本仓库下存放个人博客的源文件。持续更新,欢迎 star。
如果大家觉得那里写的不合适的可以给我提 Issue
未来考虑尝试使用 Issue 写博客,敬请期待~





附加日志 RPC:
由领导人负责调用来复制日志指令;也会用作 heartbeat
| 参数 | 解释 |
|---|---|
| term | 领导人的任期号 |
| leaderId | 领导人的 Id,以便于跟随者重定向请求 |
| prevLogIndex | 新的日志条目紧随之前的索引值 |
| prevLogTerm | prevLogIndex 条目的任期号 |
| entries[] | 准备存储的日志条目(表示心跳时为空;一次性发送多个是为了提高效率) |
| leaderCommit | 领导人已经提交的日志的索引值 |
| 返回值 | 解释 |
|---|---|
| term | 当前的任期号,用于领导人去更新自己 |
| success | 跟随者包含了匹配上 prevLogIndex 和 prevLogTerm 的日志时为真 |
接收者实现:
term < currentTerm 就返回 falseleaderCommit > commitIndex,令 commitIndex 等于 leaderCommit 和 新日志条目索引值中较小的一个
图 1 :日志由有序序号标记的条目组成。
每个条目都包含创建时的任期号(图中框中的数字),和一个状态机需要执行的指令。
一个条目当可以安全的被应用到状态机中去的时候,就认为是可以提交了。
Raft 为了保证主从日志的一致性,有以下保证:
领导人 来决定什么时候把日志条目应用到状态机中是安全的;这种日志条目被称为已提交。
Raft 算法保证所有已提交的日志条目都是持久化的并且最终会被所有可用的状态机执行。
领导人 把指令作为一条新的日志添加到日志中后(此时还未 committed,即未应用到至 复制状态机),将并行的发送 附加日志 RPC 给 跟随者,希望他们复制这条日志。
当 领导人 收到大多数 追随者 返回正确响应,将会更新本地最大的且即将被提交的日志条目的索引
领导人 会追踪发送 3中提到的索引,并且这个索引会被包含在未来的所有附加日志 附加日志 RPC 请求中,这样就能保证其他的服务器知道 领导人 的索引提交位置。
追随者 知道一条日志已经被提交,那么他也会将这条日志应用到自己的状态机中(按照日志索引的顺序)。
如果在不同的日志中的两个条目拥有相同的 索引 和 任期号,那么他们存储了相同的指令。(Raft 在任何时候都保证的特性 —— 状态机安全特性)
如果在不同的日志中的两个条目拥有相同的 索引 和 任期号,那么他们之前的所有日志条目也全部相同。(领导人一致性检查)

图 2:当一个领导人成功当选时,跟随者可能是任何情况(a-f)。
每一个盒子表示是一个日志条目;里面的数字表示任期号。
跟随者可能会缺少一些日志条目(a-b),可能会有一些未被提交的日志条目(c-d),或者两种情况都存在(e-f)。
例如,场景 f 可能会这样发生,某服务器在任期 2 的时候是领导人,已附加了一些日志条目到自己的日志中,但在提交之前就崩溃了;
很快这个机器就被重启了,在任期 3 重新被选为领导人,并且又增加了一些日志条目到自己的日志中;
在任期 2 和任期 3 的日志被提交之前,这个服务器又宕机了,并且在接下来的几个任期里一直处于宕机状态。
在每个服务器会保存以下状态
| 状态 | 在领导人里经常改变的 (选举后重新初始化) |
|---|---|
| nextIndex[] | 对于每一个服务器,需要发送给他的下一个日志条目的索引值(初始化为领导人最后索引值加一) |
| matchIndex[] | 对于每一个服务器,已经复制给他的日志的最高索引值 |
对于领导人:
N > commitIndex的 N,并且大多数的matchIndex[i] ≥ N成立,并且log[N].term == currentTerm成立,那么令 commitIndex 等于这个 N保证复制日志相同是一致性算法的主要工作也是其核心
日志特性
状态机安全特性:如果一个领导人已经在给定的索引值位置的日志条目应用到状态机中,那么其他任何的服务器在这个索引位置不会提交一个不同的日志
领导人的一致性检查
大半年前在某脉上看到 一个蚂蚁金服大佬 发的这篇文章,前两天突然回想到,特此记录一下。
本文可以说是一篇转载文章(图是本人自己画的)。
说起应用分层,大部分人都会认为这个不是很简单嘛 就 controller,service,mapper 三层。
看起来简单,很多人其实并没有把他们职责划分开,在很多代码中,controller 做的逻辑比 service 还多,service 往往当成透传了,
这其实是很多人开发代码都没有注意到的地方,反正功能也能用,至于放哪无所谓呗。
这样往往造成后面代码无法复用,层级关系混乱,对后续代码的维护非常麻烦。
的确在这些人眼中分层只是一个形式,前辈们的代码这么写的,其他项目代码这么写的,那么我也这么跟着写。
但是在真正的团队开发中每个人的习惯都不同,写出来的代码必然带着自己的标签,有的人习惯 controller 写大量的业务逻辑,
有的人习惯在service中之间调用远程服务,这样就导致了每个人的开发代码风格完全不同,后续其他人修改的时候,
一看,我靠这个人写的代码和我平常的习惯完全不同,修改的时候到底是按着自己以前的习惯改,还是跟着前辈们走,
这又是个艰难的选择,选择一旦有偏差,你的后辈又维护你的代码的时候,恐怕就要骂人了。
所以一个好的应用分层需要具备以下几点:
方便后续代码进行维护扩展
分层的效果需要让整个团队都接受
各个层职责边界清晰
在阿里的编码规范中约束的分层如下:
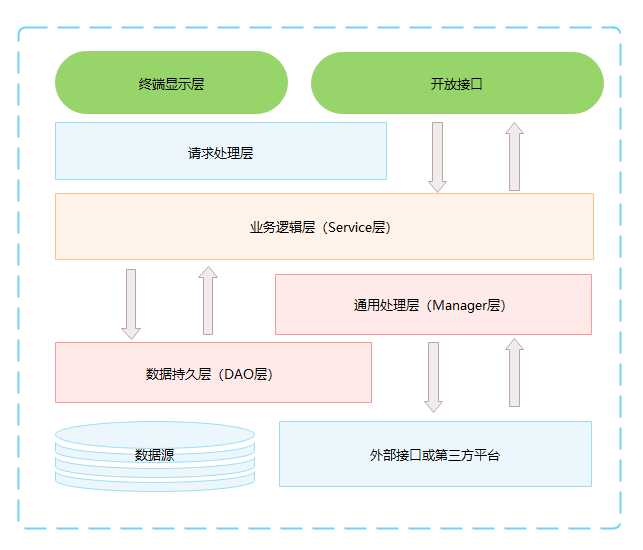
开放接口层:可直接封装 Service 方法包括成 RPC 接口;通过 Web 封装成 HTTP 接口;进行 网关安全控制、流量控制等。
终端显示层:各个端的模板渲染并执行显示的层。当前主要是 velocity 渲染,JS 渲染,JSP 渲染,移动端展示等。
Web 层:主要是对访问控制进行转发,各类基本参数校验,或者不复用的业务简单处理等。
Service 层:相对具体的业务逻辑服务层。
Manager 层:通用业务处理层,它有如下特征:
DAO 层:数据访问层,与底层 MySQL、Oracle、HBase 进行数据交互。
外部接口或第三方平台:包括其它部门 RPC 开放接口,基础平台,其它公司的 HTTP 接口。
阿里巴巴规约中的分层比较清晰简单明了,但是描述得还是过于简单了,
以及 Service 层 和 Manager 层 有很多同学还是有点分不清楚之间的关系,
就导致了很多项目中根本没有 Manager 层 的存在。下面介绍一下具体业务中应该如何实现分层
从我们的业务开发中总结了一个较为的理想模型,
这里要先说明一下由于我们的 rpc框架 选用的是 thrift 可能会比其他的一些 Rpc框架 例如 Dubbo 会多出一层,
作用和 controller 层 类似
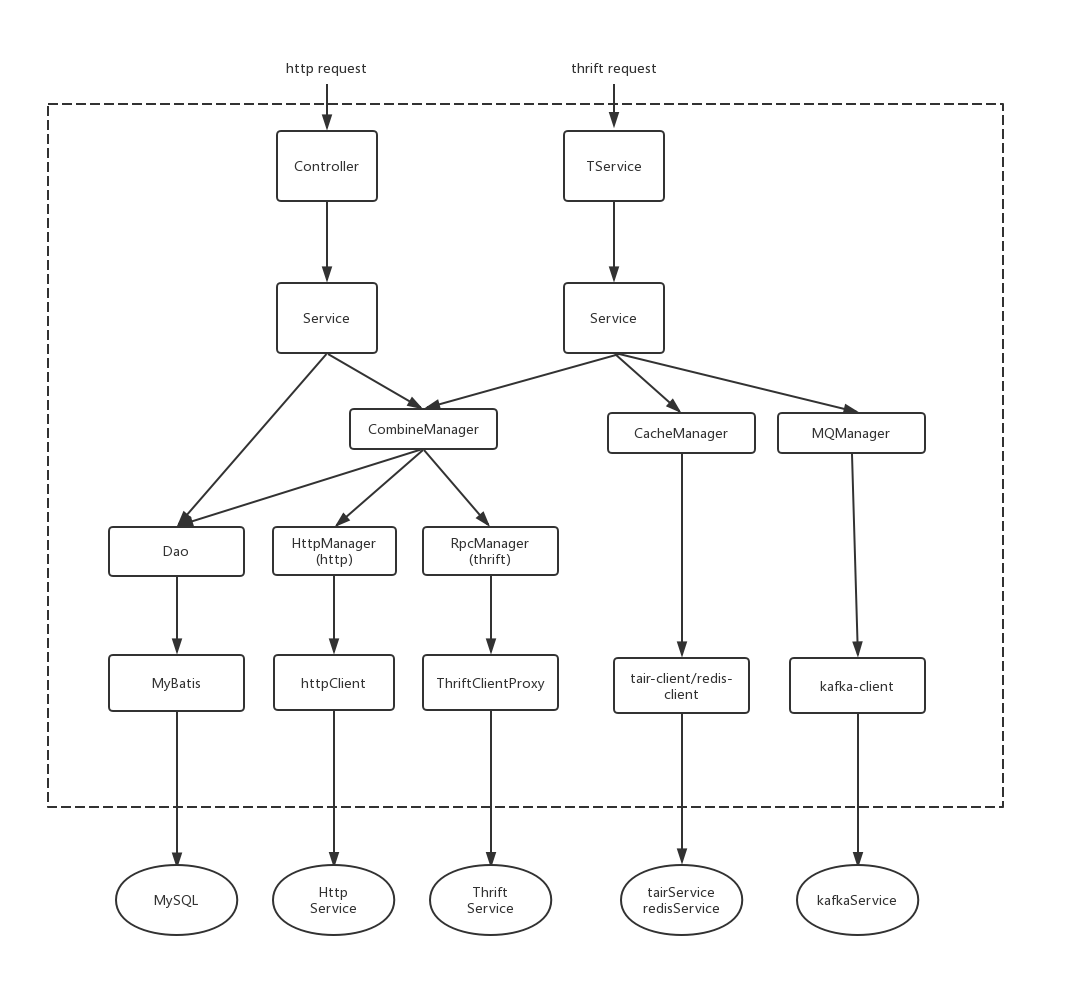
最上层 Controller 和 TService 是阿里分层规范里面的第一层:轻业务逻辑,参数校验,异常兜底。
通常这种接口可以轻易更换接口类型,所以业务逻辑必须要轻,甚至不做具体逻辑。
Service:
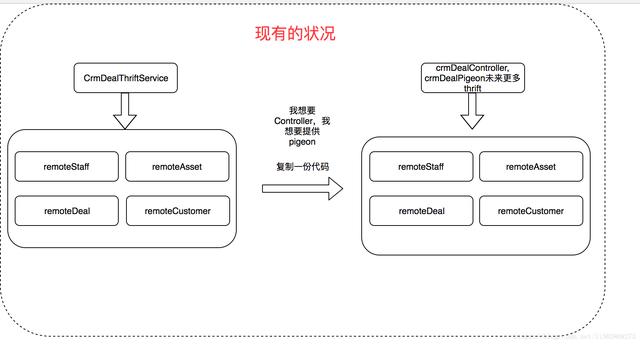
业务层,复用性较低,这里推荐每一个 Controller 方法都得对应一个 Service,
不要把业务编排放在 Controller 中去做,为什么呢?
