forthealllight / blog Goto Github PK
View Code? Open in Web Editor NEW📖我的博客,记录学习的一些笔记,如有喜欢,欢迎star
📖我的博客,记录学习的一些笔记,如有喜欢,欢迎star








































































































































































































PC端的浏览器对于PDF文件的展示没有太大的问题,给定一个PDF的链接,就可以用浏览器默认的展示样式来展示和渲染PDF文件的内容。比如一个"http://www.baidu.com/test/pdf"。 如何在移动端展示这个文件。为了在移动端展示和渲染PDF文件的内容,本文在pdfjs的基础上实现了一个简单的react组件,用于展示和渲染PDF文件。
将这个react组件,以npm包的形式发布。
这个组件的项目地址为:https://github.com/forthealllight/react-read-pdf
(如果想看使用的例子,直接下载这个代码或者clone,然后npm install和npm start即可)
使用React16.5编写的组件,用于在移动设备和PC端显示和渲染PDF文件
(在你的项目中比如先引入react,且必须保证React的版本必须在15.0以上)
安装react-read-pdf包
npm install --save react-read-pdf在PC端建议使用PDFReader:
import React from 'react';
import { PDFReader } from 'react-read-pdf';在移动端建议使用MobilePDFReader,可以自适应各种移动设备:
import React from 'react';
import { MobilePDFReader } from 'react-read-pdf';import { MobilePDFReader } from 'react-read-pdf';
export default class Test extends Component{
render(){
return <div style={{overflow:'scroll',height:600}}>
<MobilePDFReader url="http://localhost:3000/test.pdf"/>
</div>
}
}import ReactDOM from 'react-dom';
import Test from './test'
ReactDOM.render(<Test />, document.getElementById('root'));react-read-pdf 自适配于各种不同的移动设备,包括手机、平板和其他移动办公设备,下图是利用react-read-pdf在iphoneX上展示PDF的一个例子。

react-read-pdf 这个npm包主要包括了两个不同类型的组件 PDFReader 和 MobilePDFReader.
import { PDFReader } from 'react-read-pdf'
...
<PDFReader url={"http://localhost:3000/test.pdf"} ...>| 属性名称 | 类型 | 描述 |
|---|---|---|
| url | 字符串或者对象 | 如果是字符串,那么url表示的是PDF文件的绝对或者相对地址,如果是对象,可以看关于对象属性的具体描述- > url object type |
| data | 字符串 | 用二进制来描述的PDF文件,在javascript中,我们可以通过“atob”,将base64编码的PDF文件,转化为二进制编码的文件。 |
| page | 数字 | 默认值为1,表示应该渲染PDF文件的第几页 |
| scale | 数字 | 决定渲染的过程中视口的大小 |
| width | 数字 | 决定渲染过程中,视口的宽度 |
| showAllPage | 布尔值 | 默认是false,表示不会一次性渲染,只会渲染page的值所指定的那一页。如果这个值为true,则一次性渲染PDF文件所有的页 |
| onDocumentComplete | 函数 | 将PDF文件加载后,可以通过这个函数输出PDF文件的详细信息。这个函数的具体信息如下所示。 function type |
url
**PDFReader**组件的url属性
类型:
属性:
| 属性名 | 类型 | 描述 |
|---|---|---|
| url | 字符串 | 字符串,表示PDF文件的绝对或者相对地址 |
| withCredentials | 布尔值 | 决定请求是否携带cookie |
onDocumentComplete
**PDFReader**的onDocumentComplete属性
Type:
onDocumentComplete的类型是一个函数, 这个函数的第一个参数表示的是PDF文件的总页数。
PDFReader组件的url属性可以是字符串或者是对象。
下面两种方式都是被允许的。
其一是 :
<MobilePDFReader url="http://localhost:3000/test.pdf"/>另外一种方式是 :
<MobilePDFReader url={url:"http://localhost:3000/test.pdf"}/>import { MobilePDFReader } from 'react-read-pdf'
...
<MobilePDFReader url={"http://localhost:3000/test.pdf"} ...>| 属性名称 | 类型 | 描述 |
|---|---|---|
| url | 字符串 | 如果是字符串,那么url表示的是PDF文件的绝对或者相对地址 |
| page | 数字 | 默认值为1,表示应该渲染PDF文件的第几页 |
| scale | 数字或者“auto” | 默认值为“auto”,决定渲染的过程中视口的大小,推荐设置成“auto”可以根据移动设备自适应的适配scale |
| minScale | 数字 | 默认值0.25, scale可取的最小值 |
| maxScale | 数字 | 默认值10, scale可取的最大值 |
| isShowHeader | 布尔值 | 默认值为true,为了生动展示,当值为true,有默认自带的头部样式。设置为false可以去掉这个默认的样式。 |
| isShowFooter | 布尔值 | 默认值为true,为了生动展示,当值为true,有默认自带的尾部样式。设置为false可以去掉这个默认的样式。 |
| onDocumentComplete | 函数 | 将PDF文件加载后,可以通过这个函数输出PDF文件的详细信息。这个函数的具体信息如下所示。function type for details |
onDocumentComplete
**MobilePDFReader**的onDocumentComplete属性
类型: 函数
函数的参数:
| 参数名称 | 类型 | 描述 |
|---|---|---|
| totalPage | 数字 | 表示PDF文件的总页数 |
| title | 字符串 | PDF文件的标题 |
| otherObj | 对象 | PDF文件的其他扩展或者编码信息 |
scale的默认值为“auto”,强烈推荐将scale的值设置成“auto”,这样可以根据移动设备的大小自适应的改变scale的值。
yarn install (or npm install for npm)Development
yarn run start-dev
http://localhost:8080Production
yarn run start-prod
http://localhost:3000指令列表
| Command | Description |
|---|---|
yarn run start-dev |
Build app continuously (HMR enabled) and serve @ http://localhost:8080 |
yarn run start-prod |
Build app once (HMR disabled) and serve @ http://localhost:3000 |
yarn run build |
Build app to /dist/ |
yarn run test |
Run tests |
yarn run lint |
Run Typescript and SASS linter |
yarn run lint:ts |
Run Typescript linter |
yarn run lint:sass |
Run SASS linter |
yarn run start |
(alias of yarn run start-dev) |
Note: replace yarn with npm if you use npm.
简要介绍:为了SEO和加快首屏加载速度,React提供了服务端渲染(Server Side Render)。本文结合express,来介绍一下React16.x中的SSR。
本例代码:https://github.com/forthealllight/react16.0-ssr
单页应用将UI层和内容都由javascript来渲染,搜索引擎或网页爬虫需要完成的HTML结构,因此单页应用如果只在客户端渲染,不利于SEO,此外尽管我们可以通过按需加载的形式来减少首页加载的js,但是通过js来渲染DOM的时候还是会有一定的时间延迟。
因此SSR解决的问题有两个:
SEO
加速首屏加载
在React和Vue等前端框架中,SSR的本质就是由服务端执行渲染,直接将渲染结果以HTML结构的形式返回给客户端。也就是将Virtual DOM转化成字符串的形式返回给客户端。
在React15.x中,有两个方法来处理SSR:
renderToString
renderToStaticMarkup
这两个方法都是在react-dom/server中提供的,用来在服务端将virtual dom渲染成字符串。
renderToString和renderToStaticMarkup都接受一个参数,这个参数是react的组件,返回一段HTML字符串。
renderToString(react element):string
renderToStaticMarkup(react element):string
此外react-dom中给浏览器端提供了一个render方法,render方法将react组件,添加到真实的DOM节点中。render实现的就是浏览器端渲染。
归类一下:
服务端渲染:renderToString、renderToStaticMarkup——>string
客户端渲染:render——>HTML结构
下面我们以renderToString为例,通过express来实现一个服务端渲染的例子。
首先node最新版本为8.9.3,还不支持es6语法,同时为了使node支持jsx,我们需要安装babel,本文为了方便,采用了babel-cli。
首先安装babel-cli:
npm install -d babel-cli
接着安装presets:
npm install -d babel-preset-latest babel-preset-stage-0 babel-preset-react
接着我们在script中:
"start":"babel-node ./server/server.js --presets es2015,stage-0,react"
最后,就可以通过 npm run start的方式实现启动server.js,server.js是经过babel处理,可以支持ES6和jsx.
在server.js中,我们利用了express的路由和中间件模块。
let express=require('express');
let app=express();
import React from 'react';
import {renderToString,renderToStaticMarkup} from 'react-dom/server';
import HomePage from '../src/components/homepage/index.js';
var server=app.listen(8080,()=>{
var host=server.address().address;
var port=server.address().port;
console.log('server is start at',host,port);
});
//static
app.use('/dist',express.static('dist'));
app.get('/',(req,res)=>{
res.write('<!DOCTYPE html><html><head><title>Hello HomePage</title></head><body>');
res.write('<div id="app">');
res.write(renderToString(<HomePage/>));
res.write('</div></body>');
res.write('<script type="text/javascript" src="../dist/vendor.bundle.js"></script><script type="text/javascript" src="../dist/js/app.js"></script>');
res.write('</html>');
})
结构很简单,因为返回的html页面要加载静态资源,因此我们在上述的代码中还使用了express内置的静态文件模块express.static.
最后,通过npm start就能启动本地服务器,在浏览器中打开:
http://localhost:8080/ 就能看到我们SSR的例子。

renderToString:渲染的结果是带有data-reactid属性的,此时,在服务端的基础上,客户端的render不会重新渲染,只会执行组件componetDidmout中的业务,以及绑定事件等等。
renderToStaticMarkup:渲染的结果是不带有data-reactid属性的,此时不管服务端有没有渲染,在客户端中都会重新渲染该组件。
比如在renderToString的关于HomePage的返回HTML字符串结果为:
<h1 data-reactroot>Home Page</h1>
而在renderToStaticMarkup中,关于HomePage的返回HTML字符串结果为:
<h1>Home Page</h1>
在React16.x中,在客户端渲染的render的方法的基础上,增加了一个新的方法hydrate.
简单来说,如果在仅在客户端呈现内容,那么使用render方法就已经足够,如果客户端要在服务端的基础上进行渲染,那么可以使用hydrate.
使用的方法和render一样:
import {hydrate} from 'react-dom';
hydrate(<HomePage/>,document.getElementById('app'));
运行后发现提示:
Warning: render(): Calling ReactDOM.render() to hydrate server-rendered markup will stop working in React v17. Replace the ReactDOM.render() call with ReactDOM.hydrate() if you want React to attach to the server HTML.
说明React16.x中,客户端“水合”服务端,是兼容之前的render方法的,之后的版本中会移除render方法,完全用hydrate来代替。
hydrate方法,解决的是如何复用server端,ReactDOMServer的结果。
此外React16.x中,针对renderToString和renderToStaticMarkup提供了stream的方法:
这两个方法同样接受的参数为react element,但是返回的不是HTML字符串,而是一个可读流。
最后给出完整代码的地址,直接npm start就可以运行:
https://github.com/forthealllight/react16.0-ssr
如果不用babel-cli的方法,来babel node文件,用webpack的话可能会报一下错误:
RROR in ./node_modules/destroy/index.js
Module not found: Error: Can't resolve 'fs' in 'C:\Users\yuxl\Desktop\react-Scaffold-master\node_modules\destroy'
@ ./node_modules/destroy/index.js 14:17-30
@ ./node_modules/send/index.js
@ ./node_modules/express/lib/response.js
@ ./node_modules/express/lib/express.js
@ ./node_modules/express/index.js
@ ./src/server.js
ERROR in ./node_modules/etag/index.js
Module not found: Error: Can't resolve 'fs' in 'C:\Users\yuxl\Desktop\react-Scaffold-master\node_modules\etag'
@ ./node_modules/etag/index.js 22:12-25
@ ./node_modules/express/lib/utils.js
@ ./node_modules/express/lib/application.js
@ ./node_modules/express/lib/express.js
@ ./node_modules/express/index.js
@ ./src/server.js
ERROR in ./node_modules/express/lib/view.js
Module not found: Error: Can't resolve 'fs' in 'C:\Users\yuxl\Desktop\react-Scaffold-master\node_modules\express\lib'
@ ./node_modules/express/lib/view.js 18:9-22
@ ./node_modules/express/lib/application.js
@ ./node_modules/express/lib/express.js
@ ./node_modules/express/index.js
@ ./src/server.js
ERROR in ./node_modules/send/index.js
Module not found: Error: Can't resolve 'fs' in 'C:\Users\yuxl\Desktop\react-Scaffold-master\node_modules\send'
@ ./node_modules/send/index.js 23:9-22
@ ./node_modules/express/lib/response.js
@ ./node_modules/express/lib/express.js
@ ./node_modules/express/index.js
@ ./src/server.js
ERROR in ./node_modules/send/node_modules/mime/mime.js
Module not found: Error: Can't resolve 'fs' in 'C:\Users\yuxl\Desktop\react-Scaffold-master\node_modules\send\node_modules\mime'
@ ./node_modules/send/node_modules/mime/mime.js 2:9-22
@ ./node_modules/send/index.js
@ ./node_modules/express/lib/response.js
@ ./node_modules/express/lib/express.js
@ ./node_modules/express/index.js
也就是webpack在打包的时候找不到 node自带的模块,比如fs等,解决的方法是在webpack的配置文件里面增加:
target:'node'
简要介绍:在webpack的官网,给出了十几种sourcemap,那么每一种sourcemap之间有什么区别,本文在理解sourcemap的基础上,分析在生产和开发环境中,应该采用何种形式的sourcemap
我们在打包中,将开发环境中源代码经过压缩,去空格,babel编译转化,最终可以得到适用于生产环境的项目代码,这样处理后的项目代码和源代码之间差异性很大,会造成无法debug的问题。
举例来说,如果压缩等处理过的生产环境中的代码出现bug,调试的时候只能定位到压缩处理后的代码的位置,无法定位到开发环境中的源代码。
sourcemap就是为了解决上述代码定位的问题,简单理解,就是构建了处理前的代码和处理后的代码之间的桥梁。主要是方便开发人员的错误定位。这里的处理操作包括:
压缩,减小体积
将多个文件合并成同一个文件
其他语言编译成javascript,比如TypeScript和CoffeeScript等
DataURL最早是出现在HTML文件img标签中的关于图片的引用,DataURL提供了一种将图片"嵌入"到HTML中的方法。
跟传统的img的src属性指向服务器中某张图片的地址不同,在Data URL协议中,图片被转换成base64编码的字符串形式,并存储在URL中,冠以mime-type。具体通过DataURL引入图片例子如下:
<img src="data:image/gif;base64,R0lGODlhMwAxAIAAAAAAAP///
yH5BAAAAAAALAAAAAAzADEAAAK8jI+pBr0PowytzotTtbm/DTqQ6C3hGX
ElcraA9jIr66ozVpM3nseUvYP1UEHF0FUUHkNJxhLZfEJNvol06tzwrgd
LbXsFZYmSMPnHLB+zNJFbq15+SOf50+6rG7lKOjwV1ibGdhHYRVYVJ9Wn
k2HWtLdIWMSH9lfyODZoZTb4xdnpxQSEF9oyOWIqp6gaI9pI1Qo7BijbF
ZkoaAtEeiiLeKn72xM7vMZofJy8zJys2UxsCT3kO229LH1tXAAAOw==">
DataURL使用于如下的场景
访问外部资源受限
图片体积小,占用一个HTTP会话资源浪费
webpack在打包中同样支持Sourcemap,并且提供了十几种的组合。我们以官网给出的为例:
eval : 每一个模块都执行eval()过程,并且会追加//@ sourceURL
eval-source-map:每一个模块在执行eval()过程之后,并且会为每一个模块生成sourcemap文件,生成的sourcemap文件通过DataURL的方式添加
cheap-eval-source-map:跟eval-source-map相同,唯一不同的就是增加了"cheap","cheap"是指忽略了行信息。这个属性同时也不会生成不同loader模块之间的sourcemap。
cheap-module-eval-source-map:与cheap-eval-source-map相同,但是包含了不同loader模块之间的sourcemap
官网给出的例子容易让人看懵,因为官网的devtool类型都是以组合形式给出的,实际上webpack中的sourcemap的基本类型包括:eval,cheap,moudule,inline,source-map。其他的类型都是根据这5个基本类型组合而来。我们来具体分析一下这5个基本类型
eval会将每一个module模块,执行eval,执行后不会生成sourcemap文件,仅仅是在每一个模块后,增加sourceURL来关联模块处理前后的对应关系。举例来说:
webpackJsonp([1],[
function(module,exports,__webpack_require__){
eval(
...
//# sourceURL=webpack:///./src/js/index.js?'
)
},
function(module,exports,__webpack_require__){
eval(
...
//# sourceURL=webpack:///./src/static/css/app.less?./~/.npminstall/css-loader/0.23.1/css-loader!./~/.npminstall/postcss-loader/1.1.1/postcss-loader!./~/.npminstall/less-loader/2.2.3/less-loader'
)
},
function(module,exports,__webpack_require__){
eval(
...
//# sourceURL=webpack:///./src/tmpl/appTemplate.tpl?"
)
},
...])
上述是一个指定devtool:eval的压缩后的代码,我们发现压缩后的代码的每一个模块后面都增加了一端包含sourceURL的注释,sourceURL的值是压缩前的代码,这样就通过sourceURL关联了压缩前后的代码,并没有为每一个模块生成相应的sourcemap。
因为不需要生成模块的sourcemap,因此打包的速度很快。
source-map会为每一个打包后的模块生成独立的soucemap文件,举例来说:
webpackJsonp([1],[
function(e,t,i){...},
function(e,t,i){...},
function(e,t,i){...},
function(e,t,i){...},
...
])//# sourceMappingURL=index.js.map
打包后的模块在模块后面会对应引用一个.map文件,同时在打包好的目录下会针对每一个模块生成相应的.map文件,在上例中会生成一个index.js.map文件,这个文件是一个典型的sourcemap文件,形式如下:
{
"version":3,
"sources":[
"webpack:///js/index.js","webpack:///./src/js/index.js",
"webpack:///./~/.npminstall/css-loader/0.23.1/css-loader/lib/css-base.js",
...
],
"names":["webpackJsonp","module","exports"...],
"mappings":"AAAAA,cAAc,IAER,SAASC...",
"file":"js/index.js",
"sourcesContent":[...],
"sourceRoot":""
}
####( 3) inline
与source-map不同,增加inline属性后,不会生成独立的.map文件,而是将.map文件以dataURL的形式插入。如下所示:
webpackJsonp([1],[
function(e,t,i){...},
function(e,t,i){...},
function(e,t,i){...},
function(e,t,i){...},
...
])
//# sourceMappingURL=data:application/json;charset=utf-8;base64,eyJ2ZXJzaW9...
打包好模块后,在sourceMappingURL中直接将.map文件中的内容以DataURL的方式引入。
cheap属性在打包后同样会为每一个模块生成.map文件,但是与source-map的区别在于cheap生成的.map文件会忽略原始代码中的列信息。
devtool: 'eval-source-map'
"mappings": "AAAAA,QAAQC,GAAR,CAAY,aAAZ",
devtool: 'cheap-source-map'
"mappings": "AAAA",
对比增加cheap和没有cheap情况下,打包后输出的.map文件,在文件中
使用了VLQ编码,有"逗号"表示包含了列信息,显然增加cheap属性后,.map文件中不包含列信息。
此外增加cheap后也不会有loader模块之间对应的sourcemap,什么是模块之间的sourcemap呢?
因为webpack最终会将所有的非js资源,通过loader的形式转变成js资源。比如jsx语言的操作分为:
jsx——(loader)——js——(压缩等处理)——压缩后的js
如果没有loader之间的sourcemap,那么在debug的时候定义到上图中的压缩前的js处,而不能追踪到jsx中。
这样差不多就理清了webpack中所有的sourcemap类型。
在了解了webpack中所有的sourcemap基本类型后,我们来分析,如何针对开发环境和生产环境,选择合理的sourcemap属性。
在开发环境中我们使用:cheap-module-eval-source-map
在生产环境中我们使用:cheap-module-source-map。
这里需要补充说明的是,eval-source-map组合使用是指将.map以DataURL的形式引入到打包好的模块中,类似于inline属性的效果,我们在生产中,使用eval-source-map会使打包后的文件太大,因此在生产环境中不会使用eval-source-map。但是因为eval的rebuild速度快,因此我们可以在本地环境中增加eval属性。
小白前端一枚,最近在研究golang,记录自己学习过程中的一些笔记,以及自己的理解。
- go中包的依赖管理
- go中的切片
- byte 和 string
- go中的Map
- go中的struct结构体
- go中的方法
- go中的interface接口
- interface{}
首先要了解的是GOPATH的含义,GOPATH是go命令依赖的重要变量,可以通过:
go env
来查看相应的开发环境中GOPATH的值,也可以通过export GOPATH指定:
export GOPATH = /usr/local/go
指定GOPATH目录后, GOPATH目录包含了3个子目录:
此外,go的依赖管理中提供了3个主要的命令go build、go get和 go install。
典型的例子,比如下载一个dep包:
go get -u github.com/golang/dep/cmd/dep
上述的go get和go install + 远程包的方式,不能应用于需要版本管理依赖等场景,可以通过安装dep包,来实现依赖管理。dep提供了几个常用的命令,分别用于安装和更新相应的go包。
此外通过Gopkg.toml里面可以指定所依赖包的git分支,版本号等等,且在dep ensure -add中也可以指定分支和版本号,比如:
dep ensure -add github.com/pkg/foo@^1.0.1
提到包(package),必须补充一句,在go中如果在其他包中引用变量,是通过:
包名.变量名
的形式,在这里变量名必须是大写的,也就是说在go的包中,变量能否导出是根据变量的大小写来确定的,普遍认为如果变量是大写的就是在包内导出的,如果是变量小写的就是默认是包的私有变量。
在go的函数调用中,如果传递的参数是一个较大的数组,显然如果直接将数组作为实参传入,在执行函数的过程中,实际上会拷贝一份该数组,会造成内存的浪费等。标准的做法,是传入数组的指针,或者对于数组的部分引用。
这里关于数组的部分引用,就是slice切片
数组和切片之间存在着紧密的联系,slice提供了访问数组子序列的功能。所谓的切片是对于数组的部分引用,slice由三部分组成指针、长度和容量。
切片的定义方式:
var slice1 []type = make([]type, len, cap)
分别指定切片的类型,长度以及容量。
切片的初始化:
s := [] int { 1,2,3 }
或者通过已经存在的数组来实现切片的初始化,
arr = [10]int {1,2,3,4,5,6,7,8,9,10}
s:=arr[1:5] // arr[startIndex:endIndex]
go中的slice切片有一个注意点,就是如何判断切片为空,边界情况大致如下所示:
var s []int //len(s)==0,s==nil
s = nil //len(s)==0,s==nil
s = []int(nil)//len(s)==0,s==nil
s = []int{} //len(s)==0,s!=nil
显然如果通过s==nil来判断,不能区别第四种场景,因此判断切片为空的正确方式是len(s)==0.
下述的方法将返回一个byte的切片:
var test:= []byte("hello")
go遍历slice动态删除 map遍历删除安全.
map是一个无序的key/value对的集合,其中在每一个map中key是唯一的。go中的map只要坑在于map是无序的。
声明一个map:
var ages map[string]int //同样初始的情况下,ages = nil
ages == nil // true
如果声明了但是没有赋值,那么尝试插入一对key/value会报错,比如上述声明但没有初始化的情况下:
age["jony"] = 25 // 会panic
解决方法,就是给age定义后赋值:
ages = make(map[string]int)
或者定义的时候同时赋值:
ages := map[string]int{
}
此后插入不存在的key/value就不会报错。
注意:尝试从map中去一个不存在的key,默认的value值为0
我们从map的遍历结果,来说明map是无序的。比如我们以这么一个map为例:
var ages = map[string]int{
"a":21,
"b":22,
"c":23,
};
for name,age := range ages {
fmt.Printf("%s\t%d\n",name,age);
}
通过for range可以遍历map对象,分别执行三次遍历后,来看遍历的结果
第一次输出:
c 23
a 21
b 22
第二次输出:
c 23
b 22
a 21
第三次输出:
a 21
b 22
c 23
从上述的结果我们也可以看出map的每次遍历的结果都是不确定的。
注意:Map的value类型不仅仅可以是基本类型,也可以是聚合类型,比如map或者slice。
跟C++中的结构体类似,go中的结构体是一种聚合数据类型,由0个或者多个任意值聚合成实体。
声明一个结构体很简单,比如我们声明了一个Person结构体:
type Person struct {
name string
age int
salary int
}
然后可以声明一个Person类型的变量:
var person Person
然后可以通过点操作符访问和赋值。
person.age = 25
此外,可以通过取地址符号加点操作符来访问和赋值,下述取地址的方式效果与上述是相同的。
(&person).age = 25
此外,结构体也支持嵌套。
在go中没有明确的定义类,但是可以将结构体struct来类比其他语言中的class。
go中的方法与结构体相关,为了说名go中的方法,我们先从go中的函数讲起。
在go中函数声明包括函数名、形参列表、返回值列表(可省略 表示无返回值)以及函数体。
func name (parameter-list)(result-list){
}
比如我们有一个count函数可以如此简单的定义:
func count(x,y int) int {
return x + y
}
在函数定义的基础上我们来介绍一下,如何定义方法。在函数声明时,在函数名前放上一个变量,这个变量称为方法的接收器,一般是结构体类型的。
当然也不一定是结构体,基本类型数值、字符串、slice和map上面都可以作为接收器来定义方法。
声明方法的方式具体可以如下所示:
func (receive Receive) name(parameter-list)(result-list){
}
从上述的声明中也可以看出来只不过在函数的技术上增加了第一个参数接收器,为相应的接收器增加了该名称的方法。比如我们定一个Person结构体,并为其声明sellHello方法:
type Person struct {
name string
age int
salary int
}
func (person Person) sayHello() string{
return "Hello "+ person.name
}
p := Person{
name: "Jony",
age: 25,
salary:100
}
fmt.Println(p.sayHello());//输出Hello Jony
上述就是在结构体Person上定义了一个sayHello方法,在结构体被初始化后,可以通过p.sayHello()的方式直接调用。
除此之外,我们前面将到定义方法时的接收器不一定是一个结构体,接收器也可以接受基本类型等,比如:
type Mystring string;
func (mystring Mystring)sayHello() string{
return "Hello"+ string(mystring);
}
var m Mystring
m = "Jony"
fmt.Println(m.sayHello());
上述的例子同样会输出Hello Jony.
甚至nil也可以作为方法的接收器,这里就不具体举例。
在函数调用时,是对实参的一个拷贝,如果函数需要更新一个变量,或者传递的参数过大,默认拷贝太为负责,我们经常会使用指针的形式,对于方法而言也同样如此,也就是说方法的接收器可以是指针类型。
对比于上述非指针类型的方法,声明指针类型的方法具体如下所示:
func (receive *Receive) name(parameter-list)(result-list){
}
指针类型的参数作为接收器,可以修改传入参数的实际变量的值。
type Person struct {
name string
age int
salary int
}
func (person *Person) changeAge(newAge int){
(*person).age = newAge
}
p.changeAge(30);
fmt.Println(p.age); //输出了30,发现age确实发生了改变。
我们前面也说过go不是一种传统的面向对象的语言,没有类和继承的概念,go里面通过interface接口可以实现很多面向对象的特性。
接口的通俗定义:
接口提供了一种方式来说明对象的行为,接口定义了一组方法,但是不包含实现。
可以通过如下格式来定义接口:
type Namer interface {
Method1(param_list) return_type
Method2(param_list) return_type
...
}
go中的接口都很简短,一般包含了0-3个方法。
同时我们可以通过:
var ai Namer
来定义一个接口类型的变量,初始值为nil.接口类型的变量是一个指针,声明而未赋值的情况下就为nil。
go中的接口有以下需要注意的点:
上述几点都比较好理解,具体第二点,举例来说:
type Person struct {
name string
age int
salary int
}
type Say interface {
sayHello() string
}
func (person Person) sayHello() string {
return "Hello "+person.name
}
func main() {
p := new(Person)
p.name = "Jony"
var s Say;
s = p;
fmt.Println(s)
}
上述例子中,我们首先new了一个Person结构体类型的变量,并赋值给p,因为Person接口体中实现了Say接口中的所有方法sayHello等。因此我们就说Person实现了Say接口,因此Person的实例p,可以赋值给一个Say接口类型的变量s。
此时的s是个指针,指向Person结构体实例p。
任何类型只要实现了接口中的所有方法,我们就说该类型实现了该接口。这样一个接口类型的变量varI可以包含任何类型的值,在go中提供了一种安全的方式来检测它的动态类型。
if v,ok := varI.(T);ok {
Process(v)
return
}
如果转化合法,那么v是varI转化到类型T的值,ok会是true,否则v是类型T的零值,ok是false。这是一种安全的转化方式不会有错误发生。
我们还是接着上面的代码来讲我们的例子:
type Person struct {
name string
age int
salary int
}
type Say interface {
sayHello() string
}
func (person Person) sayHello() string {
return "Hello "+person.name
}
func main() {
p := new(Person)
p.name = "Jony"
var s Say;
s = p;
if t,ok := s.(*Person);ok {
fmt.Printf("The type of s is:%T\n",t);
}
}
输出的结果为The type of s is:*main.Person。也可以使用特殊的type-switch来判断。
switch t:= s.(*Person){
case *Person:
fmt.Printf("The type of s is:%T\n",t);
case nil:
...
default:
...
}
interface{}是一个空接口,任何类型的值都可以复制给interface{}类型的变量。
比如,我们首先声明一个类型为interface{}的变量:
var test interface{}
任意类型的值都可以复制给test,比如下列基本类型的值复制给test是有效的:
var test interface{}
test = 1
test = true
test ="Hello"
此外,复杂的派生类型也可以赋值给test,我们以指针类型举例:
var test interface{}
var a = 1
test = &a
interface类型的变量是没有类型的,但是我们可以人为的进行类型转换:
var test interface{}
var a string
test = "hello"
a = test.(string)
上述,可以将test转化成string类型,这样就可以赋值给string类型变量a了。通过.(类型名)的方法可以将interface{}类型的变量转化成任意的类型。
最后举一个简单的例子:
func main() {
a := make([]interface{},10)
b :=1
a[1]=&b
fmt.Println(*(a[1].(*int)))
}
上述代码发现,将interface{}类型切片中的某一元素的值复制给了int指针类型,然后进行了类型转化,将interface{}类型的变量转换成了int指针类型。
为了实现分离业务逻辑代码,实现组件内部相关业务逻辑的复用,在React的迭代中针对类组件中的代码复用依次发布了Mixin、HOC、Render props等几个方案。此外,针对函数组件,在React v16.7.0-alpha 中提出了hooks的概念,在本身无状态的函数组件,引入独立的状态空间,也就是说在函数组件中,也可以引入类组件中的state和组件生命周期,使得函数组件变得丰富多彩起来,此外,hooks也保证了逻辑代码的复用性和独立性。
本文从针对类组件的复用解决方案开始说起,先后介绍了从Mixin、HOC到Render props的演进,最后介绍了React v16.7.0-alpha 中的 hooks以及自定义一个hooks
- Mixin
- HOC
- Render props
- React hooks的介绍以及如何自定义一个hooks
Mixin是最早出现的复用类组件中业务逻辑代码的解决方案,首先来介绍以下如何适应Mixin。下面是一个Mixin的例子:
const someMixins={
printColor(){
console.log(this.state.color);
}
setColor(newColor){
this.setState({color:newColor})
}
componentDidMount(){
..
}
}下面是一个使用Mixin的组件:
class Apple extends React.Component{
//仅仅作为演示,mixins一般是通过React.createClass创建,并且ES6中没有这种写法
mixins:[someMixins]
constructor(props){
super(props);
this.state={
color:'red'
}
this.printColor=this.printColor.bind(this);
}
render(){
return <div className="m-box" onClick={this.printColor}>
这是一个苹果
</div>
}
}在类中mixin引入公共业务逻辑:
mixins:[someMixins]从上面的例子,我们来总结以下mixin的缺点:
Mixin是可以存在多个的,是一个数组的形式,且Mixin中的函数是可以调用setState方法组件中的state的,因此如果有多处Mixin的模块中修改了相同的state,会无法确定state的更新来源
ES6 classes支持的是继承的模式,而不支持Mixins
Mixin会存在覆盖,比如说两个Mixin模块,存在相同生命周期函数或者相同函数名的函数,那么会存在相同函数的覆盖问题。
Mixin已经被废除,具体缺陷可以参考Mixins Considered Harmful
为了解决Mixin的缺陷,第二种解决方案是高阶组件(high order component,简称HOC)。
HOC简单理解就是组件工厂,接受原始组件作为参数,添加完功能与业务后,返回新的组件。下面来介绍HOC参数的几个例子。
const redApple = withFruit(Apple);const redApple = withFruit(Apple,{color:'red',weight:'200g'});但是这种情况比较少用,如果对象中仅仅传递的是属性,其实完全可以通过组件的props实现值的传递,我们用HOC的主要目的是分离业务,关于UI的展示,以及一些组件中的属性和状态,我们一般通过props来指定比较方便
const redApp=withFruit(App,()=>{console.log('I am a fruit')})最常见的是仅以一个原始组件作为参数,但是在外层包裹了业务逻辑,比如react-redux的conect函数中:
class Admin extends React.Component{
}
const mapStateToProps=(state)=>{
return {
};
}
const mapDispatchToProps=(dispatch)=>{
return {
}
}
const connect(mapStateToProps,mapDispatchToProps)(Admin)HOC解决了Mixin的一些缺陷,但是HOC本身也有一些缺点:
如果原始组件A,先后通过工厂函数1,工厂函数2,工厂函数3….构造,最后生成了组件B,我们知道组件B中有很多与A组件不同的props,但是我们仅仅通过组件B,并不能知道哪个组件来自于哪个工厂函数。同时,如果有2个工厂函数同时修改了组件A的某个同名属性,那么会有属性覆盖的问题,会使得前一个工厂函数的修改结果失效。
所谓静态构建,也就是说生成的是一个新的组件,并不会马上render,HOC组件工厂是静态构建一个组件,这类似于重新声明一个组件的部分。也就是说,HOC工厂函数里面的声明周期函数,也只有在新组件被渲染的时候才会执行。
Render Props从名知义,也是一种剥离重复使用的逻辑代码,提升组件复用性的解决方案。在被复用的组件中,通过一个名为“render”(属性名也可以不是render,只要值是一个函数即可)的属性,该属性是一个函数,这个函数接受一个对象并返回一个子组件,会将这个函数参数中的对象作为props传入给新生成的组件。
这种方法跟直接的在父组件中,将父组件中的state直接传给子组件的区别是,通过Render Props不用写死子组件,可以动态的决定父组件需要渲染哪一个子组件。
或者再概括一点:
Render Props就是一个函数,做为一个属性被赋值给父组件,使得父组件可以根据该属性去渲染子组件。
首先来看常用的在类组件中常用的父子组件,父组件将自己的状态state,通过props传递给子组件。
class Son extends React.Component{
render(){
const {feature} = this.props;
return <div>
<span>My hair is {feature.hair}</span>
<span>My nose is {feature.nose}</span>
</div>
}
}
class FatherToSon extends React.Component{
constructor(){
this.state = {
hair:'black',
nose:'high'
}
}
render(){
return <Son feature = {this.state}>
}
}我们定义了父组件FatherToSon,存在自身的state,并且将自身的state通过props的方式传递给了子组件。
这种就是常见的利用组件的props父子间传值的方式,这个值可以是变量,对象,也可以是方法,但是仅仅使用只能一次性的给特定的子组件使用。如果现在有个Daughter组件也想复用父组件中的方法或者状态,那么必须新构建一个新组件:
class FatherToDaughter extends React.Component{
constructor(){
this.state = {
hair:'black',
nose:'high'
}
}
render(){
return <Daughter feature = {this.state}>
}
}从上面的例子可以看出通过标准模式的父子组件的通信方法,虽然能够传递父组件的状态和函数,但是无法实现复用。
我们根据Render Props的特点:
Render Props就是一个函数,做为一个属性被赋值给父组件,使得父组件可以根据该属性去渲染子组件。
重新去实现上述的(1)中的例子。
class FatherChild extends React.Component{
constructor(){
this.state = {
hair:'black',
nose:'high'
}
}
render(){
<React.Fragment>
{this.props.render}
</React.Fragment>
}
}此时如果子组件要复用父组件中的属性或者函数,则可以直接使用,比如子组件Son现在可以直接调用:
<FatherChild render={(obj)=>(<Son feature={obj}>)} />如果子组件Daughter要复用父组件的方法,可以直接调用:
<FatherChild render={(obj)=>(<Daughter feature={obj}>)} />从这个例子中可以看出,通过Render Props我们实现同样实现了一个组件工厂,可以实现业务逻辑代码的复用,相比与HOC,Render Props有以下几个优点。
Render Props也有一个缺点:
就是无法利用SCU这个生命周期,来实现渲染性能的优化。
hooks概念在React Conf 2018被提出来,并将在未来的版本中被引入,hooks遵循函数式编程的理念,主旨是在函数组件中引入类组件中的状态和生命周期,并且这些状态和生命周期函数也可以被抽离,实现复用的同时,减少函数组件的复杂性和易用性。
hooks相关的定义还在beta中,可以在React v16.7.0-alpha中体验,为了渲染hooks定义的函数组件,必须执行React-dom的版本也为v16.7.0-alpha,引入hooks必须先安装:
npm i -s React@16.7.0-alpha
npm i -s React-dom@16.7.0-alphahooks主要有三部分组成,State Hooks、Effect Hooks和Custom Hooks,下面分别来一一介绍。
跟类组件一样,这里的state就是状态的含义,将state引入到函数组件中,同时类组件中更新state的方法为setState,在State Hooks中也有相应的更新状态的方法。
function ExampleWithManyStates() {
// 声明各种state以及更新相应的state的方法
const [age, setAge] = useState(42);
const [fruit, setFruit] = useState('banana');
const [todos, setTodos] = useState([{ text: 'Learn Hooks' }]);
// ...
}上述就声明了3个State hooks,相应的方法为useState,该方法创建一个传入初始值,创建一个state。返回一个标识该state的变量,以及更新该state的方法。
从上述例子我们来看,一个函数组件是可以通过useState创建多个state的。此外State Hooks的定义必须在函数组件的最高一级,不能在嵌套,循环等语句中使用。
function ExampleWithManyStates() {
// 声明各种state以及更新相应的state的方法
if(Math.random()>1){
const [age, setAge] = useState(42);
const [todos, setTodos] = useState([{ text: 'Learn Hooks' }]);
}else{
const [fruit, setFruit] = useState('banana');
const [todos, setTodos] = useState([{ text: 'Learn Hooks' }]);
}
// ...
}上述的方式是不被允许的,因为一个函数组件可以存在多个State Hooks,并且useState返回的是一个数组,数组的每一个元素是没有标识信息的,完全依靠调用useState的顺序来确定哪个状态对应于哪个变量,所以必须保证使用useState在函数组件的最外层,此外后面要介绍的Effect Hooks的函数useEffect也必须在函数组件的最外层,之后会详细解释。
通过State Hooks来定义组件的状态,同样通过Effect Hooks来引入生命周期,Effect hooks通过一个useEffect的方法,以一种极为简化的方式来引入生命周期。
来看一个更新的例子:
import { useState, useEffect } from 'react';
function Example() {
const [count, setCount] = useState(0);
useEffect(() => {
document.title = `You clicked ${count} times`;
});
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}上述就是一个通过useEffect来实现组件中生命周期的例子,useEffect整合了componentDidMount和componentDidUpdate,也就是说在componentDidMount和componentDidUpdate的时候都会执行一遍useEffect的函数,此外为了实现componentWillUnmount这个生命周期函数,useEffect函数如果返回值是一个函数,这个函数就被定义成在componentWillUnmount这个周期内执行的函数。
useEffect(() => {
//componentDidMount和componentDidUpdate周期的函数体
return ()=>{
//componentWillUnmount周期的函数体
}
});如果存在多个useState和useEffect时,必须按顺序书写,定义一个useState后,紧接着就使用一个useEffect函数。
useState('Mary')
useEffect(persistForm)
useState('Poppins')
useEffect(updateTitle)因此通useState一样,useEffect函数也必须位于函数组件的最高一级。
上述我们知道useEffect其实包含了componentDidMount和componentDidUpdate,如果我们的方法仅仅是想在componentDidMount的时候被执行,那么必须传递一个空数组作为第二个参数。
useEffect(() => {
//仅在componentDidMount的时候执行
},[]);上述的方法会仅仅在componentDidMount,也就是函数组件第一次被渲染的时候执行,此后及时状态更新,也不会执行。
此外,为了减少不必要的状态更新和渲染,可以如下操作:
useEffect(() => {
//仅在componentDidMount的时候执行
},[stateName]);在上述的这个例子中,只有stateName的值发生改变,才会去执行useEffect函数。
可以将useState和useEffect的状态和生命周期函数抽离,组成一个新的函数,该函数就是一个自定义的封装完毕的hooks。
这是我写的一个hooks ---> dom-location,
可以这样引入:
npm i -s dom-location 并且可以在函数组件中使用。这个自定义的hooks也很简单,就是封装了状态和生命周期函数。
import { useState, useEffect } from 'react'
const useDomLocation = (element) => {
let [elementlocation,setElementlocation] = useState(getlocation(element));
useEffect(()=>{
element.addEventListener('resize',handleResize);
return ()=>{
element.removeEventListener('resize', handleResize);
}
},[]);
function handleResize(){
setElementlocation(getlocation(element));
}
function getlocation(E){
let rect = E.getBoundingClientRect()
let top = document.documentElement.clientTop
let left= document.documentElement.clientLeft
return{
top : rect.top - top,
bottom : rect.bottom - top,
left : rect.left - left,
right : rect.right - left
};
}
return elementlocation
}然后直接在函数中使用:
import useDomLocation from 'dom-location';
function App() {
....
let obj = useDomLocation(element);
}简要介绍:Promise允许我们通过链式调用的方式来解决“回调地狱”的问题,特别是在异步过程中,通过Promise可以保证代码的整洁性和可读性。本文主要解读Promise/A+规范,并在此规范的基础上,自己实现一个Promise.
在了解Promise规范之前,我们知道主流的高版本浏览器已经支持ECMA中的Promise.
创建一个promise实例:
var p=new Promise(function(resolve,reject){
setTimeout(function(){
resolve("success")
},1000);
console.log("创建一个新的promise");
})
p.then(function(x){
console.log(x)
})
//输出:
创建一个新的promise
success
上述是一个promise的实例,输出内容为,“创建一个promise”,延迟1000ms后,输出"success"。
从上述的例子可以看出,promise方便处理异步操作。此外promise还可以链式的调用:
var p=new Promise(function(resolve,reject){resolve()});
p.then(...).then(...).then(...)
此外Promise除了then方法外,还提供了Promise.resolve、Promise.all、Promise.race等等方法。
Promise/A+规范扩展了早期的Promise/A proposal提案,我们来解读一下Promise/A+规范。
(1)"promise"是一个对象或者函数,该对象或者函数有一个then方法
(2)"thenable"是一个对象或者函数,用来定义then方法
(3)"value"是promise状态成功时的值
(4)"reason"是promise状态失败时的值
我们明确术语的目的,是为了在自己实现promise时,保持代码的规范性(也可以跳过此小节)
(1)一个promise必须有3个状态,pending,fulfilled(resolved),rejected当处于pending状态的时候,可以转移到fulfilled(resolved)或者rejected状态。当处于fulfilled(resolved)状态或者rejected状态的时候,就不可变。
promise英文译为承诺,也就是说promise的状态一旦发生改变,就永远是不可逆的。
(2)一个promise必须有一个then方法,then方法接受两个参数:
promise.then(onFulfilled,onRejected)
其中onFulfilled方法表示状态从pending——>fulfilled(resolved)时所执行的方法,而onRejected表示状态从pending——>rejected所执行的方法。
(3)为了实现链式调用,then方法必须返回一个promise
promise2=promise1.then(onFulfilled,onRejected)
解读了Promise/A+规范之后,下面我们来看如何实现一个Promise,
首先构造一个myPromise函数,关于所有变量和函数名,应该与规范中保持相同。
function myPromise(constructor){
let self=this;
self.status="pending" //定义状态改变前的初始状态
self.value=undefined;//定义状态为resolved的时候的状态
self.reason=undefined;//定义状态为rejected的时候的状态
function resolve(value){
//两个==="pending",保证了状态的改变是不可逆的
if(self.status==="pending"){
self.value=value;
self.status="resolved";
}
}
function reject(reason){
//两个==="pending",保证了状态的改变是不可逆的
if(self.status==="pending"){
self.reason=reason;
self.status="rejected";
}
}
//捕获构造异常
try{
constructor(resolve,reject);
}catch(e){
reject(e);
}
}
同时,需要在myPromise的原型上定义链式调用的then方法:
myPromise.prototype.then=function(onFullfilled,onRejected){
let self=this;
switch(self.status){
case "resolved":
onFullfilled(self.value);
break;
case "rejected":
onRejected(self.reason);
break;
default:
}
}
上述就是一个初始版本的myPromise,在myPromise里发生状态改变,然后在相应的then方法里面根据不同的状态可以执行不同的操作。
var p=new myPromise(function(resolve,reject){resolve(1)});
p.then(function(x){console.log(x)})
//输出1
但是这里myPromise无法处理异步的resolve.比如:
var p=new myPromise(function(resolve,reject){setTimeout(function(){resolve(1)},1000)});
p.then(function(x){console.log(x)})
//无输出
为了处理异步resolve,我们修改myPromise的定义,用2个数组onFullfilledArray和onRejectedArray来保存异步的方法。在状态发生改变时,一次遍历执行数组中的方法。
function myPromise(constructor){
let self=this;
self.status="pending" //定义状态改变前的初始状态
self.value=undefined;//定义状态为resolved的时候的状态
self.reason=undefined;//定义状态为rejected的时候的状态
self.onFullfilledArray=[];
self.onRejectedArray=[];
function resolve(value){
if(self.status==="pending"){
self.value=value;
self.status="resolved";
self.onFullfilledArray.forEach(function(f){
f(self.value);
//如果状态从pending变为resolved,
//那么就遍历执行里面的异步方法
});
}
}
function reject(reason){
if(self.status==="pending"){
self.reason=reason;
self.status="rejected";
self.onRejectedArray.forEach(function(f){
f(self.reason);
//如果状态从pending变为rejected,
//那么就遍历执行里面的异步方法
})
}
}
//捕获构造异常
try{
constructor(resolve,reject);
}catch(e){
reject(e);
}
}
对于then方法,状态为pending时,往数组里面添加方法:
myPromise.prototype.then=function(onFullfilled,onRejected){
let self=this;
switch(self.status){
case "pending":
self.onFullfilledArray.push(function(){
onFullfilled(self.value)
});
self.onRejectedArray.push(function(){
onRejected(self.reason)
});
case "resolved":
onFullfilled(self.value);
break;
case "rejected":
onRejected(self.reason);
break;
default:
}
}
这样,通过两个数组,在状态发生改变之后再开始执行,这样可以处理异步resolve无法调用的问题。这个版本的myPromise就能处理所有的异步,那么这样做就完整了吗?
没有,我们做Promise/A+规范的最大的特点就是链式调用,也就是说then方法返回的应该是一个promise。
要通过then方法实现链式调用,那么也就是说then方法每次调用需要返回一个primise,同时在返回promise的构造体里面,增加错误处理部分,我们来改造then方法
myPromise.prototype.then=function(onFullfilled,onRejected){
let self=this;
let promise2;
switch(self.status){
case "pending":
promise2=new myPromise(function(resolve,reject){
self.onFullfilledArray.push(function(){
try{
let temple=onFullfilled(self.value);
resolve(temple)
}catch(e){
reject(e) //error catch
}
});
self.onRejectedArray.push(function(){
try{
let temple=onRejected(self.reason);
reject(temple)
}catch(e){
reject(e)// error catch
}
});
})
case "resolved":
promise2=new myPromise(function(resolve,reject){
try{
let temple=onFullfilled(self.value);
//将上次一then里面的方法传递进下一个Promise的状态
resolve(temple);
}catch(e){
reject(e);//error catch
}
})
break;
case "rejected":
promise2=new myPromise(function(resolve,reject){
try{
let temple=onRejected(self.reason);
//将then里面的方法传递到下一个Promise的状态里
resolve(temple);
}catch(e){
reject(e);
}
})
break;
default:
}
return promise2;
}
这样通过then方法返回一个promise就可以实现链式的调用:
p.then(function(x){console.log(x)}).then(function(){console.log("链式调用1")}).then(function(){console.log("链式调用2")})
//输出
1
链式调用1
链式调用2
这样我们虽然实现了then函数的链式调用,但是还有一个问题,就是在Promise/A+规范中then函数里面的onFullfilled方法和onRejected方法的返回值可以是对象,函数,甚至是另一个promise。
特别的为了解决onFullfilled和onRejected方法的返回值可能是一个promise的问题。
(1)首先来看promise中对于onFullfilled函数的返回值的要求
I)如果onFullfilled函数返回的是该promise本身,那么会抛出类型错误
II)如果onFullfilled函数返回的是一个不同的promise,那么执行该promise的then函数,在then函数里将这个promise的状态转移给新的promise
III)如果返回的是一个嵌套类型的promsie,那么需要递归。
IV)如果返回的是非promsie的对象或者函数,那么会选择直接将该对象或者函数,给新的promise。
根据上述返回值的要求,我们要重新的定义resolve函数,这里Promise/A+规范里面称为:resolvePromise函数,该函数接受当前的promise、onFullfilled函数或者onRejected函数的返回值、resolve和reject作为参数。
下面我们来看resolvePromise函数的定义:
function resolvePromise(promise,x,resolve,reject){
if(promise===x){
throw new TypeError("type error")
}
let isUsed;
if(x!==null&&(typeof x==="object"||typeof x==="function")){
try{
let then=x.then;
if(typeof then==="function"){
//是一个promise的情况
then.call(x,function(y){
if(isUsed)return;
isUsed=true;
resolvePromise(promise,y,resolve,reject);
},function(e){
if(isUsed)return;
isUsed=true;
reject(e);
})
}else{
//仅仅是一个函数或者是对象
resolve(x)
}
}catch(e){
if(isUsed)return;
isUsed=true;
reject(e);
}
}else{
//返回的基本类型,直接resolve
resolve(x)
}
}
改变了resolvePromise函数之后,我们在then方法里面的调用也变成了resolvePromise而不是promise。
myPromise.prototype.then=function(onFullfilled,onRejected){
let self=this;
let promise2;
switch(self.status){
case "pending":
promise2=new myPromise(function(resolve,reject){
self.onFullfilledArray.push(function(){
setTimeout(function(){
try{
let temple=onFullfilled(self.value);
resolvePromise(temple)
}catch(e){
reject(e) //error catch
}
})
});
self.onRejectedArray.push(function(){
setTimeout(function(){
try{
let temple=onRejected(self.reason);
resolvePromise(temple)
}catch(e){
reject(e)// error catch
}
})
});
})
case "resolved":
promise2=new myPromise(function(resolve,reject){
setTimeout(function(){
try{
let temple=onFullfilled(self.value);
//将上次一then里面的方法传递进下一个Promise状态
resolvePromise(temple);
}catch(e){
reject(e);//error catch
}
})
})
break;
case "rejected":
promise2=new myPromise(function(resolve,reject){
setTimeout(function(){
try{
let temple=onRejected(self.reason);
//将then里面的方法传递到下一个Promise的状态里
resolvePromise(temple);
}catch(e){
reject(e);
}
})
})
break;
default:
}
return promise2;
}
这样就能处理onFullfilled各种返回值的情况。
var p=new Promise(function(resolve,reject){resolve("初始化promise")})
p.then(function(){return new Promise(function(resolve,reject){resolve("then里面的promise返回值")})}).then(function(x){console.log(x)})
//输出
then里面promise的返回值
到这里可能有点乱,我们再理一理,首先返回值有两个:
then函数的返回值——>返回一个新promise,从而实现链式调用
then函数中的onFullfilled和onRejected方法——>返回基本值或者新的promise
这两者其实是有关联的,onFullfilled方法的返回值可以决定then函数的返回值。
npm install -g promises-aplus-tests
具体用法请看promise test然后
promises-aplus-tests myPromise.js
结果为:
说明我们的实现完全符合Promise/A+规范。
完整代码的地址
https://github.com/forthealllight/promise-achieve
interface IConstructor{
(resolve:IResolve,reject:IReject):void
}
interface IResolve {
(x:any):void
}
interface IReject {
(x:any):void
}
function myPromise(constructor:IConstructor):void{
let self:object=this;
self.status="pending";
self.value=undefined;//if pending->resolved
self.reason=undefined;//if pending->rejected
self.onFullfilledArray=[];//to deal with async(resolved)
self.onRejectedArray=[];//to deal with async(rejeced)
let resolve:IResolve;
resolve=function(value:any):void{
//pending->resolved
if(self.status==="pending"){
self.status="resolved";
self.value=value;
self.onFullfilledArray.forEach(function(f){
f(self.value);
})
}
}
let reject:IReject;
reject=function(reason:any):void{
if(self.status==="pending"){
self.status="rejected";
self.reason=reason;
self.onRejectedArray.forEach(function(f){
f(self.reason);
})
}
}
//According to the definition that the function "constructor" accept two parameters
//error catch
try {
constructor(resolve,reject);
} catch (e) {
reject(e);
}
}
单纯的写个工具函数,用ts还是有点影响可读性。
最近在做一个较为通用的前端性能监控平台,区别于前端异常监控,前端的性能监控主要需要上报和展示的是前端的性能数据,包括首页渲染时间、每个页面的白屏时间、每个页面所有资源的加载时间以及每一个页面中所以请求的响应时间等等。
本文的介绍的是如何设计一个通用的jssdk,可以以较小的侵入性,自动上报前端的性能数据。主要采用的是Performance API以及sendBeacon方法等等。主要参考的是google analytics以及阿里云前端性能监控平台的实践。
在我的项目中使用nestjs作为后端框架,nestjs是基于express的一款完美支持typescript,类java spring的node后端框架。本文主要侧重与如何上报性能数据,后端处理逻辑比较简单,不会具体介绍,因此不需要了解如何使用nestjs。本文的主要内容包含了:
- 根据Performance API获取前端性能数据
- 何时应该上报性能数据
- 如何上报性能数据
本文上报的前端性能数据包含两部分,一是通过Performance API获得的性能数据,二是自定义的在每个页面应该上报的数据。
首先来看通过Performance API所获取的数据,该数据也包含了两个部分,当前页面的性能相关数据以及当前页面资源加载和异步请求的相关数据。
window.performance.timing会返回一个对象,该对象包含了各种与页面渲染所相关的数据。本文不会具体去介绍该对象,只给出根据该对象计算相关性能数据的方法:
let times = {};
let t = window.performance.timing;
//重定向时间
times.redirectTime = t.redirectEnd - t.redirectStart;
//dns查询耗时
times.dnsTime = t.domainLookupEnd - t.domainLookupStart;
//TTFB 读取页面第一个字节的时间
times.ttfbTime = t.responseStart - t.navigationStart;
//DNS 缓存时间
times.appcacheTime = t.domainLookupStart - t.fetchStart;
//卸载页面的时间
times.unloadTime = t.unloadEventEnd - t.unloadEventStart;
//tcp连接耗时
times.tcpTime = t.connectEnd - t.connectStart;
//request请求耗时
times.reqTime = t.responseEnd - t.responseStart;
//解析dom树耗时
times.analysisTime = t.domComplete - t.domInteractive;
//白屏时间
times.blankTime = t.domLoading - t.fetchStart;
//domReadyTime
times.domReadyTime = t.domContentLoadedEventEnd - t.fetchStart;
在上面的times对象中就包含了性能相关的属性,根据performance.timing中的相关属性计算就可以得到结果。在这里我们认为domReadyTime就是首屏加载的时间,此外也可以自定义的方法上报首屏的时间:
比如有些场景可以认为是dom增量最大的点为首屏渲染完成的时间,也有一些场景可以定义可见的dom在增量最大处为首屏渲染完成的时间。
可以通过window.performance.getEntries()来获取资源的加载和请求相关的数据。每一个页面中,需要去加载很多资源比如js、css等等,同时在页面中还会存在一些异步请求。通过window.performance.getEntries()可以获得这些资源加载和异步请求所相关的数据。我们可以通过如下的方式来获取加载和异步请求的数据:
let entryTimesList = [];
let entryList = window.performance.getEntries();
entryList.forEach((item,index)=>{
let templeObj = {};
let usefulType = ['navigation','script','css','fetch','xmlhttprequest','link','img'];
if(usefulType.indexOf(item.initiatorType)>-1){
templeObj.name = item.name;
templeObj.nextHopProtocol = item.nextHopProtocol;
//dns查询耗时
templeObj.dnsTime = item.domainLookupEnd - item.domainLookupStart;
//tcp链接耗时
templeObj.tcpTime = item.connectEnd - item.connectStart;
//请求时间
templeObj.reqTime = item.responseEnd - item.responseStart;
//重定向时间
templeObj.redirectTime = item.redirectEnd - item.redirectStart;
entryTimesList.push(templeObj);
}
});
我们通过window.performance.getEntries()获得一个带有资源加载和异步请求相关数据的数组,然后根据数组中每一个元素的initiatorType属性来过滤出属性为['navigation','script','css','fetch','xmlhttprequest','link','img']之一的元素数据。
通过window.performance.timing所获的的页面渲染所相关的数据,在单页应用中改变了url但不刷新页面的情况下是不会更新的。因此如果仅仅通过该api是无法获得每一个子路由所对应的页面渲染的时间。如果需要上报切换路由情况下每一个子页面重新render的时间,需要自定义上报。
通过window.performance.getEntries()所获取的资源加载和异步请求所相关的数据,在页面切换路由的时候会重新的计算,可以实现自动的上报。
接着来确定应该何时上报性能数据,因为要处理pv(访问量)和uv(独立用户访问量),一般认为一次上报就是一次访问,那么何时上报性能数据呢。在我的系统中选择在一下场景下进行一次前端性能数据的上报:
针对上述的3种场景,特别是切换路由的情况,如果切换路由是通过改变hash值来实现的,那么只需要监听hashchange事件,如果是通过html5的history api来改变url的,那么需要重新定义pushstate和replacestate事件。具体的做法可以看我的上一篇文章:在单页应用中,如何优雅的监听url的变化。
直接给出history实现路由场景下监听url改变的方案:
var _wr = function(type) {
var orig = history[type];
return function() {
var rv = orig.apply(this, arguments);
var e = new Event(type);
e.arguments = arguments;
window.dispatchEvent(e);
return rv;
};
};
history.pushState = _wr('pushState');
history.replaceState = _wr('replaceState');
然后我们就可以根据上述场景,分别监听相应的事件,从而实现前端性能数据的上报:
addEvent(window,'load',function(e){
...deal with something
});
//监控history基础上实现的单页路由中url的变化
addEvent(window,'replaceState', function(e) {
...deal with something
});
addEvent(window,'pushState', function(e) {
...deal with something
});
//通过hash切换来实现路由的场景
addEvent(window,'hashchange',function(e){
...deal with something
});
addEvent('document','visibilitychang',function(e){
...deal with something
})
addEvent是一个兼容IE和标准DOM事件流模型的事件。
那么如何上报性能数据呢,我们第一反应就是通过ajax请求的形式来上报前端性能数据。这种方法有一些缺陷,比如必须对跨域做特殊处理以及如果页面销毁后,相应的ajax方法并不一定发送成功等问题。
其中跨域的问题比较好处理,最难解决的问题是第二点:
就是如果页面销毁,那么对应的ajax方法并不一定能成功发送。
我们可以根据google analytics(GA)中的方法,根据浏览器的兼容性以及url的长度,来采用不同的方法上报性能数据,主要原理是:
通过动态创建img标签的方式,在img.src中拼接url的方式发送请求,不存在跨域限制。如果url太长,则才用sendBeacon的方式发送请求,如果sendBeacon方法不兼容,则发送ajax post同步请求
解决在文档卸载或者页面关闭后无法完成异步ajax请求的问题,很多情况下我们会把异步变成同步。在页面卸载的unload或者beforeunload事件中执行同步方法调用。
但是同步方法调用存在一个问题,就是会推迟A页面切换进入B页面的时间。而sendBeacon方法解决了该问题,简单来说:
sendBeacon方法在页面销毁期,可以异步的发送数据,因此不会造成类似同步ajax请求那样的阻塞问题,也不会影响下一个页面的渲染
sendBeacon的调用方式为:
navigator.sendBeacon(url [, data]);
data可以为: ArrayBufferView, Blob, DOMString, 或者 FormData
为了发送参数,我们一般data制定为Blob的形式。此外还要注意的是,在sendBeacon的请求头header中,不支持Content-Type为“application/json; charset=utf-8”。
在sendBeacon的header中,只支持一下3种形式的Content—Type:
一般制定为application/x-www-form-urlencoded,完整的通过sendBeacon来发送请求的例子如下:
function sendBeacon(url,data){
//判断支不支持navigator.sendBeacon
let headers = {
type: 'application/x-www-form-urlencoded'
};
let blob = new Blob([JSON.stringify(data)], headers);
navigator.sendBeacon(url,blob);
}
后端如何处理sendBeacon请求呢,sendBeacon在的请求头中发送的是一个类似与POST的请求,因此可以类似于处理post一样来处理sendBeacon请求。
一般我们约定ajax请求的content—type为:“application/json; charset=utf-8”,而sendBeacon请求的content-type为:“application/x-www-form-urlencoded”,这样在后端处理中,就可以区别是正常的ajax post请求还是sendBeacon请求。
此外,在处理请求的时候如果存在跨域问题,通过cors跨域的方式来处理,后端需要配置:allow-control-allow-origin等,可以通过express的cors包,来简化配置:
async function bootstrap() {
const app = await NestFactory.create(ApplicationModule,instance);
app.use(cors());
await app.listen(3000)
}
bootstrap();
通过动态创建img标签的形式,指定src属性所指定的url来发送请求,首先不受跨域的限制,其次img标签动态插入,会延迟页面的卸载保证图片的插入,因此可以保证在页面的销毁期,请求可以发生。
下面是一个动态创建img标签的例子:
function imgReport(url, data) {
if (!url || !data) {
return;
}
let image = document.createElement('img');
let items = [];
items = JSON.Parse(data);
let name = 'img_' + (+new Date());
image.onload = image.onerror = function () {
};
let newUrl = url + (url.indexOf('?') < 0 ? '?' : '&') + items.join('&');
image.src = newUrl;
}
此外,我们在动态创建img标签发送请求的时候,请求的是一张图片,在后端处理的时候,要在末尾将这个图片返回,这样前端的image.onload方法才会被触发。我们以请求的地址为:localhost:8080/1.jpg为例,后端的处理逻辑为:
@Controller('1.jpg')
export class AppUploadController {
constructor(private readonly appService: AppService) {}
@Get()
getUpload(@Req() req,@Res() res): void {
...deal with some thing
res.sendFile(join(__dirname, '..', 'public/1.jpg'))
}
}
在get请求的处理中,我们通过res.sendFile(join(__dirname, '..', 'public/1.jpg'))将图片返回后,这样前端的image的onload方法才会被调用。
动态创建img标签的方法,拼接url的时候存在一定的问题,因为浏览器对url的长度是有限制的。而sendBeacon方法兼容性不是很好,最后兜底的处理方式就是发送同步的ajax请求,同步的ajax请求前面说过,会在页面销毁期之前执行,虽然会有一定程度的阻塞下一个页面的渲染。
function xmlLoadData(url,data) {
var client = new XMLHttpRequest();
client.open("POST", url,false);
client.setRequestHeader("Content-Type", "application/json; charset=utf-8");
client.send(JSON.stringify(data));
}
一般首先拼接携带参数的完整的url,判断url的长度,如果url的长度小于浏览器允许的最大长度内,那么通过动态创建img标签的形式来发送前端性能数据,如果url太长,则判断浏览器是否支持sendBeacon方法,如果支持,则通过sendBeacon方法来发送请求,否则发送同步的ajax请求。
function dealWithUrl(url,appId){
let times = performanceInfo(appId);
let items = decoupling(times);
let urlLength = (url + (url.indexOf('?') < 0 ? '?' : '&') + items.join('&')).length;
if(urlLength<2083){
imgReport(url,times);
}else if(navigator.sendBeacon){
sendBeacon(url,times);
}else{
xmlLoadData(url,times);
}
}
Atom开源且免费,一直用着也蛮舒服的,针对前端开发者介绍一下常用的atom插件。
- atom通用插件
- 前端开发常用的atom插件
- 其他有趣的atom插件
- 常见问题总结
美化文件的图标
代码格式一键美化
代码略缩小地图(没啥卵用,看着比较舒服)
插件备份
内置命令行
支持vim模式
命令行
填写路径时自动补全
快速书写html标签
在编辑器里面选取颜色
支持jsx语法
react语法支持
nodejs、js、es6代码补全
校验js和jsx语法
验证css语法是否正确
为css自动增加前缀(也没有特别有用,用postcss来代替)
闭合html标签(不是特别好用)
代码输入时有震撼效果
随机泡沫
初音
(1)使用Jshint时‘const’ is available in ES6 (use ‘esversion: 6’)
解决方法:在根目录新建一个.jshintrc文件,在该文件中输入:
{
"esversion": 6
}
或者在每一个需要使用es6语法的文件中,在文件头中输入:
/* jshint esversion: 6 */
dva的**还是很不错的,大大提升了开发效率,dva集成了Redux以及Redux的中间件Redux-saga,以及React-router等等。得益于Redux的状态管理,以及Redux-saga中通过Task和Effect来处理异步的概念,dva在这些工具的基础上高度封装,只暴露出几个简单的API就可以设计数据模型。
最近看了一下Redux-saga的源码,结合以及之前在项目中一直采用的是redux-dark模式来将reducers和sagas(generator函数处理异步)拆分到不同的子页面,每一个页面中同一个文件中包含了该页面状态的reducer和saga,这种简单的封装已经可以大大的提升项目的可读性。
最近看了dva源码,熟悉了dva是在上层如何做封装的。下面会从浅到深,淡淡在阅读dva源码过程中自己的理解。
- redux-dark模式
- dva 0.0.12版本的使用和源码理解
在使用redux和redux-saga的时候,特别是如何存放reducer函数和saga的generator函数,这两个函数是直接跟如何处理数据挂钩的。
回顾一下,在redux中使用异步中间件redux-saga后,完整的数据和信息流向:

