空间,那岂不是标题会整体延后了吗,这里可以通过 margin 的负值来出来,设置浅蓝色盒子的 margin-left 的负值与粉色盒子的宽度相同,标题也能正常显示。
那么我们将前面的 DOM 结构简化下,变成下面这样:
<div class="wrap">
<div class="text">Lorem ipsum dolor sit amet, consectetur adipisicing elit. Dignissimos labore sit vel itaque delectus atque quos magnam assumenda quod architecto perspiciatis animi.</div>
</div>刚才的粉色盒子和黄色盒子都可以用伪元素来代替。
.wrap {
height: 40px;
line-height: 20px;
overflow: hidden;
}
.wrap .text {
float: right;
margin-left: -5px;
width: 100%;
word-break: break-all;
}
.wrap::before {
float: left;
width: 5px;
content: '';
height: 40px;
}
.wrap::after {
float: right;
content: "...";
height: 20px;
line-height: 20px;
/* 为三个省略号的宽度 */
width: 3em;
/* 使盒子不占位置 */
margin-left: -3em;
/* 移动省略号位置 */
position: relative;
left: 100%;
top: -20px;
padding-right: 5px;
}实现效果:demo 地址

这里我目前看到最巧妙的方式了。只需要支持 CSS 2.1 的特性就可以了,它的优点有:
至于缺点,因为我们是模拟省略号,所以显示位置有时候没办法刚刚好,所以可以考虑:
word-break: break-all; 使一个单词能够在换行时进行拆分,这样文字和省略号贴合效果更佳。这个方法应该是我看到最好的用纯 CSS 处理的方式了,如果你有更好的方法,欢迎留言交流!
如今 React, Vue 等视图层框架大行其道,为前端开发提供了不少便利性,但是仅仅只是这些的话,缺少完善的前端路由系统,在单页应用中,我们希望能够通过前端路由来控制整个单页面应用,而后端仅仅只是获取数据接口。本文主要围绕以下三个问题来进行阐述:
接下来我们围绕一个简单的例子展开,通过路由原理将其实现。
如果觉得本文有帮助,可以点 star 鼓励下,本文所有代码都可以从 github 仓库下载,读者可以按照下述打开:
git clone https://github.com/happylindz/blog.git
cd blog/code/router
yarn建议你 clone 下来,方便你阅读代码,跟我一起测试查看效果。
最开始的时候网页都是多页面的,后来随着 ajax 技术的出现,才慢慢有了像 React、Vue 等 SPA 框架,当然,缺少路由系统的 SPA 框架有其存在的弊端:
主流的前端路由系统是通过 hash 或 history 来实现的,下面我们一探究竟。
url 上的 hash 以 # 开头,原本是为了作为锚点,方便用户在文章导航到相应的位置。因为 hash 值的改变不会引起页面的刷新,聪明的程序员就想到用 hash 值来做单页面应用的路由,并且当 url 的 hash 发生变化的时候,可以触发相应 hashchange 回调函数。
所以我们可以写一个 Router 对象,代码如下:
class Router {
constructor() {
this.routes = {};
this.currentUrl = '';
}
route(path, callback) {
this.routes[path] = callback || function() {};
}
updateView() {
this.currentUrl = location.hash.slice(1) || '/';
this.routes[this.currentUrl] && this.routes[this.currentUrl]();
}
init() {
window.addEventListener('load', this.updateView.bind(this), false);
window.addEventListener('hashchange', this.updateView.bind(this), false);
}
}<div id="app">
<ul>
<li>
<a href="#/">home</a>
</li>
<li>
<a href="#/about">about</a>
</li>
<li>
<a href="#/topics">topics</a>
</li>
</ul>
<div id="content"></div>
</div>
<script src="js/router.js"></script>
<script>
const router = new Router();
router.init();
router.route('/', function () {
document.getElementById('content').innerHTML = 'Home';
});
router.route('/about', function () {
document.getElementById('content').innerHTML = 'About';
});
router.route('/topics', function () {
document.getElementById('content').innerHTML = 'Topics';
});
</script>在对应 html 中,只要将所有链接路径前加 # 即可做成软路由,而不去触发刷新页面。
读者可以尝试并查看效果:
yarn hash
// open http://localhost:8080
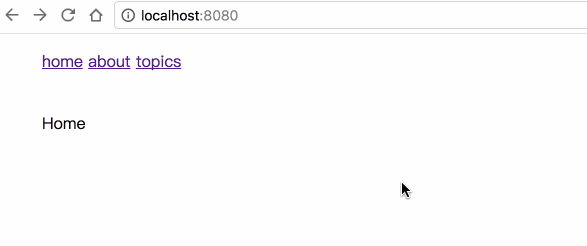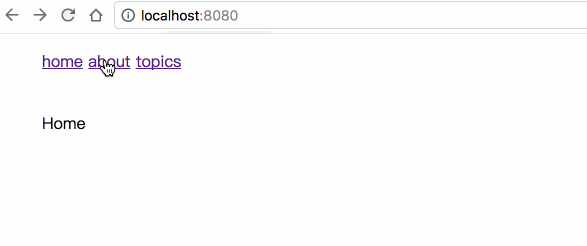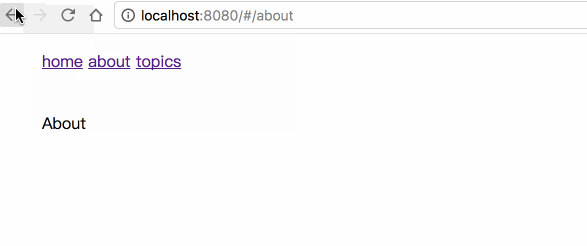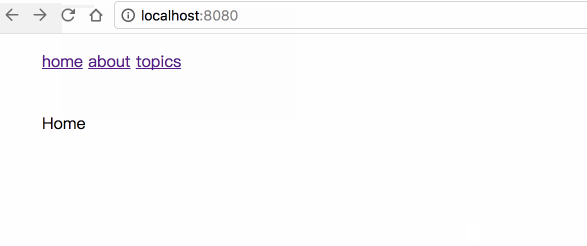
值得注意的是在第一次进入页面的时候,需要触发一次 onhashchange 事件,保证页面能够正常显示,用 hash 在做路由跳转的好处在于简单实用,便于理解,但是它虽然解决解决单页面应用路由控制的问题,但是在 url 却引入 # 号,不够美观。
History 路由是基于 HTML5 规范,在 HTML5 规范中提供了 history.pushState || history.replaceState 来进行路由控制。
当你执行 history.pushState({}, null, '/about') 时候,页面 url 会从 http://xxxx/ 跳转到 http://xxxx/about 可以在改变 url 的同时,并不会刷新页面。
先来简单看看 pushState 的用法,参数说明如下:
这么说下来 history 也有着控制路由的能力,然后,hash 的改变可以出发 onhashchange 事件,而 history 的改变并不会触发任何事件,这让我们无法直接去监听 history 的改变从而做出相应的改变。
所以,我们需要换个思路,我们可以罗列出所有可能触发 history 改变的情况,并且将这些方式一一进行拦截,变相地监听 history 的改变。
对于一个应用而言,url 的改变(不包括 hash 值得改变)只能由下面三种情况引起:
history.push(replace)State 函数只要对上述三种情况进行拦截,就可以变相监听到 history 的改变而做出调整。针对情况 1,HTML5 规范中有相应的 onpopstate 事件,通过它可以监听到前进或者后退按钮的点击,值得注意的是,调用 history.push(replace)State 并不会触发 onpopstate 事件。
经过分析,下面就简单实现一个 history 路由系统,代码如下:
class Router {
constructor() {
this.routes = {};
this.currentUrl = '';
}
route(path, callback) {
this.routes[path] = callback || function() {};
}
updateView(url) {
this.currentUrl = url;
this.routes[this.currentUrl] && this.routes[this.currentUrl]();
}
bindLink() {
const allLink = document.querySelectorAll('a[data-href]');
for (let i = 0, len = allLink.length; i < len; i++) {
const current = allLink[i];
current.addEventListener(
'click',
e => {
e.preventDefault();
const url = current.getAttribute('data-href');
history.pushState({}, null, url);
this.updateView(url);
},
false
);
}
}
init() {
this.bindLink();
window.addEventListener('popstate', e => {
this.updateView(window.location.pathname);
});
window.addEventListener('load', () => this.updateView('/'), false);
}
}Router 跟之前 Hash 路由很像,不同的地方在于 init 初始化函数,首先需要获取所有特殊的链接标签,然后监听点击事件,并阻止其默认事件,触发 history.pushState 以及更新相应的视图。
另外绑定 popstate 事件,当用户点击前进或者后退的按钮时候,能够及时更新视图,另外当刚进去页面时也要触发一次视图更新。
修改相应的 html 内容
<div id="app">
<ul>
<li><a data-href="/" href="#">home</a></li>
<li><a data-href="/about" href="#">about</a></li>
<li><a data-href="/topics" href="#">topics</a></li>
</ul>
