fengshi123 / blog Goto Github PK
View Code? Open in Web Editor NEW汇总发布的前端博文,大家一起交流学习,如果有帮助到您,欢迎 star ~
汇总发布的前端博文,大家一起交流学习,如果有帮助到您,欢迎 star ~






























































































































基于 Vue 技术栈的你如果需要选用一种移动端跨平台框架,是 Weex?React-Native?还是Flutter? 无疑,相对于后两者,因为你现在已有比较熟练的 Vue 基础,如果在其他条件一致的情况,Weex 无疑是最佳选择;但是 Weex 真的适合在实际项目中进行移动端跨平台开发吗?Weex 的开发效率、Weex 的质量是否满足需求?
本项目围绕前面提到的两点:基于 Weex 的开发效率如何?Weex 的质量是否满足需求?我们进行了相关的预研和开发,我们将在开发中遇到的问题和经验进行分享,如果你还没有 Weex 开发经验,那么这篇文章将很好的向你展示 Weex 的各方面,官方文档、生态、兼容性等等,希望你在这篇文章中找到你想要的答案。
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:https://github.com/fengshi123/blog ,汇总了作者的所有博客,也欢迎关注及 star ~
本项目 github 地址为:https://github.com/fengshi123/weex_project
在这个 Weex app 开发中,我的开发环境相关配置如下:
| 工具名称 | 版本号 |
|---|---|
| Node.js | 8.2.1 |
| Npm | 5.3.0 |
| Android Studio | 3.2 |
| Weex | 2.0.0-beta.17 |
| JDK | 1.8 |
| Weex-ui | 0.6.14 |
“Write once, run everywhere”, Weex 的定义就像是:写个 vue 前端,顺便帮你编译成性能还不错的 apk 和 ipa(当然,现实有时很骨感)。基于 Vue 设计模式,支持 web、android、ios 三端,原生端同样通过中间层转化,将控件和操作转化为原生逻辑来提高用户体验。 在 weex 中,主要包括三大部分:JS Bridge、Render、Dom,分别对应WXBridgeManager、WXRenderManager、WXDomManager,三部分通过 WXSDKManager 统一管理。其中 JS Bridge 和 Dom 都运行在独立的 HandlerThread 中,而 Render 运行在 UI 线程。 JS Bridge 主要用来和 JS 端实现进行双向通信,比如把 JS 端的 dom 结构传递给 Dom 线程。Dom 主要是用于负责 dom 的解析、映射、添加等等的操作,最后通知 UI 线程更新,而 Render 负责在 UI 线程中对 dom 实现渲染。
Weex 所有的标签也不是真实控件,JS 代码中所生成存的 dom,最后都是由 Native 端解析,再得到对应的 Native控件渲染,如 Android 中标签对应 WXTextView 控件。 Weex 中文件默认为 .vue ,而 vue 文件是被无法直接运行的,所以 vue 会被编译成 .js 格式的文件,Weex SDK会负责加载渲染这个 js 文件。Weex 可以做到跨三端的原理在于:在开发过程中,代码模式、编译过程、模板组件、数据绑定、生命周期等上层语法是一致的。不同的是在 JS Framework 层的最后,web 平台和 Native 平台,对 Virtual DOM 执行的解析方法是有区别的。
Weex 提供了一个命令行工具 weex-toolkit 来帮助开发者使用 Weex,它可以用来快速创建一个空项目、初始化 iOS 和 Android 开发环境、调试、安装插件等操作。
我们可以通过以下步骤创建一个基础的 Weex 项目:
(1)安装 weex-toolkit 工具
npm install weex-toolkit -g(2)创建新项目
weex create weex_project(3)安装项目依赖
cd weex_project3
npm install
(4)启动项目
npm start
项目启动完毕,浏览器窗口会自动打开项目首页,如下图所示:

(5)添加 Android 平台
weex platform add android
(6)可以运行下面的命令,可以在模拟器或真实设备上启动 Android 应用:
weex run android
(1)进入目录 weex_project/backend/,安装服务端应用所需要的插件包:
$ npm install(2)启动服务端应用
$ npm run start(1)如果你还没安装 weex 工具,可以运行以下命令进行安装:
$ npm install -g weex-toolkit(2)安装项目需要的插件包:
$ npm install(3)启动项目:
$ npm run startVSCode 拓展包包含下面的包:
我们主要介绍最好用的 weex-run 和 weex-debug,因为 weex-run 其可用于在热更新模式下启动 Android 及 iOS 工程;weex-debug 可用于安卓端的调试。其它的插件使用,可以查看 Weex 官网 VS Code 插件部分 ,下面我们分别介绍 weex-run 和 weex-debug:
(1)通过截图的步骤来安装 weex-run
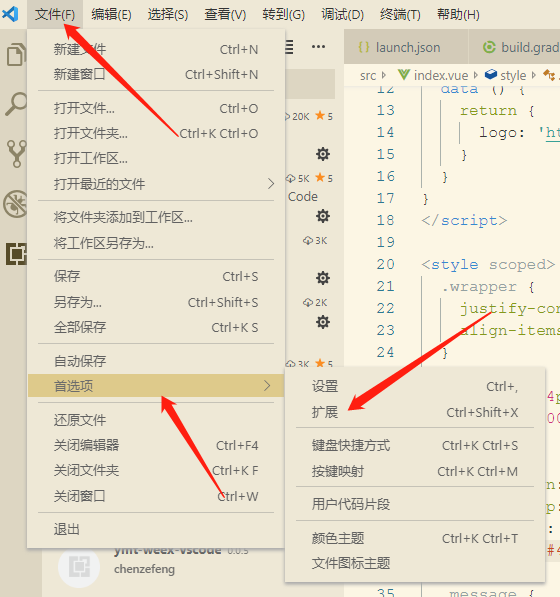
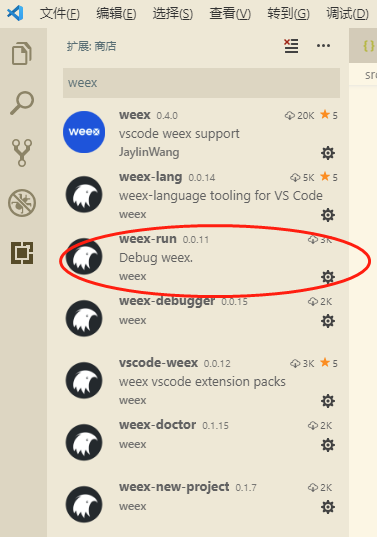
(2)启动 Android 项目
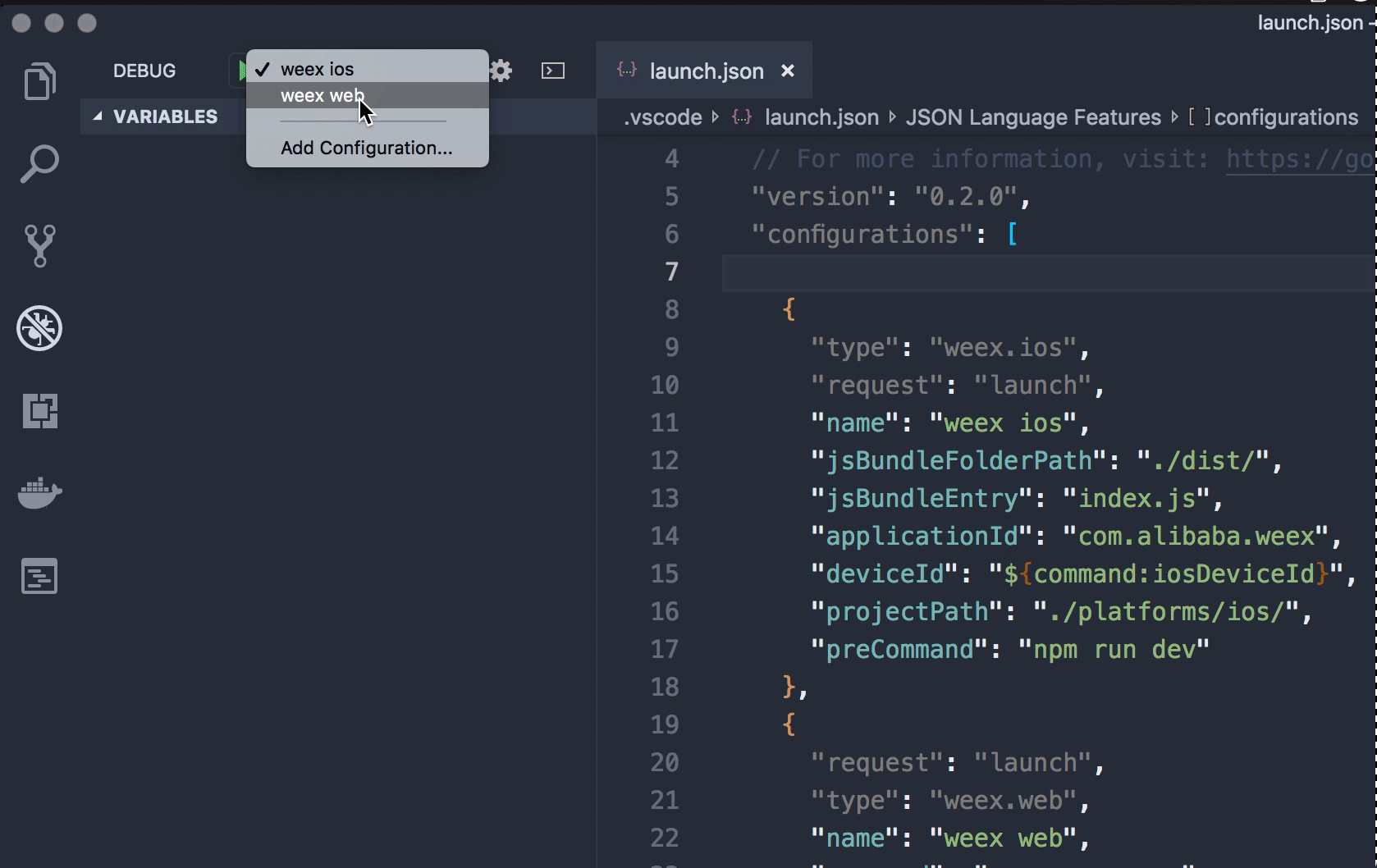
启动成功控制台输出(启动需要一定时间,如果没有报错,敬请耐心等待):
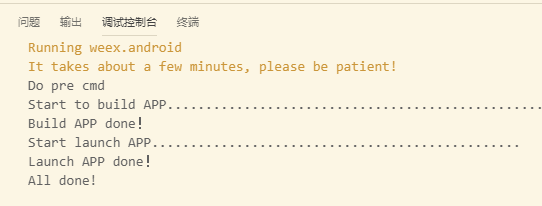
我们查看 Android 项目的热更新:

(1)安装 weex-debugger 插件
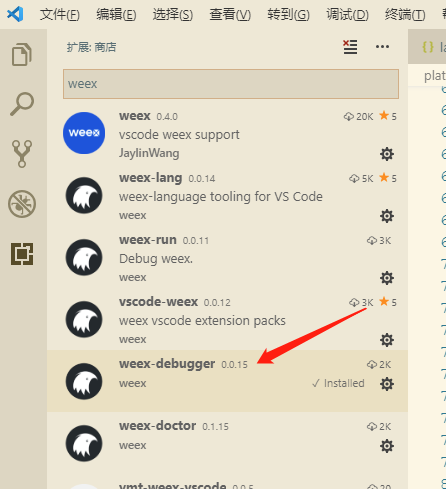
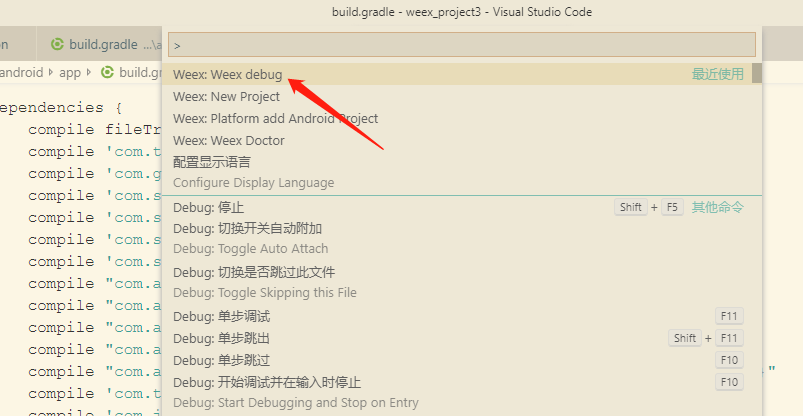
(2)ctrl + shift + p 弹出命令输入框,如下图所示输入:weex debug,然后网页会出现第 2 张截图的二维码:

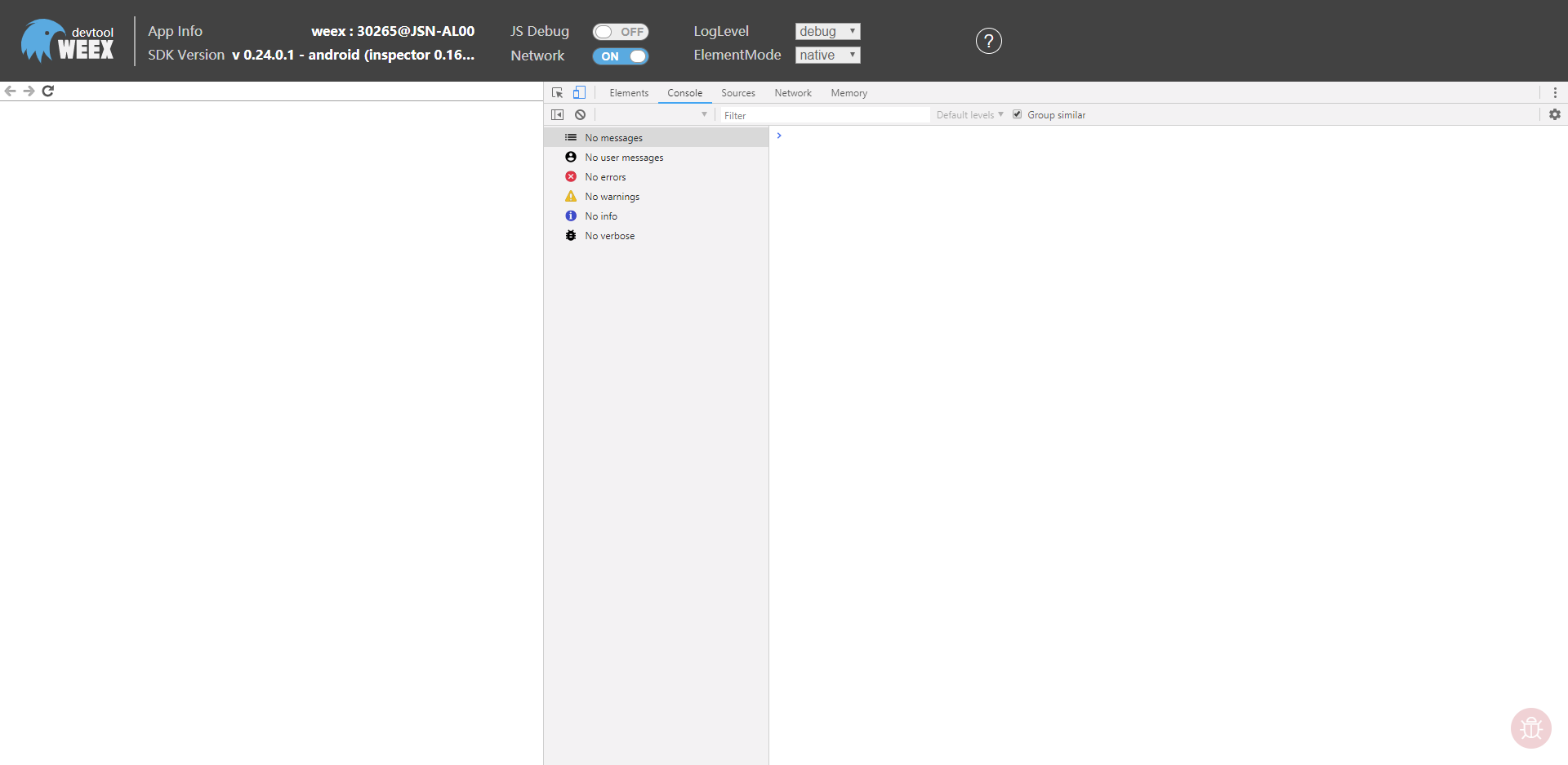
(3)用手机的 Weex Playground App 的二维码进行扫描,出现以下调试页面(一定一定要注意,手机连的 WiFi 和 你开发本地网络在同一局域网)。
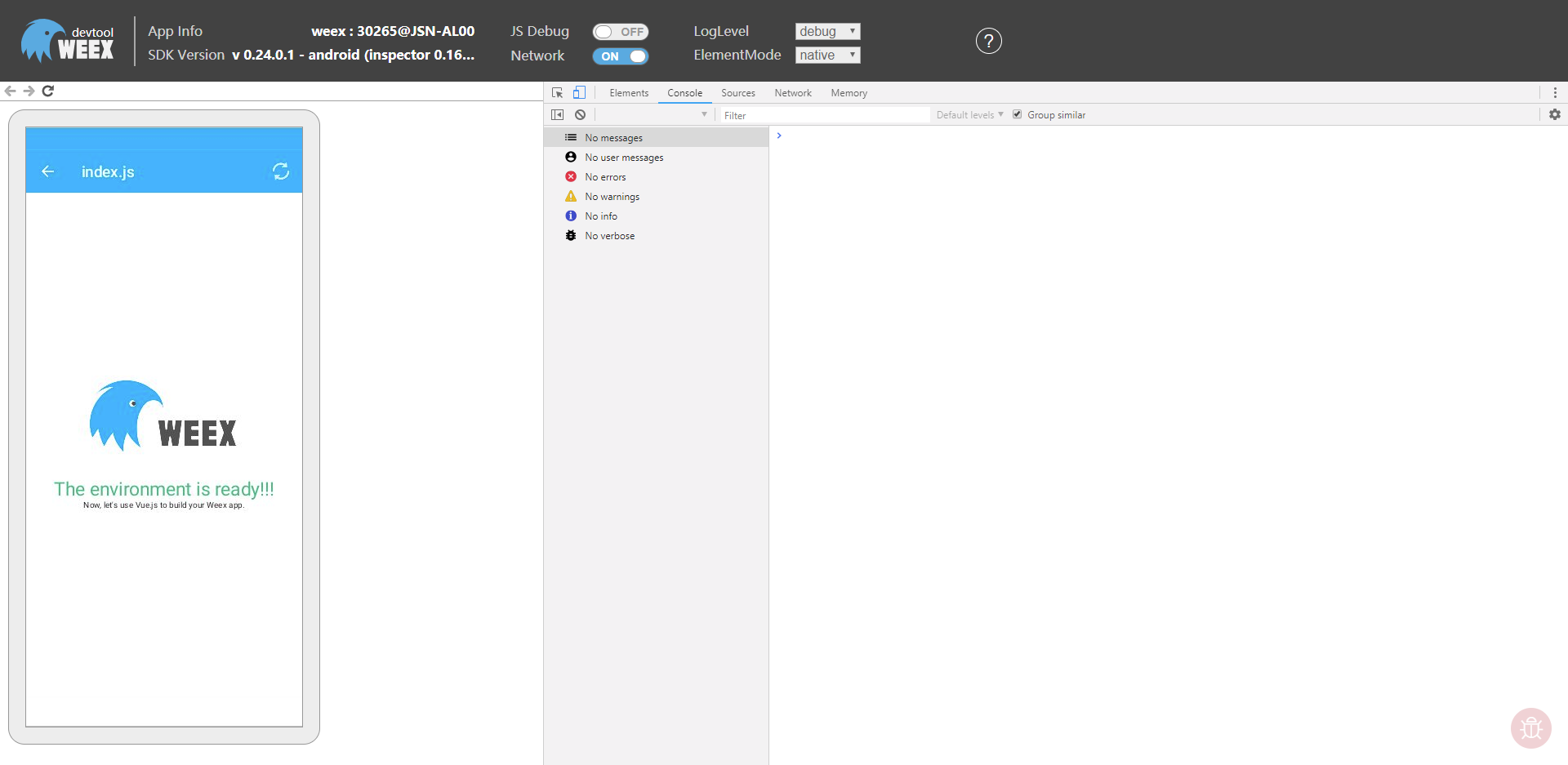
(4)再用手机的 Weex Playground App 的二维码扫描 Weex 应用的二维码,调试页面就会变成对应的 Weex 应用的调试页面,如下图所示:
Weex 项目的目录结构如下:

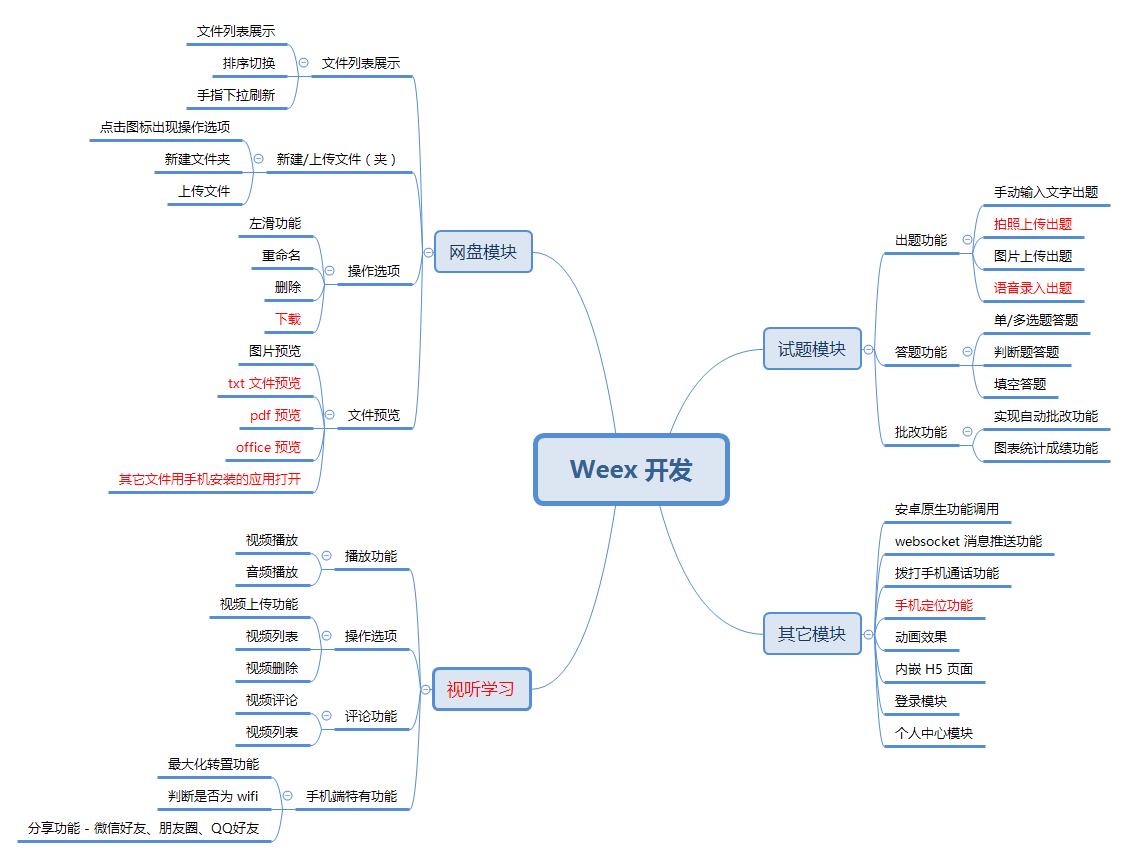
考虑到更好的体验 Weex 和 H5 在开发效率、功能性能、用户体验等方面的差异性,我们对功能模块进行精心设计,主要基于我们现在实际项目的业务,结合移动端特有的特性。相关的模块功能设计如下图所示,其中红色标注部分表示,受限于开发资源、Weex 生态方面原因,我们暂时还没完成的功能。
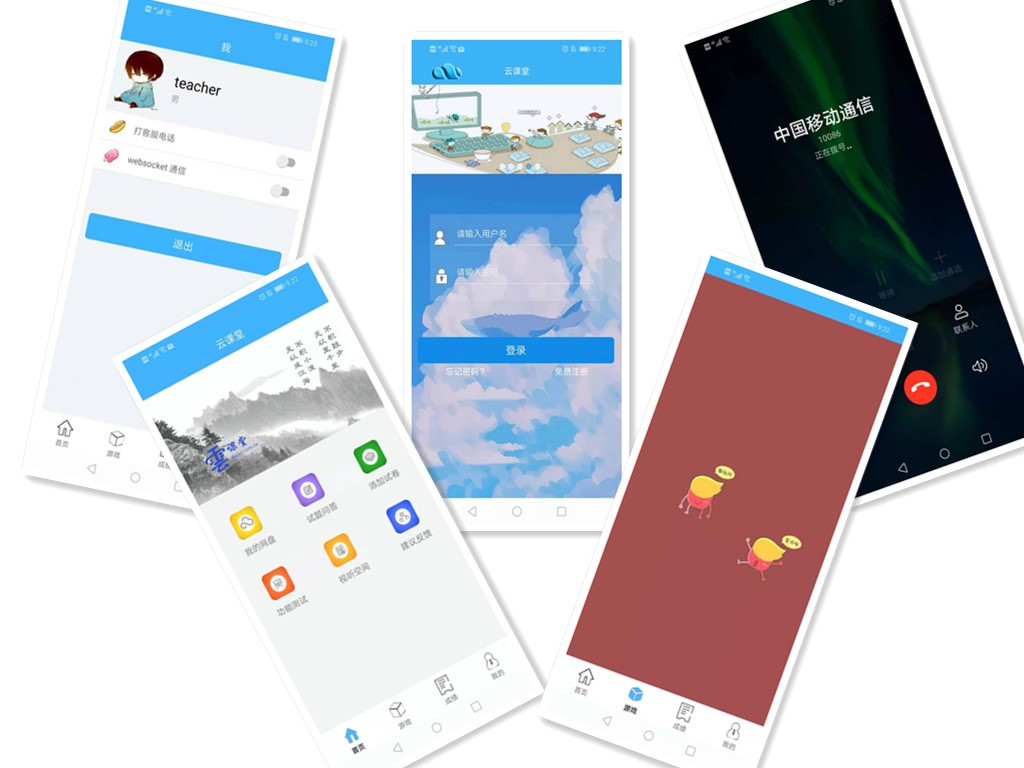
我们截取一些功能界面展示如下:
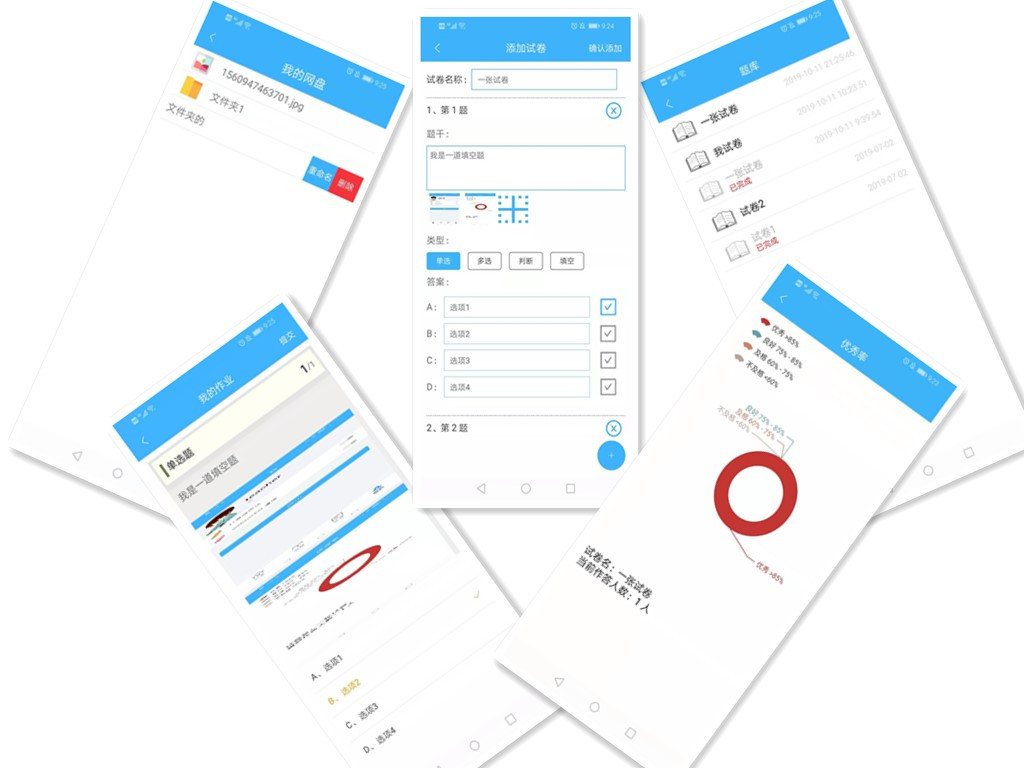
我们不介绍这个项目全部功能的实现,其它常规的功能开发,参照 Weex 官网即可,以下介绍的几个功能在 Weex 官网中并没有详细介绍或者根本没有介绍,我们在开发过程中踩了不少坑,因此将踩坑经验进行汇总,帮助大家避免踩坑:
(1)登录 token 认证
(2)图片选择/上传功能
(3)websocket 功能实现
(4)手机物理键返回上一级功能
(5)Android 如何显示本地图片
(1)token 简要介绍
在 Web 领域基于 token 的身份验证随处可见。在大多数使用 Web API 的互联网公司中,tokens 是多用户下处理认证的最佳方式。token 具有以下特性:
基于 token 的身份验证的过程如下:
(2)weex 和 express 之间实现 token 认证
express 服务端主要使用 express-jwt 插件,express-jwt 是 nodejs 的一个中间件,内部对 jsonwebtoken 进行封装使用。express-jwt 会验证指定 http 请求的 jsonwebtoken 的有效性,如果有效就将 jsonwebtoken 的值设置到 req.user 里面,然后跳转到相应的 router。
服务端 express 的代码逻辑如下:
var expressJWT = require('express-jwt');
// token 设置
app.use(expressJWT({
secret: CONSTANT.SECRET_KEY
}).unless({
// 除了以下配置的地址,其他的URL都需要验证
path: ['/getToken', /^\/public\/.*/, /^\/user_disk\/.*/]
}));
// 登录时,需要进行用户密码认证,相应路由跳转到下面一步
app.use('/getToken', tokenRouter);
// 当用户密码正确时,我们进行 token 设置
data: {
token: jsonWebToken.sign({
uid: obj.uid
}, CONSTANT.SECRET_KEY, {
expiresIn: 60 * 60 * 1
}),
}Weex 的代码逻辑如下:
// Weex 登录逻辑
login () {
let param = {
uid: this.uid,
password: this.password
};
let options = {
url: '/getToken',
method: 'POST',
body: JSON.stringify(param)
};
let vm = this;
api.fetch(options, function (ret) {
if (ret.ok && ret.data.code === 0) {
// 前端可以获取到服务端返回的 token ,并将其作为全局变量
global.token = 'Bearer ' + ret.data.data.token;
vm.$router.push('/tabIndex');
} else {
modal.toast({
message: '用户认证失败!',
duration: 1
});
}
});
}
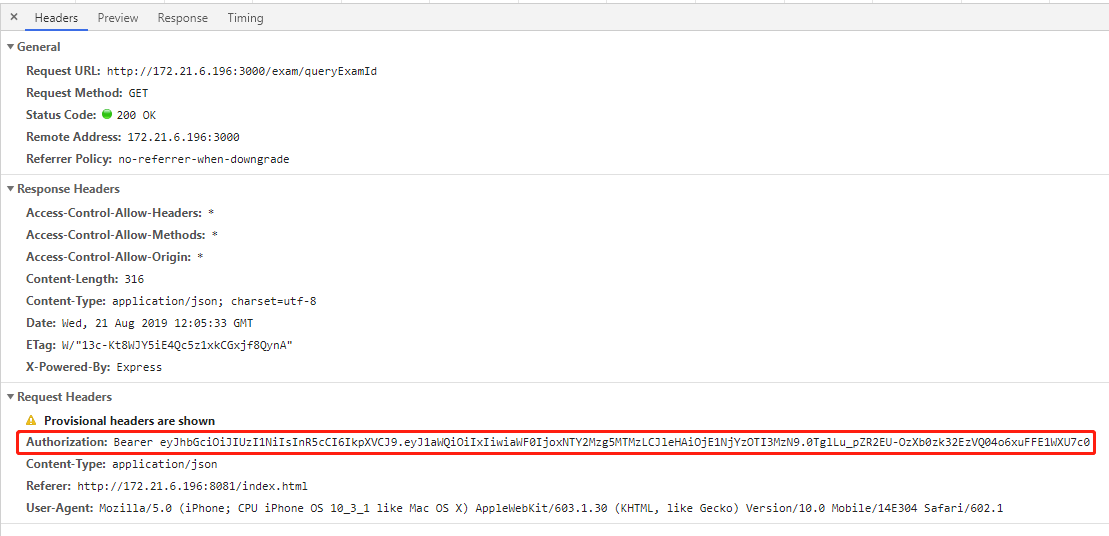
// Weex 的每次请求,头部都带上 token
initOptions.headers['Authorization'] = global.token;经过以上代码逻辑处理后,我们查看 Weex 向服务端发送的请求头部,都携带了 token,如下图所示。这样服务端 express 处理这个请求时,就可以通过解析 token 获取到对应的用户 id ,从而允许其对服务端的数据访问。
(1)存在问题
很遗憾,Weex 竟然没有提供文件选择/上传的模块,对于前端开发者来说无疑晴天霹雳,那我不是要手动去写 Android 的 java 代码,经过反复查找,真的没有文件选择/上传模块,于是我们只能自己去写 Java 代码去实现 Android 端图片选择以及上传功能。
(2)实现 Android 原生的图片选择/上传功能
在 weex_project\platforms\android\app\src\main\java\com\weex\app\extend 目录下新建 图片上传 模块的类 WXAlbumModule ,其继承 WXModule ,其主要两个方法为 choosePhoto 和 onActivityResult ,其中 choosePhoto 用于给 Weex 前端来调用,当 Weex 前端需要选择相册中的图片时,Weex 前端就调用 choosePhoto 方法;onActivityResult 是用户选择好相册中的图片后,会相应触发该事件,并将用户选择的相片以参数形式传入 onActivityResult ,从而我们可以在 onActivityResult 中进行图片的上传逻辑,图片上传完成后,Android 端会在回调事件中通知前端,图片放置在服务端的目录路径,前端可以对应进行图片显示等操作。关键代码逻辑如下,如果如果对 Java 完全一无所知的同学可以先不看,懂 java 代码的建议结合项目代码来看,会更清晰。
@JSMethod(uiThread = true)
// 给 Weex 前端调用,当用户点击时,调用该函数
public void choosePhoto(String param, JSCallback callback) {
if (ContextCompat.checkSelfPermission(mWXSDKInstance.getContext(),
Manifest.permission.WRITE_EXTERNAL_STORAGE)
!= PackageManager.PERMISSION_GRANTED) {
ActivityCompat.requestPermissions((WXPageActivity) mWXSDKInstance.getContext(),
new String[]{Manifest.permission.WRITE_EXTERNAL_STORAGE},
CAMERA_REQUEST_CODE);
} else {
choosePhoto();
}
try{
JSONObject jsonObject = new JSONObject(param);
this.type = (String)jsonObject.get("type");
this.path = (String)jsonObject.get("path");
this.url = (String)jsonObject.get("url");
this.token = (String)jsonObject.get("token");
}catch (JSONException e){
e.printStackTrace();
}
this.callback = callback;
}@Override
// 用户选择好相册中的图片后,会相应触发该事件,并将用户选择的相片以参数形式传入
public void onActivityResult(int requestCode, int resultCode, Intent data) {
if (resultCode == WXPageActivity.RESULT_OK) {
switch (requestCode) {
case CAMERA_REQUEST_CODE: {
try {
Uri selectedImage = data.getData();
String[] filePathColumns = {MediaStore.Images.Media.DATA};
Cursor c = mWXSDKInstance.getContext().getContentResolver().query(selectedImage, filePathColumns, null, null, null);
c.moveToFirst();
int columnIndex = c.getColumnIndex(filePathColumns[0]);
String picturePath = c.getString(columnIndex);
c.close();
//上传的文件
File file = new File(picturePath);
// 普通参数
HashMap<String , String> params = new HashMap<>();
params.put("path", this.path);
uploadForm(params, "file", file, "", this.url);
} catch (Exception e) {
e.printStackTrace();
}
break;
}
}
}
super.onActivityResult(requestCode, resultCode, data);
}实现好以上选择图片和上传图片的代码逻辑后,我们需要在 weex_project\platforms\android\app\src\main\java\WXApplication.java 中进行模块的注册,代码逻辑如下:
WXSDKEngine.registerModule("wxalbum", WXAlbumModule.class);Weex 前端进行调用:
const WXAlbum = weex.requireModule('wxalbum');
upload () {
let path = 'public/upload/';
let vm = this;
storage.getItem('token', event => {
let param = {
type: 'image/jpeg', // 选择的数据类型
path: path,
url: CONSTANT.SERVER_URL + '/users/upload',
token: event.data
};
WXAlbum.choosePhoto(JSON.stringify(param), ret => {
let obj = JSON.parse(ret);
vm.imgPath = '/' + path + obj.file[0].originalFilename;
modal.alert({
message: vm.imgPath,
okTitle: '确认'
}, function () {
console.log('alert callback')
})
});
})
},(1)存在问题
Weex 官网的 webSocket 章节特意标注以下警告字眼:
h5 提供 WebSockets 的 protocol 默认实现,iOS 和 Android 需要自定义实现,Android 可参考:
好吧,根本没有封装 WebSocket 功能,那我就按官网给的参考来实现吧,于是,我点击前面两个参考链接,链接打开的页面根本不存在,报 404(官网出现这种问题,实在不应该啊)。网上谷歌搜索一圈,没有发现类似的问题,还是主要查看了这个给的 url 以及结合阿里将 weex 贡献给 Apache 维护这个事情,猜测是不是 Weex 捐给 Apache 维护,github 的库目录更改,但是官网对应的 url 地址没有做修改。经过查找,确实是这个问题,在旧库中以下目录找到官网提的:DefaultWebSocketAdapter.java 和 DefaultWebSocketAdapterFactor.java :
(2)手动实现 WebSocket 功能
我们 在 weex_project\platforms\android\app\src\main\java\com\weex\app\adapter 目录底下创建 Websocket 的实现类 DefaultWebSocketAdapter.java 和工厂创建类 DefaultWebSocketAdapterFactory.java ,关键逻辑代码如下:
// 该类主要实现 Websocket 的连接、发送消息、接收消息、关闭等函数或事件
public class DefaultWebSocketAdapter implements IWebSocketAdapter {
@Override
public void connect(){...}
@Override
public void send(String data) {...}
@Override
public void close(int code, String reason) {...}
@Override
public void destroy() {...}
...
}// 该类主要为创建 Websocket 对象的工厂类
public class DefaultWebSocketAdapterFactory implements IWebSocketAdapterFactory {
@Override
public IWebSocketAdapter createWebSocketAdapter() {
return new DefaultWebSocketAdapter();
}
}在 weex_project\platforms\android\app\src\main\java\com\weex\app\WXApplication.java 中初始化 Websocket :
WXSDKEngine.initialize(this,
new InitConfig.Builder().setImgAdapter(new ImageAdapter()). setWebSocketAdapterFactory(new DefaultWebSocketAdapterFactory()).build()
);在 Weex 的前端中使用 Websocket,相关代码如下:
const ws = weex.requireModule('webSocket');
ws.WebSocket(CONSTANT.SOCKET_WS, '');
// 需要注意 web 端的写法和 android 端的写法不一样
// android 的 onxx 事件是一个方法,需要传入一个JSCallback的值,
if (weex.config.env.platform === 'Web') {
ws.onmessage = this.socketMessage;
} else {
ws.onmessage(this.socketMessage);
}(1)存在问题
我们开发的 Weex app,如果在 app 的哪个界面,点击手机的返回上一级物理键,都会导致 app 退出,好吧,Weex 也没有提供对应的事件处理,我们不得不自己再去写安卓的 java 代码去向 Weex 的 Web 端抛出这个事件。
(2)重写手机物理键返回上一级的处理逻辑
正常交互逻辑:当处于主界面时,返回上一级物理键会进行提示“再点击一次退出”,如果不是处于主界面时,会返回上一级页面。我们的实现:
在 weex_project\platforms\android\app\src\main\java\com\weex\app\WXPageActivity.java 中添加监听点击手机物理键的事件:
public void onBackPressed(){
Map<String,Object> params=new HashMap<>();
params.put("name","msg");
mInstance.fireGlobalEventCallback("androidback",params);
}在 Weex 的 vue 入口文件中,监听 androidback 事件,当接收到该事件时,进行相应的逻辑处理,代码如下所示:
listenAndroidBack () {
let vm = this;
globalEvent.addEventListener('androidback', function (e) {
if (vm.$route.name === 'tabIndex' || vm.$route.name === 'loginPage') {
if (vm.exitFlag) {
weex.requireModule('wxclose').closeApp();
} else {
modal.toast({
message: '再点一次退出',
duration: 1
});
vm.exitFlag = true;
vm.clearExitFlag();
}
} else {
vm.$router.go(-1);
}
});
},(1)存在问题
Weex 官网中 image 图片组件显示项目目录下图片,src 地址直接写成相对路径,如下所示;但是这种写法存在问题,它只支持 web 端的显示,在 Android 端是无法显示的,找不到对应图片。
<image ref="poster" src="path/to/image.png"></image>(2)Android/IOS 端显示本地图片
Weex 没有在将 vue 编译成 Android 组件时,对应将图片放置到 Android 对应的目录下,所以我们只好自己将图片手动再放置一份,其中 Android 端需要额外将图片放在 /platforms/android/app/src/main/res/drawable-xxhdpi ,IOS 放入xcode 底下的 /Source/images/下 ,然后我们在代码逻辑中,根据环境判断现在是 Web 环境、Android 环境或者 IOS 环境,再对应的获取对应目录下的图片(暂时只能做到这种程度了...),如下代码所示:
const ICON_URL = {
Web: `${WEB_IMAGE_URL}`,
android: `local:///${pureName}`,
iOS: `local:///filePng/${pureName}${suffixName}`
}
return ICON_URL[CUR_RUN_PLATFORM];Android apk 打包分 debug 版和 release 版,通常所说的打包指生成 release 版的 apk,release 版的 apk 会比debug 版的小,release 版的还会进行混淆和用自己的 keystore 签名,以防止别人反编译后重新打包替换你的应用。 下面我们主要介绍如何在 Android Studio 中对 weex 项目进行打包。
Android Studio 打开 Android 工程,目录为:weex 项目 /platforms/android 。
注:.jks” 文件 类似 apk 身份证;
(1)打包步骤如下截图:

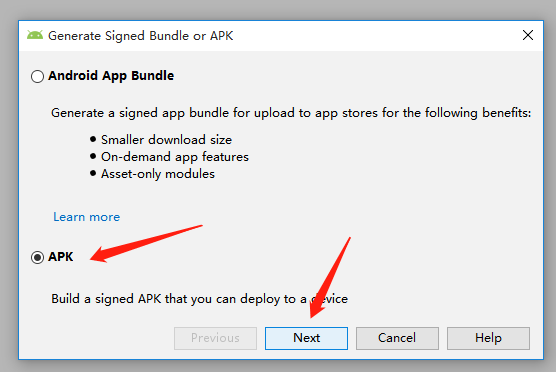
(2)我们点击选择 Create new
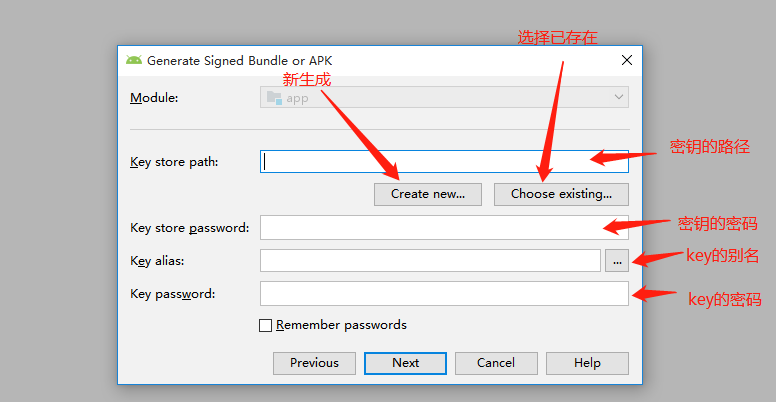
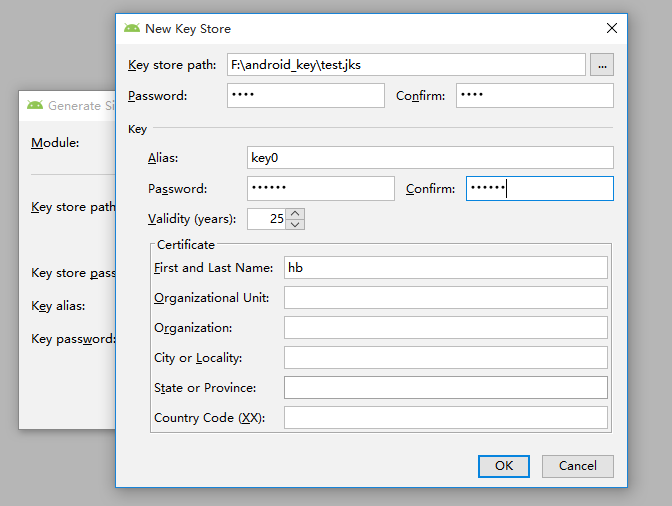
(3)生成 jks

(4)填写 key 的相关信息
(5)点击 OK 之后,可以看到如下信息已被自动填充
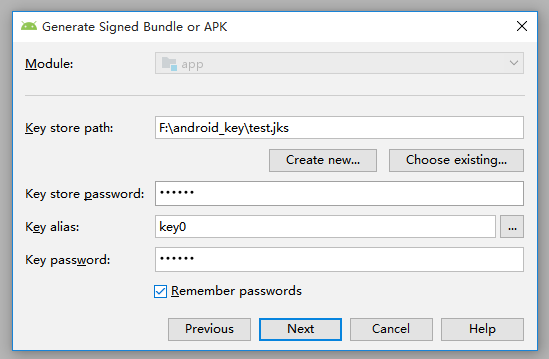
(6)点击 Next
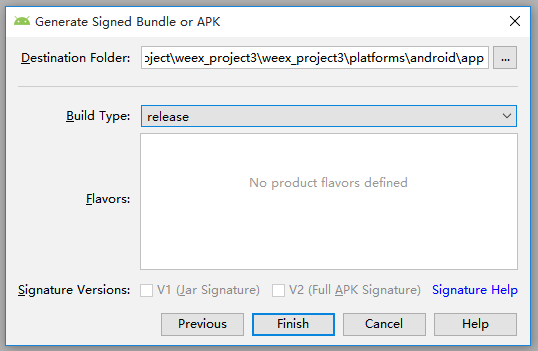
(7)点击 Finish 后,会看到 Android Studio 底部显示正在打包

(8)打包完成,会看到 Android Studio 右下角会显示打包成功的提示

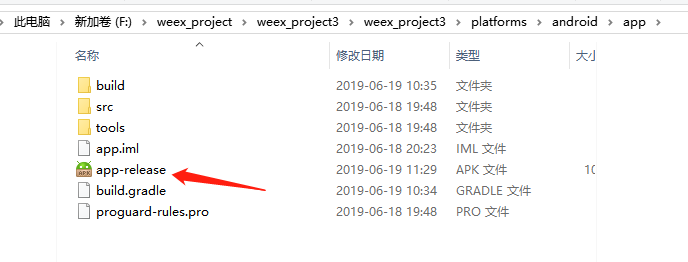
(9)查看打包好的 apk 文件
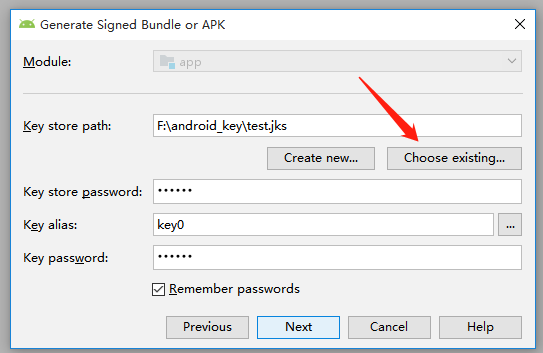
有 “.jks” 文件的打包 比 没有 ".jks" 文件的打包简单很多,直接点击 Choose existing... ,进行选择 .jks 文件,其它步骤跟没有 ".jks" 文件的打包一样,这里不再赘述。
Weex 官网经常出现无法访问的情况,频率大概一周至少一次;这就很影响开发效率了,因为在开发过程中需要经常查看官网的写法、说明等,如果访问不了,则会造成一定程度的开发 block;
Weex 官网的文档比较粗糙,如果没有比较好的前端和移动端原生开发知识储备的话,看官网的文档就很吃力了,官网很多讲解写的非常简单,都默认你同时熟练前端和移动端原生开发,而且同时有较好前端和移动端原生开发人员应该在业界还比较少吧;
Weex 生态是真的贫瘠,除了阿里自己出产的组件库 weex-ui 外,其它的相关插件几乎找不到,有也是少于100个 star 的,例如我在项目开始前设计的一些功能:拍照、图片选择上传、语音录入、通讯、定位、文件预览等等移动端的特有功能,都没有插件,都需要自己去写 Android 的原生代码,那这时就失去了利用框架提高开发效率的意义;生态跟 react-native 差的真不是一丁半点,而是根本不是一个量级;
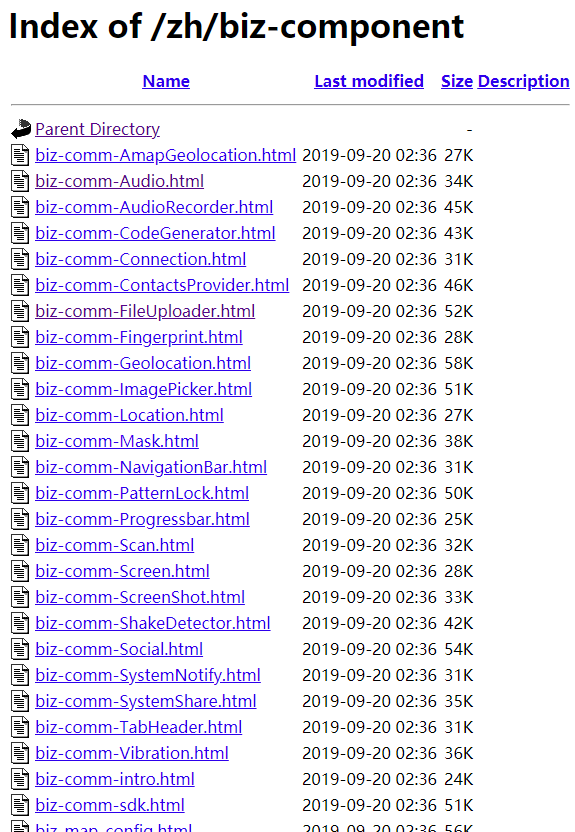
结合上一点,坊间传闻:Weex 存在两个版本,一个版本是阿里内部使用的,一个是非阿里内部使用;这个传言无从验证,但是结合第2点说的 Weex 生态贫瘠,我却无意在浏览器搜索中,发现了一系列常见功能的插件封装:https://weex.apache.org/zh/biz-component/ ,截图如下,但是这些插件并没有提供出来使用,存在 Weex 官网中,但是却没有访问入口。如果这些插件功能能提供使用,无疑将很大程度丰富 Weex 的生态。
Weex 号称 “一次撰写,多端运行”,但是存在很多兼容性问题,比如我们在 Web 端调试开完后一个功能模块,但是在 Android 端一运行,就各种跑不通,各种兼容性问题;这种问题导致,我们后期根本不敢在 Web 环境开发,例如:我们这个项目是想开发个 Android 的 app,我们最终都直接在 Android 环境下开发,这种效率肯定就没有在 Web 环境开发效率高。
Weex 默认集成 Vue 框架,而且主打 Vue 受众,但是 Weex 对 Vue 的支持度还不够,除了官网上提到的那些 vue 特性不支持外,还有很多特性没有被列出,例如:vuex 等。
本文主要基于 Weex 框架的实践进行总结,分享了 Weex 理念、Weex 的 VSCode 的第三发插件、Weex 项目的功能介绍、Weex 项目编译以及 Weex 存在的一些问题,希望对完全阅读完的你有启发和帮助,如果有不足,欢迎批评、指正、交流!
预期 十一月份 会推出姊妹篇《react-native 实践总结》,敬请关注!
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:https://github.com/fengshi123/blog ,汇总了作者的所有博客,也欢迎关注及 star ~
本项目 github 地址为:https://github.com/fengshi123/weex_project
使用 Vue 做项目也有两年时间了,对 Vue 的 api 也用的比较得心应手了,虽然对 Vue 的一些实现原理也耳有所闻,例如 虚拟DOM、flow、数据驱动、路由原理等等,但是自己并没有特意去探究这些原理的基础以及 Vue 源码是如何利用这些原理进行框架实现的,所以利用空闲时间,进行 Vue 框架相关技术原理和 Vue 框架的具体实现的整理。如果你对 Vue 的实现原理很感兴趣,那么就可以开始这系列文章的阅读,将会为你打开 Vue 的底层世界大门,对它的实现细节一探究竟。 本文为 Virtual DOM的技术原理和 Vue 框架的具体实现。
辛苦编写良久,还望手动点赞鼓励~
github地址为:github.com/fengshi123/…,上面汇总了作者所有的博客文章,如果喜欢或者有所启发,请帮忙给个 star ~,对作者也是一种鼓励。
DOM和其解析流程本节我们主要介绍真实 DOM 的解析过程,通过介绍其解析过程以及存在的问题,从而引出为什么需要虚拟DOM。一图胜千言,如下图为 webkit 渲染引擎工作流程图

所有的浏览器渲染引擎工作流程大致分为5步:创建 DOM 树 —> 创建 Style Rules -> 构建 Render 树 —> 布局 Layout -—> 绘制 Painting。
第一步,构建 DOM 树:用 HTML 分析器,分析 HTML 元素,构建一棵 DOM 树;
第二步,生成样式表:用 CSS 分析器,分析 CSS 文件和元素上的 inline 样式,生成页面的样式表;
第三步,构建 Render 树:将 DOM 树和样式表关联起来,构建一棵 Render 树(Attachment)。每个 DOM 节点都有 attach 方法,接受样式信息,返回一个 render 对象(又名 renderer),这些 render 对象最终会被构建成一棵 Render 树;
第四步,确定节点坐标:根据 Render 树结构,为每个 Render 树上的节点确定一个在显示屏上出现的精确坐标;
第五步,绘制页面:根据 Render 树和节点显示坐标,然后调用每个节点的 paint 方法,将它们绘制出来。
注意点:
1、DOM 树的构建是文档加载完成开始的? 构建 DOM 树是一个渐进过程,为达到更好的用户体验,渲染引擎会尽快将内容显示在屏幕上,它不必等到整个 HTML 文档解析完成之后才开始构建 render 树和布局。
2、Render 树是 DOM 树和 CSS 样式表构建完毕后才开始构建的? 这三个过程在实际进行的时候并不是完全独立的,而是会有交叉,会一边加载,一边解析,以及一边渲染。
3、CSS 的解析注意点? CSS 的解析是从右往左逆向解析的,嵌套标签越多,解析越慢。
4、JS 操作真实 DOM 的代价? 用我们传统的开发模式,原生 JS 或 JQ 操作 DOM 时,浏览器会从构建 DOM 树开始从头到尾执行一遍流程。在一次操作中,我需要更新 10 个 DOM 节点,浏览器收到第一个 DOM 请求后并不知道还有 9 次更新操作,因此会马上执行流程,最终执行10 次。例如,第一次计算完,紧接着下一个 DOM 更新请求,这个节点的坐标值就变了,前一次计算为无用功。计算 DOM 节点坐标值等都是白白浪费的性能。即使计算机硬件一直在迭代更新,操作 DOM 的代价仍旧是昂贵的,频繁操作还是会出现页面卡顿,影响用户体验
Virtual-DOM 基础DOM 的好处 虚拟 DOM 就是为了解决浏览器性能问题而被设计出来的。如前,若一次操作中有 10 次更新 DOM 的动作,虚拟 DOM 不会立即操作 DOM,而是将这 10 次更新的 diff 内容保存到本地一个 JS 对象中,最终将这个 JS 对象一次性 attch 到 DOM 树上,再进行后续操作,避免大量无谓的计算量。所以,用 JS 对象模拟 DOM 节点的好处是,页面的更新可以先全部反映在 JS 对象(虚拟 DOM )上,操作内存中的 JS 对象的速度显然要更快,等更新完成后,再将最终的 JS 对象映射成真实的 DOM,交由浏览器去绘制。
JS 对象模拟 DOM 树(1)如何用 JS 对象模拟 DOM 树
例如一个真实的 DOM 节点如下:
<div id="virtual-dom">
<p>Virtual DOM</p>
<ul id="list">
<li class="item">Item 1</li>
<li class="item">Item 2</li>
<li class="item">Item 3</li>
</ul>
<div>Hello World</div>
</div> 我们用 JavaScript 对象来表示 DOM 节点,使用对象的属性记录节点的类型、属性、子节点等。
element.js 中表示节点对象代码如下:
/**
* Element virdual-dom 对象定义
* @param {String} tagName - dom 元素名称
* @param {Object} props - dom 属性
* @param {Array<Element|String>} - 子节点
*/
function Element(tagName, props, children) {
this.tagName = tagName
this.props = props
this.children = children
// dom 元素的 key 值,用作唯一标识符
if(props.key){
this.key = props.key
}
var count = 0
children.forEach(function (child, i) {
if (child instanceof Element) {
count += child.count
} else {
children[i] = '' + child
}
count++
})
// 子元素个数
this.count = count
}
function createElement(tagName, props, children){
return new Element(tagName, props, children);
}
module.exports = createElement;根据 element 对象的设定,则上面的 DOM 结构就可以简单表示为:
var el = require("./element.js");
var ul = el('div',{id:'virtual-dom'},[
el('p',{},['Virtual DOM']),
el('ul', { id: 'list' }, [
el('li', { class: 'item' }, ['Item 1']),
el('li', { class: 'item' }, ['Item 2']),
el('li', { class: 'item' }, ['Item 3'])
]),
el('div',{},['Hello World'])
]) 现在 ul 就是我们用 JavaScript 对象表示的 DOM 结构,我们输出查看 ul 对应的数据结构如下:

(2)渲染用 JS 表示的 DOM 对象
但是页面上并没有这个结构,下一步我们介绍如何将 ul 渲染成页面上真实的 DOM 结构,相关渲染函数如下:
/**
* render 将virdual-dom 对象渲染为实际 DOM 元素
*/
Element.prototype.render = function () {
var el = document.createElement(this.tagName)
var props = this.props
// 设置节点的DOM属性
for (var propName in props) {
var propValue = props[propName]
el.setAttribute(propName, propValue)
}
var children = this.children || []
children.forEach(function (child) {
var childEl = (child instanceof Element)
? child.render() // 如果子节点也是虚拟DOM,递归构建DOM节点
: document.createTextNode(child) // 如果字符串,只构建文本节点
el.appendChild(childEl)
})
return el
} 我们通过查看以上 render 方法,会根据 tagName 构建一个真正的 DOM 节点,然后设置这个节点的属性,最后递归地把自己的子节点也构建起来。
我们将构建好的 DOM 结构添加到页面 body 上面,如下:
ulRoot = ul.render();
document.body.appendChild(ulRoot); 这样,页面 body 里面就有真正的 DOM 结构,效果如下图所示:

DOM 树的差异 — diff 算法diff 算法用来比较两棵 Virtual DOM 树的差异,如果需要两棵树的完全比较,那么 diff 算法的时间复杂度为O(n^3)。但是在前端当中,你很少会跨越层级地移动 DOM 元素,所以 Virtual DOM 只会对同一个层级的元素进行对比,如下图所示, div 只会和同一层级的 div 对比,第二层级的只会跟第二层级对比,这样算法复杂度就可以达到 O(n)。
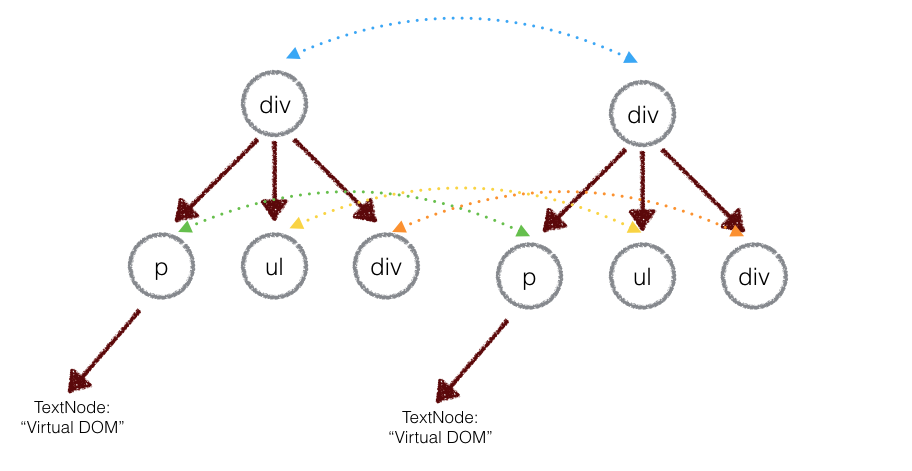
(1)深度优先遍历,记录差异
在实际的代码中,会对新旧两棵树进行一个深度优先的遍历,这样每个节点都会有一个唯一的标记:
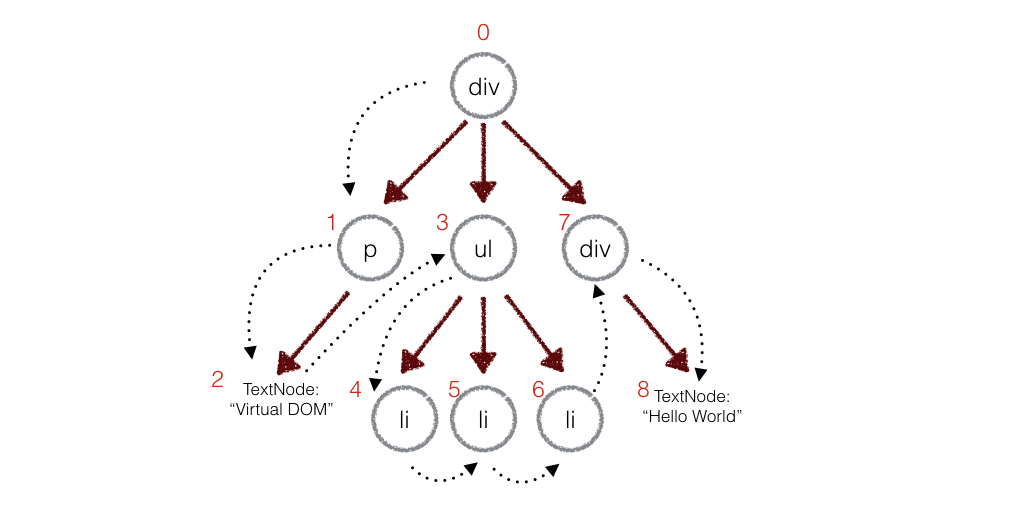
在深度优先遍历的时候,每遍历到一个节点就把该节点和新的的树进行对比。如果有差异的话就记录到一个对象里面。
// diff 函数,对比两棵树
function diff(oldTree, newTree) {
var index = 0 // 当前节点的标志
var patches = {} // 用来记录每个节点差异的对象
dfsWalk(oldTree, newTree, index, patches)
return patches
}
// 对两棵树进行深度优先遍历
function dfsWalk(oldNode, newNode, index, patches) {
var currentPatch = []
if (typeof (oldNode) === "string" && typeof (newNode) === "string") {
// 文本内容改变
if (newNode !== oldNode) {
currentPatch.push({ type: patch.TEXT, content: newNode })
}
} else if (newNode!=null && oldNode.tagName === newNode.tagName && oldNode.key === newNode.key) {
// 节点相同,比较属性
var propsPatches = diffProps(oldNode, newNode)
if (propsPatches) {
currentPatch.push({ type: patch.PROPS, props: propsPatches })
}
// 比较子节点,如果子节点有'ignore'属性,则不需要比较
if (!isIgnoreChildren(newNode)) {
diffChildren(
oldNode.children,
newNode.children,
index,
patches,
currentPatch
)
}
} else if(newNode !== null){
// 新节点和旧节点不同,用 replace 替换
currentPatch.push({ type: patch.REPLACE, node: newNode })
}
if (currentPatch.length) {
patches[index] = currentPatch
}
} 从以上可以得出,patches[1] 表示 p ,patches[3] 表示 ul ,以此类推。
(2)差异类型
DOM 操作导致的差异类型包括以下几种:
div 换成 h1;div 的子节点,把 p 和 ul 顺序互换;li 的 class 样式类删除;p 节点的文本内容更改为 “Real Dom”;以上描述的几种差异类型在代码中定义如下所示:
var REPLACE = 0 // 替换原先的节点
var REORDER = 1 // 重新排序
var PROPS = 2 // 修改了节点的属性
var TEXT = 3 // 文本内容改变 (3)列表对比算法
子节点的对比算法,例如 p, ul, div 的顺序换成了 div, p, ul。这个该怎么对比?如果按照同层级进行顺序对比的话,它们都会被替换掉。如 p 和 div 的 tagName 不同,p 会被 div 所替代。最终,三个节点都会被替换,这样 DOM 开销就非常大。而实际上是不需要替换节点,而只需要经过节点移动就可以达到,我们只需知道怎么进行移动。
将这个问题抽象出来其实就是字符串的最小编辑距离问题(Edition Distance),最常见的解决方法是 Levenshtein Distance , Levenshtein Distance 是一个度量两个字符序列之间差异的字符串度量标准,两个单词之间的 Levenshtein Distance 是将一个单词转换为另一个单词所需的单字符编辑(插入、删除或替换)的最小数量。Levenshtein Distance 是1965年由苏联数学家 Vladimir Levenshtein 发明的。Levenshtein Distance 也被称为编辑距离(Edit Distance),通过动态规划求解,时间复杂度为 O(M*N)。
定义:对于两个字符串 a、b,则他们的 Levenshtein Distance 为:
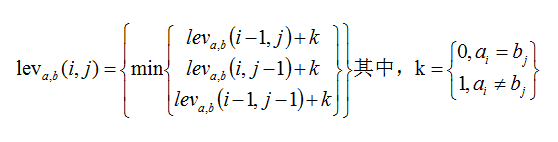
示例:字符串 a 和 b,a=“abcde” ,b=“cabef”,根据上面给出的计算公式,则他们的 Levenshtein Distance 的计算过程如下:

本文的 demo 使用插件 list-diff2 算法进行比较,该算法的时间复杂度伟 O(n*m),虽然该算法并非最优的算法,但是用于对于 dom 元素的常规操作是足够的。该算法具体的实现过程这里不再详细介绍,该算法的具体介绍可以参照:https://github.com/livoras/list-diff
(4)实例输出
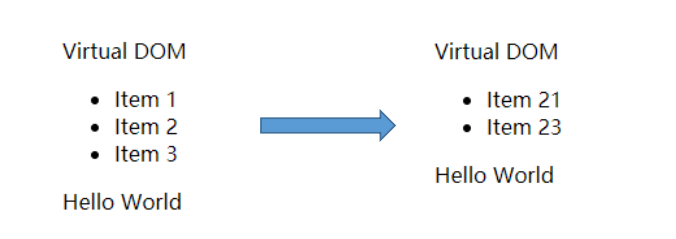
两个虚拟 DOM 对象如下图所示,其中 ul1 表示原有的虚拟 DOM 树,ul2 表示改变后的虚拟 DOM 树
var ul1 = el('div',{id:'virtual-dom'},[
el('p',{},['Virtual DOM']),
el('ul', { id: 'list' }, [
el('li', { class: 'item' }, ['Item 1']),
el('li', { class: 'item' }, ['Item 2']),
el('li', { class: 'item' }, ['Item 3'])
]),
el('div',{},['Hello World'])
])
var ul2 = el('div',{id:'virtual-dom'},[
el('p',{},['Virtual DOM']),
el('ul', { id: 'list' }, [
el('li', { class: 'item' }, ['Item 21']),
el('li', { class: 'item' }, ['Item 23'])
]),
el('p',{},['Hello World'])
])
var patches = diff(ul1,ul2);
console.log('patches:',patches);我们查看输出的两个虚拟 DOM 对象之间的差异对象如下图所示,我们能通过差异对象得到,两个虚拟 DOM 对象之间进行了哪些变化,从而根据这个差异对象(patches)更改原先的真实 DOM 结构,从而将页面的 DOM 结构进行更改。

