a simple tutorial for bagging and RF
이 repository는 ensemble learning, 그 중에서도 bagging과 random forest을 처음 접해보신 분들을 위해 작성되었습니다. 이에 따라 내용을 ensemble learning에 대한 개념적인 overview, bagging과 random forest에 대한 소개와 설명, 그리고 이를 파이썬으로 직접 실습해보는 순서로 구성하였습니다. 그리고 이 repository의 이론적인 토대는 첨부드린 논문과 고려대학교 강필성 교수님의 유튜브 강의를 참고하였음을 밝힙니다.
Ensemble learning은 기존의 머신러닝 방법론에 기반한 모델들의 inference 결과를 활용하여 종합적 판단을 내리는 머신러닝 기법을 말합니다. 예를 들어, 간단한 수준의 이진 분류 머신러닝 모델이 있다고 합시다. 정확도가 한 0.6 정도 나오는 거죠. 그런데 이러한 모델을 한 100개정도 활용한다고 했을 때, 51개 이상의 모델이 정답을 맞출 확률은
Fernández-Delgado et al. (2014)의 연구 및 실제 연구사례, 그리고 2016년에 개최된 MLconf SF에 따르면, 머신러닝 계열의 모델 중에서는 하나의 모델을 활용하는 것에 비해 앙상블 계열의 모델을 활용하는 것이 더 우수한 성능을 보일 가능성이 높으며, 이는 수학적으로도 어느 정도 증명되어 있습니다(자세한 내용은 앞서 언급드린 유튜브 강의를 참고해주시면 감사하겠습니다). 해당 증명에 따르면, 앙상블에 의한 오류의 기댓값은 각 개별 모델의 에러의 평균보다 낮으므로, 평균적으로(통계적인 의미에서) 앙상블이 우수한 성능을 보일 수 있는 것이죠. 식으로 나타내면 아래와 같겠습니다.
앞서 살펴보았던 앙상블의 개념에서 중요한 키워드는 다양한 모델, 그리고 종합입니다. 그리고 그 중에서 조금 더 중요한 것은 다양한 모델 쪽이죠. 각각의 의미를 조금 더 깊게 파고들어보겠습니다. 우선 앙상블에 사용되는 각 개별 모델은 다양해야 합니다. 쉽게 말해 동일한 추론 결과를 내면 안됩니다. 앞서 살펴보았던 정확도가 0.6인 모델의 앙상블의 예시로 돌아가 보았을 때, 각 모델이 모두 동일한 추론 결과를 낸다면, 모델이 오분류하는 객체가 모두 동일하기 때문에 사실상 하나의 모델을 사용하는 것과 다름이 없을 것입니다. 결과적으로 앙상블에 사용하는 모델들은 각각 서로 달라야하는 것이죠. 더불어, 앙상블에 활용되는 각 개별 모델들의 결과는 잘 종합되어야 합니다. 다시 아까 정확도가 0.6인 모델의 앙상블의 예시로 돌아가자면, 그 예시에서는 각 모델들의 추론 결과의 종합을 추론 결과들의 과반수에 해당하는 추론 결과를 사용함으로써 수행한다고 볼 수 있겠죠.

앙상블에서 모델의 다양성이 매우 중요하기 때문에, 방법론의 갈래를 나눌 때에도 어떻게 모델의 다양성을 확보하느냐에 따라 나누는 것이 일반적. 크게 bagging 계열과 boosting 계열로 나눌 수 있는데, 각각의 특징을 요약하자면, bagging의 경우 데이터셋의 조작을 통해 모델이 다양해지도록 "유도"한다면, boosting의 경우 base learner의 예측 결과를 반영하여 데이터셋 내지는 예측변수를 변경하여 보다 확실하게 모델이 달라지도록 만들어냅니다. 그리고 이러한 다양성 확보 방법의 차이로 인해 bagging의 경우 각 base learner 학습 및 inference가 parallel하게 이뤄질 수 있다는 점, 그리고 variance가 줄어든다는 점이 주된 특징이 되며, boosting의 경우 base learner 학습이 순서대로 진행되고 bias를 줄이는 방향으로 학습이 이뤄진다는 점이 주된 특징이 됩니다. 표로 정리하면 아래와 같습니다.