<div id="content"></div>
</div>
<script src="js/router.js"></script>
<script>
const router = new Router();
router.init();
router.route('/', function() {
document.getElementById('content').innerHTML = 'Home';
});
router.route('/about', function() {
document.getElementById('content').innerHTML = 'About';
});
router.route('/topics', function() {
document.getElementById('content').innerHTML = 'Topics';
});
</script>跟之前的 html 基本一致,区别在于用 data-href 来表示要实现软路由的链接标签。
当然上面还有情况 3,就是你在 JS 直接触发 pushState 函数,那么这时候你必须要调用视图更新函数,否则就是出现视图内容和 url 不一致的情况。
setTimeout(() => {
history.pushState({}, null, '/about');
router.updateView('/about');
}, 2000);读者可以尝试并查看效果:
yarn history
// open http://localhost:8080

React-router 的版本从 2 到 3 再到现在的 4, API 变化天翻地覆,这里我们以最新的 v4 来举例。
在 v4 版本中,提供的路由能力都是以组件的形式进行呈现,由 react-router-dom 来提供,你不需再安装 react-router,因为 react-router-dom 已经包含了这个库。下面先通过 react-router-dom 写一个简单的例子。
import { BrowserRouter as Router, Link, Route } from 'react-router-dom';
const HomeView = () => <div>Home</div>;
const AboutView = () => <div>About</div>;
const TopicsView = ({ match }) => (<div>
<h2>Topics</h2>
<ul>
<li><Link to={`${match.url}/topic1`} >Topic1</Link></li>
<li><Link to={`${match.url}/topic2`} >Topic2</Link></li>
<li><Link to={`${match.url}/topic3`} >Topic3</Link></li>
</ul>
<Route path={ `${match.url}/topic1` } component={ () => <div>Topic1</div> } />
<Route path={ `${match.url}/topic2` } component={ () => <div>Topic2</div> } />
<Route path={ `${match.url}/topic3` } component={ () => <div>Topic3</div> } />
</div>)
class App extends Component {
render() {
return (
<Router>
<div>
<ul>
<li><Link to="/">home</Link></li>
<li><Link to="/about">about</Link></li>
<li><Link to="/topics">topics</Link></li>
</ul>
<Route exact path="/" component={HomeView} />
<Route path="/about" component={AboutView} />
<Route path="/topics" component={TopicsView} />
<Route component={() => <div>Always show</div>} />
</div>
</Router>
);
}
}这是 RR4 的标准用法,实际运行效果如下:
可以看出,当 path 匹配上路由时则显示 component,匹配不上则不显示,如果没有 path 字段则默认一直显示,而 exact 字段则表示必须要完全匹配,避免像 path='/' 匹配上 path='/about' 这样的情况。
所谓的局部刷新,其本质在于:当路由发生变化时,跟当前 url 匹配的 component 正常渲染,跟当前 url 不匹配的 component 渲染为 null,没错,就是这么简单粗暴。
有了奋斗的方向后,下面我们就围绕了如何构建 Router,Link,Route 这三个组件来实现 Hash 和 History 的前端路由系统。
有了前面的理论基础,相信实现基于 React 的 Hash 路由系统应该不是什么难事吧,首先是 Link 组件的实现:
export class Link extends Component {
render() {
const { to, children } = this.props;
return <a href={`#${to}`}>{children}</a>;
}
}简单地返回一个 a 标签,并且在链接前面加 # 代表软路由,并不是真正意义的跳转。接着是 Route 组件的实现:
export class Route extends Component {
componentWillMount() {
window.addEventListener('hashchange', this.updateView, false);
}
componentWillUnmount() {
window.removeEventListener('hashchange', this.updateView, false);
}
updateView = () => {
this.forceUpdate();
}
render() {
const { path, exact, component } = this.props;
const match = matchPath(window.location.hash, { exact, path });
if (!match) {
return null;
}
if (component) {
return React.createElement(component, { match });
}
return null;
}
}实现的方式也不难:
至于这个 matchPath 的实现:
function matchPath(hash, options) {
// 截断 hash 首位的 #
hash = hash.slice(1);
const { exact = false, path } = options;
// 如果没有传入 path,代表始终匹配
if (!path) {
return {
path: null,
url: hash,
isExact: true
};
}
const match = new RegExp(path).exec(hash);
if (!match) {
// 什么都没匹配上
return null;
}
const url = match[0];
const isExact = hash === url;
if (exact && !isExact) {
// 匹配上了,但不是精确匹配
return null;
}
return {
path,
url,
isExact
};
}这样一个简单的 Hash 路由就已经实现了,当然,我们在初次加载页面的时候 hash 值是不带 /,所以导致无法加载 Index 组件,所以我们在 HashRouter 组件中添加一次 hash 的变化,这样就保证的首次加载页面的准确性。
export class HashRouter extends Component {
componentDidMount() {
window.location.hash = '/';
}
render() {
return this.props.children;
}
}到目前为止,基于 React 的 Hash 路由系统就已经实现了,我们可以将之前 React-router 的例子拿来进行测试,别忘了将组件引入路径改成我们自己写好的目录,读者也可以自己手动进行尝试。
cd hash_router_with_react/
yarn
yarn start 实现效果如下:
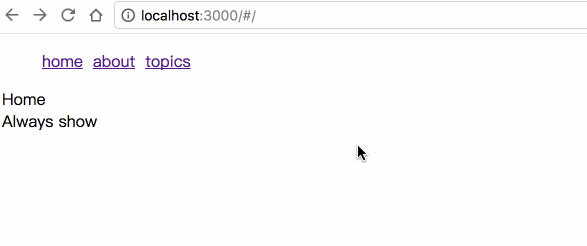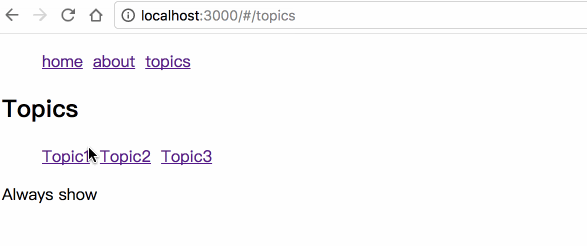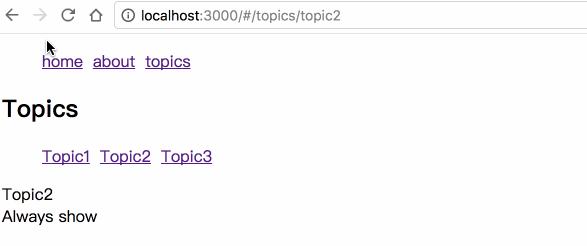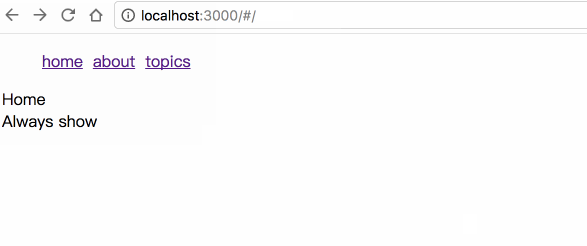
基于 React 的 Hash 路由系统实现比较简单,而 History 版的就会相对复杂一些,下面就来实现吧。
根据前面的 history 路由的实现,基于 React 的路由也是十分类似。
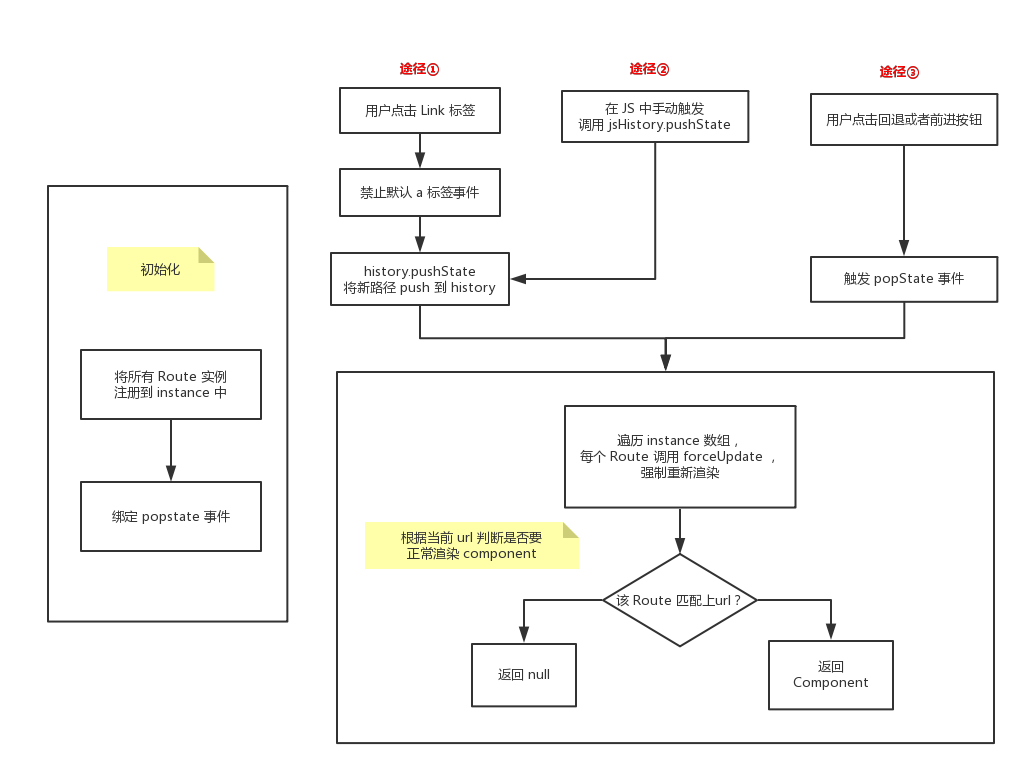
图片出处:单页面应用路由实现原理:以 React-Router 为例
大致分为两步:
代码实现如下:首先是创建 instances 数组
// 注册 component 实例
const instances = [];
const register = (component) => instances.push(component);
const unregister = (component) => instances.splice(instances.indexOf(component), 1);Route 组件大致相同,不同在于注册和卸载钩子函数的不同:初始化时需添加到 instances 中和绑定 popstate 事件。
export class Route extends Component {
componentWillMount() {
window.addEventListener('popstate', this.handlePopState);
register(this);
}
componentWillUnmount() {
window.removeEventListener('popstate', this.handlePopState);
unregister(this);
}
handlePopState = () => {
this.forceUpdate();
};
// ...
