对于数据库的期许往往会包含以下几方面,首先是易用与灵活,尽可能可以用贴近业务语言的方式存取数据,而不需要理解太多抽象的语义或者函数;然后是高性能,无论存取皆可以迅速完成;然后是高可用与可扩展,我们能够根据实际的业务需要快速扩展数据库,提供长期的可用性与数据的安全一致,而不会因为数据的爆炸性增长导致数据库的崩溃。
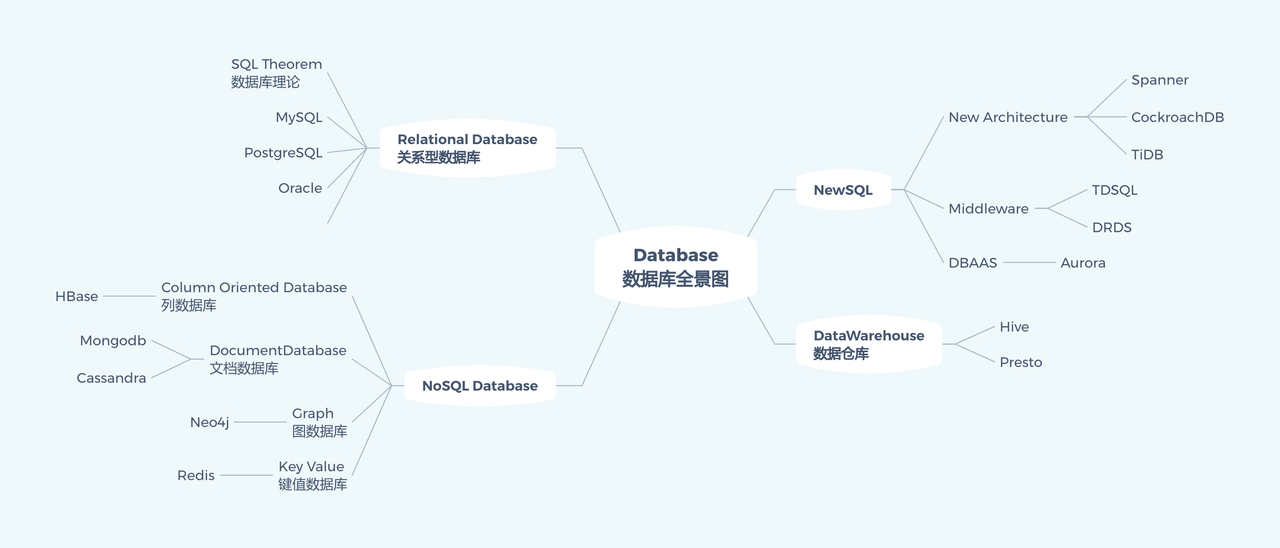
以 Oracle, MySQL, SQLServer, PostgreSQL 为代表的关系型数据库,以行存储的方式结构化地存储数据。搜索引擎擅长文本查询;与 SQL 数据库中的文本匹配(例如 LIKE)相比,搜索引擎提供了更高的查询功能和更好的开箱即用性能。文档存储提供比传统数据库更好的数据模式适应性;通过将数据存储为单个文档对象(通常表示为 JSON),它们不需要预定义模式。列式存储专门用于单列查询和值聚合,在列式存储中,诸如 SUM 和 AVG 之类的 SQL 操作要快得多,因为同一列的数据在硬盘驱动器上更紧密地存储在一起。而 OceanBase, TiDB, Spanner/F1 等 NewSQL 数据库兼具了 SQL 以及可扩展性,数据被拆分成一个个 Range,分散在不同的服务器中,通过增加服务器就可以一定程度上的线性扩容;其通过 Paxos 或者 Raft 保证多副本之间的一致性,通过 2PC,MVCC 支持不同隔离级别的事务等。

实际上,各个数据库之间也并发泾渭分明,多模异构是指在单个数据库平台中支持非结构化结构化数据在内的多种数据类型。一直以来,传统关系型数据库仅支持表单类型的结构化数据存储和访问能力,而对于层次型对象、图片影像等半结构化与非结构化数据管理无能为力。如今,随着应用类型的多样化和存储成本的降低,单一数据类型已经无法满足许多综合性业务平台的需求。数据库层面的多模异构和非结构化数据管理,将能实现结构化、半结构化和非结构化数据的统一管理,实现非结构化数据的实时访问,大大降低了运维和应用的成本。同时,非关系型数据库在访问模式上也渐渐将 SQL、K/V、文档、宽表、图等分支互相融合,支持除了 SQL 查询语言之外的其他访问模式,大大丰富了过去 NoSQL 数据库单一的设计用途。
