随着科技的飞速发展,数据呈现爆发式的增长,任何人都摆脱不了与数据打交道,社会对于“数据”方面的人才需求也在不断增大。因此了解当下企业究竟需要招聘什么样的人才?需要什么样的技能?不管是对于在校生,还是对于求职者来说,都显得很有必要。
本文基于这个问题,针对 boss 直聘网站,使用 Scrapy 框架爬取了全国热门城市大数据、数据分析、数据挖掘、机器学习、人工智能等相关岗位的招聘信息。分析比较了不同岗位的薪资、学历要求;分析比较了不同区域、行业对相关人才的需求情况;分析比较了不同岗位的知识、技能要求等。
| 开发工具/环境 | 版本 | 备注 |
|---|---|---|
| Windows | Windows10 | 系统 |
| PyCharm | Professional 2020.3 | 编写代码 |
| Anaconda3 | Anaconda3-2019.03-Windows-x86_64.exe | 运行环境 |
| 库名 | 版本 | 备注 |
|---|---|---|
| Scrapy | 2.4.1 | WEB爬虫框架 |
| SQLAlchemy | 1.3.5 | 数据库操作 |
| PyMySQL | 0.9.3 | 数据库操作 |
| pandas | 0.24.2 | 数据分析 |
| Flask | 1.1.1 | 轻量级web框架 |
该项目一共分为三个子任务完成,数据采集—数据预处理—数据分析/可视化。

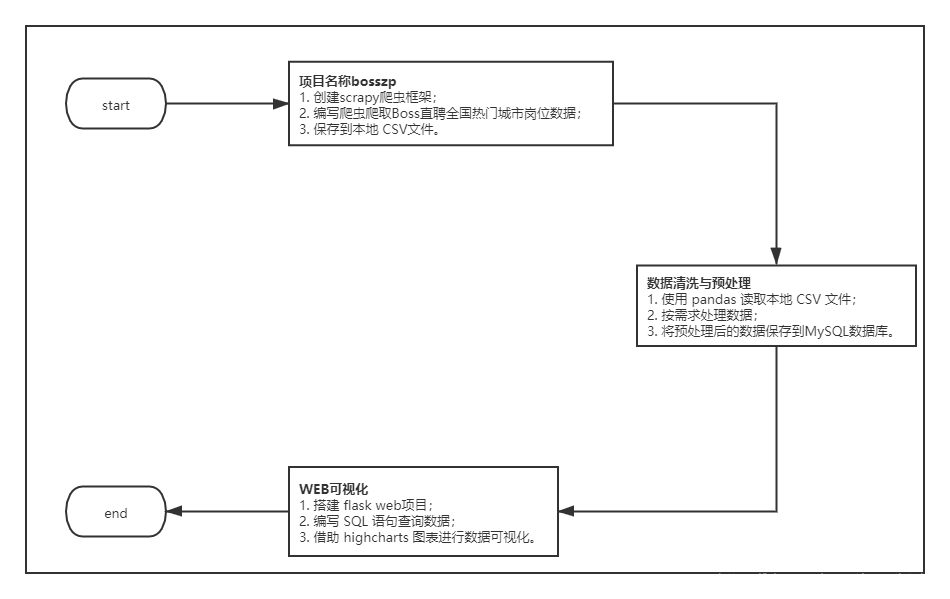
爬取 Boss直聘热门城市岗位数据,并将数据以 CSV 文件格式进行保存。如下图所示:

① 环境安装:
$ pip install scrapy② 项目创建:
$ scrapy startproject bosszp
$ cd bosszp
$ scrapy genspider boss zhipin.com
爬取 Boss 直聘网站数据,通过检测 Boss 直聘网站,发现有 Cookie,User-Agent,Referer,Robots协议等常见反爬策略。根据这些策略我们需要在settings.py 文件中做对应的一些配置和修改。具体配置如下:
① 关闭 Robots 协议
# Obey robots.txt rules
ROBOTSTXT_OBEY = False② 修改下载延迟为 60 s
# Configure a delay for requests for the same website (default: 0)
DOWNLOAD_DELAY = 60③ 禁用系统 cookie
# Disable cookies (enabled by default)
COOKIES_ENABLED = False④ 开启 item-pipelines
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'bosszhipin.pipelines.BosszhipinPipeline': 300,
} 创建和配置好 Scrapy 项目以后,我们就可以编写 Scrapy 爬虫程序了。
① 确定目标(编辑 items.py)
import scrapy
class BosszpItem(scrapy.Item):
job_name = scrapy.Field() # 岗位名
job_area = scrapy.Field() # 工作地址
job_salary = scrapy.Field() # 薪资
com_name = scrapy.Field() # 企业名称
com_type = scrapy.Field() # 企业类型
com_size = scrapy.Field() # 企业规模
finance_stage = scrapy.Field() # 融资情况
work_year = scrapy.Field() # 工作年限
education = scrapy.Field() # 学历要求
job_benefits = scrapy.Field() # 岗位福利② 编写爬虫(编辑 spiders/boss.py),需要替换成最新的 cookie
import scrapy
import json
import logging
import random
from bosszp.items import BosszpItem
class BossSpider(scrapy.Spider):
name = 'boss'
allowed_domains = ['zhipin.com']
start_urls = ['https://www.zhipin.com/wapi/zpCommon/data/cityGroup.json'] # 热门城市列表url