如果我们把业务编排放在 Controller 层 去做的话,
如果以后我们要接入 thrift,我们这里又需要把业务编排在做一次,
这样会导致我们每接入一个入口层这个代码都得重新复制一份如下图所示:
这样大量的重复工作必定会导致我们开发效率下降,所以我们需要把业务编排逻辑都得放进 Service 中去做:
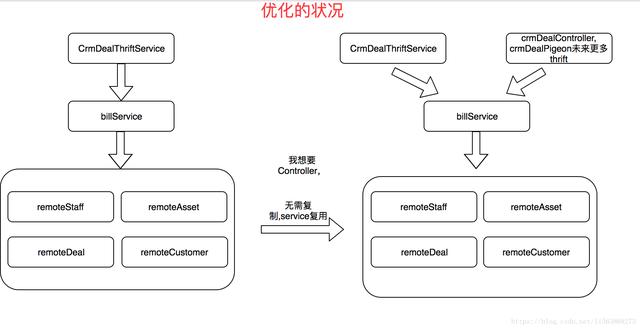
3.Manager:可复用逻辑层。这里的 Manager 可以是单个服务的,比如我们的 Cache,MQ 等等,
当然也可以是复合的,当你需要调用多个 Manager 的时候,这个可以合为一个 Manager,
比如逻辑上的连表查询等。如果是 httpManager 或 rpcManager 需要在这一层做一些数据转换
4.DAO:数据库访问层。主要负责“操作数据库的某张表,映射到某个 java对象”,
Dao 应该只允许自己的 Service 访问,其他 Service 要访问我的数据必须通过对应的 Service。
在阿里巴巴编码规约中列举了下面几个领域模型规约:
| 层次 | 领域模型 |
|---|---|
| Controller/TService | VO/DTO |
| Service/Manager | AO/BO |
每一个层基本都自己对应的领域模型,这样就导致了有些人过于追求每一层都是用自己的领域模型,
这样就导致了一个对象可能会出现 3次 甚至 4次 转换在一次请求中,当返回的时候同样也会出现 3-4次 转换,
这样有可能一次完整的请求-返回会出现很多次对象转换。如果在开发中真的按照这么来,恐怕就别写其他的了,
一天就光写这个重复无用的逻辑算了吧。
所以我们得采取一个折中的方案:
允许 Service/Manager 可以操作数据领域模型,对于这个层级来说,本来自己做的工作也是做的是业务逻辑处理和数据组装。
Controller/TService 层 的领域模型不允许传入 DAO 层,这样就不符合职责划分了。
同理,不允许DAO层的数据传入到 Controller/TService.
总的来说业务分层对于代码规范是比较重要,决定着以后的代码是否可复用,
是否职责清晰,边界清晰,所以搞清楚这一块也比较重要。
当然这种分层其实见仁见智,团队中的所有人的分层习惯也不同,所以很难权衡出一个标准的准则,
总的来说只要满足职责逻辑清晰,后续维护容易,就是好的分层。
Celery:分布式任务队列。
Celery 是基于分布式消息传递的异步任务队列/作业队列。它专注于实时操作,但也支持调度。
执行单元(称为任务)使用多处理,Eventlet 或 gevent 在单个或多个工作服务器上并发执行。任务可以异步(在后台)或同步执行(等到准备就绪)。
Celery 用于生产系统,每天处理数百万个任务。
Celery: Distributed Task Queue.
Celery is an asynchronous task queue/job queue based on distributed message passing.
It is focused on real-time operation, but supports scheduling as well.
The execution units, called tasks, are executed concurrently on a single or more worker servers using multiprocessing, Eventlet, or gevent.
Tasks can execute asynchronously (in the background) or synchronously (wait until ready).
Celery is used in production systems to process millions of tasks a day.
Basic
Python 库
首先 Celery app 初始化操作,参考Application。
其次要知道 app 配置添加方式,可以使用 app.config_from_object()。
|
`-- hackfun
|-- config
` -- config.yaml
|-- core
| -- __init__.py
` -- calc.py
|-- worker
| -- __init__.py
` -- task_handler.py
|-- __init__.py
|-- app.py
`-- celeryconfig.py
project_namespace: hackfun
celery:
app:
name: "Celery"
redis:
host: "127.0.0.1"
port: 6379
password: "123456"
celery_broker_db: 2
celery_result_db: 3
logging:
file: "/tmp/hackfun.log"
level: "INFO"
#!/usr/bin/env python
# -*- coding:utf-8 -*-
__Author__ = "HackFun"
__Date__ = "2019/6/20 4:37 PM"
# Build-in Modules
import os
# 3rd-party Modules
import yaml
# Project Modules
base_path = os.path.dirname(os.path.abspath(__file__))
config = {}
def init_config():
global config
path = os.environ.get('HACKFUN_CONFIG')
if path is None:
with open(base_path + "/config/config.yaml") as f:
config = yaml.load(f)
init_config()#!/usr/bin/env python
# -*- coding:utf-8 -*-
__Author__ = "HackFun"
__Date__ = "2019/6/20 4:37 PM"
# Build-in Modules
# 3rd-party Modules
from celery import Celery
# Project Modules
from hackfun import config
def init_celery_app(celery_config):
# redis
host = celery_config['redis']['host']
port = celery_config['redis']['port']
password = celery_config['redis']['password']
# celery
celery_broker_db = celery_config['redis']['celery_broker_db']
celery_result_db = celery_config['redis']['celery_result_db']
broker_url = f'redis://:{password}@{host}:{port}/{celery_broker_db}'
result_url = f'redis://:{password}@{host}:{port}/{celery_result_db}'
_app_celery = Celery(celery_config["name"])
_app_celery.conf.update(
dict(
broker_url=broker_url,
result_backend=result_url,
))
return _app_celery
app_celery = init_celery_app(config["celery"]["app"])
app_celery.config_from_object('hackfun.celeryconfig')#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Build-in Modules
import re
# 3rd-party Modules
from celery.schedules import crontab
from kombu import Queue
# Project Modules
from hackfun import config
def create_queue(queue_name):
return Queue(queue_name, routing_key=queue_name)