}Link 组件实现:需要阻止默认事件并且当点击的时候需要广播所有实例强制触发更新。
export class Link extends Component {
handleClick = e => {
e.preventDefault();
const { to } = this.props;
window.history.pushState({}, null, to);
instances.forEach(instance => instance.forceUpdate());
};
render() {
const { to, children } = this.props;
return (
<a href={to} onClick={this.handleClick}>
{children}
</a>
);
}
}其它的内容跟之前的 Hash 路由差不多,读者可以自行查看:
cd history_router_with_react/
yarn
yarn start
实现效果:
虽然点击前进后退按钮并不会触发所有组件更新,但上面的实现效果可能也不太优雅,因为单页应用中如果存在大量 Route 组件时,每次点击 Link 链接时候都需要迫使所有 Route 组件进行重渲染。
本文到这差不多就结束了,本文围绕着构建 hash 路由和 history 路由为线索,并最后实现了玩具版的 React-router,阐述现在主流单页面应用路由实现原理,有兴趣的建议阅读下源码,相信会有其他收获。
参考文章:
之前在对公司的前端代码脚本错误进行排查,试图降低 JS Error 的错误量,结合自己之前的经验对这方面内容进行了实践并总结,下面就此谈谈我对前端代码异常监控的一些见解。
本文大致围绕下面几点展开讨论:
对于 Javascript 而言,我们面对的仅仅只是异常,异常的出现不会直接导致 JS 引擎崩溃,最多只会使当前执行的任务终止。
<script>
error
console.log('永远不会执行');
</script>
<script>
console.log('我继续执行')
</script>
在对脚本错误进行上报之前,我们需要对异常进行处理,程序需要先感知到脚本错误的发生,然后再谈异常上报。
脚本错误一般分为两种:语法错误,运行时错误。
下面就谈谈几种异常监控的处理方式:
try-catch 在我们的代码中经常见到,通过给代码块进行 try-catch 进行包装后,当代码块发生出错时 catch 将能捕捉到错误的信息,页面也将可以继续执行。
但是 try-catch 处理异常的能力有限,只能捕获捉到运行时非异步错误,对于语法错误和异步错误就显得无能为力,捕捉不到。
try {
error // 未定义变量
} catch(e) {
console.log('我知道错误了');
console.log(e);
}
然而对于语法错误和异步错误就捕捉不到了。
try {
var error = 'error'; // 大写分号
} catch(e) {
console.log('我感知不到错误');
console.log(e);
}
一般语法错误在编辑器就会体现出来,常表现的错误信息为: Uncaught SyntaxError: Invalid or unexpected token xxx 这样。但是这种错误会直接抛出异常,常使程序崩溃,一般在编码时候容易观察得到。
try {
setTimeout(() => {
error // 异步错误
})
} catch(e) {
console.log('我感知不到错误');
console.log(e);
}
除非你在 setTimeout 函数中再套上一层 try-catch,否则就无法感知到其错误,但这样代码写起来比较啰嗦。
window.onerror 捕获异常能力比 try-catch 稍微强点,无论是异步还是非异步错误,onerror 都能捕获到运行时错误。
示例:运行时同步错误
/**
* @param {String} msg 错误信息
* @param {String} url 出错文件
* @param {Number} row 行号
* @param {Number} col 列号
* @param {Object} error 错误详细信息
*/
window.onerror = function (msg, url, row, col, error) {
console.log('我知道错误了');
console.log({
msg, url, row, col, error
})
return true;
};
error;
示例:异步错误
window.onerror = function (msg, url, row, col, error) {
console.log('我知道异步错误了');
console.log({
msg, url, row, col, error
})
return true;
};
setTimeout(() => {
error;
});
然而 window.onerror 对于语法错误还是无能为力,所以我们在写代码的时候要尽可能避免语法错误的,不过一般这样的错误会使得整个页面崩溃,还是比较容易能够察觉到的。
在实际的使用过程中,onerror 主要是来捕获预料之外的错误,而 try-catch 则是用来在可预见情况下监控特定的错误,两者结合使用更加高效。
需要注意的是,window.onerror 函数只有在返回 true 的时候,异常才不会向上抛出,否则即使是知道异常的发生控制台还是会显示 Uncaught Error: xxxxx。
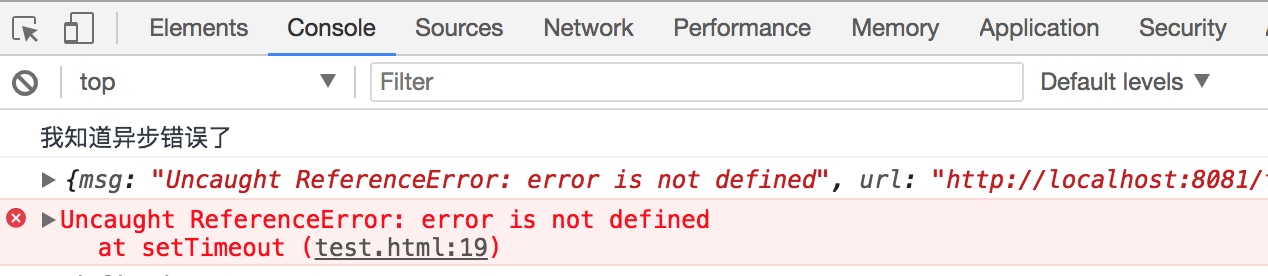
关于 window.onerror 还有两点需要值得注意
当我们遇到 <img src="./404.png"> 报 404 网络请求异常的时候,onerror 是无法帮助我们捕获到异常的。
<script>
window.onerror = function (msg, url, row, col, error) {
console.log('我知道异步错误了');
console.log({
msg, url, row, col, error
})
return true;
};
</script>
<img src="./404.png">
由于网络请求异常不会事件冒泡,因此必须在捕获阶段将其捕捉到才行,但是这种方式虽然可以捕捉到网络请求的异常,但是无法判断 HTTP 的状态是 404 还是其他比如 500 等等,所以还需要配合服务端日志才进行排查分析才可以。
<script>
window.addEventListener('error', (msg, url, row, col, error) => {
console.log('我知道 404 错误了');
console.log(
msg, url, row, col, error
);
return true;
}, true);
</script>
<img src="./404.png" alt="">
这点知识还是需要知道,要不然用户访问网站,图片 CDN 无法服务,图片加载不出来而开发人员没有察觉就尴尬了。
通过 Promise 可以帮助我们解决异步回调地狱的问题,但是一旦 Promise 实例抛出异常而你没有用 catch 去捕获的话,onerror 或 try-catch 也无能为力,无法捕捉到错误。
window.addEventListener('error', (msg, url, row, col, error) => {
console.log('我感知不到 promise 错误');
console.log(
msg, url, row, col, error
);
}, true);
Promise.reject('promise error');
new Promise((resolve, reject) => {
reject('promise error');
});
new Promise((resolve) => {
resolve();
}).then(() => {
throw 'promise error'
});
虽然在写 Promise 实例的时候养成最后写上 catch 函数是个好习惯,但是代码写多了就容易糊涂,忘记写 catch。
所以如果你的应用用到很多的 Promise 实例的话,特别是你在一些基于 promise 的异步库比如 axios 等一定要小心,因为你不知道什么时候这些异步请求会抛出异常而你并没有处理它,所以你最好添加一个 Promise 全局异常捕获事件 unhandledrejection。
window.addEventListener("unhandledrejection", function(e){
e.preventDefault()
console.log('我知道 promise 的错误了');
console.log(e.reason);
return true;
});
Promise.reject('promise error');
new Promise((resolve, reject) => {
reject('promise error');
});
new Promise((resolve) => {
resolve();
}).then(() => {
throw 'promise error'
});
当然,如果你的应用没有做 Promise 全局异常处理的话,那很可能就像某乎首页这样:
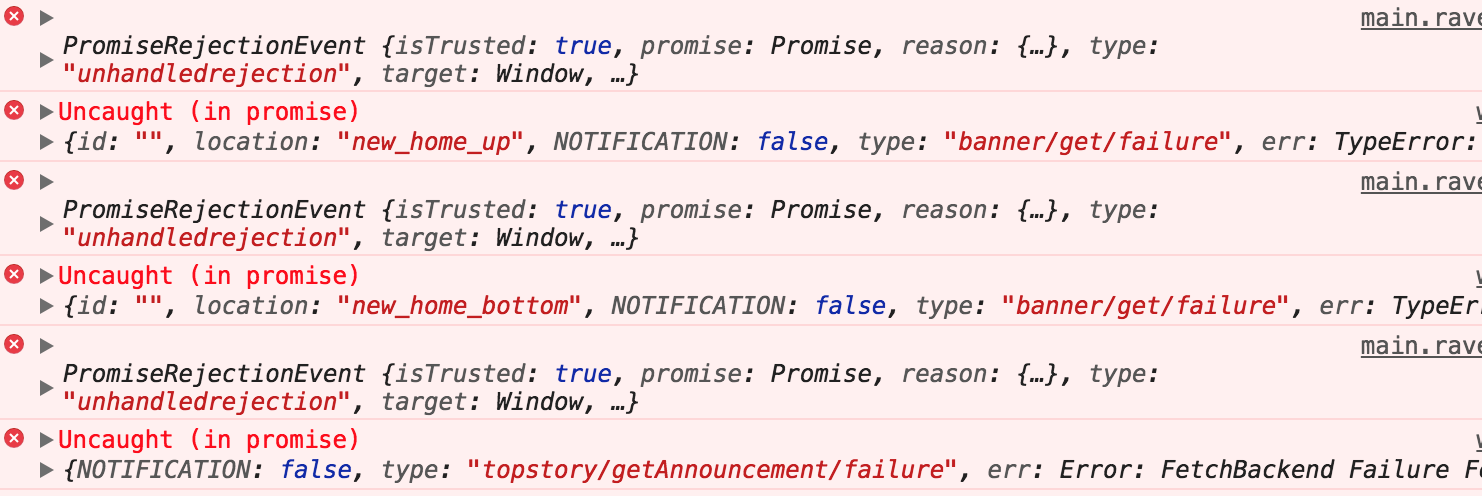
监控拿到报错信息之后,接下来就需要将捕捉到的错误信息发送到信息收集平台上,常用的发送形式主要有两种:
实例 - 动态创建 img 标签进行上报
function report(error) {
var reportUrl = 'http://xxxx/report';
new Image().src = reportUrl + 'error=' + error;
}下述例子我全部放在我的 github 上,读者可以自行查阅,后面不再赘述。
git clone https://github.com/happylindz/blog.git
cd blog/code/jserror/
npm install
因为我们在线上的版本,经常做静态资源 CDN 化,这就会导致我们常访问的页面跟脚本文件来自不同的域名,这时候如果没有进行额外的配置,就会容易产生 Script error。

可通过 npm run nocors 查看效果。
Script error 是浏览器在同源策略限制下产生的,浏览器处于对安全性上的考虑,当页面引用非同域名外部脚本文件时中抛出异常的话,此时本页面是没有权利知道这个报错信息的,取而代之的是输出 Script error 这样的信息。
这样做的目的是避免数据泄露到不安全的域中,举个简单的例子,
<script src="xxxx.com/login.html"></script>上面我们并没有引入一个 js 文件,而是一个 html,这个 html 是银行的登录页面,如果你已经登录了,那 login 页面就会自动跳转到 Welcome xxx...,如果未登录则跳转到 Please Login...,那么报错也会是 Welcome xxx... is not defined,Please Login... is not defined,通过这些信息可以判断一个用户是否登录他的帐号,给入侵者提供了十分便利的判断渠道,这是相当不安全的。
介绍完背景后,那么我们应该去解决这个问题?