在存在异步的逻辑下,在UI Component中发出一个plain object的action,然后经过redux-saga这个中间件处理,redux-saga会将这个action传入相应channel,通过redux-saga的effect方法(比如call、put、apply等方法)生成一个描述对象,然后将这个描述对象转化成具有副作用的函数并执行。
在redux-saga执行具有副作用的函数时,又可以dispatch一个action,这个action也是一个plain object,会直接传入到redux的reducer函数中进行处理,也就是说在redux-saga的task中发出的action,就是同步的action。
简单的概括:从UI组件上发出的action经过了2层的处理,分别是redux-saga中间件和redux的reducer函数。
redux-dark模式很简单,就是将同一个子页面下的redux-saga处理action的saga函数,以及reducer处理该子页面下的state的reducer函数,放在同一个文件中。
举例来说:
import { connect } from 'react-redux';
class Hello extends React.Component{
componentDidMount(){
//发出一个action,获取异步数据
this.props.dispatch({
type:'async_count'
})
}
}
export default connect({})(Hello);
从Hello组件中发出一个type = 'async_count'的action,我们用redux-dark模式来将saga和reducer函数放在同一个文件中:
import { takeEvery } from 'redux-saga/effects';
//saga
function * asyncCount(){
console.log('执行了saga异步...')
//发出一个原始的action
yield put({
type:'async'
});
}
function * helloSaga(){
//接受从UI组件发出的action
takeEvery('async_count',asyncCount);
}
//reducer
function helloReducer(state,action){
if(action.type === 'count');
return { ...state,count + 1}
}上述就是一个将saga和reducer放在同一个文件里面的例子。redux-dark模式来组织代码,可以显得比较直观,统一了数据的处理层。分拆子页面后,每一个子页面对应一个文件。可读性很高。
上述的redux-dark模式,就是一种简单的处理,而dva的话是做了更近一步的封装,dva不仅封装了redux和redux-saga,还有react-router-redux、react-router等等。使得我们可以通过很简单的配置,就能使用redux、redux-saga、react-router等。
下面首先以dva的初始版本为例来理解一下dva的源码。
来看官网给的使用dva 0.0.12的例子:
// 1. Initialize
const app = dva();
// 2. Model
app.model({
namespace: 'count',
state: 0,
effects: {
['count/add']: function*() {
console.log('count/add');
yield call(delay, 1000);
yield put({
type: 'count/minus',
});
},
},
reducers: {
['count/add' ](count) { return count + 1 },
['count/minus'](count) { return count - 1 },
},
subscriptions: [
function(dispatch) {
//..处理监听等等函数
}
],
});
// 3. View
const App = connect(({ count }) => ({
count
}))(function(props) {
return (
<div>
<h2>{ props.count }</h2>
<button key="add" onClick={() => { props.dispatch({type: 'count/add'})}}>+</button>
<button key="minus" onClick={() => { props.dispatch({type: 'count/minus'})}}>-</button>
</div>
);
});
// 4. Router
app.router(({ history }) =>
<Router history={history}>
<Route path="/" component={App} />
</Router>
);
// 5. Start
app.start(document.getElementById('root'));只要三步就完成了一个例子,如何处理action呢,我们以一个图来表示:

也就是做UI组件上发出的对象类型的action,先去根据类型匹配=model初始化时候,effects属性中的action type。
在dva初始化过程中的effects属性中的函数,其实就是redux-saga中的saga函数,在该函数中处理直接的异步逻辑,并且该函数可以二次发出同步的action。
此外dva还可以通过router方法初始化路由等。
下面来直接读读dva 0.0.12的源码,下面的代码是经过我精简后的dva的源码:
//Provider全局注入store
import { Provider } from 'react-redux';
//redux相关的api
import { createStore, applyMiddleware, compose, combineReducers } from 'redux';
//redux-saga相关的api,takeEvery和takeLatest监听等等
import createSagaMiddleware, { takeEvery, takeLatest } from 'redux-saga';
//react-router相关的api
import { hashHistory, Router } from 'react-router';
//在react-router4.0之后已经较少使用,将路由的状态存储在store中
import { routerMiddleware, syncHistoryWithStore, routerReducer as routing } from 'react-router-redux';
//redux-actions的api,可以以函数式描述reducer等
import { handleActions } from 'redux-actions';
//redux-saga非阻塞调用effect
import { fork } from 'redux-saga/effects';
function dva() {
let _routes = null;
const _models = [];
//new dva暴露了3个方法
const app = {
model,
router,
start,
};
return app;
//添加models,一个model对象包含了effects,reducers,subscriptions监听器等等
function model(model) {
_models.push(model);
}
//添加路由
function router(routes) {
_routes = routes;
}
function start(container) {
let sagas = {};
//routing是react-router-redux的routerReducer别名,用于扩展reducer,这样以后扩展后的reducer就可以处理路由变化。
let reducers = {
routing
};
_models.forEach(model => {
//对于每一个model,提取其中的reducers和effects,其中reducers用于扩展redux的reducers函数,而effects用于扩展redx-saga的saga处理函数。
reducers[model.namespace] = handleActions(model.reducers || {}, model.state);
//扩展saga处理函数,sagas是包含了所有的saga处理函数的对象
sagas = { ...sagas, ...model.effects }; ---------------------------(1)
});
reducers = { ...reducers };
//获取决定使用React-router中的那一个api
const _history = opts.history || hashHistory;
//初始化redux-saga
const sagaMiddleware = createSagaMiddleware();
//为redux添加中间件,这里添加了处理路由的中间件,以及redux-saga中间件。
const enhancer = compose(
applyMiddleware.apply(null, [ routerMiddleware(_history), sagaMiddleware ]),
window.devToolsExtension ? window.devToolsExtension() : f => f
);
const initialState = opts.initialState || {};
//通过combineReducers来扩展reducers,同时生成扩展后的store实例
const store = app.store = createStore(
combineReducers(reducers), initialState, enhancer
);
// 执行model中的监听函数,监听函数中传入store.dispatch
_models.forEach(({ subscriptions }) => {
if (subscriptions) {
subscriptions.forEach(sub => {
store.dispatch, onErrorWrapper);
});
}
});
// 根据rootSaga来启动saga,rootSaga就是redux-saga运行的主task
sagaMiddleware.run(rootSaga);
//创建history实例子,可以监听store中的state的变化。
let history;
history = syncHistoryWithStore(_history, store); --------------------------------(2)
// Render and hmr.
if (container) {
render();
apply('onHmr')(render);
} else {
const Routes = _routes;
return () => (
<Provider store={store}>
<Routes history={history} />
</Provider>
);
}
function getWatcher(k, saga) {
let _saga = saga;
let _type = 'takeEvery';
if (Array.isArray(saga)) {
[ _saga, opts ] = saga;
_type = opts.type;
}
function* sagaWithErrorCatch(...arg) {
try {
yield _saga(...arg);
} catch (e) {
onError(e);
}
}
if (_type === 'watcher') {
return sagaWithErrorCatch;
} else if (_type === 'takeEvery') {
return function*() {
yield takeEvery(k, sagaWithErrorCatch);
};
} else {
return function*() {
yield takeLatest(k, sagaWithErrorCatch);
};
}
}
function* rootSaga() {
for (let k in sagas) {
if (sagas.hasOwnProperty(k)) {
const watcher = getWatcher(k, sagas[k]);
yield fork(watcher);
} -----------------------------(3)
}
}
function render(routes) {
const Routes = routes || _routes;
ReactDOM.render((
<Provider store={store}>
<Routes history={history} />
</Provider>
), container);
}
}
}
export default dva;代码的阅读在上面都以注视的方式给出,值得注意的主要有一下3点:
const reducer = handleActions(
{
INCREMENT: (state, action) => ({
counter: state.counter + action.payload
}),
DECREMENT: (state, action) => ({
counter: state.counter - action.payload
})
},
{ counter: 0 }
);INCREMENT和DECREMENT属性的函数就可以分别处理,type = "INCREMENT"和type = "DECREMENT"的action。
在注释 (2) 处,通过react-router-redux的api,syncHistoryWithStore可以扩展history,使得history可以监听到store的变化。
在注释(3)处是一个rootSaga, 是redux-saga运行的时候的主Task,在这个Task中我们这样定义:
function* rootSaga() {
for (let k in sagas) {
if (sagas.hasOwnProperty(k)) {
const watcher = getWatcher(k, sagas[k]);
yield fork(watcher);
}
}
}从全局的包含所有saga函数的sagas对象中,获取相应的属性,并fork相应的监听,这里的监听常用的有takeEvery和takeLatest等两个redux-saga的API等。
总结:上面就是dva最早版本的源码,很简洁的使用了redux、redux-saga、react-router、redux-actions、react-router-redux等.其目的也很简单:
简化redux相关生态的繁琐逻辑
单页应用的原理从早起的根据url的hash变化,到根据H5的history的变化,实现无刷新条件下的页面重新渲染。那么在单页应用中是如何监听url的变化呢,本文将总结一下,如何在单页页面中优雅的监听url的变化。
- 单页应用原理
- 监听url中的hash变化
- 监听通过history来改变url的事件
- replaceState和pushState行为的监听
单页应用的原理,在我们的上一篇文章中React-Router源码阅读已经讲的很详细,这里做一个简单介绍。单页应用使得页面可以在无刷新的条件下重新渲染,通过hash或者html5 Bom对象中的history可以做到改变url,但是不刷新页面。
早期的前端路由是通过hash来实现的:
改变url的hash值是不会刷新页面的。
因此可以通过hash来实现前端路由,从而实现无刷新的效果。hash属性位于location对象中,在当前页面中,可以通过:
window.location.hash='edit'
来实现改变当前url的hash值。执行上述的hash赋值后,页面的url发生改变。
赋值前:http://localhost:3000
赋值后:http://localhost:3000/#edit
在url中多了以#结尾的hash值,但是赋值前后虽然页面的hash值改变导致页面完整的url发生了改变,但是页面是不会刷新的。
此外,除了可以通过window.location.hash来改变当前页面的hash值外,还可以通过html的a标签来实现:
<a href="#edit">edit</a>
HTML5的History接口,History对象是一个底层接口,不继承于任何的接口。History接口允许我们操作浏览器会话历史记录。
History提供了一些属性和方法。
History的属性:
History方法:
History.back(): 返回浏览器会话历史中的上一页,跟浏览器的回退按钮功能相同
History.forward():指向浏览器会话历史中的下一页,跟浏览器的前进按钮相同
History.go(): 可以跳转到浏览器会话历史中的指定的某一个记录页
History.pushState():pushState可以将给定的数据压入到浏览器会话历史栈中,该方法接收3个参数,对象,title和一串url。pushState后会改变当前页面url,但是不会伴随着刷新
History.replaceState():replaceState将当前的会话页面的url替换成指定的数据,replaceState后也会改变当前页面的url,但是也不会刷新页面。
上面的方法中,pushState和repalce的相同点:
就是都会改变当前页面显示的url,但都不会刷新页面。
不同点:
pushState是压入浏览器的会话历史栈中,会使得History.length加1,而replaceState是替换当前的这条会话历史,因此不会增加History.length.
通过改变hash值,或者history的repalceState和pushState都可以实现无刷新的改变url。这样还留有一个问题需要解决:
如何监听url的改变
因为我们不仅要无刷新的改变url,还要监听到这个url改变的行为,根据该行为去重新渲染视图。在下几章中,重点介绍一下如何监听url的改变。
通过hash改变了url,会触发hashchange事件,只要监听hashchange事件,就能捕获到通过hash改变url的行为。
window.onhashchange=function(event){
console.log(event);
}
//或者
window.addEventListener('hashchange',function(event){
console.log(event);
})
当hash值改变时,输出一个HashChangeEvent。该HashChangeEvent的具体值为:
{isTrusted: true, oldURL: "http://localhost:3000/", newURL: "http://localhost:3000/#teg", type: "hashchange".....}
有了监听事件,且改变hash页面不刷新,这样我们就可以在监听事件的回调函数中,执行我们展示和隐藏不同UI显示的功能,从而实现前端路由。
在上一章讲到了通过History改变url有以下几种方法:History.back()、History.forward()、History.go()、History.pushState()和History.replaceState()。
同时在history中还支持一个事件,该事件为popstate。第一想法就是如果popstate能够监听所有的history方法所导致的url变化,那么就大功告成了。遗憾的是:
History.back()、History.forward()、History.go()事件是会触发popstate事件的,但是History.pushState()和History.replaceState()不会触发popstate事件。
如果是History.back(),History.forward()、History.go()那么会触发popstate事件,我们只需要:
window.addEventListener('popstate', function(event) {
console.log(event);
})
就可以监听到相应的行为,手动调用:
window.history.go();
window.history.back();
window.history.forward();
都会触发这个事件,此外,在浏览器中点击后退和前进按钮也会触发popstate事件,这个事件内容为:
PopStateEvent {isTrusted: true, state: null, type: "popstate", target: Window, currentTarget: Window, …}
但是,History.pushState()和History.replaceState()不会触发popstate事件,举例来说:
window.addEventListener('popstate', function(event) {
console.log(event);
})
window.history.pushState({first:'first'}, "page 2", "/first"})
上述例子中不会有任何的输出,因为并没有监听的popstate事件的发生。
但是History.go和History.back()等,虽然可以触发popstate事件,但是都会刷新页面,我们在单页应用中使用的是replaceState和pushState,因此这里还有一个等待解决的问题:
如何监听replaceState和pushState行为
在上面的例子中我们发现History.replaceState和pushState确实不会触发popstate事件,那么如何监听这两个行为呢。可以通过在方法里面主动的去触发popState事件。另一种就是在方法中创建一个新的全局事件。
具体做法为:
var _wr = function(type) {
var orig = history[type];
return function() {
var rv = orig.apply(this, arguments);
var e = new Event(type);
e.arguments = arguments;
window.dispatchEvent(e);
return rv;
};
};
history.pushState = _wr('pushState');
history.replaceState = _wr('replaceState');
这样就创建了2个全新的事件,事件名为pushState和replaceState,我们就可以在全局监听:
window.addEventListener('replaceState', function(e) {
console.log('THEY DID IT AGAIN! replaceState 111111');
});
window.addEventListener('pushState', function(e) {
console.log('THEY DID IT AGAIN! pushState 2222222');
});
这样就可以监听到pushState和replaceState行为。
在前端监控系统中,或者其他场景下,如果我们需要监控当前页面下所有请求状态。可能通常请求下,我们会选择在请求的回调中去处理。这种做法的缺点就是会侵入具体的业务代码。在通常的监控中,监控部分的代码和业务部分的代码是分离的。此外,如果存在很多的请求需要被监听,通过侵入具体业务代码,为了减少代码的重复,也需要封装监听请求的逻辑。
本文通过monkey patches的方法实现了一个request-interceptor包,可以按需求监听请求。
该npm包的项目地址为:https://github.com/forthealllight/request-intercept 欢迎使用。
- 获取API请求的状态和结果
- monkey patches实现监控XMLHttpRequest请求
- monkey patches实现监控fetch请求
获取请求的方式包含了fetch和XMLHttpRequest。比如下面是一个XMLHttpRequest请求的例子:
var client = new XMLHttpRequest();
client.open("POST","http://10.12.72.16:8080/extraInfo" );
client.setRequestHeader("Content-Type", "application/json; charset=utf-8");
client.send(JSON.stringify({}));通常我们会通过client上出发的readystatechange来判断请求的状态以及得到请求的响应结果:
client.onreadystatechange = function () {
if (client .readyState==4 &&client.status==200) {
console.log(client.responseText);//
}
}XMLHttpRequest的prototype除了onreadystatechange事件外还有其他很多事件,比如onabout、onerror、onload、onloadstart等等事件。如果我们要完整的监听一个请求,那么需要实现完整的实现这些事件:
client.onabout = function(){}
client.onerror = function(){}
clinet.onload = function(){}
client.onloadstart = function(){}
....此外如果当某一个事件发生时,需要按顺序的实行一系列的函数,这样会使得事件函数内部越来越复杂,使得整体项目变的无法维护。
fetch请求也是同理,因此我们需要合理的封装监听请求的逻辑。
本文不会具体介绍如何通过monkey patches来封装监听请求的逻辑,该逻辑已经在我的npm包中实现,具体可以参考我的开源项目:
https://github.com/forthealllight/request-intercept
本文只介绍如何使用,如有兴趣,可以读一读具体如何实现这个monkey patches,在目录的source文件夹中,如有疑问,可以提issue。
该npm包的包名为:req-interceptor。首先来看对于XMLHttpRequest请求如何使用:
import { ajaxIntercept } from 'req-interceptor';
//监听
const unregister = ajaxIntercept.register({
requestAbout: function (xhr) {
// xhr is real instance of a request
console.log(xhr)
},
requestError: function (xhr) {
// xhr is real instance of a request
console.log(xhr)
},
requestLoad: function (xhr) {
// xhr is real instance of a request
console.log(xhr)
},
});
//发送请求
var client = new XMLHttpRequest();
client.open("POST","http://10.12.72.16:8080/extraInfo" );
client.setRequestHeader("Content-Type", "application/json; charset=utf-8");
client.send(JSON.stringify({}));只需要在发送请求前先调用ajaxIntercept.register函数传入监听的对象,该函数会返回一个取消监听的方法。
这样就监听之后的任意请求,在ajaxIntercept.register中的实际参数的对象中,对象的属性是一个函数,参数为xhr,xhr就是一个被监听的XMLHttpRquest,因此我们可以从xhr中拿到请求的具体响应。xhr的一个例子为:
xhr = {
readyState: 4
response: "{"success":0}"
responseText: "{"success":0}"
responseType: ""
responseURL: "http://10.12.72.16:8080/extraInfo"
responseXML: null
status: 201
statusText: "Created"
timeout: 0
}如果我们在取消对于某一个请求的监听,则调用该返回的
unregister函数,此后请求不会再被监听。
unregister();
此外我们也可以在某一个请求前添加多个监听函数:
import { ajaxIntercept } from 'req-interceptor';
//监听
const unregister1 = ajaxIntercept.register({...});
const unregister2 = ajaxIntercept.register({...});
const unregister3 = ajaxIntercept.register({...});
//请求
client.open(url,....)
如果我们想要一次性移除所有的对于请求的监听函数,可以直接调用:
ajaxIntercept.clear();对于fetch请求也是一样的。
import { fetchIntercept } from 'req-interceptor';
import { fetchIntercept } from 'req-interceptor';
const unregister = fetchIntercept.register({
request: function (url, config) {
// Modify the url or config here
return [url, config];
},
requestError: function (error) {
// Called when an error occured during another 'request' interceptor call
return Promise.reject(error);
},
response: function (response) {
// Modify the reponse object
return response;
},
responseError: function (error) {
// Handle an fetch error
return Promise.reject(error);
}
});
// Call fetch to see your interceptors in action.
fetch('http://google.com');不同的是,fetch不像XMLHttpRequest请求那样,可以监听完整的过程,fetch只有request、requestError、response和responseError这4个属性可以监听,分别映射请求的参数,请求失败,请求返回成功,请求返回失败。
同样的也可以通过返回函数来取消监听,以及通过clear函数来取消所有监听函数。
node的事件模块只包含了一个类:EventEmitter。这个类在node的内置模块和第三方模块中大量使用。EventEmitter本质上是一个观察者模式的实现,这种模式可以扩展node在多个进程或网络中运行。本文从node的EventEmitter的使用出发,循序渐进的实现一个完整的EventEmitter模块。
- EventEmitter模块的基本用法和简单实现
- node中常用的EventEmitter模块的API
- EventEmitter模块的异常处理
- 完整的实现一个EventEmitter模块
首先先了解一下EventEmitter模块的基本用法,EventEmitter本质上是一个观察者模式的实现,所谓观察者模式:
它定义了对象间的一种一对多的关系,让多个观察者对象同时监听某一个主题对象,当一个对象发生改变时,所有依赖于它的对象都将得到通知。
因此最基本的EventEmitter功能,包含了一个观察者和一个被监听的对象,对应的实现就是EventEmitter中的on和emit:
var events=require('events');
var eventEmitter=new events.EventEmitter();
eventEmitter.on('say',function(name){
console.log('Hello',name);
})
eventEmitter.emit('say','Jony yu');
eventEmitter是EventEmitter模块的一个实例,eventEmitter的emit方法,发出say事件,通过eventEmitter的on方法监听,从而执行相应的函数。
根据上述的例子,我们知道了EventEmitter模块的基础功能emit和on。下面我们实现一个包含emit和on方法的EventEmitter类。
on(eventName,callback)方法传入两个参数,一个是事件名(eventName),另一个是相应的回调函数,我们选择在on的时候针对事件名添加监听函数,用对象来包含所有事件。在这个对象中对象名表示事件名(eventName),而对象的值是一个数组,表示该事件名所对应的执行函数。
emit(eventName,...arg)方法传入的参数,第一个为事件名,其他参数事件对应的执行函数中的实参,emit方法的功能就是从事件对象中,寻找对应key为eventName的属性,执行该属性所对应的数组里面每一个执行函数。
下面来实现一个EventEmitter类
class EventEmitter{
constructor(){
this.handler={};
}
on(eventName,callback){
if(!this.handles){
this.handles={};
}
if(!this.handles[eventName]){
this.handles[eventName]=[];
}
this.handles[eventName].push(callback);
}
emit(eventName,...arg){
if(this.handles[eventName]){
for(var i=0;i<this.handles[eventName].length;i++){
this.handles[eventName][i](...arg);
}
}
}
}
上述就实现了一个简单的EventEmitter类,下面来实例化:
let event=new EventEmitter();
event.on('say',function(str){
console.log(str);
});
event.emit('say','hello Jony yu');
//输出hello Jony yu
跟在上述简单的EventEmitter模块不同,node的EventEmitter还包含了很多常用的API,我们一一来介绍几个实用的API.
| 方法名 | 方法描述 |
|---|---|
| addListener(event, listener) | 为指定事件添加一个监听器到监听器数组的尾部。 |
| prependListener(event,listener) | 与addListener相对,为指定事件添加一个监听器到监听器数组的头部。 |
| on(event, listener) | 其实就是addListener的别名 |
| once(event, listener) | 为指定事件注册一个单次监听器,即 监听器最多只会触发一次,触发后立刻解除该监听器。 |
| removeListener(event, listener) | 移除指定事件的某个监听器,监听器必须是该事件已经注册过的监听器 |
| off(event, listener) | removeListener的别名 |
| removeAllListeners([event]) | 移除所有事件的所有监听器, 如果指定事件,则移除指定事件的所有监听器。 |
| setMaxListeners(n) | 默认情况下, EventEmitters 如果你添加的监听器超过 10 个就会输出警告信息。 setMaxListeners 函数用于提高监听器的默认限制的数量。 |
| listeners(event) | 返回指定事件的监听器数组。 |
| emit(event, [arg1], [arg2], [...]) | 按参数的顺序执行每个监听器,如果事件有注册监听返回 true,否则返回 false。 |
除此之外,还有2个特殊的,不需要手动添加,node的EventEmitter模块自带的特殊事件:
| 事件名 | 事件描述 |
|---|---|
| newListener | 该事件在添加新事件监听器的时候触发 |
| removeListener | 从指定监听器数组中删除一个监听器。需要注意的是,此操作将会改变处于被删监听器之后的那些监听器的索引 |
上述node的EventEmitter的模块看起来很多很复杂,其实上述的API中包含了一些别名,仔细整理,理解其使用和实现不是很困难,下面一一对比和介绍上述的API。
addListener(eventName,listener)的作用是为指定事件添加一个监听器. 其别名为on
removeListener(eventName,listener)的作用是为移除某个事件的监听器. 其别名为off
再次需要强调的是:addListener的别名是on,removeListener的别名是off
EventEmitter.prototype.on=EventEmitter.prototype.addListener
EventEmitter.prototype.off=EventEmitter.prototype.removeListener
接着我们来看具体的用法:
var events=require('events');
var emitter=new events.EventEmitter();
function hello1(name){
console.log("hello 1",name);
}
function hello2(name){
console.log("hello 2",name);
}
emitter.addListener('say',hello1);
emitter.addListener('say',hello2);
emitter.emit('say','Jony');
//输出hello 1 Jony
//输出hello 2 Jony
emitter.removeListener('say',hello1);
emitter.emit('say','Jony');
//相应的监听say事件的hello1事件被移除
//只输出hello 2 Jony
removeListener指的是移除一个指定事件的某一个监听器,而removeAllListeners指的是移除某一个指定事件的全部监听器。
这里举例一个removeAllListeners的例子:
var events=require('events');
var emitter=new events.EventEmitter();
function hello1(name){
console.log("hello 1",name);
}
function hello2(name){
console.log("hello 2",name);
}
emitter.addListener('say',hello1);
emitter.addListener('say',hello2);
emitter.removeAllListeners('say');
emitter.emit('say','Jony');
//removeAllListeners移除了所有关于say事件的监听
//因此没有任何输出
on和once的区别是:
on的方法对于某一指定事件添加的监听器可以持续不断的监听相应的事件,而once方法添加的监听器,监听一次后,就会被消除。
比如on方法(跟addListener相同):
var events=require('events');
var emitter=new events.EventEmitter();
function hello(name){
console.log("hello",name);
}
emitter.on('say',hello);
emitter.emit('say','Jony');
emitter.emit('say','yu');
emitter.emit('say','me');
//会一次输出 hello Jony、hello yu、hello me
也就是说on方法监听的事件,可以持续不断的被触发。
我们知道当实例化EventEmitter模块之后,监听对象是一个对象,包含了所有的监听事件,而这两个特殊的方法就是针对监听事件的添加和移除的。
newListener:在添加新事件监听器触发
removeListener:在移除事件监听器时触发
以newListener为例,会在添加新事件监听器的时候触发:
var events=require('events');
var emitter=new events.EventEmitter();
function hello(name){
console.log("hello",name);
}
emitter.on('newListener',function(eventName,listener){
console.log(eventName);
console.log(listener);
});
emitter.addListener('say',hello);
//输出say和[Function: hello]
从上述的例子来看,每当添加新的事件,都会自动的emit一个“newListener”事件,且参数为eventName(新事件的名)和listener(新事件的执行函数)。
同理特殊事件removeListener也是同样的,当事件被移除,会自动emit一个"removeListener"事件。
在node中也可以通过try catch方式来捕获和处理异常,比如:
try {
let x=x;
} catch (e) {
console.log(e);
}
上述let x=x 赋值语句的错误会被捕获。这里提异常处理,那么跟事件有什么关系呢?
node中有一个特殊的事件error,如果异常没有被捕获,就会触发process的uncaughtException事件抛出,如果你没有注册该事件的监听器(即该事件没有被处理),则 Node.js 会在控制台打印该异常的堆栈信息,并结束进程。
比如:
var events=require('events');
var emitter=new events.EventEmitter();
emitter.emit('error');
在上述代码中没有监听error的事件函数,因此会触发process的uncaughtException事件,从而打印异常堆栈信息,并结束进程。
对于阻塞或者说非异步的异常捕获,try catch是没有问题的,但是:
try catch不能捕获非阻塞或者异步函数里面的异常。
举例来说:
try {
let x=x;//第二个x在使用前未定义,会抛出异常
} catch (e) {
console.log('该异常已经被捕获');
console.log(e);
}
上述代码中,以为try方法里面是同步的,因此可以捕获异常。如果try方法里面有异步的函数:
try {
process.nextTick(function(){
let x=x; //第二个x在使用前未定义,会抛出异常
});
} catch (e) {
console.log('该异常已经被捕获');
console.log(e);
}
因为process.nextTick是异步的,因此在process.nextTick内部的错误不能被捕获,也就是说try catch不能捕获非阻塞函数内的异常。
node中domain模块能被用来集中地处理多个异常操作,通过node的domain模块可以捕获非阻塞函数内的异常。
var domain=require('domain');
var eventDomain=domain.create();
eventDomain.on('error',function(err){
console.log('该异常已经被捕获了');
console.log(err);
});
eventDomain.run(function(){
process.nextTick(function(){
let x=x;//抛出异常
});
});
同样的,即使process.nextTick是一个异步函数,domain.on方法也可以捕获这个异步函数中的异常。
即使更复杂的情况下,比如异步嵌套异步的情况下,domain.on方法也可以捕获异常。
var domain=require('domain');
var eventDomain=domain.create();
eventDomain.on('error',function(err){
console.log('该异常已经被捕获了');
console.log(err);
});
eventDomain.run(function(){
process.nextTick(function(){
setTimeout(function(){
setTimeout(function(){
let x=x;
},0);
},0);
});
});
在上述的情况下,即使异步嵌套很复杂,也能在最外层捕获到异常。
在node最新的文档中,domain被废除(被标记为:Deprecated),domain从诞生之日起就有着缺陷,举例来说:
var domain = require('domain');
var EventEmitter = require('events').EventEmitter;
var e = new EventEmitter();
var timer = setTimeout(function () {
e.emit('data');
}, 10);
function next() {
e.once('data', function () {
throw new Error('something wrong here');
});
}
var d = domain.create();
d.on('error', function () {
console.log('cache by domain');
});
d.run(next);
如上述的代码是无法捕获到异常Error的,原因在于发出异常的EventEmitter实例e,以及触发异常的定时函数timer没有被domain包裹。domain模块是通过重写事件循环中的nextTick和_tickCallback来事件将process.domain注入到next包裹的所有异步事件内。
解决上述无法捕获异常的情况,只需要将e或者timer包裹进domain。
d.add(e)或者d.add(timer)
就可以成功的捕获异常。
domain模块已经在node最新的文档中被废除
node中提供了一个最外层的兜底的捕获异常的方法。非阻塞或者异步函数中的异常都会抛出到最外层,如果异常没有被捕获,那么会暴露出来,被最外层的process.on('uncaughtException')所捕获。
try {
process.nextTick(function(){
let x=x; //第二个x在使用前未定义,会抛出异常
},0);
} catch (e) {
console.log('该异常已经被捕获');
console.log(e);
}
process.on('uncaughtException',function(err){console.log(err)})
这样就能在最外层捕获异步或者说非阻塞函数中的异常。
在第二节中我们知道了EventEmitter模块的基本用法,那么根据基本的API我们可以进一步自己去实现一个EventEmitter模块。
每一个EventEmitter实例都有一个包含所有事件的对象_events,
事件的监听和监听事件的触发,以及监听事件的移除等都在这个对象_events的基础上实现。
emit的方法实现的大致功能如下程序流程图所示:

