使用PageRank算法计算给定数据集中NodeID的rank值。使用Block-Stripe Update Algorithm进行优化,并考虑dead ends 和spider trap 节点。
1、语言:Python
2、IDE:PyCharm
3、项目管理工具:git
4、调用Python包:time,tqdm,numpy,pandas,os
1、原始数据集wikidata.txt的储存形式为"FromNodeID ToNodeID",包括有入度有出度、有入度无出度、有出度无入度三种类型的节点。
2、数据共103689条,源节点共6110个,所有节点共7115个。
3、数据较多,比较稀疏,节点间联系不太紧密,若用矩阵存储空间消耗较大,应优化稀疏矩阵并实现分块算法。
4、存在dead ends 和spider trap 节点,应妥善处理。
5、exe文件wikidata.txt数据集调用位置:与PageRank.exe文件同目录
6、源码wikidata.txt数据集调用位置:与pagerank.py文件同目录
完成基本要求:
1、考虑dead ends 和spider trap 节点
2、优化稀疏矩阵
3、完成分块矩阵
4、rank值计算迭代收敛至新旧rank差值小于0.00001
5、得出最终结果
额外完成情况:
1、选取不同teleport值计算rank,进行结果对比分析
2、使用streamlit完成可视化,利于统计学分析
- 导入数据集
- 初始化
pagerank值,并将所有节点分块 - 实现
Block-Stripe Update algorithm - 计算每个节点的
rank值 - 排序,取前一百名节点
- 将结果写入
result.txt文件中
1、导入数据集,以DataFram类型存储txt文件中的数据,另外以all_node(list类型)存储所有页面的ID。
# 从txt导入数据、将数据转化成 csv 格式 nodes 输入和输出,类似于将边存起来
# 输出nodes--------dataframe 格式 和all_node --------list,frac 设置随机取文件中数的比例
def load_data(filePath, output_csv=False, frac=1.):
print('begin load data')
txt = np.loadtxt(filePath)
nodes = pd.DataFrame(data=txt, columns=['input_node', 'output_node'])
# 将值转化为int类型
nodes['input_node'] = nodes['input_node'].astype(int)
nodes['output_node'] = nodes['output_node'].astype(int)
# 设置随机取多少行
if frac != 1.:
print('random select', frac * 100, '% data')
nodes = nodes.sample(frac=frac, random_state=1)
if output_csv is True:
nodes.to_csv('WikiData.csv')
# 根据inputpage的值排序
nodes.sort_values('input_node', inplace=True)
# 重置索引
nodes.reset_index(inplace=True, drop=True)
# all_node 加载为list 有重复值
all_node = nodes['input_node'].values.tolist()
all_node.extend(nodes['output_node'].values.tolist())
# all_node 转为set 再转为list
all_node = set(all_node)
all_node = list(all_node)
# all_note 升序排列
all_node.sort()
print('load data finish')
return nodes, all_node2、生成初始PageRank值,以dict类型存储每个页面的ID及其初始rank值,并将all node块条化,用于下一步的Block-Stripe Update algorithm。
# 生成rank值
def generate_rank(all_node):
# 初始rank
initial_old_rank = 1 / len(all_node)
rank = {node:initial_old_rank for node in all_node}
print('generate initial rank finish')
return rank# 将一个列表划分为多个小列表
def list_to_groups(list_info, per_list_len):
'''
:param list_info: 列表
:param per_list_len: 每个小列表的长度
:return:
'''
list_of_group = zip(*(iter(list_info),) * per_list_len)
end_list = [list(i) for i in list_of_group] # i is a tuple
count = len(list_info) % per_list_len
end_list.append(list_info[-count:]) if count != 0 else end_list
return end_list3、块条化
# 计算每个节点的出度
def comput_node_output_time(nodes):
node_output_time = nodes.apply(pd.value_counts)['input_node']
return node_output_time
# 块条化
def block_stripe(nodes, block_node_groups):
# 存最后的各个划分后的M
node_output_time = comput_node_output_time(nodes)
# print(node_output_time[6])
M_block_list = []
# 根据input_node 进行分组进行分组
grouped = nodes.groupby('input_node')
with tqdm(total=len(block_node_groups), desc='block strip progress') as bar:
for node_group in block_node_groups:
# 将大的M 根据 划分后的node节点,进行块条化最后结果存到M_block_stripe列表中
for key, group in grouped:
output_node_list = group['output_node'].values.tolist()
intersect_set = set(node_group).intersection(output_node_list)
intersect_set = list(intersect_set)
if len(intersect_set):
