点击本页面右上角的 Watch 在弹出框中点击 Watching 订阅本博客,这样本博客的所有文章更新和评论都会在github首页出现。
公众号(刚申请,之后文章会往上面发):
有深度的Java技术博客
点击本页面右上角的 Watch 在弹出框中点击 Watching 订阅本博客,这样本博客的所有文章更新和评论都会在github首页出现。
公众号(刚申请,之后文章会往上面发):









































































































































































































关于synchronized的底层实现,网上有很多文章了。但是很多文章要么作者根本没看代码,仅仅是根据网上其他文章总结、照搬而成,难免有些错误;要么很多点都是一笔带过,对于为什么这样实现没有一个说法,让像我这样的读者意犹未尽。
本系列文章将对HotSpot的synchronized锁实现进行全面分析,内容包括偏向锁、轻量级锁、重量级锁的加锁、解锁、锁升级流程的原理及源码分析,希望给在研究synchronized路上的同学一些帮助。主要包括以下几篇文章:
更多文章见个人博客:https://github.com/farmerjohngit/myblog
大概花费了两周的实现看代码(花费了这么久时间有些忏愧,主要是对C++、JVM底层机制、JVM调试以及汇编代码不太熟),将synchronized涉及到的代码基本都看了一遍,其中还包括在JVM中添加日志验证自己的猜想,总的来说目前对synchronized这块有了一个比较全面清晰的认识,但水平有限,有些细节难免有些疏漏,还望请大家指正。
本篇文章将对synchronized机制做个大致的介绍,包括用以承载锁状态的对象头、锁的几种形式、各种形式锁的加锁和解锁流程、什么时候会发生锁升级。需要注意的是本文旨在介绍背景和概念,在讲述一些流程的时候,只提到了主要case,对于实现细节、运行时的不同分支都在后面的文章中详细分析。
本人看的JVM版本是jdk8u,具体版本号以及代码可以在这里看到。
Java中提供了两种实现同步的基础语义:synchronized方法和synchronized块, 我们来看个demo:
public class SyncTest {
public void syncBlock(){
synchronized (this){
System.out.println("hello block");
}
}
public synchronized void syncMethod(){
System.out.println("hello method");
}
}当SyncTest.java被编译成class文件的时候,synchronized关键字和synchronized方法的字节码略有不同,我们可以用javap -v 命令查看class文件对应的JVM字节码信息,部分信息如下:
{
public void syncBlock();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=1
0: aload_0
1: dup
2: astore_1
3: monitorenter // monitorenter指令进入同步块
4: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
7: ldc #3 // String hello block
9: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
12: aload_1
13: monitorexit // monitorexit指令退出同步块
14: goto 22
17: astore_2
18: aload_1
19: monitorexit // monitorexit指令退出同步块
20: aload_2
21: athrow
22: return
Exception table:
from to target type
4 14 17 any
17 20 17 any
public synchronized void syncMethod();
descriptor: ()V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED //添加了ACC_SYNCHRONIZED标记
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #5 // String hello method
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
}从上面的中文注释处可以看到,对于synchronized关键字而言,javac在编译时,会生成对应的monitorenter和monitorexit指令分别对应synchronized同步块的进入和退出,有两个monitorexit指令的原因是:为了保证抛异常的情况下也能释放锁,所以javac为同步代码块添加了一个隐式的try-finally,在finally中会调用monitorexit命令释放锁。而对于synchronized方法而言,javac为其生成了一个ACC_SYNCHRONIZED关键字,在JVM进行方法调用时,发现调用的方法被ACC_SYNCHRONIZED修饰,则会先尝试获得锁。
在JVM底层,对于这两种synchronized语义的实现大致相同,在后文中会选择一种进行详细分析。
因为本文旨在分析synchronized的实现原理,因此对于其使用的一些问题就不赘述了,不了解的朋友可以看看这篇文章。
传统的锁(也就是下文要说的重量级锁)依赖于系统的同步函数,在linux上使用mutex互斥锁,最底层实现依赖于futex,关于futex可以看我之前的文章,这些同步函数都涉及到用户态和内核态的切换、进程的上下文切换,成本较高。对于加了synchronized关键字但运行时并没有多线程竞争,或两个线程接近于交替执行的情况,使用传统锁机制无疑效率是会比较低的。
在JDK 1.6之前,synchronized只有传统的锁机制,因此给开发者留下了synchronized关键字相比于其他同步机制性能不好的印象。
在JDK 1.6引入了两种新型锁机制:偏向锁和轻量级锁,它们的引入是为了解决在没有多线程竞争或基本没有竞争的场景下因使用传统锁机制带来的性能开销问题。
在看这几种锁机制的实现前,我们先来了解下对象头,它是实现多种锁机制的基础。
因为在Java中任意对象都可以用作锁,因此必定要有一个映射关系,存储该对象以及其对应的锁信息(比如当前哪个线程持有锁,哪些线程在等待)。一种很直观的方法是,用一个全局map,来存储这个映射关系,但这样会有一些问题:需要对map做线程安全保障,不同的synchronized之间会相互影响,性能差;另外当同步对象较多时,该map可能会占用比较多的内存。
所以最好的办法是将这个映射关系存储在对象头中,因为对象头本身也有一些hashcode、GC相关的数据,所以如果能将锁信息与这些信息共存在对象头中就好了。
在JVM中,对象在内存中除了本身的数据外还会有个对象头,对于普通对象而言,其对象头中有两类信息:mark word和类型指针。另外对于数组而言还会有一份记录数组长度的数据。
类型指针是指向该对象所属类对象的指针,mark word用于存储对象的HashCode、GC分代年龄、锁状态等信息。在32位系统上mark word长度为32bit,64位系统上长度为64bit。为了能在有限的空间里存储下更多的数据,其存储格式是不固定的,在32位系统上各状态的格式如下:
可以看到锁信息也是存在于对象的mark word中的。当对象状态为偏向锁(biasable)时,mark word存储的是偏向的线程ID;当状态为轻量级锁(lightweight locked)时,mark word存储的是指向线程栈中Lock Record的指针;当状态为重量级锁(inflated)时,为指向堆中的monitor对象的指针。
重量级锁是我们常说的传统意义上的锁,其利用操作系统底层的同步机制去实现Java中的线程同步。
重量级锁的状态下,对象的mark word为指向一个堆中monitor对象的指针。
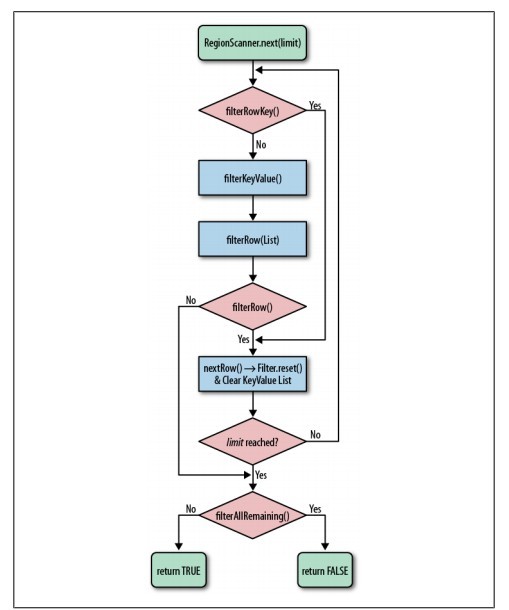
一个monitor对象包括这么几个关键字段:cxq(下图中的ContentionList),EntryList ,WaitSet,owner。
其中cxq ,EntryList ,WaitSet都是由ObjectWaiter的链表结构,owner指向持有锁的线程。
当一个线程尝试获得锁时,如果该锁已经被占用,则会将该线程封装成一个ObjectWaiter对象插入到cxq的队列尾部,然后暂停当前线程。当持有锁的线程释放锁前,会将cxq中的所有元素移动到EntryList中去,并唤醒EntryList的队首线程。
如果一个线程在同步块中调用了Object#wait方法,会将该线程对应的ObjectWaiter从EntryList移除并加入到WaitSet中,然后释放锁。当wait的线程被notify之后,会将对应的ObjectWaiter从WaitSet移动到EntryList中。
以上只是对重量级锁流程的一个简述,其中涉及到的很多细节,比如ObjectMonitor对象从哪来?释放锁时是将cxq中的元素移动到EntryList的尾部还是头部?notfiy时,是将ObjectWaiter移动到EntryList的尾部还是头部?
关于具体的细节,会在重量级锁的文章中分析。
JVM的开发者发现在很多情况下,在Java程序运行时,同步块中的代码都是不存在竞争的,不同的线程交替的执行同步块中的代码。这种情况下,用重量级锁是没必要的。因此JVM引入了轻量级锁的概念。
线程在执行同步块之前,JVM会先在当前的线程的栈帧中创建一个Lock Record,其包括一个用于存储对象头中的 mark word(官方称之为Displaced Mark Word)以及一个指向对象的指针。下图右边的部分就是一个Lock Record。
1.在线程栈中创建一个Lock Record,将其obj(即上图的Object reference)字段指向锁对象。
2.直接通过CAS指令将Lock Record的地址存储在对象头的mark word中,如果对象处于无锁状态则修改成功,代表该线程获得了轻量级锁。如果失败,进入到步骤3。
3.如果是当前线程已经持有该锁了,代表这是一次锁重入。设置Lock Record第一部分(Displaced Mark Word)为null,起到了一个重入计数器的作用。然后结束。
4.走到这一步说明发生了竞争,需要膨胀为重量级锁。
1.遍历线程栈,找到所有obj字段等于当前锁对象的Lock Record。
2.如果Lock Record的Displaced Mark Word为null,代表这是一次重入,将obj设置为null后continue。
3.如果Lock Record的Displaced Mark Word不为null,则利用CAS指令将对象头的mark word恢复成为Displaced Mark Word。如果成功,则continue,否则膨胀为重量级锁。
Java是支持多线程的语言,因此在很多二方包、基础库中为了保证代码在多线程的情况下也能正常运行,也就是我们常说的线程安全,都会加入如synchronized这样的同步语义。但是在应用在实际运行时,很可能只有一个线程会调用相关同步方法。比如下面这个demo:
import java.util.ArrayList;
import java.util.List;
public class SyncDemo1 {
public static void main(String[] args) {
SyncDemo1 syncDemo1 = new SyncDemo1();
for (int i = 0; i < 100; i++) {
syncDemo1.addString("test:" + i);
}
}
private List<String> list = new ArrayList<>();
public synchronized void addString(String s) {
list.add(s);
}
}在这个demo中为了保证对list操纵时线程安全,对addString方法加了synchronized的修饰,但实际使用时却只有一个线程调用到该方法,对于轻量级锁而言,每次调用addString时,加锁解锁都有一个CAS操作;对于重量级锁而言,加锁也会有一个或多个CAS操作(这里的’一个‘、’多个‘数量词只是针对该demo,并不适用于所有场景)。
在JDK1.6中为了提高一个对象在一段很长的时间内都只被一个线程用做锁对象场景下的性能,引入了偏向锁,在第一次获得锁时,会有一个CAS操作,之后该线程再获取锁,只会执行几个简单的命令,而不是开销相对较大的CAS命令。我们来看看偏向锁是如何做的。
当JVM启用了偏向锁模式(1.6以上默认开启),当新创建一个对象的时候,如果该对象所属的class没有关闭偏向锁模式(什么时候会关闭一个class的偏向模式下文会说,默认所有class的偏向模式都是是开启的),那新创建对象的mark word将是可偏向状态,此时mark word中的thread id(参见上文偏向状态下的mark word格式)为0,表示未偏向任何线程,也叫做匿名偏向(anonymously biased)。
case 1:当该对象第一次被线程获得锁的时候,发现是匿名偏向状态,则会用CAS指令,将mark word中的thread id由0改成当前线程Id。如果成功,则代表获得了偏向锁,继续执行同步块中的代码。否则,将偏向锁撤销,升级为轻量级锁。
case 2:当被偏向的线程再次进入同步块时,发现锁对象偏向的就是当前线程,在通过一些额外的检查后(细节见后面的文章),会往当前线程的栈中添加一条Displaced Mark Word为空的Lock Record中,然后继续执行同步块的代码,因为操纵的是线程私有的栈,因此不需要用到CAS指令;由此可见偏向锁模式下,当被偏向的线程再次尝试获得锁时,仅仅进行几个简单的操作就可以了,在这种情况下,synchronized关键字带来的性能开销基本可以忽略。
case 3.当其他线程进入同步块时,发现已经有偏向的线程了,则会进入到撤销偏向锁的逻辑里,一般来说,会在safepoint中去查看偏向的线程是否还存活,如果存活且还在同步块中则将锁升级为轻量级锁,原偏向的线程继续拥有锁,当前线程则走入到锁升级的逻辑里;如果偏向的线程已经不存活或者不在同步块中,则将对象头的mark word改为无锁状态(unlocked),之后再升级为轻量级锁。
由此可见,偏向锁升级的时机为:当锁已经发生偏向后,只要有另一个线程尝试获得偏向锁,则该偏向锁就会升级成轻量级锁。当然这个说法不绝对,因为还有批量重偏向这一机制。
当有其他线程尝试获得锁时,是根据遍历偏向线程的lock record来确定该线程是否还在执行同步块中的代码。因此偏向锁的解锁很简单,仅仅将栈中的最近一条lock record的obj字段设置为null。需要注意的是,偏向锁的解锁步骤中并不会修改对象头中的thread id。
下图展示了锁状态的转换流程:
另外,偏向锁默认不是立即就启动的,在程序启动后,通常有几秒的延迟,可以通过命令 -XX:BiasedLockingStartupDelay=0来关闭延迟。
从上文偏向锁的加锁解锁过程中可以看出,当只有一个线程反复进入同步块时,偏向锁带来的性能开销基本可以忽略,但是当有其他线程尝试获得锁时,就需要等到safe point时将偏向锁撤销为无锁状态或升级为轻量级/重量级锁。safe point这个词我们在GC中经常会提到,其代表了一个状态,在该状态下所有线程都是暂停的(大概这么个意思),详细可以看这篇文章。总之,偏向锁的撤销是有一定成本的,如果说运行时的场景本身存在多线程竞争的,那偏向锁的存在不仅不能提高性能,而且会导致性能下降。因此,JVM中增加了一种批量重偏向/撤销的机制。
存在如下两种情况:(见官方论文第4小节):
1.一个线程创建了大量对象并执行了初始的同步操作,之后在另一个线程中将这些对象作为锁进行之后的操作。这种case下,会导致大量的偏向锁撤销操作。
2.存在明显多线程竞争的场景下使用偏向锁是不合适的,例如生产者/消费者队列。
批量重偏向(bulk rebias)机制是为了解决第一种场景。批量撤销(bulk revoke)则是为了解决第二种场景。
其做法是:以class为单位,为每个class维护一个偏向锁撤销计数器,每一次该class的对象发生偏向撤销操作时,该计数器+1,当这个值达到重偏向阈值(默认20)时,JVM就认为该class的偏向锁有问题,因此会进行批量重偏向。每个class对象会有一个对应的epoch字段,每个处于偏向锁状态对象的mark word中也有该字段,其初始值为创建该对象时,class中的epoch的值。每次发生批量重偏向时,就将该值+1,同时遍历JVM中所有线程的栈,找到该class所有正处于加锁状态的偏向锁,将其epoch字段改为新值。下次获得锁时,发现当前对象的epoch值和class的epoch不相等,那就算当前已经偏向了其他线程,也不会执行撤销操作,而是直接通过CAS操作将其mark word的Thread Id 改成当前线程Id。
当达到重偏向阈值后,假设该class计数器继续增长,当其达到批量撤销的阈值后(默认40),JVM就认为该class的使用场景存在多线程竞争,会标记该class为不可偏向,之后,对于该class的锁,直接走轻量级锁的逻辑。
Java中的synchronized有偏向锁、轻量级锁、重量级锁三种形式,分别对应了锁只被一个线程持有、不同线程交替持有锁、多线程竞争锁三种情况。当条件不满足时,锁会按偏向锁->轻量级锁->重量级锁 的顺序升级。JVM种的锁也是能降级的,只不过条件很苛刻,不在我们讨论范围之内。该篇文章主要是对Java的synchronized做个基本介绍,后文会有更详细的分析。
本文为synchronized系列第二篇。主要内容为分析偏向锁的实现。
偏向锁的诞生背景和基本原理在上文中已经讲过了,强烈建议在有看过上篇文章的基础下阅读本文。
更多文章见个人博客:https://github.com/farmerjohngit/myblog
本系列文章将对HotSpot的synchronized锁实现进行全面分析,内容包括偏向锁、轻量级锁、重量级锁的加锁、解锁、锁升级流程的原理及源码分析,希望给在研究synchronized路上的同学一些帮助。主要包括以下几篇文章:
本文将分为几块内容:
1.偏向锁的入口
2.偏向锁的获取流程
3.偏向锁的撤销流程
4.偏向锁的释放流程
5.偏向锁的批量重偏向和批量撤销
本文分析的JVM版本是JVM8,具体版本号以及代码可以在这里看到。
目前网上的很多文章,关于偏向锁源码入口都找错地方了,导致我之前对于偏向锁的很多逻辑一直想不通,走了很多弯路。
synchronized分为synchronized代码块和synchronized方法,其底层获取锁的逻辑都是一样的,本文讲解的是synchronized代码块的实现。上篇文章也说过,synchronized代码块是由monitorenter和monitorexit两个指令实现的。
关于HotSpot虚拟机中获取锁的入口,网上很多文章要么给出的方法入口为interpreterRuntime.cpp#monitorenter,要么给出的入口为bytecodeInterpreter.cpp#1816。包括占小狼的这篇文章关于锁入口的位置说法也是有问题的(当然文章还是很好的,在我刚开始研究synchronized的时候,小狼哥的这篇文章给了我很多帮助)。
要找锁的入口,肯定是要在源码中找到对monitorenter指令解析的地方。在HotSpot的中有两处地方对monitorenter指令进行解析:一个是在bytecodeInterpreter.cpp#1816 ,另一个是在templateTable_x86_64.cpp#3667。
前者是JVM中的字节码解释器(bytecodeInterpreter),用C++实现了每条JVM指令(如monitorenter、invokevirtual等),其优点是实现相对简单且容易理解,缺点是执行慢。后者是模板解释器(templateInterpreter),其对每个指令都写了一段对应的汇编代码,启动时将每个指令与对应汇编代码入口绑定,可以说是效率做到了极致。模板解释器的实现可以看这篇文章,在研究的过程中也请教过文章作者‘汪先生’一些问题,这里感谢一下。
在HotSpot中,只用到了模板解释器,字节码解释器根本就没用到,R大的读书笔记中说的很清楚了,大家可以看看,这里不再赘述。
所以montorenter的解析入口在模板解释器中,其代码位于templateTable_x86_64.cpp#3667。通过调用路径:templateTable_x86_64#monitorenter->interp_masm_x86_64#lock_object进入到偏向锁入口macroAssembler_x86#biased_locking_enter,在这里大家可以看到会生成对应的汇编代码。需要注意的是,不是说每次解析monitorenter指令都会调用biased_locking_enter,而是只会在JVM启动的时候调用该方法生成汇编代码,之后对指令的解析是通过直接执行汇编代码。
其实bytecodeInterpreter的逻辑和templateInterpreter的逻辑是大同小异的,因为templateInterpreter中都是汇编代码,比较晦涩,所以看bytecodeInterpreter的实现会便于理解一点。但这里有个坑,在jdk8u之前,bytecodeInterpreter并没有实现偏向锁的逻辑。我之前看的JDK8-87ee5ee27509这个版本就没有实现偏向锁的逻辑,导致我看了很久都没看懂。在这个commit中对bytecodeInterpreter加入了偏向锁的支持,我大致了看了下和templateInterpreter对比除了栈结构不同外,其他逻辑大致相同,所以下文就按bytecodeInterpreter中的代码对偏向锁逻辑进行讲解。templateInterpreter的汇编代码讲解可以看这篇文章,其实汇编源码中都有英文注释,了解了汇编几个基本指令的作用再结合注释理解起来也不是很难。
下面开始偏向锁获取流程分析,代码在bytecodeInterpreter.cpp#1816。注意本文代码都有所删减。
CASE(_monitorenter): {
// lockee 就是锁对象
oop lockee = STACK_OBJECT(-1);
// derefing's lockee ought to provoke implicit null check
CHECK_NULL(lockee);
// code 1:找到一个空闲的Lock Record
BasicObjectLock* limit = istate->monitor_base();
BasicObjectLock* most_recent = (BasicObjectLock*) istate->stack_base();
BasicObjectLock* entry = NULL;
while (most_recent != limit ) {
if (most_recent->obj() == NULL) entry = most_recent;
else if (most_recent->obj() == lockee) break;
most_recent++;
}
//entry不为null,代表还有空闲的Lock Record
if (entry != NULL) {
// code 2:将Lock Record的obj指针指向锁对象
entry->set_obj(lockee);
int success = false;
uintptr_t epoch_mask_in_place = (uintptr_t)markOopDesc::epoch_mask_in_place;
// markoop即对象头的mark word
markOop mark = lockee->mark();
intptr_t hash = (intptr_t) markOopDesc::no_hash;
// code 3:如果锁对象的mark word的状态是偏向模式
if (mark->has_bias_pattern()) {
uintptr_t thread_ident;
uintptr_t anticipated_bias_locking_value;
thread_ident = (uintptr_t)istate->thread();
// code 4:这里有几步操作,下文分析
anticipated_bias_locking_value =
(((uintptr_t)lockee->klass()->prototype_header() | thread_ident) ^ (uintptr_t)mark) &
~((uintptr_t) markOopDesc::age_mask_in_place);
// code 5:如果偏向的线程是自己且epoch等于class的epoch
if (anticipated_bias_locking_value == 0) {
// already biased towards this thread, nothing to do
if (PrintBiasedLockingStatistics) {
(* BiasedLocking::biased_lock_entry_count_addr())++;
}
success = true;
}
// code 6:如果偏向模式关闭,则尝试撤销偏向锁
else if ((anticipated_bias_locking_value & markOopDesc::biased_lock_mask_in_place) != 0) {
markOop header = lockee->klass()->prototype_header();
if (hash != markOopDesc::no_hash) {
header = header->copy_set_hash(hash);
}
// 利用CAS操作将mark word替换为class中的mark word
if (Atomic::cmpxchg_ptr(header, lockee->mark_addr(), mark) == mark) {
if (PrintBiasedLockingStatistics)
(*BiasedLocking::revoked_lock_entry_count_addr())++;
}
}
// code 7:如果epoch不等于class中的epoch,则尝试重偏向
else if ((anticipated_bias_locking_value & epoch_mask_in_place) !=0) {
// 构造一个偏向当前线程的mark word
markOop new_header = (markOop) ( (intptr_t) lockee->klass()->prototype_header() | thread_ident);
if (hash != markOopDesc::no_hash) {
new_header = new_header->copy_set_hash(hash);
}
// CAS替换对象头的mark word
if (Atomic::cmpxchg_ptr((void*)new_header, lockee->mark_addr(), mark) == mark) {
if (PrintBiasedLockingStatistics)
(* BiasedLocking::rebiased_lock_entry_count_addr())++;
}
else {
// 重偏向失败,代表存在多线程竞争,则调用monitorenter方法进行锁升级
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
success = true;
}
else {
// 走到这里说明当前要么偏向别的线程,要么是匿名偏向(即没有偏向任何线程)
// code 8:下面构建一个匿名偏向的mark word,尝试用CAS指令替换掉锁对象的mark word
markOop header = (markOop) ((uintptr_t) mark & ((uintptr_t)markOopDesc::biased_lock_mask_in_place |(uintptr_t)markOopDesc::age_mask_in_place |epoch_mask_in_place));
if (hash != markOopDesc::no_hash) {
header = header->copy_set_hash(hash);
}
markOop new_header = (markOop) ((uintptr_t) header | thread_ident);
// debugging hint
DEBUG_ONLY(entry->lock()->set_displaced_header((markOop) (uintptr_t) 0xdeaddead);)
if (Atomic::cmpxchg_ptr((void*)new_header, lockee->mark_addr(), header) == header) {
// CAS修改成功
if (PrintBiasedLockingStatistics)
(* BiasedLocking::anonymously_biased_lock_entry_count_addr())++;
}
else {
// 如果修改失败说明存在多线程竞争,所以进入monitorenter方法
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
success = true;
}
}
// 如果偏向线程不是当前线程或没有开启偏向模式等原因都会导致success==false
if (!success) {
// 轻量级锁的逻辑
//code 9: 构造一个无锁状态的Displaced Mark Word,并将Lock Record的lock指向它
markOop displaced = lockee->mark()->set_unlocked();
entry->lock()->set_displaced_header(displaced);
//如果指定了-XX:+UseHeavyMonitors,则call_vm=true,代表禁用偏向锁和轻量级锁
bool call_vm = UseHeavyMonitors;
// 利用CAS将对象头的mark word替换为指向Lock Record的指针
if (call_vm || Atomic::cmpxchg_ptr(entry, lockee->mark_addr(), displaced) != displaced) {
// 判断是不是锁重入
if (!call_vm && THREAD->is_lock_owned((address) displaced->clear_lock_bits())) { //code 10: 如果是锁重入,则直接将Displaced Mark Word设置为null
entry->lock()->set_displaced_header(NULL);
} else {
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
}
}
UPDATE_PC_AND_TOS_AND_CONTINUE(1, -1);
} else {
// lock record不够,重新执行
istate->set_msg(more_monitors);
UPDATE_PC_AND_RETURN(0); // Re-execute
}
}再回顾下对象头中mark word的格式:
JVM中的每个类也有一个类似mark word的prototype_header,用来标记该class的epoch和偏向开关等信息。上面的代码中lockee->klass()->prototype_header()即获取class的prototype_header。
code 1,从当前线程的栈中找到一个空闲的Lock Record(即代码中的BasicObjectLock,下文都用Lock Record代指),判断Lock Record是否空闲的依据是其obj字段 是否为null。注意这里是按内存地址从低往高找到最后一个可用的Lock Record,换而言之,就是找到内存地址最高的可用Lock Record。
code 2,获取到Lock Record后,首先要做的就是为其obj字段赋值。
code 3,判断锁对象的mark word是否是偏向模式,即低3位是否为101。
code 4,这里有几步位运算的操作 anticipated_bias_locking_value = (((uintptr_t)lockee->klass()->prototype_header() | thread_ident) ^ (uintptr_t)mark) & ~((uintptr_t) markOopDesc::age_mask_in_place); 这个位运算可以分为3个部分。
第一部分((uintptr_t)lockee->klass()->prototype_header() | thread_ident) 将当前线程id和类的prototype_header相或,这样得到的值为(当前线程id + prototype_header中的(epoch + 分代年龄 + 偏向锁标志 + 锁标志位)),注意prototype_header的分代年龄那4个字节为0
第二部分 ^ (uintptr_t)mark 将上面计算得到的结果与锁对象的markOop进行异或,相等的位全部被置为0,只剩下不相等的位。
第三部分 & ~((uintptr_t) markOopDesc::age_mask_in_place) markOopDesc::age_mask_in_place为...0001111000,取反后,变成了...1110000111,除了分代年龄那4位,其他位全为1;将取反后的结果再与上面的结果相与,将上面异或得到的结果中分代年龄给忽略掉。
code 5,anticipated_bias_locking_value==0代表偏向的线程是当前线程且mark word的epoch等于class的epoch,这种情况下什么都不用做。
code 6,(anticipated_bias_locking_value & markOopDesc::biased_lock_mask_in_place) != 0代表class的prototype_header或对象的mark word中偏向模式是关闭的,又因为能走到这已经通过了mark->has_bias_pattern()判断,即对象的mark word中偏向模式是开启的,那也就是说class的prototype_header不是偏向模式。
然后利用CAS指令Atomic::cmpxchg_ptr(header, lockee->mark_addr(), mark) == mark撤销偏向锁,我们知道CAS会有几个参数,1是预期的原值,2是预期修改后的值 ,3是要修改的对象,与之对应,cmpxchg_ptr方法第一个参数是预期修改后的值,第2个参数是修改的对象,第3个参数是预期原值,方法返回实际原值,如果等于预期原值则说明修改成功。
code 7,如果epoch已过期,则需要重偏向,利用CAS指令将锁对象的mark word替换为一个偏向当前线程且epoch为类的epoch的新的mark word。
code 8,CAS将偏向线程改为当前线程,如果当前是匿名偏向则能修改成功,否则进入锁升级的逻辑。
code 9,这一步已经是轻量级锁的逻辑了。从上图的mark word的格式可以看到,轻量级锁中mark word存的是指向Lock Record的指针。这里构造一个无锁状态的mark word,然后存储到Lock Record(Lock Record的格式可以看第一篇文章)。设置mark word是无锁状态的原因是:轻量级锁解锁时是将对象头的mark word设置为Lock Record中的Displaced Mark Word,所以创建时设置为无锁状态,解锁时直接用CAS替换就好了。
code 10, 如果是锁重入,则将Lock Record的Displaced Mark Word设置为null,起到一个锁重入计数的作用。
以上是偏向锁加锁的流程(包括部分轻量级锁的加锁流程),如果当前锁已偏向其他线程||epoch值过期||偏向模式关闭||获取偏向锁的过程中存在并发冲突,都会进入到InterpreterRuntime::monitorenter方法, 在该方法中会对偏向锁撤销和升级。
这里说的撤销是指在获取偏向锁的过程因为不满足条件导致要将锁对象改为非偏向锁状态;释放是指退出同步块时的过程,释放锁的逻辑会在下一小节阐述。请读者注意本文中撤销与释放的区别。
如果获取偏向锁失败会进入到InterpreterRuntime::monitorenter方法
IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem))
...