| 방법론 계열 | 특징 | 예시 |
|---|---|---|
| bagging | 데이터셋 sampling 및 조작을 통해 base learner를 학습하므로, 병렬 처리가 가능하며(때문에 속도가 빠름) variance가 줄어듦. | Bagging, Random Forest |
| boosting | base learner의 학습 결과를 바탕으로 데이터셋이나 예측변수를 변경하므로, 병렬처리가 불가능하며 bias가 줄어듦. | AdaBoost, Gradient Boosting |
여기까지 ensemble learning에 대한 주요 개념들을 개략적으로 살펴보았습니다.
설명할 알고리즘은 다양한 알고리즘 중 bagging 계열의 두 가지 알고리즘인 bagging과 random forest입니다. 우선 bagging 부터 살펴보겠습니다.
앞서 설명한 bagging은 bagging 계열의 방법론을 통틀어 설명하기 위해 사용한 용어이고, 여기서부터 설명할 bagging은 bagging 계열 방법론 중 대표가 되는 방법론을 지칭하는 것으로, 데이터 셋을 객체 sampling을 통해 조작하여 base learner를 학습시키는 방법론을 말합니다. 그리고 여기서 객체 sampling을 진행하는 방법은 주로 bootstrapping, 즉 복원 추출입니다. 그리고 그 bootstrap을 통해 base learner를 학습시키고, 학습된 base learner의 inference 결과를 aggregation(종합)하여 unseen data, 즉 test data에 대한 inference를 수행합니다. 아래 그림과 같이 말이죠.

그런데 위 그림을 보다보면 data split을 train과 test로만 진행했기 때문에 bagging에서는 validation은 안하나 싶은 의문이 생기실 수 있습니다. Bagging에서는 validation set을 따로 나누어 validation을 수행하기보다는 OOB(Out-Of-Bag) error라 하여 base learner를 만드는 것에 포함되지 않은 sample을 대상으로 각 base learner의 validation error를 측정합니다. 이러한 방식은 random forest에서도 동일하게 적용됩니다.
Bagging에서 중요한 점은 sampling을 통해 base learner를 학습시키고 그 결과를 종합한다는 것이 전부입니다. 때문에 어떤 식으로 sampling을 할지, base learner로 무엇을 사용할지, base learner의 결과를 어떻게 종합하는지는 사실 많이 쓰이는 방법이 있을 뿐 정답은 없습니다. 일반적으로 sampling 기법의 경우 bootstraping을 사용하지만 비복원추출을 할 수도 있습니다. 그리고 base leaner의 경우, 일반적으로 complexity가 낮은 종류의 알고리즘을 활용하는 경향이 있습니다. 마지막으로 base learner의 aggregation을 위해서 앙상블 모델이 해결하는 task가 classification인지 regression인지에 따라 다릅니다만 우선 classification을 위한 모델의 경우를 위주로 설명하자면, base learner의 과반수 이상이 선택한 결과를 선택하는 majority voting 방식, base learner의 training 성능이 높은 경우의 prediction 결과에 더 높은 가중치를 두는 방식의 weighted voting 방식, 그리고 base leaner들의 prediction 결과를 input으로 하는 새로운 model을 활용하는 stacking 방식이 있습니다. 이러한 것들은 일종의 bagging에서의 hyper-parameter와 같은 것으로, 알고리즘의 사용자가 task 결과에 맞춰 tuning 해줘야 합니다.