def get_worker_queue(name=None):
name = name or 'default'
queue_kw = dict(
projectName=config.get('project_namespace', 'hackfun'),
queueName=name,
)
# celery -A hackfun.app.app_celery worker -Q hackfun#workerQueue@default -c 1
return '{projectName}#workerQueue@{queueName}'.format(**queue_kw)
'''
Some fixed Celery configs
'''
# Worker
worker_concurrency = 5
worker_prefetch_multiplier = 1
worker_max_tasks_per_child = 50
# Worker log
worker_hijack_root_logger = False
worker_log_color = False
worker_redirect_stdouts = False
# Queue
task_default_queue = get_worker_queue('default')
task_default_routing_key = task_default_queue
task_queues = [
# 默认队列
create_queue(task_default_queue),
# webhook 任务队列
create_queue(get_worker_queue('webhook')),
# 内部调用异步任务队列
create_queue(get_worker_queue('internal')),
]
# Task
task_routes = {
# webhook 调用系统,单独任务队列
'webhook.*': {'queue': get_worker_queue('webhook')},
# 内部调用异步任务,放入相应队列
'internal.*': {'queue': get_worker_queue('internal')},
}
imports = [
]
# Beat
beat_schedule = {}
# Job serialization
task_serializer = 'json'
result_serializer = 'json'
accept_content = ['json']
# Time zone
enable_utc = True
timezone = 'Asia/Shanghai'
# ============= Content for YOUR project below =============
# Tasks
imports.append('hackfun.worker.task_handler')
imports.append('hackfun.worker.timed_task')
beat_schedule['issue_timed_task_issue_daily'] = {
'daily_task': {
'task': 'hackfun.worker.timed_task.issue_daily',
'schedule': crontab(minute="0", hour='10')
}
}所有 config 相应释义,参考官方文档 Configuration and defaults
值得注意的是 celeryconfig 中 imports ,此项容易被开发者遗漏,所有异步任务 python 模块都需要被导入(各位熟悉python,应该都懂的=。=),task_handler.py 和 timed_task.py 将在后文介绍
# Project Modules
from hackfun.app import app_celery
# 将会消费 internal.* 对应的 queue,即 get_worker_queue('internal')
@app_celery.task(name="internal.print", bind=True, base=BrokerTask)
def internal_print(self, message_body, *args, **kwargs):
"""
内部调用异步任务 handler
异步任务 print 方法
:param self:
:param message_body:
:param args:
:param kwargs:
:return:
"""
result = "internal_print"
print(message_body, *args, **kwargs)
return result
# 将会消费 webhook.* 对应的 queue,即 get_worker_queue('webhook')
@app_celery.task(name="webhook.print", bind=True, base=BrokerTask)
def webhook_print(self, message_body, *args, **kwargs):
"""
webhook 调用异步任务 handler
异步任务 print 方法
:param self:
:param message_body:
:param args:
:param kwargs:
:return:
"""
result = "webhook_print"
print(message_body, *args, **kwargs)
return result异步调用方
调用方式
.apply_async(args[, kwargs[, …]]) 例如:
internal_print.apply_async(
args=("internal_print_haha", "internal_print other args"),
kwargs=dict(a=1, b=2),
).apply_async(args[, kwargs[, …]]) 例如:
internal_print.delay(
"internal_print_haha", "internal_print other args",
a=1, b=2,
)详情参考官方文档 Calling Tasks
name="internal.print",意味着调用者,异步调用此方法,将被投放到 internal.* 对应 Queue
异步执行方
worker启动命令:celery -A hackfun.app.app_celery worker -Q hackfun#workerQueue@internal -c 4
-Q 代表指定 worker 消费的队列,队列名 请看 celeryconfig.get_worker_queue 方法;
-c :worker 并发进程数;
启动命令后:将会消费 internal.* 对应的 queue,即 get_worker_queue('internal')
将参数传递 internal_print(self, message_body, *args, **kwargs)
self: base=BrokerTask 对应基类的实例,BrokerTask源码
message_body, *args, **kwargs: 其他参数全部由调用方与执行方开发人员协调,自定义。
用例中:参数类型值将得到如下结果:
| 参数列表 | 类型 | 值 |
|---|---|---|
| message_body | str | "internal_print_haha" |
| args | tuple | ("internal_print other args", ) |
| kwargs | dict | dict(a=1, b=2) |
@app_celery.task(name="internal.print", bind=True, base=BrokerTask)
def internal_print(self, message_body, *args, **kwargs):
pass异步调用方
调用方式
internal_print.apply_async(
args=("internal_print_haha", "internal_print other args"),
kwargs=dict(a=1, b=2),
)internal_print.delay(
"internal_print_haha", "internal_print other args",
a=1, b=2,
)name="internal.print",意味着调用者,异步调用此方法,将被投放到 internal.* 对应 Queue