M_block_list.append([key, node_output_time[key], intersect_set])
bar.update(1)
return M_block_list4、pageRank算法部分,取teleport值为0.85。首先初始化rank值为1/n,再迭代计算rank值,并处理dead ends 和spider trap 节点,使和为1,使其收敛至两次rank差值的和小于0.00001。
num = len(all_node)
initial_rank_new = (1 - teleport) / num
sum_new_sub_old = 1.0
# 迭代次数
i = int(1)
print("begin iteration")
while sum_new_sub_old > derta:
# 初始化new_rank
new_rank = {node: initial_rank_new for node in all_node}
for m in M_list:
temp_old_rank = old_rank[m[0]]
temp_degree = m[1]
for per_node in m[2]:
new_rank[per_node] += teleport * temp_old_rank / temp_degree
# 解决dead-ends和Spider-traps
# 所有new_rank的score加和得s,再将每一个new_rank的score加上(1-sum)/len(all_node),使和为1
s = sum(new_rank.values())
ss = (1 - s) / num
new_rank = {k: new_rank[k]+ss for k in new_rank}
# 计算sum_new_sub_old
temp_list = list(map(lambda x:abs(x[0] - x[1]), zip(new_rank.values(), old_rank.values())))
sum_new_sub_old = np.sum(temp_list)
old_rank = new_rank
print('iteraion times:', i, 'sum_new_sub_old:', sum_new_sub_old)
i += 1
print('rank compute finish')
return old_rank5、调用各函数,得出排序后的前一百个节点
# file 文件
# step块条化的步长
def mypageRank(file, step):
nodes, all_node = load_data(file, output_csv=False, frac=row_frac)
rank = generate_rank(all_node)
pre_process(nodes)
# 将allnode分成小块
block_node_groups = list_to_groups(all_node, step)
# quick block strip
start_quick_block = time.perf_counter()
M_block_list = block_stripe(nodes, block_node_groups)
end_quick_block = time.perf_counter()
print('Running time: %s Seconds' % (end_quick_block - start_quick_block))
# print(M_block_stripe)
# 计算pagerank值
start_pagerank = time.perf_counter()
new_rank = pageRank(M_block_list, rank, all_node)
end_pagerank = time.perf_counter()
print('Running time: %s Seconds' % (end_pagerank - start_pagerank))
# 转化为df类型
new_rank = pd.DataFrame(new_rank.items(), columns=['page','score'])
new_rank.set_index('page',inplace=True)
# rank排序 从大到小
new_rank.sort_values('score', inplace=True, ascending=0)
# 取前一百
sort_rank = new_rank.head(100)
# print(sort_rank)
return sort_rank6、将结果集写入result.txt中
def writeResult(new_rank):
file_path = "result.txt"
new_rank = new_rank.reset_index()
with open(file_path, "w") as f:
new_rank.apply(lambda row: f.write('['+str(int(row[0]))+'] ['+str(row[1])+']\n'), axis=1)
print('result data write finish')7、对比分析不同的teleport值的pagerank状况
def compare_teleports(file,step):
# 不同的teleport值
teleport=[0.80, 0.85, 0.90]
# 所有的网页排名
rankList=[]
for each_teleport in teleport:
tempt_rank = mypageRank(file, step, teleport=each_teleport)
tempt_rank = tempt_rank.reset_index()
rankList.append(tempt_rank['page'].tolist())
print(rankList)
# 有相同排名的页面
same_pagerank=[]
# 排名不同的页面
defferent_pagerank=[]
for i in range(101):
if rankList[0][i] == rankList[1][i] == rankList[2][i]:
same_pagerank.append(rankList[0][i])
else:
defferent_pagerank.append([rankList[0][i],rankList[1][i],rankList[2][i]])
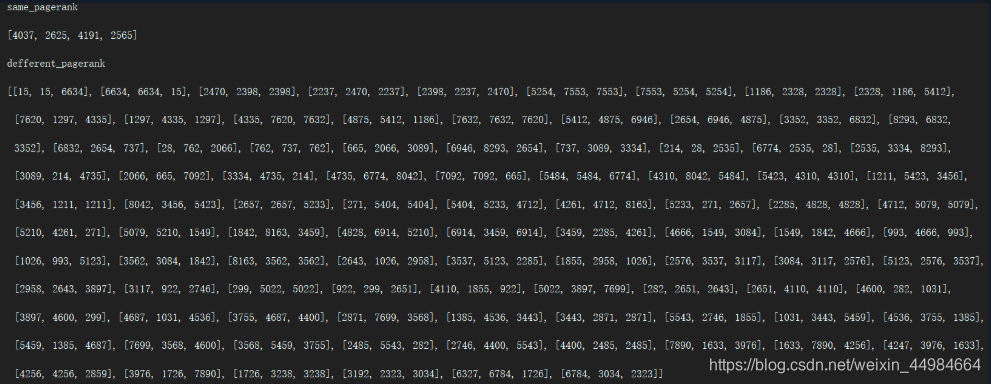
print("same_pagerank")
print(same_pagerank)
print("defferent_pagerank")
print(defferent_pagerank)
[4037] [0.004607174503437372]
[15] [0.0036798701695717694]
[6634] [0.0035865233681507303]
[2625] [0.003283681414070125]
[2398] [0.002608634199432051]
[2470] [0.0025237808578625997]