Handle h_obj(thread, elem->obj());
assert(Universe::heap()->is_in_reserved_or_null(h_obj()),
"must be NULL or an object");
if (UseBiasedLocking) {
// Retry fast entry if bias is revoked to avoid unnecessary inflation
ObjectSynchronizer::fast_enter(h_obj, elem->lock(), true, CHECK);
} else {
ObjectSynchronizer::slow_enter(h_obj, elem->lock(), CHECK);
}
...
IRT_END可以看到如果开启了JVM偏向锁,那会进入到ObjectSynchronizer::fast_enter方法中。
void ObjectSynchronizer::fast_enter(Handle obj, BasicLock* lock, bool attempt_rebias, TRAPS) {
if (UseBiasedLocking) {
if (!SafepointSynchronize::is_at_safepoint()) {
BiasedLocking::Condition cond = BiasedLocking::revoke_and_rebias(obj, attempt_rebias, THREAD);
if (cond == BiasedLocking::BIAS_REVOKED_AND_REBIASED) {
return;
}
} else {
assert(!attempt_rebias, "can not rebias toward VM thread");
BiasedLocking::revoke_at_safepoint(obj);
}
assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
}
slow_enter (obj, lock, THREAD) ;
}如果是正常的Java线程,会走上面的逻辑进入到BiasedLocking::revoke_and_rebias方法,如果是VM线程则会走到下面的BiasedLocking::revoke_at_safepoint。我们主要看BiasedLocking::revoke_and_rebias方法。这个方法的主要作用像它的方法名:撤销或者重偏向,第一个参数封装了锁对象和当前线程,第二个参数代表是否允许重偏向,这里是true。
BiasedLocking::Condition BiasedLocking::revoke_and_rebias(Handle obj, bool attempt_rebias, TRAPS) {
assert(!SafepointSynchronize::is_at_safepoint(), "must not be called while at safepoint");
markOop mark = obj->mark();
if (mark->is_biased_anonymously() && !attempt_rebias) {
//如果是匿名偏向且attempt_rebias==false会走到这里,如锁对象的hashcode方法被调用会出现这种情况,需要撤销偏向锁。
markOop biased_value = mark;
markOop unbiased_prototype = markOopDesc::prototype()->set_age(mark->age());
markOop res_mark = (markOop) Atomic::cmpxchg_ptr(unbiased_prototype, obj->mark_addr(), mark);
if (res_mark == biased_value) {
return BIAS_REVOKED;
}
} else if (mark->has_bias_pattern()) {
// 锁对象开启了偏向模式会走到这里
Klass* k = obj->klass();
markOop prototype_header = k->prototype_header();
//code 1: 如果对应class关闭了偏向模式
if (!prototype_header->has_bias_pattern()) {
markOop biased_value = mark;
markOop res_mark = (markOop) Atomic::cmpxchg_ptr(prototype_header, obj->mark_addr(), mark);
assert(!(*(obj->mark_addr()))->has_bias_pattern(), "even if we raced, should still be revoked");
return BIAS_REVOKED;
//code2: 如果epoch过期
} else if (prototype_header->bias_epoch() != mark->bias_epoch()) {
if (attempt_rebias) {
assert(THREAD->is_Java_thread(), "");
markOop biased_value = mark;
markOop rebiased_prototype = markOopDesc::encode((JavaThread*) THREAD, mark->age(), prototype_header->bias_epoch());
markOop res_mark = (markOop) Atomic::cmpxchg_ptr(rebiased_prototype, obj->mark_addr(), mark);
if (res_mark == biased_value) {
return BIAS_REVOKED_AND_REBIASED;
}
} else {
markOop biased_value = mark;
markOop unbiased_prototype = markOopDesc::prototype()->set_age(mark->age());
markOop res_mark = (markOop) Atomic::cmpxchg_ptr(unbiased_prototype, obj->mark_addr(), mark);
if (res_mark == biased_value) {
return BIAS_REVOKED;
}
}
}
}
//code 3:批量重偏向与批量撤销的逻辑
HeuristicsResult heuristics = update_heuristics(obj(), attempt_rebias);
if (heuristics == HR_NOT_BIASED) {
return NOT_BIASED;
} else if (heuristics == HR_SINGLE_REVOKE) {
//code 4:撤销单个线程
Klass *k = obj->klass();
markOop prototype_header = k->prototype_header();
if (mark->biased_locker() == THREAD &&
prototype_header->bias_epoch() == mark->bias_epoch()) {
// 走到这里说明需要撤销的是偏向当前线程的锁,当调用Object#hashcode方法时会走到这一步
// 因为只要遍历当前线程的栈就好了,所以不需要等到safepoint再撤销。
ResourceMark rm;
if (TraceBiasedLocking) {
tty->print_cr("Revoking bias by walking my own stack:");
}
BiasedLocking::Condition cond = revoke_bias(obj(), false, false, (JavaThread*) THREAD);
((JavaThread*) THREAD)->set_cached_monitor_info(NULL);
assert(cond == BIAS_REVOKED, "why not?");
return cond;
} else {
// 下面代码最终会在VM线程中的safepoint调用revoke_bias方法
VM_RevokeBias revoke(&obj, (JavaThread*) THREAD);
VMThread::execute(&revoke);
return revoke.status_code();
}
}
assert((heuristics == HR_BULK_REVOKE) ||
(heuristics == HR_BULK_REBIAS), "?");
//code5:批量撤销、批量重偏向的逻辑
VM_BulkRevokeBias bulk_revoke(&obj, (JavaThread*) THREAD,
(heuristics == HR_BULK_REBIAS),
attempt_rebias);
VMThread::execute(&bulk_revoke);
return bulk_revoke.status_code();
}
会走到该方法的逻辑有很多,我们只分析最常见的情况:假设锁已经偏向线程A,这时B线程尝试获得锁。
上面的code 1,code 2B线程都不会走到,最终会走到code 4处,如果要撤销的锁偏向的是当前线程则直接调用revoke_bias撤销偏向锁,否则会将该操作push到VM Thread中等到safepoint的时候再执行。
关于VM Thread这里介绍下:在JVM中有个专门的VM Thread,该线程会源源不断的从VMOperationQueue中取出请求,比如GC请求。对于需要safepoint的操作(VM_Operationevaluate_at_safepoint返回true)必须要等到所有的Java线程进入到safepoint才开始执行。 关于safepoint可以参考下这篇文章。
接下来我们着重分析下revoke_bias方法。第一个参数为锁对象,第2、3个参数为都为false
static BiasedLocking::Condition revoke_bias(oop obj, bool allow_rebias, bool is_bulk, JavaThread* requesting_thread) {
markOop mark = obj->mark();
// 如果没有开启偏向模式,则直接返回NOT_BIASED
if (!mark->has_bias_pattern()) {
...
return BiasedLocking::NOT_BIASED;
}
uint age = mark->age();
// 构建两个mark word,一个是匿名偏向模式(101),一个是无锁模式(001)
markOop biased_prototype = markOopDesc::biased_locking_prototype()->set_age(age);
markOop unbiased_prototype = markOopDesc::prototype()->set_age(age);
...
JavaThread* biased_thread = mark->biased_locker();
if (biased_thread == NULL) {
// 匿名偏向。当调用锁对象的hashcode()方法可能会导致走到这个逻辑
// 如果不允许重偏向,则将对象的mark word设置为无锁模式
if (!allow_rebias) {
obj->set_mark(unbiased_prototype);
}
...
return BiasedLocking::BIAS_REVOKED;
}
// code 1:判断偏向线程是否还存活
bool thread_is_alive = false;
// 如果当前线程就是偏向线程
if (requesting_thread == biased_thread) {
thread_is_alive = true;
} else {
// 遍历当前jvm的所有线程,如果能找到,则说明偏向的线程还存活
for (JavaThread* cur_thread = Threads::first(); cur_thread != NULL; cur_thread = cur_thread->next()) {
if (cur_thread == biased_thread) {
thread_is_alive = true;
break;
}
}
}
// 如果偏向的线程已经不存活了
if (!thread_is_alive) {
// 允许重偏向则将对象mark word设置为匿名偏向状态,否则设置为无锁状态
if (allow_rebias) {
obj->set_mark(biased_prototype);
} else {
obj->set_mark(unbiased_prototype);
}
...
return BiasedLocking::BIAS_REVOKED;
}
// 线程还存活则遍历线程栈中所有的Lock Record
GrowableArray<MonitorInfo*>* cached_monitor_info = get_or_compute_monitor_info(biased_thread);
BasicLock* highest_lock = NULL;
for (int i = 0; i < cached_monitor_info->length(); i++) {
MonitorInfo* mon_info = cached_monitor_info->at(i);
// 如果能找到对应的Lock Record说明偏向的线程还在执行同步代码块中的代码
if (mon_info->owner() == obj) {
...
// 需要升级为轻量级锁,直接修改偏向线程栈中的Lock Record。为了处理锁重入的case,在这里将Lock Record的Displaced Mark Word设置为null,第一个Lock Record会在下面的代码中再处理
markOop mark = markOopDesc::encode((BasicLock*) NULL);
highest_lock = mon_info->lock();
highest_lock->set_displaced_header(mark);
} else {
...
}
}
if (highest_lock != NULL) {
// 修改第一个Lock Record为无锁状态,然后将obj的mark word设置为指向该Lock Record的指针
highest_lock->set_displaced_header(unbiased_prototype);
obj->release_set_mark(markOopDesc::encode(highest_lock));
...
} else {
// 走到这里说明偏向线程已经不在同步块中了
...
if (allow_rebias) {
//设置为匿名偏向状态
obj->set_mark(biased_prototype);
} else {
// 将mark word设置为无锁状态
obj->set_mark(unbiased_prototype);
}
}
return BiasedLocking::BIAS_REVOKED;
}需要注意下,当调用锁对象的Object#hash或System.identityHashCode()方法会导致该对象的偏向锁或轻量级锁升级。这是因为在Java中一个对象的hashcode是在调用这两个方法时才生成的,如果是无锁状态则存放在mark word中,如果是重量级锁则存放在对应的monitor中,而偏向锁是没有地方能存放该信息的,所以必须升级。具体可以看这篇文章的hashcode()方法对偏向锁的影响小节(注意:该文中对于偏向锁的加锁描述有些错误),另外我也向该文章作者请教过一些问题,他很热心的回答了我,在此感谢一下!
言归正传,revoke_bias方法逻辑:
monitorenter)的时候都会以从高往低的顺序在栈中找到第一个可用的Lock Record,将其obj字段指向锁对象。每次解锁(即执行monitorexit)的时候都会将最低的一个相关Lock Record移除掉。所以可以通过遍历线程栈中的Lock Record来判断线程是否还在同步块中。Lock Record的Displaced Mark Word设置为null,然后将最高位的Lock Record的Displaced Mark Word 设置为无锁状态,最高位的Lock Record也就是第一次获得锁时的Lock Record(这里的第一次是指重入获取锁时的第一次),然后将对象头指向最高位的Lock Record,这里不需要用CAS指令,因为是在safepoint。 执行完后,就升级成了轻量级锁。原偏向线程的所有Lock Record都已经变成轻量级锁的状态。这里如果看不明白,请回顾上篇文章的轻量级锁加锁过程。偏向锁的释放入口在bytecodeInterpreter.cpp#1923
CASE(_monitorexit): {
oop lockee = STACK_OBJECT(-1);
CHECK_NULL(lockee);
// derefing's lockee ought to provoke implicit null check
// find our monitor slot
BasicObjectLock* limit = istate->monitor_base();
BasicObjectLock* most_recent = (BasicObjectLock*) istate->stack_base();
// 从低往高遍历栈的Lock Record
while (most_recent != limit ) {
// 如果Lock Record关联的是该锁对象
if ((most_recent)->obj() == lockee) {
BasicLock* lock = most_recent->lock();
markOop header = lock->displaced_header();
// 释放Lock Record
most_recent->set_obj(NULL);
// 如果是偏向模式,仅仅释放Lock Record就好了。否则要走轻量级锁or重量级锁的释放流程
if (!lockee->mark()->has_bias_pattern()) {
bool call_vm = UseHeavyMonitors;
// header!=NULL说明不是重入,则需要将Displaced Mark Word CAS到对象头的Mark Word
if (header != NULL || call_vm) {
if (call_vm || Atomic::cmpxchg_ptr(header, lockee->mark_addr(), lock) != lock) {
// CAS失败或者是重量级锁则会走到这里,先将obj还原,然后调用monitorexit方法
most_recent->set_obj(lockee);
CALL_VM(InterpreterRuntime::monitorexit(THREAD, most_recent), handle_exception);
}
}
}
//执行下一条命令
UPDATE_PC_AND_TOS_AND_CONTINUE(1, -1);
}
//处理下一条Lock Record
most_recent++;
}
// Need to throw illegal monitor state exception
CALL_VM(InterpreterRuntime::throw_illegal_monitor_state_exception(THREAD), handle_exception);
ShouldNotReachHere();
}上面的代码结合注释理解起来应该不难,偏向锁的释放很简单,只要将对应Lock Record释放就好了,而轻量级锁则需要将Displaced Mark Word替换到对象头的mark word中。如果CAS失败或者是重量级锁则进入到InterpreterRuntime::monitorexit方法中。该方法会在轻量级与重量级锁的文章中讲解。
批量重偏向和批量撤销的背景可以看上篇文章,相关实现在BiasedLocking::revoke_and_rebias中:
BiasedLocking::Condition BiasedLocking::revoke_and_rebias(Handle obj, bool attempt_rebias, TRAPS) {
...
//code 1:重偏向的逻辑
HeuristicsResult heuristics = update_heuristics(obj(), attempt_rebias);
// 非重偏向的逻辑
...
assert((heuristics == HR_BULK_REVOKE) ||
(heuristics == HR_BULK_REBIAS), "?");
//code 2:批量撤销、批量重偏向的逻辑
VM_BulkRevokeBias bulk_revoke(&obj, (JavaThread*) THREAD,
(heuristics == HR_BULK_REBIAS),
attempt_rebias);
VMThread::execute(&bulk_revoke);
return bulk_revoke.status_code();
}在每次撤销偏向锁的时候都通过update_heuristics方法记录下来,以类为单位,当某个类的对象撤销偏向次数达到一定阈值的时候JVM就认为该类不适合偏向模式或者需要重新偏向另一个对象,update_heuristics就会返回HR_BULK_REVOKE或HR_BULK_REBIAS。进行批量撤销或批量重偏向。
先看update_heuristics方法。
static HeuristicsResult update_heuristics(oop o, bool allow_rebias) {
markOop mark = o->mark();
//如果不是偏向模式直接返回
if (!mark->has_bias_pattern()) {
return HR_NOT_BIASED;
}
// 锁对象的类
Klass* k = o->klass();
// 当前时间
jlong cur_time = os::javaTimeMillis();
// 该类上一次批量撤销的时间
jlong last_bulk_revocation_time = k->last_biased_lock_bulk_revocation_time();
// 该类偏向锁撤销的次数
int revocation_count = k->biased_lock_revocation_count();
// BiasedLockingBulkRebiasThreshold是重偏向阈值(默认20),BiasedLockingBulkRevokeThreshold是批量撤销阈值(默认40),BiasedLockingDecayTime是开启一次新的批量重偏向距离上次批量重偏向的后的延迟时间,默认25000。也就是开启批量重偏向后,经过了一段较长的时间(>=BiasedLockingDecayTime),撤销计数器才超过阈值,那我们会重置计数器。
if ((revocation_count >= BiasedLockingBulkRebiasThreshold) &&
(revocation_count < BiasedLockingBulkRevokeThreshold) &&
(last_bulk_revocation_time != 0) &&
(cur_time - last_bulk_revocation_time >= BiasedLockingDecayTime)) {
// This is the first revocation we've seen in a while of an
// object of this type since the last time we performed a bulk
// rebiasing operation. The application is allocating objects in
// bulk which are biased toward a thread and then handing them
// off to another thread. We can cope with this allocation
// pattern via the bulk rebiasing mechanism so we reset the
// klass's revocation count rather than allow it to increase
// monotonically. If we see the need to perform another bulk
// rebias operation later, we will, and if subsequently we see
// many more revocation operations in a short period of time we
// will completely disable biasing for this type.
k->set_biased_lock_revocation_count(0);
revocation_count = 0;
}
// 自增撤销计数器
if (revocation_count <= BiasedLockingBulkRevokeThreshold) {
revocation_count = k->atomic_incr_biased_lock_revocation_count();
}
// 如果达到批量撤销阈值则返回HR_BULK_REVOKE
if (revocation_count == BiasedLockingBulkRevokeThreshold) {
return HR_BULK_REVOKE;
}
// 如果达到批量重偏向阈值则返回HR_BULK_REBIAS
if (revocation_count == BiasedLockingBulkRebiasThreshold) {
return HR_BULK_REBIAS;
}
// 没有达到阈值则撤销单个对象的锁
return HR_SINGLE_REVOKE;
}当达到阈值的时候就会通过VM 线程在safepoint调用bulk_revoke_or_rebias_at_safepoint, 参数bulk_rebias如果是true代表是批量重偏向否则为批量撤销。attempt_rebias_of_object代表对操作的锁对象o是否运行重偏向,这里是true。
static BiasedLocking::Condition bulk_revoke_or_rebias_at_safepoint(oop o,
bool bulk_rebias,
bool attempt_rebias_of_object,
JavaThread* requesting_thread) {
...
jlong cur_time = os::javaTimeMillis();
o->klass()->set_last_biased_lock_bulk_revocation_time(cur_time);
Klass* k_o = o->klass();
Klass* klass = k_o;
if (bulk_rebias) {
// 批量重偏向的逻辑
if (klass->prototype_header()->has_bias_pattern()) {
// 自增前类中的的epoch
int prev_epoch = klass->prototype_header()->bias_epoch();
// code 1:类中的epoch自增
klass->set_prototype_header(klass->prototype_header()->incr_bias_epoch());
int cur_epoch = klass->prototype_header()->bias_epoch();
// code 2:遍历所有线程的栈,更新类型为该klass的所有锁实例的epoch
for (JavaThread* thr = Threads::first(); thr != NULL; thr = thr->next()) {
GrowableArray<MonitorInfo*>* cached_monitor_info = get_or_compute_monitor_info(thr);
for (int i = 0; i < cached_monitor_info->length(); i++) {
MonitorInfo* mon_info = cached_monitor_info->at(i);
oop owner = mon_info->owner();
markOop mark = owner->mark();
if ((owner->klass() == k_o) && mark->has_bias_pattern()) {
// We might have encountered this object already in the case of recursive locking
assert(mark->bias_epoch() == prev_epoch || mark->bias_epoch() == cur_epoch, "error in bias epoch adjustment");
owner->set_mark(mark->set_bias_epoch(cur_epoch));
}
}
}
}
// 接下来对当前锁对象进行重偏向
revoke_bias(o, attempt_rebias_of_object && klass->prototype_header()->has_bias_pattern(), true, requesting_thread);
} else {
...
// code 3:批量撤销的逻辑,将类中的偏向标记关闭,markOopDesc::prototype()返回的是一个关闭偏向模式的prototype
klass->set_prototype_header(markOopDesc::prototype());
// code 4:遍历所有线程的栈,撤销该类所有锁的偏向
for (JavaThread* thr = Threads::first(); thr != NULL; thr = thr->next()) {
GrowableArray<MonitorInfo*>* cached_monitor_info = get_or_compute_monitor_info(thr);
for (int i = 0; i < cached_monitor_info->length(); i++) {
MonitorInfo* mon_info = cached_monitor_info->at(i);
oop owner = mon_info->owner();
markOop mark = owner->mark();
if ((owner->klass() == k_o) && mark->has_bias_pattern()) {
revoke_bias(owner, false, true, requesting_thread);
}
}
}
// 撤销当前锁对象的偏向模式
revoke_bias(o, false, true, requesting_thread);
}
...
BiasedLocking::Condition status_code = BiasedLocking::BIAS_REVOKED;
if (attempt_rebias_of_object &&
o->mark()->has_bias_pattern() &&
klass->prototype_header()->has_bias_pattern()) {
// 构造一个偏向请求线程的mark word
markOop new_mark = markOopDesc::encode(requesting_thread, o->mark()->age(),
klass->prototype_header()->bias_epoch());
// 更新当前锁对象的mark word
o->set_mark(new_mark);
status_code = BiasedLocking::BIAS_REVOKED_AND_REBIASED;
...
}
...
return status_code;
}
该方法分为两个逻辑:批量重偏向和批量撤销。
先看批量重偏向,分为两步:
code 1 将类中的撤销计数器自增1,之后当该类已存在的实例获得锁时,就会尝试重偏向,相关逻辑在偏向锁获取流程小节中。
code 2 处理当前正在被使用的锁对象,通过遍历所有存活线程的栈,找到所有正在使用的偏向锁对象,然后更新它们的epoch值。也就是说不会重偏向正在使用的锁,否则会破坏锁的线程安全性。
批量撤销逻辑如下:
code 3将类的偏向标记关闭,之后当该类已存在的实例获得锁时,就会升级为轻量级锁;该类新分配的对象的mark word则是无锁模式。
code 4处理当前正在被使用的锁对象,通过遍历所有存活线程的栈,找到所有正在使用的偏向锁对象,然后撤销偏向锁。
如果一个线程在同步块中调用了Object#wait方法, 会将该线程对应的ObjectWaiter从EntryList移除并加入到WaitSet中,然后释放锁。当wait的线程被notify之后,会将对应的ObjectWaiter从WaitSet移动到EntryList中。
个人理解是:wait调用必须在synchronized代码块里。在synchronized进入时候,就已经将ObjectWaiter从EntryList移除;所以当发生wait调用的时候,应该是直接将ObjectWaiter对象加入到WaitSet,然后释放锁,并没有从EntryList移除这一步。
请教大佬一个问题。
现在有一个场景:线程t1加锁然后释放(偏向锁),然后t2来加锁再释放(轻量锁),然后t3来加锁(轻量锁)。
当t2释放的时候,mark word应该是如下图紫色部分吧,接着t3来加锁

t3来加锁执行到源码中(如下图)的这个判断的时候,是会返回true吗?

我请教了别人,得到的回复如下图(红框部分),这使我很困惑。

如果t3(轻量锁)来加锁,这个判断是true的话,那它接着执行里面的多个判断,在当前场景下里面的if和else if不是都不成立吗?接着会执行else代码块


请大神解惑!感谢~
前一篇文章提到了限流的几种常见算法,本文将分析guava限流类RateLimiter的实现。
RateLimiter有两个实现类:SmoothBursty和SmoothWarmingUp,其都是令牌桶算法的变种实现,区别在于SmoothBursty加令牌的速度是恒定的,而SmoothWarmingUp会有个预热期,在预热期内加令牌的速度是慢慢增加的,直到达到固定速度为止。其适用场景是,对于有的系统而言刚启动时能承受的QPS较小,需要预热一段时间后才能达到最佳状态。
更多文章见个人博客:https://github.com/farmerjohngit/myblog
RateLimiter的使用很简单:
//create方法传入的是每秒生成令牌的个数
RateLimiter rateLimiter= RateLimiter.create(1);
for (int i = 0; i < 5; i++) {
//acquire方法传入的是需要的令牌个数,当令牌不足时会进行等待,该方法返回的是等待的时间
double waitTime=rateLimiter.acquire(1);
System.out.println(System.currentTimeMillis()/1000+" , "+waitTime);
}输出如下:
1548070953 , 0.0
1548070954 , 0.998356
1548070955 , 0.998136
1548070956 , 0.99982需要注意的是,当令牌不足时,acquire方法并不会阻塞本次调用,而是会算在下次调用的头上。比如第一次调用时,令牌桶中并没有令牌,但是第一次调用也没有阻塞,而是在第二次调用的时候阻塞了1秒。也就是说,每次调用欠的令牌(如果桶中令牌不足)都是让下一次调用买单。
RateLimiter rateLimiter= RateLimiter.create(1);
double waitTime=rateLimiter.acquire(1000);
System.out.println(System.currentTimeMillis()/1000+" , "+waitTime);
waitTime=rateLimiter.acquire(1);
System.out.println(System.currentTimeMillis()/1000+" , "+waitTime);输出如下:
1548072250 , 0.0
1548073250 , 999.998773
这样设计的目的是:
Last, but not least: consider a RateLimiter with rate of 1 permit per second, currently completely unused, and an expensive acquire(100) request comes. It would be nonsensical to just wait for 100 seconds, and /then/ start the actual task. Why wait without doing anything? A much better approach is to /allow/ the request right away (as if it was an acquire(1) request instead), and postpone /subsequent/ requests as needed. In this version, we allow starting the task immediately, and postpone by 100 seconds future requests, thus we allow for work to get done in the meantime instead of waiting idly.
简单的说就是,如果每次请求都为本次买单会有不必要的等待。比如说令牌增加的速度为每秒1个,初始时桶中没有令牌,这时来了个请求需要100个令牌,那需要等待100s后才能开始这个任务。所以更好的办法是先放行这个请求,然后延迟之后的请求。
另外,RateLimiter还有个tryAcquire方法,如果令牌够会立即返回true,否则立即返回false。
本文主要分析SmoothBursty的实现。
首先看SmoothBursty中的几个关键字段:
// 桶中最多存放多少秒的令牌数
final double maxBurstSeconds;
//桶中的令牌个数
double storedPermits;
//桶中最多能存放多少个令牌,=maxBurstSeconds*每秒生成令牌个数
double maxPermits;
//加入令牌的平均间隔,单位为微秒,如果加入令牌速度为每秒5个,则该值为1000*1000/5
double stableIntervalMicros;
//下一个请求需要等待的时间
private long nextFreeTicketMicros = 0L; 先看创建RateLimiter的create方法。
// permitsPerSecond为每秒生成的令牌数
public static RateLimiter create(double permitsPerSecond) {
return create(permitsPerSecond, SleepingStopwatch.createFromSystemTimer());
}
//SleepingStopwatch主要用于计时和休眠
static RateLimiter create(double permitsPerSecond, SleepingStopwatch stopwatch) {
//创建一个SmoothBursty
RateLimiter rateLimiter = new SmoothBursty(stopwatch, 1.0 /* maxBurstSeconds */);
rateLimiter.setRate(permitsPerSecond);
return rateLimiter;
}create方法主要就是创建了一个SmoothBursty实例,并调用了其setRate方法。注意这里的maxBurstSeconds写死为1.0。
@Override
final void doSetRate(double permitsPerSecond, long nowMicros) {
resync(nowMicros);
double stableIntervalMicros = SECONDS.toMicros(1L) / permitsPerSecond;
this.stableIntervalMicros = stableIntervalMicros;
doSetRate(permitsPerSecond, stableIntervalMicros);
}
void resync(long nowMicros) {
// 如果当前时间比nextFreeTicketMicros大,说明上一个请求欠的令牌已经补充好了,本次请求不用等待
if (nowMicros > nextFreeTicketMicros) {
// 计算这段时间内需要补充的令牌,coolDownIntervalMicros返回的是stableIntervalMicros
double newPermits = (nowMicros - nextFreeTicketMicros) / coolDownIntervalMicros();
// 更新桶中的令牌,不能超过maxPermits
storedPermits = min(maxPermits, storedPermits + newPermits);
// 这里先设置为nowMicros
nextFreeTicketMicros = nowMicros;
}
}
@Override
void doSetRate(double permitsPerSecond, double stableIntervalMicros) {
double oldMaxPermits = this.maxPermits;
maxPermits = maxBurstSeconds * permitsPerSecond;
if (oldMaxPermits == Double.POSITIVE_INFINITY) {
// if we don't special-case this, we would get storedPermits == NaN, below
storedPermits = maxPermits;
} else {
//第一次调用oldMaxPermits为0,所以storedPermits(桶中令牌个数)也为0
storedPermits =
(oldMaxPermits == 0.0)
? 0.0 // initial state
: storedPermits * maxPermits / oldMaxPermits;
}
}setRate方法中设置了maxPermits=maxBurstSeconds * permitsPerSecond;而maxBurstSeconds 为1,所以maxBurstSeconds 只会保存1秒中的令牌数。
需要注意的是SmoothBursty是非public的类,也就是说只能通过RateLimiter.create方法创建,而该方法中的maxBurstSeconds 是写死1.0的,也就是说我们只能创建桶大小为permitsPerSecond*1的SmoothBursty对象(当然反射的方式不在讨论范围),在guava的github仓库里有好几条issue(issue1,issue2,issue3,issue4)希望能由外部设置maxBurstSeconds ,但是并没有看到官方人员的回复。而在唯品会的开源项目vjtools中,有人提出了这个问题,唯品会的同学对guava的RateLimiter进行了拓展。
对于guava的这样设计我很不理解,有清楚的朋友可以说下~
到此为止一个SmoothBursty对象就创建好了,接下来我们分析其acquire方法。
public double acquire(int permits) {
// 计算本次请求需要休眠多久(受上次请求影响)
long microsToWait = reserve(permits);
// 开始休眠
stopwatch.sleepMicrosUninterruptibly(microsToWait);
return 1.0 * microsToWait / SECONDS.toMicros(1L);
}
final long reserve(int permits) {
checkPermits(permits);
synchronized (mutex()) {
return reserveAndGetWaitLength(permits, stopwatch.readMicros());
}
}
final long reserveAndGetWaitLength(int permits, long nowMicros) {
long momentAvailable = reserveEarliestAvailable(permits, nowMicros);
return max(momentAvailable - nowMicros, 0);
}
final long reserveEarliestAvailable(int requiredPermits, long nowMicros) {
// 这里调用了上面提到的resync方法,可能会更新桶中的令牌值和nextFreeTicketMicros
resync(nowMicros);
// 如果上次请求花费的令牌还没有补齐,这里returnValue为上一次请求后需要等待的时间,否则为nowMicros
long returnValue = nextFreeTicketMicros;
double storedPermitsToSpend = min(requiredPermits, this.storedPermits);
// 缺少的令牌数
double freshPermits = requiredPermits - storedPermitsToSpend;
// waitMicros为下一次请求需要等待的时间;SmoothBursty的storedPermitsToWaitTime返回0
long waitMicros =
storedPermitsToWaitTime(this.storedPermits, storedPermitsToSpend)
+ (long) (freshPermits * stableIntervalMicros);
// 更新nextFreeTicketMicros
this.nextFreeTicketMicros = LongMath.saturatedAdd(nextFreeTicketMicros, waitMicros);
// 减少令牌
this.storedPermits -= storedPermitsToSpend;
return returnValue;
}acquire中会调用reserve方法获得当前请求需要等待的时间,然后进行休眠。reserve方法最终会调用到reserveEarliestAvailable,在该方法中会先调用上文提到的resync方法对桶中的令牌进行补充(如果需要的话),然后减少桶中的令牌,以及计算这次请求欠的令牌数及需要等待的时间(由下次请求负责等待)。
如果上一次请求没有欠令牌或欠的令牌已经还清则返回值为nowMicros,否则返回值为上一次请求缺少的令牌个数*生成一个令牌所需要的时间。
本文讲解了RateLimiter子类SmoothBursty的源码,对于另一个子类SmoothWarmingUp的原理大家可以自行分析。相对于传统意义上的令牌桶,RateLimiter的实现还是略有不同,主要体现在一次请求的花费由下一次请求来承担这一点上。
本文为分布式Redis深度历险系列的第二篇,主要内容为Redis的Sentinel功能。
更多文章见个人博客:https://github.com/farmerjohngit/myblog
上一篇介绍了Redis的主从服务器之间是如何同步数据的。试想下,在一主一从或一主多从的结构下,如果主服务器挂了,整个集群就不可用了,单点问题并没有解决。Redis使用Sentinel解决该问题,保障集群的高可用。
保障集群高可用,要具备如下能力:
要实现上述功能,最直观的做法就是,使用一台监控服务器来监视Redis
服务器的状态。
监控服务器和主从服务器间维护一个心跳连接,当超出一定时间没有收到主服务器心跳时,主服务器就会被标记为下线,然后通知从服务器上线成为主服务器。
当原来的主服务器上线后,监控服务器会将其转换为从服务器。
按照上述流程似乎解决了集群高可用的问题,但似乎有哪里不对:如果监控服务器出了问题怎么办?我们可以在加上一个从监控服务器,当主服务器不可用的时候顶上。
但问题是谁来监控'监控服务器'呢?子子孙孙无穷尽也。。
先把疑问放在一旁,先来看下Redis Sentinel集群的实现
和上一小节的想法一样,Redis通过增加额外的Sentinel服务器来监控数据服务器,Sentinel会与所有的主服务器和从服务器保存连接,用以监听服务器状态以及向服务器下达命令。
Sentinel本身是一个特殊状态的Redis服务器,启动命令:
redis-server /xxx/sentinel.conf --sentinel,sentinel模式下的启动流程与普通redis server是不一样的,比如说不会去加载RDB文件以及AOF文件,本身也不会存储业务数据。
Sentinel启动后,会与配置文件中提供的所有主服务器建立两个连接,一个是命令连接,一个是订阅连接。
命令连接用于向服务器发送命令。
订阅连接则是用于订阅服务器的_sentinel_:hello频道,用于获取其他Sentinel信息,下文会详细说。
Sentinel会以一定频率向主服务器发送Info命令获取信息,包括主服务器自身的信息比如说服务器id等,以及对应的从服务器信息,包括ip和port。Sentinel会根据info命令返回的信息更新自己保存的服务器信息,并会与从服务器建立连接。
与和主服务器的交互相似,Sentinel也会以一定频率通过Info命令获取从服务器信息,包括:从服务器ID,从服务器与主服务器的连接状态,从服务器的优先级,从服务器的复制偏移等等。
在如何保障集群高可用小节留下了一个疑问:用如何保证监视服务器的高可用? 在这里我们可以先给出简单回答:用一个监视服务器集群(也就是Sentinel集群)。如何实现,如何保证监视服务器的一致性暂且先不说,我们只要记住需要用若干台Sentinel来保障高可用,那一个Sentinel是如何感知其他的Sentinel的呢?