# 设置多个 cookie,建议数量为 页数/2 + 1 个cookie.至少 设置 4 个
# 只需复制 __zp_stoken__ 部分即可
cookies = [ '__zp_stoken__=f330bOEgsRnsAIS5Bb2FXe250elQKNzAgMBcQZ1hvWyBjUFE1DCpKLWBtBn99Nwd%2BPHtlVRgdOi1vDEAkOz9sag50aRNRfhs6TQ9kWmNYc0cFI3kYKg5fAGVPPX0WO2JCOipvRlwbP1YFBQlHOQ%3D%3D', '__zp_stoken__=f330bOEgsRnsAIUsENEIbe250elRsb2U4Bg0QZ1hvW19mPEdeeSpKLWBtN3Y9QCN%2BPHtlVRgdOilvfTYkSTMiaFN0X3NRAGMjOgENX2krc0cFI3kYKiooQGx%2BPX0WO2I3OipvRlwbP1YFBQlHOQ%3D%3D', '__zp_stoken__=f330bOEgsRnsAITsLNnJIe250elRJMH95DBAQZ1hvW1J1ewdmDCpKLWBtBHZtagV%2BPHtlVRgdOil1LjkkR1MeRAgdY3tXbxVORWVuTxQlc0cFI3kYKgwCEGxNPX0WO2JCOipvRlwbP1YFBQlHOQ%3D%3D'
]
# 设置多个请求头
user_agents = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_0_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.1 Safari/605.1.15',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)',
]
page_no = 1 # 初始化分页
def random_header(self):
"""
随机生成请求头
:return: headers
"""
headers = {'Referer': 'https://www.zhipin.com/c101020100/?ka=sel-city-101020100'}
headers['cookie'] = random.choice(self.cookies)
headers['user-agent'] = random.choice(self.user_agents)
return headers
def parse(self, response):
"""
解析首页热门城市列表,选择热门城市进行爬取
:param response: 热门城市字典数据
:return:
"""
# 获取服务器返回的内容
city_group = json.loads(response.body.decode())
# 获取热门城市列表
hot_city_list = city_group['zpData']['hotCityList']
# 初始化空列表,存储打印信息
# city_lst = []
# for index,item in enumerate(hot_city_list):
# city_lst.apend({index+1: item['name']})
# 列表推导式:
hot_city_names = [{index + 1: item['name']} for index, item in enumerate(hot_city_list)]
print("--->", hot_city_names)
# 从键盘获取城市编号
city_no = int(input('请从上述城市列表中,选择编号开始爬取:'))
# 拼接url https://www.zhipin.com/job_detail/?query=&city=101040100&industry=&position=
# 获取城市编码code
city_code = hot_city_list[city_no - 1]['code']
# 拼接查询接口
city_url = 'https://www.zhipin.com/job_detail/?query=&city={}&industry=&position='.format(city_code)
logging.info("<<<<<<<<<<<<<正在爬取第_{}_页岗位数据>>>>>>>>>>>>>".format(self.page_no))
yield scrapy.Request(url=city_url, headers=self.random_header(), callback=self.parse_city)
def parse_city(self, response):
"""
解析岗位页数据
:param response: 岗位页响应数据
:return:
"""
if response.status != 200:
logging.warning("<<<<<<<<<<<<<获取城市招聘信息失败,ip已被封禁。请稍后重试>>>>>>>>>>>>>")
return
li_elements = response.xpath('//div[@class="job-list"]/ul/li') # 定位到所有的li标签
next_url = response.xpath('//div[@class="page"]/a[last()]/@href').get() # 获取下一页
for li in li_elements:
job_name = li.xpath('./div/div[1]//div[@class="job-title"]/span[1]/a/text()').get()
job_area = li.xpath('./div/div[1]//div[@class="job-title"]/span[2]/span[1]/text()').get()