从上述的程序图出发,我们开始实现自己的EventEmitter模块。
首先生成一个EventEmitter类,在类的初始化方法中生成这个事件对象_events.
class EventEmitter{
constructor(){
if(this._events===undefined){
this._events=Object.create(null);//定义事件对象
this._eventsCount=0;
}
}
}
_eventsCount用于统计事件的个数,也就是_events对象有多少个属性。
接着我们来实现emit方法,根据框图,我们知道emit所做的事情是在_events对象中取出相应type的属性,并执行属性所对应的函数,我们来实现这个emit方法。
class EventEmitter{
constructor(){
if(this._events===undefined){
this._events=Object.create(null);//定义事件对象
this._eventsCount=0;
}
}
emit(type,...args){
const events=this._events;
const handler=events[type];
//判断相应type的执行函数是否为一个函数还是一个数组
if(typeof handler==='function'){
Reflect.apply(handler,this,args);
}else{
const len=handler.length;
for(var i=0;li<len;i++){
Reflect.apply(handler[i],this,args);
}
}
return true;
}
}
emit方法是出发事件,并执行相应的方法,而on方法则是对于指定的事件添加监听函数。用程序来说,就是往事件对象中_events添加相应的属性.程序流程图如下所示:

接着我们来实现这个方法:
on(type,listener,prepend){
var m;
var events;
var existing;
events=this._events;
//添加事件的
if(events.newListener!==undefined){
this.emit('newListener',type,listener);
events=target._events;
}
existing=events[type];
//判断相应的type的方法是否存在
if(existing===undefined){
//如果相应的type的方法不存在,这新增一个相应type的事件
existing=events[type]=listener;
++this._eventsCount;
}else{
//如果存在相应的type的方法,判断相应的type的方法是一个数组还是仅仅只是一个方法
//如果仅仅是
if(typeof existing==='function'){
//如果仅仅是一个方法,则添加
existing=events[type]=prepend?[listener,existing]:[existing,listener];
}else if(prepend){
existing.unshift(listener);
}else{
existing.push(listener);
}
}
//链式调用
return this;
}
在on方法的基础上可以实现addListener方法和prependListener方法。
addListener方法是on方法的别名:
EventEmitter.prototype.addListener=EventEmitter.prototype.on
prependListener方法相当于在头部添加,指定prepend为true:
EventEmitter.prototype.prependListener =
function prependListener(type, listener) {
return EventEmitter.prototype.on(type, listener, true);
};
接着来看移除事件监听的方法removeListener和removeAllListeners,下面我们来看removeListener的程序流程图:
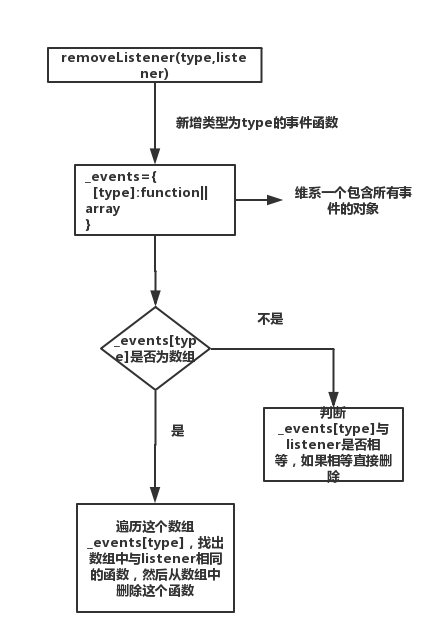
接着来看removeListener的代码:
removeListener(type,listener){
var list,events,position,i,originalListener;
events=this._events;
list=events[type];
//如果相应的事件对象的属性值是一个函数,也就是说事件只被一个函数监听
if(list===listener){
if(--this._eventsCount===0){
this._events=Object.create(null);
}else{
delete events[type];
//如果存在对移除事件removeListener的监听函数,则触发removeListener
if(events.removeListener)
this.emit('removeListener',type,listener);
}
}else if(typeof list!=='function'){
//如果相应的事件对象属性值是一个函数数组
//遍历这个数组,找出listener对应的那个函数,在数组中的位置
for(i=list.length-1;i>=0;i--){
if(list[i]===listener){
position=i;
break;
}
}
//没有找到这个函数,则返回不做任何改动的对象
if(position){
return this;
}
//如果数组的第一个函数才是所需要删除的对应listener函数,则直接移除
if(position===0){
list.shift();
}else{
list.splice(position,1);
}
if(list.length===1)
events[type]=list[0];
if(events.removeListener!==undefined)
this.emit('removeListener',type,listener);
}
return this;
}
最后来看removeAllListener,这个与removeListener相似,只要找到传入的type所对应属性的值,没有遍历过程,直接删除这个属性即可。
除此之外,还有其他的类似与once、setMaxListeners、listeners也可以在此基础上实现,就不一一举例。
本文从node的EventEmitter模块的使用出发,介绍了EventEmitter提供的常用API,然后介绍了node中基于EventEmitter的异常处理,最后自己实现了一个较为完整的EventEmitter模块。
node遵循的是单线程单进程的模式,node的单线程是指js的引擎只有一个实例,且在nodejs的主线程中执行,同时node以事件驱动的方式处理IO等异步操作。node的单线程模式,只维持一个主线程,大大减少了线程间切换的开销。
但是node的单线程使得在主线程不能进行CPU密集型操作,否则会阻塞主线程。对于CPU密集型操作,在node中通过child_process可以创建独立的子进程,父子进程通过IPC通信,子进程可以是外部应用也可以是node子程序,子进程执行后可以将结果返回给父进程。
此外,node的单线程,以单一进程运行,因此无法利用多核CPU以及其他资源,为了调度多核CPU等资源,node还提供了cluster模块,利用多核CPU的资源,使得可以通过一串node子进程去处理负载任务,同时保证一定的负载均衡型。本文从node的单线程单进程的理解触发,介绍了child_process模块和cluster模块,本文的结构安排如下:
- node中的单线程和单进程
- node中的child_process模块实现多进程
- node中的cluster模块
- 总结
首先要理解的概念是,node的单线程和单进程的模式。node的单线程于其他语言的多线程模式相比,减小了线程间切换的开销,以及在写node代码的时候不用考虑锁以及线程池的问题。node宣称的单线程模式,比其他语言更加适合IO密集型操作。那么一个经典的问题是:
node是真的单线程的吗?
提到node,我们就可以立刻想到单线程、异步IO、事件驱动等字眼。首先要明确的是node真的是单线程的吗,如果是单线程的,那么异步IO,以及定时事件(setTimeout、setInterval等)又是在哪里被执行的。
严格来说,node并不是单线程的。node中存在着多种线程,包括:
我们平时所说的单线程是指node中只有一个js引擎在主线程上运行。其他异步IO和事件驱动相关的线程通过libuv来实现内部的线程池和线程调度。libv中存在了一个Event Loop,通过Event Loop来切换实现类似于多线程的效果。简单的来讲Event Loop就是维持一个执行栈和一个事件队列,当前执行栈中的如果发现异步IO以及定时器等函数,就会把这些异步回调函数放入到事件队列中。当前执行栈执行完成后,从事件队列中,按照一定的顺序执行事件队列中的异步回调函数。

上图中从执行栈,到事件队列,最后事件队列中按照一定的顺序执行回调函数,整个过程就是一个简化版的Event Loop。此外回调函数执行时,同样会生成一个执行栈,在回调函数里面还有可能嵌套异步的函数,也就是说执行栈存在着嵌套。
也就是说node中的单线程是指js引擎只在唯一的主线程上运行,其他的异步操作,也是有独立的线程去执行,通过libv的Event Loop实现了类似于多线程的上下文切换以及线程池调度。线程是最小的进程,因此node也是单进程的。这样就解释了为什么node是单线程和单进程的。
node是单进程的,必然存在一个问题,就是无法充分利用cpu等资源。node提供了child_process模块来实现子进程,从而实现一个广义上的多进程的模式。通过child_process模块,可以实现1个主进程,多个子进程的模式,主进程称为master进程,子进程又称工作进程。在子进程中不仅可以调用其他node程序,也可以执行非node程序以及shell命令等等,执行完子进程后,以流或者回调的形式返回。
child_process提供了4个方法,用于新建子进程,这4个方法分别为spawn、execFile、exec和fork。所有的方法都是异步的,可以用一张图来描述这4个方法的区别。

上图可以展示出这4个方法的区别,我们也可以简要介绍这4中方法的不同。
spawn : 子进程中执行的是非node程序,提供一组参数后,执行的结果以流的形式返回。
execFile:子进程中执行的是非node程序,提供一组参数后,执行的结果以回调的形式返回。
exec:子进程执行的是非node程序,传入一串shell命令,执行后结果以回调的形式返回,与execFile
不同的是exec可以直接执行一串shell命令。
fork:子进程执行的是node程序,提供一组参数后,执行的结果以流的形式返回,与spawn不同,fork生成的子进程只能执行node应用。接下来的小节将具体的介绍这一些方法。
我们首先比较execFile和exec的区别,这两个方法的相同点:
执行的是非node应用,且执行后的结果以回调函数的形式返回。
不同点是:
exec是直接执行的一段shell命令,而execFile是执行的一个应用
举例来说,echo是UNIX系统的一个自带命令,我们直接可以在命令行执行:
echo hello world
结果,在命令行中会打印出hello world.
新建一个main.js文件中,如果要使用exec方法,那么则在该文件中写入:
let cp=require('child_process');
cp.exec('echo hello world',function(err,stdout){
console.log(stdout);
});
执行这个main.js,结果会输出hello world。我们发现exec的第一个参数,跟shell命令完全相似。
let cp=require('child_process');
cp.execFile('echo',['hello','world'],function(err,stdout){
console.log(stdout);
});
execFile类似于执行了名为echo的应用,然后传入参数。execFlie会在process.env.PATH的路径中依次寻找是否有名为'echo'的应用,找到后就会执行。默认的process.env.PATH路径中包含了'usr/local/bin',而这个'usr/local/bin'目录中就存在了这个名为'echo'的程序,传入hello和world两个参数,执行后返回。
像exec那样,可以直接执行一段shell是极为不安全的,比如有这么一段shell:
echo hello world;rm -rf
通过exec是可以直接执行的,rm -rf会删除当前目录下的文件。exec正如命令行一样,执行的等级很高,执行后会出现安全性的问题,而execFile不同:
execFile('echo',['hello','world',';rm -rf'])
在传入参数的同时,会检测传入实参执行的安全性,如果存在安全性问题,会抛出异常。除了execFile外,spawn和fork也都不能直接执行shell,因此安全性较高。
spawn同样是用于执行非node应用,且不能直接执行shell,与execFile相比,spawn执行应用后的结果并不是执行完成后,一次性的输出的,而是以流的形式输出。对于大批量的数据输出,通过流的形式可以介绍内存的使用。
我们用一个文件的排序和去重来举例:

上述图片示意图中,首先读取的input.txt文件中有acba未经排序的文字,通过sort程序后可以实现排序功能,输出为aabc,最后通过uniq程序可以去重,得到abc。我们可以用spawn流形式的输入输出来实现上述功能:
let cp=require('child_process');
let cat=cp.spawn('cat',['input.txt']);
let sort=cp.spawn('sort');
let uniq=cp.spawn('uniq');
cat.stdout.pipe(sort.stdin);
sort.stdout.pipe(uniq.stdin);
uniq.stdout.pipe(process.stdout);
console.log(process.stdout);
执行后,最后的结果将输入到process.stdout中。如果input.txt这个文件较大,那么以流的形式输入输出可以明显减小内存的占用,通过设置缓冲区的形式,减小内存占用的同时也可以提高输入输出的效率。
在javascript中,在处理大量计算的任务方面,HTML里面通过web work来实现,使得任务脱离了主线程。在node中使用了一种内置于父进程和子进程之间的通信来处理该问题,降低了大数据运行的压力。node中提供了fork方法,通过fork方法在单独的进程中执行node程序,并且通过父子间的通信,子进程接受父进程的信息,并将执行后的结果返回给父进程。
使用fork方法,可以在父进程和子进程之间开放一个IPC通道,使得不同的node进程间可以进行消息通信。
在子进程中:
通过process.on('message')和process.send()的机制来接收和发送消息。
在父进程中:
通过child.on('message')和process.send()的机制来接收和发送消息。
具体例子,在child.js中:
process.on('message',function(msg){
process.send(msg)
})
在parent.js中:
let cp=require('child_process');
let child=cp.fork('./child');
child.on('message',function(msg){
console.log('got a message is',msg);
});
child.send('hello world');
执行parent.js会在命令行输出:got a message is hello world
中断父子间通信的方式,可以通过在父进程中调用:
child.disconnect()
来实现断开父子间IPC通信。
exec、execFile、spawn和fork执行的子进程都是默认异步的,子进程的运行不会阻塞主进程。除此之外,child_process模块同样也提供了execFileSync、spawnSync和execSync来实现同步的方式执行子进程。
cluster意为集成,集成了两个方面,第一个方面就是集成了child_process.fork方法创建node子进程的方式,第二个方面就是集成了根据多核CPU创建子进程后,自动控制负载均衡的方式。
我们从官网的例子来看:
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`主进程 ${process.pid} 正在运行`);
// 衍生工作进程。
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`工作进程 ${worker.process.pid} 已退出`);
});
} else {
// 工作进程可以共享任何 TCP 连接。
// 在本例子中,共享的是一个 HTTP 服务器。
http.createServer((req, res) => {
res.writeHead(200);
res.end('你好世界\n');
}).listen(8000);
console.log(`工作进程 ${process.pid} 已启动`);
}
最后输出的结果为:
$ node server.js
主进程 3596 正在运行
工作进程 4324 已启动
工作进程 4520 已启动
工作进程 6056 已启动
工作进程 5644 已启动
我们将master称为主进程,而worker进程称为工作进程,利用cluster模块,使用node封装好的API、IPC通道和调度机可以非常简单的创建包括一个master进程下HTTP代理服务器 + 多个worker进程多个HTTP应用服务器的架构。
本文首先介绍了node的单线程和单进程模式,接着从单线程的缺陷触发,介绍了node中如何实现子进程的方法,对比了child_process模块中几种不同的子进程生成方案,最后简单介绍了内置的可以实现子进程以及CPU进程负载均衡的内置集成模块cluster。
对于较长的列表,比如1000个数组的数据结构,如果想要同时渲染这1000个数据,生成相应的1000个原生dom,我们知道原生的dom元素是很复杂的,如果长列表通过生成如此多的dom元素来实现,很可能使网页失去响应。
贯穿React核心的就是"virtual dom",我们同样的可以通过用虚拟列表的方式来优雅的优化长列表
- 原生dom渲染长列表的缺陷
- 虚拟列表优化长列表的原理
- 通过react-virtualized来优化长列表
- 通过react-tiny-virtual-list来优化长列表
首先我们尝试在React项目中,未做任何优化一次性渲染1000个dom,每个dom包含一个img标签,原生dom本身是很复杂的对象,加上img标签后。渲染的效果如下图所示:
从上图我们可以看出,是确确实实的生成了1000个真实的dom,进入页面后,需要渲染这1000个dom,因此白屏的时间很长。
此外,在直接渲染1000个dom节点的页面,触发滚动事件,也会使得内存用量增加,具体可以如下图所示:
此外同时渲染很多dom节点,也会造成一下几个问题:
容易失帧,因为渲染很慢,所以无法维持浏览器的帧率,主观上会显得页面卡顿
网页失去响应,事件等无法及时被触发
上述的效果都是在PC端展示的,对于特定的移动设备,直接无优化的渲染长列表所造成的问题会更加的放大。长列表的渲染在移动端的很多场景会遇到,比如微博,feeds流中等等。合理的优化长列表,可以提升用户体验。
优化长列表的原理很简单,基本原理可以一句话概括:
用数组保存所有列表元素的位置,只渲染可视区内的列表元素,当可视区滚动时,根据滚动的offset大小以及所有列表元素的位置,计算在可视区应该渲染哪些元素。
具体实现步骤如下所示:
通过虚拟列表优化后,同样的显示1000个包含图片的dom,白屏时间会大大的减少。具体效果如下图所示:

对于比无优化的情况,优化后的虚拟列表渲染速度提升很明显。
社区实现虚拟列表的React组件很多,较为常用的是react-virtualized和react-tiny-virtual-list,前一个较为全面,第二个较为轻量。接下来会分别来介绍这俩个React组件库。
react-virtualized是一个实现虚拟列表较为优秀的组件库,react-virtualized提供了一些基础组件用于实现虚拟列表,虚拟网格,虚拟表格等等,它们都可以减小不必要的dom渲染。此外还提供了几个高阶组件,可以实现动态子元素高度,以及自动填充可视区等等。
react-virtualized的基础组件包含:
值得注意的是这些基础组件都是继承于React中的PureComponent,因此当state变化的时候,只会做一个浅比较来确定重新渲染与否
。
除了这几个基础组件外,react-virtualized还提供了几个高阶组件,比如ArrowKeyStepper
、AutoSizer、CellMeasurer、InfiniteLoader等,本文具体介绍常用的AutoSizer、CellMeasurer和InfiniteLoader。
下面我们来介绍一下常用的基础组件Grid、List。
所有基础组件基本上都是基于Grid构成的,一个简单的Grid的例子如下:
import { Grid } from 'react-virtualized';
const list = [
['Jony yu', 'Software Engineer', 'Shenzhen', 'CHINA', 'GUANGZHOU'],
['Jony yu', 'Software Engineer', 'Shenzhen', 'CHINA', 'GUANGZHOU'],
['Jony yu', 'Software Engineer', 'Shenzhen', 'CHINA', 'GUANGZHOU'],
['Jony yu', 'Software Engineer', 'Shenzhen', 'CHINA', 'GUANGZHOU'],
['Jony yu', 'Software Engineer', 'Shenzhen', 'CHINA', 'GUANGZHOU'],
['Jony yu', 'Software Engineer', 'Shenzhen', 'CHINA', 'GUANGZHOU']
];
function cellRenderer ({ columnIndex, key, rowIndex, style }) {
return (
<div
key={key}
style={style}
>
{list[rowIndex][columnIndex]}
</div>
)
}
render(
<Grid
cellRenderer={cellRenderer}
columnCount={list[0].length}
columnWidth={100}
height={300}
rowCount={list.length}
rowHeight={80}
width={300}
/>,
rootEl
);
显示的效果如下图所示:
渲染网格也是只渲染可视区的dom节点,有个有趣的现象是滚动条的大小,这里Grid做了一个细节优化,只有滚动的时候才会显示滚动条,停止滚动后会隐藏滚动条。
接着来举例说明一下List的使用:
import { List } from 'react-virtualized';
import loremIpsum from "lorem-ipsum"
const rowCount = 1000;
const list = Array(rowCount).fill().map(()=>{
return loremIpsum({
count: 1,
units: 'sentences',
sentenceLowerBound: 3,
sentenceUpperBound: 3
}
})
function rowRenderer ({
key,
index,
isScrolling,
isVisible,
style
}) {
return (
<div
key={key}
style={style}
>
{list[index]}
</div>
)
}
export default class TestList extends Component{
render(){
return <div style={{height:"300px",width:"200px"}}>
<List
width={300}
height={300}
rowCount={list.length}
rowHeight={20}
rowRenderer={rowRenderer}
/>
</div>
}
}
List的使用方法也是极简,指定列表总条数rowCount,每一条的高度rowHeight以及每次渲染的函数rowRenderer,就可以构建一个渲染列表。具体的效果如下图所示:

结合List来看看react-virtualized高阶组件的使用。
首先来看使用不使用AutoSizer的缺点,如下图所示,List只能指定固定的大小,如果其所在的父元素的大小resize了,那么List是不会主动填满父元素的可视区的:

从上图可以看出来,List是无法自动填充父元素的。因此我们这里需要使用AutoSizer。AutoSizer的使用也很简单,我们只需要在List的基础上:
class TestList extends Component{
render(){
return <div>
<AutoSizer>
{({ height, width }) => (
<List
height={height}
rowCount={list.length}
rowHeight={20}
rowRenderer={rowRenderer}
width={width}
/>
)}
</AutoSizer>
</div>
}
}
效果如下图所示:
上述可以看出来增加了AutoSizer可以动态的适应父元素宽度和高度的变化。
但是也存在一个问题:
子元素太长,换行后改变了子元素的高度后无法子适应,也就是说仅仅通过基础的组件List是不支持子元素的高度动态改变的场景。
为了解决上述的子元素可以动态变化的问题,我们可以利用高阶组件CellMeasurer:
import { List,AutoSizer,CellMeasurer, CellMeasurerCache} from 'react-virtualized';
const cache = new CellMeasurerCache({ defaultHeight: 30,fixedWidth: true});
function cellRenderer ({ index, key, parent, style }) {
console.log(index)
return (
<CellMeasurer
cache={cache}
columnIndex={0}
key={key}
parent={parent}
rowIndex={index}
>
<div
style={style}
>
{list[index]}
</div>
</CellMeasurer>
);
}
对于需要渲染的List,如下所示:
class TestList extends Component{
render(){
return <div>
<AutoSizer>
{({ height, width }) => (
<List
height={height}
rowCount={list.length}
rowHeight={cache.rowHeight}
deferredMeasurementCache={cache}
rowRenderer={cellRenderer}
width={width}
/>
)}
</AutoSizer>
</div>
}
}
最后的结果如下所示:
上图我们看出来,子列表元素的高度可以动态变化,通过CellMeasurer可以实现子元素的动态高度。
最后我们来考虑这种无限滚动的场景,很多情况下我们可能需要分页加载,就是常见的在可视区内无限滚动的场景。react-virtualized提供了一个高阶组件InfiniteLoader用于实现无限滚动。
InfiniteLoader的使用很简单,只要按着文档来即可,就是分页的去在家下一页,滚动分页所调用的函数为:
function loadMoreRows ({ startIndex, stopIndex }) {
return new Promise(function(resolve,reject){
resolve()
}).then(function(){
//模拟ajax请求
let temList = Array(10).fill(1).map(()=>{
return loremIpsum({
count: 1,
units: 'sentences',
sentenceLowerBound:3,
sentenceUpperBound:3
})
})
list = list.concat(temList)
})
}
最后的效果如下:

看起来跟基础组件List一样,其实唯一的区别就是会在滚动的时候自动执行loadMoreRows函数去更新list
通过基础组件Grid、List以及高阶组件AutoSizer、CellMeasurer和InfiniteLoader,已经可以构建出比较复杂的场景,但是有一个缺陷,就是CellMeasurer虽说一定程度上支持动态子元素的高度的变化,其实是一种估算,存在很多边界情况,无法适应于动态元素的场景,特别是文本节点较多导致的高度变化。但是对于图片节点的动态高度支持没有很大的问题。
举例一种边界情况,CellMeasurer无法支持文本动态高度的情况:

从上图可以看到,慢慢缩小的过程中,如果缩的太小,并没有动态的撑大子元素的高度,出现了文字的重叠。
react-tiny-virtual-list是一个较为轻量的实现虚拟列表的组件,不同于react-virtualized支持网格以及表格等渲染优化。
react-tiny-virtual-list只支持列表,使用方便,其源码也只有700多行。
使用极其简单:
import VirtualList from 'react-tiny-virtual-list';
const data = ['A', 'B', 'C', 'D', 'E', 'F','A', 'B', 'C',
'D', 'E', 'F','A', 'B', 'C', 'D', 'E', 'F',
'A', 'B', 'C', 'D', 'E', 'F'];
export default class TinyVirtual extends Component {
render(){
return <VirtualList
width='100%'
height={200}
itemCount={data.length}
itemSize={50} // Also supports variable heights (array or function getter)
renderItem={({index, style}) =>
<div key={index} style={style}>
// The style property contains the item's absolute position Letter: {data[index]}, Row: #{index}
</div>
}
/>
}
}
最后的渲染结果也是相似的,也可以支持无限滚动等等。
但是react-tiny-virtual-list有一个致命的缺点:
完全不支持子元素的动态高度或者宽度
本文介绍了虚拟列表的优化的原理,以及常用的React可以优化虚拟列表的组件库。在接下来的文章中,会具体的介绍react-tiny-virtual-list和react-virtualized的源码,敬请期待。
js是前端开发人员必须熟练掌握的技能,这里概括js的一些必须了解的理论知识:
- 梳理js基础知识
- 查漏补缺
误区:我们经常说get请求参数的大小存在限制,而post请求的参数大小是无限制的。
实际上HTTP 协议从未规定 GET/POST 的请求长度限制是多少。对get请求参数的限制是来源与浏览器或web服务器,浏览器或web服务器限制了url的长度。为了明确这个概念,我们必须再次强调下面几点:
post/get的请求区别,具体不再赘述。
补充补充一个get和post在缓存方面的区别:
一句话可以概括:闭包就是能够读取其他函数内部变量的函数,或者子函数在外调用,子函数所在的父函数的作用域不会被释放。
(1)类的创建(es5):new一个function,在这个function的prototype里面增加属性和方法。
下面来创建一个Animal类:
// 定义一个动物类
function Animal (name) {
// 属性
this.name = name || 'Animal';
// 实例方法
this.sleep = function(){
console.log(this.name + '正在睡觉!');
}
}
// 原型方法
Animal.prototype.eat = function(food) {
console.log(this.name + '正在吃:' + food);
};
这样就生成了一个Animal类,实力化生成对象后,有方法和属性。
(2)类的继承——原型链继承
--原型链继承
function Cat(){ }
Cat.prototype = new Animal();
Cat.prototype.name = 'cat';
// Test Code
var cat = new Cat();
console.log(cat.name);
console.log(cat.eat('fish'));
console.log(cat.sleep());
console.log(cat instanceof Animal); //true
console.log(cat instanceof Cat); //true
(3)构造继承:使用父类的构造函数来增强子类实例,等于是复制父类的实例属性给子类(没用到原型)
function Cat(name){
Animal.call(this);
this.name = name || 'Tom';
}
// Test Code
var cat = new Cat();
console.log(cat.name);
console.log(cat.sleep());
console.log(cat instanceof Animal); // false
console.log(cat instanceof Cat); // true
(4)实例继承和拷贝继承
实例继承:为父类实例添加新特性,作为子类实例返回
拷贝继承:拷贝父类元素上的属性和方法
上述两个实用性不强,不一一举例。
(5)组合继承:相当于构造继承和原型链继承的组合体。通过调用父类构造,继承父类的属性并保留传参的优点,然后通过将父类实例作为子类原型,实现函数复用
function Cat(name){
Animal.call(this);
this.name = name || 'Tom';
}
Cat.prototype = new Animal();
Cat.prototype.constructor = Cat;
// Test Code
var cat = new Cat();
console.log(cat.name);
console.log(cat.sleep());
console.log(cat instanceof Animal); // true
console.log(cat instanceof Cat); // true
(6)寄生组合继承:通过寄生方式,砍掉父类的实例属性,这样,在调用两次父类的构造的时候,就不会初始化两次实例方法/属性
function Cat(name){
Animal.call(this);
this.name = name || 'Tom';
}
(function(){
// 创建一个没有实例方法的类
var Super = function(){};
Super.prototype = Animal.prototype;
//将实例作为子类的原型
Cat.prototype = new Super();
})();
// Test Code
var cat = new Cat();
console.log(cat.name);
console.log(cat.sleep());
console.log(cat instanceof Animal); // true
console.log(cat instanceof Cat); //true
promise、generator、async/await
HTML中与javascript交互是通过事件驱动来实现的,例如鼠标点击事件onclick、页面的滚动事件onscroll等等,可以向文档或者文档中的元素添加事件侦听器来预订事件。想要知道这些事件是在什么时候进行调用的,就需要了解一下“事件流”的概念。
什么是事件流:事件流描述的是从页面中接收事件的顺序,DOM2级事件流包括下面几个阶段。
addEventListener:addEventListener 是DOM2 级事件新增的指定事件处理程序的操作,这个方法接收3个参数:要处理的事件名、作为事件处理程序的函数和一个布尔值。最后这个布尔值参数如果是true,表示在捕获阶段调用事件处理程序;如果是false,表示在冒泡阶段调用事件处理程序。
IE只支持事件冒泡。
在DOM标准事件模型中,是先捕获后冒泡。但是如果要实现先冒泡后捕获的效果,对于同一个事件,监听捕获和冒泡,分别对应相应的处理函数,监听到捕获事件,先暂缓执行,直到冒泡事件被捕获后再执行捕获之间。
简介:事件委托指的是,不在事件的发生地(直接dom)上设置监听函数,而是在其父元素上设置监听函数,通过事件冒泡,父元素可以监听到子元素上事件的触发,通过判断事件发生元素DOM的类型,来做出不同的响应。
举例:最经典的就是ul和li标签的事件监听,比如我们在添加事件时候,采用事件委托机制,不会在li标签上直接添加,而是在ul父元素上添加。
好处:比较合适动态元素的绑定,新添加的子元素也会有监听函数,也可以有事件触发机制。
预加载:提前加载图片,当用户需要查看时可直接从本地缓存中渲染。
懒加载:懒加载的主要目的是作为服务器前端的优化,减少请求数或延迟请求数。
两种技术的本质:两者的行为是相反的,一个是提前加载,一个是迟缓甚至不加载。
懒加载对服务器前端有一定的缓解压力作用,预加载则会增加服务器前端压力。
mouseover:当鼠标移入元素或其子元素都会触发事件,所以有一个重复触发,冒泡的过程。对应的移除事件是mouseout
mouseenter:当鼠标移除元素本身(不包含元素的子元素)会触发事件,也就是不会冒泡,对应的移除事件是mouseleave
new 操作符新建了一个空对象,这个对象原型指向构造函数的prototype,执行构造函数后返回这个对象。
通过apply和call改变函数的this指向,他们两个函数的第一个参数都是一样的表示要改变指向的那个对象,第二个参数,apply是数组,而call则是arg1,arg2...这种形式。
通过bind改变this作用域会返回一个新的函数,这个函数不会马上执行。
clientHeight:表示的是可视区域的高度,不包含border和滚动条
offsetHeight:表示可视区域的高度,包含了border和滚动条
scrollHeight:表示了所有区域的高度,包含了因为滚动被隐藏的部分。
clientTop:表示边框border的厚度,在未指定的情况下一般为0
scrollTop:滚动后被隐藏的高度,获取对象相对于由offsetParent属性指定的父坐标(css定位的元素或body元素)距离顶端的高度。
首先是三个事件,分别是mousedown,mousemove,mouseup
当鼠标点击按下的时候,需要一个tag标识此时已经按下,可以执行mousemove里面的具体方法。
clientX,clientY标识的是鼠标的坐标,分别标识横坐标和纵坐标,并且我们用offsetX和offsetY来表示元素的元素的初始坐标,移动的举例应该是:
鼠标移动时候的坐标-鼠标按下去时候的坐标。
也就是说定位信息为:
鼠标移动时候的坐标-鼠标按下去时候的坐标+元素初始情况下的offetLeft.
还有一点也是原理性的东西,也就是拖拽的同时是绝对定位,我们改变的是绝对定位条件下的left
以及top等等值。
补充:也可以通过html5的拖放(Drag 和 drop)来实现
defer:只支持IE如果您的脚本不会改变文档的内容,可将 defer 属性加入到<script>标签中,以便加快处理文档的速度。因为浏览器知道它将能够安全地读取文档的剩余部分而不用执行脚本,它将推迟对脚本的解释,直到文档已经显示给用户为止。
async,HTML5属性仅适用于外部脚本,并且如果在IE中,同时存在defer和async,那么defer的优先级比较高,脚本将在页面完成时执行。
创建script标签,插入到DOM中
在ajax发送请求前加上 anyAjaxObj.setRequestHeader("If-Modified-Since","0")。
在ajax发送请求前加上 anyAjaxObj.setRequestHeader("Cache-Control","no-cache")。
在URL后面加上一个随机数: "fresh=" + Math.random()。
在URL后面加上时间搓:"nowtime=" + new Date().getTime()。
如果是使用jQuery,直接这样就可以了 $.ajaxSetup({cache:false})。这样页面的所有ajax都会执行这条语句就是不需要保存缓存记录。
http://www.cnblogs.com/coco1s/p/5499469.html
必要性:由于字符串、对象和数组没有固定大小,所有当他们的大小已知时,才能对他们进行动态的存储分配。JavaScript程序每次创建字符串、数组或对象时,解释器都必须分配内存来存储那个实体。只要像这样动态地分配了内存,最终都要释放这些内存以便他们能够被再用,否则,JavaScript的解释器将会消耗完系统中所有可用的内存,造成系统崩溃。
这段话解释了为什么需要系统需要垃圾回收,JS不像C/C++,他有自己的一套垃圾回收机制(Garbage Collection)。JavaScript的解释器可以检测到何时程序不再使用一个对象了,当他确定了一个对象是无用的时候,他就知道不再需要这个对象,可以把它所占用的内存释放掉了。例如:
var a="hello world";
var b="world";
var a=b;
//这时,会释放掉"hello world",释放内存以便再引用
垃圾回收的方法:标记清除、计数引用。
这是最常见的垃圾回收方式,当变量进入环境时,就标记这个变量为”进入环境“,从逻辑上讲,永远不能释放进入环境的变量所占的内存,永远不能释放进入环境变量所占用的内存,只要执行流程进入相应的环境,就可能用到他们。当离开环境时,就标记为离开环境。
垃圾回收器在运行的时候会给存储在内存中的变量都加上标记(所有都加),然后去掉环境变量中的变量,以及被环境变量中的变量所引用的变量(条件性去除标记),删除所有被标记的变量,删除的变量无法在环境变量中被访问所以会被删除,最后垃圾回收器,完成了内存的清除工作,并回收他们所占用的内存。
另一种不太常见的方法就是引用计数法,引用计数法的意思就是每个值没引用的次数,当声明了一个变量,并用一个引用类型的值赋值给改变量,则这个值的引用次数为1,;相反的,如果包含了对这个值引用的变量又取得了另外一个值,则原先的引用值引用次数就减1,当这个值的引用次数为0的时候,说明没有办法再访问这个值了,因此就把所占的内存给回收进来,这样垃圾收集器再次运行的时候,就会释放引用次数为0的这些值。
用引用计数法会存在内存泄露,下面来看原因:
function problem() {
var objA = new Object();
var objB = new Object();
objA.someOtherObject = objB;
objB.anotherObject = objA;
}
在这个例子里面,objA和objB通过各自的属性相互引用,这样的话,两个对象的引用次数都为2,在采用引用计数的策略中,由于函数执行之后,这两个对象都离开了作用域,函数执行完成之后,因为计数不为0,这样的相互引用如果大量存在就会导致内存泄露。
特别是在DOM对象中,也容易存在这种问题:
var element=document.getElementById(’‘);
var myObj=new Object();
myObj.element=element;
element.someObject=myObj;
这样就不会有垃圾回收的过程。
它的功能是将对应的字符串解析成js并执行,应该避免使用js,因为非常消耗性能(2次,一次解析成js,一次执行)
前端模块化就是复杂的文件编程一个一个独立的模块,比如js文件等等,分成独立的模块有利于重用(复用性)和维护(版本迭代),这样会引来模块之间相互依赖的问题,所以有了commonJS规范,AMD,CMD规范等等,以及用于js打包(编译等处理)的工具webpack
一个模块是能实现特定功能的文件,有了模块就可以方便的使用别人的代码,想要什么功能就能加载什么模块。
requireJS实现了AMD规范,主要用于解决下述两个问题。
1.多个文件有依赖关系,被依赖的文件需要早于依赖它的文件加载到浏览器
2.加载的时候浏览器会停止页面渲染,加载文件越多,页面失去响应的时间越长。
语法:requireJS定义了一个函数define,它是全局变量,用来定义模块。
requireJS的例子:
//定义模块
define(['dependency'], function(){
var name = 'Byron';
function printName(){
console.log(name);
}
return {
printName: printName
};
});
//加载模块
require(['myModule'], function (my){
my.printName();
}
requirejs定义了一个函数define,它是全局变量,用来定义模块:
define(id?dependencies?,factory)
在页面上使用模块加载函数:
require([dependencies],factory);
总结AMD规范:require()函数在加载依赖函数的时候是异步加载的,这样浏览器不会失去响应,它指定的回调函数,只有前面的模块加载成功,才会去执行。
因为网页在加载js的时候会停止渲染,因此我们可以通过异步的方式去加载js,而如果需要依赖某些,也是异步去依赖,依赖后再执行某些方法。
function deepClone(obj){
var newObj= obj instanceof Array ? []:{};
for(var item in obj){
var temple= typeof obj[item] == 'object' ? deepClone(obj[item]):obj[item];
newObj[item] = temple;
}
return newObj;
}
ES5的常用的对象克隆的一种方式。注意数组是对象,但是跟对象又有一定区别,所以我们一开始判断了一些类型,决定newObj是对象还是数组~
function ones(func){
var tag=true;
return function(){
if(tag==true){
func.apply(null,arguments);
tag=false;
}
return undefined
}
}
var myNewAjax=function(url){
return new Promise(function(resolve,reject){
var xhr = new XMLHttpRequest();
xhr.open('get',url);
xhr.send(data);
xhr.onreadystatechange=function(){
if(xhr.status==200&&readyState==4){
var json=JSON.parse(xhr.responseText);
resolve(json)
}else if(xhr.readyState==4&&xhr.status!=200){
reject('error');
}
}
})
}
我们假设这里有一个user对象,
Object.defineProperty(user,'name',{
set:function(key,value){
}
})
缺点:如果id不在user对象中,则不能监听id的变化
var user = new Proxy({},{
set:function(target,key,value,receiver){
}
})
这样即使有属性在user中不存在,通过user.id来定义也同样可以这样监听这个属性的变化哦~
obj={
name:yuxiaoliang,
getName:function(){
return this.name
}
}
object.defineProperty(obj,"name",{
//不可枚举不可配置
});
function product(){
var name='yuxiaoliang';
this.getName=function(){
return name;
}
}
var obj=new product();
主要存在:强制转换成number,null==undefined
" "==0 //true
"0"==0 //true
" " !="0" //true
123=="123" //true
null==undefined //true
主要的区别就是+0!=-0 而NaN==NaN
(相对比===和==的改进)
这里有一篇文章讲的是requestAnimationFrame:http://www.cnblogs.com/xiaohuochai/p/5777186.html
与setTimeout和setInterval不同,requestAnimationFrame不需要设置时间间隔,
大多数电脑显示器的刷新频率是60Hz,大概相当于每秒钟重绘60次。大多数浏览器都会对重绘操作加以限制,不超过显示器的重绘频率,因为即使超过那个频率用户体验也不会有提升。因此,最平滑动画的最佳循环间隔是1000ms/60,约等于16.6ms。
RAF采用的是系统时间间隔,不会因为前面的任务,不会影响RAF,但是如果前面的任务多的话,
会响应setTimeout和setInterval真正运行时的时间间隔。
特点:
(1)requestAnimationFrame会把每一帧中的所有DOM操作集中起来,在一次重绘或回流中就完成,并且重绘或回流的时间间隔紧紧跟随浏览器的刷新频率。
(2)在隐藏或不可见的元素中,requestAnimationFrame将不会进行重绘或回流,这当然就意味着更少的CPU、GPU和内存使用量
(3)requestAnimationFrame是由浏览器专门为动画提供的API,在运行时浏览器会自动优化方法的调用,并且如果页面不是激活状态下的话,动画会自动暂停,有效节省了CPU开销。
react-router等前端路由的原理大致相同,可以实现无刷新的条件下切换显示不同的页面。路由的本质就是页面的URL发生改变时,页面的显示结果可以根据URL的变化而变化,但是页面不会刷新。通过前端路由可以实现单页(SPA)应用,本文首先从前端路由的原理出发,详细介绍了前端路由原理的变迁。接着从react-router4.0的源码出发,深入理解react-router4.0是如何实现前端路由的。
- 通过Hash实现前端路由
- 通过H5的history实现前端路由
- React-router4.0的使用
- React-router4.0源码分析
早期的前端路由是通过hash来实现的:
改变url的hash值是不会刷新页面的。
因此可以通过hash来实现前端路由,从而实现无刷新的效果。hash属性位于location对象中,在当前页面中,可以通过:
window.location.hash='edit'
来实现改变当前url的hash值。执行上述的hash赋值后,页面的url发生改变。
赋值前:http://localhost:3000
赋值后:http://localhost:3000/#edit
在url中多了以#结尾的hash值,但是赋值前后虽然页面的hash值改变导致页面完整的url发生了改变,但是页面是不会刷新的。此外,还有一个名为hashchange的事件,可以监听hash的变化,我们可以通过下面两种方式来监听hash的变化:
window.onhashchange=function(event){
console.log(event);
}
window.addEventListener('hashchange',function(event){
console.log(event);
})
当hash值改变时,输出一个HashChangeEvent。该HashChangeEvent的具体值为:
{isTrusted: true, oldURL: "http://localhost:3000/", newURL: "http://localhost:3000/#teg", type: "hashchange".....}
有了监听事件,且改变hash页面不刷新,这样我们就可以在监听事件的回调函数中,执行我们展示和隐藏不同UI显示的功能,从而实现前端路由。
此外,除了可以通过window.location.hash来改变当前页面的hash值外,还可以通过html的a标签来实现:
<a href="#edit">edit</a>
hash的兼容性较好,因此在早期的前端路由中大量的采用,但是使用hash也有很多缺点。
HTML5的History接口,History对象是一个底层接口,不继承于任何的接口。History接口允许我们操作浏览器会话历史记录。
History提供了一些属性和方法。
History的属性:
History方法:
History.back(): 返回浏览器会话历史中的上一页,跟浏览器的回退按钮功能相同
History.forward():指向浏览器会话历史中的下一页,跟浏览器的前进按钮相同
History.go(): 可以跳转到浏览器会话历史中的指定的某一个记录页
History.pushState():pushState可以将给定的数据压入到浏览器会话历史栈中,该方法接收3个参数,对象,title和一串url。pushState后会改变当前页面url,但是不会伴随着刷新
History.replaceState():replaceState将当前的会话页面的url替换成指定的数据,replaceState后也会改变当前页面的url,但是也不会刷新页面。
上面的方法中,pushState和repalce的相同点:
就是都会改变当前页面显示的url,但都不会刷新页面。
不同点:
pushState是压入浏览器的会话历史栈中,会使得History.length加1,而replaceState是替换当前的这条会话历史,因此不会增加History.length.
history在浏览器的BOM对象模型中的重要属性,history完全继承了History接口,因此拥有History中的所有的属性和方法。
这里我们主要来看看history.length属性以及history.pushState、history.replaceState方法。
pushState和replaceState接受3个参数,分别为state对象,title标题,改变的url。
window.history.pushState({foo:'bar'}, "page 2", "bar.html");
此时,当前的url变为:
执行上述方法前:http://localhost:3000
执行上述方法后:http://localhost:3000/bar.html
如果我们输出window.history.state:
console.log(window.history.state);
// {foo:'bar'}
window.history.state就是我们pushState的第一个对象参数。
history.replaceState()方法不会改变hitroy的长度
console.log(window.history.length);
window.history.replaceState({foo:'bar'}, "page 2", "bar.html");
console.log(window.history.length);
上述前后两次输出的window.history.length是相等的。
此外。
每次触发history.back()或者浏览器的后退按钮等,会触发一个popstate事件,这个事件在后退或者前进的时候发生:
window.onpopstate=function(event){
}
注意:
history.pushState和history.replaceState方法并不会触发popstate事件。
如果用history做为路由的基础,那么需要用到的是history.pushState和history.replaceState,在不刷新的情况下可以改变url的地址,且如果页面发生回退back或者forward时,会触发popstate事件。
hisory为依据来实现路由的优点:
缺点:
了解了前端路由实现的原理之后,下面来介绍一下React-router4.0。在React-router4.0的代码库中,根据使用场景包含了以下几个独立的包:
在react-router4.0中,遵循Just Component的设计理念:
所提供的API都是以组件的形式给出。
比如BrowserRouter、Router、Link、Switch等API都是以组件的形式来使用。
下面我们以React-router4.0中的React-router-dom包来介绍常用的BrowserRouter、HashRouter、Link和Router等。
用<BrowserRouter> 组件包裹整个App系统后,就是通过html5的history来实现无刷新条件下的前端路由。
<BrowserRouter>组件具有以下几个属性:
basename: string 这个属性,是为当前的url再增加名为basename的值的子目录。
<BrowserRouter basename="test"/>
如果设置了basename属性,那么此时的:
http://localhost:3000 和 http://localhost:3000/test 表示的是同一个地址,渲染的内容相同。
getUserConfirmation: func 这个属性,用于确认导航的功能。默认使用window.confirm
forceRefresh: bool 默认为false,表示改变路由的时候页面不会重新刷新,如果当前浏览器不支持history,那么当forceRefresh设置为true的时候,此时每次去改变url都会重新刷新整个页面。
keyLength: number 表示location的key属性的长度,在react-router中每个url下都有为一个location与其对应,并且每一个url的location的key值都不相同,这个属性一般都使用默认值,设置的意义不大。
children: node children的属性必须是一个ReactNode节点,表示唯一渲染一个元素。
与<BrowserRouter>对应的是<HashRouter>,<HashRouter>使用url中的hash属性来保证不重新刷新的情况下同时渲染页面。
<Route> 组件十分重要,<Route> 做的事情就是匹配相应的location中的地址,匹配成功后渲染对应的组件。下面我们来看<Route>中的属性。
首先来看如何执行匹配,决定<Route>地址匹配的属性:
path:当location中的url改变后,会与Route中的path属性做匹配,path决定了与路由或者url相关的渲染效果。
exact: 如果有exact,只有url地址完全与path相同,才会匹配。如果没有exact属性,url的地址不完全相同,也会匹配。
举例来说,当exact不设置时:
<Route path='/home' component={Home}/>
<Route path='/home/first' component={First}/>
此时url地址为:http://localhost:3000/home/first 的时候,不仅仅会匹配到 path='/home/first'时的组件First,同时还会匹配到path='home'时候的Router。
如果设置了exact:
<Route path='/home' component={Home}/>
只有http://localhost:3000/home/first 不会匹配Home组件,只有url地址完全与path相同,只有http://localhost:3000/home才能匹配Home组件成功。
举例来说,当不设置strict的时候:
<Route path='/home/' component={Home}/>
此时http://localhost:3000/home 和 http://localhost:3000/home/
都能匹配到组件Home。匹配对于斜线“/”比较宽松。如果设置了strict属性:
<Route path='/home/' component={Home}/>
那么此时严格匹配斜线是否存在,http://localhost:3000/home 将无法匹配到Home组件。
当Route组件与某一url匹配成功后,就会继续去渲染。那么什么属性决定去渲染哪个组件或者样式呢,Route的component、render、children决定渲染的内容。
并且这3个属性所接受的方法或者组件,都会有location,match和history这3个参数。如果组件,那么组件的props中会存在从Link传递过来的location,match以及history。
<Route>定义了匹配规则和渲染规则,而<Link> 决定的是如何在页面内改变url,从而与相应的<Route>匹配。<Link>类似于html中的a标签,此外<Link>在改变url的时候,可以将一些属性传递给匹配成功的Route,供相应的组件渲染的时候使用。
举例来说:
<Link to='/home'>Home</Link>
如上所示,当to接受一个string,跳转到url为'/home'所匹配的Route,并渲染其关联的组件内接受3个对象history,location,match。
这3个对象会在下一小节会详细介绍。
举例来说:
<Link to={{pathname:'/home',search:'?sort=name',hash:'#edit',state:{a:1}}}>Home</Link>
在上个例子中,to为一个对象,点击Link标签跳转后,改变后的url为:'/home?sort=name#edit'。 但是在与相应的Route匹配时,只匹配path为'/home'的组件,'/home?sort=name#edit'。在'/home'后所带的参数不作为匹配标准,仅仅是做为参数传递到所匹配到的组件中,此外,state={a:1}也同样做为参数传递到新渲染的组件中。
介绍了 <BrowserRouter> 、 <Route> 和 <Link> 之后,使用这3个组件API就可以构建一个简单的React-router应用。这里我们之前说,每当点击Link标签跳转或者在js中使用React-router的方法跳转,从当前渲染的组件,进入新组件。在新组件被渲染的时候,会接受一个从旧组件传递过来的参数。
我们前面提到,Route匹配到相应的改变后的url,会渲染新组件,该新组件中的props中有history、location、match3个对象属性,其中hisotry对象属性最为关键。
同样以下面的例子来说明:
<Link to={{pathname:'/home',search:'?sort=name',hash:'#edit',state:{a:1}}}>Home</Link>
<Route exact path='/home' component={Home}/>
我们使用了<BrowserRouter>,该组件利用了window.history对象,当点击Link标签跳转后,会渲染新的组件Home,我们可以在Home组件中输出props中的history:
// props中的history
action: "PUSH"
block: ƒ block()
createHref: ƒ createHref(location)
go: ƒ go(n)
goBack: ƒ goBack()
goForward: ƒ goForward()
length: 12
listen: ƒ listen(listener)
location: {pathname: "/home", search: "?sort=name", hash: "#edit", state: {…}, key: "uxs9r5"}
push: ƒ push(path, state)
replace: ƒ replace(path, state)
从上面的属性明细中:
push:f 这个方法用于在js中改变url,之前在Link组件中可以类似于HTML标签的形式改变url。push方法映射于window.history中的pushState方法。
replace: f 这个方法也是用于在js中改变url,replace方法映射于window.history中的replaceState方法。
block:f 这个方法也很有用,比如当用户离开当前页面的时候,给用户一个文字提示,就可以采用history.block("你确定要离开当前页吗?")这样的提示。
go / goBack / goForward
在组件props中history的go、goBack、goForward方法,分别window.history.go、window.history.back、window.history.forward对应。
action属性很有用,比如我们在做翻页动画的时候,前进的动画是SlideIn,后退的动画是SlideOut,我们可以根据组件中的action来判断采用何种动画:
function newComponent (props)=>{
return (
<ReactCSSTransitionGroup
transitionAppear={true}
transitionAppearTimeout={600}
transitionEnterTimeout={600}
transitionLeaveTimeout={200}
transitionName={props.history.action==='PUSH'?'SlideIn':'SlideOut'}
>
<Component {...props}/>
</ReactCSSTransitionGroup>
)
}
location:object
在新组件的location属性中,就记录了从就组件中传递过来的参数,从上面的例子中,我们看到此时的location的值为:
hash: "#edit"
key: "uxs9r5"
pathname: "/home"
search: "?sort=name"
state: {a:1}
除了key这个用作唯一表示外,其他的属性都是我们从上一个Link标签中传递过来的参数。
在第三节中我们介绍了React-router的大致使用方法,读一读React-router4.0的源码。
这里我们主要分析一下React-router4.0中是如何根据window.history来实现前端路由的,因此设计到的组件为BrowserRouter、Router、Route和Link
从上一节的介绍中我们知道,点击Link标签传递给新渲染的组件的props中有一个history对象,这个对象的内容很丰富,比如:action、goBack、go、location、push和replace方法等。
React-router构建了一个History类,用于在window.history的基础上,构建属性更为丰富的实例。该History类实例化后具有action、goBack、location等等方法。
React-router中将这个新的History类的构建方法,独立成一个node包,包名为history。
npm install history -s
可以通过上述方法来引入,我们来看看这个History类的实现。
const createBrowserHistory = (props = {}) => {
const globalHistory = window.history;
......
//默认props中属性的值
const {
forceRefresh = false,
getUserConfirmation = getConfirmation,
keyLength = 6,
basename = '',
} = props;
const history = {
length: globalHistory.length,
action: "POP",
location: initialLocation,
createHref,
push,
replace,
go,
goBack,
goForward,
block,
listen
}; ---- (1)
const basename = props.basename;
const canUseHistory = supportsHistory(); ----(2)
const createKey = () =>Math.random().toString(36).substr(2, keyLength); ----(3)
const transitionManager = createTransitionManager(); ----(4)
const setState = nextState => {
Object.assign(history, nextState);
history.length = globalHistory.length;
transitionManager.notifyListeners(history.location, history.action);
}; ----(5)
const handlePopState = event => {
handlePop(getDOMLocation(event.state));
};
const handlePop = location => {
if (forceNextPop) {
forceNextPop = false;
setState();
} else {
const action = "POP";
transitionManager.confirmTransitionTo(
location,
action,
getUserConfirmation,
ok => {
if (ok) {
setState({ action, location });
} else {
revertPop(location);
}
}
);
}
}; ------(6)
const initialLocation = getDOMLocation(getHistoryState());
let allKeys = [initialLocation.key]; ------(7)
// 与pop相对应,类似的push和replace方法
const push ... replace ... ------(8)
return history ------ (9)
}
(1) 中指明了新的构建方法History所返回的history对象中所具有的属性。
(2)中的supportsHistory的方法判断当前的浏览器对于window.history的兼容性,具体方法如下:
export const supportsHistory = () => {
const ua = window.navigator.userAgent;
if (
(ua.indexOf("Android 2.") !== -1 || ua.indexOf("Android 4.0") !== -1) &&
ua.indexOf("Mobile Safari") !== -1 &&
ua.indexOf("Chrome") === -1 &&
ua.indexOf("Windows Phone") === -1
)
return false;
return window.history && "pushState" in window.history;
};
从上述判别式我们可以看出,window.history在chrome、mobile safari和windows phone下是绝对支持的,但不支持安卓2.x以及安卓4.0
(3)中用于创建与history中每一个url记录相关联的指定位数的唯一标识key, 默认的keyLength为6位
(4)中 createTransitionManager方法,返回一个集成对象,对象中包含了关于history地址或者对象改变时候的监听函数等,具体代码如下:
const createTransitionManager = () => {
const setPrompt = nextPrompt => {
};
const confirmTransitionTo = (
location,
action,
getUserConfirmation,
callback
) => {
if (typeof getUserConfirmation === "function") {
getUserConfirmation(result, callback);
} else {
callback(true);
}
}
};
let listeners = [];
const appendListener = fn => {
let isActive = true;
const listener = (...args) => {
if (isActive) fn(...args);
};
listeners.push(listener);
return () => {
isActive = false;
listeners = listeners.filter(item => item !== listener);
};
};
const notifyListeners = (...args) => {
listeners.forEach(listener => listener(...args));
};
return {
setPrompt,
confirmTransitionTo,
appendListener,
notifyListeners
};
};
setPrompt函数,用于设置url跳转时弹出的文字提示,confirmTransaction函数,会将当前生成新的history对象中的location,action,callback等参数,作用就是在回调的callback方法中,根据要求,改变传入的location和action对象。
接着我们看到有一个listeners数组,保存了一系列与url相关的监听事件数组,通过接下来的appendListener方法,可以往这个数组中增加事件,通过notifyListeners方法可以遍历执行listeners数组中的所有事件。
(5) setState方法,发生在history的url或者history的action发生改变的时候,此方法会更新history对象中的属性,同时会触发notifyListeners方法,传入当前的history.location和history.action。遍历并执行所有监听url改变的事件数组listeners。
(6)这个getDOMLocation方法就是根据当前在window.state中的值,生成新history的location属性对象,allKeys这是始终保持了在url改变时候的历史url相关联的key,保存在全局,allKeys在执行生“POP”或者“PUSH”、“Repalce”等会改变url的方法时,会保持一个实时的更新。
(7) handlePop方法,用于处理“POP”事件,我们知道在window.history中点击后退等会触发“POP”事件,这里也是一样,执行action为“POP”,当后退的时候就会触发该函数。
(8)中包含了与pop方法类似的,push和replace方法,push方法同样做的事情就是执行action为“PUSH”(“REPLACE”),该变allKeys数组中的值,唯一不同的是actio为“PUSH”的方法push是往allKeys数组中添加,而action为“REPLACE”的方法replace则是替换掉当前的元素。
(9)返回这个新生成的history对象。
其实最难弄懂的是React-router中如何重新构建了一个history工厂函数,在第一小节中我们已经详细的介绍了history生成函数createBrowserHistory的源码,接着来看Link组件就很容易了。
首先Link组件类似于HTML中的a标签,目的也很简单,就是去主动触发改变url的方法,主动改变url的方法,从上述的history的介绍中可知为push和replace方法,因此Link组件的源码为:
class Link extends React.Component {
handleClick = event => {
...
const { history } = this.context.router;
const { replace, to } = this.props;
if (replace) {
history.replace(replace);
} else {
history.push(to);
}
}
};
render(){
const { replace, to, innerRef, ...props } = this.props;
<a {...props} onClick={this.handleClick}/>
}
}
上述代码很简单,从React的context API全局对象中拿到history,然后如果传递给Link组件的属性中有replace为true,则执行history.replace(to),to 是一个包含pathname的对象,如果传递给Link组件的replace属性为false,则执行history.push(to)方法。
Route组件也很简单,其props中接受一个最主要的属性path,Route做的事情只有一件:
当url改变的时候,将path属性与改变后的url做对比,如果匹配成功,则渲染该组件的componet或者children属性所赋值的那个组件。
具体源码如下:
class Route extends React.Component {
....
constructor(){
}
render() {
const { match } = this.state;
const { children, component, render } = this.props;
const { history, route, staticContext } = this.context.router;
const location = this.props.location || route.location;
const props = { match, location, history, staticContext };
if (component) return match ? React.createElement(component, props) : null;
if (render) return match ? render(props) : null;
if (typeof children === "function") return children(props);
if (children && !isEmptyChildren(children))
return React.Children.only(children);
return null;
}
}
state中的match就是是否匹配的标记,如果匹配当前的Route的path,那么根据优先级顺序component属性、render属性和children属性来渲染其所指向的React组件。
Router组件中,是BrowserRouter、HashRouter等组件的底层组件。该组件中,定义了包含匹配规则match函数,以及使用了新history中的listener方法,来监听url的改变,从而,当url改变时,更改Router下不同path组件的isMatch结果。
class Router extends React.Component {
componentWillMount() {
const { children, history } = this.props
//调用history.listen监听方法,该方法的返回函数是一个移除监听的函数
this.unlisten = history.listen(() => {
this.setState({
match: this.computeMatch(history.location.pathname)
});
});
}
componentWillUnmount() {
this.unlisten();
}
render() {
}
}
上述首先在组件创建前调用了listener监听方法,来监听url的改变,实时的更新isMatch的结果。
本文从前端路由的原理出发,先后介绍了两种前端路由常用的方法,接着介绍了React-router的基本组件API以及用法,详细介绍了React-router的组件中新构建的history对象,最后结合React-router的API阅读了一下React-router的源码。
最近在代码中不小心不规范的,在switch里面定义了块级变量,导致页面在某些浏览器中出错,本文讨论以下switch语句中的块级作用域。
- switch语句中的块级作用域
- switch语句中的块级作用域可能存在的问题
- 规范和检测
ES6 或 TS 引入了块级作用域,通过let和const、class等可以定义块级作用域里的变量,块级作用域内的变量不存在变量提升,且存在暂时性死区。常见的if语句,for循环的循环体内都可以定义块级变量。那么switch语句中的块级作用域是什么呢? 先给出结论:
switch语句中的块级作用域,在整个switch语句中,而不是对于每一个case生成一个独立的块级作用域。
下面来举几个例子来说明这个问题:
let number = 1;
switch(number){
case 1:
let name = 'Jony';
default:
console.log(name)
}上述的代码会输出jony。
再看一个例子:
let number = 1;
switch(number){
case 1:
let name = 'Jony';
break;
case 2:
let name = 'yu';
break;
default:
console.log(name);
}这样会在重复生命的错误:
Uncaught SyntaxError: Identifier 'name' has already been declared上述两个例子说明确实switch语句中,整个switch语句构成一个块级作用域。而与case无关,每一个case并不会构成一个独立的块级作用域。
我们知道了switch语句,整个switch语句的顶层是一个块级作用域,但是还要注意case的特殊性,在case中声明的变量,并不会提升到块级作用域中。
let number = 2;
switch(number){
case 2:
name = 'yu';
break;
}在这个例子中,name虽然没有声明,但是给name赋值相当于给全局的window对象复制,也就是window.name = 'yu'。不会有任何问题。
有意思的问题来了:
let number = 2;
switch(number){
case 1:
let name = 'jony';
break;
case 2:
name = 'yu';
break;
}这个例子中,会报错,会报name未定义的错误。
Uncaught ReferenceError: name is not defined原因的话,这里虽然case里面定义的块级虽然不会存在变量提升,但是会存在暂时性死区,也就是说如果let name = 'jony' 没有执行,也就是name定义的过程没有执行,那么name在整个块级作用域内都是不可用的,都是undefined。
为了证明我们的想法,接着改写上面的例子:
let number = 1;
switch(number){
case 1:
let name = 'jony';
break;
case 2:
name = 'yu';
break;
}我们把number改成1,我们发现代码不会报任何的错误,因为此时let name的定义和赋值都被执行了。
可能会说为什么在自己的项目中,在ES6或者TS代码中即使有上述的错误使用,也没有报错?
笔者之前也有这样的问题,要明确的是是否你把ES6或者TS的代码直接转化成了es5,然后再调试或者发布的线上的,当let被编译成es5后,当然就不会存在上述switch中作用域的问题。但是现实中,编译成es5后的js文件可能太大,对于高版本浏览器我们希望直接使用ES6代码(通过type = module来判断浏览器对于ES6的支持性),那么这么上述问题就会出现。
那么如何避免这种情况呢,当然最好的方式,就是不要在case中定义块级变量,但是万一不小心写了上述的问题代码如何检测呢。
首先使用typescript,静态编译是不能出现错误提示的,因为这个错误是运行时异常。最好的方式是通过编写eslint的规范来解决上述的非法使用问题。
第一部分我们在Feact中实现了一个基础的渲染,实现了一个最重要的生命周期函数render,在本部分中,我们会为组件添加两个生命周期函数componentWillMount和componentDidMount.
这一系列的文章包括:
- 第一部分:基础渲染
- 第二部分:componentWillMount and componentDidMount
- 第三部分:基础更新
- 第四部分:setState
- 第三部分:transaction
在之间的createClass方法中,仅仅支持render方法,比如:
const Feact = {
createClass(spec) {
function Constructor(props) {
this.props = props;
}
// 只使用了构造对象中的render属性,而没有用其他的属性
Constructor.prototype.render = spec.render;
return Constructor;
}
}
我们仅仅需要一个简单的方式,就可以将spec中的其他方法添加到Constructor.prototype中,这样在createClass方式创建的组件不仅可以有render函数,还可以实现其他用户自定义的函数。
const Feact = {
createClass(spec) {
function Constructor(props) {
this.props = props;
}
Constructor.prototype =
Object.assign(Constructor.prototype, spec);
return Constructor;
}
...
}
随着Typescript的普及,在KOA2和nestjs等nodejs框架中经常看到类似于java spring中注解的写法。本文从装饰模式出发,聊聊Typescipt中的装饰器和注解。
- 什么是装饰者模式
- Typescript中的装饰器
- Typescript中的注解
- 总结
最近在看nestjs等支持Typescript的node框架,经常看到这样一种写法:
import { Controller, Get } from '@nestjs/common';
@Controller('cats')
export class CatsController {
@Get()
findAll() {
return 'This action returns all cats';
}
}
上述代码定义了一个处理url为“/cats”的控制器,该控制器对于url为“/cats”的get方法执行findAll()函数,返回相应的字符串。
在上述的代码中,用@controller('cats')修饰CatsController类,通过@get来修饰类中的findAll方法,这就是典型的装饰者模式。通过@controller('cats')和@get修饰后的类CatsController,简单来说,就是拥有了丰富的“内涵”。
下面看看具体装饰者模式的定义:
我们知道继承模式是丰富子元素“内涵”的一种重要方式,不管是继承接口还是子类继承基类。而装饰者模式可以在不改变继承关系的前提下,包装先有的模块,使其内涵更加丰富,并不会影响到原来的功能。与继承相比,更加的灵活。
javascript中的装饰器处于建议征集的第二阶段,通过babel和Typescrit都可以实现装饰器的语法。
Typescript中的装饰器与类相关,分别可以修饰类的实例函数和静态函数、类本身、类的属性、类中函数的参数以及类的set/get存取器,下面来意义介绍。
下面来介绍一下用装饰器来修饰函数,首先来看一个例子:
let temple;
function log(target, key, descriptor) {
console.log(`${key} was called!`);
temple = target;
}
class P {
@log
foo() {
console.log('Do something');
}
}
console.log(P.prototype === temple) //true
上述是实例方法foo中我们用log函数修饰,log函数接受三个参数,通过P.prototype === temple(target)可以判断,在类的实例函数的装饰器函数第一个参数为类的原型,第二个参数为函数名本身,第三个参数为该函数的描述属性。
具体总结如下,对于类的函数的装饰器函数,依次接受的参数为:
从上述的例子中我们可以看到,用装饰器来修饰相应的类的函数十分方便:
@log
foo() {
...
}
装饰函数也可以直接修饰类:
let temple
function foo(target){
console.log(target);
temple = target
}
@foo
class P{
constructor(){
}
}
temple === P //true
当装饰函数直接修饰类的时候,装饰函数接受唯一的参数,这个参数就是该被修饰类本身。上述的例子中,输出的target就是类P的本身。
此外,在修饰类的时候,如果装饰函数有返回值,该返回值会重新定义这个类,也就是说当装饰函数有返回值时,其实是生成了一个新类,该新类通过返回值来定义。
举例来说:
function foo(target){
return class extends target{
name = 'Jony';
sayHello(){
console.log("Hello "+ this.name)
}
}
}
@foo
class P{
constructor(){
}
}
const p = new P();
p.sayHello(); // 会输出Hello Jony
上面的例子可以看到,当装饰函数foo有返回值时,实际上P类已经被返回值所代表的新类所代替,因此P的实例p拥有sayHello方法。
下面我们来看类的属性的装饰器,装饰函数修饰类的属性时,在类实例化的时候调用属性的装饰函数,举例来说:
function foo(target,name){
console.log("target is",target);
console.log("name is",name)
}
class P{
@foo
name = 'Jony'
}
//会依次输出 target is f P() name is Jony
这里对于类的属性的装饰器函数接受两个参数,对于静态属性而言,第一个参数是类本身,对于实例属性而言,第一个参数是类的原型,第二个参数是指属性的名字。
接着来看类函数参数的装饰器,类函数的参数装饰器可以修饰类的构建函数中的参数,以及类中其他普通函数中的参数。该装饰器在类的方法被调用的时候执行,下面来看实例:
function foo(target,key,index){
console.log("target is",target);
console.log("key is",key);
console.log("index is",index)
}
class P{
test(@foo a){
}
}
// 依次输出 f P() , test , 0
类函数参数的装饰器函数接受三个参数,依次为类本身,类中该被修饰的函数本身,以及被修饰的参数在参数列表中的索引值。上述的例子中,会依次输出 f P() 、test和0。再次明确一下修饰函数参数的装饰器函数中的参数含义:
从上面的Typescrit中在基类中常用的装饰器后,我们发现:
装饰器可以起到分离复杂逻辑的功能,且使用上极其简单方便。与继承相比,也更加灵活,可以从装饰类,到装饰类函数的参数,可以说武装到了“牙齿”。
在了解了Typescrit中的装饰器之后,接着我们来看Typescrit中的注解。
什么是注解,所谓注解的定义就是:
为相应的类附加元数据支持。
所谓元数据可以简单的解释,就是修饰数据的数据,比如一个人有name,age等数据属性,那么name和age这些字段就是为了修饰数据的数据,可以简单的称为元数据。
元数据简单来说就是可以修饰某些数据的字段。下面给出装饰器和注解的解释和区别:
两者之间的联系:
通过注解添加元数据,然后在装饰器中获取这些元数据,完成对类、类的方法等等的修改,可以在装饰器中添加元数据的支持,比如可以可以在装饰器工厂函数以及装饰器函数中添加元数据支持等。
可以通过reflect-metadata包来实现对于元数据的操作。首先我们来看reflect-metadata的使用,首先定义使用元数据的函数:
const formatMetadataKey = Symbol("format");
function format(formatString: string) {
return Reflect.metadata(formatMetadataKey, formatString);
}
function getFormat(target: any, propertyKey: string) {
return Reflect.getMetadata(formatMetadataKey, target, propertyKey);
}
这里的format可以作为装饰器函数的工厂函数,因为format函数返回的是一个装饰器函数,上述的方法定义了元数据Sysmbol("format"),用Sysmbol的原因是为了防止元数据中的字段重复,而format定义了取元数据中相应字段的功能。
接着我们来在类中使用相应的元数据:
class Greeter {
@format("Hello, %s")
name: string;
constructor(name: string) {
this.name = message;
}
sayHello() {
let formatString = getFormat(this, "name");
return formatString.replace("%s", this.name);
}
}
const g = new Greeter("Jony");
console.log(g.sayHello());
在上述中,我们在name属性的装饰器工厂函数,执行@Format("Hello, %s"),返回一个装饰器函数,且该装饰器函数修饰了Greeter类的name属性,将“name”属性的值写入为"Hello, %s"。
然后再sayHello方法中,通过getFormat(this,"name")取到formatString为“Hello,%s”.
通过装饰器,可以方便的修饰类,以及类的方法,类的属性等,相比于继承而言更加灵活,此外,通过注解的方法,可以在Typescript中引入元数据,实现元编程等。特别是在angularjs、nestjs中,大量使用了注解,特别是nestjs构建了类似于java springMVC式的web框架。
小白一枚,最近在研究golang,记录自己学习过程中的一些笔记,以及自己的理解。
- go中协程的实现
- go中协程的sync同步锁
- go中信道channel
- go中的range
- go中的select切换协程
- go中带缓存的channel
- go中协程调度
介绍go中的协程之前,首先看以下go中的defer函数,defer函数不是普通的函数,defer函数会在普通函数返回之后执行。defer函数中可以释放函数内部变量、关闭数据库连接等等操作,举例来说:
func print(){
fmt.Println(2);
}
func main() {
defer print();
fmt.Println(1);
}
上述的例子中先输出1后输出2,说明defer确实是在普通函数调用结束之后执行的。
go中使用协程的方式来处理并发,协程可以理解成更小的线程,占用空间小且线程上下文切换的成本少。
可以再为具体的描述以下协程的好处,协程比线程更加轻量,使用4K栈的内存就可以创建它们,可以用很小的内存占用就可以处理大量的任务。
在go中,携程是通过go关键字来调用,从关键字可以看出,golang的一个十分重要的特点就是协程,有句话叫“协程在手,说go就go”。
下面我们来看一个例子:
func printOne(){
fmt.Println(1);
}
func printTwo(){
fmt.Println(2);
}
func printThree(){
fmt.Println(3);
}
func main() {
go printOne();
go printTwo();
go printThree();
}
执行上述的main函数,我们发现并没有像我们想的那样输出有123的输出,原因在于虽然协程是并发的,但是如果在协程调用前退出了调用协程的函数后,协程会随着程序的消亡而消亡。
因此我们可以在main函数中,将主函数挂起,增加等待协程调用的事件。
func main() {
go printOne();
go printTwo();
go printThree();
time.Sleep(5 * 1e9);
}
这样会有相应的go关键字修饰的协程函数的调用。我们来看分别执行3次的结果。
我们发现因为协程是并发执行的,我们无法确定其调用的顺序,因此 每次的调用主函数的返回结果都是不确定的。
从协程的上述例子中,我们可以看出使用协程的时候必须还要考虑两个问题:
问题1,可以通过sync的同步锁来实现,问题2,go中提供了channel来实现不同协程间的通信。
go中sync包提供了2个锁,互斥锁sync.Mutex和读写锁sync.RWMutex.我们用互斥锁来解决上述的不同的协程可能同时调度同一个资源的问题,改写上述的例子:
func printOne(m *sync.Mutex){
m.Lock();
... do something use DB or other source
defer m.Unlock();
}
func printTwo(m *sync.Mutex){
m.Lock();
... the same thing as printOne do something use DB or other source
defer m.Unlock();
}
func main() {
m:= new(sync.Mutex);
go printOne(m);
go printTwo(m);
time.Sleep(5 * 1e9);
}
通过互斥锁,printOne和printTwo不会竞争同一个相同的资源
go中有一种特殊的类型通道channel,可以通过channel来发送类型化的数据,实现在协程之间的通信,通过通道的通信方式也保证了同步性。
channel的声明方式很简单:
var ch1 chan string
ch1 = make(chan string)
我们用ch表示通道,通道的符号包括了流向通道(发送): ch <- int1 和从通道流出(接收) int2 = <- ch。
同时go中也支持声明单向通道:
var ch1 chan int //普通的channel
var ch2 chan <- int //只用于写int数据
var ch3 <- chan int //只用于读int数据
上述定义的都是不带缓存区,或者说长度为1的channel,这种channel的特点就是:
一旦有数据被放入channel,那么该数据必须被取走才能让另一条数据放入,这就是同步的channel,channel的发送者和接受者在同一时间只交流一条数据,然后必须等待另一边完成相应的发送和接受动作。
我们还是用上述的输出123的例子,用同步channel来实现同步的输出。
func printOne(cs chan int){
fmt.Println(1);
cs <- 1
}
func printTwo(cs chan int){
<-cs
fmt.Println(2);
defer close(cs);
}
func main() {
cs := make(chan int);
go printOne(cs);
go printTwo(cs);
time.Sleep(5 * 1e9);
}
上述的例子中会依次输出12,这样我们通过同步channel的方式实现了同步的输出。
我们前面讲到用为了等待go协程执行完成,我们在main函数中用time.sleep来挂起主函数,其实main函数本身也可以看成一个协程,如果使用channel,就不用在main函数中用time.sleep来挂起。
我们改写上述的例子:
func printOne(cs chan int){
fmt.Println(1);
cs <- 1
}
func main() {
cs := make(chan int);
go printOne(cs);
<-cs;
close(cs);
}
上述的例子中,会输出 1 ,我们并没有在主函数中通过time.sleep的方式来挂起,转而用一个等待写入的channel来代替。
注意:通道可以被显式的关闭,当需要告诉接受者不会种子提供新的值的时候,就需要关闭通道。
上面我们也讲到要及时的关闭channel,但是持续的访问数据源并检查channel是否已经关闭,并不高效。go中提供了range关键字。
range关键字在使用channel的时候,会自动等待channel的动作一直到channel关闭。通俗点将就是可以channel可以自动开关。
同样的来举例:
func input(cs chan int,count int){
for i:=1;i<=count;i++ {
cs <- i
}
}
func output(cs chan int){
for s:= range cs {
fmt.Println(s);
}
}
func main() {
cs := make(chan int);
go input(cs,5);
go output(cs);
time.Sleep(3*1e9)
}
上述的例子会依次的输出1,2,3,4,5. 通过使用range关键字,当channel被关闭时,接受者的for循环也就自动停止了。
从不同的并发执行过程中获取值可以通过关键字select来完成,它和switch控制语句非常相似,也被称为通信开关。
首先要明确select做了什么??
select中存在着一种轮询机制,select监听进入通道的数据,也可以是通道发送值的时候,监听到相应的行为后就执行case里面的操作。
select的声明:
select {
case u:= <- ch1:
...
case v:= <- ch2;
...
}
同样的来看一下具体使用select的例子:
func channel1(cs chan int,count int){
for i:=1;i<=count;i++ {
cs <- i
}
}
func channel2(cs chan int,count int){
for i:=1;i<=count;i++ {
cs <- i
}
}
func selectTest(cs1 ,cs2 chan int){
for i:=1;i<10;i++ {
select {
case u:=<-cs1:
fmt.Println(u);
case v:=<-cs2:
fmt.Println(v);
}
}
}
func main() {
cs1 := make(chan int);
cs2 := make(chan int);
go channel1(cs1,5);
go channel2(cs2,3);
go selectTest(cs1,cs2);
time.Sleep(3*1e9)
}
输出结果为:1,2,1,2,3,3,4,5 总共8个数据。且因为没有做同步控制,因此运行几次后的输出结果是不相同的。
前面讲到的都是不带缓存的channel或者说长度为1的channel,实际上channel也是可以带缓存的,我们可以在声明的时候执行channel的长度。
ch = make(chan string,3)
比如上述的例子中,指定了ch这个channel的长度为3,长度不为1的channel,就可以称之为带缓存的channel.
带缓存的channel可以连续写入,直到长度占满为止。
ch <- 1
ch <- 2
ch <- 3
讲到并发,就要提到go中的协程调度。go中的runtime包,提供了调度器的功能。runtime包提供了以下几个方法:
对于多核CPU的机器,go可以显示的指定编译器将go的协程调度到多个CPU上运行
import "runtime"
...
cpuNum:=runtime.NumCPU;
runtime.GOMAXPROCS(cpuNum)
来聊聊GO中的调度原理,首先定义以下模型的概念:
M:内核中的线程的数目
G:go中的协程,并发的最小单元,在go中通过go关键字来创建
P:处理器,即协程G的上下文,每个P会维护一个本地的协程队列。
接着来看解释GO中协程调度的经典图:
我们来解释上图:
简要介绍:谈谈promise.resove,setTimeout,setImmediate,process.nextTick在EvenLoop队列中的执行顺序
event loop都不陌生,是指主线程从“任务队列”中循环读取任务,比如
例1:
setTimeout(function(){console.log(1)},0);
console.log(2)
//输出2,1
在上述的例子中,我们明白首先执行主线程中的同步任务,当主线程任务执行完毕后,再从event loop中读取任务,因此先输出2,再输出1。
event loop读取任务的先后顺序,取决于任务队列(Job queue)中对于不同任务读取规则的限定。比如下面一个例子:
例2:
setTimeout(function () {
console.log(3);
}, 0);
Promise.resolve().then(function () {
console.log(2);
});
console.log(1);
//输出为 1 2 3
先输出1,没有问题,因为是同步任务在主线程中优先执行,这里的问题是setTimeout和Promise.then任务的执行优先级是如何定义的。
在Job queue中的队列分为两种类型:macro-task和microTask。我们举例来看执行顺序的规定,我们设
macro-task队列包含任务: a1, a2 , a3
micro-task队列包含任务: b1, b2 , b3
执行顺序为,首先执行marco-task队列开头的任务,也就是 a1 任务,执行完毕后,在执行micro-task队列里的所有任务,也就是依次执行b1, b2 , b3,执行完后清空micro-task中的任务,接着执行marco-task中的第二个任务,依次循环。
了解完了macro-task和micro-task两种队列的执行顺序之后,我们接着来看,真实场景下这两种类型的队列里真正包含的任务(我们以node V8引擎为例),在node V8中,这两种类型的真实任务顺序如下所示:
macro-task队列真实包含任务:
script(主程序代码),setTimeout, setInterval, setImmediate, I/O, UI rendering
micro-task队列真实包含任务:
process.nextTick, Promises, Object.observe, MutationObserver
由此我们得到的执行顺序应该为:
script(主程序代码)—>process.nextTick—>Promises...——>setTimeout——>setInterval——>setImmediate——> I/O——>UI rendering
在ES6中macro-task队列又称为ScriptJobs,而micro-task又称PromiseJobs
例3:
setTimeout(function () {
console.log(3);
}, 0);
Promise.resolve().then(function () {
console.log(2);
});
console.log(1);
我们先以第1小节的例子为例,这里遵循的顺序为:
script(主程序代码)——>promise——>setTimeout
对应的输出依次为:1 ——>2————>3
例子4:
setTimeout(function(){console.log(1)},0);
new Promise(function(resolve,reject){
console.log(2);
resolve();
}).then(function(){console.log(3)
}).then(function(){console.log(4)});
process.nextTick(function(){console.log(5)});
console.log(6);
//输出2,6,5,3,4,1
这个例子就比较复杂了,这里要注意的一点在定义promise的时候,promise构造部分是同步执行的,这样问题就迎刃而解了。
首先分析Job queue的执行顺序:
script(主程序代码)——>process.nextTick——>promise——>setTimeout
I) 主体部分: 定义promise的构造部分是同步的,
因此先输出2 ,主体部分再输出6(同步情况下,就是严格按照定义的先后顺序)
II)process.nextTick: 输出5
III)promise: 这里的promise部分,严格的说其实是promise.then部分,输出的是3,4
IV) setTimeout : 最后输出1
综合的执行顺序就是: 2——>6——>5——>3——>4——>1
setTimeout(function(){console.log(1)},0);
new Promise(function(resolve,reject){
console.log(2);
setTimeout(function(){resolve()},0)
}).then(function(){console.log(3)
}).then(function(){console.log(4)});
process.nextTick(function(){console.log(5)});
console.log(6);
//输出的是 2 6 5 1 3 4
这种情况跟我们(2)中的例子,区别在于promise的构造中,没有同步的resolve,因此promise.then在当前的执行队列中是不存在的,只有promise从pending转移到resolve,才会有then方法,而这个resolve是在一个setTimout时间中完成的,因此3,4最后输出。
原理:通过apply或者call方法来实现。
Function.prototype.bind=function(obj,arg){
var arg=Array.prototype.slice.call(arguments,1);
var context=this;
return function(newArg){
arg=arg.concat(Array.prototype.slice.call(newArg));
return context.apply(obj,arg);
}
}
为什么要考虑?因为在new 一个bind过生成的新函数的时候,必须的条件是要继承原函数的原型
Function.prototype.bind=function(obj,arg){
var arg=Array.prototype.slice.call(arguments,1);
var context=this;
var bound=function(newArg){
arg=arg.concat(Array.prototype.slice.call(newArg));
return context.apply(obj,arg);
}
var F=function(){}
//这里需要一个寄生组合继承
F.prototype=context.prototype;
bound.prototype=new F();
return bound;
}
首先来看setInterval的缺陷,使用setInterval()创建的定时器确保了定时器代码规则地插入队列中。这个问题在于:如果定时器代码在代码再次添加到队列之前还没完成执行,结果就会导致定时器代码连续运行好几次。而之间没有间隔。不过幸运的是:javascript引擎足够聪明,能够避免这个问题。当且仅当没有该定时器的如何代码实例时,才会将定时器代码添加到队列中。这确保了定时器代码加入队列中最小的时间间隔为指定时间。
这种重复定时器的规则有两个问题:1.某些间隔会被跳过 2.多个定时器的代码执行时间可能会比预期小。
下面举例子说明:
假设,某个onclick事件处理程序使用啦setInterval()来设置了一个200ms的重复定时器。如果事件处理程序花了300ms多一点的时间完成。
这个例子中的第一个定时器是在205ms处添加到队列中,但是要过300ms才能执行。在405ms又添加了一个副本。在一个间隔,605ms处,第一个定时器代码还在执行中,而且队列中已经有了一个定时器实例,结果是605ms的定时器代码不会添加到队列中。结果是在5ms处添加的定时器代码执行结束后,405处的代码立即执行。
function say(){
//something
setTimeout(say,200);
}
setTimeout(say,200)
或者
setTimeout(function(){
//do something
setTimeout(arguments.callee,200);
},200);
<script type="text/javascript">
var obj=new Image();
obj.src="http://www.phpernote.com/uploadfiles/editor/201107240502201179.jpg";
obj.onload=function(){
alert('图片的宽度为:'+obj.width+';图片的高度为:'+obj.height);
document.getElementById("mypic").innnerHTML="<img src='"+this.src+"' />";
}
</script>
<div id="mypic">onloading……</div>
<script type="text/javascript">
var obj=new Image();
obj.src="http://www.phpernote.com/uploadfiles/editor/201107240502201179.jpg";
obj.onreadystatechange=function(){
if(this.readyState=="complete"){
alert('图片的宽度为:'+obj.width+';图片的高度为:'+obj.height);
document.getElementById("mypic").innnerHTML="<img src='"+this.src+"' />";
}
}
</script>
<div id="mypic">onloading……</div>
setTimeout(function(){console.log(1)},0);
new Promise(function(resolve,reject){
console.log(2);
resolve();
}).then(function(){console.log(3)
}).then(function(){console.log(4)});
process.nextTick(function(){console.log(5)});
console.log(6);
//输出2,6,5,3,4,1
为什么呢?具体请参考我的文章:
从promise、process.nextTick、setTimeout出发,谈谈Event Loop中的Job queue
function sleep(ms){
var start=Date.now(),expire=start+ms;
while(Date.now()<expire);
console.log('1111');
return;
}
执行sleep(1000)之后,休眠了1000ms之后输出了1111。上述循环的方式缺点很明显,容易造成死循环。
function sleep(ms){
var temple=new Promise(
(resolve)=>{
console.log(111);setTimeout(resolve,ms)
});
return temple
}
sleep(500).then(function(){
//console.log(222)
})
//先输出了111,延迟500ms后输出222
function sleep(ms){
return new Promise((resolve)=>setTimeout(resolve,ms));
}
async function test(){
var temple=await sleep(1000);
console.log(1111)
return temple
}
test();
//延迟1000ms输出了1111
####(4).通过generate来实现
function* sleep(ms){
yield new Promise(function(resolve,reject){
console.log(111);
setTimeout(resolve,ms);
})
}
sleep(500).next().value.then(function(){console.log(2222)})
首先明确什么是promiseA+规范,参考规范的地址:
如何实现一个promise,参考我的文章:
一般不会问的很详细,只要能写出上述文章中的v1.0版本的简单promise即可。
获取一个对象的原型,在chrome中可以通过__proto__的形式,或者在ES6中可以通过Object.getPrototypeOf的形式。
那么Function.proto是什么么?也就是说Function由什么对象继承而来,我们来做如下判别。
Function.__proto__==Object.prototype //false
Function.__proto__==Function.prototype//true
我们发现Function的原型也是Function。
我们用图可以来明确这个关系:

通过递归可以简单实现对象的深度克隆,但是这种方法不管是ES6还是ES5实现,都有同样的缺陷,就是只能实现特定的object的深度复制(比如数组和函数),不能实现包装对象Number,String , Boolean,以及Date对象,RegExp对象的复制。
function deepClone(obj){
var newObj= obj instanceof Array?[]:{};
for(var i in obj){
newObj[i]=typeof obj[i]=='object'?
deepClone(obj[i]):obj[i];
}
return newObj;
}
这种方法可以实现一般对象和数组对象的克隆,比如:
var arr=[1,2,3];
var newArr=deepClone(arr);
// newArr->[1,2,3]
var obj={
x:1,
y:2
}
var newObj=deepClone(obj);
// newObj={x:1,y:2}
但是不能实现例如包装对象Number,String,Boolean,以及正则对象RegExp和Date对象的克隆,比如:
//Number包装对象
var num=new Number(1);
typeof num // "object"
var newNum=deepClone(num);
//newNum -> {} 空对象
//String包装对象
var str=new String("hello");
typeof str //"object"
var newStr=deepClone(str);
//newStr-> {0:'h',1:'e',2:'l',3:'l',4:'o'};
//Boolean包装对象
var bol=new Boolean(true);
typeof bol //"object"
var newBol=deepClone(bol);
// newBol ->{} 空对象
....
所有对象都有valueOf方法,valueOf方法对于:如果存在任意原始值,它就默认将对象转换为表示它的原始值。对象是复合值,而且大多数对象无法真正表示为一个原始值,因此默认的valueOf()方法简单地返回对象本身,而不是返回一个原始值。数组、函数和正则表达式简单地继承了这个默认方法,调用这些类型的实例的valueOf()方法只是简单返回这个对象本身。
对于原始值或者包装类:
function baseClone(base){
return base.valueOf();
}
//Number
var num=new Number(1);
var newNum=baseClone(num);
//newNum->1
//String
var str=new String('hello');
var newStr=baseClone(str);
// newStr->"hello"
//Boolean
var bol=new Boolean(true);
var newBol=baseClone(bol);
//newBol-> true
其实对于包装类,完全可以用=号来进行克隆,其实没有深度克隆一说,
这里用valueOf实现,语法上比较符合规范。
对于Date类型:
因为valueOf方法,日期类定义的valueOf()方法会返回它的一个内部表示:1970年1月1日以来的毫秒数.因此我们可以在Date的原型上定义克隆的方法:
Date.prototype.clone=function(){
return new Date(this.valueOf());
}
var date=new Date('2010');
var newDate=date.clone();
// newDate-> Fri Jan 01 2010 08:00:00 GMT+0800
对于正则对象RegExp:
RegExp.prototype.clone = function() {
var pattern = this.valueOf();
var flags = '';
flags += pattern.global ? 'g' : '';
flags += pattern.ignoreCase ? 'i' : '';
flags += pattern.multiline ? 'm' : '';
return new RegExp(pattern.source, flags);
};
var reg=new RegExp('/111/');
var newReg=reg.clone();
//newReg-> /\/111\//
简介:观察者模式或者说订阅模式,它定义了对象间的一种一对多的关系,让多个观察者对象同时监听某一个主题对象,当一个对象发生改变时,所有依赖于它的对象都将得到通知。
node中的Events模块就是通过观察者模式来实现的:
var events=require('events');
var eventEmitter=new events.EventEmitter();
eventEmitter.on('say',function(name){
console.log('Hello',name);
})
eventEmitter.emit('say','Jony yu');
这样,eventEmitter发出say事件,通过On接收,并且输出结果,这就是一个订阅模式的实现,下面我们来简单的实现一个Events模块的EventEmitter。
function Events(){
this.on=function(eventName,callBack){
if(!this.handles){
this.handles={};
}
if(!this.handles[eventName]){
this.handles[eventName]=[];
}
this.handles[eventName].push(callBack);
}
this.emit=function(eventName,obj){
if(this.handles[eventName]){
for(var i=0;o<this.handles[eventName].length;i++){
this.handles[eventName][i](obj);
}
}
}
return this;
}
这样我们就定义了Events,现在我们可以开始来调用:
var events=new Events();
events.on('say',function(name){
console.log('Hello',nama)
});
events.emit('say','Jony yu');
//结果就是通过emit调用之后,输出了Jony yu
因为是通过new的方式,每次生成的对象都是不相同的,因此:
var event1=new Events();
var event2=new Events();
event1.on('say',function(){
console.log('Jony event1');
});
event2.on('say',function(){
console.log('Jony event2');
})
event1.emit('say');
event2.emit('say');
//event1、event2之间的事件监听互相不影响
//输出结果为'Jony event1' 'Jony event2'
var a=11;
function test2(){
this.a=22;
let b=()=>{console.log(this.a)}
b();
}
var x=new test2();
//输出22
定义时绑定。
在使用react和redux的过程中,一直有一个问题,哪些状态需要放在redux中,状态需要保存在组件内的local state中,此外不合理的使用redux可能会带来状态管理混乱的问题,此外对于local state局部状态而言,react hooks提供了一个比class中的setState更好的一个替代方案。本文主要从状态管理出发,讲讲如何优雅的使用hooks来进行状态管理。
- 如何使用redux
- react hooks管理local state
- react hooks如何解决组件间的通信
首先要明确为什么要使用redux,这一点很重要,如果不知道为什么使用redux,那么在开发的过程中肯定不能合理的使用redux.首先来看redux的本质:
redux做为一款状态管理工具,主要是为了解决组件间通信的问题。
既然是组件间的通信问题,那么显然将所有页面的状态都放入redux中,是不合理的,复杂度也很高。
笔者在早期也犯了这个问题,在应用中,不管什么状态,按页面级路由拆分,全部放在redux中,页面任何状态的更改,通过react-redux的mapState和mapDispatch来实现。

redux中的状态从状态更新到反馈到视图,是一个过程链太长,从dispatch一个action出发,然后走reducer等逻辑,一个完整的链路包含:
创建action,创建redux中间件,创建相应type的reducer函数,创建mapState和mapDispatch等。
如果将所有状态都保存在redux中,那么每一个状态必须走这几步流程,及其繁琐,毫无疑问增加了代码量
全量使用redux的复杂度很高,我们当然考虑将一部分状态放在redux中,一部分状态放在local state中,但是这种情况下,很容易产生一个问题,就是如果local State跟redux中的state存在状态依赖。
举例来说,在redux中的状态中有10个学生
//redux
students = [{name:"小明",score:70},{name:"小红",score:50}....]在local state中我们保存了分数在60分以上的学生
// local state
state = [{name:"小明",score:70}]如果redux中的学生改变了,我们需要从redux中动态的获取students信息,然后改变局部的state.结合react-redux,我们需要在容器组件中使用componentWillReceivedProps或者getDerivedStateFromProps这个声明周期,来根据props改变局部的local state.
componentWillReceivedProps这里不讨论,为了更高的安全性,在react中用静态的getDerivedStateFromProps代替了componentWillReceivedProps这里不讨论,而getDerivedStateFromProps这个声明周期函数在props和state变化的时候都会去执行,因此如果我们需要仅仅在props的改变而改变局部的local state,在这个声明周期中会存在着很复杂的判断逻辑。
redux中的状态和local state中的状态相关联的越多,getDerivedStateFromProps这个声明周期函数就越复杂
给我们的启示就是尽可能的减少getDerivedStateFromProps的使用,如果实在是redux和local state有关联性,用id会比直接用对象或者数组好,比如上述的例子,我们可以将学生分组,并给一个组号,每次在redux中的学生信息发生改变的时候会改变相应的组号。
这样在getDerivedStateFromProps只需要判断组号是否改变即可:
class Container extends React.Component{
state = {
group_id:number
}
static getDerivedStateFromProps(props,state){
if(props.group_id!==state.group_id){
... 更新及格的学生
}else{
return null
}
}
}这里推荐https://github.com/paularmstrong/normalizr,如果实在redux和local state关联性强,可以先将数据范式化,范式化后的数据类似于给一个复杂结构一个id,这样子会简化getDerivedStateFromProps的逻辑.
如何使用redux,必须从redux的本质出发,redux的本质是为了解决组件间的通信问题,因此组件内部独有的状态不应该放在redux中,此外如果redux结合class类组件使用,可以将数据范式化,简化复杂的判断逻辑。
前面将了应该如何使用redux,那么如何维护local state呢,React16.8中正式增加了hooks。通过hooks管理local state,简单易用可扩展。
在hooks中的局部状态常见的有3种,分别是useState、useRef和useReducer
useState是hooks中最常见的局部状态,比如:
const [hide, setHide] = React.useState(false);
const [name, setName] = React.useState('BI');理解useState必须明确,在react hooks中:
每一次渲染都有它自己的 Props and State
一个经典的例子就是:
function Counter() {
const [count, setCount] = useState(0);
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + count);
}, 3000);
}
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
<button onClick={handleAlertClick}>
Show alert
</button>
</div>
);
}如果我按照下面的步骤去操作:
猜猜看会alert出什么?

