前端九部 frontend9.com
具有共创色彩的九部精选文章 & 成员共同编写的手册
- 《九部知识库-精选集》
- 《前端九部 - 入门者手册2019》 基础前端手册,欢迎大家积极参与完善
- 《前端九部 - 前端面试题题库》 分享自己在各种公司面试时遇到的各种面试题,探讨宇宙终极答案
九部知识库
具有共创色彩的九部精选文章 & 成员共同编写的手册











































































































































































































天地玄黄,宇宙洪荒
前端开发,重要的就是 2 个(类)文件:
一个一站式的前端开发框架,要做的就是定义、构建、使用以上文件,其中
具体到 umi 框架,使用精巧的插件体系,把上述操作更加语义化以及细化

再搜索 umi 源码,可以看到更精细的插件 hook 点
以上这几个 hook 都是比较「纯粹」的,看名字就知道了:「modify」
还有一些 hook 点就不那么 pure 了,比如:generateFiles
作用是生成 DvaContainer.js 文件,直接就写到 writeSync 了
(为啥不搞成 pure hook 呢?可以的)
还有一些 hook 点是和运行时的生命周期挂钩的,看命名也就知道了
关于 umi 命令生命周期如图所示:
传送门🚁:umijs/umi#87

然后,插件就可以选取自己需要的 hook 点进行配置,以 umi-plugin-dva 插件为例:
chenni:umi-plugin-dva/ (master✗) $ grep -rn 'api.register' * [12:28:58]
lib/index.js:210: api.register('generateFiles', () => {
lib/index.js:226: api.register('modifyRouterFile', ({
lib/index.js:241: api.register('modifyRouteComponent', ({
lib/index.js:273: api.register('modifyEntryFile', ({
lib/index.js:285: api.register('modifyAFWebpackOpts', ({
lib/index.js:298: api.register('modifyPageWatchers', ({
src/index.js:178: api.register('generateFiles', () => {
src/index.js:201: api.register('modifyRouterFile', ({ memo }) => {
src/index.js:222: api.register('modifyRouteComponent', ({ memo, args }) => {
src/index.js:255: api.register('modifyEntryFile', ({ memo }) => {
src/index.js:269: api.register('modifyAFWebpackOpts', ({ memo }) => {
src/index.js:285: api.register('modifyPageWatchers', ({ memo }) => {所以,最后再总结一下:
ref:
未完待续(代码走读:插件的加载和执行)
本文记录了 rc-menu 中对于溢出菜单项自动收起的实现,由于之前踩了挺多坑,特此记录,希望温故能知新。
问题:

rc-menu 本身自带 submenu 功能,所以通过计算 scrollWidth 和 width 之间的差距来找出所有需要收起的菜单项,将它们统一收进一个构造出的 submenu item, 这样理论上能通过最少的代码变更优雅地实现这个功能。
当计算得出所有需要收起的菜单项之后,�需要解决一个问题,那就是如何隐藏原有的菜单项目。这里给出两种可能的尝试。
renderChildren(children) {
// lastVisibleIndex 为最后一个可见的菜单项 index
const { lastVisibleIndex } = this.state;
return React.Children.map(children, (childNode, index) => {
if (lastVisibleIndex !== undefined) {
if (index <= lastVisibleIndex) {
// 菜单项可见,直接渲染
return childNode;
} else if (index === lastVisibleIndex + 1) {
// 第一个被隐藏的项目,在这个位置渲染构造出的自动收起的菜单项
return this.getOverflowedSubMenuItem();
} else {
// 隐藏菜单项
return React.cloneElement(
childNode,
// 1. 我们需要显示隐藏菜单项,因为第一个被隐藏的菜单项可能会部分可见,
// 而且无法被自动收起的占位菜单项全部遮盖
// 2. 考虑不不用 display: 'none',因为在后续的 resize 过程中,
// 我们还需要能够获得所有菜单项的 scrollWidth 来重新计算是否需要
// 在某个位置渲染自动收起的占位菜单项。
{ style: { visibility: 'hidden' } },
);
}
}
});如下图所示,因为溢出菜单项只是被隐藏起来,但是元素还是在 dom,而 ... 占位的菜单项中的元素是根据原来的元素克隆而出,而 rc-menu 使用 eventKey 作为真正的 key,克隆过程中 eventKey 没有改变,导致被克隆元素跟原有元素同 key, 所以如果一个子菜单被打开时,被隐藏的菜单项中的子菜单也会被激活。

在不明白问题的本质时,所以决定与其简单的隐藏,不如直接选择不去渲染剩下的元素,这样就不会碰到上述问题。至于所需要用来参照的元素宽度值,只要在每次需要计算的时候在页面的某个地方单独渲染菜单并记录所有元素的大小,这样就可以拿到所有元素原始的正确尺寸。
renderChildren(children) {
// lastVisibleIndex 为最后一个可见的菜单项 index
const { lastVisibleIndex } = this.state;
return React.Children.map(children, (childNode, index) => {
if (lastVisibleIndex !== undefined) {
if (index <= lastVisibleIndex) {
// 菜单项可见,直接渲染
return childNode;
} else if (index === lastVisibleIndex + 1) {
// 第一个被隐藏的项目,在这个位置渲染构造出的自动收起的菜单项
return this.getOverflowedSubMenuItem();
} else {
// 隐藏菜单项不再渲染
return null;
}
}
return childNode;
});
}
// 当需要重新计算菜单溢出收起时, memorize rendered menuSize
setChildrenSize() {
const container = document.body.appendChild(document.createElement('div'));
container.setAttribute('style', 'position: absolute; top: 0; visibility: hidden');
this.store = create({
selectedKeys: [],
openKeys: [],
activeKey: {},
});
ReactDOM.render(
<Provider store={this.store}>
<Tag {...rest}>{children}</Tag>
</Provider>, // content
container, // container
() => { // callback
const ul = container.childNodes[0];
const scrollWidth = getScrollWidth(ul);
this.props.children.forEach((c, i) => this.childrenSizes[i] = getWidth(ul.children[i]));
this.originalScrollWidth = scrollWidth;
ReactDOM.unmountComponentAtNode(container);
document.body.removeChild(container);
this.handleResize();
});
}rc-menu 的元素不可以这样随意提出,因为用户代码可能依赖各种个样的 Provider,比如 rc-menu 常常被用作导航头,所以碰到需要 router 作为 provider 的情况下,这里就会挂掉
其实为了解决第一个坑,用踩第二个坑的做法是完全没有必要的。这里只需要改变被隐藏元素的 render key 就好了。
renderChildren(children) {
// lastVisibleIndex 为最后一个可见的菜单项 index
const { lastVisibleIndex } = this.state;
return React.Children.map(children, (childNode, index) => {
if (lastVisibleIndex !== undefined) {
if (index <= lastVisibleIndex) {
// 菜单项可见,直接渲染
return childNode;
} else if (index === lastVisibleIndex + 1) {
// 第一个被隐藏的项目,在这个位置渲染构造出的自动收起的菜单项
return this.getOverflowedSubMenuItem();
} else {
// 隐藏菜单项
return React.cloneElement(
childNode,
// 这里修改 eventKey 是为了防止隐藏状态下还会触发 openkeys 事件
{ style: { visibility: 'hidden' }, eventKey: `${childNode.props.eventKey}-hidden` },
);
}
}
});
}对于子元素发生变化的情况,溢出自动收起也需要重新计算。导航头文字在不同语言环境下的切换就是最常见的例子。最简单直观的实现方式:
componentDidUpdate(prevProps) {
if (prevProps.children !== this.props.children
|| prevProps.overflowedIndicator !== this.props.overflowedIndicator
) {
// 检查更新并且重新计算溢出自动收起占位符的位置。
this.updateNodesCacheAndResize();
}
}在 ant-design 的 demo 页面,因为某种原因,在打开收起菜单中的子菜单时,会看到子菜单闪动,用户只是想打开子菜单,但是竟然看到了内部子菜单的闪动。也就是说在这个过程中子菜单重新挂载了。这是为什么呢?两个问题:
renderChildren(children) {
// 每次 componentWillReceiveProps 里,
// 将 lastVisibleIndex 初始值置成 undefined
const { lastVisibleIndex } = this.state;
return React.Children.map(children, (childNode, index) => {
// 在 componentDidUpdate 里根据上一轮获得的原始菜单大小
// 重新计算 lastVisibleIndex,然后执行下面 if 中的逻辑
if (lastVisibleIndex !== undefined) {
if (index <= lastVisibleIndex) {
// 菜单项可见,直接渲染
return childNode;
} else if (index === lastVisibleIndex + 1) {
// 第一个被隐藏的项目,在这个位置渲染构造出的自动收起的菜单项
return this.getOverflowedSubMenuItem();
} else {
// 隐藏菜单项不再渲染
return null;
}
} else {
// 第一轮 lastVisibleIndex 为 undefined
// 正常渲染菜单
return childNode;
}
});
}这样每次自上而下发生 componentDidUpdate 之后,其实元素在这个 if else 过程中发生了重新挂载。
使用 MutationObserver + ResizeObserver 而不是简单的在 componentDidUpdate 中比较 children 引用。MutationObserver 用于监听子元素个数发生变化的情况,而 ResizeObserver 用来监听菜单项宽度发生变化的情况,这样回调函数的执行才是精准高效的,这解决第一个问题。
componentDidMount() {
const menuUl = ReactDOM.findDOMNode(this);
if (!menuUl) {
return;
}
this.resizeObserver = new ResizeObserver(entries => {
entries.forEach(this.setChildrenWidthAndResize);
});
[].slice.call(menuUl.children).concat(menuUl).forEach(el => {
this.resizeObserver.observe(el);
});
this.mutationObserver = new MutationObserver(() => {
this.resizeObserver.disconnect();
[].slice.call(menuUl.children).concat(menuUl).forEach(el => {
this.resizeObserver.observe(el);
});
this.setChildrenWidthAndResize();
});
this.mutationObserver.observe(
menuUl,
{ attributes: false, childList: true, subTree: false }
);
}对于第二个问题,如何避免二次渲染并且能够
其实有了 MuationObserver + ResizeObserver 我们也避免了上述问题。因为本质上我们不再依赖 componentDidUpdate 这样的 react 生命周期函数,而是依赖原生的 js 事件,这样在回调函数中,重新计算菜单项的大小,然后 setState({ lastVisibleIndex }) 即可。
第三个坑是关于在正确的位置渲染溢出菜单项自动收起占位符的。最简单直观的方式是在菜单子元素末端渲染溢出占位符,然后用相对定位的方式来改变其在菜单项中的位置。
rc-menu 作为 antd 的基类库,在许多地方都被用到。menu 一直是以 position: static 的方式存在的,冒然将 menu 的 position 改为 relative,会导致已有代码出现各种个样的 bug。
千万不敢随意改动 position 的类型,尤其是对于最基础的基类组件库而言。如果尝试在渲染过程中将溢出占位符动态地插入原来的菜单子元素序列,那么可能造成其他的问题,比如重新计算位置信息的时候,需要用很多 if 语句去判断菜单的子元素是不是菜单项的原生子元素还是占位符;而且可能导致不必要的元素重新挂载。这里一个比较巧妙优雅的做法是,给每个菜单项后面都加一个占位符元素,正常情况下不显示,当需要的时候再显示。
renderChildren(children) {
// need to take care of overflowed items in horizontal mode
const { lastVisibleIndex } = this.state;
return (children || []).reduce((acc, childNode, index) => {
let item = childNode;
let overflowed = this.getOverflowedSubMenuItem(childNode.props.eventKey, []);
if (lastVisibleIndex !== undefined
&&
this.props.className.indexOf(`${this.props.prefixCls}-root`) !== -1
) {
if (index > lastVisibleIndex) {
item = React.cloneElement(
childNode,
// 这里修改 eventKey 是为了防止隐藏状态下还会触发 openkeys 事件
{ style: { visibility: 'hidden' }, eventKey: `${childNode.props.eventKey}-hidden` },
);
}
if (index === lastVisibleIndex + 1) {
this.overflowedItems = children.slice(lastVisibleIndex + 1).map(c => {
return React.cloneElement(
c,
// children[index].key will become '.$key' in clone by default,
// we have to overwrite with the correct key explicitly
{ key: c.props.eventKey, mode: 'vertical-left' },
);
});
overflowed = this.getOverflowedSubMenuItem(
childNode.props.eventKey,
this.overflowedItems,
);
}
}
const ret = [...acc, overflowed, item];
if (index === children.length - 1) {
// need a placeholder for calculating overflowed indicator width
ret.push(this.getOverflowedSubMenuItem(childNode.props.eventKey, [], true));
}
return ret;
}, []);
}最后再总结一下踩过的坑和得到的经验教训。

我从具体的项目中分离出了一个有趣的问题,可以描述如下:
页面上有一个按钮,每次点击它,都会发送一个ajax请求,
并且,用户可以在ajax返回之前点击它。
现在我们要实现一个功能,
以按钮的点击顺序展示ajax的响应结果。
为了以后编码的方便,先将ajax请求mock一下,
let count = 0;
// 模拟ajax请求,以随机时间返回一个比之前大一的自然数
const mockAjax = async () => {
console.warn('send ajax');
await new Promise((res, rej) => setTimeout(() => res(++count), Math.random() * 3000));
console.warn('ajax return');
return count;
};
然后,假设按钮的id为sendAjax,
<input id="sendAjax" type="button" value="Click" />

document.querySelector('#sendAjax').addEventListener('click', async () => {
const result = await mockAjax();
console.log(result);
});
一开始,我们可能会想到这样的办法。
可惜,这是有问题的。
因为click事件,可能会在后面async函数还未返回之前,再次触发。
导致前一个请求还未返回,后面又发起了新请求。
其次,我们可能还会想到,记录每一个请求的时间戳,将结果排序,
这也是有问题的,因为我们不知道未来还有多少次点击(<- 下文的关键信息),
如果无法拿到所有的结果,那么排序就有困难了。
那怎么办呢?
如果请求还未返回之前,能进行控制就好了。

于是我想到了把新请求lazy化,放到一个队列中,
如果当前有其他任务在执行,就暂不处理。
否则,如果当前是空闲的,那就把队列中的任务都取出来,依次执行。
const PromiseExecutor = class {
constructor() {
// lazy promise队列
this._queue = [];
// 一个变量锁,如果当前有正在执行的lazy promise,就等待
this._isBusy = false;
}
each(callback) {
this._callback = callback;
}
// 通过isBusy实现加锁
// 如果当前有任务正在执行,就返回,否则就按队列中任务的顺序来执行
add(lazyPromise) {
this._queue.push(lazyPromise);
if (this._isBusy) {
return;
}
this._isBusy = true;
// execute是一个async函数,执行后立即返回,返回一个promise
// 因此,add可以在execute内的promise resolved之前再次执行
this.execute();
};
async execute() {
// 按队列中的任务顺序来依次执行
while (this._queue.length !== 0) {
const head = this._queue.shift();
const value = await head();
this._callback && this._callback(value);
}
// 执行完之后,解锁
this._isBusy = false;
};
};
以上代码,我用了一个队列和变量锁,对新请求进行了管控。
其中的关键点是execute的异步性,
我们看到add函数在尾部调用了this.execute();,会立即返回。
这样就不会阻塞JavaScript线程,可以多次调用add函数了。
下面我们来看下它的使用方法吧,
const executor = new PromiseExecutor;
document.querySelector('#sendAjax').addEventListener('click', () => {
// 添加一个lazy promise
executor.add(() => mockAjax());
});
// 注册回调,该回调会按lazy promise的加入顺序,逐个获取它们resolved的值
executor.each(v => {
console.log(v);
});

上文中有一句话,启发了我,
迫使我从不同的角度重新考虑了这个问题。
我们提到,由于“我们不知道未来还有多少次点击”,所以是无法进行排序的。
因此,我发现这是一个和“无穷流”相关的问题。
即,我们不应该把事件看成回调,而是应该看成流(stream)。
所以,我们可以寻找响应式的方式来解决它。
以下两篇文章可以帮你快速回顾一下响应式编程(Reactive Programming)。
——也称反应式编程 _(:зゝ∠)_

好了,下面我们要开始进行响应式编程了。
首先,click事件可以形成一个“点击流”,
const clickStream = cont => document.querySelector('#sendAjax').addEventListener('click', cont);
这里的cont指的是Continuation,可以参考上面提到的第二篇文章。
其次,我们需要将这个“点击流”,变换成最终的“ajax结果流”,
并且保证“ajax结果流”的顺序,与“点击流”的顺序相同。
因此,问题在概念上就被简化了,
事实上,所有的stream连同operator一起,构成了一个Monad。
下面我们来编写operator吧,用来对流进行变换,我们只要记着,
“什么时候调用cont就什么时候把东西放到结果流中”,即可。
const streamWait = function (mapValueToPromise) {
const stream = this;
// 使用一个队列和一个变量锁来进行调度
// 如果当前正在处理,就入队,否则就一次性清空队列
// 并且在清空的过程中,有了新的任务还可以入队
const queue = [];
let isBusy = false;
return cont => stream(async v => {
queue.push(() => mapValueToPromise(v));
// 如果当前正在处理,就返回,不改变结果stream中的值
if (isBusy) {
return;
}
// 否则就按顺序处理,将每一个任务的返回值放到结果流中
isBusy = true;
while (queue.length !== 0) {
const head = queue.shift();
const r = await head();
cont(r);
}
// 处理完了以后,恢复空闲状态
isBusy = false;
});
};
我们再来看下怎么使用它,是不是更加通俗易懂了呀。
// 点击流
const clickStream = cont => document.querySelector('#sendAjax').addEventListener('click', cont);
// ajax结果流
const responseStream = streamWait.call(clickStream, e => mockAjax());
// 订阅结果流
responseStream(v => console.log(v));

Your mouse is a database. —— Erik Meijer
从 webpack 2 开始,开始有了 tree shaking 这项喜大普奔的技术。当你的代码使用 es6 模块系统时,webpack 可以标记导出了但未使用的 dead code ,并在丑化阶段移除它们,从而减小构建产物体积。
如果你尚未接触过此项技术,建议先阅读官方文档:Tree Shaking,以便有足够的基础阅读接下来的讨论。
如果不做任何处理,tree shaking 并不能非常显著地减小产物体积,原因简而言之,就是 tree shaking 过程中, webpack 无法判断一个模块包是否有副作用,因此即使引入了它但没有使用,webpack 也只能保守地选择保留其代码。
我们通过一个简单的例子来看下这个过程。
新建个简单的 webpack 项目:
// index.js
import { add } from './math';
// 引入了 add,但不使用
// console.log('1 + 1 =', add(1+1));// math.js
import './big-module';
export function add(a, b) {
return a + b;
}
export function mines(a, b) {
return a - b;
}// big-module.js
console.log('I am a big module');// webpack.config.js
const path = require('path');
const UglifyJsPlugin = require('uglifyjs-webpack-plugin')
module.exports = {
entry: './index.js',
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'bundle.js'
},
devtool: 'none',
mode: 'none',
optimization: {
minimize: true,
minimizer: [
new UglifyJsPlugin()
],
namedModules: true,
usedExports: true,
}
};namedModules 可以给 bundle 的模块标上名称,方便调试。
usedExports 可以标记未使用的导出模块,以便在丑化阶段移除它们。
index.js 引用了 math.js ,math.js 又引用了 big-module.js。但 index.js 并未使用 math.js 里的导出方法。按照 tree shaking 的理解,math.add 和 math.mines 方法会被移除。我们观察构建产物 bundle.js 可以验证这一结论:

math.js 里的所有导出方法都被移除了,这就减小了产物体积。但进一步可以发现,移除导出方法后的 math.js 和 big-module.js 其实并没有干任何事情,但仍然进入了产物,为什么不一并移除?其实这是可以理解的:如果单纯 import 了另个模块,webpack 无法判断引入的这个模块是否会产生副作用,比如修改 window 这种行为,所以必须保守地保留下来。
如同刚才的例子,big-module 里要打印一句话。如果仅因为 import 了但没使用而被移除的话,产物在执行的时候,就无法打印这句话了,即“有用的代码被误删”。
有副作用的模块多见于各类 polyfill。它们会修改 window 变量。
如果 tree shaking 彻底一点,把未使用但无副作用的模块一并删除,就能进一步减少产物体积。这个时候便要依赖 sideEffects 优化选项。
我们修改一点刚才的项目代码。
开启 webpack sideEffects:

声明此项目所有模块都无副作用:

重新 build 后,观察构建产物发现,math.js 和 big-module.js 都被移除了,整个 bundle 只剩下 index.js 空壳子:

所以这就是 sideEffects 优化选项的作用:“把未使用但无副作用的模块一并删除”。
正确使用此优化手段的威力巨大:

v4 beta 版时叫 pure module, 后来改成了 sideEffects
简历投递地址: chenglin.mcl#antfin.com
We want you! 让我们一起来创造惊艳的用户体验。
CSS 即层叠样式表(Cascading Stylesheet)。Web 开发中采用 CSS 技术,可以有效地控制页面的布局、字体、颜色、背景和其它效果。只需要一些简单的修改,就可以改变网页的外观和格式。
CSS3 是 CSS 的升级版本,这套新标准提供了更加丰富且实用的规范,如:盒子模型、列表模块、超链接方式、语言模块、背景和边框、文字特效、多栏布局等等。今天主要想跟大家分享CSS3 的渐变效果(Gradient)以及阴影(Shadow)和反射(Reflect)效果。
起因是之前看过一个网站叫 A Single Div,里面展示的内容都是只用了一个div + css来实现的。看过之后的感觉,就是惊叹~明明都是前端的同学,为什么别人的CSS这么优秀~


其中所有的实现基本都与background-image和box-shadow这两个属性相关,我的代码详情看这里: SingleDiv,可以自己先撸,撸不出来看网页源代码就可以啦~
background-image属性为元素设置背景图像。元素的背景占据了元素的全部尺寸,包括内边距和边框,但不包括外边距。默认地,背景图像位于元素的左上角,并在水平和垂直方向上重复。可以根据background-repeat属性来指定图像无限平铺、沿着某个轴(x 轴或 y 轴)平铺,或者根本不平铺,也可以根据background-position属性指定初始背景图像(原图像)放置的位置。
1. Regular-images普通的图片
2. Gradient-images渐变的图片