[2237] [0.0024966463532773864]
[4191] [0.002267852571667494]
[7553] [0.0021697230585072044]
[5254] [0.002150101117418488]
[2328] [0.002039271977037053]
[1186] [0.0020355462677026687]
[1297] [0.001945863150503571]
[4335] [0.0019367585416181984]
[7620] [0.0019320643268718617]
[5412] [0.0019189179235593106]
[7632] [0.0019077296980294092]
[4875] [0.0018737904507113567]
[6946] [0.0018081198050749225]
[3352] [0.0017839628618183385]
[6832] [0.0017681712453068593]
[2654] [0.0017669919851358228]
[762] [0.0017421588788387064]
[737] [0.001739631811074772]
[2066] [0.001715717207458179]
[8293] [0.0017053127452104394]
[3089] [0.0017020116691942044]
[28] [0.0016888256912545344]
[2535] [0.001666210052296104]
[3334] [0.0016569519884649915]
[214] [0.0016515289038048365]
[665] [0.0016430745189879134]
[4735] [0.0016192120631615355]
[6774] [0.0016148826402522392]
[7092] [0.001601609207759838]
[2565] [0.0015511780072943015]
[5484] [0.0015430115240872868]
[8042] [0.0014765021365621721]
[4310] [0.0014619864814301618]
[5423] [0.0014176184165645364]
[1211] [0.0014175970879110149]
[3456] [0.0014168614537389483]
[2657] [0.0013651986059371383]
[5404] [0.0013639518493002586]
[5233] [0.0013617683606434964]
[4712] [0.0013418822297917893]
[271] [0.0013262769397220763]
[4828] [0.0013006240026266485]
[5079] [0.0012991565286085615]
[4261] [0.0012857582123217378]
[5210] [0.0012802864050767075]
[8163] [0.0012629565746344754]
[6914] [0.0012605066869783243]
[3459] [0.0012573094937029603]
[2285] [0.0012416649939310765]
[1549] [0.0012415161165902123]
[1842] [0.0012351988905526224]
[4666] [0.0012119273281709394]
[993] [0.0012002657356006059]
[3084] [0.0011834791587411843]
[3562] [0.0011782029783117217]
[1026] [0.0011728823462983746]
[5123] [0.0011648749188268906]
[2958] [0.0011589398451594798]
[3537] [0.0011443145525590842]
[3117] [0.0011438150566377865]
[2576] [0.001140045496937094]
[2643] [0.0011212137583671443]
[922] [0.0011100591337117854]
[5022] [0.0011079286053123666]
[299] [0.0011040728601672785]
[1855] [0.0011014808913883945]
[3897] [0.0010990464696550076]
[2651] [0.001098727147448928]
[4110] [0.001096492003203168]
[282] [0.0010748352796162018]
[4600] [0.00107046445193244]
[1031] [0.001069225363612865]
[4687] [0.0010684729464734732]
[7699] [0.001065340401015381]
[4536] [0.0010645028185675913]
[2871] [0.0010640233671266907]
[2746] [0.0010638422464610807]
[3443] [0.001062710060466648]
[3755] [0.0010613740721404452]
[1385] [0.0010594038723553709]
[3568] [0.0010517124405240567]
[5459] [0.0010496203934445138]
[5543] [0.0010491076357212437]
[4400] [0.0010431789147054389]
[2485] [0.0010295598400788262]
[1633] [0.0010171467107603258]
[7890] [0.0010141959009645986]
[3976] [0.0010129601881975322]
[4256] [0.0010116007950401414]
[1726] [0.0009963695928501685]
[3238] [0.0009906588816136906]
[2323] [0.000986759999982124]
[6784] [0.0009820918130451163]
[3034] [0.000978998710728318]
1、执行时间:
总执行时间:6.349472296 Seconds
执行总时间随着分块数量的增多而增加,但迭代过程总时间几乎不改变,保持在1s左右完成迭代
2、迭代次数:
设置teleport=0.00001时,共迭代13次使得pagerank值趋于收敛
3、rank值最大的网页4037的rank值仅为0.004607174503437372,可知矩阵稀疏,网页间连接不太紧密。
4、取了三个不同的teleport值0.80, 0.85, 0.90对比分析其排名状况
发现排名相同的页面较少,排名不同的页面较多
说明teleport值对最后的排名结果有一定影响