Este tutorial/projeto exemplifica como uma aplicação WEB pode rodar em containers, introduz o uso de ferramentas específicas auxiliares para o desenvolvimento de projeto web, mas não trata da criação e manutenção de imagens Docker, não é necessariamente um roteiro sem viés que busca uma instrução genérica mas sim, bem associada ao meu modo de trabalho, incluindo ferramentas de minha escolha e, apesar de útil para quem procura informações para configurar seu próprio projeto, foca em explicar a organização dos recursos e tecnologias, permitindo que novos contribuidores de projetos que já adotam esta estrutura possam entender, melhorar e executar recursos já configurados.
Os exemplos abaixo são escritos para execução em um terminal linux, mas você pode facilmente executá-los em outro sistema operacional com alguns ajustes.
Este projeto considera que você já possui o Docker e o Docker Compose instalado em seu sistema operacional(veja gpupo-meta/setup-machine). Se você possui um computador sem suporte a virtualização talvéz não consiga rodar o Docker. Eu enfrentei este problema em um Mac Book Pro 2010.
Se você pretende seguir as instruções abaixo até o fim, prepare-se para trafegar mais de 3Gb de dados, entre imagens Docker e pacotes de dependência, então, se você está dependendo de sua conexão EDGE, apenas leia o conteúdo, a leitura recomendada e deixa pra executar pra valer quando estiver melhor de conexão, ok?
Vários termos usados neste tutorial possuem links que facilitarão o entendimento de quem não está familiarizado com eles, então recomendo a leitura das referências.
Alguns comandos devem ser executados em seu terminal tradicional e quando for este o caso, o símbolo 💻 estará presente, porém outros comandos requerem a execução a partir do terminal virtualizado. Quando for este o caso, o símbolo 🐳 estará próximo, indicando que a execução deve ser feita no bash do container. Como chegar lá ? Você vai aprender logo abaixo...
Um último requisito importante é paciência e dedicação pois é bastante coisa pra ler, seguir referências, executar comandos, analizar diffs e refazer até entender. Pra te motivar e também responsabilizar, eu gastei várias horas de trabalho escrevendo este tutorial, tirando as melhores técnicas do meu vaú de tesouross, para que você aí do futuro aprendesse a usá-las, então, me dê algum crédito e esforço quando seguir com este tutorial, ou, se preferir algo mais facil, por seguir por aqui ...
Se tudo estiver pronto, selecione seu personagem e vamos em frente.

🐳 Dockerized Applications rodam em containers e possuem um conjunto de serviços (services). Seguindo as melhores práticas, para cada responsabilidade é criado (preferencialmente) um serviço.
Exemplificando, em uma solução (stack) popular como a tradicional LAMP, temos as seguintes responsabilidades:
- (L) Linux, sistema operacional com suporte ao Filesystem, Ferramentas CLI, e suporte aos softwares instalados;
- (A) Apache, um webserver instalado e configurado sobre o OS (L);
- (M) Banco de dados instalado e configurado sobre o OS (L);
- (P) PHP, interpretador instalado sobre L.
Ao convertermos esse tipo de solução, devemos naturalmente pensar em 4 serviços (L, A, M e P). Entretanto, L deixa de ser fundamental pois o suporte ao Filesystem e aos Softwares já existe na dinâmica inerente de uma imagem/container. Então, as Ferramentas CLI ficam sob responsabilidade do serviço Interpretador (P).
Até aqui, nosso conjunto de serviços está assim:
- Webserver - Acessível na porta 80, recebe as requisições, responde com processamento feito pelo serviço interpretador;
- Interpretador - Acessível somente pelo Webserver ou via docker exec, atende a pedidos do Webserver, conecta-se ao Banco de dados, possui ferramentas CLI;
- Banco de dados, acessível somente pelo serviço Interpretador .