DOM 对象的差异应用到真正的 DOM 树(1)深度优先遍历 DOM 树
因为步骤一所构建的 JavaScript 对象树和 render 出来真正的 DOM 树的信息、结构是一样的。所以我们可以对那棵 DOM 树也进行深度优先的遍历,遍历的时候从步骤二生成的 patches 对象中找出当前遍历的节点差异,如下相关代码所示:
function patch (node, patches) {
var walker = {index: 0}
dfsWalk(node, walker, patches)
}
function dfsWalk (node, walker, patches) {
// 从patches拿出当前节点的差异
var currentPatches = patches[walker.index]
var len = node.childNodes
? node.childNodes.length
: 0
// 深度遍历子节点
for (var i = 0; i < len; i++) {
var child = node.childNodes[i]
walker.index++
dfsWalk(child, walker, patches)
}
// 对当前节点进行DOM操作
if (currentPatches) {
applyPatches(node, currentPatches)
}
} (2)对原有 DOM 树进行 DOM 操作
我们根据不同类型的差异对当前节点进行不同的 DOM 操作 ,例如如果进行了节点替换,就进行节点替换 DOM 操作;如果节点文本发生了改变,则进行文本替换的 DOM 操作;以及子节点重排、属性改变等 DOM 操作,相关代码如 applyPatches 所示 :
function applyPatches (node, currentPatches) {
currentPatches.forEach(currentPatch => {
switch (currentPatch.type) {
case REPLACE:
var newNode = (typeof currentPatch.node === 'string')
? document.createTextNode(currentPatch.node)
: currentPatch.node.render()
node.parentNode.replaceChild(newNode, node)
break
case REORDER:
reorderChildren(node, currentPatch.moves)
break
case PROPS:
setProps(node, currentPatch.props)
break
case TEXT:
node.textContent = currentPatch.content
break
default:
throw new Error('Unknown patch type ' + currentPatch.type)
}
})
} (3)DOM结构改变
通过将第 2.2.2 得到的两个 DOM 对象之间的差异,应用到第一个(原先)DOM 结构中,我们可以看到 DOM 结构进行了预期的变化,如下图所示:
Virtual DOM 算法主要实现上面三个步骤来实现:
用 JS 对象模拟 DOM 树 — element.js
<div id="virtual-dom">
<p>Virtual DOM</p>
<ul id="list">
<li class="item">Item 1</li>
<li class="item">Item 2</li>
<li class="item">Item 3</li>
</ul>
<div>Hello World</div>
</div> 比较两棵虚拟 DOM 树的差异 — diff.js

将两个虚拟 DOM 对象的差异应用到真正的 DOM 树 — patch.js
function applyPatches (node, currentPatches) {
currentPatches.forEach(currentPatch => {
switch (currentPatch.type) {
case REPLACE:
var newNode = (typeof currentPatch.node === 'string')
? document.createTextNode(currentPatch.node)
: currentPatch.node.render()
node.parentNode.replaceChild(newNode, node)
break
case REORDER:
reorderChildren(node, currentPatch.moves)
break
case PROPS:
setProps(node, currentPatch.props)
break
case TEXT:
node.textContent = currentPatch.content
break
default:
throw new Error('Unknown patch type ' + currentPatch.type)
}
})
} Vue 源码 Virtual-DOM 简析我们从第二章节(Virtual-DOM 基础)中已经掌握 Virtual DOM 渲染成真实的 DOM 实际上要经历 VNode 的定义、diff、patch 等过程,所以本章节 Vue 源码的解析也按这几个过程来简析。
VNode 模拟 DOM 树VNode 类简析在 Vue.js 中,Virtual DOM 是用 VNode 这个 Class 去描述,它定义在 src/core/vdom/vnode.js 中 ,从以下代码块中可以看到 Vue.js 中的 Virtual DOM 的定义较为复杂一些,因为它这里包含了很多 Vue.js 的特性。实际上 Vue.js 中 Virtual DOM 是借鉴了一个开源库 snabbdom 的实现,然后加入了一些 Vue.js 的一些特性。
export default class VNode {
tag: string | void;
data: VNodeData | void;
children: ?Array<VNode>;
text: string | void;
elm: Node | void;
ns: string | void;
context: Component | void; // rendered in this component's scope
key: string | number | void;
componentOptions: VNodeComponentOptions | void;
componentInstance: Component | void; // component instance
parent: VNode | void; // component placeholder node
// strictly internal
raw: boolean; // contains raw HTML? (server only)
isStatic: boolean; // hoisted static node
isRootInsert: boolean; // necessary for enter transition check
isComment: boolean; // empty comment placeholder?
isCloned: boolean; // is a cloned node?
isOnce: boolean; // is a v-once node?
asyncFactory: Function | void; // async component factory function
asyncMeta: Object | void;
isAsyncPlaceholder: boolean;
ssrContext: Object | void;
fnContext: Component | void; // real context vm for functional nodes
fnOptions: ?ComponentOptions; // for SSR caching
devtoolsMeta: ?Object; // used to store functional render context for devtools
fnScopeId: ?string; // functional scope id support
constructor (
tag?: string,
data?: VNodeData,
children?: ?Array<VNode>,
text?: string,
elm?: Node,
context?: Component,
componentOptions?: VNodeComponentOptions,
asyncFactory?: Function
) {
this.tag = tag
this.data = data
this.children = children
this.text = text
this.elm = elm
this.ns = undefined
this.context = context
this.fnContext = undefined
this.fnOptions = undefined
this.fnScopeId = undefined
this.key = data && data.key
this.componentOptions = componentOptions
this.componentInstance = undefined
this.parent = undefined
this.raw = false
this.isStatic = false
this.isRootInsert = true
this.isComment = false
this.isCloned = false
this.isOnce = false
this.asyncFactory = asyncFactory
this.asyncMeta = undefined
this.isAsyncPlaceholder = false
}
}这里千万不要因为 VNode 的这么属性而被吓到,或者咬紧牙去摸清楚每个属性的意义,其实,我们主要了解其几个核心的关键属性就差不多了,例如:
tag 属性即这个vnode的标签属性data 属性包含了最后渲染成真实dom节点后,节点上的class,attribute,style以及绑定的事件children 属性是vnode的子节点text 属性是文本属性elm 属性为这个vnode对应的真实dom节点key 属性是vnode的标记,在diff过程中可以提高diff的效率VNode 过程(1)初始化 vue
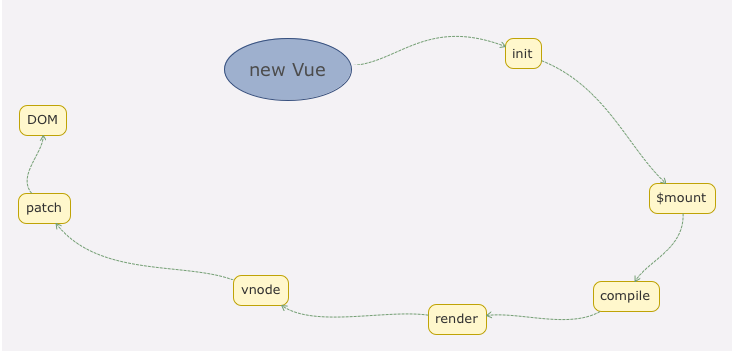
我们在实例化一个 vue 实例,也即 new Vue( ) 时,实际上是执行 src/core/instance/index.js 中定义的 Function 函数。
function Vue (options) {
if (process.env.NODE_ENV !== 'production' &&
!(this instanceof Vue)
) {
warn('Vue is a constructor and should be called with the `new` keyword')
}
this._init(options)
}通过查看 Vue 的 function,我们知道 Vue 只能通过 new 关键字初始化,然后调用 this._init 方法,该方法在 src/core/instance/init.js 中定义。
Vue.prototype._init = function (options?: Object) {
const vm: Component = this
// 省略一系列其它初始化的代码
if (vm.$options.el) {
console.log('vm.$options.el:',vm.$options.el);
vm.$mount(vm.$options.el)
}
}(2)Vue 实例挂载
Vue 中是通过 $mount 实例方法去挂载 dom 的,下面我们通过分析 compiler 版本的 mount 实现,相关源码在目录 src/platforms/web/entry-runtime-with-compiler.js 文件中定义:。
const mount = Vue.prototype.$mount
Vue.prototype.$mount = function (
el?: string | Element,
hydrating?: boolean
): Component {
el = el && query(el)
// 省略一系列初始化以及逻辑判断代码
return mount.call(this, el, hydrating)
}我们发现最终还是调用用原先原型上的 $mount 方法挂载 ,原先原型上的 $mount 方法在 src/platforms/web/runtime/index.js 中定义 。
Vue.prototype.$mount = function (
el?: string | Element,
hydrating?: boolean
): Component {
el = el && inBrowser ? query(el) : undefined
return mountComponent(this, el, hydrating)
}我们发现$mount 方法实际上会去调用 mountComponent 方法,这个方法定义在 src/core/instance/lifecycle.js 文件中
export function mountComponent (
vm: Component,
el: ?Element,
hydrating?: boolean
): Component {
vm.$el = el
// 省略一系列其它代码
let updateComponent
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
updateComponent = () => {
// 生成虚拟 vnode
const vnode = vm._render()
// 更新 DOM
vm._update(vnode, hydrating)
}
} else {
updateComponent = () => {
vm._update(vm._render(), hydrating)
}
}
// 实例化一个渲染Watcher,在它的回调函数中会调用 updateComponent 方法
new Watcher(vm, updateComponent, noop, {
before () {
if (vm._isMounted && !vm._isDestroyed) {
callHook(vm, 'beforeUpdate')
}
}
}, true /* isRenderWatcher */)
hydrating = false
return vm
}从上面的代码可以看到,mountComponent 核心就是先实例化一个渲染Watcher,在它的回调函数中会调用 updateComponent 方法,在此方法中调用 vm._render 方法先生成虚拟 Node,最终调用 vm._update 更新 DOM。
(3)创建虚拟 Node
Vue 的 _render 方法是实例的一个私有方法,它用来把实例渲染成一个虚拟 Node。它的定义在 src/core/instance/render.js 文件中:
Vue.prototype._render = function (): VNode {
const vm: Component = this
const { render, _parentVnode } = vm.$options
let vnode
try {
// 省略一系列代码
currentRenderingInstance = vm
// 调用 createElement 方法来返回 vnode
vnode = render.call(vm._renderProxy, vm.$createElement)
} catch (e) {
handleError(e, vm, `render`){}
}
// set parent
vnode.parent = _parentVnode
console.log("vnode...:",vnode);
return vnode
}Vue.js 利用 _createElement 方法创建 VNode,它定义在 src/core/vdom/create-elemenet.js 中:
export function _createElement (
context: Component,
tag?: string | Class<Component> | Function | Object,
data?: VNodeData,
children?: any,
normalizationType?: number
): VNode | Array<VNode> {
// 省略一系列非主线代码
if (normalizationType === ALWAYS_NORMALIZE) {
// 场景是 render 函数不是编译生成的
children = normalizeChildren(children)
} else if (normalizationType === SIMPLE_NORMALIZE) {
// 场景是 render 函数是编译生成的
children = simpleNormalizeChildren(children)
}
let vnode, ns
if (typeof tag === 'string') {
let Ctor
ns = (context.$vnode && context.$vnode.ns) || config.getTagNamespace(tag)
if (config.isReservedTag(tag)) {
// 创建虚拟 vnode
vnode = new VNode(
config.parsePlatformTagName(tag), data, children,
undefined, undefined, context
)
} else if ((!data || !data.pre) && isDef(Ctor = resolveAsset(context.$options, 'components', tag))) {
// component
vnode = createComponent(Ctor, data, context, children, tag)
} else {
vnode = new VNode(
tag, data, children,
undefined, undefined, context
)
}
} else {
vnode = createComponent(tag, data, context, children)
}
if (Array.isArray(vnode)) {
return vnode
} else if (isDef(vnode)) {
if (isDef(ns)) applyNS(vnode, ns)
if (isDef(data)) registerDeepBindings(data)
return vnode
} else {
return createEmptyVNode()
}
}_createElement 方法有 5 个参数,context 表示 VNode 的上下文环境,它是 Component 类型;tag表示标签,它可以是一个字符串,也可以是一个 Component;data 表示 VNode 的数据,它是一个 VNodeData 类型,可以在 flow/vnode.js 中找到它的定义;children 表示当前 VNode 的子节点,它是任意类型的,需要被规范为标准的 VNode 数组;
为了更直观查看我们平时写的 Vue 代码如何用 VNode 类来表示,我们通过一个实例的转换进行更深刻了解。
例如,实例化一个 Vue 实例:
var app = new Vue({
el: '#app',
render: function (createElement) {
return createElement('div', {
attrs: {
id: 'app',
class: "class_box"
},
}, this.message)
},
data: {
message: 'Hello Vue!'
}
})我们打印出其对应的 VNode 表示:

diff 过程Vue.js 源码的 diff 调用逻辑Vue.js 源码实例化了一个 watcher,这个 ~ 被添加到了在模板当中所绑定变量的依赖当中,一旦 model 中的响应式的数据发生了变化,这些响应式的数据所维护的 dep 数组便会调用 dep.notify() 方法完成所有依赖遍历执行的工作,这包括视图的更新,即 updateComponent 方法的调用。watcher 和 updateComponent 方法定义在 src/core/instance/lifecycle.js 文件中 。
export function mountComponent (
vm: Component,
el: ?Element,
hydrating?: boolean
): Component {
vm.$el = el
// 省略一系列其它代码
let updateComponent
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
updateComponent = () => {
// 生成虚拟 vnode
const vnode = vm._render()
// 更新 DOM
vm._update(vnode, hydrating)
}
} else {
updateComponent = () => {
vm._update(vm._render(), hydrating)
}
}
// 实例化一个渲染Watcher,在它的回调函数中会调用 updateComponent 方法
new Watcher(vm, updateComponent, noop, {
before () {
if (vm._isMounted && !vm._isDestroyed) {
callHook(vm, 'beforeUpdate')
}
}
}, true /* isRenderWatcher */)
hydrating = false
return vm
}完成视图的更新工作事实上就是调用了vm._update方法,这个方法接收的第一个参数是刚生成的Vnode,调用的vm._update方法定义在 src/core/instance/lifecycle.js中。
Vue.prototype._update = function (vnode: VNode, hydrating?: boolean) {
const vm: Component = this
const prevEl = vm.$el
const prevVnode = vm._vnode
const restoreActiveInstance = setActiveInstance(vm)
vm._vnode = vnode
if (!prevVnode) {
// 第一个参数为真实的node节点,则为初始化
vm.$el = vm.__patch__(vm.$el, vnode, hydrating, false /* removeOnly */)
} else {
// 如果需要diff的prevVnode存在,那么对prevVnode和vnode进行diff
vm.$el = vm.__patch__(prevVnode, vnode)
}
restoreActiveInstance()
// update __vue__ reference
if (prevEl) {
prevEl.__vue__ = null
}
if (vm.$el) {
vm.$el.__vue__ = vm
}
// if parent is an HOC, update its $el as well
if (vm.$vnode && vm.$parent && vm.$vnode === vm.$parent._vnode) {
vm.$parent.$el = vm.$el
}
}在这个方法当中最为关键的就是 vm.__patch__ 方法,这也是整个 virtual-dom 当中最为核心的方法,主要完成了prevVnode 和 vnode 的 diff 过程并根据需要操作的 vdom 节点打 patch,最后生成新的真实 dom 节点并完成视图的更新工作。
接下来,让我们看下 vm.__patch__ 的逻辑过程, vm.__patch__ 方法定义在 src/core/vdom/patch.js 中。
function patch (oldVnode, vnode, hydrating, removeOnly) {
......
if (isUndef(oldVnode)) {
// 当oldVnode不存在时,创建新的节点
isInitialPatch = true
createElm(vnode, insertedVnodeQueue)
} else {
// 对oldVnode和vnode进行diff,并对oldVnode打patch
const isRealElement = isDef(oldVnode.nodeType)
if (!isRealElement && sameVnode(oldVnode, vnode)) {
// patch existing root node
patchVnode(oldVnode, vnode, insertedVnodeQueue, null, null, removeOnly)
}
......
}
}在 patch 方法中,我们看到会分为两种情况,一种是当 oldVnode 不存在时,会创建新的节点;另一种则是已经存在 oldVnode ,那么会对 oldVnode 和 vnode 进行 diff 及 patch 的过程。其中 patch 过程中会调用 sameVnode 方法来对对传入的2个 vnode 进行基本属性的比较,只有当基本属性相同的情况下才认为这个2个vnode 只是局部发生了更新,然后才会对这2个 vnode 进行 diff,如果2个 vnode 的基本属性存在不一致的情况,那么就会直接跳过 diff 的过程,进而依据 vnode 新建一个真实的 dom,同时删除老的 dom 节点。
function sameVnode (a, b) {
return (
a.key === b.key &&
a.tag === b.tag &&
a.isComment === b.isComment &&
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b)
)
}diff 过程中主要是通过调用 patchVnode 方法进行的:
function patchVnode (oldVnode, vnode, insertedVnodeQueue, ownerArray, index, removeOnly) {
......
const elm = vnode.elm = oldVnode.elm
const oldCh = oldVnode.children
const ch = vnode.children
// 如果vnode没有文本节点
if (isUndef(vnode.text)) {
// 如果oldVnode的children属性存在且vnode的children属性也存在
if (isDef(oldCh) && isDef(ch)) {
// updateChildren,对子节点进行diff
if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
} else if (isDef(ch)) {
if (process.env.NODE_ENV !== 'production') {
checkDuplicateKeys(ch)
}
// 如果oldVnode的text存在,那么首先清空text的内容,然后将vnode的children添加进去
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '')
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
} else if (isDef(oldCh)) {
// 删除elm下的oldchildren
removeVnodes(elm, oldCh, 0, oldCh.length - 1)
} else if (isDef(oldVnode.text)) {
// oldVnode有子节点,而vnode没有,那么就清空这个节点
nodeOps.setTextContent(elm, '')
}
} else if (oldVnode.text !== vnode.text) {
// 如果oldVnode和vnode文本属性不同,那么直接更新真是dom节点的文本元素
nodeOps.setTextContent(elm, vnode.text)
}
......
}从以上代码得知,
diff 过程中又分了好几种情况,oldCh 为 oldVnode的子节点,ch 为 Vnode 的子节点:
oldVnode.text !== vnode.text,那么就会直接进行文本节点的替换;vnode 没有文本节点的情况下,进入子节点的 diff;oldCh 和 ch 都存在且不相同的情况下,调用 updateChildren 对子节点进行 diff;oldCh 不存在,ch 存在,首先清空 oldVnode 的文本节点,同时调用 addVnodes 方法将 ch 添加到elm 真实 dom 节点当中;oldCh 存在,ch 不存在,则删除 elm 真实节点下的 oldCh 子节点;oldVnode 有文本节点,而 vnode 没有,那么就清空这个文本节点。diff 流程分析(1)Vue.js 源码
这里着重分析下 updateChildren方法,它也是整个 diff 过程中最重要的环节,以下为 Vue.js 的源码过程,为了更形象理解 diff 过程,我们给出相关的示意图来讲解。
function updateChildren (parentElm, oldCh, newCh, insertedVnodeQueue, removeOnly) {
// 为oldCh和newCh分别建立索引,为之后遍历的依据
let oldStartIdx = 0
let newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
let oldKeyToIdx, idxInOld, vnodeToMove, refElm
// 直到oldCh或者newCh被遍历完后跳出循环
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx)
canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved left
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
if (isUndef(idxInOld)) { // New element
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx)
} else {
vnodeToMove = oldCh[idxInOld]
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(vnodeToMove, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
oldCh[idxInOld] = undefined
canMove && nodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm)
} else {
// same key but different element. treat as new element
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx)
}
}
newStartVnode = newCh[++newStartIdx]
}
}
if (oldStartIdx > oldEndIdx) {
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm
addVnodes(parentElm, refElm, newCh, newStartIdx, newEndIdx, insertedVnodeQueue)
} else if (newStartIdx > newEndIdx) {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx)
}
}在开始遍历 diff 前,首先给 oldCh 和 newCh 分别分配一个 startIndex 和 endIndex 来作为遍历的索引,当oldCh 或者 newCh 遍历完后(遍历完的条件就是 oldCh 或者 newCh 的 startIndex >= endIndex ),就停止oldCh 和 newCh 的 diff 过程。接下来通过实例来看下整个 diff 的过程(节点属性中不带 key 的情况)。
(2)无 key 的 diff 过程
我们通过以下示意图对以上代码过程进行讲解:
(2.1)首先从第一个节点开始比较,不管是 oldCh 还是 newCh 的起始或者终止节点都不存在 sameVnode ,同时节点属性中是不带 key 标记的,因此第一轮的 diff 完后,newCh 的 startVnode 被添加到 oldStartVnode的前面,同时 newStartIndex 前移一位;

(2.2)第二轮的 diff 中,满足 sameVnode(oldStartVnode, newStartVnode),因此对这2个 vnode 进行diff,最后将 patch 打到 oldStartVnode 上,同时 oldStartVnode 和 newStartIndex 都向前移动一位 ;
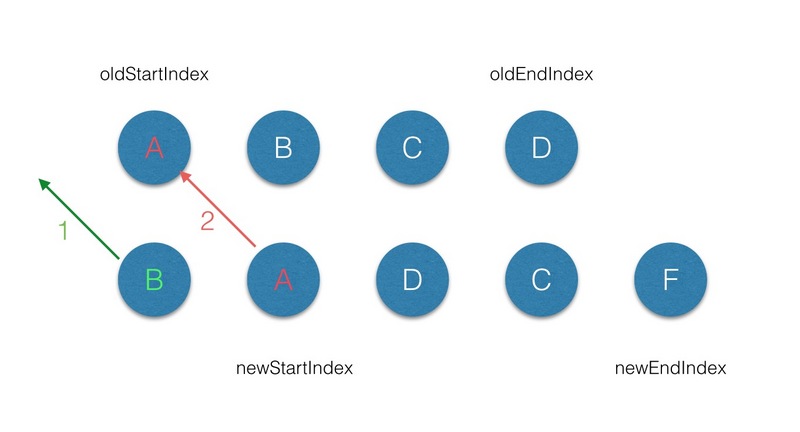
(2.3)第三轮的 diff 中,满足 sameVnode(oldEndVnode, newStartVnode),那么首先对 oldEndVnode和newStartVnode 进行 diff,并对 oldEndVnode 进行 patch,并完成 oldEndVnode 移位的操作,最后newStartIndex 前移一位,oldStartVnode 后移一位;
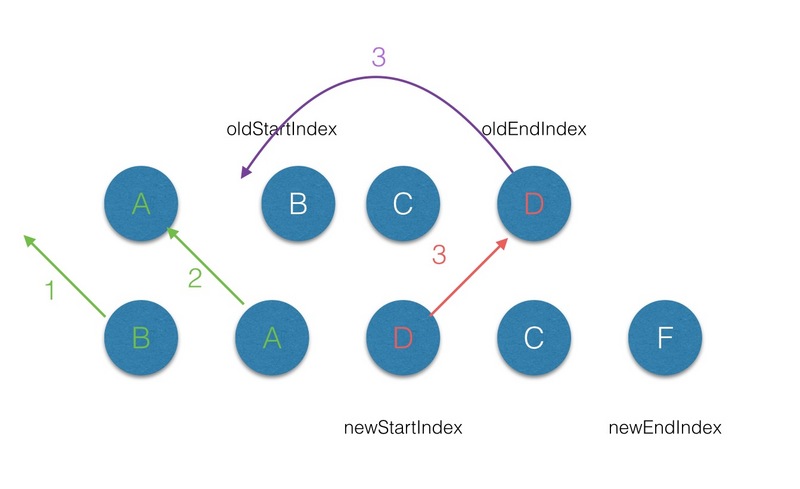
(2.4)第四轮的 diff 中,过程同步骤3;

(2.5)第五轮的 diff 中,同过程1;
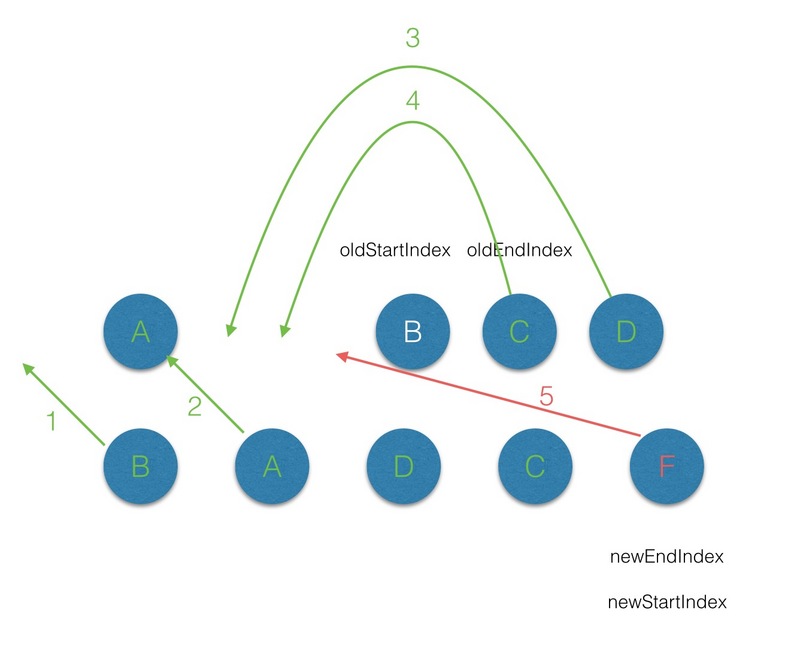
(2.6)遍历的过程结束后,newStartIdx > newEndIdx,说明此时 oldCh 存在多余的节点,那么最后就需要将这些多余的节点删除。
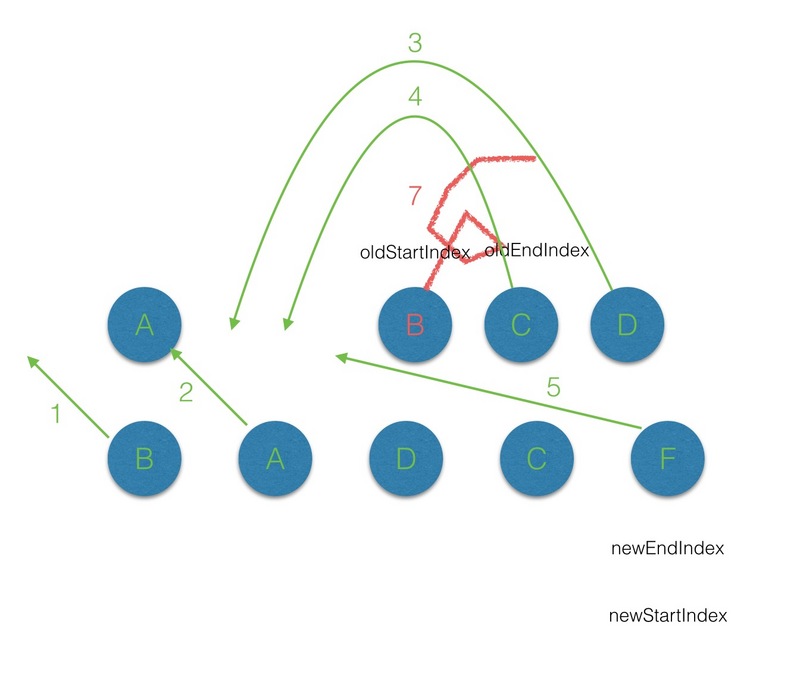
(3)有 key 的 diff 流程
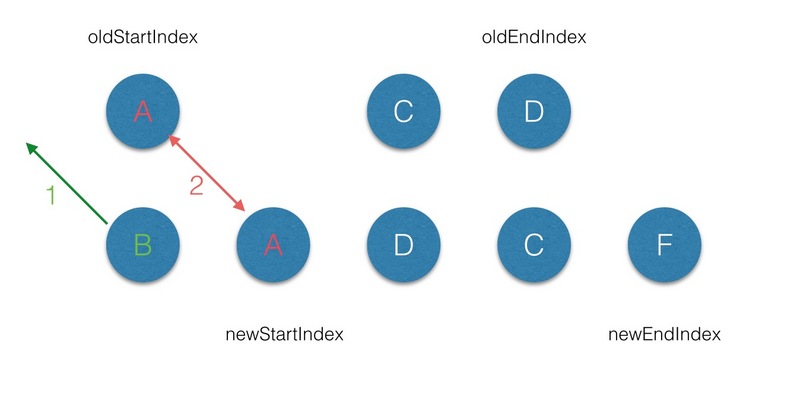
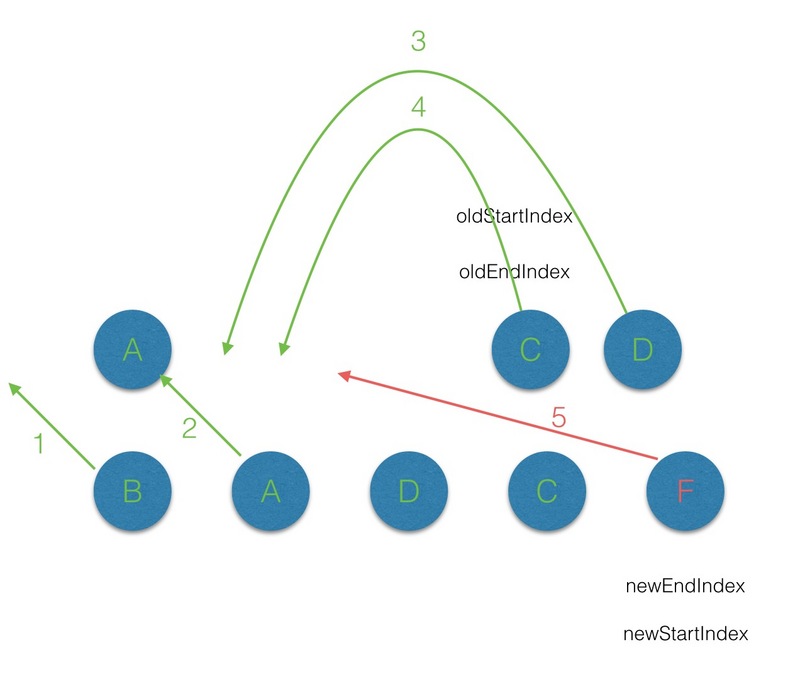
在 vnode 不带 key 的情况下,每一轮的 diff 过程当中都是起始和结束节点进行比较,直到 oldCh 或者newCh 被遍历完。而当为 vnode 引入 key 属性后,在每一轮的 diff 过程中,当起始和结束节点都没有找到sameVnode 时,然后再判断在 newStartVnode 的属性中是否有 key,且是否在 oldKeyToIndx 中找到对应的节点 :
key,那么就将这个 newStartVnode 作为新的节点创建且插入到原有的 root 的子节点中;key,那么就取出 oldCh 中的存在这个 key 的 vnode,然后再进行 diff 的过;通过以上分析,给vdom上添加 key 属性后,遍历 diff 的过程中,当起始点,结束点的搜寻及 diff 出现还是无法匹配的情况下时,就会用 key 来作为唯一标识,来进行 diff,这样就可以提高 diff 效率。
带有 Key 属性的 vnode的 diff 过程可见下图:
(3.1)首先从第一个节点开始比较,不管是 oldCh 还是 newCh 的起始或者终止节点都不存在 sameVnode,但节点属性中是带 key 标记的, 然后在 oldKeyToIndx 中找到对应的节点,这样第一轮 diff 过后 oldCh 上的B节点被删除了,但是 newCh 上的B节点上 elm 属性保持对 oldCh 上 B节点 的elm引用。

(3.2)第二轮的 diff 中,满足 sameVnode(oldStartVnode, newStartVnode),因此对这2个 vnode 进行diff,最后将 patch 打到 oldStartVnode上,同时 oldStartVnode 和 newStartIndex 都向前移动一位 ;
(3.3)第三轮的 diff 中,满足 sameVnode(oldEndVnode, newStartVnode),那么首先对 oldEndVnode 和newStartVnode 进行 diff,并对 oldEndVnode 进行 patch,并完成 oldEndVnode 移位的操作,最后newStartIndex 前移一位,oldStartVnode 后移一位;
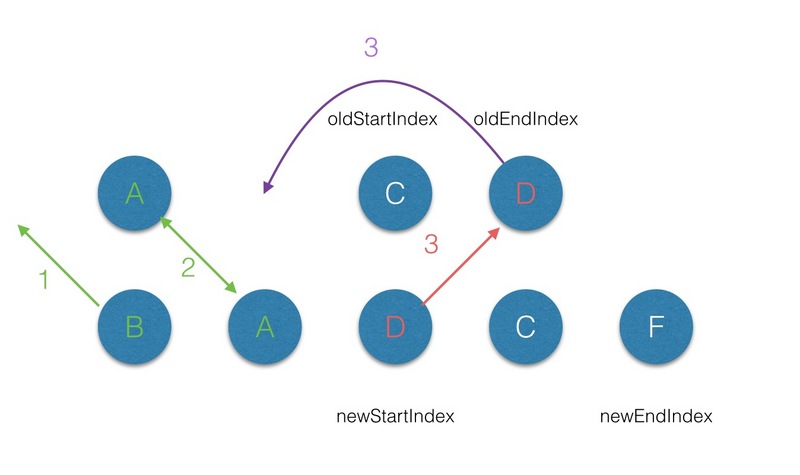
(3.4)第四轮的diff中,过程同步骤2;
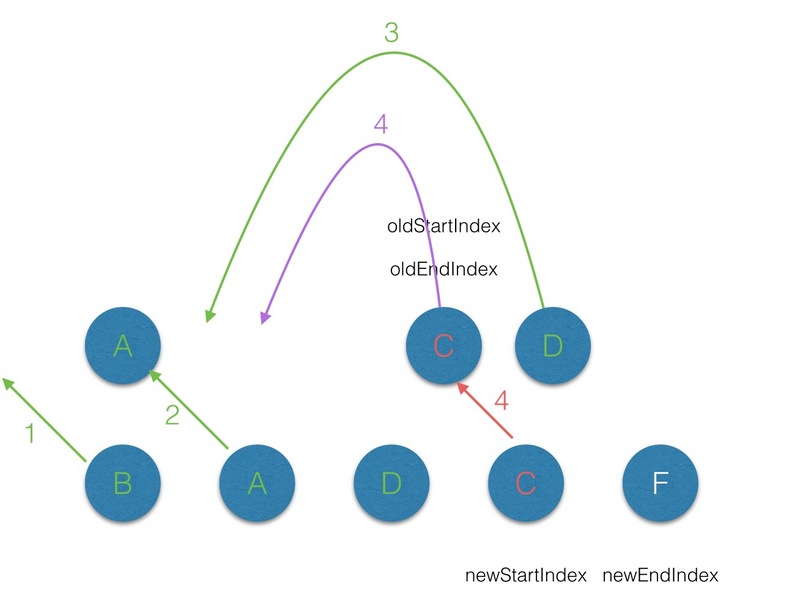
(3.5)第五轮的diff中,因为此时 oldStartIndex 已经大于 oldEndIndex,所以将剩余的 Vnode 队列插入队列最后。
patch 过程通过3.2章节介绍的 diff 过程中,我们会看到 nodeOps 相关的方法对真实 DOM 结构进行操作,nodeOps 定义在 src/platforms/web/runtime/node-ops.js 中,其为基本 DOM 操作,这里就不在详细介绍。
export function createElementNS (namespace: string, tagName: string): Element {
return document.createElementNS(namespaceMap[namespace], tagName)
}
export function createTextNode (text: string): Text {
return document.createTextNode(text)
}
export function createComment (text: string): Comment {
return document.createComment(text)
}
export function insertBefore (parentNode: Node, newNode: Node, referenceNode: Node) {
parentNode.insertBefore(newNode, referenceNode)
}
export function removeChild (node: Node, child: Node) {
node.removeChild(child)
}通过前三小节简析,我们从主线上把模板和数据如何渲染成最终的 DOM 的过程分析完毕了,我们可以通过下图更直观地看到从初始化 Vue 到最终渲染的整个过程。
本文从通过介绍真实 DOM 结构其解析过程以及存在的问题,从而引出为什么需要虚拟 DOM;然后分析虚拟DOM 的好处,以及其一些理论基础和基础算法的实现;最后根据我们已经掌握的基础知识,再一步步去查看Vue.js 的源码如何实现的。从存在问题 —> 理论基础 —> 具体实践,一步步深入,帮助大家更好的了解什么是Virtual DOM、为什么需要 Virtual DOM、以及 Virtual DOM的具体实现,希望本文对您有帮助。
辛苦编写良久,如果对你有帮助,还望手动点赞鼓励~~~~~~
github地址为:github.com/fengshi123/…,上面汇总了作者所有的博客文章,如果喜欢或者有所启发,请帮忙给个 star ~,对作者也是一种鼓励。
1、Vue 技术揭秘:https://ustbhuangyi.github.io/vue-analysis/
2、深度剖析:如何实现一个 Virtual DOM 算法:https://segmentfault.com/a/1190000004029168
3、vue核心之虚拟DOM(vdom):https://www.jianshu.com/p/af0b398602bc
4、virtual-dom(Vue实现)简析:https://segmentfault.com/a/1190000010090659
Node 在 v0.8 时直接引入了 cluster 模块,用以解决多核 CPU 的利用率问题,同时也提供了较完善的 API,用以处理进程的健壮性问题。
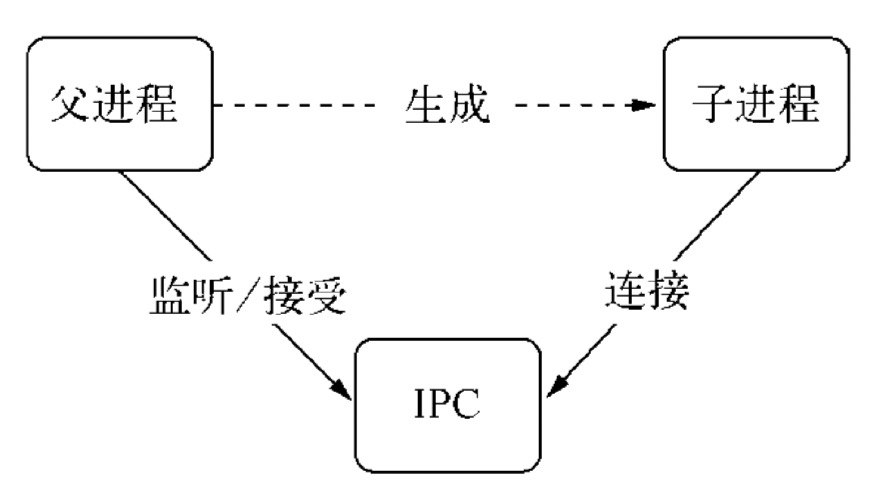
cluster 模块调用 fork 方法来创建子进程,该方法与 child_process 中的 fork 是同一个方法(玩转 node 子进程 — child_process)。 cluster 模块采用的是经典的主从模型,cluster 会创建一个 master,然后根据你指定的数量复制出多个子进程,可以使用cluster.isMaster 属性判断当前进程是 master 还是 worker (工作进程)。由 master 进程来管理所有的子进程,主进程不负责具体的任务处理,主要工作是负责调度和管理。
cluster 模块使用内置的负载均衡来更好地处理线程之间的压力,该负载均衡使用了 Round-robin 算法(也被称之为循环算法)。当使用 Round-robin 调度策略时,master accepts() 所有传入的连接请求,然后将相应的TCP请求处理发送给选中的工作进程(该方式仍然通过 IPC 来进行通信)。
官方使用实例如下所示
const cluster = require('cluster');
const cpuNums = require('os').cpus().length;
const http = require('http');
if (cluster.isMaster) {
for (let i = 0; i < cpuNums; i++){
cluster.fork();
}
// 子进程退出监听
cluster.on('exit', (worker,code,signal) => {
console.log('worker process died,id',worker.process.pid)
})
} else {
// 给子进程标注进程名
process.title = `cluster 子进程 ${process.pid}`;
// Worker可以共享同一个 TCP 连接,这里是一个 http 服务器
http.createServer((req, res)=> {
res.end(`response from worker ${process.pid}`);
}).listen(3000);
console.log(`Worker ${process.pid} started`);
}其实,cluster 模块由 child_process 和 net 模块的组合应用,cluster 启动时,会在内部启动 TCP 服务器,在 cluster.fork() 子进程时,将这个 TCP 服务器端 socket 的文件描述符发送给工作进程。如果工作进程是通过 cluster.fork() 复制出来的,那么它的环境变量里就存在 NODE_UNIQUE_ID,如果工作进程中存在 listen() 侦听网络端口的调用,它将拿到文件描述符,通过 SO_REUSEADDR 端口重用,从而实现多个子进程共享端口。
(1)fork:复制一个工作进程后触发该事件;
(2)online:复制好一个工作进程后,工作进程主动发送一条 online 消息给主进程,主进程收到消息后,触发该事件;
(3)listening:工作进程中调用 listen() (共享了服务器端 Socket)后,发送一条 listening 消息给主进程,主进程收到消息后,触发该事件;
(4)disconnect:主进程和工作进程之间 IPC 通道断开后会触发该事件;
(5)exit:有工作进程退出时会触发该事件;
(6)setup:cluster.setupMaster() 执行完后触发该事件;
这些事件大多跟 child_process 模块的事件相关,在进程间消息传递的基础上完成的封装。
cluster.on('fork', ()=> {
console.log('fork 事件... ');
})
cluster.on('online', ()=> {
console.log('online 事件... ');
})
cluster.on('listening', ()=> {
console.log('listening 事件... ');
})
cluster.on('disconnect', ()=> {
console.log('disconnect 事件... ');
})
cluster.on('exit', ()=> {
console.log('exit 事件... ');
})
cluster.on('setup', ()=> {
console.log('setup 事件... ');
})由以上可知,master 进程通过 cluster.fork() 来创建 worker 进程,其实,cluster.fork() 内部是通过 child_process.fork() 来创建子进程。也就是说:master 与 worker 进程是父、子进程的关系;其跟 child_process 创建的父子进程一样是通过 IPC 通道进行通信的。
IPC 的全称是 Inter-Process Communication,即进程间通信,进程间通信的目的是为了让不同的进程能够互相访问资源并进行协调工作。Node 中实现 IPC 通道的是管道(pipe)技术,具体实现由 libuv 提供,在 Windows 下由命名管道(named pipe)实现,*nix 系统则采用 Unix Domain Socket 实现。其变现在应用层上的进程间通信只有简单的 message 事件和 send 方法,使用十分简单。
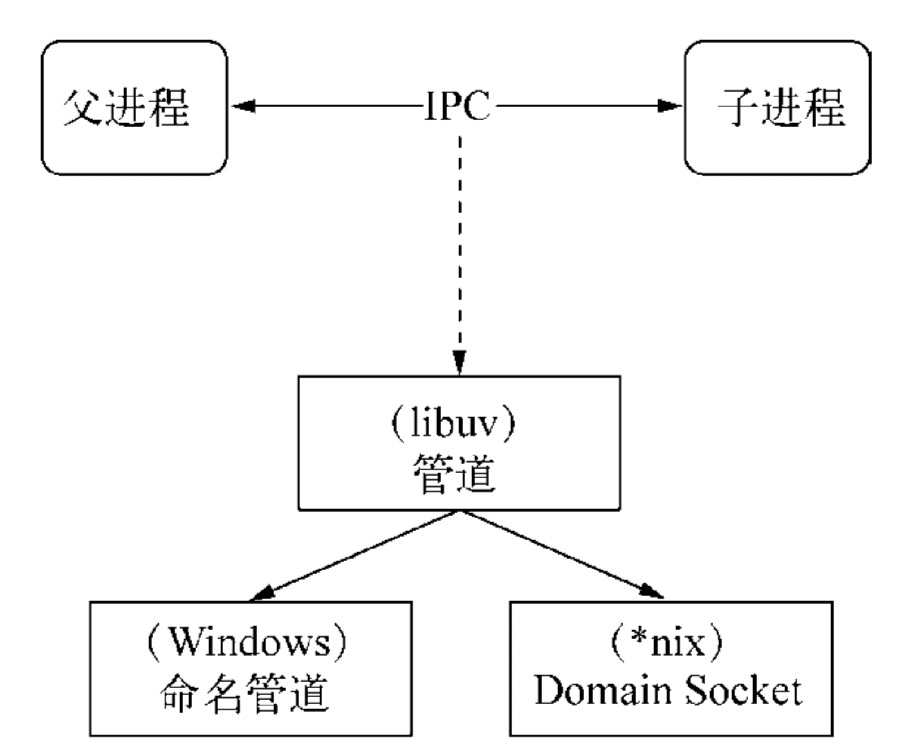
父进程在实际创建子进程之前,会创建 IPC 通道并监听它,然后才真正创建出子进程,并通过环境变量(NODE_CHANNEL_FD)告诉子进程这个 IPC 通道的文件描述符。子进程在启动过程中,根据文件描述符去连接这个已存在的 IPC 通道,从而完成父子进程之间的连接。
建立连接之后的父子进程就可以进行自由通信了。由于 IPC 通道是用命名管道或 Domain Socket 创建的,它们与网络 socket 的行为比较类似,属于双向通信。不同的是它们在系统内核中就完成了进程间的通信,而不用经过实际的网络层,非常高效。在 Node 中,IPC 通道被抽象为 Stream 对象,在调用 send 时发送数据(类似于 write ),接收到的消息会通过 message 事件(类似于 data)触发给应用层。
master 和 worker 进程在 server 实例的创建过程中,是通过 IPC 通道进行通信的,那会不会对我们的开发造成干扰呢?比如,收到一堆其实并不需要关心的消息?答案肯定是不会?那么是怎么做到的呢?
Node 引入进程间发送句柄的功能,send 方法除了能通过 IPC 发送数据外,还能发送句柄,第二个参数为句柄,如下所示
child.send(meeage, [sendHandle])句柄是一种可以用来标识资源的引用,它的内部包含了指向对象的文件描述符。例如句柄可以用来标识一个服务器端 socket 对象、一个客户端 socket 对象、一个 UDP 套接字、一个管道等。
那么句柄发送跟我们直接将服务器对象发送给子进程有没有什么差别?它是否真的将服务器对象发送给子进程?
其实 send() 方法在将消息发送到 IPC 管道前,将消息组装成两个对象,一个参数是 handle,另一个是 message,message 参数如下所示
{
cmd: 'NODE_HANDLE',
type: 'net.Server',
msg: message
}发送到 IPC 管道中的实际上是要发送的句柄文件描述符,其为一个整数值。这个 message 对象在写入到 IPC 管道时会通过 JSON.stringify 进行序列化,转化为字符串。子进程通过连接 IPC 通道读取父进程发送来的消息,将字符串通过 JSON.parse 解析还原为对象后,才触发 message 事件将消息体传递给应用层使用。在这个过程中,消息对象还要被进行过滤处理,message.cmd 的值如果以 NODE_ 为前缀,它将响应一个内部事件 internalMessage ,如果 message.cmd 值为 NODE_HANDLE,它将取出 message.type 值和得到的文件描述符一起还原出一个对应的对象。这个过程的示意图如下所示

在 cluster 中,以 worker 进程通知 master 进程创建 server 实例为例子。worker 伪代码如下:
// woker进程
const message = {
cmd: 'NODE_CLUSTER',
type: 'net.Server',
msg: message
};
process.send(message);
master 伪代码如下:
worker.process.on('internalMessage', fn);
在前面的例子中,多个 woker 中创建的 server 监听了同个端口 3000,通常来说,多个进程监听同个端口,系统会报 EADDRINUSE 异常。为什么 cluster 没问题呢?
因为独立启动的进程中,TCP 服务器端 socket 套接字的文件描述符并不相同,导致监听到相同的端口时会抛出异常。但对于 send() 发送的句柄还原出来的服务而言,它们的文件描述符是相同的,所以监听相同端口不会引起异常。
这里需要注意的是,多个应用监听相同端口时,文件描述符同一时间只能被某个进程所用,换言之就是网络请求向服务器端发送时,只有一个幸运的进程能够抢到连接,也就是说只有它能为这个请求进行服务,这些进程服务是抢占式的。
(1)每当 worker 进程创建 server 实例来监听请求,都会通过 IPC 通道,在 master 上进行注册。当客户端请求到达,master 会负责将请求转发给对应的 worker;
(2)具体转发给哪个 worker?这是由转发策略决定的,可以通过环境变量 NODE_CLUSTER_SCHED_POLICY 设置,也可以在 cluster.setupMaster(options) 时传入,默认的转发策略是轮询(SCHED_RR);
(3)当有客户请求到达,master 会轮询一遍 worker 列表,找到第一个空闲的 worker,然后将该请求转发给该worker;
pm2 是 node 进程管理工具,可以利用它来简化很多 node 应用管理的繁琐任务,如性能监控、自动重启、负载均衡等,如果在实践中没有使用过 pm2 的同学可以查看笔者的另一篇文章《pm2 实践指南》
pm2 自身是基于 cluster 模块进行封装的, 本节我们主要 pm2 的 Satan 进程、God Daemon 守护进程 以及两者之间的进程间远程调用 RPC。
撒旦(Satan),主要指《圣经》中的堕天使(也称堕天使撒旦),被看作与上帝的力量相对的邪恶、黑暗之源,是God 的对立面。
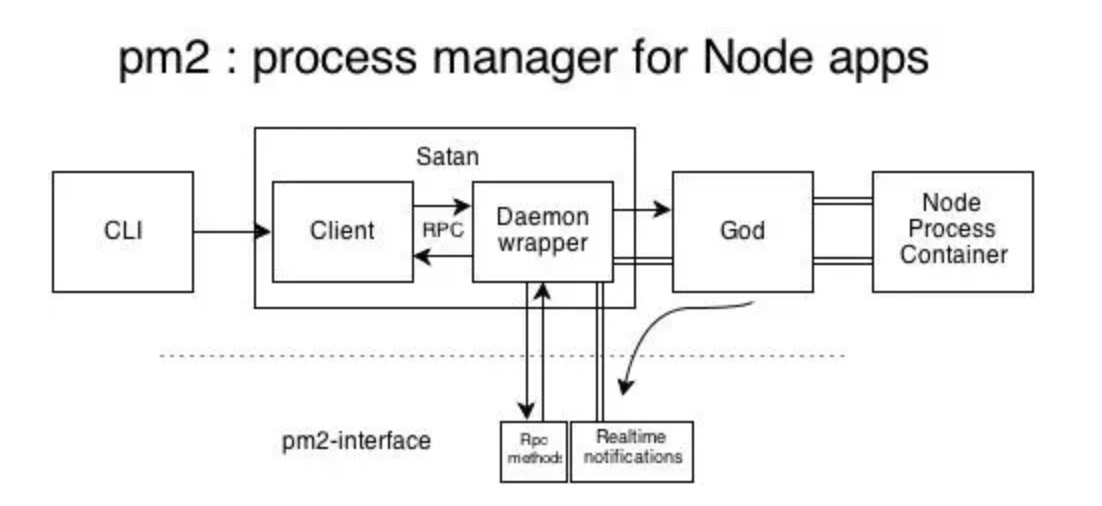
其中 Satan.js 提供程序的退出、杀死等方法,God.js 负责维持进程的正常运行,God 进程启动后一直运行,相当于 cluster 中的 Master进程,维持 worker 进程的正常运行。
RPC(Remote Procedure Call Protocol)是指远程过程调用,也就是说两台服务器A,B,一个应用部署在A 服务器上,想要调用 B 服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。同一机器不同进程间的方法调用也属于 rpc 的作用范畴。
执行流程如下所示
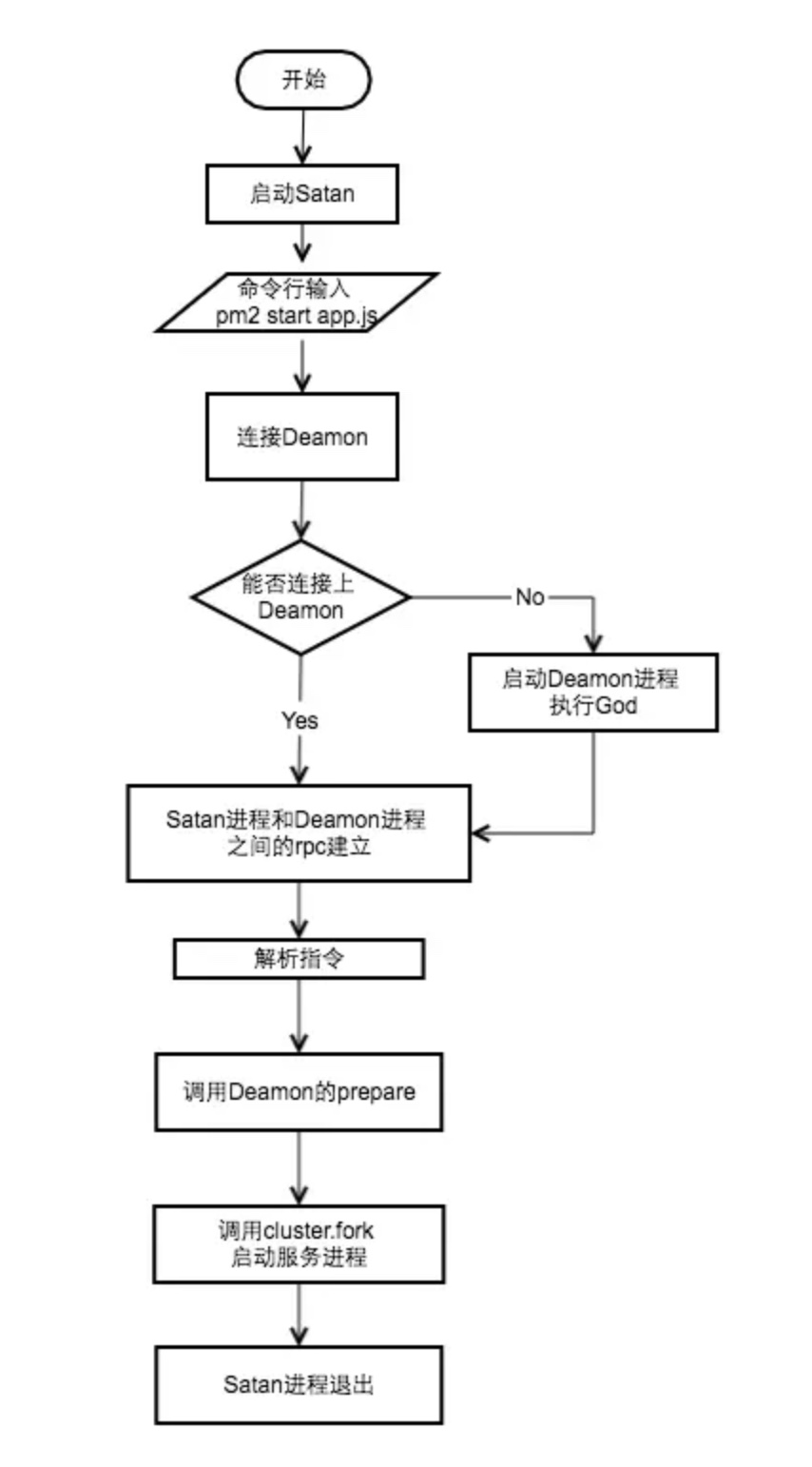
每次命令行的输入都会执行一次 satan 程序,如果 God 进程不在运行,首先需要启动 God 进程。然后根据指令,Satan 通过 rpc 调用 God 中对应的方法执行相应的逻辑。
以 pm2 start app.js -i 4 为例,God 在初次执行时会配置 cluster,同时监听 cluster 中的事件:
// 配置cluster
cluster.setupMaster({
exec : path.resolve(path.dirname(module.filename), 'ProcessContainer.js')
});
// 监听cluster事件
(function initEngine() {
cluster.on('online', function(clu) {
// worker进程在执行
God.clusters_db[clu.pm_id].status = 'online';
});
// 命令行中 kill pid 会触发exit事件,process.kill不会触发exit
cluster.on('exit', function(clu, code, signal) {
// 重启进程 如果重启次数过于频繁直接标注为stopped
God.clusters_db[clu.pm_id].status = 'starting';
// 逻辑
// ...
});
})();
在 God 启动后, 会建立 Satan 和 God 的rpc链接,然后调用 prepare 方法,prepare 方法会调用 cluster.fork 来完成集群的启动
God.prepare = function(opts, cb) {
// ...
return execute(opts, cb);
};
function execute(env, cb) {
// ...
var clu = cluster.fork(env);
// ...
God.clusters_db[id] = clu;
clu.once('online', function() {
God.clusters_db[id].status = 'online';
if (cb) return cb(null, clu);
return true;
});
return clu;
}本文从 cluster 的基本使用、事件,到 cluster 的基本实现原理,再到 pm2 如何基于 cluster 进行进程管理,带你从入门到深入原理以及了解其高阶应用,希望对你有帮助。
博客 github地址为:github.com/fengshi123/blog ,汇总了作者的所有博客,也欢迎关注及 star ~
参考文献:
1、深入理解Node.js 中的进程与线程
2、Node.js进阶:cluster模块深入剖析
3、node 中文网
4、深入浅出 nodejs
前端团队有评审代码的要求,但由于每个开发人员的水平不同,技术关注点不同,所以对代码评审的关注点不同,为了保证代码质量,团队代码风格统一,特此拟定一份《前端团队代码评审 CheckList 清单》,这样代码评审人员在评审代码时,可以参照这份清单,对代码进行评审。从而辅助整个团队提高代码质量、统一代码规范。如果你的团队还没有这么一份代码评审 CheckList 清单,也许这正是你需要的;如果你的团队已经有了代码评审参照标准,这份清单也许能起到锦上添花的效果。
辛苦整理良久,如果喜欢或者有所启发,请帮忙给个 Star ~,对作者也是一种鼓励。
eslint 检查的规范继承自 eslint-config-standard 检验规则,具体的规则介绍参照链接:https://cn.eslint.org/docs/rules/ ,这里及以下部分不再重复介绍这些检验规则。
stylelint 检查的规范继承自 stylelint-config-standard 检验规则,具体的规则介绍参照链接:https://www.npmjs.com/package/stylelint-config-standard ,这里及以下部分不再重复介绍这些检验规则。
推荐:
studentInfot
推荐:
const Car = {
make: "Honda",
model: "Accord",
color: "Blue"
};
不推荐:
const Car = {
carMake: "Honda",
carModel: "Accord",
carColor: "Blue"
};
推荐:
.block__element{}
.block--modifier{}
命名需要符合语义化,如果函数命名,可以采用加上动词前缀:
| 动词 | 含义 |
|---|---|
| can | 判断是否可执行某个动作 |
| has | 判断是否含有某个值 |
| is | 判断是否为某个值 |
| get | 获取某个值 |
| set | 设置某个值 |
推荐:
//是否可阅读
function canRead(){
return true;
}
//获取姓名
function getName{
return this.name
}
每个常量应该命名,不然看代码的人不知道这个常量表示什么意思。
推荐:
const COL_NUM = 10;
let row = Math.ceil(num/COL_NUM);
不推荐:
let row = Math.ceil(num/10);
创建对象和数组推荐使用字面量,因为这不仅是性能最优也有助于节省代码量。
推荐:
let obj = {
name:'tom',
age:15,
sex:'男'
}
不推荐:
let obj = {};
obj.name = 'tom';
obj.age = 15;
obj.sex = '男';
推荐:
const menuConfig = {
title: "Order",
// User did not include 'body' key
buttonText: "Send",
cancellable: true
};
function createMenu(config) {
config = Object.assign(
{
title: "Foo",
body: "Bar",
buttonText: "Baz",
cancellable: true
},
config
);
// config now equals: {title: "Order", body: "Bar", buttonText: "Send", cancellable: true}
// ...
}
createMenu(menuConfig);
不推荐:
const menuConfig = {
title: null,
body: "Bar",
buttonText: null,
cancellable: true
};
function createMenu(config) {
config.title = config.title || "Foo";
config.body = config.body || "Bar";
config.buttonText = config.buttonText || "Baz";
config.cancellable =
config.cancellable !== undefined ? config.cancellable : true;
}
createMenu(menuConfig);
对象成员嵌套越深,读取速度也就越慢。所以好的经验法则是:如果在函数中需要多次读取一个对象属性,最佳做法是将该属性值保存在局部变量中,避免多次查找带来的性能开销。
推荐:
let person = {
info:{
sex:'男'
}
}
function getMaleSex(){
let sex = person.info.sex;
if(sex === '男'){
console.log(sex)
}
}
不推荐:
let person = {
info:{
sex:'男'
}
}
function getMaleSex(){
if(person.info.sex === '男'){
console.log(person.info.sex)
}
}
当需要将浮点数转换成整型时,应该使用Math.floor()或者Math.round(),而不是使用parseInt()将字符串转换成数字。Math是内部对象,所以Math.floor()`其实并没有多少查询方法和调用时间,速度是最快的。
推荐:
let num = Math.floor('1.6');
不推荐:
let num = parseInt('1.6');
函数参数越少越好,如果参数超过两个,要使用 ES6的解构语法,不用考虑参数的顺序。
推荐:
function createMenu({ title, body, buttonText, cancellable }) {
// ...
}
createMenu({
title: 'Foo',
body: 'Bar',
buttonText: 'Baz',
cancellable: true
});
不推荐:
function createMenu(title, body, buttonText, cancellable) {
// ...
}
使用参数默认值 替代 使用条件语句进行赋值。
推荐:
function createMicrobrewery(name = "Hipster Brew Co.") {
// ...
}
不推荐:
function createMicrobrewery(name) {
const breweryName = name || "Hipster Brew Co.";
// ...
}
这是一条在软件工程领域流传久远的规则。严格遵守这条规则会让你的代码可读性更好,也更容易重构。如果违反这个规则,那么代码会很难被测试或者重用 。
在 JavaScript 中,永远不要污染全局,会在生产环境中产生难以预料的 bug。举个例子,比如你在 Array.prototype 上新增一个 diff 方法来判断两个数组的不同。而你同事也打算做类似的事情,不过他的 diff 方法是用来判断两个数组首位元素的不同。很明显你们方法会产生冲突,遇到这类问题我们可以用 ES2015/ES6 的语法来对 Array 进行扩展。
推荐:
class SuperArray extends Array {
diff(comparisonArray) {
const hash = new Set(comparisonArray);
return this.filter(elem => !hash.has(elem));
}
}
不推荐:
Array.prototype.diff = function diff(comparisonArray) {
const hash = new Set(comparisonArray);
return this.filter(elem => !hash.has(elem));
};
函数式变编程可以让代码的逻辑更清晰更优雅,方便测试。
推荐:
const programmerOutput = [
{
name: 'Uncle Bobby',
linesOfCode: 500
}, {
name: 'Suzie Q',
linesOfCode: 1500
}, {
name: 'Jimmy Gosling',
linesOfCode: 150
}, {
name: 'Gracie Hopper',
linesOfCode: 1000
}
];
let totalOutput = programmerOutput
.map(output => output.linesOfCode)
.reduce((totalLines, lines) => totalLines + lines, 0)
不推荐:
const programmerOutput = [
{
name: 'Uncle Bobby',
linesOfCode: 500
}, {
name: 'Suzie Q',
linesOfCode: 1500
}, {
name: 'Jimmy Gosling',
linesOfCode: 150
}, {
name: 'Gracie Hopper',
linesOfCode: 1000
}
];
let totalOutput = 0;
for (let i = 0; i < programmerOutput.length; i++) {
totalOutput += programmerOutput[i].linesOfCode;
}
为了让代码更简洁易读,如果你的函数中出现了条件判断,那么说明你的函数不止干了一件事情,违反了函数单一原则 ;并且绝大数场景可以使用多态替代
推荐:
class Airplane {
// ...
}
// 波音777
class Boeing777 extends Airplane {
// ...
getCruisingAltitude() {
return this.getMaxAltitude() - this.getPassengerCount();
}
}
// 空军一号
class AirForceOne extends Airplane {
// ...
getCruisingAltitude() {
return this.getMaxAltitude();
}
}
// 赛纳斯飞机
class Cessna extends Airplane {
// ...
getCruisingAltitude() {
return this.getMaxAltitude() - this.getFuelExpenditure();
}
}
不推荐:
class Airplane {
// ...
// 获取巡航高度
getCruisingAltitude() {
switch (this.type) {
case '777':
return this.getMaxAltitude() - this.getPassengerCount();
case 'Air Force One':
return this.getMaxAltitude();
case 'Cessna':
return this.getMaxAltitude() - this.getFuelExpenditure();
}
}
}
代码中使用了定时器 setTimeout 和 setInterval,需要在不使用时进行清除。
利用scss中的变量配置,可以进行项目的颜色、字体大小统一更改(换肤),有利于后期项目的维护。
推荐:
$--color-success: #67C23A;
$--color-warning: #E6A23C;
$--color-danger: #F56C6C;
$--color-info: #909399;
scss中的@import规则在生成css文件时就把相关文件导入进来。这意味着所有相关的样式被归纳到了同一个css文件中,而无需发起额外的下载请求,在构建我们自己的组件库时推荐使用。
@import "./base.scss";
@import "./pagination.scss";
@import "./dialog.scss";
@import "./autocomplete.scss";
@import "./dropdown.scss";
@import "./dropdown-menu.scss";
scss局部文件的文件名以下划线开头。这样,scss就不会在编译时单独编译这个文件输出css,而只把这个文件用作导入。
推荐:

scss的嵌套和父选择器标识符&能解决BEM命名的冗长,且使样式可读性更高。
推荐:
.el-input {
display: block;
&__inner {
text-align: center;
}
}
mixin混合器用来实现大段样式的重用,减少代码的冗余,且支持传参。
@mixin button-size($padding-vertical, $padding-horizontal, $font-size, $border-radius) {
padding: $padding-vertical $padding-horizontal;
font-size: $font-size;
border-radius: $border-radius;
&.is-round {
padding: $padding-vertical $padding-horizontal;
}
}
@include m(medium) {
@include button-size($--button-medium-padding-vertical, $--button-medium-padding-horizontal, $--button-medium-font-size, $--button-medium-border-radius);
}
@include m(small) {
@include button-size($--button-small-padding-vertical, $--button-small-padding-horizontal, $--button-small-font-size, $--button-small-border-radius);
}
(1)使用@extend产生 DRY CSS风格的代码(Don't repeat yourself)
(2)@mixin主要的优势就是它能够接受参数。如果想传递参数,你会很自然地选择@mixin而不是@extend
推荐:
.common-mod {
height: 250px;
width: 50%;
background-color: #fff;
text-align: center;
}
.show-mod--right {
@extend .common-mod;
float: right;
}
.show-mod--left {
@extend .common-mod;
}
插值能动态定义类名的名称,当有两个页面的样式类似时,我们会将类似的样式抽取成页面混合器,但两个不同的页面样式的命名名称根据BEM命名规范不能一样,这时我们可使用插值进行动态命名。
推荐:
@mixin home-content($class) {
.#{$class} {
position: relative;
background-color: #fff;
overflow-x: hidden;
overflow-y: hidden;
&--left {
margin-left: 160px;
}
&--noleft {
margin-left: 0;
}
}
}
可通过each遍历、map数据类型、@mixin/@include混合器、#{}插值 结合使用,从而减少冗余代码,使代码更精简。
推荐:
$img-list: (
(xlsimg, $papers-excel),
(xlsximg, $papers-excel),
(gifimg, $papers-gif),
(jpgimg, $papers-jpg),
(mp3img, $papers-mp3),
(mp4img, $papers-mp3),
(docimg, $papers-word),
(docximg, $papers-word),
(rarimg, $papers-zip),
(zipimg, $papers-zip),
(unknownimg, $papers-unknown)
);
@each $label, $value in $img-list {
.com-hwicon__#{$label} {
@include commonImg($value);
}
}
scss自带函数的应用,从而进行相关的计算,例如 mix函数的使用如下。
@include m(text) {
&:hover,
&:focus {
color: mix($--color-white, $--color-primary, $--button-hover-tint-percent);
border-color: transparent;
background-color: transparent;
}
&:active {
color: mix($--color-black, $--color-primary, $--button-active-shade-percent);
border-color: transparent;
background-color: transparent;
}
}
gulp-sass插件能实时监测scss代码检查其语法错误并将其编译成css代码,帮助开发人员检查scss语法的准确性,且其是否符合我们的预期,相关配置如下:
gulp.task('gulpsass', function() {
return gulp.src('src/style/components/hwIcon.scss')
.pipe(gulpsass().on('error', gulpsass.logError))
.pipe(gulp.dest('src/style/dest'));
});
gulp.task('watch', function() {
gulp.watch('src/style/components/hwIcon.scss', ['gulpsass']);
});
我们开发过程中自定义的组件的名称需要为多个单词,这样做可以避免跟现有的以及未来的HTML元素相冲突,因为所有的 HTML 元素名称都是单个单词的。
推荐:
Vue.component('todo-item', {
// ...
})
export default {
name: 'TodoItem',
// ...
}
不推荐:
Vue.component('todo', {
// ...
})
export default {
name: 'Todo',
// ...
}
当在组件中使用 data 属性的时候 (除了 new Vue 外的任何地方),它的值必须是返回一个对象的函数。 因为如果直接是一个对象的话,子组件之间的属性值会互相影响。
推荐:
export default {
data () {
return {
foo: 'bar'
}
}
}
不推荐:
export default {
data: {
foo: 'bar'
}
}
prop 的定义应该尽量详细,至少需要指定其类型。
推荐:
props: {
status: String
}
// 更好的做法!
props: {
status: {
type: String,
required: true,
validator: function (value) {
return [
'syncing',
'synced',
'version-conflict',
'error'
].indexOf(value) !== -1
}
}
}
不推荐:
props: ['status']
v-for 中总是有设置 key 值。在组件上总是必须用 key 配合 v-for,以便维护内部组件及其子树的状态。
推荐:
<ul>
<li
v-for="todo in todos"
:key="todo.id">
{{ todo.text }}
</li>
</ul>
不推荐:
<ul>
<li v-for="todo in todos">
{{ todo.text }}
</li>
</ul>
组件名应该倾向于完整单词而不是缩写,编辑器中的自动补全已经让书写长命名的代价非常之低了,而其带来的明确性却是非常宝贵的。不常用的缩写尤其应该避免。
推荐:
components/
|- StudentDashboardSettings.vue
|- UserProfileOptions.vue
不推荐:
components/
|- SdSettings.vue
|- UProfOpts.vue
在 JavaScript 中,用多行分隔对象的多个属性是很常见的最佳实践,因为这样更易读。
推荐:
<MyComponent
foo="a"
bar="b"
baz="c"
/>
不推荐:
<MyComponent foo="a" bar="b" baz="c"/>
组件模板应该只包含简单的表达式,复杂的表达式则应该重构为计算属性或方法。复杂表达式会让你的模板变得不那么声明式。我们应该尽量描述应该出现的是什么,而非如何计算那个值。而且计算属性和方法使得代码可以重用。
推荐:
<!-- 在模板中 -->
{{ normalizedFullName }}
// 复杂表达式已经移入一个计算属性
computed: {
normalizedFullName: function () {
return this.fullName.split(' ').map(function (word) {
return word[0].toUpperCase() + word.slice(1)
}).join(' ')
}
}
不推荐:
{{
fullName.split(' ').map(function (word) {
return word[0].toUpperCase() + word.slice(1)
}).join(' ')
}}
应该把复杂计算属性分割为尽可能多的更简单的属性。
推荐:
computed: {
basePrice: function () {
return this.manufactureCost / (1 - this.profitMargin)
},
discount: function () {
return this.basePrice * (this.discountPercent || 0)
},
finalPrice: function () {
return this.basePrice - this.discount
}
}
不推荐:
computed: {
price: function () {
var basePrice = this.manufactureCost / (1 - this.profitMargin)
return (
basePrice -
basePrice * (this.discountPercent || 0)
)
}
}
指令推荐都使用缩写形式,(用 : 表示 v-bind: 、用 @ 表示 v-on: 和用 # 表示 v-slot:)。
推荐:
<input
@input="onInput"
@focus="onFocus"
>
不推荐:
<input
v-on:input="onInput"
@focus="onFocus"
>
单文件组件应该总是让标签顺序保持为 、<script>、 <style> 。
推荐:
<!-- ComponentA.vue -->
<template>...</template>
<script>/* ... */</script>
<style>/* ... */</style>
不推荐:
<!-- ComponentA.vue -->
<template>...</template>
<style>/* ... */</style>
<script>/* ... */</script>
父子组件的通信推荐使用 prop和 emit ,而不是this.$parent或改变 prop;
兄弟组件之间的通信推荐使用 EventBus($emit / $on),而不是滥用 vuex;
祖孙组件之间的通信推荐使用 $attrs / $listeners 或 provide / inject(依赖注入) ,而不是滥用 vuex;
页面跳转,例如 A 页面跳转到 B 页面,需要将 A 页面的数据传递到 B 页面,推荐使用 路由参数进行传参,而不是将需要传递的数据保存 vuex,然后在 B 页面取出 vuex的数据,因为如果在 B 页面刷新会导致 vuex 数据丢失,导致 B 页面无法正常显示数据。
推荐:
let id = ' 123';
this.$router.push({name: 'homeworkinfo', query: {id:id}});
script 标签内部的声明顺序如下:
data > prop > components > filter > computed > watch > 钩子函数(钩子函数按其执行顺序) > methods
推荐:
如果运行时,需要非常频繁地切换,推荐使用 v-show 比较好;如果在运行时,条件很少改变,则推荐使用 v-if 比较好。
因为团队现在使用 vue 框架,所以在项目开发中尽量使用 vue 的特性去满足我们的需求,尽量(不到万不得已)不要手动操作DOM,包括:增删改dom元素、以及更改样式、添加事件等。
很多时候有些代码已经没有用了,但是没有及时去删除,这样导致代码里面包括很多注释的代码块,好的习惯是提交代码前记得删除已经确认弃用的代码,例如:一些调试的console语句、无用的弃用代码。
代码注释不是越多越好,保持必要的业务逻辑注释,至于函数的用途、代码逻辑等,要通过语义化的命令、简单明了的代码逻辑,来让阅读代码的人快速看懂。
辛苦整理良久,如果喜欢或者有所启发,请帮忙给个 Star ~,对作者也是一种鼓励。
通过上一篇文章《一文归纳 React Hooks 常用场景》,我们根据使用场景分别进行举例说明,帮助你认识理解并可以熟练运用 React Hooks 大部分特性了。本文则对 hooks 进一步加深,让我们通过自定义一些 hooks,解决我们在平时项目中非常常用的需求场景,做到代码高复用低耦合,从而加深对 hooks 的理解和运用。
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:github.com/fengshi123/… ,汇总了作者的所有博客,欢迎关注及 star ~
首先我们自定义一个 useMount hook,其功能为在 Dom 渲染之后执行相关函数,即类似于 class 组件写法中的 componentDidMount 生命周期钩子的功能。
我么基于以下原理实现:如果想执行只运行一次的 effect(仅在组件挂载和卸载时执行),可以传递一个空数组([])作为第二个参数。这就告诉 React 你的 effect 不依赖于 props 或 state 中的任何值,所以它永远都不需要重复执行。如果在函数组件中实现该功能,即代码如下所示
useEffect(() => {
console.log('mount');
}, []);现在我们将这个功能进行抽取,封装成为 useMount hook,则可以如下实现,其中该钩子支持传入一个回调执行函数 fn 作为参数。
import { useEffect } from 'react';
const useMount = (fn: () => void) => {
useEffect(() => {
fn();
}, []);
};
export default useMount;现在我们就可以在相关业务场景中使用这个 useMount hook 了,如下所示,只会在 MyPage 初次渲染时执行一次 fun,即使我们多次点击 button,使 count 不断增加,页面不断更新,也不会再执行 fun。
import React, { useCallback, useState } from 'react';
import useMount from './useMount';
const MyPage = () => {
const [count, setCount] = useState(0);
const fun = useCallback(() => {
console.log('mount');
}, []);
useMount(fun);
return (
<div >
<button type="button" onClick={() => { setCount(count + 1); }}>
增加 {count}
</button>
</div>
);
};
export default MyPage;本节我们自定义一个 useUnmount hook,其功能为在 Dom 卸载之前执行相关函数,即类似于 class 组件写法中的 componentWillUnmount 生命周期钩子的功能。
我么基于以下原理实现:如果 effect 有返回一个函数,React 将会在执行清除操作时调用它。如果在函数组件中实现该功能,即代码如下所示
useEffect(() => () => {
console.log('unmount');
});现在我们将这个功能进行抽取,封装成为 useUnmount hook,则可以如下实现,其中该钩子支持传入一个回调执行函数 fn 作为参数。
import { useEffect } from 'react';
const useUnmount = (fn: () => void) => {
useEffect(() => {
fn();
}, []);
};
export default useUnmount;现在我们就可以在相关业务场景中使用这个 useUnmount hook 了,如下所示,只会在 MyComponet 卸载时执行一次 fun。
import React, { useCallback, useState } from 'react';
import useUnmount from './useUnmount';
const MyComponent = () => {
const fun = useCallback(() => {
console.log('unmount');
}, []);
useUnmount(fun);
return <div>Hello World</div>;
};
const MyPage = () => {
const [state, setState] = useState(true);
return (
<div >
{state && <MyComponent />}
<button type="button" onClick={() => { setState(!state); }}>
切换
</button>
</div>
);
};
export default MyPage;我们都知道如果想让 function 组件重新渲染,我们不得不更新 state,但是有时候业务需要的 state 是没必要更新的,我们不能仅仅为了让组件会重新渲染而强制让一个 state 做无意义的更新,所以这个时候我们就可以自定义一个更新的 hook 来优雅的实现组件的强制更新,类似于 class 组件的 forceUpdate 的功能,实现代码如下
import { useCallback, useState } from 'react';
const useUpdate = () => {
const [, setState] = useState({});
return useCallback(() => setState({}), []);
};
export default useUpdate;useUpdate 的使用实例如下所示,点击按钮时,调用 update,会看到 Time 的值在变化,说明组件已经强制更新了。
import React from 'react';
import useUpdate from './useUpdate';
const MyPage = () => {
const update = useUpdate();
return (
<div >
<button type="button" onClick={update}>
Time: {Date.now()}
</button>
</div>
);
};
export default MyPage;平时在实现需求时,经常需要保存上一次渲染时 state 的值,so 这个 hook 就是用来保存上一次渲染状态的。如下所示为实现逻辑,主要用到 useRef.current 来存放变量。
import { useRef } from 'react';
function usePrevious<T> (state: T): T|undefined {
const prevRef = useRef<T>();
const curRef = useRef<T>();
prevRef.current = curRef.current;
curRef.current = state;
return prevRef.current;
}
export default usePrevious;usePrevious 的使用实例如下所示,当点击按钮使 count 增加时,previous 会保留 count 的上一个值。
import React, { useState } from 'react';
import usePrevious from './usePrevious';
const MyPage = () => {
const [count, setCount] = useState(0);
const previous = usePrevious(count);
return (
<div >
<div>新值:{count}</div>
<div>旧值:{previous}</div>
<button type="button" onClick={() => { setCount(count + 1); }}>
增加
</button>
</div>
);
};
export default MyPage;在 hook 中,我们使用 setTimeout 之后,需要在 dom 卸载时,手动进行 clearTimeout 将定时器移除,否则可能造成内存泄漏。假设我们在项目中多次用到,那我们则需要多次重复写移除代码,并且有时候可能由于疏忽,将其遗忘。so,为什么不能将它封装成 hook,在需要的时候调用即可。
import { useEffect } from 'react';
function useTimeout (fn: () => void, delay: number) {
useEffect(() => {
const timer = setTimeout(() => {
fn();
}, delay);
return () => {
clearTimeout(timer); // 移除定时器
};
}, [delay]);
}
export default useTimeout;如下所示,我们只需要告诉 useTimeout 多少毫秒去调用哪个方法,不需要再去考虑移除定时器的事情了。
import React, { useState } from 'react';
import useTimeout from './useTimeout';
const MyPage = () => {
const [count, setCount] = useState(0);
useTimeout(() => {
setCount(count => count + 1);
}, 3000);
return (
<div >
<button type="button">
增加 {count}
</button>
</div>
);
};
export default MyPage;useInterval 封装 setInterval 功能,其原因和用法跟 useTimeout 一样,这里不再赘述。
import { useEffect } from 'react';
function useInterval (fn: () => void, delay: number) {
useEffect(() => {
const timer = setInterval(() => {
fn();
}, delay);
return () => {
clearInterval(timer); // 移除定时器
};
}, [delay]);
}
export default useInterval;防抖在我们日常开发中是非常常见的,比如:按钮点击、文本编辑保存等,为防止用户过于频繁操作,需要进行防抖处理。**防抖的定义:任务频繁触发的情况下,只有任务触发的间隔超过指定间隔的时间,才执行代码一次。**类比于生活中的场景就例如坐公交,在一定时间内,如果有乘客陆续刷卡上车,司机就不会开车,当乘客没有刷卡了,司机才开车。
防抖功能的基本实现和相关注释如下所示
function debounce(fn,wait){
let timeout1;
return function(){
clearTimeout(timeout1); // 重新清零
let context = this; // 保存上下文
let args = arguments; // 获取传入的参数
timeout1 = setTimeout(()=> {
fn.apply(context, args);
},wait)
}
}我们将以上的实现用 hooks 自定义的方式来写,useDebounce hook 相关代码如下,其中传入的两个参数为:fn(要执行的回调方法)和 delay(防抖时间),然后该 hook 返回一个执行方法
import { useCallback, useRef } from 'react';
const useDebounce = (fn: Function, delay = 100) => {
const time1 = useRef<any>();
return useCallback((...args) => {
if (time1.current) {
clearTimeout(time1.current);
}
time1.current = setTimeout(() => {
fn(...args);
}, delay);
}, [delay]);
};
export default useDebounce;现在我们就可以在相关业务场景中使用这个 useDebounce hook 了,如下所示,我们不断点击 button,count 也不会增加,只有点击间隔超过 3000ms,count 数才会增加。
import React, { useCallback, useState } from 'react';
import useDebounce from './useDebounce';
const MyPage = () => {
const [count, setCount] = useState(0);
const fun = useCallback(() => {
setCount(count => count + 1);
}, []);
const run = useDebounce(fun, 3000);
return (
<div >
<button type="button" onClick={() => { run(); }}>
增加 {count}
</button>
</div>
);
};
export default MyPage;节流在我们日常开发中是非常常见的,比如:滚动条监听、图片放大镜效果功能等,我们不必每次鼠标滚动都触发,这样可以降低计算的频率,而不必去浪费资源。节流的定义:函数节流是指一定时间内 js 方法只跑一次。类比于生活中的场景就例如人眨眼睛,就是一定时间内眨一次。
节流功能的基本实现和相关注释如下所示,跟防抖很类似
function throttle(fn, wait){
let timeout;
return function(){
if(timeout) return; // 如果已经触发,则不再触发
let args = arguments;
let context = this;
timeout = setTimeout(()=>{
fn.apply(context,args); // 执行
timeout = null; // 执行后,将标志设置为未触发
},wait)
}
}我们将以上的实现用 hooks 自定义的方式来写,useThrottle hook 相关代码如下,其中传入的两个参数为:fn(要执行的回调方法)和 delay(节流时间),然后该 hook 返回一个执行方法
import { useCallback, useRef } from 'react';
const useThrottle = (fn: Function, delay = 100) => {
const time1 = useRef<any>();
return useCallback((...args) => {
if (time1.current) {
return;
}
time1.current = setTimeout(() => {
fn(...args);
time1.current = null;
}, delay);
}, [delay]);
};
export default useThrottle;现在我们就可以在相关业务场景中使用这个 useThrottle hook 了,如下所示,我们不断点击 button,count 只会在连续间隔 3000ms 增加一次,不会每次点击都会增加一次。
import React, { useCallback, useState } from 'react';
import useThrottle from './useThrottle';
const MyPage = () => {
const [count, setCount] = useState(0);
const fun = useCallback(() => {
setCount(count => count + 1);
}, []);
const run = useThrottle(fun, 3000);
return (
<div >
<button type="button" onClick={() => { run(); }}>
增加 {count}
</button>
</div>
);
};
export default MyPage;本文是 react hooks 三部曲中的第二篇,按照预期,后续我们会写 react hooks 三部曲中的第三篇,敬请期待。
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:github.com/fengshi123/… ,汇总了作者的所有博客,欢迎关注及 star ~
在前端,我们只需做字符串级别的操作,很少接触字节、进制等底层操作,一方面这足以满足日常需求,另一方面 在 ECMAScript 2015 (ES6) 引入 TypedArray 之前,JavaScript 语言没有读取或操作二进制数据流的机制;然而在后端,处理文件、网络协议、图片、视频等是非常常见的,尤其像文件、网络流等操作处理的都是二进制数据。为了让 javascript 能够处理二进制数据,node 封装了一个 Buffer 类,主要用于操作字节,处理二进制数据。
一个 Buffer 类似于一个整数数组,可以取下标,有 length 属性,有剪切复制操作等,很多 API 也类似数组,但 Buffer 的大小在被创建时确定,且无法调整。Buffer 处理的是字节,两位十六进制,因此在整数范围就是0~255。
Buffer 可以与string 互相转化,还可以设置字符集编码。Buffer 用来处理文件 I/O、网络 I/O 传输的二进制数据,string 用来呈现。在处理文件 I/O、网络 I/O 传输的二进制数据时,应该尽量以 Buffer 形式直接传输,速度会得到很好的提升。
Buffer 内存分配与性能优化:Buffer 是一个典型的 javascript 与 C++ 结合的模块,与性能有关的用 C++ 来实现,javascript 负责衔接和提供接口。Buffer 所占的内存不是 V8 分配的,是独立于 V8 堆内存之外的内存,通过 C++ 层面实现内存申请、javascript 分配内存。值得一提的是,每当我们使用 Buffer.alloc(size) 请求一个 Buffer 内存时,Buffer 会以 8KB 为界限来判断分配的是大对象还是小对象,小对象存入剩余内存池,不够再申请一个 8KB 的内存池;大对象直接采用 C++ 层面申请的内存。因此,对于一个大尺寸对象,申请一个大内存比申请众多小内存池快很多。
注意点:
1、Buffer 对象类似于数组,它的元素为 16 进制的两位数,即 0 到 255 的数值;不同编码的字符串占用的元素个数各不相同,例如在 UTF-8 编码下:中文占用 3 个字符,字母和半角标点符号占用 1 个字符;
2、如果给 Buffer 元素赋值如果小于 0,就将该值逐次加 256,直到得到一个 0 到 255 之间的整数;如果得到的数值大于 255,就逐次减 256,直到得到 0-255 区间的数值;如果是小数,则舍弃小数部分,只保留整数部分;
注意这个用法存在安全问题,已被废弃;
const buf1 = new Buffer([0x62, 0x75, 0x66, 0x66, 0x65, 0x72]);
console.log(buf1.toString()); // bufferconst buf2 = Buffer.alloc(10); // 长度为 10 的 buffer,初始值为 0x0?
console.log(buf2); // <Buffer 00 00 00 00 00 00 00 00 00 00>
const buf3 = Buffer.alloc(10, 1); // 长度为 10 的 buffer,初始值为 0x1?
console.log(buf3); // <Buffer 01 01 01 01 01 01 01 01 01 01>const buf4 = Buffer.from([1, 2, 3])
console.log(buf4.toString()); // <Buffer 01 02 03>
const buf5 = Buffer.from([0x62, 0x75, 0x66, 0x66, 0x65, 0x72]);
console.log(buf5); // <Buffer 62 75 66 66 65 72>默认编码 utf8
const buf6 = Buffer.from('buffer');
console.log(buf6); // <Buffer 62 75 66 66 65 72>
console.log(buf6.toString()); // buffer创建新的 Buffer 实例,并将 buffer 的数据拷贝到新的实例中去
let buff = Buffer.from('buffer');
let buff2 = Buffer.from(buff);
console.log(buff.toString()); // 输出:buffer
console.log(buff2.toString()); // 输出:buffer
buff2[0] = 0x61;
console.log(buff.toString()); // 输出:buffer
console.log(buff2.toString()); // 输出:auffer// 例子一:编码一样,内容相同 => true
var buf1 = Buffer.from('A');
var buf2 = Buffer.from('A');
console.log( buf1.equals(buf2) ); // true
// 例子二:编码一样,内容不同 => false
var buf3 = Buffer.from('A');
var buf4 = Buffer.from('B');
console.log( buf3.equals(buf4) ); // false
// 例子三:编码不一样,内容相同 => false
var buf5 = Buffer.from('ABC');
var buf6 = Buffer.from('ABC', 'hex');
console.log(buf5.equals(buf6)); // falseconst buf1 = Buffer.from('ABC');
const buf2 = Buffer.from('BCD');
const buf3 = Buffer.from('ABCD');
const buf4 = Buffer.from('ABC');
// 0
console.log(buf1.compare(buf4));
// -1
console.log(buf1.compare(buf2));
// -1
console.log(buf1.compare(buf3));
// 1
console.log(buf2.compare(buf3));
// 0
console.log(buf2.compare(buf3, 1, 3, 0, 2));跟 buf.compare(target) 大同小异,一般用于排序
const buf1 = Buffer.from('1234');
const buf2 = Buffer.from('0123');
const arr = [buf1, buf2];
// [ <Buffer 30 31 32 33>, <Buffer 31 32 33 34> ]
console.log(arr.sort(Buffer.compare));Buffer.concat(list[, totalLength])
其中 totalLength 有两点需要注意。假设 list 里面所有 buffer 的长度累加和为 length
const buff1 = Buffer.from([1, 2]);
const buff2 = Buffer.from([3, 4]);
const length = buff1.length + buff2.length;
const buff3 = Buffer.concat([buff1, buff2], length);
console.log(buff3.length); // 4
console.log(buff3); // <Buffer 01 02 03 04>
const buff4 = Buffer.concat([buff1, buff2], 3);
console.log(buff4.length); // 3
console.log(buff4); // <Buffer 01 02 03>
const buff5 = Buffer.concat([buff1, buff2], 5);
console.log(buff5.length); // 5
console.log(buff5); // <Buffer 01 02 03 04 00>buf.copy(target[, targetStart[, sourceStart[, sourceEnd]]])
var buff1 = Buffer.from([1, 2]);
var buff2 = Buffer.from([3, 4, 5]);
// 1、不传后面 3 个参数的情况
buff1.copy(buff2);
console.log(buff2); // <Buffer 01 02 05>
// 2、传后面 3 个参数的情况
buff1.copy(buff2, 1, 0, buff1.length);
console.log(buff2); // <Buffer 03 01 02>buf.indexOf(value[, byteOffset][, encoding])
跟数组的查找差不多,需要注意的是,value 可能是 String、Buffer、Integer中的任意类型。
另外,可以通过 byteOffset 来指定起始查找位置;
const buf = Buffer.from('this is a buffer');
console.log(buf.indexOf('this')); // 0
console.log(buf.indexOf(Buffer.from('a buffer'))); // 8
console.log(buf.indexOf(Buffer.from('a buffer example'))); // -1
// (97 is the decimal ASCII value for 'a')
console.log(buf.indexOf(97)); // 8
console.log(buf.indexOf('is', 3)); // 5buf.write(string[, offset[, length]][, encoding])
将 sring 写入 buf 实例,同时返回写入的字节数;
参数如下:
var buff1 = Buffer.alloc(4);
const num1 = buff1.write('a'); // 返回 1
console.log(buff1); // 打印 <Buffer 61 00 00 00>
var buff2 = Buffer.alloc(4);
const num2 = buff2.write('abc', 1, 2); // 返回 2
console.log(buff2); // 打印 <Buffer 00 61 62 00>buf.fill(value[, offset[, end]][, encoding])
用 value 填充 buf,常用于初始化 buf。参数说明如下:
var buff = Buffer.alloc(10).fill('a', 1, 3);
console.log(buff); // <Buffer 00 61 61 00 00 00 00 00 00 00>buf.toString([encoding[, start[, end]]])
var buff = Buffer.from('hello');
console.log( buff.toString() ); // hello
console.log( buff.toString('utf8', 0, 2) ); // hebuf.values()、buf.keys()、buf.entries()
var buff = Buffer.from('abcde');
for(const key of buff.keys()){
console.log('key is %d', key);
}
for(const value of buff.values()){
console.log('value is %d', value);
}
for(const pair of buff.entries()){
console.log('buff[%d] === %d', pair[0], pair[1]);
}buf.slice([start[, end]])
用于截取 buf,并返回一个新的 Buffer 实例。需要注意的是,这里返回的 Buffer 实例,指向的仍然是 buf 的内存地址,所以对新 Buffer 实例的修改,也会影响到 buf。
var buff1 = Buffer.from('abcde');
console.log(buff1); // <Buffer 61 62 63 64 65>
var buff2 = buff1.slice(1, 3);
console.log(buff2); // <Buffer 62 63>
buff2[0] = 128;
console.log(buff2); // <Buffer 80 63>
console.log(buff1); // <Buffer 61 80 63 64 65>(1)Nodejs进阶:核心模块Buffer常用API使用总结
(2)认识node核心模块--从Buffer、Stream到fs
单线程同步编程模型会因阻塞 I/O 导致硬件资源得不到更优的使用,多线程编程模型因为线程中的死锁、状态同步等问题让开发人员头疼,并且还会因为上下文的切换,导致系统不能很好提高 CPU 的使用率。
Node 在两者之间给出方案:利用单线程,远离多线程死锁、状态同步等问题;利用 I/O,让单线程远离阻塞,以更好地使用 CPU;从严格意义上而言,Node 并非真正的单线程架构,除了 JS 运行在 V8 上,是单线程外,Node 自身还有一定的 I/O 线程存在。
并且为了弥补单线程无法利用多核 CPU 的缺点,Node 提供 child_process 模块,并且提供了 fork 方法供我们实现进程的复制。
我们通过经典的示例代码来创建 worker 进程,保存为 worker.js 文件,如下所示
const http = require('http')
http.createServer((req, res)=>{
res.writeHead(200, {'Content-Type':'text-plain'});
res.end('Hello NodeJS\n');
}).listen(Math.round((1 + Math.random()) * 1000), '127.0.0.1');然后我们将 master 进程的代码保存为 master.js 文件,如下所示
const fork = require('child_process').fork;
const cpus = require('os').cpus();
for(let i=0; i<cpus.length; i++){
fork('./worker.js')
}我们通过 node master.js 命令来启动 master 进程,其能根据 CPU 数量复制出对应 Node 进程数。在 mac 系统中我们通过 ps aux | grep worker.js 查看进程的数量,如下截图所示

以上就是著名的 Master-Worker 模式,又称 **主从模式,**其中主进程不负责具体的业务处理,而是负责调度或管理工作进程,它是趋向于稳定的,而工作进程负责具体的业务逻辑。
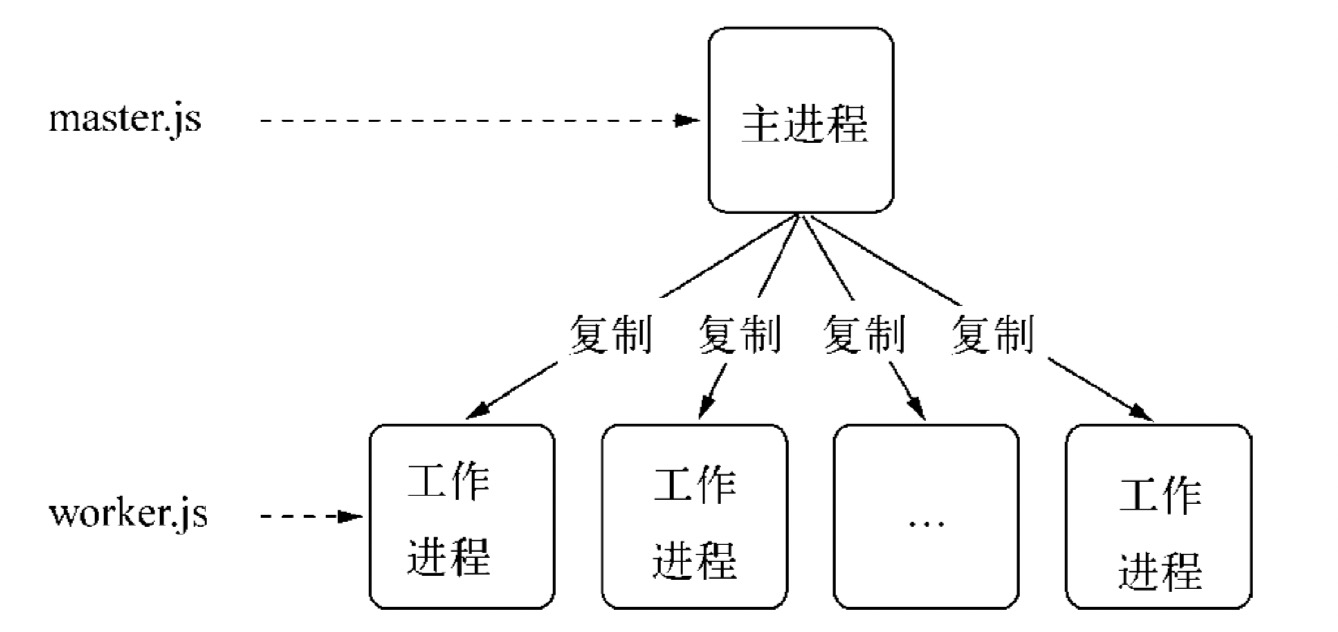
child_process 模块提供了以下 4 个方法用于创建子进程,并且每一种方法都有对应的同步版本:
基本用法和区分点如下:
const cp = require('child_process');
// spawn
cp.spawn('node', ['./dir/test1.js'],
{ stdio: 'inherit' }
);
// exec
cp.exec('node ./dir/test1.js', (err, stdout, stderr) => {
console.log(stdout);
});
// execFile
cp.execFile('node', ['./dir/test1.js'],(err, stdout, stderr) => {
console.log(stdout);
});
// fork
cp.fork('./dir/test1.js',
{ silent: false }
);
// ./dir/test1.js
console.log('test1 输出...');差异点:
差异列表如下:
| 类型 | 回调/异常 | 进程类型 | 执行类型 | 可设置超时 |
|---|---|---|---|---|
| spawn | 不支持 | 任意 | 命令 | 不支持 |
| exec | 支持 | 任意 | 命令 | 支持 |
| execFile | 支持 | 任意 | 可执行文件 | 支持 |
| fork | 不支持 | Node | JavaScript 文件 | 不支持 |
创建一个 shell,然后在 shell 里执行命令。执行完成后,将 stdout、stderr 作为参数传入回调方法。
options 参数说明:
备注:
const { exec } = require('child_process');
exec('ls', (error, stdout, stderr) => {
if (error) {
console.error('error:', error);
return;
}
console.log('stdout: ' + stdout);
console.log('stderr: ' + stderr);
})
exec('ls', {cwd: __dirname + '/dir'}, (error, stdout, stderr) => {
if (error) {
console.error('error:', error);
return;
}
console.log('stdout: ' + stdout);
console.log('stderr: ' + stderr);
})除了例子1 中支持回调函数获取子进程的输出和错误外,还提供 stdout 和 stderr 对输出和错误进行监听,示例如下所示
const child = exec('node ./dir/test1.js')
child.stdout.on('data', data => {
console.log('stdout 输出:', data);
})
child.stderr.on('data', err => {
console.log('error 输出:', err);
})跟 .exec() 类似,不同点在于,没有创建一个新的 shell,options 参数与 exec 一样;
const { execFile } = require('child_process');
// 1、执行命令
execFile('node', ['./dir/test1.js'], (error, stdout, stderr) => {
if (error) {
console.error('error:', error);
return;
}
console.log('stdout: ' + stdout);
console.log('stderr: ' + stderr);
})需要注意的是,我们执行 shell 脚本的时候,并没有重新开一个 shell,即:我们在根目录下运行 execFile 命令执行 ./dir/test2.sh 脚本,我们在 ./dir/test2.sh 脚本中执行与 test2.sh 同目录的 test1..js 文件,我们不能直接写成 node .test1.js 会找不到文件,应该从根目录去寻找;
注意:shell 脚本文件中如果需要访问 node 环境中的变量,可以将变量赋值给 process.env,这样在 shell 脚本中就可以通过 $变量名 进行直接访问;
const { execFile } = require('child_process');
// 2、执行 shell 脚本
// 在 shell 脚本中可以访问到 process.env 的属性
process.env.DIRNAME = __dirname;
execFile(`${__dirname}/dir/test2.sh`, (error, stdout, stderr) => {
if (error) {
console.error('error:', error);
return;
}
console.log('stdout: ' + stdout); // stdout: 执行 test2.sh test1 输出...
console.log('stderr: ' + stderr);
})
// ./dir/test2.sh
#! /bin/bash
echo '执行 test2.sh'
node $DIRNAME/dir/test1.js
// ./dir/test1.js
console.log('test1 输出...');(1)modulePath:子进程运行的模块;
(2)args:字符串参数列表;
(3)options 参数如下所示,其中与 exec 重复的参数就不重复介绍:
const { fork } = require('child_process');
// 1、默认 silent 为 false,子进程会输出 output from the child3
fork('./dir/child3.js', {
silent: false
});
// 2、设置 silent 为 true,则子进程不会输出
fork('./dir/child3.js', {
silent: true
});
// 3、通过 stdout 属性,可以获取到子进程输出的内容
const child3 = fork('./dir/child3.js', {
silent: true
});
child3.stdout.setEncoding('utf8');
child3.stdout.on('data', function (data) {
console.log('stdout 中输出:');
console.log(data);
});(1)command:要执行的命令;
(2)args:字符串参数列表;
(2)options 参数说明,其它重复的参数不在重复:
const spawn = require('child_process').spawn;
const ls = spawn('ls', ['-al']);
// 输出相关的数据
ls.stdout.on('data', function(data){
console.log('data from child: ' + data);
});
// 错误的输出
ls.stderr.on('data', function(data){
console.log('error from child: ' + data);
});
// 子进程结束时输出
ls.on('close', function(code){
console.log('child exists with code: ' + code);
});结果截图如下:
父子进程共用一个输出管道;
// 2、声明 stdio
var ls = spawn('ls', ['-al'], {
stdio: 'inherit'
});
ls.on('close', function(code){
console.log('child exists with code: ' + code);
});结果截图如下:
// 3、错误处理
// 3.1、场景1: 命令本身不存在,创建子进程报错
const child = spawn('bad_command');
child.on('error', (err) => {
console.log('Failed to start child process 1: ', err);
});
// 3.2、场景2: 命令存在,但运行过程报错
const child2 = spawn('ls', ['nonexistFile']);
child2.stderr.on('data', function(data){
console.log('Error msg from process 2: ' + data);
});
child2.on('error', (err) => {
console.log('Failed to start child process 2: ', err);
});在 Master-Worker 模式中,要实现主进程管理和调度工作进程的功能,需要主进程和工作进程之间的通信。Node 中父子进程通过 message 和 send 进行父子进程的通信,简单实例如下所示
// parent.js
const cp = require('child_process');
const child = cp.fork(__dirname + '/child.js');
child.on('message', (m)=>{
console.log('parent get message:', m);
})
child.send('hello Worker!');
// child.js
process.on('message', (m)=>{
console.log('child get message:', m);
})
process.send('hello Master!');如上,通过 fork 或其它 API 创建子进程后,父子进程之间可以通过 message 和 send 传递消息,其底层通过 IPC 通道。
IPC 的全称是 Inter-Process Communication,即进程间通信,进程间通信的目的是为了让不同的进程能够互相访问资源并进行协调工作。Node 中实现 IPC 通道的是管道(pipe)技术,具体实现由 libuv 提供,在 Windows 下由命名管道(named pipe)实现,*nix 系统则采用 Unix Domain Socket 实现。其变现在应用层上的进程间通信只有简单的 message 事件和 send 方法,使用十分简单。
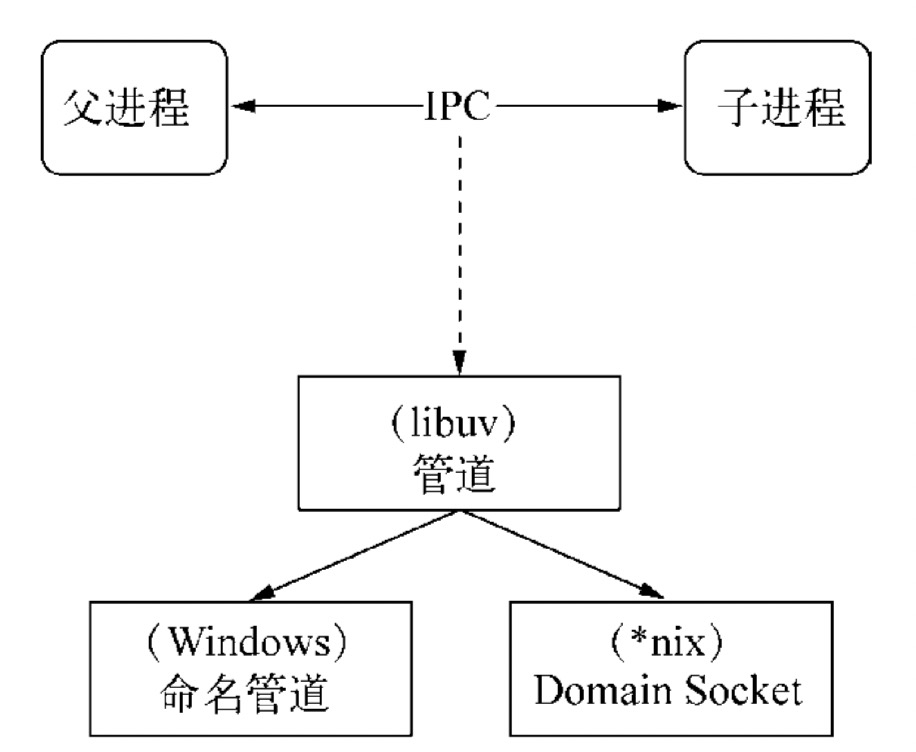
父进程在实际创建子进程之前,会创建 IPC 通道并监听它,然后才真正创建出子进程,并通过环境变量(NODE_CHANNEL_FD)告诉子进程这个 IPC 通道的文件描述符。子进程在启动过程中,根据文件描述符去连接这个已存在的 IPC 通道,从而完成父子进程之间的连接。
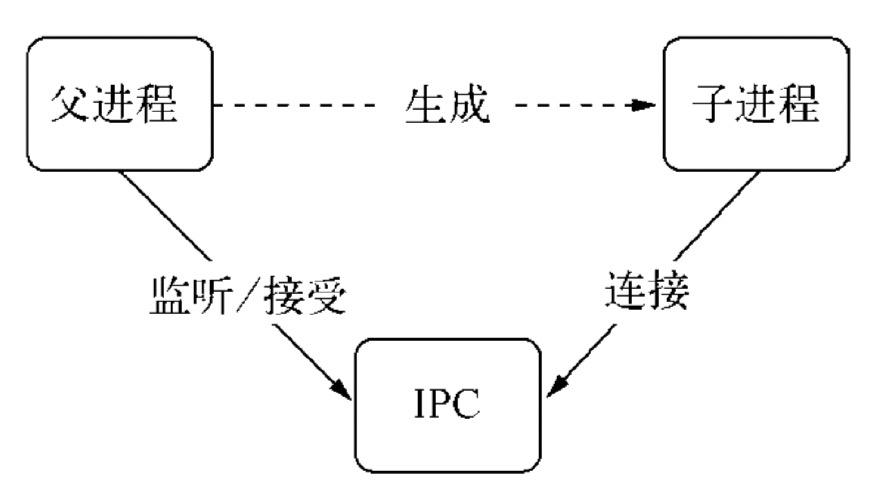
建立连接之后的父子进程就可以进行自由通信了。由于 IPC 通道是用命名管道或 Domain Socket 创建的,它们与网络 socket 的行为比较类似,属于双向通信。不同的是它们在系统内核中就完成了进程间的通信,而不用经过实际的网络层,非常高效。在 Node 中,IPC 通道被抽象为 Stream 对象,在调用 send 时发送数据(类似于 write ),接收到的消息会通过 message 事件(类似于 data)触发给应用层。
Node 引入进程间发送句柄的功能,send 方法除了能通过 IPC 发送数据外,还能发送句柄,第二个参数为句柄,如下所示
child.send(meeage, [sendHandle])句柄是一种可以用来标识资源的引用,它的内部包含了指向对象的文件描述符。例如句柄可以用来标识一个服务器端 socket 对象、一个客户端 socket 对象、一个 UDP 套接字、一个管道等。
那么句柄发送跟我们直接将服务器对象发送给子进程有没有什么差别?它是否真的将服务器对象发送给子进程?
其实 send() 方法在将消息发送到 IPC 管道前,将消息组装成两个对象,一个参数是 handle,另一个是 message,message 参数如下所示
{
cmd: 'NODE_HANDLE',
type: 'net.Server',
msg: message
}发送到 IPC 管道中的实际上是要发送的句柄文件描述符,其为一个整数值。这个 message 对象在写入到 IPC 管道时会通过 JSON.stringify 进行序列化,转化为字符串。子进程通过连接 IPC 通道读取父进程发送来的消息,将字符串通过 JSON.parse 解析还原为对象后,才触发 message 事件将消息体传递给应用层使用。在这个过程中,消息对象还要被进行过滤处理,message.cmd 的值如果以 NODE_ 为前缀,它将响应一个内部事件 internalMessage ,如果 message.cmd 值为 NODE_HANDLE,它将取出 message.type 值和得到的文件描述符一起还原出一个对应的对象。这个过程的示意图如下所示