详情请移步:css-tricks
3. Setting A Fallback Color
4. Multiple Background Images
这个属性用于给元素块添加周边阴影效果。
基本语法:{box-shadow:[inset] x-offset y-offset blur-radius spread-radius color}
.box-shadow{
box-shadow: -10px 0 10px red,/*左边阴影*/
10px 0 10px yellow,/*右边阴影*/
0 -10px 10px blue,/*顶部阴影*/
0 10px 10px green,/*底部阴影*/
0 0 20px black;/*四周都有黑色阴影*/
}
之前看到一个有意思的文章 前端人工智能?TensorFlow.js 学会游戏通关,使用tensorflow.js训练模型玩google无网页面的彩蛋T-Rex Runner 。看了下代码,恩...果断看不懂。先看下演示效果: Genetic Algorithm - T-Rex Runner,希望大家在读完这篇文章后至少能看懂源码了=。=,原理以后再扯,我也不懂。
实际上之前火爆过的flappy bird早就有多种神经网络或是强化学习的算法试验过了。但还是觉得很有意思,所以拿过来给大家做科普,顺便可以探讨下前端如何结合人工智能,可以做些什么?
TensorFlow.js 于3 月 30 日谷歌 TenosrFlow 开发者峰会正式发布,核心改编自deeplearn.js,面向JS提供一套可以在浏览器中运行的机器学习库(应该说是API,类似python)。
亮点是可以用WebGL加速,即可以用GPU加速,一般训练机器学习模型非常的消耗计算资源(比如能做机器学习计算的显卡会非常火爆)。
比如:Sketching Interfaces 从原型到代码
https://js.tensorflow.org/#getting-started
虽然部分demo可能是之前机器学习玩剩下的,但这些例子算是首次在纯浏览器中训练运行。
…
官网例子解说,目标是能够看懂t-rex-runner的代码
过程: 给定数据,训练拟合函数,输出模型,根据模型预测给定值的输出
<html>
<head>
<!-- Load TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/[email protected]"> </script>
<!-- Place your code in the script tag below. You can also use an external .js file -->
<script>
// 线性回归模型(可以理解为线性方程)
const model = tf.sequential();
model.add(tf.layers.dense({units: 1, inputShape: [1]}));
// 设定损失函数为平均方差和,训练算法为随机梯度下降算法sgd
model.compile({loss: 'meanSquaredError', optimizer: 'sgd'});
// 训练数据,X轴和y轴
const xs = tf.tensor2d([1, 2, 3, 4], [4, 1]);
const ys = tf.tensor2d([1, 3, 5, 7], [4, 1]);
// 训练数据拟合后,预测新值的输出
model.fit(xs, ys).then(() => {
model.predict(tf.tensor2d([5], [1, 1])).print();
});
</script>
</head>
<body>
</body>
</html>a set of numerical values shaped into an array of one or more dimensions.
将一系列数值切分到数组或多维中
// 2x3 Tensor
const shape = [2, 3]; // 2 rows, 3 columns
const a = tf.tensor([1.0, 2.0, 3.0, 10.0, 20.0, 30.0], shape);
a.print(); // print Tensor values
// Output: [[1 , 2 , 3 ],
// [10, 20, 30]]把一个张量想象成一个n维的数组或列表。看到这玩意让我想到了大学线性代数里的向量和矩阵,后来查到还有一个标量。
标量(单独的数,0维):
x
向量: (可以理解为一维数组)
矩阵: (可以理解为二维数组)
我们可以将标量视为零阶张量,矢量视为一阶张量,那么矩阵就是二阶张量,当然还可以更多阶...
当然对于低阶的张量,tensorflow提供了方便的API来构造:
tf.scalar, // 标量
tf.tensor1d, // 向量
tf.tensor2d, // 矩阵
tf.tensor3d // 三维数组
tf.tensor4d. // 四维数组
// 比如:
const c = tf.tensor2d([[1.0, 2.0, 3.0], [10.0, 20.0, 30.0]]);
c.print();
// Output: [[1 , 2 , 3 ],
// [10, 20, 30]]
// 还有比如
tf.zeros // 全张量初始化为0
tf.ones // 全张量初始化为1
const zeros = tf.zeros([3, 5]);
// Output: [[0, 0, 0, 0, 0],
// [0, 0, 0, 0, 0],
// [0, 0, 0, 0, 0]]张量一旦创建不可改变,但你可以在他们上做操作生成新的张量。很像React的Immutable.js的**
变量通过张量初始化,但是值可以改变
const initialValues = tf.zeros([5]);
const biases = tf.variable(initialValues); // initialize biases
biases.print(); // output: [0, 0, 0, 0, 0]
const updatedValues = tf.tensor1d([0, 1, 0, 1, 0]);
biases.assign(updatedValues); // update values of biases
biases.print(); // output: [0, 1, 0, 1, 0]张量用于存储数据,操作可以修改这些数据,返回新的张量。用下来像是以张量为基本单位进行的便捷操作,比如:
// 乘方操作
const d = tf.tensor2d([[1.0, 2.0], [3.0, 4.0]]);
const d_squared = d.square();
d_squared.print();
// Output: [[1, 4 ],
// [9, 16]]
// 张量加减乘法
const e = tf.tensor2d([[1.0, 2.0], [3.0, 4.0]]);
const f = tf.tensor2d([[5.0, 6.0], [7.0, 8.0]]);
const e_plus_f = e.add(f);
e_plus_f.print();
// Output: [[6 , 8 ],
// [10, 12]]
// 当然还可以链式操作
const sq_sum = e.add(f).square();模型: 给定输入,产生输出,像一个方程。
有的时候方程可能非常复杂,我们只有这些方程的数据,然后需要通过这些数据对这个方程进行拟合(训练),然后给出新的数据,我们就能够通过这个模型进行预测。
from网络: 根据已知数据寻找模型参数的过程就是训练,最终搜索到的映射\hat{f}被称为训练出来的模型
Tensorflow.js 给出了两种创建模型的方式,一种是通过各种操作直接描述模型,比如:
// 声明标量,方程的常量
const a = tf.scalar(2);
const b = tf.scalar(4);
const c = tf.scalar(8);
// 因为js没有操作符重载,所以各种操作不是那么直观。
function predict(input) {
// tensor存在GPU内存中,tidy用于清理除了最后返回的张量以外的中间张量,防止内存泄露,另外还有dispose函数用于清除单个张量。
return tf.tidy(() => {
// y = a * x ^ 2 + b * x + c
const x = tf.scalar(input);
const ax2 = a.mul(x.square());
const bx = b.mul(x);
const y = ax2.add(bx).add(c);
return y;
})
}
predict(2).print();
// 24第二种方式是使用tf提供的高阶API ,tf.model,用层来构建模型,什么是层?层是深度学习中的一个重要抽象概念,一个普通的神经网络通常由多个层组成,比如输入层,输出层,隐藏层,深度学习为什么深?就是因为隐藏层比较多(大于2)。
例子:
// 不要问我RNN是什么,我也不懂...
const model = tf.sequential(); // 线性模型,每一层的输入依赖于上一层的输出
model.add(
// RNN : 循环神经网络(Recurrent Neural Network) https://zybuluo.com/hanbingtao/note/541458
tf.layers.simpleRNN({
units: 20,
recurrentInitializer: 'GlorotNormal',
inputShape: [80, 4]
})
);
// SGD: 随机梯度下降算法 https://www.zybuluo.com/hanbingtao/note/448086 暂时也讲不清楚
const optimizer = tf.train.sgd(LEARNING_RATE); // 算法
model.compile({optimizer, loss: 'categoricalCrossentropy'}); // 编译
model.fit({x: data, y: labels)}); // 训练好吧,如果你一定要知道SGD是啥:
RNN是啥:
我也没看懂…不班门弄斧了…看懂了再讲…
https://js.tensorflow.org/tutorials/fit-curve.html 快速开始教程(拟合线性方程)的进阶版本,教程都可以在官网找到,了解核心概念后看这些代码应该能大概看懂了。
代码示例:
https://github.com/tensorflow/tfjs-examples/tree/master/polynomial-regression-core
运行效果:
目标方程: y = ax^3 + bx^2 + cx + d. 参数值为: a: -0.8, b: -0.2, c: 0.9, d: 0.5
运行目标:我们知道函数长这样,但具体的参数值不清楚,猜测a,b,c,d的值。训练的过程就是最小化误差的过程
const a = tf.variable(tf.scalar(Math.random()));
const b = tf.variable(tf.scalar(Math.random()));
const c = tf.variable(tf.scalar(Math.random()));
const d = tf.variable(tf.scalar(Math.random()));function predict(x) {
// y = a * x ^ 3 + b * x ^ 2 + c * x + d
return tf.tidy(() => {
return a.mul(x.pow(tf.scalar(3)))
.add(b.mul(x.square()))
.add(c.mul(x))
.add(d);
})
}判断拟合程度,一般为均方误差( 平方损失除以样本数)这个值越低,代表拟合越好。评价好坏用。
function loss(prediction, labels) {
// 预测值和真实值的差值平方取平均,比方说完全拟合,结果就是0
const error = prediction.sub(labels).square().mean();
return error;
}随机梯度下降算法(最常见的优化算法),求取目标函数(损失函数)的最小值
// 学习率,每次一小步,逐渐靠近目标值
const learningRate = 0.5;
const optimizer = tf.train.sgd(learningRate);训练多少轮,即调整多少次数值
const numIterations = 75;
async function fit(xs, ys, numIterations) {
for (let iter = 0; iter < numIterations; iter++) {
// train
optimizer.minimize(() => {
const pred = predict(xs);
return loss(pred, ys);
})
}
await tf.nextFrame();
}途中有三个恐暴龙是因为作者用的多玩家模式优化算法,通过多只恐暴龙同时训练,达到见多识广的效果(多重影分身)。
问题描述: 根据状态(输入)进行是否跳跃的预测predict(输出)。
输入:
return [
state.obstacleX / CANVAS_WIDTH, // 障碍物离暴龙的距离
state.obstacleWidth / CANVAS_WIDTH, // 障碍物宽度
state.speed / 100 // 当前游戏全局速度
];输出:
[0.2158, 0.8212]
// 其中第一维代表暴龙保持状态不变的可能性,而第二维度代表跳跃的可能性预测方式:
f([0.1428, 0.02012, 0.00549]) = [0.2158, 0.8212]表示预测结果为跳跃
训练过程嵌入生命周期,最主要在以下三个函数中嵌入训练和预测过程:
跑的过程中判断是否要跳,还是保持不动。
function handleRunning({ tRex, state }) {
return new Promise((resolve) => {
if (!tRex.jumping) { // 在跳的过程中不做判断
let action = 0;
const prediction = tRex.model.predictSingle(convertStateToVector(state));
prediction.data().then((result) => {
if (result[1] > result[0]) { // 不跳
action = 1;
tRex.lastJumpingState = state;
} else { // 跳
tRex.lastRunningState = state;
}
resolve(action);
});
} else {
resolve(0);
}
});
}crash的时候进行训练数据的收集
function handleCrash({ tRex }) {
let input = null;
let label = null;
if (tRex.jumping) { // crash的时候在跳
input = convertStateToVector(tRex.lastJumpingState);
label = [1, 0]; // 下次遇到这种情况别跳啊
} else { // crash的时候在跑
input = convertStateToVector(tRex.lastRunningState);
label = [0, 1]; // 下次遇到这种情况要跳啊
}
// 存下来crash的数据
tRex.training.inputs.push(input);
tRex.training.labels.push(label);
}function handleReset({ tRexes }) {
const tRex = tRexes[0];
if (firstTime) { // 首次初始化模型
firstTime = false;
tRex.model = new NNModel();
tRex.model.init();
tRex.training = {
inputs: [],
labels: []
};
} else { // 第二次之后开始训练
tRex.model.fit(tRex.training.inputs, tRex.training.labels);
}
}和之前的predict不同,这个函数的样子我们未知,使用神经网络模拟。看他的模型,你会发现你也能看得懂了(至少是语法层面上)。
predict(inputXs) { // 预测
const x = tensor(inputXs);
const prediction = tf.tidy(() => {
const hiddenLayer = tf.sigmoid(x.matMul(this.weights[0]).add(this.biases[0]));
const outputLayer = tf.sigmoid(hiddenLayer.matMul(this.weights[1]).add(this.biases[1]));
return outputLayer;
});
return prediction;
}
train(inputXs, inputYs) { // 单次训练
this.optimizer.minimize(() => {
const predictedYs = this.predict(inputXs);
return this.loss(predictedYs, inputYs);
});
}
fit(inputXs, inputYs, iterationCount = 100) { // 拟合,训练多次
for (let i = 0; i < iterationCount; i += 1) {
this.train(inputXs, inputYs);
}
}
loss(predictedYs, labels) { // 损益度量
const meanSquareError = predictedYs
.sub(tensor(labels))
.square()
.mean();
return meanSquareError;
}在PC时代,302跳转似乎已经成为一种模式,在非常多的场景下使用302的方式,并且并没有发现有任何的不妥,但是在这几年做移动开发的时候,却发现302跳转带来了严重的性能问题,并且在最近的几个项目里特别明显,302在移动端的主要问题在于几个方面:
在弱网环境下,一个302的请求会造成大概3s+的时间,在加上后续的200的请求,基本需要5s+的时间。
举一个例子说明:
在PC时代,做两个不同域名的信任登录,一般的做法为,访问a.com域名,然后a.com域名302到b.com域名,b.com域名使用token,从服务端去a.com的服务端验证,然后做好登录后,在302到真正的业务页面,b.com/page1.html。
这在PC时代是一个非常常用的方法,但是这种方法,在移动端就会造成严重的性能问题,一共有3次请求,前两次请求,在弱网环境下,耗时在10s左右的时候,当最后一次200的时候,可能总体时间已经超过了将近12s,12s的纯白屏,我相信对于任何用户都是无法忍受的,并且作为页面无法做任何体验上的优化,因为连一条js代码、html代码都还下来呢,并且这种性能问题,非常的隐蔽,因为常用的页面性能耗时是无法统计2次302跳转和一条200的请求时间的。
在测试阶段,由于使用的是wifi环境,性能非常好,几乎不会发现这个性能,因此这种情况,经常发现在线上,用户反馈很慢,才会注意到。这种时候,再改302的逻辑,会非常困难的。
想想OAuth的实现方式吧,这里就不说了。因此对于移动端,需要非常的注意这个问题。
实践经验:最多一次302,绝不要超过2次,否则就准备哭吧。
声明式编程可以提高程序整体的可读性(面向人、机器),包括不限于声明类型、声明依赖关系、声明API路径/方法/参数等等。从面向机器的角度,声明式的好处在于可以方便的提取这些元信息进行二次加工。声明式也是对系统整体的思考,找到关注点,划分切面,提高重用性。从命令式到声明式,是从要怎么做,到需要什么的转变。
本文偏重于 Egg 中的实践、改造,偏重于系统整体,在具体实现功能的时候,比如使用 forEach/map 替代 for 循环,使用 find/include 等替代 indexOf 之类的细节不做深入。
Controller 作为系统对外的接口,涉及到前后端交互,改变带来的提升是最明显的。
在 Java 体系里,Spring MVC 提供了一些标准的注解来支持API定义,一种普通的写法是:
@RequestMapping(value = "api/foo/{fooId}", method = RequestMethod.POST)
@ResponseBody
public Result<Void> create(HttpServletRequest request) {
Boolean xxxx = StringUtils.isBlank(request.getParameter("fooId"));
if (无权限) {
...
}
...// 日志记录
}这种声明式的写法使我们可以很容易的看出这里声明了一个 POST 的API,而不需要去找其他业务逻辑。不过这里也有一些问题,比如需要通读代码才能知道这个API的入参是 fooId,而当 Controller 的逻辑很复杂的时候呢?而权限判断之类的逻辑就更难看出了。
很显然这种写法对于看代码的人来说是不友好的。这种写法隐藏了参数信息这个我们关注的东西,自然很难去统一的处理入参,像参数格式化、校验等逻辑只能和业务逻辑写在一起。
而另一种写法就是把参数声明出来:
@RequestMapping(value = "api/foo/{fooId}", method = RequestMethod.POST, name = "创建foo")
@ResponseBody
public Result<Void> create(@PathVariable("fooId") String fooId, Optional<boolean> needBar) {
...
}(Java 也在不断的改进,比如 JDK 8 加入的 Optional<T> 类型,结合 Spring 就可以用来标识参数为可选的)
这些都是在 Java/Spring 设计之内的东西,那剩下的比如权限、日志等需求呢?其实都是同理,这种系统上的关注点,可以通过划分切面的方式把需求提取出来,写成独立的注解,而不是跟业务逻辑一起写在方法内部,这样可以使程序对人,对机器都更可读。
抽象权限切面:
/**
* 创建foo
* @param fooId
* @return
*/
@RequestMapping(value = "api/foo/{fooId}", method = RequestMethod.POST, name = '创建Foo')
@Permission(Code = PM.CREATE_FOO) // 假设权限拦截注解
@ResponseBody
public Result<Void> create(@PathVariable("fooId") String fooId) {
...
}声明式的优点不仅是对人更可读,在用程序做分析的时候也更方便。比如在日常开发中,经常有需求是后端人员需要给前端人员提供API接口文档等信息,最常用的生成文档的方式是写完善的注释,然后通过 javadoc 可以很容易的编写详细的文档,配合 Doclet API 也可以自定义 Tag,实现自定义需求。
注释是对代码的一种补充,从代码中可以提取的信息越多,注释中冗余的信息就可以越少,而声明式可以降低提取的成本。
得益于 Java 的反射机制,可以容易的根据代码提取接口的路由等信息,还可以根据这些信息直接生成前端调用的SDK进一步简化前端调用成本。
*ASP.NET WebAPI 也有很好的实现,参见官方支持:Microsoft.AspNet.WebApi.HelpPage
有了 Java 的前车之鉴,那在 Egg 中是不是也可以做相应的优化呢?当然是可以的,在类型方面有着 TypeScript 的助攻,而对比 Java 的注解,JavaScript 里的装饰器也基本够用。
改造前:
// app/controller/home.js
export class HomeController {
async getFoo() {
const { size, page } = this.ctx;
...
}
}
// app/router.js
export (app) => {
app.get('/api/foo', app.controller.home.getFoo);
}改造后:
// app/controller/home.ts
export class HomeController {
@route('/api/foo', { name: '获取Foo数据' })
async getFoo(size: number, page: number) { // js的话,去掉类型即可
...
}
}使用装饰器的 API 可以实现跟 Java 类似的写法,这种方式也同时规范了注册路由的方式及信息,以此来生成API文档、前端SDK这类功能当然也是可以实现的,详情:egg-controller 插件
JavaScript 的实现的问题就在于缺少类型,毕竟代码里都没写嘛,对于简单场景倒也足够。当然,我们也可以使用 TypeScript 来提供类型信息。
其实从 JavaScript 切换到 TypeScript 的成本很低,最简单的方式就是将后缀由 js 改成 ts,只在需要的地方写上类型即可。而类型系统会带来许多方便,编辑器智能提示,类型检查等等。像 Controller 里的API出入参类型,早晚都是要写一遍的,无论是是代码里、注释里还是文档里,所以何不一并搞定呢?而且现在 Egg 官方也提供了针对 TypeScript 便捷的使用方案,可以尝试一下。
TypeScript 在这方面对比 Java/C# 还是要弱不少,只能支持比较基础的元数据需求,而且由于 JavaScript 本身模块加载机制的原因,TypeScript 只能针对使用 decorators 的 Function、Class 添加元数据。比如泛型、复杂类型字段等信息都无法获取。不过也有曲线的解法,TypeScript 提供了 Compiler API,可以在编译时添加插件,而在编译期,由于是针对 TypeScript 代码,所以可以获取到丰富的信息,只是处理难度较大。
在其他组件层面也可以应用声明式编程来提升可读性,依赖注入就是一种典型的方式。
当我们拆分了两个组件类,A 依赖 B 的时候,最简单写法:
class A {
foo() {}
}
class B {
bar() {
const a = new A();
}
}可以看到 B 直接实例化了对象 A,而当有多个类依赖 A 的话呢?这种写法会导致创建多个 A 的实例,而放到 Egg 的环境下,Service 是有可能需要 ctx 的,那么就需要 const a = new A(this.ctx); 显然是不可行的。
Egg 的解决方案是通过 loader 机制加载类,在 ctx 设置多个 getter ,统一管理实例,在首次访问的时候初始化实例,在 Egg 项目中的写法:
public class FooService extends Service {
public foo() {
this.ctx.service.barService.bar();
...
}
}为了实现实例的管理,所有组件都统一挂载到了 ctx 上,好处是不同组件的互访问变得非常容易,不过为了实现互访问,每个组件都强依赖了 ctx,通过 ctx 去查找组件,大家应该也看出来了,这实际上在设计模式里是服务定位器模式。在 TypeScript 下,类型定义会是问题,不过 Egg 做了辅助的工具,可以根据符合目录规范的组件代码生成对应的类型定义,通过 TypeScript 合并声明的特性合并到 Egg 里去。这也是当前性价比很高的方案。
这种方案的优点是互访问方便,弊端是 ctx 上挂载了许多与 ctx 本身无关的组件,导致 ctx 的类型是分布定义的,比较复杂,而且隐藏了组件间的依赖关系,需要查看具体的业务逻辑才能知道组件间依赖关系。
那在 Java/C# 中是怎么做的呢?在 Java/C# 中 AOP/IoC 基本都是各个框架的标配,比如 Spring 中:
@Component
public class FooService {
@Autowired
private BarService barService;
public foo() {
barService.bar();
...
}
}当然,在 Java 中一般都是声明注入 IFooService 接口,然后实现一个 IFooServiceImpl,不过在前端基本上不会有人这么干,没有这么复杂的需求场景。所以依赖注入在前端来说能做的,最多是将依赖关系明确声明,将与 ctx 无关的组件与 ctx 解耦。
Egg 中使用依赖注入改造如下:
public class FooService extends Service { // 如果不依赖 ctx 数据,也可以不继承
// ts
@lazyInject()
barService: BarService;
// js
@lazyInject(BarService)
barService;
public foo() {
this.barService.bar();
...
}
}换了写法之后,可以直观的看出 FooService 依赖了 BarService,并且不再通过 ctx 获取 BarService,提高了可读性。而依赖注入作为实例化组件的关注点是可以简单的实现一些面向切面的玩法,比如依赖关系图、函数调用跟踪等等。
代码是最好的文档,代码的可读性对后续可维护性是非常重要的,对人可读关系到后续维护的成本,而对机器可读关系到自动化的可能性。声明式编程更多的是去描述要什么/有什么而非怎么做,这在描述模块/系统间的关系的时候帮助很大,无论是自动化产出文档还是自动生成调用代码亦或是Mock对接等等,这都减少了重复劳动,而在大谈智能的时代,数据也代表了另一种可能性。
趣谈异步编程之“妈妈喊你回家吃饭”,来聊一聊 javascript 中常见的几种异步编程方式。
小明饿了要吃饭,妈妈的饭要半个小时后才能做好,让小明先去读会儿书,饭好后再喊他。于是热腾腾的回调函数产生了:
function eat() {
console.log('好的,我开动咯');
}
function cooking(callback) {
console.log('妈妈认真做饭');
setTimeout(function () {
console.log('小明快过来,开饭啦');
callback();
}, 30 * 60 * 1000);
}
function read() {
console.log('小明假装正在读书');
}
cooking(eat);
read();
/* 执行顺序:
妈妈认真做饭
小明假装正在读书
小明快过来,开饭啦
好的,我开动咯
*/回调函数简单直观,对于读书中的小明来说,妈妈 cooking 是一个异步任务,完成之后妈妈直接调用 eat,以此来通知小明吃饭,于是小明有饭吃了。在 promise 出现前的很长一段时间中,回调函数是异步编程的首选。
但坑猿的是,多层回调函数也很可能会将你带入 callback hell 【回调地狱】,以至于曾经一度流传【据统计,javascript 代码注释中的脏话是所有语言中最多的】。
生活是什么?生活就是不断重复,于是很快小明又饿了。
但有追求的程序员拒绝一直重复,这次换了个玩法:
function eat() {
console.log('妈妈敲门啦,该去吃饭啦');
}
function cooking() {
console.log('妈妈认真做饭');
setTimeout(function () {
console.log('小明,出来吃饭啦');
cooking.$emit('done');
}, 30 * 60 * 1000);
}
function read() {
console.log('小明又假装正在读书');
cooking.$on('done', eat);
}
cooking();
read();
/* 执行顺序:
妈妈认真做饭
小明又假装正在读书
小明,出来吃饭啦
妈妈敲门啦,该去吃饭啦
*/可以看到,这次 eat 和 cooking 分手了,cooking 再也看不到 eat 的身影。当妈妈 cooking 完后大喝一声 done !正在 read 的小明马上屁颠屁颠地跑过来了,为什么呢?因为小明读书的时候就一直竖着耳朵在听妈妈什么时候发出这声大喝。
在事件模型中,每个对象都是独立的个体,各自管理自己的状态,通过相互之间发送和接受消息来实现对象间通信。事件模型可以将代码格式从令人绝望的嵌套状转到优美的序列状,于是 jser 们可以从 callback hell 里爬出来了吗?既傻又天真。试想一下:如果真要你将一份多重嵌套的回调函数重构成事件模型模式,你会怎么做,你需要写多少行 $on 和 $emit ,需要为多少个无聊的事件起名字,相信你只会更绝望。
事件模型是一个优秀的异步方案,但显然,他更擅长解构,不是为了解决 callback hell 而存在。
生活不止重复,也有意外。
今天小明和妈妈吵架了,互相都不说话,于是冤大头爸爸上线了,负责担任 传话筒 一职:
function eat() {
console.log('爸爸叫我去吃饭啦');
}
function cooking(){
console.log('妈妈认真做饭');
setTimeout(function () {
console.log('孩子他爸,叫小明出来吃饭');
Dad.publish("done");
}, 30 * 60 * 1000);
}
function read() {
console.log('小明依旧假装正在读书');
Dad.subscribe('done', eat);
}
cooking();
read();
/* 执行顺序:
妈妈认真做饭
小明依旧假装正在读书
孩子他爸,叫小明出来吃饭
爸爸叫我去吃饭啦
*/看完后智商在线的你可能会发现:这和事件模型有啥区别。。。
是的,它们没有本质区别,发布/订阅模式只是事件模型中比较高级的一种实现形式,加入爸爸这个 传话筒 后,所有的消息都由爸爸来传递、管理和跟踪。当勤奋的你代码量变得越来越大的时候,这个爸爸作用老大了。
Promise 是啥?
Promise 对象用于表示一个异步操作的最终状态(完成或失败),以及其返回的值。
某种角度上,它既学习了回调函数的简单直观,又借鉴了事件模型的状态内聚。一个 Promise 只有三种状态,我们需要关心 fulfilled 和 rejected ,分别用 then 和 catch 处理它们,于是回调地狱不见了,也不需要定义大堆事件,就这么简单,就这么神奇。
好吧,小明再次饿了,但这次我们让小明吃完后洗个碗,洗完碗后再拖个地......看看 Promise 怎么爬出 callback hell :
function read() {
console.log('小明认真读书');
}
function eat() {
return new Promise((resolve, reject) => {
console.log('好嘞,吃饭咯');
setTimeout(() => {
resolve('饭吃饱啦');
}, 10 * 60 * 1000)
})
}
function wash() {
return new Promise((resolve, reject) => {
console.log('唉,又要洗碗');
setTimeout(() => {
resolve('碗洗完啦');
}, 10 * 60 * 1000)
})
}
function mop() {
return new Promise((resolve, reject) => {
console.log('唉,还要拖地');
setTimeout(() => {
resolve('地拖完啦');
}, 10 * 60 * 1000)
})
}
const cooking = new Promise((resolve, reject) => {
console.log('妈妈认真做饭');
setTimeout(() => {
resolve('小明快过来,开饭啦');
}, 30 * 60 * 1000);
})
cooking.then(msg => {
console.log(msg);
return eat();
}).then(msg => {
console.log(msg);
return wash();
}).then(msg => {
console.log(msg);
return mop();
}).then(msg => {
console.log(msg);
console.log('终于结束啦,出去玩咯')
})
read();
/* 执行顺序:
妈妈认真做饭
小明认真读书
小明快过来,开饭啦
好嘞,吃饭咯
饭吃饱啦
唉,又要洗碗
碗洗完啦
唉,还要拖地
地拖完啦
终于结束啦,出去玩咯
*/ 好了,很溜吧。
“妈妈喊你回家吃饭”到此结束,但异步编程是一个很大的议题,内容远不至此,等待你持续挖掘。
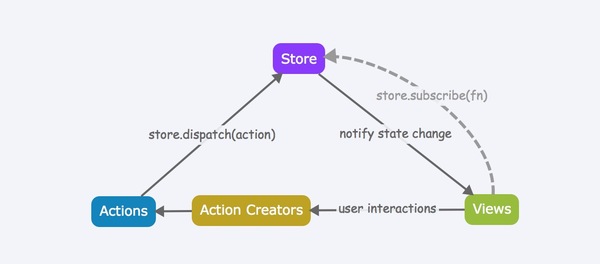
react是在13年左右开始开源的第一个版本,为什么 react 能取代我们之前用的 jQuery 这样的开发库,成为然后随着其开发理念和ReactNative这样的跨端研发库,使得 react 迅速成为最受欢迎的前端开发框架?
我们回顾下,在没有 react 这样的框架之前,我们使用 jQuery 来做前端开发的时候是什么样的、
举个简单的场景,
页面上有个按钮,点击后数字 +1,
<span>1</span> <a>+</a>
使用 jQuery,我们的代码大概是下面这样的:
$('a').on('click', () => {
let num = parseInt($('span').text(), 10);
$('span').text(++num);
});
这是在 jquery 时期很常见的代码,当时写这些代码的时候并没有觉得有什么问题,反而操作dom 的方式显得非常直观,开发者仅需要在页面上通过 获取元素,然后操作 dom 的元素即可。另外 jQuery 封装了很多的浏览器兼容性问题,让每个浏览器下的都有标准的 api 接口。
那么这种以 dom 为主的开发方式会带来什么问题呢?现在回过头去看,是能看到一些问题的,以dom为视角的开发,很多情况下是将后端渲染后的页面去做一些点缀性的交互操作。那这种交互操作对于开发的人来说,其实是很散的。在代码层面,完全看不到相关的逻辑关系。比如:
option.js
// 点击 a 按钮的时候的操作
$('.class_a').click(function() {
// code...
});
// 点击 b 按钮的时候的操作
$('.class_a .class_b').click(function() {
// code...
});
从这段代码里我们并不能看到这些 dom 操作跟我当前页面有什么关系,而更像是挂载在页面上的一段段贴片脚本,另外由于后端代码和前端的脚本是分开在不同的地方,那么当后端代码把相关的 dom 元素删除之后,很多情况下,我们并没有意识要去删除一些相关的无用的 js 代码,这会导致后续随着项目工程的越来越大,无效代码也越来越多。
那么这个问题怎么解,一个方式就是组件化,在那个年代,有很多的团队也在在这样的事情,只是那时候的方式是按照就近原则把相关的文件聚在一起,比较有名的是两个方案:一个是以 backbone 为主的 mvc 框架,一个是 facebook 的bigpipe,其实 backbone 或者 bigpipe 已经离现在的这种数据流为主的框架至少从代码结构层面已经很接近了。从工程维护的角度来讲,也都是一样的思路。那么为什么在这之后还会有 react 这样的框架出来?
很重要的一点是之前的这些框架,从思路上来说还是以 dom 操作为主,页面的渲染是一次性的,可以是后端渲染,也可以是前端通过模板引擎来渲染,但是后续的交互还是通过 dom 操作来完成。
而 react 带来的思路是 view = f(data); 页面渲染是通过 data 驱动,后续的交互操作也是通过 data 的变更来展示页面。
那这样的好处是什么呢?
1、前端与后端通过 json 来传递数据,可以方便的去做前后端分离。
2、组件化,让前端更易规模化和工程化
3、渲染层都由前端控制,且通过 virtual dom 让渲染更高效
4、页面的渲染通过数据驱动,页面变成了一个状态机,从而让之前的那种操作 dom 的不可追溯源头的方式变得更易追踪是什么操作导致的页面变化。
几年前 jQuery 还很火,基本上每个网站都有 jQuery 或者 YUI 这样的框架来做的,但是现在这类的框架变成了过时的东西,其实从很多的框架为什么会变得流行,一般都是因为它创新的思路去解决问题的方法。对我们来说也是一样,我们去解决一个遗留问题的时候,我们能否换个思路,用创新的方法去解决,或许会能打开一片新的天地。
Router 描述了请求 URL 与 Controller 的对应关系。Eggjs 约定所有的路由都需要在 app/router.js 中申明,目录结构如下:
┌ app
├── router.js
│ ├── controller
│ │ ├── home.js
│ │ ├── ...
路由和对应的处理方法分开在 2 个地方维护,开发时经常需要在 router.js 与 Controller 之间来回切换。
前后台协作时,后端需要为每个 Api 都生成一份对应的 Api 文档给前端。
得益于 JavaScript 加入的 decorator 特性,可以使我们跟 Java/C# 一样,更加直观自然的做面向切面编程:
// 基础版
@route('/intro')
async intro() { }
// 定义 Method
@route('/intro', { method: 'post' })
async intro() { }
// 增加权限
@route('/intro', { method: 'post', role: xxxRole })
async intro() { }
// Controller 级别中间件
@route('/intro', { method: 'post', role: xxxRole, beforeMiddleware: xxMiddleware })
async intro() { }
为什么设计如此复杂的功能,是不是在滥用
Decorator?
先看看 route 的功能:
Controller 级别中间件router 官方完整定义中包含的功能:路由定义、中间件、权限,及文档中未直接写的“权限”:
router.verb('router-name', 'path-match', middleware1, ..., middlewareN, app.controller.action);
比较下来会发现,只是多了“参数校验”功能。
Eggjs 中参数校验的官方实践:
class PostController extends Controller {
async create() {
const ctx = this.ctx;
try {
// 校验参数
// 如果不传第二个参数会自动校验 `ctx.request.body`
ctx.validate(createRule);
} catch (err) {
ctx.logger.warn(err.errors);
ctx.body = { success: false };
return;
}
}
};
在我们的业务实践中这个方案会有 2 个问题:
参数漏校验
比如用户提交的数据为 { a: 'a', 'b': 'b', c: 'c' },如果校验规则只定义了 a,那么 b、c 就被漏掉了,并且后续业务中可能会使用这 2 个值。
Eggjs 一个 request 生命周期内,可以随时随地通过 ctx.request 拿到用户数据
因为“参数漏校验”问题的存在,导致后续业务变的不稳定,随时可能会因为用户的异常数据导致业务崩溃,或者出现安全问题。
为了解决“参数漏校验”问题,我们做了如下约定:
Controller 也需要申明入参
class UserController extends Controller {
@route('/api/user', { method: 'post' })
async updateUser(username) {
// ...
}
}
上面的例子中,即使用户提交了海量数据,业务代码中也只能拿到 username
Controller 之外的业务不应该直接访问 ctx.request 上的数据
也就是说,当某个 Service 方法依赖用户数据时,应该通过入参获取,而不是直接访问 ctx.request
基于以上约定,分别看看 JS、TypeScript 下我们如何解决参数校验问题:
JS
@route('/api/user', {
method: 'post',
rule: {
username: { type: 'string', max: 20 },
}
})
async updateUser(username) {
// ...
}
这里使用了 egg-validate 底层依赖的 parameter 作为校验库
TypeScript
@route('/api/user', {
method: 'post'
})
async updateUser(username: R<{ type: string, max: 20 }>) {
// ...
}
没看错,手动调用 ctx.validate(createRule) 并捕获异常的逻辑确实被我们省略掉了。“懒惰”是提高生产力的第一要素。参数、规则都有了,为什么还要自己撸代码呢?
传统的前后端开发协作方式中,后端提供 Api 给前端调用,代码类似这样:
function updateUser() {
request
.post(`/api/user`, { username })
.then(ret => {
});
}
前端同学需要关注路由、参数、返回值。而这些信息 Controller 都已经有了,直接生成前台 service 用起来是不是更方便呢:
Controller 代码:
export class UserController {
@route({ url: '/api/user' })
async getUserInfo(id: number) {
return { ... };
}
}
生成的 service:
export class UserService extends Base {
/** 首页 */
async getUserInfo(id: number) {
const __data = { id };
return await this.request({
method: `get`,
url: `/api/user`,
data: __data,
});
}
}
export const metaService = new UserService();
export default new UserService();
前台使用
import { userService } from 'service/user';
const userInfo = await userService.getUserInfo(id);
对比原来的写法:
function updateUser() {
return new Promise((resolve, reject) => {
request
.post(`/api/user`, { username })
.then(ret => {
resolve(ret);
});
});
}
userService.getUserInfo 内部封装了 request 逻辑,前端不需要在关心调用过程。
我们已经把最佳实践抽象为了 egg-controller 插件,可以按下面的步骤安装使用:
安装 egg-controller
tnpm i -S egg-controller
启用插件
打开 config/plugin.js,增加以下配置
aop: {
enable: true,
package: 'egg-aop',
},
controller: {
enable: true,
package: 'egg-controller',
},
使用插件
详细用法参考 egg-controller 文档
之前,在 #27 里,介绍了流的一些基本概念,在 #25 中,又列举了一种轮询业务场景的实现,本文试图用这种理念去实现同样的轮询功能。本文的例子使用 xstream.js 来编写。
想要使用流的理念来实现业务功能,最重要的就是思维的抽象,比较直接的方法论是:
寻找一切变更的源头,理清事情之间的顺序和依赖关系。
在定时轮询整个场景中,我们可以发现,一切事情的起源是定时器,只有这个来源是不依赖于任何其他东西的,因此,我们得到了第一个数据流:
const periodic$ = xs.periodic(1000);这样,就得到了一个每秒发生一次的流。
然后,这个流导致什么事情呢?
发送一个HTTP请求,并且取回结果。
并且,我们可以注意到,这个操作是由前一个流触发的,每一次定时器的变动都会触发一次请求,因此,可以进行这么一个映射:
timer => request
所以,可以得到以下代码:
const request$ = periodic$
.map(_ => xs.fromPromise(request(endPointURL)))此处,我们把一个普通的请求转化为了流,这个流里面实际上最多只会有一个值,也就是请求结果。
需要注意的是,经过我们上面的操作,数据流的形态已经变成二阶了,也就是说,request$ 中的每个元素,都又是一个流(从 Promise 转化出来的流)
想要得到我们预期的效果,就必须对这个流降阶,最简单的方式就是 flatten:
const imageUrl$ = request$.flatten();降阶的意义是把高阶流的值提出来,并且合并到一个低阶流。刚才我们从 Promise 转出来的流,实际上每个里面只会有一个结果,本次降阶的含义大致类似于:
[[result1], [result2], [result3]] => [result1, result2, result3]
至此,我们只需直接订阅这个 imageUrl$,就可以持续不断地从其中获得新的图片地址了。
回顾整个过程,我们好像是建立了一条线路,或者一条管道,使得数据可以在其中流通。
但我们的需求还要更复杂一些,因为它是要允许通过一个开关,来控制定时拉取操作的启用与否。
那么,我们怎么才能把开关的逻辑加进去呢?
加开关的思路是在刚才的管道上加个阀门。
看看刚才的线路:
定时器 -> 请求 -> 请求结果
这个阀门加在哪里呢,很显然是加在请求和请求结果之间,因为我们的逻辑是:当开关关闭的时候,即使有还在发的请求,它的结果我们也不要了,所以在结果这里处理是比较合适的。
构造一个开关:
const switch$: Stream<boolean> = xs.create();然后,把它跟之前的请求流组合起来:
const result$ = xs.combine(
imageUrl$,
switch$,
)
.filter(arr => {
const isPolling = arr[1];
return isPolling;
})
.map(arr => {
const result = arr[0];
return result.message;
});解释一下上面的代码:
整个过程的流转关系,可以画一个图如下:
periodic$ -> request$ -> imgUrl$ -> |
| -> combine$ -> filter$ -> result$
switch$ -> |
整个视图之外的完整的逻辑如下:
import * as React from 'react';
import xs, { Stream } from 'xstream';
import { DogView } from '../DogView';
import request from '../../service/request';
const endPointURL = 'https://dog.ceo/api/breeds/image/random';
interface IAppState {
imgUrl: string;
}
export default class App extends React.Component<{}, IAppState> {
public state: IAppState = {
imgUrl: 'https://images.dog.ceo/breeds/puggle/IMG_114654.jpg',
};
private switch$: Stream<boolean> = xs.create();
private poll$: Stream<string>;
public componentWillMount() {
const request$ = xs.periodic(1000)
.map(_ => xs.fromPromise(request(endPointURL)))
.flatten();
this.poll$ = xs.combine(
request$,
this.switch$,
)
.filter(arr => {
const isPolling = arr[1];
return isPolling;
})
.map(arr => {
const result = arr[0];
return result.message;
});
this.poll$.addListener({
next: (imgUrl) => this.setState({
imgUrl,
}),
})
}
public render() {
return (
<DogView
onClickFetchImg={this.onClickFetchImg}
onStartPolling={this.onStartPolling}
onStopPolling={this.onStopPolling}
dogImgURL={this.state.imgUrl}
/>
);
}
private onClickFetchImg = async () => {
const result = await request(endPointURL);
this.setState({
imgUrl: result.message,
});
}
private onStartPolling = () => {
// 偷懒起见,这里可以用 _n,比较正式一点的话,这里可以造一个 producer,或者拿这个按钮的事件来形成新的流
this.switch$._n(true);
}
private onStopPolling = () => {
this.switch$._n(false);
}
} 从这段代码中,我们可以看到,流式编程的简洁性与高度抽象性,并且,它在工程上可以达到一种平衡,也就是:
babel 和 typescript 如今已经成为我严重依赖的两个工具了。
babel 让我们能够使用未来的 ES 特性,typescript 让我们为 js 加上静态类型,静态类型有什么好处想必用过的人都深有体会。
不管两个工具各自如何好,放在一起用总是会有些别扭的地方...
很多时候我们使用 ts 之后还是没有办法去掉 babel 的依赖,因为我们可能依赖着 babel 生态里的很多插件,比方说做 antd 按需加载的 babel-plugin-import, 而这些插件无法脱离 babel 发挥作用。
那么这个时候你一定做过这样的事情:
如果你使用 webpack 的话你的配置文件可能如下:
{
test: /\.tsx?$/,
exclude: /node_modules/,
use: [
loader: 'babel-loader',
loader: 'ts-loader',
]
}可是这里明明它们做的事情是重叠的,我们为什么不能合并它们呢?
而且大家也早就有这方面的讨论,比如:
下一代的 babel 7 带来了新的能力,让我们可以不需要在编译两轮了
这件事情推进的关键在于 Babylon(Babel 使用的解析器)有了解析 typescript 的能力,有了这一层面的支持,我们就可以只使用 babel,而不用再加一轮 ts 的编译流程了
在 babel 7 中,我们使用新的 @babel/preset-typescript (其集成了 @babel/plugin-transform-typescript)
我们的 .babelrc 配置将变成这样:
{
"presets": [
"@babel/env",
"@babel/react",
"@babel/typescript"
]
}你看是不是变得非常简洁?
有了这个,我们就可以只用 babel 就处理我们的 ts 代码了,我们也就可以去掉 ts-loader 之类的依赖了
如果你需要类型检查你可以在 package.json 中加入如下 scripts
{
"type-check": "tsc --noEmit"
}或者说你在编译一个库,你同时希望生成声明文件,那么或许你会使用如下的脚本:
{
"build": "tsc --emitDeclarationOnly && babel src --out-dir lib --extensions \".ts,.tsx\""
}不妨在下个项目中一试吧
https://zhuanlan.zhihu.com/p/28374218
https://babeljs.io/docs/en/next/babel-preset-typescript
http://artsy.github.io/blog/2017/11/27/Babel-7-and-TypeScript/
var i = 0;
while(i++<3){
window.setTimeout(function(){
console.log(i);
},0);
(function(clouser_i){
window.setTimeout(function(){
console.log('clouser:' + clouser_i);
},1000);
})(i);
}在不运行的情况下,大家思考下会输出什么结果呢?
来解释下原因吧!
这篇文章的由来,是为了解决issue而做的总结。本来以为是使用不当,造成解析问题。深入追踪后发现是依赖包express-http-proxy没考虑这种情况,“一刀切”按照普通方式处理造成的。
示例工程,请求响应的过程可以下图展示:
首先看用户的代码逻辑,很简单就是用了application/x-www-form-urlencoded,并把参数通过qs.stringify(newOptions.body)处理&连接的字符串。
既然是真实server端接收到了{'{"username":"[email protected]", "password":"123"}': ''}这种形式的body,值得怀疑的地方有:
这个和MIME类型有关,科普下相关知识点。
MIME全名叫多用途互联网邮件扩展(Multipurpose Internet Mail Extensions),指的是一系列的电子邮件技术规范,主要包括RFC 2045、RFC 2046、RFC 2047、RFC 4288、RFC 4289和RFC 2077。最初是为了将纯文本格式的电子邮件扩展到可以支持多种信息格式而定制的。后来被应用到多种协议里,包括我们常用的HTTP协议。
浏览器和服务器互发消息,消息头规定了是什么类型的消息(Content-type),消息体就要是什么样的格式,这样彼此才能正确处理和解析消息。
application/x-www-form-urlencoded # 使用HTTP的POST方法提交的表单
multipart/form-data # 同上,但主要用于表单提交时伴随文件上传的场合
这两者规定了发送表单消息的格式。 x-www-form-urlencoded会将表单内的数据转换为键值对,不同的field会用"&"符号连接;空格被替换成"+";field和value间用”=“连接。如果是手动处理参数,也要处理成这种格式。 这说明,从浏览器发送消息到代理服务器,MIME设置和body格式,都是正确的。
ant-design-pro项目中的mock主要依赖了roadhog,也就是代理是roadhog代为完成的。关键代码如下:
import proxy from 'express-http-proxy';
// ...
function createProxy(method, path, target) {
return proxy(target, {
// ...
});
}
...
devServer.use(bodyParser.json({ limit: '5mb', strict: false }));
devServer.use(
bodyParser.urlencoded({
extended: true,
limit: '5mb',
}),
);
// ...
Object.keys(config).forEach(key => {
const keyParsed = parseKey(key);
// ...
if (typeof config[key] === 'string') {
let { path } = keyParsed;
if (/\(.+\)/.test(path)) {
path = new RegExp(`^${path}$`);
}
// 创建代理
app.use(path, createProxy(keyParsed.method, path, config[key]));
} else {
// 本地mock
app[keyParsed.method](
keyParsed.path,
createMockHandler(keyParsed.method, keyParsed.path, config[key]),
);
}
});简单解释下,浏览器发送post到代理服务器,bodyParser会正确解析消息体并把数据以json格式存储到req.body。代理服务器响应的处理交由express-http-proxy去完成了。
看用户的代理配置很简单,并没有什么问题。
export default noProxy ? { 'POST /v2/api/*': 'http://127.0.0.1:3000' } : delay(proxy, 1000);调试发现,POST请求发出时,参数形式已经改变(此时已经可以定位到出错点),然后又把结果响应给代理服务器,这期间真实服务器这端没有什么问题。相关代码如下:
app.post('/', (req, res) => {
const data = req.body;
console.log('postbody', data);
res.send(data);
});express-http-proxy处理是个暗箱操作,暗箱里肯定存在处理req.body不当的地方。然后再把请求打包发送时,就造成了消息体格式问题。翻翻该包关键的代码,发现几处相关的:
# 该文件主要是处理options,会直接用浏览器端请求的headers大部分配置
/lib/requestOptions.js
# 这些文件处理body
/app/steps/buildProxyReq.js
/app/steps/decorateProxyReqBody.js
/app/steps/prepareProxyReq.js
# 该文件主要是向真实服务器发送请求,并监听真实服务器返回的数据
/app/steps/sendProxyRequest.js
# 该文件主要是响应浏览器端请求,并把真实服务器返回的数据 返回到浏览器端
/app/steps/sendUserRes.js
关键的处理不当的代码如下:
// ** 从代理服务器获取到req.body(json对象),赋值给bodyContent
var parseBody = (!options.parseReqBody) ?
Promise.resolve(null) :
requestOptions.bodyContent(req, res, options);
// ...
return Promise
.all([parseBody, ...])
.then(function(responseArray) {
Container.proxy.bodyContent = responseArray[0];
// ...
return Container;
});
if (bodyContent) {
// ** 无视content-type,把bodyContent直接转成了json字符串
bodyContent = container.options.reqAsBuffer ?
as.buffer(bodyContent, container.options) :
as.bufferOrString(bodyContent);
// ...
}
container.proxy.bodyContent = bodyContent;
if (options.parseReqBody) {
// ...
if (bodyContent.length) {
// ** 直接利用json字符串,而与content-type要求的格式不符
proxyReq.write(bodyContent);
}
proxyReq.end();
}通过issue的追踪定位和对express-http-proxy的源码分析,可以很清楚地知道,核心模块就是http,核心方法就是http.request。浏览器发送请求到代理服务器,代理服务器通过http.request发送请求到真实服务器,然后在获取数据后返回结果给浏览器。就是这么简单~
注:首发于个人博客,时间是 2015-11-07
去年的这个时候,前端社区里 React.js 势头开始超越 Angular.js,现在 React 终于变成了前端最火的库。而近几个月同样发生着另外一个有趣又类似的事:在后端被广泛使用的 Rest (RESTful API),开始受到各种质疑、特别是声称解决或替代 Rest 的方案如 GraphQL、Falcor 的出现并得到越来越多的关注,好像革命大旗举了起来。
Rest 有什么问题?大家普遍提到的有这些:
通过一个请求加载所有的信息同时使得我们的 Rest 资源保持隔离之间的冲突。 ref: GraphQL
Rest 的资源是拆分的“比较细的”,但应用里是想通过一个请求直接拿到尽可能多的数据,但对于 Rest 一次请求只能拿到某一个资源,这样就产生冲突了。
但对于这个问题,资源的 embeded 其实是可以解决的。目前对于那些有类似 “外键” 关联的资源(如一个学生数据库表里关联着老师的id),客户端发一个学生资源的请求、带上关联老师详情的 query 信息,就能把老师的详细信息关联查出来,一并发送给客户端。
常见的图片瀑布流应用(无尽列表),随着用户鼠标滚动,要不停的发送请求,显示新的图片并获得相应的图片详细信息。
这种场景下,如果设计不当,例如在用户滚动的时候,才去加载需要的细粒度资源。那么假如获取一张图片的详细信息时,就需要发送至少 5 个资源请求,用户随便拖动下滚动条,就可能需要显示10张图片,这样一下子至少要发送 10*5 个资源请求,很明显这是不能忍的也是不对的。
这类场景正确的做法是只需要发送一次请求,返回一个列表数据,并在里边包含各种子资源即可。只是如果资源粒度比较细的话,子资源需要被 embed 进来就需要拼接不少参数,比较麻烦。
举个实例:
// 资源列表如:
[{
id: 1
name: "card",
boxshot: "http://xx",
rating: 5,
bookmark: 2343,
director: "david",
// more fields
},
...
]
// Rest 请求列表资源
/list?rowOffset=0&rowSize=5&colOffset=5&colSize=15&titleprops=name,boxshot
// RPC 风格:
/list?pageSize=10x15&titleprops=name,boxshot
// 请求单个资源部分信息:
/list/123?props=name,rating,bookmark以上可以看出,Rest 请求列表资源时,可能需要加很多参数,还不如 RPC 风格来的简单。这也大概正是 Falcor 作者要解决的问题,把 RPC 里的优点拿过来,更简单的组合资源。
Falcor 作者提到的 Rest 的设计初衷(视频)
The REST interface is designed to be efficient for large-grain hypermedia data transfer, optimizing for the common case of the Web, but resulting in an interface that is not optimal for other forms of architectural interaction.
一开始我们做系分时,可能比较容易划分出有哪些资源,对资源粒度划分也可能没那么难。但把这些资源组合或规划起来、对外提供 API 时,可能就没那么容易了,会有让人纠结的地方。如:
GET /cars/711/drivers/
Returns a list of drivers for car 711
GET /cars/711/drivers/4
Returns driver #4 for car 711这些问题看起来简单,实际去设计时、却很容易做不好。
一开始 Rest 的出现,是为了解决 Rpc 的问题。Rpc 方式下,应用只有一个端点(endpoint),导致紧耦合、不易缓存。
Rpc 和 Rest 的基本区别:
SOAP Web API采用RPC(面向方法Remote Procedure Call)风格,它采用面向功能的架构,所以在设计之初首先需要考虑的是提供怎样的功能。
RESTful Web API采用ROA(面向资源Resouce Oriented Architecture)架构,所以在设计之初首先需要考虑的是有哪些资源可供操作。
引用下 richardson rest 模型:
文中作者只提到了第三层级。而上边我们提到过资源的父子资源的 embeded 试想可能的话,让所有资源都能自由的互相 embeded 或者自由的做关联,那就是更进了一步,也差不多能解决以上提到的问题。但即便做到如此,Rest 也还是有其让人觉得不爽的地方。
GraphQL / Falcor 这类方案,都是宣称解决了 Rest 的一些问题,但其实也只是特定的场景,而它们真的是更上一层楼?恐怕也不见得,待以后实践证明吧。
这个文章之前在别的地方发过,没有人讨论,所以在这里重新编写了一遍,写写自己的一点看法。
文中标题一二三不代表这些概念是同级的,只是代表我自己的思路。
我这里引入几个概念,是我自己理解所得,不权威,但有利于我自己的学习和理解。
我把页面中宽度占满屏幕,高度任意的元素(或者区域)称为块。不管是盒式布局中常提到的上中下结构、左右结构和复杂结构,都可以用这个概念简化。
如:上中下结构,可将下图的页头、主体和页脚视为三个块。

如:左右结构,可将菜单和主体组合起来的整体视为一个块。如下所示,红色框框视为一个块。

如:复杂结构,也是一样的将页面分成独立的块。不管里面元素的布局,先从整体上分析和实现。
手机中也是可以同样概念理解,即宽度占满屏幕,高度任意的一个块称为项。
如:常用移动页面的首页

如上图所示,我将图中红色边框的块称为一个项,并不理会项中是单一元素还是复杂元素。如第一项中单一的banner,第二项中四个菜单按钮,和最后那几个项中的左右上下结构。
其实上图中的标题和详细说明,这个上下结构也可以理解为一个项,只是它是放在外层大项中的小项。

理解了上述两个概念,接下来我们就比较容易理解Flex弹性布局了。要是用弹性布局,块级元素设置display:flex;行内元素设置display:inline-flex;将该元素设置为Flex容器。表明该元素内的子元素将使用弹性布局。注意设置成Flex容器之后,内部子元素(以下称为子项)的浮动和对齐属性都会失效。接下来我们对Flex容器的各个属性进行说明。
| 属性 | 说明 |
|---|---|
| flex-direction | 子项的排列方向,分为从左到右,从右到左,从上到下,从下到上 |
| flex-wrap | 子项排列不下之后是否换行,分为不换行,排到下一行,排到上一行 |
| flex-flow | 上面两个属性的组合,如可以直接设置从左到右排列,排不下排到下一行。 |
| justify-content | 子项在排列方向上的对齐方式,(横向说明)分为左对齐,右对齐,居中对齐,两端对齐中间等分布局和全部等间距布局 |
| align-items | 子项在另一个方向上的对齐方式,(横向说明)分为上对齐,下对齐,居中对齐,上下拉伸充满,子项首行文字对齐 |
| align-content | 在子项内容排列多行时整体的对齐方式(就是设置行和行之间的排列),分为全部靠上、全部靠下、居中等,IE、Safari、Firefox不支持这个属性(小程序中完全支持) |
<div style="padding: 10px;border: 1px solid black;display: flex;flex-direction:row;">
<div style="border: 1px solid red;">页头</div>
<div style="border: 1px solid blue;">主体</div>
<div style="border: 1px solid green;">页脚</div>
</div>



<div style="width:120px;padding: 10px;border: 1px solid black;display: flex;flex-direction:row;flex-wrap: nowrap;">
<div style="width:50px;border: 1px solid red;">页头</div>
<div style="width:50px;border: 1px solid blue;">主体</div>
<div style="width:50px;border: 1px solid green;">页脚</div>
</div>
这里外层容器和子项都设置了宽度,但实际的并没有效果,会自动扩展。


<div style="width:160px;padding: 10px;border: 1px solid black;display: flex;flex-flow:row wrap;">
<div style="width:50px;border: 1px solid red;">页头</div>
<div style="width:50px;border: 1px solid blue;">主体</div>
<div style="width:50px;border: 1px solid green;">页脚</div>
</div>
<div style="width:300px;height:50px;padding: 10px;border: 1px solid black;display: flex;flex-direction:row;justify-content:flex-start">
<div style="border: 1px solid red;">页头</div>
<div style="border: 1px solid blue;">主体</div>
<div style="border: 1px solid green;">页脚</div>
</div>




<div style="width:300px;height:50px;padding: 10px;border: 1px solid black;display: flex;flex-direction:row;align-items:flex-start;">
<div style="font-size:12px;border: 1px solid red;">页头</div>
<div style="font-size:24px;border: 1px solid blue;">主体</div>
<div style="font-size:36px;border: 1px solid green;">页脚</div>
</div>
5.2 flex-end 下对齐display: flex;flex-direction:row;align-items:flex-end;

5.3 center 居中对齐display: flex;flex-direction:row;align-items:center;

5.4 stretch 上下拉伸充满display: flex;flex-direction:row;align-items:stretch;

5.5 baseline 子项首行文字对齐display: flex;flex-direction:row;align-items:baseline;

<div style="width:300px;height:110px;padding: 10px;border: 1px solid black;display: flex;flex-flow:row wrap;align-content:flex-start;">
<div style="width:50px;border: 1px solid red;">页头1</div>
<div style="width:50px;border: 1px solid red;">页头2</div>
<div style="width:50px;border: 1px solid red;">页头3</div>
<div style="width:50px;border: 1px solid red;">页头4</div>
<div style="width:50px;border: 1px solid blue;">主体1</div>
<div style="width:50px;border: 1px solid blue;">主体2</div>
<div style="width:50px;border: 1px solid blue;">主体3</div>
<div style="width:50px;border: 1px solid blue;">主体4</div>
<div style="width:50px;border: 1px solid green;">页脚1</div>
<div style="width:50px;border: 1px solid green;">页脚2</div>
<div style="width:50px;border: 1px solid green;">页脚3</div>
<div style="width:50px;border: 1px solid green;">页脚4</div>
</div>





这里我将所有的布局都罗列出来,希望能让大家明白Flex的特点和用法,等到实际开发中有涉及相关内容的时候,再去查阅详细的API即可,子项也有类似的几个属性,用户设置布局和顺序,详细内容请另行查阅资料。
我自己觉得理解了什么是项,看到布局就能比较轻松地将布局切割开来。化繁为简,也有利于理解组件化。将每一个项整理出来,在项目中需要复用的就可以整理成组件。多个项目中能够复用的,就能整理成公用组件。用的高频的还能整理成UI框架。
本系列讲述在 React 项目的实际开发中,我们如何通过 es6 的特性以及 React 的特性来实现我们的代码重用,今天是第一篇,初级:
试想我们现在有这样一个需求:

这是一个很典型的在登录及注册的业务场景。在这两个页面中,我们可以看到它们之间的相同之处,同时也有一些不同的点,那么简单抽象以下,我们可以将这两个页面按下面的模块来划分。