前面说过,Sentinel在与服务器建立连接时,会建立两个连接,其中一个是订阅连接。Sentinel会定时的通过订阅连接向_sentinel_:hello频道频道发送消息(对Redis发布订阅功能不太了解的同学可以去去了解下),其中包括:
同时,Sentinel也会订阅_sentinel_:hello频道的消息,也就是说Sentinel即向该频道发布消息,又从该频道订阅消息。
Sentinel有一个字典对象sentinels,保存着监视同一主服务器的其他所有Sentinel服务器,当一个Sentinel接收到来自_sentinel_:hello频道的消息时,会先比较发送该消息的是不是自己,如果是则忽略,否则将更新sentinels中的内容,并对新的Sentinel建立连接。
Sentinel默认会以每秒一次的频率向所有建立连接的服务器(主服务器,从服务器,Sentinel服务器)发送PING命令,如果在down-after-milliseconds内都没有收到有效回复,Sentinel会将该服务器标记为主观下线,代表该Sentinel认为这台服务器已经下线了。需要注意的是不同Sentinel的down-after-milliseconds是可以不同的。
为了确保服务器真的已经下线,当Sentinel将某个服务器标记为主观下线后,它会向其他的Sentinel实例发送Sentinel is-master-down-by-addr命令,接收到该命令的Sentinel实例会回复主服务器的状态,代表该Sentinel对该主服务器的连接情况。
Sentinel会统计发出的所有Sentinel is-master-down-by-addr命令的回复,并统计同意将主服务器下线的数量,如果该数量超出了某个阈值,就会将该主服务器标记为客观下线。
当Sentinel将一个主服务器标记为客观下线后,监视该服务器的各个Sentinel会通过Raft算法进行协商,选举出一个领头的Sentinel。
建议你先看Raft算法的基础知识,再来看下文。
规则:
还记得我们在文章开头提出的如何保证Redis服务器高可用的问题吗?
答案就是使用若干台Sentinel服务器,通过Raft一致性算法来保障集群的高可用,只要Sentinel服务器有一半以上的节点都正常,那集群就是可用的。
领头Sentinel将会进行以下3个步骤进行故障转移:
1.在已下线主服务器的所有从服务器中,挑选出一个作为新的主服务器
2.将其他从服务器的主服务器设置成新的
3.将已下线的主服务器的role改成从服务器,并将其主服务器设置成新的,当该服务器重新上线后,就会一个从服务器的角色继续工作
第一步中挑选新的主服务器的规则如下:
1.过滤掉所有已下线的从服务器
2.过滤掉最近5秒没有回复过Sentinel命令的从服务器
3.过滤掉与原主服务器断开时间超过down-after-milliseconds*10的从服务器
4.根据从服务器的优先级进行排序,选择优先级最高的那个
5.如果有多个从服务器优先级相同,则选取复制偏移量最大的那个
6.如果上一步的服务器还有多个,则选取id最小的那个
hotspot/src/share/vm/interpreter/bytecodeInterpreter.cpp:
CASE(_monitorenter) : {
oop lockee = STACK_OBJECT(-1);
// derefing's lockee ought to provoke implicit null check
CHECK_NULL(lockee);
// find a free monitor or one already allocated for this object
// if we find a matching object then we need a new monitor
// since this is recursive enter
BasicObjectLock *limit = istate->monitor_base();
BasicObjectLock *most_recent = (BasicObjectLock *)istate->stack_base();
BasicObjectLock *entry = NULL;
while (most_recent != limit) {
if (most_recent->obj() == NULL)
entry = most_recent;
else if (most_recent->obj() == lockee)
break;
most_recent++;
}
if (entry != NULL) {
entry->set_obj(lockee);
int success = false;
uintptr_t epoch_mask_in_place =
(uintptr_t)markOopDesc::epoch_mask_in_place;
markOop mark = lockee->mark();
intptr_t hash = (intptr_t)markOopDesc::no_hash;
// 余下代码省略本文为分布式Redis深度历险系列的第三篇,主要内容为Redis的Cluster,也就是Redis集群功能。
更多文章见个人博客:https://github.com/farmerjohngit/myblog
Redis集群是Redis官方提供的分布式方案,整个集群通过将所有数据分成16384个槽来进行数据共享。
一个集群由多个Redis节点组成,不同的节点通过CLUSTER MEET命令进行连接:
CLUSTER MEET <ip> <port>
收到命令的节点会与命令中指定的目标节点进行握手,握手成功后目标节点会加入到集群中,看个例子,图片来自于Redis的设计与实现:
一个集群的所有数据被分为16384个槽,可以通过CLUSTER ADDSLOTS命令将槽指派给对应的节点。当所有的槽都有节点负责时,集群处于上线状态,否则处于下线状态不对外提供服务。
clusterNode的位数组slots代表一个节点负责的槽信息。
struct clusterNode {
unsigned char slots[16384/8]; /* slots handled by this node */
int numslots; /* Number of slots handled by this node */
...
}
看个例子,下图中1、3、5、8、9、10位的值为1,代表该节点负责槽1、3、5、8、9、10。
每个Redis Server上都有一个ClusterState的对象,代表了该Server所在集群的信息,其中字段slots记录了集群中所有节点负责的槽信息。
typedef struct clusterState {
// 负责处理各个槽的节点
// 例如 slots[i] = clusterNode_A 表示槽 i 由节点 A 处理
// slots[i] = null 代表该槽目前没有节点负责
clusterNode *slots[REDIS_CLUSTER_SLOTS];
}
可以通过redis-trib工具对槽重新分配,重分配的实现步骤如下:
CLUSTER GETKEYSINSLOT <slot> <count>从源节点获取最多count个槽slot的keyMIGRATE <target_ip> <target_port> <key_name> 0 <timeout> 命令,将被选中的键原子的从源节点迁移至目标节点。在槽重分配的过程中,槽中的一部分数据保存着源节点,另一部分保存在目标节点。这时如果要客户端向源节点发送一个命令,且相关数据在一个正在迁移槽中,源节点处理步骤如图:
当客户端收到一个ASK错误的时候,会根据返回的信息向目标节点重新发起一次请求。
ASK和MOVED的区别主要是ASK是一次性的,MOVED是永久性的,有点像Http协议中的301和302。
我们来看cluster下一次命令的请求过程,假设执行命令 get testKey
cluster client在运行前需要配置若干个server节点的ip和port。我们称这些节点为种子节点。
cluster的客户端在执行命令时,会先通过计算得到key的槽信息,计算规则为:getCRC16(key) & (16384 - 1),得到槽信息后,会从一个缓存map中获得槽对应的redis server信息,如果能获取到,则调到第4步
向种子节点发送slots命令以获得整个集群的槽分布信息,然后跳转到第2步重试命令
向负责该槽的server发起调用
server处理如图:
客户端如果收到MOVED错误,则根据对应的地址跳转到第4步重新请求,
客户段如果收到ASK错误,则根据对应的地址跳转到第4步重新请求,并在请求前带上ASKING标识。
以上步骤大致就是redis cluster下一次命令请求的过程,但忽略了一个细节,如果要查找的数据锁所在的槽正在重分配怎么办?
集群中每个Redis节点都会定期的向集群中的其他节点发送PING消息,如果目标节点没有在有效时间内回复PONG消息,则会被标记为疑似下线。同时将该信息发送给其他节点。当一个集群中有半数负责处理槽的主节点都将某个节点A标记为疑似下线后,那么A会被标记为已下线,将A标记为已下线的节点会将该信息发送给其他节点。
比如说有A,B,C,D,E 5个主节点。E有F、G两个从节点。
当E节点发生异常后,其他节点发送给A的PING消息将不能得到正常回复。当过了最大超时时间后,假设A,B先将E标记为疑似下线;之后C也会将E标记为疑似下线,这时C发现集群中由3个节点(A、B、C)都将E标记为疑似下线,超过集群复制槽的主节点个数的一半(>2.5)则会将E标记为已下线,并向集群广播E下线的消息。
当F、G(E的从节点)收到E被标记已下线的消息后,会根据Raft算法选举出一个新的主节点,新的主节点会将E复制的所有槽指派给自己,然后向集群广播消息,通知其他节点新的主节点信息。
选举新的主节点算法与选举Sentinel头节点的过程很像:
集群的配置纪元是一个自增计数器,它的初始值为0.
当集群里的某个节点开始一次故障转移操作时,集群配置纪元的值会被增一。
对于每个配置纪元,集群里每个负责处理槽的主节点都有一次投票的机会,而第一个向主节点要求投票的从节点将获得主节点的投票。
档从节点发现自己正在复制的主节点进入已下线状态时,从节点会想集群广播一条CLUSTER_TYPE_FAILOVER_AUTH_REQUEST消息,要求所有接收到这条消息、并且具有投票权的主节点向这个从节点投票。
如果一个主节点具有投票权(它正在负责处理槽),并且这个主节点尚未投票给其他从节点,那么主节点将向要求投票的从节点返回一条CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,表示这个主节点支持从节点成为新的主节点。
每个参与选举的从节点都会接收CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,并根据自己收到了多少条这种消息来同济自己获得了多少主节点的支持。
如果集群里有N个具有投票权的主节点,那么当一个从节点收集到大于等于N/2+1张支持票时,这个从节点就会当选为新的主节点。
因为在每一个配置纪元里面,每个具有投票权的主节点只能投一次票,所以如果有N个主节点进行投票,那么具有大于等于N/2+1张支持票的从节点只会有一个,这确保了新的主节点只会有一个。
如果在一个配置纪元里面没有从节点能收集到足够多的支持票,那么集群进入一个新的配置纪元,并再次进行选举,知道选出新的主节点为止。
最后,聊聊redis集群的其他两种实现方案。
客户端做路由,采用一致性hash算法,将key映射到对应的redis节点上。
其优点是实现简单,没有引用其他中间件。
缺点也很明显:是一种静态分片方案,扩容性差。
Jedis中的ShardedJedis是该方案的实现。
该方案在client与redis之间引入一个代理层。client的所有操作都发送给代理层,由代理层实现路由转发给不同的redis服务器。
其优点是: 路由规则可自定义,扩容方便。
缺点是: 代理层有单点问题,多一层转发的网络开销
其开源实现有twitter的twemproxy
和豌豆荚的codis
分布式redis深度历险系列到此为止了,之后一个系列会详细讲讲单机Redis的实现,包括Redis的底层数据结构、对内存占用的优化、基于事件的处理机制、持久化的实现等等偏底层的内容,敬请期待~
一句话介绍,垃圾回收就是由程序自动的回收已死对象。
已死对象就是程序中一定不会再被使用到的对象。
垃圾回收可以分为两个部分,一是如何判断对象已死,二是如何清理掉已死对象。
引用计数法比较好理解,就是为每个对象分配一个计数器,当一个对象被另一个对象引用时,其对应的计数器+1,当引用关系被解除时,计数器-1。当一个对象的计数器值为0时,则代表该对象可以被回收了。
引用计数法的优点是实现简单且回收效率高,而缺点就是无法解决循环引用的问题。
引用计数法在Python等一些语言中有使用到,但jvm并没有采用,关键原因也是其无法解决循环引用的问题(那python的循环引用对象不能被回收?)。
可达性分析是商用jvm中采用的判断对象已死算法。
该算法类似于图遍历,我们把所有对象描述为一张图,节点是对象,边是引用关系。
从GC ROOT节点出发,遍历所有节点,对于遍历到的每个节点都做一个标识,遍历完成后。没有标识的节点说明是可回收的。
这里的GC ROOT在JVM中指的是以下几类对象:
上一节介绍了垃圾回收第一步:判断对象是否可以被回收,这一小节则会阐述一些常用的回收算法。
标记清除算法也比较简单。通常使用一张表(类似)来记录哪些空间已被使用。首先通过可达性分析找到所有的垃圾,然后将其占用的空间释放掉。
该算法的问题是可能会产生大量的内存碎片。
为了解决内存碎片的问题,标记整理在标记清楚算法上做了优化,在找到所有垃圾对象后,不是直接释放掉其占用的空间,而是将所有存活对象往内存一端移动。回收完成后,所有对象都是相邻的。
复制算法将内存区域划分为两个,同一时间只有一个区域有对象,每次垃圾回收时,通过可达性分析算法,找出所有存活对象,将这些存活对象移动到另一区域。为新对象分配内存时,可以通过智能指针的形式,高效简单。
复制算法的缺点是会浪费一部分空间以便存放下次回收后存活的对象且需要一块额外的空间进行担保(当一个区域存放不下存活的对象时)。
在商用jvm中,大多使用的是分代收集算法。
根据对象的特性,可以将内存划分为3个代:年轻代,老年代,永久代(jvm8后称为元空间)。年轻代存放新分配的对象,使用的是复制算法,老年代使用标记清除or标记整理算法。其中年轻代分为一个Eden区和两个Survivor区,其比例默认为8:1:1(-XX:SurvivorRatio),新对象在Eden区分配,当Eden区存放不下时,触发一次Young GC,将Eden区和一个Survivor区域的所有存活对象拷贝到另一个Survivor区域。如果对象大小超过一定大小(-XX:PretenureSizeThreshold),则会直接在老年代分配。老年代采用标记清除或标记整理算法。
年轻代老年代比例默认为3:8(-XX:NewRatio,-Xmn),老年代一般来说要比年轻代要大,因为当年轻代空间不足以存放下新对象时,需要老年代来担保。
年轻代使用复制算法的原因是年轻代对象的创建和回收很频繁,同时大部分对象很快都会死亡,所以复制算法创建和回收对象的效率都比较高。
老年代不使用复制算法的原因是老年代对象通常存活时间比较长,如果采用复制算法,则复制存活对象的开销会比较大,且复制算法是需要其他区域担保的。 所以老年代不使用复制算法。
下文将介绍jvm中常用的垃圾回收器
使用单线程,复制算法实现。在回收的整个过程中需要Stop The World。在单核cpu 的机器上,使用单线程进行垃圾回收效率更高。
使用方法:-XX:+UseSerialGC
ps:在jdk client模式,不指定VM参数,默认是串行垃圾回收器
与Serial相似,但使用标记整理算法实现。
Serial的多线程形式,
-XX:+UseParNewGC(新生代使用并行收集器,老年代使用串行回收收集器)或者-XX:+UseConcMarkSweepGC(新生代使用并行收集器,老年代使用CMS)。
多线程的回收器,高吞吐量(=程序运行时间/(程序运行时间+回收器运行时间)),可以高效率的利用CPU时间,尽快完成程序的运算任务,适合后台应用等对响应时间要求不高的场景。
有一个自适应条件参数(-XX:+UseAdaptiveSizePolicy),当这个参数打开后,无需手动指定新生代大小(-Xmn),Eden和Survivor比例(-XX:SurvivorRatio)等参数,虚拟机会动态调节这些参数来选择最适合的停顿时间(-XX:MaxGCPauseMillis)或吞吐量( -XX:GCTimeRatio)。
Parallel Scavenge是Server级别多CPU机器上的默认GC方式,也可以通过-XX:+UseParallelGC来指定,并且可以采用-XX:ParallelGCThread来指定线程数。
Parallel Scavenge对应的老年代收集器只有Serial Old和Parallel Old。不能与CMS搭配使用的原因是,其使用的框架不同,并不是技术原因。
使用多线程和“标记-整理”算法。与Parallen Scavenge相似,只不过是运用于老年代。
基于标记清除算法实现,关注GC的暂停时间,在注重响应时间的应用上使用。
在说CMS具体步骤前,我们先看下CMS使用的垃圾标记算法:三色标记法
将堆中对象分为3个集合:白色、灰色和黑色
白色集合:需要被回收的对象
黑色集合:没有引用白色集合中的对象,且从GC ROOT可达。该集合的对象是不会被回收的
灰色集合:从根可达但是还没有扫描完其引用的所有对象,该集合的对象不会被回收,且当其引用的白色对象全部被扫描后,会将其加入到黑色集合中。
一般来说,会将被GC ROOT直接引用到的对象初始化到灰色集合,其余所有对象初始化到白色集合,然后开始执行算法:
1.将一个灰色对象加入到黑色集合
2.将其引用到的所有白色对象加入到灰色集合
3.重复上述两步,直到灰色集合为空
该算法保证从GC ROOT出发,所有没有被引用到的对象都在白色集合中,所以最后白色集合中的所有对象就是要回收的对象
分为4个过程,初始标记,并发标记,重新标记,并发清理。
初始标记:
从GC ROOT出发,找到所有被GC ROOT直接引用的节点。此过程需要Stop The World。
并发标记:
以上一步骤的节点为根节点,并发的遍历所有节点。同时会开启Write Barrier.如果在此过程中存在黑色对象增加对白色对象的引用,则会记录下来。
在这里,我们试想下如果三色标记法是先执行步骤2后执行步骤1(上面三色标记算法的步骤),会发生什么?
如下图,在GC过程中,用三色标记法遍历到A这个对象(图1),将A引用到的BCD标记为灰色。之后,在应用程序线程中创建了一个对象E,A引用了它( 图2这个阶段GC是并发标记的)。然后将A标记为黑色(图3)。在gc扫描结束后,E这个对象因为是白色的,所以将被回收掉。这显然是不能接受的,并发垃圾回收器的底线是允许一部分垃圾暂时不回收(见下面的浮动垃圾),但绝不允许从根可达的存活对象被当作垃圾处理掉!
重新标记:
因为并发标记的过程中可能有引用关系的变化,所以该阶段需要Stop The World。以GC ROOT,Writter Barrier中记录的对象为根节点,重新遍历。
这里为什么还需要再遍历GC ROOT?因为Writter Barrier是作用在堆上的,无法感知到GC ROOT上引用关系的变更。
并发清理:
并发的清理所有垃圾对象
CMS通过将步骤拆分,实现了降低STW时间的目的。但CMS也会有以下问题:
1.浮动垃圾,在并发标记的过程中(及之后阶段),可能存在原来被引用的对象变成无人引用了,而在这次gc是发现不会清理这些对象的。
2.cpu敏感,因为用户程序是和GC线程同时运行的,所以会导致GC的过程中程序运行变慢,gc运行时间增长,吞吐量降低。默认回收线程是(CPU数量+3)/4,也就是cpu不足4个时,会有一半的cpu资源给GC线程。
3.空间碎片,标记清除算法都有的问题。当碎片过多时,为大对象分配内存空间就会很麻烦,有时候就是老年代空间有大量空间剩余,但没有连续的大空间来分配当前对象,不得不提前触发full gc。CMS提供一个参数(-XX:+UseCMSCompactAtFullCollection),在Full Gc发生时开启内存合并整理。这个过程是STW的。同时还可以通过参数(-XX:CMSFullGCsBeforeCom-paction)来这只执行多少次不压缩的Full GC后,来一次压缩的。
4.需要更大的内存空间,因为是同时运行的GC和用户程序,所以不能像其他老年代收集器一样,等老年代满了再触发GC,而是要预留一定的空间。CMS可以配置当老年代使用率到达某个阈值时( -XX:CMSInitiatingOccupancyFraction=80 ),开始CMS GC。
在old GC运行的过程中,可能有大量对象从年轻代晋升,而出现老年代存放不下的问题(因为这个时候垃圾还没被回收掉),该问题叫Concurrent Model Failure,这时候会启用Serial Old收集器,重新回收整个老年代。Concurrent Model Failure一般伴随着ParNew promotion failed(晋升担保失败),解决这个问题的办法就是可以让CMS在进行一定次数的Full GC(标记清除)的时候进行一次标记整理算法,或者降低触发cms gc的阈值
讲实话,我还没太看懂,没法写自己的理解,
少年等我。。
本人两年开发经验、18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴、今日头条、滴滴等公司offer,岗位是Java后端开发,最终选择去了阿里巴巴。
面试了很多家公司,感觉大部分公司考察的点都差不多,所以将自己的心得记下来,希望能给正在找或者准备找工作的朋友提供一点帮助。另外,目前在阿里也做面试官的工作,身份从求职者变为面试官,看问题的很多角度也不一样,所以下文中既有求职者的视角,也有面试官的视角。
更多文章见个人博客:https://github.com/farmerjohngit/myblog
公众号(刚申请,之后文章会往上面发):
先说下面试流程,一般大公司都有3-4轮技术面,1轮的HR面。就阿里而言,我共经历了4轮技术面,前两轮主要是问基础和项目实现,第3轮是交叉面,两个面试官,主要是问项目实现和拓展。第4轮是部门老大面,主要就问一些架构、技术和业务的理解、个人发展比较抽象的东西了。
HR面主要就是跟你聊聊天,看看你的个人稳定性、价值观、主动性之类的,一般HR是不会挂人的,但很多人在HR面后挂了,原因其实不是你在HR面的表现不好(少数情况除外),而是你之前几面的表现一般,比60分要高一点(所以没在前面的面试直接挂了你),但是又没达到80分,这个时候公司基于hc、人才配比、与其他候选人的对比等多个维度考虑,最终决定是否给你offer。
另外要特别说下的是,今日头条对算法的考察会比较多,我面了4轮技术,每一轮都会问1到2个算法题,大概是leetcode上easy和medium难度。所以想去头条的同学最好先去leetcode上刷刷题。
另外,在求职的过程中也碰到过少数没有素质的面试官,比如一上来就一副很不屑的语气,话没说两句开始diss你的项目,给人的体验很不好。所以也请各位面试官或将来要做面试官的同学,能在面试的过程中保持基本的礼貌和尊重,就像在阿里常说的:你面试别人的时候,别人也在面试着你。
最重要的一点,不要因为几次的面试失败就开始怀疑自己,永远记住,面试的结果=实力+运气。有时候你擅长的东西可能面试官根本不会,所以他也不可能花很多时间去问他不懂的东西;有时候可能他问你的你都会,但是可能因为对方提问方式、语气等原因,答的就是不顺畅。
接下来说技术相关的考察。
总的来说,技术相关的考察主要分为两大块,一是基础,二是经验。
基础包括java基础、数据库、中间件等,来自于日常的积累和面试前的准备。
经验包括以往做过的项目、解决的问题、以及一些场景题(比如你的项目如果流量大了十倍如何保证可用)。
本文主要说基础,下篇文章将说经验。
以下都是我认为面试中经常会被考察到的知识点的整理,不够完整,但大部分都是常见面试题。
集合分为两大块:java.util包下的非线程安全集合和java.util.concurrent下的线程安全集合。
ArrayList与LinkedList的实现和区别
HashMap:了解其数据结构、hash冲突如何解决(链表和红黑树)、扩容时机、扩容时避免rehash的优化
LinkedHashMap:了解基本原理、哪两种有序、如何用它实现LRU
TreeMap:了解数据结构、了解其key对象为什么必须要实现Compare接口、如何用它实现一致性哈希
Set基本上都是由对应的map实现,简单看看就好
了解其实现原理
了解写时复制机制、了解其适用场景、思考为什么没有ConcurrentArrayList
了解实现原理、扩容时做的优化、与HashTable对比。
了解LinkedBlockingQueue、ArrayBlockingQueue、DelayQueue、SynchronousQueue
了解偏向锁、轻量级锁、重量级锁的概念以及升级机制、以及和ReentrantLock的区别
了解AtomicInteger实现原理、CAS适用场景、如何实现乐观锁
了解AQS内部实现、及依靠AQS的同步类比如ReentrantLock、Semaphore、CountDownLatch、CyclicBarrier等的实现
了解ThreadLocal使用场景和内部实现
了解线程池的工作原理以及几个重要参数的设置
推荐文章:
死磕Synchronized底层实现--概论(比较深入)
了解Java中的软引用、弱引用、虚引用的适用场景以及释放机制
推荐文章:
Java引用类型原理剖析(比较深入)
了解双亲委派机制
了解BIO和NIO的区别、了解多路复用机制
同步阻塞、同步非阻塞、异步的区别?
select、poll、eopll的区别?
java NIO与BIO的区别?
reactor线程模型是什么?
垃圾回收基本原理、几种常见的垃圾回收器的特性、重点了解CMS(或G1)以及一些重要的参数
能说清jvm的内存划分
推荐文章:JVM垃圾回收历险
bean的生命周期、循环依赖问题、spring cloud(如项目中有用过)、AOP的实现、spring事务传播
java动态代理和cglib动态代理的区别(经常结合spring一起问所以就放这里了)
spring中bean的生命周期是怎样的?
属性注入和构造器注入哪种会有循环依赖的问题?
了解一个常用RPC框架如Dubbo的实现:服务发现、路由、异步调用、限流降级、失败重试
了解一个常用消息中间件如RocketMq的实现:如何保证高可用和高吞吐、消息顺序、重复消费、事务消息、延迟消息、死信队列
redis工作模型、redis持久化、redis过期淘汰机制、redis分布式集群的常见形式、分布式锁、缓存击穿、缓存雪崩、缓存一致性问题
推荐书籍:《Redis 设计与实现》
推荐文章:
事务隔离级别、锁、索引的数据结构、聚簇索引和非聚簇索引、最左匹配原则、查询优化(explain等命令)
推荐文章:http://hedengcheng.com/?p=771
https://tech.meituan.com/2014/06/30/mysql-index.html
http://hbasefly.com/2017/08/19/mysql-transaction/
zk大致原理(可以了解下原理相近的Raft算法)、zk实现分布式锁、zk做集群master选举
HBase适用的场景、架构、merge和split、查写数据的流程。
推荐文章:http://hbasefly.com/2017/07/26/transaction-2/ 及该博客下相关文章
Storm与Map Reduce、Spark、Flink的比较。Storm高可用、消息ack机制
算法的话不是所有公司都会问,但最好还是准备下,主要是靠刷题,在leetcode上刷个100-200道easy和medium的题,然后对应公司的面经多看看,问题应该不大。
我所在的部门是阿里巴巴菜鸟网络下的国际事业部,主要是为速卖通、天猫海外、lazada等跨境电商提供国际物流解决方案。国际化是阿里巴巴集团未来三年五年的战略目标之一,目前业务也是高速发展的阶段,集团这几年也是往菜鸟这边在大量投入人才和资源。另外,菜鸟p6就有期权(集团是p7)。
招聘岗位:Java开发,base杭州
要求:
lock record最开始是什么时候被put 到线程栈的?