这里我们提出个疑问:为何通过发送句柄,多个进程可以监听到相同的端口而不引起端口监听异常的错误?
因为独立启动的进程中,TCP 服务器端 socket 套接字的文件描述符并不相同,导致监听到相同的端口时会抛出异常。但对于 send() 发送的句柄还原出来的服务而言,它们的文件描述符是相同的,所以监听相同端口不会引起异常。
这里需要注意的是,多个应用监听相同端口时,文件描述符同一时间只能被某个进程所用,换言之就是网络请求向服务器端发送时,只有一个幸运的进程能够抢到连接,也就是说只有它能为这个请求进行服务,这些进程服务是抢占式的。
通过 child_process 我们可以充分利用多核 CPU 资源,但是每个工作进程依然是在单线程上执行的,它的稳定性还不能得到完全保障。
除了 send() 方法和 message 事件外,Node 还有如下这些事件
基于以上的进程事件,我们能够通过监听子进程的 exit 事件来获知其退出的信息,我们在主进程上可以加入一些子进程管理的机制,比如重新启动一个工作进程来继续服务。
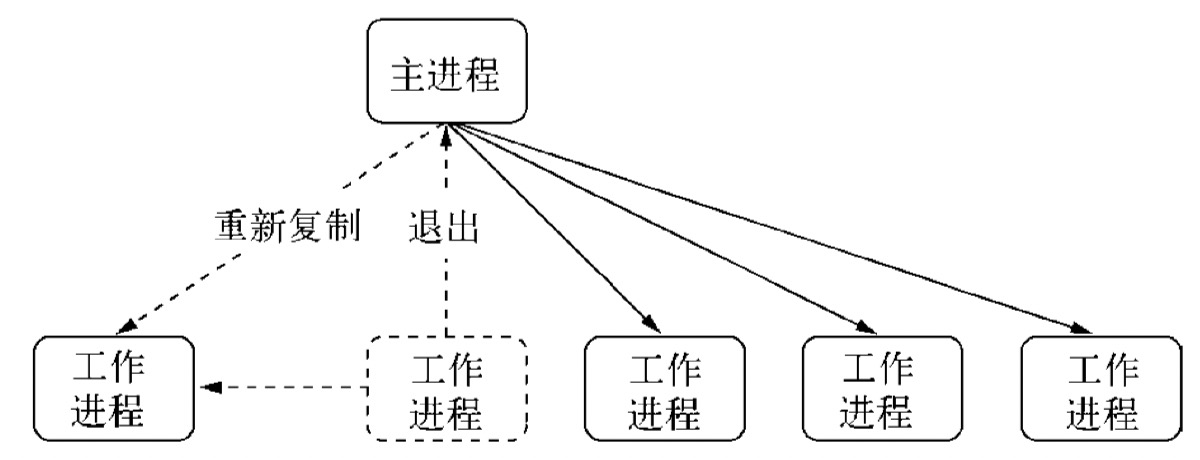
相关写法如下
// master.js
const fork = require('child_process').fork;
const cpus = require('os').cpus();
const server = require('net').createServer();
server.listen(1337);
const workers = {};
const createWorker = ()=>{
const worker = fork(__dirname + '/worker.js');
// 退出时重新启动新的进程
worker.on('exit', ()=> {
console.log('Worker' + worker.pid + ' exited.');
delete workers[worker.pid];
createWorker();
})
// 句柄转发
worker.send('server', server);
workers[worker.pid] = worker;
console.log('Create worker.pid: ' + worker.pid);
}
for(let i =0; i< cpus.length; i++){
createWorker();
}
// 进程自己退出时,让所有工作进程退出
process.on('exit', ()=>{
for(let pid in workers){
workers[pid].kill();
}
})
// worker.js
const http = require('http')
http.createServer((req, res)=>{
res.writeHead(200, {'Content-Type':'text-plain'});
res.end('handled by child, pid is ' + process.pid + '\n');
}).listen(Math.round((1 + Math.random()) * 1000), '127.0.0.1');运行以上代码,如下所示
% node ./colony/master.js
Create worker.pid: 29943
Create worker.pid: 29944
Create worker.pid: 29945
Create worker.pid: 29946
Create worker.pid: 29947
Create worker.pid: 29948
Create worker.pid: 29949
Create worker.pid: 29950当我们通过 kill 命令杀死某个进程时,如下所示
% kill 29944结果是 29944 进程退出后,自动启动了一个新的工作进程 30495,总体进程数量并没有发生改变。
Worker 29944 exited.
Create worker.pid: 30495前面我们是主动杀死一个进程,但在实际的业务中,可能有隐藏的 bug 导致工作进程退出,那我们需要处理这种异常,如下所示
// worker.js
const http = require('http')
http.createServer((req, res)=>{
res.writeHead(200, {'Content-Type':'text-plain'});
res.end('handled by child, pid is ' + process.pid + '\n');
}).listen(Math.round((1 + Math.random()) * 1000), '127.0.0.1');
const worker;
process.on('message', (m, tcp)=>{
if(m === 'server'){
worker = tcp;
worker.on('connection', (socket)=>{
server.emit('connection', socket)
})
}
})
process.on('uncaughtException', ()=>{
// 停止接收新的连接
worker.close(()=>{
process.exit(1);
})
})上述代码的处理流程是,一旦有未捕获的异常出现,工作进程就会立即停止接收新的连接,当所有的连接断开后,退出进程。主进程在侦听到工作进程的 exit 后,将会立即启动新的进程服务,以此保证整个集群中总是有进程在为用户服务的。
前面的自动重启存在问题:等到已有的所有连接断开后进程才退出,在极端的情况下,所有工作进程都停止接收新的连接,全处在等待退出的状态。所有我们需要改进这个过程,不能等到工作进程退出后才重启新的工作进程,也不能暴力退出进行,因为这样会导致已连接的用户直接断开。
我们可以在工作进程得知要退出时,向主进程发送一个自杀信号,然后才停止接收新的连接,当所有连接断开后才退出。主进程在接收到自杀信号后,立即创建新的工作进程服务。如下所示
// worker.js
process.on('uncaughtException', ()=>{
// 发送自杀信号
process.send({act: 'suicide'})
// 停止接收新的连接
worker.close(()=>{
process.exit(1);
})
})
// master.js
const createWorker = ()=>{
const worker = fork(__dirname + '/worker.js');
// 启动新的进程
worker.on('message', (message)=>{
if(message.act === 'suicide'){
createWorker();
}
})
// ...
}与前一种方案相比,创建新工作进程在前,退出异常进程在后。在异常进程退出之前,总有新的工作进程顶替它。如此,我们就完成进程的平滑重启,一旦有异常出现,主进程会创建新的工作进程来为用户服务,旧的进程一旦处理完已有连接就自动断开。这样我们的应用稳定性和健壮性大大提高。
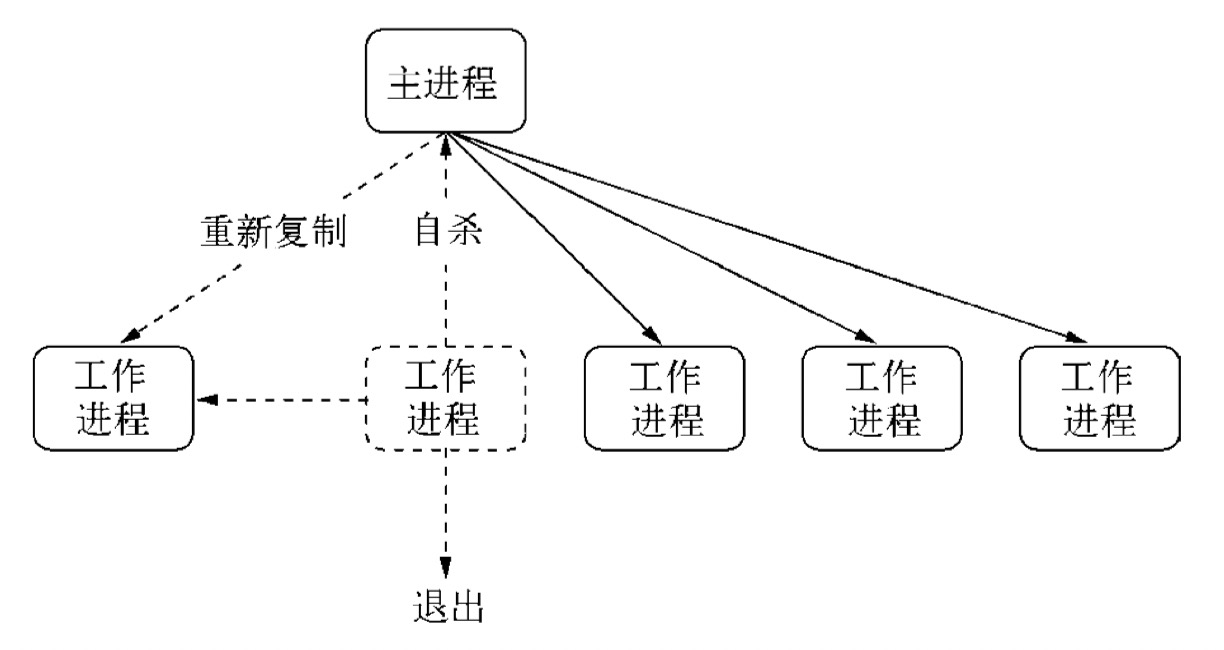
如果场景不是 HTTP 这种短连接服务,而是长连接,那么等待长连接断开可能需要比较久的时间,为此,我们需要为连接的断开设置一个超时时间,在限定的时间里进行强制退出。
process.on('uncaughtException', ()=>{
// 发送自杀信号
process.send({act: 'suicide'})
// 停止接收新的连接
worker.close(()=>{
process.exit(1);
})
// 5 秒后退出进程
setTimeout(()=>{
process.exit(1)
}, 5000)
})进程中如果出现未能捕获的异常,那意味着代码存在健壮性问题,我们需要通过日志记录下问题所在,这样便于定位和修复异常代码,如下所示
process.on('uncaughtException', (err)=>{
// 记录日志
logger.error(err);
// 发送自杀信号
process.send({act: 'suicide'})
// 停止接收新的连接
worker.close(()=>{
process.exit(1);
})
// 5 秒后退出进程
setTimeout(()=>{
process.exit(1)
}, 5000)
})通过自杀信号告知主进程可以使得新连接总是有进程服务,但是依然存在极端情况。工作进程不能无限制地被重启,如果启动过程中就发了错误,会导致工作进程被频繁重启,这种频繁重启不属于我们捕获未知异常的情况。为了消除这种无意义的重启,在满足一定规则的限制下,不应当反复重启。我们可以在单位时间内规定只能重启多少次,超过限制就放弃重启工作进程。
在多进程之间监听相同的端口,使得用户请求能够分散到多个进程上进行处理,这带来的好处是可以将 CPU 资源都利用起来。Node 默认提供的机制是采用操作系统的抢占式策略,所谓的抢占式就是在一堆工作进程中,闲着的进程对到来的请求进行争夺,谁抢到谁服务。
对于 Node 而言,需要分清的是它的繁忙是由 CPU、I/O 两个部分构成,影响抢占的是 CPU 的繁忙度,对不同的业务,可能存在 I/O 繁忙,而 CPU 较为空闲的情况,这造成某个进程能够抢到较多请求,形成负载不均衡的情况。于是在 Node 中提供了一种新的策略使得负载均衡更合理,这种新的策略叫 Round-Robin,又叫轮叫调度。这种工作方式是由主进程接受连接,将其依次分发给工作进程。分发的策略是在 N 个工作进程中,每次选择第 i = (i + 1) mod n 个进程来发送连接。
Node 不允许在多个进程之间共享数据,但在实际的业务中,往往需要共享一些数据,例如配置数据等,这在多个进程中应该一致的。为此,在不允许共享数据的情况下,我们需要一种方案和机制来实现数据在多个进程之间共享。
Node 提供的方案是通过第三方来进行数据储存,比如将数据存放到数据库、磁盘文件、缓存服务(如 Redis)中,所有工作进程在启动时将其读取进内存中。并且当数据发生改变时,还需要一种机制通知到各个子进程,使得它们的内部状态也得到更新。我们可以设计一种通知进程专门用来发送通知和查询状态是否更新,其不处理任何业务逻辑。
其它业务进程在启动时除了读取第一次数据外,还将进程信息注册到通知进程处,一旦通知进程轮询发现有数据更新后,根据注册信息,将更新后的数据发送给工作进程。
在移动端虽然整体来说大部分浏览器内核都是 webkit,而且大部分都支持 css3 的所有语法。但是,由于手机屏幕尺寸不一样,分辨率不一样,或者你需要考虑横竖屏的问题,这时候你也就不得不解决在不同手机上,不同情况下的展示效果,所以就需要一个开箱即用并且行之有效的移动端适配方案。
工欲善其事必先利其器,在具体介绍适配方案前,在本章我们会学习下适配相关的知识点,便于后续适配方案的直接上手接收。如果你对 像素 以及 viewport 的概念还不是很熟悉,可以查看前置文章《移动端响应式设计》
在前端滚滚潮流的历史发展中的不同时期分别出现了一些极具代表性的适配方案,以下分别进行简单介绍。
基于 css 的媒体查询属性 @media 分别为不同屏幕尺寸的移动设备编写不同尺寸的 css 属性,示例如下所示。虽然此方法能在一定程度上解决移动设备适配的问题,但我们也可以看出其存在以下问题,所以其已几乎被历史潮流淘汰。
@media only screen and (min-width: 375px) {
.logo {
width : 62.5px;
}
}
@media only screen and (min-width: 360px) {
.logo {
width : 60px;
}
}
@media only screen and (min-width: 320px) {
.logo {
width : 53.3333px;
}
}rem(font size of the root element)是指相对于根元素的字体大小的单位,如果我们设置 html 的 font-size 为 16px,则如果需要设置元素字体大小为 16px,则写为 1rem。但是其还是必须得借助 @media 属性来为不同大小的设备设置不同的 font-size,相对上一种方案,可以减少重复编写相同属性的代价,简单示例如下所示。
我们也能看到该方案存在以下问题:
@media only screen and (min-width: 375px) {
html {
font-size : 375px;
}
}
@media only screen and (min-width: 360px) {
html {
font-size : 360px;
}
}
@media only screen and (min-width: 320px) {
html {
font-size : 320px;
}
}
//定义方法:calc
@function calc($val){
@return $val / 1080;
}
.logo{
width : calc(180rem);
}在 rem 方案上进行改进,我们可以使用 js 动态来设置根字体,这种方案的典型代表就是 flexible 适配方案。
它的核心代码如下所示
// set 1rem = viewWidth / 10
function setRemUnit () {
var rem = docEl.clientWidth / 10
docEl.style.fontSize = rem + 'px'
}
setRemUnit();上面的代码中,将 html 节点的 font-size 设置为页面 clientWidth(布局视口)的 1/10,即 1rem 就等于页面布局视口的 1/10,这就意味着我们后面使用的 rem 都是按照页面比例来计算的。
设置 viewport 的 width 为 device-width,改变浏览器 viewport(布局视口和视觉视口)的默认宽度为理想视口宽度,从而使得用户可以在理想视口内看到完整的布局视口的内容。
等比设置 viewport 的 initial-scale、maximum-scale、minimum-scale 的值,从而实现 1 物理像素=1 css像素,以适配高倍屏的显示效果(就是在这个地方规避了大家熟知的“1px 问题”)
var metaEL= doc.querySelector('meta[name="viewport"]');
var dpr = window.devicePixelRatio;
var scale = 1 / dpr
metaEl.setAttribute('content', 'width=device-width, initial-scale=' + scale + ', maximum-scale=' + scale + ', minimum-scale=' + scale + ', user-scalable=no'); 不可否认 flexible 在兼容性不友好的某个时期还是极大帮助来成千上万的开发者,但是该方案自身是存在一些问题的。
(1)由于其缩放的缘故,video 标签的视频频播放器的样式在不同 dpr 的设备上展示差异很大;
(2)如果你去研究过 lib-flexible 的源码,那你一定知道 lib-flexible 对安卓手机的特殊处理,即:一律按 dpr = 1 处理;
if (isIPhone) {
// iOS下,对于2和3的屏,用2倍的方案,其余的用1倍方案
if (devicePixelRatio >= 3 && (!dpr || dpr >= 3)) {
dpr = 3;
} else if (devicePixelRatio >= 2 && (!dpr || dpr >= 2)){
dpr = 2;
} else {
dpr = 1;
}
} else {
// 其他设备下,仍旧使用1倍的方案
dpr = 1;
}(3)不再兼容 @media 的响应式布局,因为 @media 语法中涉及到的尺寸查询语句,查询的尺寸依据是当前设备的物理像素,和 flexible 的布局理论(即针对不同 dpr 设备等比缩放视口的 scale 值,从而同时改变布局视口和视觉视口大小)相悖,因此响应式布局在“等比缩放视口大小”的情境下是无法正常工作的;
其实 flexible 方案是在 模拟 viewport 功能,只是随着浏览器的发展及兼容性增强,viewport 已经能兼容绝大部分主流浏览器,并且 flexible 方案自身存在的问题,所有其也已几乎退出历史潮流。引用 lib-flexible 的 github 主页的原话:
由于 viewport 单位得到众多浏览器的兼容,lib-flexible 这个过渡方案已经可以放弃使用,不管是现在的版本还是以前的版本,都存有一定的问题。建议大家开始使用 viewport 来替代此方案。
vw 作为布局单位,从底层根本上解决了不同尺寸屏幕的适配问题,因为每个屏幕的百分比是固定的、可预测、可控制的。 viewport 相关概念如下:
假设我们拿到的视觉稿宽度为 750px,视觉稿中某个字体大小为 75px,则我们的 css 属性只要如下这么写,不需要额外的去用 js 进行设置,也不需要去缩放屏幕等;
.logo {
font-size: 10vw; // 1vw = 750px * 1% = 7.5px
}在 html 头部设置 mata 标签如下所示,让当前 viewport 的宽度等于设备的宽度,同时不允许用户手动缩放。
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=0">
设计师一般给宽度大小为 375px 或 750px 的视觉稿,我们采用 vw 方案的话,需要将对应的元素大小单位 px 转换为 vw 单位,这是一项影响开发效率(需要手动计算将 px 转换为 vw)且不利于后续代码维护(css 代码中一堆 vw 单位,不如 px 看的直观)的事情;好在社区提供了 postcss-px-to-viewport 插件,来将 px 自动转换为 vw,相关配置步骤如下:
(1)安装插件
npm install postcss-px-to-viewport --save-dev(2)webpack 配置
官网是使用 glup 进行配置,但是我们项目模版中是使用 webpack 进行 postcss 插件以及相关样式插件的配置,所以我们就使用 webpack 进行配置使用,不需要额外引入 gulp 编译;webpack 相关配置如下,且每个属性表示的意义进行了备注:
module.exports = {
plugins: {
// ...
'postcss-px-to-viewport': {
// options
unitToConvert: 'px', // 需要转换的单位,默认为"px"
viewportWidth: 750, // 设计稿的视窗宽度
unitPrecision: 5, // 单位转换后保留的精度
propList: ['*', '!font-size'], // 能转化为 vw 的属性列表
viewportUnit: 'vw', // 希望使用的视窗单位
fontViewportUnit: 'vw', // 字体使用的视窗单位
selectorBlackList: [], // 需要忽略的 CSS 选择器,不会转为视窗单位,使用原有的 px 等单位
minPixelValue: 1, // 设置最小的转换数值,如果为 1 的话,只有大于 1 的值会被转换
mediaQuery: false, // 媒体查询里的单位是否需要转换单位
replace: true, // 是否直接更换属性值,而不添加备用属性
exclude: undefined, // 忽略某些文件夹下的文件或特定文件,例如 'node_modules' 下的文件
include: /\/src\//, // 如果设置了include,那将只有匹配到的文件才会被转换
landscape: false, // 是否添加根据 landscapeWidth 生成的媒体查询条件
landscapeUnit: 'vw', // 横屏时使用的单位
landscapeWidth: 1125, // 横屏时使用的视窗宽度
},
},
};相关配置属性,通过注释一目了然其作用,其中需要强调的点为 propList 属性,我们配置了 font-size 不进行转换 vw,也就是说在不同手机屏幕尺寸下的字体大小是一样的。
其中 font-size 是否需要根据屏幕大小做适配,或者怎么做,一直是个争论不休的话题;考虑到我们移动端没有平板的需求,且咨询过团队业务设计师的意见,所以对模版进行以上默认配置;当然如果你的视觉要求你的项目要做字体大小适配,修改 propList 属性的配置即可。
(3)效果展示
我们在项目代码中,进行如下 css 编码:
.hello {
color: #333;
font-size: 28px;
}启动项目,我们可以看到浏览器渲染的页面中,postcss-px-to-viewport 已经帮我们做进行了 px -> vw 的转换;如下所示:
在项目中,如果设计师要求某一场景不做自适配,需为固定的宽高或大小,这时我们就需要利用 postcss-px-to-viewport 插件的 Ignoring 特性,对不需要转换的 css 属性进行标注,示例如下所示:
/* example input: */
.class {
/* px-to-viewport-ignore-next */
width: 10px;
padding: 10px;
height: 10px; /* px-to-viewport-ignore */
}
/* example output: */
.class {
width: 10px;
padding: 3.125vw;
height: 10px;
}考虑 Retina 屏场景,可能对图片的高清程度、1px 等场景有需求,所以我们预留判断 Retina 屏坑位。
相关方案如下:在入口的 html 页面进行 dpr 判断,以及 data-dpr 的设置;然后在项目的 css 文件中就可以根据 data-dpr 的值根据不同的 dpr 写不同的样式类;
(1)index.html 文件
// index.html 文件
const dpr = devicePixelRatio >= 3? 3: devicePixelRatio >= 2? 2: 1;
document.documentElement.setAttribute('data-dpr', dpr);(2)样式文件
[data-dpr="1"] .hello {
background-image: url([email protected]);
[data-dpr="2"] .hello {
background-image: url([email protected]);
}
[data-dpr="3"] .hello {
background-image: url([email protected]);
}场景:当你需要写行内样式的代码(style)时,postcss-px-to-viewport 插件 无法进行 px 单位无法转换,需要自己手动计算好 vw;
最佳实践:通过添加、修改、删除 className 的方式进行处理此类场景,不直接操作行内样式,这更符合将 js 和 css 隔离开的更佳实践。
retina 屏下 1px 问题是个常谈的问题,相比较普通屏,retina 屏的 1px 线会显得比较粗,设计美感欠缺;在视觉设计师眼里的 1px 是指设备像素 1px,而如果我们直接写 css 的大小 1px,那在 dpr = 2 时,则等于 2px 设备像素,dpr = 3 时,等于 3px 设备像素。所以对于要求处理 1px 的场景,我们要进行特殊处理。以下介绍常用的几种方法
可以使用 transform: scale(0.5) 进行 X、Y 轴的缩放,如下示例所示
.class1 {
height: 1px;
transform: scaleY(0.5);
}优点是编写简单,但是如果实现上下左右四条边框会比较难搞,并且如果有嵌套存在的话,会对包含的元素产生影响,所以结合 :before 和 :after 来使用。
此种方式能解决例如 标签上下左右边框 1px 的场景,以及有嵌套元素存在的场景,比较通用,示例如下所示
.calss1 {
position: relative;
&::after {
content:"";
position: absolute;
bottom:0px;
left:0px;
right:0px;
border-top:1px solid #666;
transform: scaleY(0.5);
}
}利用 css 对阴影处理来模拟边框,示例如下所示,底部一条线,缺点是存在阴影不好看。
.class1 {
box-shadow: 0 1px 1px -1px rgba(0, 0, 0, 0.5);
}还有如下等方式处理 1px 问题,但不推荐,了解即可
图片高清的问题:
(1)适用普通屏的图片在 retina 屏中,图片展示就会显得模糊;
(2)适用 retina 屏的图片在普通屏中,图片展示就会缺少色差、没有锐利度,并且浪费带宽;
所以如果对性能、美观要求很高的场景,需要根据 dpr 区分使用对应的图片,我们在文章 viewport 适配方案中针对 retina 屏预留了 dpr 方案,相关 css 写法如下:
[data-dpr="1"] .hello {
background-image: url([email protected]);
[data-dpr="2"] .hello {
background-image: url([email protected]);
}
[data-dpr="3"] .hello {
background-image: url([email protected]);
}
iPhoneX 取消了物理按键,改成底部小黑条,这一改动导致网页出现了比较尴尬的屏幕适配问题。对于网页而言,顶部(刘海部位)的适配问题浏览器已经做了处理,所以我们只需要关注底部与小黑条的适配问题即可(即常见的吸底导航、返回顶部等各种相对底部 fixed 定位的元素)。关于 iPhoneX 的适配方案,可以查看笔者的另一篇文章《 iPhoneX 适配方案》
Android 4.4 之下和 iOS 8 以下的版本有一定的兼容性问题(ps:几乎绝迹,大家可以统计下你们的用户使用的系统版本占比),但是社区提供了兼容性解决方案,其为 viewport 的 buggyfill:Viewport Units Buggyfill,可以访问其 github 官网查看;我们也做了对应的实践,但是考虑到性能,我们项目模版中不会进行引入,有兴趣的同学可以查看以下实践总结;
viewport-units-buggyfill 主要有两个 JavaScript 文件:viewport-units-buggyfill.js 和 viewport-units-buggyfill.hacks.js。你只需要在你的 HTML 文件中引入这两个文件,比如在 react 项目中的 index.html 引入它们;
<script src="//g.alicdn.com/fdilab/lib3rd/viewport-units-buggyfill/0.6.2/??viewport-units-buggyfill.hacks.min.js,viewport-units-buggyfill.min.js"></script>第二步,在HTML文件中调用 viewport-units-buggyfill,比如:
<script>
window.onload = function () {
window.viewportUnitsBuggyfill.init({
hacks: window.viewportUnitsBuggyfillHacks
});
}
</script>但是为保证 Viewport Units Buggyfill 起作用,我们必须在我们样式文件中用到了viewport 的单位(vw、vh、vmin 或 vmax )地方添加 content,如下所示:
.my-viewport-units-using-thingie {
width: 50vmin;
height: 50vmax;
top: calc(50vh - 100px);
left: calc(50vw - 100px);
/* hack to engage viewport-units-buggyfill */
content: 'viewport-units-buggyfill; width: 50vmin; height: 50vmax; top: calc(50vh - 100px); left: calc(50vw - 100px);';
}在 1 步骤中,我们人肉引入 content 属性,效率是非常低下的,好在社区提供了 postcss-viewport-units 插件,帮我们自动处理 content:
我们执行以下命令,进行 postcss-viewport-units 插件的安装:
tnpm i postcss-viewport-units --save-dev在我们的项目配置文件 webpack.config.js 中进行对应的插件引入配置:
{
loader: 'postcss-loader',
options: {
ident: 'postcss',
plugins: () => [
// 我们加的配置
require('postcss-viewport-units'),
],
sourceMap: isProductionEnv,
},
},我们在项目代码中,进行如下编码:
.hello {
color: #333;
font-size: 28px;
}展示的页面中,postcss-viewport-units 已经帮我们添加了 content 属性;如下所示:
它的优秀之处并非原创,它的原创之处并不优秀。事件循环是异步实现的核心。
单线程同步编程模型会因阻塞 I/O 导致硬件资源得不到更优的使用,多线程编程模型因为线程中的死锁、状态同步等问题让开发人员头疼;
Node 在两者之间给出方案:利用单线程,远离多线程死锁、状态同步等问题;利用 I/O,让单线程远离阻塞,以更好地使用 CPU;并且为了弥补单线程无法利用多核 CPU 的缺点,Node 提供 child_process 子进程,该子进程可以通过工作进程高效地利用 CPU 和 I/O。
基于 Windows 平台和 *nix 平台的差异,Node 提供了 libuv 作为抽象封装层,使得所有平台兼容性的判断都由这一层来完成,并保证上层的 Node 与下层的自定义线程池及 IOCP 之间各自独立。Node 在编译期间会判断平台条件,选择性编译 unix 目录或是 win 目录下的源文件到目标程序中,架构图如下所示
需要强调的是,虽然我们时常提到 Node 是单线程的,但是这里的单线程仅仅只是 Javascript 执行在单线程中。在 Node 中,无论是 *nix 还是 Windows 平台,内部完成 I/O 任务的另有线程池。
我们继续介绍 Node 是如何实现异步 I/O 的,完成整个异步 I/O 环节的有事件循环、观察者和请求对象。
Node 自身的执行模型 — 事件循环,它使得回调函数十分普遍。在进程启动时,Node 便会创建一个类似于 while(true) 的循环,每执行一次循环体的过程我们称为 Tick。每个 Tick 的过程就是查看是否有事件待处理,如果有,就取出事件及其相关的回调函数。如果存在关联的回调函数,就执行它们。然后进入下个循环,如果不再有事件处理,就退出进程。流程图如下所示
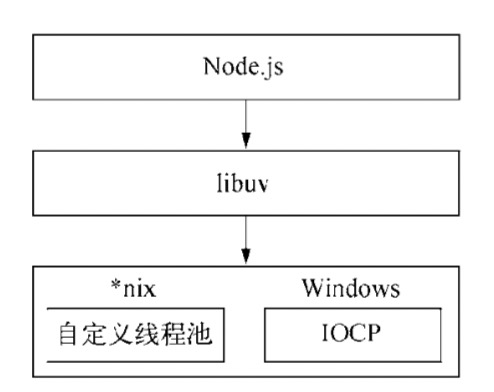
在每个 Tick 的过程中,如何判断是否有事件需要处理呢?这里必须要引入的概念是观察者。每个事件循环中有一个或者多个观察者,而判断是否有事件要处理的过程就是向这些观察者询问是否有要处理的事件。
浏览器类似的机制,事件可能来自用户的点击或者加载某些文件时产生,而这些产生的事件都有对应的观察者。在 Node 中,事件主要来源于网络请求、文件 I/O 等,这些事件对应的观察者有文件 I/O 观察者、网络 I/O 观察者等。
事件循环是一个典型的生产者/消费者模型,异步 I/O、网络请求等则是事件的生产者,源源不断为 Node 提供不同类型的事件,这些事件被传递到对应的观察者那里,事件循环则从观察者那里取出事件并处理。
在 windows 下,这个循环基于 IOCP 创建,而在 *nix 下则基于多线程创建。
对于 Node 中的异步 I/O 调用而言,回调函数不由开发者来调用。那么从我们发出调用后,到回调函数被执行,中间发生了什么呢?事实上,从 Javascript 发起调用到内核执行完 I/O 操作的过渡过程中,存在一种中间产物,叫做请求对象。请求对象是异步 I/O 过程中的重要中间产物,所有的状态都保存在这个对象中,包括送入线程池等待执行的当前方法、参数 以及 I/O 操作完毕后的回调处理函数。
Node 的经典调用方式:从 JavaScript 调用 Node 的核心模块,核心模块调用 C++ 内建模块,内建模块通过 libuv 进行系统调用。至此,会将请求对象推入线程池中等待执行,Javascript 调用则立即返回,由 Javascript 层面发起的异步调用第一阶段就此结束,Javasript 线程可以继续执行当前任务的后续操作。当前的 I/O 操作在线程池中等待执行,不管它是否阻塞 I/O,都不会影响 Javascript 线程的后续执行,如此就到了异步的目的。
组装好请求对象、送入 I/O线程池等待执行,实际上完成了异步 I/O 的第一步,回调通知是第二部分。
线程池中的 I/O 操作调用完毕之后,会讲获取的结果储存在 req->result 属性上,然后调用 PostQueuedCompletionStatus() 通知 IOCP,告知当前对象操作已经完成,并将线程归还线程池。在每次 Tick 的执行过程中,会调用 GetQueuedCompletionStatus() 方法检查线程池中是否有执行完的请求,如果存在,会将请求对象加入到 I/O 观察者的队列中,然后将其当做事件调用处理,以此达到调用 Javascript 中传入的回调函数的目的。
至此,整个异步 I/O 的流程完全结束。事件循环、观察者、请求对象、I/O 线程池这四者共同构成了 Node 异步 I/O 模型的基本要素。具体流程图如下所示
从上描述中 单线程与 I/O 线程池之间看起来自相矛盾,其实在 Node 中,除了 Javascript 运行在单线程中外,Node 自身其实是多线程的,只是 I/O 线程使用的 CPU 较少。另一个需要注意的点是:除了用户代码无法并行执行外,所有的 I/O(磁盘 I/O 和网络 I/O 等)则是可以并行起来的。
React 在 v16.8 的版本中推出了 React Hooks 新特性。在我看来,使用 React Hooks 相比于从前的类组件有以下几点好处:
关于这方面的文章,我们根据使用场景分别进行举例说明,帮助你认识理解并可以熟练运用 React Hooks 大部分特性。
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:https://github.com/fengshi123/blog ,汇总了作者的所有博客,欢迎关注及 star ~
function State(){
const [count, setCount] = useState(0);
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
)
}更新分为以下两种方式,即直接更新和函数式更新,其应用场景的区分点在于:
// 直接更新
setState(newCount);
// 函数式更新
setState(prevCount => prevCount - 1);与 class 组件中的 setState 方法不同,useState 不会自动合并更新对象,而是直接替换它。我们可以用函数式的 setState 结合展开运算符来达到合并更新对象的效果。
setState(prevState => {
// 也可以使用 Object.assign
return {...prevState, ...updatedValues};
});initialState 参数只会在组件的初始渲染中起作用,后续渲染时会被忽略。其应用场景在于:创建初始 state 很昂贵时,例如需要通过复杂计算获得;那么则可以传入一个函数,在函数中计算并返回初始的 state,此函数只在初始渲染时被调用:
const [state, setState] = useState(() => {
const initialState = someExpensiveComputation(props);
return initialState;
});(1)不像 class 中的 this.setState ,Hook 更新 state 变量总是替换它而不是合并它;
(2)推荐使用多个 state 变量,而不是单个 state 变量,因为 state 的替换逻辑而不是合并逻辑,并且利于后续的相关 state 逻辑抽离;
(3)调用 State Hook 的更新函数并传入当前的 state 时,React 将跳过子组件的渲染及 effect 的执行。(React 使用 Object.is 比较算法 来比较 state。)
function Effect(){
const [count, setCount] = useState(0);
useEffect(() => {
console.log(`You clicked ${count} times`);
});
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
)
}为防止内存泄漏,清除函数会在组件卸载前执行;如果组件多次渲染(通常如此),则在执行下一个 effect 之前,上一个 effect 就已被清除,即先执行上一个 effect 中 return 的函数,然后再执行本 effect 中非 return 的函数。
useEffect(() => {
const subscription = props.source.subscribe();
return () => {
// 清除订阅
subscription.unsubscribe();
};
});与 componentDidMount 或 componentDidUpdate 不同,使用 useEffect 调度的 effect 不会阻塞浏览器更新屏幕,这让你的应用看起来响应更快;(componentDidMount 或 componentDidUpdate 会阻塞浏览器更新屏幕)
默认情况下,React 会每次等待浏览器完成画面渲染之后延迟调用 effect;但是如果某些特定值在两次重渲染之间没有发生变化,你可以通知 React 跳过对 effect 的调用,只要传递数组作为 useEffect 的第二个可选参数即可:如下所示,如果 count 值两次渲染之间没有发生变化,那么第二次渲染后就会跳过 effect 的调用;
useEffect(() => {
document.title = `You clicked ${count} times`;
}, [count]); // 仅在 count 更改时更新如果想只运行一次的 effect(仅在组件挂载和卸载时执行),可以传递一个空数组([ ])作为第二个参数,如下所示,原理跟第 4 点性能优化讲述的一样;
useEffect(() => {
.....
}, []);要记住 effect 外部的函数使用了哪些 props 和 state 很难,这也是为什么 通常你会想要在 effect 内部 去声明它所需要的函数。
// bad,不推荐
function Example({ someProp }) {
function doSomething() {
console.log(someProp);
}
useEffect(() => {
doSomething();
}, []); // 🔴 这样不安全(它调用的 `doSomething` 函数使用了 `someProp`)
}
// good,推荐
function Example({ someProp }) {
useEffect(() => {
function doSomething() {
console.log(someProp);
}
doSomething();
}, [someProp]); // ✅ 安全(我们的 effect 仅用到了 `someProp`)
}如果处于某些原因你无法把一个函数移动到 effect 内部,还有一些其他办法:
推荐启用 eslint-plugin-react-hooks 中的 exhaustive-deps 规则,此规则会在添加错误依赖时发出警告并给出修复建议 ;
// 1、安装插件
npm i eslint-plugin-react-hooks --save-dev
// 2、eslint 配置
{
"plugins": [
// ...
"react-hooks"
],
"rules": {
// ...
"react-hooks/rules-of-hooks": "error",
"react-hooks/exhaustive-deps": "warn"
}
}(1)可以把 useEffect Hook 看做 componentDidMount,componentDidUpdate和 componentWillUnmount这三个函数的组合;
(2)在 React 的 class 组件中,render 函数是不应该有任何副作用的; 一般来说,在这里执行操作太早了,我们基本上都希望在 React 更新 DOM 之后才执行我们的操作。
用来处理多层级传递数据的方式,在以前组件树中,跨层级祖先组件想要给孙子组件传递数据的时候,除了一层层 props 往下透传之外,我们还可以使用 React Context API 来帮我们做这件事。使用例子如下所示
(1)使用 React Context API,在组件外部建立一个 Context
import React from 'react';
const ThemeContext = React.createContext(0);
export default ThemeContext;(2)使用 Context.Provider提供了一个 Context 对象,这个对象可以被子组件共享
import React, { useState } from 'react';
import ThemeContext from './ThemeContext';
import ContextComponent1 from './ContextComponent1';
function ContextPage () {
const [count, setCount] = useState(1);
return (
<div className="App">
<ThemeContext.Provider value={count}>
<ContextComponent1 />
</ThemeContext.Provider>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}
export default ContextPage;(3)useContext()钩子函数用来引入 Context 对象,并且获取到它的值
// 子组件,在子组件中使用孙组件
import React from 'react';
import ContextComponent2 from './ContextComponent2';
function ContextComponent () {
return (
<ContextComponent2 />
);
}
export default ContextComponent;
// 孙组件,在孙组件中使用 Context 对象值
import React, { useContext } from 'react';
import ThemeContext from './ThemeContext';
function ContextComponent () {
const value = useContext(ThemeContext);
return (
<div>useContext:{value}</div>
);
}
export default ContextComponent;比 useState 更适用的场景:例如 state 逻辑处理较复杂且包含多个子值,或者下一个 state 依赖于之前的 state 等;例子如下所示
import React, { useReducer } from 'react';
interface stateType {
count: number
}
interface actionType {
type: string
}
const initialState = { count: 0 };
const reducer = (state:stateType, action:actionType) => {
switch (action.type) {
case 'increment':
return { count: state.count + 1 };
case 'decrement':
return { count: state.count - 1 };
default:
throw new Error();
}
};
const UseReducer = () => {
const [state, dispatch] = useReducer(reducer, initialState);
return (
<div className="App">
<div>useReducer Count:{state.count}</div>
<button onClick={() => { dispatch({ type: 'decrement' }); }}>useReducer 减少</button>
<button onClick={() => { dispatch({ type: 'increment' }); }}>useReducer 增加</button>
</div>
);
};
export default UseReducer;interface stateType {
count: number
}
interface actionType {
type: string,
paylod?: number
}
const initCount =0
const init = (initCount:number)=>{
return {count:initCount}
}
const reducer = (state:stateType, action:actionType)=>{
switch(action.type){
case 'increment':
return {count: state.count + 1}
case 'decrement':
return {count: state.count - 1}
case 'reset':
return init(action.paylod || 0)
default:
throw new Error();
}
}
const UseReducer = () => {
const [state, dispatch] = useReducer(reducer,initCount,init)
return (
<div className="App">
<div>useReducer Count:{state.count}</div>
<button onClick={()=>{dispatch({type:'decrement'})}}>useReducer 减少</button>
<button onClick={()=>{dispatch({type:'increment'})}}>useReducer 增加</button>
<button onClick={()=>{dispatch({type:'reset',paylod:10 })}}>useReducer 增加</button>
</div>
);
}
export default UseReducer;如下所示,当父组件重新渲染时,子组件也会重新渲染,即使子组件的 props 和 state 都没有改变
import React, { memo, useState } from 'react';
// 子组件
const ChildComp = () => {
console.log('ChildComp...');
return (<div>ChildComp...</div>);
};
// 父组件
const Parent = () => {
const [count, setCount] = useState(0);
return (
<div className="App">
<div>hello world {count}</div>
<div onClick={() => { setCount(count => count + 1); }}>点击增加</div>
<ChildComp/>
</div>
);
};
export default Parent;改进:我们可以使用 memo 包一层,就能解决上面的问题;但是仅仅解决父组件没有传参给子组件的情况以及父组件传简单类型的参数给子组件的情况(例如 string、number、boolean等);如果有传复杂属性应该使用 useCallback(回调事件)或者 useMemo(复杂属性)
// 子组件
const ChildComp = () => {
console.log('ChildComp...');
return (<div>ChildComp...</div>);
};
const MemoChildComp = memo(ChildComp);假设以下场景,父组件在调用子组件时传递 info 对象属性,点击父组件按钮时,发现控制台会打印出子组件被渲染的信息。
import React, { memo, useState } from 'react';
// 子组件
const ChildComp = (info:{info:{name: string, age: number}}) => {
console.log('ChildComp...');
return (<div>ChildComp...</div>);
};
const MemoChildComp = memo(ChildComp);
// 父组件
const Parent = () => {
const [count, setCount] = useState(0);
const [name] = useState('jack');
const [age] = useState(11);
const info = { name, age };
return (
<div className="App">
<div>hello world {count}</div>
<div onClick={() => { setCount(count => count + 1); }}>点击增加</div>
<MemoChildComp info={info}/>
</div>
);
};
export default Parent;分析原因:
解决:
使用 useMemo 将对象属性包一层,useMemo 有两个参数:
import React, { memo, useMemo, useState } from 'react';
// 子组件
const ChildComp = (info:{info:{name: string, age: number}}) => {
console.log('ChildComp...');
return (<div>ChildComp...</div>);
};
const MemoChildComp = memo(ChildComp);
// 父组件
const Parent = () => {
const [count, setCount] = useState(0);
const [name] = useState('jack');
const [age] = useState(11);
// 使用 useMemo 将对象属性包一层
const info = useMemo(() => ({ name, age }), [name, age]);
return (
<div className="App">
<div>hello world {count}</div>
<div onClick={() => { setCount(count => count + 1); }}>点击增加</div>
<MemoChildComp info={info}/>
</div>
);
};
export default Parent;接着第六章节的例子,假设需要将事件传给子组件,如下所示,当点击父组件按钮时,发现控制台会打印出子组件被渲染的信息,说明子组件又被重新渲染了。
import React, { memo, useMemo, useState } from 'react';
// 子组件
const ChildComp = (props:any) => {
console.log('ChildComp...');
return (<div>ChildComp...</div>);
};
const MemoChildComp = memo(ChildComp);
// 父组件
const Parent = () => {
const [count, setCount] = useState(0);
const [name] = useState('jack');
const [age] = useState(11);
const info = useMemo(() => ({ name, age }), [name, age]);
const changeName = () => {
console.log('输出名称...');
};
return (
<div className="App">
<div>hello world {count}</div>
<div onClick={() => { setCount(count => count + 1); }}>点击增加</div>
<MemoChildComp info={info} changeName={changeName}/>
</div>
);
};
export default Parent;分析下原因:
解决:
修改父组件的 changeName 方法,用 useCallback 钩子函数包裹一层, useCallback 参数与 useMemo 类似
import React, { memo, useCallback, useMemo, useState } from 'react';
// 子组件
const ChildComp = (props:any) => {
console.log('ChildComp...');
return (<div>ChildComp...</div>);
};
const MemoChildComp = memo(ChildComp);
// 父组件
const Parent = () => {
const [count, setCount] = useState(0);
const [name] = useState('jack');
const [age] = useState(11);
const info = useMemo(() => ({ name, age }), [name, age]);
const changeName = useCallback(() => {
console.log('输出名称...');
}, []);
return (
<div className="App">
<div>hello world {count}</div>
<div onClick={() => { setCount(count => count + 1); }}>点击增加</div>
<MemoChildComp info={info} changeName={changeName}/>
</div>
);
};
export default Parent;以下分别介绍 useRef 的两个使用场景:
如下所示,使用 useRef 创建的变量指向一个 input 元素,并在页面渲染后使 input 聚焦
import React, { useRef, useEffect } from 'react';
const Page1 = () => {
const myRef = useRef<HTMLInputElement>(null);
useEffect(() => {
myRef?.current?.focus();
});
return (
<div>
<span>UseRef:</span>
<input ref={myRef} type="text"/>
</div>
);
};
export default Page1;useRef 在 react hook 中的作用, 正如官网说的, 它像一个变量, 类似于 this , 它就像一个盒子, 你可以存放任何东西. createRef 每次渲染都会返回一个新的引用,而 useRef 每次都会返回相同的引用,如下例子所示:
import React, { useRef, useEffect, useState } from 'react';
const Page1 = () => {
const myRef2 = useRef(0);
const [count, setCount] = useState(0)
useEffect(()=>{
myRef2.current = count;
});
function handleClick(){
setTimeout(()=>{
console.log(count); // 3
console.log(myRef2.current); // 6
},3000)
}
return (
<div>
<div onClick={()=> setCount(count+1)}>点击count</div>
<div onClick={()=> handleClick()}>查看</div>
</div>
);
}
export default Page1;使用场景:通过 ref 获取到的是整个 dom 节点,通过 useImperativeHandle 可以控制只暴露一部分方法和属性,而不是整个 dom 节点。
其函数签名与 useEffect 相同,但它会在所有的 DOM 变更之后同步调用 effect,这里不再举例。
关于这方面的文章,我们根据使用场景分别进行举例说明,希望有帮助到你认识理解并可以熟练运用 React Hooks 大部分特性。
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:https://github.com/fengshi123/blog ,汇总了作者的所有博客,欢迎关注及 star ~
本文并不是Vue SSR的入门指南,没有一步步介绍Vue SSR入门,如果你想要Vue SSR入门教程,建议阅读Vue官网的《Vue SSR指南》,那应该是最详细的Vue SSR入门教程了。这篇文章的意义是,主要介绍如何在SSR服务端渲染中使用最受欢迎的vue ui 库element-ui组件库和echarts插件,以及本文中介绍的实例克服尤大大给的 HackerNews Demo 需要翻墙才能运行起来的问题,新手在阅读SSR官方文档时,如果遇到疑惑点,可以直接在本文实例的基础上进行相关实验验证,从而解决疑惑。本文实例的 github地址为:github.com/fengshi123/… (欢迎 star)
官网给出的解释:
Vue.js 是构建客户端应用程序的框架。默认情况下,可以在浏览器中输出 Vue 组件,进行生成 DOM 和操作 DOM。然而,也可以将同一个组件渲染为服务端的 HTML 字符串,将它们直接发送到浏览器,最后将这些静态标记"激活"为客户端上完全可交互的应用程序。
即:SSR大致的意思就是vue在客户端将标签渲染成的整个html片段的工作在服务端完成,服务端形成的html片段直接返回给客户端这个过程就叫做服务端渲染。
(1)更好的SEO: 因为SPA页面的内容是通过Ajax获取,而搜索引擎爬取工具并不会等待Ajax异步完成后再抓取页面内容,所以在SPA中是抓取不到页面通过Ajax获取到的内容;而SSR是直接由服务端返回已经渲染好的页面(数据已经包含在页面中),所以搜索引擎爬取工具可以抓取渲染好的页面;
(2)更快的内容到达时间(首屏加载更快): SPA会等待所有vue编译后的js文件都下载完成后,才开始进行页面的渲染,文件下载等需要一定的时间等,所以首屏渲染需要一定的时间;SSR直接由服务端渲染好页面直接返回显示,无需等待下载js文件及再去渲染等,所以SSR有更快的内容到达时间;
(1)更多的开发条件限制: 例如服务端渲染只支持beforCreate和created两个钩子函数,这会导致一些外部扩展库需要特殊处理,才能在服务端渲染应用程序中运行;并且与可以部署在任何静态文件服务器上的完全静态单页面应用程序SPA不同,服务端渲染应用程序,需要处于Node.js server运行环境;
(2)更多的服务器负载:在 Node.js 中渲染完整的应用程序,显然会比仅仅提供静态文件的 server 更加大量占用 CPU 资源 (CPU-intensive - CPU 密集),因此如果你预料在高流量环境 (high traffic) 下使用,请准备相应的服务器负载,并明智地采用缓存策略。
本文示例基于尤大大给的 HackerNews Demo 进行改造,去除需要翻墙访问
https://hacker-news.firebaseio.com 的相关api , 然后项目中使用了最受欢迎的vue ui 库element-ui ,并且调研了echarts.js 插件在服务端渲染的可行性;实例的目录结构以及实例的效果图分别如下所示:
具体每个文件的相关代码的逻辑在代码中都有进行详细的注释,所以这里就不详细再介绍一遍,可以在github上面clone进行查看,这里主要看下 Vue官网上的服务端渲染的示意图
从图上可以看出,ssr 有两个入口文件,client.js 和 server.js, 都包含了应用代码,webpack 通过两个入口文件分别打包成给服务端用的 server bundle 和给客户端用的 client bundle. 当服务器接收到了来自客户端的请求之后,会创建一个渲染器 bundleRenderer,这个 bundleRenderer 会读取上面生成的server bundle文件,并且执行它的代码, 然后发送一个生成好的 html 到浏览器,等到客户端加载了 client bundle 之后,会和服务端生成的DOM 进行 Hydration(判断这个DOM 和自己即将生成的DOM 是否相同,如果相同就将客户端的vue实例挂载到这个DOM上, 否则会提示警告)。
4.1、引用 vue 文件会报文件找不到
问题: 如果引用 vue文件没有加 .vue 后缀,会报文件找不到,即:
import adminContent from './views/adminContent';复制代码
会报以下错误:
解决: 引用 vue文件时添加 .vue后缀名,即:
import adminContent from './views/adminContent.vue';复制代码
4.2、引入 element-ui 的样式时,报错
问题: 在项目中引入 element-ui 的样式时,即:
import 'element-ui/lib/theme-chalk/index.css';复制代码
会报以下的错误,不引入样式文件则不会报错:
ReferenceError: window is not defined复制代码
解决: 需要进行样式文件的解析配置:
(1)安装样式解析插件:
npm install css-loader --save复制代码
(2)在webpack.base.config.js 中进行配置css-loader:
{
test: /\.css$/,
loader: ["css-loader"]
}复制代码
4.3、引入 element-ui 的样式时,报错
问题: 在项目中引入element-ui的样式时,即:
import 'element-ui/lib/theme-chalk/index.css';复制代码
会报以下的错误,不引入样式文件则不会报错:
Module parse failed: Unexpected character '@' (1:0) You may need an
appropriate loader to handle this file type.复制代码
解决: 需要进行样式文件的解析配置:
(1)安装样式解析插件:
npm install style-loader --save复制代码
(2)在webpack.base.config.js 中进行相关配置:
{
test: /\.css$/,
loader: ["vue-style-loader", "css-loader"]
},
{
test: /\.(eot|svg|ttf|woff|woff2)(\?\S*)?$/,
loader: 'file-loader'
},复制代码
4.4、element-ui的组件 el-table 不支持服务端渲染
问题: 如果服务端渲染中的页面包含 el-table组件,从服务端返回的页面中的 el-table 组件中数据为空的,原因是 el-table 组件在mount钩子函数中初始化table数据,而服务端渲染时,不支持mount钩子函数。
解决:github 上面的 elment-ui 有分支修复了这个问题,github.com/ElemeFE/ele… ;将该分支的源码进行编译,然后替换在node_modules中替换element-ui的 lib编译包即可。
4.5、el-table 服务端渲染后,表格宽度不是 100%
问题:el-table 服务端渲染后,表格的宽度不是代码中设置的 100%,表格宽度比较小。
解决: 进行样式额外设置:
.el-table__header{
width: 100%;
}
.el-table__body{
width: 100%;
}
.el-table-column--selection{
width: 48px;
}复制代码
4.6、echarts 插件怎么支持服务端渲染?
解决: 使用 node-canvas 插件,具体使用可以查看本实例的写法,也可以查看 node-canvas 在github上面的介绍:github.com/Automattic/…
存在问题: 实例中是利用node-canvas 生成对应的图片,然后页面中引用该图片,存在问题:生成的图片没有动效的效果。(这个问题没有继续研究,因为:图片没有文字内容,seo 是不需要的;然后图片在服务端生成,在下载图片在页面中渲染,会直接在客户端渲染更节省资源吗?)
SSR有更好的SEO和更快的内容到达时间的优点,但也存在开发条件限制、服务器资源消耗多、新手上手难等缺点,所以你的项目是否需要服务端渲染,需要你结合你的项目具体进行相关指标的评估,切勿跟风,为 SSR而 SSR。
本文实例主要基于尤大大给的 HackerNews Demo 进行改造,去除需要翻墙访问https://hacker-news.firebaseio.com 的相关api , 然后项目中使用了最受欢迎的vue ui 库element-ui ,并且调研了echarts.js 插件在服务端渲染的可行性,帮助新手更好更快地入门 ssr,如果在阅读官方SSR文档的过程中,有些疑问点,可以自己在本文实例中进行相关的试验验证,然后帮助解决疑惑。如果觉得本文以及github的实例帮助到你,请帮忙给个 star ,本文实例的 github地址为:github.com/fengshi123/…
在之前《微前端探索》文章中,我们分析了微前端框架 single-spa 和 qiankun 的一些源码、原理等,本文再对社区另外一个微前端框架 icestark 做一个简单整理分析,帮助各位想探索微前端的同学有个感性的认识。
icestark 源码的主要目录结构如下所示,主要包括 packages 和 src 两个目录,相关总结整理如下,我们不会一行一行去讲解代码,如果你对某一块很感兴趣,可以自己去 github 上面 clone 代码库,源码还是非常简单易懂的。

我们学习 single-spa 的时候总结到 single-spa 是一个状态机,负责管理各个子应用的状态。所以 icestark 必然存在这个子应用的状态管理,相关的实现在 src/apps.ts 文件中,其包括以下几个主要过程/方法:
以上方法实现的思路还是比较简单的,定义个全局 microApps 数组变量来保存子应用,然后每个子应用分别有个对应的 status 变量来表示该子应用的状态是怎样的,然后进行下一步操作时会根据当前的状态进行对应的下一步操作,以下我们挑选个最“复杂”的方法 createMicroApp 来看下,我们对代码进行了相关注释,还是比较简单的,就不再赘述了。
export async function createMicroApp(app: string | AppConfig, appLifecyle?: AppLifecylceOptions) {
const appConfig = getAppConfigForLoad(app, appLifecyle);
const appName = appConfig && appConfig.name;
if (appConfig && appName) {
if (appConfig.status === NOT_LOADED || appConfig.status === LOAD_ERROR ) {
// 如果该子应用的当前状态是未加载或加载失败,执行以下逻辑
if (appConfig.title) document.title = appConfig.title;
// 更新子应用的状态
updateAppConfig(appName, { status: LOADING_ASSETS });
let lifeCycle: ModuleLifeCycle = {};
try {
// 加载子应用资源
lifeCycle = await loadAppModule(appConfig);
// in case of app status modified by unload event
if (getAppStatus(appName) === LOADING_ASSETS) {
// 更新子应用配置
updateAppConfig(appName, { ...lifeCycle, status: NOT_MOUNTED });
}
} catch (err){
// 出错,更新子应用配置
updateAppConfig(appName, { status: LOAD_ERROR });
}
if (lifeCycle.mount) {
// 进行子应用挂载
await mountMicroApp(appConfig.name);
}
} else if (appConfig.status === UNMOUNTED) {
// 如果当前的子应用是卸载状态执行以下逻辑
if (!appConfig.cached) {
// 加载 js/css 资源
await loadAndAppendCssAssets(appConfig.appAssets || { cssList: [], jsList: []});
}
// 进行挂载
await mountMicroApp(appConfig.name);
} else if (appConfig.status === NOT_MOUNTED) {
// 如果当前的子应用是没有挂载状态,则进行挂载
await mountMicroApp(appConfig.name);
} else {
console.info(`[icestark] current status of app ${appName} is ${appConfig.status}`);
}
// 返回创建的子应用的信息
return getAppConfig(appName);
} else {
console.error(`[icestark] fail to get app config of ${appName}`);
}
return null;
}我们都知道 react、vue、angular 等单应用路由劫持的实现都是:history 路由通过监听 popstate 事件、hash 路由通过监听 hashchange 路由来实现的,那么 icestark 的路由劫持是怎么做的呢,嗯哼,他们也没有变出花来,也是一样的实现原理,代码位置在 src/start.js 文件中,相关源码如下所示
const hijackHistory = (): void => {
// 监听对应的路由事件,urlChange 为事件回调函数
window.addEventListener('popstate', urlChange, false);
window.addEventListener('hashchange', urlChange, false);
};在微前端容器中,存在多个子应用共有一个 window 对象的情况,如果不进行隔离,可能多个子应用之间会存在互相影响的情况。icestark 基于 Proxy 为每个子应用启用了一个沙箱环境,代码位置在 packages/icestark-sandbox/src/index.js 文件中,相关代码实现如下所示
createProxySandbox(injection?: object) {
const { propertyAdded, originalValues, multiMode } = this;
const proxyWindow = Object.create(null) as Window;
const originalWindow = window;
const originalAddEventListener = window.addEventListener;
const originalRemoveEventListener = window.removeEventListener;
const originalSetInerval = window.setInterval;
const originalSetTimeout = window.setTimeout;
// hijack addEventListener
proxyWindow.addEventListener = (eventName, fn, ...rest) => {
const listeners = this.eventListeners[eventName] || [];
listeners.push(fn);
return originalAddEventListener.apply(originalWindow, [eventName, fn, ...rest]);
};
// hijack removeEventListener
proxyWindow.removeEventListener = (eventName, fn, ...rest) => {
const listeners = this.eventListeners[eventName] || [];
if (listeners.includes(fn)) {
listeners.splice(listeners.indexOf(fn), 1);
}
return originalRemoveEventListener.apply(originalWindow, [eventName, fn, ...rest]);
};
// hijack setTimeout
proxyWindow.setTimeout = (...args) => {
const timerId = originalSetTimeout(...args);
this.timeoutIds.push(timerId);
return timerId;
};
// hijack setInterval
proxyWindow.setInterval = (...args) => {
const intervalId = originalSetInerval(...args);
this.intervalIds.push(intervalId);
return intervalId;
};
const sandbox = new Proxy(proxyWindow, {
set(target: Window, p: PropertyKey, value: any): boolean {
target[p] = value;
},
get(target: Window, p: PropertyKey): any {
const targetValue = target[p];
if (targetValue) {
// case of addEventListener, removeEventListener, setTimeout, setInterval setted in sandbox
return targetValue;
}
},
has(target: Window, p: PropertyKey): boolean {
return p in target || p in originalWindow;
},
});
this.sandbox = sandbox;
}icestark 提供了 event/store 通信,其无非是实现了个简单的 EventEmit 实例,代码位置在 packages/icestark-data/src/event.js 文件中,相关源代码实现逻辑如下,我们进行了些代码注释,就不再赘述。
class Event implements Hooks {
eventEmitter: object;
constructor() {
this.eventEmitter = {};
}
// 事件触发
emit(key: string, ...args) {
const keyEmitter = this.eventEmitter[key];
// 执行事件注册的回调方法
keyEmitter.forEach(cb => {
cb(...args);
});
}
// 事件监听
on(key: string, callback: (value: any) => void) {
if (!this.eventEmitter[key]) {
this.eventEmitter[key] = [];
}
// 将事件回调方法放入数组中
this.eventEmitter[key].push(callback);
}
// 取消注册
off(key: string, callback?: (value: any) => void) {
if (callback === undefined) {
this.eventEmitter[key] = undefined;
return;
}
this.eventEmitter[key] = this.eventEmitter[key].filter(cb => cb !== callback);
}
has(key: string) {
const keyEmitter = this.eventEmitter[key];
return isArray(keyEmitter) && keyEmitter.length > 0;
}
}经过以上代码整理分析,我们可以看到,其实 icestark 跟 single-spa、qiankun 这些微前端框架做的事情/原理大同小异,icestark 自己去实现了子应用的状态管理,然后也去实现了沙箱、通信等这些辅助功能。
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:github.com/fengshi123/blog ,汇总了作者的所有博客,欢迎关注及 star ~
node.js 对前端来说无疑具有里程碑意义,在其越来越流行的今天,掌握 node.js 已经不仅仅是加分项,而是前端攻城师们必须要掌握的技能。而 express 以其快速、开放、极简的特性, 成为 node.js 最流行的框架,所以使用 express 进行 web 服务端的开发是个不错且可信赖的选择。但是 express 初始化后,并不马上就是一个开箱即用,各种功能完善的 web 服务端项目,例如:日志记录、错误捕获、mysql 连接、token 认证、websocket 等一系列常见的功能,需要开发者自己去安装插件进行配置完善功能,如果你对 web 服务端开发或者 express 框架不熟悉,那将是一项耗费巨大资源的工作。本文在 express 的初始架构上配置了日志记录、错误捕获、mysql 连接、token 认证、websocket 等一系列常见的功能,并且本文的项目已经在 github 开源,提供给大家学习、实际项目使用,希望能减轻大家的工作量,更高效完成工作,有更多时间提升自己的能力。
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:https://github.com/fengshi123/blog,汇总了作者的所有博客,也欢迎关注及 star ~
本项目 github 地址为:https://github.com/fengshi123/express_project
这个 express 服务端项目,相关运行环境配置如下:
| 工具名称 | 版本号 |
|---|---|
| node.js | 11.12.0 |
| npm | 6.7.0 |
| express | 4.16.0 |
| mysql | 5.7 |
(1)安装插件,进入到 express_project 目录,运行以下命令:
npm install(2)开发环境启动,进入到 express_project 目录,运行以下命令:
npm run dev(3)正式环境启动,进入到 express_project 目录,运行以下命令:
npm run start项目目录结构如下:
├─ bin 数据库初始化脚本
│ ├─ db 项目数据库安装,其中 setup.sh 为命令入口,初始化数据库
├─ common 共用方法、常量目录
├─ conf 数据库基本配置目录
├─ dao 代码主逻辑目录
├─ log 日志目录
├─ public 静态文件目录
├─ routes url 路由配置
├─ .eslintrc.js eslint 配置
├─ app.js express 入口
├─ package.json 项目依赖包配置
├─ README.md 项目说明
这里就不介绍 mysql 的安装配置,具体操作可以参照 配置文档,建议安装一个 mysql 数据库管理工具 navicat for mysql ,平时用来查看数据库数据增删改查的情况;
我们在 bin/db 目录底下,已经配置编写好了数据库初始化脚本,其中 setup.sh 为编写好的命令入口,用于连接数据库、新建数据库等,主要逻辑已经进行注释如下:
mysql -uroot -p123456 --default-character-set=utf8 <<EOF // 需要将帐号密码改成自己的
drop database if exists research; // 删除数据库
create database research character set utf8; // 新建数据库
use research; // 切换到 research 数据库,对应改成自己的
source init.sql; // 初始化 sql 建表
EOF
cmd /k我们可以在 init.sql 中插入每张表的初始数据,相关代码如下,至于表数据如何插入等简单逻辑这里就不再介绍,读者可以查看相关 sql 文件即会了解。
source t_user.sql;
source t_exam.sql;
source t_video.sql;
source t_app_version.sql;
source t_system.sql;我们在 conf/db.js 文件中配置 mysql 的基本信息,相关配置项如下,可以对应更改配置项,改成你自己的配置。
module.exports = {
mysql: {
host: '127.0.0.1',
user: 'root',
password: '123456',
database: 'research',
port: 3306
}
};对数据进行基本的增、删、改、查操作,可以通过已经配置好的文件以及逻辑进行照搬,我们以增加一个用户举例进行简单介绍,在 dao/userDao.js 文件中:
var conf = require('../conf/db'); // 引入数据库配置
var pool = mysql.createPool(conf.mysql); // 使用连接池
add: function (req, res, next) {
pool.getConnection(function (err, connection) {
if (err) {
logger.error(err);
return;
}
var param = req.body;
// 建立连接,向表中插入值
connection.query(sql.insert, [param.uid, param.name, param.password, param.role, param.sex], function (err, result) {
if (err) {
logger.error(err);
} else {
result = {
code: 0,
msg: '增加成功'
};
}
// 以json形式,把操作结果返回给前台页面
common.jsonWrite(res, result);
// 释放连接
connection.release();
});
});
},morgan 是 express 默认的日志中间件,也可以脱离 express,作为 node.js 的日志组件单独使用,morgan 的具体 api 可参考 morgan 的 github 库;这里主要介绍我们项目中,帮你进行了哪些配置、实现了哪些功能。项目在 app.js 文件中进行了以下配置:
const logger = require('morgan');
// 输出日志到目录
var accessLogStream = fs.createWriteStream(path.join(__dirname, '/log/request.log'), { flags: 'a', encoding: 'utf8' });
app.use(logger('combined', { stream: accessLogStream }));我们已经配置好以上请求日志记录,这样每次 http 请求都会记录到 log/request.log 文件中。
由于 morgan 只能记录 http 请求的日志,所以我们还需要 winston 来记录其它想记录的日志,例如:访问数据库出错等;Winston 是 node.js 上最流行的日志库之一。它被设计为一个简单通用的日志库,支持多种传输(一种传输实际上就是一种存储设备,例如日志存储在哪里)。winston 中的每一个 logger 实例在不同的日志级别可以存在多个传输配置;当然它也可以记录请求记录。winston 的具体 api 可参考 winston 的 github 库 ,我们这里不做详细的介绍。
这里主要介绍我们项目中,我们使用 winston 帮你进行了哪些配置、实现了哪些功能。项目在 common/logger.js 文件中进行了以下配置:
var { createLogger, format, transports } = require('winston');
var { combine, timestamp, printf } = format;
var path = require('path');
var myFormat = printf(({ level, message, label, timestamp }) => {
return `${timestamp} ${level}: ${message}`;
});
var logger = createLogger({
level: 'error',
format: combine(
timestamp(),
myFormat
),
transports: [
new (transports.Console)(),
new (transports.File)({
filename: path.join(__dirname, '../log/error.log')
})
]
});
module.exports = logger;通过以上 logger.js 文件配置,我们只需要在需要的地方引入该文件,然后调用 logger.error(err) 进行相应等级的日志记录,相关的错误日志就会记录到文件 log/error.log 中。
我们在项目中按模块划分请求处理,我们在 routes 目录下分别新建每个模块路由配置,例如用户模块,则为 user.js 文件,我们在 app.js 主入口文件中引入每个模块的路由,以用户模块进行举例,相关代码逻辑如下:
// 引入用户模块路由配置
var usersRouter = require('./routes/users');
// 使用用户模块的路由配置
app.use('/users', usersRouter);其中 routes/users.js 文件中的路由配置如下:
var express = require('express');
var router = express.Router();
// 增加用户
router.post('/addUser', function (req, res, next) {
userDao.add(req, res, next);
});
// 获取全部用户
router.get('/queryAll', function (req, res, next) {
userDao.queryAll(req, res, next);
});
// 删除用户
router.post('/deleteUser', function (req, res, next) {
userDao.delete(req, res, next);
});
...通过以上配置,这样客户端通过 /users 开头的请求路径,都会跳转到用户模块路由中进行处理,假设请求路径为 /users/addUser 则会进行增加用户的逻辑处理。通过这种规范和配置,这时如果增加一个新的模块,只需按照原有的规范,新增一个模块路由文件,进行相关的路由配置处理,不会影响到原有的模块路由配置,也不会出现路由冲突等。
express-jwt 是 node.js 的一个中间件,他来验证指定 http 请求的 JsonWebTokens 的有效性,如果有效就将jsonWebTokens 的值设置到 req.user 里面,然后路由到相应的 router。 此模块允许您使用 node.js 应用程序中的 JWT 令牌来验证HTTP请求。express-jwt 的具体 api 可参考 express-jwt 的 github 库 ,我们这里不做详细的介绍。
这里主要介绍我们项目中,我们使用express-jwt 帮你进行了哪些配置、实现了哪些功能。项目在 app.js 文件中进行了以下 token 拦截配置,如果没有经过 token 认证的,会返回客户端 401 认证失败;
var expressJWT = require('express-jwt');
// token 设置
app.use(expressJWT({
secret: CONSTANT.SECRET_KEY
}).unless({
// 除了以下这些 URL,其他的URL都需要验证
path: ['/getToken',
'/getToken/adminLogin',
'/appVersion/upload',
'/appVersion/download',
/^\/public\/.*/,
/^\/static\/.*/,
/^\/user_disk\/.*/,
/^\/user_video\/.*/
]
}));我们可以选择在生成 token 时,将对应登录的用户 id 注入 token 中,如文件 dao/tokenDao.js 文件中所配置的;
// uid 注入 token 中
ret = {
code: 0,
data: {
token: jsonWebToken.sign({
uid: obj.uid
}, CONSTANT.SECRET_KEY, {
expiresIn: 60 * 60 * 24
}),
}
};后续我们可以在请求中,通过请求信息 req.body.uid,获取得到先前注入 token 里面的用户 id 信息。
我们已经在项目的 app.js 中进行项目的跨域配置,这样一些客户端例如:单页面应用开发、移动应用等, 就可以跨域访问服务端对应的接口。我们在 app.js 文件中进行相关跨域配置:
app.all('*', function (req, res, next) {
res.header('Access-Control-Allow-Origin', '*');
res.header('Access-Control-Allow-Headers', '*');
res.header('Access-Control-Allow-Methods', '*');
next();
});我们在项目中配置了静态目录,用于提供静态资源文件(图片、css 文件、js 文件等)的服务;传递一个包含静态资源的目录给 express.static 中间件用于提供静态资源。如下提供 public 目录下的图片、css 文件和 javascript 文件,当然你也可以根据自己的需要,通过类似配置,创建自己静态资源目录。
app.use('/', express.static(path.join(__dirname, 'public')));如果我们如果没有对服务端程序进行处理,当服务端代码抛出异常时,会导致 node 进程退出,从而用户无法正常访问服务器,造成严重问题。我们在项目中配置使用 domain 模块,捕获 服务端程序中中抛出的异常;domain 主要的 API 有 domain.run 和 error 事件。简单的说,通过 domain.run 执行的函数中引发的异常都可以通过 domain 的 error 事件捕获。我们在 项目中配置使用 domain 的代码如下:
var domain = require('domain');
// 处理没有捕获的异常,导致 node 退出
app.use(function (req, res, next) {
var reqDomain = domain.create();
reqDomain.on('error', function (err) {
res.status(err.status || 500);
res.render('error');
});
reqDomain.run(next);
});每次修改 js 文件,我们都需要重启服务器,这样修改的内容才会生效,但是每次重启比较麻烦,影响开发效果;所以我们在开发环境中引入 nodemon 插件,实现实时热更新,自动重启项目。所以如 1.3 章节所述,我们在开发环境中启动项目应该使用 npm run dev 命令,因为我们在 package.json 文件中配置了以下命令:
"scripts": {
"dev": "nodemon ./app",
},pm2 是 node 进程管理工具,可以利用它来简化很多 node 应用管理的繁琐任务,如性能监控、自动重启、负载均衡等,而且使用非常简单。 所以我们可以使用 pm2 来启动我们的服务端程序。这里我们不详细介绍 pm2,如果还不了解的同学可以查看这篇文档。
服务端应用程序不可避免要处理文件上传的操作,我们在项目中为大家配置好 multiparty 插件,并提供相关的上传、重命名等操作,相关代码逻辑及注释在 dao/common.js 中。如果对 multiparty 插件还不了解的同学,可以参考 multiparty 插件的 github 库 ,我们这里不做详细的介绍。
var upload = function (path, req, res, next) {
return new Promise(function (resolve, reject) {
// 解析一个文件上传
var form = new multiparty.Form();
// 设置编辑
form.encoding = 'utf-8';
// 设置文件存储路径
form.uploadDir = path;
// 设置单文件大小限制
form.maxFilesSize = 2000 * 1024 * 1024;
var textObj = {};
var imgObj = {};
form.parse(req, function (err, fields, files) {
if (err) {
console.log(err);
}
Object.keys(fields).forEach(function (name) { // 文本
textObj[name] = fields[name];
});
Object.keys(files).forEach(function (name) {
if (files[name] && files[name][0] && files[name][0].originalFilename) {
imgObj[name] = files[name];
var newPath = unescape(path + '/' + files[name][0].originalFilename);
var num = 1;
var suffix = newPath.split('.').pop();
var lastIndex = newPath.lastIndexOf('.');
var tmpname = newPath.substring(0, lastIndex);
while (fs.existsSync(newPath)) {
newPath = tmpname + '_' + num + '.' + suffix;
num++;
}
fs.renameSync(files[name][0].path, newPath);
imgObj[name][0].path = newPath;
}
});
resolve([imgObj, textObj])
});
});
};服务端程序对服务器目录、文件进行操作,是频率比较高的操作,相对于 node.js 默认的 fs 文件操作模块,我们在项目中配置了 fs-extra 插件来对服务器目录、文件进行操作,fs-extra模块是系统fs模块的扩展,提供了更多便利的 API,并继承了fs模块的 API ;例如我们在项目中使用 mkdir 方法来创建文件目录、ensureDir 方法来确认目录是否存在、remove 方法来删除文件、copy 方法来复制文件等,你可以在 dao/filesDao.js 文件中看到 fs-extra 丰富的操作方法。如果你还未接触过 fs-extra 插件,建议你可以查看它的 github 库,有相关详细介绍。
为了让项目的代码风格保持良好且一致,故我们在项目中添加 eslint 来检查 js 代码规范;你可以在 .eslintignore 文件中配置哪些文件你不想通过 eslint 进行代码检查;你还可以在 .eslintrc.js 文件中配置你们团队的代码风格。
本文介绍了作者开源的一个开箱即用,各种功能完善的 web 服务端项目的相关功能,例如:mysql 结合、日志记录、错误捕获、token 认证、跨域配置、自动重启、文件上传处理、eslint 配置 等一系列常见的功能,希望能通过源码开源和文章的相关介绍,帮助读者减轻工作量,更高效完成工作,有更多时间提升自己的能力。
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:https://github.com/fengshi123/blog ,汇总了作者的所有博客,也欢迎关注及 star ~
本项目 github 地址为:https://github.com/fengshi123/express_project
iPhoneX 取消了物理按键,改成底部小黑条,这一改动导致网页出现了比较尴尬的屏幕适配问题。对于网页而言,顶部(刘海部位)的适配问题浏览器已经做了处理,所以我们只需要关注底部与小黑条的适配问题即可(即常见的吸底导航、返回顶部等各种相对底部 fixed 定位的元素)。
比如一些需要贴在底部的按钮,和呼起的tabBar和底部弹出框,在iphoneX上就会出现被小黑条遮挡内容,或者页面上出现白色空隙的问题。处理前后截图如下所示

安全区域指的是一个可视窗口范围,处于安全区域的内容不受圆角(corners)、齐刘海(sensor housing)、小黑条(Home Indicator)影响,如下图蓝色区域:

也就是说,我们要做好适配,必须保证页面可视、可操作区域是在安全区域内。
更详细说明,参考文档:Human Interface Guidelines - iPhoneX
iOS11 新增特性,苹果公司为了适配 iPhoneX 对现有 viewport meta 标签的一个扩展,用于设置网页在可视窗口的布局方式,可设置三个值。
需要注意:网页默认不添加扩展的表现是 viewport-fit=contain,需要适配 iPhoneX 必须设置 viewport-fit=cover,这是适配的关键步骤。更详细说明,参考文档:viewport-fit-descriptor

iOS11 新增特性,Webkit 的一个 CSS 函数,用于设定安全区域与边界的距离,有四个预定义的变量:
这里我们只需要关注 safe-area-inset-bottom 这个变量,因为它对应的就是小黑条的高度(横竖屏时值不一样)。
注意:当 viewport-fit=contain 时 env() 是不起作用的,必须要配合 viewport-fit=cover 使用。对于不支持 env() 的浏览器,浏览器将会忽略它。
需要注意的是之前使用的 constant() 在 iOS11.2 之后就不能使用的,但我们还是需要做向后兼容,像这样:
padding-bottom: constant(safe-area-inset-bottom); /* 兼容 iOS < 11.2 */
padding-bottom: env(safe-area-inset-bottom); /* 兼容 iOS >= 11.2 */注意:env() 跟 constant() 需要同时存在,而且顺序不能换。
更详细说明,参考文档:Designing Websites for iPhone X
新增 viweport-fit 属性,使得页面内容完全覆盖整个窗口,前面也有提到过,只有设置了 viewport-fit=cover,才能使用 env()
<meta name="viewport" content="width=device-width, viewport-fit=cover">可以通过加内边距 padding 扩展高度:
{
padding-bottom: constant(safe-area-inset-bottom);
padding-bottom: env(safe-area-inset-bottom);
}或者通过计算函数 calc 覆盖原来高度:
{
height: calc(60px(假设值) + constant(safe-area-inset-bottom));
height: calc(60px(假设值) + env(safe-area-inset-bottom));
}注意,这个方案需要吸底条必须是有背景色的,因为扩展的部分背景是跟随外容器的,否则出现镂空情况。
还有一种方案就是,可以通过新增一个新的元素(空的颜色块,主要用于小黑条高度的占位),然后吸底元素可以不改变高度只需要调整位置,像这样:
{
margin-bottom: constant(safe-area-inset-bottom);
margin-bottom: env(safe-area-inset-bottom);
}空的颜色块:
{
position: fixed;
bottom: 0;
width: 100%;
height: constant(safe-area-inset-bottom);
height: env(safe-area-inset-bottom);
background-color: #fff;
}像这种只是位置需要对应向上调整,可以仅通过下外边距 margin-bottom 来处理
{
margin-bottom: constant(safe-area-inset-bottom);
margin-bottom: env(safe-area-inset-bottom);
}或者,你也可以通过计算函数 calc 覆盖原来 bottom 值:
{
bottom: calc(50px(假设值) + constant(safe-area-inset-bottom));
bottom: calc(50px(假设值) + env(safe-area-inset-bottom));
}前言
Sass是CSS3语言的扩展,它能帮你更省事地写出更好的样式表,使你摆脱重复劳动,使工作更有创造性。因为你能更快地拥抱变化,你也将敢于在设计上创新。你写出的样式表能够自如地应对修改颜色或修改HTML标签,并编译出标准的CSS代码用于各种生产环境。Sass语法比较简单,难点在于如何将Sass运用到实际项目中,解决CSS存在的痛点,从而提高我们效率。经过实际项目的摸索,总结了以下14条实践经验进行分享,希望能帮助大家扩宽思维,更好地将Sass运用到实际项目中。在项目中,我们使用支持传统的类CSS语法—— Scss,所以以下项目经验总结分享以Scss为例。
我们可以通过变量来复用属性值,比如颜色、边框大小、图片路径等,这样可以做到更改一处,从而进行全局更改,从而实现“换肤”的功能。
实例1:我们的组件库,利用变量配置,进行统一更改组件的颜色、字体大小等(换肤):
$color-primary: #3ecacb;
$color-success: #4fc48d;
$color-warning: #f3d93f;
$color-danger: #f6588e;
$color-info: #27c6fa;
实例2:图片的配置及全局引入
Scss中图片的使用,可能存在以下2个问题:
(1)如果样式文件和使用该样式文件的vue文件不在同一目录会出现图片找不到
(2)如果将图片路径配置变量写在vue文件的style中,但是该写法导致图片和样式分离
我们可以采用将图片路径写成配置文件,然后进行全局引入,这样可以统一更改图片路径(并且该方法只会在使用相应图片时进行加载,不会导致额外性能问题):
$common-path: './primary/assets/img/';
$icon-see: $common-path+'icon-see.png';
$icon-play: $common-path+'icon-play.png';
$icon-comment: $common-path+'icon-comment.png';
$icon-checkbox: $common-path+'icon-checkbox.png';
(1)Css中的@import规则,它允许在一个css文件中导入其他css文件。然而,后果是只有执行到@import时,浏览器才会去下载其他css文件,这导致页面加载起来特别慢。
(2)Scss中的@import规则,不同的是,scss的@import规则在生成css文件时就把相关文件导入进来。这意味着所有相关的样式被归纳到了同一个css文件中,而无需发起额外的下载请求。
实例1:组件库中统一将组件的样式文件import进index.sccs中,然后如果项目中有使用组件库的地方只需要在项目的入口处,引入index.scss文件,如下所示在index.scss文件中引入各组件的样式文件:
@import "./base.scss";
@import "./webupload.scss";
@import "./message-hint.scss";
scss局部文件的文件名以下划线开头。这样,scss就不会在编译时单独编译这个文件输出css,而只把这个文件用作导入。在使用scss时,混合器mixins是最适合的使用场景,因为混合器不需要单独编译输出css文件。
实例1:将混合器的名称写成局部文件命名的方式,如下图所示
我们可以使用嵌套功能和父选择器标识符 & 来缩减重复的代码,特别如果你CSS类采用BEM命名规范,样式类命名存在冗长的问题。使用此功能,能解决BEM命名冗长的问题,且样式可读性更高。
实例1:嵌套功能和父选择器标识符 & 解决BEM冗长问题:
.tea-assignhw {
&__top {
margin: 0;
}
&__content {
padding-left: 45px;
}
&__gradeselect {
width: 158px;
}
}
**实例2:**嵌套中使用子选择器、兄弟选择器和伪类选择器
(1)子选择器
&__hint {
margin: 20px;
font-size: 14px;
> p:first-child {
font-weight: bold;
}
}
(2)兄弟选择器
&__input {
width: 220px;
& + span {
margin-left: 10px;
}
}
(3)伪类选择器
&__browse {
background: url($btn-search) no-repeat;
&:hover {
background: url($btn-search) -80px 0 no-repeat;
}
&:visited {
background: url($btn-search) -160px 0 no-repeat;
}
}
变量使你能够复用属性值,但如果想要复用一大段规则呢?传统的做法是,如果在样式表
中发现重复,就会把公共的规则抽离出来放到新的CSS类中。
在Scss中可以使用混合器@mixin和@extend继承指令来解决以上提到的复用一大段规则的场景。但两者的使用场景又有啥区别呢?
(1)@mixin主要的优势就是它能够接受参数。如果想传递参数,你会很自然地选择@mixin而不是@extend,因为@extend不能够接受参数
(2)因为混合器规则都混入到其他类中,所以在输出的样式表中不能完全避免重复。选择器继承的意思就是让一个选择器能够复用另一个选择器的所有样式,但又不重复输出这些样式属性;即使用@extend产生 DRY CSS风格的代码(Don't repeat yourself)
综上所述,如果你需要传参数,只能使用@mixin混合器,否则用@extend继承来实现更优。
实例1:@mixin混合器的使用
@mixin paneactive($image, $level, $vertical) {
background: url($image) no-repeat $level $vertical;
height: 100px;
width: 30px;
position: relative;
top: 50%;
}
&--left-active {
@include paneactive($btn-flip, 0, 0);
}
&--right-active {
@include paneactive($btn-flip, 0, -105px);
}
实例2:@extend继承的使用
.common-mod {
height: 250px;
width: 50%;
background-color: #fff;
text-align: center;
}
&-mod {
@extend .common-mod;
float: right;
}
&-mod2 {
@extend .common-mod;
}
在@include混合器时不必传入所有的参数,我们可以给参数指定一个默认值,如果所需要传的参数是 默认值,则@include时可以省略该参数;如果所需要传的参数不是默认值,则@include时则传入新的参数。
实例1:@mixin混合器默认参数值的使用
@mixin pane($dir: left) {
width: 35px;
display: block;
float: $dir;
background-color: #f1f1f1;
}
&__paneleft {
@include pane;
}
&__paneright {
@include pane(right);
}
通过 #{} 插值语句可以在选择器或属性名中使用变量。当有两个页面的样式类似时,我们会将类似的样式抽取成页面混合器,但两个不同的页面样式的命名名称根据BEM命名规范不能一样,这时我们可使用插值进行动态命名。
实例1:页面级混合器中的类名利用#{}插值进行动态设置
@mixin home-content($class) {
.#{$class} {
position: relative;
background-color: #fff;
overflow-x: hidden;
overflow-y: hidden;
&--left {
margin-left: 160px;
}
&--noleft {
margin-left: 0;
}
}
}
SassScript 支持数字的加减乘除、取整等运算 (+, -, *, /, %)
实例1:input组件根据输入框的高度设置左右内边距,如下所示:
.ps-input {
display: block;
&__inner {
-webkit-appearance: none;
padding-left: #{$--input-height + 10
};
padding-right: #{$--input-height + 10
};
}
}
scss自带一些函数,例如hsl、mix函数等。
**实例1:button组件的点击后颜色是将几种颜色根据一定的比例混合在一起,生成另一种颜色。**如下所示:
&:focus {
color: mix($--color-white, $--color-primary, $--button-hover-tint-percent);
border-color: transparent;
background-color: transparent;}
&:active {
color: mix($--color-black, $--color-primary, $--button-active-shade-percent);
border-color: transparent; background-color: transparent;
}
@for指令可以在限制的范围内重复输出样式,每次按变量的值对输出结果进行变动。
实例1:例如项目中需要设置hwicon类底下第2到8个div子节点需设置样式,如下所示:
@for $i from 2 through 8 {
.com-hwicon {
> div:nth-child(#{$i}) {
position: relative;
float: right;
}
}
}
可通过结合each遍历、map数据类型、@mixin/@include混合器、#{}插值,从而生成不同的选择器类,并且每个选择器类中的背景图片不同,如下所示:
$img-list: (
(accessimg, $papers-access),
(folderimg, $papers-folder),
(bmpimg, $papers-bmp),
(xlsimg, $papers-excel),
(xlsximg, $papers-excel),
(gifimg, $papers-gif),
(jpgimg, $papers-jpg),
(unknownimg, $papers-unknown)
);
@each $label, $value in $img-list {
.com-hwicon__#{$label} {
@include commonImg($value);
}
}
CSS不能算是严格意义的编程语言,但是在前端体系中却不能小觑。 CSS 是以描述为主的样式表,如果描述得混乱、没有规则,对于其他开发者一定是一个定时炸弹,特别是有强迫症的人群。CSS 看似简单,想要写出漂亮的 CSS 还是相当困难。所以校验 CSS 规则的行动迫在眉睫。stylelint是一个强大的现代 CSS 检测器,可以让开发者在样式表中遵循一致的约定和避免错误。
**(1)需要安装gulp、stylelint、gulp-postscss 、 postcss-reporter、stylelint-config-standard,**安装命令为:
npm install gulp stylelint gulp-postscss postcss-reporter
stylelint-config-standard--save-dev
(2)安装完成后会在项目根目录下创建gulpfile.js文件,文件gulpfile.js配置为:
var reporter = require('postcss-reporter');
var stylelint = require('stylelint');
var stylelintConfig = {
'extends': 'stylelint-config-standard',
'rules': {
'at-rule-no-unknown': [
true, {
'ignoreAtRules': [
'extend',
'include',
'mixin',
'for'
]
}
]
}
};
gulp.task('scss-lint', function() {
var processors = [
stylelint(stylelintConfig),
reporter({
clearMessages: true,
throwError: true
})
];
return gulp.src(
['src/style/*.scss']// 需要工具检查的scss文件
).pipe(postcss(processors));});
gulp.task('default', ['scss-lint']);
(3) stylelint-config-standard 检验规则
stylelint-config-standard为stylelint官方推荐的标准校验规则,具体校验规则有哪些内容,可参照官网。
(4)运行命令进行样式检查
stylefmt 是一个基于 stylelint 的代码修正工具,它可以基于stylelint的代码规范约定配置,对可修正的地方作格式化输出。
(1)gulp.js配置文件如下:
var stylefmt = require('gulp-stylefmt'); // css格式自动调整工具
gulp.task('stylefmt', function() {
return gulp.src(
['src/style/student/index.scss' // 需要工具检查的scss文件
]).pipe(stylefmt(stylelintConfig))
.pipe(gulp.dest('src/style/dest/student'));});
gulp.task('fix', ['stylefmt']);
(2)运行命令进行样式修复,如下图所示
初写scss代码时,由于对语法不熟悉等,写出来的scss代码所得到的页面效果,并不是我们想要的。这时,我们可以使用gulp-sass插件来监听scss代码,实时生成css代码,从而可以通过查看css代码,来判断所写的scss代码是否正确。
(1)gulp.js配置文件如下:
var gulpsass = require('gulp-sass');
gulp.task('gulpsass', function() {
return gulp.src('src/style/components/hwIcon.scss')
.pipe(gulpsass().on('error', gulpsass.logError))
.pipe(gulp.dest('src/style/dest'));});
gulp.task('watch', function() {
gulp.watch('src/style/components/hwIcon.scss', ['gulpsass']);
});复制代码复制代码
(2)运行命令从而监听scss文件,动态编译scss代码生成css代码文件,如下图所示
以上就是总结的14条 SCSS 实战经验总结的分享,希望对你有借鉴之处,如果对你有启发,请手动 Star~ 鼓励,如果有疑问或建议,欢迎留言讨论。
前端三大框架 Angular、React、Vue ,它们的路由解决方案 angular/router、react-router、vue-router 都是基于前端路由原理进行封装实现的,因此将前端路由原理进行了解和掌握是很有必要的,因为我们再使用的过程中也难免会遇到一些坑,一旦我们掌握了它的实现原理,那么就能在开发中对路由的使用更加游刃有余。
路由的概念起源于服务端,在以前前后端不分离的时候,由后端来控制路由,当接收到客户端发来的 HTTP 请求,就会根据所请求的相应 URL,来找到相应的映射函数,然后执行该函数,并将函数的返回值发送给客户端。对于最简单的静态资源服务器,可以认为,所有 URL 的映射函数就是一个文件读取操作。对于动态资源,映射函数可能是一个数据库读取操作,也可能是进行一些数据的处理等等。然后根据这些读取的数据,在服务器端就使用相应的模板来对页面进行渲染后,再返回渲染完毕的页面。它的好处与缺点非常明显:
SEO 好; 也正是由于后端路由还存在着自己的不足,前端路由才有了自己的发展空间。对于前端路由来说,路由的映射函数通常是进行一些 DOM 的显示和隐藏操作。这样,当访问不同的路径的时候,会显示不同的页面组件。前端路由主要有以下两种实现方案:
HashHistory当然,前端路由也存在缺陷:使用浏览器的前进,后退键时会重新发送请求,来获取数据,没有合理地利用缓存。但总的来说,现在前端路由已经是实现路由的主要方式了,前端三大框架 Angular、React、Vue ,它们的路由解决方案 angular/router、react-router、vue-router 都是基于前端路由进行开发的,因此将前端路由进行了解和
掌握是很有必要的,下面我们分别对两种常见的前端路由模式 Hash 和 History 进行讲解。
早期的前端路由的实现就是基于 location.hash 来实现的。其实现原理也很简单,location.hash 的值就是 URL 中 # 后面的内容。比如下面这个网站,它的 location.hash 的值为 '#search':
https://www.word.com#search此外,hash 也存在下面几个特性:
URL 中 hash 值只是客户端的一种状态,也就是说当向服务器端发出请求时,hash 部分不会被发送。hash 值的改变,都会在浏览器的访问历史中增加一个记录。因此我们能通过浏览器的回退、前进按钮控制hash 的切换。hashchange 事件来监听 hash 的变化。我们可以通过两种方式触发 hash 变化,一种是通过 a 标签,并设置 href 属性,当用户点击这个标签后,URL 就会发生改变,也就会触发 hashchange 事件了:
<a href="#search">search</a>还有一种方式就是直接使用 JavaScript来对 loaction.hash 进行赋值,从而改变 URL,触发 hashchange 事件:
location.hash="#search"以下实现我们采用第2种方式来实现。
我们先定义一个父类 BaseRouter,用于实现 Hash 路由和 History 路由的一些共有方法;
export class BaseRouter {
// list 表示路由表
constructor(list) {
this.list = list;
}
// 页面渲染函数
render(state) {
let ele = this.list.find(ele => ele.path === state);
ele = ele ? ele : this.list.find(ele => ele.path === '*');
ELEMENT.innerText = ele.component;
}
}我们简单实现了 push 压入功能、go 前进/后退功能,相关代码的注释都已经标上,简单易懂,就不在一 一介绍,参见如下:
export class HashRouter extends BaseRouter {
constructor(list) {
super(list);
this.handler();
// 监听 hashchange 事件
window.addEventListener('hashchange', e => {
this.handler();
});
}
// hash 改变时,重新渲染页面
handler() {
this.render(this.getState());
}
// 获取 hash 值
getState() {
const hash = window.location.hash;
return hash ? hash.slice(1) : '/';
}
// push 新的页面
push(path) {
window.location.hash = path;
}
// 获取 默认页 url
getUrl(path) {
const href = window.location.href;
const i = href.indexOf('#');
const base = i >= 0 ? href.slice(0, i) : href;
return base +'#'+ path;
}
// 替换页面
replace(path) {
window.location.replace(this.getUrl(path));
}
// 前进 or 后退浏览历史
go(n) {
window.history.go(n);
}
}Hash 模式的路由实现例子的效果图如下所示:
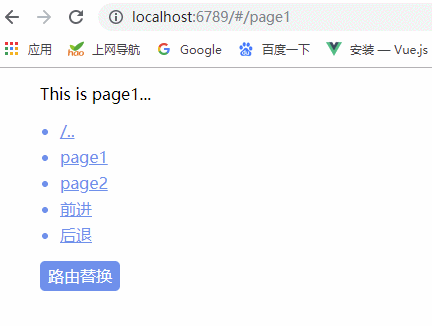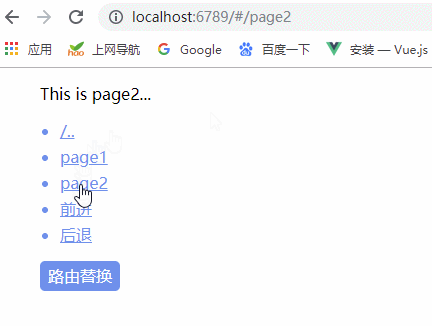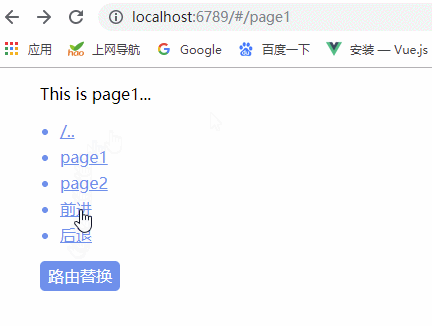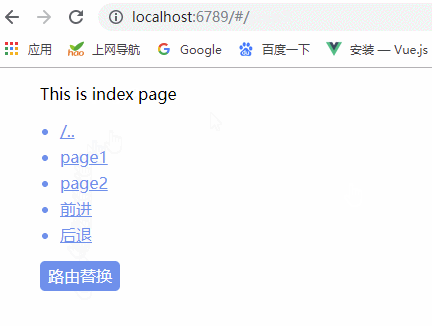
前面的 hash 虽然也很不错,但使用时都需要加上 #,并不是很美观。因此到了 HTML5,又提供了 History API 来实现 URL 的变化。其中做最主要的 API 有以下两个:history.pushState() 和 history.repalceState()。这两个 API可以在不进行刷新的情况下,操作浏览器的历史纪录。唯一不同的是,前者是新增一个历史记录,后者是直接替换当前的历史记录,如下所示:
window.history.pushState(null, null, path);
window.history.replaceState(null, null, path);此外,history 存在下面几个特性:
pushState 和 repalceState 的标题(title):一般浏览器会忽略,最好传入 null ;popstate 事件来监听 url 的变化;history.pushState() 或 history.replaceState() 不会触发 popstate 事件,这时我们需要手动触发页面渲染;我们同样简单实现了 push 压入功能、go 前进/后退功能,相关代码的注释都已经标上,简单易懂,就不在一 一介绍,参见如下:
export class HistoryRouter extends BaseRouter {
constructor(list) {
super(list);
this.handler();
// 监听 popstate 事件
window.addEventListener('popstate', e => {
console.log('触发 popstate。。。');
this.handler();
});
}
// 渲染页面
handler() {
this.render(this.getState());
}
// 获取 url
getState() {
const path = window.location.pathname;
return path ? path : '/';
}
// push 页面
push(path) {
history.pushState(null, null, path);
this.handler();
}
// replace 页面
replace(path) {
history.replaceState(null, null, path);
this.handler();
}
// 前进 or 后退浏览历史
go(n) {
window.history.go(n);
}
}History 模式的路由实现例子的效果图如下所示:

| 对比点 | Hash 模式 | History 模式 |
|---|---|---|
| 美观性 | 带着 # 字符,较丑 | 简洁美观 |
| 兼容性 | >= ie 8,其它主流浏览器 | >= ie 10,其它主流浏览器 |
| 实用性 | 不需要对服务端做改动 | 需要服务端对路由进行相应配合设置 |
本文我们大致介绍了什么路由、前端路由的源起、以及分析了两种前端路由:Hash 模式和 History 模式的原理以及简单功能实现,文中例子的代码实现已经放到 github 上面:https://github.com/fengshi123/router-example 。通过本文对前端路由原理的掌握,这时你就可以基础原理基础去阅读 vue-router 和 react-router 的源码实现了。
github地址为:https://github.com/fengshi123/blog ,上面汇总了作者所有的博客文章,如果喜欢或者有所启发,请帮忙给个 star ~,对作者也是一种鼓励。
webpack 的核心配置的创建和修改基于一个有潜在难于处理的 JavaScript 对象。虽然这对于配置单个项目来说是没有什么问题的,但当你团队中有比较多项目,并且尝试所有项目共享 webpack 配置文件时,你会觉难以入手,因为你需要考虑构建配置的可扩展性,比如某个子项目有自己独有的特征,需要进行一些个性化配置时,便会变得棘手。
webpack-chain 尝试通过提供可链式或顺流式的 API 创建和修改webpack 配置,API 的 Key 部分可以由用户指定的名称引用,这有助于跨项目修改配置方式的标准化。在 vue-cli3 以及一些开源的构建器中陆续采用了 webpack-chain 这种方式,所以本文我们会从入门到熟练上手,帮助大家熟悉 webpack-chain 的编写使用。
我们可以使用 npm 或者 yarn 的方式安装 webpack-chain 包,如下所示
npm i --save-dev webpack-chain
or
yarn add --dev webpack-chain当你安装了webpack-chain, 你就可以开始创建一个 webpack 实例,如下所示
// 导入 webpack-chain 模块,该模块导出了一个用于创建一个 webpack 配置 API 的单一构造函数。
const Config = require('webpack-chain');
// 对该单一构造函数创建一个新的配置实例
const config = new Config();
// ... 中间一系列 webpack 的配置,我们在后续的章节再陆续说明,这里暂且省略
// 导出这个修改完成的要被 webpack 使用的配置对象
module.exports = config.toConfig();webpack-chain 中的核心 API 接口之一是 ChainedMap. 一个 ChainedMap 的操作类似于 JavaScript Map, 为链式和生成配置提供了一些便利, 如果一个属性被标记一个 ChainedMap, 则它将具有如下的 API 和方法:
除非另有说明,否则这些方法将返回 ChainedMap, 允许链式调用这些方法。
// 1、从 Map 移除所有 配置
clear()
// 2、通过键值从 Map 移除单个配置
delete(key)
// 3、获取 Map 中相应键的值
// 注意:返回值是该 key 对应的值
get(key)
// 4、获取 Map 中相应键的值
// 如果键在 Map 中不存在,则 ChainedMap 中该键的值会被配置为 fn 的返回值.
// 注意:返回值是该 key 对应的值,或者 fn 返回的值
getOrCompute(key, fn)
// 5、配置 Map 中 已存在的键的值
set(key, value)
// 6、Map 中是否存在一个配置值的特定键,
// 注意:返回 boolean
has(key)
// 7、返回 Map 中已存储的所有值的数组
// 注意:返回 Array
values()
// 8、返回 Map 中全部配置的一个对象, 其中 键是这个对象属性,值是相应键的值,
entries()
// 9、 提供一个对象,这个对象的属性和值将 映射进 Map
merge(obj, omit)
// 10、对当前配置上下文执行函数 handler
batch(handler)
// 11、条件执行一个函数去继续配置
// condition: Boolean
// whenTruthy: 当条件为真,调用把 ChainedMap 实例作为单一参数传入的函数
// whenFalsy: 当条件为假,调用把 ChainedMap 实例作为单一参数传入的函数
when(condition, whenTruthy, whenFalsy)webpack-chain 中的核心 API 接口另一个是 ChainedSet,其操作类似于JavaScript Set, 为链式和生成配置提供了一些便利。 如果一个属性被标记一个 ChainedSet,则它将具有如下的 API 和方法:
除非另有说明,否则这些方法将返回 ChainedSet,允许链式调用这些方法。
// 1、添加/追加给 Set 末尾位置一个值
add(value)
// 2、添加给 Set 开始位置一个值
prepend(value)
// 3、移除Set中全部值
clear()
// 4、移除Set中一个指定的值
delete(value)
// 5、检测 Set 中是否存在一个值
// 注意:返回 boolean
has(value)
// 6、返回 Set 中值的数组.
// 注意:返回 Array
values()
// 7、连接给定的数组到 Set 尾部。
merge(arr)
// 8、对当前配置上下文执行函数 handler
batch(handler)
// 8、条件执行一个函数去继续配置
// whenTruthy: 当条件为真,调用把 ChainedSet 实例作为单一参数传入的函数
// whenFalsy: 当条件为假,调用把 ChainedSet 实例作为单一参数传入的函数
when(condition, whenTruthy, whenFalsy)除了以上提到的使用 ChainedMap 和 ChainedSet 语法编写实现功能外,webpack-chain 还提供了许多简写方法,我们在这里不在一一列出,读者可以去 webpack-chain github 官方文档 查阅。例如,devServer.hot 就是是一个简写方法,写法如下所示
// devServer 的简写方法如下
devServer.hot(true);
// 上述方法等效于
devServer.set('hot', true);跟 ChainedMap 和 ChainedSet 语法一样,简写方法在没有特别说明的情况,返回的也是原实例,因此简写方法也是支持链式语法的。
webpack-chain 支持将对象合并到配置实例,但是要注意,这不是 webpack 配置对象,如果我们需要合并 webpack-chain 对象,需要在合并前对其进行转换。
// 合并
config.merge({ devtool: 'source-map' });
// 获取 "source-map"
config.get('devtool')我们可以使用语法 config.toString() 方法将 webpack 对象转换成字符串,转换后的字符串包含命名规则、用法和插件的注释提示,如下所示
config
.module
.rule('compile')
.test(/\.js$/)
.use('babel')
.loader('babel-loader');
config.toString();
// 转换后的输出
{
module: {
rules: [
/* config.module.rule('compile') */
{
test: /\.js$/,
use: [
/* config.module.rule('compile').use('babel') */
{
loader: 'babel-loader'
}
]
}
]
}
}// 配置编译入口文件
config.entry('main').add('./src/main.js')
// 等同于以下 webpack 配置
entry: {
main: [
'./src/main.js'
]
}// 配置出口文件
config.output
.path(path.resolve(__dirname, './dist'))
.filename('[name].[chunkhash].js')
.chunkFilename('chunks/[name].[chunkhash].js')
.libraryTarget('umd');
// 等同于以下 webpack 配置
output: {
path: path.resolve(__dirname, './dist'),
filename: '[name].[chunkhash].js',
chunkFilename: 'chunks/[name].[chunkhash].js',
libraryTarget: 'umd'
},// 配置目录别名
config.resolve.alias
.set('@', path.resolve(__dirname, 'src'))
.set('assets', path.resolve(__dirname, 'src/assets'))
// 等同于以下 webpack 配置
resolve: {
alias: {
'@': path.resolve(__dirname, 'src'),
assets: path.resolve(__dirname, 'src/assets'))
}
},// 配置一个新的 loader
config.module
.rule('babel')
.test(/\.(js|jsx|mjs|ts|tsx)$/)
.include
.add(path.resolve(__dirname, 'src'))
.end()
.use('babel-loader')
.loader('babel-loader')
.options({
'presets':['@babel/preset-env']
})
// 等同于以下 webpack 配置
module: {
rules: [
{
test: /\.(js|jsx|mjs|ts|tsx)$/,
include: [
path.resolve(__dirname, 'src')
],
use: [
{
loader: 'babel-loader',
options: {
presets: [
'@babel/preset-env'
]
}
}
]
}
]
}跟新增 loader 不同的是,使用了 tap 方法,该方法的回调参数为 options 即该 loader 的配置选项对象,从而我们可以通过更改 options 对象,从而去更改 loader 配置。
config.module
.rule('babel')
.use('babel-loader')
.tap(options => {
// 修改它的选项...
options.include = path.resolve(__dirname, 'test')
return options
})config.module.rules.clear(); // 添加的 loader 都删掉.
config.module.rule('babel').uses.clear(); 删除指定 rule 用 use 添加的// 配置一个新的 plugin
config.plugin('HtmlWebpackPlugin').use(HtmlWebpackPlugin, [
{
template: path.resolve(__dirname, './src/index.html'),
minify: {
collapseWhitespace: true,
minifyJS: true,
minifyCSS: true,
removeComments: true,
removeEmptyAttributes: true,
removeRedundantAttributes: true,
useShortDoctype: true
}
}
]);
// 等同于以下 webpack 配置
plugins: [
new HtmlWebpackPlugin(
{
template: path.resolve(__dirname, './src/index.html'),
minify: {
collapseWhitespace: true,
minifyJS: true,
minifyCSS: true,
removeComments: true,
removeEmptyAttributes: true,
removeRedundantAttributes: true,
useShortDoctype: true
}
}
)
],跟新增 loader/plugin 不同的是,使用了 tap 方法,且保留了之前配置的选项,更改的选项被覆盖。
// 修改插件 HtmlWebpackPlugin
config.plugin('HtmlWebpackPlugin').tap((args) => [
{
...(args[0] || {}),
template: path.resolve(__dirname, './main.html'),
}
]);// 1、示例:仅在生产期间添加minify插件
config
.when(process.env.NODE_ENV === 'production', config => {
config
.plugin('minify')
.use(BabiliWebpackPlugin);
});
// 2、示例:只有在生产过程中添加缩小插件,否则设置 devtool 到源映射
config
.when(process.env.NODE_ENV === 'production',
config => config.plugin('minify').use(BabiliWebpackPlugin),
config => config.devtool('source-map')
);config.plugins.delete('HtmlWebpackPlugin');本文我们会从入门到熟练上手,通过介绍 webpack-chain 的语法到手动编写 webpack 的常见配置和操作,帮助大家熟悉 webpack-chain 的编写使用,希望对你有帮助。
辛苦整理良久,还望手动点赞鼓励~ 博客 github地址为:github.com/fengshi123//blog ,汇总了作者的所有博客,欢迎关注及 star ~
公司的前端项目使用Vue框架,Vue框架使用Webpack进行构建,随着项目不断迭代,项目逐渐变得庞大,然而项目的构建速度随之变得缓慢,于是对Webpack构建进行优化变得刻不容缓。经过不断的摸索和实践,通过以下方法优化后,项目的构建速度提高了50%。现将相关优化方法进行总结分享。
辛苦整理良久,如果喜欢或者有所启发,请帮忙给个 Star ~,对作者也是一种鼓励。
Loader配置 由于Loader对文件的转换操作很耗时,所以需要让尽可能少的文件被Loader处理。我们可以通过以下3方面优化Loader配置:(1)优化正则匹配(2)通过cacheDirectory选项开启缓存(3)通过include、exclude来减少被处理的文件。实践如下:
项目原配置:
{
test: /\.js$/,
loader: 'babel-loader',
include: [resolve('src'), resolve('test')]
}
优化后配置:
{
// 1、如果项目源码中只有js文件,就不要写成/\.jsx?$/,以提升正则表达式的性能
test: /\.js$/,
// 2、babel-loader支持缓存转换出的结果,通过cacheDirectory选项开启
loader: 'babel-loader?cacheDirectory',
// 3、只对项目根目录下的src 目录中的文件采用 babel-loader
include: [resolve('src')]
}
resolve.modules配置 resolve.modules 用于配置Webpack去哪些目录下寻找第三方模块。resolve.modules的默认值是[node modules],含义是先去当前目录的/node modules目录下去找我们想找的模块,如果没找到,就去上一级目录../node modules中找,再没有就去../ .. /node modules中找,以此类推,这和Node.js的模块寻找机制很相似。当安装的第三方模块都放在项目根目录的./node modules目录下时,就没有必要按照默认的方式去一层层地寻找,可以指明存放第三方模块的绝对路径,以减少寻找。
优化后配置:
resolve: {
// 使用绝对路径指明第三方模块存放的位置,以减少搜索步骤
modules: [path.resolve(__dirname,'node_modules')]
}
resolve.alias配置 resolve.alias配置项通过别名来将原导入路径映射成一个新的导入路径。
如项目中的配置使用:
alias: {
'@': resolve('src'),
},
// 通过以上的配置,引用src底下的common.js文件,就可以直接这么写
import common from '@/common.js';
resolve.extensions配置 在导入语句没带文件后缀时,Webpack 会在自动带上后缀后去尝试询问文件是否存在。默认是:extensions :[‘. js ‘,’. json ’] 。也就是说,当遇到require ( '. /data ’)这样的导入语句时,Webpack会先去寻找./data .js 文件,如果该文件不存在,就去寻找./data.json 文件,如果还是找不到就报错。如果这个列表越长,或者正确的后缀越往后,就会造成尝试的次数越多,所以 resolve .extensions 的配置也会影响到构建的性能。
• 后缀尝试列表要尽可能小,不要将项目中不可能存在的情况写到后缀尝试列表中。
• 频率出现最高的文件后缀要优先放在最前面,以做到尽快退出寻找过程。
• 在源码中写导入语句时,要尽可能带上后缀,从而可以避免寻找过程。例如在确定的情况下将 require(’. /data ’)写成require(’. /data.json ’),可以结合enforceExtension 和 enforceModuleExtension开启使用来强制开发者遵守这条优化
resolve.noParse配置 noParse配置项可以让Webpack忽略对部分没采用模块化的文件的递归解析和处理,这 样做的好处是能提高构建性能。原因是一些库如jQuery、ChartJS 庞大又没有采用模块化标准,让Webpack去解析这些文件既耗时又没有意义。 noParse是可选的配置项,类型需要是RegExp 、[RegExp]、function中的一种。例如,若想要忽略jQuery 、ChartJS ,则优化配置如下:
// 使用正则表达式
noParse: /jquerylchartjs/
// 使用函数,从 Webpack3.0.0开始支持
noParse: (content)=> {
// 返回true或false
return /jquery|chartjs/.test(content);
}
babel-plugin-transform-runtime 是Babel官方提供的一个插件,作用是减少冗余的代码 。 Babel在将ES6代码转换成ES5代码时,通常需要一些由ES5编写的辅助函数来完成新语法的实现,例如在转换 class extent 语法时会在转换后的 ES5 代码里注入 extent 辅助函数用于实现继承。babel-plugin-transform-runtime会将相关辅助函数进行替换成导入语句,从而减小babel编译出来的代码的文件大小。
HappyPack多进程解析和处理文件 由于有大量文件需要解析和处理,所以构建是文件读写和计算密集型的操作,特别是当文件数量变多后,Webpack构建慢的问题会显得更为严重。运行在 Node之上的Webpack是单线程模型的,也就是说Webpack需要一个一个地处理任务,不能同时处理多个任务。Happy Pack ( https://github.com/amireh/happypack )就能让Webpack做到这一点,它将任务分解给多个子进程去并发执行,子进程处理完后再将结果发送给主进程。
项目中HappyPack使用配置:
(1)HappyPack插件安装:
$ npm i -D happypack
(2)webpack.base.conf.js 文件对module.rules进行配置
module: {
rules: [
{
test: /\.js$/,
// 将对.js 文件的处理转交给 id 为 babel 的HappyPack实例
use:['happypack/loader?id=babel'],
include: [resolve('src'), resolve('test'),
resolve('node_modules/webpack-dev-server/client')],
// 排除第三方插件
exclude:path.resolve(__dirname,'node_modules'),
},
{
test: /\.vue$/,
use: ['happypack/loader?id=vue'],
},
]
},
(3)webpack.prod.conf.js 文件进行配置 const HappyPack = require('happypack');
// 构造出共享进程池,在进程池中包含5个子进程
const HappyPackThreadPool = HappyPack.ThreadPool({size:5});
plugins: [
new HappyPack({
// 用唯一的标识符id,来代表当前的HappyPack是用来处理一类特定的文件
id:'vue',
loaders:[
{
loader:'vue-loader',
options: vueLoaderConfig
}
],
threadPool: HappyPackThreadPool,
}),
new HappyPack({
// 用唯一的标识符id,来代表当前的HappyPack是用来处理一类特定的文件
id:'babel',
// 如何处理.js文件,用法和Loader配置中一样
loaders:['babel-loader?cacheDirectory'],
threadPool: HappyPackThreadPool,
}),
]
由于压缩JavaScript 代码时,需要先将代码解析成用 Object 抽象表示的 AST 语法树,再去应用各种规则分析和处理AST ,所以导致这个过程的计算量巨大,耗时非常多。当Webpack有多个JavaScript 文件需要输出和压缩时,原本会使用UglifyJS去一个一个压缩再输出,但是ParallelUglifyPlugin会开启多个子进程,将对多个文件的压缩工作分配给多个子进程去完成,每个子进程其实还是通过UglifyJS去压缩代码,但是变成了并行执行。所以 ParallelUglify Plugin能更快地完成对多个文件的压缩工作。
项目中ParallelUglifyPlugin使用配置:
(1)ParallelUglifyPlugin插件安装:
$ npm i -D webpack-parallel-uglify-plugin
(2)webpack.prod.conf.js 文件进行配置
const ParallelUglifyPlugin =require('webpack-parallel-uglify-plugin');
plugins: [
new ParallelUglifyPlugin({
cacheDir: '.cache/',
uglifyJs:{
compress: {
warnings: false
},
sourceMap: true
}
}),
]
复制代码
借助自动化的手段,在监听到本地源码文件发生变化时,自动重新构建出可运行的代码后再控制浏览器刷新。Webpack将这些功能都内置了,并且提供了多种方案供我们选择。
项目中自动刷新的配置:
devServer: {
watchOptions: {
// 不监听的文件或文件夹,支持正则匹配
ignored: /node_modules/,
// 监听到变化后等300ms再去执行动作
aggregateTimeout: 300,
// 默认每秒询问1000次
poll: 1000
}
},
复制代码
相关优化措施:
(1)配置忽略一些不监听的一些文件,如:node_modules。
(2)watchOptions.aggregateTirneout 的值越大性能越好,因为这能降低重新构建的频率。
(3) watchOptions.poll 的值越小越好,因为这能降低检查的频率。
DevServer 还支持一种叫做模块热替换( Hot Module Replacement )的技术可在不刷新整个网页的情况下做到超灵敏实时预览。原理是在一个源码发生变化时,只需重新编译发生变化的模块,再用新输出的模块替换掉浏览器中对应的老模块 。模块热替换技术在很大程度上提升了开发效率和体验 。
项目中模块热替换的配置:
devServer: {
hot: true,
},
plugins: [
new webpack.HotModuleReplacementPlugin(),
// 显示被替换模块的名称
new webpack.NamedModulesPlugin(), // HMR shows correct file names
]
复制代码
如果每个页面的代码都将这些公共的部分包含进去,则会造成以下问题 :
• 相同的资源被重复加载,浪费用户的流量和服务器的成本。
• 每个页面需要加载的资源太大,导致网页首屏加载缓慢,影响用户体验。
如果将多个页面的公共代码抽离成单独的文件,就能优化以上问题 。Webpack内置了专门用于提取多个Chunk中的公共部分的插件CommonsChunkPlugin。
项目中CommonsChunkPlugin的配置:
// 所有在 package.json 里面依赖的包,都会被打包进 vendor.js 这个文件中。
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
minChunks: function(module, count) {
return (
module.resource &&
/\.js$/.test(module.resource) &&
module.resource.indexOf(
path.join(__dirname, '../node_modules')
) === 0
);
}
}),
// 抽取出代码模块的映射关系
new webpack.optimize.CommonsChunkPlugin({
name: 'manifest',
chunks: ['vendor']
}),
复制代码
通过vue写的单页应用时,可能会有很多的路由引入。当打包构建的时候,javascript包会变得非常大,影响加载。如果我们能把不同路由对应的组件分割成不同的代码块,然后当路由被访问的时候才加载对应的组件,这样就更加高效了。这样会大大提高首屏显示的速度,但是可能其他的页面的速度就会降下来。
项目中路由按需加载(懒加载)的配置:
const Foo = () => import('./Foo.vue')
const router = new VueRouter({
routes: [
{ path: '/foo', component: Foo }
]
})
我们在项目进行打包后,会将开发中的多个文件代码打包到一个文件中,并且经过压缩,去掉多余的空格,且babel编译化后,最终会用于线上环境,那么这样处理后的代码和源代码会有很大的差别,当有bug的时候,我们只能定位到压缩处理后的代码位置,无法定位到开发环境中的代码,对于开发不好调式,因此sourceMap出现了,它就是为了解决不好调式代码问题的。
SourceMap的可选值如下:
开发环境推荐: cheap-module-eval-source-map
**生产环境推荐: cheap-module-source-map**
原因如下:
cheap的基本类型来忽略打包前后的列信息。bug的源代码具体的位置,比如说某个vue文件报错了,我们希望能定位到具体的vue文件,因此我们也需要module配置。map文件的形式,因此我们需要增加source-map属性。eval打包代码的时候,知道eval打包后的速度非常快,因为它不生成map文件,但是可以对eval组合使用 eval-source-map使用会将map文件以DataURL的形式存在打包后的js文件中。在正式环境中不要使用 eval-source-map, 因为它会增加文件的大小,但是在开发环境中,可以试用下,因为他们打包的速度很快。 Webpack输出的代码可读性非常差而且文件非常大,让我们非常头疼。为了更简单、直观地分析输出结果,社区中出现了许多可视化分析工具。这些工具以图形的方式将结果更直观地展示出来,让我们快速了解问题所在。接下来讲解vue项目中用到的分析工具:webpack-bundle-analyzer 。
项目中在webpack.prod.conf.js进行配置:
if (config.build.bundleAnalyzerReport) {
var BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
webpackConfig.plugins.push(new BundleAnalyzerPlugin());
}
执行 $ npm run build --report 后生成分析报告如下:
辛苦整理良久,如果喜欢或者有所启发,请帮忙给个 Star ~,对作者也是一种鼓励。
本文以前端面试官的角度出发,对 Vue 框架中一些重要的特性、框架的原理以问题的形式进行整理汇总,意在帮助作者及读者自测下 Vue 掌握的程度。本文章节结构以从易到难进行组织,建议读者按章节顺序进行阅读,当然大佬级别的请随意。希望读者读完本文,有一定的启发思考,也能对自己的 Vue 掌握程度有一定的认识,对缺漏之处进行弥补,对 Vue 有更好的掌握。 文章最后一题,欢迎同学们积极回答,分享各自的经验 ~~~
github地址为:github.com/fengshi123/…,汇总了作者的所有博客,也欢迎关注及 star ~
SPA( single-page application )仅在 Web 页面初始化时加载相应的 HTML、JavaScript 和 CSS。一旦页面加载完成,SPA 不会因为用户的操作而进行页面的重新加载或跳转;取而代之的是利用路由机制实现 HTML 内容的变换,UI 与用户的交互,避免页面的重新加载。
优点:
缺点:
v-if 是真正的条件渲染,因为它会确保在切换过程中条件块内的事件监听器和子组件适当地被销毁和重建;也是惰性的:如果在初始渲染时条件为假,则什么也不做——直到条件第一次变为真时,才会开始渲染条件块。
v-show 就简单得多——不管初始条件是什么,元素总是会被渲染,并且只是简单地基于 CSS 的 “display” 属性进行切换。
所以,v-if 适用于在运行时很少改变条件,不需要频繁切换条件的场景;v-show 则适用于需要非常频繁切换条件的场景。
Class 可以通过对象语法和数组语法进行动态绑定:
<div v-bind:class="{ active: isActive, 'text-danger': hasError }"></div>
data: {
isActive: true,
hasError: false
}<div v-bind:class="[isActive ? activeClass : '', errorClass]"></div>
data: {
activeClass: 'active',
errorClass: 'text-danger'
}Style 也可以通过对象语法和数组语法进行动态绑定:
<div v-bind:style="{ color: activeColor, fontSize: fontSize + 'px' }"></div>
data: {
activeColor: 'red',
fontSize: 30
}<div v-bind:style="[styleColor, styleSize]"></div>
data: {
styleColor: {
color: 'red'
},
styleSize:{
fontSize:'23px'
}
}所有的 prop 都使得其父子 prop 之间形成了一个单向下行绑定 :父级 prop 的更新会向下流动到子组件中,但是反过来则不行。这样会防止从子组件意外改变父级组件的状态,从而导致你的应用的数据流向难以理解。
额外的,每次父级组件发生更新时,子组件中所有的 prop 都将会刷新为最新的值。这意味着你不应该在一个子组件内部改变 prop。如果你这样做了,Vue 会在浏览器的控制台中发出警告。子组件想修改时,只能通过 $emit 派发一个自定义事件,父组件接收到后,由父组件修改。
有两种常见的试图改变一个 prop 的情形 :
props: ['initialCounter'],
data: function () {
return {
counter: this.initialCounter
}
}props: ['size'],
computed: {
normalizedSize: function () {
return this.size.trim().toLowerCase()
}
}computed: 是计算属性,依赖其它属性值,并且 computed 的值有缓存,只有它依赖的属性值发生改变,下一次获取 computed 的值时才会重新计算 computed 的值;
watch: 更多的是「观察」的作用,类似于某些数据的监听回调 ,每当监听的数据变化时都会执行回调进行后续操作;
运用场景:
当我们需要进行数值计算,并且依赖于其它数据时,应该使用 computed,因为可以利用 computed 的缓存特性,避免每次获取值时,都要重新计算;
当我们需要在数据变化时执行异步或开销较大的操作时,应该使用 watch,使用 watch 选项允许我们执行异步操作 ( 访问一个 API ),限制我们执行该操作的频率,并在我们得到最终结果前,设置中间状态。这些都是计算属性无法做到的。
由于 JavaScript 的限制,Vue 不能检测到以下数组的变动:
vm.items[indexOfItem] = newValuevm.items.length = newLength为了解决第一个问题,Vue 提供了以下操作方法:
// Vue.set
Vue.set(vm.items, indexOfItem, newValue)
// vm.$set,Vue.set的一个别名
vm.$set(vm.items, indexOfItem, newValue)
// Array.prototype.splice
vm.items.splice(indexOfItem, 1, newValue)为了解决第二个问题,Vue 提供了以下操作方法:
// Array.prototype.splice
vm.items.splice(newLength)(1)生命周期是什么?
Vue 实例有一个完整的生命周期,也就是从开始创建、初始化数据、编译模版、挂载 Dom -> 渲染、更新 -> 渲染、卸载等一系列过程,我们称这是 Vue 的生命周期。
(2)各个生命周期的作用
| 生命周期 | 描述 |
|---|---|
| beforeCreate | 组件实例被创建之初,组件的属性生效之前 |
| created | 组件实例已经完全创建,属性也绑定,但真实 dom 还没有生成,$el 还不可用 |
| beforeMount | 在挂载开始之前被调用:相关的 render 函数首次被调用 |
| mounted | el 被新创建的 vm.$el 替换,并挂载到实例上去之后调用该钩子 |
| beforeUpdate | 组件数据更新之前调用,发生在虚拟 DOM 打补丁之前 |
| update | 组件数据更新之后 |
| activited | keep-alive 专属,组件被激活时调用 |
| deadctivated | keep-alive 专属,组件被销毁时调用 |
| beforeDestory | 组件销毁前调用 |
| destoryed | 组件销毁后调用 |
(3)生命周期示意图
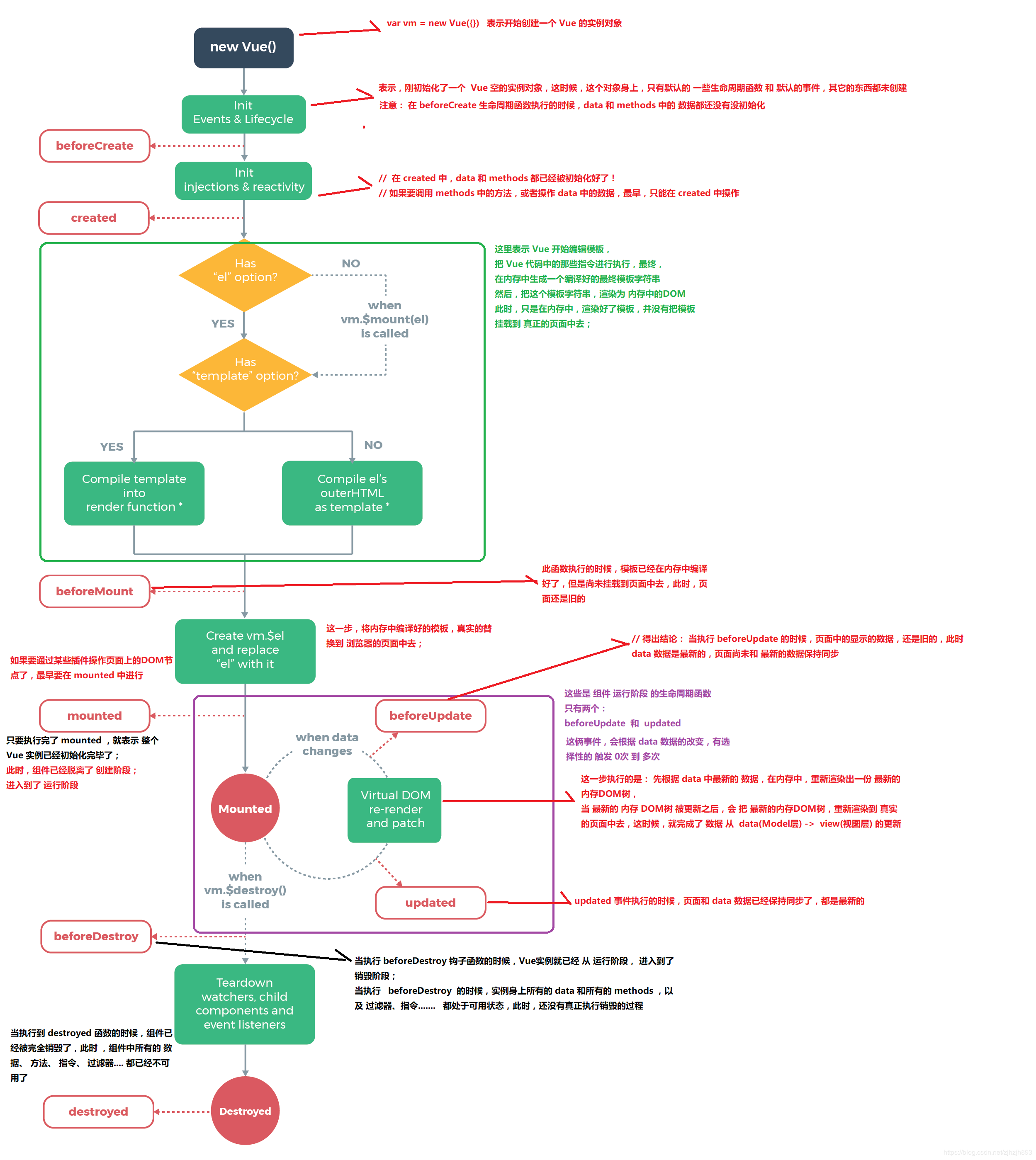
Vue 的父组件和子组件生命周期钩子函数执行顺序可以归类为以下 4 部分:
加载渲染过程
父 beforeCreate -> 父 created -> 父 beforeMount -> 子 beforeCreate -> 子 created -> 子 beforeMount -> 子 mounted -> 父 mounted
子组件更新过程
父 beforeUpdate -> 子 beforeUpdate -> 子 updated -> 父 updated
父组件更新过程
父 beforeUpdate -> 父 updated
销毁过程
父 beforeDestroy -> 子 beforeDestroy -> 子 destroyed -> 父 destroyed
可以在钩子函数 created、beforeMount、mounted 中进行调用,因为在这三个钩子函数中,data 已经创建,可以将服务端端返回的数据进行赋值。但是本人推荐在 created 钩子函数中调用异步请求,因为在 created 钩子函数中调用异步请求有以下优点:
在钩子函数 mounted 被调用前,Vue 已经将编译好的模板挂载到页面上,所以在 mounted 中可以访问操作 DOM。vue 具体的生命周期示意图可以参见如下,理解了整个生命周期各个阶段的操作,关于生命周期相关的面试题就难不倒你了。
比如有父组件 Parent 和子组件 Child,如果父组件监听到子组件挂载 mounted 就做一些逻辑处理,可以通过以下写法实现:
// Parent.vue
<Child @mounted="doSomething"/>
// Child.vue
mounted() {
this.$emit("mounted");
}以上需要手动通过 $emit 触发父组件的事件,更简单的方式可以在父组件引用子组件时通过 @hook 来监听即可,如下所示:
// Parent.vue
<Child @hook:mounted="doSomething" ></Child>
doSomething() {
console.log('父组件监听到 mounted 钩子函数 ...');
},
// Child.vue
mounted(){
console.log('子组件触发 mounted 钩子函数 ...');
},
// 以上输出顺序为:
// 子组件触发 mounted 钩子函数 ...
// 父组件监听到 mounted 钩子函数 ... 当然 @hook 方法不仅仅是可以监听 mounted,其它的生命周期事件,例如:created,updated 等都可以监听。
keep-alive 是 Vue 内置的一个组件,可以使被包含的组件保留状态,避免重新渲染 ,其有以下特性:
为什么组件中的 data 必须是一个函数,然后 return 一个对象,而 new Vue 实例里,data 可以直接是一个对象?
// data
data() {
return {
message: "子组件",
childName:this.name
}
}
// new Vue
new Vue({
el: '#app',
router,
template: '<App/>',
components: {App}
})因为组件是用来复用的,且 JS 里对象是引用关系,如果组件中 data 是一个对象,那么这样作用域没有隔离,子组件中的 data 属性值会相互影响,如果组件中 data 选项是一个函数,那么每个实例可以维护一份被返回对象的独立的拷贝,组件实例之间的 data 属性值不会互相影响;而 new Vue 的实例,是不会被复用的,因此不存在引用对象的问题。
我们在 vue 项目中主要使用 v-model 指令在表单 input、textarea、select 等元素上创建双向数据绑定,我们知道 v-model 本质上不过是语法糖,v-model 在内部为不同的输入元素使用不同的属性并抛出不同的事件:
以 input 表单元素为例:
<input v-model='something'>
相当于
<input v-bind:value="something" v-on:input="something = $event.target.value">如果在自定义组件中,v-model 默认会利用名为 value 的 prop 和名为 input 的事件,如下所示:
父组件:
<ModelChild v-model="message"></ModelChild>
子组件:
<div>{{value}}</div>
props:{
value: String
},
methods: {
test1(){
this.$emit('input', '小红')
},
},Vue 组件间通信是面试常考的知识点之一,这题有点类似于开放题,你回答出越多方法当然越加分,表明你对 Vue 掌握的越熟练。Vue 组件间通信只要指以下 3 类通信:父子组件通信、隔代组件通信、兄弟组件通信,下面我们分别介绍每种通信方式且会说明此种方法可适用于哪类组件间通信。
(1)props / $emit 适用 父子组件通信
这种方法是 Vue 组件的基础,相信大部分同学耳闻能详,所以此处就不举例展开介绍。
(2)ref 与 $parent / $children 适用 父子组件通信
ref:如果在普通的 DOM 元素上使用,引用指向的就是 DOM 元素;如果用在子组件上,引用就指向组件实例$parent / $children:访问父 / 子实例(3)EventBus ($emit / $on) 适用于 父子、隔代、兄弟组件通信
这种方法通过一个空的 Vue 实例作为**事件总线(事件中心),用它来触发事件和监听事件,从而实现任何组件间的通信,包括父子、隔代、兄弟组件。
(4)$attrs/$listeners 适用于 隔代组件通信
$attrs:包含了父作用域中不被 prop 所识别 (且获取) 的特性绑定 ( class 和 style 除外 )。当一个组件没有声明任何 prop 时,这里会包含所有父作用域的绑定 ( class 和 style 除外 ),并且可以通过 v-bind="$attrs" 传入内部组件。通常配合 inheritAttrs 选项一起使用。$listeners:包含了父作用域中的 (不含 .native 修饰器的) v-on 事件监听器。它可以通过 v-on="$listeners" 传入内部组件(5)provide / inject 适用于 隔代组件通信
祖先组件中通过 provider 来提供变量,然后在子孙组件中通过 inject 来注入变量。 provide / inject API 主要解决了跨级组件间的通信问题,不过它的使用场景,主要是子组件获取上级组件的状态,跨级组件间建立了一种主动提供与依赖注入的关系。
(6)Vuex 适用于 父子、隔代、兄弟组件通信
Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式。每一个 Vuex 应用的核心就是 store(仓库)。“store” 基本上就是一个容器,它包含着你的应用中大部分的状态 ( state )。
Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式。每一个 Vuex 应用的核心就是 store(仓库)。“store” 基本上就是一个容器,它包含着你的应用中大部分的状态 ( state )。
(1)Vuex 的状态存储是响应式的。当 Vue 组件从 store 中读取状态的时候,若 store 中的状态发生变化,那么相应的组件也会相应地得到高效更新。
(2)改变 store 中的状态的唯一途径就是显式地提交 (commit) mutation。这样使得我们可以方便地跟踪每一个状态的变化。
主要包括以下几个模块:
Vue.js 是构建客户端应用程序的框架。默认情况下,可以在浏览器中输出 Vue 组件,进行生成 DOM 和操作 DOM。然而,也可以将同一个组件渲染为服务端的 HTML 字符串,将它们直接发送到浏览器,最后将这些静态标记"激活"为客户端上完全可交互的应用程序。
即:SSR大致的意思就是vue在客户端将标签渲染成的整个 html 片段的工作在服务端完成,服务端形成的html 片段直接返回给客户端这个过程就叫做服务端渲染。
服务端渲染 SSR 的优缺点如下:
(1)服务端渲染的优点:
(2) 服务端渲染的缺点:
如果没有 SSR 开发经验的同学,可以参考本文作者的另一篇 SSR 的实践文章《Vue SSR 踩坑之旅》,里面 SSR 项目搭建以及附有项目源码。
vue-router 有 3 种路由模式:hash、history、abstract,对应的源码如下所示:
switch (mode) {
case 'history':
this.history = new HTML5History(this, options.base)
break
case 'hash':
this.history = new HashHistory(this, options.base, this.fallback)
break
case 'abstract':
this.history = new AbstractHistory(this, options.base)
break
default:
if (process.env.NODE_ENV !== 'production') {
assert(false, `invalid mode: ${mode}`)
}
}其中,3 种路由模式的说明如下:
hash: 使用 URL hash 值来作路由。支持所有浏览器,包括不支持 HTML5 History Api 的浏览器;
history : 依赖 HTML5 History API 和服务器配置。具体可以查看 HTML5 History 模式;
abstract : 支持所有 JavaScript 运行环境,如 Node.js 服务器端。如果发现没有浏览器的 API,路由会自动强制进入这个模式.
(1)hash 模式的实现原理
早期的前端路由的实现就是基于 location.hash 来实现的。其实现原理很简单,location.hash 的值就是 URL 中 # 后面的内容。比如下面这个网站,它的 location.hash 的值为 '#search':
https://www.word.com#searchhash 路由模式的实现主要是基于下面几个特性:
(2)history 模式的实现原理
HTML5 提供了 History API 来实现 URL 的变化。其中做最主要的 API 有以下两个:history.pushState() 和 history.repalceState()。这两个 API 可以在不进行刷新的情况下,操作浏览器的历史纪录。唯一不同的是,前者是新增一个历史记录,后者是直接替换当前的历史记录,如下所示:
window.history.pushState(null, null, path);
window.history.replaceState(null, null, path);history 路由模式的实现主要基于存在下面几个特性:
Model–View–ViewModel (MVVM) 是一个软件架构设计模式,由微软 WPF 和 Silverlight 的架构师 Ken Cooper 和 Ted Peters 开发,是一种简化用户界面的事件驱动编程方式。由 John Gossman(同样也是 WPF 和 Silverlight 的架构师)于2005年在他的博客上发表
MVVM 源自于经典的 Model–View–Controller(MVC)模式 ,MVVM 的出现促进了前端开发与后端业务逻辑的分离,极大地提高了前端开发效率,MVVM 的核心是 ViewModel 层,它就像是一个中转站(value converter),负责转换 Model 中的数据对象来让数据变得更容易管理和使用,该层向上与视图层进行双向数据绑定,向下与 Model 层通过接口请求进行数据交互,起呈上启下作用。如下图所示:
(1)View 层
View 是视图层,也就是用户界面。前端主要由 HTML 和 CSS 来构建 。
(2)Model 层
Model 是指数据模型,泛指后端进行的各种业务逻辑处理和数据操控,对于前端来说就是后端提供的 api 接口。
(3)ViewModel 层
ViewModel 是由前端开发人员组织生成和维护的视图数据层。在这一层,前端开发者对从后端获取的 Model 数据进行转换处理,做二次封装,以生成符合 View 层使用预期的视图数据模型。需要注意的是 ViewModel 所封装出来的数据模型包括视图的状态和行为两部分,而 Model 层的数据模型是只包含状态的,比如页面的这一块展示什么,而页面加载进来时发生什么,点击这一块发生什么,这一块滚动时发生什么这些都属于视图行为(交互),视图状态和行为都封装在了 ViewModel 里。这样的封装使得 ViewModel 可以完整地去描述 View 层。
MVVM 框架实现了双向绑定,这样 ViewModel 的内容会实时展现在 View 层,前端开发者再也不必低效又麻烦地通过操纵 DOM 去更新视图,MVVM 框架已经把最脏最累的一块做好了,我们开发者只需要处理和维护 ViewModel,更新数据视图就会自动得到相应更新。这样 View 层展现的不是 Model 层的数据,而是 ViewModel 的数据,由 ViewModel 负责与 Model 层交互,这就完全解耦了 View 层和 Model 层,这个解耦是至关重要的,它是前后端分离方案实施的重要一环。
我们以下通过一个 Vue 实例来说明 MVVM 的具体实现,有 Vue 开发经验的同学应该一目了然:
(1)View 层
<div id="app">
<p>{{message}}</p>
<button v-on:click="showMessage()">Click me</button>
</div>(2)ViewModel 层
var app = new Vue({
el: '#app',
data: { // 用于描述视图状态
message: 'Hello Vue!',
},
methods: { // 用于描述视图行为
showMessage(){
let vm = this;
alert(vm.message);
}
},
created(){
let vm = this;
// Ajax 获取 Model 层的数据
ajax({
url: '/your/server/data/api',
success(res){
vm.message = res;
}
});
}
})(3) Model 层
{
"url": "/your/server/data/api",
"res": {
"success": true,
"name": "IoveC",
"domain": "www.cnblogs.com"
}
}Vue 数据双向绑定主要是指:数据变化更新视图,视图变化更新数据,如下图所示:
即:
其中,View 变化更新 Data ,可以通过事件监听的方式来实现,所以 Vue 的数据双向绑定的工作主要是如何根据 Data 变化更新 View。
Vue 主要通过以下 4 个步骤来实现数据双向绑定的:
实现一个监听器 Observer:对数据对象进行遍历,包括子属性对象的属性,利用 Object.defineProperty() 对属性都加上 setter 和 getter。这样的话,给这个对象的某个值赋值,就会触发 setter,那么就能监听到了数据变化。
实现一个解析器 Compile:解析 Vue 模板指令,将模板中的变量都替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,调用更新函数进行数据更新。
实现一个订阅者 Watcher:Watcher 订阅者是 Observer 和 Compile 之间通信的桥梁 ,主要的任务是订阅 Observer 中的属性值变化的消息,当收到属性值变化的消息时,触发解析器 Compile 中对应的更新函数。
实现一个订阅器 Dep:订阅器采用 发布-订阅 设计模式,用来收集订阅者 Watcher,对监听器 Observer 和 订阅者 Watcher 进行统一管理。
以上四个步骤的流程图表示如下,如果有同学理解不大清晰的,可以查看作者专门介绍数据双向绑定的文章《0 到 1 掌握:Vue 核心之数据双向绑定》,有进行详细的讲解、以及代码 demo 示例。

如果被问到 Vue 怎么实现数据双向绑定,大家肯定都会回答 通过 Object.defineProperty() 对数据进行劫持,但是 Object.defineProperty() 只能对属性进行数据劫持,不能对整个对象进行劫持,同理无法对数组进行劫持,但是我们在使用 Vue 框架中都知道,Vue 能检测到对象和数组(部分方法的操作)的变化,那它是怎么实现的呢?我们查看相关代码如下:
/**
* Observe a list of Array items.
*/
observeArray (items: Array<any>) {
for (let i = 0, l = items.length; i < l; i++) {
observe(items[i]) // observe 功能为监测数据的变化
}
}
/**
* 对属性进行递归遍历
*/
let childOb = !shallow && observe(val) // observe 功能为监测数据的变化通过以上 Vue 源码部分查看,我们就能知道 Vue 框架是通过遍历数组 和递归遍历对象,从而达到利用 Object.defineProperty() 也能对对象和数组(部分方法的操作)进行监听。
Proxy 的优势如下:
Object.defineProperty 的优势如下:
受现代 JavaScript 的限制 ,Vue 无法检测到对象属性的添加或删除。由于 Vue 会在初始化实例时对属性执行 getter/setter 转化,所以属性必须在 data 对象上存在才能让 Vue 将它转换为响应式的。但是 Vue 提供了 Vue.set (object, propertyName, value) / vm.$set (object, propertyName, value) 来实现为对象添加响应式属性,那框架本身是如何实现的呢?
我们查看对应的 Vue 源码:vue/src/core/instance/index.js
export function set (target: Array<any> | Object, key: any, val: any): any {
// target 为数组
if (Array.isArray(target) && isValidArrayIndex(key)) {
// 修改数组的长度, 避免索引>数组长度导致splcie()执行有误
target.length = Math.max(target.length, key)
// 利用数组的splice变异方法触发响应式
target.splice(key, 1, val)
return val
}
// key 已经存在,直接修改属性值
if (key in target && !(key in Object.prototype)) {
target[key] = val
return val
}
const ob = (target: any).__ob__
// target 本身就不是响应式数据, 直接赋值
if (!ob) {
target[key] = val
return val
}
// 对属性进行响应式处理
defineReactive(ob.value, key, val)
ob.dep.notify()
return val
}我们阅读以上源码可知,vm.$set 的实现原理是:
如果目标是数组,直接使用数组的 splice 方法触发相应式;
如果目标是对象,会先判读属性是否存在、对象是否是响应式,最终如果要对属性进行响应式处理,则是通过调用 defineReactive 方法进行响应式处理( defineReactive 方法就是 Vue 在初始化对象时,给对象属性采用 Object.defineProperty 动态添加 getter 和 setter 的功能所调用的方法)
优点:
缺点:
虚拟 DOM 的实现原理主要包括以下 3 部分:
如果对以上 3 个部分还不是很了解的同学,可以查看本文作者写的另一篇详解虚拟 DOM 的文章《深入剖析:Vue核心之虚拟DOM》
key 是为 Vue 中 vnode 的唯一标记,通过这个 key,我们的 diff 操作可以更准确、更快速。Vue 的 diff 过程可以概括为:oldCh 和 newCh 各有两个头尾的变量 oldStartIndex、oldEndIndex 和 newStartIndex、newEndIndex,它们会新节点和旧节点会进行两两对比,即一共有4种比较方式:newStartIndex 和oldStartIndex 、newEndIndex 和 oldEndIndex 、newStartIndex 和 oldEndIndex 、newEndIndex 和 oldStartIndex,如果以上 4 种比较都没匹配,如果设置了key,就会用 key 再进行比较,在比较的过程中,遍历会往中间靠,一旦 StartIdx > EndIdx 表明 oldCh 和 newCh 至少有一个已经遍历完了,就会结束比较。具体有无 key 的 diff 过程,可以查看作者写的另一篇详解虚拟 DOM 的文章《深入剖析:Vue核心之虚拟DOM》
所以 Vue 中 key 的作用是:key 是为 Vue 中 vnode 的唯一标记,通过这个 key,我们的 diff 操作可以更准确、更快速
更准确:因为带 key 就不是就地复用了,在 sameNode 函数 a.key === b.key 对比中可以避免就地复用的情况。所以会更加准确。
更快速:利用 key 的唯一性生成 map 对象来获取对应节点,比遍历方式更快,源码如下:
function createKeyToOldIdx (children, beginIdx, endIdx) {
let i, key
const map = {}
for (i = beginIdx; i <= endIdx; ++i) {
key = children[i].key
if (isDef(key)) map[key] = i
}
return map
}如果没有对 Vue 项目没有进行过优化总结的同学,可以参考本文作者的另一篇文章《 Vue 项目性能优化 — 实践指南 》,文章主要介绍从 3 个大方面,22 个小方面详细讲解如何进行 Vue 项目的优化。
(1)代码层面的优化
(2)Webpack 层面的优化
(3)基础的 Web 技术的优化
开启 gzip 压缩
浏览器缓存
CDN 的使用
使用 Chrome Performance 查找性能瓶颈
Vue 3.0 正走在发布的路上,Vue 3.0 的目标是让 Vue 核心变得更小、更快、更强大,因此 Vue 3.0 增加以下这些新特性:
(1)监测机制的改变
3.0 将带来基于代理 Proxy 的 observer 实现,提供全语言覆盖的反应性跟踪。这消除了 Vue 2 当中基于 Object.defineProperty 的实现所存在的很多限制:
只能监测属性,不能监测对象
检测属性的添加和删除;
检测数组索引和长度的变更;
支持 Map、Set、WeakMap 和 WeakSet。
新的 observer 还提供了以下特性:
(2)模板
模板方面没有大的变更,只改了作用域插槽,2.x 的机制导致作用域插槽变了,父组件会重新渲染,而 3.0 把作用域插槽改成了函数的方式,这样只会影响子组件的重新渲染,提升了渲染的性能。
同时,对于 render 函数的方面,vue3.0 也会进行一系列更改来方便习惯直接使用 api 来生成 vdom 。
(3)对象式的组件声明方式
vue2.x 中的组件是通过声明的方式传入一系列 option,和 TypeScript 的结合需要通过一些装饰器的方式来做,虽然能实现功能,但是比较麻烦。3.0 修改了组件的声明方式,改成了类式的写法,这样使得和 TypeScript 的结合变得很容易。
此外,vue 的源码也改用了 TypeScript 来写。其实当代码的功能复杂之后,必须有一个静态类型系统来做一些辅助管理。现在 vue3.0 也全面改用 TypeScript 来重写了,更是使得对外暴露的 api 更容易结合 TypeScript。静态类型系统对于复杂代码的维护确实很有必要。
(4)其它方面的更改
vue3.0 的改变是全面的,上面只涉及到主要的 3 个方面,还有一些其他的更改:
本题为开放题目,欢迎大家在评论区畅所欲言,分享自己的踩坑、填坑经历,提供前车之鉴,避免大伙再次踩坑 ~~~
本文以前端面试官的角度出发,对 Vue 框架中一些重要的特性、框架的原理以问题的形式进行整理汇总,意在帮助作者及读者自测下 Vue 掌握的程度。 希望对读完本文的你有帮助、有启发,如果有不足之处,欢迎批评指正交流!
github地址为:github.com/fengshi123/…,汇总了作者的所有博客,也欢迎关注及 star ~
像素单位有设备像素、逻辑像素、CSS 像素 3 种。
设备像素(device pixels)也叫物理像素,指的是显示器上的真实像素,每个像素的大小是屏幕固有的属性,屏幕出厂以后就不会再改变。
设备分辨率描述的就是这个显示器的宽和高分别是多少个设备像素,例如常见的显示器的分辨率为 1920 * 1080。
设备像素和设备分辨率是由操作系统来管理的,浏览器不知道、也不必知道设备分辨率的大小,它主要根据逻辑分别率(下一小节介绍)来计算的。
设备独立像素(device independent pixels)是操作系统定义的一种像素单位,应用程序将设备独立像素告诉操作系统,操作系统再将设备独立像素转化为设备像素,从而控制屏幕上真正的物理像素点。
为什么需要在应用程序与设备像素之间定义这么一种单位呢?为什么应用程序不应该直接使用设备像素?
例如原先在 1280×720 设备分辨率的显示屏中,显示高度为 12 个设备像素的字体,现在放到设备分辨率为 2560 ×1440 的显示屏中,如果要想得到原先的大小,则需要 24 个设备像素,如果应用程序直接使用设备像素,那么编写应用程序则将变得非常困难,需要编写应用程序逻辑:字体在一些屏幕上高度为 12 个设备像素,在另一些屏幕上却需要 24 个设备像素。
因此操作系统定义了一个单位:设备独立像素。操作系统保证:用设备独立像素定义的尺寸,不管屏幕的参数如何,都能以合适的大小显示(这也是设备独立像素名字的由来)。操作系统是如何做到的呢?对于那些像素密度高的屏幕,将多个设备像素划分为一个逻辑像素。至于将多少设备像素划分为一个逻辑像素,这由操作系统决定。
对于上面的例子:“原本高度为 12 个设备像素的字体,现在高度为 24 个设备像素才能得到相同的大小”,操作系统会将一个逻辑像素定义为 2*2个 真实像素,从而设备独立像素尺寸不需要改变,而且不管在新、旧设备上,显示的尺寸大致相同。
设备独立像素与设备像素之间的比例是多少,显示器厂商和操作系统厂商会通过调查研究来得出最利于观看的比例。普遍规律是,屏幕的像素密度越高,就需要更多的设备像素来显示一个设备独立像素。
逻辑分辨率用屏幕的 宽高 来表示(单位:设备独立像素),我们通过操作系统的分辨率设置来改变设备独立像素的大小。例如屏幕的设备分辨率是19201200(单位:设备像素),我们可以在当前的分辨率下设置逻辑分辨率是1280*800(单位:设备独立像素)。那么横、纵方向的设备像素数量恰好是设备独立像素的1.5倍。这也意味着,设备独立像素的边长是设备像素边长的1.5倍。
在 CSS 中使用的 px 都是指 css 像素,比如 width: 128px。css 像素的大小是很容易变化的,当我们缩放页面的时候,元素的 css 像素数量不会改变,改变的只是每个 css 像素的大小。也就是说 width: 128px 的元素在缩放200% 以后,宽度依然是 128 个 css 像素,只不过每个 css 像素的宽度和高度变为原来的两倍。如果原本元素宽度为 128 个设备独立像素,那么缩放 200% 以后元素宽度为 256 个设备独立像素。
(1)css 像素与设备独立像素的关系
缩放比例就是 css 像素边长/设备独立像素边长;
在缩放比例为 100% 的情况下,1 个 css 像素大小等于 1 个设备独立像素;
在缩放比例为 200% 的情况下,1 个 css 像素大小等于 (2 * 2) 个设备独立像素;
(2)css 像素与设备像素的关系
window.devicePixelRatio 设备像素比,devicePixelRatio = (在相同长度的直线上)设备像素的数量 / CSS 像素的数量。这个比例也等价于 CSS 像素边长/设备像素边长。如 devicePixelRatio = 2,表示在相同长度的直线上,设备像素的数量是 CSS 像素数量的 2 倍,因此 CSS 像素的边长是设备像素的 2 倍。
缩放会导致 CSS 像素边长的改变,从而导致 window.devicePixelRatio 的改变!
viewport 表示浏览器的可视区域,也就是浏览器中用来显示网页的那部分区域。存在三种 viewport 分别为 layout viewport、visual viewport 以及 ideal viewport,我们接下来分别介绍三种。
layout viewport 为布局视口,即网页布局的区域,它是 html 元素的父容器,只要不在 css 中修改 元素的宽度, 元素的宽度就会撑满 layout viewport 的宽度。
很多时候浏览器窗口没有办法显示出 layout viewport 的全貌,但是它确实是已经被加载出来了,这个时候滚动条就出现了,你需要通过滚动条来浏览 layout viewport 其他的部分。
layout viewport 用 css 像素来衡量尺寸,在缩放、调整浏览器窗口的时候不会改变。缩放、调整浏览器窗口改变的只是 visual viewport。
在桌面浏览器中,缩放100% 的时候,Layout Viewport 宽度等于内容窗口的宽度。(你几乎不会在电脑上见过横向滚动条,除非你调整缩放)
但是在移动端,缩放为 100% 的时候,Layout Viewport 不一定等于内容窗口的大小。当你用手机浏览浏览宽大的网页(这些网页没有采用响应式设计)的时候,你只能一次浏览网页的一个部分,然后通过手指滑动浏览其他部分。这就说明整个网页(Layout Viewport)已经加载出来了,只不过你要一部分一部分地看。
visual viewport 为视觉视口,就是显示在屏幕上的网页区域,它往往只显示 layout viewport 的一部分。
visual viewport 就像一台摄像机,layout viewport 就像一张纸,摄像机对准纸的哪个部分,你就能看见哪个部分。你可以改变摄像机的拍摄区域大小(调整浏览器窗口大小),也可以调整摄像机的距离(调整缩放比例),这些方法都可以改变 visual viewport,但是 layout viewport 始终不变。