这样我们就得到了三个组件,分别是
由于 Header 和 Footer 是纯展示性组件,那么我们可以使用 React 的 stateless 组件。由于「登录」与「注册」的标题以及副标题不一样,所以我们需要传递两个 props 值进来,示例代码如下:
import React from "react";
const Header = props => {
return (
<div>
<h1>{props.title}</h1>
<h2>{props.subTitle}</h2>
</div>
);
};
export default Header;
同样的 Footer 的我们也可以使用该方式来剥离成公共组件。不过需要注意的是,与 Header 只有标题和副标题不同的是, Footer 的左侧内容和右侧内容其实是不是固定的,这个时候我们传递进来的 props 需要更灵活,而 Footer 要做的事情是帮传递进来的组件预留位置,此处我们简单以 left 、 right 来区分,示例代码如下:
import React from "react";
const Footer = props => {
return (
<div className="footer">
<div className="options">{props.left}</div>
<div className="options">{props.right}</div>
</div>
);
};
export default Footer;
这样我们的 Header 和 Footer 就有了,接下来是 Content 区域,与其他两个组件不同的是,Content 里面有个 「登录」或者「注册」按钮,点击后我们需要去触发相关的请求。那这样的组件我们该怎么写,这个时候有两种思路,第一种是组件中将业务逻辑内聚,由于该组件中需要用到 React 的生命周期函数,所以我们使用常规的 React.Component 来创建组件 如下:
import React from "react";
class Content extends React.Component {
constructor(props) {
super(props);
this.state = {
loading: false
};
}
renderType = type => {
if (type === "login") {
return (
<div>
<input placeholder="帐号" />
<input placeholder="密码" />
<input type="submit" value="登录" />
</div>
);
} else if (type === "regist") {
return (
<div>
<input placeholder="帐号" />
<input placeholder="密码" />
<input type="submit" value="注册" />
</div>
);
} else {
return null;
}
};
render() {
return this.renderType(this.props.type);
}
}
export default Content;
通过将逻辑内聚到组件的好处是我们有很多的状态是可以公用的,比如密码的正则判断等,但是带来的一个坏处是不太友好的扩展性。但是带来的是在业务中使用的简洁性。
最后我们可以简单的将登录注册以以下代码展示:
// Login
function Login() {
return (
<div className="App">
<Header title={"登录"} subTitle={"欢迎来到"} />
<Content type="login" />
<Footer left={'登录'} right="找回密码" />
</div>
);
}
// regist
function Regist() {
return (
<div className="App">
<Header title={"注册"} subTitle={"欢迎注册"} />
<Content type="regist" />
<Footer left={'登录'} right="直接登录" />
</div>
);
}
新知识很多,且学且珍惜。
在选择要系统地学习一个新的 __框架/库 __之前,首先至少得学会先去思考以下两点:
然后,才会带着更多的好奇心去了解:它的由来、它名字的含义、它引申的一些概念,以及它具体的使用方式...
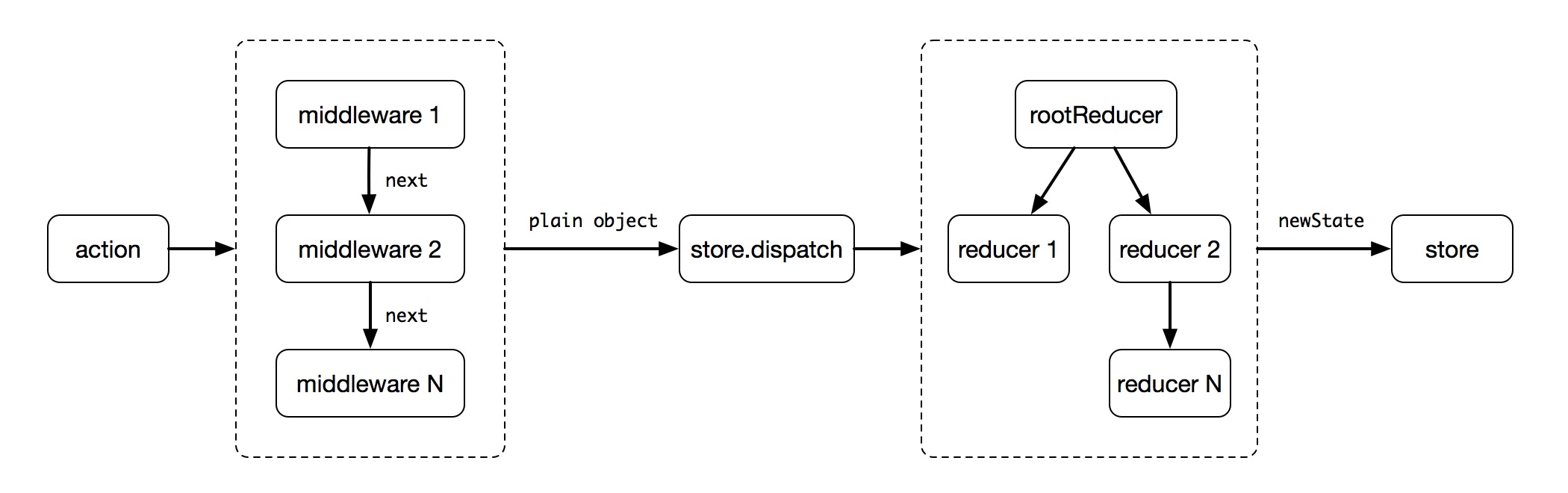
本文尝试通过 自我学习/自我思考 的方式,谈谈对 redux-saga 的学习和理解。
『Redux-Saga』是一个 库(Library),更细致一点地说,大部分情况下,它是以 Redux 中间件 的形式而存在,主要是为了更优雅地 管理 Redux 应用程序中的 副作用(Side Effects)。
那么,什么是 Side Effects?
来看看 Wikipedia 的专业解释(敲黑板,划重点):
Side effects are the most common way that a program interacts with the outside world (people, filesystems, other computers on networks).
映射在 Javascript 程序中,Side Effects 主要指的就是:异步网络请求、__本地读取 localStorage/Cookie __等外界操作:
Asynchronous things like__ data fetching__ and impure things like accessing the browser cache
虽然中文上翻译成 “副作用”�,但并不意味着不好,这完全取决于特定的 Programming Paradigm(编程范式),比如说:
Imperative programming is known for its frequent utilization of side effects.
所以,在 Web 应用,侧重点在于 Side Effects 的 优雅管理(manage),而不是 消除(eliminate)。
说到这里,很多人就会有疑问:相比于 redux-thunk 或者 redux-promise, 同样在处理 Side Effects(比如:异步请求)的问题上,redux-saga 会有什么优势?
这里是指 redux-saga vs redux-thunk。
首先,从简单的字面意义就能看出:背后的**来源不同 —— Thunk vs Saga Pattern。
这里就不展开讲述了,感兴趣的同学,推荐认真阅读以下两篇文章:
其次,再从程序的角度来看:使用方式上的不同。
Note:以下示例会省去部分 Redux 代码,如果你对 Redux 相关知识还不太了解,那么《Redux 卍解》了解一下。
一般情况下,actions 都是符合 FSA 标准的(即:a plain javascript object),像下面这样:
{
type: 'ADD_TODO',
payload: {
text: 'Do something.'
}
};它代表的含义是:每次执行 dispatch(action) 会通知 reducer ++将 action.payload(数据) 以 action.type 的方式(操作)++__同步更新__到 本地 store 。
而一个 丰富多变的 Web 应用,payload 数据往往来自于远端服务器,为了能将 __异步获取数据 __这部分代码跟 UI 解耦,redux-thunk 选择以 middleware 的形式来增强 redux store 的 dispatch 方法(即:支持了 dispatch(function)),从而在拥有了 ++异步获取数据能力++ 的同时,又可以进一步将 ++数据获取相关的业务逻辑++ 从 View 层分离出去。
来看看以下代码:
// action.js
// ---------
// actionCreator(e.g. fetchData) 返回 function
// function 中包含了业务数据请求代码逻辑
// 以回调的方式,分别处理请求成功和请求失败的情况
export function fetchData(someValue) {
return (dispatch, getState) => {
myAjaxLib.post("/someEndpoint", { data: someValue })
.then(response => dispatch({ type: "REQUEST_SUCCEEDED", payload: response })
.catch(error => dispatch({ type: "REQUEST_FAILED", error: error });
};
}
// component.js
// ------------
// View 层 dispatch(fn) 触发异步请求
// 这里省略部分代码
this.props.dispatch(fetchData({ hello: 'saga' }));如果同样的功能,用 redux-saga 如何实现呢?它的优势在哪里?
先来看下代码,大致感受下(后面会细讲):
// saga.js
// -------
// worker saga
// 它是一个 generator function
// fn 中同样包含了业务数据请求代码逻辑
// 但是代码的执行逻辑:看似同步 (synchronous-looking)
function* fetchData(action) {
const { payload: { someValue } } = action;
try {
const result = yield call(myAjaxLib.post, "/someEndpoint", { data: someValue });
yield put({ type: "REQUEST_SUCCEEDED", payload: response });
} catch (error) {
yield put({ type: "REQUEST_FAILED", error: error });
}
}
// watcher saga
// 监听每一次 dispatch(action)
// 如果 action.type === 'REQUEST',那么执行 fetchData
export function* watchFetchData() {
yield takeEvery('REQUEST', fetchData);
}
// component.js
// -------
// View 层 dispatch(action) 触发异步请求
// 这里的 action 依然可以是一个 plain object
this.props.dispatch({
type: 'REQUEST',
payload: {
someValue: { hello: 'saga' }
}
});将从上面的代码,与之前的进行对比,可以归纳以下几点:
最简单完整的一个单向数据流,从 hello saga 说起。
先来看看,如何将 store 和 saga 关联起来?
import { createStore, applyMiddleware } from 'redux';
import createSagaMiddleware from 'redux-saga';
import rootSaga from './sagas';
import rootReducer from './reducers';
// 创建 saga middleware
const sagaMiddleware = createSagaMiddleware();
// 注入 saga middleware
const enhancer = applyMiddleware(sagaMiddleware);
// 创建 store
const store = createStore(rootReducer, /* preloadedState, */ enhancer);
// 启动 saga
sagaMiddleWare.run(rootSaga);代码分析:
createSagaMiddleware 创建 sagaMiddleware(当然创建时,你也可以传递一些可选的配置参数)。store.dispatch(action),数据流都会经过 sagaMiddleware 这一道工序,进行必要的 “加工处理”(比如:发送一个异步请求)。整合以上分析:程序启动时,run(rootSaga) 会开启 sagaMiddleware 对某些 action 进行监听,当后续程序中有触发 dispatch(action) (比如:用户点击)的时候,由于数据流会经过 sagaMiddleware,所以 sagaMiddleware 能够判断当前 action 是否有被监听?如果有,就会进行相应的操作(比如:发送一个异步请求);如果没有,则什么都不做。
所以来看看,初始化程序时,rootSaga 具体可以做些什么?
// sagas/index.js
import { fork, takeEvery�, put } from 'redux-saga/effects';
import { push } from 'react-router-redux';
import ajax from '../utils/ajax';
export default function* rootSaga() {
// 初始化程序(欢迎语 :-D)
console.log('hello saga');
// 首次判断用户是否登录
yield fork(function* fetchLogin() {
try {
// 异步请求用户信息
const user = yield call(ajax.get, '/userLogin');
if (user) {
// 将用户信息存入 本地 store
yield put({ type: 'UPDATE_USER', payload: user })
} else {
// 路由跳转到 403 页面
yield put(push('/403'));
}
} catch (e) {
// 请求异常
yield put(push('/500'));
}
});
// watcher saga 监听 dispatch 传过来的 action
// 如果 action.type === 'FETCH_POSTS' 那么 请求帖子列表数据
yield takeEvery('FETCH_POSTS', function* fetchPosts() {
// 从 store 中获取用户信息
const user = yield select(state => state.user);
if (user) {
// TODO: 获取当前用户发的帖子
}
});
}如同前面所说,rootSaga 里面的代码会在程序启动时,会依次被执行:
takeEvery 方法会注册一个 watcher saga,对 { type: 'FETCH\_POSTS' } 的 action 实施监听,后续会执行与之匹配的 worker saga(比如:fetchPosts)。PS:通常情况下,在无需进行 saga 按需加载 的情况下,rootSaga 里会集中 引入并注册 程序中所有用到的 watcher saga(就像 combine rootReducer 那样)。
最后再看看,程序启动后,一个完整的单向数据流是如何形成的?
import React from 'react';
import { connect } from 'react-redux';
// 关联 store 中 state.posts 字段 (即:帖子列表数据)
@connect(({ posts }) => ({ posts }))
class App extends React.PureComponent {
componentDidMount() {
// dispatch(action) 触发数据请求
this.props.dispatch({ type: 'FETCH_POSTS' });
}
render() {
const { posts = [] } = this.props;
return (
<ul>
{ posts.map((post, index) => (<li key={index}>{ post.title }</li>)) }
</ul>
);
}
}
export default App;当组件 <App /> 被执行挂载后,通过 dispatch({ type: 'FETCH\_POSTS' }) 通知 sagaMiddleware 寻找到 匹配的 watcher saga 后,执行对应的 woker saga,从而发起数据异步请求 ...... 最终 <App/> 会在得到最新 posts 数据后,执行 re-render 更新 UI。
至此,以上三个部分代码实现了基于 redux-saga 的一次 __完整单向数据流,__如果用一张图来表现的话 ,应该是这样:
文章看到这里,对于一个 redux-saga 新手而言,可能会留有这样的疑惑: 上述代码中 put/call/fork/takeEvery 这些方法是干什么用的?这就是接下来要详细讨论的 saga effects。
前面说到,saga 是一个 generator function,这就意味着它的执行原理必然是下面这样:
function isPromise(value) {
return value && typeof value.then === 'function';
}
const iterator = saga(/* ...args */);
// 方法一:
// 一步一步,手动执行
let result;
result = iterator.next();
result = iterator.next(result.value);
result = iterator.next(result.value);
// ...
// done!!
// 方法二:
// 函数封装,自主执行
function next(args) {
const result = iterator.next(args);
if (result.done) {
// 执行结束
console.log(result.value);
} else {
// 根据 yielded 的值,决定什么时候继续执行(resume)
if (isPromise(result.value)) {
result.value.then(next);
} else {
next(result.value)
}
}
}
next();也就是说,generator function 在未执行完前(即:result.done === false),它的控制权始终掌握在__ 执行者(caller)__手中,即:
而 caller 本身要实现上面上述功能需要依赖原生 API :iterator.next(value) ,value 就是 yield expression 的返回值。
举个例子:
function* gen() {
const value = yield Promise.reslove('hello saga');
console.log('value: ', value); // value??
}单纯的看 gen 函数,没人知道 value 的值会是多少?
这完全取决于 gen 的执行者(caller),如果使用上面的 next 方法来执行它,value 的值就是 'hello saga',因为 next 方法对 expression 为 promise 时,做了特殊处理(这不就是缩小版的 co 么~ wow~⊙o⊙)。
换句话说,expression 可以是任何值,关键是 caller 如何来解释 expression,并返回合理的值 !
以此结论,推理来看:
讲了这么多,那么 effect 到底是什么呢?先来看看官方解释:
An effect is a plain JavaScript Object containing some instructions to be executed by the saga middleware.
意思是说:effect 本质上是一个普通对象,包含着一些指令信息,这些指令最终会被 saga middleware 解释并执行。
用一段代码来解释上述这句话:
function* fetchData() {
// 1. 创建 effect
const effect = call(ajax.get, '/userLogin');
console.log('effect: ', effect);
// effect:
// {
// CALL: {
// context: null,
// args: ['/userLogin'],
// fn: ajax.get,
// }
// }
// 2. 执行 effect,即:调用 ajax.get('/userLogin')
const value = yield effect;
console.log('value: ', value);
}可以明显的看出:
这里的 __call effect __表示执行 ajax.get('user/Login') ,又因为它的返回值是 promise, 为了等待异步结果返回,fetchData 函数会暂时处于 阻塞 状态。
除了上述所说的 call effect 之外,redux-saga 还提供了很多其他 effect 类型,它们都是由对应的 effect factory 生成,在 saga 中应用于不同的场景,比较常用的是:
其中,比较难以理解的就属:如何区分 call 和 fork?什么是阻塞/非阻塞?这是接下来要讲的。
前面已经提到,saga 中 call 和 fork 都是用来执行指定函数 fn,区别在于:
举个例子,假设 fn 函数返回一个 promise:
// 模拟数据异步获取
function fn() {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve('hello saga');
}, 2000);
});
}
function* fetchData() {
// 等待 2 秒后,打印欢迎语(阻塞)
const greeting = yield call(fn);
console.log('greeting: ', greeting);
// 立即打印 task 对象(非阻塞)
const task = yield fork(fn);
console.log('task: ', task);
}显然,fork 的异步非阻塞特性更适合于在后台运行一些不影响主流程的代码(比如:后台打点/开启监听),这往往是加快页面渲染的一种方式,有点类似于 Egg 的 runInBackground,倘若在这种情况下,你依然要获取返回结果,可以这样做:
const task = yield fork(fn);
// 0.16.0 api
task.done().then((greeting) => {
console.log('greeting: ', greeting);
});
// 1.0.0-beta.0 api
task.toPromise().then((greeting) => {
console.log('greeting: ', greeting);
});PS:这里的函数 fn 是一个 normal function,其实它还可以是一个 generator function(被称作是 Child Saga)。
最后的最后,再简单聊聊 saga 中的错误处理方式?
在 saga 中,无论是请求失败,还是代码异常,均可以通过 try catch 来捕获。
倘若访问一个接口出现代码异常,可能是网络请求问题,也可能是后端数据格式问题,但不管怎样,给予日志上报或友好的错误提示是不可缺少的,这也往往体现了代码的健壮性,一般会这么做:
function* saga() {
try {
const data = yield call(fetch, '/someEndpoint');
return data;
} catch(e) {
// 日志上报
logger.error('request error: ', e);
// 错误提示
antd.message.error('请求失败');
}
}这是最正确的处理方式,但这里更想讨论的是:++如果忘记写 try catch 进行异常捕获,结果会怎么样?++
就好比下面这样:
function* saga1 () { /* ... */ }
function* saga2 () { throw new Error('模拟异常'); }
function* saga3 () { /* ... */ }
function* rootSaga() {
yield fork(saga1);
yield fork(saga2);
yield fork(saga3);
}
// 启动 saga
sagaMiddleware.run(rootSaga);假设 saga2 出现代码异常了,且没有进行异常捕获,这样的异常会导致整个 Web App 崩溃么?答案是:肯定的!
来具体解释下:
redux-saga 中执行 sagaMiddleware.run(rootsaga) 或 fork(saga) 时,均会返回一个 task 对象(上文中说到),嵌套的 task 之间会存在__ 父子关系,__就比如上述代码:
现在某一个 childTask 异常了(比如这里的: saga2),那么它的 parentTask(如:rootTask)收到通知先会执行自身的 cancel 操作,再通知其他 childTask(如:saga1,saga3) 同样执行 cancel 操作。(这其实正是 Saga Pattern 的**)
但这就意味着,用户可能会因为一个按钮点击引发的异常,而导致整个 Web 应用的功能均无法使用!!
那么,面对这样的问题,如何优化呢?隔离 childTask 是首先想到的一种方案。
export default function* root() {
yield spawn(saga1);
yield spawn(saga2);
yield spawn(saga3);
}使用 spawn 替换 fork,它们的区别在于 spawn 返回 __ isolate task__,不存在 父子关系,也就是说,即使 saga2 挂了,rootSaga 也不受影响,saga1 和 saga3 自然更不会受影响,依然可以正常工作。
但这样的方案并不是让人最满意的!如果因为某一次网络原因,导致 saga2 挂了,在不刷新页面的情况下,用户连重试的机会都不给,显然是不合理的,那么如果可以做到 saga 自动重启呢?社区里已经有一个比较好的方案了:
function* rootSaga () {
const sagas = [ saga1, saga2, saga3 ];
yield sagas.map(saga =>
spawn(function* () {
while (true) {
try {
yield call(saga);
} catch (e) {
console.log(e);
}
}
})
);
}上述代码通过在最上层为每一个 childSaga 添加异常捕获,并通过 while(true) {} 循环自动创建新的 childTask 取代 异常 childTask,以保证功能依然可用(这就类似于 Egg 中某一个 woker 进程 挂了,自动重启一个新的 woker 进程一样)。
OK,差不多就先讲这些吧... 完!
这个 DEMO(https://codepen.io/pinggod/pen/QBOrjo)的初衷是为用户营造一种无限缩放和平移的视觉假象,典型应用是各类地图应用、可视化编辑器。
<defs>
<pattern id="grid-tiny" width="12" height="12" patternUnits="userSpaceOnUse">
<circle cx="1" cy="1" r="0.5" fill="#BCC7D1"></circle>
</pattern>
<pattern id="grid" width="24" height="24" patternUnits="userSpaceOnUse">
<rect x="0" y="0" width="24" height="24" fill="url(#grid-tiny)"></rect>
<circle cx="1" cy="1" r="1" fill="#C8D3DE"></circle>
</pattern>
</defs>在 SVG 中 defs 元素用于声明可复用元素,该元素本身不会被渲染出来,上面的代码声明了一个 24*24 像素尺寸的网格背景。接下来使用它为 rect 元素添加背景:
<rect x={x} y={y} width={width} height={height} fill="url(#grid)" transform="translate(-1, -1)"/>在上面的代码中,除了用于填充背景的 fill 属性,需要重点了解一下 x/y 和 width/height,属性:
这四个属性在画布缩放过程中需要实时计算和更新,是用于营造无限画布假象的关键之一。
触发缩放和平移的方式不局限于键盘、鼠标等设备的行为,DEMO 中使用 MAC 触摸板的双指缩放和双指平移操作作为演示,它们都会触发 wheel 事件。目前没有规范的浏览器属性区分 MAC 触摸板的双指平移和双指缩放行为,所以 DEMO 中使用特性检测的方式进行区分:
DEMO 中涉及两个坐标系:屏幕坐标系和 SVG 坐标系,它们都是笛卡尔坐标系,区别在于 Y 轴方向不同。开发者通过 event 事件获取到的信息,是用户屏幕坐标系的信息,需要开发者显式转换 SVG 元素所在的坐标系:
// 通过 event 获取用户在屏幕坐标系上的行为信息
const pointOnScreen = this.getPointOnScreen(event);
// 将屏幕坐标系上的点转换到 SVG 坐标系上
const pointOnSVG = pointOnScreen.matrixTransform(svgCTM);
// 获取缩放倍数,根据双指缩放的幅度和方向在 1 ~ 1.1(放大)和 -1 ~ -0.9(缩小)之间
const zoom = this.getScale(ctm, deltaY);
const modifier = (
this.svgNode
.createSVGMatrix()
.translate(pointOnSVG.x, pointOnSVG.y)
.scale(zoom)
.translate(-pointOnSVG.x, -pointOnSVG.y)
);
this.setState({
// https://developer.mozilla.org/en-US/docs/Web/API/SVGMatrix
// CTM,current transform matrix
ctm: ctm.multiply(modifier),
});平移操作相对于缩放要简单很多,只需要修改 ctm 中 e 和 f 值即可:
ctm.e -= Math.ceil(deltaX / 2.0);
ctm.f -= Math.ceil(deltaY / 2.0);
this.setState({ ctm });备注: 本文仅代表作者观点。
在一个中台系统内,前端与后端并不是架构上匹敌的两方。前端工程的切实定位是:连接用户和系统的桥梁。一个系统好比冰山,说它有十份,前端是那暴露在水面的两份,还有八份在水底。上游对接 UI 和交互,下游对接后端。要讨论中台系统的前端技术发展出路(不讨论程序员的基本素养),需要从以下点出发:
中台系统: 中台系统是一类面向特定用户的信息系统,使用者多是计算机专业领域人员而非 C 端消费级用户。比如公司内部系统监控平台,运维系统,云系统的控制台。
中台系统几乎都是 web 系统。web 前端的实质是浏览器技术,而浏览器是在 http 层工作的软件。 前端工程师首先需要在自身领域深耕。需要扎实掌握基础技术:
html, css, javascript, es.next, typescript
# typescript 趋势无法阻抗
前端已经走向了工程化,技术栈收敛到了某些特定的框架和工具,这些也是必须掌握的,
- 至少一个 UI 框架(React/Redux,Vue 等)
- 工程化工具(webpack, babel, node,CI 工具等)
浏览器是跑在 http 协议上的软件,所以和 http 有关的知识也是必须的:
- 流行 ajax 库的使用,比如 axios, fetch
- http protocol(cors, csrf, proxy, http header, http2, cache, etc)
- 流行动态 web server 的使用,比如 eggjs, express
- 流行静态 web server 的使用,nginx
浏览器技术的任何趋势也应该是一个 web 前端工程师关注的方向,比如,
PWA, serviceWorker, http2
「异步」是前端开发中最为常见的场景,所以需要掌握:
一种描述异步的模型:Promise, Generator (co, redux-saga 等), RxJs
一个优秀的工程师除了在自己的领域深挖以外,也应该要熟练掌握上下游的技术栈。 中台系统多是基于 java 构建的,在这层上一个前端工程师应该掌握:
- 一门 java mvc 技术,比如 Spring MVC, Sofa MVC 4
- 数据库技术(你需要懂别人的领域建模)
你的系统要和用户打交道,设计师只能给你指导,实现者还是前端工程师。掌握一定的交互知识和设计工具是必要的:
- 交互知识:Don't Make Me Think, Revisited: A Common Sense Approach to Web Usability
- 一个 wireframing 工具的基本使用,比如 sketch,axure,OmniGraffle
在可以看到的未来十年内,引领和驱动行业、影响社会的技术是:1. 云技术。2. AI 技术。 云技术虽然已经发展多年,还远未达到它盛开的阶段,AI 技术才是方兴未艾。
云技术的发展与当年微机操作系统的发展在某些模式上及其相像,四十年前的人们无法想象今天操作系统和应用软件的安装升级是一个普通用户就能搞定的,以 Docker、K8s 为代表的容器技术已经为云的发展打开了一片广阔的蓝海,我们无法想象今后的云变为什么样子,但可以确定的是云将无处不在,云的使用将会异常简单,所有的复杂度都将会被标准化的技术所吃掉。以后只会有端和云的区分,而不再有前端和后端的区分。
AI 是计算机能力的分水岭,在这以前的计算机只有计算能力,而之后的计算机将会有推理和决策能力,人类的大量计算工作已经在几十年间被各种计算机和芯片所取代,可以预见人类的推理和决策工作也将普遍被 AI 芯片所取代,届时人类的将会去从事创造性的工作,目前看这个是计算机无能为力的。
在这样的大背景下前端工程师将何去何从?我认为短期看是 数据的可视化呈现。云的运转离不开各种全局视角,AI 的推理终究要表达给人,作为机器与人交流的桥梁 - 前端,如何把这些信息友好和快速地展现给用户,是一个持续存在的工程领域。所以为了迎接行业趋势,前端工程师需要:
- 熟练掌握一门绘图工具,比如 G2/G6,D3,echart,tableau 等
- 以 webGL 为基础的渲染工具
- 熟练掌握统计学和图论的知识
- 容器技术和云领域知识(Docker、K8s, Service Mesh, 中间件技术)
- AI 领域知识(智能决策,智能识别,TensionFlow)
前端技术要解决的本质问题是 计算机系统中数据的展现和传输,「展现」是面向用户的功能概括,「传输」是面向后端的功能概括,这之上所列举的各种技能都是为这两个目标所服务的。当然你也可以说前端工程师可以用 js 语言开发 node.js 服务端应用,但其实你已经在谈全栈开发而脱离了狭义的前端技术范畴。
目前大学是不会把前端技术作为必修课的,如果你是一个在校的大学生,那么在学好计算机专业课的同时,请先从 React/Vue 和 es6 入手,同时在学习过程中持续补充 javascript,html,css 等基础知识,争取在一年之内达到能够写得出一个中小规模前端应用,看得懂别人代码的程度。
本文框定了web 前端这个范围,native 与前端的融合目前看也是一个大趋势,前文说到在将来我们只会有端和云的区分,所以 native 上的端技术上也是一个可以大有作为的领域,目前看 flutter/react native 以及 h5 容器技术/小程序都是可以深入的方向。
俗话说一叶知秋,如果说快速发展的前端有个主线串点成线,个人觉得是模块化的发展,因为模块所具备的特性,决定了其组织结构的可能性,以及人与人的合作模式。我们可以藉由模块化的发展,来了解前端的变化
早期 js 被作为脚本语言,协助表单校验等界面辅助增强,那时候前端也简单,不需要模块化
后来利用命名空间做代码拆分
YAHOO.util.Event.stopPropagation(p_oEvent); // YUI2 比如这个时期 YUI3, 这里出现了清晰的模块定义,和通过闭包来做模块运行空间
// 定义模块
YUI.add('hello', function(Y) {
Y.sayHello = function() {
Y.DOM.set(el, 'innerHTML', 'hello!');
}
}, '1.0.0',
requires: ['dom']);
...
// 使用模块
YUI().use('hello', function(Y) {
Y.sayHello('entry'); // <div id="entry">hello!</div>
})感觉已经很久之前了,但其实也才 14年左右,前端的模块化已经有了一些规范, CMD (延迟执行)、AMD (提前执行)、CommonJS(当时主要是服务端模块化) 模块规范以及基于模块做工程化的讨论非常激烈,是个百家争鸣的时代
那时 seajs 比较火,写法是这样
// 通过 define 来定义定义模块
define(function(require, exports, module) {
// 通过 require 引入依赖
var $ = require('jquery');
var Spinning = require('./spinning');
// 通过 exports 对外提供接口
exports.doSomething = ...
// 或者通过 module.exports 提供整个接口
module.exports = ...
});// 使用模块
seajs.config({
base: "../sea-modules/",
alias: {
"jquery": "jquery/jquery/1.10.1/jquery.js"
}
})
// 加载入口模块
seajs.use("../static/hello/src/main")那时的源服务也是需要自己处理,比如 spm 的发展,远没有今天的成熟,都是摸着石头过河,那时的前端圈子讨论问题态度非常认真,问答质量也非常之高。
后来随着发展, AMD、CMD 的浏览器端模块规范都逐渐淡化,以及构建环节的兴起,COMMONJS 模块规范 和 npmjs 作为源的体系逐渐壮大,形成如今的前端模块体系。
真的是分久必合,在 NPM 这个时期,前端模块 和 Nodejs 模块都收入 NPM 包管理,npm 包的 package.json 对模块的描述能力,以及安装卸载方式,增强了模块的控制和表述能力。前端和nodeJS,模块的处理,都融合在一起,兼具数量和多样性,爆发出很多活力,新的设计和想法层出不穷,并迅速传播。
因为是编译前置,因此写法上简单很多。
require("module");
require("../file.js");
module.exports ={ handle};Webpack 作为如今前端打包的事实标准方案,提出了一切皆模块的**,使得 CSS、HTML、JS 都能转化为相同的模块进行处理,结合 NPM 体系 使得前端模块管理日趋成熟. 也正是 Webpack的灵活,才在处理js版本,css、js 写法兼容等方面有很大帮助。
基于模块的发展和演化,未来可能会在几个方面有空间
tldr: 如果你很熟悉 react context & react portals,这篇文章对于你的价值不大
react 版本以及过时的 antd 版本[email protected] 没有 <Drawer /> 组件antd@latest 中的 <Drawer /> 保持一致
示例:
按照 自顶向下 的设计思维,抽屉组件由三部分组成:
content 部分平淡无奇,简单的 flex 布局即可搞定。重点放在 container 和 mask 的部分
有了布局之后,即可定义组件接口。这里给出接口的最小集:
visible: boolean,控制抽屉的显示和隐藏onClose: function,外部容器用于控制抽屉关闭的函数title: string or obeject,抽屉标题栏的显示内容,可以是简单字符串或是复杂对象(下拉菜单等)footer: object,抽屉底部区域,一般来说由若干个 <Button /> 组成完成上述设计之后,写出以下代码:
几点说明:
push 用于判断 父抽屉 是否需要因为 子抽屉 而发生位移mask 遮罩层需要从 opacity: 0 过渡到 opacity: 0.3,并添加一些别的 css 属性,后面会解释content 部分添加特殊的 css 属性,后面会解释content 部分是隐藏在浏览器窗口的最右侧的。而 container 和 mask 部分是以 100% 的 width 和 height 直接覆盖在整个窗口之上的,并通过 z-index 和 pointer-events 这两个 css 属性来让用户感知不到他们的存在,后面会解释先长话短说,z-index 要很大,确保抽屉能在所有页面内容的最上层,且 container 和 mask 部分在抽屉隐藏的状态,不能影响页面其他内容的操作。
下面是具体做法:
z-index: 在没有很极限的特殊情况下,设置为 1000 即可
pointer-events
除了指示该元素不是鼠标事件的目标之外,值 none 表示鼠标事件 “穿透” 该元素并且指定该元素“下面”的任何东西。因此,给 container 部分添加 pointer-events: none; 之后,即使它拥有一个很大的 z-index,抽屉外部的下层内容还是可以响应到用户的鼠标事件
回到 line: 37/38/45,由于 mask 部分需要响应 onClose 事件,content 部分需要响应抽屉内部的所有鼠标事件,因此,在抽屉打开的状态下,需要给 mask 和 content 部分添加 pinter-events: auto;
下面给出样式代码,content 的样式名为 .drawer, 其内部的部分省略
完成以上两步之后,一个基本的 单层 抽屉就做好了,很 simple 也很 basic
下面进行嵌套设计
多层嵌套的核心在于:子抽屉拉出时,父抽屉需要向左位移一定的距离。针对这一点,有以下几个问题
如何在 子抽屉 中控制 父抽屉 的行为?如果嵌套的层次很多,采用一堆的 callback 和 props 来控制显然是不合适的。实际上在 三层抽屉 的情况下,代码就已经很丑了
位移的是整个 container 部分还是只是 content 部分?虽然乍一看,这两种做法在视觉效果上类似,但仔细一想,根据需求,mask 部分是一个 fade in & fade out 的效果,所以在一开始的组件布局设计中, container 和 mask 部分是一开始就覆盖在页面之上的,抽屉打开时,仅仅只是把 content 部分从右侧隐藏区域拉出来。因此,在子抽屉打开时,如果父抽屉位移的是 content 部分,那在最后父抽屉关闭时,还需要把先前这段位移的距离再补回来,就不是简单的 tranlateX(100%) 了。所以位移整个 container 应该才是比较方便的做法
多层抽屉的情况下,<Drawer /> 组件渲染到 dom 中应该是怎样的层级关系?举例来说,如果层级关系如下所示:
<div id='root'>
// ...
// 页面 A 中包含了一个多层嵌套的抽屉
<div>
// ...
// 第一层抽屉
<Drawer>
// 第二层抽屉
<Drawer>
</Drawer>
</Drawer>
</div>
</div>根据第二个问题中,子抽屉打开时,父抽屉发生位移的是整个 container 部分,那么按照上面的层级关系,父抽屉的 container 实际上是包裹着子抽屉的,所以其实此时子抽屉也发生了不该发生的位移。因此,这样的设计显然是不合理的,替代为:
<div id='root'>
// ...
// 页面 A 中包含了一个多层嵌套的抽屉
<div>
// ...
</div>
</div>
// 第一层抽屉
<Drawer>
</Drawer>
// 第二层抽屉
<Drawer>
</Drawer>如上面的代码所示,最终渲染到 dom 中之后,抽屉应当于 root 并列,但在书写代码的层面,<Drawer /> 还是采用正常的嵌套逻辑写在 A 页面中,即在 virtual dom 中,<Drawer /> 是嵌套的,在 真实 dom 中,<Drawer /> 是独立且并列的
下面来解决这几个问题
Technically this part can be regard as an analysis of source code of antd-drawer and rc-drawer
回顾一下 Redux 的做法,Redux 通过 Context 机制实现了管理全局 state 的功能,使得任意位置的组件都能够很方便地获取到任何它想要的 props,这里不赘述
回到上面的第一个问题:如何在 子抽屉 中控制 父抽屉 的行为? 如果能在多层嵌套的抽屉中建立一个上下文,子抽屉 能够控制离它最近的 父抽屉 的行为,那么这个问题就解决了
Context 的定义:
Context provides a way to pass data through the component tree without having to pass props down manually at every level.
Context is primarily used when some data needs to be accessible by many components at different nesting levels.
具体的 API 和使用方法这里不展开了。这里得出的结论是:通过 Provider 和 Consumer 的形式,父抽屉 可以把自己本身(或者自己内部的某些属性和方法)传递给 子抽屉,这样 子抽屉 就可以去控制 父抽屉 的位移行为了。后面会给出具体代码
Portals 的定义:
Portals provide a first-class way to render children into a DOM node that exists outside the DOM hierarchy of the parent component.
A typical use case for portals is when a parent component has an
overflow: hiddenorz-indexstyle, but you need the child to visually “break out” of its container. For example, dialogs, hovercards, and tooltips.
回到上面的第三个问题,实际上已经可以很明显地从 Portals 的定义中找到答案。同样给出结论:使用 ReactDOM.createPortal() 这个方法,把 <Drawer /> 组件直接渲染到 document.body 中去
下面给出完整的 <Drawer /> 代码
几点说明:
DrawerContext 定义了嵌套抽屉的上下文,方法中传入 null 表示最顶层的抽屉没有父抽屉parentDrawer 的值是通过 line 104 的 DrawerContext.Provider 传递过来的push 定义为 number 类型,可以理解为”被子抽屉 push 了几次“,并根据 push 的值来渲染父抽屉的位移距离createPortal 的过程中,不能直接把 <Drawer /> 扔到 document.body 中,要在外面包裹一层 <div> ,然后再扔到body 中。因为 <Drawer /> 最外层的 contaner 部分有 z-index 属性,如果直接扔到 body 中,在多层嵌套的情况下会有问题(暂时没找到原因)最终示例:
至此,一个扩展性还不错的多层嵌套抽屉就写好了。当然还可以做很多优化,比如添加更多可配置属性,控制抽屉的 destroy 行为等
想说的是,在刚开始写这个组件时,觉得是个很简单的普通组件,无非是控制一些动画效果而已。当然,通过一些简单粗暴的代码,也确实能够实现一开始提到的那些需求
但那样就没意思了
CSS 有一个简明易懂的结构:一个 CSS 文件就是一个样式表,一个样式表中有多 个样式,一个样式中有选择器和样式规则两部分,一个样式规则包含样式属性和样式值两部分……作为一名前端工程师,CSS 在个人的职业技能树上占有非常重要的地位,是核心技能之一。在过去的一年多时间中,我很多的工作都是围绕 JS 展开的,希望趁最近的时间做一些 CSS 方面的复习和总结,先从选择器入手,介绍已经被大多数浏览器所支持的 CSS 1 ~ CSS 3 选择器。如果你想知道自己的浏览器支持哪些选择器,可以点击 http://css4-selectors.com/browser-selector-test/ 进行在线测试。本文中介绍的选择器实践经验,大多来自于文末的参考资料,推荐各位学习或复习。
目前最新的浏览器全部支持 CSS 3 及之前的选择器,这些选择器的总数在四十以内,下面我们一个个介绍这些选择器的用法和常见误区。
通配符选择器得名于其使用的符号 *,它可以用于选择文档中的所有元素,但不能选择伪元素。此外,还有一种无效情况:
<div>
<p>Lorem ipsum dolor sit amet...</p>
</div>在上述 HTML 结构中,p 是 div 的直接子级,如果开发者使用如下样式,则找不到相应的元素:
div * p { color: red; }这是因为 CSS 中的通配符选择器 * 不能为空,而我们在正则表达式中使用的 * 则可以表示空,这两者之间的区别需要小心对待。
元素选择器、类选择器、ID 选择器几乎是必不可少的选择器,相信大家已经对它们谙熟于胸了:
p { color: red; }
.red { color: red; }
#logo { color: red; }如果一个页面有多个
id="logo"的元素,那么#logo { color: red; }会对这些元素生效吗?在 chrome canary 54 上答案是会的,但不建议这样使用 ID。
属性选择器可以根据元素属性进行选择,上述的类选择器和 ID 选择器可以使用属性选择器来模仿(模仿后功能相似,但权重不同),属性选择器包含以下几种类型:
[class="red"],匹配 class 属性等于 red 的元素[class~="red"],匹配 class 属性中包含 red 单词的元素,class="red danger tip" 是有效的,class="redius" 则是无效的[class|="red"],匹配 class 属性的值以 red 开头的元素[class^="red"],匹配 class 属性的值以 red 开头的元素[class*="red"],匹配 class 属性的值包含 red 字符串的元素[class$="red"],匹配 class 属性的值以 red 结尾的元素这里的 [class|="red"] 和 [class^="red"] 相似,区别在于,[class|="red"] 属性值不能包含特殊字符,在 chrome cannary 54 测试只能是数字或字母。制定 [class|="red"] 选择器的初衷是为了匹配语言子码,比如下面的样式对 lang 属性值为 en / en-US / en-GB 元素都有效:
[lang|=en] { color: red; }上面介绍的选择器都是单一使用的选择器,更实用的方式是将多个多种选择器组合起来,对文档元素进行精确定位:
div p,后代选择器,浏览器解析选择器时按照从右往左的顺序进行选择,所以这里会先找出所有的 p 元素,然后找出 p 元素之上有 div 元素的 p 元素div > p,直接后代选择器,在这里就是要找出所有直接子元素是 p 元素的 div 元素div + p,相邻元素选择器,在这里选择的 p 元素有两个要求:与 div 元素同级且相邻,中间没有其他元素;在 HTML 文档中位于 div 元素之后,最终会选择每个 div 元素之后的一个 p 元素div ~ p,同类选择器,和相邻选择器相似,不同之处在于,这里选择的 p 元素不必与 div 元素相邻,只需要在 HTML 文档中位于 div 元素之后即可,最终会选择每个 div 元素之后的多个 p 元素伪类元素的特殊性在于它们是动态存在的,只有用户触发了某些事件(鼠标悬停、移入移出等)才会生效,常见的伪类选择器包括::link、:visited、:focus、:hover、:avtive,需要注意的是在使用的时候,它们的声明顺序会影响页面效果,这是因为它们具有相同的权重,有关权重的问题我们会在下一节介绍。
下面是一些和元素位置相关的伪类选择器:
li:first-child,这里选中的 li 元素必须是其父级的第一个子元素li:last-child,这里选中的 li 元素必须是其父级的最后一个子元素li:only-child,这里选中的 li 元素必须是其父级的唯一子元素li:nth-child(N),这里的 N 可以是表达式(2n+1 / -n+1 ...)、odd、even,选中的 li 元素必须是其父级的第 N 个子元素li:nth-last-child(N):这里选中的 li 元素必须是其父级的倒数第 N 个子元素li:first-of-type,这里选中的 li 不一定是父级的第一个子元素,但一定是父级的第一个 li 元素li:last-of-type,这里选中的 li 不一定是父级的最后一个子元素,但一定是父级的最后一个 li 元素li:only-of-type,这里选中的 li 不一定是父级唯一的子元素,但一定是父级唯一的 li 元素li:nth-of-type(N),这里选中的 li 不一定是父级的第 N 个子元素,但一定是父级的第 N 个 li 元素li:nth-last-of-type(N),这里选中的 li 不一定是父级的倒数第 N 个子元素,但一定是父级的倒数第 N 个 li 元素上述以 -child 结尾的选择器,往往对元素在 DOM 结构中的位置和数量有严格要求,以 -of-type 结尾的选择器则要宽松很多。
其他伪类选择器:
:root,在 HTML 文档中,匹配 html 元素:empty,匹配那些没有子元素的元素,比如 <p></p> 就没有子元素,但是 <p> </p> 是有子元素的:target,该选择器和 URI 有关,如果 URI 是 http://a.com/index.html#abc,那么匹配的就是页面上 ID 属性值为 abc 的元素:enabled,大多用于表单,选择所有未被禁用的元素,未被禁用的元素可以接受焦点,可以被激活,可以输入文本:disabled,大多用于表单,选择所有禁用的元素,禁用的元素通常不能接受焦点,不能被激活,不能被单击或输入文本:checked,大多用于表单,选择所有 selected 或 checked 元素:not(S),否定伪类选择器,这里的 S 可以是其他选择器,比如 :not(p:empty) 选中了非空的 p 元素:lang,语言规范选择器,使用该类的前提是 HTML 元素上设置了 lang 属性,该选择器会根据该属性的值进行匹配,匹配成功则选中最后是伪元素选择器,它们所创建的元素也是动态和虚拟的,其内容可以在触发某些事件时动态生成,目前(CSS 3 以之前)一共有五种伪元素选择器:
::first-letter,通俗来说,该选择器用于选择块级元素的第一行的第一个字符。严格来说,选择块级元素、内联块元素、表格标题、表格单元格或列表项中的第一个已格式化的文本行::first-line,通俗来说,该选择器用于选择块级元素的第一行li::before,在另一个元素之前生成一个伪元素,值得注意的是,它只会渲染某些内容,但不会称为 DOM 树上的真实节点li::after,在另一个元素之后生成一个伪元素,值得注意的是,它只会渲染某些内容,但不会称为 DOM 树上的真实节点::selection,选择用户选中的文档元素,常用于自定义用户选择部分内容的样式,该选择可用的样式并不多,最新浏览器都支持 color 和 background 属性,其他的属性具有兼容性问题当有多个选择器指向同一个 HTML 元素时,它们之间就会发生竞争,争取成为最后生效的样式。既然有竞争,就会有相应的判定规则,这个规则的核心就是不同类型的选择器具有不同的权重,下面的选择器权重从上到下依次减弱:
!important 拥有最高优先级<style></style> 内置样式当根据以上顺序比较权重,结果相同时,会继续比较选择器出现的前后顺序,晚出现的选择器会覆盖早出现的选择器,即使它们的权重相同。为了简化对权重的计算,我们可以按照以下顺序编写 CSS 演示:
/* 通配符选择器 */
/* 元素选择器 */
/* 类、属性、伪选择器 */
/* ID 选择器 */ 实际开发中使用场景多变,还需要根据实际情况适当调整。Chris Coyier 在 《Specifics on CSS Specificity》 中使用了可量化的方式衡量样式的权重,有兴趣地可以前往学习。
EditorConfig 是一套用于统一代码格式的解决方案。简单来说,EditorConfig 可以让代码在不同的编辑器保持一致的代码格式。支持各种主流编辑器和 IDE。
以 sublime 为例,安装 EditorConfig 插件。
当打开一个文件时,EditorConfig插件会在打开文件的目录和其每一级父目录查找.editorconfig文件,直到有一个配置文件root=true。EditorConfig配置文件从上往下读取,并且路径最近的文件最后被读取。匹配的配置属性按照属性应用在代码上,所以最接近代码文件的属性优先级最高。
注意:Windows 用户在项目根目录创建.editorconfig文件,可以先创建“.editorconfig.”文件,系统会自动重名为.editorconfig。
EditorConfig文件使用INI格式。斜杠(/)作为路径分隔符,#或者;作为注释。EditorConfig文件使用UTF-8格式、CRLF或LF作为换行符。
通配符:
root: 表明是最顶层的配置文件,发现设为true时,才会停止查找.editorconfig文件。
indent_style: 设置缩进风格,tab或者空格。tab是hard tabs,space为soft tabs。
indent_size: 缩进的宽度,即列数,整数。如果indent_style为tab,则此属性默认为tab_width。
tab_width: 设置tab的列数。默认是indent_size。
end_of_line: 换行符,lf、cr和crlf
charset: 编码,latin1、utf-8、utf-8-bom、utf-16be和utf-16le,不建议使用utf-8-bom。
trim_trailing_whitespace: 设为true表示会除去行尾的任意空白字符。
insert_final_newline: 设为true表明使文件以一个空白行结尾
root = true
[*]
indent_style = space
indent_size = 2
end_of_line = lf
charset = utf-8
trim_trailing_whitespace = true
insert_final_newline = true
[*.md]
trim_trailing_whitespace = false
#无线Web开发经验谈
以下各种经验来自各个方面的渠道,有些并没有标注的具体人员,所以这里先说明,这些都是前端同学的智慧结晶(可能有本公司,也可能是其他公司的),本人在自己的经验之外同时也收集了其他的经验,集合了在一起。对于新人或者想了解无线开发的同学提供一些参考。
无线Web开发是基于智能手机上的游览器进行的Web开发。现在智能手机主要有Android和IOS两种操作系统的,因此基于手机Web的开发,主要是基于Android和IOS两种操作系统上的web开发。
基于两种操作系统的Web开发的共同点:
不同点:
在说具体的移动Web开发之前,需要先说一下手机的特点,手机的特点影响着很大方面的手机Web开发,因此在说语言前,先需要了解一下手机的特点。
智能手机是这两年发展起来的,其硬件发展的非常迅速,不过无论其硬件发展多块,由于手机的特点,性能和功能是一个平衡点。因为谁也不会用一个性能超好,但是手机非常烫并且只能用1个小时的机器。因此在很多方面,手机上的性能是受到一定限制。web这块受这个影响叫native的方面要大很多。因此web这块不是编译型语言,只能动态在手机上运行,再加之webkit核心所占的内存较大,是单进程单线程应用,其受CPU、内存的影响更大。
手机Web开发在性能上影响较大的是页面渲染问题,而js脚本性能问题不再突出,这个主要归功于在android上使用了v8引擎,大大提升了脚本的执行性能。这个和PC上的情况完全不同,因为在PC上,由于其高性能的硬件,加上强劲的显卡,使得页面渲染的性能非常之高。而在手机上完全不同,有限的硬件性能,加上没有显卡这类专门处理显示的硬件,使得所有页面渲染的工作都由CPU来执行。加上CPU本身的执行频率有限,就会造成页面渲染缓慢。因此在手机上,会发现当页面出现大量的渲染变化的时候,会出现卡顿现象。比如长列表滑动,页面切换动画等等。这些条件都限制了HTML5的功能发挥,因此在涉及到动态变化的时候,更加需要小心处理。
键盘也是和PC不同之处,在刚刚做手机Web开发的时候,会经常忘记的。由于现在的手机使用了软键盘,因此软键盘在某些时候,会成为页面的一部分。键盘是一个非常特别的设备,说特别是因为,不同的手机对于键盘对于html页面的布局的实现不同。下面通过以下几个方面,阐述手机键盘的特点:
键盘的布局 由于手机界面非常小,因此键盘会占住手机屏幕的一大部分,对于键盘对html的页面布局影响,如果从来没有做过的人,也许不会注意到,android和ios的处理方式,android中各个厂商处理的方式又有所不同。ios对于从下方推出键盘的时候,如果输入控件在页面推出之后,在键盘的高度的上方的话,则键盘是以一个浮层的方式弹出,并且将那个触发的控件推到键盘的上方。如果那个控件在页面底部,如果推出的键盘会覆盖该控件,系统会将整个页面向上推,直到将那个控件推到键盘上方为止。而android的实现的不同,有部分的android的实现和ios一样,有些android的机型的实现却不同,如果发现触发的input控件比键盘的高度底的时候,会自动将整个document的高度增加,增加到这个控件的高度超过键盘的高度为止。由于实现的不同,会造成以下两个问题,
键盘的类型 在手机上有各种键盘类型,比较常用的键盘有全键盘,数字键盘,符号键盘,email键盘,搜索键盘,金额键盘,电话键盘等。不过由于web的限制,能真正使用的可以说非常的有限,并且在ios和android上的实现不同。而且弹出的键盘类型也不禁相同。这个在下述input有详述,这个就不重复说了。总结一句话,键盘的弹起,完全依赖系统和厂商的实现。键盘的类型是无法定制的。
键盘的事件 弹起和收起键盘。这个也是非常纠结的问题。在ios6之前,当控件获得focus的时候,如果不是用户触发的事件,键盘是不会弹起的,在ios6之后,设置了一个属性可以做到,在android上,只要不是用户触发的事件都无法触发。暂时还没有解决方案。键盘的收起,可以通过js的blur的方式来实现。
页面滚动是非常常用的功能,不过在原生手机上,无法支持局部滚动的,不过ios5之后,出现了一个支持局部滚动的CSS属性,-webkit-overflow-scrolling: touch的属性,不过里面有一定的缺陷,在某些滚动中,会失效,因此建议不使用。
就页面需要说一个非常的规则,因为这个会直接影响web的开发。就是在页面进行惯性滑动的时候(手指松开的滑动),处于性能的考虑,浏览器是会把页面上的渲染进行锁定的状态。也就说,当页面进行滑动的时候,js动态修改上面的元素是无效的。直到页面滚动停止,这是个非常特殊的规则。在IOS和android上都会存在,在ios上显得突出。在日常评估的时候,一定需要这个特性,这个特性决定了某些滑动中的功能是无法实现的,比如说某个元素到某个位置从static编程fixed的状态,或者进行状态转换。在滑动的时候,即使js动态设置了,页面也不会响应,直到滚动结束。因此在native中很多触摸控制的效果,在web上却无法完美实现。
附注:对于ios的滚动的系统细节实现可以参考此地址:http://www.iunbug.com/archives/2012/09/19/411.html
页面滚动有个其他的问题,就是在ios的系统里,就算网页头了,还能继续往上面拉,有一个力反馈的效果,并且这个效果是无法取消的,看上去很酷和很美。但是在实际项目中,几乎是用不到这个看上去很美的效果,反而会造成很奇怪的感觉,特别是做成webapp的时候,一个完整的界面有导航头的时候,还能在往上拉动,极其诡异的感觉对于用户而言。并且这个滚动是系统实现的,没有方法去除,因此判断一个app是web还是native的,就可以通过这种方式来判断,拉到顶,再往上拉,如果能网上拉,并且出现的不是上拉刷新,而是一个ios的默认背景,则就是web了,不过反之不一定是native,因为web可以直接禁用滚动,通过css3或js来实现模拟滚动,不过这类滚动会造成很严重的性能问题,特别是对整个长页面的滚动。
模态窗口在项目中也是非常常用的一种功能,模态窗口可以通过js的alert、confirm等调用,不过移动模态的窗口,有一个问题,就是在模态窗口的头部,会出现当前url的地址,并且无法去除,这个在交互的眼中,是无法接受的。因此模态窗口,在实际场景中,使用的较少。大家在今后评估项目的时候,需要注意。
