Notice: This project has been migrated to deno starting from v4.0.0 due to pkg being deprecated.
The Flaresolverr proxy feature requires FlareSolverr
For the headless/headfull browser feature, you may want to install the appropriate chrome or firefox version here, if a browser is already available locally, you can set it on the configuration file.
mx-scraper --help --verbose
mx-scraper --infos
mx-scraper -h -v
mx-scraper --show-plugins -v
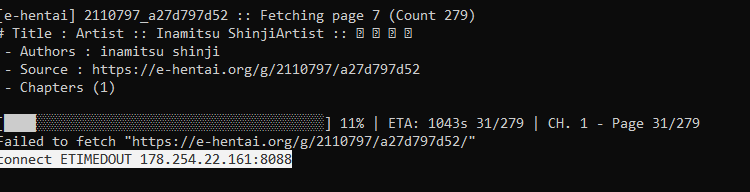
mx-scraper --show-plugins -v -cs
mx-scraper --search-plugin -v http://link/to/a/title
mx-scraper --auto --fetch http://link/to/a/title
mx-scraper --plugin <PLUGIN_NAME> --fetch-all title1 title2 title3
mx-scraper --auto --fetch-all --download --parallel http://link/to/title1 http://link/to/title2
mx-scraper --auto --download --parallel --fetch-file list.txt --meta-only
mx-scraper -a -d -pa -ff list.txt -mo
mx-scraper -a -d -pa -ff list.txt
mx-scraper -v -d --load-plan danbooru.yaml --plan-params TAG=bocchi_the_rock! "TITLE=Bocchi The Rock"- Download deno
- Install puppeteer
- Install FlareSolverr or update the configuration file if an instance is available on your network
- Run the following commands to make sure everything is working
# Cache dependencies
deno cache --config=./src/config.json --lock-write ./src/main.ts
# Testing (some tests require Flaresolverr)
deno test -A --config=./src/config.json ./tests
# Running (dev)
deno run -A --config=./src/config.json ./src/main.ts --infos
# Compiling
# deno compile -A --output mx-scraper --config=./src/config.json ./src/main.ts --is_compiled_binaryHtmlParser engine can be used through a local graphql client, this is very
useful if you want to understand how a web page is generated. A server can be
spawn with the --dev-parser flag (available by default on
http://localhost:3000/graphql).