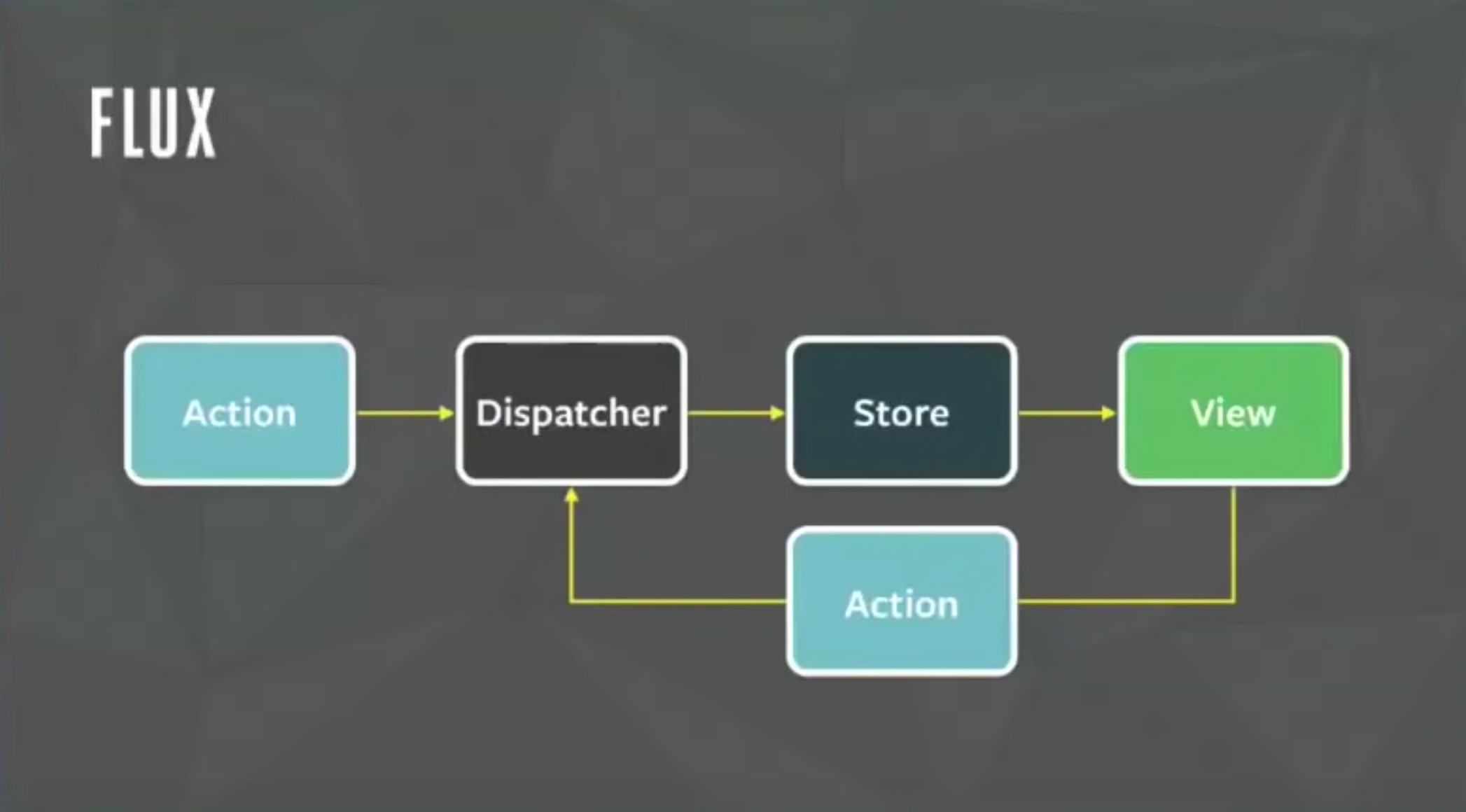
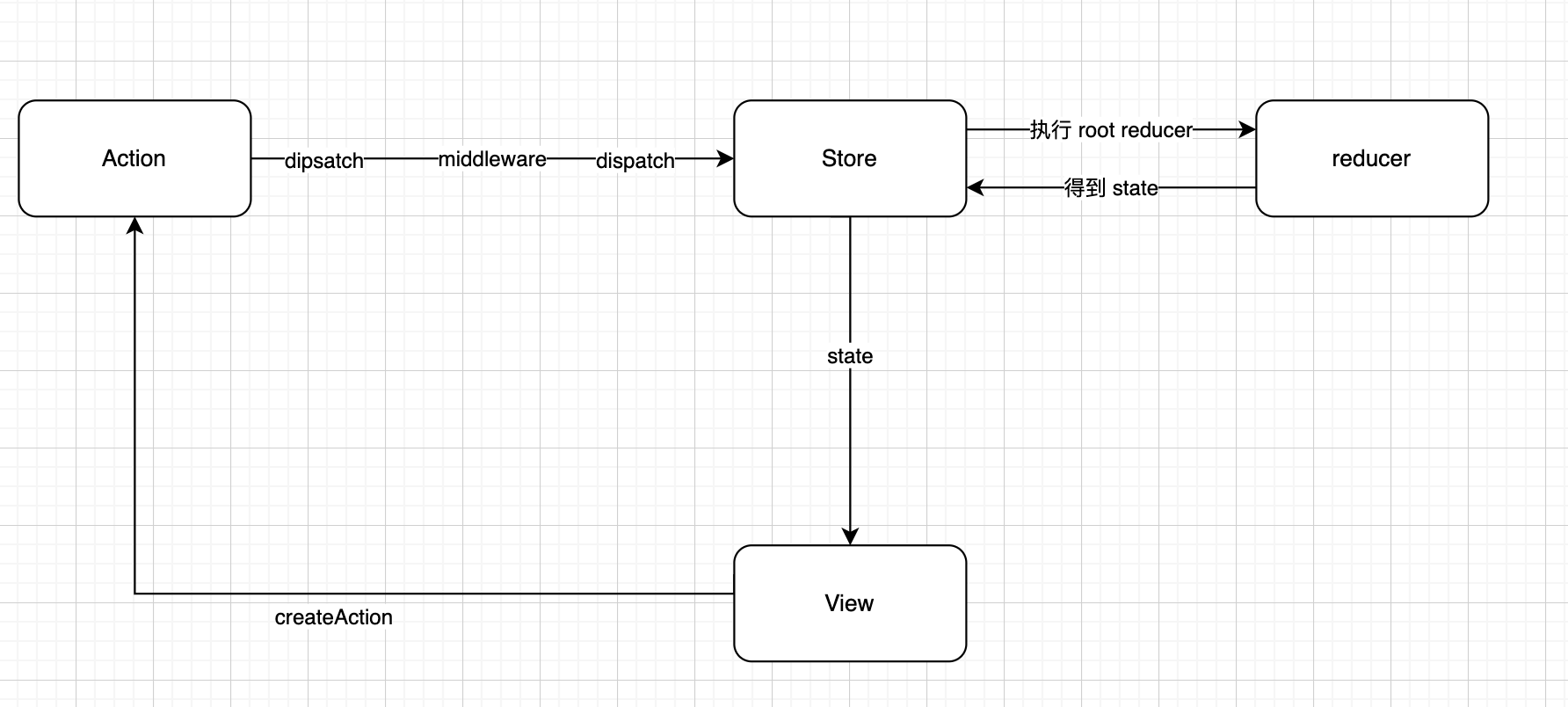
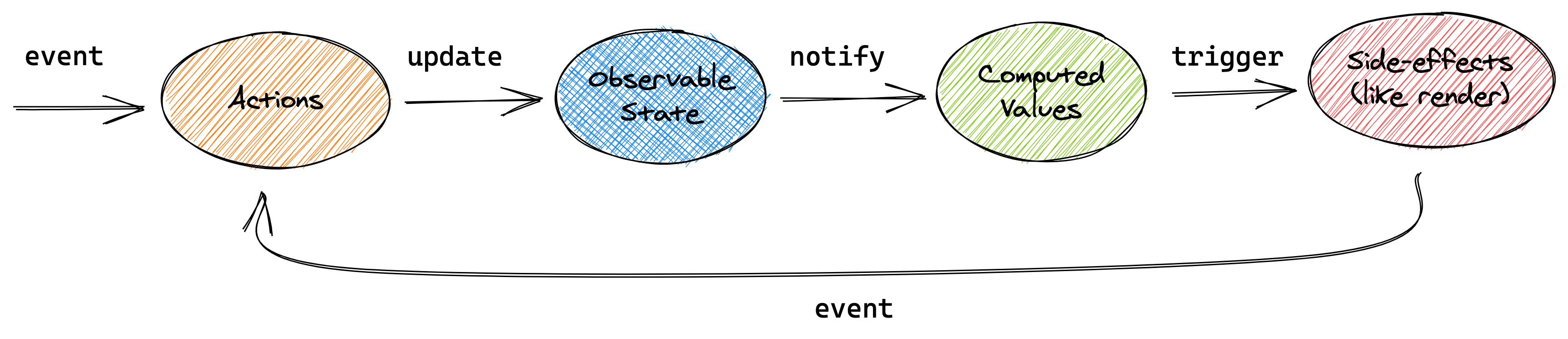
Proxy
拦截方式
Mobx 暴露的拦截的 API 有多种,概括来说可以分为装饰器式和基于 observable 方法调用。
装饰器
对装饰器不太明白的同学,可以见我以往一篇文章:装饰器原理探究 ,通过分析转译后的 ES 代码得出装饰器的行为。
由于装饰器在 ES 里还处于提案中且各阶段的装饰器行为不一致,故 mobx 6.x 起就淘汰了装饰器的写法(也可以手动开启),本文的源码分析基于 mobx 5.x 版本(所述原理与 6.x 一模一样),此时装饰器基于 babel
{
"plugins": [
["@babel/plugin-proposal-decorators", { "legacy": true }],
]
}该配置下实现,使用历史遗留(stage 1)的装饰器中的语法和行为。
import { observable } from 'mobx';
class A {
@observable a = 1;
}此处 @observable 装饰器的行为其实就是在实例化前往 A 的原型上挂 getter setter。
{
configurable: true,
enumerable: enumerable,
get: function() {
initializeInstance(this)
return this[prop]
},
set: function(value) {
initializeInstance(this)
this[prop] = value
}
}在实例化时会执行 instance.a = 1 赋值操作,触发 setter ,走到 mobx 处理类实例的逻辑:
1. 往实例上挂 对象管理类(adm)
2. 递归包装 value , 并收集在 adm
3. 为实例上的 key (a) 挂 getter setter
{
configurable: true,
enumerable: true,
get() {
// 收集依赖
return this[$mobx].read(propName)
},
set(v) {
// 触发更新
this[$mobx].write(propName, v)
}
}宏观来讲,此后访问装饰的属性就会走到 this[$mobx].read(propName) 收集副作用,当属性改变就走到 this[$mobx].write(propName, v) 执行副作用。
observable 命令式调用
命令式调用就是如下这种:
const xxx = observable(xxx) || observable.xx(xxx);
一定会有一个返回值,当我们操作返回值的时候,就会做收集 | 执行副作用的行为。
下面会挨个解析各个类型的拦截情况。
先说明个概念,在 Mobx里,所有需要被观察的 value ,除了数组、Set,都会被 ObservableValue 类包装(为了方便之后对其实例简称 OV ),做的工作就是:
(1)使用 enhancer 处理 value
(2)管理(1)中包装后的 value (读写、收集依赖等)
enhancer 有多种,若用户不作额外配置,Mobx 里默认对每个 value 使用 deepEnhancer 进行包装,其实就是递归对这个 value 做 observable 命令式调用 的操作。
primitive value
对于原始类型 value ,Mobx 里只支持使用 observable.box(val) 这个 API 进行拦截,其实内部就是返回了个 OV。
如果读写分别用 OV 暴露 get set API。
object
使用 observable.object(val) 进行拦截,内部做了三件事:
- 新建一个空对象 { }, 并给 { } 挂上 对象管理类(adm)
- Proxy 拦截 { },并把代理对象保存在 adm.proxy
- 遍历 val 的 keys:
- 递归包装 value , 并收集 OV 在 adm
- 在 { } 挂上每个 key 的 getter setter (同装饰器挂的 getter setter 一样)
- 返回代理对象
Proxy 的 handlers 有:
// 暂时只关注读写
{
get(target: IIsObservableObject, name: PropertyKey) {
// ... 忽略暂时无关代码
const adm = getAdm(target)
// 拿到 OV
const observable = adm.values.get(name)
if (observable instanceof Atom) {
// 此处等同于调用 adm.read(propName)
const result = (observable as any).get()
// ...
return result
}
// ...
},
set(target: IIsObservableObject, name: PropertyKey, value: any) {
if (!isPropertyKey(name)) return false
set(target, name, value)
// 这个 set 方法针对对象最终执行如下
// // ...
// if (isObservableObject(obj)) {
// const adm = ((obj as any) as IIsObservableObject)[$mobx]
// // 拿到 OV
// const existingObservable = adm.values.get(key)
// if (existingObservable) {
// adm.write(key, value)
// }
// // ...
// }
// //...
return true
},
}由上可知,此处的读取处理最终也是和装饰器方式修饰的对象属性的读写处理相同。
array