本篇即是希望能够概述常见数据库的使用与内部原理,让我们对数据库有更深入的理解。
笔者所有文章遵循 知识共享 署名-非商业性使用-禁止演绎 4.0 国际许可协议,欢迎转载,尊重版权。如果觉得本系列对你有所帮助,欢迎给我家布丁买点狗粮(支付宝扫码)~
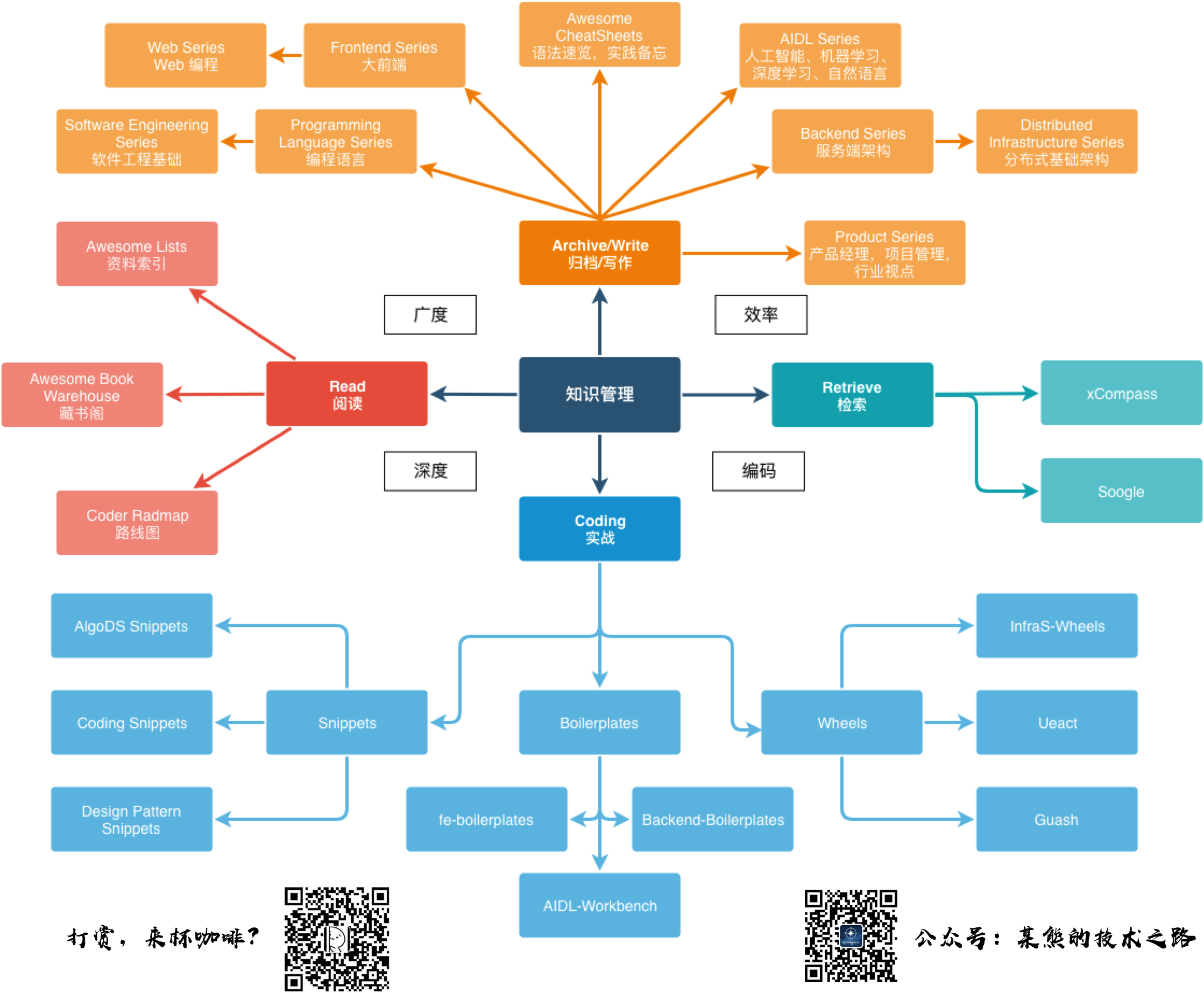

您可以通过以下导航来在 Gitbook 中阅读笔者的系列文章,涵盖了技术资料归纳、编程语言与理论、Web 与大前端、服务端开发与基础架构、云计算与大数据、数据科学与人工智能、产品设计等多个领域:
-
知识体系:《Awesome Lists | CS 资料集锦》、《Awesome CheatSheets | 速学速查手册》、《Awesome Interviews | 求职面试必备》、《Awesome RoadMaps | 程序员进阶指南》、《Awesome MindMaps | 知识脉络思维脑图》、《Awesome-CS-Books | 开源书籍(.pdf)汇总》
-
编程语言:《编程语言理论》、《Java 实战》、《JavaScript 实战》、《Go 实战》、《Python 实战》、《Rust 实战》
-
Web 与大前端:《现代 Web 全栈开发与工程架构》、《数据可视化》、《iOS》、《Android》、《混合开发与跨端应用》
-
服务端开发实践与工程架构:《服务端基础》、《微服务与云原生》、《测试与高可用保障》、《DevOps》、《Spring》、《信息安全与渗透测试》
-
数据科学,人工智能与深度学习:《数理统计》、《数据分析》、《机器学习》、《深度学习》、《自然语言处理》、《工具与工程化》、《行业应用》
此外,你还可前往 xCompass 交互式地检索、查找需要的文章/链接/书籍/课程;或者在 MATRIX 文章与代码索引矩阵中查看文章与项目源代码等更详细的目录导航信息。最后,你也可以关注微信公众号:『某熊的技术之路』以获取最新资讯。