Isso exemplifica uma solução comum, mas vamos nos aprofundar um pouco no nosso modo de trabalho:
Se cada conjunto de serviços possui um Webserver que responde na porta 80 da máquina do programador, então somente um projeto pode estar levantado por vez, ou então cada projeto precisa de uma porta exclusiva. Imagine a situação caótica disto em um ambiente de produção. Para resolver isso, cada projeto recebe como parâmetro um subdominio (ex: http://helloworld.localhost) e seu webserver não atende em porta pública, mas sim conecta-se ao serviço httpd-gateway que fará o devido roteamento assim que o browser requisitar pelo subdominio configurado.
Também neste ponto, temos uma questão a ser tratada: O serviço do Banco de dados. Em um ambiente de desenvolvimento, precisamos de uma base local para testes funcionais, desenvolvimento, testes unitários, etc ... mas no ambiente de produção não precisamos do serviço de banco de dados pois este roda em local diferente da aplicação.
Então possuímos dois conjuntos de serviços: Um para desenvolvimento e outro reduzido para o ambiente de produção.
Esses conjuntos são definidos no arquivo docker-compose.yaml, então em um projeto temos duas versões destas configurações Resources/docker-compose.dev.yaml e Resources/docker-compose.prod.yaml e o desenvolvedor faz um link simbólico para a raiz do projeto : 💻
ln -sn Resources/docker-compose.dev.yaml ./docker-compose.yaml
Ainda no nosso exemplo, baseado na conversão de uma stack LAMP, optamos por utilizar o webserver NGINX ao invés do Apache e como usamos o PHP como serviço, nossa opção é pelo PHP-FPM. A base de dados é MariaDB.
Para complicar um pouco mais, sabemos que no ambiente de produção não é necessário todos os pacotes que o ambiente de desenvolvimento utiliza, então, nosso serviço PHP no conjunto do desenvolvimento possui mais coisas que o mesmo serviço do conjunto de produção.
Para resolver isso, a imagem utilizada pelo serviço Interpretador no conjunto de desenvolvimento é uma extensão da imagem PHP-FPM com aditivos para o desenvolvedor.
Por exemplo, a extensão php-xdebug existe na imagem do ambiente de desenvolvimento mas não na imagem usada no ambiente de produção.
Nosso conjunto de serviços DEV neste momento está assim:
- NGINX (Webserver) - Acessível via proxy, recebe as requisições, responde com processamento feito pelo serviço interpretador;
- PHP-FPM (Interpretador )- Acessível somente pelo Webserver ou via docker exec, atende a pedidos do Webserver, conecta-se ao Banco de dados, possui ferramentas CLI;
- MariaDB (Banco de dados), acessível somente pelo serviço Interpretador .
No exemplo de configuração Resources/docker-compose.dev.yaml usa-se a imagem gpupo/container-orchestration:symfony-dev para o serviço de nome php-fpm.
A imagem pública gpupo/container-orchestration:symfony-dev é uma extensão da imagem oficial php-fpm sobre debian com a adição de ferramentas necessárias ao desenvolvimento PHP e também de atividades com NodeJS para trabalho com o Webpack.
Para padronizar e facilitar automatização, o serviço do interpretador sempre recebe o nome "php-fpm".
Este atual projeto possibilita um mão na massa de acordo com essa explicação.

Passo 1, levantar o httpd-gateway: 💻
git clone https://github.com/gpupo/httpd-gateway.git;
pushd httpd-gateway;
make setup;
make alone;
popd;
Passo 2, clonar e levantar este projeto: 💻
git clone https://github.com/gpupo-meta/dockerized-helloworld.git;
cd dockerized-helloworld;
docker-compose up -d;
Passo 3, testar o acesso a http://dockerized-helloworld.localhost/helloworld.php ou se preferir, via linha de comando: 💻
curl http://dockerized-helloworld.localhost/helloworld.php
Se tudo correu bem até aqui, em http://dockerized-helloworld.localhost/phpinfo.php você acessa informações sobre o serviço PHP em uso.