偏向锁从内存低位置向上寻找空闲lock record,什么情况下会找不到?找不到的话会怎样?
#12, 这篇文章的图裂了, 用浏览器直接打开显示Cannot proxy the given URL, 开代理也看不到.
Java中的对象都是在JVM堆中分配的,其好处在于开发者不用关心对象的回收。但有利必有弊,堆内内存主要有两个缺点:1.GC是有成本的,堆中的对象数量越多,GC的开销也会越大。2.使用堆内内存进行文件、网络的IO时,JVM会使用堆外内存做一次额外的中转,也就是会多一次内存拷贝。
和堆内内存相对应,堆外内存就是把内存对象分配在Java虚拟机堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机),这样做的结果就是能够在一定程度上减少垃圾回收对应用程序造成的影响。
我们先看下堆外内存的实现原理,再谈谈它的应用场景。
更多文章见个人博客:https://github.com/farmerjohngit/myblog
Java中分配堆外内存的方式有两种,一是通过ByteBuffer.java#allocateDirect得到以一个DirectByteBuffer对象,二是直接调用Unsafe.java#allocateMemory分配内存,但Unsafe只能在JDK的代码中调用,一般不会直接使用该方法分配内存。
其中DirectByteBuffer也是用Unsafe去实现内存分配的,对堆内存的分配、读写、回收都做了封装。本篇文章的内容也是分析DirectByteBuffer的实现。
我们从堆外内存的分配回收、读写两个角度去分析DirectByteBuffer。
//ByteBuffer.java
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}ByteBuffer#allocateDirect中仅仅是创建了一个DirectByteBuffer对象,重点在DirectByteBuffer的构造方法中。
DirectByteBuffer(int cap) { // package-private
//主要是调用ByteBuffer的构造方法,为字段赋值
super(-1, 0, cap, cap);
//如果是按页对齐,则还要加一个Page的大小;我们分析只pa为false的情况就好了
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
//预分配内存
Bits.reserveMemory(size, cap);
long base = 0;
try {
//分配内存
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
//将分配的内存的所有值赋值为0
unsafe.setMemory(base, size, (byte) 0);
//为address赋值,address就是分配内存的起始地址,之后的数据读写都是以它作为基准
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
//pa为false的情况,address==base
address = base;
}
//创建一个Cleaner,将this和一个Deallocator对象传进去
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}DirectByteBuffer构造方法中还做了挺多事情的,总的来说分为几个步骤:
Java的堆外内存回收设计是这样的:当GC发现DirectByteBuffer对象变成垃圾时,会调用Cleaner#clean回收对应的堆外内存,一定程度上防止了内存泄露。当然,也可以手动的调用该方法,对堆外内存进行提前回收。
我们先看下Cleaner#clean的实现:
public class Cleaner extends PhantomReference<Object> {
...
private Cleaner(Object referent, Runnable thunk) {
super(referent, dummyQueue);
this.thunk = thunk;
}
public void clean() {
if (remove(this)) {
try {
//thunk是一个Deallocator对象
this.thunk.run();
} catch (final Throwable var2) {
...
}
}
}
}
private static class Deallocator
implements Runnable
{
private static Unsafe unsafe = Unsafe.getUnsafe();
private long address;
private long size;
private int capacity;
private Deallocator(long address, long size, int capacity) {
assert (address != 0);
this.address = address;
this.size = size;
this.capacity = capacity;
}
public void run() {
if (address == 0) {
// Paranoia
return;
}
//调用unsafe方法回收堆外内存
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
}Cleaner继承自PhantomReference,关于虚引用的知识,可以看我之前写的文章
简单的说,就是当字段referent(也就是DirectByteBuffer对象)被回收时,会调用到Cleaner#clean方法,最终会调用到Deallocator#run进行堆外内存的回收。
Cleaner是虚引用在JDK中的一个典型应用场景。
然后再看下DirectByteBuffer构造方法中的第二步,reserveMemory
static void reserveMemory(long size, int cap) {
//maxMemory代表最大堆外内存,也就是-XX:MaxDirectMemorySize指定的值
if (!memoryLimitSet && VM.isBooted()) {
maxMemory = VM.maxDirectMemory();
memoryLimitSet = true;
}
//1.如果堆外内存还有空间,则直接返回
if (tryReserveMemory(size, cap)) {
return;
}
//走到这里说明堆外内存剩余空间已经不足了
final JavaLangRefAccess jlra = SharedSecrets.getJavaLangRefAccess();
//2.堆外内存进行回收,最终会调用到Cleaner#clean的方法。如果目前没有堆外内存可以回收则跳过该循环
while (jlra.tryHandlePendingReference()) {
//如果空闲的内存足够了,则return
if (tryReserveMemory(size, cap)) {
return;
}
}
//3.主动触发一次GC,目的是触发老年代GC
System.gc();
//4.重复上面的过程
boolean interrupted = false;
try {
long sleepTime = 1;
int sleeps = 0;
while (true) {
if (tryReserveMemory(size, cap)) {
return;
}
if (sleeps >= MAX_SLEEPS) {
break;
}
if (!jlra.tryHandlePendingReference()) {
try {
Thread.sleep(sleepTime);
sleepTime <<= 1;
sleeps++;
} catch (InterruptedException e) {
interrupted = true;
}
}
}
//5.超出指定的次数后,还是没有足够内存,则抛异常
throw new OutOfMemoryError("Direct buffer memory");
} finally {
if (interrupted) {
// don't swallow interrupts
Thread.currentThread().interrupt();
}
}
}
private static boolean tryReserveMemory(long size, int cap) {
//size和cap主要是page对齐的区别,这里我们把这两个值看作是相等的
long totalCap;
//totalCapacity代表通过DirectByteBuffer分配的堆外内存的大小
//当已分配大小<=还剩下的堆外内存大小时,更新totalCapacity的值返回true
while (cap <= maxMemory - (totalCap = totalCapacity.get())) {
if (totalCapacity.compareAndSet(totalCap, totalCap + cap)) {
reservedMemory.addAndGet(size);
count.incrementAndGet();
return true;
}
}
//堆外内存不足,返回false
return false;
}在创建一个新的DirecByteBuffer时,会先确认有没有足够的内存,如果没有的话,会通过一些手段回收一部分堆外内存,直到可用内存大于需要分配的内存。具体步骤如下:
tryHandlePendingReference方法回收已经变成垃圾的DirectByteBuffer对象对应的堆外内存,直到可用内存足够,或目前没有垃圾DirectByteBuffer对象-XX:+DisableExplicitGC,那System.gc();是无效的详细分析下第2步是如何回收垃圾的:tryHandlePendingReference最终调用到的是Reference#tryHandlePending方法,在之前的文章中有介绍过该方法
static boolean tryHandlePending(boolean waitForNotify) {
Reference<Object> r;
Cleaner c;
try {
synchronized (lock) {
//pending由jvm gc时设置
if (pending != null) {
r = pending;
// 如果是cleaner对象,则记录下来
c = r instanceof Cleaner ? (Cleaner) r : null;
// unlink 'r' from 'pending' chain
pending = r.discovered;
r.discovered = null;
} else {
// waitForNotify传入的值为false
if (waitForNotify) {
lock.wait();
}
// 如果没有待回收的Reference对象,则返回false
return waitForNotify;
}
}
} catch (OutOfMemoryError x) {
...
} catch (InterruptedException x) {
...
}
// Fast path for cleaners
if (c != null) {
//调用clean方法
c.clean();
return true;
}
...
return true;
}可以看到,tryHandlePendingReference的最终效果就是:如果有垃圾DirectBytebuffer对象,则调用对应的Cleaner#clean方法进行回收。clean方法在上面已经分析过了。
public ByteBuffer put(byte x) {
unsafe.putByte(ix(nextPutIndex()), ((x)));
return this;
}
final int nextPutIndex() {
if (position >= limit)
throw new BufferOverflowException();
return position++;
}
private long ix(int i) {
return address + ((long)i << 0);
}
public byte get() {
return ((unsafe.getByte(ix(nextGetIndex()))));
}
final int nextGetIndex() { // package-private
if (position >= limit)
throw new BufferUnderflowException();
return position++;
}读写的逻辑也比较简单,address就是构造方法中分配的native内存的起始地址。Unsafe的putByte/getByte都是native方法,就是写入值到某个地址/获取某个地址的值。
堆外内存分配回收也是有开销的,所以适合长期存在的对象
堆外内存能有效避免因GC导致的暂停问题。
因为堆外内存只能存储字节数组,所以对于复杂的DTO对象,每次存储/读取都需要序列化/反序列化,
用堆外内存读写文件性能更好
关于堆外内存IO为什么有更好的性能这点展开一下。
BIO的文件写FileOutputStream#write最终会调用到native层的io_util.c#writeBytes方法
void
writeBytes(JNIEnv *env, jobject this, jbyteArray bytes,
jint off, jint len, jboolean append, jfieldID fid)
{
jint n;
char stackBuf[BUF_SIZE];
char *buf = NULL;
FD fd;
...
// 如果写入长度为0,直接返回0
if (len == 0) {
return;
} else if (len > BUF_SIZE) {
// 如果写入长度大于BUF_SIZE(8192),无法使用栈空间buffer
// 需要调用malloc在堆空间申请buffer
buf = malloc(len);
if (buf == NULL) {
JNU_ThrowOutOfMemoryError(env, NULL);
return;
}
} else {
buf = stackBuf;
}
// 复制Java传入的byte数组数据到C空间的buffer中
(*env)->GetByteArrayRegion(env, bytes, off, len, (jbyte *)buf);
if (!(*env)->ExceptionOccurred(env)) {
off = 0;
while (len > 0) {
fd = GET_FD(this, fid);
if (fd == -1) {
JNU_ThrowIOException(env, "Stream Closed");
break;
}
//写入到文件,这里传递的数组是我们新创建的buf
if (append == JNI_TRUE) {
n = (jint)IO_Append(fd, buf+off, len);
} else {
n = (jint)IO_Write(fd, buf+off, len);
}
if (n == JVM_IO_ERR) {
JNU_ThrowIOExceptionWithLastError(env, "Write error");
break;
} else if (n == JVM_IO_INTR) {
JNU_ThrowByName(env, "java/io/InterruptedIOException", NULL);
break;
}
off += n;
len -= n;
}
}
}
GetByteArrayRegion其实就是对数组进行了一份拷贝,该函数的实现在jni.cpp宏定义中,找了很久才找到
//jni.cpp
JNI_ENTRY(void, \
jni_Get##Result##ArrayRegion(JNIEnv *env, ElementType##Array array, jsize start, \
jsize len, ElementType *buf)) \
...
int sc = TypeArrayKlass::cast(src->klass())->log2_element_size(); \
//内存拷贝
memcpy((u_char*) buf, \
(u_char*) src->Tag##_at_addr(start), \
len << sc); \
...
} \
JNI_END可以看到,传统的BIO,在native层真正写文件前,会在堆外内存(c分配的内存)中对字节数组拷贝一份,之后真正IO时,使用的是堆外的数组。要这样做的原因是
1.底层通过write、read、pwrite,pread函数进行系统调用时,需要传入buffer的起始地址和buffer count作为参数。如果使用java heap的话,我们知道jvm中buffer往往以byte[] 的形式存在,这是一个特殊的对象,由于java heap GC的存在,这里对象在堆中的位置往往会发生移动,移动后我们传入系统函数的地址参数就不是真正的buffer地址了,这样的话无论读写都会发生出错。而C Heap仅仅受Full GC的影响,相对来说地址稳定。
2.JVM规范中没有要求Java的byte[]必须是连续的内存空间,它往往受宿主语言的类型约束;而C Heap中我们分配的虚拟地址空间是可以连续的,而上述的系统调用要求我们使用连续的地址空间作为buffer。
以上内容来自于 知乎 ETIN的回答 https://www.zhihu.com/question/60892134/answer/182225677
BIO的文件读也一样,这里就不分析了。
NIO的文件写最终会调用到IOUtil#write
static int write(FileDescriptor fd, ByteBuffer src, long position,
NativeDispatcher nd, Object lock)
throws IOException
{
//如果是堆外内存,则直接写
if (src instanceof DirectBuffer)
return writeFromNativeBuffer(fd, src, position, nd, lock);
// Substitute a native buffer
int pos = src.position();
int lim = src.limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
//创建一块堆外内存,并将数据赋值到堆外内存中去
ByteBuffer bb = Util.getTemporaryDirectBuffer(rem);
try {
bb.put(src);
bb.flip();
// Do not update src until we see how many bytes were written
src.position(pos);
int n = writeFromNativeBuffer(fd, bb, position, nd, lock);
if (n > 0) {
// now update src
src.position(pos + n);
}
return n;
} finally {
Util.offerFirstTemporaryDirectBuffer(bb);
}
}
/**
* 分配一片堆外内存
*/
static ByteBuffer getTemporaryDirectBuffer(int size) {
BufferCache cache = bufferCache.get();
ByteBuffer buf = cache.get(size);
if (buf != null) {
return buf;
} else {
// No suitable buffer in the cache so we need to allocate a new
// one. To avoid the cache growing then we remove the first
// buffer from the cache and free it.
if (!cache.isEmpty()) {
buf = cache.removeFirst();
free(buf);
}
return ByteBuffer.allocateDirect(size);
}
}
可以看到,NIO的文件写,对于堆内内存来说也是会有一次额外的内存拷贝的。
堆外内存的分析就到这里结束了,JVM为堆外内存做这么多处理,其主要原因也是因为Java毕竟不是像C这样的完全由开发者管理内存的语言。因此即使使用堆外内存了,JVM也希望能在合适的时候自动的对堆外内存进行回收。
在阅读JVM源码的时候,有很多地方都看不懂,但是又查询不到相关资料。如
CASE(_monitorenter): {
// lockee 就是锁对象
oop lockee = STACK_OBJECT(-1);
// derefing's lockee ought to provoke implicit null check
CHECK_NULL(lockee);
// code 1:找到一个空闲的Lock Record
BasicObjectLock* limit = istate->monitor_base();
.......如代码中的指针istate就不是很明白是什么意思,导致代码阅读很艰难。大佬有什么学习心得或者学习方法吗,是否可以传授一些经验呢
十分感谢
在<关于同步的一点思考-上>中介绍了几种实现锁的方式以及linux底层futex的实现原理
ReentrantLock的实现网上有很多文章了,本篇文章会简单介绍下其java层实现,重点放在分析竞争锁失败后如何阻塞线程。
因篇幅有限,synchronized的内容将会放到下篇文章。
ReentrantLock是jdk中常用的锁实现,其实现逻辑主语基于AQS(juc包中的大多数同步类实现都是基于AQS);接下来会简单介绍AQS的大致原理,关于其实现细节以及各种应用,之后会写一篇文章具体分析。
AQS是类AbstractQueuedSynchronizer.java的简称,JUC包下的ReentrantLock、CyclicBarrier、CountdownLatch都使用到了AQS。
其大致原理如下:
其中tryAcquire方法是抽象方法,具体实现取决于实现类,我们常说的公平锁和非公平锁的区别就在于该方法的实现。
ReentrantLock分为公平锁和非公平锁,我们只看公平锁。
ReentrantLock.lock会调用到ReentrantLock#FairSync.lock中:
FairSync.java
static final class FairSync extends Sync {
final void lock() {
acquire(1);
}
/**
* Fair version of tryAcquire. Don't grant access unless
* recursive call or no waiters or is first.
*/
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
AbstractQueuedSynchronizer.java
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
可以看到FairSync.lock调用了AQS的acquire方法,而在acquire中首先调用tryAcquire尝试获得锁,以下两种情况返回true:
重入如果tryAcquire失败则调用acquireQueued阻塞当前线程。acquireQueued最终会调用到LockSupport.park()阻塞线程。
个人认为,要深入理解锁机制,一个很重要的点是理解系统是如何阻塞线程的。
LockSupport.java
public static void park(Object blocker) {
Thread t = Thread.currentThread();
setBlocker(t, blocker);
UNSAFE.park(false, 0L);
setBlocker(t, null);
}
park方法的参数blocker是用于负责这次阻塞的同步对象,在AQS的调用中,这个对象就是AQS本身。我们知道synchronized关键字是需要指定一个对象的(如果作用于方法上则是当前对象或当前类),与之类似blocker就是LockSupport指定的对象。
park方法调用了native方法UNSAFE.park,第一个参数代表第二个参数是否是绝对时间,第二个参数代表最长阻塞时间。
其实现如下,只保留核心代码,完整代码看查看unsafe.cpp
Unsafe_Park(JNIEnv *env, jobject unsafe, jboolean isAbsolute, jlong time){
...
thread->parker()->park(isAbsolute != 0, time);
...
}
park方法在os_linux.cpp中(其他操作系统的实现在os_xxx中)
void Parker::park(bool isAbsolute, jlong time) {
...
//获得当前线程
Thread* thread = Thread::current();
assert(thread->is_Java_thread(), "Must be JavaThread");
JavaThread *jt = (JavaThread *)thread;
//如果当前线程被设置了interrupted标记,则直接返回
if (Thread::is_interrupted(thread, false)) {
return;
}
if (time > 0) {
//unpacktime中根据isAbsolute的值来填充absTime结构体,isAbsolute为true时,time代表绝对时间且单位是毫秒,否则time是相对时间且单位是纳秒
//absTime.tvsec代表了对于时间的秒
//absTime.tv_nsec代表对应时间的纳秒
unpackTime(&absTime, isAbsolute, time);
}
//调用mutex trylock方法
if (Thread::is_interrupted(thread, false) || pthread_mutex_trylock(_mutex) != 0) {
return;
}
//_counter是一个许可的数量,跟ReentrantLock里定义的许可变量基本都是一个原理。 unpack方法调用时会将_counter赋值为1。
//_counter>0代表已经有人调用了unpark,所以不用阻塞
int status ;
if (_counter > 0) { // no wait needed
_counter = 0;
//释放mutex锁
status = pthread_mutex_unlock(_mutex);
return;
}
//设置线程状态为CONDVAR_WAIT
OSThreadWaitState osts(thread->osthread(), false /* not Object.wait() */);
...
//等待
_cur_index = isAbsolute ? ABS_INDEX : REL_INDEX;
pthread_cond_timedwait(&_cond[_cur_index], _mutex, &absTime);
...
//释放mutex锁
status = pthread_mutex_unlock(_mutex) ;
}
park方法用POSIX的pthread_cond_timedwait方法阻塞线程,调用pthread_cond_timedwait前需要先获得锁,因此park主要流程为:
pthread_mutex_trylock尝试获得锁,如果获取锁失败则直接返回pthread_cond_timedwait进行等待pthread_mutex_unlock释放锁另外,在阻塞当前线程前,会调用OSThreadWaitState的构造方法将线程状态设置为CONDVAR_WAIT,在Jvm中Thread状态枚举如下
enum ThreadState {
ALLOCATED, // Memory has been allocated but not initialized
INITIALIZED, // The thread has been initialized but yet started
RUNNABLE, // Has been started and is runnable, but not necessarily running
MONITOR_WAIT, // Waiting on a contended monitor lock
CONDVAR_WAIT, // Waiting on a condition variable
OBJECT_WAIT, // Waiting on an Object.wait() call
BREAKPOINTED, // Suspended at breakpoint
SLEEPING, // Thread.sleep()
ZOMBIE // All done, but not reclaimed yet
};
由上文我们可以知道LockSupport.park方法最终是由POSIX的
pthread_cond_timedwait的方法实现的。
我们现在就进一步看看pthread_mutex_trylock,pthread_cond_timedwait,pthread_mutex_unlock这几个方法是如何实现的。
Linux系统中相关代码在glibc库中。
pthread_mutex_trylock先看trylock的实现,
代码在glibc的pthread_mutex_trylock.c文件中,该方法代码很多,我们只看主要代码
//pthread_mutex_t是posix中的互斥锁结构体
int
__pthread_mutex_trylock (mutex)
pthread_mutex_t *mutex;
{
int oldval;
pid_t id = THREAD_GETMEM (THREAD_SELF, tid);
switch (__builtin_expect (PTHREAD_MUTEX_TYPE (mutex),
PTHREAD_MUTEX_TIMED_NP))
{
case PTHREAD_MUTEX_ERRORCHECK_NP:
case PTHREAD_MUTEX_TIMED_NP:
case PTHREAD_MUTEX_ADAPTIVE_NP:
/* Normal mutex. */
if (lll_trylock (mutex->__data.__lock) != 0)
break;
/* Record the ownership. */
mutex->__data.__owner = id;
++mutex->__data.__nusers;
return 0;
}
}
//以下代码在lowlevellock.h中
#define __lll_trylock(futex) \
(atomic_compare_and_exchange_val_acq (futex, 1, 0) != 0)
#define lll_trylock(futex) __lll_trylock (&(futex))
mutex默认用的是PTHREAD_MUTEX_NORMAL类型(与PTHREAD_MUTEX_TIMED_NP相同);
因此会先调用lll_trylock方法,lll_trylock实际上是一个cas操作,如果mutex->__data.__lock==0则将其修改为1并返回0,否则返回1。
如果成功,则更改mutex中的owner为当前线程。
pthread_mutex_unlockpthread_mutex_unlock.c
int
internal_function attribute_hidden
__pthread_mutex_unlock_usercnt (mutex, decr)
pthread_mutex_t *mutex;
int decr;
{
if (__builtin_expect (type, PTHREAD_MUTEX_TIMED_NP)
== PTHREAD_MUTEX_TIMED_NP)
{
/* Always reset the owner field. */
normal:
mutex->__data.__owner = 0;
if (decr)
/* One less user. */
--mutex->__data.__nusers;
/* Unlock. */
lll_unlock (mutex->__data.__lock, PTHREAD_MUTEX_PSHARED (mutex));
return 0;
}
}
pthread_mutex_unlock将mutex中的owner清空,并调用了lll_unlock方法
lowlevellock.h
#define __lll_unlock(futex, private) \
((void) ({ \
int *__futex = (futex); \
int __val = atomic_exchange_rel (__futex, 0); \
\
if (__builtin_expect (__val > 1, 0)) \
lll_futex_wake (__futex, 1, private); \
}))
#define lll_unlock(futex, private) __lll_unlock(&(futex), private)
#define lll_futex_wake(ftx, nr, private) \
({ \
DO_INLINE_SYSCALL(futex, 3, (long) (ftx), \
__lll_private_flag (FUTEX_WAKE, private), \
(int) (nr)); \
_r10 == -1 ? -_retval : _retval; \
})
lll_unlock分为两个步骤:
FUTEX_WAIT在休眠,所以通过调用系统函数FUTEX_WAKE唤醒休眠线程FUTEX_WAKE 在上一篇文章有分析,futex机制的核心是当获得锁时,尝试cas更改一个int型变量(用户态操作),如果integer原始值是0,则修改成功,该线程获得锁,否则就将当期线程放入到 wait queue中,wait queue中的线程不会被系统调度(内核态操作)。
futex变量的值有3种:0代表当前锁空闲,1代表有线程持有当前锁,2代表存在锁冲突。futex的值初始化时是0;当调用try_lock的时候会利用cas操作改为1(见上面的trylock函数);当调用lll_lock时,如果不存在锁冲突,则将其改为1,否则改为2。
#define __lll_lock(futex, private) \
((void) ({ \
int *__futex = (futex); \
if (__builtin_expect (atomic_compare_and_exchange_bool_acq (__futex, \
1, 0), 0)) \
{ \
if (__builtin_constant_p (private) && (private) == LLL_PRIVATE) \
__lll_lock_wait_private (__futex); \
else \
__lll_lock_wait (__futex, private); \
} \
}))
#define lll_lock(futex, private) __lll_lock (&(futex), private)
void
__lll_lock_wait_private (int *futex)
{
//第一次进来的时候futex==1,所以不会走这个if
if (*futex == 2)
lll_futex_wait (futex, 2, LLL_PRIVATE);
//在这里会把futex设置成2,并调用futex_wait让当前线程等待
while (atomic_exchange_acq (futex, 2) != 0)
lll_futex_wait (futex, 2, LLL_PRIVATE);
}
pthread_cond_timedwaitpthread_cond_timedwait用于阻塞线程,实现线程等待,
代码在glibc的pthread_cond_timedwait.c文件中,代码较长,你可以先简单过一遍,看完下面的分析再重新读一遍代码
int
int
__pthread_cond_timedwait (cond, mutex, abstime)
pthread_cond_t *cond;
pthread_mutex_t *mutex;
const struct timespec *abstime;
{
struct _pthread_cleanup_buffer buffer;
struct _condvar_cleanup_buffer cbuffer;
int result = 0;
/* Catch invalid parameters. */
if (abstime->tv_nsec < 0 || abstime->tv_nsec >= 1000000000)
return EINVAL;
int pshared = (cond->__data.__mutex == (void *) ~0l)
? LLL_SHARED : LLL_PRIVATE;
//1.获得cond锁
lll_lock (cond->__data.__lock, pshared);
//2.释放mutex锁
int err = __pthread_mutex_unlock_usercnt (mutex, 0);
if (err)
{
lll_unlock (cond->__data.__lock, pshared);
return err;
}
/* We have one new user of the condvar. */
//每执行一次wait(pthread_cond_timedwait/pthread_cond_wait),__total_seq就会+1
++cond->__data.__total_seq;
//用来执行futex_wait的变量
++cond->__data.__futex;
//标识该cond还有多少线程在使用,pthread_cond_destroy需要等待所有的操作完成
cond->__data.__nwaiters += 1 << COND_NWAITERS_SHIFT;
/* Remember the mutex we are using here. If there is already a
different address store this is a bad user bug. Do not store
anything for pshared condvars. */
//保存mutex锁
if (cond->__data.__mutex != (void *) ~0l)
cond->__data.__mutex = mutex;
/* Prepare structure passed to cancellation handler. */
cbuffer.cond = cond;
cbuffer.mutex = mutex;
/* Before we block we enable cancellation. Therefore we have to
install a cancellation handler. */
__pthread_cleanup_push (&buffer, __condvar_cleanup, &cbuffer);
/* The current values of the wakeup counter. The "woken" counter
must exceed this value. */
//记录futex_wait前的__wakeup_seq(为该cond上执行了多少次sign操作+timeout次数)和__broadcast_seq(代表在该cond上执行了多少次broadcast)
unsigned long long int val;
unsigned long long int seq;
val = seq = cond->__data.__wakeup_seq;
/* Remember the broadcast counter. */
cbuffer.bc_seq = cond->__data.__broadcast_seq;
while (1)
{
//3.计算要wait的相对时间
struct timespec rt;
{
#ifdef __NR_clock_gettime
INTERNAL_SYSCALL_DECL (err);
int ret;
ret = INTERNAL_VSYSCALL (clock_gettime, err, 2,
(cond->__data.__nwaiters
& ((1 << COND_NWAITERS_SHIFT) - 1)),
&rt);
# ifndef __ASSUME_POSIX_TIMERS
if (__builtin_expect (INTERNAL_SYSCALL_ERROR_P (ret, err), 0))
{
struct timeval tv;
(void) gettimeofday (&tv, NULL);
/* Convert the absolute timeout value to a relative timeout. */
rt.tv_sec = abstime->tv_sec - tv.tv_sec;
rt.tv_nsec = abstime->tv_nsec - tv.tv_usec * 1000;
}
else
# endif
{
/* Convert the absolute timeout value to a relative timeout. */
rt.tv_sec = abstime->tv_sec - rt.tv_sec;
rt.tv_nsec = abstime->tv_nsec - rt.tv_nsec;
}
#else
/* Get the current time. So far we support only one clock. */
struct timeval tv;
(void) gettimeofday (&tv, NULL);
/* Convert the absolute timeout value to a relative timeout. */
rt.tv_sec = abstime->tv_sec - tv.tv_sec;
rt.tv_nsec = abstime->tv_nsec - tv.tv_usec * 1000;
#endif
}
if (rt.tv_nsec < 0)
{
rt.tv_nsec += 1000000000;
--rt.tv_sec;
}
/*---计算要wait的相对时间 end---- */
//是否超时
/* Did we already time out? */
if (__builtin_expect (rt.tv_sec < 0, 0))
{
//被broadcast唤醒,这里疑问的是,为什么不需要判断__wakeup_seq?
if (cbuffer.bc_seq != cond->__data.__broadcast_seq)
goto bc_out;
goto timeout;
}
unsigned int futex_val = cond->__data.__futex;
//4.释放cond锁,准备wait
lll_unlock (cond->__data.__lock, pshared);
/* Enable asynchronous cancellation. Required by the standard. */
cbuffer.oldtype = __pthread_enable_asynccancel ();
//5.调用futex_wait
/* Wait until woken by signal or broadcast. */
err = lll_futex_timed_wait (&cond->__data.__futex,
futex_val, &rt, pshared);
/* Disable asynchronous cancellation. */
__pthread_disable_asynccancel (cbuffer.oldtype);
//6.重新获得cond锁,因为又要访问&修改cond的数据了
lll_lock (cond->__data.__lock, pshared);
//__broadcast_seq值发生改变,代表发生了有线程调用了广播
if (cbuffer.bc_seq != cond->__data.__broadcast_seq)
goto bc_out;
//判断是否是被sign唤醒的,sign会增加__wakeup_seq
//第二个条件cond->__data.__woken_seq != val的意义在于
//可能两个线程A、B在wait,一个线程调用了sign导致A被唤醒,这时B因为超时被唤醒
//对于B线程来说,执行到这里时第一个条件也是满足的,从而导致上层拿到的result不是超时
//所以这里需要判断下__woken_seq(即该cond已经被唤醒的线程数)是否等于__wakeup_seq(sign执行次数+timeout次数)
val = cond->__data.__wakeup_seq;
if (val != seq && cond->__data.__woken_seq != val)
break;
/* Not woken yet. Maybe the time expired? */
if (__builtin_expect (err == -ETIMEDOUT, 0))
{
timeout:
/* Yep. Adjust the counters. */
++cond->__data.__wakeup_seq;
++cond->__data.__futex;
/* The error value. */
result = ETIMEDOUT;
break;
}
}
//一个线程已经醒了所以这里__woken_seq +1
++cond->__data.__woken_seq;
bc_out:
//
cond->__data.__nwaiters -= 1 << COND_NWAITERS_SHIFT;
/* If pthread_cond_destroy was called on this variable already,
notify the pthread_cond_destroy caller all waiters have left
and it can be successfully destroyed. */
if (cond->__data.__total_seq == -1ULL
&& cond->__data.__nwaiters < (1 << COND_NWAITERS_SHIFT))
lll_futex_wake (&cond->__data.__nwaiters, 1, pshared);
//9.cond数据修改完毕,释放锁
lll_unlock (cond->__data.__lock, pshared);
/* The cancellation handling is back to normal, remove the handler. */
__pthread_cleanup_pop (&buffer, 0);
//10.重新获得mutex锁
err = __pthread_mutex_cond_lock (mutex);
return err ?: result;
}
上面的代码虽然加了注释,但相信大多数人第一次看都看不懂。
我们来简单梳理下,上面代码有两把锁,一把是mutex锁,一把cond锁。另外,在调用pthread_cond_timedwait前后必须调用pthread_mutex_lock(&mutex);和pthread_mutex_unlock(&mutex);加/解mutex锁。
因此pthread_cond_timedwait的使用大致分为几个流程:
pthread_cond_timedwait调用前)pthread_cond_timedwait调用后)看到这里,你可能有几点疑问:为什么需要两把锁?mutex锁和cond锁的作用是什么?