首先可以想到的方案肯定是同源化策略,将 JS 文件内联到 html 或者放到同域下,虽然能简单有效地解决 script error 问题,但是这样无法利用好文件缓存和 CDN 的优势,不推荐使用。正确的方法应该是从根本上解决 script error 的错误。
首先为页面上的 script 标签添加 crossOrigin 属性
// http://localhost:8080/index.html
<script>
window.onerror = function (msg, url, row, col, error) {
console.log('我知道错误了,也知道错误信息');
console.log({
msg, url, row, col, error
})
return true;
};
</script>
<script src="http://localhost:8081/test.js" crossorigin></script>
// http://localhost:8081/test.js
setTimeout(() => {
console.log(error);
});当你修改完前端代码后,你还需要额外给后端在响应头里加上 Access-Control-Allow-Origin: localhost:8080,这里我以 Koa 为例。
const Koa = require('koa');
const path = require('path');
const cors = require('koa-cors');
const app = new Koa();
app.use(cors());
app.use(require('koa-static')(path.resolve(__dirname, './public')));
app.listen(8081, () => {
console.log('koa app listening at 8081')
});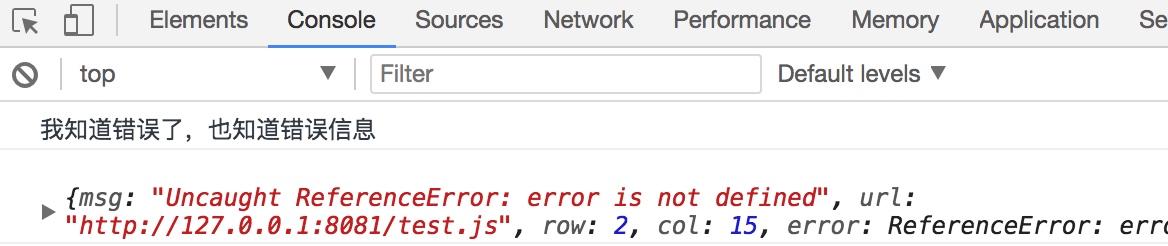
读者可通过 npm run cors 详细的跨域知识我就不展开了,有兴趣可以看看我之前写的文章:跨域,你需要知道的全在这里
你以为这样就完了吗?并没有,下面就说一些 Script error 你不常遇见的点:
我们都知道 JSONP 是用来跨域获取数据的,并且兼容性良好,在一些应用中仍然会使用到,所以你的项目中可能会用这样的代码:
// http://localhost:8080/index.html
window.onerror = function (msg, url, row, col, error) {
console.log('我知道错误了,但不知道错误信息');
console.log({
msg, url, row, col, error
})
return true;
};
function jsonpCallback(data) {
console.log(data);
}
const url = 'http://localhost:8081/data?callback=jsonpCallback';
const script = document.createElement('script');
script.src = url;
document.body.appendChild(script);因为返回的信息会当做脚本文件来执行,一旦返回的脚本内容出错了,也是无法捕捉到错误的信息。

解决办法也不难,跟之前一样,在添加动态添加脚本的时候加上 crossOrigin,并且在后端配上相应的 CORS 字段即可.
const script = document.createElement('script');
script.crossOrigin = 'anonymous';
script.src = url;
document.body.appendChild(script);读者可以通过 npm run jsonp 查看效果

知道原理之后你可能会觉得没什么,不就是给每个动态生成的脚本添加 crossOrigin 字段嘛,但是在实际工程中,你可能是面向很多库来编程,比如使用 jQuery,Seajs 或者 webpack 来异步加载脚本,许多库封装了异步加载脚本的能力,以 jQeury 为例你可能是这样来触发异步脚本。
$.ajax({
url: 'http://localhost:8081/data',
dataType: 'jsonp',
success: (data) => {
console.log(data);
}
})假如这些库中没有提供 crossOrigin 的能力的话(jQuery jsonp 可能有,假装你不知道),那你只能去修改人家写的源代码了,所以我这里提供一个思路,就是去劫持 document.createElement,从根源上去为每个动态生成的脚本添加 crossOrigin 字段。
document.createElement = (function() {
const fn = document.createElement.bind(document);
return function(type) {
const result = fn(type);
if(type === 'script') {
result.crossOrigin = 'anonymous';
}
return result;
}
})();
window.onerror = function (msg, url, row, col, error) {
console.log('我知道错误了,也知道错误信息');
console.log({
msg, url, row, col, error
})
return true;
};
$.ajax({
url: 'http://localhost:8081/data',
dataType: 'jsonp',
success: (data) => {
console.log(data);
}
})效果也是一样的,读者可以通过 npm run jsonpjq 来查看效果:

这样重写 createElement 理论上没什么问题,但是入侵了原本的代码,不保证一定不会出错,在工程上还是需要多尝试下看看再使用,可能存在兼容性上问题,如果你觉得会出现什么问题的话也欢迎留言讨论下。
关于 Script error 的问题就写到这里,如果你理解了上面的内容,基本上绝大部分的 Script error 都能迎刃而解。
当你的页面有使用 iframe 的时候,你需要对你引入的 iframe 做异常监控的处理,否则一旦你引入的 iframe 页面出现了问题,你的主站显示不出来,而你却浑然不知。
首先需要强调,父窗口直接使用 window.onerror 是无法直接捕获,如果你想要捕获 iframe 的异常的话,有分好几种情况。
如果你的 iframe 页面和你的主站是同域名的话,直接给 iframe 添加 onerror 事件即可。
<iframe src="./iframe.html" frameborder="0"></iframe>
<script>
window.frames[0].onerror = function (msg, url, row, col, error) {
console.log('我知道 iframe 的错误了,也知道错误信息');
console.log({
msg, url, row, col, error
})
return true;
};
</script>读者可以通过 npm run iframe 查看效果:
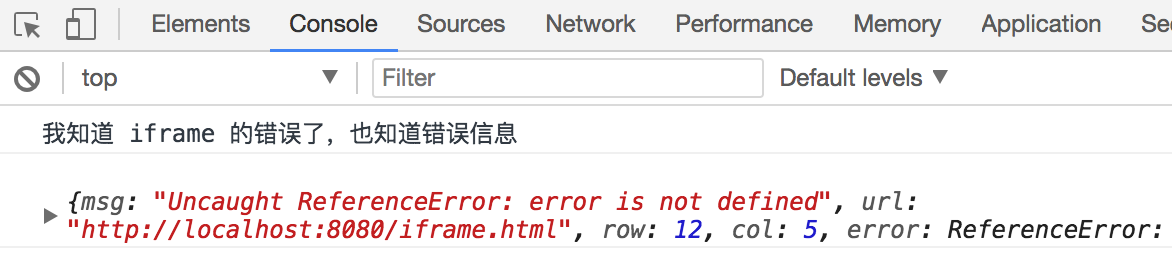
如果你嵌入的 iframe 页面和你的主站不是同个域名的,但是 iframe 内容不属于第三方,是你可以控制的,那么可以通过与 iframe 通信的方式将异常信息抛给主站接收。与 iframe 通信的方式有很多,常用的如:postMessage,hash 或者 name 字段跨域等等,这里就不展开了,感兴趣的话可以看:跨域,你需要知道的全在这里
如果是非同域且网站不受自己控制的话,除了通过控制台看到详细的错误信息外,没办法捕获,这是出于安全性的考虑,你引入了一个百度首页,人家页面报出的错误凭啥让你去监控呢,这会引出很多安全性的问题。
线上的代码几乎都经过了压缩处理,几十个文件打包成了一个并丑化代码,当我们收到 a is not defined 的时候,我们根本不知道这个变量 a 究竟是什么含义,此时报错的错误日志显然是无效的。
第一想到的办法是利用 sourcemap 定位到错误代码的具体位置,详细内容可以参考:Sourcemap 定位脚本错误
另外也可以通过在打包的时候,在每个合并的文件之间添加几行空格,并相应加上一些注释,这样在定位问题的时候很容易可以知道是哪个文件报的错误,然后再通过一些关键词的搜索,可以快速地定位到问题的所在位置。
如果你的网站访问量很大,假如网页的 PV 有 1kw,那么一个必然的错误发送的信息就有 1kw 条,我们可以给网站设置一个采集率:
Reporter.send = function(data) {
// 只采集 30%
if(Math.random() < 0.3) {
send(data) // 上报错误信息
}
}这个采集率可以通过具体实际的情况来设定,方法多样化,可以使用一个随机数,也可以具体根据用户的某些特征来进行判定。
上面差不多是我对前端代码监控的一些理解,说起来容易,但是一旦在工程化运用,难免需要考虑到兼容性等种种问题,读者可以通过自己的具体情况进行调整,前端代码异常监控对于我们的网站的稳定性起着至关重要的作用。如若文中所有不对的地方,还望指正。
最近在重拾 webpack 一些知识点,希望对前端模块化有更多的理解,以前对 webpack 打包机制有所好奇,没有理解深入,浅尝则止,最近通过对 webpack 打包后的文件进行查阅,对其如何打包 JS 文件有了更深的理解,希望通过这篇文章,能够帮助读者你理解:
本文所有示例代码全部放在我的 Github 上,看兴趣的可以看看:
git clone https://github.com/happylindz/blog.git
cd blog/code/webpackBundleAnalysis
npm install首先现在 webpack 作为当前主流的前端模块化工具,在 webpack 刚开始流行的时候,我们经常通过 webpack 将所有处理文件全部打包成一个 bundle 文件, 先通过一个简单的例子来看:
// src/single/index.js
var index2 = require('./index2');
var util = require('./util');
console.log(index2);
console.log(util);
// src/single/index2.js
var util = require('./util');
console.log(util);
module.exports = "index 2";
// src/single/util.js
module.exports = "Hello World";
// 通过 config/webpack.config.single.js 打包
const webpack = require('webpack');
const path = require('path')
module.exports = {
entry: {
index: [path.resolve(__dirname, '../src/single/index.js')],
},
output: {
path: path.resolve(__dirname, '../dist'),
filename: '[name].[chunkhash:8].js'
},
}通过 npm run build:single 可看到打包效果,打包内容大致如下(经过精简):
// dist/index.xxxx.js
(function(modules) {