Random forest를 한 문장으로 요약하면 'decision tree가 base learner이고 매 분기마다 변수선택을 수행하는 bagging'입니다. Base learner를 decision tree로 사용하기 때문에 decision node split을 수행해야 하는데, 원래의 decision tree에서는 분기를 수행하기 위해 모든 변수를 탐색하지만 random forest의 base learner의 경우 분기를 수행하기 위해 변수를 선택하여 탐색합니다. 그림을 보면 아래와 같겠죠.

원리는 크게 bagging과 다르지 않지만, random forest에서는 몇가지 더 살펴볼 만한 부분이 있습니다. 우선 살펴볼 부분은 왜 base learner로 사용되는 decision tree에 변수를 제한한 split을 수행하냐는 부분입니다. 이는 앙상블 모델과 decision tree의 원리에 깊은 관련이 있습니다. 앙상블 모델의 base learner는 일반적으로 complexity가 낮은 모델을 사용합니다. Decision tree의 기준으로 complexity가 낮다는 것은 split을 많이 하지 않는다는 것을 의미합니다. 그리고 decision tree의 split은 변수 중 information gain을 비롯한 split 이후 node의 impurity를 낮추는 변수를 선택하여 진행됩니다. 결국 split을 많이 하지 않는 decision tree는 만약 몇 가지 변수가 다른 변수에 비해 뛰어난 성능을 가지고 있다면, 아무리 샘플링을 다르게 하더라도 비슷한 decision tree의 분류 로직을 만들게 될 것입니다. 이는 앙상블 모델의 base learner 들의 다양성이 낮아지게 만들게 되는 결과로 이어집니다. 이 때문에 random forest에서는 split을 변수를 제한한 상태에서 진행함으로써 변수를 제한하지 않는 경우에 비해 더 다양한 종류의
두번째로 random forest에서 살펴볼 부분은 일반화 오차(generalization error)에 대한 부분입니다. 앙상블에 활용하는 base learner가 충분히 많은 경우 일반화 오차
우선
마지막으로 살펴볼 부분은 random forest의 feature importance 도출 방법입니다. Random forest의 변수 중요도 산출 방법으로는 분류 결과를 기반으로 추후 통계 분석을 진행하는 방법도 있겠지만, OOB(Out-Of-Bag) error를 이용하는 방법이 일반적인 방법입니다. Random forest를 학습시킨 후, 각 base leanrer
여기까지 bagging과 random forest의 이론적 내용이었습니다.
우선 실험에 앞서 필요한 모듈 등의 버젼은 아래와 같습니다.
| env_name | version |
|---|---|
| python | 3.8.3 |
| numpy | 1.19.2 |
| matplotlib | 3.5.2 |
| pandas | 1.4.3 |
| sklearn | 1.1.3 |
사용할 데이터셋은 MNIST입니다. 필요한 데이터를 미리 다운받은 것이 있어 이 repo에 올려두었으니 참고하시길 바랍니다. 이 MNIST 데이터 중 7에 대한 데이터와 나머지 데이터를 활용하여 7의 데이터를 1로, 나머지를 0으로 labeling 하였습니다. 전처리 코드는 아래와 같습니다.
- 기본 전처리: 데이터 로딩 및 기본적인 labeling에 관련한 전처리를 진행하였습니다. 1 label의 경우 626개, 0 label은 6265개 입니다.
import pandas as pd
import numpy as np
import random
import gzip
# MNIST preprocessing to tabular data
with gzip.open('train-images-idx3-ubyte.gz', 'rb') as f:
df = np.frombuffer(f.read(), np.uint8, offset=16).reshape(-1, 28*28)
with gzip.open('train-labels-idx1-ubyte.gz', 'rb') as f:
digit_label = np.frombuffer(f.read(), np.uint8, offset=8)
df = pd.DataFrame(df)
df['target'] = digit_label
df.target = np.where(df.target == 7, 1, 0)
size = sum(df.target == 1)
index_set_0 = df.loc[df.target == 0].index.tolist()
index_set_1 = df.loc[df.target == 1].index.tolist()
random.seed(1201)
sample_index_0 = list(random.sample(index_set_0, size))
sample_index_1 = list(random.sample(index_set_1, round(size/10)))
total_index = sample_index_1 + sample_index_0
df = df.iloc[total_index, :].reset_index(drop=True)
df.target.value_counts()- k-fold 함수: 추후 학습 및 성능 평가를 위해 k-fold cross validation 함수를 만들었습니다. 각 1과 0의 비율이 보존되도록 하였습니다.