说mutex锁的作用之前,我们回顾一下java的Object.wait的使用。Object.wait必须是在synchronized同步块中使用。试想下如果不加synchronized也能运行Object.wait的话会存在什么问题?
Object condObj=new Object();
voilate int flag = 0;
public void waitTest(){
if(flag == 0){
condObj.wait();
}
}
public void notifyTest(){
flag=1;
condObj.notify();
}
如上代码,A线程调用waitTest,这时flag==0,所以准备调用wait方法进行休眠,这时B线程开始执行,调用notifyTest将flag置为1,并调用notify方法,注意:此时A线程还没调用wait,所以notfiy没有唤醒任何线程。然后A线程继续执行,调用wait方法进行休眠,而之后不会有人来唤醒A线程,A线程将永久wait下去!
Object condObj=new Object();
voilate int flag = 0;
public void waitTest(){
synchronized(condObj){
if(flag == 0){
condObj.wait();
}
}
}
public void notifyTest(){
synchronized(condObj){
flag=1;
condObj.notify();
}
}
在有锁保护下的情况下, 当调用condObj.wait时,flag一定是等于0的,不会存在一直wait的问题。
回到pthread_cond_timedwait,其需要加mutex锁的原因就呼之欲出了:保证wait和其wait条件的原子性
不管是glibc的pthread_cond_timedwait/pthread_cond_signal还是java层的Object.wait/Object.notify,Jdk AQS的Condition.await/Condition.signal,所有的Condition机制都需要在加锁环境下才能使用,其根本原因就是要保证进行线程休眠时,条件变量是没有被篡改的。
注意下mutex锁释放的时机,回顾上文中pthread_cond_timedwait的流程,在第2步时就释放了mutex锁,之后调用futex_wait进行休眠,为什么要在休眠前就释放mutex锁呢?原因也很简单:如果不释放mutex锁就开始休眠,那其他线程就永远无法调用signal方法将休眠线程唤醒(因为调用signal方法前需要获得mutex锁)。
在线程被唤醒之后还要在第10步中重新获得mutex锁是为了保证锁的语义(思考下如果不重新获得mutex锁会发生什么)。
cond锁的作用其实很简单: 保证对象cond->data的线程安全。
在pthread_cond_timedwait时需要修改cond->data的数据,如增加__total_seq(在这个cond上一共执行过多少次wait)增加__nwaiters(现在还有多少个线程在wait这个cond),所有在修改及访问cond->data时需要加cond锁。
这里我没想明白的一点是,用mutex锁也能保证cond->data修改的线程安全,只要晚一点释放mutex锁就行了。为什么要先释放mutex,重新获得cond来保证线程安全? 是为了避免mutex锁住的范围太大吗?
该问题的答案可以见评论区@11800222 的回答:
mutex锁不能保护cond->data修改的线程安全,调用signal的线程没有用mutex锁保护修改cond的那段临界区。
pthread_cond_wait/signal这一对本身用cond锁同步就能睡眠唤醒。
wait的时候需要传入mutex是因为睡眠前需要释放mutex锁,但睡眠之前又不能有无锁的空隙,解决办法是让mutex锁在cond锁上之后再释放。
而signal前不需要释放mutex锁,在持有mutex的情况下signal,之后再释放mutex锁。
唤醒休眠线程的代码比较简单,主要就是调用lll_futex_wake。
int
__pthread_cond_signal (cond)
pthread_cond_t *cond;
{
int pshared = (cond->__data.__mutex == (void *) ~0l)
? LLL_SHARED : LLL_PRIVATE;
//因为要操作cond的数据,所以要加锁
lll_lock (cond->__data.__lock, pshared);
/* Are there any waiters to be woken? */
if (cond->__data.__total_seq > cond->__data.__wakeup_seq)
{
//__wakeup_seq为执行sign与timeout次数的和
++cond->__data.__wakeup_seq;
++cond->__data.__futex;
...
//唤醒wait的线程
lll_futex_wake (&cond->__data.__futex, 1, pshared);
}
/* We are done. */
lll_unlock (cond->__data.__lock, pshared);
return 0;
}
本文对Java简单介绍了ReentrantLock实现原理,对LockSupport.park底层实现pthread_cond_timedwait机制做了详细分析。
看完这篇文章,你可能还会有疑问:Synchronized锁的实现和ReentrantLock是一样的吗?Thread.sleep/Object.wait休眠线程的原理和LockSupport.park有什么区别?linux内核层的futex的具体是如何实现的?
这些问题,之后的文章会一一解答,尽请期待~
VM_RevokeBias revoke(&obj, (JavaThread*) THREAD);
VMThread::execute(&revoke);
return revoke.status_code();
Redis深度历险分为两个部分,单机Redis和分布式Redis。
更多文章见个人博客:https://github.com/farmerjohngit/myblog
本文为分布式Redis深度历险系列的第一篇,主要内容为Redis的复制功能。
Redis的复制功能的作用和大多数分布式存储系统一样,就是为了支持主从设计,主从设计的好处有以下几点:
Redis的复制主要分为同步和命令传播两个步骤:
同步可以理解为全量,是将主服务器某一时刻的所有数据全部同步到从服务器。
命令传播可以理解为增量,当主服务器数据被修改时,主服务器向从服务器发送对应的数据修改命令。
同步分为以下几个步骤:
1.从服务器向主服务器发送SYNC命令(执行SLAVE OF命令的第一步也会执行SYNC)
2.主服务器在收到从服务器命令时,会执行BGSAVE,也就是新开一个子进程将内存中的数据保存到RDB文件中。同时使用一个内存缓冲区记录从现在开始执行的写命令,该内存缓冲区的作用就是记录RDB文件生成期间的增量。
3.向从服务器发送RDB文件
4.将缓冲区中的写命令发送给从服务器
同步可以分为两种情况,一种是从服务器第一次连接主服务器,另一种是从服务与主服务器的网络链接断开了,重新连上主服务器并重新同步。
命令传播实现逻辑比较简单,当主服务器执行了写命令后,为了保证从服务器与主服务器数据的一致性,主服务器会将写命令发送给从服务器,从服务器执行完收到的写命令后其数据就能和主服务器保持一致了(当然会有延时),注意,从服务器对于客户端来说是只读的,因此从服务器的所有数据都是来自于主服务器的同步or命令传播。
假设Redis主从服务器之间的网络环境不太可靠,我们来看看上述复制方法会出现什么问题。假设有主服务器A和从服务器B,主服务器中目前存在1-10000共一万条数据。
1.初始连接,从服务器第一次从主服务器同步数据,同步完成后,从服务器也有1-10000共一万条数据。
2.主服务器新增10001,10002两条数据
3.通过命令传播,从服务器也新增10001,10002两条数据
4.这时候主从服务器之间的网络断开
5.主服务器新增数据10003,因为网络断开,所以从服务器感受不到数据变化
6.网络恢复,从服务器重新连接上主服务器,并发送SYNC命令,进行同步操作
7.主服务器将所有数据发送给从服务器(1-10003)
从上述步骤中可以看到,当从服务器重新连接上主服务器时,会重新进行全量同步,造成大量不必要的IO开销,如果网络环境不稳定时,会导致主服务器一直将内存中的数据写到磁盘再发送给从服务器。
为了解决老版复制问题,Redis2.8对于复制功能进行了优化。实现如下:
1.主服务器会维护一个偏移量,每次向服务器传播N个字节的数据时,该偏移量就会加上N,比如说一开始是0,接受到一条set key1 value1后,其偏移量就为13(真实偏移可能不是13,只是举个例子)。//这里可能要看下代码确认
2.从服务器也维护一个偏移量,当从服务器收到到主服务器的N个字节数据时,该偏移量会加上N。
3.主服务器维护一个固定大小的缓冲区,每次接受到客户端写命令后,都会将对应命令往这个缓冲区写入。当写入内容超出固定大小后,会覆盖原来的数据。
4.主服务器有一个唯一id
5.从服务器连接上主服务时,会向主服务器发送上一次连接的主服务器的id以及偏移量,这里又分几种情况:
如果从服务器没传id或者id与当前主服务器不匹配,那主服务器将传送全量数据
如果从服务器的offset在缓冲区中不能找到(落后太多导致缓冲区已经被新数据覆盖了),那也会进行全量同步
如果offset能在缓冲区找到,则主服务从offset开始,将缓冲区的数据依次发送给从服务器。(有做pipeline的优化吗)
以上就是新版复制的大致思路,要注意的是,主服务器缓冲区的大小设置很关键,如果设置的太大会导致空间浪费,如果太小会导致网络环境不好时,其退化为老版复制。
之前我就踩过这样的坑:在上云时,redis集群在两个不同机房,主从之前网络环境不太稳定,而redis机器上存储的value比较大,很容易就将缓冲区占满导致每次全量同步,形成恶性循环,从服务器落后不可读,主服务器不可写(当从Redis落后太多时,主Redis将拒绝写入,具体参数可以配置的,下文还会提到)
所以建议将缓冲区大小设置为平均重连间隔*每秒写入数据量*2
从服务器默认会每秒一次的频率向主服务器发送心跳:
REPLCONF AÇK <replication_offset>,
replication_offset代表从服务器当前的复制偏移量。
心跳有三个作用:
1.检测主从服务器的网络连接
2.实现min-slaves功能
3.检测命令丢失
主服务器会记录从服务器上次发送心跳是什么时间,根据这个时间,我们能知道主从服务器之间的连接是不是出现了故障
Redis为了保证数据的安全性,可以配置当从服务器小于min-slaves-to-write个或者min-slaves-to-write个从服务器的延迟都大于等于min-slaves-max-lag时,主服务器拒绝写。
主从之间的复制,其实是以主服务器作为从服务器的客户端来实现的(在Redis中,所有服务器之间的数据传递都是以该种方式)。假设主服务器向从服务器发送一条写命令,但网络出现异常,从服务器并没有收到该命令。
这就会导致数据不一致的状态(你可能想主服务器发送命令时,如果从没返回失败,进行重发不就好了吗?如果说从成功执行了命令,但是再回复主的时候出现了问题,那主如果重发就会造成数据异常了)。所以主服务器会根据心跳信息来决定要发送的数据。看个例子:
初始,主服务器和从服务器偏移量都是100。
主服务器收到客户端的写命令,将偏移量改成110,同时向从服务器发送写命令,但因网络原因,从服务器并没有收到,其偏移量仍然是100。主服务器根据心跳发现从服务器的偏移量是100落后于自己,所以会将100-110的数据进行重发。
看到这里,你可能对于上述方案的正确性感到质疑:在从服务器接收到100-110的数据前,它发送心跳包告诉主服务器自己当前偏移为100,然后接收到了100-110的数据。这时下个心跳还没发出,主服务器认为从服务器落后于自己,再次发送100-110的数据,导致从服务器再次写入100-110的数据,导致数据异常!
如果你有想到这个问题,说明你是有在认真思考了~
其实是不存在这种情况的,原因是redis是单线程的!记住单线程三个字,再回头看一遍问题描述,相信你能想明白~
<<Redis的设计与实现>> 黄建宏著, 强烈推荐!
先说明下,本文要讨论的多线程读写是指一个线程写,一个或多个线程读,不包括多线程同时写的情况。
更多文章见个人博客:https://github.com/farmerjohngit/myblog
试想下这样一个场景:一个线程往hashmap中写数据,一个线程往hashmap中读数据。 这样会有问题吗?如果有,那是什么问题?
相信大家都知道是有问题的,但至于到底是什么问题,可能就不是那么显而易见了。
问题有两点。
一是内存可见性的问题,hashmap存储数据的table并没有用voliate修饰,也就是说读线程可能一直读不到数据的最新值。
二是指令重排序的问题,get的时候可能得到的是一个中间状态的数据,我们看下put方法的部分代码。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
...
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = new Node<>(hash, key, value, next);
...
}
可以看到,在put操作时,如果table数组的指定位置为null,会创建一个Node对象,并放到table数组上。但我们知道jvm中 tab[i] = new Node<>(hash, key, value, next);这样的操作不是原子的,并且可能因为指令重排序,导致另一个线程调用get取tab[i]的时候,拿到的是一个还没有调用完构造方法的对象,导致不可预料的问题发生。
上述的两个问题可以说都是因为HashMap中的内部属性没有被voliate修饰导致的,如果HashMap中的对象全部由voliate修饰,则一个线程写,一个线程读的情况是不会有问题(这里是我的猜测,证实这个猜测正确性的一点依据是ConcurrentHashMap的get并没有加锁,也就是说在Map结构里读写其实是不冲突)。见下方区sora-zero同学的评论
有的同学对于 Object obj = new Object();这样的操作在多线程的情况下会拿到一个未初始化的对象这点可能有疑惑,这里也做个简单的说明。以上java语句分为4个步骤:
以上步骤看起来也是没有问题的,毕竟创建的对象要调用完构造方法后才会被引用。
但问题是jvm是会对指令进行重排序的,重排之后可能是第4步先于第3步执行,那这时候另外一个线程读到的就是没有还执行构造方法的对象,导致未知问题。jvm重排只保证重排前和重排后在单线程中的结果一致性。
注意java中引用的赋值操作一定是原子的,比如说a和b均是对象的情况下不管是32位还是64位jvm,a=b操作均是原子的。但如果a和b是long或者double原子型数据,那在32位jvm上a=b不一定是原子的(看jvm具体实现),有可能是分成了两个32位操作。 但是对于voliate的long,double 变量来说,其赋值是原子的。具体可以看这里https://docs.oracle.com/javase/specs/jls/se7/html/jls-17.html#jls-17.7
跳出hashmap,在数据库中都是要用mvcc机制避免加读写锁。也就是说如果不用mvcc,数据库是要加读写锁的,那为什么数据库要加读写锁呢?原因是写操作不是原子的,如果不加读写锁或mvcc,可能会读到中间状态的数据,以HBase为例,Hbase写流程分为以下几个步骤:
1.获得行锁
2.开启mvcc
3.写到内存buffer
4.写到append log
5.释放行锁
6.flush log
7.mvcc结束(这时才对读可见)
试想,如果没有不走 2,7 也不加读写锁,那在步骤3的时候,其他的线程就能读到该数据。如果说3之后出现了问题,那该条数据其实是写失败的。也就是说其他线程曾经读到过不存在的数据。
同理,在mysql中,如果不用mvcc也不用读写锁,一个事务还没commit,其中的数据就能被读到,如果用读写锁,一个事务会对中更改的数据加写锁,这时其他读操作会阻塞,直到事务提交,对于性能有很大的影响,所以大多数情况下数据库都采用MVCC机制实现非锁定读。
在上篇文章中,说了java后端面试中常问的基础问题,而面试除了考察基础以外,很重要的另一部分是'经验','经验'泛指以往做过的项目、解决的问题、以及一些开放性问题。
本文主要说两点:1.项目 2.开放性问题。注意两篇文章针对都的是java一线研发岗位。
更多文章见个人博客:https://github.com/farmerjohngit/myblog
公众号(刚申请,之后文章会往上面发):
先说点题外话,有同学对于上篇文章中有些看法:比如,xxx的底层实现和大多数程序员日常开发几乎无关,有种应付考试的感觉。
我说说我的观点,
第一,大厂面试就是会问jvm、中间件、数据库等原理性的问题,你要想去大厂就必须在日常中积累和在面试前准备。简单粗暴吧?
第二,挺多公司被调侃是面试时造火箭,工作时拧螺丝。这样的情况是很普遍的,那大厂为什么喜欢问这些问题?我认为原因有几点:
1.人才储备,可能你面试的岗位平时就是搬搬砖,不会涉及到有技术深度的问题,但是对于大公司而言,必须要确保当出现技术难题时是有人来解决的。 比如很多部门的并发量并不高,但是面试时也会问高并发相关的问题,其目的就是为了确保万一QPS高起来了,部门里的人都是有方案、有经验的。这么说应该很容易明白吧。
2.筛选人才,如果两个候选人,一个对于所有的框架都只是会使用,另一个除了会使用以外还清楚框架内部是如何实现的。如果你是面试官,你会选谁呢?
3.有技术热情的人一定会对某块领域上有过比较深入研究(可以是jvm、中间件、数据库以及其他)
回到本文正题,先来聊聊项目。
对于简历上写的项目,要从这几个方面去准备:
项目介绍:用最简洁的语言介绍清楚你的项目,包括项目的背景、方案、用到的关键技术、承担的角色,介绍时不要扯太多细节,让面试官有个大致了解就行,面试官遇到感兴趣的点时自然会追问。准备时要考虑到面试官可能完全不了解你的业务(比如面试官是做电商的,你的是金融项目)。
项目架构:能把项目的架构说清楚,能画出项目架构图,能说清楚项目在整个系统中的位置。
项目价值:想清楚做这个项目的价值在哪里?比如让业务数据提高了XX点、开发效率提升了XX倍。比较忌讳的是直接说老板让我做所以我就做了。
技术选型:如何做技术选型的?有考虑过哪些技术方案,是什么让你选择了最终的方案?
数据:项目带来的成果,比如业务项目转化率或点击率提高了XXX。对系统日常数据要有个大概印象,比如集群的总QPS是什么量级,大概多少台机器等,真正参与了的基本上也都知道,就怕是把别人项目说成自己的,这些数据一问就很容易看出来。
预案:很多小公司的项目实现功能就好了,对于可用性、一致性等要求没那么高。但在面试前准备时需要对项目中有缺陷的点做好预案。举个例子:数据落库后要发消息通知到其他系统,可能你的项目中是:
// 1.数据落库
writeToDB();
// 2.发消息
sendMsg();以上伪代码的问题是写完数据库后,如果系统挂了(可能是你的系统挂了也可能是消息中间件挂了)导致消息没发送成功,就会有不一致的情况发生。可能你的项目中漏发几条消息也没关系,但是当面试官问到如何保证写DB和发消息同时成功或同时失败时,你心中要有预案。
规划(如有):项目之后要做成什么样子,要添加哪些功能,目前有哪些做的不好的地方需要优化。
下面是我面试被问的比较多的场景题、系统设计方面的题,开放题跟个人经历也有关系,所以仅供参考。
分布式事务这块实现方案比较多,互联网公司很少用2pc这样的方案,一般都是保证事务的最终一致性,常用事务消息实现(以及tcc等)。要知道如何利用事务消息去实现最终一致性,以及事务性消息是如何实现的。
分布式事务没有一个绝对的方案,都是因业务场景的不同而不同。举个例子,电商场景中如何保证订单落库和减库存、锁券的最终一致性的(不同公司有不同方案,只是列举个我知道的)。
收到用户下单请求时,在订单库中创建一条不可见订单。
同步调用减库存接口,如失败跳转到4
同步调用锁券接口,成功跳转到5,失败跳转到4
发送一条废单消息,收到消息后回库存、回券
将订单改为可见
分布式事务的问题,我面试的公司基本上都问过。
这个一般会结合你的项目来问,比如上游系统请求量过大、依赖的下游非核心应用挂掉、系统出问题如何及时发现等等。主要是从限流、降级、监控、报警、主从备份、容灾等角度出发
实现分布式锁常见方案有:利用db的唯一键、redis、zk等。其中redis实现分布锁应该是用的最多的。关于如何用redis实现分布式锁可以看下这篇文章,当然更严谨的实现还是看redis的分布式锁官方实现:Redisson
我们经常会在DB和应用之间加一层Redis缓存,以提高查询效率,但是当数据发生更新时,如何保证缓存与DB的数据一致性呢?可以看看这篇文章,之后我也写写阿里是如何保证缓存一致性的。
Redis缓存穿透、缓存雪崩和缓存击穿几个问题,在网上都有比较成熟的解决方案了。比如加空value、设置随机超时时间、加互斥锁等方式
如海量日志数据,提取出某日访问百度次数最多的那个IP。
一般是hash+归并、布隆过滤、Map Reduce的思路
这篇文章说的很好了
常见限流的方案,如令牌桶算法,可以看下我之前写的来谈谈限流-从概念到实现、来谈谈限流-RateLimiter源码分析
一些常见线上问题比如系统的cpu占用过高、RT突然飙升、频繁发生full gc、OOM等如何定位并解决?
这主要来自于日常的积累了,排查问题主要依赖监控、日志、常用工具(top jstack jmap jstat vmstat等)。
去年底找工作找了2个多月,中间也经历了很多坎坷,庆幸的是最后结果还不错,也祝各位在找工作的朋友拿到满意的offer。
有这样一个场景,在HBase中需要分页查询,同时根据某一列的值进行过滤。
不同于RDBMS天然支持分页查询,HBase要进行分页必须由自己实现。据我了解的,目前有两种方案, 一是《HBase权威指南》中提到的用PageFilter加循环动态设置startRow实现,详细见这里。但这种方法效率比较低,且有冗余查询。因此京东研发了一种用额外的一张表来保存行序号的方案。 该种方案效率较高,但实现麻烦些,需要维护一张额外的表。
不管是方案也好,人也好,没有最好的,只有最适合的。
在我司的使用场景中,对于性能的要求并不高,所以采取了第一种方案。本来使用的美滋滋,但有一天需要在分页查询的同时根据某一列的值进行过滤。根据列值过滤,自然是用SingleColumnValueFilter(下文简称SCVFilter)。代码大致如下,只列出了本文主题相关的逻辑,
Scan scan = initScan(xxx);
FilterList filterList=new FilterList();
scan.setFilter(filterList);
filterList.addFilter(new PageFilter(1));
filterList.addFilter(new SingleColumnValueFilter(FAMILY,ISDELETED, CompareFilter.CompareOp.EQUAL, Bytes.toBytes(false)));数据如下
row1 column=f:content, timestamp=1513953705613, value=content1
row1 column=f:isDel, timestamp=1513953705613, value=1
row1 column=f:name, timestamp=1513953725029, value=name1
row2 column=f:content, timestamp=1513953705613, value=content2
row2 column=f:isDel, timestamp=1513953744613, value=0
row2 column=f:name, timestamp=1513953730348, value=name2
row3 column=f:content, timestamp=1513953705613, value=content3
row3 column=f:isDel, timestamp=1513953751332, value=0
row3 column=f:name, timestamp=1513953734698, value=name3
在上面的代码中。向scan添加了两个filter:首先添加了PageFilter,限制这次查询数量为1,然后添加了一个SCVFilter,限制了只返回isDeleted=false的行。
上面的代码,看上去无懈可击,但在运行时却没有查询到数据!
刚好最近在看HBase的代码,就在本地debug了下HBase服务端Filter相关的查询流程。
首先看下HBase Filter的流程,见图:
然后再看PageFilter的实现逻辑。
public class PageFilter extends FilterBase {
private long pageSize = Long.MAX_VALUE;
private int rowsAccepted = 0;
/**
* Constructor that takes a maximum page size.
*
* @param pageSize Maximum result size.
*/
public PageFilter(final long pageSize) {
Preconditions.checkArgument(pageSize >= 0, "must be positive %s", pageSize);
this.pageSize = pageSize;
}
public long getPageSize() {
return pageSize;
}
@Override
public ReturnCode filterKeyValue(Cell ignored) throws IOException {
return ReturnCode.INCLUDE;
}
public boolean filterAllRemaining() {
return this.rowsAccepted >= this.pageSize;
}
public boolean filterRow() {
this.rowsAccepted++;
return this.rowsAccepted > this.pageSize;
}
}其实很简单,内部有一个计数器,每次调用filterRow的时候,计数器都会+1,如果计数器值大于pageSize,filterrow就会返回true,那之后的行就会被过滤掉。
再看SCVFilter的实现逻辑。
public class SingleColumnValueFilter extends FilterBase {
private static final Log LOG = LogFactory.getLog(SingleColumnValueFilter.class);
protected byte [] columnFamily;
protected byte [] columnQualifier;
protected CompareOp compareOp;
protected ByteArrayComparable comparator;
protected boolean foundColumn = false;
protected boolean matchedColumn = false;
protected boolean filterIfMissing = false;
protected boolean latestVersionOnly = true;
/**
* Constructor for binary compare of the value of a single column. If the
* column is found and the condition passes, all columns of the row will be
* emitted. If the condition fails, the row will not be emitted.
* <p>
* Use the filterIfColumnMissing flag to set whether the rest of the columns
* in a row will be emitted if the specified column to check is not found in
* the row.
*
* @param family name of column family
* @param qualifier name of column qualifier
* @param compareOp operator
* @param comparator Comparator to use.
*/
public SingleColumnValueFilter(final byte [] family, final byte [] qualifier,
final CompareOp compareOp, final ByteArrayComparable comparator) {
this.columnFamily = family;
this.columnQualifier = qualifier;
this.compareOp = compareOp;
this.comparator = comparator;
}
@Override
public ReturnCode filterKeyValue(Cell c) {
if (this.matchedColumn) {
// We already found and matched the single column, all keys now pass
return ReturnCode.INCLUDE;
} else if (this.latestVersionOnly && this.foundColumn) {
// We found but did not match the single column, skip to next row
return ReturnCode.NEXT_ROW;
}
if (!CellUtil.matchingColumn(c, this.columnFamily, this.columnQualifier)) {
return ReturnCode.INCLUDE;
}
foundColumn = true;
if (filterColumnValue(c.getValueArray(), c.getValueOffset(), c.getValueLength())) {
return this.latestVersionOnly? ReturnCode.NEXT_ROW: ReturnCode.INCLUDE;
}
this.matchedColumn = true;
return ReturnCode.INCLUDE;
}
private boolean filterColumnValue(final byte [] data, final int offset,
final int length) {
int compareResult = this.comparator.compareTo(data, offset, length);
switch (this.compareOp) {
case LESS:
return compareResult <= 0;
case LESS_OR_EQUAL:
return compareResult < 0;
case EQUAL:
return compareResult != 0;
case NOT_EQUAL:
return compareResult == 0;
case GREATER_OR_EQUAL:
return compareResult > 0;
case GREATER:
return compareResult >= 0;
default:
throw new RuntimeException("Unknown Compare op " + compareOp.name());
}
}
public boolean filterRow() {
// If column was found, return false if it was matched, true if it was not
// If column not found, return true if we filter if missing, false if not
return this.foundColumn? !this.matchedColumn: this.filterIfMissing;
}
}在HBase中,对于每一行的每一列都会调用到filterKeyValue,SCVFilter的该方法处理逻辑如下:
1. 如果已经匹配过对应的列并且对应列的值符合要求,则直接返回INCLUE,表示这一行的这一列要被加入到结果集
2. 否则如latestVersionOnly为true(latestVersionOnly代表是否只查询最新的数据,一般为true),并且已经匹配过对应的列(但是对应的列的值不满足要求),则返回EXCLUDE,代表丢弃该行
3. 如果当前列不是要匹配的列。则返回INCLUDE,否则将matchedColumn置为true,代表以及找到了目标列
4. 如果当前列的值不满足要求,在latestVersionOnly为true时,返回NEXT_ROW,代表忽略当前行还剩下的列,直接跳到下一行
5. 如果当前列的值满足要求,将matchedColumn置为true,代表已经找到了对应的列,并且对应的列值满足要求。这样,该行下一列再进入这个方法时,到第1步就会直接返回,提高匹配效率
再看filterRow方法,该方法调用时机在filterKeyValue之后,对每一行只会调用一次。
SCVFilter中该方法逻辑很简单:
1. 如果找到了对应的列,如其值满足要求,则返回false,代表将该行加入到结果集,如其值不满足要求,则返回true,代表过滤该行
2. 如果没找到对应的列,返回filterIfMissing的值。
是不是因为将PageFilter添加到SCVFilter的前面,当判断第一行的时候,调用PageFilter的filterRow,导致PageFilter的计数器+1,但是进行到SCVFilter的filterRow的时候,该行又被过滤掉了,在检验下一行时,因为PageFilter计数器已经达到了我们设定的pageSize,所以接下来的行都会被过滤掉,返回结果没有数据。
在FilterList中,先加入SCVFilter,再加入PageFilter
Scan scan = initScan(xxx);
FilterList filterList=new FilterList();
scan.setFilter(filterList);
filterList.addFilter(new SingleColumnValueFilter(FAMILY,ISDELETED, CompareFilter.CompareOp.EQUAL, Bytes.toBytes(false)));
filterList.addFilter(new PageFilter(1));结果是我们期望的第2行的值。
当要将PageFilter和其他Filter使用时,最好将PageFilter加入到FilterList的末尾,否则可能会出现结果个数小于你期望的数量。
(其实正常情况PageFilter返回的结果数量可能大于设定的值,因为服务器集群的PageFilter是隔离的。)
其实,在排查问题的过程中,并没有这样顺利,因为问题出在线上,所以我在本地查问题时自己造了一些测试数据,令人惊讶的是,就算我先加入SCVFilter,再加入PageFilter,返回的结果也是符合预期的。
测试数据如下:
row1 column=f:isDel, timestamp=1513953705613, value=1
row1 column=f:name, timestamp=1513953725029, value=name1
row2 column=f:isDel, timestamp=1513953744613, value=0
row2 column=f:name, timestamp=1513953730348, value=name2
row3 column=f:isDel, timestamp=1513953751332, value=0
row3 column=f:name, timestamp=1513953734698, value=name3
当时在本地一直不能复现问题。很是苦恼,最后竟然发现使用SCVFilter查询的结果还和数据的列的顺序有关。
在服务端,HBase会对客户端传递过来的filter封装成FilterWrapper。
class RegionScannerImpl implements RegionScanner {
RegionScannerImpl(Scan scan, List<KeyValueScanner> additionalScanners, HRegion region)
throws IOException {
this.region = region;
this.maxResultSize = scan.getMaxResultSize();
if (scan.hasFilter()) {
this.filter = new FilterWrapper(scan.getFilter());
} else {
this.filter = null;
}
}
....