// 已经加载过的模块
var installedModules = {};
// 模块加载函数
function __webpack_require__(moduleId) {
if(installedModules[moduleId]) {
return installedModules[moduleId].exports;
}
var module = installedModules[moduleId] = {
i: moduleId,
l: false,
exports: {}
};
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
module.l = true;
return module.exports;
}
return __webpack_require__(__webpack_require__.s = 3);
})([
/* 0 */
(function(module, exports, __webpack_require__) {
var util = __webpack_require__(1);
console.log(util);
module.exports = "index 2";
}),
/* 1 */
(function(module, exports) {
module.exports = "Hello World";
}),
/* 2 */
(function(module, exports, __webpack_require__) {
var index2 = __webpack_require__(0);
index2 = __webpack_require__(0);
var util = __webpack_require__(1);
console.log(index2);
console.log(util);
}),
/* 3 */
(function(module, exports, __webpack_require__) {
module.exports = __webpack_require__(2);
})]);将相对无关的代码剔除掉后,剩下主要的代码:
__webpack_require__ 模块加载,先判断 installedModules 是否已加载,加载过了就直接返回 exports 数据,没有加载过该模块就通过 modules[moduleId].call(module.exports, module, module.exports, __webpack_require__) 执行模块并且将 module.exports 给返回。很简单是不是,有些点需要注意的是:
modules[moduleId].call(module.exports, module, module.exports, __webpack_require__) 保证了模块加载时 this 的指向 module.exports 并且传入默认参数,很简单,不过多解释。webpack 单文件打包的方式应付一些简单场景就足够了,但是我们在开发一些复杂的应用,如果没有对代码进行切割,将第三方库(jQuery)或框架(React) 和业务代码全部打包在一起,就会导致用户访问页面速度很慢,不能有效利用缓存,你的老板可能就要找你谈话了。
那么 webpack 多文件入口如何进行代码切割,让我先写一个简单的例子:
// src/multiple/pageA.js
const utilA = require('./js/utilA');
const utilB = require('./js/utilB');
console.log(utilA);
console.log(utilB);
// src/multiple/pageB.js
const utilB = require('./js/utilB');
console.log(utilB);
// 异步加载文件,类似于 import()
const utilC = () => require.ensure(['./js/utilC'], function(require) {
console.log(require('./js/utilC'))
});
utilC();
// src/multiple/js/utilA.js 可类比于公共库,如 jQuery
module.exports = "util A";
// src/multiple/js/utilB.js
module.exports = 'util B';
// src/multiple/js/utilC.js
module.exports = "util C";这里我们定义了两个入口 pageA 和 pageB 和三个库 util,我们希望代码切割做到:
那么 webpack 需要怎么配置呢?
// 通过 config/webpack.config.multiple.js 打包
const webpack = require('webpack');
const path = require('path')
module.exports = {
entry: {
pageA: [path.resolve(__dirname, '../src/multiple/pageA.js')],
pageB: path.resolve(__dirname, '../src/multiple/pageB.js'),
},
output: {
path: path.resolve(__dirname, '../dist'),
filename: '[name].[chunkhash:8].js',
},
plugins: [
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
minChunks: 2,
}),
new webpack.optimize.CommonsChunkPlugin({
name: 'manifest',
chunks: ['vendor']
})
]
}单单配置多 entry 是不够的,这样只会生成两个 bundle 文件,将 pageA 和 pageB 所需要的内容全部放入,跟单入口文件并没有区别,要做到代码切割,我们需要借助 webpack 内置的插件 CommonsChunkPlugin。
首先 webpack 执行存在一部分运行时代码,即一部分初始化的工作,就像之前单文件中的 __webpack_require__,这部分代码需要加载于所有文件之前,相当于初始化工作,少了这部分初始化代码,后面加载过来的代码就无法识别并工作了。
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
minChunks: 2,
})这段代码的含义是,在这些入口文件中,找到那些引用两次的模块(如:utilB),帮我抽离成一个叫 vendor 文件,此时那部分初始化工作的代码会被抽离到 vendor 文件中。
new webpack.optimize.CommonsChunkPlugin({
name: 'manifest',
chunks: ['vendor'],
// minChunks: Infinity // 可写可不写
})这段代码的含义是在 vendor 文件中帮我把初始化代码抽离到 mainifest 文件中,此时 vendor 文件中就只剩下 utilB 这个模块了。你可能会好奇为什么要这么做?
因为这样可以给 vendor 生成稳定的 hash 值,每次修改业务代码(pageA),这段初始化时代码就会发生变化,那么如果将这段初始化代码放在 vendor 文件中的话,每次都会生成新的 vendor.xxxx.js,这样不利于持久化缓存,如果不理解也没关系,下次我会另外写一篇文章来讲述这部分内容。
另外 webpack 默认会抽离异步加载的代码,这个不需要你做额外的配置,pageB 中异步加载的 utilC 文件会直接抽离为 chunk.xxxx.js 文件。
所以这时候我们页面加载文件的顺序就会变成:
mainifest.xxxx.js // 初始化代码
vendor.xxxx.js // pageA 和 pageB 共同用到的模块,抽离
pageX.xxxx.js // 业务代码
当 pageB 需要 utilC 时候则异步加载 utilC
执行 npm run build:multiple 即可查看打包内容,首先来看下 manifest 如何做初始化工作(精简版)?
// dist/mainifest.xxxx.js
(function(modules) {
window["webpackJsonp"] = function webpackJsonpCallback(chunkIds, moreModules) {
var moduleId, chunkId, i = 0, callbacks = [];
for(;i < chunkIds.length; i++) {
chunkId = chunkIds[i];
if(installedChunks[chunkId])
callbacks.push.apply(callbacks, installedChunks[chunkId]);
installedChunks[chunkId] = 0;
}
for(moduleId in moreModules) {
if(Object.prototype.hasOwnProperty.call(moreModules, moduleId)) {
modules[moduleId] = moreModules[moduleId];
}
}
while(callbacks.length)
callbacks.shift().call(null, __webpack_require__);
if(moreModules[0]) {
installedModules[0] = 0;
return __webpack_require__(0);
}
};
var installedModules = {};
var installedChunks = {
4:0
};
function __webpack_require__(moduleId) {
// 和单文件一致
}
__webpack_require__.e = function requireEnsure(chunkId, callback) {
if(installedChunks[chunkId] === 0)
return callback.call(null, __webpack_require__);
if(installedChunks[chunkId] !== undefined) {
installedChunks[chunkId].push(callback);
} else {
installedChunks[chunkId] = [callback];
var head = document.getElementsByTagName('head')[0];
var script = document.createElement('script');
script.type = 'text/javascript';
script.charset = 'utf-8';
script.async = true;
script.src = __webpack_require__.p + "" + chunkId + "." + ({"0":"pageA","1":"pageB","3":"vendor"}[chunkId]||chunkId) + "." + {"0":"e72ce7d4","1":"69f6bbe3","2":"9adbbaa0","3":"53fa02a7"}[chunkId] + ".js";
head.appendChild(script);
}
};
})([]);与单文件内容一致,定义了一个自执行函数,因为它不包含任何模块,所以传入一个空数组。除了定义了 __webpack_require__,还另外定义了两个函数用来进行加载模块。