job_salary = li.xpath('./div/div[1]//span[@class="red"]/text()').get()
com_name = li.xpath('./div/div[1]/div[2]//div[@class="company-text"]/h3/a/text()').get()
com_type = li.xpath('./div/div[1]/div[2]/div[1]/p/a/text()').get()
com_size = li.xpath('./div/div[1]/div[2]/div[1]/p/text()[2]').get()
finance_stage = li.xpath('./div/div[1]/div[2]/div[1]/p/text()[1]').get()
work_year = li.xpath('./div/div[1]/div[1]/div[1]/div[2]/p/text()[1]').get()
education = li.xpath('./div/div[1]/div[1]/div[1]/div[2]/p/text()[2]').get()
job_benefits = li.xpath('./div/div[2]/div[2]/text()').get()
item = BosszpItem(job_name=job_name, job_area=job_area, job_salary=job_salary, com_name=com_name,
com_type=com_type, com_size=com_size,
finance_stage=finance_stage, work_year=work_year, education=education,
job_benefits=job_benefits)
yield item
if next_url == "javascript:;":
logging.info('<<<<<<<<<<<<<热门城市岗位数据已爬取结束>>>>>>>>>>>>>')
logging.info("<<<<<<<<<<<<<一共爬取了_{}_页岗位数据>>>>>>>>>>>>>".format(self.page_no))
return
next_url = response.urljoin(next_url) # 网址拼接
self.page_no += 1
logging.info("<<<<<<<<<<<<<正在爬取第_{}_页岗位数据>>>>>>>>>>>>>".format(self.page_no))
yield scrapy.Request(url=next_url, headers=self.random_header(), callback=self.parse_city)③ 保存数据(编辑 pipelines.py)
from itemadapter import ItemAdapter
class BosszpPipeline:
def process_item(self, item, spider):
"""
保存数据到本地 csv 文件
:param item: 数据项
:param spider:
:return:
"""
with open(file='全国-热门城市岗位数据.csv', mode='a+', encoding='utf8') as f:
f.write(
'{job_name},{job_area},{job_salary},{com_name},{com_type},{com_size},{finance_stage},{work_year},'
'{education},{job_benefits}'.format(
**item))
return item④ 运行爬虫
$ scrapy crawl boss⑤ 编辑本地 CSV 文件
数据爬取完成后,打开 CSV 文件,复制下方文本粘贴在文件第一行。
job_name,job_area,job_salary,com_name,com_type,com_size,finance_stage,work_year,education,job_benefits

注意:
- 如果爬虫执行过程中出现
xxxxx DEBUG: Redirecting (302) to xxxxxxx问题,替换最新的cookie即可解决。- 目前版本替换新的
cookie以后,不能从断点继续爬取。- 如需断点继续爬取,需重写
start_requests()函数。
完成上面爬虫程序的编写与运行,我们就能将 Boss 直聘热门城市岗位数据爬取到本地。通过观察发现爬取到的数据出现了大量的脏数据和高耦合的数据。我们需要对这些脏数据进行清洗与预处理后才能正常使用。
需求:
- 读取
全国-热门城市岗位数据.csv文件- 对重复行进行清洗。
- 对
工作地址字段进行预处理。要求:北京·海淀区·西北旺 --> 北京,海淀区,西北旺。分隔成3个字段- 对
薪资字段进行预处理。要求:30-60K·15薪 --> 最低:30,最高:60- 对
工作经验字段进行预处理。要求:经验不限/在校/应届 :0,1-3年:1,3-5年:2,5-10年:3,10年以上:4- 对
企业规模字段进行预处理。要求:500人以下:0,500-999:1,1000-9999:2,10000人以上:3- 对
岗位福利字段进行预处理。要求:将描述中的中文','(逗号),替换成英文','(逗号)- 对缺失值所在行进行清洗。