在无线Web开发中,在head头部遇到最常见的问题,就是viewport的设置
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0, user-scalable=0"/>
对于这里面的设置,大家可以Google一下,有非常详细的叙述,我这里不太重复,以下有几个地址,大家可以做下参考
https://developer.mozilla.org/en-US/docs/Mozilla/Mobile/Viewport_meta_tag
https://developer.apple.com/library/safari/documentation/appleapplications/reference/SafariHTMLRef/Articles/MetaTags.html
等,其实更加具体的,大家可以再overstackflow或者google进行查询。
最佳实践:
HTML5的标签使用
在无线Web的开发中,大家会经常使用HTML5的tag标签,对于HTML5的大多数标签使用起来不会遇到问题,
比如说nav、footer、article等标签,这些展示型的标签一般可以安全使用,如果不是非常确定某个HTML5标签是否可以使用,建议参考http://caniuse.com/。
此类标签是非常特殊的标签,因为这个是和用户交互最紧密的一类标签,也是问题最多的一类标签。
IOS和Android在HTML5标签上最大的区别莫过于input类型的标签,并且不同Android机对于input类型的实现也大有不同,同时不同的类型的input,会弹出不同的键盘类型,特别是ios。一般在开发过程中常常会碰到需要弹出键盘的需求,以下可以做参考。这些控件的一个比较重要的特点是交互界面由浏览器实现,无法通过css、html来进行定制,因此对于日常评审交互搞、视觉稿的需求的时候,一定要非常谨慎,可能多一个逗号,都是修改不了的。
下面列出比较保险的几个类型:
需要谨慎使用的类型:
由于上述的问题,经常会收到这种需求,就是非常渴望去完整实现某个控件,在PC端,由于发展了很多年,机制较为完整,可以用js来模拟实现,不过在手机端,由于手机、平台等各方因素,使用js来模拟某个控件并不是一个明智之举。各种经验表明,使用js来模拟的控件,在某些机型和平台上会出现非常诡异而又无法解决的问题。因此对于JS定制控件,除非你有非常大的把握,否则不要轻易触碰
手机浏览器对于CSS3的支持,总体上支持的比较好,不过由于Android的碎片化,手机碎片化以及IOS的各种版本,在很多地方需要谨慎操作。
如果说起手机Web的CSS,就需要说起-webkit-的前缀的CSS的属性。这些前缀是专门为了webkit核心的浏览器设置的属性,可能很多-webkit-的属性,已经成功通用的属性了,不需要再加前缀。不过为了兼容低版本的浏览器,在设置的时候,还是需要加上-webkit-前缀
CSS3有很多类型,大致可以分为以下类型,布局类型、渲染类型、选择器类型、动画类型。
在讲以上布局之前,需要说一下关于CSS的reset的问题。关于这个问题,需要追溯到HTML4的时代,在那个时候,由于PC有各种游览器、各种标准、造成对于HTML的各个标签所带的默认样式的不同,结果造成要在各个平台统一一个样式会非常难。因此出现了reset,所谓reset的意思是把所有HTML的标签的默认样式进行重置,这样方便在所有平台进行页面制作开发。跨入无线Web的时代之后,reset是否还要存在,业界有着非常多的讨论。主要分为两派:reset派和normalize派。reset派认为就算是到了移动时代,还是有各种碎片化的问题,需要reset,而normalize的一派认为,到了无线Web,很多规范已经收到了很多厂商的支持,最出名的要属Google和苹果,因此不需要进行reset,只需要将那些标签进行统一化,即可。
因此,在市面上做移动开发,有两种CSS模式,reset模式和normalize的模式。个人认为,两者没有绝对的好与坏。主要看这个项目的特性。
不过就大多数项目而言,一般产品经理和交互都会要求在各个平台需要有个统一的产品表现,因此在实际项目里,reset可能用的会更多一点。
布局类型的CSS,是指这些属性影响着HTML的布局方式。HTML4最经典要属position、float等这些使用频率极高的属性,对于它的使用方式,估计无数文档已经有了,我这里不在不在复述。在以下介绍一种布局类型:flex。在以前的开发过程中,可能对于前端开发者而言,最痛苦的,莫过于水平布局,在table布局遭到唾弃之后,div的布局兴起,大量开始使用float的布局,不过使用float布局,也有其痛点,就是float的实现在不同游览器的实现,特别是IE系列中的 6、7等,表现很诡异,需要非常多的trick,才能保证没问题。进入移动时代,可以使用flex布局。
对于flex的布局,大家可以网上进行google,这里不进行描述,对于flex的使用方式,到处都有,我这里所说的,是其中隐含的潜规则。
| Chrome | Safari | firefox | Opera | IE | Android | iOS |
|---|---|---|---|---|---|---|
| 21+ (modern) 20- (old) | 3.1+ (old) | 2-21 (old) 22+ (new) | 12.1+ (modern) | 10+ (hybrid) | 2.1+ (old) | 3.2+ (old) |
固定布局fixed可以说在PC上使用的非常多的一个属性,在手机上使用fixed属性,需要非常的谨慎小心。以下专门分两个平台详叙述:
before,after 可以说用的最多的可能是这两个CSS属性。其具体的含义,可以参考各种文档,这里就不详细述说。这里说的是它的一般使用场景。before和after原先在w3c的定义中,主要在节点的前面和后面插入一段内容,因此在before和after中必须要有content的属性以及数值。不过在在实际项目中,通过它自动在节点前和后面插入一个节点,通常不会插入一个文字,而是一个绝对定位的图标之类的元素。虽然这个实现在html中加个结构可以实现,不过通过before和after来插入的节点,有个好处,就是能是html的结构显得更加精简和语义化更加强。不过带来的不便之处,就是进行问题的排查,因此无法直接通过查看html结构查看before和after的元素类型。不过现代游览器自带的debugger工具,都能够进行查看,问题不是很大。因此对于这两个伪类,推荐大家使用。
渲染类型是指该类型的主要的功能是在渲染html结构上,说的通俗一点,就是在结构上加上各种颜色,尺寸。可以说CSS的一大部分做的都是这些事情,渲染类型按照不同的角度,可以分为很多种类型,不过以下从维度的区分,2D和3D。
绝大多数的CSS的属性都属于2D的渲染。由于在CSS3中加入大量的有用的2D渲染的属性,以前需要使用图片才能实现的效果,现在通过CSS的设置也可以实现,以下主要说明比较常用的属性,以及使用注意点。
3D渲染是个非常cool的属性,它能将页面上的元素进行3D化的渲染,实现各种非常炫酷的效果。不过由于其非常的先进性,所以能支持3D的属性的机型、版本、厂商也会有很多的不同。因此这里说3D,并不是要使用3D里面的属性,而是使用其特性。
从实践的角度来看,3D的最大的好处,它使用了硬件加速功能,虽然可能直接使用它的各种属性有困难,但是它却给我们一个很多的硬件加速特性支持。因此在做页面动画的时候,即使不是做3D的变化,却可以通过3D的设置开启硬件加速功能。使用 translateZ(0);可以是当前的节点开启硬件加速功能,又不会带来任何的渲染变化。这里很多人会认为使用2D的动画会开启硬件加速,其实不是,必须使用3D,才会开启,这个需要注意
CSS3提供了大量新的选择器,使得选择一个节点变得非常简单,CSS3的选择器很多,大多数在手机里都支持,不过对于日常项目的开发,以下的几种类型会非常常用的,大家可以做参考,对于其他的选择器,可以参考网上。
这个也是非常常用的伪类,特别是用在布局中,有一个非常的经典的场景,就是一个列表,要求一个列表项的上边和组后一个列表项的下边是圆角。之前如果需要实现的话,需要额外增加class来实现的。如果使用这些伪类的话,就非常的简单。
在诸多的CSS选择器中,属性选择器是个非常好用的一个类型,比较常用的一种场景是input的样式修改,因此input的属性比较丰富,针对具体某一类的input类型的样式修改,如果通过以前的方式,只能通过增加class的名字。现在使用属性选择器后,代码量和复杂度会大幅度降低。
动画类型是CSS3中一个比较有用的一种类型,它可以实现节点的动画效果,配合js,可以让其动画变得非常的丰富。不过对于如果正确使用动画上,也需要处处小心,最关键的是性能问题。
很多在PC上没有的性能问题,一旦到手机上就会变得非常的明显。其中动画就是。由于网页的DOM的特性,动画是非常消耗性能的,再加上网页是单进程单线程的,因此所有的程序运行都会在一根ui线程里运行。手机上的性能还没有达到PC上的性能,因此动画的性能问题在手机上显得异常突出。
就算今后手机双核、四核也不会根本改变这个现状,其主要原因是单线程,即使有多个CPU,同一个时间也只能用一个CPU,如果要彻底提高性能,现在一个可能的方案是使用webworker,建立多线程的方式。不过支持webworker的手机并不是很多。所以近阶段性能永远是动画的一个痛。
不过不用过于悲观,也不是不能使用,但是在使用上,需要小心谨慎,可以准从以下标准(没有绝对也没有一定,看实际效果)
以上是使用前的注意点,如果已经确定都没有问题的话,开始进入正题。一般使用2D动画,主要会使用以下两个属性,transition和animation。
不过在使用的时候,需要注意以下几点:width和height,如果设置成auto的话,动画变化会比较诡异,建议动画起始都是具体的像素或者百分比。background如果变化的是图片的话,图片切换的效果并不是非常理想,避免对不同的图片进行变化,不过可以考虑使用background position,进行位置的变化。
从实践的角度来看,transition和animation使用的场景不太一样,transition适合用在短而小的动画上面,animation适合用在会不断重复的场景里。在使用动画动画的时候,需要注意几件事情:
综上所述,在手机web上使用动画的时候,需要谨慎。
智能手机对js的支持比较好,对于es5的规范支持的比较好,不过还是考虑到版本兼容性问题,以下列出一些在实践中检验通过的一些方法:
html5为了我们提供了一个非常好的DOM选择器,就是document.querySelector和document.querySelectorAll这两个方法,这两个方法在android2.1+以及ios3+以后,都可以使用,其接受的参数为css选择器。在实际web开发中,有一部大部分工作会用到DOM的操作,通过这个神器,可以解决大多数的DOM的操作。建议大家使用的时候,可以多多使用这两个方法。
其他的DOM的选择器的兼容性并不是太好,建议不要使用。
对于jquery大家应该会非常的熟悉,在web手机上也有一个轻量级的类库工具,那就是Zepto,它的很多api接口保持和jquery的接口兼容,其体积非常小,gzip的包在10k左右,非常适合在手机上的无线环境中加载。建议大家在使用类库的时候,推荐使用,其api地址为:http://zeptojs.com/
说到移动开发,不得不说一下这个click事件,在手机上被叫的最多的就是点击的反应慢,就是click惹出来的事情。情况是在这样,在手机早期,浏览器有系统级的放大和缩小的功能,用户在屏幕上点击两次之后,系统会触发站点的放大/缩小功能。不过由于系统需要判断用户在点击之后,有没有接下来的第二次点击,因此在用户点击第一次的时候,会强制等待300ms,等待用户在这个时间内,是否有用户第二次的提交,如果没有的话,就会click的事件,否则就会触发放大/缩小的效果。
这个设计本来没有问题,但是在绝大多数的手机操作中,用户的单击事件的概率大大大于双击的,因此所有用户的点击都必须要等300ms,才能触发click事件,造成给用户给反应迟钝的反应,这个难以解决。业界普遍解决的方案是自己通过touch的事件完成tap,替代click。不过tap事件来实际的应用中存在下面所说的问题。
不过有个好消息,就是手机版chrome21.0之后,对于viewport width=device-width,并且禁止缩放的设置,click点击将取消300ms的强制等待时间,这个会是web的响应时间大大提升。ios至今还没有此类消息。不过这个还需要有一段时间。
javascript有很多用户交互相关事件,在移动上有一些比较特有的事件,大家在日常开发中,可能会接触到,这些事件的特性,这里说一下:
##基础知识
###meta标签
meta标签,这些meta标签在开发webapp时起到非常重要的作用
<meta content="width=device-width; initial-scale=1.0; maximum-scale=1.0; user-scalable=0" name="viewport" />
<meta content="yes" name="apple-mobile-web-app-capable" />
<meta content="black" name="apple-mobile-web-app-status-bar-style" />
<meta content="telephone=no" name="format-detection" />
第一个meta标签表示:强制让文档的宽度与设备的宽度保持1:1,并且文档最大的宽度比例是1.0,且不允许用户点击屏幕放大浏览;
尤其要注意的是content里多个属性的设置一定要用分号+空格来隔开,如果不规范将不会起作用。
注意根据 public_00 提供的资料补充,content 使用分号作为分隔,在老的浏览器是支持的,但不是规范写法。
规范的写法应该是使用逗号分隔,参考 Safari HTML Reference - Supported Meta Tags 和 Android - Supporting Different Screens in Web Apps
其中:
第二个meta标签是iphone设备中的safari私有meta标签,它表示:允许全屏模式浏览;
第三个meta标签也是iphone的私有标签,它指定的iphone中safari顶端的状态条的样式;
第四个meta标签表示:告诉设备忽略将页面中的数字识别为电话号码
在设置了initial-scale=1 之后,我们终于可以以1:1 的比例进行页面设计了。
关于viewport,还有一个很重要的概念是:iphone 的safari 浏览器完全没有滚动条,而且不是简单的“隐藏滚动条”,
是根本没有这个功能。iphone 的safari 浏览器实际上从一开始就完整显示了这个网页,然后用viewport 查看其中的一部分。
当你用手指拖动时,其实拖的不是页面,而是viewport。浏览器行为的改变不止是滚动条,交互事件也跟普通桌面不一样。
(请参考:指尖的下JS 系列文章)
更详细的 viewport 相关的知识也可以参考
##移动开发事件
###手势事件
###触摸事件
###屏幕旋转事件
###检测触摸屏幕的手指何时改变方向
###touch事件支持的相关属性
###判断屏幕是否旋转
function orientationChange() {
switch(window.orientation) {
case 0:
alert("肖像模式 0,screen-width: " + screen.width + "; screen-height:" + screen.height);
break;
case -90:
alert("左旋 -90,screen-width: " + screen.width + "; screen-height:" + screen.height);
break;
case 90:
alert("右旋 90,screen-width: " + screen.width + "; screen-height:" + screen.height);
break;
case 180:
alert("风景模式 180,screen-width: " + screen.width + "; screen-height:" + screen.height);
break;
};};
###添加事件监听
addEventListener('load', function(){
orientationChange();
window.onorientationchange = orientationChange;
});
###双手指滑动事件:
// 双手指滑动事件
addEventListener('load', function(){ window.onmousewheel = twoFingerScroll;},
false // 兼容各浏览器,表示在冒泡阶段调用事件处理程序 (true 捕获阶段)
);
function twoFingerScroll(ev) {
var delta =ev.wheelDelta/120; //对 delta 值进行判断(比如正负) ,而后执行相应操作
return true;
};
###JS 单击延迟
click 事件因为要等待单击确认,会有 300ms 的延迟,体验并不是很好。
开发者大多数会使用封装的 tap 事件来代替click 事件,所谓的 tap 事件由 touchstart 事件 + touchmove 判断 + touchend 事件封装组成。
Creating Fast Buttons for Mobile Web Applications
Eliminate 300ms delay on click events in mobile Safari
##WebKit CSS:
携程 UED 整理的 Webkit CSS 文档 ,全面、方便查询,下面为常用属性。
①“盒模型”的具体描述性质的包围盒块内容,包括边界,填充等等。
-webkit-border-bottom-left-radius: radius;
-webkit-border-top-left-radius: horizontal_radius vertical_radius;
-webkit-border-radius: radius; //容器圆角
-webkit-box-sizing: sizing_model; 边框常量值:border-box/content-box
-webkit-box-shadow: hoff voff blur color; //容器阴影(参数分别为:水平X 方向偏移量;垂直Y 方向偏移量;高斯模糊半径值;阴影颜色值)
-webkit-margin-bottom-collapse: collapse_behavior; 常量值:collapse/discard/separate
-webkit-margin-start: width;
-webkit-padding-start: width;
-webkit-border-image: url(borderimg.gif) 25 25 25 25 round/stretch round/stretch;
-webkit-appearance: push-button; //内置的CSS 表现,暂时只支持push-button
②“视觉格式化模型”描述性质,确定了位置和大小的块元素。
direction: rtl
unicode-bidi: bidi-override; 常量:bidi-override/embed/normal
③“视觉效果”描述属性,调整的视觉效果块内容,包括溢出行为,调整行为,能见度,动画,变换,和过渡。
clip: rect(10px, 5px, 10px, 5px)
resize: auto; 常量:auto/both/horizontal/none/vertical
visibility: visible; 常量: collapse/hidden/visible
-webkit-transition: opacity 1s linear; 动画效果 ease/linear/ease-in/ease-out/ease-in-out
-webkit-backface-visibility: visibler; 常量:visible(默认值)/hidden
-webkit-box-reflect: right 1px; 镜向反转
-webkit-box-reflect: below 4px -webkit-gradient(linear, left top, left bottom,
from(transparent), color-stop(0.5, transparent), to(white));
-webkit-mask-image: -webkit-gradient(linear, left top, left bottom, from(rgba(0,0,0,1)), to(rgba(0,0,0,0)));; //CSS 遮罩/蒙板效果
-webkit-mask-attachment: fixed; 常量:fixed/scroll
-webkit-perspective: value; 常量:none(默认)
-webkit-perspective-origin: left top;
-webkit-transform: rotate(5deg);
-webkit-transform-style: preserve-3d; 常量:flat/preserve-3d; (2D 与3D)
④“生成的内容,自动编号,并列出”描述属性,允许您更改内容的一个组成部分,创建自动编号的章节和标题,和操纵的风格清单的内容。
content: “Item” counter(section) ” “;
This resets the counter.
First section
>two section
three section
counter-increment: section 1;
counter-reset: section;
⑤“分页媒体”描述性能与外观的属性,控制印刷版本的网页,如分页符的行为。
page-break-after: auto; 常量:always/auto/avoid/left/right
page-break-before: auto; 常量:always/auto/avoid/left/right
page-break-inside: auto; 常量:auto/avoid
⑥“颜色和背景”描述属性控制背景下的块级元素和颜色的文本内容的组成部分。
-webkit-background-clip: content; 常量:border/content/padding/text
-webkit-background-origin: padding; 常量:border/content/padding/text
-webkit-background-size: 55px; 常量:length/length_x/length_y
⑦ “字型”的具体描述性质的文字字体的选择范围内的一个因素。报告还描述属性用于下载字体定义。
unicode-range: U+00-FF, U+980-9FF;
⑧“文本”描述属性的特定文字样式,间距和自动滚屏。
text-shadow: #00FFFC 10px 10px 5px;
text-transform: capitalize; 常量:capitalize/lowercase/none/uppercase
word-wrap: break-word; 常量:break-word/normal
-webkit-marquee: right large infinite normal 10s; 常量:direction(方向) increment(迭代次数) repetition(重复) style(样式) speed(速度);
-webkit-marquee-direction: ahead/auto/backwards/down/forwards/left/reverse/right/up
-webkit-marquee-incrementt: 1-n/infinite(无穷次)
-webkit-marquee-speed: fast/normal/slow
-webkit-marquee-style: alternate/none/scroll/slide
-webkit-text-fill-color: #ff6600; 常量:capitalize, lowercase, none, uppercase
-webkit-text-security: circle; 常量:circle/disc/none/square
-webkit-text-size-adjust: none; 常量:auto/none;
-webkit-text-stroke: 15px #fff;
-webkit-line-break: after-white-space; 常量:normal/after-white-space
-webkit-appearance: caps-lock-indicator;
-webkit-nbsp-mode: space; 常量: normal/space
-webkit-rtl-ordering: logical; 常量:visual/logical
-webkit-user-drag: element; 常量:element/auto/none
-webkit-user-modify: read- only; 常量:read-write-plaintext-only/read-write/read-only
-webkit-user-select: text; 常量:text/auto/none
⑨“表格”描述的布局和设计性能表的具体内容。
-webkit-border-horizontal-spacing: 2px;
-webkit-border-vertical-spacing: 2px;
-webkit-column-break-after: right; 常量:always/auto/avoid/left/right
-webkit-column-break-before: right; 常量:always/auto/avoid/left/right
–webkit-column-break-inside: logical; 常量:avoid/auto
-webkit-column-count: 3; //分栏
-webkit-column-rule: 1px solid #fff;
style:dashed,dotted,double,groove,hidden,inset,none,outset,ridge,solid
⑩“用户界面”描述属性,涉及到用户界面元素在浏览器中,如滚动文字区,滚动条,等等。报告还描述属性,范围以外的网页内容,如光标的标注样式和显示当您按住触摸触摸
目标,如在iPhone上的链接。
-webkit-box-align: baseline,center,end,start,stretch 常量:baseline/center/end/start/stretch
-webkit-box-direction: normal;常量:normal/reverse
-webkit-box-flex: flex_valuet
-webkit-box-flex-group: group_number
-webkit-box-lines: multiple; 常量:multiple/single
-webkit-box-ordinal-group: group_number
-webkit-box-orient: block-axis; 常量:block-axis/horizontal/inline-axis/vertical/orientation
–webkit-box-pack: alignment; 常量:center/end/justify/start
动画过渡
这是 Webkit 中最具创新力的特性:使用过渡函数定义动画。
-webkit-animation: title infinite ease-in-out 3s;
animation 有这几个属性:
-webkit-animation-name: //属性名,就是我们定义的keyframes
-webkit-animation-duration:3s //持续时间
-webkit-animation-timing-function: //过渡类型:ease/ linear(线性) /ease-in(慢到快)/ease-out(快到慢) /ease-in-out(慢到快再到慢) /cubic-bezier
-webkit-animation-delay:10ms //动画延迟(默认0)
-webkit-animation-iteration-count: //循环次数(默认1),infinite 为无限
-webkit-animation-direction: //动画方式:normal(默认 正向播放); alternate(交替方向,第偶数次正向播放,第奇数次反向播放)
这些同样是可以简写的。但真正让我觉的很爽的是keyframes,它能定义一个动画的转变过程供调用,过程为0%到100%或from(0%)到to(100%)。简单点说,只要你有想法,你想让元素在这个过程中以什么样的方式改变都是很简单的。
-webkit-transform: 类型(缩放scale/旋转rotate/倾斜skew/位移translate)
scale(num,num) 放大倍率。scaleX 和 scaleY(3),可以简写为:scale(* , *)
rotate(*deg) 转动角度。rotateX 和 rotateY,可以简写为:rotate(* , *)
Skew(*deg) 倾斜角度。skewX 和skewY,可简写为:skew(* , *)
translate(*,*) 坐标移动。translateX 和translateY,可简写为:translate(* , *)。
###页面描述
<link rel="apple-touch-icon-precomposed" href="http://www.xxx.com/App_icon_114.png" />
<link rel="apple-touch-icon-precomposed" sizes="72x72" href="http://www.xxx.com/App_icon_72.png" />
<link rel="apple-touch-icon-precomposed" sizes="114x114" href="http://www.xxx.com/App_icon_114.png" />
这个属性是当用户把连接保存到手机桌面时使用的图标,如果不设置,则会用网页的截图。有了这,就可以让你的网页像APP一样存在手机里了
<link rel="apple-touch-startup-image" href="/img/startup.png" />
这个是APP启动画面图片,用途和上面的类似,如果不设置,启动画面就是白屏,图片像素就是手机全屏的像素
<meta name="apple-mobile-web-app-status-bar-style" content="black-translucent" />
这个描述是表示打开的web app的最上面的时间、信号栏是黑色的,当然也可以设置其它参数,详细参数说明请参照:Safari HTML Reference - Supported Meta Tags
<meta name="apple-touch-fullscreen" content="yes" />
<meta name="apple-mobile-web-app-capable" content="yes" />
iPhone 4的一个 CSS 像素实际上表现为一块 2×2 的像素。所以图片像是被放大2倍一样,模糊不清晰。
解决办法:
1、页面引用
<link rel="stylesheet" media="screen and (-webkit-device-pixel-ratio: 0.75)" href="ldpi.css" />
<link rel="stylesheet" media="screen and (-webkit-device-pixel-ratio: 1.0)" href="mdpi.css" />
<link rel="stylesheet" media="screen and (-webkit-device-pixel-ratio: 1.5)" href="hdpi.css" />
<link rel="stylesheet" media="screen and (-webkit-device-pixel-ratio: 2.0)" href="retina.css" />
2、CSS文件里
#header {
background:url(mdpi/bg.png);
}
@media screen and (-webkit-device-pixel-ratio: 1.5) {
/*CSS for high-density screens*/
#header {
background:url(hdpi/bg.png);
}
}
##移动 Web 开发技巧
###点击与click事件
对于a标记的点击导航,默认是在onclick事件中处理的。而移动客户端对onclick的响应相比PC浏览器有着明显的几百毫秒延迟。
在移动浏览器中对触摸事件的响应顺序应当是:
ontouchstart -> ontouchmove -> ontouchend -> onclick
因此,如果确实要加快对点击事件的响应,就应当绑定ontouchend事件。
使用click会出现绑定点击区域闪一下的情况,解决:给该元素一个样式如下
-webkit-tap-highlight-color: rgba(0,0,0,0);
如果不使用click,也不能简单的用touchstart或touchend替代,需要用touchstart的模拟一个click事件,并且不能发生touchmove事件,或者用zepto中的tap(轻击)事件。
body
{
-webkit-overflow-scrolling: touch;
}
用iphone或ipad浏览很长的网页滚动时的滑动效果很不错吧?不过如果是一个div,然后设置 height:200px;overflow:auto;的话,可以滚动但是完全没有那滑动效果,很郁闷吧?
我看到很多网站为了实现这一效果,用了第三方类库,最常用的是iscroll(包括新浪手机页,百度等)
我一开始也使用,不过自从用了-webkit-overflow-scrolling: touch;样式后,就完全可以抛弃第三方类库了,把它加在body{}区域,所有的overflow需要滚动的都可以生效了。
###锁定 viewport
ontouchmove="event.preventDefault()" //锁定viewport,任何屏幕操作不移动用户界面(弹出键盘除外)。
###利用 Media Query监听
Media Query 相信大部分人已经使用过了。其实 JavaScript可以配合 Media Query这么用:
var mql = window.matchMedia("(orientation: portrait)");
mql.addListener(handleOrientationChange);
handleOrientationChange(mql);
function handleOrientationChange(mql) {
if (mql.matches) {
alert('The device is currently in portrait orientation ')
} else {
alert('The device is currently in landscape orientation')
}}
借助了 Media Query 接口做的事件监听,所以很强大!
也可以通过获取 CSS 值来使用 Media Query 判断设备情况,详情请看:JavaScript 依据 CSS Media Queries 判断设备的方法。
###rem最佳实践
rem是非常好用的一个属性,可以根据html来设定基准值,而且兼容性也很不错。不过有的时候还是需要对一些莫名其妙的浏览器优雅降级。以下是两个实践
http://jsbin.com/vaqexuge/4/edit 这有个demo,发现chrome当font-size小于12时,rem会按照12来计算。因此设置基准值要考虑这一点
可以用以下的代码片段保证在低端浏览器下也不会出问题
html { font-size: 62.5%; }
body { font-size: 14px; font-size: 1.4rem; } /* =14px /
h1 { font-size: 24px; font-size: 2.4rem; } / =24px */
###当前点击元素样式:
-webkit-tap-highlight-color: 颜色
###检测判断 iPhone/iPod
开发特定设备的移动网站,首先要做的就是设备侦测了。下面是使用Javascript侦测iPhone/iPod的UA,然后转向到专属的URL。
if((navigator.userAgent.match(/iPhone/i)) || (navigator.userAgent.match(/iPod/i))) {
if (document.cookie.indexOf("iphone_redirect=false") == -1) {
window.location = "http://m.example.com";
}
}
虽然Javascript是可以在水果设备上运行的,但是用户还是可以禁用。它也会造成客户端刷新和额外的数据传输,所以下面是服务器端侦测和转向:
if(strstr($_SERVER['HTTP_USER_AGENT'],'iPhone') || strstr($_SERVER['HTTP_USER_AGENT'],'iPod')) {
header('Location: http://yoursite.com/iphone');
exit();
}
###阻止屏幕旋转时字体自动调整
html, body, form, fieldset, p, div, h1, h2, h3, h4, h5, h6 {-webkit-text-size-adjust:none;}
###模拟:hover伪类
因为iPhone并没有鼠标指针,所以没有hover事件。那么CSS :hover伪类就没用了。但是iPhone有Touch事件,onTouchStart 类似 onMouseOver,onTouchEnd 类似 onMouseOut。所以我们可以用它来模拟hover。使用Javascript:
var myLinks = document.getElementsByTagName('a');
for(var i = 0; i < myLinks.length; i++){
myLinks[i].addEventListener(’touchstart’, function(){this.className = “hover”;}, false);
myLinks[i].addEventListener(’touchend’, function(){this.className = “”;}, false);
}
然后用CSS增加hover效果:
a:hover, a.hover { /* 你的hover效果 */ }
这样设计一个链接,感觉可以更像按钮。并且,这个模拟可以用在任何元素上。
###Flexbox 布局
http://www.w3.org/TR/css3-flexbox/
###居中问题
居中是移动端跟pc端共同的噩梦。这里有两种兼容性比较好的新方案。
table布局法
.box{
text-align:center;
display:table-cell;
vertical-align:middle;
}
老版本flex布局法
.box{
display:-webkit-box;
-webkit-box-pack: center;
-webkit-box-align: center;
text-align:center;
}
以上两种其实分别是retchat跟ionic的布局基石。
这里有更详细的更多的选择http://www.zhouwenbin.com/%E5%9E%82%E7%9B%B4%E5%B1%85%E4%B8%AD%E7%9A%84%E5%87%A0%E7%A7%8D%E6%96%B9%E6%B3%95/ 来自周文彬的博客
###处理 Retina 双倍屏幕
(经典)Using CSS Sprites to optimize your website for Retina Displays
使用CSS3的background-size优化苹果的Retina屏幕的图像显示
使用 CSS sprites 来优化你的网站在 Retina 屏幕下显示
(案例)CSS IMAGE SPRITES FOR RETINA (HIRES) DEVICES
###input类型为date情况下不支持placeholder(来自于江水)
这其实是浏览器自己的处理。因为浏览器会针对此类型 input 增加 datepicker 模块。
对 input type date 使用 placeholder 的目的是为了让用户更准确的输入日期格式,iOS 上会有 datepicker 不会显示 placeholder 文字,但是为了统一表单外观,往往需要显示。Android 部分机型没有 datepicker 也不会显示 placeholder 文字。
桌面端(Mac)
移动端
解决方法:
<input placeholder="Date" class="textbox-n" type="text" onfocus="(this.type='date')" id="date">
因为text是支持placeholder的。因此当用户focus的时候自动把type类型改变为date,这样既有placeholder也有datepicker了
###viewport导致文字无故折行
http://www.iunbug.com/archives/2013/04/23/798.html
###引导用户安装并打开app
来自 http://gallery.kissyui.com/redirectToNative/1.2/guide/index.html kissy mobile
通过iframe src发送请求打开app自定义url scheme,如taobao://home(淘宝首页) 、etao://scan(一淘扫描));
如果安装了客户端则会直接唤起,直接唤起后,之前浏览器窗口(或者扫码工具的webview)推入后台;
如果在指定的时间内客户端没有被唤起,则js重定向到app下载地址。
大概实现代码如下
goToNative:function(){
if(!body) {
setTimeout(function(){
doc.body.appendChild(iframe);
}, 0);
} else {
body.appendChild(iframe);
}
setTimeout(function() {
doc.body.removeChild(iframe);
gotoDownload(startTime);//去下载,下载链接一般是itunes app store或者apk文件链接
/**
* 测试时间设置小于800ms时,在android下的UC浏览器会打开native app时并下载apk,
* 测试android+UC下打开native的时间最好大于800ms;
*/
}, 800);
}
需要注意的是 如果是android chrome 25版本以后,在iframe src不会发送请求,
原因如下https://developers.google.com/chrome/mobile/docs/intents ,通过location href使用intent机制拉起客户端可行并且当前页面不跳转。
window.location = 'intent://' + schemeUrl + '#Intent;scheme=' + scheme + ';package=' + self.package + ';end';
补充一个来自三水清的详细讲解 http://js8.in/2013/12/16/ios%E4%BD%BF%E7%94%A8schema%E5%8D%8F%E8%AE%AE%E8%B0%83%E8%B5%B7app/
###active的兼容(来自薛端阳)
今天发现,要让a链接的CSS active伪类生效,只需要给这个a链接的touch系列的任意事件touchstart/touchend绑定一个空的匿名方法即可hack成功
<style>
a {
color: #000;
}
a:active {
color: #fff;
}
</style>
<a herf=”asdasd”>asdasd</a>
<script>
var a=document.getElementsByTagName(‘a’);
for(var i=0;i<a.length;i++){
a[i].addEventListener(‘touchstart’,function(){},false);
}
</script>
###消除transition闪屏
两个方法:使用css3动画的时尽量利用3D加速,从而使得动画变得流畅。动画过程中的动画闪白可以通过 backface-visibility 隐藏。
-webkit-transform-style: preserve-3d;
/*设置内嵌的元素在 3D 空间如何呈现:保留 3D*/
-webkit-backface-visibility: hidden;
/*(设置进行转换的元素的背面在面对用户时是否可见:隐藏)*/
###测试是否支持svg图片
document.implementation.hasFeature("http:// www.w3.org/TR/SVG11/feature#Image", "1.1")
参考地址:http://blog.youyo.name/archives/smarty-phones-webapp-deverlop-advance.html
ios的safari提供一种“隐私模式”,如果你的webapp考虑兼容这个模式,那么在使用html5的本地存储的一种————localStorage时,可能因为“隐私模式”下没有权限读写localstorge而使代码抛出错误,导致后续的js代码都无法运行了。
既然在safari的“隐私模式”下,没有调用localStorage的权限,首先想到的是先判断是否支持localStorage,代码如下:
if('localStorage' in window){
//需要使用localStorage的代码写在这
}else{
//不支持的提示和向下兼容代码
}
测试发现,即使在safari的“隐私模式”下,’localStorage’ in window的返回值依然为true,也就是说,if代码块内部的代码依然会运行,问题没有得到解决。
接下来只能相当使用try catch了,虽然这是一个不太推荐被使用的方法,使用try catch捕获错误,使后续的js代码可以继续运行,代码如下:
try{
if('localStorage' in window){
//需要使用localStorage的代码写在这
}else{
//不支持的提示和向下兼容代码
}
}catch(e){
// 隐私模式相关提示代码和不支持的提示和向下兼容代码
}
所以,提醒大家注意,在需要兼容ios的safari的“隐私模式”的情况下,本地存储相关的代码需要使用try catch包裹并降级兼容。
###安卓手机点击锁定页面效果问题
有些安卓手机,页面点击时会停止页面的javascript,css3动画等的执行,这个比较蛋疼。不过可以用阻止默认事件解决。详细见
http://stackoverflow.com/questions/10246305/android-browser-touch-events-stop-display-being-updated-inc-canvas-elements-h
function touchHandlerDummy(e)
{
e.preventDefault();
return false;
}
document.addEventListener("touchstart", touchHandlerDummy, false);
document.addEventListener("touchmove", touchHandlerDummy, false);
document.addEventListener("touchend", touchHandlerDummy, false);
###消除ie10里面的那个叉号
IE Pseudo-elements
input:-ms-clear{display:none;}
###关于ios与os端字体的优化
mac下网页中文字体优化
UIWebView font is thinner in portrait than landscape
navigator.standalone
####隐藏地址栏 & 处理事件的时候,防止滚动条出现:
// 隐藏地址栏 & 处理事件的时候 ,防止滚动条出现
addEventListener('load', function(){
setTimeout(function(){ window.scrollTo(0, 1); }, 100);
});
####判断是否为iPhone:
// 判断是否为 iPhone :
function isAppleMobile() {
return (navigator.platform.indexOf('iPad') != -1);
};
###localStorage:
var v = localStorage.getItem('n') ? localStorage.getItem('n') : ""; // 如果名称是 n 的数据存在 ,则将其读出 ,赋予变量 v 。
localStorage.setItem('n', v); // 写入名称为 n、值为 v 的数据
localStorage.removeItem('n'); // 删除名称为 n 的数据
###使用特殊链接:
如果你关闭自动识别后 ,又希望某些电话号码能够链接到 iPhone 的拨号功能 ,那么可以通过这样来声明电话链接 ,
<a href="tel:12345654321">打电话给我</a>
<a href="sms:12345654321">发短信</a>
或用于单元格:
<td onclick="location.href='tel:122'">
###自动大写与自动修正
要关闭这两项功能,可以通过autocapitalize 与autocorrect 这两个选项:
<input type="text" autocapitalize="off" autocorrect="off" />
###不让 Android 识别邮箱
<meta content="email=no" name="format-detection" />
###禁止 iOS 弹出各种操作窗口
-webkit-touch-callout:none
###禁止用户选中文字
-webkit-user-select:none
###动画效果中,使用 translate 比使用定位性能高
Why Moving Elements With Translate() Is Better Than Pos:abs Top/left
###拿到滚动条
window.scrollY
window.scrollX
比如要绑定一个touchmove的事件,正常的情况下类似这样(来自呼吸二氧化碳)
$('div').on('touchmove', function(){
//.….code
{});
而如果中间的code需要处理的东西多的话,fps就会下降影响程序顺滑度,而如果改成这样
$('div').on('touchmove', function(){
setTimeout(function(){
//.….code
},0);
{});
把代码放在setTimeout中,会发现程序变快.
###关于 iOS 系统中,Web APP 启动图片在不同设备上的适应性设置
###position:sticky与position:fixed布局
http://www.zhouwenbin.com/positionsticky-%E7%B2%98%E6%80%A7%E5%B8%83%E5%B1%80/
http://www.zhouwenbin.com/sticky%E6%A8%A1%E6%8B%9F%E9%97%AE%E9%A2%98/
###关于 iOS 系统中,中文输入法输入英文时,字母之间可能会出现一个六分之一空格
可以通过正则去掉
this.value = this.value.replace(/\u2006/g, '');
###关于android webview中,input元素输入时出现的怪异情况
见下图
Android Web 视图,至少在 HTC EVO 和三星的 Galaxy Nexus 中,文本输入框在输入时表现的就像占位符。情况为一个类似水印的东西在用户输入区域,一旦用户开始输入便会消失(见图片)。
在 Android 的默认样式下当输入框获得焦点后,若存在一个绝对定位或者 fixed 的元素,布局会被破坏,其他元素与系统输入字段会发生重叠(如搜索图标将消失为搜索字段),可以观察到布局与原始输入字段有偏差(见截图)。
这是一个相当复杂的问题,以下简单布局可以重现这个问题:
<label for="phone">Phone: *</label>
<input type="tel" name="phone" id="phone" minlength="10" maxlength="10" inputmode="latin digits" required="required" />
解决方法
-webkit-user-modify: read-write-plaintext-only
详细参考http://www.bielousov.com/2012/android-label-text-appears-in-input-field-as-a-placeholder/
注意,该属性会导致中文不能输入词组,只能单个字。感谢鬼哥与飞(游勇飞)贡献此问题与解决方案
另外,在position:fixed后的元素里,尽量不要使用输入框。更多的bug可参考
http://www.cosdiv.com/page/M0/S882/882353.html
依旧无法解决(摩托罗拉ME863手机),则使用input:text类型而非password类型,并设置其设置 -webkit-text-security: disc; 隐藏输入密码从而解决。
###JS动态生成的select下拉菜单在Android2.x版本的默认浏览器里不起作用
解决方法删除了overflow-x:hidden; 然后在JS生成下来菜单之后focus聚焦,这两步操作之后解决了问题。(来自岛都-小Qi)
###Andriod 上去掉语音输入按钮
input::-webkit-input-speech-button {display: none}
##IE10 的特殊鼠标事件
##iOS 输入框最佳实践
Mobile-friendly input of a digits + spaces string (a credit card number)
HTML5 input type number vs tel
iPhone: numeric keyboard for text input
Text Programming Guide for iOS - Managing the Keyboard
HTML5 inputs and attribute support
##往返缓存问题
点击浏览器的回退,有时候不会自动执行js,特别是在mobilesafari中。这与**往返缓存(bfcache)**有关系。有很多hack的处理方法,可以参考
http://stackoverflow.com/questions/24046/the-safari-back-button-problem
http://stackoverflow.com/questions/11979156/mobile-safari-back-button
##计时器
https://www.imququ.com/post/ios-none-freeze-timer.html
还有一种利用work的方式,在写ing。。
<audio autoplay ><source src="audio/alarm1.mp3" type="audio/mpeg"></audio>
系统默认情况下 audio的autoplay属性是无法生效的,这也是手机为节省用户流量做的考虑。
如果必须要自动播放,有两种方式可以解决。
1.捕捉一次用户输入后,让音频加载,下次即可播放。
//play and pause it once
document.addEventListener('touchstart', function () {
document.getElementsByTagName('audio')[0].play();
document.getElementsByTagName('audio')[0].pause();
});
这种方法需要捕获一次用户的点击事件来促使音频跟视频加载。当加载后,你就可以用javascript控制音频的播放了,如调用audio.play()
2.利用iframe加载资源
var ifr=document.createElement("iframe");
ifr.setAttribute('src', "http://mysite.com/myvideo.mp4");
ifr.setAttribute('width', '1px');
ifr.setAttribute('height', '1px');
ifr.setAttribute('scrolling', 'no');
ifr.style.border="0px";
document.body.appendChild(ifr);
这种方式其实跟第一种原理是一样的。当资源加载了你就可以控制播放了,但是这里使用iframe来加载,相当于直接触发资源加载。
注意,使用创建audio标签并让其加载的方式是不可行的。
慎用这种方法,会对用户造成很糟糕的影响。。
##iOS 6 跟 iPhone 5
###IP5 的媒体查询
@media (device-height: 568px) and (-webkit-min-device-pixel-ratio: 2) {
/* iPhone 5 or iPod Touch 5th generation */
}
###媒体查询,响应不同启动图片
<link href="startup-568h.png" rel="apple-touch-startup-image" media="(device-height: 568px)">
<link href="startup.png" rel="apple-touch-startup-image" sizes="640x920" media="(device-height: 480px)">
###拍照上传
<input type=file accept="video/*">
<input type=file accept="image/*">
不支持其他类型的文件 ,如音频,Pages文档或PDF文件。 也没有getUserMedia摄像头的实时流媒体支持。
###可以使用的 HTML5 高级 api
###智能应用程序横幅
有了智能应用程序横幅,当网站上有一个相关联的本机应用程序时,Safari浏览器可以显示一个横幅。 如果用户没有安装这个应用程序将显示“安装”按钮,或已经安装的显示“查看”按钮可打开它。
在 iTunes Link Maker 搜索我们的应用程序和应用程序ID。
<meta name="apple-itunes-app" content="app-id=9999999">
可以使用 app-argument 提供字符串值,如果参加iTunes联盟计划,可以添加元标记数据
<meta name="apple-itunes-app" content="app-id=9999999, app-argument=xxxxxx">
<meta name="apple-itunes-app" content="app-id=9999999, app-argument=xxxxxx, affiliate-data=partnerId=99&siteID=XXXX">
横幅需要156像素(设备是312 hi-dpi)在顶部,直到用户在下方点击内容或关闭按钮,你的网站才会展现全部的高度。 它就像HTML的DOM对象,但它不是一个真正的DOM。
CSS3 滤镜
-webkit-filter: blur(5px) grayscale (.5) opacity(0.66) hue-rotate(100deg);
交叉淡变
background-image: -webkit-cross-fade(url("logo1.png"), url("logo2.png"), 50%);
Safari中的全屏幕
除了chrome-less 主屏幕meta标签,现在的iPhone和iPod Touch(而不是在iPad)支持全屏幕模式的窗口。 没有办法强制全屏模式,它需要由用户启动(工具栏上的最后一个图标)。需要引导用户按下屏幕上的全屏图标来激活全屏效果。 可以使用onresize事件检测是否用户切换到全屏幕。
支持requestAnimationFrameAPI
支持image-set,retina屏幕的利器
-webkit-image-set(url(low.png) 1x, url(hi.jpg) 2x)
应用程序缓存限制增加至25MB。
Web View(pseudobrowsers,PhoneGap/Cordova应用程序,嵌入式浏览器) 上Javascript运行比Safari慢3.3倍(或者说,Nitro引擎在Safari浏览器是Web应用程序是3.3倍速度)。
autocomplete属性的输入遵循DOM规范
来自DOM4的Mutation Observers已经实现。 您可以使用WebKitMutationObserver构造器捕获DOM的变化
Safari不再总是对用 -webkit-transform:preserve-3d 的元素创建硬件加速
支持window.selection 的Selection API
Canvas更新 :createImageData有一个参数,现在有两个新的功能做好准备,用webkitGetImageDataHD和webkitPutImageDataHD提供高分辨率图像 。
更新SVG处理器和事件构造函数
##IOS7
iOS 7 的 Safari 和 HTML5:问题,变化和新 API(张金龙翻译)
##webview相关
#Cache开启和设置
browser.getSettings().setAppCacheEnabled(true);
browser.getSettings().setAppCachePath("/data/data/[com.packagename]/cache");
browser.getSettings().setAppCacheMaxSize(5*1024*1024); // 5MB
#LocalStorage相关设置
browser.getSettings().setDatabaseEnabled(true);
browser.getSettings().setDomStorageEnabled(true);
String databasePath = browser.getContext().getDir("databases", Context.MODE_PRIVATE).getPath();
browser.getSettings().setDatabasePath(databasePath);//Android webview的LocalStorage有个问题,关闭APP或者重启后,就清楚了,所以需要browser.getSettings().setDatabase相关的操作,把LocalStoarge存到DB中
myWebView.setWebChromeClient(new WebChromeClient(){
@Override
public void onExceededDatabaseQuota(String url, String databaseIdentifier, long currentQuota, long estimatedSize, long totalUsedQuota, WebStorage.QuotaUpdater quotaUpdater)
{
quotaUpdater.updateQuota(estimatedSize * 2);
}
}
#浏览器自带缩放按钮取消显示
browser.getSettings().setBuiltInZoomControls(false);
#几个比较好的实践
使用localstorage缓存html
使用lazyload,还要记得lazyload占位图虽然小,但是最好能提前加载到缓存
延时加载执行js
主要原因就在于Android Webview的onPageFinished事件,Android端一般是用这个事件来标识页面加载完成并显示的,也就是说在此之前,会一直loading,但是Android的OnPageFinished事件会在Javascript脚本执行完成之后才会触发。如果在页面中使用JQuery,会在处理完DOM对象,执行完$(document).ready(function() {});事件自会后才会渲染并显示页面。
##移动端调适篇
###手机抓包与配host
在PC上,我们可以很方便地配host,但是手机上如何配host,这是一个问题。
这里主要使用fiddler和远程代理,实现手机配host的操作,具体操作如下:
首先,保证PC和移动设备在同一个局域网下;
PC上开启fiddler,并在设置中勾选“allow remote computers to connect”
首先,保证PC和移动设备在同一个局域网下;
PC上开启fiddler,并在设置中勾选“allow remote computers to connect”