}在查询数据时,在HRegion的nextInternal方法中,会调用FilterWrapper的filterRowCellsWithRet方法
FilterWrapper相关代码如下:
/**
* This is a Filter wrapper class which is used in the server side. Some filter
* related hooks can be defined in this wrapper. The only way to create a
* FilterWrapper instance is passing a client side Filter instance through
* {@link org.apache.hadoop.hbase.client.Scan#getFilter()}.
*
*/
final public class FilterWrapper extends Filter {
Filter filter = null;
public FilterWrapper( Filter filter ) {
if (null == filter) {
// ensure the filter instance is not null
throw new NullPointerException("Cannot create FilterWrapper with null Filter");
}
this.filter = filter;
}
public enum FilterRowRetCode {
NOT_CALLED,
INCLUDE, // corresponds to filter.filterRow() returning false
EXCLUDE // corresponds to filter.filterRow() returning true
}
public FilterRowRetCode filterRowCellsWithRet(List<Cell> kvs) throws IOException {
this.filter.filterRowCells(kvs);
if (!kvs.isEmpty()) {
if (this.filter.filterRow()) {
kvs.clear();
return FilterRowRetCode.EXCLUDE;
}
return FilterRowRetCode.INCLUDE;
}
return FilterRowRetCode.NOT_CALLED;
}
}这里的kvs就是一行数据经过filterKeyValue后没被过滤的列。
可以看到当kvs不为empty时,filterRowCellsWithRet方法中会调用指定filter的filterRow方法,上面已经说过了,PageFilter的计数器就是在其filterRow方法中增加的。
而当kvs为empty时,PageFilter的计数器就不会增加了。再看我们的测试数据,因为行的第一列就是SCVFilter的目标列isDeleted。回顾上面SCVFilter的讲解我们知道,当一行的目标列的值不满足要求时,该行剩下的列都会直接被过滤掉!
对于测试数据第一行,走到filterRowCellsWithRet时kvs是empty的。导致PageFilter的计数器没有+1。还会继续遍历剩下的行。从而使得返回的结果看上去是正常的。
而出问题的数据,因为在列isDeleted之前还有列content,所以当一行的isDeleted不满足要求时,kvs也不会为empty。因为列content的值已经加入到kvs中了(这些数据要调用到SCVFilter的filterrow的时间会被过滤掉)。
从实现上来看HBase的Filter的实现还是比较粗糙的。效率也比较感人,不考虑网络传输和客户端内存的消耗,基本上和你在客户端过滤差不多。
线程同步可以说在日常开发中是用的很多,
但对于其内部如何实现的,一般人可能知道的并不多。
本篇文章将从如何实现简单的锁开始,介绍linux中的锁实现futex的优点及原理,最后分析java中同步机制如wait/notify, synchronized, ReentrantLock。
首先,如果要你实现操作系统的锁,该如何实现?先想想这个问题,暂时不考虑性能、可用性等问题,就用最简单、粗暴的方式。当你心中有个大致的思路后,再接着往下看。
下文中的代码都是伪代码。
最容易想到可能是自旋:
volatile int status=0;
void lock(){
while(!compareAndSet(0,1)){
}
//get lock
}
void unlock(){
status=0;
}
boolean compareAndSet(int except,int newValue){
//cas操作,修改status成功则返回true
}
上面的代码通过自旋和cas来实现一个最简单的锁。
这样实现的锁显然有个致命的缺点:耗费cpu资源。没有竞争到锁的线程会一直占用cpu资源进行cas操作,假如一个线程获得锁后要花费10s处理业务逻辑,那另外一个线程就会白白的花费10s的cpu资源。(假设系统中就只有这两个线程的情况)。
要解决自旋锁的性能问题必须让竞争锁失败的线程不忙等,而是在获取不到锁的时候能把cpu资源给让出来,说到让cpu资源,你可能想到了yield()方法,看看下面的例子:
volatile int status=0;
void lock(){
while(!compareAndSet(0,1)){
yield();
}
//get lock
}
void unlock(){
status=0;
}
当线程竞争锁失败时,会调用yield方法让出cpu。需要注意的是该方法只是当前让出cpu,有可能操作系统下次还是选择运行该线程。其实现是
将当期线程移动到所在优先调度队列的末端(操作系统线程调度了解一下?有时间的话,下次写写这块内容)。也就是说,如果该线程处于优先级最高的调度队列且该队列只有该线程,那操作系统下次还是运行该线程。
自旋+yield的方式并没有完全解决问题,当系统只有两个线程竞争锁时,yield是有效的。但是如果有100个线程竞争锁,当线程1获得锁后,还有99个线程在反复的自旋+yield,线程2调用yield后,操作系统下次运行的可能是线程3;而线程3CAS失败后调用yield后,操作系统下次运行的可能是线程4...
假如运行在单核cpu下,在竞争锁时最差只有1%的cpu利用率,导致获得锁的线程1一直被中断,执行实际业务代码时间变得更长,从而导致锁释放的时间变的更长。
你可能从一开始就想到了,当竞争锁失败后,可以将用Thread.sleep将线程休眠,从而不占用cpu资源:
volatile int status=0;
void lock(){
while(!compareAndSet(0,1)){
sleep(10);
}
//get lock
}
void unlock(){
status=0;
}
上述方式我们可能见的比较多,通常用于实现上层锁。该方式不适合用于操作系统级别的锁,因为作为一个底层锁,其sleep时间很难设置。sleep的时间取决于同步代码块的执行时间,sleep时间如果太短了,会导致线程切换频繁(极端情况和yield方式一样);sleep时间如果设置的过长,会导致线程不能及时获得锁。因此没法设置一个通用的sleep值。就算sleep的值由调用者指定也不能完全解决问题:有的时候调用锁的人也不知道同步块代码会执行多久。
那可不可以在获取不到锁的时候让线程释放cpu资源进行等待,当持有锁的线程释放锁的时候将等待的线程唤起呢?
volatile int status=0;
Queue parkQueue;
void lock(){
while(!compareAndSet(0,1)){
//
lock_wait();
}
//get lock
}
void synchronized unlock(){
lock_notify();
}
void lock_wait(){
//将当期线程加入到等待队列
parkQueue.add(nowThread);
//将当期线程释放cpu
releaseCpu();
}
void lock_notify(){
//得到要唤醒的线程
Thread t=parkList.poll();
//唤醒等待线程
wakeAThread(t);
}
上面是伪代码,描述这种设计**,至于释放cpu资源、唤醒等待线程的的具体实现,后文会再说。这种方案相比于sleep而言,只有在锁被释放的时候,竞争锁的线程才会被唤醒,不会存在过早或过晚唤醒的问题。
对于锁冲突不严重的情况,用自旋锁会更适合,试想每个线程获得锁后很短的一段时间内就释放锁,竞争锁的线程只要经历几次自旋运算后就能获得锁,那就没必要等待该线程了,因为等待线程意味着需要进入到内核态进行上下文切换,而上下文切换是有成本的并且还不低,如果锁很快就释放了,那上下文切换的开销将超过自旋。
目前操作系统中,一般是用自旋+等待结合的形式实现锁:在进入锁时先自旋一定次数,如果还没获得锁再进行等待。
linux底层用futex实现锁,futex由一个内核层的队列和一个用户空间层的atomic integer构成。当获得锁时,尝试cas更改integer,如果integer原始值是0,则修改成功,该线程获得锁,否则就将当期线程放入到 wait queue中(即操作系统的等待队列)。
上述说法有些抽象,如果你没看明白也没关系。我们先看一下没有futex之前,linux是怎么实现锁的。
在futex诞生之前,linux下的同步机制可以归为两类:用户态的同步机制 和内核同步机制。 用户态的同步机制基本上就是利用原子指令实现的自旋锁。关于自旋锁其缺点也说过了,不适用于大的临界区(即锁占用时间比较长的情况)。
内核提供的同步机制,如semaphore等,使用的是上文说的自旋+等待的形式。 它对于大小临界区和都适用。但是因为它是内核层的(释放cpu资源是内核级调用),所以每次lock与unlock都是一次系统调用,即使没有锁冲突,也必须要通过系统调用进入内核之后才能识别。
理想的同步机制应该是没有锁冲突时在用户态利用原子指令就解决问题,而需要挂起等待时再使用内核提供的系统调用进行睡眠与唤醒。换句话说,在用户态的自旋失败时,能不能让进程挂起,由持有锁的线程释放锁时将其唤醒?
如果你没有较深入地考虑过这个问题,很可能想当然的认为类似于这样就行了(伪代码):
void lock(int lockval) {
//trylock是用户级的自旋锁
while(!trylock(lockval)) {
wait();//释放cpu,并将当期线程加入等待队列,是系统调用
}
}
boolean trylock(int lockval){
int i=0;
//localval=1代表上锁成功
while(!compareAndSet(lockval,0,1)){
if(++i>10){
return false;
}
}
return true;
}
void unlock(int lockval) {
compareAndSet(lockval,1,0);
notify();
}
上述代码的问题是trylock和wait两个调用之间存在一个窗口:
如果一个线程trylock失败,在调用wait时持有锁的线程释放了锁,当前线程还是会调用wait进行等待,但之后就没有人再将该线程唤醒了。
我们来看看futex的方法定义:
//uaddr指向一个地址,val代表这个地址期待的值,当*uaddr==val时,才会进行wait
int futex_wait(int *uaddr, int val);
//唤醒n个在uaddr指向的锁变量上挂起等待的进程
int futex_wake(int *uaddr, int n);
futex_wait真正将进程挂起之前会检查addr指向的地址的值是否等于val,如果不相等则会立即返回,由用户态继续trylock。否则将当期线程插入到一个队列中去,并挂起。
futex内部维护了一个队列,在线程挂起前会线程插入到其中,同时对于队列中的每个节点都有一个标识,代表该线程关联锁的uaddr。这样,当用户态调用futex_wake时,只需要遍历这个等待队列,把带有相同uaddr的节点所对应的进程唤醒就行了。
作为优化,futex维护的其实是个类似java 中的concurrent hashmap的结构。其持有一个总链表,总链表中每个元素都是一个带有自旋锁的子链表。调用futex_wait挂起的进程,通过其uaddr hash到某一个具体的子链表上去。这样一方面能分散对等待队列的竞争、另一方面减小单个队列的长度,便于futex_wake时的查找。每个链表各自持有一把spinlock,将"*uaddr和val的比较操作"与"把进程加入队列的操作"保护在一个临界区中。
另外,futex是支持多进程的,当使用futex在多进程间进行同步时,需要考虑同一个物理内存地址在不同进程中的虚拟地址是不同的。
本文讲述了实现锁的几种形式以及linux中futex的实现,下篇文章会讲讲Java中ReentrantLock,包括其java层的实现以及使用到的LockSupport.park的底层实现。
在现代操作系统里,由于系统资源可能同时被多个应用程序访问,如果不加保护,那各个应用程序之间可能会产生冲突,对于恶意应用程序更可能导致系统奔溃。这里所说的系统资源包括文件、网络、各种硬件设备等。比如要操作文件必须借助操作系统提供的api(比如linux下的fopen)。
系统调用在我们工作中无时无刻不打着交道,那系统调用的原理是什么呢?在其过程中做了哪些事情呢?
本文将阐述系统调用原理,让大家对于系统调用有一个清晰的认识。
更多文章见个人博客:https://github.com/farmerjohngit/myblog
现代cpu通常有多种特权级别,一般来说特权级总共有4个,编号从Ring 0(最高特权)到Ring 3(最低特权),在Linux上之用到Ring 0和RIng 3,用户态对应Ring 3,内核态对应Ring 0。
普通应用程序运行在用户态下,其诸多操作都受到限制,比如改变特权级别、访问硬件等。特权高的代码能将自己降至低等级的级别,但反之则是不行的。而系统调用是运行在内核态的,那么运行在用户态的应用程序如何运行内核态的代码呢?操作系统一般是通过中断来从用户态切换到内核态的。学过操作系统课程的同学对中断这个词肯定都不陌生。
中断一般有两个属性,一个是中断号,一个是中断处理程序。不同的中断有不同的中断号,每个中断号都对应了一个中断处理程序。在内核中有一个叫中断向量表的数组来映射这个关系。当中断到来时,cpu会暂停正在执行的代码,根据中断号去中断向量表找出对应的中断处理程序并调用。中断处理程序执行完成后,会继续执行之前的代码。
中断分为硬件中断和软件中断,我们这里说的是软件中断,软件中断通常是一条指令,使用这条指令用户可以手动触发某个中断。例如在i386下,对应的指令是int,在int指令后指定对应的中断号,如int 0x80代表你调用第0x80号的中断处理程序。
中断号是有限的,所有不会用一个中断来对应一个系统调用(系统调用有很多)。Linux下用int 0x80触发所有的系统调用,那如何区分不同的调用呢?对于每个系统调用都有一个系统调用号,在触发中断之前,会将系统调用号放入到一个固定的寄存器,0x80对应的中断处理程序会读取该寄存器的值,然后决定执行哪个系统调用的代码。
在Linux2.5(具体版本不是很确定)之前的版本,是使用int 0x80这样的方式实现系统调用的,但其实int指令这样的形式性能不太好,原因如下(出自这篇文章):
在 x86 保护模式中,处理 INT 中断指令时,CPU 首先从中断描述表 IDT 取出对应的门描述符,判断门描述符的种类,然后检查门描述符的级别 DPL 和 INT 指令调用者的级别 CPL,当 CPL<=DPL 也就是说 INT 调用者级别高于描述符指定级别时,才能成功调用,最后再根据描述符的内容,进行压栈、跳转、权限级别提升。内核代码执行完毕之后,调用 IRET 指令返回,IRET 指令恢复用户栈,并跳转会低级别的代码。
其实,在发生系统调用,由 Ring3 进入 Ring0 的这个过程浪费了不少的 CPU 周期,例如,系统调用必然需要由 Ring3 进入 Ring0(由内核调用 INT 指令的方式除外,这多半属于 Hacker 的内核模块所为),权限提升之前和之后的级别是固定的,CPL 肯定是 3,而 INT 80 的 DPL 肯定也是 3,这样 CPU 检查门描述符的 DPL 和调用者的 CPL 就是完全没必要。
正是由于如此,在linux2.5开始支持一种新的系统调用,其基于Intel 奔腾2代处理器就开始支持的一组专门针对系统调用的指令sysenter/sysexit。sysenter 指令用于由 Ring3 进入 Ring0,sysexit指令用于由 Ring0 返回 Ring3。由于没有特权级别检查的处理,也没有压栈的操作,所以执行速度比 INT n/IRET 快了不少。
本文分析的是int指令,新型的系统调用机制可以参见下面几篇文章:
https://www.ibm.com/developerworks/cn/linux/kernel/l-k26ncpu/index.html
https://www.jianshu.com/p/f4c04cf8e406
我们以系统调用fork为例,fork函数的定义在glibc(2.17版本)的unistd.h
/* Clone the calling process, creating an exact copy.
Return -1 for errors, 0 to the new process,
and the process ID of the new process to the old process. */
extern __pid_t fork (void) __THROWNL;fork函数的实现代码比较难找,在nptl\sysdeps\unix\sysv\linux\fork.c中有这么一段代码
weak_alias (__libc_fork, __fork)
libc_hidden_def (__fork)
weak_alias (__libc_fork, fork)其作用简单的说就是将__libc_fork当作__fork的别名,所以fork函数的实现是在__libc_fork中,核心代码如下
#ifdef ARCH_FORK
pid = ARCH_FORK ();
#else
# error "ARCH_FORK must be defined so that the CLONE_SETTID flag is used"
pid = INLINE_SYSCALL (fork, 0);
#endif我们分析定义了ARCH_FORK的情况,ARCH_FORK定义在nptl\sysdeps\unix\sysv\linux\i386\fork.c中,代码如下:
#define ARCH_FORK() \
INLINE_SYSCALL (clone, 5, \
CLONE_CHILD_SETTID | CLONE_CHILD_CLEARTID | SIGCHLD, 0, \
NULL, NULL, &THREAD_SELF->tid)INLINE_SYSCALL代码在sysdeps\unix\sysv\linux\i386\sysdep.h
#undef INLINE_SYSCALL
#define INLINE_SYSCALL(name, nr, args...) \
({ \
unsigned int resultvar = INTERNAL_SYSCALL (name, , nr, args); \
if (__builtin_expect (INTERNAL_SYSCALL_ERROR_P (resultvar, ), 0)) \
{ \
__set_errno (INTERNAL_SYSCALL_ERRNO (resultvar, )); \
resultvar = 0xffffffff; \
} \
(int) resultvar; })INLINE_SYSCALL主要是调用同文件下的INTERNAL_SYSCALL
# define INTERNAL_SYSCALL(name, err, nr, args...) \
({ \
register unsigned int resultvar; \
EXTRAVAR_##nr \
asm volatile ( \
LOADARGS_##nr \
"movl %1, %%eax\n\t" \
"int $0x80\n\t" \
RESTOREARGS_##nr \
: "=a" (resultvar) \
: "i" (__NR_##name) ASMFMT_##nr(args) : "memory", "cc"); \
(int) resultvar; })
#define __NR_clone 120
这里是一段内联汇编代码, 其中__NR_##name的值为 __NR_clone即120。这里主要是两个步骤:
int $0x80陷入中断int $0x80指令会让cpu陷入中断,执行对应的0x80中断处理函数。不过在这之前,cpu还需要进行栈切换。
因为在linux中,用户态和内核态使用的是不同的栈(可以看看这篇文章),两者负责各自的函数调用,互不干扰。在执行int $0x80时,程序需要由用户态切换到内核态,所以程序当前栈也要从用户栈切换到内核栈。与之对应,当中断程序执行结束返回时,当前栈要从内核栈切换回用户栈。
这里说的当前栈指的就是ESP寄存器的值所指向的栈。ESP的值位于用户栈的范围,那程序的当前栈就是用户栈,反之亦然。此外寄存器SS的值指向当前栈所在的页。因此,将用户栈切换到内核栈的过程是:
反之,从内核栈切换回用户栈的过程:恢复ESP、SS等寄存器的值,也就是用保存在内核栈的原ESP、SS等值设置回对应寄存器。
在切换到内核栈之后,就开始执行中断向量表的0x80号中断处理程序。中断处理程序除了系统调用(0x80)还有如除0异常(0x00)、缺页异常(0x14)等等,在arch\i386\kernel\traps.c文件的trap_init方法中描述了中断处理程序向中断向量表注册的过程:
void __init trap_init(void)
{
#ifdef CONFIG_EISA
void __iomem *p = ioremap(0x0FFFD9, 4);
if (readl(p) == 'E'+('I'<<8)+('S'<<16)+('A'<<24)) {
EISA_bus = 1;
}
iounmap(p);
#endif
#ifdef CONFIG_X86_LOCAL_APIC
init_apic_mappings();
#endif
set_trap_gate(0,÷_error);
set_intr_gate(1,&debug);
set_intr_gate(2,&nmi);
set_system_intr_gate(3, &int3); /* int3-5 can be called from all */
set_system_gate(4,&overflow);
set_system_gate(5,&bounds);
set_trap_gate(6,&invalid_op);
set_trap_gate(7,&device_not_available);
set_task_gate(8,GDT_ENTRY_DOUBLEFAULT_TSS);
set_trap_gate(9,&coprocessor_segment_overrun);
set_trap_gate(10,&invalid_TSS);
set_trap_gate(11,&segment_not_present);
set_trap_gate(12,&stack_segment);
set_trap_gate(13,&general_protection);
set_intr_gate(14,&page_fault);
set_trap_gate(15,&spurious_interrupt_bug);
set_trap_gate(16,&coprocessor_error);
set_trap_gate(17,&alignment_check);
#ifdef CONFIG_X86_MCE
set_trap_gate(18,&machine_check);
#endif
set_trap_gate(19,&simd_coprocessor_error);
set_system_gate(SYSCALL_VECTOR,&system_call);
/*
* Should be a barrier for any external CPU state.
*/
cpu_init();
trap_init_hook();
}SYSCALL_VECTOR定义如下:
#define SYSCALL_VECTOR 0x80
所以0x80对应的处理程序就是system_call这个方法,该方法位于arch\i386\kernel\entry.S
ENTRY(system_call)
//code 1: 保存各种寄存器
SAVE_ALL
...
jnz syscall_trace_entry
//如果传入的系统调用号大于最大的系统调用号,则跳转到无效调用处理
cmpl $(nr_syscalls), %eax
jae syscall_badsys
syscall_call:
//code 2: 根据系统调用号(存储在eax中)来调用对应的系统调用程序
call *sys_call_table(,%eax,4)
//保存系统调用返回值到eax寄存器中
movl %eax,EAX(%esp) # store the return value
...
restore_all:
//code 3:恢复各种寄存器的值 以及执行iret指令
RESTORE_ALL
...
主要分为几步:
1.保存各种寄存器
2.根据系统调用号执行对应的系统调用程序,将返回结果存入到eax中
3.恢复各种寄存器
其中保存各种寄存器的SAVE_ALL定义在entry.S中:
#define SAVE_ALL \
cld; \
pushl %es; \
pushl %ds; \
pushl %eax; \
pushl %ebp; \
pushl %edi; \
pushl %esi; \
pushl %edx; \
pushl %ecx; \
pushl %ebx; \
movl $(__USER_DS), %edx; \
movl %edx, %ds; \
movl %edx, %es;sys_call_table定义在entry.S中:
.data
ENTRY(sys_call_table)
.long sys_restart_syscall /* 0 - old "setup()" system call, used for restarting */
.long sys_exit
.long sys_fork
.long sys_read
.long sys_write
.long sys_open /* 5 */
...
.long sys_sigreturn
.long sys_clone /* 120 */
...
sys_call_table就是系统调用表,每一个long元素(4字节)都是一个系统调用地址,所以 *sys_call_table(,%eax,4)的含义就是sys_call_table上偏移量为0+%eax*4元素所指向的系统调用,即第%eax个系统调用。上文中fork系统调用最终设置到eax的值是120,那最终执行的就是sys_clone这个函数,注意其实现和第2个系统调用sys_fork基本一样,只是参数不同,关于fork和clone的区别可以看这里,代码如下:
//kernel\fork.c
asmlinkage int sys_fork(struct pt_regs regs)
{
return do_fork(SIGCHLD, regs.esp, ®s, 0, NULL, NULL);
}
asmlinkage int sys_clone(struct pt_regs regs)
{
unsigned long clone_flags;
unsigned long newsp;
int __user *parent_tidptr, *child_tidptr;
clone_flags = regs.ebx;
newsp = regs.ecx;
parent_tidptr = (int __user *)regs.edx;
child_tidptr = (int __user *)regs.edi;
if (!newsp)
newsp = regs.esp;
return do_fork(clone_flags, newsp, ®s, 0, parent_tidptr, child_tidptr);
}一次系统调用的基本过程已经分析完,剩下的具体处理逻辑和本文无关就不分析了,有兴趣的同学可以自己看看。
整体调用流程图如下:
想写这篇文章的原因主要是年前在看《《程序员的自我修养》》这本书,之前对于系统调用这块有一些了解但很零碎和模糊,看完本书系统调用这一章后消除了我许多疑问。总体来说这是一本不错的书,但我相关的基础比较薄弱,所以收获不多。
本文为死磕Synchronized底层实现第三篇文章,内容为重量级锁实现。
本系列文章将对HotSpot的synchronized锁实现进行全面分析,内容包括偏向锁、轻量级锁、重量级锁的加锁、解锁、锁升级流程的原理及源码分析,希望给在研究synchronized路上的同学一些帮助。主要包括以下几篇文章:
更多文章见个人博客:https://github.com/farmerjohngit/myblog
当出现多个线程同时竞争锁时,会进入到synchronizer.cpp#slow_enter方法
void ObjectSynchronizer::slow_enter(Handle obj, BasicLock* lock, TRAPS) {
markOop mark = obj->mark();
assert(!mark->has_bias_pattern(), "should not see bias pattern here");
// 如果是无锁状态
if (mark->is_neutral()) {
lock->set_displaced_header(mark);
if (mark == (markOop) Atomic::cmpxchg_ptr(lock, obj()->mark_addr(), mark)) {
TEVENT (slow_enter: release stacklock) ;
return ;
}
// Fall through to inflate() ...
} else
// 如果是轻量级锁重入
if (mark->has_locker() && THREAD->is_lock_owned((address)mark->locker())) {
assert(lock != mark->locker(), "must not re-lock the same lock");
assert(lock != (BasicLock*)obj->mark(), "don't relock with same BasicLock");
lock->set_displaced_header(NULL);
return;
}
...
// 这时候需要膨胀为重量级锁,膨胀前,设置Displaced Mark Word为一个特殊值,代表该锁正在用一个重量级锁的monitor
lock->set_displaced_header(markOopDesc::unused_mark());
//先调用inflate膨胀为重量级锁,该方法返回一个ObjectMonitor对象,然后调用其enter方法
ObjectSynchronizer::inflate(THREAD, obj())->enter(THREAD);
}在inflate中完成膨胀过程。
ObjectMonitor * ATTR ObjectSynchronizer::inflate (Thread * Self, oop object) {
...
for (;;) {
const markOop mark = object->mark() ;
assert (!mark->has_bias_pattern(), "invariant") ;
// mark是以下状态中的一种:
// * Inflated(重量级锁状态) - 直接返回
// * Stack-locked(轻量级锁状态) - 膨胀
// * INFLATING(膨胀中) - 忙等待直到膨胀完成
// * Neutral(无锁状态) - 膨胀
// * BIASED(偏向锁) - 非法状态,在这里不会出现
// CASE: inflated
if (mark->has_monitor()) {
// 已经是重量级锁状态了,直接返回
ObjectMonitor * inf = mark->monitor() ;
...
return inf ;
}
// CASE: inflation in progress
if (mark == markOopDesc::INFLATING()) {
// 正在膨胀中,说明另一个线程正在进行锁膨胀,continue重试
TEVENT (Inflate: spin while INFLATING) ;
// 在该方法中会进行spin/yield/park等操作完成自旋动作
ReadStableMark(object) ;
continue ;
}
if (mark->has_locker()) {
// 当前轻量级锁状态,先分配一个ObjectMonitor对象,并初始化值
ObjectMonitor * m = omAlloc (Self) ;
m->Recycle();
m->_Responsible = NULL ;
m->OwnerIsThread = 0 ;
m->_recursions = 0 ;
m->_SpinDuration = ObjectMonitor::Knob_SpinLimit ; // Consider: maintain by type/class
// 将锁对象的mark word设置为INFLATING (0)状态
markOop cmp = (markOop) Atomic::cmpxchg_ptr (markOopDesc::INFLATING(), object->mark_addr(), mark) ;
if (cmp != mark) {
omRelease (Self, m, true) ;
continue ; // Interference -- just retry
}
// 栈中的displaced mark word
markOop dmw = mark->displaced_mark_helper() ;
assert (dmw->is_neutral(), "invariant") ;
// 设置monitor的字段
m->set_header(dmw) ;
// owner为Lock Record
m->set_owner(mark->locker());
m->set_object(object);
...
// 将锁对象头设置为重量级锁状态
object->release_set_mark(markOopDesc::encode(m));
...
return m ;
}
// CASE: neutral
// 分配以及初始化ObjectMonitor对象
ObjectMonitor * m = omAlloc (Self) ;
// prepare m for installation - set monitor to initial state
m->Recycle();
m->set_header(mark);
// owner为NULL
m->set_owner(NULL);
m->set_object(object);
m->OwnerIsThread = 1 ;
m->_recursions = 0 ;
m->_Responsible = NULL ;
m->_SpinDuration = ObjectMonitor::Knob_SpinLimit ; // consider: keep metastats by type/class
// 用CAS替换对象头的mark word为重量级锁状态
if (Atomic::cmpxchg_ptr (markOopDesc::encode(m), object->mark_addr(), mark) != mark) {
// 不成功说明有另外一个线程在执行inflate,释放monitor对象
m->set_object (NULL) ;
m->set_owner (NULL) ;
m->OwnerIsThread = 0 ;
m->Recycle() ;
omRelease (Self, m, true) ;
m = NULL ;
continue ;
// interference - the markword changed - just retry.
// The state-transitions are one-way, so there's no chance of
// live-lock -- "Inflated" is an absorbing state.