- 将处理后的数据保存到 MySQL 数据库
① 在 bosszp 项目下新建 clean 包,在 模块下新建 dataclean.py 模块。如下图所示:
② 在 dataclean.py 文件内编写清洗与预处理的代码。
# -*- coding:utf-8 -*-
"""
作者:jhzhong
功能:对岗位数据进行清洗与预处理
需求:
1. 读取 `全国-热门城市岗位数据.csv` 文件
2. 对重复行进行清洗。
3. 对`工作地址`字段进行预处理。要求:北京·海淀区·西北旺 --> 北京,海淀区,西北旺。分隔成3个字段
4. 对`薪资`字段进行预处理。要求:30-60K·15薪 --> 最低:30,最高:60
5. 对`工作经验`字段进行预处理。要求:经验不限/在校/应届 :0,1-3年:1,3-5年:2,5-10年:3,10年以上:4
6. 对`企业规模`字段进行预处理。要求:500人以下:0,500-999:1,1000-9999:2,10000人以上:3
7. 对`岗位福利`字段进行预处理。要求:将描述中的中文','(逗号),替换成英文','(逗号)
8. 对缺失值所在行进行清洗。
9. 将处理后的数据保存到 MySQL 数据库
"""
# 导入模块
import pandas as pd
from sqlalchemy import create_engine
import logging
# 读取 全国-热门城市岗位招聘数据.csv 文件
all_city_zp_df = pd.read_csv('../全国-热门城市岗位数据.csv', encoding='utf8')
# 对重复行进行清洗。
all_city_zp_df.drop_duplicates(inplace=True)
# 对`工作地址`字段进行预处理。要求:北京·海淀区·西北旺 --> 北京,海淀区,西北旺。分隔成3个字段
all_city_zp_area_df = all_city_zp_df['job_area'].str.split('·', expand=True)
all_city_zp_area_df = all_city_zp_area_df.rename(columns={0: "city", 1: "district", 2: "street"})
# 对`薪资`字段进行预处理。要求:30-60K·15薪 --> 最低:30,最高:60
all_city_zp_salary_df = all_city_zp_df['job_salary'].str.split('K', expand=True)[0].str.split('-', expand=True)
all_city_zp_salary_df = all_city_zp_salary_df.rename(columns={0: 'salary_lower', 1: 'salary_high'})
# 对`工作经验`字段进行预处理。要求:经验不限/在校/应届 :0,1-3年:1,3-5年:2,5-10年:3,10年以上:4
def fun_work_year(x):
if x in "1-3年":
return 1
elif x in "3-5年":
return 2
elif x in "5-10年":
return 3
elif x in "10年以上":
return 4
else:
return 0
all_city_zp_df['work_year'] = all_city_zp_df['work_year'].apply(lambda x: fun_work_year(x))
# 对`企业规模`字段进行预处理。要求:500人以下:0,500-999:1,1000-9999:2,10000人以上:3
def fun_com_size(x):
if x in "500-999人":
return 1
elif x in "1000-9999人":
return 2
elif x in "10000人以上":
return 3
else:
return 0
# 对`岗位福利`字段进行预处理。要求:将描述中的中文','(逗号),替换成英文','(逗号)
all_city_zp_df['job_benefits'] = all_city_zp_df['job_benefits'].str.replace(',', ',')
# 合并所有数据集
clean_all_city_zp_df = pd.concat([all_city_zp_df, all_city_zp_salary_df, all_city_zp_area_df], axis=1)
# 删除冗余列
clean_all_city_zp_df.drop('job_area', axis=1, inplace=True) # 删除原区域
clean_all_city_zp_df.drop('job_salary', axis=1, inplace=True) # 删除原薪资
# 对缺失值所在行进行清洗。
clean_all_city_zp_df.dropna(axis=0, how='any', inplace=True)
clean_all_city_zp_df.drop(axis=0,
index=(clean_all_city_zp_df.loc[(clean_all_city_zp_df['job_benefits'] == 'None')].index),