手机上设置代理,代理IP为PC的IP地址,端口为8888(这是fiddler的默认端口)。通常手机上可以直接设置代理,如果没有,可以去下载一个叫ProxyDroid的APP来实现代理的设置。
此时你会发现,用手机上网,走的其实是PC上的fiddler,所有的请求包都会在fiddler中列出来,配合willow使用,即可实现配host,甚至是反向代理的操作。
也可以用CCProxy之类软件,还有一种方法就是买一个随身wifi,然后手机连接就可以了!
###高级抓包
iPhone上使用Burp Suite捕捉HTTPS通信包方法
mobile app 通信分析方法小议(iOS/Android)
实时抓取移动设备上的通信包(ADVsock2pipe+Wireshark+nc+tcpdump)
###静态资源缓存问题
一般用代理软件代理过来的静态资源可以设置nocache避免缓存,但是有的手机比较诡异,会一直缓存住css等资源文件。由于静态资源一般都是用版本号管理的,我们以charles为例子来处理这个问题
charles 选择静态的html页面文件-saveResponse。之后把这个文件保存一下,修改一下版本号。之后继续发请求,
刚才的html页面文件 右键选择 --map local 选择我们修改过版本号的html文件即ok。这其实也是fiddler远程映射并修改文件的一个应用场景。
##移动浏览器篇
###微信浏览器
因为微信浏览器屏蔽了一部分链接图片,所以需要引导用户去打开新页面,可以用以下方式判断微信浏览器的ua
function is_weixn(){
var ua = navigator.userAgent.toLowerCase();
if(ua.match(/MicroMessenger/i)=="micromessenger") {
return true;
} else {
return false;
}
}
后端判断也很简单,比如php
function is_weixin(){
if ( strpos($_SERVER['HTTP_USER_AGENT'], 'MicroMessenger') !== false ) {
return true;
}
return false;
}
###【UC浏览器】video标签脱离文档流
场景:
测试环境:UC浏览器 8.7/8.6 + Android 2.3/4.0 。
Demo:http://t.cn/zj3xiyu
解决方案:不使用transform属性。translate用top、margin等属性替代。
###【UC浏览器】video标签总在最前
场景:
测试环境:UC浏览器 8.7/8.6 + Android 2.3/4.0 。
###【UC浏览器】position:fixed 属性在UC浏览器的奇葩现象
场景:设置了position: fixed 的元素会遮挡z-index值更高的同辈元素。
在8.6的版本,这个情况直接出现。
在8.7之后的版本,当同辈元素的height大于713这个「神奇」的数值时,才会被遮挡。
测试环境:UC浏览器 8.8_beta/8.7/8.6 + Android 2.3/4.0 。
Demo:http://t.cn/zYLTSg6
###【QQ手机浏览器】不支持HttpOnly
场景:带有HttpOnly属性的Cookie,在QQ手机浏览器版本从4.0开始失效。JavaScript可以直接读取设置了HttpOnly的Cookie值。
测试环境:QQ手机浏览器 4.0/4.1/4.2 + Android 4.0 。
###【MIUI原生浏览器】浏览器地址栏hash不改变
场景:location.hash 被赋值后,地址栏的地址不会改变。
但实际上 location.href 已经更新了,通过JavaScript可以顺利获取到更新后的地址。
虽然不影响正常访问,但用户无法将访问过程中改变hash后的地址存为书签。
测试环境:MIUI 4.0
###【Chrome Mobile】fixed元素无法点击
场景:父元素设置position: fixed;
子元素设置position: absolute;
此时,如果父元素/子元素还设置了overflow: hidden 则出现“父元素遮挡该子元素“的bug。
视觉(view)层并没有出现遮挡,只是无法触发绑定在该子元素上的事件。可理解为:「看到点不到」。
补充: 页面往下滚动,触发position: fixed;的特性时,才会出现这个bug,在最顶不会出现。
测试平台: 小米1S,Android4.0的Chrome18
demo: http://maplejan.sinaapp.com/demo/fixed_chromemobile.html
解决办法: 把父元素和子元素的overflow: hidden去掉。
以上来源于 http://www.cnblogs.com/maplejan/archive/2013/04/26/3045928.html
##库的使用实践
###zepto.js
###使用zeptojs内嵌到android webview影响正常滚动时
https://github.com/madrobby/zepto/blob/master/src/touch.js 去掉61行,其实就是使用原生的滚动
###iscroll4
iscroll4 的几个bug(来自 http://www.mansonchor.com/blog/blog_detail_64.html 内有详细讲解)
1.滚动容器点击input框、select等表单元素时没有响应】
onBeforeScrollStart: function (e) { e.preventDefault(); }
改为
onBeforeScrollStart: function (e) { var nodeType = e.explicitOriginalTarget © e.explicitOriginalTarget.nodeName.toLowerCase():(e.target © e.target.nodeName.toLowerCase():'');if(nodeType !='select'&& nodeType !='option'&& nodeType !='input'&& nodeType!='textarea') e.preventDefault(); }
2.往iscroll容器内添加内容时,容器闪动的bug
源代码的
has3d = 'WebKitCSSMatrix' in window && 'm11' in new WebKitCSSMatrix()
改成
has3d = false
在配置iscroll时,useTransition设置成false
3.过长的滚动内容,导致卡顿和app直接闪退
4.左右滚动时,不能正确响应正文上下拉动
iscroll的闪动问题也与渲染有关系,可以参考
运用webkit绘制渲染页面原理解决iscroll4闪动的问题
iscroll4升级到5要注意的问题
###iscroll或者滚动类框架滚动时不点击的方法
可以使用以下的解决方案(利用data-setapi)
<a ontouchmove="this.s=1" ontouchend="this.s || window.open(this.dataset.href),this.s=0" target="_blank" data-href="http://www.hao123.com/topic/pig">黄浦江死猪之谜</a>
也可以用这种方法
$(document).delegate('[data-target]', 'touchmove', function () {
$(this).attr('moving','moving');
})
$(document).delegate('[data-target]', 'touchend', function () {
if ($(this).attr('moving') !== 'moving') {
//做你想做的。。
$(this).attr('moving', 'notMoving');
} else {
$(this).attr('moving', 'notMoving');
}
})
##移动端字体问题
知乎专栏 - [无线手册-4] dp、sp、px傻傻分不清楚[完整]
Resolution Independent Mobile UI
Pixel density, retina display and font-size in CSS
##跨域问题
手机浏览器也是浏览器,在ajax调用外部api的时候也存在跨域问题。当然利用 PhoneGap 打包后,由于协议不一样就不存在跨域问题了。
但页面通常是需要跟后端进行调试的。一般会报类似
XMLHttpRequest cannot load XXX
Origin null is not allowed by Access-Control-Allow-Origin.
以及
XMLHttpRequest cannot load http://. Request header field Content-Type is not allowed by Access-Control-Allow-Headers."
这时候可以让后端加上两个http头
Access-Control-Allow-Origin "*"
Access-Control-Allow-Headers "Origin, X-Requested-With, Content-Type, Accept"
第一个头可以避免跨域问题,第二个头可以方便ajax请求设置content-type等配置项
这个会存在一些安全问题,可以参考这个问题的讨论 http://www.zhihu.com/question/22992229
##PhoneGap 部分
http://snoopyxdy.blog.163.com/blog/static/60117440201432491123551 这里有一大堆snoopy总结的phonggap开发坑
###Should not happen: no rect-based-test nodes found
在 Android 项目中的 assets 中的 HTML 页面中加入以下代码,便可解决问题
window,html,body{
overflow-x:hidden !important;
-webkit-overflow-scrolling: touch !important;
overflow: scroll !important;
}
参考:
###ContactFindOptions is not defined
出现这个问题可能是因为 Navigator 取 contacts 时绑定的 window.onload
注意使用 PhoneGap 的 API 时,一定要在 devicereay 事件的处理函数中使用 API
document.addEventListener("deviceready", onDeviceReady, false);
function onDeviceReady() {
callFetchContacts();
}
function callFetchContacts(){
var options = new ContactFindOptions();
options.multiple = true;
var fields = ["displayName", "name","phoneNumbers"];
navigator.contacts.find(fields, onSuccess, onError,options);
}
##iOS safari BUG 总结##
safari对DOM中元素的冒泡机制有个奇葩的BUG,仅限iOS版才会触发~~~
BUG重现用例请见线上DEMO: 地址
###bug表现与规避###
在进行事件委托时,如果将未存在于DOM的元素事件直接委托到body上的话,会导致事件委托失效,调试结果为事件响应到body子元素为止,既没有冒泡到body上,也没有被body所捕获。但如果事件是DOM元素本身具有的,则不会触发bug。换而言之,只有元素的非标准事件(比如click事件之于div)才会触发此bug。
因为bug是由safari的事件解析机制导致,无法修复,但是有多种手段可以规避
如何避免bug触发:不要委托到body结点上,委托到任意指定父元素都可以,或者使用原生具有该事件的元素,如使用click事件触发就用a标签包一层。
已触发如何修补:safari对事件的解析非常特殊,如果一个事件曾经被响应过,则会一直冒泡(捕获)到根结点,所以对于已大规模触发的情况,只需要在body元素的所有子元素绑定一个空事件就好了,如:
("body > *").on("click", function(){};);
可能会对性能有一定影响,但是使用方便,大家权衡考虑吧~~~
有时候人们很喜欢造一些名字很吓人的名词,让人一听这个名词就觉得自己不可能学会,从而让人望而却步。但是其实这些名词背后所代表的东西其实很简单。来自React.js 小书
a higher-order component is a function that takes a component and returns a new component.
翻译:高阶组件就是一个函数,且该函数接受一个组件作为参数,并返回一个新的组件。
理解了吗?看了定义似懂非懂?继续往下看。
我们通过普通函数来理解什么是高阶组件哦~
welcome,一个goodbye。两个函数先从localStorage读取了username,然后对username做了一些处理。function welcome() {
let username = localStorage.getItem('username');
console.log('welcome ' + username);
}
function goodbey() {
let username = localStorage.getItem('username');
console.log('goodbey ' + username);
}
welcome();
goodbey();我们发现两个函数有一句代码是一样的,这叫冗余唉。不好不好~(你可以把那一句代码理解成平时的一大堆代码)
我们要写一个中间函数,读取username,他来负责把username传递给两个函数。
function welcome(username) {
console.log('welcome ' + username);
}
function goodbey(username) {
console.log('goodbey ' + username);
}
function wrapWithUsername(wrappedFunc) {
let newFunc = () => {
let username = localStorage.getItem('username');
wrappedFunc(username);
};
return newFunc;
}
welcome = wrapWithUsername(welcome);
goodbey = wrapWithUsername(goodbey);
welcome();
goodbey();好了,我们里面的wrapWithUsername函数就是一个“高阶函数”。
他做了什么?他帮我们处理了username,传递给目标函数。我们调用最终的函数welcome的时候,根本不用关心username是怎么来的。
我们增加个用户study函数。
function study(username){
console.log(username+' study');
}
study = wrapWithUsername(study);
study();这里你是不是理解了为什么说wrapWithUsername是高阶函数?我们只需要知道,用wrapWithUsername包装我们的study函数后,study函数第一个参数是username。
我们写平时写代码的时候,不用关心wrapWithUsername内部是如何实现的。
高阶组件就是一个没有副作用的纯函数。
我们把上一节的函数统统改成react组件。
welcome函数转为react组件。
import React, {Component} from 'react'
class Welcome extends Component {
constructor(props) {
super(props);
this.state = {
username: ''
}
}
componentWillMount() {
let username = localStorage.getItem('username');
this.setState({
username: username
})
}
render() {
return (
<div>welcome {this.state.username}</div>
)
}
}
export default Welcome;goodbey函数转为react组件。
import React, {Component} from 'react'
class Goodbye extends Component {
constructor(props) {
super(props);
this.state = {
username: ''
}
}
componentWillMount() {
let username = localStorage.getItem('username');
this.setState({
username: username
})
}
render() {
return (
<div>goodbye {this.state.username}</div>
)
}
}
export default Goodbye;按照上一节wrapWithUsername函数的思路,我们来写一个高阶组件(高阶组件就是一个函数,且该函数接受一个组件作为参数,并返回一个新的组件)。
import React, {Component} from 'react'
export default (WrappedComponent) => {
class NewComponent extends Component {
constructor() {
super();
this.state = {
username: ''
}
}
componentWillMount() {
let username = localStorage.getItem('username');
this.setState({
username: username
})
}
render() {
return <WrappedComponent username={this.state.username}/>
}
}
return NewComponent
}这样我们就能简化Welcome组件和Goodbye组件。
import React, {Component} from 'react';
import wrapWithUsername from 'wrapWithUsername';
class Welcome extends Component {
render() {
return (
<div>welcome {this.props.username}</div>
)
}
}
Welcome = wrapWithUsername(Welcome);
export default Welcome;import React, {Component} from 'react';
import wrapWithUsername from 'wrapWithUsername';
class Goodbye extends Component {
render() {
return (
<div>goodbye {this.props.username}</div>
)
}
}
Goodbye = wrapWithUsername(Goodbye);
export default Goodbye;看到没有,高阶组件就是把username通过props传递给目标组件了。目标组件只管从props里面拿来用就好了。
到这里位置,高阶组件就讲完了。你再返回去理解下定义,是不是豁然开朗~
你现在理解react-redux的connect函数~
把redux的state和action创建函数,通过props注入给了Component。
你在目标组件Component里面可以直接用this.props去调用redux state和action创建函数了。
ConnectedComment = connect(mapStateToProps, mapDispatchToProps)(Component);相当于这样
// connect是一个返回函数的函数(就是个高阶函数)
const enhance = connect(mapStateToProps, mapDispatchToProps);
// 返回的函数就是一个高阶组件,该高阶组件返回一个与Redux store
// 关联起来的新组件
const ConnectedComment = enhance(Component);antd的Form也是一样的
const WrappedNormalLoginForm = Form.create()(NormalLoginForm);参考地址:
文章名称来自豆瓣高分电影列表, 电影名为《这个杀手不太冷》
我们假设你有一定的前端知识,简单使用过React但不了解他的原理以及为什么要用它。
通过这篇文章你会了解到这些问题的答案:
看文章之前请记住:
在js中的所有东西都是js。
首先上一段我们熟悉的jsx代码, 这种在js中写类似html代码的方式就是jsx。
<MyButton color="blue" shadowSize={2}>
Click Me
</MyButton>
其实jsx是React.createElement(component, props, …children) 函数的语法糖。这段代码编译之后就成了:
React.createElement(
MyButton,
{color: 'blue', shadowSize: 2},
'Click Me'
)仔细观察一下熟悉的DOM代码
<div class='box' id='content'>
<div class='title'>Hello</div>
<button>Click</button>
</div>
想一下如何用 JavaScript 对象来表现一个 DOM 元素的结构
{
tag: 'div',
attrs: { className: 'box', id: 'content'},
children: [
{
tag: 'div',
arrts: { className: 'title' },
children: ['Hello']
},
{
tag: 'button',
attrs: null,
children: ['Click']
}
]
}你会发现每个DOM结构都可以通过DOM名称, DOM属性,DOM子元素来表示,DOM一层套一层形成了DOM树。
你比较下html方式的UI表示和js方式的UI表示的代码行数你就知道了:
所以React用jsx语法让我们能在js中可以用HTML的方式描述UI。但这坨代码肯定不是标准的js是吧,直接运行肯定是不行的,所以需要编译。其实就是树的递归调用啊…想想你写斐波那契数列程序的时候画的图。
<div>
<h1 className='title'>React 小书</h1>
</div>
=>
React.createElement(
"div",
null,
React.createElement(
"h1",
{ className: 'title' },
"React 小书"
)
)
)光是生成了一堆函数调用并不是真正的DOM,它只是包含了生成一个DOM树所需要的所有信息,我们称它为VDOM(虚拟DOM)。那么用什么东西把它变成真正的DOM呢? 想一下你每次是怎么引入React的?
import React, { Component } from 'react'
import ReactDOM from 'react-dom'
class Header extends Component {
...
}
ReactDOM.render(
<Header />,
document.getElementById('root')
)除了基本的React库,用于扩展的Component组件基类, 这个react-dom是什么? ReactDOM用于渲染组件并构造DOM树,然后插入到页面上的某个挂载点上。
因为这个UI信息并不一定要渲染到网页上,比如渲染到Canvas上,渲染到手机上。
总结下过程:
// JSX -> VDOM: 将jsx编译成vdom
let vdom = <div id="foo">Hello!</div>;
// VDOM -> DOM: 将vdom渲染成dom
let dom = render(vdom);
// add the tree to <body>: 将dom插入到挂载点
document.body.appendChild(dom); 因为原生的DOM操作非常费时, 和 DOM 操作比起来,js 计算是极其便宜,有了Vdom之后我们可以直接在这个js对象上操作,而不用直接与DOM打交道。这样的话可以减少浏览器的重排,极大的优化性能。React会在每次数据变化之后更新DOM,但不是更新真实的DOM,而是存在内存中的JS对象,不管你数据怎么变化,React都可以以最小的代价来更新 DOM。
虚拟DOM是React的一个非常重要的概念,不同的类React框架中对虚拟DOM的实现有差异,造成了其性能的千差万别。VDOM比较复杂,这期不介绍。
为什么我即使没在这个js中用到React也需要引入React这个库?
答: 还记得在文章开头说过的在js中的所有东西都是js吗? 只要你在这个js文件中用到了jsx语法,那么这个jsx会被翻译成React.createElement()的形式,你看如果你不引入React库,这段代码能执行吗?
不对啊,有时候我不需要引入这两个库也能用React,怎么解释?
答: 那是因为你把react和react-dom放在html文件的标签中了, React成为全局变量
为什么React的组件名一定要大写?
答: 因为普通的html标签都是小写的, div, a, p,那么React如何区分是已有的HTML标签还是用户自定义的组件呢?就是首字母大小写, 如果你小写你的组件名称,react会把它当原生html标签,然后报错因为找不到
为什么组件必须要有一个顶层节点?
答:React15以下组件需要包一个顶层节点,否则会报_Adjacent XJS elements must be wrapped in an enclosing tag _的错,为什么呢? 再复习一遍在js当中所有东西都是js ,并列的两个tag 会渲染成什么样子?React.createElement(...) React.createElement(...) 并不符合语法,但如果做成数组形式返回其实是可以的,因此React16中终于支持了返回数组的写法。这个问题的issue14年就已提出来了,有兴趣的同学可以研究一下。
render() {
return [
<li key="A">First item</li>,
<li key="B">Second item</li>,
<li key="C">Third item</li>,
];
}说了那么多,我还是觉得jquery还有vm模板好用,那么我为什么要迁移到React + jsx中来呢?
=> 因为一方面用jsx+React我们可以使用js的所有语法和能力,而使用模板引擎通常只能使用其提供的有限的模板语法。
举个栗子🌰,循环列表,在vm中我们只能用这样的语法写:
<ul>
#foreach ( $product in $allProducts )
<li> $product </li>
#end
</ul>
而在jsx中, 我们可以:
// 用map写
let list = items => items.map( p => <li> {p} </li> );
// 用循环写
let list = [];
for (let i = 0 ; i < items.length: i++) {
list.push(<li>{items[i]}</li>);
}
// 用forEach写
let list = [];
items.forEach(item => list.push(<li>{item}</li>))
// 用while写
// 用for...of写
// ...总之你爱怎么写就怎么写。这极大地拓展了前端写界面的能力,前端同学心里美滋滋。
另一方面jsx结合React能发挥它前端组件化的优势,提高代码复用率,避免手动操作DOM等,这里不赘述。
这个是jsx提供给你插入表达式的,包括变量,表达式计算,函数调用都可以放在里面。如何判断是否是表达式? 看他可不可以放在等于号右边。
所以if, for这样的就不是表达式了,所以我们也不能在{}中写for循环和if判断,但我们可以把结果暂存到变量中,然后插入到{}中,或者用?表达式啊。
另外这个表达式不仅可以用在标签内部,还能用在标签的属性上,属性props是jsx的一个重要概念。
首先我们聊聊为什么要组件化,组件化是为了代码的复用和分治。比如你的同事写了一个红色的按钮组件,有了React,我只要引入一下就可以用到我的工程里了,太棒了。但是等等,我的工程里需要的是一个蓝色的按钮,难道我要去改组件的代码?我希望我可以传一个颜色参数进去改变组件的样式,而这个需求的实现方式就是props。你可以理解为函数的参数,传入不同的参数,输出不同的值,没有参数的函数功能太过限定了。
所以 props的作用是让外部能对组件自己进行配置。
<div className="sidebar" color="red"/>
注意props一旦传入到组件中,它就是只读的,不可以再赋值。如果 props 渲染过程中可以被修改,那么就会导致这个组件显示形态和行为变得不可预测,这样会可能会给组件使用者带来困惑
让我们再来复习一下开篇的话: 在js中的所有东西都是js。当然不止class,同样的还有htmlFor替代for。
React.createElement(
MyButton,
{class: 'blue', shadowSize: 2},
'Click Me'
)通常的说辞是class是js的保留字。不过翻译成js好像没什么问题? 即使class是js的保留词依然可以用在属性语法中才对,只是不能做变量标识。是的,就有类react框架preact直接用的class,详见issue,甚至还有自动用babel帮我们做转换的jsx-html-class
React中用className的原因参考quora,总结一下原因有两点:
el.className=...,而不是el.setAttribute('class', ...),Attributes一般赋值字符串,而属性名可以赋值对象,更灵活。所以jsx中的className和HMTL的className属性表现一致,没毛病来来来,新鲜的React技巧便宜卖,10元一条,请扫我的付款码…好吧,其实都是jsx-in-depth里的。
<MyComponent message="<3" />
===
<MyComponent message={'<3'} /><MyTextBox autocomplete />
===
<MyTextBox autocomplete={true} />function App2() {
const props = {firstName: 'Ben', lastName: 'Hector'};
return <Greeting {...props} />;
}{String(myVariable)}。这个可以用来做条件渲染,注意showHeader得是一个boolean值,不能是0这样的伪false值。<div>
{showHeader && <Header />}
<Content />
</div>to be continued :)
早些时候,前端开发是没有「构建」这个步骤的,从写法的浏览器兼容到复用都很麻烦。如今前端高速发展及前端往工程化的进步,觉得主要有两个基石:
首先是「模块化」的推广和完善,npm 提供了规范的书写方式,从之前各具特色的写法困难的解读与适配,变成业界规范,正是因为达成共识的规范,车同轨,书同文,连接协作分享才成为可能,社区和生态也才能诞生。
另一个基石是「构建」的趋于成熟,尤其是构建**的成熟。在几年前还是 glup 这类把构建抽象为流任务,对 css,js 的 文件压缩合并合图等粗浅处理,如今发展到 webpack 提出的 web 资源都当作模块的设计**,这个**上的转变现在看来真算个里程碑,各种资源具备了统一的描述和加载方式,这样丰富灵活的统一操作和处理,组织成更细力度和更大规模的应用才成为可能,webpack 也成为如今的事实标准,这就是如今习以为常的「构建」步骤,它是各类模块的粘合剂,使得模块之间能顺利协作连接,形成各种功能实体,推进前端往工程化迈进。
事情都是有利有弊,因为各类模块的种类繁多以及处理方式多样,和 webpack 先进的**与生俱来的就是它高昂的配置成本,它需要支持各类模块的编排构建,势必保持通用型非常灵活,有大量的配置可以灵活处理各类模块的编译方式。二八原则看,对于大部分项目来说,并不需要那么多配置,因此程序上一般处理方式就是加一层,收掉底层复杂的配置,透露简洁的使用方案给上层。 这就是 atool-build 诞生的原因和希望解决的问题。如今虽然已经不怎么更新,但作为 被 1425 个仓库,725个包依赖的模块(2018.09.01 统计),仍可以从它的设计里学习借鉴很多。
经过这么多年的发展,前端方面主要会面临的问题包括不同浏览器兼容,不同版本的 css,js 语言兼容,以及组件化方案等。早期大家还会写写原生的处理兼容问题,但如今各类浏览器+各个js、css版本,已经达到很难写完整的地步。
另外还有前端语言本身的写法问题,这在早期做页面时候问题不大,但随着前端的发展在规模和复杂度有了更高的要求,纯css,js的写法就变得相当繁琐。比如css作为描述型语言,容易上手写法简单,但是在做大型应用时候,纯手写会相当繁琐。js 因为弱类型的特性,灵活是一方面,但在大型应用的协作和描述上,不够透明成为一种负担。
因此趋势是手动变自动,通过预处理和构建编译去解决这些问题,其实这类也有很多方案。而 webpack 一切皆 pack 的统一处理特性,使得它成为承载以上各类问题处理方案的很好的载体。而事实上,基于 webpack 的 atool-build,确实也封装了这些年解决 web 开发问题的沉淀下来的各类处理插件,了解它们要解决的问题,也就基本看全了前端这几年的各个方向发展和沉淀,接下来我们会做大致介绍。
好,终于到了主角 ant-tool/atool-build 登场了, 基于之上背景,之所以去读 atool-build,是希望对以下有所了解
atool-build 核心代码其实只有几行逻辑
// 根据配置,生成 webpack 编译器
const compiler = webpack(webpackConfig);
...
if (args.watch) {
// 编译文件,并在文件变化时再次编辑
compiler.watch(args.watch || 200, doneHandler);
} else {
// 编译文件
compiler.run(doneHandler);
}接下来我们看一下 atool-build 默认集成了 webpack 哪些配置,解决了哪些问题。这里不可避免的需要涉及 webpack 的一些配置,但不需过多深入理解,这里大概理解 webpack 的两个概念:loader 和 plugin 就可以了,其中 loader 用于对模块的源代码进行转换,让 webpack 能够去处理那些非 JavaScript 文件(webpack 自身只理解 JavaScript),从而所有类型的文件转换为 webpack 能够处理的有效模块被用于转换某些类型的模块,而插件则可以用于执行范围更广的任务。
首先是构建环节基本的输入输出,主要配置在 src/getWebpackCommonConfig.js 这个文件
const pkgPath = join(args.cwd, 'package.json');
const pkg = existsSync(pkgPath) ? require(pkgPath) : {};
const jsFileName = args.hash ? '[name]-[chunkhash].js' : '[name].js';
const cssFileName = args.hash ? '[name]-[chunkhash].css' : '[name].css';
const commonName = args.hash ? 'common-[chunkhash].js' : 'common.js';
...
const config = {
// 输入:在项目根目录 package.json 的 entry 配置要构建的文件
entry: pkg.entry,
...
// 输出:构建生成文件输出到 dist 目录
output: {
path: join(process.cwd(), './dist/'),
filename: jsFileName,
chunkFilename: jsFileName,
},
};然后是第三方模块的找寻方式
resolve: {
// 配置第三方模块的找寻地址
modules: ['node_modules', join(__dirname, '../node_modules')],
// 当引入模块没有文件后缀,尝试根据这些文件后缀来找寻是否存在相应文件
extensions: ['.web.tsx', '.web.ts', '.web.jsx', '.web.js', '.ts', '.tsx', '.js', '.jsx', '.json'],
},到这里,基本的构建阶段的输入输出配置就完成了。接下来是配置各类资源的处理。如上所说,webpack 对非 js 的文件处理是通过配置各类 loader 来做转换的. 需要注意的是,loader 的运行顺序是按数组倒序运行的。
因为入口文件一般都是 js 文件,先看看 js 的编译
可以简单理解为都是 js 语言加上一些领域写法的变体,需要转换到原生js才能正常使用
{
test: /\.jsx?$/,
exclude: /node_modules/,
loader: 'babel-loader',
options: babelOptions,
},
{
test: /\.tsx?$/,
use: [
{
loader: 'babel-loader',
options: babelOptions,
},
{
loader: 'ts-loader',
options: {
transpileOnly: true,
compilerOptions: tsQuery,
},
},
],
},babel 可以简单理解为,转换 js 成配置版本,使得一些浏览器尚未支持的特性,能降级为老版本实现,使得浏览器能够正常运行,在 atool-build 配置是
{
cacheDirectory: tmpdir(),
presets: [
require.resolve('babel-preset-es2015-ie'),
require.resolve('babel-preset-react'),
require.resolve('babel-preset-stage-0'),
],
plugins: [
require.resolve('babel-plugin-add-module-exports'),
require.resolve('babel-plugin-transform-decorators-legacy'),
],
};typeScript 可以简单理解为,有类型的 js,即在编写时候增加类型提示等辅助功能,但也不是原生的,需要做编译转化为原生 js,在 atool-build 配置是
{
target: 'es6',
jsx: 'preserve',
moduleResolution: 'node',
declaration: false,
sourceMap: true,
};以上就是js 的基本构建处理了。接下来看看 css,即通过入口文件引入的css的 处理
{
test(filePath) {
return /\.css$/.test(filePath) && !/\.module\.css$/.test(filePath);
},
use: ExtractTextPlugin.extract({
use: [
{
loader: 'css-loader',
options: {
sourceMap: true,
},
},
{
loader: 'postcss-loader',
options: postcssOptions,
},
],
}),
},
{
test: /\.module\.css$/,
use: ExtractTextPlugin.extract({
use: [
{
loader: 'css-loader',
options: {
sourceMap: true,
modules: true,
localIdentName: '[local]___[hash:base64:5]',
},
},
{
loader: 'postcss-loader',
options: postcssOptions,
},
],
}),
},
{
test(filePath) {
return /\.less$/.test(filePath) && !/\.module\.less$/.test(filePath);
},
use: ExtractTextPlugin.extract({
use: [
{
loader: 'css-loader',
options: {
sourceMap: true,
},
},
{
loader: 'postcss-loader',
options: postcssOptions,
},
{
loader: 'less-loader',
options: {
sourceMap: true,
modifyVars: theme,
},
},
],
}),
},
{
test: /\.module\.less$/,
use: ExtractTextPlugin.extract({
use: [
{
loader: 'css-loader',
options: {
sourceMap: true,
modules: true,
localIdentName: '[local]___[hash:base64:5]',
},
},
{
loader: 'postcss-loader',
options: postcssOptions,
},
{
loader: 'less-loader',
options: {
sourceMap: true,
modifyVars: theme,
},
},
],
}),
},这里需要对 postCSS 有一定了解主要是处理 css 存在版本问题,以及各类浏览器写法问题。
const postcssOptions = {
sourceMap: true,
plugins: [
rucksack(),
autoprefixer({
browsers: ['last 2 versions', 'Firefox ESR', '> 1%', 'ie >= 8', 'iOS >= 8', 'Android >= 4'],
}),
],
};
通过入口文件 import 的其它非js类文件,也需配置对应的处理 loader
{
test: /\.woff(\?v=\d+\.\d+\.\d+)?$/,
loader: 'url-loader',
options: {
limit: 10000,
minetype: 'application/font-woff',
},
},
{
test: /\.woff2(\?v=\d+\.\d+\.\d+)?$/,
loader: 'url-loader',
options: {
limit: 10000,
minetype: 'application/font-woff',
},
},
{
test: /\.ttf(\?v=\d+\.\d+\.\d+)?$/,
loader: 'url-loader',
options: {
limit: 10000,
minetype: 'application/octet-stream',
},
},
{ test: /\.eot(\?v=\d+\.\d+\.\d+)?$/,
loader: 'url-loader',
options: {
limit: 10000,
minetype: 'application/vnd.ms-fontobject',
},
},
{
test: /\.svg(\?v=\d+\.\d+\.\d+)?$/,
loader: 'url-loader',
options: {
limit: 10000,
minetype: 'image/svg+xml',
},
},
{
test: /\.(png|jpg|jpeg|gif)(\?v=\d+\.\d+\.\d+)?$/i,
loader: 'url-loader',
options: {
limit: 10000,
},
},
{
test: /\.html?$/,
loader: 'file-loader',
options: {
name: '[name].[ext]',
},
},atool-build 内置了一些插件。注意插件的执行依赖于 webpack 的事件机制,并不是顺序执行。
// 打包出各个入口的共同文件 common.js
new webpack.optimize.CommonsChunkPlugin({
name: 'common',
filename: commonName,
}),
// 将样式文件单独打包
new ExtractTextPlugin({
filename: cssFileName,
disable: false,
allChunks: true,
}),
// 大小写识别
new CaseSensitivePathsPlugin(),
// 错误提示增强
new FriendlyErrorsWebpackPlugin({
onErrors: (severity, errors) => {
...
},
}),另外为了优化打包过程体验,还使用了 ProgressPlugin
new ProgressPlugin((percentage, msg, addInfo) => {
const stream = process.stderr;
if (stream.isTTY && percentage < 0.71) {
stream.cursorTo(0);
stream.write(`📦 ${chalk.magenta(msg)} (${chalk.magenta(addInfo)})`);
stream.clearLine(1);
} else if (percentage === 1) {
console.log(chalk.green('\nwebpack: bundle build is now finished.'));
}
}),// 使用 babel 转换代码为 es5
"build": "rm -rf lib && babel src --out-dir lib",
// 发布 npm 包和发布代码
"pub": "npm run build && npm publish && rm -rf lib && git push origin"
// babel-node 和 babel-istanbul
// $(npm bin) 本地命令行路径
// babel-node 和 babel-istanbul
"test": "babel-node $(npm bin)/babel-istanbul cover $(npm bin)/_mocha -- --no-timeouts",
// 支持 es6 的 mocha
"debug": "$(npm bin)/mocha --require babel-core/register --no-timeouts",
// 使用 eslint 规范代码格式
"lint": "eslint --ext .js src",
// 现实覆盖率
"coveralls": "cat ./coverage/lcov.info | coveralls",http://ant-tool.github.io/atool-build.html
api 设计还是非常简洁,突出本质
program
.version(require('../package').version, '-v, --version')
.option('-o, --output-path <path>', 'output path')
.option('-w, --watch [delay]', 'watch file changes and rebuild')
.option('--hash', 'build with hash and output map.json')
.option('--publicPath <publicPath>', 'publicPath for webpack')
.option('--devtool <devtool>', 'sourcemap generate method, default is null')
.option('--config <path>', 'custom config path, default is webpack.config.js')
.option('--no-compress', 'build without compress')
.option('--silent', 'close notifier')
.option('--notify', 'activates notifications for build results')
.option('--json', 'running webpack with --json, ex. result.json')
.option('--verbose', 'run with more logging messages.')通过配置 webpack.config.js 来扩展,这个好处是灵活,缺点是函数式过于灵活不受管控,容易变成坑, 比如去掉 common 的设置要这样写
webpackConfig.plugins.some(function(plugin, i){
if(plugin instanceof webpack.optimize.CommonsChunkPlugin) {
webpackConfig.plugins.splice(i, 1);
return true;
}
});这个问题逐渐暴露难以收敛,构建的元能力没有得到很好的沉淀,作者在 这里 做了详细说明。
模块运营非常不容易,首先是使用方式多样,需求多样。API 设计,模块定位,以及各类运行的问题都要处理,在各类问题和需求中保证一定的形态。
尤其是处在变化的前端,工具的发展规划甚为不易,既要保持简洁,又要灵活,还要稳定,以及贴合趋势的发展,和在各种变化中保持本心, 可以看看这篇 pigcan: 支付宝前端构建工具的发展和未来的选择
在做H5活动页面的时候,
PD大人可能会说:哎呀,这个页面要分享到微信和钉钉里去的,做的时候注意一下~
当时你一想这有啥好注意的,直接上呗,拍拍胸脯就保证会分享得美美哒~
然后页面上线后,PD一分享就成了酱紫:
PD大人瞬间抓狂,你是在逗我吗!!!
So,接下来就要告诉你如何优雅的操作,秒秒钟满足PD大人的需求!!
在传播过程中,美美哒的页面可以分享成酱紫~
PD大人可以配置标题、文案、和小图片~
① 引入钉钉sdk:https://g.alicdn.com/ilw/ding/0.9.9/scripts/dingtalk.js
② 引入之后将得到全局变量dd
③ 像写jquery一样,待环境准备就绪之后再执行任务
dd.ready(function(){
; // 执行任务
});④ 配置分享options
dd.biz.util.share({
type: 0, //分享类型,0:全部组件 默认; 1:只能分享到钉钉;2:不能分享,只有刷新按钮
url: 'https://taobao.com',
title: '页面标题',
content: '页面内容简介',
image: '100*100px的正方形小图片',
onSuccess : function() {
// onSuccess将在分享完成之后回调
// 比如分享之后积分+10这种操作就可以放在这个回调里面
},
onFail : function(err) {
// onFail将在分享完成之后回调
}
});① 接入微信sdk:https://res.wx.qq.com/open/js/jweixin-1.2.0.js
② 引入之后将得到全局变量wx
③ 通过config接口注入权限校验配置
wx.config({
debug: true,
appId: '', // 必填,企业号的唯一标识,此处填写企业号corpid
timestamp: , // 必填,生成签名的时间戳
nonceStr: '', // 必填,生成签名的随机串
signature: '',// 必填,签名,见附录1
jsApiList: [] // 必填,需要使用的JS接口列表,所有JS接口列表见附录2
});
// 这些配置项都需要从企业号获取的,可以④ 因此你得需要一个企业号或者说是公众号,在设置 > 公众号设置 >js接口安全域名,在域名中添加分享要用到的域名,例如share.com,只有这样才能通过权限校验,还需要开发提供一个获取微信获取jssdk签名的接口
⑤ 通过ready接口处理成功验证
wx.ready(() => {
wx.onMenuShareTimeline({
title: '',
desc: '',
link: '',
imgUrl: '',
success: function() {},
cancel: function() {}
});
wx.onMenuShareAppMessage({
title: '',
desc: '',
link: '',
imgUrl: '',
success: function() {},
cancel: function() {}
});
wx.onMenuShareQQ({
title: '',
desc: '',
link: '',
imgUrl: '',
success: function() {},
cancel: function() {}
});
wx.xxxxx({}) // 详见分享接口
});更新:现在你可以通过
yarn create umi --plugin来创建插件的脚手架(基于 create-umi)。
UmiJS 称做为是一个可插拔的企业级 react 应用框架,“可插拔”就体现在它的插件机制。关于 umi 的更多介绍可以查看它的官方文档。这里就不再赘述,想要学习 umi 插件开发的同学应该先对 umi 框架有一定的认识,至少应该先参考快速上手使用 umi 搭建一个简单的应用。
你想要开发一个 umi 插件首先要确认的是插件机制能够带给你什么,为什么要用插件,什么场景用插件才是正确的选择。不能因为用插件而用插件,首先要认识到插件是用来解决什么问题的才能最大限度的用好插件。
那么什么场景需要用插件呢?
简单点说就是:当一个功能涉及到前端的各个部分(比如 HTML,CSS,JSS)或者构建阶段等不同位置的逻辑时,而你又希望能够极简的使用并能够方便的提供给其它项目复用该功能。那么你就应该使用插件来实现你的功能。
umi 的插件机制在项目的各个阶段和各个部分提供了不同的接口,使得插件能够在 web 开发中在不同的阶段对不同的部分去执行它需要的操作。比如如下的一些例子:
当然这些例子只是 umi 的部分能力,更多的接口可以参考 umi 的文档插件开发。
这篇文章我们就以一个实际的例子来说明 umi 的开发。比如在我们的项目中经常要使用 lodash,那么我们可能要实现 lodash 的按需打包,也有可能为了减小包的体积使用 CDN 版本的 lodash。要实现这样的功能需要修改 webpack 配置,还需要在 HTML 中添加 lodash 的地址。这显然是繁琐的(这个例子其实也还算简单,实际工程中可能会有更繁琐的一些功能)。我们期望开发者能够很方便的使用这个功能,并且可以简单的在各个项目中复用。在不使用插件的情况下,我们可以需要如下的步骤:
那么我们期望开发一个 umi-plugin-lodash 的插件,使得 lodash 使用能够简化为:
具体的插件配置我们希望能够像下面这样简单:
export default {
plugins: [
['umi-plugin-lodash', {
version: '4.0.0', // 不指定则默认是最新
external: true, // 默认 false,为 true 的情况下使用 CDN,否则使用按需打包的 npm 包
}]
],
};那么我们接下来就看看如何开发这个插件。
注:该部分只在 mac 下测试过。
下面这一段是从 umi 的官网上面摘抄的:
在 umi 中,插件实际上就是一个 JS 模块,你需要定义一个插件的初始化方法并默认导出。如下示例:
export default (api, opts) => {
// your plugin code here
};需要注意的是,如果你的插件需要发布为 npm 包,那么你需要发布之前做编译,确保发布的代码里面是 ES5 的代码。
该初始化方法会收到两个参数,第一个参数 api,umi 提供给插件的接口都是通过它暴露出来的。第二个参数 opts 是用户在初始化插件的时候填写的。
在我们这个例子中我们希望以一个 npm 包的形式来使用该插件,那么我们需要使用 npm 命令来初始化这么一个包:
mkdir umi-plugin-lodash
cd umi-plugin-lodash
npm init # entry point 修改为 lib/index.js然后我们创建一个 src/index.js 文件。初始化代码为:
export default (api, opts) => {
console.log('i am lodash plugin');
};然后安装 babel-cli, babel-preset-es2015 和 babel-preset-stage-1,安装它们是为了能将我们的代码编译成 ES5 的,这样可以适配更低版本的 NodeJS。安装之后在 package.json 中配置 scripts 添加 dev 为 babel src --watch --presets=es2015,stage-1 --out-dir lib。
这样当你在根目录下运行 npm run dev 时就会自动监听 src 中的文件编号并且实时编译到 lib 中了。
{
"name": "umi-plugin-lodash",
"version": "1.0.0",
"description": "Easy to ues lodash in UmiJS.",
"main": "lib/index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
+ "dev": "babel src --watch --presets=es2015,stage-1 --out-dir lib"
},
...
+ "devDependencies": {
+ "babel-cli": "^6.26.0",
+ "babel-preset-es2015": "^6.24.1",
+ "babel-preset-stage-1": "^6.24.1"
+ }
}解析来我们再创建一个文件夹 example 来存放测试的代码。
mkdir example然后在里面创建 .umirc.js 和 pages/index.js 文件。其中 umirc.js 为:
export default {
plugins: [
['umi-plugin-lodash'],
]
}pages/index.js 为:
export default () => {
return <div>hello world!</div>;
};为了能够让这个示例项目能够找到 umi-plugin-lodash 这个包,我们需要在 umi-plugin-lodash 更目录下运行 npm link,这样它会把这个包 link 到全局环境中。然后在到 example 目录运行 npm link umi-plugin-lodash 来把这个全局的包 link 到 example 下面。
然后进入 example 目录运行 CLEAR_CONSOLE=none umi dev 你将会在控制台看到插件的输出 i am lodash plugin。还可以访问浏览器 http://localhost:8000/ 看到页面显示 hello world!。如下所示:
如果你报没有 umi 这个命令或者不知道为什么页面能够不配置路由就显示出来,那么你应该先看看 umi 官方文档中的快速开始。
然后你就可以愉快的开始开发了,需要注意的是通过 tnpm run dev 后插件的代码会被实时编译到 lib 目录下,但是你还是需要重新执行 CLEAR_CONSOLE=none umi dev 才能够让插件生效,但是不需要重新执行 npm 的 link 命令。
首先我们在 umi-plugin-lodash 中按照 lodash 的包,然后通过 umi 的插件接口 chainWebpackConfig 来添加一个别名 umi/lodash 来关联上插件中的 lodash 包。这样就可以在项目中通过 umi/lodash 来使用 lodash 了,这里使用 umi/lodash 而不是 lodash 的原因是为了让项目中免去安装 lodash,另外不能直接使用 lodash 别名避免出现影响其他第三方库的 lodash 引用版本的问题。代码如下:
const { dirname } = require('path');
export default (api, opts) => {
api.chainWebpackConfig(webpackConfig => {
webpackConfig.resolve.alias.set(
'umi/lodash',
dirname(
require.resolve('lodash/package'),
),
);
});
};然后我们在 pages/index.js 中测试它。
import { uniq } from 'umi/lodash';
export default () => {
return <div>{uniq([1, 2, 2])}</div>;
};重启之后,如果顺利你就可以在浏览器中看到输出 12。
比如上面的例子中我们的代码只使用了 uniq,那么如果不做任何处理的话最终打包的代码就会包含 lodash 全部代码,为了实现按需打包,我们还需要引入 babel-plugin-import 包:
function importPlugin(key) {
return [
require.resolve('babel-plugin-import'),
{
libraryName: key,
libraryDirectory: '',
camel2DashComponentName: false,
},
key,
];
}
// ...
api.modifyAFWebpackOpts(memo => {
return {
...memo,
babel: {
...(memo.babel || {}),
plugins: [
importPlugin('umi/lodash'),
importPlugin('lodash'),
],
},
};
});
// ...完整代码在 github 中查看源代码。
这里我们除了实现 umi/lodash 的按需打包,同时也顺带把通过 lodash 引用的 lodash 也打包了,这样可能可以减少一些使用了 ldoash 的第三方包的体积。
你可以通过运行 ANALYZE=1 umi build 来查看结果。
为了更大限度的优化性能,我们可以把 lodash external 掉,这要求我们往 HTML 添加 lodash 的 JS 并配置 external。
代码如下:
api.modifyAFWebpackOpts(memo => {
if (opts.external) {
return {
...memo,
externals: {
...(memo.externals || []),
'umi/lodash': '_',
'lodash': '_',
}
}
}
return memo;
});
api.addHTMLHeadScript(() => {
if (opts.external) {
if (opts.version) {
return {
src: `https://cdnjs.cloudflare.com/ajax/libs/lodash.js/${opts.version}/lodash.min.js`,
};
} else {
throw new Error('if you need external lodash, version is required!');
}
}
return [];
});完整的代码请直接参考 umi-plugin-lodash。
首先让我们来添加一个 build 命令用于编译代码:
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"dev": "babel src --watch --presets=es2015,stage-1 --out-dir lib",
+ "build": "babel src --presets=es2015,stage-1 --out-dir lib"
},记得发布之前需要添加 .gitignore 的文件:
node_modules
.umi
.umi_production
dist
然后运行如下命令就可以把这个包发布到 npm 中,在项目中愉快的使用了:
npm run build
npm publishumi-plugin-lodash 这个包当前还是 0.x 版本,还有待完善,欢迎讨论和 PR。
你是否在业务中面对 ECharts bug 无可奈何?
你是否对 ECharts 心生向往,却在源码面前望而却步?
你是否想为开源做点贡献,却不知道哪里需要你?
这是一次由 ECharts 核心开发者羡辙亲自带领大家一起走近源码的视频教程,是了解 ECharts 原理的第一手资料,不容错过!
把干货讲得生动有趣,希望让更多的人可以自己修改 ECharts 源码,面对 bug 和新需求不再求人!
我们 B 站见!再不上车就晚啦~~
https://www.bilibili.com/video/av31172702/
本质上都是为了提升前端应用特别是 h5 应用的性能。react 服务端渲染能提升首屏渲染的性能以及提供 SEO 的优化。
react 服务端渲染能带来性能提升(首屏渲染)以及 SEO 优化。带来这些好处的同时,也会带来一些额外的开销。一是应用编写会带来一些额外的复杂度,二是服务端渲染会带来额外的服务端计算开销。
在考虑是否需要 react 服务端渲染时,我们需要综合考虑性能和代价。对于性能要求很高的面向 c 端的应用,应该考虑使用 react 服务端渲染。同时,为了不使服务器端有过高的计算压力,节省服务端资源,需要采取各种方法优化服务端渲染的性能。例如采用缓存,首屏部分内容服务端渲染,其他内容懒加载等技术。
参考阿里 node 现有的方案,我们可以考虑采用 egg + react + webpack 的方案。
从 The Performance Cost of Server Side Rendered React on Node.js 这篇文章我们可以看到,react 服务端渲染的性能还是较弱的,原因是基于 virtual-dom 的模板引擎相对基于字符串的模板引擎,其复杂度一定是相对较高的。但是我们也能看到,最近 react 服务端渲染的性能在不断提升,基本已经和 Nunjucks 模板差不多了。
如果要推进 react 服务端渲染,需要有可以实践的场景。如果没有应用场景,那么只能在技术学习中去推进。而实际场景和我们在学习研究中的场景存在不同,同时学习研究中如果没有实际问题场景,那么会面临很多选择却不知到底该如何抉择的问题。也就是到底要解决什么问题不明确的话,行动就会变得很盲目。例如,要实现 react 服务端渲染平台,支持活动页服务端渲染和做服务端渲染框架,支持 h5 app 服务端渲染,要解决的问题是很不一样的。总之,首先要明确要解决的问题,然后确定要采用的方案,最后再推进服务端渲染的落地。
正则表达式:用于匹配满足某些规则的文本的代码。描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
经常会用到,但确可能会记不清,所以将基本的用法汇总与此。无论何时看,总可以温故知新~
常用元字符
* 指定*前边的内容可以连续重复使用任意次以使整个表达式得到匹配。如果你想查找元字符本身的话,需要使用转义字符\来取消这些字符的特殊意义。\.匹配.,\\匹配\。
例子
hi ==> hi/history/high/white等;
\bhi\b ==> 只会精确的匹配查找hi单词;
.* ==> 匹配任意数量的不含换行的字符
\bhi\b.*\blucy\b ==> 显示一个单词hi,然后是人一个字符(但不能是换行),最后是lucy这个单词;
0\d\d-\d\d\d\d\d\d\d ==> 以0开头,然后是两个数字,然后是一个连字符“-”,最后是7个数字(固定电话);
\ba\w*\b ==> 以字母a开头的单词——先是某个单词开始处(\b),然后是字母a,
然后是任意数量的字母或数字(\w*),最后是单词结束处(\b)。常用限定符
0\d{2}-\d{8} ==> {2}表示前面的\d必须连续重复匹配2次,所以意思同上(固定电话);
\d+ ==> 匹配1个或更多连续的数字.
\b\w{6}\b ==> 匹配刚好6个字符的单词。
\d{5,12} ==> {5,12}则是重复的次数不能少于5次,不能多于12次,否则都不匹配。
Windows\d+ ==> 匹配Windows后面跟1个或更多数字。常用反义字符
\S+ ==> 匹配不包含空白符的字符串.
<a[^>]+> ==> 匹配用尖括号括起来的以a开头的字符串。通过()指定子表达式。
常用分组语法
断言:声明一个应该为真的事实。正则表达式中只有断言正确才会继续匹配。我们要捕获的内容前后必须是某些特定的内容,但又不捕获这些特定类容的时候,使用零宽断言。
‘industr(?:y|ies) ;
//匹配’industry’或’industries’返回值仅仅industry或者industries本身,而没有括号中的分组。
‘Windows (?=95|98|NT|2000)’;
//匹配 "Windows2000" 中的 "Windows"
//不匹配 "Windows3.1" 中的 "Windows"。 \b\w+(?=ing\b) ==> 匹配以ing结尾的单词的前面部分(除了ing以外的部分),如查找I'm singing while you're dancing.时,它会匹配sing和danc。
(?<=\bre)\w+\b ==> 会匹配以re开头的单词的后半部分(除了re以外的部分),例如在查找reading a book时,它匹配ading。
(?<=\s)\d+(?=\s) ==> 匹配以空白符间隔的数字(再次强调,不包括这些空白符)。
\b\w*q[^u]\w*\b ==> 匹配包含后面不是字母u的字母q的单词。Iraq,Benq,这个表达式就会出错。
\b\w*q(?!u)\w*\b ==> 能解决这样的问题,因为它只匹配一个位置,并不消费任何字符。
\d{3}(?!\d) ==> 匹配三位数字,而且这三位数字的后面不能是数字。
\b((?!abc)\w)+\b ==> 匹配不包含连续字符串abc的单词。
(?<=<(\w+)>).*(?=<\/\1>) ==> 匹配不包含属性的简单HTML标签内里的内容。当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。以这个表达式为例:a.b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索aabab的话,它会匹配整个字符串aabab。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号?。这样.?就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
a.*?b匹配最短的,以a开始,以b结束的字符串。如果把它应用于aabab的话,它会匹配aab(第一到第三个字符)和ab(第四到第五个字符)。
为什么第一个匹配是aab(第一到第三个字符)而不是ab(第二到第三个字符)?简单地说,因为正则表达式有另一条规则,比懒惰/贪婪规则的优先级更高:最先开始的匹配拥有最高的优先权——The match that begins earliest wins。
懒惰限定符
字符类
[aeiou] ==> 匹配任何一个英文元音字母a或e或i或o或u。
[.?!] ==> 匹配标点符号.或?或!。
[a-z0-9A-Z_] ==> 完全等同于\w(如果只考虑英文的话)。
分支条件
正则表达式里的分枝条件指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用|把不同的规则分隔开。
0\d{2}-\d{8}|0\d{3}-\d{7} ==> 能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如010-12345678),一种是4位区号,7位本地号(0376-2233445)。
\d{5}-\d{4}|\d{5} ==> 用于匹配美国的邮政编码。美国邮编的规则是5位数字,或者用连字号间隔的9位数字。
注意:使用分枝条件时,要注意各个条件的顺序。
如果你把它改成\d{5}|\d{5}-\d{4}的话,那么就只会匹配5位的邮编(以及9位邮编的前5位)。原因是匹配分枝条件时,将会从左到右地测试每个条件,如果满足了某个分枝的话,就不会去再管其它的条件了。
分组
可以用小括号来指定子表达式(也叫做分组),然后你就可以指定这个子表达式的重复次数了,你也可以对子表达式进行其它一些操作。
(\d{1,3}.){3}\d{1,3} ==> 是一个简单的IP地址匹配表达式。要理解这个表达式,请按下列顺序分析它:\d{1,3}匹配1到3位的数字,(\d{1,3}.){3}匹配三位数字加上一个英文句号(这个整体也就是这个分组)重复3次,最后再加上一个一到三位的数字(\d{1,3})。
IP地址中每个数字都不能大于255.
((2[0-4]\d|25[0-5]|[01]?\d\d?).){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)
向后引用
后向引用用于重复搜索前面某个分组匹配的文本。例如,\1代表分组1匹配的文本。
使用小括号指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
• 分组0对应整个正则表达式
• 实际上组号分配过程是要从左向右扫描两遍的:第一遍只给未命名组分配,第二遍只给命名组分配--因此所有命名组的组号都大于未命名的组号
• 你可以使用(?:exp)这样的语法来剥夺一个分组对组号分配的参与权.
\b(\w+)\b\s+\1\b ==> 可以用来匹配重复的单词,像go go, 或者kitty kitty。这个表达式首先是一个单词,
也就是单词开始处和结束处之间的多于一个的字母或数字(\b(\w+)\b),这个单词会被捕获到编号为1的分组中,
然后是1个或几个空白符(\s+),最后是分组1中捕获的内容(也就是前面匹配的那个单词)(\1)。算是一篇老文了,讲 redux 原理的。
说起Flux,之前曾写过一篇《ReFlux细说》的文章,重点对比讲述了Flux的另外两种实现形式:『Facebook Flux vs Reflux』,有兴趣的同学可以一并看看。
时过境迁,现在社区里,Redux的风头早已盖过其他Flux,它与React的组合使用更是大家所推荐的。
Redux很火,很流行,并不是没有道理!!它本身灵感来源于Flux,但却不局限于Flux,它还带来了一些新的概念和**,集成了immutability的同时,也促成了Redux自身生态圈。
笔者在看完redux和react-redux源码后,觉得它的一些**和原理拿出来聊一聊,会更有利于使用者的了解和使用Redux。
(注:如果你是初学者,可以先阅读一下Redux中文文档,了解Redux基础知识。)
作为Flux的一种实现形式,Redux自然保持着数据流的单向性,用一张图来形象说明的话,可以是这样:
上面这张图,在展现单向数据流的同时,还为我们引出了几个熟悉的模块:Store、Actions、Action Creators、以及Views。
相信大家都不会陌生,因为它们就是Flux设计模式中所提到的几个重要概念,在这里,Redux沿用了它们,并在这基础之上,又融入了两个重要的新概念:Reducers和Middlewares(稍后会讲到)。
接下来,我们先说说Redux在已有概念上的一些变化,之后再聊聊Redux带来的几个新概念。
Store — 数据存储中心,同时连接着Actions和Views(React Components)。
连接的意思大概就是:
setState进行重新渲染组件(re-render)。上面这三步,其实是Flux单向数据流所表达出来的**,然而要实现这三步,才是Redux真正要做的工作。
下面,我们通过答疑的方式,来看看Redux是如何实现以上三步的?
问:Store如何接收来自Views的Action?
答:每一个Store实例都拥有dispatch方法,Views只需要通过调用该方法,并传入action对象作为形参,Store自然就就可以收到Action,就像这样:
store.dispatch({
type: 'INCREASE'
});
问:Store在接收到Action之后,需要根据Action.type和Action.payload修改存储数据,那么,这部分逻辑写在哪里,且怎么将这部分逻辑传递给Store知道呢?
答:数据修改逻辑写在Reducer(一个纯函数)里,Store实例在创建的时候,就会被传递这样一个reducer作为形参,这样Store就可以通过Reducer的返回值更新内部数据了,先看一个简单的例子(具体的关于reducer我们后面再讲):
// 一个reducer
function counterReducer(state = 0, action) {
switch (action.type) {
case 'INCREASE':
return state + 1;
case 'DECREASE':
return state - 1;
default:
return state;
}
}
// 传递reducer作为形参
let store = Redux.createStore(counterReducer);
问:Store通过Reducer修改好了内部数据之后,又是如何通知Views需要获取最新的Store数据来更新的呢?
答:每一个Store实例都提供一个subscribe方法,Views只需要调用该方法注册一个回调(内含setState操作),之后在每次dispatch(action)时,该回调都会被触发,从而实现重新渲染;对于最新的Store数据,可以通过Store实例提供的另一个方法getState来获取,就像下面这样:
let unsubscribe = store.subscribe(() =>
console.log(store.getState())
);
所以,按照上面的一问一答,Redux.createStore()方法的内部实现大概就是下面这样,返回一个包含上述几个方法的对象:
function createStore(reducer, initialState, enhancer) {
var currentReducer = reducer
var currentState = initialState
var listeners = []
// 省略若干代码
//...
// 通过reducer初始化数据
dispatch({ type: ActionTypes.INIT })
return {
dispatch,
subscribe,
getState,
replaceReducer
}
}
总结归纳几点:
dispatch(action)来完成,即:action -> reducers -> store消息发布/订阅(pub/sub)的功能,也正是因为这个功能,它才能够同时连接着Actions和Views。
Reducer,这个名字来源于数组的一个函数 — reduce,它们俩比较相似的地方在于:接收一个旧的prevState,返回一个新的nextState。
在上文讲解Store的时候,得知:Reducer是一个纯函数,用来修改Store数据的。
这种修改数据的方式,区别于其他Flux,所以我们疑惑:通过Reducer修改数据给我们带来了哪些好处?
这里,我列出了两点:
Redux有一个原则:单一数据源,即:整个React Web应用,只有一个Store,存储着所有的数据。
这个原则,其实也不难理解,倘若多个Store存在,且Store之间存在数据关联的情况,处理起来往往会是一件比较头疼的事情。
然而,单一Store存储数据,就有可能面临着另一个问题:数据结构嵌套太深,数据访问变得繁琐,就像下面这样:
let store = {
a: 1,
b: {
c: true,
d: {
e: [2, 3]
}
}
};
// 增加一项: 4
store.b.d.e = [...store.b.d.e, 4]; // es7 spread
console.log(store.b.d.e); // [2, 3, 4]
这样的store.b.d.e数据访问和修改方式,对于刚接手的项目,或者不清楚数据结构的同学,简直是晴天霹雳!!
为此,Redux提出通过定义多个reducer对数据进行拆解访问或者修改,最终再通过combineReducers函数将零散的数据拼装回去,将是一个不错的选择!
在JavaScript中,数据源其实就是一个object tree,object中的每一个key都可以认为是tree的一个节点,每一个叶子节点都含有一个value(非plain object),就像下面这张图所描述的:
而我们对数据的修改,其实就是对叶子节点value的修改,为了避免每次都从tree的根节点r开始访问,可以为每一个叶子节点创建一个reducer,并将该叶子节点的value直接传递给该reducer,就像下面这样:
// state 就是store.b.d.e的值
// [2, 3]为默认初始值
function eReducer(state = [2, 3], action) {
switch (action.type) {
case 'ADD':
return [...state, 4]; // 修改store.b.d.e的值
default:
return state;
}
}
如此,每一个reducer都将直接对应数据源(store)的某一个字段(如:store.b.d.e),这样的直接的修改方式会变得简单很多。
拆解之后,数据就会变得零散,要想将修改后的数据再重新拼装起来,并统一返回给store,首先要做的就是:将一个个reducer自上而下一级一级地合并起,最终得到一个rootReducer。
合并reducer时,需要用到Redux另一个api:combineReducers,下面这段代码,是对上述store的数据拆解:
import { combineReducers } from 'redux';
// 叶子reducer
function aReducer(state = 1, action) {/*...*/}
function cReducer(state = true, action) {/*...*/}
function eReducer(state = [2, 3], action) {/*...*/}
const dReducer = combineReducers({
e: eReducer
});
const bReducer = combineReducers({
c: cReducer,
d: dReducer
});
// 根reducer
const rootReducer = combineReducers({
a: aReducer,
b: bReducer
});
这样的话,rootReducer的返回值就是整个object tree。
总结一点:Redux通过一个个reducer完成了对整个数据源(object tree)的拆解访问和修改。
React在利用组件(Component)构建Web应用时,其实无形中创建了两棵树:虚拟dom树和组件树,就像下图所描述的那样(原图):
所以,针对这样的树状结构,如果有数据更新,使得某些组件应该得到重新渲染(re-render)的话,比较推荐的方式就是:自上而下渲染(top-down rendering),即顶层组件通过props传递新数据给子孙组件。
然而,每次需要更新的组件,可能就是那么几个,但是React并不知道,它依然会遍历执行每个组件的render方法,将返回的newVirtualDom和之前的prevVirtualDom进行diff比较,然后最后发现,计算结果很可能是:该组件所产生的真实dom无需改变!/(ㄒoㄒ)/~~(无用功导致的浪费性能)
所以,为了避免这样的性能浪费,往往我们都会利用组件的生命周期函数shouldComponentUpdate进行判断是否有必要进行对该组件进行更新(即,是否执行该组件render方法以及进行diff计算)?
就像这样:
shouldComponentUpdate(nextProps) {
if (nextProps.e !== this.props.e) { // 这里的e是一个字段,可能是对象引用,也可能是数值,布尔值
return true; // 需要更新
}
return false; // 无需更新
}
但,往往这样的比较,对于字面值还行,对于对象引用(object,array),就糟糕了,因为:
let prevProps = {
e: [2, 3]
};
let nextProps = prevProps;
nextProps.e.push(4);
console.log(prevProps.e === nextProps.e); // 始终为true
虽然你可以通过deepEqual来解决这个问题,但对嵌套较深的结构,性能始终会是一个问题。
所以,最后对于对象引用的比较,就引出了不可变数据(immutable data)这个概念,大体的意思就是:一个数据被创建了,就不可以被改变(mutation)。
如果你想改变数据,就得重新创建一个新的数据(即新的引用),就像这样:
let prevProps = {
e: [2, 3]
};
let nextProps = {
e:[...prevProps.e, 4] // es7 spread
};
console.log(prevProps.e === nextProps.e); // false
也许,你已经发现每个Reducer函数在修改数据的时候,正是这样做的,最后返回的都是一个新的引用,而不是直接修改引用的数据,就像这样:
function eReducer(state = [2, 3], action) {
switch (action.type) {
case 'ADD':
return [...state, 4]; // 并没有直接地通过state.push(4),修改引用的数据
default:
return state;
}
}
最后,因为combineReducers的存在,之前的那个object tree的整体数据结构就会发生变化,就像下面这样:
现在,你就可以在shouldComponentUpdate函数中,肆无忌惮地比较对象引用了,因为数据如果变化了,比较的就会是两个不同的对象!
总结一点:Redux通过一个个reducer实现了不可变数据(immutability)。
PS:当然,你也可以通过使用第三方插件(库)来实现immutable data,比如:React.addons.update、Immutable.js。(只不过在Redux中会显得那么没有必要)。
Middleware — 中间件,最初的**毫无疑问来自:Express。
中间件讲究的是对数据的流式处理,比较优秀的特性是:链式组合,由于每一个中间件都可以是独立的,因此可以形成一个小的生态圈。
在Redux中,Middlerwares要处理的对象则是:Action。
每个中间件可以针对Action的特征,可以采取不同的操作,既可以选择传递给下一个中间件,如:next(action),也可以选择跳过某些中间件,如:dispatch(action),或者更直接了当的结束传递,如:return。
标准的action应该是一个plain object,但是对于中间件而言,action还可以是函数,也可以是promise对象,或者一个带有特殊含义字段的对象,但不管怎样,因为中间件会对特定类型action做一定的转换,所以最后传给reducer的action一定是标准的plain object。
比如说:
action.meta.delay,具体如下:// 用 { meta: { delay: N } } 来让 action 延迟 N 毫秒。
const timeoutScheduler = store => next => action => {
if (!action.meta || !action.meta.delay) {
return next(action)
}
let timeoutId = setTimeout(
() => next(action),
action.meta.delay
)
return function cancel() {
clearTimeout(timeoutId)
}
}
那么问题来了,这么多的中间件,如何使用呢?
先看一个简单的例子:
import { createStore, applyMiddleware } from 'redux';
import thunk from 'redux-thunk';
import createLogger from 'redux-logger';
import rootReducer from '../reducers';
// store扩展
const enhancer = applyMiddleware(
thunk,
createLogger()
);
const store = createStore(rootReducer, initialState, enhancer);
// 触发action
store.dispatch({
type: 'ADD',
num: 4
});
注意:单纯的Redux.createStore(...)创建的Store实例,在执行store.dispatch(action)的时候,是不会执行中间件的,只是单纯的action分发。
要想给Store实例附加上执行中间件的能力,就必须改造createStore函数,最新版的Redux是通过传入store扩展(store enhancer)来解决的,而具有中间件功能的store扩展,则需要使用applyMiddleware函数生成,就像下面这样:
// store扩展
const enhancer = applyMiddleware(
thunk,
createLogger()
);
const store = createStore(rootReducer, initialState, enhancer);
上面的写法是新版Redux才有的,以前的写法则是这样的(新版兼容的哦):
// 旧写法
const createStoreWithMiddleware = applyMiddleware(
thunk,
createLogger()
)(createStore);
const store = createStoreWithMiddleware(reducer, initialState)
至于改造后的createStore方法为何拥有了执行中间件的能力,大家可以看一下appapplyMiddleware的源码。
最后,简单用一张图来验证一句话的正确性:中间件提供的是位于 action 被发起之后,到达 reducer 之前的扩展点。
为了让Redux能够更好地与React配合使用,react-redux库的引入就显得必不可少。
react-redux主要暴露出两个api:
Provider存在的意义在于:想通过context的方式将唯一的数据源store传递给任意想访问的子孙组件。
比如,下面要说的connect方法在创建Container Component时,就需要通过这种方式得到store,这里就不展开说了。
不熟悉React context的同学,可以看看官方介绍。
Redux中的connect方法,跟Reflux.connect方法有点类似,最主要的目的就是:让Component与Store进行关联,即Store的数据变化可以及时通知Views重新渲染。
下面这段源码(来自connect.js),能够说明上述观点:
trySubscribe() {
if (shouldSubscribe && !this.unsubscribe) {
// 跟store关联,消息订阅
this.unsubscribe = this.store.subscribe(this.handleChange.bind(this))
this.handleChange()
}
}
handleChange() {
if (!this.unsubscribe) {
return
}
const prevStoreState = this.state.storeState
const storeState = this.store.getState()
if (!pure || prevStoreState !== storeState) {
this.hasStoreStateChanged = true
this.setState({ storeState }) // 组件重新渲染
}
}
另外,connect方法,还引出了另外两个概念,即:容器组件(Container Component)和展示组件(Presentational Component)。
感兴趣的同学,可以看下这篇文章《Presentational and Container Components》,了解两者的区别,这里就不展开讨论了。
这篇文章可能不是一篇标准的技术文章,里面有不少个人对部分产品的理解,有不对的地方还请见谅指正。可视化建站里涉及很多,包括画布及布局,event 绑定,路由等,本文主要讲述的画布及布局相关。
可视化建站这个轮子,在 “ata”、“语雀” 中搜索,有不少的介绍,但不像前端其他前端轮子那么好造。不乏艺高人胆大的轮子工匠,想造出一个好轮子却不是那么轻松。这也许是因为可视化建站是设计与编程的中间地带,需要平衡处理感性与理性、自由与约束,这既是一种新的设计方式,也是一种新的编程方式。而这往往给可视化建站带来很多挑战,让不少可视化建站两边不讨好:设计也没有做好,编程也不好用;设计者不用,开发者也不用。
但是,对可视化的探索却没有停止,不管是做运营及展示页,还是做特定管理页,以及中台应用,不少团队都在尝试,就像在热力学定律发现之前,人们对永动机的热情,而这些热情,也推动了更多的成就。
在可视化建站里,这里的自由,指的是在用户可以自由拖拽元素,就像用画布,比如 photoshop,sketch,ppt 等。而半自由是指用户只能将元素拖拽到特定的地方,比如使用 protostrap 只能将 Button 拖动到某几个位置,而不能放在你想的任意位置。