Passo 4, acesso ao terminal do serviço Interpretador: 💻
docker-compose exec php-fpm bash
Você verá que ao executar o comando acima é lançado para o ambiente virtualizado onde o diretório atual é /var/www/app.
Se você listar os arquivos do diretório /var/www/app verá que são exatamente os mesmos da raiz deste projeto.
Isto se dá pelo fato que que mapeamos o diretório nos parâmetros volumes existentes nos arquivos docker-compose*.yaml
Apesar de você ter instalado em seu sistema operacional, todo um conjunto de interpretadores como por exemplo o PHP, preferenciamente os comandos de manutenção e execução relacionados ao projeto devem ser executados a partir do serviço (container), que possui a versão, configuração e ferramentas escolhidas para o projeto. Após acessar o terminal do serviço Interpretador, instale as dependências 🐳 :
make install
Você pode agora chamar o APP CLI deste projeto: 🐳
bin/dockerized-helloworld
Execução do "Hello World" : 🐳
bin/dockerized-helloworld greeting "Arnold Schwarzenegger"
Dúvidas? Se você precisa de ajuda para entender um dos conceitos acima, crie uma issue,
e marque-a com o label question.

A partir deste ponto, a exploração de uma stack tradicional como a LAMP já ficou para trás. A seguir temos incrementos que lidam com a forma de trabalho usando a imagem gpupo/container-orchestration:symfony-dev e outras ferramentas opensource.gpupo.com.
Para a gestão de dependências CSS/Javascript utilizamos o YARN que já está devidamente instalado e configurado na imagem gpupo/container-orchestration:symfony-dev utilizada no service PHP-FPM do Stack de desenvolvimento.
Assim como o comando composer install instala os pacotes PHP definidos em compose.json, o comando yarn install instala os pacotes NPM definidos em package.json: 🐳
yarn install
Existindo a necessidade de acrescentar um pacote ao projeto, consultamos https://www.npmjs.com/ ou https://yarnpkg.com para encontrar o identificador do pacote. Exemplo: babel-plugin-transform-es2015-parameters 🐳.
yarn add babel-plugin-transform-es2015-parameters --dev
O exemplo acima adiciona um pacote que é carregado apenas no ambiente de desenvolvimento já que utilizamos o parâmetro --dev.
A partir das instruções de assets/js/helloworld.js será compilado o arquivo public/build/helloworld.min.js : 🐳
yarn build
Podemos testar o resultado da seguinte maneira : 🐳
nodejs public/build/helloworld.min.js
Uma escrita moderna de código javascript utiliza ES6 também conhecido como ECMAScript 6 ou ES2015.
Aqui entra o Babel, um compilador Javascript que nos permite utilizar uma série de recursos ES6.
Não vou detalhar o uso do ES6 aqui nesse documento mas logo abaixo seguem links para o aprendizado da sintaxe.
Em nosso projetto dockerized-helloworld todas as ferramentas necessárias para compilar javascript ES6 forma instaladas quando você executou yarn install.
O javascript assets/js/helloworld-ES2015.js foi compilado pelo yarn build em public/build/helloworld-ES2015.min.js
Podemos testar o resultado da seguinte maneira : 🐳
nodejs public/build/helloworld-ES2015.min.js
Claro, para que tudo funcionasse foi preciso algumas configurações nos arquivos .babelrc (instruções para compilação), package.json (quais pacotes NPM instalar) e webpack.config.js (quais arquivos compilar e onde fazer o output) e não vou abordar a configuração mas vou deixar links em leitura recomendada que tratam disso.
O Sass é uma linguagem baseada em CSS que depois de compilada gera o tradicional CSS.
O arquivo assets/scss/app.scss inclui todo o css do Bootstrap 4 (disponível na configugação de pacotes e instalados pelo yarn install) e algum código de exemplo que é compilado no path public/build/app.min.css.