使用 observable.array(val) 进行拦截,内部做了五件事:
- 初始化 数组管理类 (adm) ,挂载在 [ ] 上,再把 [ ] 挂载在 adm.values
- Proxy 拦截 [ ],并把代理对象挂载在 adm.proxy
- 遍历 val,递归包装每个元素
- 更新 3 中一个个 OV 在 adm.values 里
- 返回代理对象
Handler 如下:
get(target, name) {
if (name === $mobx) return target[$mobx]
if (name === "length") return target[$mobx].getArrayLength()
if (typeof name === "number") {
return arrayExtensions.get.call(target, name)
}
if (typeof name === "string" && !isNaN(name as any)) {
return arrayExtensions.get.call(target, parseInt(name))
}
if (arrayExtensions.hasOwnProperty(name)) {
// arrayExtensions 捕获数组方法
return arrayExtensions[name]
}
return target[name]
},
set(target, name, value): boolean {
if (name === "length") {
target[$mobx].setArrayLength(value)
}
if (typeof name === "number") {
arrayExtensions.set.call(target, name, value)
}
if (typeof name === "symbol" || isNaN(name)) {
target[name] = value
} else {
// numeric string
arrayExtensions.set.call(target, parseInt(name), value)
}
return true
},以读取为例说明,在 arrayExtensions 里是这样的:
get(index: number): any | undefined {
const adm: ObservableArrayAdministration = this[$mobx]
if (adm) {
if (index < adm.values.length) {
adm.atom.reportObserved()
return adm.dehanceValue(adm.values[index])
}
// ...
}
return undefined
},
set(index: number, newValue: any) {
const adm: ObservableArrayAdministration = this[$mobx]
const values = adm.values
if (index < values.length) {
// update at index in range
checkIfStateModificationsAreAllowed(adm.atom)
const oldValue = values[index]
// ...
// 新的被 enhancer 包装过的 value
newValue = adm.enhancer(newValue, oldValue)
const changed = newValue !== oldValue
if (changed) {
values[index] = newValue // 改变 adm 里收集的旧 value
// 通知更新
adm.notifyArrayChildUpdate(index, newValue, oldValue)
}
}
// ...
}之前说过,数组不会被 ObservableValue 包装,因为在其管理类里面,已经实现了 ObservableValue 的工作,也就是:
(1)使用 enhancer 处理 value
(2)管理(1)中包装后的 value (读写、收集依赖等)
其实, arrayExtensions 里的操作,核心也是收集依赖和触发更新。
map
使用 observable.map(val) 进行拦截,内部做了三件事:
- 初始化 map 管理类
- 遍历 val ,挨个 ObservableValue 包装 value,收集在管理类的
this._data 上
- 返回 map 管理类实例
返回的实例,有 Map 的 API 方法,以读写为例:
get(key: K): V | undefined {
// this._data.get(key)!.get() 等同于调用对象 adm 的 adm.read(propName)
// 收集依赖
if (this.has(key)) return this.dehanceValue(this._data.get(key)!.get())
return this.dehanceValue(undefined)
}
set(key: K, value: V) {
const hasKey = this._has(key)
// ...
if (hasKey) {
this._updateValue(key, value)
} else {
this._addValue(key, value)
}
return this
}
_updateValue(key: K, newValue: V | undefined) {
// 拿到 ObservableV
const observable = this._data.get(key)!
// enhancer 新 value,然后对比旧 value 是否相等
newValue = (observable as any).prepareNewValue(newValue) as V
if (newValue !== globalState.UNCHANGED) {
// ...