ideal viewport 为理想视口,不同的设备有自己不同的 ideal viewport,ideal viewport 的宽度等于移动设备的屏幕宽度,所以其是最适合移动设备的 viewport。只要在 css 中把某一元素的宽度设为 ideal viewport 的宽度(单位用 px ),那么这个元素的宽度就是设备屏幕的宽度了,也就是宽度为100% 的效果。ideal viewport 的意义在于,无论在何种分辨率的屏幕下,那些针对ideal viewport 而设计的网站,不需要用户手动缩放,也不需要出现横向滚动条,都可以完美的呈现给用户。
移动设备默认的 viewport 是 layout viewport,也就是那个比屏幕要宽的 viewport,但在进行移动设备网站的开发时,我们需要的是 ideal viewport。那么怎么才能得到 ideal viewport 呢?
我们在开发 h5 页面时,最经常见的标签如下所示
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=0">该 meta 标签的作用是让当前 viewport 的宽度等于设备的宽度,同时不允许用户手动缩放。如果你不这样的设定的话,那就会使用那个比屏幕宽的默认 viewport(layout viewport),也就是说会出现横向滚动条。
相关的属性意义如下所示
| width | 设置 layout viewport 的宽度,为一个正整数,或字符串 "width-device" |
|---|---|
| height | 设置页面的初始缩放值,为一个数字,可以带小数 |
| initial-scale | 允许用户的最小缩放值,为一个数字,可以带小数 |
| minimum-scale | 允许用户的最大缩放值,为一个数字,可以带小数 |
| maximum-scale | 设置 layout viewport 的高度,这个属性对我们并不重要,很少使用 |
| user-scalable | 是否允许用户进行缩放,值为"no"或"yes", no 代表不允许,yes 代表允许 |
node版本持续更新,一些node的新特性只有在node的较高版本中才可以使用。但是如果将node版本切换到较高版本,就会导致对现有项目的一些依赖造成环境不兼容。所以,需要一个工具对node版本进行管理,允许开发环境同时存在多个node版本,开发人员可以随意切换。
辛苦整理良久,如果喜欢或者有所启发,请帮忙给个 Star ~,对作者也是一种鼓励。
nvm全称Node Version Manager是 Nodejs 版本管理器,它让我们能方便的对 Nodejs 的版本进行切换。 nvm 的官方版本只支持 Linux 和 Mac。 Windows 用户,可以用 nvm-windows。
nvm-windows 最新下载地址:github.com/coreybutler…
如图所示:
以上标注的4个下载文件分别是指:
nvm-noinstall.zip: 这个是绿色免安装版本,但是使用之前需要配置
nvm-setup.zip:这是一个安装包,下载之后点击安装,无需配置就可以使用,方便。
Source code(zip):zip压缩的源码
Sourc code(tar.gz):tar.gz的源码,一般用于linux系统
我们这里选择使用第一个nvm-noinstall.zip绿色免安装版本。
(1)nvm-noinstall.zip下载完成后进行解压缩,得到以下所示的文件列表:
(2)我们在E盘底下新建文件夹E:/nvm,将第(1)步解压缩得到的文件列表复制到该文件夹,新建文件夹E:/nodejs用于存放node的安装依赖
(3)双击 install.cmd 然后会让你输入”压缩文件解压或拷贝到的一个绝对路径” 先不用管它,直接回车,成功后,会在 C 盘的根目录生成一个settings.txt的文本文件,把这个文件剪切到E:\nvm目录中,然后我们把它的内容配置成以下所示:
(1)第2步点击install.cmd文件后,会在环境变量的系统变量中,生成两个环境变量:NVM_HOME 和 NVM_SYMLINK 我们开始修改这两个变量名的变量值:NVM_HOME的变量值为:E:\nvm; NVM_SYMLINK的变量值为:E:\nodejs,然后在在Path的最前面输入: ;%NVM_HOME%;%NVM_SYMLINK%; 如下所示
(2)打开一个cmd窗口输入命令:nvm v ,那么我们会看到当前nvm的版本信息,说明nvm安装配置成功,如下所示:
nvm install // 安装指定版本,如:安装v6.2.0,可nvm install v6.2.0nvm uninstall //删除已安装的指定版本,语法与install类似nvm use //切换使用指定的版本nodenvm ls //列出所有安装的版本nvm ls-remote //列出所以远程服务器的版本(官方node version list)nvm current //显示当前的版本nvm alias //给不同的版本号添加别名nvm unalias //删除已定义的别名nvm reinstall-packages //在当前版本node环境下,重新全局安装指定版本号的npm包npm全局路径 进入命令模式,输入npm config set prefix “E:\nvm\npm” 回车,然后新建变量名为:NPM_HOME,变量值为 :E:\nvm\npm在Path的最前面添加;%NPM_HOME%,注意了,这个一定要添加在 %NVM_SYMLINK%之前,所以我们直接把它放到Path的最前面。
使用nvm管理node版本的相关示例如下所示:
1、请用管理员身份运行命令管理器,否则可能出错。
2、先设置 node 和 npm 的淘宝镜像,这样成功率和下载速度会更高点。
3、nvm安装目录,最好不要存在空格。否则,nvm可以安装成功,但使用nvm use x.y.z(nodejs的切换)会有问题。
辛苦整理良久,如果喜欢或者有所启发,请帮忙给个 Star ~,对作者也是一种鼓励。
本文的编写主要是最近在使用 midway 编写后端应用,midway 的 IOC 控制反转能力跟我们平时常写的前端应用,例如 react、vue 这些单应用还是有蛮大区别的,所以促使我想一探究竟,这种类 Spring IOC 容器是如何用 JavaScript 来实现的。为方便读者阅读,本文的组织结构依次为 TS 装饰器、Reflect Metadata、IOC 容器源码简单解读、以及自定义实现 IOC 容器。阅读完本文后,我希望你能有这样的感悟:元数据(metadata)和 装饰器(Decorator) 本是 ES 中两个独立的部分,但是结合它们, 竟然能实现 控制反转 这样的能力。本文的所有演示实例都已经上传到 github 仓库 ioc-container ,读者可以克隆下来进行调试运行。
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:github.com/fengshi123/blog ,汇总了作者的所有博客,欢迎关注及 star ~
(1)类型声明
type ClassDecorator = <TFunction extends Function>
(target: TFunction) => TFunction | void;参数:
target: 类的构造器。
返回:
如果类装饰器返回了一个值,它将会被用来代替原有的类构造器的声明。因此,类装饰器适合用于继承一个现有类并添加一些属性和方法。例如我们可以添加一个 toString 方法给所有的类来覆盖它原有的 toString 方法,以及增加一个新的属性 school,如下所示
type Consturctor = { new (...args: any[]): any };
function School<T extends Consturctor>(BaseClass: T) {
// 新构造器继承原有的构造器,并且返回
return class extends BaseClass {
// 新增属性 school
public school = 'qinghua'
// 重写方法 toString
toString() {
return JSON.stringify(this);
}
};
}
@School
class Student {
public name = 'tom';
public age = 14;
}
console.log(new Student().toString())
// {"name":"tom","age":14,"school":"qinghua"}
但是存在一个问题:装饰器并没有类型保护,这意味着在类装饰器的构造函数中新增的属性,通过原有的类实例将报无法找到的错误,如下所示
type Consturctor = { new (...args: any[]): any };
function School<T extends Consturctor>(BaseClass: T){
return class extends BaseClass {
// 新增属性 school
public school = 'qinghua'
};
}
@School
class Student{
getSchool() {
return this.school; // Property 'school' does not exist on type 'Student'
}
}
new Student().school // Property 'school' does not exist on type 'Student'这是 一个TypeScript的已知的缺陷。 目前我们能做的可以额外提供一个类用于提供类型信息,如下所示
type Consturctor = { new (...args: any[]): any };
function School<T extends Consturctor>(BaseClass: T){
return class extends BaseClass {
// 新增属性 school
public school = 'qinghua'
};
}
// 新增一个类用于提供类型信息
class Base {
school: string;
}
@School
class Student extends Base{
getSchool() {
return this.school;
}
}
new Student().school)
(1)类型声明
type PropertyDecorator = (
target: Object,
propertyKey: string | symbol
) => void;我们可以通过属性装饰器给属性添加对应的验证判断,如下所示
function NameObserve(target: Object, property: string): void {
console.log('target:', target)
console.log('property:', property)
let _property = Symbol(property)
Object.defineProperty(target, property, {
set(val){
if(val.length > 4){
throw new Error('名称不能超过4位!')
}
this[_property] = val;
},
get: function() {
return this[_property];
}
})
}
class Student {
@NameObserve
public name: string; // target: Student {} key: 'name'
}
const stu = new Student();
stu.name = 'jack'
console.log(stu.name); // jack
// stu.name = 'jack1'; // Error: 名称不能超过4位!
export default Student;
(1)类型声明:
type MethodDecorator = <T>(
target: Object,
propertyKey: string | symbol,
descriptor: TypedPropertyDescriptor<T>
) => TypedPropertyDescriptor<T> | void;方法装饰器不同于属性装饰器的地方在于 descriptor 参数。 通过这个参数我们可以修改方法原本的实现,添加一些共用逻辑。 例如我们可以给一些方法添加打印输入与输出的能力
function logger(target: Object, property: string,
descriptor: PropertyDescriptor): PropertyDescriptor | void {
const origin = descriptor.value;
console.log(descriptor)
descriptor.value = function(...args: number[]){
console.log('params:', ...args)
const result = origin.call(this, ...args);
console.log('result:', result);
return result;
}
}
class Person {
@logger
add(x: number, y: number){
return x + y;
}
}
const person = new Person();
const result = person.add(1, 2);
console.log('查看 result:', result) // 3
访问器装饰器总体上讲和方法装饰器很接近,唯一的区别在于描述器中有的 key 不同:
方法装饰器的描述器的 key 为:
访问器装饰器的描述器的key为:
例如,我们可以对访问器进行统一更改:
function descDecorator(target: Object, property: string,
descriptor: PropertyDescriptor): PropertyDescriptor | void {
const originalSet = descriptor.set;
const originalGet = descriptor.get;
descriptor.set = function(value: any){
return originalSet.call(this, value)
}
descriptor.get = function(): string{
return 'name:' + originalGet.call(this)
}
}
class Person {
private _name = 'tom';
@descDecorator
set name(value: string){
this._name = value;
}
get name(){
return this._name;
}
}
const person = new Person();
person.name = ('tom');
console.log('查看:', person.name) // name:'tom'
类型声明:
type ParameterDecorator = (
target: Object,
propertyKey: string | symbol,
parameterIndex: number
) => void;单独的参数装饰器能做的事情很有限,它一般都被用于记录可被其它装饰器使用的信息。
function ParamDecorator(target: Object, property: string,
paramIndex: number): void {
console.log(property);
console.log(paramIndex);
}
class Person {
private name: string;
public setNmae(@ParamDecorator school: string, name: string){ // setNmae 0
this.name = school + '_' + name
}
}
装饰器只在解释执行时应用一次,如下所示,这里的代码会在终端中打印 apply decorator,即便我们其实并没有使用类 A。
function f(C) {
console.log('apply decorator')
return C
}
@f
class A {}
// output: apply decorator
不同类型的装饰器的执行顺序是明确定义的:
示例如下所示
function f(key: string): any {
console.log("evaluate: ", key);
return function () {
console.log("call: ", key);
};
}
@f("Class Decorator")
class C {
@f("Static Property")
static prop?: number;
@f("Static Method")
static method(@f("Static Method Parameter") foo:any) {}
constructor(@f("Constructor Parameter") foo:any) {}
@f("Instance Method")
method(@f("Instance Method Parameter") foo:any) {}
@f("Instance Property")
prop?: number;
}
/* 输出顺序如下
evaluate: Instance Method
evaluate: Instance Method Parameter
call: Instance Method Parameter
call: Instance Method
evaluate: Instance Property
call: Instance Property
evaluate: Static Property
call: Static Property
evaluate: Static Method
evaluate: Static Method Parameter
call: Static Method Parameter
call: Static Method
evaluate: Class Decorator
evaluate: Constructor Parameter
call: Constructor Parameter
call: Class Decorator
*/我们从上注意到执行实例属性 prop 晚于实例方法 method 然而执行静态属性 static prop 早于静态方法static method。 这是因为对于属性/方法/访问器装饰器而言,执行顺序取决于声明它们的顺序。
然而,同一方法中不同参数的装饰器的执行顺序是相反的, 最后一个参数的装饰器会最先被执行。
function f(key: string): any {
console.log("evaluate: ", key);
return function () {
console.log("call: ", key);
};
}
class C {
method(
@f("Parameter Foo") foo,
@f("Parameter Bar") bar
) {}
}
/* 输出顺序如下
evaluate: Parameter Foo
evaluate: Parameter Bar
call: Parameter Bar
call: Parameter Foo
*/
我们可以对同一目标应用多个装饰器。它们的组合顺序为:
如下示例所示
function f(key: string) {
console.log("evaluate: ", key);
return function () {
console.log("call: ", key);
};
}
class C {
@f("Outer Method")
@f("Inner Method")
method() {}
}
/* 输出顺序如下
evaluate: Outer Method
evaluate: Inner Method
call: Inner Method
call: Outer Method
*/
在 ES6 的规范当中,ES6 支持元编程,核心是因为提供了对 Proxy 和 Reflect 对象的支持。简单来说这个 API 的作用就是可以实现对变量操作的函数化,也就是反射。然而 ES6 的 Reflect 规范里面还缺失一个规范,那就是 Reflect Metadata。这会造成什么样的情境呢?
由于 JS/TS 现有的 装饰器更多的是存在于对函数或者属性进行一些操作,比如修改他们的值,代理变量,自动绑定 this 等等功能。但是却无法实现通过反射来获取究竟有哪些装饰器添加到这个类/方法上... 这就限制了 JS 中元编程的能力。
此时 Relfect Metadata 就派上用场了,可以通过装饰器来给类添加一些自定义的信息。然后通过反射将这些信息提取出来(当然你也可以通过反射来添加这些信息)。
综合一下, JS 中对 Reflect Metadata 的诉求,简单概括就是:
TypeScript 在 1.5+ 的版本已经支持 reflect-metadata,但是我们在使用的时候还需要额外进行安装,如下所示
关于 reflect-metadata 的基本使用 api 可以阅读 reflect-metadata 文档,其包含常见的增删改查基本功能,我们来看下其基本的使用示例,其中 Reflect.metadata 当作 Decorator 使用,当修饰类时,在类上添加元数据,当修饰类属性时,在类原型的属性上添加元数据,如:
import "reflect-metadata";
@Reflect.metadata('classMetaData', 'A')
class SomeClass {
@Reflect.metadata('methodMetaData', 'B')
public someMethod(): string {
return 'hello someMethod';
}
}
console.log(Reflect.getMetadata('classMetaData', SomeClass)); // 'A'
console.log(Reflect.getMetadata('methodMetaData', new SomeClass(), 'someMethod')); // 'B当然跟我们平时看到的 IOC 不同,我们进一步结合装饰器,如下所示,与前面的功能是一样的
import "reflect-metadata";
function classDecorator(): ClassDecorator {
return target => {
// 在类上定义元数据,key 为 `classMetaData`,value 为 `a`
Reflect.defineMetadata('classMetaData', 'A', target);
};
}
function methodDecorator(): MethodDecorator {
return (target, key, descriptor) => {
// 在类的原型属性 'someMethod' 上定义元数据,key 为 `methodMetaData`,value 为 `b`
Reflect.defineMetadata('methodMetaData', 'B', target, key);
};
}
@classDecorator()
class SomeClass {
@methodDecorator()
someMethod() {}
}
console.log(Reflect.getMetadata('classMetaData', SomeClass)); // 'A'
console.log(Reflect.getMetadata('methodMetaData', new SomeClass(), 'someMethod')); // 'B'在 TS 中的 reflect-metadata 的功能是经过增强的,其添加 "design:type"、"design:paramtypes" 和 "design:returntype" 这 3 个类型相关的元数据
示例如下所示
import "reflect-metadata";
@Reflect.metadata('type', 'class')
class A {
constructor(
public name: string,
public age: number
) { }
@Reflect.metadata(undefined, undefined)
method(name: string, age: number):boolean {
return true
}
}
const t1 = Reflect.getMetadata('design:type', A.prototype, 'method')
const t2 = Reflect.getMetadata('design:paramtypes', A.prototype, 'method')
const t3 = Reflect.getMetadata('design:returntype', A.prototype, 'method')
console.log(t1) // [Function: Function]
console.log(...t2) // [Function: String] [Function: Number]
console.log(t3) // [Function: Boolean]
我们可以从 github 上克隆 midway 仓库的代码到本地,然后进行代码阅读以及 debug 调试。本篇博文我们主要想探究下 midway 的依赖注入合控制反转是如何实现的,其主要源码存在于两个目录:packages/core 和 packages/decorator,其中 packages/core 包含依赖注入的核心实现,加载对象的class,同步、异步创建对象实例化,对象的属性绑定等。
IOC 容器就像是一个对象池,管理着每个对象实例的信息(Class Definition),所以用户无需关心什么时候创建,当用户希望拿到对象的实例 (Object Instance) 时,可以直接拿到依赖对象的实例,容器会 自动将所有依赖的对象都自动实例化。packages/core 中主要有以下几种,分别处理不同的逻辑:
packages/decorator 包含装饰器 provide.ts、inject.ts 的实现,在midwayjs中是有一个装饰器管理类DecoratorManager, 用来管理 midwayjs 的所有装饰器:
实现装饰器 Provider 类,作用为将对应类注册到 IOC 容器中。
import 'reflect-metadata'
import * as camelcase from 'camelcase'
import { class_key } from './constant'
// Provider 装饰的类,表示要注册到 IOC 容器中
export function Provider (identifier?: string, args?: Array<any>) {
return function (target: any) {
// 类注册的唯一标识符
identifier = identifier ?? camelcase(target.name)
Reflect.defineMetadata(class_key, {
id: identifier, // 唯一标识符
args: args || [] // 实例化所需参数
}, target)
return target
}
}
实现装饰器 Inject 类,作用为将对应的类注入到对应的地方。
import 'reflect-metadata'
import { props_key } from './constant'
export function Inject () {
return function (target: any, targetKey: string) {
// 注入对象
const annotationTarget = target.constructor
let props = {}
// 同一个类,多个属性注入类
if (Reflect.hasOwnMetadata(props_key, annotationTarget)) {
props = Reflect.getMetadata(props_key, annotationTarget)
}
//@ts-ignore
props[targetKey] = {
value: targetKey
}
Reflect.defineMetadata(props_key, props, annotationTarget)
}
}管理容器 Container 的实现,用于绑定实例信息并且在对应的地方获取它们。
import 'reflect-metadata'
import { props_key } from './constant'
export class Container {
bindMap = new Map()
// 绑定类信息
bind(identifier: string, registerClass: any, constructorArgs: any[]) {
this.bindMap.set(identifier, {registerClass, constructorArgs})
}
// 获取实例,将实例绑定到需要注入的对象上
get<T>(identifier: string): T {
const target = this.bindMap.get(identifier)
if (target) {
const { registerClass, constructorArgs } = target
// 等价于 const instance = new registerClass([...constructorArgs])
const instance = Reflect.construct(registerClass, constructorArgs)
const props = Reflect.getMetadata(props_key, registerClass)
for (let prop in props) {
const identifier = props[prop].value
// 递归进行实例化获取 injected object
instance[prop] = this.get(identifier)
}
return instance
}
}
}启动时扫描所有文件,获取文件导出的所有类,然后根据元数据进行绑定。
import * as fs from 'fs'
import { resolve } from 'path'
import { class_key } from './constant'
// 启动时扫描所有文件,获取定义的类,根据元数据进行绑定
export function load(container: any, path: string) {
const list = fs.readdirSync(path)
for (const file of list) {
if (/\.ts$/.test(file)) {
const exports = require(resolve(path, file))
for (const m in exports) {
const module = exports[m]
if (typeof module === 'function') {
const metadata = Reflect.getMetadata(class_key, module)
// register
if (metadata) {
container.bind(metadata.id, module, metadata.args)
}
}
}
}
}
}三个示例类如下所示
// class A
import { Provider } from "../provide";
import { Inject } from "../inject";
import B from './classB'
import C from './classC'
@Provider('a')
export default class A {
@Inject()
private b: B
@Inject()
c: C
print () {
this.c.print()
}
}
// class B
import { Provider } from '../provide'
@Provider('b', [10])
export default class B {
n: number
constructor (n: number) {
this.n = n
}
}
// class C
import { Provider } from '../provide'
@Provider()
export default class C {
print () {
console.log('hello')
}
}我们能从以下示例结果中看到,我们已经实现了一个基本的 IOC 容器能力。
import { Container } from './container'
import { load } from './load'
import { class_path } from './constant'
const init = function () {
const container = new Container()
// 通过加载,会先执行装饰器(设置元数据),
// 再由 container 统一管理元数据中,供后续使用
load(container, class_path)
const a:any = container.get('a') // A { b: B { n: 10 }, c: C {} }
console.log(a);
a.c.print() // hello
}
init()本文的依次从 TS 装饰器、Reflect Metadata、IOC 容器源码简单解读、以及自定义实现 IOC 容器四个部分由零到一编写自定义 IOC 容器,希望对你有所启发。本文的所有演示实例都已经上传到 github 仓库 ioc-container ,读者可以克隆下来进行调试运行。
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:github.com/fengshi123/blog ,汇总了作者的所有博客,欢迎关注及 star ~
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:https://github.com/fengshi123/blog ,汇总了作者的所有博客,也欢迎关注及 star ~
(1)组件名称和定义该组件的文件名称建议要保持一致;
推荐:
import Footer from './Footer';不推荐:
import Footer from './Footer/index';(2)不要使用 displayName 属性来定义组件的名称,应该在 class 或者 function 关键字后面直接声明组件的名称。
推荐:
export default class MyComponent extends React.Component {
}不推荐:
export default React.Component({
displayName: 'MyComponent',
});推荐:
// 组件名称
MyComponent
// 属性名称
onClick
// 样式属性
backgroundColor(1)当标签没有子元素的时候,始终使用自闭合的标签 。
推荐:
// Good
<Component />不推荐:
<Component></Component>(2)如果标签有多行属性,关闭标签要另起一行 。
推荐:
<Component
bar="bar"
baz="baz"
/>不推荐:
<Component
bar="bar"
baz="baz" />(3)在自闭标签之前留一个空格。
推荐:
<Foo />不推荐:
<Foo/>
<Foo />
<Foo
/>(4)当组件跨行时,要用括号包裹 JSX 标签。
推荐:
render() {
return (
<MyComponent className="long body" foo="bar">
<MyChild />
</MyComponent>
);
}不推荐:
render() {
return <MyComponent className="long body" foo="bar">
<MyChild />
</MyComponent>;
}JSX 语法使用下列的对齐方式 :
// 推荐
<Foo
superLongParam="bar"
anotherSuperLongParam="baz"
/>
// 如果组件的属性可以放在一行(一个属性时)就保持在当前一行中
<Foo bar="bar" />
// 多行属性采用缩进
<Foo
superLongParam="bar"
anotherSuperLongParam="baz"
>
<Quux />
</Foo>
// 不推荐
<Foo superLongParam="bar"
anotherSuperLongParam="baz" />JSX 的属性都采用双引号,其他的 JS 都使用单引号 ,因为 JSX 属性 不能包含转义的引号, 所以当输入 "don't" 这类的缩写的时候用双引号会更方便。
推荐:
<Foo bar="bar" />
<Foo style={{ left: '20px' }} />不推荐:
<Foo bar='bar' />
<Foo style={{ left: "20px" }} />React 中样式可以使用 style 行内样式,也可以使用 className 属性来引用外部 CSS 样式表中定义的 CSS 类,我们推荐使用 className 来定义样式。并且推荐使用 SCSS 来替换传统的 CSS 写法,具体 SCSS 提高效率的写法可以参照先前总结的文章。
defaultProps 推荐使用静态属性定义,不推荐在 class 外进行定义。
推荐:
class Example extends React.Component {
static defaultProps = {
name: 'stranger'
}
render() {
// ...
}
}不推荐:
class Example extends React.Component {
render() {
// ...
}
}
Example.propTypes = {
name: PropTypes.string
};key 帮助 React 识别哪些元素改变了,比如被添加或删除。因此你应当给数组中的每一个元素赋予一个确定的标识。 当元素没有确定 id 的时候,万不得已你可以使用元素索引 index 作为 key,但是要主要如果列表项目的顺序可能会变化,如果使用索引来用作 key 值,因为这样做会导致性能变差,还可能引起组件状态的问题。
推荐:
{todos.map(todo => (
<Todo
{...todo}
key={todo.id}
/>
))}不推荐:
{todos.map((todo, index) =>
<Todo
{...todo}
key={index}
/>
)}React 为组件绑定事件处理器提供 4 种方法,有 public class fields 语法、构造函数中进行绑定、在回调中使用箭头函数、使用 Function.prototype.bind 进行绑定,我们推荐使用 public class fields 语法,在不满足需求情况下使用箭头函数的写法(传递参数给事件处理器)。
推荐:
handleClick = () => {
console.log('this is:', this);
}
<button onClick={this.handleClick}> Click me </button>不推荐:
constructor(props) {
super(props);
this.handleClick = this.handleClick.bind(this);
}
handleClick(){
console.log('this is:', this);
}
<button onClick={this.handleClick}> Click me </button>除了 state 初始化外,其它地方修改 state,需要使用 setState( ) 方法,否则如果直接赋值,则不会重新渲染组件。
推荐:
this.setState({comment: 'Hello'});不推荐:
this.state.comment = 'hello';出于性能考虑,React 可能会把多个 setState( ) 调用合并成一个调用;因为 this.props 和 this.state 可能会异步更新,所以这种场景下需要让 setState() 接收一个函数而不是一个对象 。
推荐:
this.setState((state, props) => ({
counter: state.counter + props.increment
}));不推荐:
this.setState({
counter: this.state.counter + this.props.increment,
});组件应该有严格的代码顺序,这样有利于代码维护,我们推荐每个组件中的代码顺序一致性。
class Example extends Component {
// 静态属性
static defaultProps = {}
// 构造函数
constructor(props) {
super(props);
this.stae={}
}
// 声明周期钩子函数
// 按照它们执行的顺序
// 1. componentWillMount
// 2. componentWillReceiveProps
// 3. shouldComponentUpdate
// 4. componentDidMount
// 5. componentDidUpdate
// 6. componentWillUnmount
componentDidMount() { ... }
// 事件函数/普通函数
handleClick = (e) => { ... }
// 最后,render 方法
render() { ... }
}使用高阶组件解决横切关注点问题,而不是使用 mixins ,mixins 导致的相关问题可以参照文档;
shouldComponentUpdate 钩子函数和 React.PureComponent 类都是用来当 state 和 props 变化时,避免不必要的 render 的方法。shouldComponentUpdate 钩子函数需要自己手动实现浅比较的逻辑,React.PureComponent 类则默认对 props 和 state 进行浅层比较,并减少了跳过必要更新的可能性。 我们推荐使用 React.PureComponent 避免不要的 render。
如果多个组件需要反映相同的变化数据,建议将共享状态提升到最近的共同父组件中去;从而依靠自上而下的数据流,而不是尝试在不同组件间同步 state。
如果某个属性在组件树的不同层级的组件之间需要用到,我们应该使用 Context 提供在组件之间共享此属性的方式,而不不是显式地通过组件树的逐层传递 props。
Refs 提供了一种方式,允许我们访问 DOM 节点或在 render 方法中创建的 React 元素 。我们推荐使用 createRef API 的方式 或者 回调函数的方式使用 Refs ,而不是使用 this.refs.textInput 这种过时的方式访问 refs ,因为它存在一些 问题。
建议使用路由懒加载当前用户所需要的内容,这样能够显著地提高你的应用性能。尽管并没有减少应用整体的代码体积,但你可以避免加载用户永远不需要的代码,并在初始加载的时候减少所需加载的代码量。
推荐:
const OtherComponent = React.lazy(() => import('./OtherComponent'));不推荐:
import OtherComponent from './OtherComponent';推荐在 componentDidMount这个生命周期函数中发起 AJAX 请求。这样做你可以拿到 AJAX 请求返回的数据并通过 setState 来更新组件。
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:https://github.com/fengshi123/blog ,汇总了作者的所有博客,也欢迎关注及 star ~
Webpack 本质上是一种事件流的机制,它的工作流程就是将各个插件串联起来,而实现这一切的核心就是 tapable,Webpack 中最核心的,负责编译的 Compiler 和 负责创建 bundles 的 Compilation 都是 tapable 构造函数的实例;

打开 Webpack 4.0 的源码中一定会看到下面这些以 Sync、Async 开头,以 Hook 结尾的方法,这些都是 tapable 核心库的类,为我们提供不同的事件流执行机制,我们称为 “钩子”。
上面的实现事件流机制的 “钩子” 大方向可以分为两个类别,“同步” 和 “异步”,“异步” 又分为两个类别,“并行” 和 “串行”,而 “同步” 的钩子都是串行的。
| 序号 | 钩子名称 | 执行方式 | 使用要点 |
|---|---|---|---|
| 1 | SyncHook | 同步串行 | 不关心监听函数的返回值; |
| 2 | SyncBailHook | 同步串行 | 只要监听函数中有一个函数的返回值不为空(不为 undefined) ,则跳过剩下所有的逻辑; |
| 3 | SyncWaterfallHook | 同步串行 | 上一个监听函数的返回值可以传给下一个监听函数 ; |
| 4 | SyncLoopHook | 同步循环 | 当监听函数被触发的时候,如果该监听函数返回 true 时则这个监听函数会反复执行,如果回 undefined 则表示退出循环 |
| 5 | AsyncParallelHook | 异步并发 | 不关心监听函数的返回值 |
| 6 | AsyncParallelBailHook | 异步并发 | 只要监听函数的返回值不为 undefined,就会忽略后面的监听函数执行,直接跳跃到 callAsync 等触发函数绑定的回调函数,然后执行这个被绑定的回调函数 |
| 7 | AsyncSeriesHook | 异步串行 | 不关系 callback() 的参数 |
| 8 | AsyncSeriesBailHook | 异步串行 | callback() 的参数不为 undefined,就会直接执行 callAsync 等触发函数绑定的回调函数 |
| 9 | AsyncSeriesWaterfallHook | 异步串行 | 上一个监听函数的中的 callback(err, data) 的第二个参数,可以作为下一个监听函数的参数 |
SyncHook 为串行同步执行,不关心事件处理函数的返回值,在触发事件之后,会按照事件注册的先后顺序执行所有的事件处理函数。
// SyncHook 钩子的使用
const { SyncHook } = require("tapable");
// 创建实例
let syncHook = new SyncHook(["name", "age"]);
// 注册事件
syncHook.tap("1", (name, age) => console.log("1", name, age));
syncHook.tap("2", (name, age) => {
console.log("2", name, age)
setTimeout(()=>{
console.log("3", name, age)
},1000)
});
syncHook.tap("4", (name, age) => console.log("4", name, age));
// 触发事件,让监听函数执行
syncHook.call("panda", 18);
/*
1 panda 18
2 panda 18
4 panda 18
3 panda 18
*/在 tapable 解构的 SyncHook 是一个类,注册事件需先创建实例,创建实例时支持传入一个数组,数组内存储事件触发时传入的参数,实例的 tap 方法用于注册事件,支持传入两个参数,第一个参数为事件名称,在 Webpack 中一般用于存储事件对应的插件名称(名字随意,只是起到注释作用), 第二个参数为事件处理函数,函数参数为执行 call 方法触发事件时所传入的参数的形参。
// 模拟 SyncHook 类
class SyncHook {
constructor(args) {
this.args = args;
this.tasks = [];
}
tap(name, task) {
this.tasks.push(task);
}
call(...args) {
// 也可在参数不足时抛出异常
if (args.length < this.args.length) throw new Error("参数不足");
// 传入参数严格对应创建实例传入数组中的规定的参数,执行时多余的参数为 undefined
args = args.slice(0, this.args.length);
// 依次执行事件处理函数
this.tasks.forEach(task => task(...args));
}
}
module.exports = {SyncHook};SyncBailHook 同样为串行同步执行,如果事件处理函数执行时有一个返回值不为空(即返回值不为 undefined),则跳过剩下未执行的事件处理函数(如类的名字,意义在于保险)。
// SyncBailHook 钩子的使用
const { SyncBailHook } = require("tapable");
// 创建实例
let syncBailHook = new SyncBailHook(["name", "age"]);
// 注册事件
syncBailHook.tap("1", (name, age) => console.log("1", name, age));
syncBailHook.tap("2", (name, age) => {
console.log("2", name, age);
return '2';
});
syncBailHook.tap("3", (name, age) => console.log("3", name, age));
// 触发事件,让监听函数执行
syncBailHook.call("panda", 18);
// 1 panda 18
// 2 panda 18通过上面的用法可以看出,SyncHook 和 SyncBailHook 在逻辑上只是 call 方法不同,导致事件的执行机制不同。
// 模拟 SyncBailHook 类
class SyncBailHook {
constructor(args) {
this.args = args;
this.tasks = [];
}
tap(name, task) {
this.tasks.push(task);
}
call(...args) {
// 传入参数严格对应创建实例传入数组中的规定的参数,执行时多余的参数为 undefined
args = args.slice(0, this.args.length);
// 依次执行事件处理函数,如果返回值不为空,则停止向下执行
let i = 0, ret;
do {
ret = this.tasks[i++](...args);
} while (!ret);
}
}
module.exports = {SyncBailHook};SyncWaterfallHook 为串行同步执行,上一个事件处理函数的返回值作为参数传递给下一个事件处理函数,依次类推,正因如此,只有第一个事件处理函数的参数可以通过 call 传递,而 call 的返回值为最后一个事件处理函数的返回值。
// SyncWaterfallHook 钩子的使用
const { SyncWaterfallHook } = require("tapable");
// 创建实例
let syncWaterfallHook = new SyncWaterfallHook(["name", "age"]);
// 注册事件
syncWaterfallHook.tap("1", (name, age) => {
console.log("1", name, age);
return "1";
});
syncWaterfallHook.tap("2", data => {
console.log("2", data);
return "2";
});
syncWaterfallHook.tap("3", data => {
console.log("3", data);
return "3"
});
// 触发事件,让监听函数执行
let ret = syncWaterfallHook.call("panda", 18);
console.log("call", ret);
// 1 panda 18
// 2 1
// 3 2
// call 3SyncWaterfallHook 名称中含有 “瀑布”,通过上面代码可以看出 “瀑布” 形象生动的描绘了事件处理函数执行的特点,与 SyncHook 和 SyncBailHook 的区别就在于事件处理函数返回结果的流动性,接下来看一下 SyncWaterfallHook 类的实现。
// 模拟 SyncWaterfallHook 类
class SyncWaterfallHook {
constructor(args) {
this.args = args;
this.tasks = [];
}
tap(name, task) {
this.tasks.push(task);
}
call(...args) {
// 传入参数严格对应创建实例传入数组中的规定的参数,执行时多余的参数为 undefined
args = args.slice(0, this.args.length);
// 依次执行事件处理函数,事件处理函数的返回值作为下一个事件处理函数的参数
let [first, ...others] = this.tasks;
return this.tasks.reduce((pre,cur)=>{
return cur(...pre);
},args)
}
}
module.exports = {SyncWaterfallHook};上面代码中 call 的逻辑是将存储事件处理函数的 tasks 拆成两部分,分别为第一个事件处理函数,和存储其余事件处理函数的数组,使用 reduce 进行归并,将第一个事件处理函数执行后的返回值作为归并的初始值,依次调用其余事件处理函数并传递上一次归并的返回值。
SyncLoopHook 为串行同步执行,事件处理函数返回 true 表示继续循环,即循环执行当前事件处理函数,返回 undefined 表示结束循环,SyncLoopHook 与 SyncBailHook 的循环不同,SyncBailHook 只决定是否继续向下执行后面的事件处理函数,而 SyncLoopHook 的循环是指循环执行每一个事件处理函数,直到返回 undefined 为止,才会继续向下执行其他事件处理函数,执行机制同理。
// SyncLoopHook 钩子的使用
// const { SyncLoopHook } = require("tapable");
const { SyncLoopHook } = require("./SyncLoopHook.js");
// 创建实例
let syncLoopHook = new SyncLoopHook(["name", "age"]);
// 定义辅助变量
let total1 = 0;
let total2 = 0;
// 注册事件
syncLoopHook.tap("1", (name, age) => {
console.log("1", name, age, total1);
return total1++ < 2 ? true : undefined;
});
syncLoopHook.tap("2", (name, age) => {
console.log("2", name, age, total2);
return total2++ < 2 ? true : undefined;
});
syncLoopHook.tap("3", (name, age) => console.log("3", name, age));
// 触发事件,让监听函数执行
syncLoopHook.call("panda", 18);
// 1 panda 18 0
// 1 panda 18 1
// 1 panda 18 2
// 2 panda 18 0
// 2 panda 18 1
// 2 panda 18 2
// 3 panda 18通过上面的执行结果可以清楚的看到 SyncLoopHook 的执行机制,但有一点需要注意,返回值必须严格是 true 才会触发循环,多次执行当前事件处理函数,必须严格返回 undefined,才会结束循环,去执行后面的事件处理函数,如果事件处理函数的返回值不是 true 也不是 undefined,则会死循环。
在了解 SyncLoopHook 的执行机制以后,我们接下来看看 SyncLoopHook 的 call 方法是如何实现的。
// 模拟 SyncLoopHook 类
class SyncLoopHook {
constructor(args) {
this.args = args;
this.tasks = [];
}
tap(name, task) {
this.tasks.push(task);
}
call(...args) {
// 传入参数严格对应创建实例传入数组中的规定的参数,执行时多余的参数为 undefined
args = args.slice(0, this.args.length);
// 依次执行事件处理函数,如果返回值为 true,则继续执行当前事件处理函数
// 直到返回 undefined,则继续向下执行其他事件处理函数
let that = this;
this.tasks.forEach(task => {
let ret;
do {
ret = task(...args);
} while (ret === true || !(ret === undefined));
});
}
}
module.exports = {SyncLoopHook};在上面代码中可以看到 SyncLoopHook 类 call 方法的实现更像是 SyncHook 和 SyncBailHook 的 call 方法的结合版,外层循环整个 tasks 事件处理函数队列,内层通过返回值进行循环,控制每一个事件处理函数的执行次数。
Async 类型的钩子
Async 类型可以使用 tap、tapSync 和 tapPromise 注册不同类型的插件 “钩子”,分别通过 call、callAsync 和 promise 方法调用,我们下面会针对 AsyncParallelHook 和 AsyncSeriesHook 的 async 和 promise 两种方式分别介绍和模拟。
AsyncParallelHook 为异步并行执行,通过 tapAsync 注册的事件,通过 callAsync 触发,通过 tapPromise 注册的事件,通过 promise 触发(返回值可以调用 then 方法)。
callAsync 的最后一个参数为回调函数,在所有事件处理函数执行完毕后执行;
异步并行是指,事件处理函数内三个定时器的异步操作最长时间为 3s,而三个事件处理函数执行完成总共用时接近 3s,所以三个事件处理函数是几乎同时执行的,不需等待。
所有 tabAsync 注册的事件处理函数最后一个参数都为一个回调函数 done,每个事件处理函数在异步代码执行完毕后调用 done 函数,则可以保证 callAsync 会在所有异步函数都执行完毕后执行。
(1)例子
// AsyncParallelHook 钩子:tapAsync/callAsync 的使用
const { AsyncParallelHook } = require("tapable");
// 创建实例
let asyncParallelHook = new AsyncParallelHook(["name", "age"]);
// 注册事件
console.time("time");
asyncParallelHook.tapAsync("1", (name, age, done) => {
console.log("1 start", name, age, new Date());
setTimeout(() => {
console.log("1", name, age, new Date());
done();
}, 1000);
});
asyncParallelHook.tapAsync("2", (name, age, done) => {
console.log("2 start", name, age, new Date());
setTimeout(() => {
console.log("2", name, age, new Date());
done();
}, 2000);
});
asyncParallelHook.tapAsync("3", (name, age, done) => {
console.log("3 start", name, age, new Date());
setTimeout(() => {
console.log("3", name, age, new Date());
done();
console.timeEnd("time");
}, 3000);
});
// 触发事件,让监听函数执行
asyncParallelHook.callAsync("panda", 18, () => {
console.log("complete");
});
/*
1 start panda 18 2020-02-06T09:49:37.168Z
2 start panda 18 2020-02-06T09:49:37.172Z
3 start panda 18 2020-02-06T09:49:37.173Z
1 panda 18 2020-02-06T09:49:38.193Z
2 panda 18 2020-02-06T09:49:39.174Z
3 panda 18 2020-02-06T09:49:40.174Z
complete
time: 3011.469ms
*/要使用 tapPromise 注册事件,对事件处理函数有一个要求,必须返回一个 Promise 实例,而 promise 方法也返回一个 Promise 实例,callAsync 的回调函数在 promise 方法中用 then 的方式代替。
// AsyncParallelHook 钩子:tapPromise/promise 的使用
const { AsyncParallelHook } = require("tapable");
// 创建实例
let asyncParallelHook = new AsyncParallelHook(["name", "age"]);
// 注册事件
console.time("time");
asyncParallelHook.tapPromise("1", (name, age) => {
return new Promise((resolve, reject) => {
settimeout(() => {
console.log("1", name, age, new Date());
resolve("1");
}, 1000);
});
});
asyncParallelHook.tapPromise("2", (name, age) => {
return new Promise((resolve, reject) => {
settimeout(() => {
console.log("2", name, age, new Date());
resolve("2");
}, 2000);
});
});
asyncParallelHook.tapPromise("3", (name, age) => {
return new Promise((resolve, reject) => {
settimeout(() => {
console.log("3", name, age, new Date());
resolve("3");
console.timeEnd("time");
}, 3000);
});
});
// 触发事件,让监听函数执行
asyncParallelHook.promise("panda", 18).then(ret => {
console.log(ret);
});
// 1 panda 18 2018-08-07T12:17:21.741Z
// 2 panda 18 2018-08-07T12:17:22.736Z
// 3 panda 18 2018-08-07T12:17:23.739Z
// time: 3006.542ms
// [ '1', '2', '3' ]AsyncSeriesHook 为异步串行执行,与 AsyncParallelHook 相同,通过 tapAsync 注册的事件,通过 callAsync 触发,通过 tapPromise 注册的事件,通过 promise 触发,可以调用 then 方法。
与 AsyncParallelHook 的 callAsync 方法类似,AsyncSeriesHook 的 callAsync 方法也是通过传入回调函数的方式,在所有事件处理函数执行完毕后执行 callAsync 的回调函数。
// AsyncSeriesHook 钩子:tapAsync/callAsync 的使用
const { AsyncSeriesHook } = require("tapable");
// 创建实例
let asyncSeriesHook = new AsyncSeriesHook(["name", "age"]);
// 注册事件
console.time("time");
asyncSeriesHook.tapAsync("1", (name, age, next) => {
settimeout(() => {
console.log("1", name, age, new Date());
next();
}, 1000);
});
asyncSeriesHook.tapAsync("2", (name, age, next) => {
settimeout(() => {
console.log("2", name, age, new Date());
next();
}, 2000);
});
asyncSeriesHook.tapAsync("3", (name, age, next) => {
settimeout(() => {
console.log("3", name, age, new Date());
next();
console.timeEnd("time");
}, 3000);
});
// 触发事件,让监听函数执行
asyncSeriesHook.callAsync("panda", 18, () => {
console.log("complete");
});
// 1 panda 18 2018-08-07T14:40:52.896Z
// 2 panda 18 2018-08-07T14:40:54.901Z
// 3 panda 18 2018-08-07T14:40:57.901Z
// complete
// time: 6008.790ms与 AsyncParallelHook 类似,tapPromise 注册事件的事件处理函数需要返回一个 Promise 实例,promise 方法最后也返回一个 Promise 实例。
// AsyncSeriesHook 钩子:tapPromise/promise 的使用
const { AsyncSeriesHook } = require("tapable");
// 创建实例
let asyncSeriesHook = new AsyncSeriesHook(["name", "age"]);
// 注册事件
console.time("time");
asyncSeriesHook.tapPromise("1", (name, age) => {
return new Promise((resolve, reject) => {
settimeout(() => {
console.log("1", name, age, new Date());
resolve("1");
}, 1000);
});
});
asyncSeriesHook.tapPromise("2", (name, age) => {
return new Promise((resolve, reject) => {
settimeout(() => {
console.log("2", name, age, new Date());
resolve("2");
}, 2000);
});
});
asyncParallelHook.tapPromise("3", (name, age) => {
return new Promise((resolve, reject) => {
settimeout(() => {
console.log("3", name, age, new Date());
resolve("3");
console.timeEnd("time");
}, 3000);
});
});
// 触发事件,让监听函数执行
asyncSeriesHook.promise("panda", 18).then(ret => {
console.log(ret);
});
// 1 panda 18 2018-08-07T14:45:52.896Z
// 2 panda 18 2018-08-07T14:45:54.901Z
// 3 panda 18 2018-08-07T14:45:57.901Z
// time: 6014.291ms
// [ '1', '2', '3' ]在上面 Async 异步类型的 “钩子中”,我们只着重介绍了 “串行” 和 “并行”(AsyncParallelHook 和 AsyncSeriesHook)以及回调和 Promise 的两种注册和触发事件的方式,还有一些其他的具有一定特点的异步 “钩子” 我们并没有进行分析,因为他们的机制与同步对应的 “钩子” 非常的相似。
AsyncParallelBailHook 和 AsyncSeriesBailHook 分别为异步 “并行” 和 “串行” 执行的 “钩子”,返回值不为 undefined,即有返回值,则立即停止向下执行其他事件处理函数,实现逻辑可结合 AsyncParallelHook 、AsyncSeriesHook 和 SyncBailHook。
AsyncSeriesWaterfallHook 为异步 “串行” 执行的 “钩子”,上一个事件处理函数的返回值作为参数传递给下一个事件处理函数,实现逻辑可结合 AsyncSeriesHook 和 SyncWaterfallHook。
在 tapable 源码中,注册事件的方法 tab、tapSync、tapPromise 和触发事件的方法 call、callAsync、promise 都是通过 compile 方法快速编译出来的,我们本文中这些方法的实现只是遵照了 tapable 库这些 “钩子” 的事件处理机制进行了模拟,以方便我们了解 tapable,为学习 Webpack 原理做了一个铺垫,在 Webpack 中,这些 “钩子” 的真正作用就是将通过配置文件读取的插件与插件、加载器与加载器之间进行连接,“并行” 或 “串行” 执行,相信在我们对 tapable 中这些 “钩子” 的事件机制有所了解之后,对于学习 Webpack 的源码应该会更得心应手。
当被问到 Vue 数据双向绑定原理的时候,大家可能都会脱口而出:Vue 内部通过 Object.defineProperty方法属性拦截的方式,把 data 对象里每个数据的读写转化成 getter/setter,当数据变化时通知视图更新。虽然一句话把大概原理概括了,但是其内部的实现方式还是值得深究的,本文就以通俗易懂的方式剖析 Vue 内部双向绑定原理的实现过程。然后再根据 Vue 源码的数据双向绑定实现,来进一步巩固加深对数据双向绑定的理解认识。以下为我们实现的数据双向绑定的效果图:
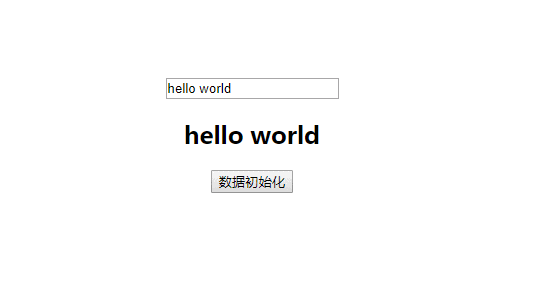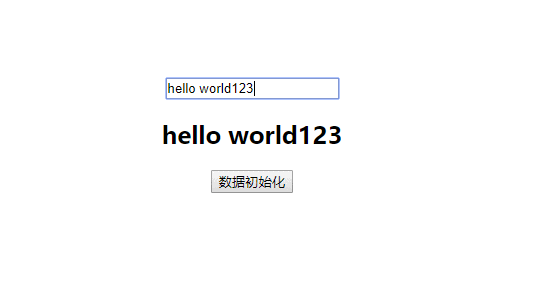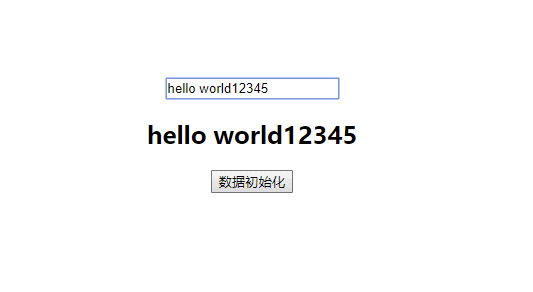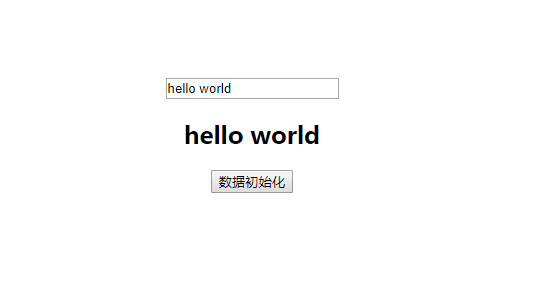
github地址为:github.com/fengshi123/…,上面汇总了作者所有的博客文章,如果喜欢或者有所启发,请帮忙给个 star ~,对作者也是一种鼓励。
MVVM 数据双向绑定主要是指:数据变化更新视图,视图变化更新数据,如下图所示:

即:
Data 中的数据同步变化。即 View => Data 的变化。Data 中的数据变化时,文本节点的内容同步变化。即 Data => View 的变化。其中,View 变化更新 Data ,可以通过事件监听的方式来实现,所以我们本文主要讨论如何根据 Data 变化更新 View。
我们会通过实现以下 4 个步骤,来实现数据的双向绑定:
1、实现一个监听器 Observer ,用来劫持并监听所有属性,如果属性发生变化,就通知订阅者;
2、实现一个订阅器 Dep,用来收集订阅者,对监听器 Observer 和 订阅者 Watcher 进行统一管理;
3、实现一个订阅者 Watcher,可以收到属性的变化通知并执行相应的方法,从而更新视图;
4、实现一个解析器 Compile,可以解析每个节点的相关指令,对模板数据和订阅器进行初始化。
以上四个步骤的流程图表示如下:

该实例的源码已经放到 github 上面:https://github.com/fengshi123/mvvm_example 。
监听器 Observer 的实现,主要是指让数据对象变得“可观测”,即每次数据读或写时,我们能感知到数据被读取了或数据被改写了。要使数据变得“可观测”,Vue 2.0 源码中用到 Object.defineProperty() 来劫持各个数据属性的 setter / getter,Object.defineProperty 方法,在 MDN 上是这么定义的:
Object.defineProperty() 方法会直接在一个对象上定义一个新属性,或者修改一个对象的现有属性, 并返回这个对象。
Object.defineProperty 语法,在 MDN 上是这么定义的:
Object.defineProperty(obj, prop, descriptor)
(1)参数
obj
要在其上定义属性的对象。
prop
要定义或修改的属性的名称。
descriptor
将被定义或修改的属性描述符。
(2)返回值
被传递给函数的对象。
(3)属性描述符
Object.defineProperty() 为对象定义属性,分 数据描述符 和 存取描述符 ,两种形式不能混用。
数据描述符和存取描述符均具有以下可选键值:
configurable当且仅当该属性的 configurable 为 true 时,该属性描述符才能够被改变,同时该属性也能从对应的对象上被删除。默认为 false。
enumerable当且仅当该属性的 enumerable 为 true 时,该属性才能够出现在对象的枚举属性中。默认为 false。
数据描述符具有以下可选键值:
value该属性对应的值。可以是任何有效的 JavaScript 值(数值,对象,函数等)。默认为 undefined。
writable当且仅当该属性的 writable 为 true 时,value 才能被赋值运算符改变。默认为 false。
存取描述符具有以下可选键值:
get一个给属性提供 getter 的方法,如果没有 getter 则为 undefined。当访问该属性时,该方法会被执行,方法执行时没有参数传入,但是会传入this对象(由于继承关系,这里的this并不一定是定义该属性的对象)。默认为 undefined。
set一个给属性提供 setter 的方法,如果没有 setter 则为 undefined。当属性值修改时,触发执行该方法。该方法将接受唯一参数,即该属性新的参数值。默认为 undefined。
(1)字面量定义对象
首先,我们先看一下假设我们通过以下字面量的方式定义一个对象:
let person = {
name:'tom',
age:15
}我们可以通过 person.name 和 person.age 直接读写这个 person 对应的属性值,但是,当这个 person 的属性被读取或修改时,我们并不知情。那么,应该如何定义一个对象,它的属性被读写时,我们能感知到呢?
(2)Object.defineProperty() 定义对象
假设我们通过 Object.defineProperty() 来定义一个对象:
let val = 'tom'
let person = {}
Object.defineProperty(person,'name',{
get(){
console.log('name属性被读取了...');
return val;
},
set(newVal){
console.log('name属性被修改了...');
val = newVal;
}
})我们通过 object.defineProperty() 方法给 person 的 name 属性定义了 get() 和set()进行拦截,每当该属性进行读或写操作的时候就会触发get()和set() ,这样,当对象的属性被读写时,我们就能感知到了。测试结果图如下所示:

(3)改进方法
通过第(2)步的方法,person 数据对象已经是“可观测”的了,能满足我们的需求了。但是如果数据对象的属性比较多的情况下,我们一个一个为属性去设置,代码会非常冗余,所以我们进行以下封装,从而让数据对象的所有属性都变得可观测:
/**
* 循环遍历数据对象的每个属性
*/
function observable(obj) {
if (!obj || typeof obj !== 'object') {
return;
}
let keys = Object.keys(obj);
keys.forEach((key) => {
defineReactive(obj, key, obj[key])
})
return obj;
}
/**
* 将对象的属性用 Object.defineProperty() 进行设置
*/
function defineReactive(obj, key, val) {
Object.defineProperty(obj, key, {
get() {
console.log(`${key}属性被读取了...`);
return val;
},
set(newVal) {
console.log(`${key}属性被修改了...`);
val = newVal;
}
})
}通过以上方法封装,我们可以直接定义 person:
let person = observable({
name: 'tom',
age: 15
});这样定义的 person 的 两个属性都是“可观测”的。
发布-订阅模式又叫观察者模式,它定义对象间的一种一对多的依赖关系,当一个对象的状态改变时,所有依赖于它的对象都将得到通知。
(1)发布—订阅模式的优点:
(2)发布—订阅模式的生活实例
我们以售楼处的例子来举例说明发布-订阅模式:
小明最近看上了一套房子,到了售楼处之后才被告知,该楼盘的房子早已售罄。好在售楼 MM 告诉小明,不久后还有一些尾盘推出,开发商正在办理相关手续,手续办好后便可以购买。
但到底是什么时候,目前还没有人能够知道。 于是小明记下了售楼处的电话,以后每天都会打电话过去询问是不是已经到了购买时间。除 了小明,还有小红、小强、小龙也会每天向售楼处咨询这个问题。一个星期过后,售楼 MM 决定辞职,因为厌倦了每天回答 1000个相同内容的电话。
当然现实中没有这么笨的销售公司,实际上故事是这样的:小明离开之前,把电话号码留在 了售楼处。售楼 MM 答应他,新楼盘一推出就马上发信息通知小明。小红、小强和小龙也是一样,他们的电话号码都被记在售楼处的花名册上,新楼盘推出的时候,售楼 MM会翻开花名册,遍历上面的电话号码,依次发送一条短信来通知他们。这就是发布-订阅模式在现实中的例子。
完成了数据的'可观测',即我们知道了数据在什么时候被读或写了,那么,我们就可以在数据被读或写的时候通知那些依赖该数据的视图更新了,为了方便,我们需要先将所有依赖收集起来,一旦数据发生变化,就统一通知更新。其实,这就是前一节所说的“发布订阅者”模式,数据变化为“发布者”,依赖对象为“订阅者”。
现在,我们需要创建一个依赖收集容器,也就是消息订阅器 Dep,用来容纳所有的“订阅者”。订阅器 Dep 主要负责收集订阅者,然后当数据变化的时候后执行对应订阅者的更新函数。
创建消息订阅器 Dep:
function Dep () {
this.subs = [];
}
Dep.prototype = {
addSub: function(sub) {
this.subs.push(sub);
},
notify: function() {
this.subs.forEach(function(sub) {
sub.update();
});
}
};
Dep.target = null;有了订阅器,我们再将 defineReactive 函数进行改造一下,向其植入订阅器:
defineReactive: function(data, key, val) {
var dep = new Dep();
Object.defineProperty(data, key, {
enumerable: true,
configurable: true,
get: function getter () {
if (Dep.globalWatcher) {
dep.addWatcher(Dep.globalWatcher);
}
return val;
},
set: function setter (newVal) {
if (newVal === val) {
return;
}
val = newVal;
dep.notify();
}
});
}从代码上看,我们设计了一个订阅器 Dep 类,该类里面定义了一些属性和方法,这里需要特别注意的是它有一个静态属性 Dep.target,这是一个全局唯一 的Watcher,因为在同一时间只能有一个全局的 Watcher 被计算,另外它的自身属性 subs 也是 Watcher 的数组。
订阅者 Watcher 在初始化的时候需要将自己添加进订阅器 Dep 中,那该如何添加呢?我们已经知道监听器Observer 是在 get 函数执行了添加订阅者 Wather 的操作的,所以我们只要在订阅者 Watcher 初始化的时候触发对应的 get 函数去执行添加订阅者操作即可,那要如何触发 get 的函数,再简单不过了,只要获取对应的属性值就可以触发了,核心原因就是因为我们使用了 Object.defineProperty( ) 进行数据监听。这里还有一个细节点需要处理,我们只要在订阅者 Watcher 初始化的时候才需要添加订阅者,所以需要做一个判断操作,因此可以在订阅器上做一下手脚:在 Dep.target 上缓存下订阅者,添加成功后再将其去掉就可以了。订阅者 Watcher 的实现如下:
function Watcher(vm, exp, cb) {
this.vm = vm;
this.exp = exp;
this.cb = cb;
this.value = this.get(); // 将自己添加到订阅器的操作
}
Watcher.prototype = {
update: function() {
this.run();
},
run: function() {
var value = this.vm.data[this.exp];
var oldVal = this.value;
if (value !== oldVal) {
this.value = value;
this.cb.call(this.vm, value, oldVal);
}
},
get: function() {
Dep.target = this; // 全局变量 订阅者 赋值
var value = this.vm.data[this.exp] // 强制执行监听器里的get函数
Dep.target = null; // 全局变量 订阅者 释放
return value;
}
};订阅者 Watcher 分析如下:
订阅者 Watcher 是一个 类,在它的构造函数中,定义了一些属性:
node 节点的 v-model 等指令的属性值 或者插值符号中的属性。如 v-model="name",exp 就是name;Watcher 绑定的更新函数;当我们去实例化一个渲染 watcher 的时候,首先进入 watcher 的构造函数逻辑,就会执行它的 this.get() 方法,进入 get 函数,首先会执行:
Dep.target = this; // 将自己赋值为全局的订阅者实际上就是把 Dep.target 赋值为当前的渲染 watcher ,接着又执行了:
let value = this.vm.data[this.exp] // 强制执行监听器里的get函数
在这个过程中会对 vm 上的数据访问,其实就是为了触发数据对象的 getter。
每个对象值的 getter 都持有一个 dep,在触发 getter 的时候会调用 dep.depend() 方法,也就会执行this.addSub(Dep.target),即把当前的 watcher 订阅到这个数据持有的 dep 的 watchers 中,这个目的是为后续数据变化时候能通知到哪些 watchers 做准备。
这样实际上已经完成了一个依赖收集的过程。那么到这里就结束了吗?其实并没有,完成依赖收集后,还需要把 Dep.target 恢复成上一个状态,即:
Dep.target = null; // 释放自己而 update() 函数是用来当数据发生变化时调用 Watcher 自身的更新函数进行更新的操作。先通过 let value = this.vm.data[this.exp]; 获取到最新的数据,然后将其与之前 get() 获得的旧数据进行比较,如果不一样,则调用更新函数 cb 进行更新。
至此,简单的订阅者 Watcher 设计完毕。
通过监听器 Observer 订阅器 Dep 和订阅者 Watcher 的实现,其实就已经实现了一个双向数据绑定的例子,但是整个过程都没有去解析 dom 节点,而是直接固定某个节点进行替换数据的,所以接下来需要实现一个解析器 Compile 来做解析和绑定工作。解析器 Compile 实现步骤:
我们下面对 '{{变量}}' 这种形式的指令处理的关键代码进行分析,感受解析器 Compile 的处理逻辑,关键代码如下:
compileText: function(node, exp) {
var self = this;
var initText = this.vm[exp]; // 获取属性值
this.updateText(node, initText); // dom 更新节点文本值
// 将这个指令初始化为一个订阅者,后续 exp 改变时,就会触发这个更新回调,从而更新视图
new Watcher(this.vm, exp, function (value) {
self.updateText(node, value);
});
}完成监听器 Observer 、订阅器 Dep 、订阅者 Watcher 和解析器 Compile 的实现,我们就可以模拟初始化一个Vue 实例,来检验以上的理论的可行性了。我们通过以下代码初始化一个 Vue 实例,该实例的源码已经放到 github 上面:https://github.com/fengshi123/mvvm_example ,有兴趣的可以 git clone:
<body>
<div id="mvvm-app">
<input v-model="title">
<h2>{{title}}</h2>
<button v-on:click="clickBtn">数据初始化</button>
</div>
</body>
<script src="../dist/bundle.js"></script>
<script type="text/javascript">
var vm = new MVVM({
el: '#mvvm-app',
data: {
title: 'hello world'
},
methods: {
clickBtn: function (e) {
this.title = 'hello world';
}
},
});
</script>运行以上实例,效果图如下所示,跟实际的 Vue 数据绑定效果是不是一样!
以上第二章节到第六章节,从监听器 Observer 、订阅器 Dep 、订阅者 Watcher 和解析器 Compile 的实现,完成了一个简单的 Vue 数据绑定实例的实现。本章节,我们从 Vue 源码层面分析监听器 Observer 、订阅器 Dep 、订阅者 Watcher 的实现,帮助大家了解 Vue 源码如何实现数据双向绑定。
我们在本小节主要介绍 监听器 Observer 实现,核心就是利用 Object.defineProperty 给数据添加了 getter 和 setter,目的就是为了在我们访问数据以及写数据的时候能自动执行一些逻辑 。
(1)initState
在 Vue 的初始化阶段,_init 方法执行的时候,会执行 initState(vm) 方法,它的定义在 src/core/instance/state.js 中。
export function initState (vm: Component) {
vm._watchers = []
const opts = vm.$options
if (opts.props) initProps(vm, opts.props)
if (opts.methods) initMethods(vm, opts.methods)
if (opts.data) {
initData(vm)
} else {
observe(vm._data = {}, true /* asRootData */)
}
if (opts.computed) initComputed(vm, opts.computed)
if (opts.watch && opts.watch !== nativeWatch) {
initWatch(vm, opts.watch)
}
}initState 方法主要是对 props、methods、data、computed 和 wathcer 等属性做了初始化操作。这里我们重点分析 data,对于其它属性的初始化我们在以后的文章中再做介绍。
(2)initData
function initData (vm: Component) {
let data = vm.$options.data
data = vm._data = typeof data === 'function'
? getData(data, vm)
: data || {}
if (!isPlainObject(data)) {
data = {}
process.env.NODE_ENV !== 'production' && warn(
'data functions should return an object:\n' +
'https://vuejs.org/v2/guide/components.html#data-Must-Be-a-Function',
vm
)
}
// proxy data on instance
const keys = Object.keys(data)
const props = vm.$options.props
const methods = vm.$options.methods
let i = keys.length
while (i--) {
const key = keys[i]
if (process.env.NODE_ENV !== 'production') {
if (methods && hasOwn(methods, key)) {
warn(
`Method "${key}" has already been defined as a data property.`,
vm
)
}
}
if (props && hasOwn(props, key)) {
process.env.NODE_ENV !== 'production' && warn(
`The data property "${key}" is already declared as a prop. ` +
`Use prop default value instead.`,
vm
)
} else if (!isReserved(key)) {
proxy(vm, `_data`, key)
}
}
// observe data
observe(data, true /* asRootData */)
}data 的初始化主要过程也是做两件事,一个是对定义 data 函数返回对象的遍历,通过 proxy 把每一个值 vm._data.xxx 都代理到 vm.xxx 上;另一个是调用 observe 方法观测整个 data 的变化,把 data 也变成响应式,我们接下去主要介绍 observe 。
(3)observe
observe 的功能就是用来监测数据的变化,它的定义在 src/core/observer/index.js 中:
export function observe (value: any, asRootData: ?boolean): Observer | void {
if (!isObject(value) || value instanceof VNode) {
return
}
let ob: Observer | void
if (hasOwn(value, '__ob__') && value.__ob__ instanceof Observer) {
ob = value.__ob__
} else if (
shouldObserve &&
!isServerRendering() &&
(Array.isArray(value) || isPlainObject(value)) &&
Object.isExtensible(value) &&
!value._isVue
) {
ob = new Observer(value)
}
if (asRootData && ob) {
ob.vmCount++
}
return ob
}observe 方法的作用就是给非 VNode 的对象类型数据添加一个 Observer,如果已经添加过则直接返回,否则在满足一定条件下去实例化一个 Observer 对象实例。接下来我们来看一下 Observer 的作用。
(4)Observer
Observer 是一个类,它的作用是给对象的属性添加 getter 和 setter,用于依赖收集和派发更新:
xport class Observer {
value: any;
dep: Dep;
vmCount: number; // number of vms that have this object as root $data
constructor (value: any) {
this.value = value
this.dep = new Dep()
this.vmCount = 0
def(value, '__ob__', this)
if (Array.isArray(value)) {
if (hasProto) {
protoAugment(value, arrayMethods)
} else {
copyAugment(value, arrayMethods, arrayKeys)
}
this.observeArray(value)
} else {
this.walk(value)
}
}
/**
* Walk through all properties and convert them into
* getter/setters. This method should only be called when
* value type is Object.
*/
walk (obj: Object) {
const keys = Object.keys(obj)
for (let i = 0; i < keys.length; i++) {
defineReactive(obj, keys[i])
}
}
/**
* Observe a list of Array items.
*/
observeArray (items: Array<any>) {
for (let i = 0, l = items.length; i < l; i++) {
observe(items[i])
}
}
}Observer 的构造函数逻辑很简单,首先实例化 Dep 对象, Dep 对象,我们第2小节会介绍。接下来会对 value 做判断,对于数组会调用 observeArray 方法,否则对纯对象调用 walk 方法。可以看到 observeArray 是遍历数组再次调用 observe 方法,而 walk 方法是遍历对象的 key 调用 defineReactive 方法,那么我们来看一下这个方法是做什么的。
(5)defineReactive
defineReactive 的功能就是定义一个响应式对象,给对象动态添加 getter 和 setter,它的定义在 src/core/observer/index.js 中:
export function defineReactive (
obj: Object,
key: string,
val: any,
customSetter?: ?Function,
shallow?: boolean
) {
const dep = new Dep()
const property = Object.getOwnPropertyDescriptor(obj, key)
if (property && property.configurable === false) {
return
}
// cater for pre-defined getter/setters
const getter = property && property.get
const setter = property && property.set
if ((!getter || setter) && arguments.length === 2) {
val = obj[key]
}
let childOb = !shallow && observe(val)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
const value = getter ? getter.call(obj) : val
if (Dep.target) {
dep.depend()
if (childOb) {
childOb.dep.depend()
if (Array.isArray(value)) {
dependArray(value)
}
}
}
return value
},
set: function reactiveSetter (newVal) {
const value = getter ? getter.call(obj) : val
/* eslint-disable no-self-compare */
if (newVal === value || (newVal !== newVal && value !== value)) {
return
}
/* eslint-enable no-self-compare */
if (process.env.NODE_ENV !== 'production' && customSetter) {
customSetter()
}
// #7981: for accessor properties without setter
if (getter && !setter) return
if (setter) {
setter.call(obj, newVal)
} else {
val = newVal
}
childOb = !shallow && observe(newVal)
dep.notify()
}
})
}defineReactive 函数最开始初始化 Dep 对象的实例,接着拿到 obj 的属性描述符,然后对子对象递归调用 observe 方法,这样就保证了无论 obj 的结构多复杂,它的所有子属性也能变成响应式的对象,这样我们访问或修改 obj 中一个嵌套较深的属性,也能触发 getter 和 setter。
订阅器Dep 是整个 getter 依赖收集的核心,它的定义在 src/core/observer/dep.js 中:
export default class Dep {
static target: ?Watcher;
id: number;
subs: Array<Watcher>;
constructor () {
this.id = uid++
this.subs = []
}
addSub (sub: Watcher) {
this.subs.push(sub)
}
removeSub (sub: Watcher) {
remove(this.subs, sub)
}
depend () {
if (Dep.target) {
Dep.target.addDep(this)
}
}
notify () {
// stabilize the subscriber list first
const subs = this.subs.slice()
if (process.env.NODE_ENV !== 'production' && !config.async) {
// subs aren't sorted in scheduler if not running async
// we need to sort them now to make sure they fire in correct
// order
subs.sort((a, b) => a.id - b.id)
}
for (let i = 0, l = subs.length; i < l; i++) {
subs[i].update()
}
}
}
// The current target watcher being evaluated.
// This is globally unique because only one watcher
// can be evaluated at a time.
Dep.target = nullDep 是一个 Class,它定义了一些属性和方法,这里需要特别注意的是它有一个静态属性 target,这是一个全局唯一 Watcher,这是一个非常巧妙的设计,因为在同一时间只能有一个全局的 Watcher 被计算,另外它的自身属性 subs 也是 Watcher 的数组。Dep 实际上就是对 Watcher 的一种管理,Dep 脱离 Watcher 单独存在是没有意义的。
订阅者Watcher 的一些相关实现,它的定义在 src/core/observer/watcher.js 中
export default class Watcher {
vm: Component;
expression: string;
cb: Function;
id: number;
deep: boolean;
user: boolean;
lazy: boolean;
sync: boolean;
dirty: boolean;
active: boolean;
deps: Array<Dep>;
newDeps: Array<Dep>;
depIds: SimpleSet;
newDepIds: SimpleSet;
before: ?Function;
getter: Function;
value: any;
constructor (
vm: Component,
expOrFn: string | Function,
cb: Function,
options?: ?Object,
isRenderWatcher?: boolean
) {
this.vm = vm
if (isRenderWatcher) {
vm._watcher = this
}
vm._watchers.push(this)
// options
if (options) {
this.deep = !!options.deep
this.user = !!options.user
this.lazy = !!options.lazy
this.sync = !!options.sync
this.before = options.before
} else {
this.deep = this.user = this.lazy = this.sync = false
}
this.cb = cb
this.id = ++uid // uid for batching
this.active = true
this.dirty = this.lazy // for lazy watchers
this.deps = []
this.newDeps = []
this.depIds = new Set()
this.newDepIds = new Set()
this.expression = process.env.NODE_ENV !== 'production'
? expOrFn.toString()
: ''
// parse expression for getter
if (typeof expOrFn === 'function') {
this.getter = expOrFn
} else {
this.getter = parsePath(expOrFn)
if (!this.getter) {
this.getter = noop
process.env.NODE_ENV !== 'production' && warn(
`Failed watching path: "${expOrFn}" ` +
'Watcher only accepts simple dot-delimited paths. ' +
'For full control, use a function instead.',
vm
)
}
}
this.value = this.lazy
? undefined
: this.get()
}
。。。。。。
}Watcher 是一个 Class,在它的构造函数中,定义了一些和 Dep 相关的属性 ,其中,this.deps 和 this.newDeps 表示 Watcher 实例持有的 Dep 实例的数组;而 this.depIds 和 this.newDepIds 分别代表 this.deps 和 this.newDeps 的 id Set 。
(1)过程分析
当我们去实例化一个渲染 watcher 的时候,首先进入 watcher 的构造函数逻辑,然后会执行它的 this.get() 方法,进入 get 函数,首先会执行:
pushTarget(this)实际上就是把 Dep.target 赋值为当前的渲染 watcher 并压栈(为了恢复用)。接着又执行了:
value = this.getter.call(vm, vm)这个时候就触发了数据对象的 getter 。
么每个对象值的 getter 都持有一个 dep,在触发 getter 的时候会调用 dep.depend() 方法,也就会执行 Dep.target.addDep(this)。
刚才我们提到这个时候 Dep.target 已经被赋值为渲染 watcher,那么就执行到 addDep 方法:
addDep (dep: Dep) {
const id = dep.id
if (!this.newDepIds.has(id)) {
this.newDepIds.add(id)
this.newDeps.push(dep)
if (!this.depIds.has(id)) {
dep.addSub(this)
}
}
}
这时候会做一些逻辑判断(保证同一数据不会被添加多次)后执行 dep.addSub(this),那么就会执行 this.subs.push(sub),也就是说把当前的 watcher 订阅到这个数据持有的 dep 的 subs 中,这个目的是为后续数据变化时候能通知到哪些 subs 做准备。所以在 vm._render() 过程中,会触发所有数据的 getter,这样实际上已经完成了一个依赖收集的过程。
当我们在组件中对响应的数据做了修改,就会触发 setter 的逻辑,最后调用 watcher 中的 update 方法:
update () {
/* istanbul ignore else */
if (this.lazy) {
this.dirty = true
} else if (this.sync) {
this.run()
} else {
queueWatcher(this)
}
}这里会对于 Watcher 的不同状态,会执行不同的更新逻辑。
以上主要分析了 Vue 数据双向绑定的关键代码,其原理图可以表示如下:

本文通过监听器 Observer 、订阅器 Dep 、订阅者 Watcher 和解析器 ·的实现,模拟初始化一个 Vue 实例,帮助大家了解数据双向绑定的基本原理。接着,从 Vue 源码层面介绍了 Vue 数据双向绑定的实现过程,了解 Vue 源码的实现逻辑,从而巩固加深对数据双向绑定的理解认识。希望本文对您有帮助。
github地址为:github.com/fengshi123/…,上面汇总了作者所有的博客文章,如果喜欢或者有所启发,请帮忙给个 star ~,对作者也是一种鼓励。
1、Vue 的双向绑定原理及实现:https://www.cnblogs.com/canfoo/p/6891868.html
2、Vue 技术揭秘:https://ustbhuangyi.github.io/vue-analysis/
本文基于 React Native 的实践项目进行总结, 该项目基于 React Native 和 H5 在开发效率、功能性能、用户体验等方面的差异性,对功能模块进行精心设计,主要基于我们现在实际项目的业务,结合移动端特有的特性。
本文围绕 React Native 项目的环境配置、运行,React Native 介绍,项目的主要功能介绍,React Native 开发存在的坑等多个方面进行展开。如果你还没有 React Native 开发经验,那么这篇文章将很好的向你展示 React Native 的各方面,包括官方文档、生态、兼容性等等,希望你在这篇文章中找到你想要的答案。
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:https://github.com/fengshi123/blog ,汇总了作者的所有博客,也欢迎关注及 star ~
本项目 github 地址为:https://github.com/fengshi123/react_native_project
配套的服务端 express 项目 github 地址为:https://github.com/fengshi123/express_project
在这个 React Native App 开发中,我的开发环境相关配置如下:
| 工具名称 | 版本号 |
|---|---|
| node.js | 11.12.0 |
| npm | 6.7.0 |
| yarn | 1.17.3 |
| Android Studio | 3.4.1 |
| JDK | 1.8 |
| react | 16.8.6 |
| react-native | 0.60.5 |
(1)安装 yarn、react-native 命令行工具
$ npm install -g yarn react-native-cli(2)设置 yarn 镜像源
$ yarn config set registry https://registry.npm.taobao.org --global
$ yarn config set disturl https://npm.taobao.org/dist --global(3)安装第三方插件
进入到 react_native_project 目录底下,安装第三方插件:
$ yarn(4)Android Studio 配置
Android Studio 的配置这里不再做介绍,可以参考 react-native 官网;
(5)编译并运行项目
$ react-native run-android(6)启动项目
第 5 步后,如果真机或模拟器提示,Metro 没有启动,可关闭第 5 步开启的 node 窗口,再重启 Metro:
npm start(7)服务端配套项目
记得 clone 本项目配套的服务端 express 项目,并启动它。
“ Learn once, write anywhere ”,React Native 的定义就像是:学习 React ,同时掌握 web 与 app 两种开发技能。 React Native 使用 React 的设计模式,开发者编写 js 代码,通过 React Native 的中间层转化为原生控件和操作,拥有接近原生开发的用户体验。下面引用官网上 4 条特性:
(1)使用 JavaScript 和 React 编写原生移动应用
React Native 使你只使用 JavaScript 也能编写原生移动应用。 它在设计原理上和 React 一致,通过声明式的组件机制来搭建丰富多彩的用户界面。
(2)React Native 应用是真正的移动应用
React Native 产出的并不是“网页应用”, 或者说“HTML5应用”,又或者“混合应用”。 最终产品是一个真正的移动应用,从使用感受上和用 Objective-C 或 Java 编写的应用相比几乎是无法区分的。 React Native 所使用的基础 UI 组件和原生应用完全一致。 你要做的就是把这些基础组件使用 JavaScript 和 React 的方式组合起来。
(3)别再傻等编译了
React Native 让你可以快速迭代开发应用。 比起传统原生应用漫长的编译过程,现在你可以在瞬间刷新你的应用。开启 Hot Reloading 的话,甚至能在保持应用运行状态的情况下热替换新代码!
(4)可随时呼叫原生外援
React Native 完美兼容使用 Objective-C、Java 或是 Swift 编写的组件。 如果你需要针对应用的某一部分特别优化,中途换用原生代码编写也很容易。 想要应用的一部分用原生,一部分用 React Native 也完全没问题。
考虑到更好的体验 React Native 和 H5 在开发效率、功能性能、用户体验等方面的差异性,我们对功能模块进行精心设计,主要基于我们现在实际项目的业务,结合移动端特有的特性。相关的模块功能设计如下图所示。