A mágica de yarn build acontece porque o webpack compila e minimiza nossos arquivos javascript e sass. Mais do que isso, ele recebe a indicação de que o arquivo assets/scss/app.scss está sendo requerido por assets/js/app.js e o inclui no processo de build.
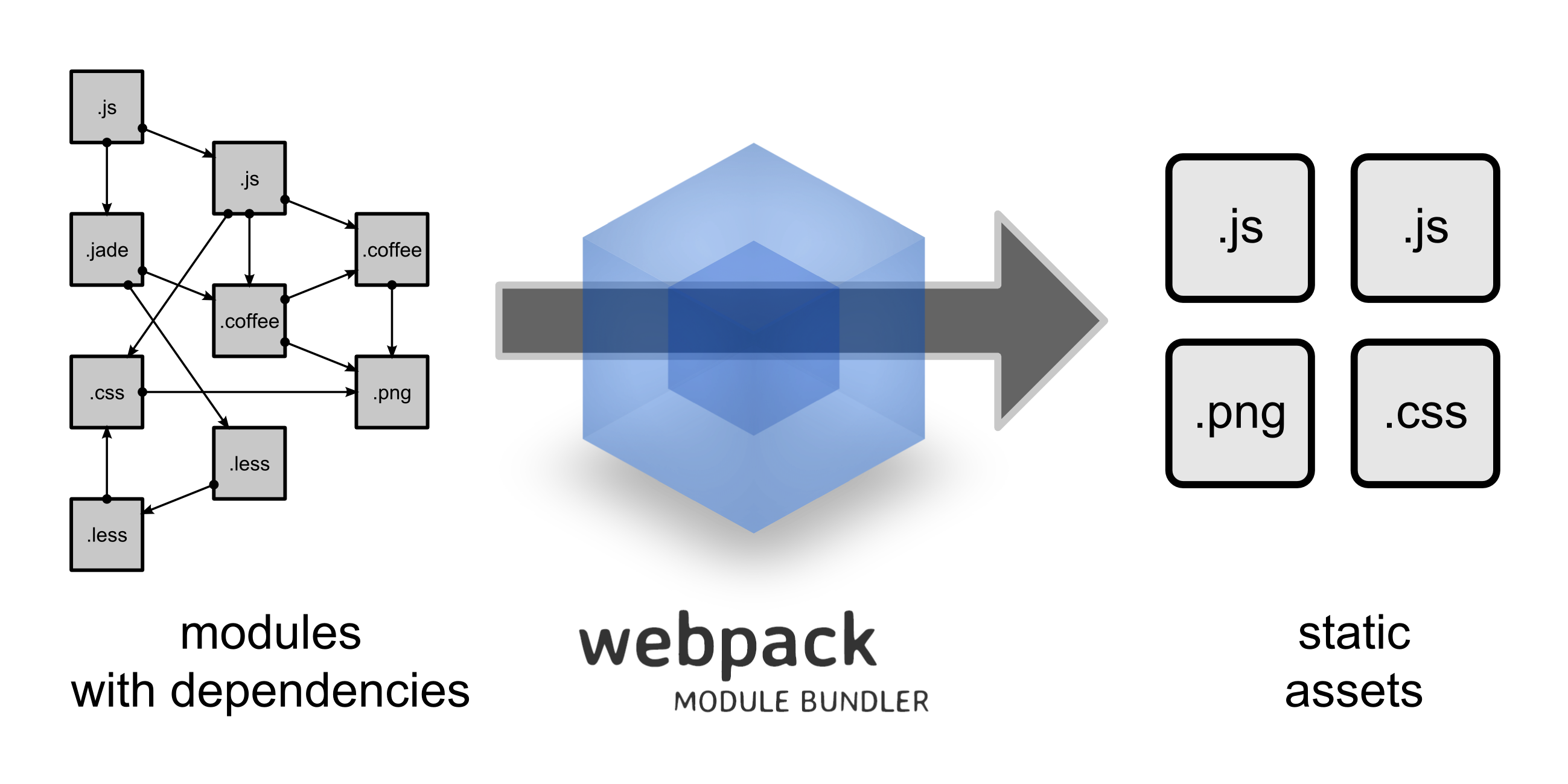
Sua configuração é feita a partir do arquivo webpack.config.js.