}
...
return m ;
}
}
inflate中是一个for循环,主要是为了处理多线程同时调用inflate的情况。然后会根据锁对象的状态进行不同的处理:
1.已经是重量级状态,说明膨胀已经完成,直接返回
2.如果是轻量级锁则需要进行膨胀操作
3.如果是膨胀中状态,则进行忙等待
4.如果是无锁状态则需要进行膨胀操作
其中轻量级锁和无锁状态需要进行膨胀操作,轻量级锁膨胀流程如下:
1.调用omAlloc分配一个ObjectMonitor对象(以下简称monitor),在omAlloc方法中会先从线程私有的monitor集合omFreeList中分配对象,如果omFreeList中已经没有monitor对象,则从JVM全局的gFreeList中分配一批monitor到omFreeList中。
2.初始化monitor对象
3.将状态设置为膨胀中(INFLATING)状态
4.设置monitor的header字段为displaced mark word,owner字段为Lock Record,obj字段为锁对象
5.设置锁对象头的mark word为重量级锁状态,指向第一步分配的monitor对象
无锁状态下的膨胀流程如下:
1.调用omAlloc分配一个ObjectMonitor对象(以下简称monitor)
2.初始化monitor对象
3.设置monitor的header字段为 mark word,owner字段为null,obj字段为锁对象
4.设置锁对象头的mark word为重量级锁状态,指向第一步分配的monitor对象
至于为什么轻量级锁需要一个膨胀中(INFLATING)状态,代码中的注释是:
// Why do we CAS a 0 into the mark-word instead of just CASing the
// mark-word from the stack-locked value directly to the new inflated state?
// Consider what happens when a thread unlocks a stack-locked object.
// It attempts to use CAS to swing the displaced header value from the
// on-stack basiclock back into the object header. Recall also that the
// header value (hashcode, etc) can reside in (a) the object header, or
// (b) a displaced header associated with the stack-lock, or (c) a displaced
// header in an objectMonitor. The inflate() routine must copy the header
// value from the basiclock on the owner's stack to the objectMonitor, all
// the while preserving the hashCode stability invariants. If the owner
// decides to release the lock while the value is 0, the unlock will fail
// and control will eventually pass from slow_exit() to inflate. The owner
// will then spin, waiting for the 0 value to disappear. Put another way,
// the 0 causes the owner to stall if the owner happens to try to
// drop the lock (restoring the header from the basiclock to the object)
// while inflation is in-progress. This protocol avoids races that might
// would otherwise permit hashCode values to change or "flicker" for an object.
// Critically, while object->mark is 0 mark->displaced_mark_helper() is stable.
// 0 serves as a "BUSY" inflate-in-progress indicator.我没太看懂,有知道的同学可以指点下~
膨胀完成之后,会调用enter方法获得锁
void ATTR ObjectMonitor::enter(TRAPS) {
Thread * const Self = THREAD ;
void * cur ;
// owner为null代表无锁状态,如果能CAS设置成功,则当前线程直接获得锁
cur = Atomic::cmpxchg_ptr (Self, &_owner, NULL) ;
if (cur == NULL) {
...
return ;
}
// 如果是重入的情况
if (cur == Self) {
// TODO-FIXME: check for integer overflow! BUGID 6557169.
_recursions ++ ;
return ;
}
// 当前线程是之前持有轻量级锁的线程。由轻量级锁膨胀且第一次调用enter方法,那cur是指向Lock Record的指针
if (Self->is_lock_owned ((address)cur)) {
assert (_recursions == 0, "internal state error");
// 重入计数重置为1
_recursions = 1 ;
// 设置owner字段为当前线程(之前owner是指向Lock Record的指针)
_owner = Self ;
OwnerIsThread = 1 ;
return ;
}
...
// 在调用系统的同步操作之前,先尝试自旋获得锁
if (Knob_SpinEarly && TrySpin (Self) > 0) {
...
//自旋的过程中获得了锁,则直接返回
Self->_Stalled = 0 ;
return ;
}
...
{
...
for (;;) {
jt->set_suspend_equivalent();
// 在该方法中调用系统同步操作
EnterI (THREAD) ;
...
}
Self->set_current_pending_monitor(NULL);
}
...
}
EnterI方法获得锁或阻塞EnterI方法比较长,在看之前,我们先阐述下其大致原理:
一个ObjectMonitor对象包括这么几个关键字段:cxq(下图中的ContentionList),EntryList ,WaitSet,owner。
其中cxq ,EntryList ,WaitSet都是由ObjectWaiter的链表结构,owner指向持有锁的线程。
当一个线程尝试获得锁时,如果该锁已经被占用,则会将该线程封装成一个ObjectWaiter对象插入到cxq的队列的队首,然后调用park函数挂起当前线程。在linux系统上,park函数底层调用的是gclib库的pthread_cond_wait,JDK的ReentrantLock底层也是用该方法挂起线程的。更多细节可以看我之前的两篇文章:关于同步的一点思考-下,linux内核级同步机制--futex
当线程释放锁时,会从cxq或EntryList中挑选一个线程唤醒,被选中的线程叫做Heir presumptive即假定继承人(应该是这样翻译),就是图中的Ready Thread,假定继承人被唤醒后会尝试获得锁,但synchronized是非公平的,所以假定继承人不一定能获得锁(这也是它叫"假定"继承人的原因)。
如果线程获得锁后调用Object#wait方法,则会将线程加入到WaitSet中,当被Object#notify唤醒后,会将线程从WaitSet移动到cxq或EntryList中去。需要注意的是,当调用一个锁对象的wait或notify方法时,如当前锁的状态是偏向锁或轻量级锁则会先膨胀成重量级锁。
synchronized的monitor锁机制和JDK的ReentrantLock与Condition是很相似的,ReentrantLock也有一个存放等待获取锁线程的链表,Condition也有一个类似WaitSet的集合用来存放调用了await的线程。如果你之前对ReentrantLock有深入了解,那理解起monitor应该是很简单。
回到代码上,开始分析EnterI方法:
void ATTR ObjectMonitor::EnterI (TRAPS) {
Thread * Self = THREAD ;
...
// 尝试获得锁
if (TryLock (Self) > 0) {
...
return ;
}
DeferredInitialize () ;
// 自旋
if (TrySpin (Self) > 0) {
...
return ;
}
...
// 将线程封装成node节点中
ObjectWaiter node(Self) ;
Self->_ParkEvent->reset() ;
node._prev = (ObjectWaiter *) 0xBAD ;
node.TState = ObjectWaiter::TS_CXQ ;
// 将node节点插入到_cxq队列的头部,cxq是一个单向链表
ObjectWaiter * nxt ;
for (;;) {
node._next = nxt = _cxq ;
if (Atomic::cmpxchg_ptr (&node, &_cxq, nxt) == nxt) break ;
// CAS失败的话 再尝试获得锁,这样可以降低插入到_cxq队列的频率
if (TryLock (Self) > 0) {
...
return ;
}
}
// SyncFlags默认为0,如果没有其他等待的线程,则将_Responsible设置为自己
if ((SyncFlags & 16) == 0 && nxt == NULL && _EntryList == NULL) {
Atomic::cmpxchg_ptr (Self, &_Responsible, NULL) ;
}
TEVENT (Inflated enter - Contention) ;
int nWakeups = 0 ;
int RecheckInterval = 1 ;
for (;;) {
if (TryLock (Self) > 0) break ;
assert (_owner != Self, "invariant") ;
...
// park self
if (_Responsible == Self || (SyncFlags & 1)) {
// 当前线程是_Responsible时,调用的是带时间参数的park
TEVENT (Inflated enter - park TIMED) ;
Self->_ParkEvent->park ((jlong) RecheckInterval) ;
// Increase the RecheckInterval, but clamp the value.
RecheckInterval *= 8 ;
if (RecheckInterval > 1000) RecheckInterval = 1000 ;
} else {
//否则直接调用park挂起当前线程
TEVENT (Inflated enter - park UNTIMED) ;
Self->_ParkEvent->park() ;
}
if (TryLock(Self) > 0) break ;
...
if ((Knob_SpinAfterFutile & 1) && TrySpin (Self) > 0) break ;
...
// 在释放锁时,_succ会被设置为EntryList或_cxq中的一个线程
if (_succ == Self) _succ = NULL ;
// Invariant: after clearing _succ a thread *must* retry _owner before parking.
OrderAccess::fence() ;
}
// 走到这里说明已经获得锁了
assert (_owner == Self , "invariant") ;
assert (object() != NULL , "invariant") ;
// 将当前线程的node从cxq或EntryList中移除
UnlinkAfterAcquire (Self, &node) ;
if (_succ == Self) _succ = NULL ;
if (_Responsible == Self) {
_Responsible = NULL ;
OrderAccess::fence();
}
...
return ;
}
主要步骤有3步:
这里需要特别说明的是_Responsible和_succ两个字段的作用:
当竞争发生时,选取一个线程作为_Responsible,_Responsible线程调用的是有时间限制的park方法,其目的是防止出现搁浅现象。
_succ线程是在线程释放锁是被设置,其含义是Heir presumptive,也就是我们上面说的假定继承人。
重量级锁释放的代码在ObjectMonitor::exit:
void ATTR ObjectMonitor::exit(bool not_suspended, TRAPS) {
Thread * Self = THREAD ;
// 如果_owner不是当前线程
if (THREAD != _owner) {
// 当前线程是之前持有轻量级锁的线程。由轻量级锁膨胀后还没调用过enter方法,_owner会是指向Lock Record的指针。
if (THREAD->is_lock_owned((address) _owner)) {
assert (_recursions == 0, "invariant") ;
_owner = THREAD ;
_recursions = 0 ;
OwnerIsThread = 1 ;
} else {
// 异常情况:当前不是持有锁的线程
TEVENT (Exit - Throw IMSX) ;
assert(false, "Non-balanced monitor enter/exit!");
if (false) {
THROW(vmSymbols::java_lang_IllegalMonitorStateException());
}
return;
}
}
// 重入计数器还不为0,则计数器-1后返回
if (_recursions != 0) {
_recursions--; // this is simple recursive enter
TEVENT (Inflated exit - recursive) ;
return ;
}
// _Responsible设置为null
if ((SyncFlags & 4) == 0) {
_Responsible = NULL ;
}
...
for (;;) {
assert (THREAD == _owner, "invariant") ;
// Knob_ExitPolicy默认为0
if (Knob_ExitPolicy == 0) {
// code 1:先释放锁,这时如果有其他线程进入同步块则能获得锁
OrderAccess::release_store_ptr (&_owner, NULL) ; // drop the lock
OrderAccess::storeload() ; // See if we need to wake a successor
// code 2:如果没有等待的线程或已经有假定继承人
if ((intptr_t(_EntryList)|intptr_t(_cxq)) == 0 || _succ != NULL) {
TEVENT (Inflated exit - simple egress) ;
return ;
}
TEVENT (Inflated exit - complex egress) ;
// code 3:要执行之后的操作需要重新获得锁,即设置_owner为当前线程
if (Atomic::cmpxchg_ptr (THREAD, &_owner, NULL) != NULL) {
return ;
}
TEVENT (Exit - Reacquired) ;
}
...
ObjectWaiter * w = NULL ;
// code 4:根据QMode的不同会有不同的唤醒策略,默认为0
int QMode = Knob_QMode ;
if (QMode == 2 && _cxq != NULL) {
// QMode == 2 : cxq中的线程有更高优先级,直接唤醒cxq的队首线程
w = _cxq ;
assert (w != NULL, "invariant") ;
assert (w->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
ExitEpilog (Self, w) ;
return ;
}
if (QMode == 3 && _cxq != NULL) {
// 将cxq中的元素插入到EntryList的末尾
w = _cxq ;
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ;
}
assert (w != NULL , "invariant") ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
// Append the RATs to the EntryList
// TODO: organize EntryList as a CDLL so we can locate the tail in constant-time.
ObjectWaiter * Tail ;
for (Tail = _EntryList ; Tail != NULL && Tail->_next != NULL ; Tail = Tail->_next) ;
if (Tail == NULL) {
_EntryList = w ;
} else {
Tail->_next = w ;
w->_prev = Tail ;
}
// Fall thru into code that tries to wake a successor from EntryList
}
if (QMode == 4 && _cxq != NULL) {
// 将cxq插入到EntryList的队首
w = _cxq ;
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ;
}
assert (w != NULL , "invariant") ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
// Prepend the RATs to the EntryList
if (_EntryList != NULL) {
q->_next = _EntryList ;
_EntryList->_prev = q ;
}
_EntryList = w ;
// Fall thru into code that tries to wake a successor from EntryList
}
w = _EntryList ;
if (w != NULL) {
// 如果EntryList不为空,则直接唤醒EntryList的队首元素
assert (w->TState == ObjectWaiter::TS_ENTER, "invariant") ;
ExitEpilog (Self, w) ;
return ;
}
// EntryList为null,则处理cxq中的元素
w = _cxq ;
if (w == NULL) continue ;
// 因为之后要将cxq的元素移动到EntryList,所以这里将cxq字段设置为null
for (;;) {
assert (w != NULL, "Invariant") ;
ObjectWaiter * u = (ObjectWaiter *) Atomic::cmpxchg_ptr (NULL, &_cxq, w) ;
if (u == w) break ;
w = u ;
}
TEVENT (Inflated exit - drain cxq into EntryList) ;
assert (w != NULL , "invariant") ;
assert (_EntryList == NULL , "invariant") ;
if (QMode == 1) {
// QMode == 1 : 将cxq中的元素转移到EntryList,并反转顺序
ObjectWaiter * s = NULL ;
ObjectWaiter * t = w ;
ObjectWaiter * u = NULL ;
while (t != NULL) {
guarantee (t->TState == ObjectWaiter::TS_CXQ, "invariant") ;
t->TState = ObjectWaiter::TS_ENTER ;
u = t->_next ;
t->_prev = u ;
t->_next = s ;
s = t;
t = u ;
}
_EntryList = s ;
assert (s != NULL, "invariant") ;
} else {
// QMode == 0 or QMode == 2‘
// 将cxq中的元素转移到EntryList
_EntryList = w ;
ObjectWaiter * q = NULL ;
ObjectWaiter * p ;
for (p = w ; p != NULL ; p = p->_next) {
guarantee (p->TState == ObjectWaiter::TS_CXQ, "Invariant") ;
p->TState = ObjectWaiter::TS_ENTER ;
p->_prev = q ;
q = p ;
}
}
// _succ不为null,说明已经有个继承人了,所以不需要当前线程去唤醒,减少上下文切换的比率
if (_succ != NULL) continue;
w = _EntryList ;
// 唤醒EntryList第一个元素
if (w != NULL) {
guarantee (w->TState == ObjectWaiter::TS_ENTER, "invariant") ;
ExitEpilog (Self, w) ;
return ;
}
}
}在进行必要的锁重入判断以及自旋优化后,进入到主要逻辑:
code 1 设置owner为null,即释放锁,这个时刻其他的线程能获取到锁。这里是一个非公平锁的优化;
code 2 如果当前没有等待的线程则直接返回就好了,因为不需要唤醒其他线程。或者如果说succ不为null,代表当前已经有个"醒着的"继承人线程,那当前线程不需要唤醒任何线程;
code 3 当前线程重新获得锁,因为之后要操作cxq和EntryList队列以及唤醒线程;
code 4根据QMode的不同,会执行不同的唤醒策略;
根据QMode的不同,有不同的处理方式:
只有QMode=2的时候会提前返回,等于0、3、4的时候都会继续往下执行:
1.如果EntryList的首元素非空,就取出来调用ExitEpilog方法,该方法会唤醒ObjectWaiter对象的线程,然后立即返回;
2.如果EntryList的首元素为空,就将cxq的所有元素放入到EntryList中,然后再从EntryList中取出来队首元素执行ExitEpilog方法,然后立即返回;
以上对QMode的归纳参考了这篇文章。另外说下,关于如何编译JVM,可以看看该博主的这篇文章,该博主弄了一个docker镜像,傻瓜编译~
QMode默认为0,结合上面的流程我们可以看这么个demo:
public class SyncDemo {
public static void main(String[] args) {
SyncDemo syncDemo1 = new SyncDemo();
syncDemo1.startThreadA();
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
syncDemo1.startThreadB();
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
syncDemo1.startThreadC();
}
final Object lock = new Object();
public void startThreadA() {
new Thread(() -> {
synchronized (lock) {
System.out.println("A get lock");
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("A release lock");
}
}, "thread-A").start();
}
public void startThreadB() {
new Thread(() -> {
synchronized (lock) {
System.out.println("B get lock");
}
}, "thread-B").start();
}
public void startThreadC() {
new Thread(() -> {
synchronized (lock) {
System.out.println("C get lock");
}
}, "thread-C").start();
}
}默认策略下,在A释放锁后一定是C线程先获得锁。因为在获取锁时,是将当前线程插入到cxq的头部,而释放锁时,默认策略是:如果EntryList为空,则将cxq中的元素按原有顺序插入到到EntryList,并唤醒第一个线程。也就是当EntryList为空时,是后来的线程先获取锁。这点JDK中的Lock机制是不一样的。
原理弄清楚了,顺便总结了几点Synchronized和ReentrantLock的区别:
ReentrantLock#isLocked判断;ReentrantLock#lockInterruptibly方法是可以被中断的;总的来说Synchronized的重量级锁和ReentrantLock的实现上还是有很多相似的,包括其数据结构、挂起线程方式等等。在日常使用中,如无特殊要求用Synchronized就够了。你深入了解这两者其中一个的实现,了解另外一个或其他锁机制都比较容易,这也是我们常说的技术上的相通性。
据我所知,Java的方法调用会把当前方法打包成一个栈帧压入线程的虚拟机栈中,方法执行完之后栈帧出栈,如下图的位置

文章说的“在当前的线程的栈帧中创建一个Lock Record”(如下图),请问一下这个栈帧是位于上图的哪一个区域。
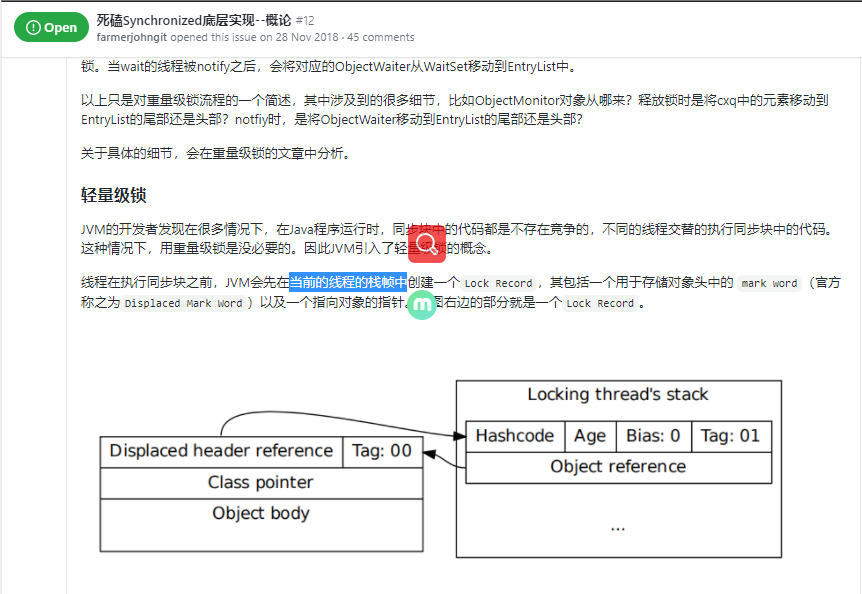
但是下图又说是当前线程栈中创建一个Lock Record,这里是否有一处是笔误呢,如果下图是正确的,当前线程栈指的是图一的线程的虚拟机栈吗。

第二个问题:是不是遇到Synchronized关键字就会执行_monitorenter指令?

最后一个问题:如果只要遇到Synchronized关键字都会执行_monitorenter指令,那下图红框部分代码应该是不管偏向锁、轻量锁或重量锁应该都会执行吧,这里注释code1说“找到一个空闲的Lock Record”,那也就是说不管偏向、轻量或重量锁都会先找一下有没有空闲的Lock Record? 这块代码关于Lock Record的关系使我很疑惑,轻量锁的时候不是遇到Synchronized都会创建一个Lock Record吗。
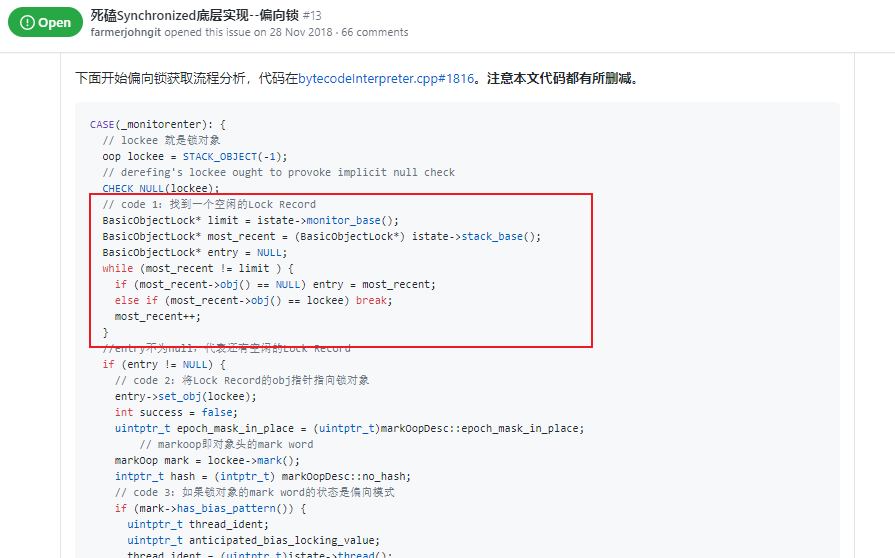
在关于同步的一点思考-下一文中,我们知道glibc的pthread_cond_timedwait底层是用linux futex机制实现的。
更多文章见个人博客:https://github.com/farmerjohngit/myblog
理想的同步机制应该是没有锁冲突时在用户态利用原子指令就解决问题,而需要挂起等待时再使用内核提供的系统调用进行睡眠与唤醒。换句话说,在用户态的自旋失败时,能不能让进程挂起,由持有锁的线程释放锁时将其唤醒?
如果你没有较深入地考虑过这个问题,很可能想当然的认为类似于这样就行了(伪代码):
void lock(int lockval) {
//trylock是用户级的自旋锁
while(!trylock(lockval)) {
wait();//释放cpu,并将当期线程加入等待队列,是系统调用
}
}
boolean trylock(int lockval){
int i=0;
//localval=1代表上锁成功
while(!compareAndSet(lockval,0,1)){
if(++i>10){
return false;
}
}
return true;
}
void unlock(int lockval) {
compareAndSet(lockval,1,0);
notify();
}
上述代码的问题是trylock和wait两个调用之间存在一个窗口:
如果一个线程trylock失败,在调用wait时持有锁的线程释放了锁,当前线程还是会调用wait进行等待,但之后就没有人再唤醒该线程了。
为了解决上述问题,linux内核引入了futex机制,futex主要包括等待和唤醒两个方法:futex_wait和futex_wake,其定义如下
//uaddr指向一个地址,val代表这个地址期待的值,当*uaddr==val时,才会进行wait
int futex_wait(int *uaddr, int val);
//唤醒n个在uaddr指向的锁变量上挂起等待的进程
int futex_wake(int *uaddr, int n);
futex在真正将进程挂起之前会检查addr指向的地址的值是否等于val,如果不相等则会立即返回,由用户态继续trylock。否则将当期线程插入到一个队列中去,并挂起。
在关于同步的一点思考-上文章中对futex的背景与基本原理有介绍,对futex不熟悉的人可以先看下。
本文将深入分析futex的实现,让读者对于锁的最底层实现方式有直观认识,再结合之前的两篇文章(关于同步的一点思考-上和关于同步的一点思考-下)能对操作系统的同步机制有个全面的理解。
下文中的进程一词包括常规进程与线程。
在看下面的源码分析前,先思考一个问题:如何确保挂起进程时,val的值是没有被其他进程修改过的?
代码在kernel/futex.c中
static int futex_wait(u32 __user *uaddr, int fshared,
u32 val, ktime_t *abs_time, u32 bitset, int clockrt)
{
struct hrtimer_sleeper timeout, *to = NULL;
struct restart_block *restart;
struct futex_hash_bucket *hb;
struct futex_q q;
int ret;
...
//设置hrtimer定时任务:在一定时间(abs_time)后,如果进程还没被唤醒则唤醒wait的进程
if (abs_time) {
...
hrtimer_init_sleeper(to, current);
...
}
retry:
//该函数中判断uaddr指向的值是否等于val,以及一些初始化操作
ret = futex_wait_setup(uaddr, val, fshared, &q, &hb);
//如果val发生了改变,则直接返回
if (ret)
goto out;
//将当前进程状态改为TASK_INTERRUPTIBLE,并插入到futex等待队列,然后重新调度。
futex_wait_queue_me(hb, &q, to);
/* If we were woken (and unqueued), we succeeded, whatever. */
ret = 0;
//如果unqueue_me成功,则说明是超时触发(因为futex_wake唤醒时,会将该进程移出等待队列,所以这里会失败)
if (!unqueue_me(&q))
goto out_put_key;
ret = -ETIMEDOUT;
if (to && !to->task)
goto out_put_key;
/*
* We expect signal_pending(current), but we might be the
* victim of a spurious wakeup as well.
*/
if (!signal_pending(current)) {
put_futex_key(fshared, &q.key);
goto retry;
}
ret = -ERESTARTSYS;
if (!abs_time)
goto out_put_key;
...
out_put_key:
put_futex_key(fshared, &q.key);
out:
if (to) {
//取消定时任务
hrtimer_cancel(&to->timer);
destroy_hrtimer_on_stack(&to->timer);
}
return ret;
}
在将进程阻塞前会将当期进程插入到一个等待队列中,需要注意的是这里说的等待队列其实是一个类似Java HashMap的结构,全局唯一。
struct futex_hash_bucket {
spinlock_t lock;
//双向链表
struct plist_head chain;
};
static struct futex_hash_bucket futex_queues[1<<FUTEX_HASHBITS];
着重看futex_wait_setup和两个函数futex_wait_queue_me
static int futex_wait_setup(u32 __user *uaddr, u32 val, int fshared,
struct futex_q *q, struct futex_hash_bucket **hb)
{
u32 uval;
int ret;
retry:
q->key = FUTEX_KEY_INIT;
//初始化futex_q
ret = get_futex_key(uaddr, fshared, &q->key, VERIFY_READ);
if (unlikely(ret != 0))
return ret;
retry_private:
//获得自旋锁
*hb = queue_lock(q);
//原子的将uaddr的值设置到uval中
ret = get_futex_value_locked(&uval, uaddr);
...
//如果当期uaddr指向的值不等于val,即说明其他进程修改了
//uaddr指向的值,等待条件不再成立,不用阻塞直接返回。
if (uval != val) {
//释放锁
queue_unlock(q, *hb);
ret = -EWOULDBLOCK;
}
...
return ret;
}
函数futex_wait_setup中主要做了两件事,一是获得自旋锁,二是判断*uaddr是否为预期值。
static void futex_wait_queue_me(struct futex_hash_bucket *hb, struct futex_q *q,
struct hrtimer_sleeper *timeout)
{
//设置进程状态为TASK_INTERRUPTIBLE,cpu调度时只会选择
//状态为TASK_RUNNING的进程
set_current_state(TASK_INTERRUPTIBLE);
//将当期进程(q封装)插入到等待队列中去,然后释放自旋锁
queue_me(q, hb);
//启动定时任务
if (timeout) {
hrtimer_start_expires(&timeout->timer, HRTIMER_MODE_ABS);
if (!hrtimer_active(&timeout->timer))
timeout->task = NULL;
}
/*
* If we have been removed from the hash list, then another task
* has tried to wake us, and we can skip the call to schedule().
*/
if (likely(!plist_node_empty(&q->list))) {
//如果没有设置过期时间 || 设置了过期时间且还没过期
if (!timeout || timeout->task)
//系统重新进行进程调度,这个时候cpu会去执行其他进程,该进程会阻塞在这里
schedule();
}
//走到这里说明又被cpu选中运行了
__set_current_state(TASK_RUNNING);
}
futex_wait_queue_me中主要做几件事:
在futex_wait_setup方法中会加自旋锁;在futex_wait_queue_me中将状态设置为TASK_INTERRUPTIBLE,调用queue_me将当期线程插入到等待队列中,然后才释放自旋锁。也就是说检查uaddr的值的过程跟进程挂起的过程放在同一个临界区中。当释放自旋锁后,这时再更改addr地址的值已经没有关系了,因为当期进程已经加入到等待队列中,能被wake唤醒,不会出现本文开头提到的没人唤醒的问题。
总结下futex_wait流程:
TASK_INTERRUPTIBLEfutex_wake
static int futex_wake(u32 __user *uaddr, int fshared, int nr_wake, u32 bitset)
{
struct futex_hash_bucket *hb;
struct futex_q *this, *next;
struct plist_head *head;
union futex_key key = FUTEX_KEY_INIT;
int ret;
...
//根据uaddr的值填充&key的内容
ret = get_futex_key(uaddr, fshared, &key, VERIFY_READ);
if (unlikely(ret != 0))
goto out;
//根据&key获得对应uaddr所在的futex_hash_bucket
hb = hash_futex(&key);
//对该hb加自旋锁
spin_lock(&hb->lock);
head = &hb->chain;
//遍历该hb的链表,注意链表中存储的节点是plist_node类型,而而这里的this却是futex_q类型,这种类型转换是通过c中的container_of机制实现的
plist_for_each_entry_safe(this, next, head, list) {
if (match_futex (&this->key, &key)) {
...