inplace=True)
# 将处理后的数据保存到 MySQL 数据库
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/bosszp_db?charset=utf8')
clean_all_city_zp_df.to_sql('t_boss_zp_info', con=engine, if_exists='replace')
logging.info("Write to MySQL Successfully!") ③ 运行程序,检查数据是否清洗成功和插入到数据库
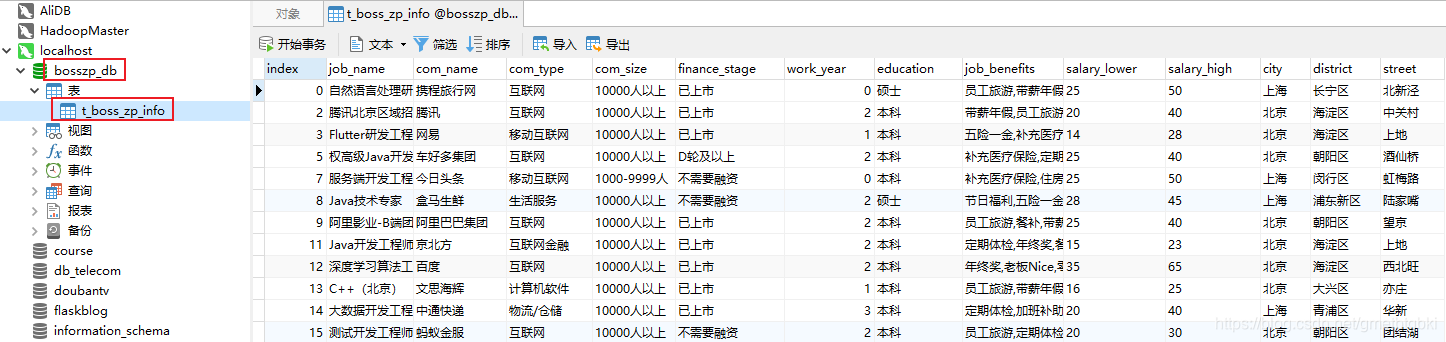
成功运行上面两个流程后,我们已经得到了可用于数据分析的高质量数据。拿到这些数据以后,我们使用 python + sql 脚本的方式对数据进行多维度分析,并使用 highcharts 工具进行数据可视化。整个分析可视化通过轻量化 WEB 框架 Flask 来进行部署。
① 安装 Flask
$ pip install flask② 搭建 Flask 项目环境
在 bosszp 项目下,新建 web 包,在 web 包下分别创建 templates 文件夹、static文件夹和 run.py 文件。
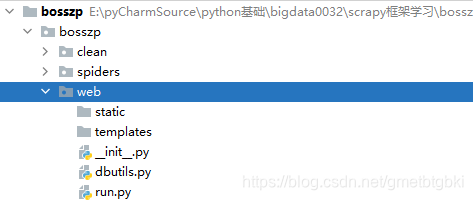
小贴士:
Flask框架目录介绍:
web/--flask项目名
static/-- 存放静态资源。如js,css,img等
templates/-- 存放网页模板。如*.html
run.py-- 编写应用程序
Flask web项目环境搭建好以后,我们就可以开始做数据分析和可视化了。
① 新建数据库工具模块 dbutils.py
# -*- coding:utf-8 -*-
"""
作者:jhzhong
功能:连接数据库,封装了操作数据库的增删改查等常见操作函数
"""
import pymysql
import logging
class DBUtils(object):
# 初始化连接对象和游标对象
_db_conn = None
_db_cursor = None
"""
数据库工具类 初始化方法
传入 host,user,password,db 进行数据库连接
"""
def __init__(self, host, user, password, db, port=3306, charset='utf8'):
try:
self._db_conn = pymysql.connect(host=host, user=user, password=password, port=port, db=db, charset=charset)
self._db_cursor = self._db_conn.cursor()
except Exception as e:
logging.error(e)
def get_one(self, sql_str, args=None):
"""
查询单个结果,返回具体的数据内容
:param sql_str: sql语句
:param args: 参数列表
:return: result
"""
try:
if self._db_conn is not None:
self._db_cursor.execute(sql_str, args=args)
result = self._db_cursor.fetchone()
return result
else:
logging.error("请检查数据库连接")
except Exception as e:
logging.error(e)
# 查询多个结果
def get_all(self, sql_str, args=None):
"""
查询多个结果,返回元组对象
:param sql_str: sql 语句
:param args: 参数列表
:return: result
"""
try:
if self._db_conn is not None:
self._db_cursor.execute(sql_str, args=args)
result = self._db_cursor.fetchall()
return result
else:
logging.error("请检查数据库连接")
except Exception as e:
logging.error(e)
# 插入数据
def insert(self, sql_str, args=None):
"""
向数据库插入数据,返回影响行数(int)
:param sql_str: sql 语句
:param args: 参数列表
:return: affect_rows
"""
try:
if self._db_conn is not None:
affect_rows = self._db_cursor.execute(sql_str, args=args)
self._db_conn.commit()
return affect_rows
else:
logging.error("请检查数据库连接")
except Exception as e:
self._db_conn.rollback()
logging.error(e)
# 修改数据
def modify(self, sql_str, args=None):