也可以放在这里

还有这里

但是其他的就不行了,你不能将 Button 很只直观的放在这里

在半自由的可视化建站里,元素都很听话,就算你引诱元素把它拖放到其他位置,当你一旦放开它,元素会自己跑到它该待的地方。这是因为,在半自由的可视化建站里,所有的拖拽行为其实只是在“拖动代码”,因为代码是结构化的,用户所拖动的元素就是其他的一部分代码,这部分代码只能在结构化中的某个位置。比如之前的例子:
<Row>
<Col>
这里可以放代码
</Col>
<Col>
这里也可以放代码
</Col>
<Col>
还有这里可以放代码
</Col>
</Row>所以用户拖拽的 Button,也就只能在这几个位置。比如当用户将 Button 拖动到第一个 Col,程序可以检测到用户的鼠标,当用户放开鼠标,不管你是在第一个 Col 的哪个位置,代码就被拖到了第一个 Col:
<Row>
<Col>
<Button /> 这个就是拖拽的 Button
</Col>
<Col>
这里也可以放代码
</Col>
<Col>
还有这里可以放代码
</Col>
</Row>这也就是为什么说是在拖代码了。而要是想调整这个 Button 的高度,颜色等,往往可以选中这个 Button,在右侧的属性区域里进行操作。这部分也可以理解为写代码,只是没有在代码中直接写。
对于公司内部,半自由的产品有不少,比如 乐高,DesignLab,金蝉 还有不少针对后台的管理平台。这部分应用有其开发价值,但也有其局限:对于开发者可能还比较好理解,但对于设计者却有不小的学习要求。因为这只是换了个地方写代码,对于产品的体验,本质上是在线写代码。
在半自由定位中,有一种技术是 mouseEnter 方法,也就是当鼠标进入某个元素后进行判断。比如之前的例子,Col 检测到 mouseEnter,就可以将当前拖拽的元素代码放到代码结构中。除了将拖拽元素作为子元素,还可以将其放到 Col 前面及后面,也就是说,拖拽元素可以放在 mouseEnter 元素的前面、后面作为兄弟节点,也可以放到 mouseEnter 元素里面作为子节点。比如拖拽“元素1”到“mouseEnter元素”里:

接着再拖拽“元素2”进入“mouseEnter元素”:

这里的问题在于,如果是想新拖拽的“元素2”在前面呢?直观的操作是将“元素2”拖拽到这里位置:

那就需要程序进行判断,选择是在元素1前还是后(只有这两个选择)。选择位置有不少方法,比如插入尝试判断,比如有 1,2,3,4,5,6 位置可以放元素,那就尝试插入,之后判断下鼠标位置距离这几个元素哪个最近:

比如发现插入到3的位置跟鼠标距离最近

这是这个方法的问题在于效率低,以及元素换行后计算错误的问题。比如元素插入后换行,使得计算结果为插入到2位置距离比位置3小,元素插入不符合直观感受。

而更好的方式是直接判断距离而不进行尝试插入。将鼠标位置跟元素的距离计算出来,选择距离小的,表示会在这个元素的前、后。

再通过位置关系判断出是元素前还是元素后。但这个方法还是有一点问题,就是会有探测不对的情况。比如下面的例子就是鼠标距离上面的元素更近,而要是拖拽了一个 Row,那放到上面元素下面则不符合直观感受。

进一步的提升直观感受则需要判断拖拽的元素是什么,之后就可以用区域来判断位置。比如 Row 就是按照一个区域来放,而 Button 则属于一个区域。而这所有的方法,仅仅是为了让用户体验好一点,但是半自由拖拽还是对体验带来很多限制。半自由画布即是一个代码编辑器,当用户拖拽好后,代码结构也就有了。可以进行之后的流程,比如发布、下载代码等。在某个意义上,半自由可以认为是代码编辑的辅助。
自由意味着责任,这就是为什么大多数人都畏惧它的缘故
我们渴望自由,但自由拖拽的可视化建站很少。不少可自由拖拽的可视化建站仅仅是 ui demo,用于 pd 进行产品原型设计,是属于可视化画板而不是可视化建站。
了解到的公司内部第一个可自由拖拽的是 iceland。用户可以自由拖拽元素,之后 iceland 会尝试为用户拖拽的页面生成代码,这是一个很不错的项目,但是问题在于 iceland 更像一个 ui demo,尝试生成的代码不少使用 flex,以及猜测。比如元素间的关系,比如相交元素的处理。比如不同的元素关系,在 iceland 里不需要描述,也没有地方可以描述,iceland 通过算法来猜测关系及生成代码。但不可否认,iceland 还是走在前面,为自由拖拽的可视化建站进行尝试。iceland 的猜测,比如相交元素的关系处理。那是否有更直观简单的自由拖拽呢?
设计者使用 sketch,photoshop 进行了页面设计,需要说明的地方通过文字说明(比如这里需要固定;这里需要跟随屏幕自适应等)及跟前端开发的沟通和默契(居中的元素会根据浏览器自适应居中)一起完成了全部的设计。所以可以认为
静态设计 + 额外信息 = 动态设计
比如下面的设计 Input 之间是自适应的,而 Button 之间是固定的:

那这部分 “额外信息” 除了通过文字说明、沟通及前端经验,还有什么办法没呢?比如任意拖拽的元素我们发现可以将其位置关系确定下来。任意两个元素,有3种关系:相交,包含,不相交也不包含。考虑到相交的情况在页面中不常用,要是有需求也被组件实现了,所以可以认为相交的关系是不合法的(比如程序检测到相交则 ui 报错)。那元素与元素就只有两个合法关系:包含,不相交也不包含。
一个简单的元素可以简化为一个矩形,复杂的元素可以抽象为多个矩形(比如带有 border 的 div),所以元素的关系就是计算矩形间的关系。两个矩形,宽度高度,x左边,y左边都是知道的,计算是“相交,包含,不相交也不包含”这3种关系种的哪种关系
function getRelation(a, b) {
const { minx: minx1, miny: miny1, maxx: maxx1, maxy: maxy1 } = a;
const { minx: minx2, miny: miny2, maxx: maxx2, maxy: maxy2 } = b;
if (minx1 < minx2 && miny1 < miny2 && maxx1 > maxx2 && maxy1 > maxy2) {
return 前者包含后者;
}
if (minx1 > minx2 && miny1 > miny2 && maxx1 < maxx2 && maxy1 < maxy2) {
return 后者包含前者;
}
const minx = Math.max(minx1, minx2);
const miny = Math.max(miny1, miny2);
const maxx = Math.min(maxx1, maxx2);
const maxy = Math.min(maxy1, maxy2);
if (minx > maxx || miny > maxy) {
return 不相交;
}
return 相交;
}所有的矩形关系确定后,就可用得到一个 list,每个 list 里面是一个 tree。小的矩形包含于大的矩形,大的矩形拖动,小的矩形也会被拖动。而所有的相交则被视为不合法,ui 会有报错。那现在则构建出了一个可以任意拖拽的画布,以及有元素的关系。
画布中所有的元素都是一个层级的绝对定位,就算一个元素包含另外一个元素。这么做的好处是画布更加自由,没有任何的结构,所有的结构都是之后计算的:比如拖拽一个大的元素,其包含的小的元素也一起被拖动。小的元素也可以很轻松拖拽出来。比如拖拽大的元素小元素跟着动

实际为同一个层级的元素

但是,这里仅仅还只是画布,跟可以运行还有距离。在半自由的可视化建站里,运行时往往就是用户拖拽出的代码,具体的就是以 html,css 为基于的布局方案,比如 flex 等。但是在自由布局里,也许这不是一个好的选择。更直接的方式是在同一个层级里直接标注出元素的关系:

所有的箭头都可以设置为“固定”及“自适应”。“固定”是指这里距离是固定的,而“自适应”是指这个关系可以根据算法来分配。对于“固定”比较好理解,那“自适应”呢?比如:

“元素1”左侧的宽度是“自适应”(标记为 len1),“元素3”右边的距离是“自使用”(标注为 len2)
剩下的宽度 = 总宽度 - 元素1宽度 - 元素2宽度 - 元素3宽度
len1 = 剩下的宽度 * len1的原始比例
len2 = 剩下的宽度 * len2的原始比例其中,总宽度是指当前层级的上层所在的宽度,而 len1及len2的原始比例是其在画布中的宽度比例(用户拖拽多宽即原始宽度)。可以看到,“额外信息”采用了更近客观的方式来表述,而复杂的 html,css 概念也全部被省略,用户不需要了解 css 概念,只需要先拖拽好页面,之后给不同的元素选择好关系即可(固定还是自适应)。而元素有默认的关系,即使用户不去选择,也可以搭建出不错的页面。
而对于元素,也有“固定”及“自适应”的选择。不同的地方在于,元素还有一个隐藏的选择“自身”(可不暴露给用户),可以让元素根据子元素来进行变化。那所有的关系就是:固定(fixed),自适应(auto),自身(self),所有的计算方式为:
元素宽度 = switch
fixed: 原始画布值
auto: ( 总宽度 - 所有 fixed 之和 - 所有 self 之和 ) * 原始画布值比例
self: 所有 children 最右侧的元素的边 + 原始画布值右边距离
元素高度 = switch
默认: 所有 children 最下侧的元素的边 + 原始画布值下边距离
self: 不限制
元素左边 = switch
fixed: 原始画布值
auto: ( 总宽度 - 所有 fixed 之和 - 所有 self 之和 ) * 原始画布值比例计算方式有了,那是否需要分行和分列?比如 iceland,会计算出元素所在的行和所在的列得到一个 tree 结构用来生成代码。但是在以上方法中,是没有明确的分行和分列的,因为隐藏的分行和分列会给用户带来干扰,用户要是有需求,可以再用一个矩形来包含所有的元素,成本也很低。
元素的宽度,高度,位置都是计算得到的,我们可以使用 react-cool-layout 来作为运行时。在画布中通过自由拖拽及选择关系得到元素的位置信息,在运行时得到计算公式及带入 react-cool-layout。
react-cool-layout 中我们只需要给出元素的关系,之后页面的 resize 及元素的大小位置变化都可以根据我们给的计算公式来进行。比如:
<Layout>
<Layout.Item
id="1"
left={100},
width={100}
top={100}
>
左侧的元素
</Layout.Item>
<Layout.Item
id="2"
left={lib => lib.get('1').left + lib.get('1').width + 100},
width={100}
top={100}
>
右侧的元素在左侧元素的右边 100px
</Layout.Item>
</Layout>当左侧元素1宽度变化后,右侧元素还是距离左侧元素 100px
这里给的很简单,只是一个例子。实际需要将之前的公式带入到 react-cool-layout 进行计算。而值得说明的地方在于,在画布阶段所有的元素实际都是一个层级方便自由拖拽,但是在运行时,是根据层级进行渲染的,在一个层级里,没有的元素都是绝对定位进行计算。所以,对于元素是需要做处理的,比如 antd 的组件作为元素,则需要进行处理成可以使用该计算方式的元素。
这个计算方式还可以再进一步根据已有的项目进行优化,尝试做到不再需要手动去做“额外信息”,而是通过已有的信息来分析出最可能的“额外信息”。未来应该是对于画布及布局会更近方便。编写代码开始有新的方式,可视化建站这个轮子还得进行下去。
在团队内部已经开始使用可视化进行探索,比如 http://www.sofastack.tech/ 就是用这套方式,开发者在 nemo(一个可视化开发平台,暂没有开源)通过拖拽元素搭建出来。可视化看起来简单,其实不简单。而使用可视化开发也不应该简单理解为没有成本,而是对于代码编程开发来说是另外的一个编程方式。所以,可视化编程是一个更好的方向。
我们经常能看到大量介绍前端如何进行性能优化的文章。然而很多文章只介绍了如何优化性能,却未能给出一个可计算,可采集的性能量化标准。甚至看到一些文章,在介绍自己做了优化后的性能时,提到页面加载速度提升了多少多少,但是当你去问他你怎么测量性能的时,却不能给出一个科学的、通用的方法。
其实,在进行性能优化前,首先需要确定性能衡量标准。前端性能大致分为两块,页面加载性能和页面渲染性能。页面加载性能指的是我们通常所说的首屏加载性能。页面渲染性能指的是用户在操作页面时页面是否能流畅运行。滚动应与手指的滑动一样快,并且动画和交互应如丝般顺滑。这两种页面性能,都需要有可量化的衡量标准。
本文参考了谷歌提出的性能衡量方式。首先确定以用户体验为中心的性能衡量标准。然后,针对这些性能标准,制定采集性能数据的方法,以及性能数据分析方法。最后,结合性能量化标准,提出优化性能的方法。
下表是与页面加载性能相关的用户体验。
| 用户体验 | 描述 |
|---|---|
| 它在发生吗? | 网页浏览顺利开始了吗?服务端有响应吗? |
| 它是否有用? | 用户是否能看到足够的内容? |
| 它是否可用? | 用户是否可以和页面交互,还是页面仍在忙于加载? |
| 它是否令人愉快的? | 交互是否流程和自然,没有卡段或闪烁? |
与用户体验相关,制定以下度量标准:
First paint and first contentful paint (它在发生吗?)
FP 和 FCP 分别是页面首次绘制和首次内容绘制。首次绘制包括了任何用户自定义的背景绘制,它是首先将像素绘制到屏幕的时刻。首次内容绘制是浏览器将第一个 DOM 渲染到屏幕的时间。该指标报告了浏览器首次呈现任何文本、图像、画布或者 SVG 的时间。这两个指标其实指示了我们通常所说的白屏时间。
参考 api: https://w3c.github.io/paint-timing/
在控制台查看 paint 性能:
window.performance.getEntriesByType('paint')在代码中查看 paint 性能:
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
// `entry` is a PerformanceEntry instance.
console.log(entry.entryType);
console.log(entry.startTime);
console.log(entry.duration);
}
});
// register observer for long task notifications
observer.observe({entryTypes: ["paint"]});ssr:
csr:
First meaningful paint and hero element timing(它是否有用?)
FMP(首次有意义绘制) 是回答“它是否有用?”的度量标准。因为很难有一个通用标准来指示所有的页面当前时刻的渲染达是否到了有用的程度,所以当前并没有制定标准。对于开发者,我们可以根据自己的页面来确定那一部分是最重要的,然后度量这部分渲染出的时间作为FMP。
chrome 提供的性能分析工具 Lighthouse 可以测量出页面的 FMP,在查阅了一些资料后,发现 Lighthouse 使用的算法是:页面绘制布局变化最大的那次绘制(根据 页面高度/屏幕高度 调节权重)
First meaningful paint = Paint that follows biggest layout change
layout significance = number of layout objects added / max(1, page height / screen height)
参考:Time to First Meaningful Paint: a layout-based approach
ssr:
csr:
Long tasks(它是否令人愉快的?)
我们知道,js 是单线程的,js 用事件循环的方式来处理各个事件。当用户有输入时,触发相应的事件,浏览器将相应的任务放入事件循环队列中。js 单线程逐个处理事件循环队列中的任务。
如果有一个任务需要消耗特别长的时间,那么队列中的其他任务将被阻塞。同时,js 线程和 ui 渲染线程是互斥的,也就是说,如果 js 在执行,那么 ui 渲染就被阻塞了。此时,用户在使用时将会感受到卡顿和闪烁,这是当前 web 页面不好的用户体验的主要来源。
Lonag tasks API 认为一个任务如果超过了 50ms 那么可能是有问题的,它会将这些任务展示给应用开发者。选择 50ms 是因为这样才能满足RAIL 模型 中用户响应要在 100ms 内的要求。
const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
// `entry` is a PerformanceEntry instance.
console.log(entry.entryType);
console.log(entry.startTime); // DOMHighResTimeStamp
console.log(entry.duration); // DOMHighResTimeStamp
}
});
// register observer for long task notifications
observer.observe({entryTypes: ['longtask']});发散出去,React 最新的 Fiber 架构。就是为了解决 js 代码在执行过程中的 Long tasks 问题。reconciliation (协调器) 是 React 用于 diff 虚拟 dom 树并决定哪一部分需要更新的算法。协调器在不同的渲染平台是可以共用的(web, native)。而 react 之前的设计中,是一次性计算完子树的更新结果,然后立刻重新渲染出来。这样就很容易造成 Long tasks 问题。Fiber 架构就是为了解决这个问题,Fiber 的核心就是把长任务拆成多个短任务,并分配有不同的优先级,然后对这些任务进行调度执行,从而达将重要内容先渲染并且不阻塞 gui 渲染线程的目的。
Time to interactive(它是否可用?)
TTI(可交互时间) 指的是应用既在视觉上都已渲染出了,又可以响应用户的输入了。应用不能响应用户输入的原因主要包括:
TTI 指明了页面的 js 脚本都被加载完成且主线程处于空闲状态了的时间。
下面是一段开发者经常用来 hack 检查页面中长任务的代码:
// detect long tasks hack
(function detectLongFrame() {
var lastFrameTime = Date.now();
requestAnimationFrame(function() {
var currentFrameTime = Date.now();
if (currentFrameTime - lastFrameTime > 50) {
// Report long frame here...
}
detectLongFrame(currentFrameTime);
});
}()); hack 方式存在一些副作用:
性能测量的代码最重要的准则是它不该使性能变差。
Lighthouse 和 Web Page Test 为我们本地开发提供了非常好的性能测试工具,而且对于我们前面提到的各项测量标准都有较好的支持。但是,这些工具不能在用户的机器上运行,所以它们不能反映用户真实的用户体验。
幸运的是,随着新 API 的推出,我们可以再用户设备上测量这些性能而不需要付出用可能使性能变差的 hack 的方式。
这些新的 API 是 PerformanceObserver, PerformanceEntry, 以及 DOMHighResTimeStamp。
// 性能度量结果对象数组
const metrics = [];
if ('PerformanceLongTaskTiming' in window) {
const observer = new PerformanceObserver(list => {
for (const entry of list.getEntries()) {
const metricName = entry.name;
const time = Math.round(entry.startTime + entry.duration);
metrics.push({
eventCategory: 'Performance Metrics',
eventAction: metricName,
eventValue: time,
nonInteraction: true
});
}
});
observer.observe({ entryTypes: ['paint'] });
}标准中并未定义 FMP,我们需要根据页面的实际情况来定 FMP。一个较好的方式是测量页面关键元素渲染的时间。参考文章 User Timing and Custom Metrics。
测量 css 加载完成时间:
<link rel="stylesheet" href="/sheet1.css">
<link rel="stylesheet" href="/sheet4.css">
<script>
performance.mark("stylesheets done blocking");
</script>测量关键图片加载完成时间:
<img src="hero.jpg" onload="performance.clearMarks('img displayed'); performance.mark('img displayed');">
<script>
performance.clearMarks("img displayed");
performance.mark("img displayed");
</script>测量文字类元素加载完成时间:
<p>This is the call to action text element.</p>
<script>
performance.mark("text displayed");
</script>计算加载时间:
function measurePerf() {
var perfEntries = performance.getEntriesByType("mark");
for (var i = 0; i < perfEntries.length; i++) {
console.log("Name: " + perfEntries[i].name +
" Entry Type: " + perfEntries[i].entryType +
" Start Time: " + perfEntries[i].startTime +
" Duration: " + perfEntries[i].duration + "\n");
}
}采用谷歌提供的 tti-polyfill。
import ttiPolyfill from './path/to/tti-polyfill.js';
ttiPolyfill.getFirstConsistentlyInteractive().then((tti) => {
ga('send', 'event', {
eventCategory: 'Performance Metrics',
eventAction: 'TTI',
eventValue: tti,
nonInteraction: true,
});
});const observer = new PerformanceObserver((list) => {
for (const entry of list.getEntries()) {
ga('send', 'event', {
eventCategory: 'Performance Metrics',
eventAction: 'longtask',
eventValue: Math.round(entry.startTime + entry.duration),
eventLabel: JSON.stringify(entry.attribution),
});
}
});
observer.observe({entryTypes: ['longtask']});当我们收集了用户侧的性能数据,我们需要把这些数据用起来。真实用户性能数据是十分有用的,原因包括:
下面是一个用图表来分析数据的例子:
这个例子展示了 PC 端和移动端的 TTI 分布。可以看到移动端的 TTI 普遍长于 PC 端。
PC 端:
| 比例 | TTI(seconds) |
|---|---|
| 50% | 2.3 |
| 75% | 4.7 |
| 90% | 8.3 |
移动端:
| 比例 | TTI(seconds) |
|---|---|
| 50% | 3.9 |
| 75% | 8.0 |
| 90% | 12.6 |
对这些图表使的分析得我们能快速地了解到真实用户的体验。从上面的表格我们能看到,10% 的移动端用户在 12s 后才能开始页面交互!
利用用户侧性能数据,我们可以分析性能是如何影响商业的。例如,如果你想分析目标达成率或者电商转化率:
如果证明他们之间是有关联的,那么这就很容易阐述性能对业务的重要性,且性能是应该被优化的。
我们知道,如果页面加载时间过长,用户就会经常选择放弃。不幸的是,这就意味着我们所有采集到的性能数据存在着幸存者偏差——性能数据不包括那些因为放弃加载页面的用户(一般都是因为加载时间过长)。
统计用户放弃加载会比较麻烦,因为一般我们将埋点脚本放在较后加载。用户放弃加载页面时,可能我们的埋点脚本还未加载。但是谷歌数据分析服务提供了Measurement Protocol 。利用它可以进行数据上报:
<script>
window.__trackAbandons = () => {
// Remove the listener so it only runs once.
document.removeEventListener('visibilitychange', window.__trackAbandons);
const ANALYTICS_URL = 'https://www.google-analytics.com/collect';
const GA_COOKIE = document.cookie.replace(
/(?:(?:^|.*;)\s*_ga\s*\=\s*(?:\w+\.\d\.)([^;]*).*$)|^.*$/, '$1');
const TRACKING_ID = 'UA-XXXXX-Y';
const CLIENT_ID = GA_COOKIE || (Math.random() * Math.pow(2, 52));
// Send the data to Google Analytics via the Measurement Protocol.
navigator.sendBeacon && navigator.sendBeacon(ANALYTICS_URL, [
'v=1', 't=event', 'ec=Load', 'ea=abandon', 'ni=1',
'dl=' + encodeURIComponent(location.href),
'dt=' + encodeURIComponent(document.title),
'tid=' + TRACKING_ID,
'cid=' + CLIENT_ID,
'ev=' + Math.round(performance.now()),
].join('&'));
};
document.addEventListener('visibilitychange', window.__trackAbandons);
</script>需要注意的是,在页面加载完成后,我们要移除监听,因为此时监听用户放弃加载已经没有意义,因为已经加载完成。
document.removeEventListener('visibilitychange', window.__trackAbandons);我们定义了以用户为中心的性能量化标准,就是为了指导我们优化性能。
最简单的优化性能的方式是减少需要传输给客户端的 js 代码。但是如果我们已经无法缩小 js 代码体积,那就需要思考如何传输我们的 js 代码。
<head> 移除影响 FP/FCP 的 css 和 js 代码<head> 中if ('requestIdleCallback' in window) {
// Use requestIdleCallback to schedule work.
} else {
// Do what you’d do today.
}TODO:
DOMContentLoaded 事件
当初始的 HTML 文档被完全加载和解析完成之后,DOMContentLoaded 事件被触发,而无需等待样式表、图像和子框架的完成加载。
load 事件
当页面资源及其依赖资源已完成加载时,将触发load事件。当 onload 事件触发时,页面上所有的DOM,样式表,脚本,图片都已经加载完成了。
顺序是:DOMContentLoaded -> load。
单纯地用 load 事件或者 DOMContentLoaded 事件来衡量页面性能,并不能很好地反馈出站在用户角度的页面性能。
再过 3 年左右,00 后就要加入职场大军了。。。真是一个令人伤心的消息==!
小鲜肉们个个生龙活虎,而且说不定娃娃时代就开始写代码了呢!
"老腊肉"们该何去何从?
设置这个话题请大家畅所欲言~
工作中需要实现尾部红色警告的一个圆环倒计时,网上搜了一圈,同时满足css,单边颜色渐变,圆形的案例还真没有,光单边颜色渐变的案例都几乎没有。那我自己实现一个吧,不做不知道,一做吓一跳,竟然花了好几个小时才完成,特此记录一下,有缘人拿去。
直接上结果图

这个进度条可以拆解成两部分
思考下思路:一个盒子,三个边是绿色,一个边是绿色到红色的渐变色,然后用border-radius弯曲成一个圆。
哈哈,这么一想,好简单啊。
but,but,只有单边颜色渐变用css是没法实现的。吐血~,不信你去试试,去查查。
难点就在如何实现单边颜色渐变这里。
follow me~
这步非常简单

<div class='box'>
<div class='green-border'></div>
</div>
<style>
*{
box-sizing: border-box;
}
.box {
width: 240px;
height: 240px;
}
.green-border {
width: 100%;
height: 100%;
border-radius: 50%;
border: 20px solid #00a853;
border-bottom-color: transparent;
transform: rotate(45deg);
}
</style>
难点就在这里,我们画一个从上到下渐变的方块,放在空白圆环那里。

<div class='red-gradients'></div>
<style>
.box{
position: relative;
}
.red-gradients {
width: 120px;
height: 120px;
background: linear-gradient(to right, #00a853, #F04134);
position: absolute;
bottom: 0;
left: 0;
z-index: 1;
}
</style>
接下来我们要覆盖多余的内容,圆内放一个div,盖住多余的部分。外面的通过box的overflow:hidden来隐藏。
<div class='inner-circle'></div>
<style>
.box{
border-radius: 50%;
overflow: hidden;
}
.inner-circle {
width: 200px;
height: 200px;
border-radius: 50%;
position: absolute;
z-index: 2;
top: 20px;
left: 20px;
background-color: white;
}
</style>

大功告成了,真是机智!
接下来我们讲讲如何实现灰色动态进度条。
算了,不写了~网上讲圆环进度条的一大堆,我就不重复讲了,随便找个例子推荐下:https://www.xiabingbao.com/css/2015/07/27/css3-animation-circle.html
完整源码在这里,祝你好运!
前端发展到今天,组件化的概念已经深入人心,特别是 react 得到广泛应用以来,应该没有哪一个从业者会说自己从没写过 component 了!而自己这几年的工作、除了业务支持外主要的技术积淀、也都围绕着 ant design (mobile) 前端组件库。个人早期参与的是 PC 组件的建设、之前也专门针对 Tree / TreeSelect 组件总结了一些开发心得,近两三年主要参与建立起了 mobile 组件库。
PC 和 Mobile 组件开发大多地方都是类似的,主要的区别体现在前者是本身功能复杂、后者是运行环境复杂。本文涵盖了 PC 和 Mobile 组件,主要分析一些实际的 case 以及相应的设计方式,又因为主要是杂谈、所以不是很有“起承转合”的严谨工整文采风格~ 那么我们就开始聊聊吧!😁
function TreeView() {
}function TreeView(config) {
this.cfg = extend({}, config);
}另外:组件的属性 只能通过方法来访问;组件的属性 value change 后组件自动映射变化。
TreeView.prototype.xx = function () { };mixin 进来带有 on / off / fire 等方法的事件系统,为组件级别添加事件,屏蔽底层的 dom 事件,方便使用。
最后、组件使用方式:new 出组件实例即可。
现在使用的 react / vue 等框架,我们组件写法和用法已经跟早期的有很大不同,比如我们很少写 new 了,而是都基于统一的框架 API 在写了。
class TreeView extends React.Component {
state = {};
static getDerivedStateFromProps(props, prevState) {}
render() {}
}框架提供了 render / didmount 等生命周期函数,你只需在里边写需要的逻辑即可,其他活框架帮你干。
当然在 React 确定王者地位之前,比如 Backbone 库的设计 (View Events EventBus)、Angular 等相关众多的 MVVM 框架设计都成一时经典、有些至今应用依旧广泛。所以,组件设计甚至整个系统架构设计,可以说是 兵无定式 水无常形?😏
react-component 这里的大多数组件是 ant design 的底层依赖,他们大都很好的遵循了我们的一些设计原则,这里简单概括下:
职责清晰、单一职责
开放与封闭
高内聚、低耦合
避免信息冗余
API 尽量和已知概念保持一致
这些原则有没有跟 OOP 或一些优秀软件架构的原则很类似?是的,像是真理的普适性~ 😀
Form 组件应该是涉及到数据类的前端应用最需要的组件之一,我们以 antd 依赖的 rc-form 为例分析一下功能细节:
Tab 组件大概是所有移动 H5 应用的标配组件,而且这个组件跟 PC 的 Tab 组件应用环境很不一样。我们在 antd-mobile@1 版本里直接使用了 PC 的 rc-tabs, 结果用户反馈了很多问题,比如:
以上问题在 antd-mobile issues 里有许多讨论,我们只能重新设计,比如改变了 TabTitle 和 TabPane 一一对应的关系、自动生成 panel 容器等,解决了以上诸多痛点问题。
其他组件,比如:
destroy方法?怎么提供出来。这里有很多的细节,需要权衡和确认、甚至要重新设计。看看都觉得好累啊 😂
我觉得每一个合格的前端工程师,都要至少有开发几个组件、遇到并解决一些问题的经历,这些正是前端的基石和底盘呀。当然,我所说的都是错的~ 杂谈就谈到这里吧。😊
忘了重要事、欢迎大家来一起交流组件设计心得~

这是上一篇 怎样按触发顺序执行异步任务 的引文,感谢阅读。。
更多文章:知乎专栏 - 业余程序员的个人修养
xstream是专门为cycle.js定制开发的函数响应式流库(functional reactive stream library)。
它很简洁,只提供了Stream,Listener,Producer,MemoryStream四个概念。
我们先来学习xstream,然后再挖掘流(stream)与CPS的关系。
流可以看做一个事件流,流上面可以绑定多个监听器,
当流中某事件发生的时,会自动广播。
有了流之后,我们就可以对流的整体进行操作了。
在xstream中对流进行变换,是通过operator实现的,
operator处理一个或多个流,返回一个新的流。
let stream2=stream1.map(/*...*/);
let stream3=stream2.filter(/*...*/);
如上,map和filter就是operator。
监听器用于处理当前发生的事件,时刻接受流中对所发生事件的广播。
在xstream中,监听器是一个包含next,error,complete方法的对象,
流中每次事件发生,都会自动调用监听器的next方法,
流中有错误发生时,会调用error方法,
整个流停止,不再有事件发生时,调用complete方法。
let listener={
next:val=>{/*...*/},
error:err=>{/*...*/},
complete:()=>{/*...*/}
};
生产者用来生成流。
它是一个包含start和stop方法的对象,用于表示流的开始和终止。
start函数中会使用listener,因此,listener的next方法实际上是在这里调用的。
import xs from 'xstream';
let producer={
start(listener){
// listener.next(/*...*/)
},
stop(){/*...*/}
};
let stream=xs.create(producer);
有记忆的流,和普通的流在operator方面和listener方面并无二致,
唯一不同的是,有记忆的流可以将当前事件中的值传给下一个事件。
(这里对主题帮助不大,我们暂且略过
我们学习了xstream的API,现在终于可以看到它的全貌了,
import xs from 'xstream';
let producer = {
start: listener => {
let i = 0;
while (++i) {
if (i > 10) {
break;
}
listener.next(i);
}
},
stop: () => { }
};
let stream1 = xs.create(producer);
let stream2 = stream1.map(x => x * 2);
stream2.addListener({
next: val => console.log(val),
error: val => { },
complete: () => { }
});
最后结果会输出从2到20的偶数。
我们看到实际上是在流中调用了listener,即通过listener.next(i)广播了i,
然后,流经历了一系列的变换,导致流广播的值发生了改变,
体现到最后的listener中,接收的值就不是最开始的i了,
而是i经历了x=> x*2之后的值i*2。
认识到问题的本质后,我们可以将流看成以下形式,
let stream = cont => {
let i = 0;
while (++i) {
if (i > 10) {
break;
}
cont(i);
}
}
其中,cont表示continuation。
(continuation的话题比较大,这里不影响阅读,暂略
listener然后我们先不考虑对流进行变换,我们直接模拟挂载listener的场景,
stream(x => console.log(x));
好了,这个时候,实际上我们是将流的continuation传给了它,
结果自然是输出从1到10的数字了。
我们怎样对流进行变换呢,
实际上,我们需要做的就是将一个流变成另一个流,
或者说白了,就是改变cont,然后进行传递(CPS
这可能比较晦涩难懂,我们直接看例子吧,模拟一下x=>x*2,
(这是可以运行的
let stream1 = cont => {
let i = 0;
while (++i) {
if (i > 10) {
break;
}
cont(i);
}
};
let stream2 = cont => {
let newCont = v => cont(v * 2);
stream1(newCont);
};
// 简写为
// let stream2 = cont => stream1(v => cont(v * 2));
stream2(x=>console.log(x));
map,filter和merge我们来尝试实现xstream中几个常用的operator,它们都返回一个新的流。
//map是对流中的每个值进行变换
let map = function (fn) {
let stream = this;
return cont => stream(x => cont(fn(x)));
};
let stream2 = map.call(stream1, x => x * 2);
//filter是对流中的值进行过滤
let filter = function (fn) {
let stream = this;
return cont => stream(x => fn(x) && cont(x));
};
let stream3 = filter.call(stream1, x => x % 2 != 0);
//merge是合并两个流
let merge = function (otherStream) {
let stream = this;
return cont => {
stream(cont);
otherStream(cont);
};
};
let stream4 = merge.call(stream2, stream3);
xstream采用了流的概念,实现了事件源与事件处理逻辑的分离,
而且,对流的变换都是一些纯函数,组合起来更方便,
因此成就了cycle.js这个优美的框架,从而MVI全新的架构模式破土而出,
这一切,一定会在人机交互界面的解决方案上开启新的篇章啊。
代码:
<ul class="wrap">
<ol class="item">one</ol>
<ol class="item">two</ol>
<ol class="item">three</ol>
<ol class="item">four</ol>
<ol class="item">five</ol>
<ol class="item">six</ol>
<ol class="item">seven</ol>
<ol class="item">eight</ol>
<ol class="item">nine</ol>
</ul>.wrap {
display: flex;
border: 2px red solid;
width: 400px;
height: 50px;
align-items: center;
overflow: auto;
}
.item {
width: 100px;
flex-shrink: 0;
background: green;
margin-right: 4px;
}效果:

flex-shrink: 0; 表示 flex 元素超出容器时,宽度不压缩,这样就能撑开元素的宽度,使得出现滚动条。
代码:
<ul class="wrap">
<ol class="item">one</ol>
<ol class="item">two</ol>
<ol class="item">three</ol>
<ol class="item">four</ol>
<ol class="item">five</ol>
<ol class="item">six</ol>
<ol class="item">seven</ol>
<ol class="item">eight</ol>
<ol class="item">nine</ol>
</ul>.wrap {
display: inline-flex;
border: 2px red solid;
width: auto;
height: 50px;
align-items: center;
overflow: auto;
}
.item {
width: 100px;
flex-shrink: 0;
background: green;
margin-right: 4px;
}效果:

这里在容器上需要用 display: inline-flex;,这样才能撑开容器;
一种复杂的情况是,我们希望 item 是纵向布局的,但是支持布满一列后换行,同时,在横向能够撑开容器的宽度。我们自然会想到用如下的代码实现:
<div class="container">
<div class="photo"></div>
<div class="photo"></div>
<div class="photo"></div>
<div class="photo"></div>
<div class="photo"></div>
</div>.container {
display: inline-flex;
flex-flow: column wrap;
align-content: flex-start;
height: 350px;
background: blue;
}
.photo {
width: 150px;
height: 100px;
background: red;
margin: 2px;
}然而在 chrome 浏览器下,效果如下:

容器的宽度未被撑开。
有两种方式解决这个问题。
在之前代码的基础上,我们添加如下 js 代码:
$(document).ready(function() {
$('.container').each(function( index ) {
var lastChild = $(this).children().last();
var newWidth = lastChild.position().left - $(this).position().left + lastChild.outerWidth(true);
$(this).width(newWidth);
})
});结果如下:

代码:
<div class="container">
<div class="photo"></div>
<div class="photo"></div>
<div class="photo"></div>
<div class="photo"></div>
<div class="photo"></div>
</div>.container {
display: inline-flex;
writing-mode: vertical-lr;
flex-wrap: wrap;
align-content: flex-start;
height: 250px;
background: blue;
}
.photo {
writing-mode: horizontal-tb;
width: 150px;
height: 100px;
background: red;
margin: 2px;
}效果如下:

最近看到google的一道面试题,很有意思,我觉得是和解析器相关的,正好我之前做过相关的工作,所以在这里写一篇关于解析器的入门文章吧。
题目是非常简单的,就是如何去解析一个ip地址。
Convert an IPv4 address in the format of null-terminated C string into a 32-bit integer.
For example, given an IP address “172.168.5.1”, the output should be a 32-bit integer
with “172” as the highest order 8 bit, 168 as the second highest order 8 bit, 5 as the
second lowest order 8 bit, and 1 as the lowest order 8 bit. That is,
"172.168.5.1" => 2896692481
Requirements:
1. You can only iterate the string once.
2. You should handle spaces correctly: a string with spaces between a digit and a dot is
a valid input; while a string with spaces between two digits is not.
"172[Space].[Space]168.5.1" is a valid input. Should process the output normally.
"1[Space]72.168.5.1" is not a valid input. Should report an error.
3. Please provide unit tests
其实这个题包含两个问题,首先要正确的解析IP地址字符串,解析时要兼容数字旁的空格,还有就是要把解析的4个8bit合并为一个32bit的integer整形数字。
parser部分很简单,因为只是一个非常简单的数字和.构成的字符串,没有二义性,甚至连嵌套文法结构都没有,都不需要递归下降法。
所以我觉得这个解题的过程可以共享出来,让大家对parser有个最最基本的认识。
这里不像龙书,开篇晃悠一下nfa dfa直接就转到lalr了,又是first表又是follwe表,项集族,goto状态转换表,最右句柄,移进,规约。
一堆东西直接把很多对编译系统不熟悉的小码农和老码农们忽悠晕了,所以大家对编译原理的认识基本都停留在了复杂的parser技术上了,也没有针对ast之后的语义部分再做研究。
其实简单文法的parser实现起来非常简单,我们不需要使用上下文无关文法来指导我们的代码去parse,更不需要自己实现一遍bison。
我们直接手写一个最简单的自上向下的parser。
首先我们看示例ip地址: 172.168.5.1
我们写parser其实第一件事就是针对需求,抽象出文法结构,这个ip地址的文法很简单
NUMBER DOT NUMBER DOT NUMBER DOT NUMBER
只包含两种终结符,一个是数字NUMBER,一个是点符号DOT。
但是在附加的要求中,NUMBER前后允许有空白字符,而且这个空白字符是可有可无的。
所以我们需要增加一个名为SpaceOrEmpty的文法单元来代表可有可无的空格,所以我们把这个文法扩展为:
IP ->
SpaceOrEmpty NUMBER SpaceOrEmpty
DOT
SpaceOrEmpty NUMBER SpaceOrEmpty
DOT
SpaceOrEmpty NUMBER SpaceOrEmpty
DOT
SpaceOrEmpty NUMBER SpaceOrEmpty
NUMBER DOT都是简单的词法单元,也就是我们在编译原理里说的终结符。
而SpaceOrEmpty是非终结符,他表示可有可无的空格,可以推导为:
SpaceOrEmpty ->
MULTISPACE || EMPTY
MULTISPACE表示1个或多个空白字符,而EMPTY表示空字符,就是什么都没匹配到,也要返回匹配成功,因为是空字符嘛。
好了,文法结构有了,非常简单,包括四种终结符:NUMBER DOT MULTISPACE EMPTY
我们开始定义读取四种终结符(词法单元)的函数吧:
getMultiSpace //读取1或多个空白字符
getNumber //读取一个数字
getDot //读取一个英文的.字符
getEmpty //直接返回一个空字符串,这个有些奇怪,但它是用来组织文法结构时,和其他子解析器进行或运算,来表示其他子解析器是可有可无的
那么我们先实现第一个getMultiSpace解析函数吧:
/**
* @param str 待解析字符串
* @param position 从字符串第几位开始解析
*
* @returns {{name: string, type: string, success: boolean, token: string, length: number}}
*/
function getMultiSpace(str, position){
let validCharReg = /^\s$/; //该词法单元允许的输入
let token = '';
while(position < str.length) {
let currentChar = str[position];
if (validCharReg.test(currentChar)) {
token += currentChar;
}else{ //一旦遇到不合法输入就退出解析
break;
}
position += 1;
}
return {
name: 'MULTISPACE',
type: 'TERMINAL',
success: token !== '', //解析是否成功
token, //解析结果
length: token.length, //解析结果长度
};
}
console.log(getMultiSpace('', 0))
console.log(getMultiSpace(' ', 0))
console.log(getMultiSpace(' ', 0))
console.log(getMultiSpace(' a', 0))
console.log(getMultiSpace(' a ', 0))然后我们实现getNumber,和getMultiSpace没什么区别:
/**
* @param str 待解析字符串
* @param position 从字符串第几位开始解析
*
* @returns {{name: string, type: string, success: boolean, token: string, length: number}}
*/
function getNumber(str, position){
let validCharReg = /^\d$/; //该词法单元允许的输入
let token = '';
while(position < str.length) {
let currentChar = str[position];
if (validCharReg.test(currentChar)) {
token += currentChar;
}else{ //一旦遇到不合法输入就退出解析
break;
}
position += 1;
}
return {
name: 'NUMBER',
type: 'TERMINAL',
success: token !== '', //解析是否成功
token, //解析结果
length: token.length, //解析结果长度
};
}
console.log(getMultiSpace('', 0))
console.log(getMultiSpace('1', 0))
console.log(getMultiSpace('12', 0))
console.log(getMultiSpace('12a', 0))
console.log(getMultiSpace('12a3', 0))接下来是解析一个.字符,和前面有点区别,它不是解析多个字符,解析一个字符就好了,所以我们增加了isMultiChar的条件变量
/**
* @param str 待解析字符串
* @param position 从字符串第几位开始解析
*
* @returns {{name: string, type: string, success: boolean, token: string, length: number}}
*/
function getDot(str, position){
let validCharReg = /^\.$/; //该词法单元允许的输入
let token = '';
let isMultiChar = false;
do{
let currentChar = str[position];
if (validCharReg.test(currentChar)) {
token += currentChar;
}else{ //一旦遇到不合法输入就退出解析
break;
}
position += 1;
}while(isMultiChar);
return {
name: 'DOT',
type: 'TERMINAL',
success: token !== '', //解析是否成功
token, //解析结果
length: token.length, //解析结果长度
};
}
console.log(getMultiSpace('', 0))
console.log(getMultiSpace('.', 0))
console.log(getMultiSpace('..', 0))
console.log(getMultiSpace('.a', 0))
console.log(getMultiSpace('.a.', 0))最后我们实现一个比较特殊的词法单元解析器getEmpty
/**
* @returns {{name: string, type: string, success: boolean, token: string, length: number}}
*/
function getEmpty(){
return {
name: 'EMPTY',
type: 'TERMINAL',
success: true,
token: '',
length: 0,
};
}我们可以看到,getEmpty直接返回一个解析成功的结果,因为它的作用比较特殊,后面我们会详细交代。
好了,现在我们有了四个终结符MULTISPACE NUMBER DOT EMPTY的词法解析器,
接下来,我们还要有SpaceOrEmpty 和 最终的 IP 两个语法结构的解析器。
我们先定义getSpaceOrEmpty,它由 getMultiSpace和getEmpty进行或运算得到。
/**
*
* @param str
* @param position
* @returns {{success: boolean, name: string, type: string, childs: Array, length: number}}
*/
function getSpaceOrEmpty(str, position){
let childs = [];
let length = 0;
let multiSpace = getMultiSpace(str, position);
if(multiSpace.success){
childs.push(multiSpace);
length += multiSpace.length;
}else{
childs.push(getEmpty());
length += 0;
}
return {
success: childs.length > 0,
name: 'SpaceOrEmpty',
type: 'NONTERMINAL',
childs,
length,
}
}
console.log(getSpaceOrEmpty('', 0));
console.log(getSpaceOrEmpty(' ', 0));好了,到我们可以处理最终的文法结构,就是getIp了
/**
*
* @param str
* @param position
* @returns {{name: string, type: string, success: boolean, childs: Array, length: number}}
*/
function getIp(str, position){
let childs = [];
let length = 0;
let parsers = [
getSpaceOrEmpty,
getNumber, //1 number1
getSpaceOrEmpty,
getDot,
getSpaceOrEmpty,
getNumber, //5 number2
getSpaceOrEmpty,
getDot,
getSpaceOrEmpty,
getNumber, //9 number3
getSpaceOrEmpty,
getDot,
getSpaceOrEmpty,
getNumber, //13 number4
getSpaceOrEmpty,
];
for(let i=0; i<parsers.length; i++){
let child = parsers[i](str, position);
childs.push(child);
length += child.length;
position += child.length;
if(!child.success){
break;
}
}
return {
name: 'IP',
type: 'NONTERMINAL',
success: length === str.length,
childs,
length,
number1: parseInt(childs[1].token, 10),
number2: parseInt(childs[5].token, 10),
number3: parseInt(childs[9].token, 10),
number4: parseInt(childs[13].token, 10),
};
}
console.log(getIp('192.168.0.1', 0))
console.log(getIp('192 .168.0.1', 0))
console.log(getIp(' 192.168.0.1', 0))
console.log(getIp('192. 168 .0.1', 0))
console.log(getIp('192. 168 .0.1 00', 0)) //false
console.log(getIp('192. 168 .0..100', 0)) //false最后,我们得到了IP地址的ast结构,接下来我们把它转换为32bit的整数即可:
/**
* @param str
* @returns {*}
*/
function ipConv(str){
let ast = getIp(str, 0);
if(ast.success){
return {
success: true,
ipStr: str,
ipAst: ast,
ipInteger: ast.number1 * Math.pow(2,24) + (ast.number2 << 16) + (ast.number3 << 8) + ast.number4,
}
}else{
return {
success: false,
ipStr: str,
}
}
}
console.log(ipConv('192.168.0.1'));
console.log(ipConv('192.168.0..1'));
console.log(ipConv('172.168.5.1'));至于上面为什么最高的8位不使用<<24,因为左移运算在js中的限制,可以自己试一下。
到这里两个问题都解决掉了。
你有没有遇到过这样的问题:
读完本文希望你能对React的组件生命周期有一定的了解,编写React代码的时候能够更加得心应手,注意本文的生命周期讲的主要是浏览器端渲染,这是后端和全栈的主要使用方式,服务端渲染有些不一样,请注意区分,我们会在文中进行简单说明。
Update: 更新为React16版本,React16由于异步渲染等特性会让之前的一些方法如componentWillMount变得不够安全高效逐步废弃,详见Legacy Methods
如果你做过安卓开发方面的编程,那么你应该了解onCreate,onResume,onDestrory等常见生命周期方法,生命周期函数说白了就是让我们在一个组件的各个阶段都提供一些钩子函数来让开发者在合适的时间点可以介入并进行一些操作,比如初始化(onCreate)的时候我们应该初始化组件相关的状态和变量,组件要销毁(onDestrory)时,我们应该把一些数据结构销毁掉以节约内存,防止后台任务一直运行。在java类中也存在一个最常见的钩子函数contructor,你可以在这里调用super方法初始化父类,也可以在这里初始化各种变量。
我们先看下下面的图建立一个React组件生命周期的直观认识,图为React 16的生命周期,总的来说React组件的生命周期分为三个部分: 装载期间(Mounting) ,更新期间(Updating) 和卸载期间(Unmounting) ,React16多出来一个componentDidCatch() 函数用于捕捉错误。知道什么时候去使用哪些生命周期函数对于掌握和理解React是非常重要的,你可以看到这些生命周期函数有一定的规律,比如在某件事情发生之前调用的会用xxxWillxxx,而在这之后发生的会用xxxDidxxx。
// 图来源于网络(侵删)

接下来我们就这三个阶段分别介绍一下各个生命周期函数,详细的生命周期函数解释可以看官方文档 React.Component。
组件被实例化并挂载在到DOM树这一过程称为装载,在装载期调用的生命周期函数依次为
上图中还有一些函数比如getDefaultProps, getInitialState等是在你不是用ES6的class创建组件而是用createReactClass函数创建函数时暴露的方法,分别用于定义属性和设置初始状态,详见React-without-es6,这里我们不再赘述。
通常推荐使用继承组件类的方式进行组件创建,即class Analysis extends Component{}
构造函数,和java class的构造函数一样,用于初始化这个组件的一些状态和操作,如果你是通过继承React.Component子类来创建React的组件的,那么你应当首先调用super(props) 初始化父类。
在contructor函数中,你可以__初始化state__,比如this.state = {xxx}; ,不要在构造函数中使用setState()函数,强行使用的话React会报错。其次你可以在构造函数中__进行函数bind__,如:
this.handleClick = this.handleClick.bind(this);一个示例contructor实现如下:
constructor(props) {
super(props);
this.state = {
color: '#fff'
};
this.handleClick = this.handleClick.bind(this);
}如果你不需要初始化状态也不需要绑定handle函数的this,那么你可以不实现constructor函数,由默认实现代替。
注意js的this指向比较特殊,比如以下的例子作为onClick回调函数由button组件去调用的时候不会把组件类的上下文带过去。
handleClick() {
console.log('handleClick', this); // undefined
}
...
<button onClick={this.handleClick}>click</button>这种问题推荐三种可能的解决方式,其核心均为将函数的this强制绑定到组件类上:
handleClick = () => {
console.log('handleClick', this); // Component
}这个函数会在render函数被调用之前调用,包括第一次的初始化组件以及后续的更新过程中,每次接收新的props之后都会返回一个对象作为新的state,返回null则说明不需要更新state。
该方法主要用来替代componentWillReceiveProps方法,willReceiveProps经常被误用,导致了一些问题,因此在新版本中被标记为unsafe。以掘金上的🌰为例,componentWillReceiveProps的常见用法如下,根据传进来的属性值判断是否要load新的数据
class ExampleComponent extends React.Component {
state = {
isScrollingDown: false,
};
componentWillReceiveProps(nextProps) {
if (this.props.currentRow !== nextProps.currentRow) {
// 检测到变化后更新状态、并请求数据
this.setState({
isScrollingDown: nextProps.currentRow > this.props.currentRow,
});
this.loadAsyncData()
}
}
loadAsyncData() {/* ... */}
}但这个方法的一个问题是外部组件多次频繁更新传入多次不同的 props,而该组件将这些更新 batch 后仅仅触发单次自己的更新,这种写法会导致不必要的异步请求,相比下来getDerivedStateFromProps配合componentDidUpdate的写法如下:
class ExampleComponent extends React.Component {
state = {
isScrollingDown: false,
lastRow: null,
};
static getDerivedStateFromProps(nextProps, prevState) {
// 不再提供 prevProps 的获取方式
if (nextProps.currentRow !== prevState.lastRow) {
return {
isScrollingDown: nextProps.currentRow > prevState.lastRow,
lastRow: nextProps.currentRow,
};
}
// 默认不改动 state
return null;
}
componentDidUpdate() {
// 仅在更新触发后请求数据
this.loadAsyncData()
}
loadAsyncData() {/* ... */}
}这种方式只在更新触发后请求数据,相比下来更节省资源。
注意getDerivedStateFromProps是一个static方法,意味着拿不到实例的this
该方法在一个React组件中是必须实现的,你可以看成是一个java interface的接口
这是React组件的核心方法,用于根据状态state和属性props渲染一个React组件。我们应该保持该方法的纯洁性,这会让我们的组件更易于理解,只要state和props不变,每次调用render返回的结果应当相同,所以请__不要在render方法中改变组件状态,也不要在在这个方法中和浏览器直接交互__。
componentDidMount方法会在render方法之后立即被调用,该方法在整个React生命周期中只会被调用一次。React的组件树是一个树形结构,此时你可以认为这个组件以及他下面的所有子组件都已经渲染完了,所以在这个方法中你可以调用和真实DOM相关的操作了。
有些组件的启动工作是依赖 DOM 的,例如动画的启动,而 componentWillMount 的时候组件还没挂载完成,所以没法进行这些启动工作,这时候就可以把这些操作放在 componentDidMount 当中。
我们推荐可以在这个函数中__发送异步请求__,在回调函数中调用setState()设置state,等数据到达后触发重新渲染。但注意尽量__不要__在这个函数中__直接调用__setState()设置状态,这会触发一次额外的重新渲染,可能造成性能问题。
下面的代码演示了如何在componentDidMount加载数据并设置状态:
componentDidMount() {
console.log('componentDidMount');
fetch("https://api.github.com/search/repositories?q=language:java&sort=stars")
.then(res => res.json())
.then((result) => {
this.setState({ // 触发render
items: result.items
});
})
.catch((error) => { console.log(error)});
// this.setState({color: xxx}) // 不要这样做
}当组件的状态或属性变化时会触发更新,更新过程中会依次调用以下方法:
你可以用这个方法来告诉React是否要进行下一次render(),默认这个函数放回true,即每次更新状态和属性的时候都进行组件更新。注意这个函数如果返回false并不会导致子组件也不更新。
这个钩子函数__一般不需要实现, __如果你的组件性能比较差或者渲染比较耗时,你可以考虑使React.PureComponent 重新实现该组件,PureComponent默认实现了一个版本的shouldComponentUpdate会进行state和props的比较。当然如果你有自信,可以自己实现比较nextProps和nextState是否发生了改变。
该函数通常是优化性能的紧急出口,是个大招,不要轻易用,如果要用可以参考Immutable 详解及 React 中实践 .
该方法的触发时间为update发生的时候,在render之后dom渲染之前返回一个值,作为componentDidUpdate的第三个参数。该函数与 componentDidUpdate 一起使用可以取代 componentWillUpdate 的所有功能,比如以下是官方的例子:
class ScrollingList extends React.Component {
constructor(props) {
super(props);
this.listRef = React.createRef();
}
getSnapshotBeforeUpdate(prevProps, prevState) {
// Are we adding new items to the list?
// Capture the scroll position so we can adjust scroll later.
if (prevProps.list.length < this.props.list.length) {
const list = this.listRef.current;
return list.scrollHeight - list.scrollTop;
}
return null;
}
componentDidUpdate(prevProps, prevState, snapshot) {
// If we have a snapshot value, we've just added new items.
// Adjust scroll so these new items don't push the old ones out of view.
// (snapshot here is the value returned from getSnapshotBeforeUpdate)
if (snapshot !== null) {
const list = this.listRef.current;
list.scrollTop = list.scrollHeight - snapshot;
}
}
render() {
return (
<div ref={this.listRef}>{/* ...contents... */}</div>
);
}
}该方法会在更新完成后被立即调用,你可以在这个方法中进行__DOM操作__,或者__做一些异步调用。__这个和首次装载过程后调用componentDidMount是类似的,不一样的是你可能需要判断下属性是否变化了再发起网络请求,如:
componentDidUpdate(prevProps) { // 来自网络
if(prevProps.myProps !== this.props.myProp) {
// this.props.myProp has a different value
// we can perform any operations that would
// need the new value and/or cause side-effects
// like AJAX calls with the new value - this.props.myProp
}
}卸载期间是指组件被从DOM树中移除时,调用的相关方法为:
该方法会在组件被卸载之前被调用,如果你学过C++,那么这玩意和析构函数差不多,在方法里清理内存之类的,当然如果你用java请不用在意。如上所述,你可以在这个函数中进行相关清理工作,比如删除定时器之类的。
下面给个示例代码:
componentWillUnmount() {
console.log('componentWillUnmount');
// 清除timer
clearInterval(this.timerID1);
clearTimeout(this.timerID2);
// 关闭socket
this.myWebsocket.close();
// 取消消息订阅...
}React16中新增了一个生命周期函数:
在react组件中如果产生的错误没有被被捕获会被抛给上层组件,如果上层也不处理的话就会抛到顶层导致浏览器白屏错误,在React16中我们可以实现这个方法来捕获__子组件__产生的错误,然后在父组件中妥善处理,比如搞个弹层通知用户网页崩溃等。
在这个函数中请只进行错误恢复相关的处理,不要做其他流程控制方面的操作。比如:
componentDidCatch(error, info) { // from react.org
// Display fallback UI
this.setState({ hasError: true });
// You can also log the error to an error reporting service
logErrorToMyService(error, info);
}componentWillMount,componentWillUpdate, componentWillReceiveProps等生命周期方法在下个主版本中会被废弃?
根据这份RFC,是的,这些生命周期方法被认为是不安全的,在React16中被重命名为UNSAFE_componentWillMount,UNSAFE_componentWillUpdate,UNSAFE_componentWillReceiveProps,而在更下个大版本中他们会被废弃。详见 React 16.3版本发布公告。
总结一下,以上讲的这些生命周期都有自己存在的意义,但在React使用过程中我们最常用到的生命周期函数是如下几个:
其他的逻辑一般和用户的操作有关(各种handleClickXXXX),当然需要用到其他生命周期函数可以按需正确使用。如果阅读文章过程中遇到问题欢迎评论进行修正。
光说不练假把式
继上文「umi 插件体系的一些初步理解」从理论层面分析 umi 插件后,本文将实战一个迷你 umi 插件。
代码源码在此:https://github.com/frontend9/umi-plugin-demo
可以码文互看😄
首先,安装 umi
tnpm i umi -S
其次,编写示例页面,得益于 umi 的「约定优于配置」理念,只需要一个文件即可
// pages/index.js
export default () => <div>Index Page</div>OK,跑一下
npx umi dev

新建 umi-plugin-hello 文件夹,在里面添加 package.json 及 src/index.js
// package.json
{
"name": "umi-plugin-hello",
"version": "0.0.2",
"main": "./lib/index.js",
"scripts": {
"build": "node_modules/babel-cli/bin/babel.js src --out-dir lib"
},
"devDependencies": {
"babel-cli": "^6.26.0",
"babel-core": "^6.26.0",
"babel-preset-es2015": "^6.24.1"
},
"babel": {
"presets": ["es2015"]
}
}
这里使用 babel 配置 build 命令,这样在构建时就会把源码中 ES6 转码为 ES5(社区约定,一般 npm 包都是转码的)。
// src/index.js
export default function(api, opts = {}) {
api.register('modifyHTML', ({ memo }) => {
memo = memo.replace(
'</head>',
`
<script>alert("Wow~~~ it works.")</script>
</head>
`.trim(),
);
return memo;
});
}这个就是插件逻辑了:
modifyHTML 这个 hook 点,并且提供一个 function 用于改写 HTML 文件。memo,这个 memo 即是 umi 在执行插件 hook 时的 HTML 全文内容。然后,依次执行
就会在本地生成一个 npm 包。
回到工程根目录,执行
tnpm i ~/tmp.729/umi-plugin-hello/umi-plugin-hello-0.0.2.tgz
安装上一步产出的 umi 插件 npm 包。(注意:npm 包路径使用全路径。)
然后,新建 .umirc.js 引入插件
// .umirc.js
export default {
plugins: [
'umi-plugin-hello',
],
};
最后,重新 run 一下工程,就可以了!