Você pode acionar o webpack diretamente da seguinte maneira : 🐳
export PATH="$(yarn bin):$PATH";
webpack --config webpack.config.js;
Isto é muito útil para testarmos novas configurações.
Para visualizar uma página que carrega o javascript e o css compilado, abra http://dockerized-helloworld.localhost/bootstrap.php .
- Learn ES2015
- Let’s Learn ES2015
- Google ES2015
- O Guia do ES6: TUDO que você precisa saber
- Using Webpack 4 — A “really” quick start
- How to include Bootstrap in your project with Webpack
- Webpack 4: Extract CSS from Javascript files with mini-css-extract-plugin
- CSS menos sofrido com Sass
- Sass Basics
- Webpack manual
A partir deste momento vamos incluir novos services em nosso projeto e para isso vamos deixar de usar o docker-compose file atual e passaremos a usar o arquivo Resources/docker-compose.extra-services.yaml.
Para isso, vamos aos passos de configuração:
Passo 1, derrube os serviços atuais : 💻
docker-compose down
Passo 2, substitua o link simbólico de docker-compose.yaml (que atualmente aponta para Resources/docker-compose.dev.yaml) para Resources/docker-compose.extra-services.yaml : 💻
ln -snf Resources/docker-compose.extra-services.yaml ./docker-compose.yaml
Passo 3, levante os Serviços : 💻
docker-compose up -d
Agora, no subdomínio phpmyadmin-dockerized-helloworld.localhost você poderá acessar o PhpMyAdmin
No arquivo Resources/docker-compose.dev.yaml eu incluí o serviço que oferece o PhpMyAdmin, usando a imagem Docker oficial.
O Redis é um armazenamento de estrutura de dados de chave-valor de código aberto e na memória e usamos frequentemente em aplicações PHP para substituir o Cache APC.
Tradicionalmente, uma aplicação grava logs em um arquivo como por exemplo, uma aplicação Symfony 4 gravará seus logs em var/logs/dev.log, var/logs/prod.log ou var/logs/dev.log, mas nós que estamos projetando uma aplicação que roda em containers precisamos de uma forma melhor de armazenar estes registros pois, um dos fundamentos do uso de containers é que cada container é projetado para atender um processamento por um tempo determinado e é descartável. Não podemos perder os logs da aplicação a cada vez que recriamos um container ou mudamos a imagem na qual ele é baseado. Poderíamos resolver este problema com a técnica de mapeamento de um diretório da máquina host para var/logs mas isto continua centralizando os logs em uma máquina e em uma arquitetura de nuvem, usamos muitas máquinas, então teríamos que abrir muitos diretórios para buscar uma informação e a partir de certa quantidade de máquinas, fazer isto se torna inviável. Então, uma engenharia que resolve de maneira muito habilidosa este problema é enviar todos os logs para um servidor de logs. Simples assim. 💥
Para montar esse servidor usamos basicamente 4 services:

- (R) RabbitMQ;
- (E) Elasticsearch;
- (L) Logstash;
- (K) Kibana.
Nossa aplicação, utilizando um drive específico (php-amqplib/php-amqplib), envia os logs para um servidor RabbitMQ que os guarda em uma fila.
O Logstash conecta no RabbitMQ e coleta os registros de log, (transforma-os se necessário) e grava-os no Elasticsearch. O Kibana é uma interface de leitura e exploração destes logs que estão gravados no Elasticsearch.