"""
更新数据,返回影响行数(int)
:param sql_str: sql 语句
:param args: 参数列表
:return: affect_rows
"""
return self.insert(sql_str=sql_str, args=args)
# 删除数据
def delete(self, sql_str, args=None):
"""
删除数据,返回影响行数(int)
:param sql_str: sql 语句
:param args: 参数列表
:return: affect_rows
"""
return self.insert(sql_str=sql_str, args=args)
def __del__(self):
"""
程序运行结束后,会默认调用 __del__ 方法
销毁对象
"""
if self._db_conn is not None:
self._db_cursor.close()
self._db_conn.close()② 在 templates 文件夹下新建 index.html,并进行编辑
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8"/>
<title>Boss岗位分析可视化</title>
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta http-equiv="x-ua-compatible" content="ie=edge">
<link rel="icon" href="{{ url_for('static', filename = 'img/favicon.png') }}">
<link rel="stylesheet" href="{{ url_for('static',filename = 'css/mystyle.css') }}">
<script src="{{ url_for('static', filename = 'js/jquery-1.8.3.min.js') }}"></script>
<script src="{{ url_for('static', filename = 'highcharts/highcharts.js') }}"></script>
<script src="{{ url_for('static', filename = 'highcharts/highcharts-more.js') }}"></script>
<!-- <script src="https://code.highcharts.com.cn/highcharts/modules/exporting.js"></script> -->
<script src="{{ url_for('static', filename = 'highcharts/oldie.js') }}"></script>
<script src="{{ url_for('static', filename = 'highcharts/wordcloud.js') }}"></script>
<script src="{{ url_for('static', filename = 'highcharts/dark-unica.js') }}"></script>
<script src="{{ url_for('static', filename = 'js/word.js') }}"></script>
<script src="{{ url_for('static', filename = 'js/packgebubble.js') }}"></script>
<script src="{{ url_for('static', filename = 'js/pie.js') }}"></script>
<script src="{{ url_for('static', filename = 'js/cylindrical.js') }}"></script>
<script src="{{ url_for('static', filename = 'js/fan.js') }}"></script>
<script src="{{ url_for('static', filename = 'js/order.js') }}"></script>
</head>
<body>
<!-- 首页设置 -->
<div class="index">
<!-- 标题栏 -->
<div class="title">
<p>Boss直聘岗位分析可视化</p>
</div>
<div class="paint_area">
<div class="data_frame_top">
<div class="data_frame_left_top">
<div id="pie"></div>
</div>
<div class="data_frame_middle_top">
<div id="packedbubble"></div>
<!-- middle_top -->
</div>
<div class="data_frame_right_top">
<p style="color: #FFFFFF;font-size: 20px;font-family: 'Unica One', sans-serif">学历占比</p>