// 更新并通知更新
observable.setNewValue(newValue as V)
// ...
}
}set
使用 observable.set(val) 进行拦截,内部做了三件事:
- 初始化 set 管理类
- 遍历 val ,挨个 enhancer 包装 value,收集在管理类的
this._data 上
- 返回 set 管理类实例
和 Map 一样,返回的 set 管理类也有 Set 的相关 API,以获取所有 values 和 add 为例:
add(value: T) {
// ...
if (!this.has(value)) {
transaction(() => {
// 往本地缓存的 _data 里新增 enhancer 后的 value
this._data.add(this.enhancer(value, undefined))
// 通知依赖更新
this._atom.reportChanged()
})
// ...
}
return this
}
keys(): IterableIterator<T> {
return this.values()
}
values(): IterableIterator<T> {
// 通知收集依赖
this._atom.reportObserved()
const self = this
let nextIndex = 0
const observableValues = Array.from(this._data.values())
// 在 for of 中挨个读 _data 的值
return makeIterable<T>({
next() {
return nextIndex < observableValues.length
? { value: self.dehanceValue(observableValues[nextIndex++]), done: false }
: { done: true }
}
} as any)
}由上述可知,其实就是对于不同的数据结构,处理的核心的就是拦截被观察者 getter setter 或相关 API,达到在读取时收集依赖,变化时通知依赖更新的目的。
Derivation
Mobx 里有派生的概念,类似于观察者。在 Derivation 内使用了 Proxy 的产物,每当产物有变化时则派生(通知)了 Derivation(观察者)。
一些概念:
transaction
引用了数据库事务的概念,Mobx 中的事务用于批量处理 Reaction(Derivation 管理者) 的执行,避免不必要的重新计算。Mobx 的事务实现比较简单,使用 startBatch 和 endBatch 来开始和结束一个事务:
function startBatch() {
// 通过一个全局的变量 inBatch 标识事务嵌套的层级
globalState.inBatch++
}
function endBatch() {
// 最外层事务结束时,才开始执行重新计算
if (--globalState.inBatch === 0) {
// 执行所有 Reaction
runReactions()
// 处理不再被观察的 ObservableV
const list = globalState.pendingUnobservations
for (let i = 0; i < list.length; i++) {
const observable = list[i]
observable.isPendingUnobservation = false
if (observable.observers.length === 0) {
observable.onBecomeUnobserved()
}
}
globalState.pendingUnobservations = []
}
}例如,一个 Action 开始和结束时同时伴随着事务的启动和结束,确保 Action 中(可能多次)对状态的修改只触发一次 Reaction 的重新执行。
function startAction() {
// ...
startBatch()
// ...
}
function endAction() {
// ...
endBatch()
// ...
}Reaction
Reaction 就是 Derivation 的管理者,实现了 Derivation 的接口:
interface IDerivation extends IDepTreeNode {
// 依赖数组
observing: IObservable[]
// 每次执行收集到的新依赖数组
newObserving: null | IObservable[]
// 依赖的状态
dependenciesState: IDerivationState
// 每次执行都会有一个 uuid,配合 Observable 的 lastAccessedBy 属性做简单的性能优化
runId: number
// 执行时新收集的未绑定依赖数量
unboundDepsCount: number
// 依赖过期时执行
onBecomeStale()
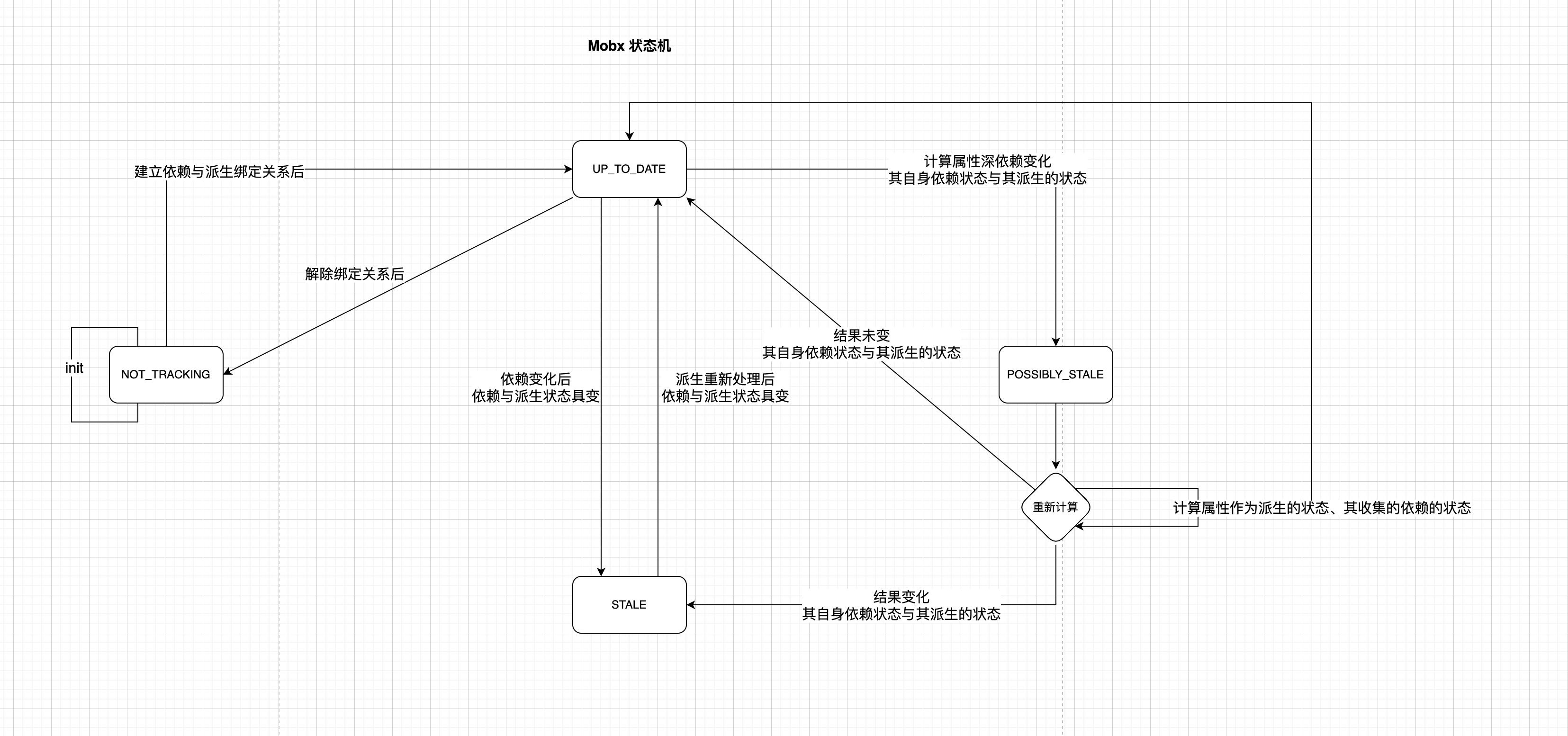
}Derivation 状态机

Derivation 通过 dependenciesState 属性标记依赖的四种状态:
- NOT_TRACKING:在执行之前,或事务之外,或未被观察(计算值)时,所处的状态。此时 Derivation 没有任何关于依赖树的信息。枚举值-1
- UP_TO_DATE:表示所有依赖都是最新的,这种状态下不会重新计算。枚举值0
- POSSIBLY_STALE:计算值才有的状态,表示深依赖发生了变化,但不能确定浅依赖是否变化,在重新计算之前会检查。枚举值1
- STALE:过期状态,即浅依赖发生了变化,Derivation 需要重新计算。枚举值2
任何状态都趋于 UP_TO_DATE。
------------------------- 2 ------------------------- STALE
↓
-------------↓--- 1 ------------------ POSSIBLY_STALE
↓ ↓
------- 0 -------- UP_TO_DATE
↑
-1--- NOT_TRACKING
状态机的规律是:
-
初始都是 NOT_TRACKING,绑定起依赖和派生关系后集体变为 U_T_D。
解绑则回退为 NOT_TRACKING。
-
某收集的依赖发生变化时,其自身依赖状态和 Derivation (onBecomeStale后)都变为 STALE。
在 Derivation 重新处理后,其自身和收集的依赖都变为 U_T_D。
-
计算属性计算后(含第一次),自身派生状态、收集的依赖状态都变为 U_T_D。(符合 2 第二句 Derivation 重新处理后,其自身和收集的依赖都变为 U_T_D)在第一次被绑定后,符合 1。
若计算属性收集的某依赖 A 状态发生变化时,将 A 状态和 计算属性派生状态(onBecomeStale后) 为 STALE(符合 2 第一句),并且把 计算属性依赖状态、计算属性派生的 Derivation 置为 P_STALE(区别)。在计算属性重新计算后自身派生状态、收集的所有依赖状态变更为 U_T_D(符合 2 第二句),若计算结果无变更,把计算属性依赖状态、计算属性派生的 Derivation 变回 U_T_D 。若有变更,则把 计算属性派生的 Derivation 变为 STALE,接着重新处理 计算属性派生的 Derivation,把其和其收集的依赖(含计算属性作为依赖)状态 变为 U_P_D。