def kfold(data, fold, seed):
import random
idx_set_1 = data.loc[data.target== 1].index.tolist()
idx_set_0 = data.loc[data.target == 0].index.tolist()
size_1 = round(len(idx_set_1)/fold)
size_0 = round(len(idx_set_0)/fold)
folded_idx_set = []
for i in range(fold):
if (i == fold-1):
folded_idx_set.append(idx_set_1+idx_set_0)
else:
random.seed(seed)
folded_idx_set.append(list(random.sample(idx_set_1, size_1))+list(random.sample(idx_set_0, size_0)))
idx_set_1 = list(set(idx_set_1)-set(folded_idx_set[len(folded_idx_set)-1]))
idx_set_0 = list(set(idx_set_0)-set(folded_idx_set[len(folded_idx_set)-1]))
return folded_idx_set
kfold_idx_set = kfold(data=df, fold=5, seed=1201)
trn_X = []
trn_y = []
tst_X = []
tst_y = []
index_set = df.index.tolist()
for i in range(5):
total_idx = set(index_set)
trn_X.append(df.loc[list(total_idx-set(kfold_idx_set[i])), list(range(0,784))])
trn_y.append(df.loc[list(total_idx-set(kfold_idx_set[i])), 'target'])
tst_X.append(df.loc[kfold_idx_set[i], list(range(0,784))])
tst_y.append(df.loc[kfold_idx_set[i]]['target'])
- t-SNE 시각화: 시각화를 진행하여 실ㅈ
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore") # warning 무시
tsne = TSNE(n_components=2, random_state = 1201)
tsne_data = tsne.fit_transform(df[list(range(0,784))])
tsne_data = pd.DataFrame(tsne_data, columns=['z1', 'z2'])
plt.figure(figsize=(10,10))
plt.title('TSNE')
plt.scatter(tsne_data.z1, tsne_data.z2, c=df.target, cmap=plt.cm.brg, alpha=0.7)시각화 결과는 아래와 같습니다. 결과를 통해 앙상블을 비롯한 머신러닝 모델에 의한 분류가 그렇게 어렵지 않을 것임을 짐작 할 수 있습니다.

우선 앙상블 모델링을 진행하기에 앞서 evaluation 함수를 만들었습니다. 평가 지표로는 TPR, TNR, precision, f1을 선정하였습니다.
from sklearn.metrics import confusion_matrix
def evaluation(model, X, y):
y_pred = model.predict(X)
tn, fp, fn, tp = confusion_matrix(y, y_pred).ravel()
return [tp/(fn+tp), tn/(fp+tn), tp/(fp+tp), 2*tp/(fp+2*tp+fn)]단일 모델과의 비교를 위해 RBF 커널을 활용하여 SVM으로 분류를 진행하였습니다. cost는 10으로 하였습니다. 코드와 실험결과는 아래와 같습니다.
from sklearn.svm import SVC
import time
eval_data = []
for fold_num in range(5):
st = time.time()
model = SVC(kernel='rbf', C=10)
model.fit(trn_X[fold_num], trn_y[fold_num])
tt = time.time() - st
eval_data.append([fold_num+1, tt] + evaluation(model, tst_X[fold_num], tst_y[fold_num]))
eval_data = pd.DataFrame(eval_data, columns=['fold', 'time', 'TPR', 'TNR', 'precision', 'f1'])
eval_data.to_csv('SVM_evaldf.csv', index=False)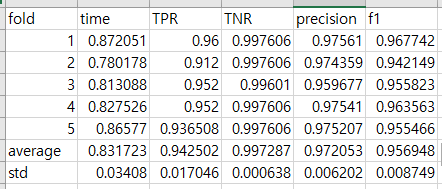
평균적으로 1초 이내의 시간으로 높은 성능을 보이는 모델을 만들었음을 알 수 있습니다. 이를 bagging 모델 등과 비교해보겠습니다.