本文阅读的 Vuex 版本:v2.3.0
没有接触过 Vuex 的同学,建议先看一下 官方文档
Vuex 是一个专为 Vue.js 应用程序开发的 状态管理模式 。它采用 集中式存储 管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。在分析源码之前,先来看一个简单的 Vuex 使用示例。
// js/store/index.js
// Vuex 的安装与初始化
require('es6-promise').polyfill(); // webpack2.0已将polyfill拆分出去需要自己引入
import Vue from 'vue';
import Vuex from 'vuex';
import actions from './actions';
import mutations from './mutations';
import getters from './getters';
import video from './modules/video';
import usercenter from './modules/usercenter';
import strategy from './modules/strategy';
Vue.use(Vuex);
const debug = process.env.NODE_ENV !== 'production';
export default new Vuex.Store({
modules: {
video,
usercenter,
strategy
},
// public state
state: {
count: 0
},
// public mutaions
mutations,
// public actions
actions,
// public getters
getters,
strict: debug
});// js/store/modules/video.js
// video 模块的定义
import * as types from '../mutation-types';
const state = {
testData: 1
};
const mutations = {
[types.TESTADD] (state, val) {
// 这里的 `state` 对象是模块的局部状态
state.testData += val.val;
},
};
const actions = {};
const getters = {};
export default {
namespaced: true,
state,
mutations,
actions,
getters
};// js/main.js
// 在 app 的主入口注入 store
import store from 'store/index';
//...
// 创建和挂载根实例
const appVm = new Vue({
store,
router,
components: {
app
}
}).$mount('#main-app');上面的示例中,展示了在 Vue 中使用 Vuex 的基本示例。可以归结为以下四个核心步骤:
Vue.use(Vuex)export default new Vuex.Store({...})import store from 'store/index'new Vue({store, ...})第4步完成之后,我们就可以在任意 Vue Component 中使用 this.$store 来访问 store 中的 state,并通过 this.$store.commit() 和 this.$store.dispatch() 来分别调用 mutations 和 actions,以此来完成 state 的变更动作。
在面对陌生项目的时候,阅读源码往往容易摸不着头脑。我的思路是从 Vuex 使用者的角度入手,找到使用入口,并沿着入口的处理逻辑一步步深入。所以在回顾完上面给出的 Vuex 使用示例之后,一个很明显的入口语句就是:
Vue.use(Vuex)所以下面会从这行代码入手,对 Vuex 的源码进行拆解。为了提升阅读体验,逻辑较为复杂的部分只截取了核心片段,对细节比较关心的同学建议 clone 一份源码下来自己咀嚼。
为了便于理解,我把 Vuex 源码的核心逻辑拆解为下面三个部分。这三个部分完成了从 Vuex 的安装,到 store 的构建,再到如何追踪 state 变化的所有工作。
之前提到, Vue.use(Vuex) 作为研究源码的入口,完成的第一个工作,就是在 Vue 中进行 Vuex 的安装工作。
关于 Vue.use() 的用法,官方文档的解释如下:
安装 Vue.js 插件。如果插件是一个对象,必须提供
install方法。如果插件是一个函数,它会被作为 install 方法。install 方法将被作为 Vue 的参数调用。
可以看出,插件安装的核心原理,就是调用插件所提供的 install 方法。它的源码 主要完成了以下几个工作:
所以,接下来一个很自然的想法,就是去看 Vuex 提供的 install 方法。
// location: src/store.js
// line: 450
export function install (_Vue) {
if (Vue) {
if (process.env.NODE_ENV !== 'production') {
console.error(
'[vuex] already installed. Vue.use(Vuex) should be called only once.'
)
}
return
}
Vue = _Vue
applyMixin(Vue)
}这里的变量 Vue 是 store.js 文件在最开始的位置所定义的一个全局变量,用来存储安装对象,也为了保证 install 方法只会被执行一次, _Vue 是 use 方法中传入的 Vue 实例。install 方法的最后调用了 applyMixin(Vue) ,这是真正的安装动作,源码如下:
export default function (Vue) {
const version = Number(Vue.version.split('.')[0])
if (version >= 2) {
const usesInit = Vue.config._lifecycleHooks.indexOf('init') > -1
Vue.mixin(usesInit ? { init: vuexInit } : { beforeCreate: vuexInit })
} else {
// ...
}
/**
* Vuex init hook, injected into each instances init hooks list.
*/
function vuexInit () {
const options = this.$options
// store injection
if (options.store) {
this.$store = typeof options.store === 'function'
? options.store()
: options.store
} else if (options.parent && options.parent.$store) {
this.$store = options.parent.$store
}
}
}可以看,Vuex 插件安装的本质,是调用了 Vue.mixin() 这个方法。这是Vue 为插件作者所提供的 混合机制 ,它在全局注册了一个混合,进而会影响到注册之后所有创建的每个 Vue 实例。
到这里可以发现,Vuex 的插件安装原理,就是向 Vue 示例注入了一个全局混合。
在上面的 applyMixin(Vue) 方法中, vuexInit() 这个 function 解释了 store 是如何在 Vue 组件中进行注入与传递的。
首先 store 作为 Vue 实例的一个 option 被注入到根部组件,而后所有的子组件都从其父组件的 options 中去寻找这个 store 属性,这样层层传递下去,所有的组件就都可以通过 this.$store 来访问全局的 store 了。
到这里位置,vuex 的安装工作以及 store 的注入工作都已经完成了,对应地也就解决四个核心步骤中的第一步。接下来关注第二步, new Vuex.store({...}) 是如何对 store 进行构造的。
在 store.js 的构造函数中,函数的一开始做了一系列的安全验证工作,代码片段如下:
// location: src/store.js
// line: 10
if (process.env.NODE_ENV !== 'production') {
assert(Vue, `must call Vue.use(Vuex) before creating a store instance.`)
assert(typeof Promise !== 'undefined', `vuex requires a Promise polyfill.`)
assert(this instanceof Store, `Store must be called with the new operator.`)
}
// location: src/util.js
// line: 64
export function assert (condition, msg) {
if (!condition) throw new Error(`[vuex] ${msg}`)
}顺便提一下,整个 Vuex 中这样的验证工作做了很多,这对组件开发提供了一个很规范的思路,用最简洁的代码完成组件的安全验证,值得学习。
做完验证工作之后,构造函数对 state 、plugins、strict 这几个参数做了初始化工作,代码如下:
const {
plugins = [],
strict = false
} = options
let {
state = {}
} = options
if (typeof state === 'function') {
state = state()
}采用 解构赋值 的方式,将传入构造函数的参数进行内部定义,可以看到这里 state 也可以通过 function 的方式来定义。
在定义完 state 等一些参数之后,构造函数定义了一系列的内部状态:
// location: src/store.js
// line: 28
// store internal state
// 表示提交状态
// 保证对 Vuex 中 state 的修改只能在 mutation 中进行,而不能在外部随意修改state。
this._committing = false
// 存放用户定义的所有的 actions
this._actions = Object.create(null)
// 存放用户定义的所有的 mutations
this._mutations = Object.create(null)
// 存放用户定义的所有的 getters
this._wrappedGetters = Object.create(null)
// 存放用户定义的所有的 modules
this._modules = new ModuleCollection(options)
// 存放 modules 和其 namespace 的对应关系
this._modulesNamespaceMap = Object.create(null)
// 用于 vuex 的相关插件,存放所有对 mutations 变化的订阅者
this._subscribers = []
// 用于 vuex 的相关插件,用来观测 state 的变化
this._watcherVM = new Vue()这几个状态的含义已通过注释的方式给出,在完成这些内部状态的定义之后,后续的代码逻辑就是对这些状态的赋值操作。
在对上述的内部状态进行赋值的时候,Vuex 是按照 modules 的层次逻辑逐层展开的。最开始的 demo 中可以看出,Vuex 提供 modules 机制。在没有 modules 的情况下, 所有的 state, mutations, actions, getters 都会”挂载“在同一个节点上,随着系统规模的扩大,整个逻辑会显得非常臃肿,不便于维护。
modules 机制很好地解决了这个问题,不同模块将拥有自己独立的 state, mutations, actions, getters ,模块间公共的部分可以提炼出来挂在“根节点”上,私有的部分作为“子节点”,按照 命名空间 的指定规则依次进行挂载。
需要注意的是,Vuex 内部并不是一个树的结构,树的查找和插入操作复杂度都比较高,为了便于理解,这里用 挂载 这个词来形容整个 modules 的层次构建。实际上 Vuex 是 “扁平化” 处理的,所有的 modules 都有一个 path 字段,来定义 modules 的层次结构,所以也可以理解为是一个 flatten 化的 tree。
Vuex 对 modules 进行层次构建的代码如下:
// location: src/store.js
// line: 51
// init root module.
// this also recursively registers all sub-modules
// and collects all module getters inside this._wrappedGetters
installModule(this, state, [], this._modules.root)
// location: src/store.js
// line: 253
function installModule (store, rootState, path, module, hot) {
const isRoot = !path.length
const namespace = store._modules.getNamespace(path)
// register in namespace map
if (module.namespaced) {
store._modulesNamespaceMap[namespace] = module
}
// set state
if (!isRoot && !hot) {
const parentState = getNestedState(rootState, path.slice(0, -1))
const moduleName = path[path.length - 1]
store._withCommit(() => {
Vue.set(parentState, moduleName, module.state)
})
}
const local = module.context = makeLocalContext(store, namespace, path)
module.forEachMutation((mutation, key) => {
const namespacedType = namespace + key
registerMutation(store, namespacedType, mutation, local)
})
module.forEachAction((action, key) => {
const namespacedType = namespace + key
registerAction(store, namespacedType, action, local)
})
module.forEachGetter((getter, key) => {
const namespacedType = namespace + key
registerGetter(store, namespacedType, getter, local)
})
module.forEachChild((child, key) => {
installModule(store, rootState, path.concat(key), child, hot)
})
}可以看到, installModule 方法会根据 namespace 参数,递归 地对 modules 进行构建。
代码的前半段,取出了 module 的私有 state ,以 Vue.set() 的方法,挂载到 parentState 下面。
代码的后半段,对 module 内的 mutations,actions,getters进行注册操作。注意这里的 local 变量,它定义了每个 module 各自独立的 dispatch 和 commit 方法,实质就是,在设置了 namespace 的情况下,这两个方法会在 action / mutation 的 type 前面,加上 module 的 path,来完成正确的调用操作。
注册部分,以 mutations 为例,所有 modules 的 mutations 最终都存储在 store._mutaions 这个在之前预先定义好的私有变量中。在不设置 namespace 的情况下,同名的 mutations 会放在同一个数组里面,示例如下:
// without namespace
store._mutations = {
'increment' : [
function() {...} // 来自 moduleA 的 increment
function() {...} // 来自 moduleB 的 increment
]
}
// with namespace
store._mutations = {
'A/increment' : [
function() {...}
],
'B/increment' : [
function() {...}
]
}所以从这里可以看出,没有 namespace 的情况下,发起 this.$store.commit('increment', payload)操作之后,来自不同 module 的同名 mutations,最终会被同时调用。加上 namespace 之后,就可以进行独立调用:this.$store.commit('A/increment', payload),this.$store.commit('B/increment', payload)。
所以如果模块之间涉及 同名 mutations 时,一定要在 module 的定义位置,加上 namespaces: true。
到这里位置,整个 store 的形状基本已经搭建完成了,state,actions,mutations,getters都已按照 modules 的层级关系,递归地完成了初始化。可以理解为:store 内部的 状态,以及对这些状态进行变更的 逻辑 ,都已填充完毕,接下来要做的就是绑定 commit 和 dispatch 这两个核心方法,来完成对逻辑的 调度 。
commit 和 dispatch 的逻辑较为相似,这里以 commit 方法为例:
// location: src/store.js
// line: 74
commit (_type, _payload, _options) {
// check object-style commit
const {
type,
payload,
options
} = unifyObjectStyle(_type, _payload, _options)
const mutation = { type, payload }
const entry = this._mutations[type]
if (!entry) {
if (process.env.NODE_ENV !== 'production') {
console.error(`[vuex] unknown mutation type: ${type}`)
}
return
}
this._withCommit(() => {
entry.forEach(function commitIterator (handler) {
handler(payload)
})
})
this._subscribers.forEach(sub => sub(mutation, this.state))
if (
process.env.NODE_ENV !== 'production' &&
options && options.silent
) {
console.warn(
`[vuex] mutation type: ${type}. Silent option has been removed. ` +
'Use the filter functionality in the vue-devtools'
)
}
}commit 方法的第一步,调用了unifyObjectStyle() 这个函数,由于 Vuex 的 commit 操作提供两种传参风格,所以要对传入的参数做统一处理。
// style A
store.commit('increment', {
amount: 10
})
// style B
store.commit({
type: 'increment',
amount: 10
})然后 commit 方法会根据传入的 type 参数,去找到相应 mutation 的回调函数来执行,可以看到执行动作用 this._withCommit() 方法进行了包裹,这里就用到了前面提到的 this._committing 变量。
// location: src/store.js
// line: 187
_withCommit (fn) {
const committing = this._committing
this._committing = true
fn()
this._committing = committing
}这个方法保证了所有的 state 变更操作,都会把 this._committing 置为 true ,一旦 state 变更时这个值为 false 时,就说明采用了异常方法进行了状态修改,然后就会进行报错。这个在下文的 严格模式 中会提及。
this._withCommit() 方法的内部,可以看到用了 entry.forEach() ,这就解释了前文提到的,在没有 namespace 的情况下,同名函数都会被执行的原因。
在完成 mutation 的回调之后,会调用 this.subscribers 中注册的所有回调,那些 Vuex 相关插件的订阅回调就会被执行。
到这里位置,整个 store 的初始化工作就算完成了,实现了 store 内部有关 状态(state),逻辑(mutations/actions/getters) 和 调度(commit/dispatch) 的填充。但整个 store 的构造函数并没有结束,在构造函数的最后,store 回答了那个困扰我很久的问题:为什么 getters 能够响应 state 的变化?
store 构造函数的最后,执行了如下操作:
// location: src/store.js
// line: 56
// initialize the store vm, which is responsible for the reactivity
// (also registers _wrappedGetters as computed properties)
resetStoreVM(this, state)
// apply plugins
plugins.concat(devtoolPlugin).forEach(plugin => plugin(this))最后一行很容易理解,就是完成 Vuex 的插件注册,其中 devtoolPlugin 是内置的默认插件, Chrome 的 Vue 扩展中,里面的 Vuex 时光穿梭 功能,就是通过这个插件实现的。
重点在 resetStoreVM(this, state) 部分,它的代码如下:
// location: src/store.js
// line: 207
function resetStoreVM (store, state, hot) {
const oldVm = store._vm
// bind store public getters
store.getters = {}
const wrappedGetters = store._wrappedGetters
const computed = {}
forEachValue(wrappedGetters, (fn, key) => {
// use computed to leverage its lazy-caching mechanism
computed[key] = () => fn(store)
Object.defineProperty(store.getters, key, {
get: () => store._vm[key],
enumerable: true // for local getters
})
})
// use a Vue instance to store the state tree
// suppress warnings just in case the user has added
// some funky global mixins
const silent = Vue.config.silent
Vue.config.silent = true
store._vm = new Vue({
data: {
$$state: state
},
computed
})
Vue.config.silent = silent
// enable strict mode for new vm
if (store.strict) {
enableStrictMode(store)
}
if (oldVm) {
if (hot) {
// dispatch changes in all subscribed watchers
// to force getter re-evaluation for hot reloading.
store._withCommit(() => {
oldVm._data.$$state = null
})
}
Vue.nextTick(() => oldVm.$destroy())
}
}这段代码的关键核心,就是 store._vm 这个变量,它的 本质是一个 Vue 实例 。在这个 Vue 实例中,state 作为 data 传入,而 computed 属性则挂载了所有的 getters!因此,通过 Vue 的响应式原理,Vuex 实现了 state 和 getters 的响应式跟踪。
到这里就可以解释清楚了,之所以 mutation 修改了 state 之后,组件会感知到 state 的变化,getters 也会感知到 state 的变化,是因为 Vuex store 的本质,是构建了一个 Vue 实例,而所有 mutations,actions 所涉及的逻辑操作,都是对这个 Vue 实例进行 data 修改。进而其实可以发现,Vuex 响应式的原理,和 Vue 官方提出的 **事件总线 其实是一个道理的。
在 resetStoreVM(this, state) 的最后,对严格模式和热重载进行了响应的处理。
在 开发环境 下开启严格模式之后,Vuex 会跟踪所有 state 的变化过程,并且这是一种 深度跟踪 ,对复杂对象依旧有效。这么做的目的是,devtoolPlugin 能够记录 state 的状态和变化,并且所有不是通过 mutations 而触发的 state 变更,都会报错。在 生产环境 下,严格模式通常会被关闭,以此来提高性能。
另外,Vuex 提供 mutations / actions / modules 的 热重载 功能,上面代码片段的末尾部分,就是在 热重载 的模式下,强制刷新所有监听者(watchers),并且将上一个状态的 oldVm 销毁,节省内存。
到这里为止, Vuex 源码分析的核心部分就算结束了,源码中还定义了一些辅助函数,包括 mapState, mapGetters,mapActions,mapMutations。这些都在 helpers.js 中有所定义,感兴趣的可以自行了解。
再回到最开始的 demo 中,四个核心步骤的原理基本都得到了解释:
Vue.use(Vuex)export default new Vuex.Store({...})import store from 'store/index'new Vue({store, …})对于步骤1,3,4:对应了 安装插件 部分,这其中涉及了 Vue 安装插件的本质,以及 store 在组件之间层层注入的本质,最关键的部分在于 混合机制 。
对于步骤2:对应了 store 初始化 部分,这部分解释了 store 的构建过程,分为 状态 ,逻辑 和 调度 三个部分。关键部分在于 命名空间的扁平化处理。
最后在实际的使用过程中,追踪状态变更 部分解释了 Vuex 的响应式原理的实现方案,他的核心在于构建了一个 Vue 实例。
老板说这个新项目叫我全权负责,心里又是鸡冻又是迷茫==!
想想都头大,老司机们带带我 😭
这篇文章接着CC的 js实现最简单的解析器:如何解析一个ip地址 继续讲。
CC的文章教了大家实现一个简单的解析器,大家是不是觉得并不难呢?那么我们接下来就讲讲如何解析一个更复杂的带有递归的结构。
这里我们不用广为人知的四则运算做例子,而是采用在论坛广泛使用的 UBB。如果你不熟悉 UBB 也没有关系,UBB 没有严格的统一标准,这次我们解析的是如下最基础的结构。
// 基础的 UBB 文本, [b] 为开始标签, [/b] 为结束标签
// 注意:结束标签和开始标签必须一一配对
[b]some bold text[/b]
渲染效果:
some bold text
// 标签可以相互嵌套,这里我们允许任意标签任意深度嵌套
[b]I'm bold and [i]I'm italic[/i][/b]
渲染效果:
I'm bold and I'm italic
我们简化的 UBB 只考虑上述两条规则,接下来我们看看我们此次的目标。
在现实中,我们时常需要把 UBB 代码转换为 HTML 或者其他形式(比如 markdown)。想要完成这样的转换有许多方法。当然,直接使用正则替换是一种简单方法,但是更好的做法是先把它转换为 AST (Abstract Syntax Tree),再做目标生成。
所以我们的 Parser 并不会直接生成实际目标,而是读入 UBB 代码,生成对应的 AST,后续 ATS 转实际目标的工作另外交由后面的后端处理。
这样做主要有以下几点好处:
针对我们这里简化的 UBB 我们可以定义如下的 AST 形式:
// 标签节点
TagNode
tagName: string // 标签名,比如 [b][/b] 的标签名是 b
children: (TagNode | TextNode)[] // 该节点的子节点们,可以是 Tag 也可以是 Text
// 文本节点
TextNode
text: string // 文本的内容
// UBB 文本
[b]I'm bold and [i]I'm italic[/i][/b]
==>
// AST 示意图
TagNode[b]
/ \
| |
TextNode TagNode[i]
|
TextNode
无需多说,大家应该已经明白我们定义的 AST 结构了。再接下来我们为开始写 parse 做一些准备工作。
我们做 parse 之前需要对原始文本进行 Tokenize(分词)。分词会把原始文本转换成 Token 流,这样我们的 parser 就可以基于这个流而不是原始文本进行处理。对于十分复杂的分词,我们有 lex 之类的工具帮助我们,而在这里我们可以直接自己手写对 UBB 的分词。
UBB 的分词很简单,我们定义如下三种 token:
START_TAG: \[\w+] // 例如 [b]
END_TAG: \[\/\w+] // 例如 [/b]
TEXT: [^\[\]]* // 不含 [ 和 ] 的普通文本
我们下面写一个 Tokenize 函数,这里我直接使用 Typescript,因为这样可读性更强。如果你不熟悉 TS 也没有关系,完全可以看懂。
const enum TokenType {
/** 开始标签 */
START_TAG,
/** 结束标签 */
END_TAG,
/** 普通文本 */
TEXT,
}
interface IToken {
/** Token 类型 */
type: TokenType
/** Token 值 */
rawText: string
}
/**
* 将 UBB 文本分词为 Token 流
* @param UBBText UBB 文本
*/
function* tokenize(UBBText: string): IterableIterator<IToken> {
const tagReg = /\[.+?]/gi
let lastIndex = 0
while(true) {
const tag = tagReg.exec(UBBText)
if (!tag)
break
if (lastIndex !== tag.index) {
yield {
type: TokenType.TEXT,
rawText: UBBText.slice(lastIndex, tag.index)
}
}
lastIndex = tag.index + tag[0].length
// END_TAG
if (tag[0][1] === '/') {
yield {
type: TokenType.END_TAG,
rawText: tag[0]
}
// START_TAG
} else {
yield {
type: TokenType.START_TAG,
rawText: tag[0]
}
}
}
if (lastIndex !== UBBText.length) {
yield {
type: TokenType.TEXT,
rawText: UBBText.slice(lastIndex)
}
}
}现在我们可以很方便的构造一个分词迭代器了,我们只需不断的调用这个迭代器,便可以从中取出一个个 token。
其次,我们需要明确一下 UBB 的文法,根据两条简单的 UBB 规则我们可以书写如下的文法:
S -> <UBB>
<UBB> ->
| <TAG> <UBB>
| TEXT <UBB>
| ε
| $
<TAG> ->
| START_TAG <UBB> END_TAG
其中带 <> 的就是非终结符;而不带 <> 的是终结符,也就是我们之前定义的 token;
S 是一个开始符合,表示文法开始;
$ 是一个特殊的终结符,表示文法结束;
ε 也是一个特殊符号,表示空。
这里的语法规则十分简单,且是 LL(1) 文法,这保证了我们可以使用递归下降的方法来解析。这里我就不详细的阐述一些关于LL,LR等理论知识了,有兴趣大家可以自己去编译原理书中了解。
很多人学习编译原理的时候,都会花很长的时间学习 parse 部分知识,其实 parse 并不难,编译原理的精髓也并不在 parse。
这里我们不需要使用 yacc 之类的更强大的工具,而是教大家手写这个简单的递归下降。
我们先做一个 Parser 类把架子搭好,再来讲什么叫递归下降。
/************
* AST Part *
************/
class TagNode {
tagName: string
children: (TagNode | TextNode)[]
constructor(tagName: string) {
this.tagName = tagName
this.children = []
}
}
class TextNode {
text: string
constructor(text: string) {
this.text = text
}
}
/**************
* Parse Part *
**************/
class Parser {
tokenization: IterableIterator<IToken>
token: IToken | null
constructor(tokenization: IterableIterator<IToken>) {
this.tokenization = tokenization
this.token = null
}
/** 读取下一个 token */
nextToken() {
const { value, done } = this.tokenization.next()
if (done) {
this.token = null
} else {
this.token = value
}
}
Tag() {/* ... */}
UBB() {/* ... */}
START_TAG() {/* ... */}
END_TAG() {/* ... */}
TEXT() {/* ... */}
S() {/* ... */}
$() {/* ... */}
}重点关注 Parser 里大写字母开头的成员函数,不难发现这就是我们文法规则里的每一项的一一对应。
到这里我们可以谈谈递归下降分析具体指什么了。
递归下降分析法是一种自顶向下的分析方法,文法的每个非终结符对应一个递归过程(函数)。分析过程就是从文法开始符出发执行一组递归过程(函数),这样向下推导直到推出句子;或者说从根节点出发,自顶向下为输入串寻找一个最左匹配序列,建立一棵语法树。
说的有点拗口,但是不急,我们往下看。
先前我们说到过 UBB 的文法是带有递归结构的,这样的递归结构恰好可以使用递归下降的方法解析。
形象的说,递归下降的过程就是根据文法规则一个个“吃”掉 token 流中的所有 token 的过程。
这里是我们分析的开始,让我们从文法 S -> <UBB> 出发,从填充我们的 S() 方法开始,吃掉第一个 token。
S() {
// 先吃一个 token
this.nextToken()
// 然后根据规则 S -> <UBB> 我们调用 UBB()
this.UBB()
}跟随 S -> <UBB> 的文法,现在我们想吃掉这个 <UBB>了。
所以我们接下来看看的 UBB() 怎么写
UBB() {
// token === null 意味着 token 流已经被吃完了
// 对应规则 <UBB> -> $
if (this.token === null) {
this.$()
return
}
// 如果我们吃了一个 START_TAG,
// 那么根据 <UBB> -> <TAG> <UBB> 的规则,我们调用 TAG() 来继续吃
if (this.token.type === TokenType.START_TAG) {
this.TAG()
this.UBB()
return
// 如果我们吃了一个 TEXT
// 那么我们选择规则 <UBB> -> TEXT <UBB>
} else if (this.token.type === TokenType.TEXT) {
this.TEXT()
this.UBB()
return
}
// 如果当前 token 不在文法规则内(比如读到了 END_TAG),那么什么也不做
}好,我们继续往下走。
假设我们在 STEP 2 里吃的 token 是一个 TEXT,那么我们会继续调用 TEXT() 去吃掉这个 TEXT,就像这样:
TEXT() {
// ...
// 这里写我们处理 TEXT 的一些代码
// 吃掉这个 TEXT token
this.nextToken()
}那么假如我们在 STEP 2 走了另一条路, 我们在 STEP 2 里吃的 token 是一个 START_TAG,那么接下来我们会调用 TAG() ,随后 TAG() 会调用 START_TAG()吃掉 START_TAG,随后再 ...
讲到这里,我想现在聪明的你应该明白所谓的递归下降是怎么一回事了。
试想如果我们现在是这样的一个 UBB 做例子:
[b]bold[i]italic[/i][/b]
我们会经历这样一次递归下降过程:
S()
-> UBB()
-> TAG()
-> START_TAG() // 吃掉了 START_TAG: [b]
-> UBB()
-> TEXT() // 吃掉了 TEXT: bold
-> UBB()
-> START_TAG() // 吃掉了 START_TAG: [i]
-> UBB()
-> TEXT() // 吃掉了 TEXT: italic
-> UBB()
-> END_TAG() // 吃掉了 END_TAG: [/i]
-> END_TAG() // 吃掉了 END_TAG: [/b]
-> UBB()
->$() // 结束了
到这里,我们可以贴上完整的递归下降 parser 的代码了。
class Parser {
tokenization: IterableIterator<IToken>
token: IToken | null
/** 用于跟踪构建 AST 过程中的当前插入节点 */
node: TagNode
nodeStack: TagNode[]
constructor(tokenization: IterableIterator<IToken>) {
this.tokenization = tokenization
this.token = null
this.node = new TagNode('root')
this.nodeStack = []
}
nextToken() {
const { value, done } = this.tokenization.next()
if (done) {
this.token = null
} else {
this.token = value
}
}
TAG() {
// <TAG> -> START_TAG <UBB> END_TAG
this.START_TAG()
this.UBB()
this.END_TAG()
}
UBB() {
// <UBB> -> $
if (this.token === null) {
this.$()
return
}
// <UBB> -> <TAG> <UBB>
if (this.token.type === TokenType.START_TAG) {
this.TAG()
this.UBB()
return
// <UBB> -> TEXT <UBB>
} else if (this.token.type === TokenType.TEXT) {
this.TEXT()
this.UBB()
return
}
}
START_TAG() {
// 在 AST 中插入一个新的 TagNode
const newNode = new TagNode(this.token.rawText)
this.node.children.push(newNode)
this.nodeStack.push(this.node)
this.node = newNode
// 吃掉这个 START_TAG
this.nextToken()
}
END_TAG() {
this.node = this.nodeStack.pop()
this.nextToken()
}
TEXT() {
const newNode = new TextNode(this.token.rawText)
this.node.children.push(newNode)
this.nextToken()
}
S() {
this.nextToken()
this.UBB()
}
$() {
// 什么都不用做
}
}可以看到,我们在非终结符的节点里递归调用别的处理函数,在终结符对应的函数里则直接进行吃掉对应 token 并做必要处理。
正如这里,我们在 START_TAG, END_TAG, TEXT 三个终止符对应的函数中插入了一些构建 AST 的代码,这部分代码非常简单,想必不用我做多余的解释。
现在我们已经写完我们的 parser 了。
我们可以写一段简单的代码尝试驱动我们的 parser 试试:
;(function main(UBBText: string) {
const parser = new Parser(tokenize(UBBText))
parser.S()
console.log(JSON.stringify(parser.node, null, 2))
})('[b]bold[i]italic[/i][/b]')你将会得到这样的输出:
{
"tagName": "root",
"children": [
{
"tagName": "[b]",
"children": [
{
"text": "bold"
},
{
"tagName": "[i]",
"children": [
{
"text": "italic"
}
]
}
]
}
]
}Good!这符合我们的预期。
至此,我相信你已经掌握了如何使用递归下降分析法来 parse 一个带递归的复杂文本,这个方法已经可以应对绝大多数的需要 parser 场景了。
那么到此为止你是不是想问这有什么实际应用?
可能日后你做 DSL (Domain Specific Language)的时候会有用吧,又或者说,你可以说,“parser 其实一点也不难。”
什么是左递归?
如果在之前写文法的时候,我们有这么一个需求:TEXT 会被空格(SPACE)分割
也就是说文本 I'm bold应该被解析成I'm 和bold两个 token
这个时候你可能会写出这样的文法:
<TERM> -> <TERM> SPACE TEXT
| TEXT
这就变成了左递归的文法。
左递归会导致我们在写递归下降的时候出问题。不难发现,在这个左递归的文法中我们的代码里会在 TERM()里再次调用 TERM(),这就成了缺失退出条件的无限递归。
而左递归是可以消除的。
消除的通用方法是做如下的文法变换:
// 直接左递归文法
A -> Ab
| a
==>
// 清除左递归之后
A -> aB
B -> bB
| ε
根据这个方法,我们之前的左递归的文法可以变为:
// 引入新非终结符 <T>
<TERM> -> TEXT <T>
<T> -> SPACE TEXT <T>
| ε
这样我们就解决了左递归带来的问题。
做 parser 很重要的一块是错误处理。
就拿 UBB 来说,如果开始标签和结束标签不匹配那怎么办?这在我们上面的 parser 中根本没有考虑。
这里做法有很多,我给出一些建议和可行的处理方法:
dva 封装了 redux-saga,以 effects 的概念呈现,以 generator 函数 组织代码,优雅地处理了 React 应用中数据层的异步逻辑。本文以 umi 作为开发框架,展示如何在 dva/redux-saga 中实现如下的 轮询(polling) 逻辑。本文中涉及的代码在此。

保证你的开发环境中有安装 node (版本 >= 8),并根据 官方文档 快速安装 umi。
umi 是 基于约定 的前端开发框架。umi 深度整合了 dva,使得开发基于 dva 的应用更加便捷。本文中使用的 umi 版本是 2.0.0-beta.17,安装命令为
npm i -g [email protected].
环境安装完毕后,创建目录并通过 umi g 命令行创建第一个页面,
mkdir demo-umi-polling
cd demo-umi-polling
npm init -y
mkdir src
cd src
umi g page index
得到一个最简单的工程目录结构,
.
├── package.json
└── src
└── pages
├── index.css
└── index.js
执行 npm i ,然后启动本地开发服务器,
umi dev
如果一切顺利,可以在浏览器中看到下面的页面,

umi 默认采用了「目录即路由」的约定,并且深度整合了 dva,你不需要做诸如 app = dva(),app.model(),app.router(),app.start() 这些事情,框架会根据「约定」自动帮你做了。
umi 采取插件机制,启动对 dva 的支持只需要安装插件 umi-plugin-react。
如果是使用 [email protected] 的话,需安装插件
umi-plugin-dva,但强烈建议您使用 umi@2。
首先,安装 umi-plugin-react,
npm i --save umi-plugin-react
然后,在 umi 的配置中打开对 dva 的支持,
// 在工程根目录建立文件 .umirc.js,然后写入内容
export default {
plugins: [
['umi-plugin-react', {
dva: true,
}],
],
};然后,书写 model 定义,
/**
* umi 约定 src 下的 models 目录可以用来放置 model 定义,
* 因此,我们在 src 下建立 models 目录,并在其中建立文件 foo.js,文件名不重要。
*/
const namespace = 'bar';
export default {
namespace,
state: {
dogImgURL: 'https://images.dog.ceo/breeds/puggle/IMG_114654.jpg',
},
}强烈建议安装浏览器插件 Redux DevTools 来监视 dva model,

最后,我们的目录变为下面的结构,
.
├── .umirc.js
├── package.json
└── src
├── models
│ └── foo.js
└── pages
├── index.css
└── index.js
重新启动开发服务器,并打开 Redux DevTools,会看到 model 已经生效了。

在实现轮询之前,我们先实现点击按钮获取图片的功能。要使用的 webapi 是:
# 随机获取狗狗的图片
https://dog.ceo/api/breeds/image/random
首先,我们把 dva model 中的图片 URL 注入页面展示。
import { PureComponent } from 'react';
import styles from './index.css';
import { connect } from 'dva';
import fooModel from '../models/foo';
const { namespace } = fooModel;
const mapStateToProps = (state) => {
const { dogImgURL } = state[namespace];
return { dogImgURL };
};
@connect(mapStateToProps)
export default class IndexPage extends PureComponent {
render() {
return (
<div>
<div className={styles.normal}>
<h1>Show random dog picture</h1>
</div>
<div>
<img src={this.props.dogImgURL} alt="dog image" height="300" />
</div>
</div>
);
}
}不出意外应该看到下图,

然后,我们使用 webapi 动态地获取图片 URL,点击按钮触发 webapi 的调用。
做网络请求的库很多,我们这里使用 dva 提供的 isomorphic-fetch,并提供简单的封装。
fetch 函数是 W3C 标准,返回 Promise,想对 fetch 函数有更多了解,可以参考这篇 google 的文章 introduction-to-fetch 。
在 src 目录下建立目录和文件 utils/request.js,写入以下内容,
import fetch from 'dva/fetch';
function status(response) {
if (response.status >= 200 && response.status < 300) {
return Promise.resolve(response);
} else {
return Promise.reject(new Error(response.statusText));
}
}
function json(response) {
return response.json();
}
function err(err) {
console.error(err);
}
export default function request(url, option) {
return fetch(url, option)
.then(status)
.then(json)
}在 model 中加入 webapi 获取图片的逻辑。
import request from '../utils/request';
const namespace = 'bar';
const acTyp = {
fetch_dogImg: 'fetch_dogImg',
fetch_dogImg_success: 'fetch_dogImg_success',
};
Object.freeze(acTyp);
export default {
namespace,
acTyp,
state: {
dogImgURL: 'https://images.dog.ceo/breeds/puggle/IMG_114654.jpg',
},
effects: {
*[acTyp.fetch_dogImg](_, sagaEffects) {
const { call, put } = sagaEffects;
const rsp = yield call(request, 'https://dog.ceo/api/breeds/image/random');
yield put({ type: acTyp.fetch_dogImg_success, dogImgURL: rsp.message });
},
},
reducers: {
[acTyp.fetch_dogImg_success](state, { dogImgURL }) {
return { ...state, dogImgURL };
},
},
}给页面添加按钮,绑定点击事件。
import { PureComponent } from 'react';
import styles from './index.css';
import { connect } from 'dva';
import fooModel from '../models/foo';
const { namespace, acTyp } = fooModel;
const mapStateToProps = (state) => {
const { dogImgURL } = state[namespace];
return { dogImgURL };
};
const mpaDispatchToProps = (dispatch) => {
return {
onClickFetchImg() {
return dispatch({ type: `${namespace}/${acTyp.fetch_dogImg}` });
},
};
};
@connect(mapStateToProps, mpaDispatchToProps)
export default class IndexPage extends PureComponent {
render() {
return (
<div>
<div className={styles.normal}>
<h1>Show random dog picture</h1>
</div>
<div>
<img src={this.props.dogImgURL} alt="dog image" height="300" />
</div>
<div style={{ marginTop: '16px' }}>
<button onClick={this.props.onClickFetchImg}>点击获取图片</button>
</div>
</div>
);
}
}最后,我们的目录结构变为,
.
├── .umirc.js
├── package.json
└── src
├── models
│ └── foo.js
├── pages
│ ├── index.css
│ └── index.js
└── utils
└── request.js
效果如下图所示,而且看到 action 在点击后被派发,

在 redux-saga 中,实现轮询逻辑需要两个包含 while (true) 循环的 saga。一个用来监听轮询启动和暂停的指令,起着 saga watcher 的作用,一个用来间隔性地调用 webapi,起着 saga worker 的作用。暂停轮询时需要使用 race effect。二话不说,直接上代码。
首先,在 model 文件中加入轮询的逻辑,
import request from '../utils/request';
+function delay(millseconds) {
+ return new Promise(function(resolve) {
+ setTimeout(resolve, millseconds);
+ });
+}
+
const namespace = 'bar';
const acTyp = {
fetch_dogImg: 'fetch_dogImg',
fetch_dogImg_success: 'fetch_dogImg_success',
+ start_polling_dogImg: 'start_polling_dogImg',
+ stop_polling_dogImg: 'stop_polling_dogImg',
};
Object.freeze(acTyp);
+const endPointURL = 'https://dog.ceo/api/breeds/image/random';
+
+function* pollingDogImgSagaWorker(sagaEffects) {
+ const { call, put } = sagaEffects;
+ while (true) {
+ const rsp = yield call(request, endPointURL);
+ yield call(delay, 1000);
+ yield put({ type: acTyp.fetch_dogImg_success, dogImgURL: rsp.message });
+ }
+}
+
export default {
namespace,
acTyp,
state: {
dogImgURL: 'https://images.dog.ceo/breeds/puggle/IMG_114654.jpg',
},
effects: {
*[acTyp.fetch_dogImg](_, sagaEffects) {
const { call, put } = sagaEffects;
- const rsp = yield call(request, 'https://dog.ceo/api/breeds/image/random');
+ const rsp = yield call(request, endPointURL);
yield put({ type: acTyp.fetch_dogImg_success, dogImgURL: rsp.message });
},
+ 'poll dog image': [function*(sagaEffects) {
+ const { call, take, race } = sagaEffects;
+ while (true) {
+ yield take(acTyp.start_polling_dogImg);
+ yield race([
+ call(pollingDogImgSagaWorker, sagaEffects),
+ take(acTyp.stop_polling_dogImg),
+ ]);
+ }
+ }, { type: 'watcher' }],
},
reducers: {
[acTyp.fetch_dogImg_success](state, { dogImgURL }) {
return { ...state, dogImgURL };
},
+ [acTyp.start_polling_dogImg](state) {
+ return { ...state };
+ },
+ [acTyp.stop_polling_dogImg](state) {
+ return { ...state };
+ },
},
}
然后,在页面中加入可以派发 action 的按钮,
import { PureComponent } from 'react';
import styles from './index.css';
import { connect } from 'dva';
import fooModel from '../models/foo';
const { namespace, acTyp } = fooModel;
const mapStateToProps = (state) => {
const { dogImgURL } = state[namespace];
return { dogImgURL };
};
const mpaDispatchToProps = (dispatch) => {
return {
onClickFetchImg() {
return dispatch({ type: `${namespace}/${acTyp.fetch_dogImg}` });
},
+ onStartPolling() {
+ return dispatch({ type: `${namespace}/${acTyp.start_polling_dogImg}` });
+ },
+ onStopPolling() {
+ return dispatch({ type: `${namespace}/${acTyp.stop_polling_dogImg}` });
+ },
};
};
@connect(mapStateToProps, mpaDispatchToProps)
export default class IndexPage extends PureComponent {
render() {
return (
<div>
<div className={styles.normal}>
<h1>Show random dog picture</h1>
</div>
<div>
<img src={this.props.dogImgURL} alt="dog image" height="300" />
</div>
<div style={{ marginTop: '16px' }}>
<button onClick={this.props.onClickFetchImg}>点击获取图片</button>
+ <button onClick={this.props.onStartPolling}>启动图片轮询</button>
+ <button onClick={this.props.onStopPolling}>停止图片轮询</button>
</div>
</div>
);
}
}如果一切顺利,将会看到本文开头展示的画面,
这里着重解释一下轮询的过程:
'poll dog image' 这个 saga watcher 会随着 dva runtime 的启动而启动,随之进入 while true 的循环当中。但是因为 yield take 而阻塞。start_polling_dogImg action 后,恢复了 watcher 的运行。call(pollingDogImgSagaWorker, sagaEffects) effect 和 take(acTyp.stop_polling_dogImg) effect 都是阻塞式的,所以 'poll dog image' watcher 阻塞在了 yield race 上。
pollingDogImgSagaWorker,仅从此 saga 内部看是永远不会结束的。所以轮询开始后,就每隔一段时间请求一次 webapi。stop_polling_dogImg action 的时候,第二个 effect 阻塞结束,于是 yield race 的阻塞也结束了,同时它会去结束第一个 effect。'poll dog image' 再次阻塞在了 yield take 处,等待启动轮询的 action 派发。没有晦涩的程序跳转,没有递归的 setTimeout,更没有闭包之外的状态变量。笔者认为 redux-saga 提供了一种非常优雅且易于推理的描述异步过程的方式。
作者需要您的支持,如果您觉得本文对您有帮助,请留个言或点个赞 😄,谢谢。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.