结果是弹出了3,alert会“捕获”我点击按钮时候的状态,也就是说每一次的渲染都会有独立的props和state.
在react hooks中,我们知道了每一次的渲染都会有独立的props和state,那么如果我们需要跟类组件一样,每次都能拿到最新的渲染值时,应该怎么做呢?此时我们可以用useRef
useRef提供了一个Mutable可变的数据
我们来修改上述的例子,来是的alert为5:
function Counter() {
const [count, setCount] = useState(0)
const late = useRef(0)
function handleAlertClick() {
setTimeout(() => {
alert('You clicked on: ' + late.current)
}, 3000)
}
useEffect(() => {
late.current = count
})
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>Click me</button>
<button onClick={handleAlertClick}>Show alert</button>
</div>
)
}如此修改以后就不是alert3 而是弹出5
react hooks中也提供了useReducer来管理局部状态.
当你想更新一个状态,并且这个状态更新依赖于另一个状态的值时,你可能需要用useReducer去替换它们。
同样的用例子来说明:
function Counter() {
const [state, dispatch] = useReducer(reducer, initialState);
const { count, step } = state;
useEffect(() => {
const id = setInterval(() => {
dispatch({ type: 'tick' });
}, 1000);
return () => clearInterval(id);
}, [dispatch]);
return (
<>
<h1>{count}</h1>
<input value={step} onChange={e => {
dispatch({
type: 'step',
step: Number(e.target.value)
});
}} />
</>
);
}
const initialState = {
count: 0,
step: 1,
};
function reducer(state, action) {
const { count, step } = state;
if (action.type === 'tick') {
return { count: count + step, step };
} else if (action.type === 'step') {
return { count, step: action.step };
} else {
throw new Error();
}
}解释上面的结果主要来看useEffect部分:
useEffect(() => {
const id = setInterval(() => {
dispatch({ type: 'tick' });
}, 1000);
return () => clearInterval(id);
}, [dispatch]);在state中的count依赖与step,但是使用了useReducer后,我们不需要在useEffect的依赖变动数组中使用step,转而用dispatch来替代,这样的好处就是减少不必要的渲染行为.
此外:局部状态不推荐使用 useReducer ,会导致函数内部状态过于复杂,难以阅读。 useReducer 建议在多组件间通信时,结合 useContext 一起使用。
react hooks中的局部状态管理相比于类组件而言更加简介,那么如果我们组件采用react hooks,那么如何解决组件间的通信问题。
最基础的想法可能就是通过useContext来解决组件间的通信问题。
比如:
function useCounter() {
let [count, setCount] = useState(0)
let decrement = () => setCount(count - 1)
let increment = () => setCount(count + 1)
return { count, decrement, increment }
}
let Counter = createContext(null)
function CounterDisplay() {
let counter = useContext(Counter)
return (
<div>
<button onClick={counter.decrement}>-</button>
<p>You clicked {counter.count} times</p>
<button onClick={counter.increment}>+</button>
</div>
)
}
function App() {
let counter = useCounter()
return (
<Counter.Provider value={counter}>
<CounterDisplay />
<CounterDisplay />
</Counter.Provider>
)
}在这个例子中通过createContext和useContext,可以在App的子组件CounterDisplay中使用context,从而实现一定意义上的组件通信。
此外,在useContext的基础上,为了其整体性,业界也有几个比较简单的封装:
https://github.com/jamiebuilds/unstated-next
https://github.com/diegohaz/constate
但是其本质都没有解决一个问题:
如果context太多,那么如何维护这些context
也就是说在大量组件通信的场景下,用context进行组件通信代码的可读性很差。这个类组件的场景一致,context不是一个新的东西,虽然用了useContext减少了context的使用复杂度。
hooks组件间的通信,同样可以使用redux来实现。也就是说:
在React hooks中,redux也有其存在的意义
在hooks中存在一个问题,因为不存在类似于react-redux中connect这个高阶组件,来传递mapState和mapDispatch, 解决的方式是通过redux-react-hook或者react-redux的7.1 hooks版本来使用。
在redux-react-hook中提供了StoreContext、useDispatch和useMappedState来操作redux中的store,比如定义mapState和mapDispatch的方式为:
import {StoreContext} from 'redux-react-hook';
ReactDOM.render(
<StoreContext.Provider value={store}>
<App />
</StoreContext.Provider>,
document.getElementById('root'),
);
import {useDispatch, useMappedState} from 'redux-react-hook';
export function DeleteButton({index}) {
// Declare your memoized mapState function
const mapState = useCallback(
state => ({
canDelete: state.todos[index].canDelete,
name: state.todos[index].name,
}),
[index],
);
// Get data from and subscribe to the store
const {canDelete, name} = useMappedState(mapState);
// Create actions
const dispatch = useDispatch();
const deleteTodo = useCallback(
() =>
dispatch({
type: 'delete todo',
index,
}),
[index],
);
return (
<button disabled={!canDelete} onClick={deleteTodo}>
Delete {name}
</button>
);
}这也是官方较为推荐的,react-redux 的hooks版本提供了useSelector()、useDispatch()、useStore()这3个主要方法,分别对应与mapState、mapDispatch以及直接拿到redux中store的实例.
简单介绍一下useSelector,在useSelector中除了能从store中拿到state以外,还支持深度比较的功能,如果相应的state前后没有改变,就不会去重新的计算.
举例来说,最基础的用法:
import React from 'react'
import { useSelector } from 'react-redux'
export const TodoListItem = props => {
const todo = useSelector(state => state.todos[props.id])
return <div>{todo.text}</div>
}实现缓存功能的用法:
import React from 'react'
import { useSelector } from 'react-redux'
import { createSelector } from 'reselect'
const selectNumOfDoneTodos = createSelector(
state => state.todos,
todos => todos.filter(todo => todo.isDone).length
)
export const DoneTodosCounter = () => {
const NumOfDoneTodos = useSelector(selectNumOfDoneTodos)
return <div>{NumOfDoneTodos}</div>
}
export const App = () => {
return (
<>
<span>Number of done todos:</span>
<DoneTodosCounter />
</>
)
}在上述的缓存用法中,只要todos.filter(todo => todo.isDone).length不改变,就不会去重新计算.
react中完整的状态管理分为全局状态和局部状态,而react hooks简化了局部状态,使得管理局部状态以及控制局部渲染极其方便,但是react hooks本质上还是一个视图组件层的,并没有完美的解决组件间的通信问题,也就是说,redux等状态管理机和react hooks本质上并不矛盾。
在我的实践中,用redux实现组件间的通信而react hooks来实现局部的状态管理,使得代码简单已读的同时,也减少了很多不必要的redux样板代码.
在json对象嵌套比较复杂的情况下,可以将复杂的嵌套对象转化成范式化的数据。比如后端返回的json对象比较复杂,前端需要从复杂的json对象中提取数据然后呈现在页面上,复杂的json嵌套,使得前端展示的逻辑比较混乱。
特别的,如果我们使用了flux或者redux等作为我们前端的状态管理机(state对象),通过控制state对象的变化,从而呈现不同的视图层的展示,如果我们在状态管理的时候,将state对象范式化,可以减小state对象操作的复杂性,从而可以清晰的展示视图更新的过程。
- 什么是数据范式化和反范式化
- 数据范式化的实现
- jest编写简单的单元测试
本文的源码地址为:https://github.com/forthealllight/normalize
本文不会具体介绍在数据库中关于范式的定义,广义的数据范式化,就是除了最外层属性之外,其他关联的属性用外键来引用。
数据范式化的好处有:可以减少数据的冗余
比如有一个person对象如下所示:
{
'id':1,
'name':'xiaoliang',
'age':20,
'hobby':[{
id:30,
desp:'足球'
},{
id:40,
desp:'篮球'
},{
id:50,
desp:'羽毛球'
}]
}
在上述的对象中,hobby存在嵌套,我们将perosn的无嵌套的其他属性作为主属性,而hobby属性表示的是需要外键来引用的属性,我们将id作为外键的名称,将上述的嵌套对象经过范式化处理可以得到:
{
person:{
'1':{
'id':1,
'name':'xiaoliang',
'age':20,
'hobby':['30','40','50']
}
},
hobby:{
'30':{
id:'30',
desp:'足球'
},
'40':{
id:'40',
desp:'篮球',
},
'50':{
id:'50',
desp:'羽毛球'
}
}
}
上述对象就是范式化之后的结果,我们发现主对象person里面的hobby属性中,此时变成了id号组成的数组,通过id作为外键来索引另一个对象hobby中的具体值。
那么这样做到底有什么好处呢?
比如我们现在新增了一个人id为2:
{
'id':2,
'name':'xiaoyu',
'age':20,
'hobby':[{
id:30,
desp:'足球'
}]
}
他的兴趣还好中同样包含了足球,那么如果有复杂嵌套对象的形式,对象变成如下的形式:
[
{
'id':1,
'name':'xiaoliang',
'age':20,
'hobby':[{
id:30,
desp:'足球'
},{
id:40,
desp:'篮球'
},{
id:50,
desp:'羽毛球'
}]
},
{
'id':2,
'name':'xiaoyu',
'age':20,
'hobby':[{
id:30,
desp:'足球'
}]
}
]
上述的这个对象嵌套层级就比较深,比如现在我们发现hobby中的足球的描述发生了变化,比如:
desp:'足球'——> desp:'英式足球'
如果在上述的嵌套对象中直接改变,我们需要改变两处位置,其一是id为1的person中的id为30的hobby的desp,另一处是id为2处的person的id为30处的hobby的desp.
这还是person只有2个实例的情况,如果person的实例更多,那么,如果仅仅一个hobby改变,就需要改变多处位置。也就显得操作比较冗余。
如果用数据范式化来处理,效果如何呢?,将上述的对象范式化得到:
{
person:{
'1':{
'id':1,
'name':'xiaoliang',
'age':20,
'hobby':['30','40','50']
},
'2':{
'id':2,
'name':'xiaoyu',
'age':30,
'hobby':[30]
}
},
hobby:{
'30':{
id:'30',
desp:'足球'
},
'40':{
id:'40',
desp:'篮球',
},
'50':{
id:'50',
desp:'羽毛球'
}
}
}
此时如果同样的发生了:
***desp:'足球'——> desp:'英式足球'***
这样的变化,映射之后只需要改变,hobby被查询对象:
hobby:{
'30':{
id:'30',
desp:'英式足球'
},
......
}
这样,无论有多少实例引用了id为30的这个hobby,我们修改所引起的操作只需要一处就能到位。
那么数据范式化有什么缺点呢?
一句话可以概括数据范式化的缺点:查询性能低下
从上述范式化后的数据可以看出:
person:{
'1':{
'id':1,
'name':'xiaoliang',
'age':20,
'hobby':['30','40','50']
},
'2':{
'id':2,
'name':'xiaoyu',
'age':30,
'hobby':[30]
}
}
在上述范式化的数据里,hobby是通过id来表示,如果要索引每个id的具体值和对象,比如要到上一层的“hobby”对象中去查询。而原始的嵌套对象可以很直观的展示出来,每一个id所对应的hobby对象是什么。
下面我们来尝试编写范式化(normalize)和反范式化的函数(denormalize).
| 函数名称 | 函数的具体表示 |
| schema.Entity(name, [entityParams], [entityConfig]) |
--name为该schema的名称 --entityParams为可选参数, 定义该schema的外键,定义的外键可以不存在 --entityConfig为可选参数,目前仅支持一个参数 定义该entity的主键,默认值为字符串'id' |
| normalize(data, entity) |
-- data 需要范式化的数据,必须为符合schema定义的对象或由该类对象组成的数组 -- entity实例 |
| denormalize (normalizedData, entity, entities) |
-- normalizedData -- entity -同上 -- entities 同上 |
实现数据范式化和反范式化,主要是上面3个函数,下面我们来一一分析。
本文需要范式化的原始数据为:
const originalData = {
"id": "123",
"author": {
"uid": "1",
"name": "Paul"
},
"title": "My awesome blog post",
"comments": {
total: 100,
result: [{
"id": "324",
"commenter": {
"uid": "2",
"name": "Nicole"
}
}]
}
}
范式化之前必须对嵌套对象进行处理,深层嵌套的情况下,需要用实体Entity进行解构,层级最深的实体需要首先被定义,然后一层层的解耦到最外层。
该实体的构造方法,接受3个参数,第一个参数name,表示范式化后的对象的属性的名称,第二个参数entityParams,表示实体化后,原始的嵌套对象和一定义的实体之间的一一对应关系,第三个参数表示的是
用来索引嵌套对象的主键,默认的情况下,我们用id来索引。
上述实例的实体化为:
const user = new schema.Entity('users', {}, {
idAttribute: 'uid'
})
const comment = new schema.Entity('comments', {
commenter: user
})
const article = new schema.Entity('articles', {
author: user,
comments: {
result: [ comment ]
}
});
实体化还是从最里层到最外层。并且第三个参数表示索引的主键。
如何实现构造方法呢?schema.Entity的实现代码为,首先定义一个类:
export default class EntitySchema {
constructor (name, entityParams = {}, entityConfig = {}) {
const idAttribute = entityConfig.idAttribute || 'id'
this.name = name
this.idAttribute = idAttribute
this.init(entityParams)
}
/**
* [获取当前schema的名字]
* @return {[type]} [description]
*/
getName () {
return this.name
}
getId (input) {
let key = this.idAttribute
return input[key]
}
/**
* [遍历当前schema中的entityParam,entityParam中可能存在schema]
* @param {[type]} entityParams [description]
* @return {[type]} [description]
*/
init (entityParams) {
if (!this.schema) {
this.schema = {}
}
for (let key in entityParams) {
if (entityParams.hasOwnProperty(key)) {
this.schema[key] = entityParams[key]
}
}
}
}
定义一个EntitySchema类,构造方法中,因为entityParams存在嵌套的情况,因此需要在init方法中遍历entityParams中的schema属性。此外为了定义了获取主键和name名的方法,getName和getId。
上述就是范式化的函数,接受两个参数,第一个参数为原始的需要被范式化的数据,第二个参数为最外层的实体。同样在上述例子原始数据被范式化,可以通过如下方式来实现:
normalize(originData,articles)
上述的例子中,最外层的实体为articles。
那么如何实现该范式化,首先考虑到最外层的实体,可能存在嵌套,且最外层实体的对象的属性值不一定是一个schema实体,也可能是数组等结构,因此要分别处理schema实体和非schema实体的情况:
const flatten = (value, schema, addEntity) => {
if (typeof schema.getName === 'undefined') {
return noSchemaNormalize(schema, value, flatten, addEntity)
}
return schemaNormalize(schema, value, flatten, addEntity)
}
如果传入的是一个schema实体:
const schemaNormalize = (schema, data, flatten, addEntity) => {
const processedEntity = {...data}
const currentSchema = schema
Object.keys(currentSchema.schema).forEach((key) => {
const schema = currentSchema.schema[key]
const temple = flatten(processedEntity[key], schema, addEntity)
// console.log(key,temple);
processedEntity[key] = temple
})
addEntity(currentSchema, processedEntity)
return currentSchema.getId(data)
}
那么情况为递归该schema,直到从最外层的schema递归到最里层的schema.
如果传入的不是一个schema实体:
const noSchemaNormalize = (schema, data, flatten, addEntity) => {
// 非schema实例要分别针对对象类型和数组类型做不同的处理
const object = { ...data }
const arr = []
let tag = schema instanceof Array
Object.keys(schema).forEach((key) => {
if (tag) {
const localSchema = schema[key]
const value = flatten(data[key], localSchema, addEntity)
arr.push(value)
} else {
const localSchema = schema[key]
const value = flatten(data[key], localSchema, addEntity)
object[key] = value
}
})
// 根据判别的结果,返回不同的值,可以是对象,也可以是数组
if (tag) {
return arr
} else {
return object
};
}
如果不是一个实体,那么分为是一个对象和是一个数组两种情况分别来处理。
最后有一个addEntity,递归到里层,再往外层,得到对应的schema的name所包含的id,和此id所指向的具体对象。
const addEntities = (entities) => (schema, processedEntity) => {
const schemaKey = schema.getName()
const id = schema.getId(processedEntity)
if (!(schemaKey in entities)) {
entities[schemaKey] = {}
}
const existingEntity = entities[schemaKey][id]
if (existingEntity) {
entities[schemaKey][id] = Object.assgin(existingEntity, processedEntity)
} else {
entities[schemaKey][id] = processedEntity
}
}
最后我们的normalize方法具体为:
const normalize = (data, schema) => {
const entities = {}
const addEntity = addEntities(entities)
const result = flatten(data, schema, addEntity)
return { entities, result }
}
denormalize反范式化方法,接受3个参数,其中normalizedData 和entities表示范式化后的对象的属性,而entity表示最外层的实体。
调用的方式为:
const normalizedData = normalize(originalData, article);
// 还原范式化数据
const {result, entities} = normalizedData
const denormalizedData = denormalize(result, article, entities)
反范式化的具体代码与范式化相似,就不具体说明,详情请看源代码。
直接给出简单的单元测试代码:
//范式化数据用例,原始数据
const originalData = {
"id": "123",
"author": {
"uid": "1",
"name": "Paul"
},
"title": "My awesome blog post",
"comments": {
total: 100,
result: [{
"id": "324",
"commenter": {
"uid": "2",
"name": "Nicole"
}
}]
}
}
//范式化数据用例,范式化后的结果数据
const normalizedData={
result: "123",
entities: {
"articles": {
"123": {
id: "123",
author: "1",
title: "My awesome blog post",
comments: {
total: 100,
result: [ "324" ]
}
}
},
"users": {
"1": { "uid": "1", "name": "Paul" },
"2": { "uid": "2", "name": "Nicole" }
},
"comments": {
"324": { id: "324", "commenter": "2" }
}
}
}
//开始测试上述用例下的,范式化结果对比
test('test originalData to normalizedData', () => {
const user = new schema.Entity('users', {}, {
idAttribute: 'uid'
});
const comment = new schema.Entity('comments', {
commenter: user
});
const article = new schema.Entity('articles', {
author: user,
comments: {
result: [ comment ]
}
});
const data = normalize(originalData, article);
expect(data).toEqual(normalizedData);
});
//开始测试上述例子,反范式化的结果对比
test('test normalizedData to originalData',()=>{
const user = new schema.Entity('users', {}, {
idAttribute: 'uid'
});
// Define your comments schema
const comment = new schema.Entity('comments', {
commenter: user
});
// Define your article
const article = new schema.Entity('articles', {
author: user,
comments: {
result: [ comment ]
}
});
const data = normalize(originalData, article)
//还原范式化数据
const {result,entities}=data;
const denormalizedData=denormalize(result,article,entities);
expect(denormalizedData).toEqual(originalData)
})
在上一章介绍了如何在React,通过虚拟列表的形式优化长列表。介绍了虚拟列表的原理,以及比较常用的优化长列表的组件库React-virtualized和React-tiny-virtual-list。本文中来读一读React-tiny-virtual-list源码。
- 虚拟列表的原理简介
- React-tiny-virtual-list组件的使用
- React-tiny-virtual-list的源码分析
- React-tiny-virtual-list的总结
优化长列表的原理很简单,基本原理可以一句话概括:
用数组保存所有列表元素的位置,只渲染可视区内的列表元素,当可视区滚动时,根据滚动的offset大小以及所有列表元素的位置,计算在可视区应该渲染哪些元素。
具体实现步骤如下所示:
通过虚拟列表的方式,不需要同时渲染很多dom节点,只需要渲染出可视区的dom节点,这种方式可以大大减小渲染时间,提升用户体验。
React-tiny-virtual-list是一个极简的React虚拟列表优化组件库,我们来看如何使用这个组件:
import VirtualList from 'react-tiny-virtual-list';
const data = ['A', 'B', 'C', 'D', 'E', 'F','G','H','I','J','K','L'];
class TinyVirtual extends Component {
render(){
return <VirtualList
width={"100%"}
height={200}
itemCount={data.length}
itemSize={50}
renderItem={({index, style}) =>
<div key={index} style={style}>
The style property contains the item's absolute position Letter: {data[index]}, Row: #{index}
</div>
}
/>
}
}
效果为:

该组件中通过width和height分别定义了宽度和高度,通过itemCount定义了所有需要被渲染成dom节点的数据数组的长度。itemSize定义了渲染的每一个dom的高度,而renderItem定义了如何结合数据来渲染一个dom。
此外react-tiny-virtual-list的List组件还有scrollDirection属性决定是垂直滚动还是水平滚动,以及recomputeSizes函数用于重新计算列表中每一个dom元素的高度等。
下面我们来根据常用的width、height、itemCount、itemSize和renderItem来分析React-tiny-virtual-list的源码。React-tiny-virtual-list的源码包含了一个VirtualList组件,以及处理关于保存了VirtualList组件所渲染的列表元素的位置,同时决定其能否在可视区显示的工具类——SizeAndPositionManager类。
下面来一一分析:
首先来看这个VirtualList组件初始化和render的方法中做了哪些事情,在初始化VirtualList组件时:
itemSizeGetter = (itemSize) => {
return index => this.getSize(index, itemSize);
};
sizeAndPositionManager = new SizeAndPositionManager({
itemCount: this.props.itemCount,
itemSizeGetter: this.itemSizeGetter(this.props.itemSize),
estimatedItemSize: this.getEstimatedItemSize(),
});
state = {
offset:
this.props.scrollOffset ||
(this.props.scrollToIndex != null &&
this.getOffsetForIndex(this.props.scrollToIndex)) ||
0,
scrollChangeReason: SCROLL_CHANGE_REASON.REQUESTED,
};
在初始化的时候,在state中定义并赋值了整个列表应该滚动到哪一个位置的offset属性,可以根据该值来决定整个列表中,哪几个列dom需要在可视区内被渲染。
并且根据虚拟列表的原理我们指导,需要在内存中保存列表中每一个dom元素的相对于父元素的位置等信息,并且在父元素滚动等操作的时候需要更新子元素列的位置信息。在这里我们通过一个SizeAndPositionManager类来实现。
首先看这个类的状态定义:
class SizeAndPositionManager {
constructor({itemCount, itemSizeGetter, estimatedItemSize}: Options) {
this.itemSizeGetter = itemSizeGetter;
this.itemCount = itemCount;
this.estimatedItemSize = estimatedItemSize;
this.itemSizeAndPositionData = {};
this.lastMeasuredIndex = -1;
}
这个类中有itemSizeGetter方法用于获取从props传入的每一个子元素size的值,以及列表总列数等信息。itemSizeAndPositionData对象用户保存每一列的大小和相对于父元素的定位信息。lastMeasuredIndex表示可视区内最后一个元素的索引。
此外在VirtualList组件的初始化中还有:
styleCache= {};
用于在内存中保存所有子元素的样式,通过index索引。初始化结束后,再来看render的过程:
render() {
const {
estimatedItemSize,
height,
...props
} = this.props;
const {offset} = this.state;//保存在当前的父元素中,相对于顶部父亲元素滚动的举例offset
const {start, stop} = this.sizeAndPositionManager.getVisibleRange({
containerSize: this.props[sizeProp[scrollDirection]] || 0,
offset,
overscanCount,
}); //根据父元素滚动的距离,以及父元素的高度等信息,来决定父元素可视区内应该展示哪几个子元素
const items: React.ReactNode[] = []; //保存应该在可视区内被渲染的子列表数组
//找出应该在可视区内被渲染的子列表元素的index之后,就需要通过this.getStyle方法来获取该元素的样式以及在父元素汇总的距离。获取渲染元素的索引值,以及样式之后,通过在属性中通过props传入的renderItem方法,构建应该渲染出的列表元素。
if (typeof start !== 'undefined' && typeof stop !== 'undefined') {
for (let index = start; index <= stop; index++) {
items.push(
renderItem({
index,
style: this.getStyle(index, false),
}),
);
}
return (
<div ref={this.getRef} {...props} style={wrapperStyle}>
<div style={innerStyle}>{items}</div>
</div>
);
}
其中需要在于this.getStyle方法:
getStyle(index: number, sticky: boolean) {
const style = this.styleCache[index];
if (style) {
return style;
}
const {scrollDirection = DIRECTION.VERTICAL} = this.props;
const {
size,
offset,
} = this.sizeAndPositionManager.getSizeAndPositionForIndex(index);
return (this.styleCache[index] = sticky
? {
...STYLE_STICKY_ITEM,
[sizeProp[scrollDirection]]: size,
[marginProp[scrollDirection]]: offset,
[oppositeMarginProp[scrollDirection]]: -(offset + size),
zIndex: 1,
}
: {
...STYLE_ITEM,
[sizeProp[scrollDirection]]: size,
[positionProp[scrollDirection]]: offset,
});
}
首先从styleCache的内存中去查找,如果找到就直接返回,否则就根据在初始的时候定义的this.sizeAndPositionManager的getSizeAndPositionForIndex中根据索引来得到响应元素的大小,以及相对于父元素的位置,并以index为索引保存在styleCache内存中。
此外,在render的return中,我们通过ref的方式在virtual dom中获取了父元素。
getRef = (node) => {
this.rootNode = node;
};
在VirtualList组件的componentDidMount的声明周期中开始监听滚动事件:
const {scrollOffset, scrollToIndex} = this.props;
this.rootNode.addEventListener('scroll', this.handleScroll, {
passive: true,
});
接着来看处理滚动事件的函数this.handleScroll:
handleScroll = (event) => {
const {onScroll} = this.props;
const offset = this.getNodeOffset();
if (
offset < 0 ||
this.state.offset === offset ||
event.target !== this.rootNode
) {
return;
}
this.setState({
offset,
scrollChangeReason: SCROLL_CHANGE_REASON.OBSERVED,
});
if (typeof onScroll === 'function') {
onScroll(offset, event);
}
};
getNodeOffset() {
const {scrollDirection = DIRECTION.VERTICAL} = this.props;
return this.rootNode[scrollProp[scrollDirection]];
}
在这个handleScroll事件中,通过getNodeOffset方法可以获得滚动后父元素滚动的高度,然后在this.setState方法中更新这个offset的值。只要state中的offset的值发生变化,就会重新触发render,在render中根据新的offset来确定可视区应该显示哪些列表。
最近已经使用过一段时间的nestjs,让人写着有一种java spring的感觉,nestjs可以使用express的所有中间件,此外完美的支持typescript,与数据库关系映射typeorm配合使用可以快速的编写一个接口网关。本文会介绍一下作为一款企业级的node框架的特点和优点。
- 从依赖注入(DI)谈起
- 装饰器和注解
- nestjs的“洋葱模型”
- nestjs的特点总结
从angular1.x开始,实现了依赖注入或者说控制反转的模式,angular1.x中就有controller(控制器)、service(服务),模块(module)。笔者在早年间写过一段时间的angular1.3,下面举例来说明:
var myapp=angular.module('myapp',['ui.router']);
myapp.controller('test1',function($scope,$timeout){}
myapp.controller('test2',function($scope,$state){}上面这个就是angular1.3中的一个依赖注入的例子,首先定义了模块名为“myapp”的module, 接着在myapp这个模块中定义controller控制器。将myapp模块的控制权交给了myapp.controller函数。具体的依赖注入的流程图如下所示:
myapp这个模块如何定义,由于它的两个控制器决定,此外在控制器中又依赖于$scope、$timeout等服务。这样就实现了依赖注入,或者说控制反转。
用一个例子来通俗的讲讲什么是依赖注入。
class Cat{
}
class Tiger{
}
class Zoo{
constructor(){
this.tiger = new Tiger();
this.cat = new Cat();
}
}
上述的例子中,我们定义Zoo,在其constructor的方法中进行对于Cat和Tiger的实例化,此时如果我们要为Zoo增加一个实例变量,比如去修改Zoo类本身,比如我们现在想为Zoo类增加一个Fish类的实例变量:
class Fish{}
class Zoo{
constructor(){
this.tiger = new Tiger();
this.cat = new Cat();
this.fish = new Fish();
}
}此外如果我们要修改在Zoo中实例化时,传入Tiger和Cat类的变量,也必须在Zoo类上修改。这种反反复复的修改会使得Zoo类并没有通用性,使得Zoo类的功能需要反复测试。
我们设想将实例化的过程以参数的形式传递给Zoo类:
class Zoo{
constructor(options){
this.options = options;
}
}
var zoo = new Zoo({
tiger: new Tiger(),
cat: new Cat(),
fish: new Fish()
})我们将实力化的过程放入参数中,传入给Zoo的构造函数,这样我们就不用在Zoo类中反复的去修改代码。这是一个简单的介绍依赖注入的例子,更为完全使用依赖注入的可以为Zoo类增加静态方法和静态属性:
class Zoo{
static animals = [];
constructor(options){
this.options = options;
this.init();
}
init(){
let _this = this;
animals.forEach(function(item){
item.call(_this,options);
})
}
static use(module){
animals.push([...module])
}
}
Zoo.use[Cat,Tiger,Fish];
var zoo = new Zoo(options);上述我们用Zoo的静态方法use往Zoo类中注入Cat、Tiger、Fish模块,将Zoo的具体实现移交给了Cat和Tiger和Fish模块,以及构造函数中传入的options参数。
在nestjs中也参考了angular中的依赖注入的**,也是用module、controller和service。
@Module({
imports:[otherModule],
providers:[SaveService],
controllers:[SaveController,SaveExtroController]
})
export class SaveModule {}
上面就是nestjs中如何定一个module,在imports属性中可以注入其他模块,在prividers注入相应的在控制器中需要用到的service,在控制器中注入需要的controller。
在nestjs中,完美的拥抱了typescript,特别是大量的使用装饰器和注解,对于装饰器和注解的理解可以参考我的这篇文章:Typescript中的装饰器和注解。我们来看使用了装饰器和注解后,在nestjs中编写业务代码有多么的简洁:
import { Controller, Get, Req, Res } from '@nestjs/common';
@Controller('cats')
export class CatsController {
@Get()
findAll(@Req() req,@Res() res) {
return 'This action returns all cats';
}
}
上述定义两个一个处理url为“/cats”的控制器,对于这个路由的get方法,定义了findAll函数。当以get方法,请求/cats的时候,就会主动的触发findAll函数。
此外在findAll函数中,通过req和res参数,在主题内也可以直接使用请求request以及对于请求的响应response。比如我们通过req上来获取请求的参数,以及通过res.send来返回请求结果。
这里简单讲讲在nestjs中是如何分层的,也就是说请求到达服务端后如何层层处理,直到响应请求并将结果返回客户端。
在nestjs中在service的基础上,按处理的层次补充了中间件(middleware)、异常处理(Exception filters)、管道(Pipes),守卫(Guards),以及拦截器(interceptors)在请求到打真正的处理函数之间进行了层层的处理。

上图中的逻辑就是分层处理的过程,经过分层的处理请求才能到达服务端处理函数,下面我们来介绍nestjs中的层层模型的具体作用。
在nestjs中的middle完全跟express的中间件一摸一样。不仅如此,我们还可以直接使用express中的中间件,比如在我的应用中需要处理core跨域:
import * as cors from 'cors';
async function bootstrap() {
onst app = await NestFactory.create(/* 创建app的业务逻辑*/)
app.use(cors({
origin:'http://localhost:8080',
credentials:true
}));
await app.listen(3000)
}
bootstrap();在上述的代码中我们可以直接通过app.use来使用core这个express中的中间件。从而使得server端支持core跨域等。
初此之外,跟nestjs的中间件也完全保留了express中的中间件的特点:
在nestjs中,中间件跟express中完全一样,除了可以复用express中间件外,在nestjs中针对某一个特定的路由来使用中间件也十分的方便:
class ApplicationModule implements NestModule {
configure(consumer: MiddlewareConsumer) {
consumer
.apply(LoggerMiddleware)
.forRoutes('cats');
}
}上面就是对于特定的路由url为/cats的时候,使用LoggerMiddleware中间件。
Exception filters异常过滤器可以捕获在后端接受处理任何阶段所跑出的异常,捕获到异常后,然后返回处理过的异常结果给客户端(比如返回错误码,错误提示信息等等)。
我们可以自定义一个异常过滤器,并且在这个异常过滤器中可以指定需要捕获哪些异常,并且对于这些异常应该返回什么结果等,举例一个自定义过滤器用于捕获HttpException异常的例子。
@Catch(HttpException)
export class HttpExceptionFilter implements ExceptionFilter {
catch(exception: HttpException, host: ArgumentsHost) {
const ctx = host.switchToHttp();
const response = ctx.getResponse();
const request = ctx.getRequest();
const status = exception.getStatus();
response
.status(status)
.json({
statusCode: status,
timestamp: new Date().toISOString(),
path: request.url,
});
}
}我们可以看到host是实现了ArgumentsHost接口的,在host中可以获取运行环境中的信息,如果在http请求中那么可以获取request和response,如果在socket中也可以获取client和data信息。
同样的,对于异常过滤器,我们可以指定在某一个模块中使用,或者指定其在全局使用等。
Pipes一般用户验证请求中参数是否符合要求,起到一个校验参数的功能。
比如我们对于一个请求中的某些参数,需要校验或者转化参数的类型:
@Injectable()
export class ParseIntPipe implements PipeTransform<string, number> {
transform(value: string, metadata: ArgumentMetadata): number {
const val = parseInt(value, 10);
if (isNaN(val)) {
throw new BadRequestException('Validation failed');
}
return val;
}
}上述的ParseIntPipe就可以把参数转化成十进制的整型数字。我们可以这样使用:
@Get(':id')
async findOne(@Param('id', new ParseIntPipe()) id) {
return await this.catsService.findOne(id);
}对于get请求中的参数id,调用new ParseIntPipe方法来将id参数转化成十进制的整数。
Guards守卫,其作用就是决定一个请求是否应该被处理函数接受并处理,当然我们也可以在middleware中间件中来做请求的接受与否的处理,与middleware相比,Guards可以获得更加详细的关于请求的执行上下文信息。
通常Guards守卫层,位于middleware之后,请求正式被处理函数处理之前。
下面是一个Guards的例子:
@Injectable()
export class AuthGuard implements CanActivate {
canActivate(
context: ExecutionContext,
): boolean | Promise<boolean> | Observable<boolean> {
const request = context.switchToHttp().getRequest();
return validateRequest(request);
}
}这里的context实现了一个ExecutionContext接口,该接口中具有丰富的执行上下文信息。
export interface ArgumentsHost {
getArgs<T extends Array<any> = any[]>(): T;
getArgByIndex<T = any>(index: number): T;
switchToRpc(): RpcArgumentsHost;
switchToHttp(): HttpArgumentsHost;
switchToWs(): WsArgumentsHost;
}
export interface ExecutionContext extends ArgumentsHost {
getClass<T = any>(): Type<T>;
getHandler(): Function;
}除了ArgumentsHost中的信息外,ExecutionContext还包含了getClass用户获取对于某一个路由处理的,控制器。而getClass用于获取返回对于指定路由后台处理时的处理函数。
对于Guards处理函数,如果返回true,那么请求会被正常的处理,如果返回false那么请求会抛出异常。
拦截器可以给每一个需要执行的函数绑定,拦截器将在该函数执行前或者执行后运行。可以转换函数执行后返回的结果等。
概括来说:
interceptors拦截器在函数执行前或者执行后可以运行,如果在执行后运行,可以拦截函数执行的返回结果,修改参数等。
再来举一个超时处理的例子:
@Injectable()
export class TimeoutInterceptor implements NestInterceptor{
intercept(
context:ExecutionContext,
call$:Observable<any>
):Observable<any>{
return call$.pipe(timeout(5000));
}
}该拦截器可以定义在控制器上,可以处理超时请求。
最后总结一下nestjs的优缺。
nestjs的优点:
在线上项目中,需要统计产品中用户行为和使用情况,从而可以从用户和产品的角度去了解用户群体,从而升级和迭代产品,使其更加贴近用户。用户行为数据可以通过前端数据监控的方式获得,除此之外,前端还需要实现性能监控和异常监控。性能监控包括首屏加载时间、白屏时间、http请求时间和http响应时间。异常监控包括前端脚本执行报错等。
实现前端监控有三个步骤:前端埋点和上报、数据处理和数据分析。本文针对整个前端监控,设计适用的方案。本文的主要内容分为:
- 为什么需要前端监控
- 常用前端埋点方案总结
- 前端埋点方案选型和前端上报方案设计
- 前端监控结果可视化展示系统的设计
前端监控的目的是:
获取用户行为以及跟踪产品在用户端的使用情况,并以监控数据为基础,指明产品优化的方向。
前端监控可以分为三类:数据监控、性能监控和异常监控。下面我们来一一的了解。
数据监控,顾名思义就是监听用户的行为。常见的数据监控包括:
统计这些数据是有意义的,比如我们知道了用户来源的渠道,可以促进产品的推广,知道用户在每一个页面停留的时间,可以针对停留较长的页面,增加广告推送等等。
性能监控指的是监听前端的性能,主要包括监听网页或者说产品在用户端的体验。常见的性能监控数据包括:
这些性能监控的结果,可以展示前端性能的好坏,根据性能监测的结果可以进一步的去优化前端性能,比如兼容低版本浏览器的动画效果,加快首屏加载等等。
此外,产品的前端代码在执行过程中也会发生异常,因此需要引入异常监控。及时的上报异常情况,可以避免线上故障的发上。虽然大部分异常可以通过try catch的方式捕获,但是比如内存泄漏以及其他偶现的异常难以捕获。常见的需要监控的异常包括:
在上一节中介绍了前端监控的作用,那么如何实现前端监控呢,实现前端监控的步骤为:前端埋点和上报、数据处理和数据分析。首要的步骤就是前端埋点和上报,也就是数据的收集阶段。数据收集的丰富性和准确性会影响对产品线上效果的判别结果。
目前常见的前端埋点方法分为三种:代码埋点、可视化埋点和无痕埋点。下面一一介绍每一种埋点的方法。
代码埋点,就是以嵌入代码的形式进行埋点,比如需要监控用户的点击事件,会选择在用户点击时,插入一段代码,保存这个监听行为或者直接将监听行为以某一种数据格式直接传递给server端。此外比如需要统计产品的PV和UV的时候,需要在网页的初始化时,发送用户的访问信息等。
代码埋点的优点:
缺点:
通过可视化交互的手段,代替代码埋点。将业务代码和埋点代码分离,提供一个可视化交互的页面,输入为业务代码,通过这个可视化系统,可以在业务代码中自定义的增加埋点事件等等,最后输出的代码耦合了业务代码和埋点代码。
可视化埋点听起来比较高大上,实际上跟代码埋点还是区别不大。也就是用一个系统来实现手动插入代码埋点的过程。
缺点:
无埋点并不是说不需要埋点,而是全部埋点,前端的任意一个事件都被绑定一个标识,所有的事件都别记录下来。通过定期上传记录文件,配合文件解析,解析出来我们想要的数据,并生成可视化报告供专业人员分析因此实现“无埋点”统计。
从语言层面实现无埋点也很简单,比如从页面的js代码中,找出dom上被绑定的事件,然后进行全埋点。
无埋点的优点:
缺点:
第一章中介绍了前端所需要监听的信息,在第二章中介绍了前端埋点的常见方式,本文来根据需求,来定制我们的埋点和上报方案。
首先我们需要明确一个产品或者网页,普遍需要监控和上报的数据。监控的分为三个阶段:用户进入网页首页、用户在网页内部交互和交互中报错。每一个阶段需要监控和上报的数据如下图所示:

在实际项目中考虑到上报数据的灵活定制,以及减少数据传输和服务器的压力,在所需埋点处不多的情况下,常用的方式是代码埋点。
以用户进入首页为例,我们在首页渲染完成后会发送事件类型和类型相关的数据给server端,告知首页的监控信息。