下面以 AutoRun、Computed Value 、React Render 为例分析 Derivation 的源码。
AutoRun
流程
常规用法是:
首先,会为 AutoRun 这个 Derivation 初始化一个 Reaction 用于管理:
function autorun(
view: (r: IReactionPublic) => any, // cb
opts: IAutorunOptions = EMPTY_OBJECT // 忽略
): IReactionDisposer {
const name: string = (opts && opts.name) || (view as any).name || "Autorun@" + getNextId()
const runSync = !opts.scheduler && !opts.delay
let reaction: Reaction
if (runSync) {
// normal autorun
// 用一个 reaction 来管理该 autorun
reaction = new Reaction(
name,
function(this: Reaction) {
this.track(reactionRunner)
},
opts.onError,
opts.requiresObservable
)
}
function reactionRunner() {
view(reaction)
}
// 将该 reaction 列入计划表
reaction.schedule()
// 返回销毁方法
return reaction.getDisposer()
}计划表维护了一个全局的数组,里面存的 Reactions 就是该 batch(批次) 中需要执行的 Reaction。
schedule() {
// Reaction 已经在重新计算的计划表内,直接返回
if (!this._isScheduled) {
this._isScheduled = true
// 该 Reaction 加入全局的待重新计算数组中
globalState.pendingReactions.push(this)
runReactions()
}
}export function runReactions() {
// 惰性更新,若此时处于事务中,inBatch > 0,会直接返回
if (globalState.inBatch > 0 || globalState.isRunningReactions) return
reactionScheduler(runReactionsHelper)
}function runReactionsHelper() {
globalState.isRunningReactions = true
// 取出当前批次收集的所有 Reaction
const allReactions = globalState.pendingReactions
let iterations = 0
// 当执行 Reaction 时,可能触发新的 Reaction(Reaction 内允许设置 Observable的值),加入到 pendingReactions 中
while (allReactions.length > 0) {
// 设定 Reaction 计算的最大迭代次数,避免造成死循环
if (++iterations === MAX_REACTION_ITERATIONS) {
// ... error
allReactions.splice(0) // clear reactions
}
let remainingReactions = allReactions.splice(0)
for (let i = 0, l = remainingReactions.length; i < l; i++)
remainingReactions[i].runReaction()
}
globalState.isRunningReactions = false
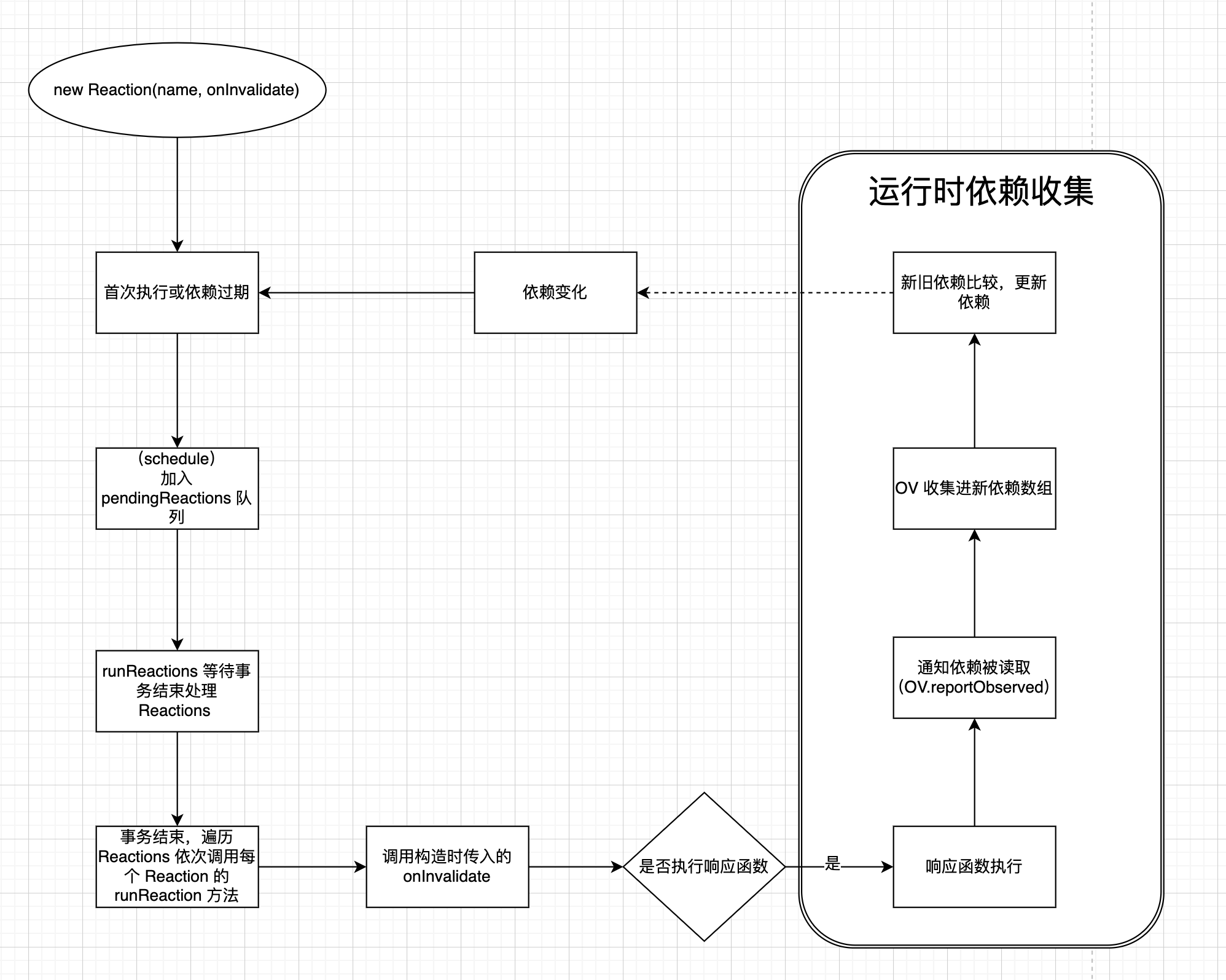
}接下来就是执行 Reaction 的逻辑了,主要目的是运行 cb ,收集用到的 OV。
runReaction() {
if (!this.isDisposed) {
// 开启一个事务处理,因为运行 cb 的过程中可能会再加 Reaction 到计划表(比如依赖更新)
startBatch()
this._isScheduled = false
// 判断 Reaction 收集的依赖状态
// 如状态机所示,只有在 NO_TRACKING | STALE | 判断 COMPUTED 值变化时才会执行 Reaction
if (shouldCompute(this)) {
this._isTrackPending = true
try {
// 处理 cb
this.onInvalidate()
// ...
} catch (e) {
this.reportExceptionInDerivation(e)
}
}
endBatch()
}
}this.onInvalidate 这里就开始处理 cb 了,核心逻辑是:
function trackDerivedFunction<T>(derivation: IDerivation, f: () => T, context: any) {
// ...
// 把 Reaction 和之前收集的被观察者状态都置为 UP_TO_DATE
changeDependenciesStateTo0(derivation)
derivation.newObserving = new Array(derivation.observing.length + 100)
// 记录新的依赖的数量
derivation.unboundDepsCount = 0
// 每次执行都分配一个 uid
derivation.runId = ++globalState.runId
// 当前 Derivation 记录到全局的 trackingDerivation 中,这样被观察的 Observable 在其 reportObserved 方法中就能获取到该 Derivation
const prevTracking = globalState.trackingDerivation
globalState.trackingDerivation = derivation
let result
if (globalState.disableErrorBoundaries === true) {
// debug 环境不 catch 异常,若出错堆栈清晰
result = f.call(context)
} else {
try {
// 执行响应函数 cb ,收集使用到的所有依赖,加入 newObserving 数组中
result = f.call(context)
} catch (e) {
result = new CaughtException(e)
}
}
globalState.trackingDerivation = prevTracking
// 比较新旧依赖,更新依赖
bindDependencies(derivation)
// 如果配置了 requiresObservable 但是 cb 内没引用 OV 的话,报警告
warnAboutDerivationWithoutDependencies(derivation)
// ...