bagging classifier를 이용하여 분류를 진행하였습니다. 사용한 base learner는 decision tree와 svm으로 둘 다 sklearn의 default setting을 사용하였습니다. 그리고 estimator의 수는 100부터 500까지 바꾸면서 실험을 진행했고, 병렬처리 코어의 수는 8로 하였습니다. 코드와 결과는 아래와 같습니다.
from sklearn.ensemble import BaggingClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from tqdm import tqdm
import time
base_learner_list = [DecisionTreeClassifier(), SVC()]
for i in range(1, 6):
for j in range(2):
eval_data = []
for fold_num in tqdm(range(5)):
base_learner = base_learner_list[j]
st = time.time()
model = BaggingClassifier(base_estimator=base_learner, n_estimators=100*i, random_state=1201, n_jobs=8)
model.fit(trn_X[fold_num], trn_y[fold_num])
tt = time.time() - st
eval_data.append([fold_num+1, tt] + evaluation(model, tst_X[fold_num], tst_y[fold_num]))
eval_data = pd.DataFrame(eval_data, columns=['fold', 'time', 'TPR', 'TNR', 'precision', 'f1'])
if j ==0 :
eval_data.to_csv('bagging_DT_evaldf_'+str(i)+'.csv', index=False)
else:
eval_data.to_csv('bagging_SVM_evaldf_'+str(i)+'.csv', index=False)- base learner가 decision tree인 경우의 결과
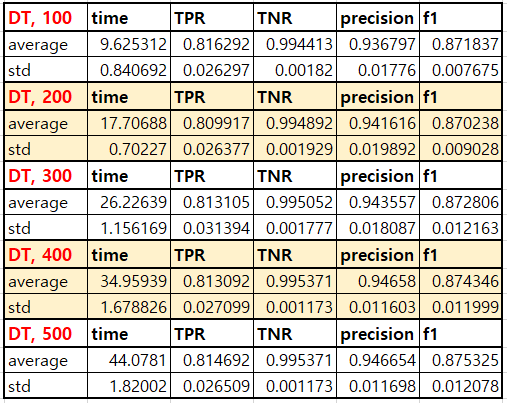
결과표에서 붉은 글자는 그 글자가 해당된 영역의 데이터가 생성된 모델과 그 모델의 base learner 수를 표시합니다. 위 표를 보면 시간이 훨씬 늘어났지만 성능은 오히려 전체적으로 떨어졌음을 알 수 있습니다. 더불어 estimator의 수가 증가하면 시간은 반드시 증가하지만 좋은 성능 및 낮은 분산을 보장하지 않음 또한 알 수 있습니다.
- base learner가 SVM인 경우의 결과

위 표를 보면 decision tree를 사용했을 때에 비해서도 시간은 훨씬 오래 걸렸으나, 성능은 그에 비해 소폭 증가하였음을 알 수 있습니다. 하지만 여전히 SVM 하나를 사용한 결과에 비하여 좋지 않은 성능을 보임을 알 수 있습니다.
이어서 Random forest를 이용해 실험을 진행해보겠습니다.