Para nossa 🐳 Dockerized Application não é interessante responsabilizar-se pela configuração da stack RELK, então eu preparei este conjunto de serviços em um lugar secreto, que você simplesmente vai levantar com o seguinte setup: 💻
make relk@up
Logstash config: 🐳
curl -XPOST -D- 'http://kibana:5601/api/saved_objects/index-pattern' \
-H 'Content-Type: application/json' \
-H 'kbn-version: 6.2.4' \
-d '{"attributes":{"title":"logstash-*","timeFieldName":"@timestamp"}}'Agora vamos testar o envio de logs: 🐳
bin/dockerized-helloworld log:generator 100
Se tudo correu bem você terá acesso aos serviços:
- RabbitMQ, user
admin, passwordd0ck3r1zzd - Kibana
- Logstash API
Para o nosso tutorial, o mais importante é que você consiga visualizar os logs gerados pela aplicação e para isso deverá acessar o Kibana e escolher no menu o item Discover. Você deverá ver uma tela semelhante a essa:

📝 Essa mesma lógica de envio de logs para um local centralizado pode ser adotada por qualquer software, não somente Apps PHP. O httpd-gateway está preparado para também enviar os logs do NGINX para um servidor de logs, em um ambiente de produção.
- Muita informação é ruído e pouca informação é inadequado. É difícil encontrar o equilíbrio do ideal, mas esse é o desafio. No caso de microsserviços, pense também na rastreabilidade entre serviços, como o uso de um identificador do
service. Outra coisa a ter em mente é que os logs são temporais, não permanentes, com vida útil de alguns meses. - Siga severity levels (Syslog Protocol).
- Estruture seus logs. Siga um padrão JSON acordado para o registro. Isso facilita a análise e a pesquisa.
- Grave os registros com cuidado sem não prejudicar o desempenho.
- Considere que o servidor de log pode estar indisponível e sua aplicação precisa resistir a isso.
- Em uma aplicação PHP sólida, utilize o Monolog. Veja Symfony Guide Logging.
De fato você já está acostumado a persistir fora da aplicação informações como os dados no banco relacional. Um artefato importante a ser persistido externamente são arquivos estáticos enviados por usuários a partir de formulários de upload por exemplo. Para atender esta demanda eu uso o projeto Content Butler associado ao Doctrine PHP Content Repository ODM que trata estes assets como objetos e os gerencia em um servidor Apache Jackrabbit.
Make é uma ferramenta para automatização de build criada em 1976 e desenhada para resolver problemas durante o processo de build, originalmente usada em projetos de linguagem C e que passou a ser amplamente utilizada em projetos Unix Like.
Seu arquivo de configuração é o Makefile que está na raiz deste projeto. É nesse arquivo que configuramos targets. Cada target é uma sequencia de instruções, que pode por sua vez depender de outros targets.
A sintaxe de um target é:
## Coment
target: [prerequisite]
command1
[command2]Devido à configuração customizada de nosso Makefile, se você simplesmente executar make sem especificar qual target quer acionar, uma lista de targets e suas descrições será exibida. Experimente : 🐳
make

Na verdade, logo no começo deste tutorial eu pedi para que você executace make install. Isto fez com que fosse acionado o target install configurado no Makefile:
## Composer Install
install:
composer self-update
composer install --prefer-distO target install segue o script de atualizar o Composer e instalar as dependências PHP. Se o objetivo deste target fosse de instalar tudo o que o projeto precisa, o que faz sentido em um target destes em um projeto real, poderíamos acrescentar a chamada para instalação dos pacotes NPM e ainda a necessidade de realizar o build após instalação:
## Instala as dependências o que o projeto precisa
install:
composer self-update
composer install --prefer-dist
yarn install
yarn buildExperimente o target bash que vai lhe lançar diretamente no bash do serviço PHP-FPM:
make bash
A imagem gpupo/container-orchestration:symfony-dev possui ferramentas de quality assurance que nos ajudam a manter a qualidade da escrita e da engenharia.
Neste projeto seguimos PHP Standards Recommendations(PSR) e também padrões sugeridos pelo projeto Symfony com objetivo facilitar a reutilização de código entre os diversos projetos que implementem determinado padrão.