截取一些功能展示如下:

我们的项目目录结构如下:
├─ .vscode 编辑器配置
├─ android android 原生目录
├─ ios ios 原生目录
├─node_modules 项目依赖包
├─ src 代码主目录
│ ├─assets 存放样式文件
│ │ ├─images 存放图片
│ │ └─styles 样式文件的 js 目录
│ │ ├─index.js 存放图片路径,可以参照主页面模块写法
│ ├─components 存放块级组件
│ ├─navigation 存放导航配置
│ │ ├─ index.js 导航配置主文件
│ ├─pages 存放页面级组件,不同模块不同目录
│ └─utils 存放工具方法
│ │ ├─ constant.js 一些常量配置,例如:服务器 IP 端口等
│ │ ├─ globalVar.js 一些全部变量
│ │ └─ request.js ajax 请求
├─.eslintrc.js eslint 配置
├─.gitignore.js git 忽略配置
├─index.js 项目入口
├─package.json 项目依赖包配置
此模块包含功能:文件夹创建、重命名、文件上传、下载、侧滑操作、长按列表操作、下拉刷新操作、文件预览(包含图片)等。
(1) 使用插件
react-native-popup-menu(2)功能实现
yarn add react-native-popup-menu
在 react_native_project/src/pages/netDisk/NetDisk.js 组件中实现相应逻辑,关键代码及注释如下:
// 插件引入
import {
Menu,
MenuProvider,
MenuOptions,
MenuOption,
MenuTrigger,
} from 'react-native-popup-menu';
// render
<MenuProvider>
<Menu>
<MenuTrigger
onAlternativeAction={() => this.getDirFile(rowData.item)}
triggerOnLongPress={true}
customStyles={triggerStyles}>
<Image
source={ rowData.item.icon }
style={styles.thumbnail}
/>
<View>
<Text>{rowData.item.name}</Text>
<Text>{dayjs(rowData.item.time).format('YYYY-MM-DD HH:mm:ss')}</Text>
</View>
<View>
{
rowData.item.type === 'dir'?
<NBIcon type="AntDesign" name="right"/> : null
}
</View>
</MenuTrigger>
<MenuOptions customStyles={optionsStyles}>
<MenuOption value={1} text='重命名' onSelect={() => {this.setState({
modalVisible: true,
fileItem: rowData.item,
dialogType: 'Rename',
hasInputText: true,
inputVal: rowData.item.name,
isSideSlip: false
});}}/>
<MenuOption value={2} text='删除' onSelect={() => {
this.setState({
modalVisible: true,
fileItem: rowData.item,
dialogType: 'Delete',
confirmText: '确定删除?',
hasInputText: false,
isSideSlip: false
});
}}/>
<MenuOption value={3} text='下载'
onSelect={() => this.downloadFile(rowData.item)} disabled={rowData.item.type === 'dir'}/>
</MenuOptions>
</Menu>
</MenuProvider>(3)注意事项
(4)参考文档
(1)使用插件
react-native-swipe-list-view(2)功能实现
yarn add react-native-swipe-list-view
在 react_native_project/src/pages/netDisk/NetDisk.js 组件中实现相应逻辑,关键代码及注释如下:
// 插件引入
import { SwipeListView } from 'react-native-swipe-list-view/lib/index';
// render
<SwipeListView
style={styles.list}
data={this.state.filesList}
renderItem={ (rowData) => (
<TouchableHighlight
style={styles.rowFront}
underlayColor={'#AAA'}
>
<View style={{flexDirection:'row',flex: 1,alignItems:'center'}}>
<Text>{rowData.item.name}</Text>
</View>
</TouchableHighlight>
)}
renderHiddenItem={ (rowData, rowMap) => {
return (
<View style={styles.standaloneRowBack} key={rowData.item.time}>
<NbButton style={[styles.backRightBtn, styles.backRightBtnLeft]} onPress={() =>{
this.setState({
modalVisible: true,
fileItem: rowData.item,
fileIndex: rowData.item.key,
fileRowMap: rowMap,
dialogType: 'Rename',
hasInputText: true,
inputVal: rowData.item.name,
isSideSlip: true
});
}}>
<Text style={styles.backTextWhite}>重命名</Text>
</NbButton>
<NbButton style={[styles.backRightBtn, styles.backRightBtnRight]} onPress={() => {
this.setState({
modalVisible: true,
fileItem: rowData.item,
fileIndex: rowData.item.key,
fileRowMap: rowMap,
dialogType: 'Delete',
confirmText: '确定删除?',
hasInputText: false,
isSideSlip: true
});
}}>
<Text style={styles.backTextWhite}>删除</Text>
</NbButton>
</View>
);}
}
rightOpenValue={-150}
stopRightSwipe={-150}
disableRightSwipe={true}
swipeToOpenPercent={20}
swipeToClosePercent={0}
/>(3)注意事项
// 关闭侧滑
closeRow(rowMap, rowKey) {
if (rowMap[rowKey]) {
rowMap[rowKey].closeRow();
}
}(4)参考文档
(1) 使用插件
rn-fetch-blob(2)功能实现
yarn add rn-fetch-blob
因为该插件涉及到 Android 原生功能,所以配置完该插件,需要重新编译 Android。
在 react_native_project/src/pages/netDisk/NetDisk.js 组件中实现相应逻辑,关键代码及注释如下:
// 插件引入
import RNFetchBlob from 'rn-fetch-blob';
// 下载方法
async actualDownload(item) {
let dirs = RNFetchBlob.fs.dirs;
const android = RNFetchBlob.android;
RNFetchBlob.config({
fileCache : true,
path: `${dirs.DownloadDir}/${item.name}`,
// android only options, these options be a no-op on IOS
addAndroidDownloads : {
// Show notification when response data transmitted
notification : true,
// Title of download notification
title : '下载完成',
// File description (not notification description)
description : 'An file.',
mime : getMimeType(item.name.split('.').pop()),
// Make the file scannable by media scanner
mediaScannable : true,
}
})
.fetch('GET', `${CONSTANT.SERVER_URL}${item.path}`)
.then(async(res) => {
await android.actionViewIntent(res.path(), getMimeType(item.name.split('.').pop()));
});
}(3)注意事项
// 问题
So basically this needs to be added to line 122-123 of file android/src/main/java/com/RNFetchBlob/RNFetchBlob.java:
// 解决办法
intent.addFlags(Intent.FLAG_ACTIVITY_NEW_TASK);
If above is not working do to the below step: overwrite the 121 line in android/src/main/java/com/RNFetchBlob/RNFetchBlob.java:
intent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK); // 121 line
intent.addFlags(Intent.FLAG_GRANT_READ_URI_PERMISSION); // 122 line(4)参考文档
(1)使用插件
// 获取本机文件
react-native-file-selector(2)功能实现
yarn add react-native-file-selector
因为该插件涉及到 Android 原生功能,所以添加完该插件,需要重新编译 Android。
在 react_native_project/src/pages/netDisk/NetDisk.js 组件中实现相应逻辑,关键代码及注释如下:
// 插件引入
import RNFileSelector from 'react-native-file-selector';
// 选择文件并上传
RNFileSelector.Show(
{
title: '请选择文件',
onDone: (filePath) => {
let data = new FormData();
let file = { uri: 'file://' + filePath, type: 'multipart/form-data', name: escape(path.basename(filePath))};
data.append('file', file);
let options = {
url: '/files/uploadFile', // 请求 url
data: data,
tipFlag: true, // 默认统一提示,如果需要自定义提示,传入 true
};
request(options).then(async (res) => {
if (res.status == 200) {
await this.fetchData();
ToastAndroid.show(
'上传成功',
ToastAndroid.SHORT,
ToastAndroid.CENTER
);
}
});
},
onCancel: () => {
ToastAndroid.show(
'取消上传',
ToastAndroid.SHORT,
ToastAndroid.CENTER
);
}
}
);(3)注意事项
(4)参考文档
(1) 使用插件
react-native-doc-viewer(2)功能实现
yarn add react-native-doc-viewer
因为该插件涉及到 Android 原生功能,所以添加完该插件,需要重新编译 Android。
在 react_native_project/src/pages/netDisk/NetDisk.js 组件中实现相应逻辑,关键代码及注释如下:
// 插件引入
import OpenFile from 'react-native-doc-viewer';
// 文件预览
OpenFile.openDoc([{
url: `${CONSTANT.SERVER_URL}${item.path}`,
fileName: item.name.split('.').shift(),
cache: false,
fileType: item.name.split('.').pop()
}], (error) => {
if (error) {
this.setState({ animating: false });
console.log(error);
ToastAndroid.show('请先安装相关应用软件', ToastAndroid.SHORT);
} else {
this.setState({ animating: false });
// ToastAndroid.show('该文件不支持预览', ToastAndroid.SHORT);
}
});(3)注意事项
node_modules/react-native-doc-viewer/android/src/main/java/com/reactlibrary/RNReactNativeDocViewerModule.java 文件中import com.facebook.react.views.webview.ReactWebViewManager;(4)参考文档
(1) 使用插件
react-native-image-zoom-viewer(2)功能实现
react-native-image-zoom-viewer
在 react_native_project/src/pages/netDisk/NetDisk.js 组件中实现相应逻辑,关键代码及注释如下:
// 插件引入
import ImageViewer from 'react-native-image-zoom-viewer';
// 图片预览方法
saveImg(url) {
let promise = CameraRoll.saveToCameraRoll(url);
promise.then((result) => {
console.log(result);
ToastAndroid.show('已保存到相册', ToastAndroid.SHORT);
}).catch((error) => {
console.log(error);
ToastAndroid.show('保存失败', ToastAndroid.SHORT);
});
}
// render
<Modal
transparent={true}
visible={imgModalVisible}
onRequestClose={() => this.props.closeImg()}>
<ImageViewer
onCancel={()=> this.props.closeImg()}
onClick={(onCancel) => {onCancel();}}
onSave={(url) => this.saveImg(url)}
saveToLocalByLongPress={true}
imageUrls={images}
index={imgIndex}
doubleClickInterval={1000}
menuContext={{ 'saveToLocal': '保存到相册', 'cancel': '取消' }}/>
</Modal>(3)注意事项
(4)参考文档
此模块包含功能:音/视频上传、下载、删除、判断网络、播放、全屏播放、转向全屏播放、评论、分享等功能,其中上传、下载、删除功能在网盘模块和试题模块已说明。
(1)使用插件
react-native-video(2)功能实现
yarn add react-native-video
因为该插件涉及到 Android 原生功能,所以添加完该插件,需要重新编译 Android。
在 react_native_project/src/pages/video/VideoPlayer.js 组件中实现相应逻辑,关键代码及注释如下:
// 插件引入
import Video from 'react-native-video';
// 视频进度时间方法
function formatTime(second) {
let h = 0, i = 0, s = parseInt(second);
if (s > 60) {
i = parseInt(s / 60);
s = parseInt(s % 60);
}
// 补零
let zero = function (v) {
return (v >> 0) < 10 ? '0' + v : v;
};
return [zero(h), zero(i), zero(s)].join(':');
}
// render
// 自带参数和方法请看 api
<Video
ref={(ref) => this.videoPlayer = ref}
source={{uri: CONSTANT.SERVER_URL + '/' + this.state.videoUrl}}
rate={this.state.playRate}
volume={this.state.volume}
muted={this.state.isMuted}
paused={!this.state.isPlaying}
resizeMode={'contain'}
playWhenInactive={false}
playInBackground={false}
ignoreSilentSwitch={'ignore'}
progressUpdateInterval={250.0}
onLoadStart={this._onLoadStart}
onLoad={this._onLoaded}
onProgress={this._onProgressChanged}
onEnd={this._onPlayEnd}
onError={this._onPlayError}
onBuffer={this._onBuffering}
style={{ width: this.state.videoWidth, height: this.state.videoHeight}}
/>(3)参考文档
(1) 使用插件
react-native-orientation(2)功能实现
yarn add react-native-orientation
因为该插件涉及到 Android 原生功能,所以添加完该插件,需要重新编译 Android。
在 react_native_project/src/pages/video/VideoPlayer.js 组件中实现相应逻辑,关键代码及注释如下:
// 插件引入
import Orientation from 'react-native-orientation';
// 点击工具栏上的全屏按钮
onControlShrinkPress() {
if (this.state.isFullScreen) {
Orientation.lockToPortrait();
} else {
Orientation.lockToLandscapeRight();
}
}
// 屏幕旋转时宽高会发生变化,可以在onLayout的方法中做处理,比监听屏幕旋转更加及时获取宽高变化
_onLayout = (event) => {
//获取根View的宽高
let {width, height} = event.nativeEvent.layout;
// 一般设备横屏下都是宽大于高,这里可以用这个来判断横竖屏
let isLandscape = (width > height);
if (isLandscape && !this.showKeyboard){
this.setState({
videoWidth: width,
videoHeight: height,
isFullScreen: true,
});
} else {
this.setState({
videoWidth: width,
videoHeight: width * 9/16,
isFullScreen: false,
});
}
Orientation.unlockAllOrientations();
};(3)参考文档
(1) 使用插件
react-native-wechat(2)功能实现
yarn add react-native-wechat
因为该插件涉及到 Android 原生功能,所以添加完该插件,需要重新编译 Android。
在 react_native_project/src/components/video/VideoShare.js 组件中实现相应逻辑,关键代码及注释如下:
// 插件引入
import * as WeChat from 'react-native-wechat';
// const wxAppId = ''; // 微信开放平台注册的app id
// const wxAppSecret = ''; // 微信开放平台注册得到的app secret
// WeChat.registerApp(wxAppId);
// 分享
shareItemSelectedAtIndex(index) {
// this.props.onShareItemSelected && this.props.onShareItemSelected(index);
WeChat.isWXAppInstalled().then((isInstalled) => {
this.setState({
isWXInstalled: isInstalled
});
if (isInstalled && index === 0) {
WeChat.shareToSession({
title: this.state.videoTitle,
type: 'video',
videoUrl: CONSTANT.SERVER_URL + '/' + this.state.videoUrl
}).catch((error) => {
console.log(error.message);
});
} else if (isInstalled && index === 1) {
WeChat.shareToTimeline({
title: this.state.videoTitle,
type: 'video',
videoUrl: CONSTANT.SERVER_URL + '/' + this.state.videoUrl
}).catch((error) => {
console.log(error.message);
});
} else {
console.log('微信未安装');
}
});
}(3)参考文档
(1)使用插件
react-native-image-crop-picker (2)功能实现
yarn add react-native-image-crop-picker
因为该插件涉及到 Android 原生功能,所以添加完该插件,需要重新编译 Android。
在 react_native_project/src/components/exam/ImageAudioTab.js 组件中实现相应逻辑,关键代码及注释如下:
// 插件引入
import ImagePicker from 'react-native-image-crop-picker';
// 从相册选择图片
ImagePicker.openPicker(paramObj).then(image => {
this.props.handleImage(qsIndex, image);
}).catch(err => {
console.log(err);
});
// 调用摄像头功能
openCamera(qsIndex) {
ImagePicker.openCamera({
width: 300,
height: 400,
cropping: true,
}).then(image => {
this.props.handleImage(qsIndex, image);
}).catch(err => {
console.log(err);
});
}(3)注意事项
(4)参考文档
(1) 使用插件
react-native-audio // 语音录入
react-native-sound // 语音播放
react-native-spinkit // 动画效果(2)功能实现
yarn add react-native-audio react-native-sound react-native-spinkit
因为语音录入插件涉及到 Android 原生功能,所以添加完该插件,需要重新编译 Android。
在 react_native_project/src/components/exam/ImageAudioTab.js 组件中实现相应逻辑,关键代码及注释如下:
// 插件引入
import { AudioRecorder, AudioUtils } from 'react-native-audio';
import Sound from 'react-native-sound';
import Spinkit from 'react-native-spinkit';
// 音频路径配置
prepareRecordingPath = (path) => {
const option = {
SampleRate: 44100.0, //采样率
Channels: 2, //通道
AudioQuality: 'High', //音质
AudioEncoding: 'aac', //音频编码
OutputFormat: 'mpeg_4', //输出格式
MeteringEnabled: false, //是否计量
MeasurementMode: false, //测量模式
AudioEncodingBitRate: 32000, //音频编码比特率
IncludeBase64: true, //是否是base64格式
AudioSource: 0, //音频源
};
AudioRecorder.prepareRecordingAtPath(path, option);
}
// 开始录音
startSoundRecording(qsIndex, stemAudio) {
if (stemAudio.length >= 5) {
ToastAndroid.show('每道题最多 5 段语音哦', ToastAndroid.SHORT);
return;
}
console.log('startSoundRecording....');
// 请求授权
AudioRecorder.requestAuthorization()
.then(isAuthor => {
if (isAuthor) {
this.prepareRecordingPath(this.audioPath + qsIndex + '_' + stemAudio.length + '.aac');
// 录音进展
AudioRecorder.onProgress = (data) => {
this.recordTime = Math.floor(data.currentTime);
};
// 完成录音
AudioRecorder.onFinished = (data) => {
// data 返回需要上传到后台的录音数据;
this.isRecording = false;
if (!this.recordTime) {
ToastAndroid.show('录音时间太短...', ToastAndroid.SHORT);
return;
}
this.props.handleAudio(qsIndex, data.audioFileURL, this.recordTime);
// 重置为 0
this.recordTime = 0;
};
// 录音
AudioRecorder.startRecording();
this.isRecording = true;
}
});
}
// 结束录音
stopSoundRecording() {
console.log('stopSoundRecording....');
// 已经被节流操作拦截,没有在录音
if (!this.isRecording) {
return;
}
AudioRecorder.stopRecording();
}
// 播放录音
playSound(qsIndex, index, stemAudio, audioFlag, path) {
this.props.changeAudioState(qsIndex, index, 2);
let whoosh = new Sound(path.slice(7), '', (err) => {
if (err) {
return console.log(err);
}
whoosh.play(success => {
if (success) {
console.log('success - 播放成功');
} else {
console.log('fail - 播放失败');
}
this.props.changeAudioState(qsIndex, index, 1);
});
});
}(3)注意事项
(4)参考文档
(1) 使用插件
victory-native // 图标绘制插件
react-native-svg // svg 图片绘制(2)功能实现
yarn add victory-native react-native-svg
因为该插件涉及到 Android 原生功能,所以添加完该插件,需要重新编译 Android。
在 react_native_project/src/pages/exam/ResultStatistics.js 组件中实现相应逻辑,关键代码及注释如下:
// 插件引入
import {
VictoryPie,
VictoryLegend,
VictoryTooltip
} from 'victory-native';
// 图形绘制组件使用
<VictoryLegend
orientation="vertical"
data={[
{
name: '不及格 < 60 分',
symbol: { fill: colorScale[0], type: 'square' },
},
{
name: '及格 60 - 75 分',
symbol: { fill: colorScale[1], type: 'square' },
},
{
name: '良好 75 - 85 分',
symbol: { fill: colorScale[2], type: 'square' },
},
{
name: '优秀 > 85 分',
symbol: { fill: colorScale[3], type: 'square' },
}
]}
width={180}
height={125}
/>
<VictoryPie
colorScale={colorScale}
data={[
{ y: this.state.result[3], label: '不及格:' + this.state.result[3] + '人'},
{ y: this.state.result[2], label: '及格:' + this.state.result[2] + '人' },
{ y: this.state.result[1], label: '良好:' + this.state.result[1] + '人' },
{ y: this.state.result[0], label: '优秀:' + this.state.result[0] + '人' }
]}
innerRadius={60}
height={300}
width={345}
animate={{
duration: 2000
}}
labelComponent={
<VictoryTooltip
active={({ datum }) => datum.y === 0 ? false : true}
constrainToVisibleArea={true}
flyoutHeight={30}
flyoutStyle={{ strokeWidth: 0.1}}
/>
}
/>(3)注意事项
(4)参考文档
(1)使用插件
Linking // react native 自带的插件 (2)功能实现
在 react_native_project/src/components/user/ListItem.js 组件中实现相应逻辑,关键代码及注释如下:
// 拨打电话功能 or 短信功能
call(flag) {
let tel = flag === 1 ? 'tel:10086' : 'smsto:10086';
Linking.canOpenURL(tel).then(supported => {
if (!supported) {
ToastAndroid.show.show('您未授权通话和短信权限');
} else {
return Linking.openURL(tel);
}
}).catch(err => console.error('An error occurred', err));
}(3)注意事项
(4)参考文档
(1) 使用插件
(2)功能实现
在 react_native_project/android/app/src/main/java/com/react_native_project/module 目录中创建实现类 LocationModule.java,需要注意的是这个类需要实现 ReactContextBaseJavaModule 这个类:
public class LocationModule extends ReactContextBaseJavaModule {
private final ReactApplicationContext mContext;
public LocationModule(ReactApplicationContext reactContext) {
super(reactContext);
mContext = reactContext;
}
/**
* @return js调用的模块名
*/
@Override
public String getName() {
return "LocationModule";
}
/**
* 使用ReactMethod注解,使这个方法被js调用
*/
@ReactMethod
public void getLocation(Callback locationCallback) {
// 省略一些逻辑实现 ...
locationCallback.invoke(lat,lng,country,locality);
}else{
locationCallback.invoke(false);
}
}
}对刚刚实现定位功能的模块进行注册,在 react_native_project/android/app/src/main/java/com/react_native_project/module 目录中创建注册包管理类 LocationReactPackage .java,相关逻辑如下:
public class LocationReactPackage implements ReactPackage {
/**
* @param reactContext 上下文
* @return 需要调用的原生控件
*/
@Override
public List<ViewManager> createViewManagers(ReactApplicationContext reactContext) {
return Collections.emptyList();
}
/**
* @param reactContext 上下文
* @return 需要调用的原生模块
*/
@Override
public List<NativeModule> createNativeModules(
ReactApplicationContext reactContext) {
List<NativeModule> modules = new ArrayList<>();
modules.add(new LocationModule(reactContext));
return modules;
}
}在 react_native_project/android/app/src/main/java/com/react_native_project/MainApplication.java 中添加包管理类,相关逻辑如下:
protected List<ReactPackage> getPackages() {
@SuppressWarnings("UnnecessaryLocalVariable")
List<ReactPackage> packages = new PackageList(this).getPackages();
packages.add(new LocationReactPackage());
return packages;
}我们在 react_native_project/src/components/user/ListItem.js 组件中实现相应逻辑,关键代码及注释如下:
import { NativeModules } from 'react-native';
// 获取地理位置
showLocation() {
NativeModules.LocationModule.getLocation((lat, lng, country, locality) => {
let str = '获取位置信息失败,您可能手机位置信息没有开启!';
if (lat && lng) {
str = country + ',' + locality + ',纬度:' + lat + ',' + '经度:' + lng;
}
ToastAndroid.show(str, ToastAndroid.SHORT);
});
}(3)注意事项
(4)参考文档
(1) 使用插件
rn-fetch-blob(2)功能实现
yarn add rn-fetch-blob
因为该插件涉及到 Android 原生功能,所以添加完该插件,需要重新编译 Android。
我们实现在线升级功能的大概逻辑是,在 app 管理端上传 apk 安装包,然后点击发布,这时服务端会通过 websocket 将最新发布的版本号通知 app,app 收到最新版本号,会跟当前的 app 版本比较,如果当前版本号小于最新版本号,则会弹窗提示有最新版本,询问用户是否下载安装,用户如果确认安装最新版本,则会从服务器下载最新的 apk,并进行安装。在 react_native_project/src/components/user/ListItem.js 组件中实现相应逻辑,关键代码及注释如下:
import RNFetchBlob from 'rn-fetch-blob';
checkUpdate = () => {
const android = RNFetchBlob.android;
//下载成功后文件所在path
const downloadDest = `${
RNFetchBlob.fs.dirs.DownloadDir
}/app_release.apk`;
RNFetchBlob.config({
//配置手机系统通知栏下载文件通知,下载成功后点击通知可运行apk文件
addAndroidDownloads: {
useDownloadManager: true,
title: 'RN APP',
description: 'An APK that will be installed',
mime: 'application/vnd.android.package-archive',
path: downloadDest,
mediaScannable: true,
notification: true
}
}).fetch(
'GET',
CONSTANT.SERVER_URL+'/appVersion/download?path='+this.newVersionInfo.path
).then(res => {
//下载成功后自动打开运行已下载apk文件
android.actionViewIntent(
res.path(),
'application/vnd.android.package-archive'
);
});
}(3)注意事项
(4)参考文档
4.1、运行 react-native run-android 出现错误:Task :app:mergeDebugAssets FAILED OR Task :app:processDebugResources FAILED 。
解决:
cd android && ./gradlew clean
cd .. && react-native run-android4.2、如果手机真机出现连接不上开发开发服务器的情况。
解决:
命令窗口运行以下命令:
adb reverse tcp:8081 tcp:80814.3、kotlin 相关 jar 包无法下载。
解决:
对应的插件的 android/build.gradle 配置阿里云仓库(例如遇到这个问题时,是在插件 react-native-webview)
// Maven中心仓库墙内版
maven { url "https://maven.aliyun.com/repository/central" }
// jCenter中心仓库墙内版
maven { url "https://maven.aliyun.com/repository/jcenter" }
maven{url 'http://maven.aliyun.com/nexus/content/groups/public/'}4.4、文件预览插件:react-native-doc-viewer安装完 run-android 编译失败。
解决:
Could be fixed by removing the import in node_modules/react-native-doc-viewer/android/src/main/java/com/reactlibrary/RNReactNativeDocViewerModule.java
Remove the ununsed import:
import com.facebook.react.views.webview.ReactWebViewManager;4.5、第三方插件 rn-fetch-blob 下载文档无法打开。
解决:
So basically this needs to be added to line 122-123 of file android/src/main/java/com/RNFetchBlob/RNFetchBlob.java:
intent.addFlags(Intent.FLAG_ACTIVITY_NEW_TASK);
If above is not working do to the below step: overwrite the 121 line in android/src/main/java/com/RNFetchBlob/RNFetchBlob.java:
intent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK); // 121 line
intent.addFlags(Intent.FLAG_GRANT_READ_URI_PERMISSION); // 122 line本文主要基于 React Native 框架的实践进行总结,分享了 React Native 理念、React Native 项目的功能介绍、React Native 项目编译以及 React Native 存在的一些坑,希望对完全阅读完的你有启发和帮助,如果有不足,欢迎批评、指正、交流!
姐妹篇《 Weex 实践总结 》,可以进行 React Native 和 Weex 的对比。
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:https://github.com/fengshi123/blog ,汇总了作者的所有博客,也欢迎关注及 star ~
本项目 github 地址为:https://github.com/fengshi123/react_native_project
配套的服务端 express 项目 github 地址为:https://github.com/fengshi123/express_project
Vue 框架通过数据双向绑定和虚拟 DOM 技术,帮我们处理了前端开发中最脏最累的 DOM 操作部分, 我们不再需要去考虑如何操作 DOM 以及如何最高效地操作 DOM;但 Vue 项目中仍然存在项目首屏优化、Webpack 编译配置优化等问题,所以我们仍然需要去关注 Vue 项目性能方面的优化,使项目具有更高效的性能、更好的用户体验。本文是作者通过实际项目的优化实践进行总结而来,希望读者读完本文,有一定的启发思考,从而对自己的项目进行优化起到帮助。本文内容分为以下三部分组成:
github地址为:github.com/fengshi123/…,汇总了作者的所有博客,也欢迎关注及 star ~
v-if 是 真正 的条件渲染,因为它会确保在切换过程中条件块内的事件监听器和子组件适当地被销毁和重建;也是惰性的:如果在初始渲染时条件为假,则什么也不做——直到条件第一次变为真时,才会开始渲染条件块。
v-show 就简单得多, 不管初始条件是什么,元素总是会被渲染,并且只是简单地基于 CSS 的 display 属性进行切换。
所以,v-if 适用于在运行时很少改变条件,不需要频繁切换条件的场景;v-show 则适用于需要非常频繁切换条件的场景。
computed: 是计算属性,依赖其它属性值,并且 computed 的值有缓存,只有它依赖的属性值发生改变,下一次获取 computed 的值时才会重新计算 computed 的值;
watch: 更多的是「观察」的作用,类似于某些数据的监听回调 ,每当监听的数据变化时都会执行回调进行后续操作;
运用场景:
当我们需要进行数值计算,并且依赖于其它数据时,应该使用 computed,因为可以利用 computed 的缓存特性,避免每次获取值时,都要重新计算;
当我们需要在数据变化时执行异步或开销较大的操作时,应该使用 watch,使用 watch 选项允许我们执行异步操作 ( 访问一个 API ),限制我们执行该操作的频率,并在我们得到最终结果前,设置中间状态。这些都是计算属性无法做到的。
(1)v-for 遍历必须为 item 添加 key
在列表数据进行遍历渲染时,需要为每一项 item 设置唯一 key 值,方便 Vue.js 内部机制精准找到该条列表数据。当 state 更新时,新的状态值和旧的状态值对比,较快地定位到 diff 。
(2)v-for 遍历避免同时使用 v-if
v-for 比 v-if 优先级高,如果每一次都需要遍历整个数组,将会影响速度,尤其是当之需要渲染很小一部分的时候,必要情况下应该替换成 computed 属性。
推荐:
<ul>
<li
v-for="user in activeUsers"
:key="user.id">
{{ user.name }}
</li>
</ul>
computed: {
activeUsers: function () {
return this.users.filter(function (user) {
return user.isActive
})
}
}不推荐:
<ul>
<li
v-for="user in users"
v-if="user.isActive"
:key="user.id">
{{ user.name }}
</li>
</ul>Vue 会通过 Object.defineProperty 对数据进行劫持,来实现视图响应数据的变化,然而有些时候我们的组件就是纯粹的数据展示,不会有任何改变,我们就不需要 Vue 来劫持我们的数据,在大量数据展示的情况下,这能够很明显的减少组件初始化的时间,那如何禁止 Vue 劫持我们的数据呢?可以通过 Object.freeze 方法来冻结一个对象,一旦被冻结的对象就再也不能被修改了。
export default {
data: () => ({
users: {}
}),
async created() {
const users = await axios.get("/api/users");
this.users = Object.freeze(users);
}
};Vue 组件销毁时,会自动清理它与其它实例的连接,解绑它的全部指令及事件监听器,但是仅限于组件本身的事件。 如果在 js 内使用 addEventListene 等方式是不会自动销毁的,我们需要在组件销毁时手动移除这些事件的监听,以免造成内存泄露,如:
created() {
addEventListener('click', this.click, false)
},
beforeDestroy() {
removeEventListener('click', this.click, false)
}对于图片过多的页面,为了加速页面加载速度,所以很多时候我们需要将页面内未出现在可视区域内的图片先不做加载, 等到滚动到可视区域后再去加载。这样对于页面加载性能上会有很大的提升,也提高了用户体验。我们在项目中使用 Vue 的 vue-lazyload 插件:
(1)安装插件
npm install vue-lazyload --save-dev(2)在入口文件 man.js 中引入并使用
import VueLazyload from 'vue-lazyload'然后再 vue 中直接使用
Vue.use(VueLazyload)或者添加自定义选项
Vue.use(VueLazyload, {
preLoad: 1.3,
error: 'dist/error.png',
loading: 'dist/loading.gif',
attempt: 1
})(3)在 vue 文件中将 img 标签的 src 属性直接改为 v-lazy ,从而将图片显示方式更改为懒加载显示:
<img v-lazy="/static/img/1.png">以上为 vue-lazyload 插件的简单使用,如果要看插件的更多参数选项,可以查看 vue-lazyload 的 github 地址。
Vue 是单页面应用,可能会有很多的路由引入 ,这样使用 webpcak 打包后的文件很大,当进入首页时,加载的资源过多,页面会出现白屏的情况,不利于用户体验。如果我们能把不同路由对应的组件分割成不同的代码块,然后当路由被访问的时候才加载对应的组件,这样就更加高效了。这样会大大提高首屏显示的速度,但是可能其他的页面的速度就会降下来。
路由懒加载:
const Foo = () => import('./Foo.vue')
const router = new VueRouter({
routes: [
{ path: '/foo', component: Foo }
]
})我们在项目中经常会需要引入第三方插件,如果我们直接引入整个插件,会导致项目的体积太大,我们可以借助 babel-plugin-component ,然后可以只引入需要的组件,以达到减小项目体积的目的。以下为项目中引入 element-ui 组件库为例:
(1)首先,安装 babel-plugin-component :
npm install babel-plugin-component -D(2)然后,将 .babelrc 修改为:
{
"presets": [["es2015", { "modules": false }]],
"plugins": [
[
"component",
{
"libraryName": "element-ui",
"styleLibraryName": "theme-chalk"
}
]
]
}(3)在 main.js 中引入部分组件:
import Vue from 'vue';
import { Button, Select } from 'element-ui';
Vue.use(Button)
Vue.use(Select)如果你的应用存在非常长或者无限滚动的列表,那么需要采用 窗口化 的技术来优化性能,只需要渲染少部分区域的内容,减少重新渲染组件和创建 dom 节点的时间。 你可以参考以下开源项目 vue-virtual-scroll-list 和 vue-virtual-scroller 来优化这种无限列表的场景的。
服务端渲染是指 Vue 在客户端将标签渲染成的整个 html 片段的工作在服务端完成,服务端形成的 html 片段直接返回给客户端这个过程就叫做服务端渲染。
(1)服务端渲染的优点:
更好的 SEO: 因为 SPA 页面的内容是通过 Ajax 获取,而搜索引擎爬取工具并不会等待 Ajax 异步完成后再抓取页面内容,所以在 SPA 中是抓取不到页面通过 Ajax 获取到的内容;而 SSR 是直接由服务端返回已经渲染好的页面(数据已经包含在页面中),所以搜索引擎爬取工具可以抓取渲染好的页面;
更快的内容到达时间(首屏加载更快): SPA 会等待所有 Vue 编译后的 js 文件都下载完成后,才开始进行页面的渲染,文件下载等需要一定的时间等,所以首屏渲染需要一定的时间;SSR 直接由服务端渲染好页面直接返回显示,无需等待下载 js 文件及再去渲染等,所以 SSR 有更快的内容到达时间;
(2)服务端渲染的缺点:
更多的开发条件限制: 例如服务端渲染只支持 beforCreate 和 created 两个钩子函数,这会导致一些外部扩展库需要特殊处理,才能在服务端渲染应用程序中运行;并且与可以部署在任何静态文件服务器上的完全静态单页面应用程序 SPA 不同,服务端渲染应用程序,需要处于 Node.js server 运行环境;
更多的服务器负载:在 Node.js 中渲染完整的应用程序,显然会比仅仅提供静态文件的 server 更加大量占用CPU 资源,因此如果你预料在高流量环境下使用,请准备相应的服务器负载,并明智地采用缓存策略。
如果你的项目的 SEO 和 首屏渲染是评价项目的关键指标,那么你的项目就需要服务端渲染来帮助你实现最佳的初始加载性能和 SEO,具体的 Vue SSR 如何实现,可以参考作者的另一篇文章《Vue SSR 踩坑之旅》。如果你的 Vue 项目只需改善少数营销页面(例如 /, /about, /contact 等)的 SEO,那么你可能需要预渲染,在构建时 (build time) 简单地生成针对特定路由的静态 HTML 文件。优点是设置预渲染更简单,并可以将你的前端作为一个完全静态的站点,具体你可以使用 prerender-spa-plugin 就可以轻松地添加预渲染 。
在 vue 项目中除了可以在 webpack.base.conf.js 中 url-loader 中设置 limit 大小来对图片处理,对小于 limit 的图片转化为 base64 格式,其余的不做操作。所以对有些较大的图片资源,在请求资源的时候,加载会很慢,我们可以用 image-webpack-loader 来压缩图片:
(1)首先,安装 image-webpack-loader :
npm install image-webpack-loader --save-dev(2)然后,在 webpack.base.conf.js 中进行配置:
{
test: /\.(png|jpe?g|gif|svg)(\?.*)?$/,
use:[
{
loader: 'url-loader',
options: {
limit: 10000,
name: utils.assetsPath('img/[name].[hash:7].[ext]')
}
},
{
loader: 'image-webpack-loader',
options: {
bypassOnDebug: true,
}
}
]
}Babel 插件会在将 ES6 代码转换成 ES5 代码时会注入一些辅助函数,例如下面的 ES6 代码:
class HelloWebpack extends Component{...}这段代码再被转换成能正常运行的 ES5 代码时需要以下两个辅助函数:
babel-runtime/helpers/createClass // 用于实现 class 语法
babel-runtime/helpers/inherits // 用于实现 extends 语法 在默认情况下, Babel 会在每个输出文件中内嵌这些依赖的辅助函数代码,如果多个源代码文件都依赖这些辅助函数,那么这些辅助函数的代码将会出现很多次,造成代码冗余。为了不让这些辅助函数的代码重复出现,可以在依赖它们时通过 require('babel-runtime/helpers/createClass') 的方式导入,这样就能做到只让它们出现一次。babel-plugin-transform-runtime 插件就是用来实现这个作用的,将相关辅助函数进行替换成导入语句,从而减小 babel 编译出来的代码的文件大小。
(1)首先,安装 babel-plugin-transform-runtime :
npm install babel-plugin-transform-runtime --save-dev(2)然后,修改 .babelrc 配置文件为:
"plugins": [
"transform-runtime"
]如果要看插件的更多详细内容,可以查看babel-plugin-transform-runtime 的 详细介绍。
如果项目中没有去将每个页面的第三方库和公共模块提取出来,则项目会存在以下问题:
所以我们需要将多个页面的公共代码抽离成单独的文件,来优化以上问题 。Webpack 内置了专门用于提取多个Chunk 中的公共部分的插件 CommonsChunkPlugin,我们在项目中 CommonsChunkPlugin 的配置如下:
// 所有在 package.json 里面依赖的包,都会被打包进 vendor.js 这个文件中。
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
minChunks: function(module, count) {
return (
module.resource &&
/\.js$/.test(module.resource) &&
module.resource.indexOf(
path.join(__dirname, '../node_modules')
) === 0
);
}
}),
// 抽取出代码模块的映射关系
new webpack.optimize.CommonsChunkPlugin({
name: 'manifest',
chunks: ['vendor']
})如果要看插件的更多详细内容,可以查看 CommonsChunkPlugin 的 详细介绍。
当使用 DOM 内模板或 JavaScript 内的字符串模板时,模板会在运行时被编译为渲染函数。通常情况下这个过程已经足够快了,但对性能敏感的应用还是最好避免这种用法。
预编译模板最简单的方式就是使用单文件组件——相关的构建设置会自动把预编译处理好,所以构建好的代码已经包含了编译出来的渲染函数而不是原始的模板字符串。
如果你使用 webpack,并且喜欢分离 JavaScript 和模板文件,你可以使用 vue-template-loader,它也可以在构建过程中把模板文件转换成为 JavaScript 渲染函数。
当使用单文件组件时,组件内的 CSS 会以 <style> 标签的方式通过 JavaScript 动态注入。这有一些小小的运行时开销,如果你使用服务端渲染,这会导致一段 “无样式内容闪烁 (fouc) ” 。将所有组件的 CSS 提取到同一个文件可以避免这个问题,也会让 CSS 更好地进行压缩和缓存。
查阅这个构建工具各自的文档来了解更多:
我们在项目进行打包后,会将开发中的多个文件代码打包到一个文件中,并且经过压缩、去掉多余的空格、babel编译化后,最终将编译得到的代码会用于线上环境,那么这样处理后的代码和源代码会有很大的差别,当有 bug的时候,我们只能定位到压缩处理后的代码位置,无法定位到开发环境中的代码,对于开发来说不好调式定位问题,因此 sourceMap 出现了,它就是为了解决不好调式代码问题的。
SourceMap 的可选值如下(+ 号越多,代表速度越快,- 号越多,代表速度越慢, o 代表中等速度 )

开发环境推荐: cheap-module-eval-source-map
生产环境推荐: cheap-module-source-map
原因如下:
cheap: 源代码中的列信息是没有任何作用,因此我们打包后的文件不希望包含列相关信息,只有行信息能建立打包前后的依赖关系。因此不管是开发环境或生产环境,我们都希望添加 cheap 的基本类型来忽略打包前后的列信息;
module :不管是开发环境还是正式环境,我们都希望能定位到bug的源代码具体的位置,比如说某个 Vue 文件报错了,我们希望能定位到具体的 Vue 文件,因此我们也需要 module 配置;
soure-map :source-map 会为每一个打包后的模块生成独立的 soucemap 文件 ,因此我们需要增加source-map 属性;
eval-source-map:eval 打包代码的速度非常快,因为它不生成 map 文件,但是可以对 eval 组合使用 eval-source-map 使用会将 map 文件以 DataURL 的形式存在打包后的 js 文件中。在正式环境中不要使用 eval-source-map, 因为它会增加文件的大小,但是在开发环境中,可以试用下,因为他们打包的速度很快。
Webpack 输出的代码可读性非常差而且文件非常大,让我们非常头疼。为了更简单、直观地分析输出结果,社区中出现了许多可视化分析工具。这些工具以图形的方式将结果更直观地展示出来,让我们快速了解问题所在。接下来讲解我们在 Vue 项目中用到的分析工具:webpack-bundle-analyzer 。
我们在项目中 webpack.prod.conf.js 进行配置:
if (config.build.bundleAnalyzerReport) {
var BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
webpackConfig.plugins.push(new BundleAnalyzerPlugin());
}执行 $ npm run build --report 后生成分析报告如下:
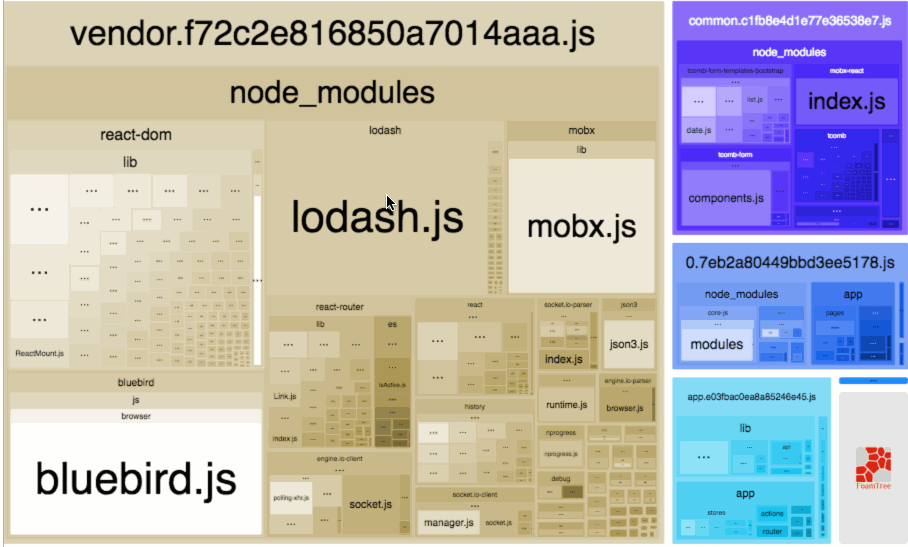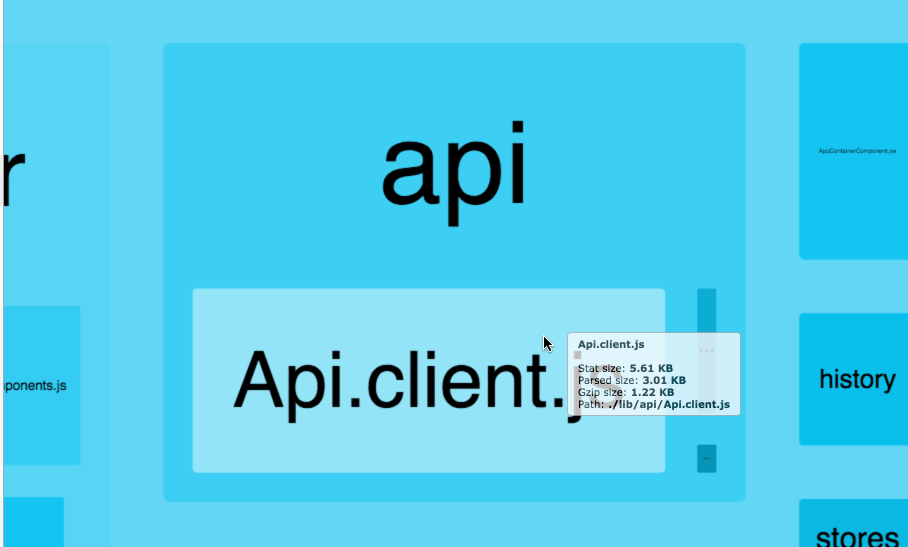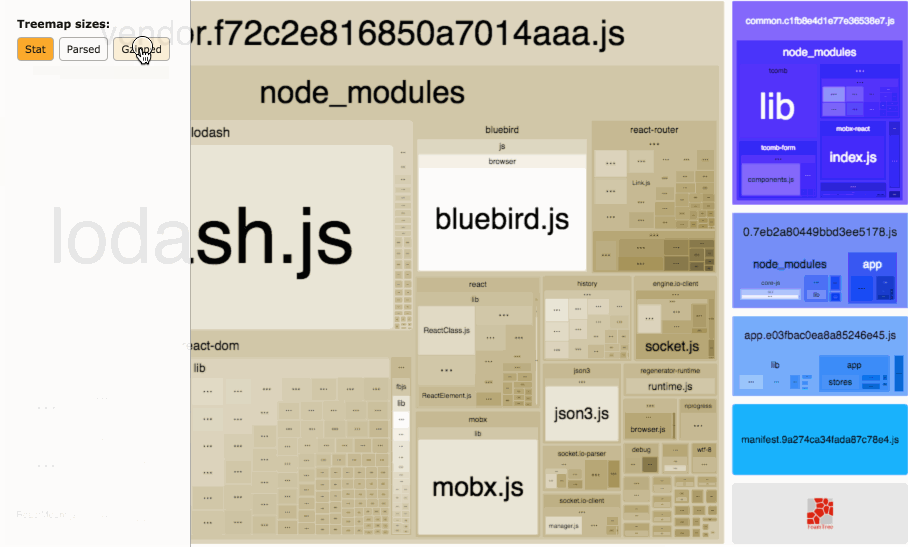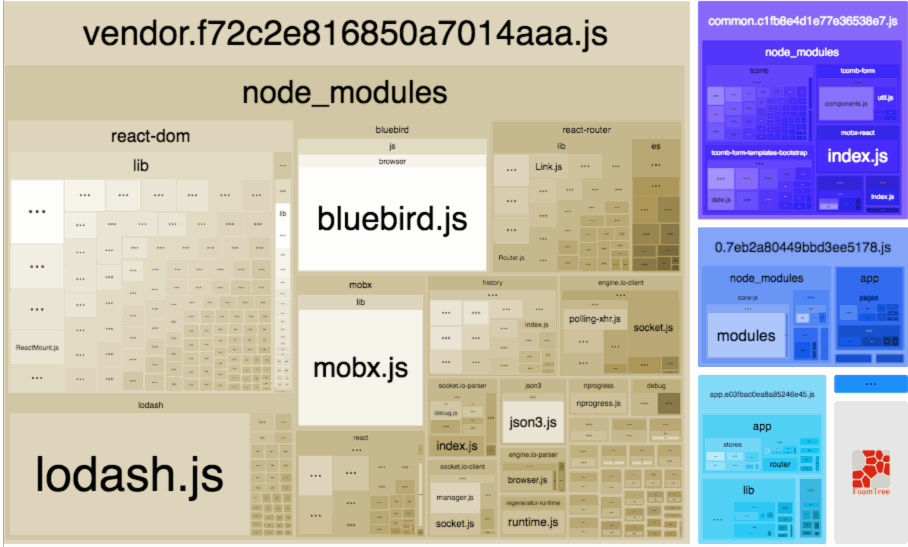
如果你的 Vue 项目使用 Webpack 编译,需要你喝一杯咖啡的时间,那么也许你需要对项目的 Webpack 配置进行优化,提高 Webpack 的构建效率。具体如何进行 Vue 项目的 Webpack 构建优化,可以参考作者的另一篇文章《 Vue 项目 Webpack 优化实践》
gzip 是 GNUzip 的缩写,最早用于 UNIX 系统的文件压缩。HTTP 协议上的 gzip 编码是一种用来改进 web 应用程序性能的技术,web 服务器和客户端(浏览器)必须共同支持 gzip。目前主流的浏览器,Chrome,firefox,IE等都支持该协议。常见的服务器如 Apache,Nginx,IIS 同样支持,gzip 压缩效率非常高,通常可以达到 70% 的压缩率,也就是说,如果你的网页有 30K,压缩之后就变成了 9K 左右
以下我们以服务端使用我们熟悉的 express 为例,开启 gzip 非常简单,相关步骤如下:
npm install compression --savevar compression = require('compression');
var app = express();
app.use(compression())重启服务,观察网络面板里面的 response header,如果看到如下红圈里的字段则表明 gzip 开启成功 :
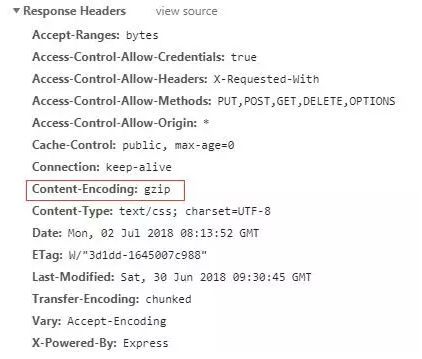
为了提高用户加载页面的速度,对静态资源进行缓存是非常必要的,根据是否需要重新向服务器发起请求来分类,将 HTTP 缓存规则分为两大类(强制缓存,对比缓存),如果对缓存机制还不是了解很清楚的,可以参考作者写的关于 HTTP 缓存的文章《深入理解HTTP缓存机制及原理》,这里不再赘述。
浏览器从服务器上下载 CSS、js 和图片等文件时都要和服务器连接,而大部分服务器的带宽有限,如果超过限制,网页就半天反应不过来。而 CDN 可以通过不同的域名来加载文件,从而使下载文件的并发连接数大大增加,且CDN 具有更好的可用性,更低的网络延迟和丢包率 。
Chrome 的 Performance 面板可以录制一段时间内的 js 执行细节及时间。使用 Chrome 开发者工具分析页面性能的步骤如下。
更多关于 Performance 的内容可以点击这里查看。
本文通过以下三部分组成:Vue 代码层面的优化、webpack 配置层面的优化、基础的 Web 技术层面的优化;来介绍怎么去优化 Vue 项目的性能。 希望对读完本文的你有帮助、有启发,如果有不足之处,欢迎批评指正交流!
github地址为:github.com/fengshi123/…,汇总了作者的所有博客,也欢迎关注及 star ~
随着前端历史化进程的推进,出现了两种前端开发模式,MPA 多页面应用模式和 SPA 单页面应用模式,其分别有自己的独到之处以及不足点。
(1)MPA 模式
例如中后台系统涵盖多个业务模块,分别由不同的团队负责,并且每个业务模块都有独立的域名,访问不同的业务模块会重新刷新浏览器或者新开标签页的方式来实现系统间的跳转。MPA 模式的优点在于部署简单、各个业务模块之间隔离,天然具备技术栈无关、独立开发、独立部署的特性;其缺点也明显,不同模块之间切换会造成浏览器重刷,不同产品域名之间相互跳转,流程体验上会存在明显的断点。
(2)SPA 模式
相信现在前端应用几乎由 SPA 三大马车 Vue、React、Angular 构建开发,应用之间页面跳转通过监听浏览器 URL 进行页面的卸载/挂载,所以其优点是天生具备体验上的优势,页面之间切换无需刷新浏览器,能极大的保证多产品之间流程操作串联时的流程性;缺点则在于各应用模块是强耦合的,并且随着应用的需求迭代,会产生巨石应用。
微前端是一种类似于微服务的架构,它将微服务的理念应用于浏览器端,即将单页面前端应用由单一的单体应用转变为多个小型前端应用聚合为一的应用。其集合了 MPA 模式和 SPA 模式各自的优势,通常的微前端架构具有以下优势:
在早期,微前端概念出现之前,我们整合多个团队多个应用,我们不约而同的选择即为 iframe。iframe 最大的特性就是提供了浏览器原生的硬隔离方案,不论是样式隔离、js 隔离这类问题统统都能被完美解决。但它的最大问题也在于它的隔离性无法被突破,导致应用间上下文无法被共享,随之带来的开发体验、产品体验的问题。
single-spa 是很多微前端框架的基石(其本身就是微前端框架,但很多大厂、微前端框架基于其进行二次封装),所以深刻知道其原理是对微前端的探究和实践的基础。single-spa 是一个将多个单页面应用聚合为一个整体应用的 javascript 微前端框架。
single-spa 具体的教程以及 api 可以查看 single-spa 官网,也建议在阅读以下章节内容时,先自行稍微简单阅读下其官网,知道其是什么、能做什么等。本章节,我们直接使用 single-spa 官网提供的实践实例来进行描述 single-spa 的使用,并且带着对现象背后的思考引出下一章节的原理解析。
git clone https://github.com/joeldenning/coexisting-vue-microfrontends.git
在基座应用和子应用目录,分别安装依赖包,然后分别启动应用:
// root-html-file
cd root-html-file
npm install
npm run serve
// navbar
cd navbar
npm install
npm run serve
// app1
cd app1
npm install
npm run serve
// app2
cd app2
npm install
npm run serve
(1)我们查看基座应用的实例代码,基座应用中进行子应用的注册(registerApplication)调用了 single-spa 的 registerApplication 函数,其内部实现了些啥,registerApplication 完再进行 start 启动,start 是做什么的,内部又是怎么实现的?
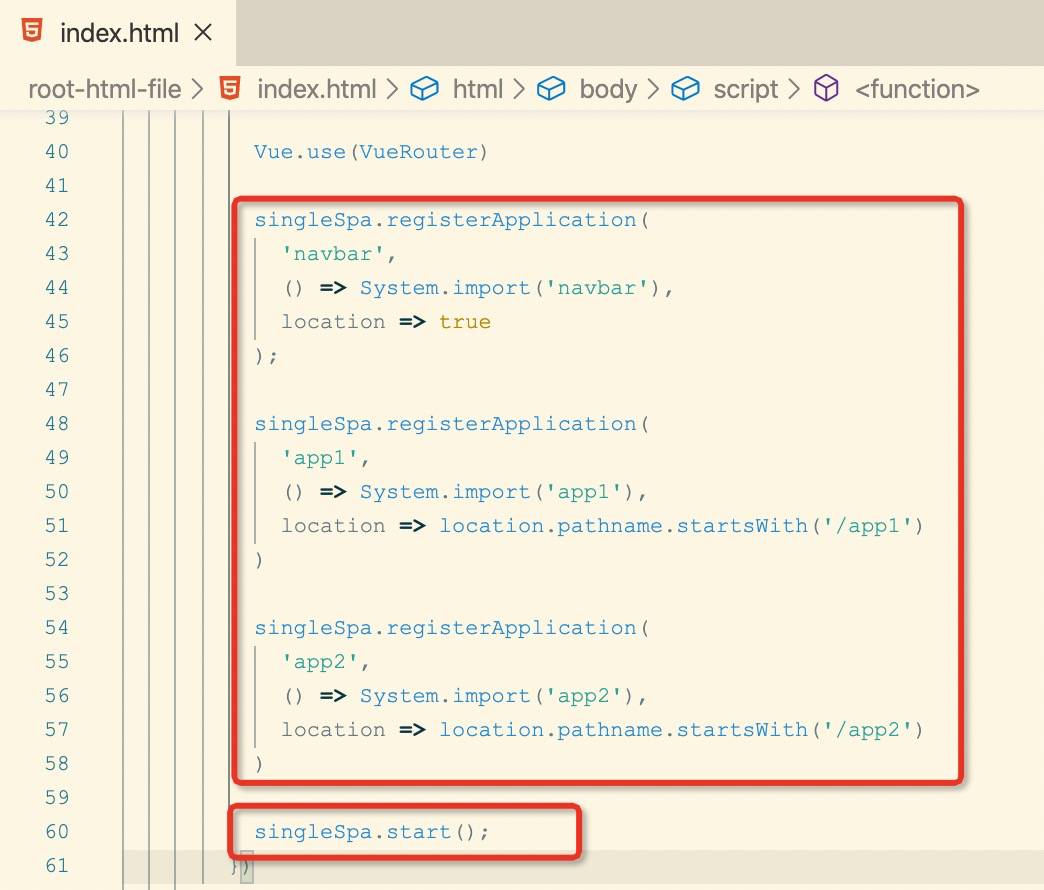
(2)我们查看子应用的入口执行文件 main.js 发现子应用都会导出 3 个周期函数 bootstrap/mount/unmount,那这三个周期函数又是在什么时候执行呢?
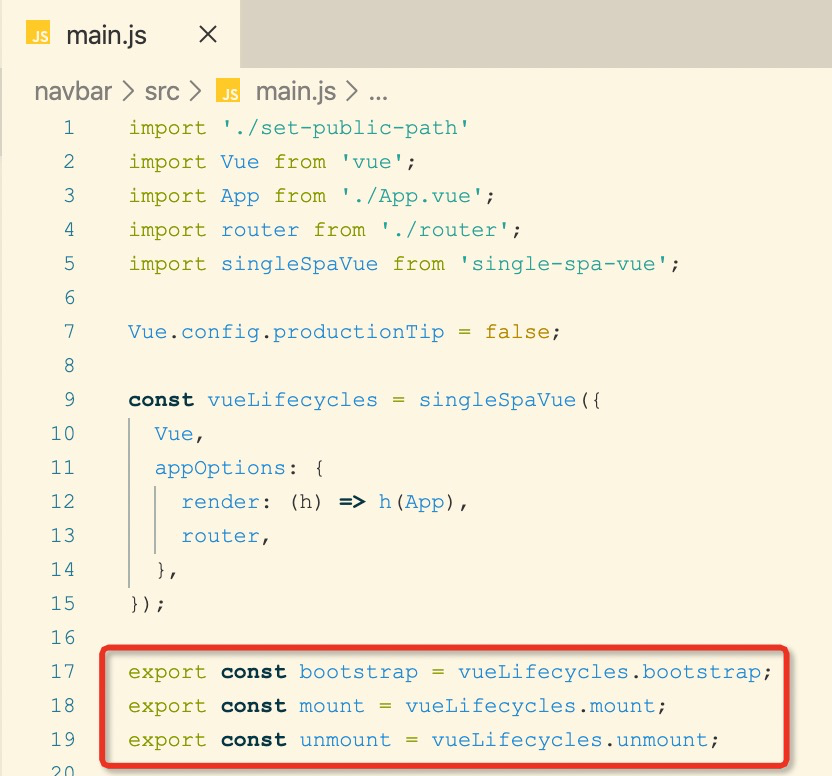
(3)我们通过浏览器访问 http://localhost:5000/ ,可得以下页面。通过看实例代码,我们可以发现以下页面是基座应用 navbar 的页面,那 single-spa 是怎么做到这个路由匹配的,以及点击 App1、App2 会分别跳转到 app1、app2 子应用的页面,且不会刷新页面,也就是 single-spa 的关键功能点 —— url 路由匹配;
(4)我们不断点击 App1 App2,观察浏览器调试框 network tab 选项,我们会发现:切换到不同的子应用,只会在第一次渲染子应用时才会去加载子应用渲染所需的资源,后续的切换不会再加载相关资源;观察浏览器调试框 Elements 选项,我们会发现:不同子应用的 Dom 结构会随着子应用的切换,而对应地挂载、卸载,那 single-spa 是如何进行子应用的资源下载、挂载和卸载呢?