异步执行方
worker启动命令:celery -A hackfun.app.app_celery worker -Q hackfun#workerQueue@internal -c 4
启动命令后:将会消费 internal.* 对应的 queue,即 get_worker_queue('internal')
将参数传递 internal_print(self, message_body, *args, **kwargs)
self: base=BrokerTask 对应基类的实例,BrokerTask源码
message_body, *args, **kwargs: 其他参数全部由调用方与执行方开发人员协调,自定义。
用例中:参数类型值将得到如下结果:
| 参数列表 | 类型 | 值 |
|---|---|---|
| message_body | str | "internal_print_haha" |
| args | tuple | ("internal_print other args", ) |
| kwargs | dict | dict(a=1, b=2) |
@app_celery.task(name="webhook.print", bind=True, base=BrokerTask)
def webhook_print(self, message_body, *args, **kwargs):
pass异步调用方
调用方式
webhook_print.apply_async(
args=("webhook_print_haha", "webhook_print other args"),
kwargs=dict(a=3, b=4),
)webhook_print.delay(
"webhook_print_haha", " webhook_print other args",
a=3, b=4,
)name="webhook.print",意味着调用者,异步调用此方法,将被投放到 webhook.* 对应 Queue
异步执行方
worker启动命令:celery -A hackfun.app.app_celery worker -Q hackfun#workerQueue@webhook -c 4
启动命令后:将会消费 webhook.* 对应的 Queue,即 get_worker_queue('webhook')
将参数传递 webhook_print(self, message_body, *args, **kwargs)
self: base=BrokerTask 对应基类的实例,BrokerTask源码
message_body, *args, **kwargs: 其他参数全部由调用方与执行方开发人员协调,自定义。
用例中:参数类型值将得到如下结果:
| 参数列表 | 类型 | 值 |
|---|---|---|
| message_body | str | "webhook_print_haha" |
| args | tuple | ("webhook_print other args", ) |
| kwargs | dict | dict(a=3, b=4) |
worker启动命令:celery -A hackfun.app.app_celery worker -Q hackfun#workerQueue@webhook -c 4
更多 worker 启动命令参数,参考官方文档
对失败进行重试处理
任务投放(调用方)
如果连接失败,Celery 将自动重试发送消息,并且可以配置重试行为 - 例如重试频率或最大重试次数;- 或者一起禁用。
可以在调用时指定,投放失败是否重试:internal.apply_async((2, 2), retry=False)
详情参考官方文档 Message Sending Retry
任务执行(执行方)
可以在装饰器中指定 重试次数 以及 重试任务间隔:@app_celery.task(name="internal.print", bind=True, base=BrokerTask, default_retry_delay=30, max_retries=3)
max_retries = 3放弃前的最大重试次数。如果设置为None,它将永远不会停止重试。
default_retry_delay = 180应执行重试任务之前的默认时间(以秒为单位)。默认为3分钟。
重试详情,参考官方文档 Retrying
更多 @app.task() 参数,参考官方文档 celery.app.task
同时 装饰器中 base=BrokerTask 为基类,class BrokerTask(app_celery.Task): 继承自 app.Task
Celery 官方提供四种handle。详情:Handlers
after_return(self, status, retval, task_id, args, kwargs, einfo)
on_failure(self, exc, task_id, args, kwargs, einfo)
on_retry(self, exc, task_id, args, kwargs, einfo)
on_success(self, retval, task_id, args, kwargs)
BrokerTask 可以基于app.Task 的 Handlers
实现自定义功能。例如,任务执行:
重试时,做一些日志打印
错误时,是否可以考虑持久化错误任务,后续排查;或者放入一个类似 DLQ(之所以,说类似 DLQ;是因为,严格意义上 DLQ 可能不太恰当,篇幅有限不再赘述:) wiki解释:Dead letter queue) 的地方等;
成功,可以做一些结果持久化/事件通知等。
内存泄漏问题
Celery 有可能发生内存泄露,可以像这样设置:CELERYD_MAX_TASKS_PER_CHILD = 40 # 每个worker执行了多少任务就会死掉
worker_max_tasks_per_child 配置项,往 celeryconfig.py 文件里,像其他选项一样,添加即可。
相关配置项详情,参考官方文档:worker_max_tasks_per_child
对失败任务处理
内存泄漏问题,不可忽视
Celery 是比较强大的异步任务框架,遇到问题时,多看官方文档,以及在开源社区的提问(相信大多数问题已经有人提问,且有合理的解答);这真的非常重要。
定时任务忘记写了,后续有空补一下 -:)
timedelta
crontab
相关文档

18年毕业,17年11月份出去实习+转正至今(马马虎虎算一年经验了吧=。=)。
某C轮小厂,做 Python开发工程师。(工作制:965,算时薪比的话还是相当可观的,手动滑稽: ))
目前薪资:正常价格,你懂得!
对方规模不能太小,起码不能比我司还低吧
薪资:package 25w(按 base * 12 算的,说白了就是 20k左右/月,这是猎头提议的:低了没必要跳槽)
其他,貌似除了薪资其他的也没啥好说的?
题外话: 这个是直接告知到对方公司的,作为参考
我提交的附件,在另外一个仓库里:MyBlog-py3/parse
包括问题描述(PS:除了 README 里面的问题描述部分,其他都是自己写的)。
通过。猎头说推了四个,我一个人过了(我也是奇怪,题目本身貌似没难度;是我文档写的太好了么=。=)
现场面试:2轮技术面+HR面(2019年5月27日下午兩點开始)
我重点说的 【ScanEngine】 ,这个从设计到实现基本我一个人搞定的,除了脚本部分编写。
题外话
这个项目是我公司项目,仓库里面放的是终极精简版本(连README都没有,不是我风格呀 :-)),后续有机会完善一下。
MyISAM 与 InnoDB 关于锁方面的区别
索引管理
锁管理
题外话:
设计:
基本答得可以,就问了三个问题,聊的时间蛮长的。
可能主要是自己项目占用时间比较多,才会让后面直接进入主题的吧。
前两个问题基本是我再说,聊得算是不错;最后一个问题,我给了个思路,然后面试官问一下细节,不是最优方案,但还凑合,大部分设计算是合理。
总体来说,这一面感觉就是,如果能让面试官对你的项目感兴趣,那么你基本这轮面试就成功了,因为大部分都在谈你熟悉的东西,让你很容易发挥。
第一次尝试
思考阶段
交流过程
第二次尝试
思考阶段
交流过程
第三次尝试
思考阶段
没有机会说了
了解 Proxy 机制吗?它的包与普通的包有什么区别?
只说了表面的问题,扯了正向代理、反向代理,然后从网络分区相关点去回答,但是他貌似希望让我细聊整个 HTTP 协议细节相关,这个后续需要总结了
简单查了一下:HTTP 1.1 以后相关
HTTP 与 HTTPS 的 区别?
HTTPS 如何做到保密的?
整个流程说一下?