如果埋点的事件不是很多,上报可以时时进行,比如监控用户的交互事件,可以在用户触发事件后,立刻上报用户所触发的事件类型。如果埋点的事件较多,或者说网页内部交互频繁,可以通过本地存储的方式先缓存上报信息,然后定期上报。
接着来确定需要埋点上报的数据,上报的信息包括用户个人信息以及用户行为,主要数据可以分为:
who: appid(系统或者应用的id),userAgent(用户的系统、网络等信息)
when: timestamp(上报的时间戳)
from where: currentUrl(用户当前url),fromUrl(从哪一个页面跳转到当前页面),type(上报的事件类型),element(触发上报事件的元素)
what: 上报的自定义扩展数据data:{},扩展数据中可以按需求定制,比如包含uid等信息
上报数据的对象为:
{
----------------上报接口本身提供--------------------
currentUrl,
fromUrl,
timestamp,
userAgent:{
os,
netWord,
}
----------------业务代码配置和自定义上报数据------------
type,
appid,
element,
data:{
uid,
uname
}
}
我们以上报首屏加载事件为例,DOM提供了document的DOMContentLoaded事件来监听dom挂载,提供了window的load事件来监听页面所有资源加载渲染完毕。
<script type="text/javascript">
var start=Date.now();
document.addEventListener('DOMContentLoaded', function() {
fetch('some api',{
type:'dom complete',
data:{
domCompletedTime:Date.now()-start
}
})
});
window.addEventListener('load', function() {
fetch('some api',{
type:'load complete',
data:{
LoadCompletedTime:Date.now()-start
}
})
});
</script>
在上报数据的前后端通信中,需要和server端协商加密机制,利用 OpenSSL库来实现的加密,OpenSSL已经是一个广泛被采用的加密算法。前端可以采用node的crypto模块。
首先来看hash算法,crypto.createHash() 来创建一个Hash实例,可利用的hash算法如下:
md5
sha1
sha256
sha512
ripemd160
以sha256算法加密为例:
const str="123445";//需要加密的字段
const hash=crypto.createHash('sha256');//指定加密算法
hash.update(str); //通过算法加密相应的字段
const result=hash.digest('hex');//转化成十六进制
当后端得到前端上报的信息之后,经过数据分析和处理,需要前端可视化的展示数据分析后的结果。
可以在开源中后台系统ant-design-pro的基础上进行二次开发,首先要明确展示信息。展示的信息包括单个用户和整体应用。
对于单个用户来说需要展示的监控信息为:
对于全体用户需要展示的信息为:
删选功能集合:
简要介绍:用了一段时间redux,今天看了一下redux的源码,大致整理了心得如下。
applyMiddleware.js
bindActionCreators.js
combineReducers.js
compose.js
createStore.js
index.js
首先我们来看index.js主js的内容,很简单,就是引入和模块和抛出模块,这里有一句提醒内容,如果是production生产环境并且js已经被压缩,会输出warning信息
function isCrushed() {}
if (
process.env.NODE_ENV !== 'production' &&
typeof isCrushed.name === 'string' &&
isCrushed.name !== 'isCrushed'
) {
warning(
'You are currently using minified code outside of NODE_ENV === \'production\'. ' +
'This means that you are running a slower development build of Redux. ' +
'You can use loose-envify (https://github.com/zertosh/loose-envify) for browserify ' +
'or DefinePlugin for webpack (http://stackoverflow.com/questions/30030031) ' +
'to ensure you have the correct code for your production build.'
)
}
注: isCrushed.name 函数名.name是一个es6的属性,返回函数的名称。
除了index.js外,我们接下去从redux实现的接口,来深度分析一下Redux的源码。
我们首先从compose.js入手,首先redux贯穿始终的是函数式变成的**,个人对于函数式编程的理解为:
首先是纯函数(相同的输入产生相同的输出)
在范畴论理,状态或者输出表示点,函数表示边,从点到点的转移可以看成运算符,函数也是一种运算符,因为运算符是纯净的,因此函数式编程中的函数也是纯净的
函数式编程中的函数,与变量等价,可以作为参数传递或者成为其他函数函数体里的一部分
因为是函数式编程,便于函数的组合,这里有一个curry和compose的组合过程
基础了解函数式编程之后,下面我们来看compose.js的源码:
export default function compose(...funcs) {
if (funcs.length === 0) {
return arg => arg
}
if (funcs.length === 1) {
return funcs[0]
}
return funcs.reduce((a, b) => (...args) => a(b(...args)))
}
这个compose其实很简单,传入的参数为函数数组,返回的为reduce从左到右合并后的新的函数。是一个类似于链式调用的过程。
来看:
funcs.reduce((a, b) => (...args) => a(b(...args)))
这句特别重要,组合函数的这部非常重要,我们发现...args参数会依次的从右到左执行,比如将b(...args)的执行结果,传入a中作为参数继续执行。
applyMiddleware.js其实是基于compose.js来实现的
export default function applyMiddleware(...middlewares) {
return (createStore) => (reducer, preloadedState, enhancer) => {
const store = createStore(reducer, preloadedState, enhancer)
let dispatch = store.dispatch
let chain = []
const middlewareAPI = {
getState: store.getState,
dispatch: (action) => dispatch(action)
}
chain = middlewares.map(middleware => middleware(middlewareAPI))
dispatch = compose(...chain)(store.dispatch)
return {
...store,
dispatch
}
}
}
上述代码如果applyMiddleware(...Middleware)(createStore)这样调用,会生成一个新的createStore函数,用于创建新的createStore,新在哪里呢?就是链式的调用了所有的middleware:
let chain = []
const middlewareAPI = {
getState: store.getState,
dispatch: (action) => dispatch(action)
}
chain = middlewares.map(middleware => middleware(middlewareAPI))
dispatch = compose(...chain)(store.dispatch)
来看上述的代码,chain是一个函数数组,是middleware({})执行后的返回函数的数组,compose(...chain)是链式的组合函数,这里的...args是初始时候的store.dispatch,当最右边的函数以store.dispatch为参数,执行后生成一个新的store.dispatch,又向外传递,因此middleware是从右到左执行的。
从上述的描述中,我们知道了middle的书写形式,如果以纯函数的形式,首先第一个参数应该是{getState:'',dispatch:''},第二个参数是store.dispatch,第三个参数应该是action,因此最基本形式的middleware应该是:
return ({ dispatch, getState }) => next => action => {
}
我们以redux-thunk为例,redux-thunk中间件是严格按照上述的形式,
代码只有13行:
function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
if (typeof action === 'function') {
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
const thunk = createThunkMiddleware();
thunk.withExtraArgument = createThunkMiddleware;
export default thunk;
这个中间件的功能其实很简单,也就是action如果是一个函数就选择执行这个函数,并且action函数执行的时候,会传入dispatch和getState.
createStore相对而言会较为的复杂,我们还是从接口出发。
getState():返回当前的state树
dispatch(action):分发action,是改变state的唯一方法
subscribe(listener):添加一个监听器,当state变化的时候,执行监听器里面的函数。
unsubscribe(listener):subscribe的返回值,用于移除监听器
replaceReducer(nextReducer):替换store中当前的reducer
首先明确createStore的形参,形参有3个,分别是reducer(处理函数),initState(初始化state),enhancer(一个高阶函数,可以改变store的接口)。
export default function createStore(reducer, preloadedState, enhancer) {
}
let currentState = preloadedState
function getState() {
return currentState
}
getState函数比较简单,类似于一个get的方法,返回currentState的值
function dispatch(action) {
if (!isPlainObject(action)) {
throw new Error(
'Actions must be plain objects. ' +
'Use custom middleware for async actions.'
)
}
if (typeof action.type === 'undefined') {
throw new Error(
'Actions may not have an undefined "type" property. ' +
'Have you misspelled a constant?'
)
}
if (isDispatching) {
throw new Error('Reducers may not dispatch actions.')
}
try {
isDispatching = true
currentState = currentReducer(currentState, action)
} finally {
isDispatching = false
}
const listeners = currentListeners = nextListeners
for (let i = 0; i < listeners.length; i++) {
const listener = listeners[i]
listener()
}
return action
}
dispatch也不复杂,去掉判断类型(因为action必须是对象)的部分,其实只有2步:
try {
isDispatching = true
currentState = currentReducer(currentState, action)
} finally {
isDispatching = false
}
const listeners = currentListeners = nextListeners
for (let i = 0; i < listeners.length; i++) {
const listener = listeners[i]
listener()
}
这就很显然易见了,就是执行currentReducer()传入当前的currentState和action,返回新的state,并且执行监听函数数组里面的所有函数。
function subscribe(listener) {
if (typeof listener !== 'function') {
throw new Error('Expected listener to be a function.')
}
let isSubscribed = true
ensureCanMutateNextListeners()
nextListeners.push(listener)
return function unsubscribe() {
if (!isSubscribed) {
return
}
isSubscribed = false
ensureCanMutateNextListeners()
const index = nextListeners.indexOf(listener)
nextListeners.splice(index, 1)
}
}
监听函数也挺简单,就是一个简单的移入和移出,这是一个底层 API。多数情况下,你不会直接使用它,会使用一些 React(或其它库)的绑定。比如react-redux中的容器组件中的props改变会自动的更新(也算一个监听过程)。
function replaceReducer(nextReducer) {
if (typeof nextReducer !== 'function') {
throw new Error('Expected the nextReducer to be a function.')
}
currentReducer = nextReducer
dispatch({ type: ActionTypes.INIT })
}
这个函数就更加的简单了,replaceReducer是为了改变当前的reducer,因此只要将currentReducer赋值为形参即可。
最复杂的部分就是combineReducer.js了
示属性名,value是一个小的reduce函数:
export default function combineReducers(reducers) {
}
const reducerKeys = Object.keys(reducers)
const finalReducers = {}
for (let i = 0; i < reducerKeys.length; i++) {
const key = reducerKeys[i]
finalReducers[key] = reducers[key]
}
assertReducerShape(finalReducers);
function assertReducerShape(reducers) {
Object.keys(reducers).forEach(key => {
const reducer = reducers[key]
const initialState = reducer(undefined, { type: ActionTypes.INIT })
其原理也很简单,state的属性名和reducer对象的key是相对的,因此也就是在所有的小的reduce函数中,传入相对的state[key],action,依次执行后得到一个新的newState,然后与state做比较,选择性返回。
return function combination(state = {}, action) {
let hasChanged = false
const nextState = {}
for (let i = 0; i < finalReducerKeys.length; i++) {
const key = finalReducerKeys[i]
const reducer = finalReducers[key]
const previousStateForKey = state[key]
const nextStateForKey = reducer(previousStateForKey, action)
if (typeof nextStateForKey === 'undefined') {
const errorMessage = getUndefinedStateErrorMessage(key, action)
throw new Error(errorMessage)
}
nextState[key] = nextStateForKey
hasChanged = hasChanged || nextStateForKey !== previousStateForKey
}
return hasChanged ? nextState : state
}
}
这个一般比较少用,这里就不分析源码了,只简单的阐述功能,
bindActionCreators()把 action creators 转成拥有同名 keys 的对象,但使用 dispatch 把每个 action creator 包围起来,这样可以直接调用它们。
在接下来的五篇文章中,会用通俗的方式“重新构造”一个React,通过完成一个简易版本的React的构造,可以帮助我们理解React是如何实现的,以及组件的生命周期存在的原因和作用。
这一系列的文章包括:
- 第一部分:基础渲染
- 第二部分:componentWillMount and componentDidMount
- 第三部分:基础更新
- 第四部分:setState
- 第三部分:transaction
声明:
这个系列的文章基于React15.3,所以最新的React的特性比如Fiber等是不支持的,本系列根据React的原理所构建的"Peact"尽可能的实现React的相关功能,但没有完全实现。
在React中有三种不同的实体类型:原生的DOM元素、虚拟React元素(Virtual React Elements)和组件(Components)。
这就是我们通常所说的dom元素,浏览器使用真实的dom元素来组织web网页,在某一时刻,React会通过调用document.createElement()方法去创建一个真实的dom元素,或者使用浏览器的DOM API去更新真实的dom元素, 更新的元素的API比如:element.insertBefore(), element.nodeValue等等.
一个虚拟的react元素在内存中控制真实的DOM元素,在更新前如何渲染.这个react元素可以代表的是一个原生的dom元素或者是开发者自己定义的组件.
译者注:这里的虚拟React元素,就是React virtual dom的关键,主要流程为:
用户dom操作——>改变虚拟React元素——>在浏览器渲染
"组件(Component)"在React中是一个特殊的术语,React可以在组件中实现不同的工作,不同的组件实现了不同的功能,比如ReactDOM提供了ReactDOMComponent实现了虚拟React元素渲染到真实的DOM元素的映射。
在React中,自定义的组件可以通过React.createClass()或者es6形式的,class extend React.Component的方式创建一个类组件。在类组件中会有componentWillMount、shouldComponentUpdate等生命周期函数.组件的生命周期函数是React的一个难点。组件中的生命周期函数除了一些开发者常用的,还有形如mountComponent和receiveComponent等,开发者很少使用的生命钩子.
定义React类组件是声明式的,在需要使用的时候再去实例化,在React的类组件中,我们是这样声明式的定义的:
class MyComponent extends React.Component{
render(){
return <div>hello</div>
}
}
将jsx语言编译后可以得到:
class MyComponent extends React.Component{
render(){
return React.createElement('div',null,'hello')
}
}
从上述代码中,我们可能有一个疑问,在组件实例化的时候,是不是在调用React.createElement之前就已经创建了一个真实的dom元素.其实并不是这样,组件在实例化后,会通过render方法来调用React.createElement去创建真实的dom元素.React声明式的创建组件的方式,可以控制真实dom的渲染.
基于上述的虚拟react元素,以及自定义组件的原理,我们来仿造一个简单的类React实现上述功能,用Peact来表示.Peact应该有一个render方法:
Feact.render(<h1>hello world</h1>, document.getElementById('root'));
首先抛弃jsx语法,直接用Peact.createElement来代替(jsx语法最后也需要创建原生dom元素):
Feact.render(
Feact.createElement('h1', null, 'hello world'),
document.getElementById('root')
)
来看Peact.createElement方法的实现:
const Feact = {
createElement(type, props, children) {
const element = {
type,
props: props || {}
};
if (children) {
element.props.children = children;
}
return element;
}
}
在Feact.createElement方法中,返回的element对象可以表示我们所需要渲染到浏览器的元素信息.
接着来看render方法的实现,在Feact.render()方法中,参数为我们所需要渲染的信息,以及在哪里渲染.render方法是构建Feact app的最根本的方法,我们首先通过如下方式来定义render方法:
const Feact = {
createElement() { /* as before */ },
render(element, container) {
const componentInstance = new FeactDOMComponent(element);
return componentInstance.mountComponent(container);
}
};
当render被调用后,我们就可以得到一个完成的web网页。在render方法中,通过FeactDOMComponent方法将渲染信息映射成真实的dom元素,我们来看FeactDOMComponent方法的具体实现:
class FeactDOMComponent{
contructor(element){
this._currentElement=element;
}
mountComponent(container){
const domElement=document.createElement(this._currentElement.type);
const text=this._currentElement.props.children;
const textNode=document.createTextNode(text);
domElement.appendChild(textNode);
container.appendChild(domElement);
this._hostNode = domElement;//会在第三章用到
return domElement;
}
}
在render方法中不仅可以渲染单个简单编码的元素,还应该可以渲染自定义的组件, 实现Peact.createClass自定义组件的方法如下:
const Feact = {
createClass(spec) {
function Constructor(props) {
this.props = props;
}
Constructor.prototype.render = spec.render;
return Constructor;
},
render(element, container) {
// our previous implementation can't
// handle user defined components,
// so we need to rethink this method
}
};
const MyTitle = Feact.createClass({
render() {
return Feact.createElement('h1', null, this.props.message);
}
};
//显示声明了一个MyTitle组件,接着是创建实例化的过程,原文缺省了实例化的过程。
let Title=new MyTitle(props);
Feact.render({
Feact.createElement(MyTitle, { message: 'hey there Feact' }),
document.getElementById('root')
);
之前定义的方法无法渲染自定义的组件,因此我们需要修改Feact.render()方法来使其可以渲染自定义组件。
Feact = {
render(element, container) {
const componentInstance =
new FeactCompositeComponentWrapper(element);
return componentInstance.mountComponent(container);
}
}
class FeactCompositeComponentWrapper {
constructor(element) {
this._currentElement = element;
}
mountComponent(container) {
const Component = this._currentElement.type;
const componentInstance = new Component(this._currentElement.props);
const element = componentInstance.render();
const domComponentInstance = new FeactDOMComponent(element);
return domComponentInstance.mountComponent(container);
}
}
给予了用户去定义组件的能力,并且Feact可以根据props传递过来的值动态的更新和渲染dom节点。
在之前自定义组件的方法中,自定义的组件只能返回原生的dom元素,不能返回组件,也就是自定义组件目前不能嵌套式的在组件中返回组件,比如我们要实现这样的组件,有可能在组件中返回组件。
const MyMessage = Feact.createClass({
render() {
if (this.props.asTitle) {
return Feact.createElement(MyTitle, {
message: this.props.message
});
} else {
return Feact.createElement('p', null, this.props.message);
}
}
}
上述的自定义组件MyMessage可以选择性的返回组件或者是原生的dom元素。这种类型的自定义组件,按之前定义的 FeactCompositeComponentWrapper方法是无法渲染的,因此对于这种组件我们需要重新的定义 FeactCompositeComponentWrapper方法。
class FeactCompositeComponentWrapper {
constructor(element) {
this._currentElement = element;
}
mountComponent(container) {
const Component = this._currentElement.type;
const componentInstance =
new Component(this._currentElement.props);
let element = componentInstance.render();
while (typeof element.type === 'function') {
element = (new element.type(element.props)).render();
}
const domComponentInstance = new FeactDOMComponent(element);
domComponentInstance.mountComponent(container);
}
}
在mountComponent方法中,如果还是组件需要一个while循环,直到循环取到最底层的原生dom元素。
第一个版本的Feact.render()只能渲染原生的dom节点,而第二个版本的Feact.render()只能渲染组件,因此我们需要一个通用的方法,既可以渲染原生的dom节点,又可以渲染组件。具体修改的Feact.render()方法如下所示:
const TopLevelWrapper = function(props) {
this.props = props;
};
TopLevelWrapper.prototype.render = function() {
return this.props;
};
const Feact = {
render(element, container) {
const wrapperElement =
this.createElement(TopLevelWrapper, element);
const componentInstance =
new FeactCompositeComponentWrapper(wrapperElement);
// as before
}
};
具体实现就是用一个上层的组件TopLevelWrapper包裹,并且其render方法返回的是props,在FeactCompositeComponentWrapper中判断是原生的dom元素还是组件,并进行渲染。
简要介绍:Webpack4.0.1版本已经发布了2周了,下面用体验一下Webpack4.0
Node.js 4 is no longer supported. Source Code was upgraded to a higher ecmascript version
明确不支持node.js4.X,在本文中使用的是:
node -v
v8.9.3
CLI has been move to webpack-cli, you need to install webpack-cli to use the CLI
将CLI移入到webpack-cli中,需要安装webpack-cli
npm i webpack webpack-cli -d
在官网给出的示例中,可以不用配置entry和output,默认的entry:'/src',
默认的output:'./dist',但是零配置的情况下'./src'的入口文件的文件名必须是index.js,否则会报错。
|—src
| --app.js
ERROR in Entry module not found: Error: Can't resolve './src' in 'C:\Users\yuxl\Desktop\react-webpack'
默认入口为src目录下的index.js文件,输出为dist下的main.js文件
在之前的版本中,针对生产环境和开发环境,需要做不同的配置,
常见的都是指定标量,然后在webpack.config.js配置文件中,进行环境判别,比如:
"scripts":{
"prod":"NODE_ENV=production webpack -p"
}
判别出环境后,再在配置文件中,根据不同的环境做不同的打包工作。
或者是生成两个配置文件,webpack.dev.js和webpack.prod.js,分别对应于两个环境。
我们发现如果直接这样运行:
"scripts":{
"build":"webpack"
}
npm run build,会有一个提示:
The 'mode' option has not been set. Set 'mode' option to 'development' or 'production' to enable defaults for this environment.
在Webpack中,提供了mode变量,用于配置运行环境,mode的值可以为development,表示的是开发模式,或者是production,表示的是生产模式。
我们以生产环境为例:
"scripts":{
"build":"webpack --mode production"
}
打包后:
Asset Size Chunks Chunk Names
main.js 561 bytes 0 [emitted] main
Entrypoint main = main.js
[0] ./src/index.js 19 bytes {0} [built]
打包后的代码是经过压缩等处理的。在Webpack中约定了针对开发环境和生成环境的一些默认操作。
production enables all kind of optimizations to generate optimized bundles
生产环境使用了所有的optimizations优化配置,来得到优化后的bundles结果。顾名思义也就是production中采用了配置中所有的内置optimization。
development enables comments and hint for development and enables the eval devtool
在开发环境中,使用了所有的评论和提示功能,并且在devtool中设置了sourcemap的类型为eval。
补充一下:
{
devtool:eval
}
这样配置sourcemap,在webpack中不会生成具体的.map文件,只是以sourceURL的形式。具体可见devtool.
production doesn't support watching, development is optimized for fast incremental rebuilds
在生产环境中不支持文件的监听,在开发环境中的约定配置使得重新build的速度更快。
production also enables module concatenating (Scope Hoisting)
在生产环境中支持Scope Hoisting, Scope Hoisting 指将所有的打包后的文件放在一个函数里,所带来的好处有,其一函数声明少了,文件的体积比之前小,其二就是运行代码所创建的函数作用域也少了。
There is a hidden none mode which disables everything
mode还可以选择模式为none,无任何约定配置。
CommonsChunkPlugin was removed -> optimization.splitChunks, optimization.runtimeChunk
移除了CommonsChunkPlugin,并用内置的optimization.splitChunks.
我们以公共的react和redux为例,比如在button.js中:
require('react');
require('redux');
在index.js中引用了button.js:
require('./components/button.js');
那么,如果不进行optimization.splitChunks.配置,打包后的结构分析图为:

发现打包后的main.js中存在 redux和react。业务代码中存在第三方插件库redux和react,显然是不合理的。
笔者没有找到optimization.splitChunks的文档,只能试着尝试一下,参数如下:
optimization: {
splitChunks: {
minSize: 1,
chunks: "initial",
name:"vendor"
}
}
更改配置后,我们可以得到的打包后的分析图为:

我们发现此时达到了CommonsChunkPlugin复用第三方代码的问题,但是也存在一个问题,我们发现vendor.js中,有包含业务代码index.js。(这个目前还没解决,到时候看optimization.splitChunks再试一下)。
此外,webpack4.0之前只支持.js类型,webpack4.0增加到了5种扩展名文件,还有webpack4.0也增加了tree shaking
对于Typescript项目的编码规范而言,主要有两种选择ESLint和TSLint。ESLint不仅能规范js代码,通过配置解析器,也能规范TS代码。此外由于性能问题,TypeScript 官方决定全面采用ESLint,甚至把仓库作为测试平台,而 ESLint 的 TypeScript 解析器也成为独立项目,专注解决双方兼容性问题。
最近在我的项目的编码规范中全量的用ESLint代替了TSLint,针对其中遇到的问题做一个记录。
- 用ESLint来规范Typescript代码
- 用ESLint来规范React代码
- 结合Prettier和ESLint来规范代码
- 在VSCode中使用ESLint
- husky和lint-staged构建代码工作流
- gitlab的CI/CD来规范代码
首先安装依赖:
npm i -d eslint @typescript-eslint/parser @typescript-eslint/eslint-plugin这三个依赖分别是:
安装好这3个依赖包之后,在根目录下新建.eslintrc.js文件,该文件中定义了ESLint的基础配置,一个最为简单的配置如下所示:
module.exports = {
parser: '@typescript-eslint/parser', //定义ESLint的解析器
extends: ['plugin:@typescript-eslint/recommended'],//定义文件继承的子规范
plugins: ['@typescript-eslint'],//定义了该eslint文件所依赖的插件
env:{ //指定代码的运行环境
browser: true,
node: true,
}
}如果在你的TS项目中同时使用了React,那么为了检测和规范React代码的书写必须安装插件eslint-plugin-react,然后增加配置:
module.exports = {
parser: '@typescript-eslint/parser',
extends: [
'plugin:react/recommended'
'plugin:@typescript-eslint/recommended'
], //使用推荐的React代码检测规范
plugins: ['@typescript-eslint'],
env:{
browser: true,
node: true,
},
settings: { //自动发现React的版本,从而进行规范react代码
"react": {
"pragma": "React",
"version": "detect"
}
},
parserOptions: { //指定ESLint可以解析JSX语法
"ecmaVersion": 2019,
"sourceType": 'module',
"ecmaFeatures":{
jsx:true
}
}
rules: {
}
}在Rules中可以自定义你的React代码编码规范。
Prettier中文的意思是漂亮的、美丽的,是一个流行的代码格式化的工具,我们来看如何结合ESLint来使用。首先我们需要安装三个依赖:
npm i -g prettier eslint-config-prettier eslint-plugin-prettier其中:
然后在项目的根目录下创建.prettierrc.js文件:
module.exports = {
"printWidth": 120,
"semi": false,
"singleQuote": true,
"trailingComma": "all",
"bracketSpacing": false,
"jsxBracketSameLine": true,
"arrowParens": "avoid",
"insertPragma": true,
"tabWidth": 4,
"useTabs": false
};接着修改.eslintrc.js文件,引入prettier:
module.exports = {
parser: '@typescript-eslint/parser',
extends:[
'prettier/@typescript-eslint',
'plugin:prettier/recommended'
],
settings: {
"react": {
"pragma": "React",
"version": "detect"
}
},
parserOptions: {
"ecmaVersion": 2019,
"sourceType": 'module',
"ecmaFeatures":{
jsx:true
}
},
env:{
browser: true,
node: true,
} 上述新增的extends的配置中:
为了开发方便我们可以在VSCode中集成ESLint的配置,使得代码在保存或者代码变动的时候自动进行ESLint的fix过程。
首先需要安装VSCode的ESLint插件,安装插件完毕后,在settings.json文件中修改其配置文件为:
{
"eslint.enable": true, //是否开启vscode的eslint
"eslint.autoFixOnSave": true, //是否在保存的时候自动fix eslint
"eslint.options": { //指定vscode的eslint所处理的文件的后缀
"extensions": [
".js",
".vue",
".ts",
".tsx"
]
},
"eslint.validate": [ //确定校验准则
"javascript",
"javascriptreact",
{
"language": "html",
"autoFix": true
},
{
"language": "vue",
"autoFix": true
},
{
"language": "typescript",
"autoFix": true
},
{
"language": "typescriptreact",
"autoFix": true
}
]
}主要注意的有两点:
首先来看husky,Husky 能够帮你阻挡住不好的代码提交和推送,首先我们在package.json中定义如下的script:
"scripts": {
"lint": "eslint src --fix --ext .ts,.tsx "
}
接着在package.json定义husky的配置:
"husky": {
"hooks": {
"pre-commit": "npm run lint"
}
},
我们在git的hook的阶段来执行相应的命令,比如上述的例子是在pre-commit这个hook也就是在提交之前进行lint的检测。
接着来看lint-staged,上述我们通过在husky的pre-comit这个hook中执行一个npm命令来做lint校验。除了定义个npm lint命令外,我们也可以直接通过使用lint-staged,来在提交前检测代码的规范。
使用lint-staged来规范代码的方式如下,我们修改package.json文件为:
{
"husky": {
"hooks": {
"pre-commit": "lint-staged"
}
},
"lint-staged": {
"*.{.ts,.tsx}": [
"eslint",
"git add"
]
}
}
同样在git commit的时候会做lint的检测。
仅仅通过git的hook来执行代码的规范检测有一个问题,我们可以在git commit的时候通过--no-verify来跳过代码的规范检测。但是某些情况下,我们对于某一个重要分支,该分支上的代码必须完整通过代码的规范检测,此时我们可以使用gitlab的CI/CD。
同样在package.json中增加一个lint的npm 命令:
"scripts": {
"lint": "eslint src --fix --ext .ts,.tsx "
}
然后在根目录增加.gitlab-ci.yml文件,该文件中的配置为:
stages:
- lint
before_script:
- git fetch --all
- npm install
lint:
stage: lint
script:
- npm run lint
only
- 特定分支1
- 特定分支2
然后配置相应的gitlab runner,这里不具体详描,最后的结果就是在我们指定的分支上的提交或者merge都会进行所配置的命令检测。这样保证了特定分支不受git commit跳过操作--no-verify的影响。
Redux-saga使用心得总结(包含样例代码),本文的样例代码地址:样例代码地址 ,欢迎star
最近将项目中redux的中间件,从redux-thunk替换成了redux-saga,做个笔记总结一下redux-saga的使用心得,阅读本文需要了解什么是redux,redux中间件的用处是什么?如果弄懂上述两个概念,就可以继续阅读本文。
- redux-thunk处理副作用的缺点
- redux-saga写一个hellosaga
- redux-saga的使用技术细节
- redux-saga实现一个登陆和列表样例
redux中的数据流大致是:
UI—————>action(plain)—————>reducer——————>state——————>UI

redux是遵循函数式编程的规则,上述的数据流中,action是一个原始js对象(plain object)且reducer是一个纯函数,对于同步且没有副作用的操作,上述的数据流起到可以管理数据,从而控制视图层更新的目的。
但是如果存在副作用,比如ajax异步请求等等,那么应该怎么做?
如果存在副作用函数,那么我们需要首先处理副作用函数,然后生成原始的js对象。如何处理副作用操作,在redux中选择在发出action,到reducer处理函数之间使用中间件处理副作用。
redux增加中间件处理副作用后的数据流大致如下:
UI——>action(side function)—>middleware—>action(plain)—>reducer—>state—>UI

在有副作用的action和原始的action之间增加中间件处理,从图中我们也可以看出,中间件的作用就是:
转换异步操作,生成原始的action,这样,reducer函数就能处理相应的action,从而改变state,更新UI。
在redux中,thunk是redux作者给出的中间件,实现极为简单,10多行代码:
function createThunkMiddleware(extraArgument) {
return ({ dispatch, getState }) => next => action => {
if (typeof action === 'function') {
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
const thunk = createThunkMiddleware();
thunk.withExtraArgument = createThunkMiddleware;
export default thunk;
这几行代码做的事情也很简单,判别action的类型,如果action是函数,就调用这个函数,调用的步骤为:
action(dispatch, getState, extraArgument);
发现实参为dispatch和getState,因此我们在定义action为thunk函数是,一般形参为dispatch和getState。
hunk的缺点也是很明显的,thunk仅仅做了执行这个函数,并不在乎函数主体内是什么,也就是说thunk使
得redux可以接受函数作为action,但是函数的内部可以多种多样。比如下面是一个获取商品列表的异步操作所对应的action:
export default ()=>(dispatch)=>{
fetch('/api/goodList',{ //fecth返回的是一个promise
method: 'get',
dataType: 'json',
}).then(function(json){
var json=JSON.parse(json);
if(json.msg==200){
dispatch({type:'init',data:json.data});
}
},function(error){
console.log(error);
});
};
从这个具有副作用的action中,我们可以看出,函数内部极为复杂。如果需要为每一个异步操作都如此定义一个action,显然action不易维护。
action不易维护的原因:
跟redux-thunk不同的是,redux-saga是控制执行的generator,在redux-saga中action是原始的js对象,把所有的异步副作用操作放在了saga函数里面。这样既统一了action的形式,又使得异步操作集中可以被集中处理。
redux-saga是通过genetator实现的,如果不支持generator需要通过插件babel-polyfill转义。我们接着来实现一个输出hellosaga的例子。
export function * helloSaga() {
console.log('Hello Sagas!');
}
在main.js中:
import { createStore, applyMiddleware } from 'redux'
import createSagaMiddleware from 'redux-saga'
import { helloSaga } from './sagas'
const sagaMiddleware=createSagaMiddleware();
const store = createStore(
reducer,
applyMiddleware(sagaMiddleware)
);
sagaMiddleware.run(helloSaga);
//会输出Hello, Sagas!
和调用redux的其他中间件一样,如果想使用redux-saga中间件,那么只要在applyMiddleware中调用一个createSagaMiddleware的实例。唯一不同的是需要调用run方法使得generator可以开始执行。
redux-saga除了上述的action统一、可以集中处理异步操作等优点外,redux-saga中使用声明式的Effect以及提供了更加细腻的控制流。
redux-saga中最大的特点就是提供了声明式的Effect,声明式的Effect使得redux-saga监听原始js对象形式的action,并且可以方便单元测试,我们一一来看。
首先来看redux-thunk的大体过程:
action1(side function)—>redux-thunk监听—>执行相应的有副作用的方法—>action2(plain object)
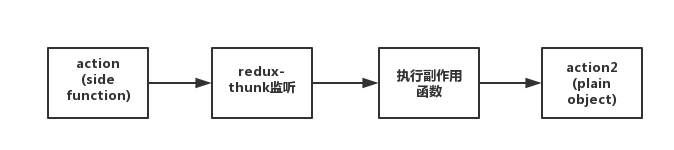
转化到action2是一个原始js对象形式的action,然后执行reducer函数就会更新store中的state。
而redux-saga的大体过程如下:
action1(plain object)——>redux-saga监听—>执行相应的Effect方法——>返回描述对象—>恢复执行异步和副作用函数—>action2(plain object)

对比redux-thunk我们发现,redux-saga中监听到了原始js对象action,并不会马上执行副作用操作,会先通过Effect方法将其转化成一个描述对象,然后再将描述对象,作为标识,再恢复执行副作用函数。
通过使用Effect类函数,可以方便单元测试,我们不需要测试副作用函数的返回结果。只需要比较执行Effect方法后返回的描述对象,与我们所期望的描述对象是否相同即可。
举例来说,call方法是一个Effect类方法:
import { call } from 'redux-saga/effects'
function* fetchProducts() {
const products = yield call(Api.fetch, '/products')
// ...
}
上述代码中,比如我们需要测试Api.fetch返回的结果是否符合预期,通过调用call方法,返回一个描述对象。这个描述对象包含了所需要调用的方法和执行方法时的实际参数,我们认为只要描述对象相同,也就是说只要调用的方法和执行该方法时的实际参数相同,就认为最后执行的结果肯定是满足预期的,这样可以方便的进行单元测试,不需要模拟Api.fetch函数的具体返回结果。
import { call } from 'redux-saga/effects'
import Api from '...'
const iterator = fetchProducts()
// expects a call instruction
assert.deepEqual(
iterator.next().value,
call(Api.fetch, '/products'),
"fetchProducts should yield an Effect call(Api.fetch, './products')"
)
下面来介绍几个Effect中常用的几个方法,从低阶的API,比如take,call(apply),fork,put,select等,以及高阶API,比如takeEvery和takeLatest等,从而加深对redux-saga用法的认识(这节可能比较生涩,在第三章中会结合具体的实例来分析,本小节先对各种Effect有一个初步的了解)。
引入:
import {take,call,put,select,fork,takeEvery,takeLatest} from 'redux-saga/effects'
take这个方法,是用来监听action,返回的是监听到的action对象。比如:
const loginAction = {
type:'login'
}
在UI Component中dispatch一个action:
dispatch(loginAction)
在saga中使用:
const action = yield take('login');
可以监听到UI传递到中间件的Action,上述take方法的返回,就是dipath的原始对象。一旦监听到login动作,返回的action为:
{
type:'login'
}
call和apply方法与js中的call和apply相似,我们以call方法为例:
call(fn, ...args)
call方法调用fn,参数为args,返回一个描述对象。不过这里call方法传入的函数fn可以是普通函数,也可以是generator。call方法应用很广泛,在redux-saga中使用异步请求等常用call方法来实现。
yield call(fetch,'/userInfo',username)
在前面提到,redux-saga做为中间件,工作流是这样的:
UI——>action1————>redux-saga中间件————>action2————>reducer..
从工作流中,我们发现redux-saga执行完副作用函数后,必须发出action,然后这个action被reducer监听,从而达到更新state的目的。相应的这里的put对应与redux中的dispatch,工作流程图如下:

从图中可以看出redux-saga执行副作用方法转化action时,put这个Effect方法跟redux原始的dispatch相似,都是可以发出action,且发出的action都会被reducer监听到。put的使用方法:
yield put({type:'login'})
put方法与redux中的dispatch相对应,同样的如果我们想在中间件中获取state,那么需要使用select。select方法对应的是redux中的getState,用户获取store中的state,使用方法:
const state= yield select()
fork方法在第三章的实例中会详细的介绍,这里先提一笔,fork方法相当于web work,fork方法不会阻塞主线程,在非阻塞调用中十分有用。
takeEvery和takeLatest用于监听相应的动作并执行相应的方法,是构建在take和fork上面的高阶api,比如要监听login动作,好用takeEvery方法可以:
takeEvery('login',loginFunc)
takeEvery监听到login的动作,就会执行loginFunc方法,除此之外,takeEvery可以同时监听到多个相同的action。
takeLatest方法跟takeEvery是相同方式调用:
takeLatest('login',loginFunc)
与takeLatest不同的是,takeLatest是会监听执行最近的那个被触发的action。
接着我们来实现一个redux-saga样例,存在一个登陆页,登陆成功后,显示列表页,并且,在列表页,可
以点击登出,返回到登陆页。例子的最终展示效果如下:

样例的功能流程图为:

接着我们按照上述的流程来一步步的实现所对应的功能。
登陆页的功能包括
用户名输入框和密码框onchange时触发的函数为:
changeUsername:(e)=>{
dispatch({type:'CHANGE_USERNAME',value:e.target.value});
},
changePassword:(e)=>{
dispatch({type:'CHANGE_PASSWORD',value:e.target.value});
}
在函数中最后会dispatch两个action:CHANGE_USERNAME和CHANGE_PASSWORD。
在saga.js文件中监听这两个方法并执行副作用函数,最后put发出转化后的action,给reducer函数调用:
function * watchUsername(){
while(true){
const action= yield take('CHANGE_USERNAME');
yield put({type:'change_username',
value:action.value});
}
}
function * watchPassword(){
while(true){
const action=yield take('CHANGE_PASSWORD');
yield put({type:'change_password',
value:action.value});
}
}
最后在reducer中接收到redux-saga的put方法传递过来的action:change_username和change_password,然后更新state。
在UI中发出的登陆事件为:
toLoginIn:(username,password)=>{
dispatch({type:'TO_LOGIN_IN',username,password});
}
登陆事件的action为:TO_LOGIN_IN.对于登入事件的处理函数为:
while(true){
//监听登入事件
const action1=yield take('TO_LOGIN_IN');
const res=yield call(fetchSmart,'/login',{
method:'POST',
body:JSON.stringify({
username:action1.username,
password:action1.password
})
if(res){
put({type:'to_login_in'});
}
});
在上述的处理函数中,首先监听原始动作提取出传递来的用户名和密码,然后请求是否登陆成功,如果登陆成功有返回值,则执行put的action:to_login_in.
登陆成功后的页面功能包括:
import {delay} from 'redux-saga';
function * getList(){
try {
yield delay(3000);
const res = yield call(fetchSmart,'/list',{
method:'POST',
body:JSON.stringify({})
});
yield put({type:'update_list',list:res.data.activityList});
} catch(error) {
yield put({type:'update_list_error', error});
}
}
为了演示请求过程,我们在本地mock,通过redux-saga的工具函数delay,delay的功能相当于延迟xx秒,因为真实的请求存在延迟,因此可以用delay在本地模拟真实场景下的请求延迟。
const action2=yield take('TO_LOGIN_OUT');
yield put({type:'to_login_out'});
与登入相似,登出的功能从UI处接受action:TO_LOGIN_OUT,然后转发action:to_login_out
function * getList(){
try {
yield delay(3000);
const res = yield call(fetchSmart,'/list',{
method:'POST',
body:JSON.stringify({})
});
yield put({type:'update_list',list:res.data.activityList});
} catch(error) {
yield put({type:'update_list_error', error});
}
}
function * watchIsLogin(){
while(true){
//监听登入事件
const action1=yield take('TO_LOGIN_IN');
const res=yield call(fetchSmart,'/login',{
method:'POST',
body:JSON.stringify({
username:action1.username,
password:action1.password
})
});
//根据返回的状态码判断登陆是否成功
if(res.status===10000){
yield put({type:'to_login_in'});
//登陆成功后获取首页的活动列表
yield call(getList);
}
//监听登出事件
const action2=yield take('TO_LOGIN_OUT');
yield put({type:'to_login_out'});
}
}
通过请求状态码判断登入是否成功,在登陆成功后,可以通过:
yield call(getList)
的方式调用获取活动列表的函数getList。这样咋一看没有什么问题,但是注意call方法调用是会阻塞主线程的,具体来说:
在call方法调用结束之前,call方法之后的语句是无法执行的
如果call(getList)存在延迟,call(getList)之后的语句 const action2=yieldtake('TO_LOGIN_OUT')在call方法返回结果之前无法执行
在延迟期间的登出操作会被忽略。
用框图可以更清楚的分析:
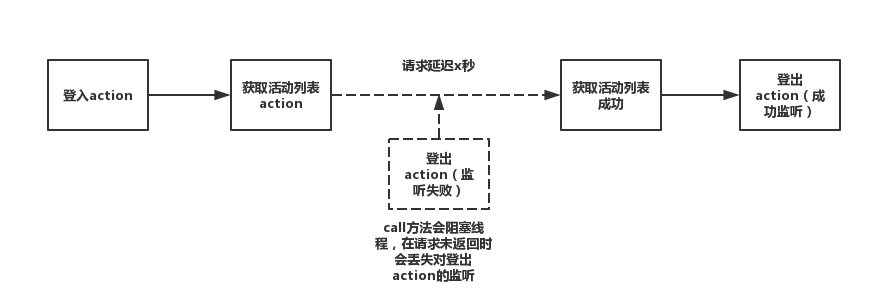
call方法调用阻塞主线程的具体效果如下动图所示:
白屏时为请求列表的等待时间,在此时,我们点击登出按钮,无法响应登出功能,直到请求列表成功,展示列表信息后,点击登出按钮才有相应的登出功能。也就是说call方法阻塞了主线程。
我们在第二章中,介绍了fork方法可以类似与web work,fork方法不会阻塞主线程。应用于上述例子,我们可以将:
yield call(getList)
修改为:
yield fork(getList)
这样展示的结果为:

通过fork方法不会阻塞主线程,在白屏时点击登出,可以立刻响应登出功能,从而返回登陆页面。
通过上述章节,我们可以概括出redux-saga做为redux中间件的全部优点:
统一action的形式,在redux-saga中,从UI中dispatch的action为原始对象
集中处理异步等存在副作用的逻辑
通过转化effects函数,可以方便进行单元测试
完善和严谨的流程控制,可以较为清晰的控制复杂的逻辑。
简介:就是用来装页面上的元素的矩形区域。CSS中的盒子模型包括IE盒子模型和标准的W3C盒子模型。
box-sizing(有3个值哦):border-box,padding-box,content-box.


