[CVPR 2023] The Official implementation of PyramidFlow. If you have any issues reproducing our work, please create a new issue, and we will reply as soon as possible.
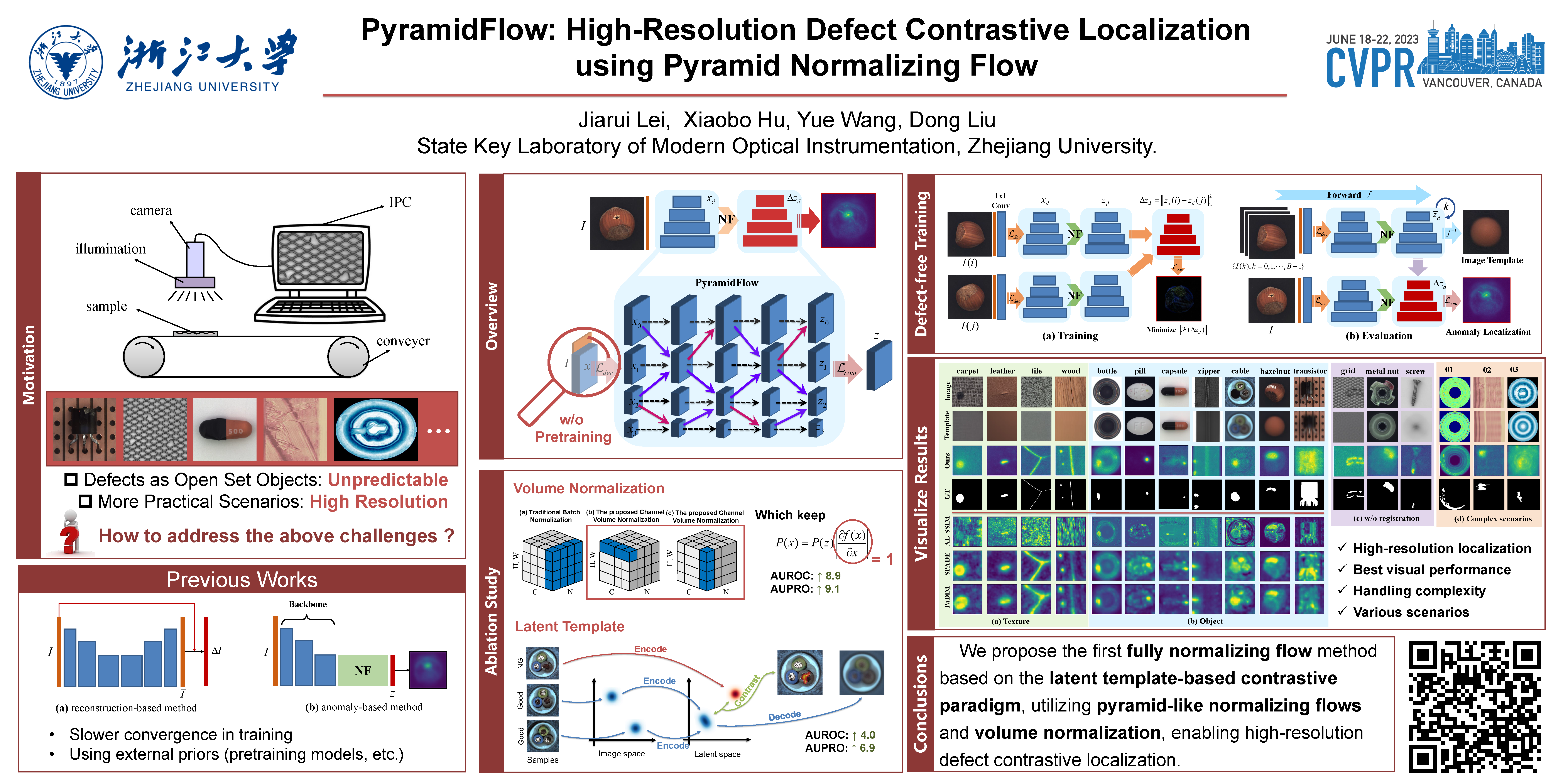
PyramidFlow is the first fully normalizing flow method, that can be trained end-to-end from scratch without external priors, which is based on the latent template-based contrastive paradigm, enabling high-resolution defect contrastive localization.
PyramidFlow: High-Resolution Defect Contrastive Localization Using Pyramid Normalizing Flow,
Jiarui Lei, Xiaobo Hu, Yue Wang, Dong Liu,
CVPR 2023 (arXiv 2303.02595)
During industrial processing, unforeseen defects may arise in products due to uncontrollable factors. Although unsupervised methods have been successful in defect localization, the usual use of pre-trained models results in low-resolution outputs, which damages visual performance. To address this issue, we propose PyramidFlow, the first fully normalizing flow method without pre-trained models that enables high-resolution defect localization. Specifically, we propose a latent template-based defect contrastive localization paradigm to reduce intra-class variance, as the pre-trained models do. In addition, PyramidFlow utilizes pyramid-like normalizing flows for multi-scale fusing and volume normalization to help generalization. Our comprehensive studies on MVTecAD demonstrate the proposed method outperforms the comparable algorithms that do not use external priors, even achieving state-of-the-art performance in more challenging BTAD scenarios.
- torch >= 1.9.0
- torchvision
- albumentations
- numpy
- scipy
- skimage
- sklearn
- logging
- glob
- PIL
Our demo code requires MVTecAD dataset, which is default placed at ../mvtec_anomaly_detection relative to the path of our code.
After installing the above requirement packages, run the below commands
git clone https://github.com/gasharper/PyramidFlow.git
cd PyramidFlow
wget https://raw.githubusercontent.com/gasharper/autoFlow/main/autoFlow.pyrun python train.py to train using default classes (tile) with default settings.
cls. category used to train the model. default is tile.datapath. The path of MVTecAD dataset. default is../mvtec_anomaly_detection.encoder. Which encoder/backbone is used. default is resnet18.numLayer. Num of pyramid layer (aka. laplacian pyramid layer). default is auto.volumeNorm. Which volume normalization technique is used. default is auto.kernelSize. The convolutional kernel size in normalizing flow. default is 7.numChannel. The convolutional channel in normalizing flow. default is 16.numStack. Num of block stacked in normalizing flow. default is 4.gpu. Training using which GPU device. default is 0.batchSize. Training batch size. default is 2.saveMemory. Whether use autoFlow to save memory during training. default is True, but training slower.
If you find this code useful, don't forget to star the repo ⭐ and cite the paper:
@InProceedings{Lei_2023_CVPR,
author = {Lei, Jiarui and Hu, Xiaobo and Wang, Yue and Liu, Dong},
title = {PyramidFlow: High-Resolution Defect Contrastive Localization Using Pyramid Normalizing Flow},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023},
pages = {14143-14152}
}







