如何信任 CA 什么的等等
确实 HTTPS 问的非常细节。我只说了大致流程,细节部分基本答得不好(有点胡说的意味),并且被发现明显是来面试前随便看了一下,没仔细钻研的(挂的导火索=。=)
二面总的来说,答得不满意。
一个简单的算法问题,也答得不好;而后面几个问题问的 HTTP/HTTPS 相关的知识(然而我确实只是来前随便看了两眼),之前没有琢磨。
老实说:下层协议个人真心挺自信的(来自看完 《TCP/IP 详解 卷一》的自信),基本很多都 真的动手操作过(之前在学校网络安全玩的)。
不多说了,下一步直接把 RFC文档 翻出来,常用协议全部再看一遍,再用一下许久不用的 wireshark。
两点面到四点半,还是有所收获的。
总的来说,问的东西并不深奥,基本都是需要掌握的。
几乎没有问任何语言相关基础;本次是毕业后的第一次面试,体验还算行,这种面试节奏是我喜欢的,这次准备不够充分,以后继续努力。
本次关键:
心里因素,多少有一些,以后多面试,继续调整就好了。
二面面试官,连续三个问题答的都有瑕疵。最后问题更是直接暴露,对问题本身回答的不上心,没自己动手过的,然后用看到的表面理论乱说。(本人自己都看不下去)
不会直接过就好了,记住似懂非懂等于不懂(当然可能面试官有可能就是想考察这个点,直接过也有可能存在挂的风险,看情况吧)。
自己太菜呀,继续加油:-)
本文介绍 HTTPS 如何做到安全,所有相关名词解释均来自 维基百科,后续引用就不在每次赘述了。
HTTP 的 URL 是由 “http://” 起始与默认使用 端口 80,而 HTTPS 的 URL 则是由 “https://” 起始与默认使用 端口 443。
HTTP 不是安全的,而且攻击者可以通过 嗅探 和 中间人攻击 等手段,获取网站帐户和敏感信息等。
HTTPS 的设计可以防止前述攻击,在正确配置时是安全的。
那么 HTTPS 为什么安全呢,密码学保证?证书又是什么?
引自 Wiki:
超文本传输安全协议(英语:HyperText Transfer Protocol Secure,缩写:HTTPS;
常称为HTTP over TLS、HTTP over SSL或HTTP Secure)是一种通过计算机网络进行安全通信的传输协议。
HTTPS经由HTTP进行通信,但利用SSL/TLS来加密数据包。
HTTPS开发的主要目的,是提供对网站服务器的身份认证,保护交换数据的隐私与完整性。
这个协议由网景公司(Netscape)在1994年首次提出,随后扩展到互联网上。
HTTP HTTPS
+------------+ +-----------+
| | | HTTP |
| HTTP | | |
| | +-----------+
+------------+ |SSL or TLS |
| | | |
| TCP | +-----------+
| | | TCP |
+------------+ | |
| | +-----------+
| IP | | IP |
| | | |
+------------+ +-----------+
如果任何人使用公钥加密明文,得到的密文可以透过不安全的途径(如网络)发送,只有对应的私钥持有者才可以解密得到明文;
其他人即使从网络上窃取到密文及加密公钥,也无法(在数以年计的合理时间内)解密得出明文。
典型例子是在网络银行或购物网站上,因为客户需要输入敏感消息,浏览器连接时使用网站服务器提供的公钥加密并上传数据,
可保证只有信任的网站服务器才能解密得知消息,不必担心敏感个人信息因为在网络上传送而被窃取。
对称密钥算法(英语:Symmetric-key algorithm)又称为对称加密、私钥加密、共享密钥加密,是密码学中的一类加密算法。
这类算法在加密和解密时使用相同的密钥,或是使用两个可以简单地相互推算的密钥。
事实上,这组密钥成为在两个或多个成员间的共同秘密,以便维持专属的通信联系。
与公开密钥加密相比,要求双方获取相同的密钥是对称密钥加密的主要缺点之一。
常见的对称加密算法有 DES、3DES、AES、Blowfish、IDEA、RC5、RC6。
对称加密的速度比公钥加密快很多,在很多场合都需要对称加密。
公开密钥密码学(英语:Public-key cryptography,也称非对称式密码学)是密码学的一种算法,
它需要两个密钥,一个是公开密钥,另一个是私有密钥;一个用作加密,另一个则用作解密。
使用其中一个密钥把明文加密后所得的密文,只能用相对应的另一个密钥才能解密得到原本的明文;
甚至连最初用来加密的密钥也不能用作解密。由于加密和解密需要两个不同的密钥,故被称为非对称加密;
不同于加密和解密都使用同一个密钥的对称加密。
虽然两个密钥在数学上相关,但如果知道了其中一个,并不能凭此计算出另外一个;
因此其中一个可以公开,称为公钥,任意向外发布;
不公开的密钥为私钥,必须由用户自行严格秘密保管,绝不透过任何途径向任何人提供,也不会透露给被信任的要通信的另一方。
基于公开密钥加密的特性,它还提供数字签名的功能,使电子文件可以得到如同在纸本文件上亲笔签署的效果。
公开密钥基础建设透过信任数字证书认证机构的根证书、及其使用公开密钥加密作数字签名核发的公开密钥认证,形成信任链架构,
已在TLS实现并在万维网的HTTP以HTTPS、在电子邮件的SMTP以STARTTLS引入。
另一方面,信任网络则采用去中心化的概念,取代了依赖数字证书认证机构的公钥基础设施,
因为每一张电子证书在信任链中最终只由一个根证书授权信任,信任网络的公钥则可以累积多个用户的信任。
PGP就是其中一个例子。
在现实世界上可作比拟的例子是,一个传统保管箱,开门和关门都是使用同一条钥匙,这是对称加密;
而一个公开的邮箱,投递口是任何人都可以寄信进去的,这可视为公钥;而只有信箱主人拥有钥匙可以打开信箱,这就视为私钥。
数字证书认证机构(英语:Certificate Authority,缩写为CA),也称为电子商务认证中心、电子商务认证授权机构,
是负责发放和管理数字证书的权威机构,并作为电子商务交易中受信任的第三方,承担公钥体系中公钥的合法性检验的责任。
证书实际是由证书签证机关(CA)签发的对用户的公钥的认证。
证书的内容包括:电子签证机关的信息、公钥用户信息、公钥、权威机构的签字和有效期等等。
当前,证书的格式和验证方法普遍遵循 X.509 国际标准。
加密:ca认证将文字转换成不能直接阅读的形式(即密文)的过程称为加密。
解密:将密文转换成能够直接阅读的文字(即明文)的过程称为解密。
如打算在电子文档上实现签名的目的,可使用数字签名。RSA公钥体制可实现对数字信息的数字签名,方法如下:
信息发送者用其私钥对从所传报文中提取出的特征数据(或称数字指纹)进行RSA算法操作,以保证发信人无法抵赖曾发过该信息(即不可抵赖性),同时也确保信息报文在传递过程中未被篡改(即完整性)。当信息接收者收到报文后,就可以用发送者的公钥对数字签名进行验证。
在数字签名中有重要作用的数字指纹是通过一类特殊的散列函数(HASH函数)生成的。对这些HASH函数的特殊要求是:
用一个证书来证明另一个证书是可信的,例如 C 机构公章和 A 机构公章在同一张介绍信上,注明公章 C 信任公章 A,A 也是可信的。
简单说,信任关系是可以传递的,只要你信任头一个证书,后续的证书都是可以信任的。
C 信任 A,A 信任 A1,A1 信任 A2,A、A1、A2 都是可信任的。
在密码学和计算机安全领域,根证书(root certificate)是属于根证书颁发机构(CA)的公钥证书,是在公开密钥基础建设中,信任链的起点。
在证书的信任链中,A1 可以由 A 证明可信任,A 由 C 证明可信任,C 由谁证明可信任呢?