区别:从图中我们可以看出,这两种盒子模型最主要的区别就是width的包含范围,在标准的盒子模型中,width指content部分的宽度,在IE盒子模型中,width表示content+padding+border这三个部分的宽度,故这使得在计算整个盒子的宽度时存在着差异:
标准盒子模型的盒子宽度:左右border+左右padding+width
IE盒子模型的盒子宽度:width
在CSS3中引入了box-sizing属性,box-sizing:content-box;表示标准的盒子模型,box-sizing:border-box表示的是IE盒子模型
最后,前面我们还提到了,box-sizing:padding-box,这个属性值的宽度包含了左右padding+width
也很好理解性记忆,包含什么,width就从什么开始算起。
采用meta viewport的方式
采用 border-image的方式
采用transform: scale()的方式
Animation和transition大部分属性是相同的,他们都是随时间改变元素的属性值,他们的主要区别是transition需要触发一个事件才能改变属性,而animation不需要触发任何事件的情况下才会随时间改变属性值,并且transition为2帧,从from .... to,而animation可以一帧一帧的。
文章链接:
http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html?utm_source=tuicool(语法篇)
http://www.ruanyifeng.com/blog/2015/07/flex-examples.html(实例篇)
Flex是Flexible Box的缩写,意为"弹性布局",用来为盒状模型提供最大的灵活性。
布局的传统解决方案,基于盒状模型,依赖 display属性 + position属性 + float属性。它对于那些特殊布局非常不方便,比如,垂直居中就不容易实现。
简单的分为容器属性和元素属性
容器的属性:
项目的属性(元素的属性):
比如说,用flex实现圣杯布局
直译成:块级格式化上下文,是一个独立的渲染区域,并且有一定的布局规则。
那些元素会生成BFC:
css:
div{
width: 400px;
height: 400px;
position: relative;
border: 1px solid #465468;
}
img{
position: absolute;
margin: auto;
top: 0;
left: 0;
right: 0;
bottom: 0;
}
html:
<div>
<img src="mm.jpg">
</div>
定位为上下左右为0,margin:0可以实现脱离文档流的居中.
.container{
width: 500px;
height: 400px;
border: 2px solid #379;
position: relative;
}
.inner{
width: 480px;
height: 380px;
background-color: #746;
position: absolute;
top: 50%;
left: 50%;
margin-top: -190px; /*height的一半*/
margin-left: -240px; /*width的一半*/
}
补充:其实这里也可以将marin-top和margin-left负值替换成,
transform:translateX(-50%)和transform:translateY(-50%)
设置父元素的display:table-cell,并且vertical-align:middle,这样子元素可以实现垂直居中。
css:
div{
width: 300px;
height: 300px;
border: 3px solid #555;
display: table-cell;
vertical-align: middle;
text-align: center;
}
img{
vertical-align: middle;
}
将父元素设置为display:flex,并且设置align-items:center;justify-content:center;
css:
.container{
width: 300px;
height: 200px;
border: 3px solid #546461;
display: -webkit-flex;
display: flex;
-webkit-align-items: center;
align-items: center;
-webkit-justify-content: center;
justify-content: center;
}
.inner{
border: 3px solid #458761;
padding: 20px;
}
渲染线程分为main thread和compositor thread,如果css动画只改变transform和opacity,这时整个CSS动画得以在compositor trhead完成(而js动画则会在main thread执行,然后出发compositor thread进行下一步操作),特别注意的是如果改变transform和opacity是不会layout或者paint的。
区别:
块元素:独占一行,并且有自动填满父元素,可以设置margin和pading以及高度和宽度
行元素:不会独占一行,width和height会失效,并且在垂直方向的padding和margin会失
效。
display: -webkit-box
-webkit-box-orient:vertical
-webkit-line-clamp:3
overflow:hidden
opacity=0,该元素隐藏起来了,但不会改变页面布局,并且,如果该元素已经绑定一些事件,如click事件,那么点击该区域,也能触发点击事件的visibility=hidden,该元素隐藏起来了,但不会改变页面布局,但是不会触发该元素已经绑定的事件display=none,把元素隐藏起来,并且会改变页面布局,可以理解成在页面中把该元素删除掉一样。
多个相邻(兄弟或者父子关系)普通流的块元素垂直方向marigin会重叠
折叠的结果为:
两个相邻的外边距都是正数时,折叠结果是它们两者之间较大的值。
两个相邻的外边距都是负数时,折叠结果是两者绝对值的较大值。
两个外边距一正一负时,折叠结果是两者的相加的和。
简要介绍:前端开发中,静态网页通常需要适应不同分辨率的设备,常用的自适应解决方案包括媒体查询、百分比、rem和vw/vh等。本文从px单位出发,分析了px在移动端布局中的不足,接着介绍了几种不同的自适应解决方案。
- px和视口
- 媒体查询
- 百分比
- 自适应场景下的rem解决方案
- 通过vw/vh来实现自适应
在静态网页中,我们经常用像素(px)作为单位,来描述一个元素的宽高以及定位信息。在pc端,通常认为css中,1px所表示的真实长度是固定的。
那么,px真的是一个设备无关,跟长度单位米和分米一样是固定大小的吗?
答案是否定的,下面图1.1和图1.2分别表示pc端下和移动端下的显示结果,在网页中我们设置的font-size统一为16px。

图1.1 pc端下font-size为16px时的显示结果

图1.2 移动端下font-size为16px时的显示结果
从上面两幅图的对比可以看出,字体都是16px,显然在pc端中文字正常显示,而在移动端文字很小,几乎看不到,说明在css中1px并不是固定大小,直观从我们发现在移动端1px所表示的长度较小,所以导致文字显示不清楚。
那么css中的1px的真实长度到底由什么决定呢?
为了理清楚这个概念我们首先介绍像素和视口的概念
像素是网页布局的基础,一个像素表示了计算机屏幕所能显示的最小区域,像素分为两种类型:css像素和物理像素。
我们在js或者css代码中使用的px单位就是指的是css像素,物理像素也称设备像素,只与设备或者说硬件有关,同样尺寸的屏幕,设备的密度越高,物理像素也就越多。下表表示css像素和物理像素的具体区别:
| css像素 | 为web开发者提供,在css中使用的一个抽象单位 |
|---|---|
| 物理像素 | 只与设备的硬件密度有关,任何设备的物理像素都是固定的 |
那么css像素与物理像素的转换关系是怎么样的呢?为了明确css像素和物理像素的转换关系,必须先了解视口是什么。
广义的视口,是指浏览器显示内容的屏幕区域,狭义的视口包括了布局视口、视觉视口和理想视口
布局视口定义了pc网页在移动端的默认布局行为,因为通常pc的分辨率较大,布局视口默认为980px。也就是说在不设置网页的viewport的情况下,pc端的网页默认会以布局视口为基准,在移动端进行展示。因此我们可以明显看出来,默认为布局视口时,根植于pc端的网页在移动端展示很模糊。
视觉视口表示浏览器内看到的网站的显示区域,用户可以通过缩放来查看网页的显示内容,从而改变视觉视口。视觉视口的定义,就像拿着一个放大镜分别从不同距离观察同一个物体,视觉视口仅仅类似于放大镜中显示的内容,因此视觉视口不会影响布局视口的宽度和高度。
理想视口或者应该全称为“理想的布局视口”,在移动设备中就是指设备的分辨率。换句话说,理想视口或者说分辨率就是给定设备物理像素的情况下,最佳的“布局视口”。
上述视口中,最重要的是要明确理想视口的概念,在移动端中,理想视口或者说分辨率跟物理像素之间有什么关系呢?
为了理清分辨率和物理像素之间的联系,我们介绍一个用DPR(Device pixel ratio)设备像素比来表示,则可以写成:
1 DPR = 物理像素/分辨率
在不缩放的情况下,一个css像素就对应一个dpr,也就是说,在不缩放
1 CSS像素 = 物理像素/分辨率
此外,在移动端的布局中,我们可以通过viewport元标签来控制布局,比如一般情况下,我们可以通过下述标签使得移动端在理想视口下布局:
<meta id="viewport" name="viewport" content="width=device-width; initial-scale=1.0; maximum-scale=1; user-scalable=no;">
上述meta标签的每一个属性的详细介绍如下:
| 属性名 | 取值 | 描述 |
|---|---|---|
| width | 正整数 | 定义布局视口的宽度,单位为像素 |
| height | 正整数 | 定义布局视口的高度,单位为像素,很少使用 |
| initial-scale | [0,10] | 初始缩放比例,1表示不缩放 |
| minimum-scale | [0,10] | 最小缩放比例 |
| maximum-scale | [0,10] | 最大缩放比例 |
| user-scalable | yes/no | 是否允许手动缩放页面,默认值为yes |
其中我们来看width属性,在移动端布局时,在meta标签中我们会将width设置称为device-width,device-width一般是表示分辨率的宽,通过width=device-width的设置我们就将布局视口设置成了理想的视口。
上述我们了解到了当通过viewport元标签,设置布局视口为理想视口时,1个css像素可以表示成:
1 CSS像素 = 物理像素/分辨率
我们直到,在pc端的布局视口通常情况下为980px,移动端以iphone6为例,分辨率为375 * 667,也就是说布局视口在理想的情况下为375px。比如现在我们有一个750px * 1134px的视觉稿,那么在pc端,一个css像素可以如下计算:
PC端: 1 CSS像素 = 物理像素/分辨率 = 750 / 980 =0.76 px
而在iphone6下:
iphone6:1 CSS像素 = 物理像素 /分辨率 = 750 / 375 = 2 px
也就是说在PC端,一个CSS像素可以用0.76个物理像素来表示,而iphone6中 一个CSS像素表示了2个物理像素。此外不同的移动设备分辨率不同,也就是1个CSS像素可以表示的物理像素是不同的,因此如果在css中仅仅通过px作为长度和宽度的单位,造成的结果就是无法通过一套样式,实现各端的自适应。
在前面我们说到,不同端的设备下,在css文件中,1px所表示的物理像素的大小是不同的,因此通过一套样式,是无法实现各端的自适应。由此我们联想:
如果一套样式不行,那么能否给每一种设备各一套不同的样式来实现自适应的效果?
答案是肯定的。
使用@media媒体查询可以针对不同的媒体类型定义不同的样式,特别是响应式页面,可以针对不同屏幕的大小,编写多套样式,从而达到自适应的效果。举例来说:
@media screen and (max-width: 960px){
body{
background-color:#FF6699
}
}
@media screen and (max-width: 768px){
body{
background-color:#00FF66;
}
}
@media screen and (max-width: 550px){
body{
background-color:#6633FF;
}
}
@media screen and (max-width: 320px){
body{
background-color:#FFFF00;
}
}
上述的代码通过媒体查询定义了几套样式,通过max-width设置样式生效时的最大分辨率,上述的代码分别对分辨率在0~320px,320px~550px,550px~768px以及768px~960px的屏幕设置了不同的背景颜色。
通过媒体查询,可以通过给不同分辨率的设备编写不同的样式来实现响应式的布局,比如我们为不同分辨率的屏幕,设置不同的背景图片。比如给小屏幕手机设置@2x图,为大屏幕手机设置@3x图,通过媒体查询就能很方便的实现。
但是媒体查询的缺点也很明显,如果在浏览器大小改变时,需要改变的样式太多,那么多套样式代码会很繁琐。
除了用px结合媒体查询实现响应式布局外,我们也可以通过百分比单位 " % " 来实现响应式的效果。
比如当浏览器的宽度或者高度发生变化时,通过百分比单位,通过百分比单位可以使得浏览器中的组件的宽和高随着浏览器的变化而变化,从而实现响应式的效果。
为了了解百分比布局,首先要了解的问题是:
css中的子元素中的百分比(%)到底是谁的百分比?
直观的理解,我们可能会认为子元素的百分比完全相对于直接父元素,height百分比相对于height,width百分比相对于width。当然这种理解是正确的,但是根据css的盒式模型,除了height、width属性外,还具有padding、border、margin等等属性。那么这些属性设置成百分比,是根据父元素的那些属性呢?此外还有border-radius和translate等属性中的百分比,又是相对于什么呢?下面来具体分析。
(1)子元素height和width的百分比
子元素的height或width中使用百分比,是相对于子元素的直接父元素,width相对于父元素的width,height相对于父元素的height。比如:
<div class="parent">
<div class="child"></div>
</div>
如果设置:
.father{
width:200px;
height:100px;
}
.child{
width:50%;
height:50%;
}
展示的效果为:

(2) top和bottom 、left和right
子元素的top和bottom如果设置百分比,则相对于直接非static定位(默认定位)的父元素的高度,同样
子元素的left和right如果设置百分比,则相对于直接非static定位(默认定位的)父元素的宽度。
展示的效果为:

(3)padding
子元素的padding如果设置百分比,不论是垂直方向或者是水平方向,都相对于直接父亲元素的width,而与父元素的height无关。
举例来说:
.parent{
width:200px;
height:100px;
background:green;
}
.child{
width:0px;
height:0px;
background:blue;
color:white;
padding-top:50%;
padding-left:50%;
}
展示的效果为:

子元素的初始宽高为0,通过padding可以将父元素撑大,上图的蓝色部分是一个正方形,且边长为100px,说明padding不论宽高,如果设置成百分比都相对于父元素的width。
(4)margin
跟padding一样,margin也是如此,子元素的margin如果设置成百分比,不论是垂直方向还是水平方向,都相对于直接父元素的width。这里就不具体举例。
(5)border-radius
border-radius不一样,如果设置border-radius为百分比,则是相对于自身的宽度,举例来说:
<div class="trangle"></div>
设置border-radius为百分比:
.trangle{
width:100px;
height:100px;
border-radius:50%;
background:blue;
margin-top:10px;
}
展示效果为:

除了border-radius外,还有比如translate、background-size等都是相对于自身的,这里就不一一举例。
百分比单位在布局上应用还是很广泛的,这里介绍一种应用。
比如我们要实现一个固定长宽比的长方形,比如要实现一个长宽比为4:3的长方形,我们可以根据padding属性来实现,因为padding不管是垂直方向还是水平方向,百分比单位都相对于父元素的宽度,因此我们可以设置padding-top为百分比来实现,长宽自适应的长方形:
<div class="trangle"></div>
设置样式让其自适应:
.trangle{
height:0;
width:100%;
padding-top:75%;
}
通过设置padding-top:75%,相对比宽度的75%,因此这样就设置了一个长宽高恒定比例的长方形,具体效果展示如下:

从上述对于百分比单位的介绍我们很容易看出如果全部使用百分比单位来实现响应式的布局,有明显的以下两个缺点:
(1)计算困难,如果我们要定义一个元素的宽度和高度,按照设计稿,必须换算成百分比单位。
(2)从小节1可以看出,各个属性中如果使用百分比,相对父元素的属性并不是唯一的。比如width和height相对于父元素的width和height,而margin、padding不管垂直还是水平方向都相对比父元素的宽度、border-radius则是相对于元素自身等等,造成我们使用百分比单位容易使布局问题变得复杂。
首先来看,什么是rem单位。rem是一个灵活的、可扩展的单位,由浏览器转化像素并显示。与em单位不同,rem单位无论嵌套层级如何,都只相对于浏览器的根元素(HTML元素)的font-size。默认情况下,html元素的font-size为16px,所以:
1 rem = 16px
为了计算方便,通常可以将html的font-size设置成:
html{ font-size: 62.5% }
这种情况下:
1 rem = 10px
rem单位都是相对于根元素html的font-size来决定大小的,根元素的font-size相当于提供了一个基准,当页面的size发生变化时,只需要改变font-size的值,那么以rem为固定单位的元素的大小也会发生响应的变化。
因此,如果通过rem来实现响应式的布局,只需要根据视图容器的大小,动态的改变font-size即可。
function refreshRem() {
var docEl = doc.documentElement;
var width = docEl.getBoundingClientRect().width;
var rem = width / 10;
docEl.style.fontSize = rem + 'px';
flexible.rem = win.rem = rem;
}
win.addEventListener('resize', refreshRem);
上述代码中将视图容器分为10份,font-size用十分之一的宽度来表示,最后在header标签中执行这段代码,就可以动态定义font-size的大小,从而1rem在不同的视觉容器中表示不同的大小,用rem固定单位可以实现不同容器内布局的自适应。
如果在响应式布局中使用rem单位,那么存在一个单位换算的问题,rem2px表示从rem换算成px,这个就不说了,只要rem乘以相应的font-size中的大小,就能换算成px。更多的应用是px2rem,表示的是从px转化为rem。
比如给定的视觉稿为750px(物理像素),如果我们要将所有的布局单位都用rem来表示,一种比较笨的办法就是对所有的height和width等元素,乘以相应的比例,现将视觉稿换算成rem单位,然后一个个的用rem来表示。另一种比较方便的解决方法就是,在css中我们还是用px来表示元素的大小,最后编写完css代码之后,将css文件中的所有px单位,转化成rem单位。
px2rem的原理也很简单,重点在于预处理以px为单位的css文件,处理后将所有的px变成rem单位。可以通过两种方式来实现:
1) webpack loader的形式:
npm install px2rem-loader
在webpack的配置文件中:
module.exports = {
// ...
module: {
rules: [{
test: /\.css$/,
use: [{
loader: 'style-loader'
}, {
loader: 'css-loader'
}, {
loader: 'px2rem-loader',
// options here
options: {
remUni: 75,
remPrecision: 8
}
}]
}]
}
}
2)webpack中使用postcss plugin
npm install postcss-loader
在webpack的plugin中:
var px2rem = require('postcss-px2rem');
module.exports = {
module: {
loaders: [
{
test: /\.css$/,
loader: "style-loader!css-loader!postcss-loader"
}
]
},
postcss: function() {
return [px2rem({remUnit: 75})];
}
}
网易新闻的移动端页面使用了rem布局,具体例子如下:
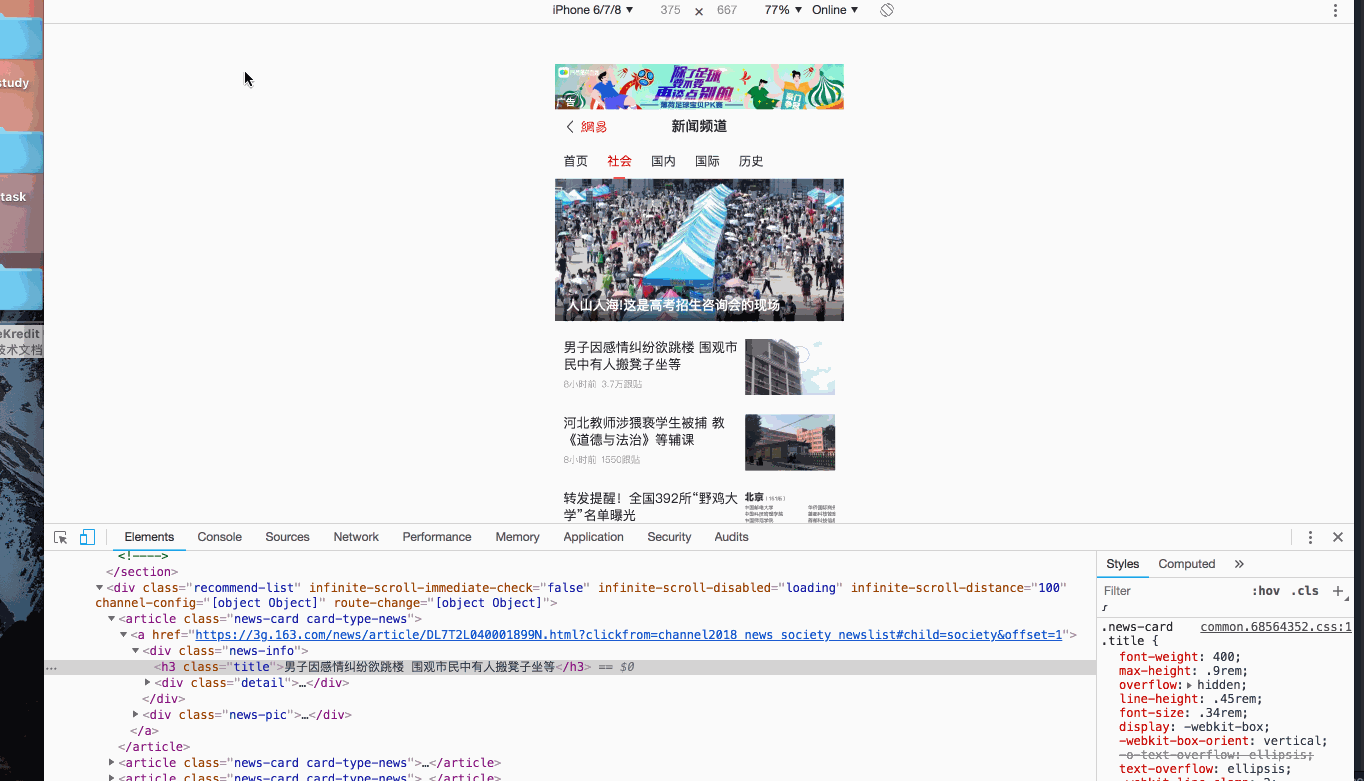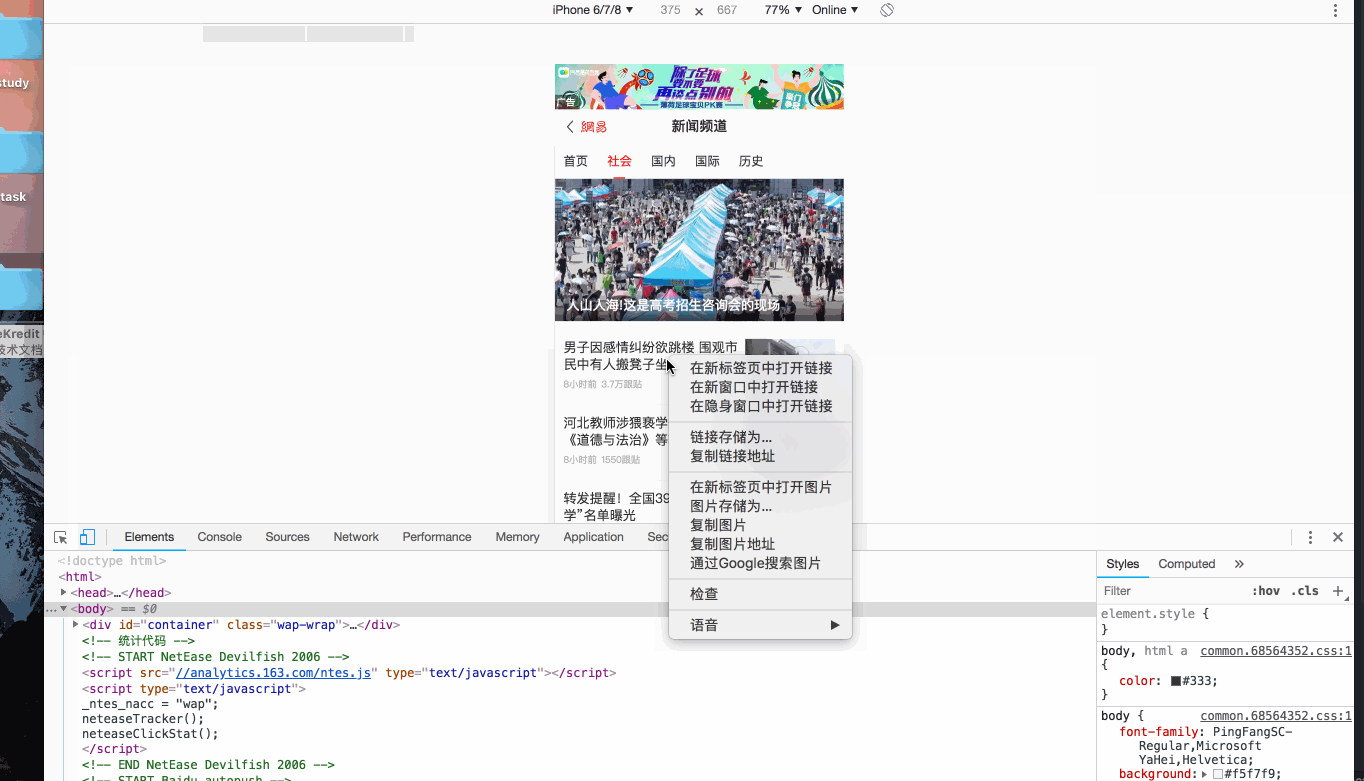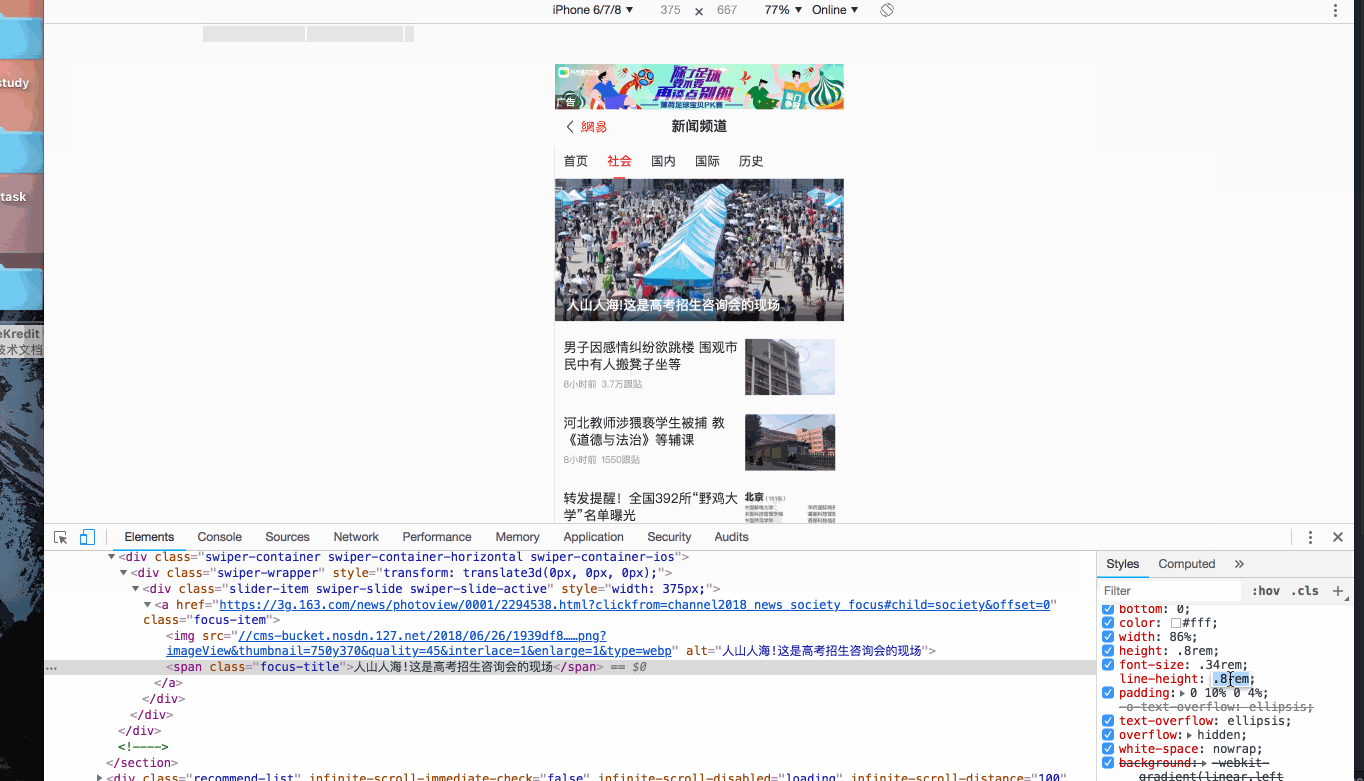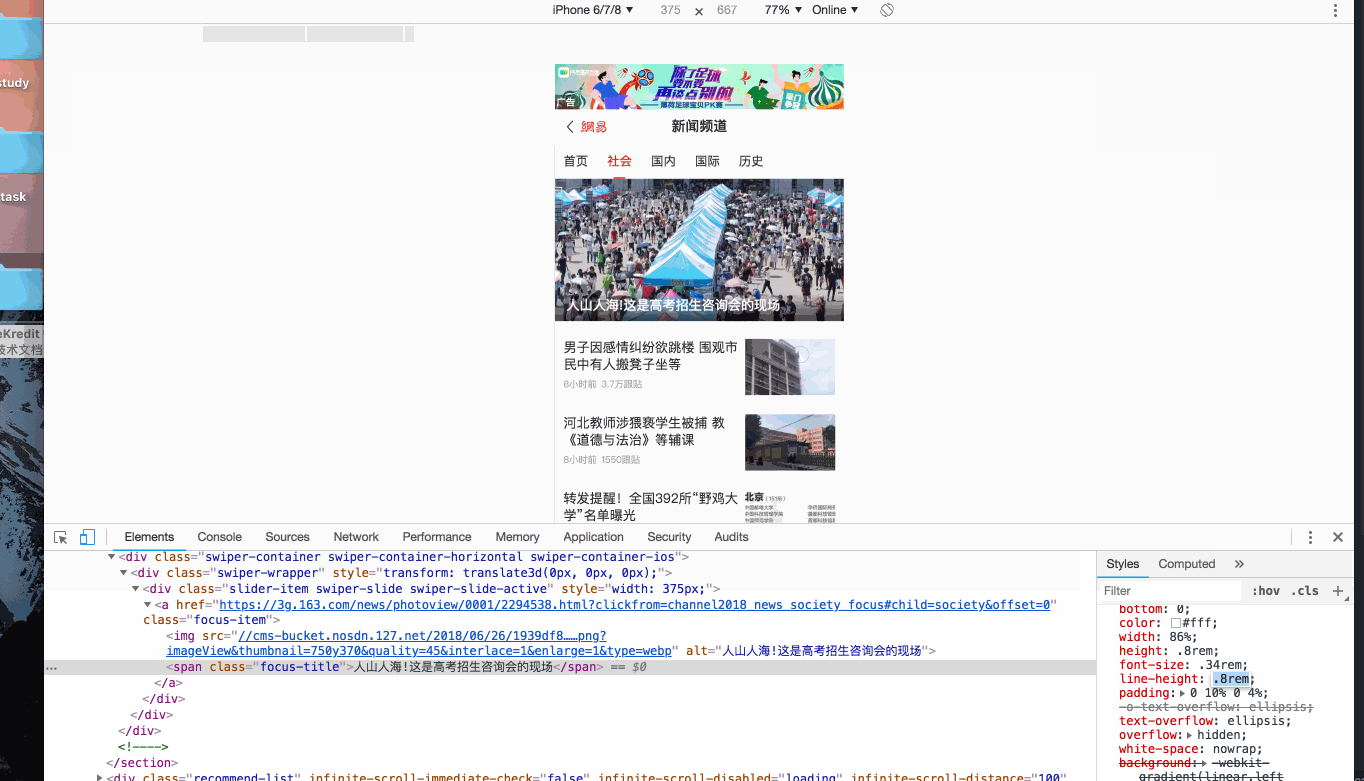
通过rem单位,可以实现响应式的布局,特别是引入相应的postcss相关插件,免去了设计稿中的px到rem的计算。rem单位在国外的一些网站也有使用,这里所说的rem来实现布局的缺点,或者说是小缺陷是:
在响应式布局中,必须通过js来动态控制根元素font-size的大小。
也就是说css样式和js代码有一定的耦合性。且必须将改变font-size的代码放在css样式之前。
css3中引入了一个新的单位vw/vh,与视图窗口有关,vw表示相对于视图窗口的宽度,vh表示相对于视图窗口高度,除了vw和vh外,还有vmin和vmax两个相关的单位。各个单位具体的含义如下:
| 单位 | 含义 |
|---|---|
| vw | 相对于视窗的宽度,视窗宽度是100vw |
| vh | 相对于视窗的高度,视窗高度是100vh |
| vmin | vw和vh中的较小值 |
| vmax | vw和vh中的较大值 |
这里我们发现视窗宽高都是100vw/100vh,那么vw或者vh,下简称vw,很类似百分比单位。vw和%的区别为:
| 单位 | 含义 |
|---|---|
| % | 大部分相对于祖先元素,也有相对于自身的情况比如(border-radius、translate等) |
| vw/vh | 相对于视窗的尺寸 |
从对比中我们可以发现,vw单位与百分比类似,单确有区别,前面我们介绍了百分比单位的换算困难,这里的vw更像"理想的百分比单位"。任意层级元素,在使用vw单位的情况下,1vw都等于视图宽度的百分之一。
同样的,如果要将px换算成vw单位,很简单,只要确定视图的窗口大小(布局视口),如果我们将布局视口设置成分辨率大小,比如对于iphone6/7 375*667的分辨率,那么px可以通过如下方式换算成vw:
1px = (1/375)*100 vw
此外,也可以通过postcss的相应插件,预处理css做一个自动的转换,postcss-px-to-viewport可以自动将px转化成vw。
postcss-px-to-viewport的默认参数为:
var defaults = {
viewportWidth: 320,
viewportHeight: 568,
unitPrecision: 5,
viewportUnit: 'vw',
selectorBlackList: [],
minPixelValue: 1,
mediaQuery: false
};
通过指定视窗的宽度和高度,以及换算精度,就能将px转化成vw。
可以在https://caniuse.com/ 查看各个版本的浏览器对vw单位的支持性。
从上图我们发现,绝大多数的浏览器支持vw单位,但是ie9-11不支持vmin和vmax,考虑到vmin和vmax单位不常用,vw单位在绝大部分高版本浏览器内的支持性很好,但是opera浏览器整体不支持vw单位,如果需要兼容opera浏览器的布局,不推荐使用vw。
小结:本文介绍在布局中常用的单位,比如px、%、rem和vw等等,以及不同的单位在响应式布局中的优缺点。
学习webgl也有小半年的时间了,有了一些心得和体会,在这里做一个记录,整个系列的代码都会给出,这篇文章是这个系列的第一篇文章,带你走进webgl的世界。
- 什么是webgl
- 用webgl画点
- 用webgl实现一个彩色正方形
这个系列的源码地址为:源码的地址为: https://github.com/forthealllight/webgl-demo
在介绍什么是webgl之前,我们来看一个最简单的webgl程序。
<html lang="en">
<head>
<title>WebGL Demo</title>
<meta charset="utf-8">
</head>
<body>
<canvas id="glcanvas" width="640" height="480"></canvas>
</body>
<script>
main();
// start here
function main() {
const canvas = document.querySelector("#glcanvas");
// Initialize the GL context
const gl = canvas.getContext("webgl");
// Only continue if WebGL is available and working
if (!gl) {
alert("你的浏览器不支持webgl");
return;
}
// Set clear color to black, fully opaque
gl.clearColor(0.0, 0.0, 0.0, 1.0);
// Clear the color buffer with specified clear color
gl.clear(gl.COLOR_BUFFER_BIT);
}
</script>
</html>上述就是一个webgl的例子,做的事情很简单就是清空了webgl画布的颜色。在上述的例子中,我们没有引入什么其他的插件,就构建了一个webgl程序,因为webgl本身就是浏览器层面的。Webgl是内嵌在浏览器中的,你不必安装任何插件或者库,如果浏览器支持webgl,就可以通过getContext的方法创建一个webgl实例。
const gl = canvas.getContext("webgl");一提到webgl就容易跟3D渲染绘图联系在一起,实际上这两者并没有绝对关联,webgl也可以用来绘制2D平面图形,2D动画等等。那么webgl到底是什么呢?一句话概括就是:
通过绘图渲染技术OpenGL在浏览器里面进行图形渲染的技术
了解过图形渲染技术的同学都听过OpenGL等,我们可以通过C语言,在window等平台上编写复杂和渲染出复杂的图形,通过OpenGL绘制和渲染图形有很高的平台要求以及编程语言的限制。而Webgl源自于OpenGL,从OpenGL2.0的着色器行为中诞生了适用于移动式穿戴设备的OpenGL ES标准,在这个标准下演化出了webgl,使得我们可以通过结合javascript语言和GLSL ES着色器语言,在浏览器中绘制出复杂的图形,不需要编译也不需要引入任何插件.
接着我们来看如何用webgl来绘制一个完整的图案,绘制图案跟上一小节最简单的清空画布的webgl程序不同。我们需要webgl中的两个重要的概念——着色器。
webgl的本质就是通过顶点着色器和片元着色器,将图形渲染到浏览器中。之后我们会详细的介绍顶点着色器和片元着色器,这里可以简单的理解为顶点着色器决定了每个顶点的位置,片元着色器决定了图形的颜色。
绘制图案之前必须进行着色器程序初始化,根据着色球类型创建着色器对象,将着色器对象编译后绑定到程序对象,最后编译和连接程序对象从而完整了初始化的过程,接下来就可以使用程序对象来绘制图形。
上面的两段话特别绕,总结就是:
GLSL着色器语言是以字符串的形式存在浏览器中的,为了能够将字符串编译成可以在显卡中运行的着色器程序,必须进行着色器程序初始化
在初始化着色器程序中我们必须用到两个对象着色器对象和程序对象,我们来简单介绍一下这两者。
我们用图来区别这两者的关系:

从这个图可以看出层级关系,我们要初始化着色器程序,就是按照如下的层级关系依次来初始化。
结合上面图形的层次结构,以及上述的7步初始化着色器的步骤,我们可以来介绍着色器初始化函数initShaderProgram
function initShaderProgram(gl, vsSource, fsSource) {
const vertexShader = loadShader(gl, gl.VERTEX_SHADER, vsSource); //创建顶点着色器对象
const fragmentShader = loadShader(gl, gl.FRAGMENT_SHADER, fsSource);//创建片元着色器对象
// Create the shader program
const shaderProgram = gl.createProgram();
gl.attachShader(shaderProgram, vertexShader);
gl.attachShader(shaderProgram, fragmentShader);
gl.linkProgram(shaderProgram);
return shaderProgram;
}这就是最上层的程序对象的创建过程,至于着色器对象的创建可以通过如下函数
loadShader:
function loadShader(gl, type, source) {
const shader = gl.createShader(type);
gl.shaderSource(shader, source);
gl.compileShader(shader);
return shader;
}上述我们就完成了着色器程序的初始化,就可以在浏览器中编译GLSL ES语言渲染出图形。下面我们来看最简单的画点
我们上一小节将了如何初始化着色器,初始化着色器可以通过initShaderProgram方法,我们可以用webgl来画一个最简单的size为10的点
首先通过字符串的方式定义顶点着色器和片元着色器:
const vsSource = `
ashouttribute vec4 aVertexPosition;
uniform mat4 uModelViewMatrix;
uniform mat4 uProjectionMatrix;
void main() {
gl_Position = vec4(0.0,0.0,0.0,1.0);
gl_PointSize = 10.0;
}
`;
// Fragment shader program
const fsSource = `
void main() {
gl_FragColor = vec4(1.0, 1.0, 1.0, 1.0);
}
`;然后将这两个字符串传入initShaderProgram程序,就完成了着色器初始化。
const shaderProgram = initShaderProgram(gl, vsSource, fsSource)最后清空画布,并使用这个着色器程序开始画图:
gl.clearColor(0.0, 0.0, 0.0, 1.0);
gl.clearDepth(1.0);
gl.clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT)
gl.useProgram(shaderProgram);
gl.drawArrays(gl.POINTS,0,1);这样就在浏览器中画出了一个点。

源码的地址为: https://github.com/forthealllight/webgl-demo/tree/master/demo1
最后我们来实现一个较为复杂的例子,用webgl来画一个正方形。我们可以通过4次每次画一个点,画4个点,然后将这4个点连起来就成为了一个正方形,此外如果我们要一次性的画出4个点并连成正方形,就需要使用缓冲区。
我们可以简单理解,缓冲区保存了很多信息,我们可以读取缓冲区的信息,在一次绘制中绘出我们想要的图形。
我们来看创建一个缓冲区的步骤:
这个五步可以简记为:创建-绑定-写入-分配-开启这么几步,并且我们要使用缓冲区对象这五步是必不可免的.
我们可以定义initBuffers方法来创建缓冲区,我们可以分别创建一个顶点缓冲区(用于读取图形的顶点坐标)以及片元缓冲区(用于读取每个片元的颜色信息)
function initBuffers(gl) {
//顶点缓冲区
const positionBuffer = gl.createBuffer();
gl.bindBuffer(gl.ARRAY_BUFFER, positionBuffer);
const positions = [
1.0, 1.0,
-1.0, 1.0,
1.0, -1.0,
-1.0, -1.0,
];
gl.bufferData(gl.ARRAY_BUFFER, new Float32Array(positions), gl.STATIC_DRAW);
var colors = [
1.0, 1.0, 1.0, 1.0, // white
1.0, 0.0, 0.0, 1.0, // red
0.0, 1.0, 0.0, 1.0, // green
0.0, 0.0, 1.0, 1.0, // blue
];
//颜色缓冲区
const colorBuffer = gl.createBuffer();
gl.bindBuffer(gl.ARRAY_BUFFER, colorBuffer);
gl.bufferData(gl.ARRAY_BUFFER, new Float32Array(colors), gl.STATIC_DRAW);
return {
position: positionBuffer,
color: colorBuffer,
};
}然后,在绘图的时候,通过:
gl.bindBuffer();
gl.vertexAttribPointer();
gl.enableVertexAttribArray()来分别使用缓冲区,除了缓冲区外,我们还需要在顶点着色器和片元着色器中定义全局变量,来接受从缓冲区的传递过来的值。这里先省略,后期在详细介绍缓冲区和着色器的时候会提到.
最后给出绘制出来的图像:

源码的地址为: https://github.com/forthealllight/webgl-demo/tree/master/demo2
最后补充一下,在第二张的画一个点的例子中,我们机会没有引入任何插件,实际上虽然webgl是浏览器内置的不需要引入,但是为了方便矩阵操作等,也有一些比较实用的工具
总结一下ES6/ES7中promise、generator和async/await中的异常捕获方法
简要介绍:ES6中为了处理异步,增加了promise、generator和async,它们各自都有不同的内部异常捕获方法,本文总结一下promise、generator和async的异常捕获方法。
- Promise的异常捕获方式
- generator的异常捕获方式
- async/await的异常捕获方式
- 总结
var promise=new Promise(function(resolve,reject){
try {
throw new Error('test');
}catch(e){
reject(e)
}
})
在Promise的构造体内进行错误处理,类似于我们在ES5中的错误处理方式。
生成Promise实例后,我们可以通过Promise原型上的catch方法来捕获Promise实例内部的错误。
var promise=new Promise(function(resolve,reject){
reject(new Error('test'));
})
promise.catch(function(e){
//something to deal with the error
console.log(e)
})
上述的例子,跟(1)中是类似的,此外catch方法还可以处理链式调用中的错误,比如:
var promise=new Promise(function(resolve,reject){
resolve();
})
promise.then(function(){
// if some error throw
}).then(function(){
// if some error throw
}).catch(function(e){
//something to deal with the error
console.log(e)
})
// Error : test1
上述的代码中,最后一个catch方法可以捕获前面链式调用过程中任何一步then方法里面所抛出的错误。
catch方面里面还可以再抛错误,这个错误会被后面的catch捕获
var promise=new Promise(function(resolve,reject){
reject(new Error('test1'))
})
promise.catch(function(e){
console.log(e);
throw new Error('test2')
}).catch(function(e){
console.log(e)
})
// Error : test1
// Error : test2
如果组成Promise.all的promise有自己的错误捕获方法,那么Promise.all中的catch就不能捕获该错误。
var p1=new Promise(function(resolve,reject){
reject(new Error('test1'))
}).catch(function(e){
console.log("由p1自身捕获",e);
})
var p2=new Promise(function(resolve,reject){
resolve();
})
var p=Promise.all([p1,p2]);
p.then(function(){
}).catch(function(e){
//在此处捕获不到p1中的error
console.log(e)
})
//由p1自身捕获 Error: test1
ES2018中可以通过Promise.try来同步处理,可能是异步也可能是同步的函数。
function f(){}
Promise.try(f);
console.log(2);
上述的f方法,不管是同步还是异步,都会执行该方法,再输出2。
在Promise.try的错误处理中,通过catch方法既可以捕获f是同步函数情况下的错误,也可以捕获f是异步函数情况下的错误。
function f(){}
Promise.try(f).then(function(){
}).catch(function(e){
})
在promise实例resolve之后,错误无法被捕获。
var promise=new Promise(function(resolve,reject){
resolve();
throw new Error('test');//该错误无法被捕获
})
promise.then(function(){
//
}).then(function(e){
console.log(e)
})
该错误可以用尾调用resolve来避免。
function * F(){
try{
yield 1
}catch(e){
console.log(e)
}
}
var f=F();
f.throw(new Error('test1'))
上述这样在内部不能捕获到test1错误,为什么呢? 这个generator的原理有关,调用F()仅仅返回一个状态生成器,并没有执行generator里面的方法,因此在f上直接跑错误是无法捕获的。
那么怎么才能捕获错误呢?采用如下的方式:
function * F(){
try{
yield 1
}catch(e){
console.log(e)
}
}
var f=F();
f.next()//增加了一句next执行,可以执行generator里面的内容
f.throw(new Error('test1'))
//捕获错误 Error test1
这样就能捕获该错误。
此外捕获错误后,会执行一次next方法
function * F(){
try{
yield 1
}catch(e){
console.log(e)
}
yield 2
return 3
}
var f=F();
f.next(); //{value :1,done:false}
f.throw(new Error('test1')) //{value:2,done:false}
f.next(); //{value:3,done:true}
到次,我们现在直到在generator中,next、throw和done都会执行一次next方法。
function F(){
yield 1;
yield 2;
return 3;
}
var f=F();
try{
f.throw(new Error('test1'))
}catch(e){
console.log(e)
}
// Error test1
在构造体外部捕获,可以直接f.throw
function F(){
yield 1;
throw new Error('test1');
yield 2;
return 3
}
var f=F();
f.next() // {value:1,done:false}
f.next() // {value:undefined,done:true}
上述例子中,只要错误没有被处理,就会返回done:true就停止执行generator
因为async的返回值也是个promise,跟promise的错误处理差不多。
此外,async里面throw Error 相当于返回Promise.reject。
async function F(){
throw new Error('test1')
}
var f=F();
f.catch(function(e){console.log(e)});
// Error:test1
在async中,await的错误相当于Promise.reject
async function F(){
await Promise.reject('Error test1').catch(function(e){
console.log(e)
})
}
var f=F(); // Error:test1
await如果返回的是reject状态的promise,如果不被捕获,就会中断async函数的执行。
async function F(){
await Promise.reject('Error test1');
await 2
}
var f=F()
上述代码中,前面的Promise.reject没有被捕获,所以不会执行await 2
Promise、generator错误都可以在构造体里面被捕获,而async/await返回的是promise,可以通过catch直接捕获错误。
generator 抛出的错误,以及await 后接的Promise.reject都必须被捕获,否则会中断执行。
简要介绍:再看redux文档的时候,发现了createStore是允许第三个参数的,看了一下源码明白了第三个参数的作用。
第三个参数enhancer, 是一个组合 store creator 的高阶函数,返回一个
新的强化过的 store creator。这与 middleware 相似,它也允许你通过
复合函数改变 store 接口。
export default function createStore(reducer, preloadedState, enhancer) {
if (typeof preloadedState === 'function' && typeof enhancer === 'undefined') {
enhancer = preloadedState
preloadedState = undefined
}
if (typeof enhancer !== 'undefined') {
if (typeof enhancer !== 'function') {
throw new Error('Expected the enhancer to be a function.')
}
return enhancer(createStore)(reducer, preloadedState)
}
去掉前面一些类型判断,我们来看这一句:
return enhancer(createStore)(reducer, preloadedState)
这句的形式像什么,柯里化后传入的第一个参数为createStore,这很类
似于我们再定义中间件的时候,applyMiddleware这个函数,这个函数
返回了提升后的createStore。
因此在applyMiddleware的时候,就会存在两种写法,这里我们以利用redux-thunk为例。
import thunk from 'redux-thunk'
let createStoreWithMiddleware = applyMiddleware(thunk)(createStore)
import thunk from 'redux-thunk'
let createStoreWithMiddleware = createStore(reducer,preState,applyMiddleware(thunk))
最近在项目中基本上全部使用了React Hooks,历史项目也用React Hooks重写了一遍,相比于Class组件,React Hooks的优点可以一句话来概括:就是简单,在React hooks中没有复杂的生命周期,没有类组件中复杂的this指向,没有类似于HOC,render props等复杂的组件复用模式等。本篇文章主要总结一下在React hooks工程实践中的经验。
- React hooks中的渲染行为
- React hooks中的性能优化
- React hooks中的状态管理和通信
理解React hooks的关键,就是要明白,hooks组件的每一次渲染都是独立,每一次的render都是一个独立的作用域,拥有自己的props和states、事件处理函数等。概括来讲:
每一次的render都是一个互不相关的函数,拥有完全独立的函数作用域,执行该渲染函数,返回相应的渲染结果
而类组件则不同,类组件中的props和states在整个生命周期中都是指向最新的那次渲染.
React hooks组件和类组件的在渲染行为中的区别,看起来很绕,我们可以用图来区别,