}getter 里干了啥?(追踪依赖)
执行 cb 的时候,读取到 observable 的值,以装饰器修饰方式为例,会走到:
read(key: PropertyKey) {
return this.values.get(key)!.get()
}this.values.get(key) 拿到的就是 OV,OV 的 get:
public get(): T {
this.reportObserved()
return this.dehanceValue(this.value)
}
function reportObserved(observable: IObservable): boolean {
// ...
const derivation = globalState.trackingDerivation
if (derivation !== null) {
// 避免重复收集 OV
if (derivation.runId !== observable.lastAccessedBy) {
observable.lastAccessedBy = derivation.runId
derivation.newObserving![derivation.unboundDepsCount++] = observable
if (!observable.isBeingObserved) {
observable.isBeingObserved = true
observable.onBecomeObserved() // 触发监听钩子
}
}
return true
} else if (observable.observers.size === 0 && globalState.inBatch > 0) {
// 如果 OV 没有 derivation 观察了,准备清除 Observable
queueForUnobservation(observable)
}
return false
}其实就是把 OV 收集在 Reaction 的 newObserving 上,至此追踪依赖就结束了。
处理依赖
接着就是处理收集到的依赖:
- 替换 Derivation 的依赖数组为新收集的依赖
- 找出新旧依赖数组不相交的元素,解绑旧依赖数组中不相交的 OV 与该 Derivation 的关系(OV 不再收集 Derivation),绑定新依赖数组中不相交的 OV 与该 Derivation 的关系
function bindDependencies(derivation: IDerivation) {
// invariant(derivation.dependenciesState !== IDerivationState.NOT_TRACKING, "INTERNAL ERROR bindDependencies expects derivation.dependenciesState !== -1");
const prevObserving = derivation.observing
const observing = (derivation.observing = derivation.newObserving!)
// 记录更新依赖过程中,新观察的 Derivation 的最新状态
let lowestNewObservingDerivationState = IDerivationState.UP_TO_DATE
// Go through all new observables and check diffValue: (this list can contain duplicates):
// 0: first occurrence, change to 1 and keep it
// 1: extra occurrence, drop it
// 遍历新的 observing 数组,使用 diffValue 这个属性来辅助 diff 过程:
// 所有 Observable 的 diffValue 初值都是0(要么刚被创建,继承自 BaseAtom 的初值0;
// 要么经过上次的 bindDependencies 后,置为了0)
// 如果 diffValue 为0,保留该 Observable,并将 diffValue 置为1
// 如果 diffValue 为1,说明是重复的依赖,无视掉
let i0 = 0,
l = derivation.unboundDepsCount // 新收集的 ObservableValue 数量
for (let i = 0; i < l; i++) {
const dep = observing[i]
if (dep.diffValue === 0) {
// 这次此次 Reaction 最新收集的依赖
dep.diffValue = 1
// i0 不等于 i,即前面有重复的 dep 被无视,依次往前移覆盖
if (i0 !== i) observing[i0] = dep
i0++
}
// Upcast is 'safe' here, because if dep is IObservable, `dependenciesState` will be undefined,
// not hitting the condition
if (((dep as any) as IDerivation).dependenciesState > lowestNewObservingDerivationState) {
lowestNewObservingDerivationState = ((dep as any) as IDerivation).dependenciesState
}
}
observing.length = i0 // 只保留最新一次追踪 Reaction 收集的依赖
derivation.newObserving = null // newObserving shouldn't be needed outside tracking (statement moved down to work around FF bug, see #614)
// Go through all old observables and check diffValue: (it is unique after last bindDependencies)
// 0: it's not in new observables, unobserve it
// 1: it keeps being observed, don't want to notify it. change to 0
// 遍历 prevObserving 数组,检查 diffValue:(经过上一次的 bindDependencies 后,该数组中不会有重复)
// 如果为 0,说明没有在 newObserving 中出现,调用 removeObserver 将 dep 和 derivation 间的联系移除
// 如果为 1,依然被观察,将 diffValue 置为0(在下面的循环有用处)
l = prevObserving.length
while (l--) {
const dep = prevObserving[l]
if (dep.diffValue === 0) {
removeObserver(dep, derivation)
}
dep.diffValue = 0
}
// Go through all new observables and check diffValue: (now it should be unique)
// 0: it was set to 0 in last loop. don't need to do anything.
// 1: it wasn't observed, let's observe it. set back to 0
// 再次遍历新的 observing 数组,检查 diffValue
// 如果为0,说明是在上面的循环中置为了0,即是本来就被观察的依赖,什么都不做
// 如果为1,说明是新增的依赖,调用 addObserver 新增依赖,并将 diffValue 置为0,为下一次 bindDependencies 做准备
while (i0--) {
const dep = observing[i0]
if (dep.diffValue === 1) {
dep.diffValue = 0
addObserver(dep, derivation)
}
}
// Some new observed derivations may become stale during this derivation computation
// so they have had no chance to propagate staleness (#916)
// 某些新观察的 Derivation 可能在依赖更新过程中过期
// 避免这些 Derivation 没有机会传播过期的信息(#916)
if (lowestNewObservingDerivationState !== IDerivationState.UP_TO_DATE) {
derivation.dependenciesState = lowestNewObservingDerivationState
derivation.onBecomeStale()
}
}上面用了 diffValue 标志位,降低朴素算法的时间复杂度为线性,给个例子吧:
const a = {};
const b = {};
const c = {};
const prev = [a, b];
const curr = [b, c];
// 找出不相交的 a, c 并做一些处理你会怎么做?
// 朴素算法的处理就是 O(n^2)
prev.forEach((p, ip) => {
curr.forEach((c, ic) => {
// includes 时间复杂度为 O(n),假设用户用 set,has 是常数级的,暂且视此处也为常数级
if (p !== c && prev.includes(c)) {
// 解绑
}
if (p !== c && !prev.includes(c)) {
// 绑定
}
})
})如果加个 diffValue 作为标志的话,算法就为:
const a = {d: 0};
const b = {d: 0};
const c = {d: 0};
const prev = [a, b];
const curr = [b, c];
curr.forEach(c => c.d = 1);
prev.forEach(p => {
if (p.d === 0) {
// 解绑
}
p.d = 0;
})
curr.forEach(c => {
if (c.d === 1) {
// 绑定
}
c.d = 0;
})至此,依赖关系处理完了,该 Derivation 上收集了使用的 OV,每个 OV 也收集了派生的 Derivation。并且把该 Derivation、之前收集的依赖的状态置为了 UP_TO_DATE。
derivation.dependenciesState = IDerivationState.UP_TO_DATE
OV.lowestObserverState = IDerivationState.UP_TO_DATE
新绑定的依赖状态为 NOT_TRACKING | UP_TO_DATE。
setter 里干了啥?
同样以装饰器修饰的属性为例:
write(key: PropertyKey, newValue) {
const instance = this.target
// 拿到 OV
const observable = this.values.get(key)
// 处理计算值情况
if (observable instanceof ComputedValue) {
observable.set(newValue)
return
}
// enhance 新值,Object.is 对比新旧值
newValue = (observable as any).prepareNewValue(newValue)
if (newValue !== globalState.UNCHANGED) {
// 值变化
// ...
(observable as ObservableValue<any>).setNewValue(newValue)
// ...
}
}
setNewValue(newValue: T) {
const oldValue = this.value
this.value = newValue
this.reportChanged()
// ...
}
reportChanged() {
startBatch()
// 通知变化
propagateChanged(this)
endBatch()
}通知变化其实做了三件事情:
- 把 OV 的状态变为 STALE
- 遍历 OV 绑定的所有 Derivation,并处理
- 处理完一个 Derivation 则变更其状态为 STALE
export function propagateChanged(observable: IObservable) {
// invariantLOS(observable, "changed start");
if (observable.lowestObserverState === IDerivationState.STALE) return
observable.lowestObserverState = IDerivationState.STALE
// Ideally we use for..of here, but the downcompiled version is really slow...