Random Forest를 이용하여 분류를 진행하였습니다. 앞서와 동일하게 estimator의 수는 100부터 500까지 바꾸면서 실험을 진행했고, 병렬처리 코어의 수는 8로 하였습니다. 코드와 결과는 아래와 같습니다.
from sklearn.ensemble import BaggingClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from tqdm import tqdm
import time
base_learner_list = [DecisionTreeClassifier(), SVC()]
for i in range(1, 6):
for j in range(2):
eval_data = []
for fold_num in tqdm(range(5)):
base_learner = base_learner_list[j]
st = time.time()
model = BaggingClassifier(base_estimator=base_learner, n_estimators=100*i, random_state=1201, n_jobs=8)
model.fit(trn_X[fold_num], trn_y[fold_num])
tt = time.time() - st
eval_data.append([fold_num+1, tt] + evaluation(model, tst_X[fold_num], tst_y[fold_num]))
eval_data = pd.DataFrame(eval_data, columns=['fold', 'time', 'TPR', 'TNR', 'precision', 'f1'])
if j ==0 :
eval_data.to_csv('bagging_DT_evaldf_'+str(i)+'.csv', index=False)
else:
eval_data.to_csv('bagging_SVM_evaldf_'+str(i)+'.csv', index=False)
결과를 보면, 다른 bagging 방법론들에 비해 매우 빠른 속도를 보이며, SVM을 이용한 bagging 보다는 성능이 떨어지고, decision tree만 이용한 bagging 보다는 성능이 좋음을 확인할 수 있었습니다.
이상으로 실험을 마무리하겠습니다.
앞서 실험에서의 주요 실험 결과를 요약하면 크게 3가지로 볼 수 있습니다.
- 단일 SVM > SVM bagging > random forest > DT bagging의 순으로 성능이 좋음.
- estimator의 증가는 bagging 계열 방법론에서 성능을 딱히 높이지 않음.
- 속도는 random forest > DT bagging > SVM bagging의 순으로 빠름.
이러한 결과가 산출된 이유를 짐작해보자면 아마도 데이터의 규모, 특성, 그리고 방법론의 특성이 맞물린 결과 아닐까 생각됩니다. 현재 데이터 셋은 MNIST 기반의 변형 데이터셋이고 784개의 변수와 약 700개의 row를 가진 상황입니다. 이를 고려해보면 객체의 수에 비해 변수의 수가 많고 변수의 예측력의 질이 좋지 않은 경우가 많을 것이라고 예상할 수 있습니다. 쉽게 말해 차원 축소가 유용할 수 있는 상황인 셈이죠. 우선 이러한 점에서 어떤 변수를 택해서 예측에 사용하는 base learner 들로 구성된 알고리즘을 가진 DT bagging, random forest의 성능이 좋지 않은 결과가 나온 것이 이해가 됩니다. 더불어, RBF SVM의 경우 일종의 새로운 representation을 이용해서 학습한다고도 볼 수 있기 때문에 쓸모없는 변수가 많고 더불어 변수간의 상호작용이 있는 이러한 MNIST 같은 데이터셋에서 좋은 성능을 보일 수 있어 이러한 결과가 나오는 것에 일조한 것으로 보입니다. 마지막으로 estimator의 수가 의미가 없는 점은 아무래도 데이터의 규모가 작아 데이터에서 학습해야 하는 다양한 relationship이 적었기 때문이라고 생각됩니다.
이를 통해 얻을 수 있는 insight는 다음과 같습니다.
- 데이터 규모가 작고, 새로운 representation, 비선형적인 경계면이 필요한 분류 문제에서는 RBF SVM을 사용해보는 것이 좋을 수 있다.
- 데이터 규모가 커질 경우 random forest를 통해 데이터에서 얻을 수 있는 대략적인 정보를 빠르게 얻고 분석의 파이프라인을 빠르게 확립해 볼 수 있다.
- bagging SVM은 데이터의 수가 아주 많은 경우 그냥 SVM에 비해 빠르게, 그러나 비슷한 성능을 낼 수 있을 것으로 보인다.
지금까지 ensemble learning의 이론적 배경, 개념, 그리고 이 이론적 내용을 기반으로 한 실험 진행과정과 결과를 살펴보았습니다. 실제 실험의 진행 코드는 ensemble_tutorial.ipynb에 있으며, 제가 참고한 자료와 실습을 진행한 데이터셋은 올려두었습니다. 감사합니다.