上图表示在React hooks组件的渲染过程,从图中可以看出,react hooks组件的每一次渲染都是一个独立的函数,会生成渲染区专属的props和state. 接着来看类组件中的渲染行为:
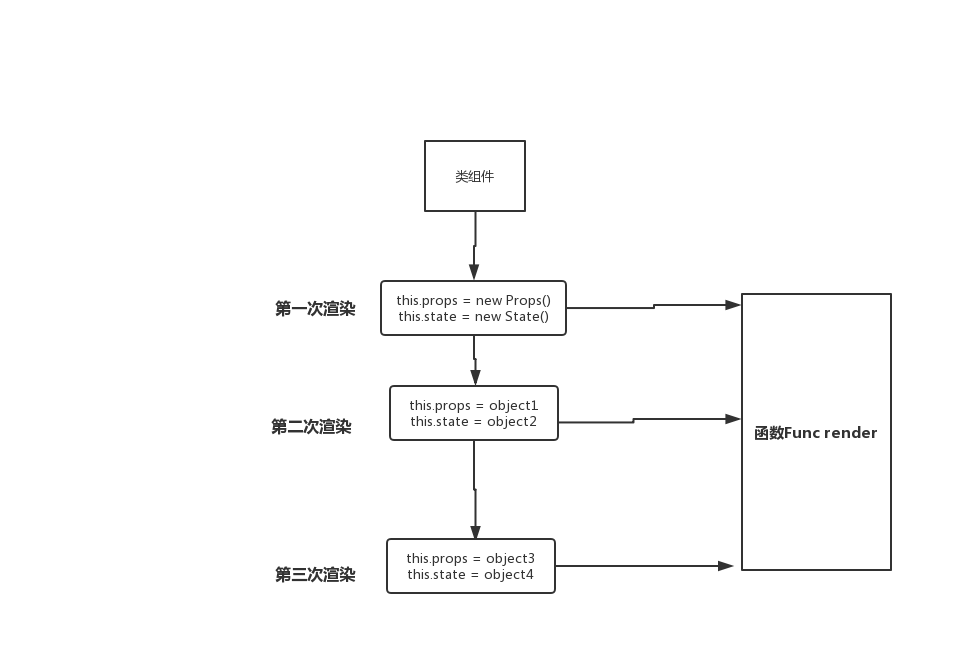
类组件中在渲染开始的时候会在类组件的构造函数中生成一个props和state,所有的渲染过程都是在一个渲染函数中进行的并且,每一次的渲染中都不会去生成新的state和props,而是将值赋值给最开始被初始化的this.props和this.state。
理解了React hooks的渲染行为,就指示了我们如何在工程中使用。首先因为React hooks组件在每一次渲染的过程中都会生成独立的所用域,因此,在组件内部的子函数和变量等在每次生命的时候都会重新生成,因此我们应该减少在React hooks组件内部声明函数。
写法一:
function App() {
const [counter, setCounter] = useState(0);
function formatCounter(counterVal) {
return `The counter value is ${counterVal}`;
}
return (
<div className="App">
<div>{formatCounter(counter)}</div>
<button onClick={() => setCounter(prevState => ++prevState)}>
Increment
</button>
</div>
);
}写法二:
function formatCounter(counterVal) {
return `The counter value is ${counterVal}`;
}
function App() {
const [counter, setCounter] = useState(0);
return (
<div className="App">
<div>{formatCounter(counter)}</div>
<button onClick={()=>onClick(setCounter)}>
Increment
</button>
</div>
);
}App组件是一个hooks组件,我们知道了React hooks的渲染行为,那么写法1在每次render的时候都会去重新声明函数formatCounter,因此是不可取的。我们推荐写法二,如果函数与组件内的state和props无相关性,那么可以声明在组件的外部。如果函数与组件内的state和props强相关性,那么我们下节会介绍useCallback和useMemo的方法。
React hooks中的state和props,在每次渲染的过程中都是重新生成和独立的,那么我们如果需要一个对象,从开始到一次次的render1 , render2, ...中都是不变的应该怎么做呢。(这里的不变是不会重新生成,是引用的地址不变的意思,其值可以改变)
我们可以使用useRef,创建一个“常量”,该常量在组件的渲染期内始终指向同一个引用地址。
通过useRef,可以实现很多功能,比如在某次渲染的时候,拿到前一次渲染中的state。
function App(){
const [count,setCount] = useState(0)
const prevCount = usePrevious(count);
return (
<div>
<h1>Now: {count}, before: {prevCount}</h1>
<button onClick={() => setCount(count + 1)}>Increment</button>
</div>
);
}
function usePrevious(value) {
const ref = useRef();
useEffect(() => {
ref.current = value;
}, [value]);
return ref.current;
}上述的例子中,我们通过useRef()创建的ref对象,在整个usePrevious组件的周期内都是同一个对象,我们可以通过更新ref.current的值,来在App组件的渲染过程中,记录App组件渲染中前一次渲染的state.
这里其实还有一个不容易理解的地方,我们来看usePrevious:
function usePrevious(value) {
const ref = useRef();
useEffect(() => {
ref.current = value;
}, [value]);
return ref.current;
}这里的疑问是:为什么当value改变的时候,返回的ref.current指向的是value改变之前的值?
也就是说:
为什么useEffect在return ref.current之后才执行?
为了解释这个问题,我们来聊聊神奇的useEffect.
hooks组件的每一次渲染都可以看成一个个独立的函数 render1,render2 ... rendern,那么这些render函数之间是怎么关联的呢,还有上小节的问题,为什么在usePrevious中,useEffect在return ref.current之后才执行。带着这两个疑问我们来看看在hooks组件中,最为神奇的useEffect。
用一句话概括就是:
每一渲染都会生成不同的render函数,并且每一次渲染通过useEffect会生成一个不同的Effects,Effects在每次渲染后声效。
每次渲染除了生成不同的作用域外,如果该hooks组件中使用了useEffect,通过useEffect还会生成一个独有的effects,该effects在渲染完成后生效。
举例来说:
function Counter() {
const [count, setCount] = useState(0);
useEffect(() => {
document.title = `You clicked ${count} times`;
});
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}上述的例子中,完成的逻辑是:
<p>You clicked 0 times</p><p>You clicked 1 times</p>也就是说每次渲染render中,effect位于同步执行队列的最后面,在dom更新或者函数返回后在执行。
我们在来看usePrevious的例子:
function usePrevious(value) {
const ref = useRef();
useEffect(() => {
ref.current = value;
}, [value]);
return ref.current;
}因为useEffect的机制,在新的渲染过程中,先返回ref.current再执行deps依赖更新ref.current,因此usePrevios总是返回上一次的值。
现在我们知道,在一次渲染render中,有自己独立的state,props,还有独立的函数作用域,函数定义,effects等,实际上,在每次render渲染中,几乎所有都是独立的。我们最后来看两个例子:
(1)
function Counter() {
const [count, setCount] = useState(0);
useEffect(() => {
setTimeout(() => {
console.log(`You clicked ${count} times`);
}, 3000);
});
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}(2)
function Counter() {
const [count, setCount] = useState(0);
setTimeout(() => {
console.log(`You clicked ${count} times`);
}, 3000);
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}这两个例子中,我们在3内点击5次Click me按钮,那么输出的结果都是一样的。
You clicked 0 times
You clicked 1 times
You clicked 2 times
You clicked 3 times
You clicked 4 times
You clicked 5 times
总而言之,每一次渲染的render,几乎都是独立和独有的,除了useRef创建的对象外,其他对象和函数都没有相关性.
前面我们讲了React hooks中的渲染行为,也初步
提到了说将与state和props无关的函数,声明在hooks组件外面可以提高组件的性能,减少每次在渲染中重新声明该无关函数. 除此之外,React hooks还提供了useMemo和useCallback来优化组件的性能.
(1).useCallback
有些时候我们必须要在hooks组件内定义函数或者方法,那么推荐用useCallback缓存这个方法,当useCallback的依赖项不发生变化的时候,该函数在每次渲染的过程中不需要重新声明
useCallback接受两个参数,第一个参数是要缓存的函数,第二个参数是一个数组,表示依赖项,当依赖项改变的时候会去重新声明一个新的函数,否则就返回这个被缓存的函数.
function formatCounter(counterVal) {
return `The counter value is ${counterVal}`;
}
function App(props) {
const [counter, setCounter] = useState(0);
const onClick = useCallback(()=>{
setCounter(props.count)
},[props.count]);
return (
<div className="App">
<div>{formatCounter(counter)}</div>
<button onClick={onClick}>
Increment
</button>
</div>
);
}上述例子我们在第一章的例子基础上增加了onClick方法,并缓存了这个方法,只有props中的count改变的时候才需要重新生成这个方法。
(2).useMemo
useMemo与useCallback大同小异,区别就是useMemo缓存的不是函数,缓存的是对象(可以是jsx虚拟dom对象),同样的当依赖项不变的时候就返回这个被缓存的对象,否则就重新生成一个新的对象。
为了实现组件的性能优化,我们推荐:
在react hooks组件中声明的任何方法,或者任何对象都必须要包裹在useCallback或者useMemo中。
(3)useCallback,useMemo依赖项的比较方法
我们来看看useCallback,useMemo的依赖项,在更新前后是怎么比较的
import is from 'shared/objectIs';
function areHookInputsEqual(
nextDeps: Array<mixed>,
prevDeps: Array<mixed> | null,
) {
if (prevDeps === null) {
return false;
}
if (nextDeps.length !== prevDeps.length) {
return false
}
for (let i = 0; i < prevDeps.length && i < nextDeps.length; i++) {
if (is(nextDeps[i], prevDeps[i])) {
continue;
}
return false;
}
return true;
}其中is方法的定义为:
function is(x: any, y: any) {
return (
(x === y && (x !== 0 || 1 / x === 1 / y)) || (x !== x && y !== y)
);
}
export default (typeof Object.is === 'function' ? Object.is : is);这个is方法就是es6的Object.is的兼容性写法,也就是说在useCallback和useMemo中的依赖项前后是通过Object.is来比较是否相同的,因此是浅比较。
react hooks中的局部状态管理相比于类组件而言更加简介,那么如果我们组件采用react hooks,那么如何解决组件间的通信问题。
最基础的想法可能就是通过useContext来解决组件间的通信问题。
比如:
function useCounter() {
let [count, setCount] = useState(0)
let decrement = () => setCount(count - 1)
let increment = () => setCount(count + 1)
return { count, decrement, increment }
}
let Counter = createContext(null)
function CounterDisplay() {
let counter = useContext(Counter)
return (
<div>
<button onClick={counter.decrement}>-</button>
<p>You clicked {counter.count} times</p>
<button onClick={counter.increment}>+</button>
</div>
)
}
function App() {
let counter = useCounter()
return (
<Counter.Provider value={counter}>
<CounterDisplay />
<CounterDisplay />
</Counter.Provider>
)
}在这个例子中通过createContext和useContext,可以在App的子组件CounterDisplay中使用context,从而实现一定意义上的组件通信。
此外,在useContext的基础上,为了其整体性,业界也有几个比较简单的封装:
https://github.com/jamiebuilds/unstated-next
https://github.com/diegohaz/constate
但是其本质都没有解决一个问题:
如果context太多,那么如何维护这些context
也就是说在大量组件通信的场景下,用context进行组件通信代码的可读性很差。这个类组件的场景一致,context不是一个新的东西,虽然用了useContext减少了context的使用复杂度。
hooks组件间的通信,同样可以使用redux来实现。也就是说:
在React hooks中,redux也有其存在的意义
在hooks中存在一个问题,因为不存在类似于react-redux中connect这个高阶组件,来传递mapState和mapDispatch, 解决的方式是通过redux-react-hook或者react-redux的7.1 hooks版本来使用。
在redux-react-hook中提供了StoreContext、useDispatch和useMappedState来操作redux中的store,比如定义mapState和mapDispatch的方式为:
import {StoreContext} from 'redux-react-hook';
ReactDOM.render(
<StoreContext.Provider value={store}>
<App />
</StoreContext.Provider>,
document.getElementById('root'),
);
import {useDispatch, useMappedState} from 'redux-react-hook';
export function DeleteButton({index}) {
// Declare your memoized mapState function
const mapState = useCallback(
state => ({
canDelete: state.todos[index].canDelete,
name: state.todos[index].name,
}),
[index],
);
// Get data from and subscribe to the store
const {canDelete, name} = useMappedState(mapState);
// Create actions
const dispatch = useDispatch();
const deleteTodo = useCallback(
() =>
dispatch({
type: 'delete todo',
index,
}),
[index],
);
return (
<button disabled={!canDelete} onClick={deleteTodo}>
Delete {name}
</button>
);
}这也是官方较为推荐的,react-redux 的hooks版本提供了useSelector()、useDispatch()、useStore()这3个主要方法,分别对应与mapState、mapDispatch以及直接拿到redux中store的实例.
简单介绍一下useSelector,在useSelector中除了能从store中拿到state以外,还支持深度比较的功能,如果相应的state前后没有改变,就不会去重新的计算.
举例来说,最基础的用法:
import React from 'react'
import { useSelector } from 'react-redux'
export const TodoListItem = props => {
const todo = useSelector(state => state.todos[props.id])
return <div>{todo.text}</div>
}实现缓存功能的用法:
import React from 'react'
import { useSelector } from 'react-redux'
import { createSelector } from 'reselect'
const selectNumOfDoneTodos = createSelector(
state => state.todos,
todos => todos.filter(todo => todo.isDone).length
)
export const DoneTodosCounter = () => {
const NumOfDoneTodos = useSelector(selectNumOfDoneTodos)
return <div>{NumOfDoneTodos}</div>
}
export const App = () => {
return (
<>
<span>Number of done todos:</span>
<DoneTodosCounter />
</>
)
}在上述的缓存用法中,只要todos.filter(todo => todo.isDone).length不改变,就不会去重新计算.
之前在一个移动端的抽奖页面中,在抽奖结果的展示窗口需要弹幕轮播显示,之前踩过一些小坑,现在总结一下前端弹幕效果的实现方式。
- css3实现乞丐版的弹幕
- css3弹幕性能优化
- canvas实现弹幕
- canva弹幕的扩展功能
首先来看如何通过css的方法实现一个最简单的弹幕:
首先在html中定义一条弹幕的dom结构:
<div class="block">我是弹幕</div>
弹幕的移动可以通过移动这个block来实现,以从右向左移动的弹幕为例,弹幕的初始位置在容器的最左侧且贴边隐藏(弹幕的最左边与容器的最右贴合),可以通过绝对定位加transform来实现:
.block{
position:absolute;
}
初始位置:
from{
left:100%;
transform:translateX(0)
}
移动到最左边的结束位置为(弹幕的最右边与容器的最左边贴合):
to{
left:0;
transform:translateX(-100%)
}
起始位置和结束位置的具体图示如下所示:

根据起始位置和结束位置可以定义完整的两帧弹幕动画:
@keyframes barrage{
from{
left:100%;
transform:translateX(0);
}
to{
left:0;
transform:translateX(-100%);
}
}
给弹幕元素引入这个动画:
.block{
position:absolute;
/* other decorate style */
animation:barrage 5s linear 0s;
}
这样就可以实现一个乞丐版的弹幕效果:

首先明确一下css的渲染过程
其中如果I)中和II)中的属性发生变化会发生reflow(回流),如果仅仅III)中的属性发生改变,只会发生repaint(重绘)。显然从css的渲染过程我们也可以看出来:reflow(回流)必伴随着重绘。
reflow(回流):当render树中的一部分或者全部因为大小边距等问题发生改变而需要重建的过程叫做回流
repaint(重绘):当元素的一部分属性发生变化,如外观背景色不会引起布局变化而需要重新渲染的过程叫做重绘
reflow(回流)会影响浏览器css的渲染速度,因此在做网页性能优化的时候要减少回流的发生。
在第一节,我们通过left属性,实现了弹幕的效果,left会改变元素的布局,因此会发生reflow(回流),表现在移动端页面上会造成弹幕动画的卡顿。
我们直到了第一节中的弹幕动画存在卡顿的问题,下面我们看看如何解决动画的卡顿。
在浏览器中用css开启硬件加速,使用GPU(Graphics Processing Unit)可以提升网页性能。鉴于此,我们可以发挥GPU的力量,从而使我们的网站或应用表现的更为流畅。
CSS animations, transforms 以及 transitions 不会自动开启GPU加速,而是由浏览器的缓慢的软件渲染引擎来执行。那我们怎样才可以切换到GPU模式呢,很多浏览器提供了某些触发的CSS规则。
比较常见的方式是,我们可以通过3d变化(translate3d属性)来开启硬件加速,鉴于此,我们修改动画为:
@keyframes barrage{
from{
left:100%;
transform:translate3d(0,0,0);
}
to{
left:0;
transform:translate3d(-100%,0,0);
}
}
这样就可以通过开启硬件加速的方式,优化网页性能。但是这种方式没有从根本上解决问题,同时使用GPU增加了内存的使用,会减少移动设备的电池寿命等等。
第二种方法,就是想办法在弹幕动画的前后不改变left属性的值,这样就不会发生reflow。
我们想仅仅通过translateX来确定弹幕节点的初始位置,但是translateX(-100%)是相对于弹幕节点本身的,而不是相对于父元素,因此我们耦合js和css,在js中获取弹幕节点所在的父元素的宽度,接着根据宽度来定义弹幕节点的初始位置。
以父元素为body时为例:
//css
.block{
position:absolute;
left:0;
visibility:hidden;
/* other decorate style */
animation:barrage 5s linear 0s;
}
//js
let style = document.createElement('style');
document.head.appendChild(style);
let width = window.innerWidth;
let from = `from { visibility: visible; -webkit-transform: translateX(${width}px); }`;
let to = `to { visibility: visible; -webkit-transform: translateX(-100%); }`;
style.sheet.insertRule(`@-webkit-keyframes barrage { ${from} ${to} }`, 0);
除了耦合js计算了父元素的宽度,从而确定弹幕节点的初始位置之外,这里在弹幕节点中我们为了防止初始位置就有显示,增加了visibility:hidden属性。防止弹幕节点在未确定初始位置时就显示在父容器内。只有弹幕开始从初始位置滚动,才会变得可见。
但是这种css的实现方式,在实现弹幕的扩展功能方面比较麻烦,比如如何控制弹幕暂停等等。
除了通过css实现弹幕的方法之外,通过canvas也可以实现弹幕。
通过canvas实现弹幕的原理就是时时的重绘文字,下面来一步步的实现。
获取画布
let canvas = document.getElementById('canvas');
let ctx = canvas.getContext('2d');
绘制文字
ctx.font = '20px Microsoft YaHei';
ctx.fillStyle = '#000000';
ctx.fillText('canvas 绘制文字', x, y);
上面的fillText就是实现弹幕效果的主要api,其中x表示横方向的坐标,y表示纵方向的坐标,只要时时的改变x,y进行重绘,就可以实现动态的弹幕效果。
清除绘制内容
ctx.clearRect(0, 0, width, height);
具体实现
通过定时器,定时改变x,y,每次改变之前先进性清屏,然后根据改变后的x,y进行重绘。当存在多条弹幕的情况下,定义:
let colorArr=_this.getColor(color); 弹幕数组多对应的颜色数组
let numArrL=_this.getLeft(); 弹幕数组所对应的x坐标位置数组
let numArrT=_this.getTop(); 弹幕数组所对应的y坐标位置数组
let speedArr=_this.getSpeed(); 弹幕数组所对应的弹幕移动速度数组
定时的重绘弹幕函数为:
_this.timer=setInterval(function(){
ctx.clearRect(0,0,canvas.width,canvas.height);
ctx.save();
for(let j=0;j<barrageList.length;j++){
numArrL[j]-=speedArr[j];
ctx.fillStyle = colorArr[j]
ctx.fillText(barrageList[j],numArrL[j],numArrT[j]);
ctx.restore();
},16.7);
实现的效果为:

通过canvas实现弹幕的方式,很方便做比如暂停弹幕滚动等扩展功能,此外,也可以给弹幕增加头像,给每条弹幕增加边框等等功能,以后再补充。
最后给一个简单的react弹幕组件;https://github.com/forthealllight/react-barrage
本章所基于的RxJS的版本问5.5.9,在本章中介绍RxJS的基础知识,比如Observable、Observer、Subscription、Subject以及Operation等
- 了解RxJS的设计**
- 掌握RxJS的基础用法
- 梳理RxJS的接口API
简单理解RxJS的设计**,之前实现了PromiseA+规范下的promise,创建一个Promise后,有一个状态的初始值pending,两个状态的改变值,fullfilled和rejected.在Promise的订阅机制中,一旦状态发生改变,状态的改变就是不可逆的.而RxJS不同,Observable相当于一个消息生成器,给消息生成器设置处理函数,通过消息生成器传递信息给处理函数,处理函数作为订阅者执行相应的逻辑,并返回结果.
因为Observable这个消息生成器是多值的,因此订阅者执行后返回的值也是多值的。
来看RxJS的基本用法,简单的介绍Observable、Observer、Subscription、Subject以及Operation的使用
第一步创建可观察对象:
import Rx from 'rxjs/Rx';
const observable=Rx.Observable.create(
function subscribe(observer){
try{
observer.next(1);
observer.next(2);
observer.next(3);
observer.complete();
}catch(e){
observer.error(e);
}
})
在每一个可观察对象中会推送消息给订阅者,比如在上述函数中通过在next、complete和error方法中传递参数的形式将消息推送给订阅者。
第二步,创建订阅者
const observer={
next:x=>console.log(x),
error:error=>console.log(error),
complete:()=>console.log('Observer got a complete notification')
}
订阅者有几个函数属性,用于接受可观察对象中的值并执行。
第三步,建立观察订阅关系:
observable.subscribe(observer);
执行返回的结果为:
1
2
3
Observer got a complete notification
const observable=Rx.Observable.create(function subscribe(observer){
try{
observer.next(1);
observer.next(2);
observer.next(3);
setTimeout(()=>{
observer.next(4)
},1000)
}catch(e){
observer.error(e);
}
});
const observer={
next:x=>console.log(x),
error:error=>console.log(error),
complete:()=>console.log('Observer got a complete notification')
}
console.log('before');
observable.subscribe(observer);
console.log('after');
通过setTimeout异步推送值给next方法,输出结果为:
before
1
2
3
after
4
var subscription = observable.subscribe(observer);
subscription.unsubscribe();
RxJS中的Subject是一种特殊的Observable,通过Subject定义的可观察对象可以被多个Observer订阅.
const subject=new Rx.Subject();
subject.subscribe({
next:(v)=>console.log('observerA:'+v)
});
subject.subscribe({
next:(v)=>console.log('observerB:'+v)
});
subject.next(1);
subject.next(2);
输出信息为:
observerA: 1
observerB: 1
observerA: 2
observerB: 2
Subject也有几种特殊的类型,BehaviorSubject、ReplaySubject 和 AsyncSubject。依次来看每一种类型是如何使用的:
通过BehaviorSubject构建的观察者,会将最新值发送给订阅者,并且观察者一旦创建就是有初值的:
const subject=new Rx.BehaviorSubject(0);
如上述的代码中创建了一个观察者,默认值为0,也就是上述代码其实默认执行了:
subject.next(0)
因此,如果:
const subject=new Rx.BehaviorSubject(0);
subject.subscribe({
next:(v)=>console.log('observerA:'+v)
});
虽然我们没有在subject中传入值,但是因为有默认值,因此在控制台输出:
observerA:0
BehaviorSubject方法定义的观察者,会始终使用最新值,也就是将最新值传递给订阅者.完整的例子为:
const subject=new Rx.BehaviorSubject(0);
subject.subscribe({
next:(v)=>console.log('observerA:'+v)
});
subject.next(1);
subject.next(2);
subject.subscribe({
next:(v)=>console.log('observerB:'+v)
});
subject.next(3);
输出的值为:
observerA: 0
observerA: 1
observerA: 2
observerB: 2
observerA: 3
observerB: 3
注意创建第二个订阅者B时,因为最新的next函数的参数是2,因此第二个订阅者会输出2
ReplaySubject可以缓存旧的观察者的值,传递给新的订阅者,在构造的函数中可以制定缓存旧值的个数.直接看例子:
const subject = new Rx.ReplaySubject(3); // 为新的订阅者缓冲3个值
subject.subscribe({
next: (v) => console.log('observerA: ' + v)
});
subject.next(1);
subject.next(2);
subject.next(3);
subject.next(4);
subject.subscribe({
next: (v) => console.log('observerB: ' + v)
});
subject.next(5);
在observerB订阅之前,我们在观察者中保留了最新的3个值,此时最新的3个值分别为2,3,4,因此在observerB订阅时,就会输出2,3,4,完成的输出为:
observerA: 1
observerA: 2
observerA: 3
observerA: 4
observerB: 2
observerB: 3
observerB: 4
observerA: 5
observerB: 5
此外,可以设置时间,来缓存多少时间段内的观察者的值。
AsyncSubject只有在可观察对象complete的时候,才会将最新的值传递给订阅者,举例来说:
const subject = new Rx.AsyncSubject();
subject.subscribe({
next: (v) => console.log('observerA: ' + v)
});
subject.next(1);
subject.next(2);
subject.next(3);
subject.next(4);
subject.subscribe({
next: (v) => console.log('observerB: ' + v)
});
subject.next(5);
subject.complete();
输出的结果为:
observerA: 5
observerB: 5
小提示:Observer也可以只是一个函数的形式,这种清空下这个函数等同与next属性的函数,也就是说,下面两种方法是等价的:
subject.subscribe({
next:(v)=>console.log('observerB:'+v)
})
和省略的条件下:
subject.subscribe(v=>console.log('observerB:'+v))
可观察对象上有很多操作符,比如.map(...)、.filter(...)等等,操作符的本身是一个纯函数,接受一个Observable,返回一个新的Observable,并且如果对订阅新生成的Observable,那么同时也会使得旧的观Observable也被订阅.
举例来说:
function multiplyByTen(input) {
var output = Rx.Observable.create(function subscribe(observer) {
input.subscribe({
next: (v) => observer.next(10 * v),
error: (err) => observer.error(err),
complete: () => observer.complete()
});
});
return output;
}
var input = Rx.Observable.from([1, 2, 3, 4]);
var output = multiplyByTen(input);
output.subscribe(x => console.log(x));
在上述的例子中,multiplyByTen就类似于一个操作符函数,该函数接受一个Observable,这里为input,同时返回一个新的Observable,这里为output,最后我们在新创建的Observable上进行订阅:
output.subscribe(x => console.log(x));
因为旧的Observable此时也同时被订阅,因此输出的结果为:
10
20
30
40
实例操作符定义在Observable原型上,在该实例操作符所定义的方法中,通过this取得实例的具体值:
Rx.Observable.prototype.multiplyByTen = function multiplyByTen() {
var input = this;
return Rx.Observable.create(function subscribe(observer) {
input.subscribe({
next: (v) => observer.next(10 * v),
error: (err) => observer.error(err),
complete: () => observer.complete()
});
});
}
在实例方法中,不需要给该方法传递具体Observable作为参数输入,而是在Observable本身上直接调用.实例调用的方法为:
var observable = Rx.Observable.from([1, 2, 3, 4]).multiplyByTen();
observable.subscribe(x => console.log(x));
静态方法就是纯函数,接受Observable作为参数.比如在我们上述使用的Rx.Observable.create,就是一个常见的静态方法
Observable中的操作符很多我们来举几个例子。
可以将任何值转化成一个可观察对象Observable,这里的任何值包括数组、类数组对象、promise、迭代对象以及类可观察者对象.首先,比如我们可以将一个数组转化成一个Observable:
const array=[10,20,30];
var result=Rx.Observable.from(array);
result.subscribe(x=>console.log(x));
如果传入的是数组,那么会返回一个next数组值的Observable,最后的输出为:
10
20
30
如果from接受的参数是一个迭代对象,比如generator构造的状态机,那么会有:
var iterator = generateDoubles(3);
var result = Rx.Observable.from(iterator).take(10);
result.subscribe(x => console.log(x));
输入的结果为:
3 6 12 24 48 96 192 384 768 1536
该操作符与事件有关,将Dom事件,nodejs中通过EventEmitter所出发的事件等转化成一个可观察对象Observer,举例来看DOM事件的例子:
var clicks = Rx.Observable.fromEvent(document, 'click');
clicks.subscribe(x => console.log(x));
这样,点击docment后会在next方法中传入一个鼠标事件对象MouseEvent,因此点击,在订阅者中会输出一个鼠标事件对象.输出的结果为:
MouseEvent {isTrusted: true, screenX: 48, screenY: 123, clientX: 35, clientY: 25, …}
此外,fromEvent还可以接受第三个参数option,默认的事件是遵循在冒泡阶段执行,默认为false,如果将option设置为true,将在冒泡阶段进行.比如:
var clicksInDocument=Rx.Observable.fromEvent(document, 'click', true);
var clicksInDiv = Rx.Observable.fromEvent(someDivInDocument, 'click');
clicksInDocument.subscribe(() => console.log('document'));
clicksInDiv.subscribe(() => console.log('div'));
如果不设置option,那么应该先输出div,后输出document,但是此时的情况下设置了option为true,那么会先输出document,后输出div,事件在捕获阶段进行.
该操作符将添加事件的函数,转化成一个可观察的Observable,举例来说:
function addClickHandler(handler) {
document.addEventListener('click', handler);
}
function removeClickHandler(handler) {
document.removeEventListener('click', handler);
}
var clicks = Rx.Observable.fromEventPattern(
addClickHandler,
removeClickHandler
);
clicks.subscribe(x => console.log(x));
上述的过程中有两个函数,这两个函数内部是执行的事件添加的过程,通过fromEventPattern可以将函数转化成可观察对象,最后输出的值也是一个MouseEvent.
该操作符将promise转化成一个可观察的Observable,举例来说:
var result = Rx.Observable.fromPromise(fetch('http://myserver.com/'));
result.subscribe(x => console.log(x), e => console.error(e));
上述代码中fetch返回一个promise,我们将这个promise转化成一个可观察的Observable对象.next方法对应与fullied,同时error方法对应了rejected.
创建一个可观察对象Observable,定时的输出(emit)连续的序列.举例来说:
var numbers = Rx.Observable.interval(1000);
numbers.subscribe(x => console.log(x));
上述的方法会以生序的方式输出序列.
输出结果为1,2,3,...每个数字间隔1000ms
顾名思义,merge操作符就是将几个可观察对象融合,生成一个组合形式的新的可观察对象,举例来看:
var clicks = Rx.Observable.fromEvent(document, 'click');
var timer = Rx.Observable.interval(1000);
var clicksOrTimer = Rx.Observable.merge(clicks, timer);
clicksOrTimer.subscribe(x => console.log(x));
通过merge方法将interval和click方法融合,这样之后,新的Observable会有2个可观察的属性,对于订阅者而言,输出信息为,依次输出1,2,3...,当有点击事件发生时,输出MouseEvent
该操作符表示生成一个不会emit出任何信息的可观察Observable,举例来说:
function info() {
console.log('Will not be called');
}
var result = Rx.Observable.never().startWith(7);
result.subscribe(x => console.log(x), info, info);
该方法不会有任何的emit过程,只在初始的时候输出了7
该操作符表示将一组数据在一次中完全输出,同时一次性完全输出后,可观察的状态变为complete.举例来说:
var numbers = Rx.Observable.of(10, 20, 30);
var letters = Rx.Observable.of('a', 'b', 'c');
var interval = Rx.Observable.interval(1000);
var result = numbers.concat(letters).concat(interval);
result.subscribe(x => console.log(x));
输出结果为:一次性输出10,20,30,a,b,c
然后定时输出:1,2,3,4...
该操作符表示同时输出一段范围内的值,举例来说:
var numbers = Rx.Observable.range(1, 10);
numbers.subscribe(x => console.log(x));
输出的值为1,2,3,4,5,6,7,8,9,10
该操作符表示延迟emit,举例来说:
var clicks = Rx.Observable.fromEvent(document, 'click');
var delayedClicks = clicks.delay(1000); // each click emitted after 1 second
delayedClicks.subscribe(x => console.log(x));
上述的方法表示点击后,延迟1000ms才进行emit.
顾名思义,该操作符表示的是去抖动,也就是说规定,多次重复的事件中,只执行最近的一次
var clicks = Rx.Observable.fromEvent(document, 'click');
var result = clicks.debounce(() => Rx.Observable.interval(1000));
result.subscribe(x => console.log(x));
在上述的例子中,就实现了debounce,此时按钮事件在1秒内只能被执行一次.并且emit的是最近的一次的观察信息。
节流,限制了可观察信息emit的频率,举例来说:
var clicks = Rx.Observable.fromEvent(document, 'click');
var result = clicks.throttle(ev => Rx.Observable.interval(1000));
result.subscribe(x => console.log(x));
上面的代码说明,可观察信息emit的频率最高为1hz(1/1000ms)
调度器控制了何时启动订阅以及可观察对象何时emit,普通的Observable通过observeOn方法来指定调度器,
var observable = Rx.Observable.create(function (observer) {
observer.next(1);
observer.next(2);
observer.next(3);
observer.complete();
})
.observeOn(Rx.Scheduler.async);
console.log('just before subscribe');
observable.subscribe({
next: x => console.log('got value ' + x),
error: err => console.error('something wrong occurred: ' + err),
complete: () => console.log('done'),
});
console.log('just after subscribe');
上述是一个异步调度的过程,输出的信息为:
just before subscribe
just after subscribe
got value 1
got value 2
got value 3
done
先输出同步信息,再输出异步调度信息.
如果指定:
observeOn(Rx.Scheduler.queue);
那就是顺序执行先入先出,输出的信息为:
just before subscribe
got value 1
got value 2
got value 3
done
just after subscribe
此外,所有的操作符默认都是有第三个参数,用于指定调度器.
https的SSL加密是在传输层实现的。
http: 超文本传输协议,是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。
https: 是以安全为目标的HTTP通道,简单讲是HTTP的安全版,即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。
https协议的主要作用是:建立一个信息安全通道,来确保数组的传输,确保网站的真实性。
http传输的数据都是未加密的,也就是明文的,网景公司设置了SSL协议来对http协议传输的数据进行加密处理,简单来说https协议是由http和ssl协议构建的可进行加密传输和身份认证的网络协议,比http协议的安全性更高。
主要的区别如下:
客户端在使用HTTPS方式与Web服务器通信时有以下几个步骤,如图所示。
客户端和服务端都需要直到各自可收发,因此需要三次握手。
简化三次握手:
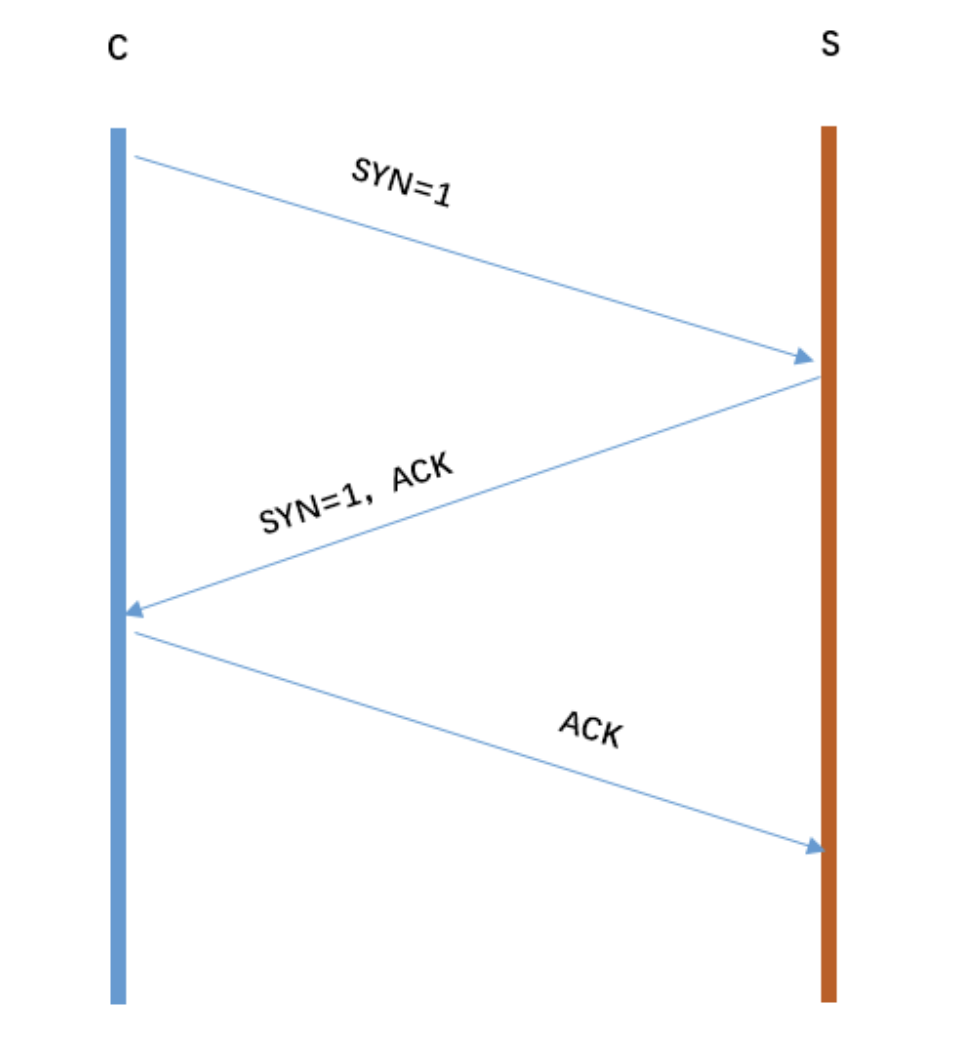
从图片可以得到三次握手可以简化为:C发起请求连接S确认,也发起连接C确认我们再看看每次握手的作用:第一次握手:S只可以确认 自己可以接受C发送的报文段第二次握手:C可以确认 S收到了自己发送的报文段,并且可以确认 自己可以接受S发送的报文段第三次握手:S可以确认 C收到了自己发送的报文段
(1)TCP是面向连接的,udp是无连接的即发送数据前不需要先建立链接。
(2)TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付。 并且因为tcp可靠,面向连接,不会丢失数据因此适合大数据量的交换。
(3)TCP是面向字节流,UDP面向报文,并且网络出现拥塞不会使得发送速率降低(因此会出现丢包,对实时的应用比如IP电话和视频会议等)。
(4)TCP只能是1对1的,UDP支持1对1,1对多。
(5)TCP的首部较大为20字节,而UDP只有8字节。
(6)TCP是面向连接的可靠性传输,而UDP是不可靠的。
WebSocket是HTML5中的协议,支持持久连续,http协议不支持持久性连接。Http1.0和HTTP1.1都不支持持久性的链接,HTTP1.1中的keep-alive,将多个http请求合并为1个
基本请求如下:
GET /chat HTTP/1.1
Host: server.example.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: x3JJHMbDL1EzLkh9GBhXDw==
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13
Origin: http://example.com
多了下面2个属性:
Upgrade:webSocket
Connection:Upgrade
告诉服务器发送的是websocket
Sec-WebSocket-Key: x3JJHMbDL1EzLkh9GBhXDw==
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13
请求的返回头里面,用于浏览器解析的重要参数就是OSS的API文档里面的返回http头,决定用户下载行为的参数。
下载的情况下:
1. x-oss-object-type:
Normal
2. x-oss-request-id:
598D5ED34F29D01FE2925F41
3. x-oss-storage-class:
Standard
能够被残障人士使用的网站才能称得上一个易用的(易访问的)网站。
残障人士指的是那些带有残疾或者身体不健康的用户。
使用alt属性:
<img src="person.jpg" alt="this is a person"/>
有时候浏览器会无法显示图像。具体的原因有:
什么是Bom? Bom是浏览器对象。有哪些常用的Bom属性呢?
location.href-- 返回或设置当前文档的URL
location.search -- 返回URL中的查询字符串部分。例如 http://www.dreamdu.com/dreamdu.php?id=5&name=dreamdu 返回包括(?)后面的内容?id=5&name=dreamdu
location.hash -- 返回URL#后面的内容,如果没有#,返回空
location.host -- 返回URL中的域名部分,例如www.dreamdu.com
location.hostname -- 返回URL中的主域名部分,例如dreamdu.com
location.pathname -- 返回URL的域名后的部分。例如 http://www.dreamdu.com/xhtml/ 返回/xhtml/
location.port -- 返回URL中的端口部分。例如 http://www.dreamdu.com:8080/xhtml/ 返回8080
location.protocol -- 返回URL中的协议部分。例如 http://www.dreamdu.com:8080/xhtml/ 返回(//)前面的内容http:
location.assign -- 设置当前文档的URL
location.replace() -- 设置当前文档的URL,并且在history对象的地址列表中移除这个URL location.replace(url);
location.reload() -- 重载当前页面
history.go() -- 前进或后退指定的页面数 history.go(num);
history.back() -- 后退一页
history.forward() -- 前进一页
navigator.userAgent -- 返回用户代理头的字符串表示(就是包括浏览器版本信息等的字符串)
navigator.cookieEnabled -- 返回浏览器是否支持(启用)cookie
首先补充一下,http和https的区别,相比于http,https是基于ssl加密的http协议
简要概括:http2.0是基于1999年发布的http1.0之后的首次更新。
产生原因:
解决方法:
fetch发送post请求的时候,总是发送2次,第一次状态码是204,第二次才成功?
原因很简单,因为你用fetch的post请求的时候,导致fetch 第一次发送了一个Options请求,询问服务器是否支持修改的请求头,如果服务器支持,则在第二次中发送真正的请求。
共同点:都是保存在浏览器端,并且是同源的
Cookie:cookie数据始终在同源的http请求中携带(即使不需要),即cookie在浏览器和服务器间来回传递。而sessionStorage和localStorage不会自动把数据发给服务器,仅在本地保存。cookie数据还有路径(path)的概念,可以限制cookie只属于某个路径下,存储的大小很小只有4K左右。 (key:可以在浏览器和服务器端来回传递,存储容量小,只有大约4K左右)
sessionStorage:仅在当前浏览器窗口关闭前有效,自然也就不可能持久保持,localStorage:始终有效,窗口或浏览器关闭也一直保存,因此用作持久数据;cookie只在设置的cookie过期时间之前一直有效,即使窗口或浏览器关闭。(key:本身就是一个回话过程,关闭浏览器后消失,session为一个回话,当页面不同即使是同一页面打开两次,也被视为同一次回话)
localStorage:localStorage 在所有同源窗口中都是共享的;cookie也是在所有同源窗口中都是共享的。(key:同源窗口都会共享,并且不会失效,不管窗口或者浏览器关闭与否都会始终生效)
补充说明一下cookie的作用:
保存用户登录状态。例如将用户id存储于一个cookie内,这样当用户下次访问该页面时就不需要重新登录了,现在很多论坛和社区都提供这样的功能。 cookie还可以设置过期时间,当超过时间期限后,cookie就会自动消失。因此,系统往往可以提示用户保持登录状态的时间:常见选项有一个月、三个 月、一年等。
跟踪用户行为。例如一个天气预报网站,能够根据用户选择的地区显示当地的天气情况。如果每次都需要选择所在地是烦琐的,当利用了 cookie后就会显得很人性化了,系统能够记住上一次访问的地区,当下次再打开该页面时,它就会自动显示上次用户所在地区的天气情况。因为一切都是在后 台完成,所以这样的页面就像为某个用户所定制的一样,使用起来非常方便
定制页面。如果网站提供了换肤或更换布局的功能,那么可以使用cookie来记录用户的选项,例如:背景色、分辨率等。当用户下次访问时,仍然可以保存上一次访问的界面风格。
在HTML页面中,如果在执行脚本时,页面的状态是不可相应的,直到脚本执行完成后,页面才变成可相应。web worker是运行在后台的js,独立于其他脚本,不会影响页面你的性能。并且通过postMessage将结果回传到主线程。这样在进行复杂操作的时候,就不会阻塞主线程了。
如何创建web worker:
HTML5语义化标签是指正确的标签包含了正确的内容,结构良好,便于阅读,比如nav表示导航条,类似的还有article、header、footer等等标签。
定义:iframe元素会创建包含另一个文档的内联框架
提示:可以将提示文字放在<iframe></iframe>之间,来提示某些不支持iframe的浏览器
缺点:
Doctype声明于文档最前面,告诉浏览器以何种方式来渲染页面,这里有两种模式,严格模式和混杂模式。
XSS(跨站脚本攻击)是指攻击者在返回的HTML中嵌入javascript脚本,为了减轻这些攻击,需要在HTTP头部配上,set-cookie:
结果应该是这样的:Set-Cookie=.....
HTTP是一个无状态协议,因此Cookie的最大的作用就是存储sessionId用来唯一标识用户
就是用URL定位资源,用HTTP描述操作
可以参考我的这篇文章:
响应式布局的常用解决方案对比(媒体查询、百分比、rem和vw/vh)
<meta name="viewport" content="width=device-width, user-scalable=no">
检测到touchend事件后,立刻出发模拟click事件,并且把浏览器300毫秒之后真正出发的事件给阻断掉
使用typescript陆续也有1年多的时间,总结一下自己在typescript工程实践中的一些经验,主要包含了以下几个方面。
- Typescript工程初始化
- Typescript内置函数
- 易混淆typescript知识点
- 其他心得补充
刚开始迁移到typescript的时候,不知道从何开始,我们首先想到的就是如何将typescript编译成javascript.我们先从tsconfig.json讲起。
tsconfig.json是typescript编辑的配置项,该配置决定了如何将typescript编译成ECMAscript,这里介绍比较重要的配置项:
"compilerOptions": {
"target": "es2018", //可选属性es3,es5,esnext等
"module": "esnext", //可选commonjs,AMD,UMD,esnext等
}这两个是比较关键的配置项,决定了将typescript编译成ECMAscript,以及采用何种模块系统,我们诚然可以直接将target设置成es5,这样就不需要通过typescript先编译成es6,然后用babel再将es6编译成es5,但是一般在项目的迁移中,大部分就项目可能使用的是es6,如果我们先将typescript编译成es6,我们可以复用就项目中babel的配置,将typescript编译完成了es6,继续编译成es5.
整个流程应该是:
typescript ————————> es2018/es6 ————————> es3/es5
上述流程中typescript经过tsc编译成es6,然后通过babel将es6编译成es5。如果是没有历史包袱的typescript项目也可以直接通过tsc将typescript编译成es5:
typescript ————————> es3/es5
此外,除了tsc可以编译typescript以外,还可以使用webpack插件,比如ts-loader。从babel7.0开始,babel也支持typescript的编译。
除了target指定typescript的编译结果外,我们在tsconfig.json还有一个比较重要的属性就是module,一般而言,对于工程项目类我们使用module:esnext,对于插件或者工具类使用module:umd。在最后一节的心得补充中,会详细的讲讲不同模块化影响以及要注意的地方。
除了这几个配置属性外,一定要强调的一个属性就是noImplicitAny,这个属性决定是否禁用any,建议初始化项目的时候把这个属性设置成true,这样避免将typescript当成anyscript使用,因为本质typescript最大的优点就是类型检测,如果使用any会跳过类型检测。
在工程中,我们会选择用webpack来打包编译typescript,常使用的webpack配置包含了结合tsconfig来使用路径别名,ts-loader和typings-for-css-modules-loader.
在webpack中,大量使用了路径别名,结合tsconfig.json文件中的path,可以使用路径别名的同时,使得对于目录中不同文件有静态提示。
//webpack.config
export default {
resolve:{
alias: {
'@component': path.resolve(__dirname,'../app/cdn/component')
}
}
}
在tsconfig.json文件中:
{
"paths":{
"@component/*":["app/cdn/component/*"],
}
}
此外,在webpack中使用ts-loader来编译typescript.
最后如果我们常见的在项目中使用less或者sass来编写模块化的css,并使用 CSS module 的方案来防止样式冲突。我们在webpack中使用了 typings-for-css-modules-loader ,这个loader会监听 Less 文件的变化,在 Less 文件的同级目录下自动生成后缀名为 .less.d.ts 声明文件,方便在 tsx 文件中引入样式。
在我之前的一篇文章中总结过在typescript中如何使用eslint,在Typescript项目中,如何优雅的使用ESLint和Prettier
eslint解决了编码规范的问题,不仅仅使得代码清晰易读,还避免了很多运行时可能报错的问题,比如下面一个例子中:
let number = 2;
switch(number){
case 1:
let name = 'jony';
break;
case 2:
name = 'yu';
break;
}这个例子就是经典的switch的块级作用域问题,上述的代码编译的时候不会报错,但是在执行的时候会报错。这种运行时的错误,在typescript的语法中是不可避免的,我们可以通过eslint的编码规范来避免这种有可能出现运行时报错的代码。
对于Typescript项目的编码规范而言,主要有两种选择ESLint和TSLint。ESLint不仅能规范js代码,通过配置解析器,也能规范TS代码。此外由于性能问题,TypeScript 官方决定全面采用ESLint,甚至把仓库作为测试平台,而 ESLint 的 TypeScript 解析器也成为独立项目,专注解决双方兼容性问题。
在typescript的使用中,最经常,最频繁的就是写各种声明,包括接口声明、枚举等等,通过Typescript的内置函数,可以复用一些类型声明,简洁且有效减少了代码量。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