首先讲解代码前需要理解两个概念,分别是 module 和 chunk
__webpack_require__ 加载的模块,同样的使用数组下标作为 moduleId 且是唯一不重复的。那么为什么要区分 chunk 和 module 呢?
首先使用 installedChunks 来保存每个 chunkId 是否被加载过,如果被加载过,则说明该 chunk 中所包含的模块已经被放到了 modules 中,注意是 modules 而不是 installedModules。我们先来简单看一下 vendor chunk 打包出来的内容。
// vendor.xxxx.js
webpackJsonp([3,4],{
3: (function(module, exports) {
module.exports = 'util B';
})
});在执行完 manifest 后就会先执行 vendor 文件,结合上面 webpackJsonp 的定义,我们可以知道 [3, 4] 代表 chunkId,当加载到 vendor 文件后,installedChunks[3] 和 installedChunks[4] 将会被置为 0,这表明 chunk3,chunk4 已经被加载过了。
webpackJsonpCallback 一共有两个参数,chuckIds 一般包含该 chunk 文件依赖的 chunkId 以及自身 chunkId,moreModules 代表该 chunk 文件带来新的模块。
var moduleId, chunkId, i = 0, callbacks = [];
for(;i < chunkIds.length; i++) {
chunkId = chunkIds[i];
if(installedChunks[chunkId])
callbacks.push.apply(callbacks, installedChunks[chunkId]);
installedChunks[chunkId] = 0;
}
for(moduleId in moreModules) {
if(Object.prototype.hasOwnProperty.call(moreModules, moduleId)) {
modules[moduleId] = moreModules[moduleId];
}
}
while(callbacks.length)
callbacks.shift().call(null, __webpack_require__);
if(moreModules[0]) {
installedModules[0] = 0;
return __webpack_require__(0);
}简单说说 webpackJsonpCallback 做了哪些事,首先判断 chunkIds 在 installedChunks 里有没有回调函数函数未执行完,有的话则放到 callbacks 里,并且等下统一执行,并将 chunkIds 在 installedChunks 中全部置为 0, 然后将 moreModules 合并到 modules。
这里面只有 modules[0] 是不固定的,其它 modules 下标都是唯一的,在打包的时候 webpack 已经为它们统一编号,而 0 则为入口文件即 pageA,pageB 各有一个 module[0]。
然后将 callbacks 执行并清空,保证了该模块加载开始前所以前置依赖内容已经加载完毕,最后判断 moreModules[0], 有值说明该文件为入口文件,则开始执行入口模块 0。
上面解释了一大堆,但是像 pageA 这种同步加载 manifest, vendor 以及 pageA 文件来说,每次加载的时候 callbacks 都是为空的,因为它们在 installedChunks 中的值要嘛为 undefined(未加载), 要嘛为 0(已被加载)。installedChunks[chunkId] 的值永远为 false,所以在这种情况下 callbacks 里根本不会出现函数,如果仅仅是考虑这样的场景,上面的 webpackJsonpCallback 完全可以写成下面这样:
var moduleId, chunkId, i = 0, callbacks = [];
for(;i < chunkIds.length; i++) {
chunkId = chunkIds[i];
installedChunks[chunkId] = 0;
}
for(moduleId in moreModules) {
if(Object.prototype.hasOwnProperty.call(moreModules, moduleId)) {
modules[moduleId] = moreModules[moduleId];
}
}
if(moreModules[0]) {
installedModules[0] = 0;
return __webpack_require__(0);
}但是考虑到异步加载 js 文件的时候(比如 pageB 异步加载 utilC 文件),就没那么简单,我们先来看下 webpack 是如何加载异步脚本的:
// 异步加载函数挂载在 __webpack_require__.e 上
__webpack_require__.e = function requireEnsure(chunkId, callback) {
if(installedChunks[chunkId] === 0)
return callback.call(null, __webpack_require__);
if(installedChunks[chunkId] !== undefined) {
installedChunks[chunkId].push(callback);
} else {
installedChunks[chunkId] = [callback];
var head = document.getElementsByTagName('head')[0];
var script = document.createElement('script');
script.type = 'text/javascript';
script.charset = 'utf-8';
script.async = true;
script.src = __webpack_require__.p + "" + chunkId + "." + ({"0":"pageA","1":"pageB","3":"vendor"}[chunkId]||chunkId) + "." + {"0":"e72ce7d4","1":"69f6bbe3","2":"9adbbaa0","3":"53fa02a7"}[chunkId] + ".js";
head.appendChild(script);
}
};大致分为三种情况,(已经加载过,正在加载中以及从未加载过)
我们通过 utilC 生成的 chunk 来进行讲解:
webpackJsonp([2,4],{
4: (function(module, exports) {
module.exports = "util C";
})
});pageB 需要异步加载这个 chunk:
webpackJsonp([1,4],[
/* 0 */
(function(module, exports, __webpack_require__) {
const utilB = __webpack_require__(3);
console.log(utilB);
const utilC = () => __webpack_require__.e/* nsure */(2, function(require) {
console.log(__webpack_require__(4))
});
utilC();
})
]);当 pageB 进行某种操作需要加载 utilC 时就会执行 __webpack_require__.e(2, callback) 2,代表需要加载的模块 chunkId(utilC),异步加载 utilC 并将 callback 添加到 installedChunks[2] 中,然后当 utilC 的 chunk 文件加载完毕后,chunkIds 包含 2,发现 installedChunks[2] 是个数组,里面还有之前还未执行的 callback 函数。
既然这样,那我就将我自己带来的模块先放到 modules 中,然后再统一执行之前未执行完的 callbacks 函数,这里指的是存放于 installedChunks[2] 中的回调函数 (可能存在多个),这也就是说明这里的先后顺序:
// 先将 moreModules 合并到 modules, 再去执行 callbacks, 不然之前未执行的 callback 依赖于新来的模块,你不放进 module 我岂不是得不到想要的模块
for(moduleId in moreModules) {
if(Object.prototype.hasOwnProperty.call(moreModules, moduleId)) {
modules[moduleId] = moreModules[moduleId];
}
}
while(callbacks.length)
callbacks.shift().call(null, __webpack_require__);经过我对打包文件的观察,从 webpack1 到 webpack2 在打包文件上有下面这些主要的改变:
首先,moduleId[0] 不再为入口执行函数做保留,所以说不用傻傻看到 moduleId[0] 就认为是打包文件的入口模块,取而代之的是 window["webpackJsonp"] = function webpackJsonpCallback(chunkIds, moreModules, executeModules) {} 传入了第三个参数 executeModules,是个数组,如果参数存在则说明它是入口模块,然后就去执行该模块。
if(executeModules) {
for(i=0; i < executeModules.length; i++) {
result = __webpack_require__(__webpack_require__.s = executeModules[i]);
}
}其次,webpack2 中会默认加载 OccurrenceOrderPlugin 这个插件,即你不用 plugins 中添加这个配置它也会默认执行,那它有什么用途呢?主要是在 webpack1 中 moduleId 的不确定性导致的,在 webpack1 中 moduleId 取决于引入文件的顺序,这就会导致这个 moduleId 可能会时常发生变化, 而 OccurrenceOrderPlugin 插件会按引入次数最多的模块进行排序,引入次数的模块的 moduleId 越小,比如说上面引用的 utilB 模块引用次数为 2(最多),所以它的 moduleId 为 0。
webpackJsonp([3],[
/* 0 */
(function(module, exports) {
module.exports = 'util B';
})
]);最后说下在异步加载模块时, webpack2 是基于 Promise 的,所以说如果你要兼容低版本浏览器,需要引入 Promise-polyfill,另外为引入请求添加了错误处理。
__webpack_require__.e = function requireEnsure(chunkId) {
var promise = new Promise(function(resolve, reject) {
installedChunkData = installedChunks[chunkId] = [resolve, reject];
});
installedChunkData[2] = promise;
// start chunk loading
var head = document.getElementsByTagName('head')[0];
var script = document.createElement('script');
script.type = 'text/javascript';
script.charset = 'utf-8';
script.async = true;
script.timeout = 120000;
script.src = __webpack_require__.p + "" + chunkId + "." + {"0":"ae9c5f5f","1":"0ac69acb","2":"20651a9c","3":"0cdc6c84"}[chunkId] + ".js";
var timeout = setTimeout(onScriptComplete, 120000);
script.onerror = script.onload = onScriptComplete;
function onScriptComplete() {
// 防止内存泄漏
script.onerror = script.onload = null;
clearTimeout(timeout);
var chunk = installedChunks[chunkId];
if(chunk !== 0) {
if(chunk) {
chunk[1](new Error('Loading chunk ' + chunkId + ' failed.'));
}
installedChunks[chunkId] = undefined;
}
};
head.appendChild(script);
return promise;
};可以看出,原本基于回调函数的方式已经变成基于 Promise 做异步处理,另外添加了 onScriptComplete 用于做脚本加载失败处理。
在 webpack1 的时候,如果由于网络原因当你加载脚本失败后,即使网络恢复了,你再次进行某种操作需要同个 chunk 时候都会无效,主要原因是失败之后没把 installedChunks[chunkId] = undefined; 导致之后不会再对该 chunk 文件发起异步请求。
而在 webpack2 中,当脚本请求超时了(2min)或者加载失败,会将 installedChunks[chunkId] 清空,当下次重新请求该 chunk 文件会重新加载,提高了页面的容错性。
这些是我在打包文件中看到主要的区别,难免有所遗漏,如果你有更多的见解,欢迎在评论区留言。
什么是 tree shaking,即 webpack 在打包的过程中会将没用的代码进行清除(dead code)。一般 dead code 具有一下的特征:
是不是很神奇,那么需要怎么做才能使 tree shaking 生效呢?