如果你对以上的一些现象 or 实现不知所以然,并且你很想去了解下原理,那么下一章节的内容 — 原理解析将很适合你。
用一句话概括 single-spa 的原理:single-spa 是一个状态机 ,框架只负责维护各个子应用的状态,其中怎么加载子应用、挂载子应用、卸载子应用等,都由子应用自身控制,从而 single-spa 框架有很好的扩展性。
我们可以从 single-spa 的 github 官网 clone 源码查看,sinlge-spa 的功能源码主要集中在 src 目录下,src 目录下各个文件的主要功能汇总如下图
我们了解大概的源码目录及功能后,我们再回过头去逐一探究下第二部分的一些 api 以及功能的原理。在一些代码注释讲解部分,我们省略掉一些不影响原理理解的参数校验等。
registerApplication 注册方法在文件 /src/applications/app.js 中定义,代码及注释如下所示,其主要做了三件事情:
(1)registerApplication 注册方法代码如下:
export function registerApplication(
appNameOrConfig,
appOrLoadApp,
activeWhen,
customProps
) {
// hb: 格式化用户传入的应用配置参数,保证传入的参数是合法的
const registration = sanitizeArguments(
appNameOrConfig,
appOrLoadApp,
activeWhen,
customProps
);
// hb: 已经存在相同名称的应用报错
if (getAppNames().indexOf(registration.name) !== -1)
throw Error(
formatErrorMessage(
21,
__DEV__ &&
`There is already an app registered with name ${registration.name}`,
registration.name
)
);
// 将每个应用的配置信息都存放到 apps 数组中
apps.push(
assign(
{
loadErrorTime: null,
status: NOT_LOADED,
parcels: {},
devtools: {
overlays: {
options: {},
selectors: [],
},
},
},
registration
)
);
if (isInBrowser) {
ensureJQuerySupport();
reroute();
}
}(2)loadApps 方法代码如下:
// hb: 整体返回一个立即resolved的promise,通过微任务来加载apps
function loadApps() {
return Promise.resolve().then(() => {
// hb: 返回封装后的 app,包括给其附上生命周期等
const loadPromises = appsToLoad.map(toLoadPromise);
console.log('查看 loadPromises :', loadPromises);
return (
Promise.all(loadPromises)
.then(callAllEventListeners)
// there are no mounted apps, before start() is called, so we always return []
.then(() => [])
.catch((err) => {
callAllEventListeners();
throw err;
})
);
});
}(3)toLoadPromise 方法核心代码如下:
export function toLoadPromise(app) {
return Promise.resolve().then(() => {
if (app.loadPromise) {
// hb: 说明 app 已经被加载
return app.loadPromise;
}
if (app.status !== NOT_LOADED && app.status !== LOAD_ERROR) {
return app;
}
app.status = LOADING_SOURCE_CODE;
let appOpts, isUserErr;
return (app.loadPromise = Promise.resolve()
.then(() => {
// hb: loadApp 即是用户传入的参数 () => System.import('navbar'),
// 所以加载子应用其实就是通过用户自己传入的加载方式,即使如果不用 System.import 也可以;
// 没有明白属性获取来干嘛用 getProps(app) ???
const loadPromise = app.loadApp(getProps(app));
// hb: 子应用导出的必须是个对象,且包含 3 个生命周期:bootstrap、mount、unmount
return loadPromise.then((val) => {
app.loadErrorTime = null;
appOpts = val;
app.status = NOT_BOOTSTRAPPED;
// hb: 在app对象上挂载生命周期方法,每个方法都接收一个props作为参数,方法内部执行子应用导出的生命周期函数,并确保生命周期函数返回一个promise
app.bootstrap = flattenFnArray(appOpts, "bootstrap");
app.mount = flattenFnArray(appOpts, "mount");
app.unmount = flattenFnArray(appOpts, "unmount");
app.unload = flattenFnArray(appOpts, "unload");
app.timeouts = ensureValidAppTimeouts(appOpts.timeouts);
// hb: 执行到这里说明子应用已成功加载,删除app.loadPromise属性
delete app.loadPromise;
return app;
});
})
.catch((err) => {
// hb: 加载失败,稍后重新加载
delete app.loadPromise;
let newStatus;
if (isUserErr) {
newStatus = SKIP_BECAUSE_BROKEN;
} else {
newStatus = LOAD_ERROR;
app.loadErrorTime = new Date().getTime();
}
handleAppError(err, app, newStatus);
return app;
}));
});
}我们从上一小节已经知道 registerApplication 时会对注册并且 url 路径匹配到的子应用进行下载,也是说如果只注册,会下载匹配子应用的资源,但是并不会进行初始化或者渲染;那么 start 方法的作用即进行子应用的初始化和渲染,代码如下所示,我们可以看到在 start 方法中主要调用 reroute 方法,在 reroute 方法中会区分是 start 前还是后,如果是 start 前,则就像上一小节所讲的,是注册时进行子应用资源的下载;如果是 start 后,则调用 performAppChanges 方法,对不同状态的子应用进行对应操作
(1)start 方法代码
// hb: 调用 start 之前,应用会被加载,但不会初始化、挂载和卸载,有了 start 可以更好的控制应用的流程
export function start(opts) {
started = true;
if (opts && opts.urlRerouteOnly) {
setUrlRerouteOnly(opts.urlRerouteOnly);
}
if (isInBrowser) {
reroute();
}
}(2)reroute 方法
export function reroute(pendingPromises = [], eventArguments) {
const {
appsToUnload, // hb: 需要被移除的
appsToUnmount, // hb: 需要被卸载的
appsToLoad, // hb: 需要被加载的
appsToMount, // hb: 需要被挂载的
} = getAppChanges();
let appsThatChanged;
// hb: 是否 start 调用 isStarted 为 false 时表示是 start 调用
if (isStarted()) {
appChangeUnderway = true;
appsThatChanged = appsToUnload.concat(
appsToLoad,
appsToUnmount,
appsToMount
);
return performAppChanges();
} else {
appsThatChanged = appsToLoad;
return loadApps();
}
// hb: 整体返回一个立即resolved的promise,通过微任务来加载apps
function loadApps() {
return Promise.resolve().then(() => {
// hb: 返回封装后的 app,包括给其附上生命周期等
const loadPromises = appsToLoad.map(toLoadPromise);
return (
Promise.all(loadPromises)
.then(callAllEventListeners)
// there are no mounted apps, before start() is called, so we always return []
.then(() => [])
.catch((err) => {
callAllEventListeners();
throw err;
})
);
});
}
function performAppChanges() {
return Promise.resolve().then(() => {
// hb: 移除应用 => 更改应用状态,执行unload生命周期函数,执行一些清理动作
// 其实一般情况下这里没有真的移除应用
const unloadPromises = appsToUnload.map(toUnloadPromise);
// hb: 先卸载再移除
const unmountUnloadPromises = appsToUnmount
.map(toUnmountPromise)
.map((unmountPromise) => unmountPromise.then(toUnloadPromise));
const allUnmountPromises = unmountUnloadPromises.concat(unloadPromises);
const unmountAllPromise = Promise.all(allUnmountPromises);
unmountAllPromise.then(() => {
window.dispatchEvent(
new CustomEvent(
"single-spa:before-mount-routing-event",
getCustomEventDetail(true)
)
);
});
// hb: 待加载的进行加载 并且进行挂载
const loadThenMountPromises = appsToLoad.map((app) => {
return toLoadPromise(app).then((app) =>
tryToBootstrapAndMount(app, unmountAllPromise)
);
});
// hb: 待挂载的进行挂载
const mountPromises = appsToMount
.filter((appToMount) => appsToLoad.indexOf(appToMount) < 0)
.map((appToMount) => {
return tryToBootstrapAndMount(appToMount, unmountAllPromise);
});
return unmountAllPromise
.catch((err) => {
callAllEventListeners();
throw err;
})
.then(() => {});
});
}
}我们查看子应用的入口执行文件 main.js 发现子应用都会导出 3 个周期函数 bootstrap/mount/unmount,那这三个周期函数又是在什么时候执行呢?
其实在下载完子应用资源后,会将子应用的生命周期函数添加在 app(single-spa 中每个子应用是一个 app 对象,然后汇总成数组 apps)的属性中,然后 single-spa 会在子应用 app 状态更新时对应执行其生命周期函数。
(1)加载方法中处理子应用生命周期方法的代码
export function toLoadPromise(app) {
app.status = NOT_BOOTSTRAPPED;
// hb: 在app对象上挂载生命周期方法,每个方法都接收一个props作为参数,方法内部执行子应用导出的生命周期函数,并确保生命周期函数返回一个promise
app.bootstrap = flattenFnArray(appOpts, "bootstrap");
app.mount = flattenFnArray(appOpts, "mount");
app.unmount = flattenFnArray(appOpts, "unmount");
app.unload = flattenFnArray(appOpts, "unload");
app.timeouts = ensureValidAppTimeouts(appOpts.timeouts);
});
})(2)flattenFnArray 方法
// hb: 返回一个接受 props 作为参数的函数,这个函数负责执行子应用中的生命周期函数,
// 并确保生命周期函数返回的结果为promise
export function flattenFnArray(appOrParcel, lifecycle) {
let fns = appOrParcel[lifecycle] || [];
fns = Array.isArray(fns) ? fns : [fns];
if (fns.length === 0) {
fns = [() => Promise.resolve()];
}
return function (props) {
return fns.reduce((resultPromise, fn, index) => {
return resultPromise.then(() => {
const thisPromise = fn(props);
});
}, Promise.resolve());
};
}通过实例发现我们的基座应用能根据不同的 URL 对应挂载/卸载我们的子应用,且不会刷新页面,那么 single-spa 是如何做到 url 路由匹配的呢?其实如果大家有了解过 vue-router、react-router 这些单页面应用的路由切换原理的话,其无非应用了 hashchange 事件来监听 hash 路由的变化、popstate事件来监听 history 路由的变化,其 single-spa 的 url 路由匹配的原理是一模一样的(基础 api 就那些,难道还能变出花来吗),在 /src/navigation/navigation-events.js 文件中定义相关操作。
window.addEventListener("hashchange", urlReroute);
window.addEventListener("popstate", urlReroute);而且我们在注册子应用时,把子应用路由匹配规则作为参数进行传入了,single-spa 在 /src/applications/app.helpers.js 中使用这个传入的路由匹配判断条件进行判断该子应用是否应该处于活跃(挂载)状态,相关代码如下,其中 app.activeWhen 即为传入路由匹配函数。到此,我们就差不多知道了 single-spa 是如何做到当 url 切换时,匹配到相应子应用的。
// hb: 是否应该活跃状态(url 匹配到路由)
export function shouldBeActive(app) {
try {
return app.activeWhen(window.location);
} catch (err) {
handleAppError(err, app, SKIP_BECAUSE_BROKEN);
return false;
}
}我们通过以上已经知道 single-spa 控制着子应用的状态变化,例如在注册时进行子应用资源的下载、进行子应用的挂载/卸载,我们第三章节中是通过我们注册应用时传入的下载方式 System.import 进行下载的,并不是 single-spa 内部有资源下载方式;那么挂载/卸载呢?其实挂载/卸载也是通过各个子应用自己传入对应的生命周期函数进行对应的操作,我们查看子应用使用的插件 single-spa-vue(不是 single-spa) 的挂载/卸载生命周期函数,可以看到对应生命周期函数进行 dom 元素的挂载和卸载。而在 single-spa 内部仅仅是在对应的子应用状态执行子应用对应的生命周期函数,single-spa 本身只起控制状态的作用,它自己本身不亲自操刀的,无论下载、挂载、卸载等,这样也能做到更好的扩展性,用户想怎么下载、挂载、卸载,他们自己来决定,只要你传入规范的参数即可。
(1)single-spa-vue 的挂载/卸载生命周期函数
// 挂载生命周期函数
function mount(opts, mountedInstances, props) {
return Promise
.resolve()
.then(() => {
const appOptions = {...opts.appOptions}
if (props.domElement && !appOptions.el) {
appOptions.el = props.domElement;
}
if (!appOptions.el) {
const htmlId = `single-spa-application:${props.name}`
appOptions.el = `#${htmlId.replace(':', '\\:')} .single-spa-container`
let domEl = document.getElementById(htmlId)
if (!domEl) {
domEl = document.createElement('div')
domEl.id = htmlId
document.body.appendChild(domEl)
}
// single-spa-vue@>=2 always REPLACES the `el` instead of appending to it.
// We want domEl to stick around and not be replaced. So we tell Vue to mount
// into a container div inside of the main domEl
if (!domEl.querySelector('.single-spa-container')) {
const singleSpaContainer = document.createElement('div')
singleSpaContainer.className = 'single-spa-container'
domEl.appendChild(singleSpaContainer)
}
mountedInstances.domEl = domEl
}
if (!appOptions.render && !appOptions.template && opts.rootComponent) {
appOptions.render = (h) => h(opts.rootComponent)
}
if (!appOptions.data) {
appOptions.data = {}
}
appOptions.data = {...appOptions.data, ...props}
mountedInstances.instance = new opts.Vue(appOptions);
if (mountedInstances.instance.bind) {
mountedInstances.instance = mountedInstances.instance.bind(mountedInstances.instance);
}
})
}
// 卸载生命周期函数
function unmount(opts, mountedInstances) {
return Promise
.resolve()
.then(() => {
mountedInstances.instance.$destroy();
mountedInstances.instance.$el.innerHTML = '';
delete mountedInstances.instance;
if (mountedInstances.domEl) {
mountedInstances.domEl.innerHTML = ''
delete mountedInstances.domEl
}
})
}相信阅读到这里的读者,此时脑海中对笔者关于 single-spa 的原理总结也深有感触吧,single-spa 是一个状态机 ,框架只负责维护各个子应用的状态,其中怎么加载子应用、挂载子应用、卸载子应用等,都由子应用自身控制,从而 single-spa 框架有很好的扩展性。
通过本章节的阅读,我门深刻理解 single-spa 框架的运行机制,但是 single-spa 作为最底层架构,在实际场景中还是存在一些问题的,如下所示,下一章节我们将围绕这些问题去探讨如何解决。
qiankun(乾坤) 就是一款由蚂蚁金服推出的比较成熟的微前端框架,基于 single-spa 进行二次开发,用于将 Web 应用由单一的单体应用转变为多个小型前端应用聚合为一的应用。如果还不了解该框架的同学,可以先查阅qiankun 官网;本章节我们主要围绕第三节抛出的几个疑问,来探讨下 qiankun(乾坤)是如何处理的。
qiankun 使用 import-html-entry 插件将子应用的 html 作为入口,框架会将 HTML document 作为子节点塞到主框架的容器中。就算子应用更新了,其入口 html 文件的 url 始终不会变,并且完整的包含了所有的初始化资源 url,所以不用再自行维护子应用的资源列表了。并且对旧有的项目作为子应用接入成本几乎为零,开发体验与独立开发时保持不变,相较于 single-spa 的 js entry 而言更加灵活、方便、体验更好。
由于微前端场景下,不同技术栈的子应用会被集成到同一个运行时中,子应用之间难免会出现样式互相干扰的问题。样式隔离有两个思路,第一个是使用类似于 CSS Module 或者 BEM 的方案,本质上是通过约定来避免冲突,对于新项目来说,这种方案成本很低,但是如果涉及到与老项目一同运行,那改造成本将会非常高昂;第二个思路是在子应用卸载的时候同时卸载掉样式表,技术原理是浏览器会对所有的样式表的插入、移除做整个 CSSOM 的重构,从而达到 插入、卸载样式的目的,这样即能保证,在一个时间点里,只有一个应用的样式表是生效的。
qiankun 框架采用的是第二种思路,使用 import-html-entry,通过解析 html entry 中的 和 <style> 标签获取样式信息,下载样式文件,并最终以 <style> 标签的形式插入到主框架的容器中去,在子应用卸载时一并移除,这样确保不同子应用之间避免样式冲突。
相较于样式隔离来说,js 隔离显得更为重要。因为在 SPA 的场景下,类似内存泄漏、全局变量冲突等问题的影响会被放大,可能某个子应用内的问题会影响到其他应用的运行。而且这种问题通常非常难以排查和定位,一旦发生,解决成本非常高。
qiankun 框架基于 Proxy 为每个子应用启用了一个沙箱环境,所有子应用对 proxy/window 对象值的存取都受到了控制。设置值只会作用在沙箱内部的 updateValueMap 集合上,取值也是优先取子应用独立状态池(updateValueMap)中的值,没有找到的话,才再从主应用的 proxy/window 对象中取值,这样确保了各子应用的全局 js 互相冲突污染。
通常从我们从业务的角度出发划分各个子应用,尽可能减少应用间的通信,从而简化整个应用,使得我们的微前端架构可以更加灵活可控,但是有些场景下,各子应用之间的相互通信还是存在的。
qiankun 框架提供了 Actions 通信(观察者模式) ,内部提供了 initGlobalState 方法用于注册 MicroAppStateActions 实例用于通信,该实例有三个方法,分别是:
本文介绍了微前端的由来,分析微前端出现的必要性;然后总结了 iframe 用来聚合应用存在的一些问题;再通过 single-spa 的实例现象和 api 使用去探讨 single-spa 实现的原理;最后通过 qiankun 微前端框架探讨在实际场景中微前端模式存在哪些必解问题,以及如何去解决的。通过循序渐进,从了解微前端,到了解相关框架的原理,再到实际场景问题解决,从而全方面的“认识”微前端。
随着计算机硬件的不断升级,开发者越发觉得Javascript性能优化的好不好对网页的执行效率影响不明显,所以一些性能方面的知识被很多开发者忽视。但在某些情况下,不优化的Javascript代码必然会影响用户的体验。因此,即使在当前硬件性能已经大大提升的时代,在编写Javascript代码时,若能遵循Javascript规范和注意一些性能方面的知识,对于提升代码的可维护性和优化性能将大有好处。那么,接下来我们讨论几种能够提高JavaScript性能的方法。
如果喜欢或者有所启发,欢迎 Star~,对作者也是一种鼓励。
(1)将<script>标签放到<body>标签的底部
(2)可以合并多个js文件,减少页面中<script>标签改善性能
(3)使用 defer 属性,加载后续文档元素的过程将和script.js的加载并行进行,但是 script.js 的执行要在所有元素解析完成之后,DOMContentLoaded 事件触发之前完成。
(4)使用 async 属性,加载和渲染后续文档元素的过程将和script.js的加载与执行并行进行
(5)动态加载脚本元素,无论在何时启动瞎子,文件的下载和执行过程都不会阻塞页面其它进程
var script = document.createElement('script');
script.type = 'text/javascript';
script.src = 'file.js';
document.getElementsByTagName('head')[0].appendChild(script);
标识符所在的作用域链的位置越深,那么它的标识符解析的性能就越慢。所以一个好的性能提升的经验法则是:如果某个跨作用域的值在函数中被引用一次以上,那么就把它存储到局部变量里。
function fun1() {
// 将全局变量的引用先存储在一个局部变量中,然后使用这个局部变量代替全局变量,从而提高
// 性能;不然每次(3次)都要遍历整个作用域链找到
document var doc = document;
var bd = doc.body;
var links = doc.getElementsByTagName('a');
doc.getElementById('btn').onclick = function(){
console.log('btn');
}
}
方法或属性在原型链中存在的位置越深,搜索它的性能也就越慢,所以要避免N多层原型链的写法。
对象的嵌套成员,对象成员嵌套越深,读取速度也就越慢。所以好的经验法则是:如果在函数中需要多次读取一个对象属性,最佳做法是将该属性值保存在局部变量中,避免多次查找带来的性能开销。
function f() {
// 因为在以下函数中需要3次用到DOM对象属性,所以先将它存储在一个局部变量
// 中,然后使用这个局部变量代替它进行后续操作,从而提高性能
var dom = YaHOO.util.Dom;
if(Dom.hasClass(element,'selected')){
Dom.removeClass(elemet,'selected');
}else{
Dom.addClass(elemet,'selected');
}
}
用js访问和操作DOM都会带来性能损失,可通过以下几点来减少性能损失:
(1)尽可能减少DOM访问次数;
(2)如果需要多次访问某个DOM节点,请使用局部变量存储它的引用;
(3)小心处理HTML集合,因为它实时连系着底层文档;我们可以把集合的长度缓存到一个变量中,并在迭代中使用它;
(4)下述情况会发生重排:
DOM元素;可通过以下方式减少重排:
offsetTop,offsetLeft,offsetWidthoffsetHeight,``scrollTop,scrollLeft,scrollWidth,scrollHeight,clientTop,clientLeft,clientWidth,clientHeight,getComputedStyle()等;function f() {
// 推荐使用以下操作
var el1 = document.getElementById('mydiv');
el1.style.cssText = 'border:1px;padding:2px;margin:3px';
// 不推荐使用以下操作
var el2 = document.getElementById('mydiv');
el2.style.border = '1px';
el2.style.padding = '2px';
el2.style.margin = '3px';
}
当需要批量修改DOM时,可以通过以下步骤减少重绘和重排的次数:
使用事件委托(事件逐层冒泡并能被父级元素捕获,使用事件代理,只需给外层元素绑定一个处理器,就可以处理其子元素上触发的所用事件),因为给DOM元素绑定事件以及浏览器需要跟踪每个事件处理器都需要消耗性能。
str += 'one'+'two';
str= str+'one'+'two';
后者方式会比前者少在内存中创建一个临时字符串,所以性能有相应的提升,所以,所以推荐后者的写法。
创建对象和数组推荐使用字面量,因为这不仅是性能最优也有助于节省代码量。
var obj = {
name:'tom',
age:15,
sex:'男'
}
如果需要遍历数组,应该先缓存数组长度,将数组长度放入局部变量中,避免多次查询数组长度。
JS提供了三种循环:for(;;)、while()、for(in)。在这三种循环中 for(in)的效率最差,因为它需要查询Hash键,因此应尽量少用for(in)循环,for(;;)、while()循环的性能基本持平。
尽量少使用eval,每次使用eval需要消耗大量时间,这时候使用JS所支持的闭包可以实现函数模板。
当需要将数字转换成字符时,采用如下方式:"" + 1。从性能上来看,将数字转换成字符时,有如下公式:("" +) > String() > .toString() > new String()。String()属于内部函数,所以速度很快。而.toString()要查询原型中的函数,所以速度逊色一些,new String()需要重新创建一个字符串对象,速度最慢。
当需要将浮点数转换成整型时,应该使用Math.floor()或者Math.round()。而不是使用parseInt(),该方法用于将字符串转换成数字。而且Math是内部对象,所以Math.floor()其实并没有多少查询方法和调用时间,速度是最快的。
如果喜欢或者有所启发,欢迎 Star~,对作者也是一种鼓励。
如果你负责前端的基础能力建设,发布各种功能/插件包犹如家常便饭,所以熟悉对 npm 包的发布与管理是非常有必要的,故此有了本篇总结文章。本篇文章一方面总结,一方面向社区贡献开箱即用的 npm 开发、编译、发布、调试模板,希望帮助到有需要的同学。
辛苦整理良久,还望手动点赞鼓励~
npm sdk 模板仓库为:https://github.com/fengshi123/npm-sdk
博客 github地址为:https://github.com/fengshi123/blog ,汇总了作者的所有博客,欢迎关注及 star ~
根据以下命令能初始化一个 npm 包项目,命令交互过程中会让你填入 项目名称、版本、作者等信息,可以直接回车跳过(使用默认设置)
npm init --save很多时候,一个项目包往往不只是你一个人在管理的,这时需要给其他一起维护的同学开通发布的权限,相关使用命令如下:
# 查看模块 owner, 其中 demo 为模块名称
$ npm owner ls demo
# 添加一个发布者, 其中 xxx 为要添加同学的 npm 账号
$ npm owner add xxx demo
# 删除一个发布者
$ npm owner rm xxx demo更新版本号共有以下选项(major | minor | patch | premajor | preminor | prepatch | prerelease) ,注意项目的git status 必须是clear,才能使用这些命令。
# major 主版本号,并且不向下兼容 1.0.0 -> 2.0.0
$ npm version major
# minor 次版本号,有新功能且向下兼容 1.0.0 -> 1.1.0
$ npm version minor
# patch 修订号,修复一些问题、优化等 1.0.0 -> 1.0.1
$ npm version patch
# premajor 预备主版本 1.0.0 -> 2.0.0-0
$ npm version premajor
# preminor 预备次版本 1.0.0 -> 1.1.0-0
$ npm version major
# prepatch 预备修订号版本 1.0.0 -> 1.0.1-0
$ npm version major
# prerelease 预发布版本 1.0.0 -> 1.0.0-0
$ npm version major版本号更新后,我们就可以进行版本的发布
$ npm publish很多时候一些新改动,并不能直接发布到稳定版本上(稳定版本的意思就是使用 npm install demo 即可下载的最新版本),这时可以发布一个 “预发布版本“,不会影响到稳定版本。
# 发布一个 prelease 版本,tag=beta
$ npm version prerelease
$ npm publish --tag beta比如原来的版本号是 1.0.1,那么以上发布后的版本是 1.0.1-0,用户可以通过 npm install demo@beta 或者 npm install demo@1.0.1-0 来安装,用户通过 npm install demo 安装的还是 1.0.1 版本。
# 首先可以查看当前所有的最新版本,包括 prerelease 与稳定版本
$ npm dist-tag ls
# 设置 1.0.1-1 版本为稳定版本
$ npm dist-tag add [email protected] latest这时候,latest 稳定版本已经是 1.0.1-1 了,用户可以直接通过 npm install demo 即可安装该版本。
# 将 beta 版本移除
$ tnpm dist-tag rm demo beta# 当我们发布完对应的版本,可以通过以下命令将版本号推送到远程仓库, 其中 xxx 为对应分支
$ git push origin xxx --tags可以通过 npm info 来查看模块的详细信息。
$ npm info
$ npm i typescript -D在根目录新建 tsconfig.json,配置项具体的意义可以参考 ts 官方文档
{
"version": "1.8.0",
"compilerOptions": {
"outDir": "build/compiled",
"lib": [ "es6" ],
"target": "es5",
"module": "commonjs",
"moduleResolution": "node",
"emitDecoratorMetadata": true,
"experimentalDecorators": true,
"sourceMap": true,
"noImplicitAny": true,
"declaration": true
},
"exclude": [ "build", "node_modules" ]
}安装 @types/node 让 node 的核心包具备类型提示
$ npm i @types/node -D在根目录新建 src 目录,用于存放所有的 TypeScript 源文件,然后在 src 下新建 index.ts 作为入口文件
// src/index.ts
console.log('hello npm-sdk!');在开发阶段为了能直接执行并且监听 ts 文件的变化,安装 ts-node-dev
$ npm i ts-node-dev -D在 package.json 中定义一个启动脚本
"scripts": {
"start": "ts-node-dev --respawn --transpile-only src/index.ts"
}这样我们就可以实时进行编译,如下所示
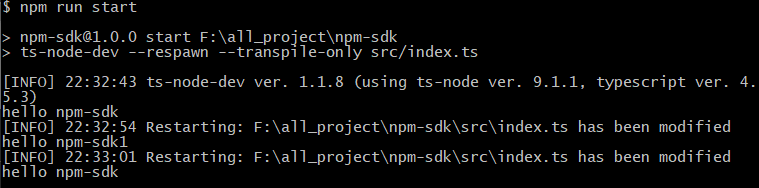
$ npm i eslint -D$ ./node_modules/.bin/eslint --init根据交互命令提示对应生成配置文件如下所示,可以根据团队的代码风格进行对应的配置 .eslintrc.js
module.exports = {
env: {
browser: true,
es2021: true
},
extends: [
'standard'
],
parser: '@typescript-eslint/parser',
parserOptions: {
ecmaVersion: 13,
sourceType: 'module'
},
plugins: [
'@typescript-eslint'
],
rules: {
}
}node_modules/可以通过在 package.json 中配置对应的校验命令和修复命令,如下所示
"scripts": {
"lint": "eslint --ext .ts .",
"lint:fix":"eslint --fix --ext .ts ."
},利用 commitlint 和 husky 工具进行代码提交时拦截验证,安装如下
$ npm i @commitlint/cli @commitlint/config-conventional husky lint-staged --D在 package.json 中进行对应的配置,当 commit 代码时,如果代码中存在 eslint 错误,那么就会进行报错提示
"husky":{
"hooks":{
"pre-commit":"lint-staged",
"commit-msg":"commitlint -e $HUSKY_GIT_PARAMS"
},
"lint-staged":{
".ts":[
"eslint --fix"
]
},
"commitlint":{
"extends":[
"@commitlint/config-conventional"
]
}
},我们可以增加对应的 typescript 编译命令,如下所示
"scripts": {
"build:cjs": "tsc --outDir lib",
"build:es": "tsc -m esNext --outDir esm",
"build": "rd /s /q lib esm && npm run build:cjs && npm run build:es",
},配置对应的入口地址,其中 module 和 main 的区别是,module 主要在 tree shaking 时会用到。
"main": "lib/index.js",
"module": "esm/index.js",
可以通过 npm link 在正式项目中进行调试,在我们的包目录中安装完发布的线上包后,可以执行以下命令将当前项目 node_modules 底下安装的对应包关联到本地全局 npm 目录的 node_modules 目录下,命令如下
$ npm link [email protected]执行命令如下所示
然后在对应的 npm sdk 目录下进行关联
$ npm link
// 关联成功后如下所示
D:\nvm\npm\node_modules\npm-sdk -> F:\all_project\npm-sdk到这里,通过以上两个步骤的关联,将项目中使用到的 sdk 包,关联到该 sdk 包对应的开发目录,我们就可以在本地对 sdk 包进行调试。
本文从 npm 各种常用命令、到 sdk 中使用 typescript、以及使用 eslint 强校验、再到编译/本地调试,从零到一演示如何搭建发布一个 NPM 包,NPM SDK 模板仓库为:https://github.com/fengshi123/npm-sdk,有需要的同学可以直接 clone 进行使用。
博客 github地址为:https://github.com/fengshi123/blog ,汇总了作者的所有博客,欢迎关注及 star ~
在 Web 应用程序中使用的所有组件建议都从 react-router-dom 导入
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:github.com/fengshi123/… ,汇总了作者的所有博客,欢迎关注及 star ~
npm i react-router-dom --save路由组件分为两种:BrowserRouter(history 模式) 和 HashRouter(hash 模式),用法一样,但是 url 展示不一样,其中 hash 模式带有 # 号符,如下所示:
class App extends React.Component {
render () {
return (
<BrowserRouter>
<Route path="/page1" exact component={Page1}></Route>
<Route path="/page2" exact component={Page2}></Route>
<Route path="/page3/:id" exact component={Page3}></Route>
</BrowserRouter>
);
}
}class App extends React.Component {
render () {
return (
<HashRouter>
<Route path="/page1" exact component={Page1}></Route>
<Route path="/page2" exact component={Page2}></Route>
<Route path="/page3/:id" exact component={Page3}></Route>
</HashRouter>
);
}
}string 类型,用来指定路由跳转路径,如下所示,根据 path 和 url 匹配到对应的页面
// 路由配置
<Route path="/page1" exact component={Page1}></Route>
// 页面访问
http://localhost:3000/page1boolean 类型,用来精确匹配路由,如果为 true 则精确匹配,否则为正常匹配;如下所示
// exact = true 时
// 路由配置
<Route path="/page1" exact component={Page1}></Route>
// 浏览器通过以下 url 访问不到 page1 页面
http://localhost:3000/page1/one
// exact = fasle 时
// 路由配置
<Route path="/page1" exact={false} component={Page1}></Route>
// 浏览器通过以下 url 可以访问到 page1 页面
http://localhost:3000/page1/oneboolean 类型,用来设置是否区分路由大小写,如果为 true 则区分大小写,否则不区分;如下所示
// sensitive = true 时
// 路由配置
<Route path="/page1" sensitive component={Page1}></Route>
// 浏览器通过以下 url 访问不到 page1 页面
http://localhost:3000/PAGE1
// sensitive = fasle 时
// 路由配置
<Route path="/page1" sensitive={false} component={Page1}></Route>
// 浏览器通过以下 url 可以访问到 page1 页面
http://localhost:3000/PAGE1boolean 类型,对路径末尾斜杠的匹配。如果为 true,path 为 '/page1/' 将不能匹配 '/page1' 但可以匹配 '/page1/one'。;如下所示
// 路由配置
// strict = true 时
<Route path="/page1/" strict component={Page1}></Route>
// 浏览器通过以下 url 访问不到 page1 页面
http://localhost:3000/page1
// 浏览器通过以下 url 可以访问到 page1 页面
http://localhost:3000/page1/one
// strict = fasle 时
// 路由配置
<Route path="/page1/" strict={false} component={Page1}></Route>
// 浏览器通过以下 url 可以访问到 page1 页面
http://localhost:3000/page1
http://localhost:3000/page1/one设置路由对应渲染的组件,如下所示
<Route path="/page1/" exact component={Page1}></Route>(1)通过写 render 函数返回具体的 dom,如下所示
<Route path="/page1/" exact render={() => (<div>this is page</div>)}></Route>(2) 也可以通过写 render 函数返回组件,如下所示
<Route path="/page1/" exact render={() => (<Page1/>)}></Route>这样写的好处是,不仅可以通过 render 方法传递 props 属性,并且可以传递自定义属性:
<Route path='/about' exact render={(props) => {
return <Page1 {...props} name={'name1'} />
}}></Route>然后,就可在 Page1 组件中获取 props 和 name 属性:
componentDidMount() {
console.log(this.props)
}
// this.props:
// history: {length: 9, action: "POP", location: {…}, createHref: ƒ, push: ƒ, …}
// location: {pathname: "/home", search: "", hash: "", state: undefined, key: "ad7bco"}
// match: {path: "/home", url: "/home", isExact: true, params: {…}}
// name: "name1"如果路由 Route 外部包裹 Switch 时,路由匹配到对应的组件后,就不会继续渲染其他组件了。但是如果外部不包裹 Switch 时,所有路由组件会先渲染一遍,然后选择所有匹配的路由进行显示。
(1)当没有使用 Switch 时,如下所示
// 路由配置
<BrowserRouter>
<Route path="/page1" component={Page1}></Route>
<Route path="/" component={Page2}></Route>
<Route path="/page3/:id" exact component={Page3}></Route>
</BrowserRouter>
// 当面访问以下 url 时,浏览器会同时显示 page1 和 page2 页面的内容
http://localhost:3000/page1(2)当使用 Switch 时,如下所示
// 路由配置
<BrowserRouter>
<Switch>
<Route path="/page1" component={Page1}></Route>
<Route path="/" component={Page2}></Route>
<Route path="/page3/:id" exact component={Page3}></Route>
</Switch>
</BrowserRouter>
// 当面访问以下 url 时,浏览器只会显示 page1 页面的内容
http://localhost:3000/page1Link 和 NavLink 都可以用来指定路由跳转,NavLink 的可选参数更多。
(1)通过字符串执行路由跳转
<Link to='/page2'>
<span>跳转到 page2</span>
</Link> (2)通过对象指定路由跳转
<Link to={{
pathname: '/page2',
search: '?name=name1',
hash: '#someHash',
state: { age: 11 }
}}>
<span>跳转到 page2</span>
</Link>**(3) replace **
如果设置 replace 为 true 时,表示路由重定向,即新地址替换掉上一次访问的地址;
这是 的特殊版,顾名思义这就是为页面导航准备的。因为导航需要有 “激活状态”。
(1)activeClassName: string
导航选中激活时候应用的样式名,默认样式名为 active
<NavLink
to="/page2"
activeClassName="selected"
>跳转到 page2</NavLink>(2)activeStyle: object
如果不想使用样式名就直接写 style,如下所示
<NavLink
to="/page2"
activeStyle={{ color: 'green', fontWeight: 'bold' }}
>跳转到 page2</NavLink>(3)exact: bool
若为 true,只有当访问地址严格匹配时激活样式才会应用,跟 3.2 的 exact 一个道理;
(4)strict: bool
若为 true,只有当访问地址后缀斜杠严格匹配(有或无)时激活样式才会应用,跟 3.4 的 exact 一个道理;
(5)isActive: func
决定导航是否激活,或者在导航激活时候做点别的事情。不管怎样,它不能决定对应页面是否可以渲染。
将导航到一个新的地址,即重定向;如下所示,当页面访问到 /page3 时,页面会直接重定向到 page3.
<BrowserRouter>
<Switch>
<Route path="/page1" exact component={Page1}></Route>
<Route path="/page2" exact component={Page2}></Route>
<Route path="/page3" exact component={Page3}></Route>
</Switch>
</BrowserRouter>当然,也可以使用对象的形式,如下所示
<Redirect
to={{
pathname: "/page3",
search: "?name=tom",
state: { age: 11 }
}}
/>支持字符串作为参数跳转,如下所示
this.props.history.push('/page2');同样支持对象作为参数进行路由跳转,如下所示
this.props.history.push({
pathname: '/page2',
state: {
name:'tom'
}
});跳转到对应的页面,我们打印出对应 history 对象,可以看到有以下属性
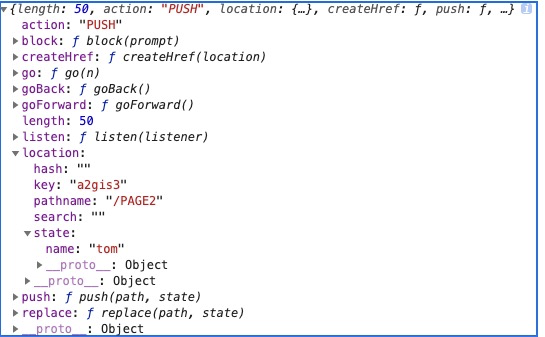
以上 history 对象的属性和方法解释如下:
withRouter 可以将一个非路由组件包裹为路由组件,使这个非路由组件也能访问到当前路由的 match, location, history对象。使用场景:即如果想在路由页面的子组件中,进行路由的跳转,需要使用 withRouter 进行包裹,否则子组件是访问不到路由对象的。
(1)没有使用 withRouter 的场景
如下代码所示,我们没有使用 withRouter 对 Component1 组件进行包裹,当我们在 Component1 中调用 history 时会报错 TypeError: Cannot read property 'push' of undefined
class Component1 extends React.Component<any> {
handleClick () {
this.props.history.push('/page2');
}
render () {
return <div onClick={() => this.handleClick()}>this is component1</div>;
}
}
export default Component1;(2)使用 withRouter 的场景
如下代码所示,我们使用 withRouter 对 Component1 组件进行包裹,当我们在 Component1 中调用 history 时能正常进行路由页面跳转
class Component1 extends React.Component<any> {
handleClick () {
this.props.history.push('/page2');
}
render () {
return <div onClick={() => this.handleClick()}>this is component1</div>;
}
}
export default withRouter(Component1);路由配置如下
<Route path="/page2/:id" exact component={Page2}></Route>路由跳转代码如下
this.props.history.push('/page2/1000');参数获取代码如下
this.props.match.params; // {id: "1000"}query 方式可以传递任意类型的值,但是页面的 url 也是由 query 的值拼接的,url 很长且是明文传输。
路由传参如下
//数据定义
const data = {id:3,name:sam,age:36};
const path = {
pathname: '/user',
query: data,
}
this.props.history.push(path);页面获取路由传过来的参数如下
//页面取值
const data = this.props.location.query;路由跳转传参如下
this.props.history.push({
pathname: '/page2',
state: {
name:'tom'
}
});参数获取代码如下
this.props.history.location.state // name: tom通过前面几节,介绍了路由的基本使用 api,本小节我们介绍下在正式项目中如何使用 react 路由。
我们一般在项目目录底下会新建路由配置文件 /router/index.ts,进行项目路由的相关配置
const routes = [
{
path: '/page1',
component: Page1,
routes: []
},
{
path: '/page2',
component: Page2,
sensitive: false,
routes: [
{
path: '/page2/page21',
component: Page21
}
]
},
{
path: '/page2',
component: Page3
},
{
path: '/',
component: Page1
}
];
export default routes;我们通常会在 App.tsx 中进行项目的路由配置,相关代码如下
import routes from './router/index';
class App extends React.Component {
render () {
return (
<BrowserRouter>
<Switch>
{routes.map((route) => (
<Route
path={route.path}
key={route.path}
sensitive={route.sensitive}
render={(props: any) => (
<route.component {...props} routes={route.routes} />
)}
/>
))}
</Switch>
</BrowserRouter>
);
}
}如果你的项目中有嵌套路由,则还需要在对应的页面中进行嵌套子路由的配置,如下所示
render () {
const routes = this.props.routes || [];
return (
<div>
<div onClick={() => this.handleClick()}>this is page2</div>
<Switch>
{routes.map((route) => (
<Route
path={route.path}
key={route.path}
render={(props: any) => (
<route.component {...props} />
)}
/>
))}
</Switch>
</div>
);
}通过以上配置后,我们就完成整个 react 项目的路由配置,后续我们在功能需求迭代中,只需要尽情地编写业务代码以及使用 Link/NavLink 或者 this.props.history 进行路由的跳转即可。
前端三大框架 Angular、React、Vue ,它们的路由解决方案 angular/router、react-router、vue-router 都是基于前端路由原理进行封装实现的 ,具体可以查看笔者之前写的一篇文章《深度剖析:前端路由原理》,这里不再赘述。
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:github.com/fengshi123/… ,汇总了作者的所有博客,欢迎关注及 star ~
缓存的重要性不言而喻,通过网络请求资源缓慢并且降低了客户端的用户体验,增添了服务端的负担。很多短期之内不会经常发生变化的资源文件没必要每次访问都想服务端进行数据请求,而缓存策略的使用就是为了改善客户端的呈现时间,降低服务端的负担。 以下“理论知识 + 实践操作”来彻底弄懂 HTTP 缓存机制及原理!
如果喜欢或者有所启发,欢迎 Star~,对作者也是一种鼓励。
为方便大家理解,我假设览器存在一个缓存数据库,用于存储缓存信息。在客户端第一次请求数据时,此时缓存数据库中没有对应的缓存数据,需要请求服务器,服务器返回后,将数据存储至缓存数据库中。如下流程图所示:
根据是否需要重新向服务器发起请求来分类,将HTTP缓存规则分为两大类(强制缓存,对比缓存)在详细介绍这两种规则之前,先通过时序图的方式,让大家对这两种规则有个简单了解。
(1)已存在缓存数据时,仅基于强制缓存,请求数据的流程如下所示:
(2)已存在缓存数据时,仅基于对比缓存,请求数据的流程如下所示:
我们可以看到两类缓存规则的不同,强制缓存如果生效,不需要再和服务器发生交互,而对比缓存不管是否生效,都需要与服务端发生交互。
两类缓存规则可以同时存在,强制缓存优先级高于对比缓存,也就是说,当执行强制缓存的规则时,如果缓存生效,直接使用缓存,不再执行对比缓存规则。
注意:
(1)如果使用了Pragma: 'no-cache'的话,再设置Expires或者Cache-Control,就没有用了,说明Pragma的权值比后两者高。
(2)如果设置了Expires之后,客户端在需要请求数据的时候,首先会对比当前系统时间和这个Expires时间,如果没有超过Expires时间,则直接读取本地磁盘中的缓存数据,不发送请求。
2.1、Cache-Control 字段
2.1.1、Cache-Control 作为请求头字段
(1)Cache-Control: no-cache
使用no-cache指令的目的是为了防止从缓存中返回过期的资源。 客户端发送的请求中如果包含 no-cache 指令,则表示客户端将不会接收缓存的资源。每次请求都是从服务器获取资源,返回304。
(2)Cache-Control: no-store
使用no-store 指令表示请求的资源不会被缓存,下次任何其它请求获取该资源,还是会从服务器获取,返回 200,即资源本身。
2.1.2、Cache-Control 作为响应头字段
Cache-Control: public
当指定使用 public 指令时,则明确表明其他用户也可利用缓存。
Cache-Control: private
当指定 private 指令后,响应只以特定的用户作为对象,这与 public 指令的行为相反。 缓存服务器会对该特定用户提供资源缓存的服务,对于其他用户发送 过来的请求,代理服务器则不会返回缓存。
Cache-Control: no-cache
如果服务器返回的响应中包含no-cache指令,每次客户端请求,必需先向服务器确认其有效性,如果资源没有更改,则返回304.
Cache-Control: no-store
不对响应的资源进行缓存,即用户下次请求还是返回 200,返回资源本身。
Cache-Control: max-age=604800(单位:秒)
资源缓存在本地浏览器的时间,如果超过该时间,则重新向服务器获取。
2.2、请求头部字段 & 响应头部字段
2.2.1、请求头部字段
2.2.2、响应头部字段
注意:
(1)If-None-Match的优先级比If-Modified-Since高,所以两者同时存在时,遵从前者。
1、实验1 — 请求的资源没修改,验证2种缓存出现的情形
服务端使用 node.js , 客户端使用 axios 进行请求:
1.1、请求头部 / 响应头部 设置
(1)服务端响应头部设置:
res.setHeader('Cache-Control', 'public, max-age=10');
(2)客户端请求头部使用默认设置
1.2、实验步骤
(1)请求 3 次,第一次请求请求资源;第二次在10秒内再次请求该资源,第三次在 10 秒后再次请求该资源(实验过程中,服务端的资源没有进行改变)
1.3、实验结果
3 次请求的 HTTP 信息如下图所示,从图中的信息可以得出,第一次请求该资源是从服务器获取;第二次(10 秒内)请求该资源是直接从浏览器缓存中获取该资源(没有向服务器确认);第三次(10 秒后)请求该资源时,因为资源缓存时间(10 秒)过期,所以向服务器获取资源,服务器判断该资源与本地缓存的资源没有做更改,所以返回 304,让客户端直接从浏览器缓存中获取该资源;以下,根据 HTTP 头部信息详细介绍三个操作的交互过程。
1.3.1、第一次请求资源
第一次请求资源的请求头部和响应头部的截图如下所示,因为第一次请求该资源,本地并没有缓存,所以直接从服务器获取该资源;我们从截图可以看到,服务器返回改资源的响应头部中包含3个属性与资源缓存相关:
(1)cache-control: public, max-age=10
缓存规则的设置,我们这个示例中,设置缓存规则为 public, 并且设置缓存过期时间为10秒;
(2)etag: W/"95f15b-16994d7ebf6"
资源的唯一标识符,客户端下次访问该资源时,会在请求头中携带 etag 去向服务器确认,该资源是否被修改;
(3)last-modified: Tue, 19 Mar 2019 07:26:12 GMT
资源最后一次修改时间,客户端下次访问该资源时,会在请求头中携带该信息去向服务器进行匹配,该资源是否被修改;
1.3.2、第二次请求资源(10秒内,即在缓存时间失效前)
第二次请求资源的请求头部和响应头部的截图如下所示,因为第二次请求该资源,该资源本地缓存还没失效,所以就直接从浏览器缓存中获取该资源。
1.3.3、第三次请求资源(10秒后,即在缓存时间失效后)
第三次请求资源的请求头部和响应头部的截图如下所示,因为第三次请求该资源,该资源本地缓存已经失效,所以在请求头部中加入If-Modified-Since和 If-None-Match 属性,来向服务器进行确认该资源是否有被更改。
2、实验2 — 请求的资源进行修改,验证2种缓存出现的情形
服务端使用node.js, 客户端使用 axios 进行请求:
2.1、请求头部 / 响应头部 设置
(1)服务端响应头部设置:
res.setHeader('Cache-Control', 'public, max-age=20');
(2)客户端请求头部使用默认设置
2.2、实验步骤
(1)请求 3 次,第一次请求资源;然后在服务器对请求的资源进行修改,第二次在 20 秒内再次请求该资源,第三次在 20 秒后再次请求该资源
2.3、实验结果
3 次请求的 HTTP 信息如下图所示,从图中的信息可以得出,第一次请求该资源是从服务器获取;第二次(20 秒内)请求该资源是直接从浏览器缓存中获取该资源(没有向服务器确认);第三次(20 秒后)请求该资源时,因为资源缓存时间(20 秒)过期,所以向服务器获取资源,服务器判断该资源与本地缓存的资源不同,所以重新返回该资源;以下,根据 HTTP 头部信息详细介绍三个操作的交互过程。
2.3.1、第一次请求资源
第一次请求资源的请求头部和响应头部的截图如下所示,具体详细信息与 1.3.1 小节相同,在此不同重复介绍。
2.3.2、第二次请求资源(20 秒内,即在缓存时间失效前)
第二次请求资源的请求头部和响应头部的截图如下所示,(注意:即使此时服务器上的资源已经更改,但是由于缓存在浏览器中的资源没有过期,所以还是从缓存中返回旧资源)。
2.3.3、第三次请求资源(20 秒后,即在缓存时间失效后)
第三次请求资源的请求头部和响应头部的截图如下所示,因为第三次请求该资源,该资源本地缓存已经失效,所以在请求头部中加入If-Modified-Since和If-None-Match属性,来向服务器进行确认该资源是否有被更改,从下图中可以看到,响应头部的属性 etag 与 请求头部的属性 If-None-Match 不同,响应头部的属性If-Modified-Since与 请求头部的属性 last-modified 不同;所以服务器返回该资源的最新资源。
1、对于强制缓存,服务器通知浏览器一个缓存时间,在缓存时间内,下次请求,直接用缓存,不在时间内,执行比较缓存策略。
2、对于比较缓存,将缓存信息中的Etag和Last-Modified通过请求发送给服务器,由服务器校验,返回304状态码时,浏览器直接使用缓存。
总结流程图如下所示:
如果喜欢或者有所启发,欢迎 Star~,对作者也是一种鼓励。
pm2 是 node 进程管理工具,可以利用它来简化很多 node 应用管理的繁琐任务,如性能监控、自动重启、负载均衡等,因为在工作中遇到服务器重启后,需要一个个去重新启动每个服务,这样不仅繁琐、效率低,而且容易遗忘开启一些服务,所以特地对 pm2 进行一次比较全面的学习+实践,在解决工作问题的同时,进行一次较完整的学习实践总结,现分享给大家。
辛苦整理良久,还望手动点赞鼓励~
博客 github地址为:https://github.com/fengshi123/blog ,汇总了作者的所有博客,也欢迎关注及 star ~
1、运行以下命令进行全局安装
$ npm install -g pm22、安装完之后,会自动创建以下目录:
$HOME/.pm2/logs // 包括所有应用的日志
$HOME/.pm2/pids // 包括所有应用的 pids
$HOME/.pm2/dump.pm2 // 开机自启动配置
$HOME/.pm2/pm2.log // pm2 日志
$HOME/.pm2/pm2.pid // pm2 pid1、启动命令
$ pm2 start app.js启动成功后,我们对应可以看到启动的服务的一些信息,如下所示:

2、命令行参数
我们可以在最基本的启动命令后面,添加一些参数选项,去满足我们的需求,常用的参数选项如下所示:
我们在启动命令后面加入以上的一些参数,完整的启动命令如下所示:
$ pm2 start app.js --watch -i max -n first_app启动成功后的截图如下,我们通过截图可以看到启动的应用名称变为 first_app,然后启动四个进程,说明我们在启动命令后面添加的参数已经起作用。

3、重启命令
$ pm2 restart app.js4、停止命令
停止特定的应用,可以通过 pm2 list 先获取应用的名字或者进程的 id,然后再调用以下命令停止相应的应用;
$ pm2 stop app_name | app_id如果需要停止全部的应用,则使用以下命令:
$ pm2 stop all5、删除命令
删除特定的应用,可以通过 pm2 list 先获取应用的名字或者进程的 id,然后再调用以下命令删除相应的应用;
$ pm2 delete app_name | app_id如果需要删除全部的应用,则使用以下命令:
$ pm2 delete all6、查看有哪些进程
$ pm2 list7、查看某个进程的信息
$ pm2 descripe app_name | app_id
相应的进程信息输出如下所示:
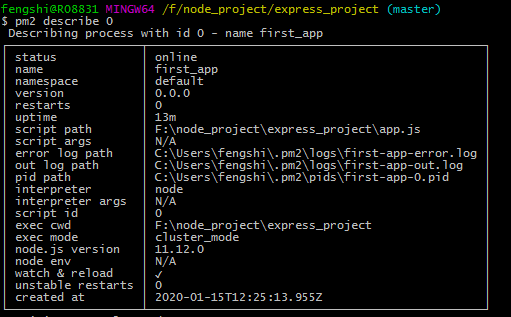
如果我们使用命令行参数定义一些选项,那么每次启动进程时,都需要敲上一大堆的命令,非常繁琐;所以我们可以使用配置文件来将命令行参数进行配置,配置文件里的配置项跟命令行参数是基本一致的;如下所示,我们在 express_project 项目 中添加 pm2 的配置文件 pm2.json ,然后在 package.json 文件中配置启动命令 "pm2": "pm2 start pm2.json" ,这样我们只需要运行 npm run pm2 就可以使用 pm2 启动我们的 express 项目,并且相关运行参数直接在 pm2.json 中配置好了。相关配置项表示的意义在下面文件中都已经注释说明,就不在一一解释了。
{
"apps": {
"name": "express_project", // 项目名
"script": "app.js", // 执行文件
"cwd": "./", // 根目录
"args": "", // 传递给脚本的参数
"interpreter": "", // 指定的脚本解释器
"interpreter_args": "", // 传递给解释器的参数
"watch": true, // 是否监听文件变动然后重启
"ignore_watch": [ // 不用监听的文件
"node_modules",
"public"
],
"exec_mode": "cluster_mode", // 应用启动模式,支持 fork 和 cluster 模式
"instances": "max", // 应用启动实例个数,仅在 cluster 模式有效 默认为 fork
"error_file": "./logs/app-err.log", // 错误日志文件
"out_file": "./logs/app-out.log", // 正常日志文件
"merge_logs": true, // 设置追加日志而不是新建日志
"log_date_format": "YYYY-MM-DD HH:mm:ss", // 指定日志文件的时间格式
"min_uptime": "60s", // 应用运行少于时间被认为是异常启动
"max_restarts": 30, // 最大异常重启次数
"autorestart": true, // 默认为 true, 发生异常的情况下自动重启
"restart_delay": "60" // 异常重启情况下,延时重启时间
"env": {
"NODE_ENV": "production", // 环境参数,当前指定为生产环境
"REMOTE_ADDR": ""
},
"env_dev": {
"NODE_ENV": "development", // 环境参数,当前指定为开发环境
"REMOTE_ADDR": ""
},
"env_test": { // 环境参数,当前指定为测试环境
"NODE_ENV": "test",
"REMOTE_ADDR": ""
}
}
}可以使用 -i 参数配置集群数,实现负载均衡,相关命令如下,可以查看 官网章节;
$ pm2 start app.js -i 3 // 开启三个进程
$ pm2 start app.js -i max // 根据机器CPU核数,开启对应数目的进程 我们可以通过打开日志文件查看日志外,还可以通过 pm2 logs 来查看实时日志,这点有对于线上问题排查;日志查看命令如下:
$ pm2 logs则我们可以在命令窗口实时看到日志输出:
我们可以使用以下命令,查看当前通过 pm2 运行的进程的状态;
$ pm2 monit
动态监控界面如下所示:
我们可以使用 --max-memory-restart 参数来限制内存使用上限,当超过使用内存上限后自动重启;
$ pm2 start app.js --max-memory-restart 100M在 linux 中,设置开机自启动,只需要执行以下两个步骤:
pm2 startup,即在/etc/init.d/ 目录下生成 pm2-root 的启动脚本,且自动将 pm2-root 设为服务;pm2 save ,会将当前 pm2 所运行的应用保存在 /root/.pm2/dump.pm2 下,当开机重启时,运行pm2-root 服务脚本,并且到 /root/.pm2/dump.pm2 下读取应用并启动;但在 windows 中运行 pm2 startup 时,会报以下错误,因为其不适合 windows 系统;
我们需要额外安装其它库,如下所示:
$ npm install pm2-windows-startup -g
$ pm2-startup install然后我们只需要运行以下保存命令,就可以将现在正在运行的服务添加到开机自启动命令中;后面即使服务器开机重启,也会将我们保存的服务自动重启;
$ pm2 save本文讲述了 pm2 安装、pm2 基本常用命令、pm2 配置文件、以及 pm2 的高阶应用,通过本文的阅读,基本能够使用 pm2 来管理你的 node 应用,至于一些不常用的特性,可以访问 pm2 官网; 并且通过本文的实践,作者还优化了之前开源的 express 项目的 pm2 管理,对应的博客文章《一个开箱即用,功能完善的 Express 项目》,希望对你有帮助。
参考文献:
本文为作者第二次专门对 Webpack 的知识点进行深入和实践,根据理解和实践的结果进行总结的;
文章内容参考书籍《深入浅出 Webpack》,因为该书籍基于 Webpack 3.4.0 版本,本文的实践基于 Webpack 4.28.2 版本,所以也踩了不少由于模块版本问题出现的坑,已经汇总到第 6 章节 踩坑汇总,大家记得避免踩坑;也印证了那句哲理:纸上得来终觉浅,绝知此事要躬行 ...
博客 github地址为:https://github.com/fengshi123/blog ,汇总了作者的所有博客,也欢迎关注及 star ~
本文实践 demo 的 github 地址为:https://github.com/fengshi123/webpack_project
构建工具就是将源代码转换成可执行的 JavaScript、CSS、HTML 代码,包括以下内容:
代码转换:将 TypeScript 编译成 JavaScript、将 SCSS 编译成 CSS 等;
文件优化:压缩 JavaScript、CSS、HTML 代码,压缩合并图片等;
代码分割:提取多个页面的公共代码,提取首屏不需要执行部分的代码,让其异步加载;
模块合并:在采用模块化的项目里会有很多个模块和文件,需要通过构建功能将模块分类合并成一个文件;
自动刷新:监听本地源代码的变化,自动重新构建、刷新浏览器;
代码校验:在代码被提交到仓库前需要校验代码是否符合规范,以及单元测试是否通过;
自动发布:更新代码后,自动构建出线上发布代码并传输给发布系统;
Webpack 有以下几个核心概念:
Entry :入口,Webpack 执行构建的第一步将从 entry 开始,可抽象成输入;
Module:模块,配置处理模块的规则;在 Webpack 里一切皆模块,一个模块对应一个文件;Webpack 会从配置的 Entry 开始递归找出所有依赖的模块;
Loader:模块转换器,用于将模块的原内容按照需求转换成新内容;
Resolve:配置寻找模块的规则;
Plugin:扩展插件,在 Webpack 构建流程中的特定时机会广播对应的事件,插件可以监听这些事情的发生,在特定的时机做对应的事情;
Output:输出结果,在 Webpack 经过一系列处理并得出最终想要的代码后输出结果;
Chunk:代码块,一个 Chunk 由多个模块组合而成,用于代码合并与分割;
(1)初始化参数:从配置文件和 Shell 语句中读取与合并参数,得出最终的参数;
(2)开始编译:用上一步得到的参数初始化 Compiler 对象,加载所有配置的插件,通过执行对象的 run 方法开始执行编译;
(3)确定入口:根据配置中的 entry 找出所有入口文件;
(4)编译模块:从入口文件出发,调用所有配置的 Loader 对模块进行翻译,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理;
(5)完成模块编译:在经过第 4 步使用 Loader 翻译完所有模块后,得到了每个模块被翻译后的最终内容及它们之间的依赖关系;
(6)输出资源:根据入口和模块之间的依赖关系,组装成一个个包含多个模块的 Chunk,再将每个 Chunk 转换成一个单独的文件加入输出列表中,这是可以修改输出内容的最后机会;
(7)输出完成:在确定好输出内容后,根据配置确定输出的路径和文件名,将文件的内容写入文件系统中;
在以上过程中,Webpack 会在特定的时间点广播特定的事件,插件在监听到感兴趣的事件后会执行特定的逻辑,并且插件可以调用 Webpack 提供的 API 改变 Webpack 的运行结果;
1、新建 Web 项目
新建一个目录,再进入项目根目录执行 npm init 来初始化最简单的采用了模块化开发的项目;最终生成 package.json 文件;
$ npm init2、安装 Webpack 到本项目
(1)查看 Webpack 版本
运行以下命令可以查看 Webpack 的版本号
$ npm view webpack versions(2)安装 Webpack
可以选择(1)步骤罗列得到的 Webpack 版本号,也可以安装最新稳定版、最新体验版本,相关命令如下所示,我选择安装 4.28.2 版本(没有为什么,就想装个 4.x 的版本);
// 安装指定版本
npm i -D webpack@4.28.2
// 安装最新稳定版
npm i -D webpack
// 安装最新体验版本
npm i -D webpack@beta(3)安装 Webpack 脚手架
需要安装 Webpack 脚手架,才能在命令窗口执行 Webpack 命令,运行以下命令安装 Webpack 脚手架;
$ npm i -D webpack-cli3、使用 Webpack
使用 Webpack 构建一个采用 CommonJS 模块化编写的项目;
(1)新建页面入口文件 index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Webpack</title>
</head>
<body>
<!--导入 Webpack 输出的 JavaScript 文件-->
<script src="./dist/bundle.js"></script>
</body>
</html>(2)新建需要用到的 JS 文件
show.js 文件
// 操作 DOM 元素,把 content 显示到网页上
function show(content) {
window.document.getElementById('app').innerText = 'Hello,' + content;
}
// 通过 CommonJS 规范导出 show 函数
module.exports = show;main.js 文件
// 通过 CommonJS 规范导入 show 函数
const show = require('./show.js');
// 执行 show 函数
show('Webpack');(3)新建 Webpack 配置文件 webpack.config.js
const path = require('path');
module.exports = {
// JavaScript 执行入口文件
entry: './main.js',
output: {
// 把所有依赖的模块合并输出到一个 bundle.js 文件
filename: 'bundle.js',
// 输出文件都放到 dist 目录下
path: path.resolve(__dirname, './dist'),
}
};(4)执行 webpack 命令进行构建
在 package.json 文件中配置编译命令,如下所示:
"scripts": {
"build": "webpack --config webpack.config.js",
},执行以下命令进行项目的 Webpack 编译,成功后会在项目根目录下生成编译目录 dist ;
$ npm run build(5)运行 index.html
编译成功后,我们用浏览器打开 index.html 文件,能看到页面成功显示 “Hello Webpack”;
本节通过为之前的例子添加样式,来尝试使用 Loader;
(1)新建样式文件 main.css
#app{
text-align: center;
color:'#999';
}(2)将 main.css 文件引入入口文件 main.js 中,如下所示:
// 通过 CommonJS 规范导入 CSS 模块
require('./main.css');
// 通过 CommonJS 规范导入 show 函数
const show = require('./show.js');
// 执行 show 函数
show('Webpack');(3)Loader 配置
以上修改后去执行 Webpack 构建是会报错的,因为 Webpack 不原生支持解析 CSS 文件。要支持非 JavaScript 类型的文件,需要使用 Webpack 的 Loader 机制;
(3.1)运行以下命令,安装 style-loader 和 css-loader,其中:
$ npm i -D style-loader css-loader(3.2)进行以下配置
module:{
rules:[
{
// 用正则去匹配要用该 loader 转换的 CSS 文件
test:/\.css$/,
use:['style-loader','css-loader']
}
]
}(4)查看结果
编译后,刷新 index.html ,查看刚刚的样式 loader 已经起作用;

(1)安装样式提取插件 extract-text-webpack-plugin
$ npm i -D extract-text-webpack-plugin@next(2)plugin 文件配置如下
module:{
rules:[
{
// 用正则去匹配要用该 loader 转换的 CSS 文件
test:/\.css$/,
use:ExtractTextPlugin.extract({
use:['css-loader']
}),
}
]
},
plugins:[
new ExtractTextPlugin({
// 从 .js 文件中提取出来的 .css 文件的名称
filename:`[name]_[hash:8].css`
}),
](3)查看结果
通过以上配置后,执行 Webapack 的执行命令,发现在 dist 目录下,生成对应的 css 文件;存在的坑点:
(1)执行以下命令安装 webpack-dev-server
$ npm i -D webpack-dev-server在 package.json 中配置启动命令
"scripts": {
"build": "webpack --config webpack.config.js",
"dev": "webpack-dev-server",
},运行命令后,就可以启动 HTTP 服务
$ npm run dev
启动结果如下所示,我们可以通过 http://localhost:8080/ 访问我们的 index.html 的demo

(2)实时预览
我们在运行命令后面添加参数 --watch 实现实时预览,配置如下所示:
"scripts": {
"dev": "webpack-dev-server --watch"
},然后我们修改 main.js 的传入参数,发现并不能实时预览,也没有报错!!! why?
踩坑:
在 index.html 中需要将 js 的路径修改为:
<script src="bundle.js"></script> 而不能是之前的(因为这个是编译生成的,并不是通过 devServer 生成放在内存的)
<script src="./dist/bundle.js"></script> (3)模块热替换
可以通过配置 -- hot 进行模块热替换;
关于优化的实践之前有进行过实践了,这里不再累述,感兴趣的童鞋可以查看作者写的另一篇文章《Vue项目Webpack优化实践,构建效率提高50% 》
(1)Loader 为模块转换器,用于将模块的原内容按照需求转换成新内容;
(2)Loader 的职责是单一的,只需要完成一种转换,遵守单一职责原则;
(3)Webpack 为 Loader 提供了一系列 API 供 Loader 调用,例如:
手写一个 loader 源码,其功能是将 /hello/gi 转换成 HELLO,当然这个 loader 其实没啥实际意义,纯碎是为了写 loader 而写 loader;当然如果你实际业务有需要编写 loader 需求,那就要反思这个业务的合理性,因为庞大的社区,一般合理的需求都能找到对应的 loader。
(1)源码编写
在原有的项目底下,新建目录 custom-loader 作为我们编写 loader 的名称,执行 npm init 命令,新建一个模块化项目,然后新建 index.js 文件,相关源码如下:
function convert(source){
return source && source.replace(/hello/gi,'HELLO');
}
module.exports = function(content){
return convert(content);
}(2)Npm link 模块注册
正常我们安装 Loader 是从 Npm 公有仓库安装,也即将 Loader 发布到 Npm 仓库,然后再安装到本地使用;但是我们可以使用 Npm link 做到在不发布模块的情况下,将本地的一个正在开发的模块的源码链接到项目的 node_modules 目录下,让项目可以直接使用本地的 Npm 模块;
在 custom-loader 目录底下,运行以下命令,将本地模块注册到全局:
$ npm link成功结果如下:

然后在项目根目录执行以下命令,将注册到全局的本地 Npm 模块链接到项目的 node_modules 下:
$ npm link custom-loader
成功结果如下,并且在 node_modules 目录下能查找到对应的 loader;

该配置跟第一章节的 Webpack 配置并没有任何区别,这里不再详述,配置参考如下:
module:{
rules:[
{
test:/\.js/,
use:['custom-loader'],
include:path.resolve(__dirname,'show')
}
]
}执行运行 or 编译命令,就能看到我们的 loader 起作用了。
Webpack 就像一条生产线,要经过一系列处理流程后才能将源文件转换成输出结果,这条生产线上的每个处理流程的职责都是单一的,多个流程之间存在依赖关系,只有在完成当前处理后才能提交给下一个流程去处理。插件就像生产线中的某个功能,在特定的时机对生产线上的资源进行处理。
Webpack 通过 Tapable 来组织这条复杂的生产线。 Webpack 在运行过程中会广播事件,插件只需要监听它所关心的事件,就能加入到这条生产线中,去改变生产线的运作。 Webpack 的事件流机制保证了插件的有序性,使得整个系统扩展性很好。
手写一个 plugin 源码,其功能是在 Webpack 编译成功或者失败时输出提示;当然这个 plugin 其实没啥实际意义,纯碎是为了写 plugin 而写 plugin;当然如果你实际业务有需要编写 plugin 需求,那就要反思这个业务的合理性,因为庞大的社区,一般合理的需求都能找到对应的 plugin。
(1)源码编写
在原有的项目底下,新建目录 custom-plugin 作为我们编写 plugin 的名称,执行 npm init 命令,新建一个模块化项目,然后新建 index.js 文件,相关源码如下:
class CustomPlugin{
constructor(doneCallback, failCallback){
// 保存在创建插件实例时传入的回调函数
this.doneCallback = doneCallback;
this.failCallback = failCallback;
}
apply(compiler){
// 成功完成一次完整的编译和输出流程时,会触发 done 事件
compiler.plugin('done',(stats)=>{
this.doneCallback(stats);
})
// 在编译和输出的流程中遇到异常时,会触发 failed 事件
compiler.plugin('failed',(err)=>{
this.failCallback(err);
})
}
}
module.exports = CustomPlugin;(2)Npm link 模块注册
跟 Loader 注册一样,我们使用 npm link 进行注册;
在 custom-plugin 目录底下,运行以下命令,将本地模块注册到全局:
$ npm link然后在项目根目录执行以下命令,将注册到全局的本地 Npm 模块链接到项目的 node_modules 下:
$ npm link custom-plugin
如果一切顺利,可以在 node_modules 目录下能查找到对应的 plugin;
该配置跟第一章节的 Webpack 配置并没有任何区别,这里不再详述,配置参考如下:
plugins:[
new CustomPlugin(
stats => {console.info('编译成功!')},
err => {console.error('编译失败!')}
),
],执行运行 or 编译命令,就能看到我们的 plugin 起作用了。
1、css-loader 以下配置
rules:[
{
// 用正则去匹配要用该 loader 转换的 CSS 文件
test:/\.css$/,
use:['style-loader','css-loader?minimize']
}
]报以下错误:
- options has an unknown property 'minimize'. These properties are valid:
object { url?, import?, modules?, sourceMap?, importLoaders?, localsConventio n?, onlyLocals?, esModule? }原因:
minimize 属性在新版本已经被移除,
解决:
先去掉 minimize 选项;
2、ExtractTextPlugin 编译以下错误:

原因:
extract-text-webpack-plugin 版本号问题
参考链接:webpack/webpack#6568
解决:
重新安装 extract-text-webpack-plugin
$ npm i -D extract-text-webpack-plugin@next3、修复第2个坑之后,ExtractTextPlugin 编译继续报以下错误:

原因:
不存在 contenthash 这个变量
解决:
更改 extract-text-webpack-plugin 的配置:
plugins:[
new ExtractTextPlugin({
// 从 .js 文件中提取出来的 .css 文件的名称
filename:`[name]_[hash:8].css`
}),
]4、添加 HappyPack 后,编译 CSS 文件时报以下错误:

原因:
css-loader 版本的问题
解决:
重新安装 [email protected]
本文主要基于 Webpack 的作用、核心概念、流程,Webpack 的基础配置,Webpack 优化,编写 Loader,编写 Plugin ,从理论到实践,从基础到较难,对 Webpack 进行总结掌握,希望对你也有帮助。还是那句话:纸上得来终觉浅,绝知此事要躬行 ...,如果你没有手敲过,一定要多动动手 !
博客 github地址为:https://github.com/fengshi123/blog ,汇总了作者的所有博客,也欢迎关注及 star ~
本文实践 demo 的 github 地址为:https://github.com/fengshi123/webpack_project
1、POST请求: HTTP/1.1 协议规定的 HTTP请求方法有OPTIONS、GET、HEAD、POST、PUT、DELETE、TRACE、CONNECT 这几种。其中 POST` 一般用来向服务端提交数据。
2、Content-Type: 是指http/https发送信息至服务器时的内容编码类型,Content-Type用于表明发送数据流的类型,服务器根据编码类型使用特定的解析方式,获取数据流中的数据。四种常见的 POST 请求的 Content-Type 数据类型:
application/x-www-form-urlencodedmultipart/form-dataapplication/jsontext/xml3、Express.js: Express 是一个保持最小规模的灵活的 Node.js Web 应用程序开发框架,为 Web 和移动应用程序提供一组强大的功能。
本文我们主要介绍 Post 请求的 4 种 Content-Type 数据类型,以及如何使用 Express 来对每种 Content-Type 类型进行解析。已经将完整的代码实例上传到 github,github地址为:github.com/fengshi123/… ,欢迎 star 。
最常见的 POST 提交数据的方式,浏览器的原生 form 表单,如果不设置 enctype 属性,那么最终就会默认以 application/x-www-form-urlencoded 方式提交数据。
1.1、前端请求代码
var reqParam = "name=jack";
xhr.setRequestHeader('Content-type', 'application/x-www-form-urlencoded');
xhr.send(reqParam);
1.2、服务端解析代码
app.post('/urlencoded', bodyParser.urlencoded({extend:true}), function (req, res) {
var result = {
name: req.body.name,
sex: '男',
age: 15
};
res.send(result);
});
1.3、浏览器请求 / 响应截图
请求:
响应:
使用表单上传文件时,必须指定表单的 enctype属性值为 multipart/form-data. 请求体被分割成多部分,每部分使用 --boundary分割开始,紧接着内容描述信息,最后是字段具体内容(文本或二进制);如果传输的是文件,还要包含文件名和文件类型信息;
2.1、前端请求代码
var reqParam = new FormData(document.form2);
xhr.send(reqParam);
2.2、服务端解析代码
express 提供了两种插件 formidable 和 multiparty 来处理数据类型为multipart/form-data的情况,以下我们分别用两个插件进行处理;
2.2.1、formidable 插件
(1)安装插件
npm install formidable --save复制代码
(2)服务端解析处理
app.post('/formData1', function (req, res) {
var form = new formidable.IncomingForm();
form.uploadDir = "upload/";
form.parse(req, function (err, fields, files) {
var obj = {};
Object.keys(fields).forEach(function (name) {
obj[name] = fields[name];
});
Object.keys(files).forEach(function (name) {
if (files[name] && files[name].name) {
obj[name] = files[name];
fs.renameSync(files[name].path, form.uploadDir + files[name].name);
}
});
res.send(obj);
});
});
2.2.2、multiparty 插件
(1)安装插件
npm install multiparty--save
(2)服务端解析处理
app.post('/formData2', function (req, res) {
// 解析一个文件上传
var form = new multiparty.Form();
//设置编辑
form.encoding = 'utf-8';
//设置文件存储路径
form.uploadDir = "upload/";
//设置单文件大小限制
form.maxFilesSize = 2000 * 1024 * 1024;
form.parse(req, function (err, fields, files) {
var obj = {};
Object.keys(fields).forEach(function (name) {
obj[name] = fields[name];
});
Object.keys(files).forEach(function (name) {
if (files[name] && files[name][0] && files[name][0].originalFilename) {
obj[name] = files[name];
fs.renameSync(files[name][0].path, form.uploadDir + files[name][0].originalFilename);
}
});
res.send(obj);
});
});
2.3、浏览器请求 / 响应截图
请求:
响应:
application/json 这个 Content-Type 作为响应头,用来告诉服务端消息主体是序列化后的 JSON 字符串。由于 JSON 规范的流行,除了低版本 IE 之外的各大浏览器都原生支持 JSON.stringify,服务端语言也都有处理 JSON 的函数,使用 JSON 不会遇上什么麻烦。
3.1、前端请求代码
var reqParam = {
name: 'jack'
};
xhr.setRequestHeader('Content-type', 'application/json');
xhr.send(JSON.stringify(reqParam));
3.2、服务端解析代码
app.post('/applicationJson', bodyParser.json(), function (req, res) {
var result = {
name: req.body.name,
sex: '男',
age: 15
};
res.send(result);
});
3.3、浏览器请求 / 响应截图
请求:
响应:
它是一种使用 HTTP 作为传输协议,XML 作为编码方式的远程调用规范,它的使用也很广泛,能很好的支持已有的 XML-RPC 服务。不过,XML 结构还是过于臃肿,一般场景用 JSON 会更灵活方便。
4.1、前端请求代码
var text = '<?xml version="1.0"?><methodCall><methodName>examples.getStateName</methodName>' + '<params><param><value><i4>41</i4></value></param></params></methodCall>';
xhr.setRequestHeader('Content-type', 'text/xml');
xhr.send(text);
4.2、服务端解析代码
app.post('/textXml', bodyParser.urlencoded({extend:true}), function (req, res) {
var result = '';
req.on('data', function (chunk) {
result += chunk;
});
req.on('end', function () {
res.send(result);
});
});
4.3、浏览器请求 / 响应截图
请求:
响应:
1、对于跨域请求,当contentType改为application/json,将触发浏览器发送一个预检OPTIONS请求到服务器,再发送正常的 post 请求;
2、使用 new FormData(),然后设置 Content-type 为 application/x-www-form-urlencoded 或者 multipart/form-data 会导致后端无法正常解析,解决方法:就是不进行头部设置,Content-type会默认 为 multipart/form-data,服务端正常解析;
3、contentType 设置为 application/x-www-form-urlencoded 时,传给后端的请求参数为JSON字符串,chrome 调试框查看发送的请求参数多了冒号,如下所示:
这是因为application/x-www-form-urlencoded 它将被解析成键值对展示,但是字符串进去是没有改变的,但是展示的时候能看见。解决方法:如果为 JSON字符串,则设置数据类型为 application/json;
本文我们主要介绍 Post 请求的 4 种 Content-Type 数据类型,以及如何使用 Express 来对每种 Content-Type 类型进行解析。已经将完整的代码实例上传到 github,github地址为:github.com/fengshi123/… ,欢迎 star 。demo 截图如下所示:
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.