<div id="fan">
</div>
</div>
</div>
<div class="data_frame_bottom">
<div class="data_frame_left_bottom">
<div id="cylindrical"></div>
</div>
<!-- 词云图 -->
<div class="data_frame_middle_bottom">
<div id="word_cloud"></div>
</div>
<div class="data_frame_right_bottom">
<div id="order">
<center>
<p style="font-size: 20px;font-family: 'Unica One', sans-serif">企业招聘Top 10</p>
<table>
<thead>
<tr>
<th>排名</th>
<th>公司名称</th>
<th>岗位数量</th>
</tr>
</thead>
<tbody id="J_TbData">
</tbody>
</table>
</center>
</div>
</div>
</div>
</div>
<!-- <div class="footer">
<p>Copyright © 公众号 jhzhong share</p>
</div> -->
</div>
<script>
</script>
</body>
</html>③ 在 static 文件夹下分别建 js、css 、img 和 highcharts 文件夹。
highcharts\ 文件夹下放入以下静态文件
highcharts.js
highcharts-more.js
dark-unica.js
wordcloud.js
oldie.jsstatic 下的静态资源下载地址:
④ 编写 run.py
# -*- coding:utf-8 -*-
"""
作者:jhzhong
功能:数据分析于可视化
"""
from flask import Flask, render_template
from bosszp.web.dbutils import DBUtils
import json
app = Flask(__name__)
def get_db_conn():
"""
获取数据库连接
:return: db_conn 数据库连接对象
"""
return DBUtils(host='localhost', user='root', password='123456', db='bosszp_db')
def msg(status, data='未加载到数据'):
"""
:param status: 状态码 200成功,201未找到数据
:param data: 响应数据
:return: 字典 如{'status': 201, 'data': ‘未加载到数据’}
"""
return json.dumps({'status': status, 'data': data})
@app.route('/')
def index():
"""
首页
:return: index.html 跳转到首页
"""
return render_template('index.html')
@app.route('/getwordcloud')
def get_word_cloud():
"""
获取岗位福利词云数据
:return:
"""
db_conn = get_db_conn()
text = \
db_conn.get_one(sql_str="SELECT GROUP_CONCAT(job_benefits) FROM t_boss_zp_info")[0]
if text is None:
return msg(201)
return msg(200, text)
@app.route('/getjobinfo')
def get_job_info():
"""
获取热门岗位招聘区域分布
:return:
"""
db_conn = get_db_conn()
results = db_conn.get_all(
sql_str="SELECT city,district,COUNT(1) as num FROM t_boss_zp_info GROUP BY city,district")
# {"city":"北京","info":[{"district":"朝阳区","num":27},{"海淀区":43}]}
if results is None or len(results) == 0:
return msg(201)
data = []
city_detail = {}
for r in results:
info = {'name': r[1], 'value': r[2]}
if r[0] not in city_detail:
city_detail[r[0]] = [info]
else:
city_detail[r[0]].append(info)
for k, v in city_detail.items():
temp = {'name': k, 'data': v}
data.append(temp)
return msg(200, data)
@app.route('/getjobnum')
def get_job_num():