首先,模块引入要基于 ES6 模块机制,不再使用 commonjs 规范,因为 es6 模块的依赖关系是确定的,和运行时的状态无关,可以进行可靠的静态分析,然后清除没用的代码。而 commonjs 的依赖关系是要到运行时候才能确定下来的。
其次,需要开启 UglifyJsPlugin 这个插件对代码进行压缩。
我们先写一个例子来说明:
// src/es6/pageA.js
import {
utilA,
funcA, // 引入 funcA 但未使用, 故 funcA 会被清除
} from './js/utilA';
import utilB from './js/utilB'; // 引入 utilB(函数) 未使用,会被清除
import classC from './js/utilC'; // 引入 classC(类) 未使用,不会被清除
console.log(utilA);
// src/es6/js/utilA.js
export const utilA = 'util A';
export function funcA() {
console.log('func A');
}
// src/es6/js/utilB.js
export default function() {
console.log('func B');
}
if(false) { // 被清除
console.log('never use');
}
while(true) {}
console.log('never use');
// src/es6/js/utilC.js
const classC = function() {} // 类方法不会被清除
classC.prototype.saySomething = function() {
console.log('class C');
}
export default classC;打包的配置也很简单:
const webpack = require('webpack');
const path = require('path')
module.exports = {
entry: {
pageA: path.resolve(__dirname, '../src/es6/pageA.js'),
},
output: {
path: path.resolve(__dirname, '../dist'),
filename: '[name].[chunkhash:8].js'
},
plugins: [
new webpack.optimize.CommonsChunkPlugin({
name: 'manifest',
minChunks: Infinity,
}),
new webpack.optimize.UglifyJsPlugin({
compress: {
warnings: false
}
})
]
}通过 npm run build:es6 对压缩的文件进行分析:
// dist/pageA.xxxx.js
webpackJsonp([0],[
function(o, t, e) {
'use strict';
Object.defineProperty(t, '__esModule', { value: !0 });
var n = e(1);
e(2), e(3);
console.log(n.a);
},
function(o, t, e) {
'use strict';
t.a = 'util A';
},
function(o, t, e) {
'use strict';
for (;;);
console.log('never use');
},
function(o, t, e) {
'use strict';
const n = function() {};
n.prototype.saySomething = function() {
console.log('class C');
};
}
],[0]);引入但是没用的变量,函数都会清除,未执行的代码也会被清除。但是类方法是不会被清除的。因为 webpack 不会区分不了是定义在 classC 的 prototype 还是其它 Array 的 prototype 的,比如 classC 写成下面这样:
const classC = function() {}
var a = 'class' + 'C';
var b;
if(a === 'Array') {
b = a;
}else {
b = 'classC';
}
b.prototype.saySomething = function() {
console.log('class C');
}
export default classC;webpack 无法保证 prototype 挂载的对象是 classC,这种代码,静态分析是分析不了的,就算能静态分析代码,想要正确完全的分析也比较困难。所以 webpack 干脆不处理类方法,不对类方法进行 tree shaking。
更多的 tree shaking 的副作用可以查阅:Tree shaking class methods
scope hoisting,顾名思义就是将模块的作用域提升,在 webpack 中不能将所有所有的模块直接放在同一个作用域下,有以下几个原因:
在 webpack3 中,这些情况生成的模块不会进行作用域提升,下面我就举个例子来说明:
// src/hoist/utilA.js
export const utilA = 'util A';
export function funcA() {
console.log('func A');
}
// src/hoist/utilB.js
export const utilB = 'util B';
export function funcB() {
console.log('func B');
}
// src/hoist/utilC.js
export const utilC = 'util C';
// src/hoist/pageA.js
import { utilA, funcA } from './utilA';
console.log(utilA);
funcA();
// src/hoist/pageB.js
import { utilA } from './utilA';
import { utilB, funcB } from './utilB';
funcB();
import('./utilC').then(function(utilC) {
console.log(utilC);
})这个例子比较典型,utilA 被 pageA 和 pageB 所共享,utilB 被 pageB 单独加载,utilC 被 pageB 异步加载。
想要 webpack3 生效,则需要在 plugins 中添加 ModuleConcatenationPlugin。
webpack 配置如下:
const webpack = require('webpack');
const path = require('path')
module.exports = {
entry: {
pageA: path.resolve(__dirname, '../src/hoist/pageA.js'),
pageB: path.resolve(__dirname, '../src/hoist/pageB.js'),
},
output: {
path: path.resolve(__dirname, '../dist'),
filename: '[name].[chunkhash:8].js'
},
plugins: [
new webpack.optimize.ModuleConcatenationPlugin(),
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
minChunks: 2,
}),
new webpack.optimize.CommonsChunkPlugin({
name: 'manifest',
minChunks: Infinity,
})
]
}运行 npm run build:hoist 进行编译,简单看下生成的 pageB 代码:
webpackJsonp([2],{
2: (function(module, __webpack_exports__, __webpack_require__) {
"use strict";
var utilA = __webpack_require__(0);
// CONCATENATED MODULE: ./src/hoist/utilB.js
const utilB = 'util B';
function funcB() {
console.log('func B');
}
// CONCATENATED MODULE: ./src/hoist/pageB.js
funcB();
__webpack_require__.e/* import() */(0).then(__webpack_require__.bind(null, 3)).then(function(utilC) {
console.log(utilC);
})
})
},[2]);通过代码分析,可以得出下面的结论:
好了,讲到这差不多就完了,理解上面的内容对前端模块化会有更多的认知,如果有什么写的不对或者不完整的地方,还望补充说明,希望这篇文章能帮助到你。
在 ES6 中,我们知道 import、export 取代了 require、module.exports 用来引入和导出模块,但是如果不了解 ES6 模块特性的话,代码可能就会运行出一些匪夷所思的结果,下面我将通过这篇文章为你揭开 ES6 模块机制特点。
基础的 ES6 模块用法我就不介绍了,如果你还没使用过 ES6 模块的话,推荐看:ECMAScript 6 入门 - Module 的语法
说起 ES6 模块特性,那么就先说说 ES6 模块跟 CommonJS 模块的不同之处。
ES6 模块跟 CommonJS 模块的不同,主要有以下两个方面:
这个怎么理解呢?我们一步步来看:
CommonJS 模块输出的是值的拷贝,也就是说,一旦输出一个值,模块内部的变化就影响不到这个值。
// a.js
var b = require('./b');
console.log(b.foo);
setTimeout(() => {
console.log(b.foo);
console.log(require('./b').foo);
}, 1000);
// b.js
let foo = 1;
setTimeout(() => {
foo = 2;
}, 500);
module.exports = {
foo: foo,
};
// 执行:node a.js
// 执行结果:
// 1
// 1
// 1上面代码说明,b 模块加载以后,它的内部 foo 变化就影响不到输出的 exports.foo 了。这是因为 foo 是一个原始类型的值,会被缓存。所以如果你想要在 CommonJS 中动态获取模块中的值,那么就需要借助于函数延时执行的特性。
// a.js
var b = require('./b');
console.log(b.foo());
setTimeout(() => {
console.log(b.foo());
console.log(require('./b').foo());
}, 1000);
// b.js
var foo = 1;
setTimeout(() => {
foo = 2;
}, 500);
module.exports = {
foo: () => {
return foo;
},
};
// 执行:node a.js
// 执行结果:
// 1
// 2
// 2所以我们可以总结一下:
所以如果你要处处获取到模块内的最新值的话,也可以你每次更新数据的时候每次都要去更新 module.exports 上的值,比如:
// a.js
var b = require('./b');
console.log(b.foo);
setTimeout(() => {
console.log(b.foo);
console.log(require('./b').foo);
}, 1000);
// b.js
module.exports.foo = 1; // 同 exports.foo = 1
setTimeout(() => {
module.exports.foo = 2;
}, 500);
// 执行:node a.js
// 执行结果:
// 1
// 2
// 2然而在 ES6 模块中就不再是生成输出对象的拷贝,而是动态关联模块中的值。
// a.js
import { foo } from './b';
console.log(foo);
setTimeout(() => {
console.log(foo);
import('./b').then(({ foo }) => {
console.log(foo);
});
}, 1000);
// b.js
export let foo = 1;
setTimeout(() => {
foo = 2;
}, 500);
// 执行:babel-node a.js
// 执行结果:
// 1
// 2
// 2关于第二点,ES6 模块编译时执行会导致有以下两个特点:
从第一条来看,在文件中的任何位置引入 import 模块都会被提前到文件顶部。
// a.js
console.log('a.js')
import { foo } from './b';
// b.js
export let foo = 1;
console.log('b.js 先执行');
// 执行结果:
// b.js 先执行
// a.js从执行结果我们可以很直观地看出,虽然 a 模块中 import 引入晚于 console.log('a'),但是它被 JS 引擎通过静态分析,提到模块执行的最前面,优于模块中的其他部分的执行。
由于 import 是静态执行,所以 import 具有提升效果即 import 命令在模块中的位置并不影响程序的输出。
正常的引入模块是没办法看出变量声明提升的特性,需要通过循环依赖加载才能看出。
// a.js
import { foo } from './b';
console.log('a.js');
export const bar = 1;
export const bar2 = () => {
console.log('bar2');
}
export function bar3() {
console.log('bar3');
}
// b.js
export let foo = 1;
import * as a from './a';
console.log(a);
// 执行结果:
// { bar: undefined, bar2: undefined, bar3: [Function: bar3] }
// a.js从上面的例子可以很直观地看出,a 模块引用了 b 模块,b 模块也引用了 a 模块,export 声明的变量也是优于模块其它内容的执行的,但是具体对变量赋值需要等到执行到相应代码的时候。(当然函数声明和表达式声明不一样,这一点跟 JS 函数性质一样,这里就不过多解释)
好了,讲完了 ES6 模块和 CommonJS 模块的不同点之后,接下来就讲讲相同点:
这个很好理解,无论是 ES6 模块还是 CommonJS 模块,当你重复引入某个相同的模块时,模块只会执行一次。
// a.js
import './b';
import './b';
// b.js
console.log('只会执行一次');
// 执行结果:
// 只会执行一次结合上面说的特性,我们来看一个比较经典的例子,循环依赖,当你理解了上面所讲的特性之后,下次遇到模块循环依赖代码的执行结果就很容易理解了。
先来看看下面的例子:
// a.js
console.log('a starting');
exports.done = false;
const b = require('./b');
console.log('in a, b.done =', b.done);
exports.done = true;
console.log('a done');
// b.js
console.log('b starting');
exports.done = false;
const a = require('./a');
console.log('in b, a.done =', a.done);
exports.done = true;
console.log('b done');
// node a.js
// 执行结果:
// a starting
// b starting
// in b, a.done = false
// b done
// in a, b.done = true
// a done结合之前讲的特性很好理解,当你从 b 中想引入 a 模块的时候,因为 node 之前已经加载过 a 模块了,所以它不会再去重复执行 a 模块,而是直接去生成当前 a 模块吐出的 module.exports 对象,因为 a 模块引入 b 模块先于给 done 重新赋值,所以当前 a 模块中输出的 module.exports 中 done 的值仍为 false。而当 a 模块中输出 b 模块的 done 值的时候 b 模块已经执行完毕,所以 b 模块中的 done 值为 true。
从上面的执行过程中,我们可以看到,在 CommonJS 规范中,当遇到 require() 语句时,会执行 require 模块中的代码,并缓存执行的结果,当下次再次加载时不会重复执行,而是直接取缓存的结果。正因为此,出现循环依赖时才不会出现无限循环调用的情况。虽然这种模块加载机制可以避免出现循环依赖时报错的情况,但稍不注意就很可能使得代码并不是像我们想象的那样去执行。因此在写代码时还是需要仔细的规划,以保证循环模块的依赖能正确工作。
所以有什么办法可以出现循环依赖的时候避免自己出现混乱呢?一种解决方式便是将每个模块先写 exports 语法,再写 requre 语句,利用 CommonJS 的缓存机制,在 require() 其他模块之前先把自身要导出的内容导出,这样就能保证其他模块在使用时可以取到正确的值。比如:
// a.js
exports.done = true;
let b = require('./b');
console.log(b.done)
// b.js
exports.done = true;
let a = require('./a');
console.log(a.done)这种写法简单明了,缺点是要改变每个模块的写法,而且大部分同学都习惯了在文件开头先写 require 语句。
跟 CommonJS 模块一样,ES6 不会再去执行重复加载的模块,又由于 ES6 动态输出绑定的特性,能保证 ES6 在任何时候都能获取其它模块当前的最新值。
// a.js
console.log('a starting')
import {foo} from './b';
console.log('in b, foo:', foo);
export const bar = 2;
console.log('a done');
// b.js
console.log('b starting');
import {bar} from './a';
export const foo = 'foo';
console.log('in a, bar:', bar);
setTimeout(() => {
console.log('in a, setTimeout bar:', bar);
})
console.log('b done');
// babel-node a.js
// 执行结果:
// b starting
// in a, bar: undefined
// b done
// a starting
// in b, foo: foo
// a done
// in a, setTimeout bar: 2如果没看懂执行结果的话,那说明没理解前面说的 ES6 模块特性,麻烦重新再看一遍吧!