C 不需要证明自己是可信任的,因为它是权威机构,这就是根证书(处于树结构的顶端)。
由于根证书在信任链中的重要角色,一旦证书机构的私钥外泄,将可能导致整个信任链被摧毁,影响广及众多客户,
所以认证机构会使用各种方法保护根证书,例如硬件安全模块。
防止 浏览器 与 服务端 数据传输时被 中间人攻击,
若暂不理解 HTTPS 为什么需要 证书机制,请先看下文 HTTPS 过程详解。
服务端和浏览器之间要实现安全的密钥交换该如何实现?
如果单纯使用对象加密算法,服务端与浏览器必须要交换密钥,密钥直接用明文传输很容易被窃取,无法保证密钥的安全性。
服务端 基于非对称加密算法随机生成一堆密钥对 x,y,目前算很安全,只有服务端知道
服务端把 x 留在本地,把 y 用明文传输到 浏览器(y可能被窃取)
浏览器拿到 y 后,先随机生成第三个对称加密的密钥 z,然后用 y 加密 z 得到最新的 f
(本质上就是用非对称加密 保证 对称加密的安全性),将 f 发送到 服务端(因为 x, y 是成对的,
只用 x 才能解密 y 加密的结果,所以 y 泄露也无法解密 k)
服务端 拿到 f 之后,用 x 解密得到 z,至此 浏览器 和 服务端 都有对称加密的密钥 z,可以进行通信加密。
思考一下,方案二 是否 安全 和 完美?
实际上,方案二可以在一定程度上防止 嗅探,但无法防范 网络数据修改(中间人攻击)。
在 服务端 和 浏览器 交换密钥的过程中,中间人接收网站发送的 密钥 y 保存下来,改用自己生成的密钥;
伪造成 服务端 与 浏览器 交互,同时使用密钥 y 伪造成 浏览器 与 服务端交互。
方案二 不安全的根源是缺乏可靠的身份认证,浏览器 无法鉴别自己受到的密钥是不是来自 真正的 服务端。
因此需要引入 CA证书机制(身份认证),基于 CA证书 进行密钥交换(具体 CA机制可查看介绍 CA相关文章)。
此时得到方案三。
服务端 首先花钱从 权威CA 机构购买一个数字证书,证书通常包含一个私钥和一个公钥证书文件
浏览器 访问 服务端 时将公钥证书文件发送给 浏览器
浏览器 验证收到的证书(权威机构担保真假,主流 浏览器 和 操作系统 都会内置权威 CA机构 的根证书)
如果证书科学,就随机生成一个对称加密密钥 k,使用公钥加密 k,得到密钥 c
将密钥 c 发送给 服务端,服务端 根据私钥解密出 密钥 k,至此密钥交换完成。
这就是 HTTPS 加密传输的过程。
了解 HTTPS 机制,你需要了解
对称加密与非对称加密
CA 证书机制
本质上就是,在第一次交换密钥时,用 非对称加密 保证 对称加密 的安全性。
在交换密钥时,使用 非对称加密 算法;之后交互过程,使用 对称加密 算法。
希望自己的面经能给朋友们,一点点提示,也是对自己的一份总结报告。
若您对以下内容存在意见或建议,可以随时提 Issue 沟通交流。
从面试的公司也看的出来比较真实了;本人并非大佬,贵在真实。
求职过程:全部通过 Boss 投递,没找猎头,也没有内推。老实说刚满 1年,也不太好找人推。。。
18年某普本毕业,17年11月份出去实习+转正至今(马马虎虎算一年经验了吧=。=)。
目前(工作制:965,算时薪比的话还是相当可观的,手动滑稽: )
以下是这段时间,本人求职过程,公司投递以及offer情况,大致能想到的就这些,投递每家公司的JD都有贴出来。(意向岗位:golang 开发工程师)
全部通过 Boss 投递,没找猎头,也没有内推。老实说刚满 1年,不太好意思找人推。。。
地点:上海
PS:1000人以下的企业,简历挂的就没统计了,因为自己毕业一年,会尝试投一些小公司 3-5、5-10 年岗;
因此可能还是有一些数量的,没有什么实际价值,就不一一写了。
0-100 人
100-1000 人
1000人以上
【兑观信息科技技术】—— Golang 工程师(数据处理)
基础部分
其他
多系统间 rpc 来回调用问题
多链路排错(时延、异常等),全链路追踪吧
多版本依赖包管理:A依赖B、C.1;B依赖C.2,版本强依赖,如何解决
一个接口希望内部接口调用不用做验证、外部接口调用(不用摘要或加密认证;不用 IP 段白名单)
MySQL 两个进程
HTTP 如何保持长连接
负载均衡算法和健康检查算法
【晓信】—— Golang工程师(方向:toC、数据处理)
说一下进程、线程与协程
说一下用户态线程
进程间通信
用户态和内核态有什么区别
MySQL 索引有哪些
什么是缺页中断
B+ 树优势
LRU 算法如何实现
redis 的淘汰算法(redis的LRU并的非我们使用我们所实现的那种,淘汰略有偏差,但总体合理。见官方网文档: https://redis.io/topics/lru-cache)
说一下 Raft (领导人选举+日志复制 说了一遍)
ISO 七层协议(我说比较了解 TCP/IP 四层)
四层也可以讲一遍(从上到下说了一遍)
说一下 ARP 协议,有什么用
大文件处理:日志处理。(答: Golang channel: ReadLogLineByLineChan -> CountChan -> 结果持久化)
对微服务的理解?
docker 了解多少
【亿鼎云】 —— golang开发工程师(DevOps 方向)
一轮技术面
MySQL 有哪些索引?