"""
获取个城市岗位数量
:return:
"""
db_conn = get_db_conn()
results = db_conn.get_all(sql_str="SELECT city,COUNT(1) num FROM t_boss_zp_info GROUP BY city")
if results is None or len(results) == 0:
return msg(201)
if results is None or len(results) == 0:
return msg(201)
data = []
for r in results:
data.append(list(r))
return msg(200, data)
@app.route('/getcomtypenum')
def get_com_type_num():
"""
获取企业类型占比
:return:
"""
db_conn = get_db_conn()
results = db_conn.get_all(
sql_str="SELECT com_type, ROUND(COUNT(1)/(SELECT SUM(t1.num) FROM (SELECT COUNT(1) num FROM t_boss_zp_info GROUP BY com_type) t1)*100,2) percent FROM t_boss_zp_info GROUP BY com_type")
if results is None or len(results) == 0:
return msg(201)
data = []
for r in results:
data.append({'name': r[0], 'y': float(r[1])})
return msg(200, data)
# 扇形图
@app.route('/geteducationnum')
def geteducationnum():
"""
获取学历占比
:return:
"""
db_conn = get_db_conn()
results = db_conn.get_all(
sql_str="SELECT t1.education,ROUND(t1.num/(SELECT SUM(t2.num) FROM(SELECT COUNT(1) num FROM t_boss_zp_info t GROUP BY t.education)t2)*100,2) FROM( SELECT t.education,COUNT(1) num FROM t_boss_zp_info t GROUP BY t.education) t1")
if results is None or len(results) == 0:
return msg(201)
data = []
for r in results:
data.append([r[0], float(r[1])])
return msg(200, data)
# 获取排行榜
@app.route('/getorder')
def getorder():
"""
获取企业招聘数量排行榜
:return:
"""
db_conn = get_db_conn()
results = db_conn.get_all(
sql_str="SELECT t.com_name,COUNT(1) FROM t_boss_zp_info t GROUP BY t.com_name ORDER BY COUNT(1) DESC LIMIT 10")
if results is None or len(results) == 0:
return msg(201)
data = []
for i, r in enumerate(results):
data.append({'id': i + 1,
'name': r[0],
'num': r[1]})
return msg(200, data)
if __name__ == '__main__':
app.run(host='127.0.0.1', port=8080, debug=True)⑤ 运行 run.py
$ export FLASK_APP=run.py
$ python -m flask run
* Running on http://127.0.0.1:8080/外部可见的服务器
运行服务器后,会发现只有你自己的电脑可以使用服务,而网络中的其他电脑却 不行。缺省设置就是这样的,因为在调试模式下该应用的用户可以执行你电脑中 的任意 Python 代码。
如果你关闭了调试器或信任你网络中的用户,那么可以让服务器被公开访问。 只要在命令行上简单的加上 --host=0.0.0.0 即可:
$ flask run --host=0.0.0.0
这行代码告诉你的操作系统监听所有公开的 IP 。
现在在浏览器中打开 http://127.0.0.1:8080/ ,应该可以看到可视化大屏了。
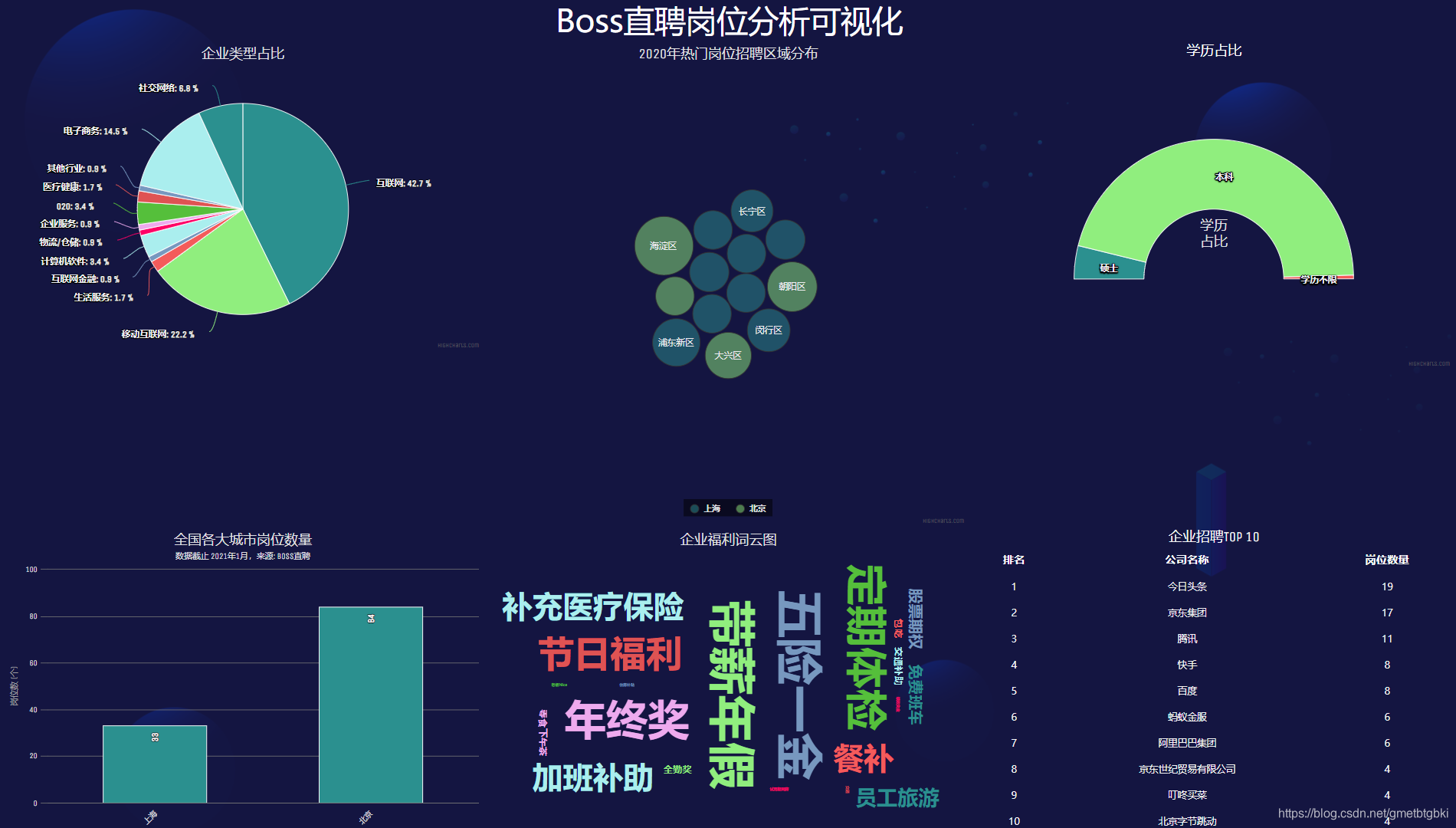
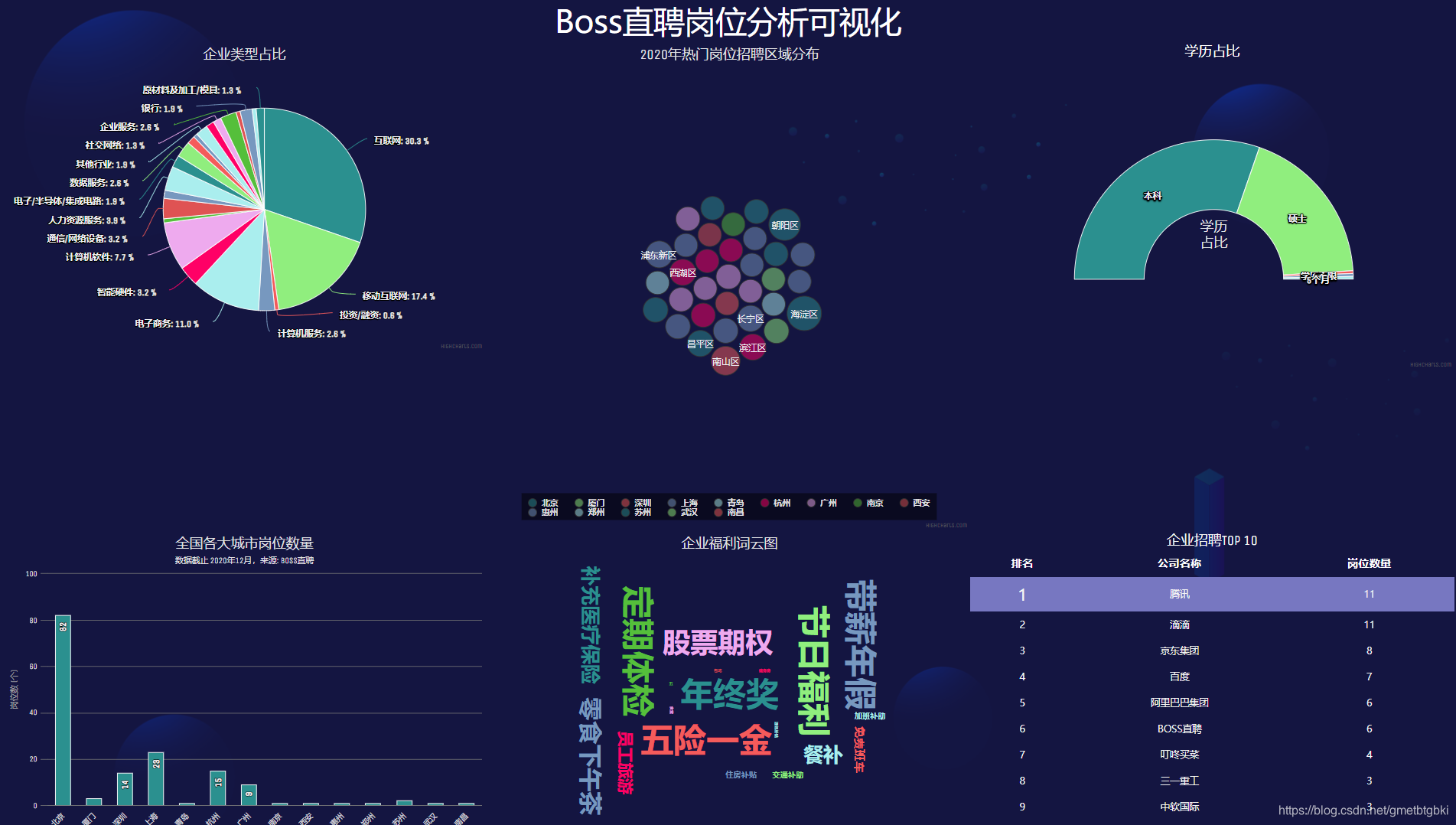
本文主要讲解了Boss直聘网站数据爬取分析与可视化的实现流程及代码编写。目前项目任然还有很多的不足和考虑不全面的地方,当然如果您有疑问的地方和更好的优化建议也请给我留言,我一定尽力的去回复和改进这些地方。