// 如果被解除 observableValue 和 Observer 的绑定关系,这里就不会遍历到。
observable.observers.forEach(d => {
if (d.dependenciesState === IDerivationState.UP_TO_DATE) {
// ...
// 遍历 OV 绑定的所有 Derivation,并处理
d.onBecomeStale()
}
d.dependenciesState = IDerivationState.STALE
})
// invariantLOS(observable, "changed end");
}d.onBecomeStale() 干了啥呢?
其实就是再把该 Derivation 加入计划表,排期执行 Reaction,重复我们上面的流程。
onBecomeStale() {
this.schedule()
}Reaction 流程概览

Computed Value
CV 是比较特殊的存在,即作为依赖,也作为派生。它是用它的副作用里的依赖,是它内部依赖的派生。
流程
在 Mobx 里也是用一个类 ComputedValue 来管理:
class ComputedValue {
dependenciesState = IDerivationState.NOT_TRACKING // 作为派生的初始状态
lowestObserverState = IDerivationState.UP_TO_DATE // 作为依赖的初始状态
observing: IObservable[] = [] // CV 作为派生,收集的所有依赖
newObserving = null // 每 batch 执行中新收集的依赖
observers = new Set<IDerivation>() // CV 作为依赖,收集的所有派生
// ...
constructor(options: IComputedValueOptions<T>) {
// 检错机制,参数必须含 get
invariant(options.get, "missing option for computed: get")
// getter 回调作为内部依赖的派生
this.derivation = options.get!
this.name = options.name || "ComputedValue@" + getNextId()
// 处理 setter
// ...
// 对于新旧计算结果的对比方法,默认 Object.is
this.equals =
options.equals ||
((options as any).compareStructural || (options as any).struct
? comparer.structural
: comparer.default)
// getter 回调计算的上下文
this.scope = options.context
// 是否必须要求在副作用内使用计算属性
this.requiresReaction = !!options.requiresReaction
// 是否一直强制绑定计算属性以及内部依赖。 (默认当计算属性没被用时,会同步解绑计算属性与其内部依赖)
this.keepAlive = !!options.keepAlive
}
}每次当计算属性被访问时,会触发内部 get 方法,主要做两件事:
- 通知被观察
- 评估是否需要计算,若需要,则处理一些状态改变。
public get(): T {
if (this.isComputing) fail(`Cycle detected in computation ${this.name}: ${this.derivation}`)
if (globalState.inBatch === 0 && this.observers.size === 0 && !this.keepAlive) {
// 在非副作用里访问,简单计算出返回值
if (shouldCompute(this)) {
this.warnAboutUntrackedRead()
startBatch() // See perf test 'computed memoization'
this.value = this.computeValue(false)
endBatch()
}
} else {
// 在副作用里访问
// 通知被观察,加入 Reaction.newObserving,之后会建立起计算属性与其派生的绑定关系
reportObserved(this)
// 评估作为 Derivation 是否需要计算
// 若需要,重新计算完后,自身作为 D 的状态变为 U_T_D 。依赖状态变更为 U_T_D
// 若值有改变,则改变自身作为 OV 的状态为 STALE,收集的观察者(第一次读取时没有)的状为 STALE
if (shouldCompute(this)) if (this.trackAndCompute()) propagateChangeConfirmed(this)
}
const result = this.value!
if (isCaughtException(result)) throw result.cause
return result
}评估计算
第一次访问肯定需要计算的,我们来看下评估计算的方法:
export function shouldCompute(derivation: IDerivation): boolean {
switch (derivation.dependenciesState) {
case IDerivationState.UP_TO_DATE:
return false
case IDerivationState.NOT_TRACKING: // 第一次访问时
case IDerivationState.STALE:
return true
case IDerivationState.POSSIBLY_STALE: {
// 暂时跳过
}
}
}在知道允许计算后,就开始计算和追踪依赖了
private trackAndCompute(): boolean {
// ...
const oldValue = this.value
// 有没有解除计算属性与其内部依赖的绑定关系,第一次肯定是没有绑定关系的
const wasSuspended =
/* see #1208 */ this.dependenciesState === IDerivationState.NOT_TRACKING
// 新计算的值
const newValue = this.computeValue(true)
const changed =
wasSuspended ||
isCaughtException(oldValue) ||
isCaughtException(newValue) ||
!this.equals(oldValue, newValue)
if (changed) {
// 若有改变则赋新值
this.value = newValue
}
return changed
}
computeValue(track: boolean) {
this.isComputing = true
globalState.computationDepth++
let res: T | CaughtException
if (track) {
// 不仅计算、也追踪内部依赖
res = trackDerivedFunction(this, this.derivation, this.scope)
} else {
// 简单重新计算
if (globalState.disableErrorBoundaries === true) {
res = this.derivation.call(this.scope)
} else {
try {
res = this.derivation.call(this.scope)
} catch (e) {
res = new CaughtException(e)
}
}
}
globalState.computationDepth--
this.isComputing = false
return res
}trackDerivedFunction 很熟悉了,在讲解 AutoRun 时分析过了,主要就是干了三件事,其实就是计算和追踪依赖:
- 因为派生即将执行,所以改变派生与依赖的状态为 U_T_D
- 执行派生
- 建立派生与依赖的绑定关系
如果结果有改变的话,就执行 propagateChangeConfirmed(this),也就是改变 CV 作为依赖、以及其派生的状态为 STALE 了。
export function propagateChangeConfirmed(observable: IObservable) {
// invariantLOS(observable, "confirmed start");
// 让 computedValue 作为 OV ,改变自身状态与其收集的 Derivation 都为不稳定
if (observable.lowestObserverState === IDerivationState.STALE) return
observable.lowestObserverState = IDerivationState.STALE
// 第一次访问计算属性时,还未建立起派生与计算属性的绑定关系,所以 observers 为空
// 之后访问的情况下,就会把派生的状态由 P_S 转为 STALE 了
observable.observers.forEach(d => {
if (d.dependenciesState === IDerivationState.POSSIBLY_STALE)
d.dependenciesState = IDerivationState.STALE
else if (
d.dependenciesState === IDerivationState.UP_TO_DATE // this happens during computing of `d`, just keep lowestObserverState up to date.
) // 当派生已经开始重新处理时会遇到这个情况,此时不需要改变计算属性作为 OV 的状态和派生的状态了,因为派生已经重新处理了,并且也会拿到最新的计算值,此时直接把计算属性作为 OV 的状态设为 U_T_D 就好
// 比如,计算属性的派生是与依赖 A 与计算属性绑定的
// 某个 action 里面先改变了计算属性的深依赖值,再改变依赖 A 的值
// 此时派生的状态会先变 P_S ,再变为 STALE,
// 在一轮 batch 结束后,重新处理派生 Reaction,会直接重新计算计算属性的值,走到这个判断条件内,不需要再管派生应不应该重新处理了,人家已经由依赖 A 的变化确定要处理了。
observable.lowestObserverState = IDerivationState.UP_TO_DATE
})
// invariantLOS(observable, "confirmed end");
}之后在计算属性的派生接着处理,就会把计算属性作为依赖的状态和派生自己的状态变为 U_T_D,等着下一次依赖改变再次处理了。
计算属性的派生内其他依赖改变
这种情况会再次读取计算属性的值,但由于 shouldCompute 会评估计算属性的派生状态为 U_T_D,也就是其深依赖没有改变,所以会直接取上一次计算的结果来使用,不会再有其他任何处理。
计算属性的依赖改变
这种情况下就会按依赖变化的正常流程走,AutoRun 里讲过,触发深依赖的 setter,改变深依赖和派生(计算属性)的状态为 STALE,然后执行派生的 onBecomeStale() 方法。
onBecomeStale() 方法对于 Reaction 而言就是加入计划表,等待 batch 结束统一再次处理一遍 Reaction。对于计算属性而言稍微有点变化:
- 会改变计算属性作为 OV 的状态为 P_S,改变计算属性的派生的状态为 P_S
- 把计算属性的派生列入计划表
onBecomeStale() {
propagateMaybeChanged(this)
}
export function propagateMaybeChanged(observable: IObservable) {
// invariantLOS(observable, "maybe start");
if (observable.lowestObserverState !== IDerivationState.UP_TO_DATE) return
observable.lowestObserverState = IDerivationState.POSSIBLY_STALE
observable.observers.forEach(d => {
if (d.dependenciesState === IDerivationState.UP_TO_DATE) {
d.dependenciesState = IDerivationState.POSSIBLY_STALE
if (d.isTracing !== TraceMode.NONE) {
logTraceInfo(d, observable)
}
// 将 Reaction 加入计划表,等待重新处理
d.onBecomeStale()
}
})
// invariantLOS(observable, "maybe end");
}然后等深依赖的 batch 结束,就会在计划表取出 Reaction 做处理,回到 Autorun 里的逻辑:
runReaction() {
if (!this.isDisposed) {
// 开启一个事务处理,因为运行 cb 的过程中可能会再加 Reaction 到计划表(比如依赖更新)
startBatch()
this._isScheduled = false
// 判断 Reaction 收集的依赖状态
// 如状态机所示,只有在 NO_TRACKING | STALE | 判断 COMPUTED 值变化时才会执行 Reaction
if (shouldCompute(this)) {
this._isTrackPending = true
try {
// 处理 cb
this.onInvalidate()
// ...