唯一索引和普通索引有什么区别?插入、删除?
说一下 Raft(Leader 选举 + 日志复制;实际 basic raft paper 是有问题的,但是这个时候我还没接触过)
举了几个 Basic Raft 未解决的异常情况,问我如何解决。
说一下 我的 ScanEngine 项目,和之前差不多(某不知名小厂面经系列 - 1)
一般用什么做系统间通信。
我们现在常用的是 redis,也会用到 kafka。
如果让你不使用第三方(redis、kafka 等这些),那么你会怎么做?(答:以文件的方式,直接往磁盘写数据)
总监面
说一下 我的 ScanEngine 项目
和之前差不多(某不知名小厂面经系列 - 1)
问了更多细节,包括使用的 框架,以及思路。
因为使用的是 Python 的 Celery 框架,因此总监还问了一句,假设我们要用那么我们还需要考虑学习成本是吗?
最后,你觉得你的项目是否还有不足的地方?
你网络这块了解还挺好的吧?(还可以吧)
两个主机通过交换机,ping 一下;说一下整个过程。(二层)
比较两个网络拓扑图A、B,可能存在 A比B多一些节点。也可能存在 A与B中相同节点,配置不相同。输出:以及多出的节点以及配置不同节点。
人事主管
自己有什么优缺点
为什么离职
其他
结果:挂了。(HR回复:几个面试官综合讨论了一下,可能目前和我们的岗位需求不是非常匹配,很抱歉,这次没有机会做同事了[皱眉])
【Innotech】—— Golang工程师(业务线:萌推;电商)
一轮电话面
给我一条SQL 语句,问我哪个用到了索引(考点:最左匹配原则)
简单讲一下你的 分布式任务调度系统
给一个缓存的场景,如何处理(大概就是想问:先删缓存再更新DB,还是先更新DB再删缓存)
现场技术面
自我介绍
说一下 raft。(Leader 选举 + 日志复制)
raft **有融入到自己的系统中吗?(答:暂时没用过,但我热爱研究,其实 basic raft 是存在一些问题的嘛,我也会在开源社区做一些探讨。巴拉巴拉说了一堆。。。转移话题大法=。=)
看你做了个 爬虫-搜索引擎 项目,这里面 随机IP代理 怎么实现的?
HTTP 协议了解多少,可以简单描述一下 包结构嘛?
说一下 你知道的 HTTP Header?
重定向如何实现的?
讲一下 HTTPS
写道算法题吧。
设计个 视频弹幕系统,接口设计+请求流程+弹幕存储?所有过程随意发挥。
本人的回答,后续会贴到我的仓库 github/blog,感兴趣的可以追一下
个人意愿是非常想去今日头条
自己转 Golang 技术栈也有部分原因是因为这个(我们常说语言是次要的,重要的是工程设计**;不过对 title 较低的人来说,语言契合度比较高,那应该最好不过了)
奈何自从校招给过面试机会外,毕业至今已经投过两次,结果简历均未通过。
本打算年底去头条再试一次,谁知 头条HR 在 BOSS 上,主动找我;我一个没忍住就又投了。结果呢,如上文中描述,简历又挂了;
哎,近期内可能暂时就别想进了;期待好心人,能给我捞起来=.=。。。
PS:可能有大佬会说,头条有啥好的,又是大小周/压力也不小什么的。这玩意看个人吧;有取舍,说也说不清楚,各位大佬们也没必要和小弟纠结这个问题,哈哈。
自己对比打听了一下几个 offer,接了:Innotech
目前是打算接了 Innotech 的 offer,电商是我比较感兴趣的方向;刚好薪资待遇也符合目前期望
我也从侧面打听过,萌推 现在是他们内部评分算是比较高的
砸钱也确实比较狠,不管是招人给推荐奖金,还是薪资待遇,都算是可劲砸的那种(据某被内推的3年左右经验,资深title 的老哥说:内推只要去面试就 1000 内推奖金;候选人入职再给:8000)
和HR讨论了一下,一年算下来总包,应该拿个 16 薪左右,即使被忽悠我也开心=。=,毕竟比现在涨幅还是有一些的(现在15k以下 * 14)
电商业务,对技术及业务理解度相对会有挑战,同时也是快速提升个人能力的机会
给同为应聘者朋友们一些建议,也是自身感受
校招
若盆友你仍未毕业且符合校招条件,那么请立即往各个大厂实习岗投递简历;否则在毕业后的三年内,考虑进入大厂将会变得相当困难,除非真的非常非常优秀(技术岗)
基础很重要,很多校招面经都有所提到;此次主题还是社招,就不再赘述了
1-3 年社招
一般大多数公司(不包括头条)
基本不会问太多算法基础,应付面试 LeetCode 上面刷百来道基本够用
对简历上写的所有点,都应该掌握
如果觉得自己其他方面不够出色,那么打牢基础好了
对自己使用的开源应用或工具应当深入研究
网络:
操作系统:应付面试的话,看《现代操作系统》那本,把下面三章看完,基本够用
算法基础:如前面所说,LeetCode 上刷个百来道
其他基础自由发挥,尽情展现
可能有人问,假如面试官不问,是不是就亏了
社招的话,可能相对更看重工程设计能力
剩下没想到的,后续若有我会补充至此;目前,请朋友们自行补充
这一段时间,面试结果
可能 offer 质量并不是说非常高,但是起码这个结果,在自己这里算是基本过了关的
从投递结果来看
客观原因:自己的履历确实不怎么精彩,没法打动多数大厂的面试官(自己太菜)
有打听过一些其他原因
未来考虑在努力完善自身经历的情况下,也尝试通过:内推+猎头推 的方式寻求机会
祝各位朋友能有自己的方式获得更多面试机会 : )
考虑接下来这两年就在这家努力奋斗了,之后再去试一下 头条或者其他一线类大厂。就是有这么个大厂的心节=。=,咱也不用问,您可能也不想问
朝这个目标去,起码不会出什么大错嘛;即使后面想法改变了,那也肯定是因为有了更优选;因此,目前奔着实现这个目标走走看了。
最后,可爱的盆友们,人生不易;你我都加油啦!!!哈哈 : )
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.