ES6 模块在编译时就会静态分析,优先于模块内的其他内容执行,所以导致了我们无法写出像下面这样的代码:
if(some condition) {
import a from './a';
}else {
import b from './b';
}
// or
import a from (str + 'b');因为编译时静态分析,导致了我们无法在条件语句或者拼接字符串模块,因为这些都是需要在运行时才能确定的结果在 ES6 模块是不被允许的,所以 动态引入 import() 应运而生。
import() 允许你在运行时动态地引入 ES6 模块,想到这,你可能也想起了 require.ensure 这个语法,但是它们的用途却截然不同的。
require.ensure 的出现是 webpack 的产物,它是因为浏览器需要一种异步的机制可以用来异步加载模块,从而减少初始的加载文件的体积,所以如果在服务端的话 require.ensure 就无用武之地了,因为服务端不存在异步加载模块的情况,模块同步进行加载就可以满足使用场景了。 CommonJS 模块可以在运行时确认模块加载。
而 import() 则不同,它主要是为了解决 ES6 模块无法在运行时确定模块的引用关系,所以需要引入 import()
我们先来看下它的用法:
举个简单的使用例子:
// a.js
const str = './b';
const flag = true;
if(flag) {
import('./b').then(({foo}) => {
console.log(foo);
})
}
import(str).then(({foo}) => {
console.log(foo);
})
// b.js
export const foo = 'foo';
// babel-node a.js
// 执行结果
// foo
// foo当然,如果在浏览器端的 import() 的用途就会变得更广泛,比如 按需异步加载模块,那么就和 require.ensure 功能类似了。
因为是基于 Promise 的,所以如果你想要同时加载多个模块的话,可以是 Promise.all 进行并行异步加载。
Promise.all([
import('./a.js'),
import('./b.js'),
import('./c.js'),
]).then(([a, {default: b}, {c}]) => {
console.log('a.js is loaded dynamically');
console.log('b.js is loaded dynamically');
console.log('c.js is loaded dynamically');
});还有 Promise.race 方法,它检查哪个 Promise 被首先 resolved 或 reject。我们可以使用import()来检查哪个CDN速度更快:
const CDNs = [
{
name: 'jQuery.com',
url: 'https://code.jquery.com/jquery-3.1.1.min.js'
},
{
name: 'googleapis.com',
url: 'https://ajax.googleapis.com/ajax/libs/jquery/3.1.1/jquery.min.js'
}
];
console.log(`------`);
console.log(`jQuery is: ${window.jQuery}`);
Promise.race([
import(CDNs[0].url).then(()=>console.log(CDNs[0].name, 'loaded')),
import(CDNs[1].url).then(()=>console.log(CDNs[1].name, 'loaded'))
]).then(()=> {
console.log(`jQuery version: ${window.jQuery.fn.jquery}`);
});当然,如果你觉得这样写还不够优雅,也可以结合 async/await 语法糖来使用。
async function main() {
const myModule = await import('./myModule.js');
const {export1, export2} = await import('./myModule.js');
const [module1, module2, module3] =
await Promise.all([
import('./module1.js'),
import('./module2.js'),
import('./module3.js'),
]);
}动态 import() 为我们提供了以异步方式使用 ES 模块的额外功能。 根据我们的需求动态或有条件地加载它们,这使我们能够更快,更好地创建更多优势应用程序。
讲到这,我们从 ES6、CommonJS 模块加载机制到动态模块 import() 导入,读完本文相信你能够更加理解 ES6 模块加载机制,对一些奇怪的输出也会有自己的判断,希望本文对你有所帮助!
衡量网站的性能的指标有很多,其中有项重要的指标就是网站的首屏时间,为此前端工程师们都是绞尽脑汁想尽办法进行优化自己的应用,诸如像服务端渲染,懒加载,CDN 加速,ServiceWorker 等等方法,今天介绍的 preload/prefetch 是一种简单,但却事半功倍的优化手段。
在网络请求中,我们在使用到某些资源比如:图片,JS,CSS 等等,在执行之前总需要等待资源的下载,如果我们能做到预先加载资源,那在资源执行的时候就不必等待网络的开销,这时候就轮到 preload 大显身手的时候了。
preload 顾名思义就是一种预加载的方式,它通过声明向浏览器声明一个需要提交加载的资源,当资源真正被使用的时候立即执行,就无需等待网络的消耗。
它可以通过 Link 标签进行创建:
<!-- 使用 link 标签静态标记需要预加载的资源 -->
<link rel="preload" href="/path/to/style.css" as="style">
<!-- 或使用脚本动态创建一个 link 标签后插入到 head 头部 -->
<script>
const link = document.createElement('link');
link.rel = 'preload';
link.as = 'style';
link.href = '/path/to/style.css';
document.head.appendChild(link);
</script>当浏览器解析到这行代码就会去加载 href 中对应的资源但不执行,待到真正使用到的时候再执行,另一种方式方式就是在 HTTP 响应头中加上 preload 字段:
Link: <https://example.com/other/styles.css>; rel=preload; as=style
这种方式比通过 Link 方式加载资源方式更快,请求在返回还没到解析页面的时候就已经开始预加载资源了。
讲完 preload 的用法再来看下它的浏览器兼容性,根据 caniuse.com 上的介绍:IE 和 Firefox 都是不支持的,兼容性覆盖面达到 73%。
prefetch 跟 preload 不同,它的作用是告诉浏览器未来可能会使用到的某个资源,浏览器就会在闲时去加载对应的资源,若能预测到用户的行为,比如懒加载,点击到其它页面等则相当于提前预加载了需要的资源。它的用法跟 preload 是一样的:
<!-- link 模式 -->
<link rel="prefetch" href="/path/to/style.css" as="style">
<!-- HTTP 响应头模式 -->
Link: <https://example.com/other/styles.css>; rel=prefetch; as=style讲完用法再讲浏览器兼容性,prefetch 比 preload 的兼容性更好,覆盖面可以达到将近 80%。
当一个资源被 preload 或者 prefetch 获取后,它将被放在内存缓存中等待被使用,如果资源位存在有效的缓存极致(如 cache-control 或 max-age),它将被存储在 HTTP 缓存中可以被不同页面所使用。
正确使用 preload/prefetch 不会造成二次下载,也就说:当页面上使用到这个资源时候 preload 资源还没下载完,这时候不会造成二次下载,会等待第一次下载并执行脚本。
对于 preload 来说,一旦页面关闭了,它就会立即停止 preload 获取资源,而对于 prefetch 资源,即使页面关闭,prefetch 发起的请求仍会进行不会中断。
preload 是告诉浏览器页面必定需要的资源,浏览器一定会加载这些资源,而 prefetch 是告诉浏览器页面可能需要的资源,浏览器不一定会加载这些资源。所以建议:对于当前页面很有必要的资源使用 preload,对于可能在将来的页面中使用的资源使用 prefetch。
用 “preload” 和 “prefetch” 情况下,如果资源不能被缓存,那么都有可能浪费一部分带宽,在移动端请慎用。
没有用到的 preload 资源在 Chrome 的 console 里会在 onload 事件 3s 后发生警告。
原因是你可能为了改善性能使用 preload 来缓存一定的资源,但是如果没有用到,你就做了无用功。在手机上,这相当于浪费了用户的流量,所以明确你要 preload 对象。
用下面的代码段可以检测 <link rel=”preload”> 是否被支持:
const preloadSupported = () => {
const link = document.createElement('link');
const relList = link.relList;
if (!relList || !relList.supports)
return false;
return relList.supports('preload');
};在 Chrome 46 以后的版本中,不同的资源在浏览器渲染的不同阶段进行加载的优先级如下图所示:
一个资源的加载的优先级被分为五个级别,分别是:
从图中可以看出:(以 Blink 为例)
而 script 脚本资源就比较特殊,优先级不一,脚本根据它们在文件中的位置是否异步、延迟或阻塞获得不同的优先级:
自己网站资源优先级也可以通过 Chrome 控制台 Network 一栏进行查看.
使用 async/defer 属性在加载脚本的时候不阻塞 HTML 的解析,defer 加载脚本执行会在所有元素解析完成,DOMContentLoaded 事件触发之前完成执行。它的用途其实跟 preload 十分相似。你可以使用 defer 加载脚本在 head 末尾,这比将脚本放在 body 底部效果来的更好。
HTTP/2 PUSH 功能可以让服务器在没有相应的请求情况下预先将资源推送到客户端。这个跟 preload/prefetch 预加载资源的思路类似,将下载和资源实际执行分离的方法,当脚本真正想要请求文件的时候,发现脚本就存在缓存中,就不需要去请求网络了。
我们假设浏览器正在加载一个页面,页面中有个 CSS 文件,CSS 文件又引用一个字体库,对于这样的场景,
若使用 HTTP/2 PUSH,当服务端获取到 HTML 文件后,知道以后客户端会需要字体文件,它就立即主动地推送这个文件给客户端,如下图:
而对于 preload,服务端就不会主动地推送字体文件,在浏览器获取到页面之后发现 preload 字体才会去获取,如下图:
对于 Server Push 来说,如果服务端渲染 HTML 时间过长的话则很有效,因为这时候浏览器除了干等着,做不了其它操作,但是不好的地方是服务器需要支持 HTTP/2 协议并且服务端压力也会相应增大。对于更多 Server Push 和 preload 的对比可以参考这篇文章:HTTP/2 PUSH(推送)与HTTP Preload(预加载)大比拼
现代浏览器很聪明,就如 Chrome 浏览器,它会在解析 HTML 时收集外链,并在后台并行下载,它也实现了提前加载以及加载和执行分离。
它相比于 preload 方式而言:
preload/prefetch 是个好东西,能让浏览器提前加载需要的资源,将资源的下载和执行分离开来,运用得当的话可以对首屏渲染带来不小的提升,可以对页面交互上带来极致的体验。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.