} catch (e) {
this.reportExceptionInDerivation(e)
}
}
endBatch()
}
}评估计算
此时派生的状态就是 P_S,评估计算时就会走到下面的逻辑:
- 找到派生依赖的计算属性,并重新计算,改变计算属性深依赖和自身作为派生的状态为 U_T_D
- 若重新计算值有变化,则会改变计算属性作为 OV 的状态和计算属性派生的状态为 STALE,接着处理派生,让派生回调重新执行,重新建立依赖绑定关系。
- 若重新计算值没变化,则直接返回旧值,改变派生和计算属性作为 OV 的状态为 U_T_D,阻止派生继续处理。
export function shouldCompute(derivation: IDerivation): boolean {
switch (derivation.dependenciesState) {
case IDerivationState.UP_TO_DATE:
return false
case IDerivationState.NOT_TRACKING:
case IDerivationState.STALE:
return true
case IDerivationState.POSSIBLY_STALE: {
// state propagation can occur outside of action/reactive context #2195
const prevAllowStateReads = allowStateReadsStart(true)
// 此处对 CV 的 get 不需要 reportObserved (untrackedStart 的作用),之后会再执行进行收集
// 这里的主要目的是:判断重新计算的值有没有改变,然后根据结果做一些状态变更
const prevUntracked = untrackedStart() // no need for those computeds to be reported, they will be picked up in trackDerivedFunction.
const obs = derivation.observing, // 拿到所有 OV
l = obs.length
for (let i = 0; i < l; i++) {
const obj = obs[i]
// 找到 CV 的 OV
if (isComputedValue(obj)) {
if (globalState.disableErrorBoundaries) {
obj.get()
} else {
try {
// 再次调用 get 重新计算,具体逻辑上面分析过
obj.get()
} catch (e) {
// we are not interested in the value *or* exception at this moment, but if there is one, notify all
// 如果 CV getter 执行异常,那就默认让副作用继续执行一次
untrackedEnd(prevUntracked)
allowStateReadsEnd(prevAllowStateReads)
return true
}
}
// if ComputedValue `obj` actually changed it will be computed and propagated to its observers.
// and `derivation` is an observer of `obj`
// invariantShouldCompute(derivation)
// 若重新计算有变化了,其派生的状态会变成 STALE
if ((derivation.dependenciesState as any) === IDerivationState.STALE) {
untrackedEnd(prevUntracked)
allowStateReadsEnd(prevAllowStateReads)
// 允许派生运行
return true
}
}
}
// 如果重新计算值没有变化,则重置派生与计算属性作为依赖的状态为 U_T_D
changeDependenciesStateTo0(derivation)
untrackedEnd(prevUntracked)
allowStateReadsEnd(prevAllowStateReads)
// 不允许派生继续运行
return false
}
}
}
以上,就达到了计算属性依赖无变化时直接应用旧计算值(避免多余计算)、计算属性依赖变化且重新计算值变化时才会重新处理副作用(避免无效副作用)的目的。
React render
类组件
我们可以用 @observer 去装饰一个组件:
import { observer } from 'mobx-react';
@observer
class AComponent {
render() {
return ...;
};
}实际 observer 做的核心工作就把 render 函数作为派生(用一个派生包住),然后每次 track 重新执行 render 的行为来收集依赖,当依赖改变的时候,就触发 React.Component.prototype.forceUpdate() 去强制重新执行 render 收集依赖、更新视图。
N.B. observer 装饰后,React 的一些 lifecycle 钩子无法触发,所以其实内部还做了一些伪造钩子的操作比如 shouldUpdate、willUnMount 以及一些优化和 fix bug 的操作,对于这些操作这里跳过,只讲核心原理代码。
我们来看看源码里是怎样实现的:
export function observer<T extends IReactComponent>(component: T): T {
// ... 错误操作的报警
// ... 处理 ForwardRef
// 处理 Function component 暂且跳过
if (
typeof component === "function" &&
(!component.prototype || !component.prototype.render) &&
!component["isReactClass"] &&
!Object.prototype.isPrototypeOf.call(React.Component, component)
) {
return observerLite(component as React.StatelessComponent<any>) as T
}
// Class Component
return makeClassComponentObserver(component as React.ComponentClass<any, any>) as T
}
export function makeClassComponentObserver(
componentClass: React.ComponentClass<any, any>
): React.ComponentClass<any, any> {
// 组件原型
const target = componentClass.prototype
if (componentClass[mobxObserverProperty]) {
// 错误操作报警
const displayName = getDisplayName(target)
console.warn(
`The provided component class (${displayName})
has already been declared as an observer component.`
)
} else {
// 表示组件已被 Mobx 作为观察者
componentClass[mobxObserverProperty] = true
}
// 错误报警
if (target.componentWillReact)
throw new Error("The componentWillReact life-cycle event is no longer supported")
// 实现 shouldComponentUpdate
if (componentClass["__proto__"] !== PureComponent) {
if (!target.shouldComponentUpdate) target.shouldComponentUpdate = observerSCU
else if (target.shouldComponentUpdate !== observerSCU)
// n.b. unequal check, instead of existence check, as @observer might be on superclass as well
throw new Error(
"It is not allowed to use shouldComponentUpdate in observer based components."
)
}
// 将 Props、State 包装成 OV
makeObservableProp(target, "props")
makeObservableProp(target, "state")
// 原始 render
const baseRender = target.render
// 被拦截的 render,只首次 mount 会调这个
target.render = function () {
// 原始 render 外部包了一层派生
return makeComponentReactive.call(this, baseRender)
}
patch(target, "componentWillUnmount", function () {
if (isUsingStaticRendering() === true) return
// 组件卸载时,解绑派生与依赖的绑定,避免内存泄漏
this.render[mobxAdminProperty]?.dispose()
this[mobxIsUnmounted] = true
if (!this.render[mobxAdminProperty]) {
// Render may have been hot-swapped and/or overriden by a subclass.
const displayName = getDisplayName(this)
console.warn(
`The reactive render of an observer class component (${displayName})
was overriden after MobX attached. This may result in a memory leak if the
overriden reactive render was not properly disposed.`
)
}
})
return componentClass
}
function makeComponentReactive(render: any) {
if (isUsingStaticRendering() === true) return render.call(this)
// 处理 forceUpdate 带来的副作用 ...
const initialName = getDisplayName(this)
const baseRender = render.bind(this)
let isRenderingPending = false
// 创建一个派生, 带来的副作用就是第二个回调参数
const reaction = new Reaction(`${initialName}.render()`, () => {
if (!isRenderingPending) {
// N.B. Getting here *before mounting* means that a component constructor has side effects (see the relevant test in misc.js)
// This unidiomatic React usage but React will correctly warn about this so we continue as usual
// See #85 / Pull #44
isRenderingPending = true
if (this[mobxIsUnmounted] !== true) {
let hasError = true
try {
// 处理 forceUpdate 带来的副作用 ...