Se você ainda não está familiarizado com as PSRs, saiba que existem PSRs para implementações de autoload (PSR-4), sugestões de estilos de código, como posição de chaves, indentação (Usar tabulações ou espaços?) (PSR-1 e PSR-2).
Existem também propostas em draft para padronização dos docblock de documentação (PSR-5) e uma interface para requisições HTTP (PSR-7)
Mais informações leia o FAQ e visite o repositório no GitHub com os padrões já aceitos.
- PSR-1: Basic Coding Standard
- PSR-2: Coding Style Guide
- PSR-4: Autoloading Standard
- PSR-5: PHPDoc (draft)
- Symfony Coding Standards
Uma ferramenta muito importante é o php-cs-fixer que vai alinhar o código escrito de acordo com as regras de padrão selecionados para o projeto.
No arquivo .php_cs.dist é configurado este conjunto de regras.
Vamos a um exemplo prático! Apesar de funcionar, o arquivo src/Traits/VeryWrongCodeStyleTrait.php está mal escrito e ignora vários padrões de escrita. Mas que padrões são estes? Rode o php-cs-fixer: 🐳
make php-cs-fixer
Se você executar um git diff verá algo assim:
<?php
+declare(strict_types=1);
+
+/*
+ * This file is part of gpupo/dockerized-helloworld
+ * Created by Gilmar Pupo <[email protected]>
+ * For the information of copyright and license....
+ *
+ */
+
namespace Gpupo\DockerizedHelloworld\Traits;
-use JMS\Serializer\Annotation as JMS,
- Doctrine\ODM\MongoDB\Mapping\Annotations as ODM,
- PDO;
+use Doctrine\ODM\MongoDB\Mapping\Annotations as ODM;
+use JMS\Serializer\Annotation as JMS;
/**
- * Very wrong code style
- *
- *
- *
+ * Very wrong code style.
*/
-trait VeryWrongCodeStyleTrait {
-
+trait VeryWrongCodeStyleTrait
+{
/**
* @var string
* @ODM\Field(type="string")
private $name;
/**
- * Set name
+ * Set name.
+ *
+ * @param string $name
*
- * @param string $name
* @return mixed
*/
Nesse diff que o arquivo recebeu modificações:
- Adicionou a declaração
declare(strict_types=1);. - Adicionou o HEADER padrão a todos os arquivos PHP do projeto.
- Organizou em ordem alfabética as declarações de uso.
- Escreveu com um
usepor linha, como pede o CS configurado. - Removeu o
use PDOpois a classe PDO não recebe nenhum uso nas linhas do arquivo. - Trocou as
{de lugar, de acordo com o codding style definido. - Adicionou ponto final a linhas de documentação.
📝 É uma boa prática você utilizar o make php-cs-fixer após terminar o desenvolvimento de uma feature PHP.
Para voltar a classe ao seu estado anterior e lhe permitir aproveitar melhor este tutorial:
git checkout src/Traits/VeryWrongCodeStyleTrait.php
Outra ferramenta importante é o PHP_CodeSniffer que também irá nos ajudar a manter um padrão acordado e é configurado no arquivo phpcs.xml.dist
Experimente: 🐳
make phpcbf
As ferramentas php-cs-fixer, PHP_CodeSniffer complementam-se e uma pode apontar uma melhoria que outra não pegou. Com o make podemos criar um target se seja ajunte uma coleção de outros targets. Em nosso Makefile, o target cs se presta isso: 🐳
make cs
O PHPMD - Ruleset for PHP Mess Detector that enforces coding standards é configurado no arquivo .phpmd.xml. 🐳
make phpmd
Phan, static analyzer para o PHP. Está configurado no arquivo config/phan.php e vai nos apontar melhorias e possíveis erros da aplicação: 🐳
make phan
make phpstan
make phploc
O Makefile está configurado para rodar os testes Unitários: 🐳
make phpunit
Você verá algo semelhante a essa saída:

o diretório tests/ guarda nos testes unitários que são executados pelo phpunit. Apesar de apenas existir o teste tests/Console/Command/GreetingCommandTest.php que valida a saudação emitida pelo comando de console bin/dockerized-helloworld greeting executado anteriormente, algumas técnicas interessantes são utilizadas, como a validação repetida usando dataproviders e o teste do output de um Command.