// forceUpdate 强制重渲染
if (!this[skipRenderKey]) Component.prototype.forceUpdate.call(this)
hasError = false
} finally {
// 处理 forceUpdate 带来的副作用 ...
if (hasError) reaction.dispose()
}
}
}
})
reaction["reactComponent"] = this
reactiveRender[mobxAdminProperty] = reaction
// 之后 forceUpdate 的时候,重新执行的 render 都只是 reactiveRender
this.render = reactiveRender
function reactiveRender() {
isRenderingPending = false
let exception = undefined
let rendering = undefined
// 为该 reaction 派生收集原 render 函数内的依赖
reaction.track(() => {
try {
// 执行原 render 函数,拿到虚拟节点
rendering = _allowStateChanges(false, baseRender)
} catch (e) {
exception = e
}
})
if (exception) {
throw exception
}
// 返回虚拟节点给 React
return rendering
}
return reactiveRender.call(this)
}函数组件
函数组件要达到的目的和类组件是一致的,都是 rerender 重新收集依赖,依赖变化触发 rerender。但是函数组件不能用 forceUpdate 这个 API,所以 Mobx 内部用了 React hooks 的小 trick 去实现了 forceUpdate 的效果。
由于这种小 trick 带来的副作用更多,所以这部分 mobx-react-light 里的处理很冗余,提炼代码来做讲解:
function observerLite(baseFuncComponent) {
return function(props) {
const [tick, setTick] = useState(0);
// 利用 useState 伪造 forceUpdate
function forceUpdate() {
setTick(tick + 1);
}
// 造一个函数组件的派生,useMemo 保证派生不会 rebuild
// 组件内依赖变化时,invoke forceUpdate,rerender
const r = useMemo(() => new Reaction('包裹函数组件的派生', forceUpdate), []);
// 组件卸载时解绑派生与依赖,避免内存泄漏
useEffect(() => () => r.dispose(), []);
let vnodes = null;
// 每轮 rerender 重新执行函数组件,追踪依赖
r.track(() => {
vnodes = baseFuncComponent({...props, tick});
})
// 返回虚拟节点给 React
return vnodes;
}
}其余 API
action
以装饰器 action 修饰函数 fn 为例,其实就是重写了 fn 的描述符,把函数体由 createAction 包了一层:
return {
// name 函数名、descriptor.value 函数体
value: createAction(name, descriptor.value),
enumerable: false,
configurable: true, // See #1477
writable: true // for typescript, this must be writable, otherwise it cannot inherit :/ (see inheritable actions test)
}export function createAction(actionName: string, fn: Function, ref?: Object): Function & IAction {
// ...
// 外部调用 fn 时,真正执行的是这个方法
const res = function() {
// executeAction 内部核心工作就是让 fn 的执行处于一轮事务当中
return executeAction(actionName, fn, ref || this, arguments)
}
;(res as any).isMobxAction = true
// ...
return res as any
}export function executeAction(actionName: string, fn: Function, scope?: any, args?: IArguments) {
const runInfo = _startAction(actionName, scope, args)
try {
return fn.apply(scope, args)
} catch (err) {
runInfo.error = err
throw err
} finally {
_endAction(runInfo)
}
}
// startAction 除了 startBatch 以外的操作,都是为了确实新开启一轮事务的纯净性,不被之前上下文的操作所影响。
export function _startAction(actionName: string, scope: any, args?: IArguments): IActionRunInfo {
// ...
let startTime: number = 0
// 在 action 里,对 OV 的读取不收集方法 fn。因为 action 方法并不是副作用,而是要改变依赖的动作。
const prevDerivation = untrackedStart()
startBatch() // 开启一轮新事务
// 允许对依赖写
const prevAllowStateChanges = allowStateChangesStart(true)
// 允许对依赖读
const prevAllowStateReads = allowStateReadsStart(true)
// 记录该轮事务的一些信息,方便 endAction 时回退,保持开启事务前的状态纯净。
const runInfo = {
prevDerivation,
prevAllowStateChanges,
prevAllowStateReads,
notifySpy,
startTime,
actionId: nextActionId++,
parentActionId: currentActionId
}
currentActionId = runInfo.actionId
return runInfo
}
// 除了结束事务的操作,其余都是根据记录的该轮事务的一些信息,回退保持开启事务前的状态纯净。
export function _endAction(runInfo: IActionRunInfo) {
if (currentActionId !== runInfo.actionId) {
fail("invalid action stack. did you forget to finish an action?")
}
currentActionId = runInfo.parentActionId
if (runInfo.error !== undefined) {
globalState.suppressReactionErrors = true
}
// 回退开启事务前依赖的改变权限
allowStateChangesEnd(runInfo.prevAllowStateChanges)
// 回退开启事务前依赖的读取权限
allowStateReadsEnd(runInfo.prevAllowStateReads)
// 结束事务,准备批量处理收集的 Reaction
endBatch()
// 回退开启事务前的派生追踪
untrackedEnd(runInfo.prevDerivation)
// ...
globalState.suppressReactionErrors = false
}其实看源码一目了然了,主要目的就是让 action 的函数执行身处于一轮新的事务中,好处就是为了多次改变某 Derivation 的依赖时,只处理一次。回归上文讲得 transaction 的概念:
一个 Action 开始和结束时同时伴随着事务的启动和结束,确保 Action 中(可能多次)对状态的修改只触发一次 Reaction 的重新执行。
额外 API
额外的 API 在熟悉了上文的所有内容后,阅读起来应该比较简单了,鉴于 API 太多,不一一做分析,感兴趣自行挖掘。
Mobx 设计**
Mobx 作者 Michel Weststrate 有在一篇推文中阐述过 Mobx 设计理念,但是有点过于细节,不熟悉 Mobx 机制的同学可能不太看得懂。以下,在基于这篇推文结合上述源码,我用中文提炼一下,感兴趣可以去看原文。
对状态改变作出反应永远好过于对状态改变作出动作
针对这点其实与 Vue 响应式传递的理念相同,就是数据驱动。
再分析这句话,“作出反应” 意味着状态与副作用的绑定关系由框架(库)给你做好,状态改变自动通知到副作用,不用使用者(开发者)人为地处理。
“作出动作”则是在使用者已知状态更改的情况下,手动去通知副作用更新。 这起码就有一个操作是使用者必做的:手动在副作用内订阅状态的变化,这至少带来两个缺陷:
- 无法保证订阅量的冗余性,可能订阅多了可能少了,导致应用出现不符合预期的情况。
- 会让业务代码变得更 dirty,不好组织
最小的、一致的订阅集
以 render 作为副作用举例,假如 render 里有条件语句:
render() {
if (依赖 A) {
return 组件 1;
}
return 依赖 B ? 组件 2 : 组件 3;
}首先,如果交给用户手动订阅,必须只能依赖 A、B 的状态一起订阅才行,如果订阅少了无法出现预期的 re-render。
然后交给框架去做处理怎样才好? 依赖 A、B 一起订阅当然没毛病,但是假设依赖 A、B 初始化时都有值,我们有必要让 render 订阅依赖 B 的状态吗?
没必要,为什么?想一想如果此时依赖 B 的状态变化了 re-render 呈现的效果会有什么不同吗?
所以在初始化时就订阅所有的状态是冗余的,假如应用程序复杂、状态多了,没必要的内存分配就会更多,对性能有损耗。
故 Mobx 实现了运行时处理依赖的机制,保证副作用绑定的是最小的、一致的订阅集。源码参见上述 “getter 里干了啥?” 与 “处理依赖” 章节。
派生计算的合理性
说人话就是:杜绝丢失计算、冗余计算。
丢失计算:Mobx 的策略是引入状态机的概念去管理依赖与派生,让数学的逻辑性保证不会丢失计算。
冗余计算:
- 对于非计算属性状态,引入事务概念,保证同一批次中所有对状态的同步更改,状态对应的派生只计算一次。
- 对于计算属性,计算属性作为派生时,当其依赖变化,计算属性不会立即重新计算,会等到计算属性自身作为状态所绑定的派生再次用到计算属性值时才去重新计算。并且计算出相同值会阻止派生继续处理。
通用性(笔者补充)
就 Mobx 库本身,与 UI render 没有绑定关系,与 event loop 中异步机制没绑定关系。
所以 Mobx 不像 Vue 2.x 响应式处理一样,需要收集 Wachter 然后赶在 ui render 前异步迭代处理 Wachter 对应的副作用。更新粒度也不一样,Vue 2.x 是组件, Mobx 就是副作用,副作用可以但不仅是组件。
不知道 Vue 3.x 把响应式抽成一个 package 后还是不是这样,没研读过其源码了。(不过 Vue 2.x 源码记得当时研究了很久,现在也忘得差不多了,现在再去捡起来又觉得耗时且带来的收益不大,可恶又无奈的学习边际效应 -_-||)
故:Mobx 适用于任一使用 ES 语法的场景。
若觉得有帮助,欢迎 star watch ✍🏼
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")