Vamos para algo mais simples ...
Nosso projeto dockerized-helloworld usa a gpupo/common que contém o comando vendor/bin/developer-toolbox que pode nos ajudar a criar um teste unitário esqueleto a partir de uma classe existente.
Se quisermos criar um teste unitário para o objeto Gpupo\DockerizedHelloworld\Entity\Person: 🐳
vendor/bin/developer-toolbox generate --class='Gpupo\DockerizedHelloworld\Entity\Person'
O comando acima gerará o arquivo tests/Entity/PersonTest.php que deve conter um conteúdo semelhante a este:
<?php
//...
namespace Gpupo\DockerizedHelloworld\Tests\Entity;
use PHPUnit\Framework\TestCase as CoreTestCase;
use Gpupo\DockerizedHelloworld\Entity\Person;
/**
* @coversDefaultClass \Gpupo\DockerizedHelloworld\Entity\Person
* ...
*/
class PersonTest extends CoreTestCase
{
public function dataProviderPerson()
{
$expected = [
"name" => "d1b72da",
];
$object = new Person();
return [[$object, $expected]];
}
/**
* @testdox Have a getter getName() to get Name
* @dataProvider dataProviderPerson
* @cover ::getName
* @small
* @test
*
* @param Person $person Main Object
* @param array $expected Fixture data
*/
public function testGetName(Person $person, array $expected)
{
$person->setName($expected['name']);
$this->assertSame($expected['name'], $person->getName());
}
/**
* @testdox Have a setter setName() to set Name
* @dataProvider dataProviderPerson
* @cover ::setName
* @small
* @test
*
* @param Person $person Main Object
* @param array $expected Fixture data
*/
public function testSetName(Person $person, array $expected)
{
$person->setName($expected['name']);
$this->assertSame($expected['name'], $person->getName());
}
}Execute os testes Unitários: 🐳
make phpunit
Lembre-se de que o arquivo tests/Entity/PersonTest.php é um rascunho inicial
e você precisa continuar seu desenvolvimento para transformá-lo em um teste de qualidade.
Quando você tentar editar o arquivo tests/Entity/PersonTest.php em seu IDE, não conseguirá gravar suas alterações, o que nos leva para a próxima fase ...

Os arquivos gerados a partir da shell session do 🐳 container não possuem o mesmo dono que os arquivos gerados na session da 💻 máquina host. Isto porque os linux users são diferentes em cada session. Em um caso muito comum, o arquivo gerado pela session do container pertencerá ao root do container e também ao root do host, e seu usuário atual, na máquina do host não poderá editá-lo. Existem várias formas de contornar isso. Serei agressivo, na escolha do contorno, dizendo ao projeto "dê-me tudo isso aqui, pois é meu!" com sudo + chown: 💻
sudo chown -R $USER:$USER ./
....

Muito bem, você zerou o jogo :) 🏁
Você pode contribuir com este projeto criando uma Pull Request ou informando o bug/melhoria em issues. Isto inclui correções ortográficas.
Veja a lista de melhorias que precisam de desenvolvimento.
Para desligar todos os container levantados durante a execução deste tutorial, você pode usar este comando: 💻
docker stop $(docker ps -a -q)
📝 Agora um extra, se você configurou seu computador usando o gpupo-meta/setup-machine, basta executar: 💻
docker-stop-all
Depois de carregar milhões de bits em imagens Docker, talvez você precise liberar removendo todas as imagens Docker em cache: 💻
docker-remove-all