//唤醒对应进程
wake_futex(this);
if (++ret >= nr_wake)
break;
}
}
//释放自旋锁
spin_unlock(&hb->lock);
put_futex_key(fshared, &key);
out:
return ret;
}
futex_wake流程如下:
futex_hash_bucket,即代码中的hbwake_futex唤起等待的进程wake_futex中将制定进程状态设置为TASK_RUNNING并加入到系统调度列表中,同时将进程从futex的等待队列中移除掉,具体代码就不分析了,有兴趣的可以自行研究。
Java中的ReentrantLock,Object.wait和Thread.sleep等等底层都是用futex进行线程同步,理解futex的实现能帮助你更好的理解与使用这些上层的同步机制。另外因篇幅与精力有限,涉及到进程调度的相关内容没有具体分析,不过并不妨碍理解文章内容,
我们知道kafka是基于TCP连接的。其并没有像很多中间件使用netty作为TCP服务器。而是自己基于Java NIO写了一套。关于kafka为什么没有选用netty的原因可以看这里。
对Java NIO不太了解的同学可以先看下这两篇文章,本文需要读者对NIO有一定的了解。
https://segmentfault.com/a/1190000012316621
https://www.jianshu.com/p/0d497fe5484a
更多文章见个人博客:https://github.com/farmerjohngit/myblog
先看下Kafka Client的网络层架构,图片来自于这篇文章。
本文主要分析的是Network层。
Network层有两个重要的类:Selector和KafkaChannel。
这两个类和Java NIO层的java.nio.channels.Selector和Channel有点类似。
Selector几个关键字段如下
// jdk nio中的Selector
java.nio.channels.Selector nioSelector;
// 记录当前Selector的所有连接信息
Map<String, KafkaChannel> channels;
// 已发送完成的请求
List<Send> completedSends;
// 已收到的请求
List<NetworkReceive> completedReceives;
// 还没有完全收到的请求,对上层不可见
Map<KafkaChannel, Deque<NetworkReceive>> stagedReceives;
// 作为client端,调用connect连接远端时返回true的连接
Set<SelectionKey> immediatelyConnectedKeys;
// 已经完成的连接
List<String> connected;
// 一次读取的最大大小
int maxReceiveSize;从网络层来看kafka是分为client端(producer和consumer,broker作为从时也是client)和server端(broker)的。本文将分析client端是如何建立连接,以及收发数据的。server也是依靠Selector和KafkaChannel进行网络传输。在Network层两端的区别并不大。
kafka的client端启动时会调用Selector#connect(下文中如无特殊注明,均指org.apache.kafka.common.network.Selector)方法建立连接。
public void connect(String id, InetSocketAddress address, int sendBufferSize, int receiveBufferSize) throws IOException {
if (this.channels.containsKey(id))
throw new IllegalStateException("There is already a connection for id " + id);
// 创建一个SocketChannel
SocketChannel socketChannel = SocketChannel.open();
// 设置为非阻塞模式
socketChannel.configureBlocking(false);
// 创建socket并设置相关属性
Socket socket = socketChannel.socket();
socket.setKeepAlive(true);
if (sendBufferSize != Selectable.USE_DEFAULT_BUFFER_SIZE)
socket.setSendBufferSize(sendBufferSize);
if (receiveBufferSize != Selectable.USE_DEFAULT_BUFFER_SIZE)
socket.setReceiveBufferSize(receiveBufferSize);
socket.setTcpNoDelay(true);
boolean connected;
try {
// 调用SocketChannel的connect方法,该方法会向远端发起tcp建连请求
// 因为是非阻塞的,所以该方法返回时,连接不一定已经建立好(即完成3次握手)。连接如果已经建立好则返回true,否则返回false。一般来说server和client在一台机器上,该方法可能返回true。
connected = socketChannel.connect(address);
} catch (UnresolvedAddressException e) {
socketChannel.close();
throw new IOException("Can't resolve address: " + address, e);
} catch (IOException e) {
socketChannel.close();
throw e;
}
// 对CONNECT事件进行注册
SelectionKey key = socketChannel.register(nioSelector, SelectionKey.OP_CONNECT);
KafkaChannel channel;
try {
// 构造一个KafkaChannel
channel = channelBuilder.buildChannel(id, key, maxReceiveSize);
} catch (Exception e) {
...
}
// 将kafkachannel绑定到SelectionKey上
key.attach(channel);
// 放入到map中,id是远端服务器的名称
this.channels.put(id, channel);
// connectct为true代表该连接不会再触发CONNECT事件,所以这里要单独处理
if (connected) {
// OP_CONNECT won't trigger for immediately connected channels
log.debug("Immediately connected to node {}", channel.id());
// 加入到一个单独的集合中
immediatelyConnectedKeys.add(key);
// 取消对该连接的CONNECT事件的监听
key.interestOps(0);
}
}这里的流程和标准的NIO流程差不多,需要单独说下的是socketChannel#connect方法返回true的场景,该方法的注释中有提到
* <p> If this channel is in non-blocking mode then an invocation of this
* method initiates a non-blocking connection operation. If the connection
* is established immediately, as can happen with a local connection, then
* this method returns <tt>true</tt>. Otherwise this method returns
* <tt>false</tt> and the connection operation must later be completed by
* invoking the {@link #finishConnect finishConnect} method.也就是说在非阻塞模式下,对于local connection,连接可能在马上就建立好了,那该方法会返回true,对于这种情况,不会再触发之后的connect事件。因此kafka用一个单独的集合immediatelyConnectedKeys将这些特殊的连接记录下来。在接下来的步骤会进行特殊处理。
之后会调用poll方法对网络事件监听:
public void poll(long timeout) throws IOException {
...
// select方法是对java.nio.channels.Selector#select的一个简单封装
int readyKeys = select(timeout);
...
// 如果有就绪的事件或者immediatelyConnectedKeys非空
if (readyKeys > 0 || !immediatelyConnectedKeys.isEmpty()) {
// 对已就绪的事件进行处理,第2个参数为false
pollSelectionKeys(this.nioSelector.selectedKeys(), false, endSelect);
// 对immediatelyConnectedKeys进行处理。第2个参数为true
pollSelectionKeys(immediatelyConnectedKeys, true, endSelect);
}
addToCompletedReceives();
...
}
private void pollSelectionKeys(Iterable<SelectionKey> selectionKeys,
boolean isImmediatelyConnected,
long currentTimeNanos) {
Iterator<SelectionKey> iterator = selectionKeys.iterator();
// 遍历集合
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 移除当前元素,要不然下次poll又会处理一遍
iterator.remove();
// 得到connect时创建的KafkaChannel
KafkaChannel channel = channel(key);
...
try {
// 如果当前处理的是immediatelyConnectedKeys集合的元素或处理的是CONNECT事件
if (isImmediatelyConnected || key.isConnectable()) {
// finishconnect中会增加READ事件的监听
if (channel.finishConnect()) {
this.connected.add(channel.id());
this.sensors.connectionCreated.record();
...
} else
continue;
}
// 对于ssl的连接还有些额外的步骤
if (channel.isConnected() && !channel.ready())
channel.prepare();
// 如果是READ事件
if (channel.ready() && key.isReadable() && !hasStagedReceive(channel)) {
NetworkReceive networkReceive;
while ((networkReceive = channel.read()) != null)
addToStagedReceives(channel, networkReceive);
}
// 如果是WRITE事件
if (channel.ready() && key.isWritable()) {
Send send = channel.write();
if (send != null) {
this.completedSends.add(send);
this.sensors.recordBytesSent(channel.id(), send.size());
}
}
// 如果连接失效
if (!key.isValid())
close(channel, true);
} catch (Exception e) {
String desc = channel.socketDescription();
if (e instanceof IOException)
log.debug("Connection with {} disconnected", desc, e);
else
log.warn("Unexpected error from {}; closing connection", desc, e);
close(channel, true);
} finally {
maybeRecordTimePerConnection(channel, channelStartTimeNanos);
}
}
}因为immediatelyConnectedKeys中的连接不会触发CONNNECT事件,所以在poll时会单独对immediatelyConnectedKeys的channel调用finishConnect方法。在明文传输模式下该方法会调用到PlaintextTransportLayer#finishConnect,其实现如下:
public boolean finishConnect() throws IOException {
// 返回true代表已经连接好了
boolean connected = socketChannel.finishConnect();
if (connected)
// 取消监听CONNECt事件,增加READ事件的监听
key.interestOps(key.interestOps() & ~SelectionKey.OP_CONNECT | SelectionKey.OP_READ);
return connected;
}关于immediatelyConnectedKeys更详细的内容可以看看这里。
kafka发送数据分为两个步骤:
1.调用Selector#send将要发送的数据保存在对应的KafkaChannel中,该方法并没有进行真正的网络IO。
// Selector#send
public void send(Send send) {
String connectionId = send.destination();
// 如果所在的连接正在关闭中,则加入到失败集合failedSends中
if (closingChannels.containsKey(connectionId))
this.failedSends.add(connectionId);
else {
KafkaChannel channel = channelOrFail(connectionId, false);
try {
channel.setSend(send);
} catch (CancelledKeyException e) {
this.failedSends.add(connectionId);
close(channel, false);
}
}
}
//KafkaChannel#setSend
public void setSend(Send send) {
// 如果还有数据没有发送出去则报错
if (this.send != null)
throw new IllegalStateException("Attempt to begin a send operation with prior send operation still in progress.");
// 保存下来
this.send = send;
// 添加对WRITE事件的监听
this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);
}Selector#poll,在第一步中已经对该channel注册了WRITE事件的监听,所以在当channel可写时,会调用到pollSelectionKeys将数据真正的发送出去。private void pollSelectionKeys(Iterable<SelectionKey> selectionKeys,
boolean isImmediatelyConnected,
long currentTimeNanos) {
Iterator<SelectionKey> iterator = selectionKeys.iterator();
// 遍历集合
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 移除当前元素,要不然下次poll又会处理一遍
iterator.remove();
// 得到connect时创建的KafkaChannel
KafkaChannel channel = channel(key);
...
try {
...
// 如果是WRITE事件
if (channel.ready() && key.isWritable()) {
// 真正的网络写
Send send = channel.write();
// 一个Send对象可能会被拆成几次发送,write非空代表一个send发送完成
if (send != null) {
// completedSends代表已发送完成的集合
this.completedSends.add(send);
this.sensors.recordBytesSent(channel.id(), send.size());
}
}
...
} catch (Exception e) {
...
} finally {
maybeRecordTimePerConnection(channel, channelStartTimeNanos);
}
}
}当可写时,会调用KafkaChannel#write方法,该方法中会进行真正的网络IO:
public Send write() throws IOException {
Send result = null;
if (send != null && send(send)) {
result = send;
send = null;
}
return result;
}
private boolean send(Send send) throws IOException {
// 最终调用SocketChannel#write进行真正的写
send.writeTo(transportLayer);
if (send.completed())
// 如果写完了,则移除对WRITE事件的监听
transportLayer.removeInterestOps(SelectionKey.OP_WRITE);
return send.completed();
}如果远端有发送数据过来,那调用poll方法时,会对接收到的数据进行处理。
public void poll(long timeout) throws IOException {
...
// select方法是对java.nio.channels.Selector#select的一个简单封装
int readyKeys = select(timeout);
...
// 如果有就绪的事件或者immediatelyConnectedKeys非空
if (readyKeys > 0 || !immediatelyConnectedKeys.isEmpty()) {
// 对已就绪的事件进行处理,第2个参数为false
pollSelectionKeys(this.nioSelector.selectedKeys(), false, endSelect);
// 对immediatelyConnectedKeys进行处理。第2个参数为true
pollSelectionKeys(immediatelyConnectedKeys, true, endSelect);
}
addToCompletedReceives();
...
}
private void pollSelectionKeys(Iterable<SelectionKey> selectionKeys,
boolean isImmediatelyConnected,
long currentTimeNanos) {
Iterator<SelectionKey> iterator = selectionKeys.iterator();
// 遍历集合
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 移除当前元素,要不然下次poll又会处理一遍
iterator.remove();
// 得到connect时创建的KafkaChannel
KafkaChannel channel = channel(key);
...
try {
...
// 如果是READ事件
if (channel.ready() && key.isReadable() && !hasStagedReceive(channel)) {
NetworkReceive networkReceive;
// read方法会从网络中读取数据,但可能一次只能读取一个req的部分数据。只有读到一个完整的req的情况下,该方法才返回非null
while ((networkReceive = channel.read()) != null)
// 将读到的请求存在stagedReceives中
addToStagedReceives(channel, networkReceive);
}
...
} catch (Exception e) {
...
} finally {
maybeRecordTimePerConnection(channel, channelStartTimeNanos);
}
}
}
private void addToStagedReceives(KafkaChannel channel, NetworkReceive receive) {
if (!stagedReceives.containsKey(channel))
stagedReceives.put(channel, new ArrayDeque<NetworkReceive>());
Deque<NetworkReceive> deque = stagedReceives.get(channel);
deque.add(receive);
}在之后的addToCompletedReceives方法中会对该集合进行处理。
private void addToCompletedReceives() {
if (!this.stagedReceives.isEmpty()) {
Iterator<Map.Entry<KafkaChannel, Deque<NetworkReceive>>> iter = this.stagedReceives.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry<KafkaChannel, Deque<NetworkReceive>> entry = iter.next();
KafkaChannel channel = entry.getKey();
// 对于client端来说该isMute返回为false,server端则依靠该方法保证消息的顺序
if (!channel.isMute()) {
Deque<NetworkReceive> deque = entry.getValue();
addToCompletedReceives(channel, deque);
if (deque.isEmpty())
iter.remove();
}
}
}
}
private void addToCompletedReceives(KafkaChannel channel, Deque<NetworkReceive> stagedDeque) {
// 将每个channel的第一个NetworkReceive加入到completedReceives
NetworkReceive networkReceive = stagedDeque.poll();
this.completedReceives.add(networkReceive);
this.sensors.recordBytesReceived(channel.id(), networkReceive.payload().limit());
}读出数据后,会先放到stagedReceives集合中,然后在addToCompletedReceives方法中对于每个channel都会从stagedReceives取出一个NetworkReceive(如果有的话),放入到completedReceives中。
这样做的原因有两点:
mute掉,即不再从该channel上读取数据。当处理完成之后,才将该channelunmute,即之后可以从该socket上读取数据。而client端则是通过InFlightRequests#canSendMore控制。代码中关于这段逻辑的注释如下:
/* In the "Plaintext" setting, we are using socketChannel to read & write to the network. But for the "SSL" setting,
* we encrypt the data before we use socketChannel to write data to the network, and decrypt before we return the responses.
* This requires additional buffers to be maintained as we are reading from network, since the data on the wire is encrypted
* we won't be able to read exact no.of bytes as kafka protocol requires. We read as many bytes as we can, up to SSLEngine's
* application buffer size. This means we might be reading additional bytes than the requested size.
* If there is no further data to read from socketChannel selector won't invoke that channel and we've have additional bytes
* in the buffer. To overcome this issue we added "stagedReceives" map which contains per-channel deque. When we are
* reading a channel we read as many responses as we can and store them into "stagedReceives" and pop one response during
* the poll to add the completedReceives. If there are any active channels in the "stagedReceives" we set "timeout" to 0
* and pop response and add to the completedReceives.
* Atmost one entry is added to "completedReceives" for a channel in each poll. This is necessary to guarantee that
* requests from a channel are processed on the broker in the order they are sent. Since outstanding requests added
* by SocketServer to the request queue may be processed by different request handler threads, requests on each
* channel must be processed one-at-a-time to guarantee ordering.
*/本文分析了kafka network层的实现,在阅读kafka源码时,如果不把network层搞清楚会比较迷,比如req/resp的顺序保障机制、真正进行网络IO的不是send方法等等。
本文为死磕Synchronized底层实现第三篇文章,内容为轻量级锁实现。
轻量级锁并不复杂,其中很多内容在偏向锁一文中已提及过,与本文内容会有部分重叠。
另外轻量级锁的背景和基本流程在概论中已有讲解。强烈建议在看过两篇文章的基础下阅读本文。
本系列文章将对HotSpot的synchronized锁实现进行全面分析,内容包括偏向锁、轻量级锁、重量级锁的加锁、解锁、锁升级流程的原理及源码分析,希望给在研究synchronized路上的同学一些帮助。主要包括以下几篇文章:
更多文章见个人博客:https://github.com/farmerjohngit/myblog
本文分为两个部分:
1.轻量级锁获取流程
2.轻量级锁释放流程
本人看的JVM版本是jdk8u,具体版本号以及代码可以在这里看到。
下面开始轻量级锁获取流程分析,代码在bytecodeInterpreter.cpp#1816。
CASE(_monitorenter): {
oop lockee = STACK_OBJECT(-1);
...
if (entry != NULL) {
...
// 上面省略的代码中如果CAS操作失败也会调用到InterpreterRuntime::monitorenter
// traditional lightweight locking
if (!success) {
// 构建一个无锁状态的Displaced Mark Word
markOop displaced = lockee->mark()->set_unlocked();
// 设置到Lock Record中去
entry->lock()->set_displaced_header(displaced);
bool call_vm = UseHeavyMonitors;
if (call_vm || Atomic::cmpxchg_ptr(entry, lockee->mark_addr(), displaced) != displaced) {
// 如果CAS替换不成功,代表锁对象不是无锁状态,这时候判断下是不是锁重入
// Is it simple recursive case?
if (!call_vm && THREAD->is_lock_owned((address) displaced->clear_lock_bits())) {
entry->lock()->set_displaced_header(NULL);
} else {
// CAS操作失败则调用monitorenter
CALL_VM(InterpreterRuntime::monitorenter(THREAD, entry), handle_exception);
}
}
}
UPDATE_PC_AND_TOS_AND_CONTINUE(1, -1);
} else {
istate->set_msg(more_monitors);
UPDATE_PC_AND_RETURN(0); // Re-execute
}
}如果锁对象不是偏向模式或已经偏向其他线程,则success为false。这时候会构建一个无锁状态的mark word设置到Lock Record中去,我们称Lock Record中存储对象mark word的字段叫Displaced Mark Word。
如果当前锁的状态不是无锁状态,则CAS失败。如果这是一次锁重入,那直接将Lock Record的 Displaced Mark Word设置为null。
我们看个demo,在该demo中重复3次获得锁,
synchronized(obj){
synchronized(obj){
synchronized(obj){
}
}
}假设锁的状态是轻量级锁,下图反应了mark word和线程栈中Lock Record的状态,可以看到右边线程栈中包含3个指向当前锁对象的Lock Record。其中栈中最高位的Lock Record为第一次获取锁时分配的。其Displaced Mark word的值为锁对象的加锁前的mark word,之后的锁重入会在线程栈中分配一个Displaced Mark word为null的Lock Record。
为什么JVM选择在线程栈中添加Displaced Mark word为null的Lock Record来表示重入计数呢?首先锁重入次数是一定要记录下来的,因为每次解锁都需要对应一次加锁,解锁次数等于加锁次数时,该锁才真正的被释放,也就是在解锁时需要用到说锁重入次数的。一个简单的方案是将锁重入次数记录在对象头的mark word中,但mark word的大小是有限的,已经存放不下该信息了。另一个方案是只创建一个Lock Record并在其中记录重入次数,Hotspot没有这样做的原因我猜是考虑到效率有影响:每次重入获得锁都需要遍历该线程的栈找到对应的Lock Record,然后修改它的值。
所以最终Hotspot选择每次获得锁都添加一个Lock Record来表示锁的重入。
接下来看看InterpreterRuntime::monitorenter方法
IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem))
...
Handle h_obj(thread, elem->obj());
assert(Universe::heap()->is_in_reserved_or_null(h_obj()),
"must be NULL or an object");
if (UseBiasedLocking) {
// Retry fast entry if bias is revoked to avoid unnecessary inflation
ObjectSynchronizer::fast_enter(h_obj, elem->lock(), true, CHECK);
} else {
ObjectSynchronizer::slow_enter(h_obj, elem->lock(), CHECK);
}
...
IRT_ENDfast_enter的流程在偏向锁一文已经分析过,如果当前是偏向模式且偏向的线程还在使用锁,那会将锁的mark word改为轻量级锁的状态,同时会将偏向的线程栈中的Lock Record修改为轻量级锁对应的形式。代码位置在biasedLocking.cpp#212。
// 线程还存活则遍历线程栈中所有的Lock Record
GrowableArray<MonitorInfo*>* cached_monitor_info = get_or_compute_monitor_info(biased_thread);
BasicLock* highest_lock = NULL;
for (int i = 0; i < cached_monitor_info->length(); i++) {
MonitorInfo* mon_info = cached_monitor_info->at(i);
// 如果能找到对应的Lock Record说明偏向的线程还在执行同步代码块中的代码
if (mon_info->owner() == obj) {
...
// 需要升级为轻量级锁,直接修改偏向线程栈中的Lock Record。为了处理锁重入的case,在这里将Lock Record的Displaced Mark Word设置为null,第一个Lock Record会在下面的代码中再处理
markOop mark = markOopDesc::encode((BasicLock*) NULL);
highest_lock = mon_info->lock();
highest_lock->set_displaced_header(mark);
} else {
...
}
}
if (highest_lock != NULL) {
// 修改第一个Lock Record为无锁状态,然后将obj的mark word设置为指向该Lock Record的指针
highest_lock->set_displaced_header(unbiased_prototype);
obj->release_set_mark(markOopDesc::encode(highest_lock));
...
} else {
...
}我们看slow_enter的流程。
void ObjectSynchronizer::slow_enter(Handle obj, BasicLock* lock, TRAPS) {
markOop mark = obj->mark();
assert(!mark->has_bias_pattern(), "should not see bias pattern here");
// 如果是无锁状态
if (mark->is_neutral()) {
//设置Displaced Mark Word并替换对象头的mark word
lock->set_displaced_header(mark);
if (mark == (markOop) Atomic::cmpxchg_ptr(lock, obj()->mark_addr(), mark)) {
TEVENT (slow_enter: release stacklock) ;
return ;
}
} else
if (mark->has_locker() && THREAD->is_lock_owned((address)mark->locker())) {
assert(lock != mark->locker(), "must not re-lock the same lock");
assert(lock != (BasicLock*)obj->mark(), "don't relock with same BasicLock");
// 如果是重入,则设置Displaced Mark Word为null
lock->set_displaced_header(NULL);
return;
}
...
// 走到这一步说明已经是存在多个线程竞争锁了 需要膨胀为重量级锁
lock->set_displaced_header(markOopDesc::unused_mark());
ObjectSynchronizer::inflate(THREAD, obj())->enter(THREAD);
}
CASE(_monitorexit): {
oop lockee = STACK_OBJECT(-1);
CHECK_NULL(lockee);
// derefing's lockee ought to provoke implicit null check
// find our monitor slot
BasicObjectLock* limit = istate->monitor_base();
BasicObjectLock* most_recent = (BasicObjectLock*) istate->stack_base();
// 从低往高遍历栈的Lock Record
while (most_recent != limit ) {
// 如果Lock Record关联的是该锁对象
if ((most_recent)->obj() == lockee) {
BasicLock* lock = most_recent->lock();
markOop header = lock->displaced_header();
// 释放Lock Record
most_recent->set_obj(NULL);
// 如果是偏向模式,仅仅释放Lock Record就好了。否则要走轻量级锁or重量级锁的释放流程
if (!lockee->mark()->has_bias_pattern()) {
bool call_vm = UseHeavyMonitors;
// header!=NULL说明不是重入,则需要将Displaced Mark Word CAS到对象头的Mark Word
if (header != NULL || call_vm) {
if (call_vm || Atomic::cmpxchg_ptr(header, lockee->mark_addr(), lock) != lock) {
// CAS失败或者是重量级锁则会走到这里,先将obj还原,然后调用monitorexit方法
most_recent->set_obj(lockee);
CALL_VM(InterpreterRuntime::monitorexit(THREAD, most_recent), handle_exception);
}
}
}
//执行下一条命令
UPDATE_PC_AND_TOS_AND_CONTINUE(1, -1);
}
//处理下一条Lock Record
most_recent++;
}
// Need to throw illegal monitor state exception
CALL_VM(InterpreterRuntime::throw_illegal_monitor_state_exception(THREAD), handle_exception);
ShouldNotReachHere();
}轻量级锁释放时需要将Displaced Mark Word替换到对象头的mark word中。如果CAS失败或者是重量级锁则进入到InterpreterRuntime::monitorexit方法中。
//%note monitor_1
IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorexit(JavaThread* thread, BasicObjectLock* elem))
Handle h_obj(thread, elem->obj());
...
ObjectSynchronizer::slow_exit(h_obj(), elem->lock(), thread);
// Free entry. This must be done here, since a pending exception might be installed on
//释放Lock Record
elem->set_obj(NULL);
...
IRT_ENDmonitorexit调用完slow_exit方法后,就释放Lock Record。
void ObjectSynchronizer::slow_exit(oop object, BasicLock* lock, TRAPS) {
fast_exit (object, lock, THREAD) ;
}
void ObjectSynchronizer::fast_exit(oop object, BasicLock* lock, TRAPS) {
...
markOop dhw = lock->displaced_header();
markOop mark ;
if (dhw == NULL) {
// 重入锁,什么也不做
...
return ;
}
mark = object->mark() ;
// 如果是mark word==Displaced Mark Word即轻量级锁,CAS替换对象头的mark word
if (mark == (markOop) lock) {
assert (dhw->is_neutral(), "invariant") ;
if ((markOop) Atomic::cmpxchg_ptr (dhw, object->mark_addr(), mark) == mark) {
TEVENT (fast_exit: release stacklock) ;
return;
}
}
//走到这里说明是重量级锁或者解锁时发生了竞争,膨胀后调用重量级锁的exit方法。
ObjectSynchronizer::inflate(THREAD, object)->exit (true, THREAD) ;
}该方法中先判断是不是轻量级锁,如果是轻量级锁则将替换mark word,否则膨胀为重量级锁并调用exit方法,相关逻辑将在重量级锁的文章中讲解。
Java中一共有4种引用类型(其实还有一些其他的引用类型比如FinalReference):强引用、软引用、弱引用、虚引用。其中强引用就是我们经常使用的Object a = new Object(); 这样的形式,在Java中并没有对应的Reference类。
本篇文章主要是分析软引用、弱引用、虚引用的实现,这三种引用类型都是继承于Reference这个类,主要逻辑也在Reference中。
更多文章见个人博客:https://github.com/farmerjohngit/myblog
在分析前,先抛几个问题?
1.网上大多数文章对于软引用的介绍是:在内存不足的时候才会被回收,那内存不足是怎么定义的?什么才叫内存不足?
2.网上大多数文章对于虚引用的介绍是:形同虚设,虚引用并不会决定对象的生命周期。主要用来跟踪对象被垃圾回收器回收的活动。真的是这样吗?
3.虚引用在Jdk中有哪些场景下用到了呢?
我们先看下Reference.java中的几个字段
public abstract class Reference<T> {
//引用的对象
private T referent;
//回收队列,由使用者在Reference的构造函数中指定
volatile ReferenceQueue<? super T> queue;
//当该引用被加入到queue中的时候,该字段被设置为queue中的下一个元素,以形成链表结构
volatile Reference next;
//在GC时,JVM底层会维护一个叫DiscoveredList的链表,存放的是Reference对象,discovered字段指向的就是链表中的下一个元素,由JVM设置
transient private Reference<T> discovered;
//进行线程同步的锁对象
static private class Lock { }
private static Lock lock = new Lock();
//等待加入queue的Reference对象,在GC时由JVM设置,会有一个java层的线程(ReferenceHandler)源源不断的从pending中提取元素加入到queue
private static Reference<Object> pending = null;
}一个Reference对象的生命周期如下:

主要分为Native层和Java层两个部分。
Native层在GC时将需要被回收的Reference对象加入到DiscoveredList中(代码在referenceProcessor.cpp中process_discovered_references方法),然后将DiscoveredList的元素移动到PendingList中(代码在referenceProcessor.cpp中enqueue_discovered_ref_helper方法),PendingList的队首就是Reference类中的pending对象。 具体代码就不分析了,有兴趣的同学可以看看这篇文章。
看看Java层的代码
private static class ReferenceHandler extends Thread {
...
public void run() {
while (true) {
tryHandlePending(true);
}
}
}
static boolean tryHandlePending(boolean waitForNotify) {
Reference<Object> r;
Cleaner c;
try {
synchronized (lock) {
if (pending != null) {
r = pending;
//如果是Cleaner对象,则记录下来,下面做特殊处理
c = r instanceof Cleaner ? (Cleaner) r : null;
//指向PendingList的下一个对象
pending = r.discovered;
r.discovered = null;
} else {
//如果pending为null就先等待,当有对象加入到PendingList中时,jvm会执行notify
if (waitForNotify) {
lock.wait();
}
// retry if waited
return waitForNotify;
}
}
}
...
// 如果时CLeaner对象,则调用clean方法进行资源回收
if (c != null) {
c.clean();
return true;
}
//将Reference加入到ReferenceQueue,开发者可以通过从ReferenceQueue中poll元素感知到对象被回收的事件。
ReferenceQueue<? super Object> q = r.queue;
if (q != ReferenceQueue.NULL) q.enqueue(r);
return true;
}流程比较简单:就是源源不断的从PendingList中提取出元素,然后将其加入到ReferenceQueue中去,开发者可以通过从ReferenceQueue中poll元素感知到对象被回收的事件。
另外需要注意的是,对于Cleaner类型(继承自虚引用)的对象会有额外的处理:在其指向的对象被回收时,会调用clean方法,该方法主要是用来做对应的资源回收,在堆外内存DirectByteBuffer中就是用Cleaner进行堆外内存的回收,这也是虚引用在java中的典型应用。
看完了Reference的实现,再看看几个实现类里,各自有什么不同。
public class SoftReference<T> extends Reference<T> {
static private long clock;
private long timestamp;
public SoftReference(T referent) {
super(referent);
this.timestamp = clock;
}
public SoftReference(T referent, ReferenceQueue<? super T> q) {
super(referent, q);
this.timestamp = clock;
}
public T get() {
T o = super.get();
if (o != null && this.timestamp != clock)
this.timestamp = clock;
return o;
}
}软引用的实现很简单,就多了两个字段:clock和timestamp。clock是个静态变量,每次GC时都会将该字段设置成当前时间。timestamp字段则会在每次调用get方法时将其赋值为clock(如果不相等且对象没被回收)。
那这两个字段的作用是什么呢?这和软引用在内存不够的时候才被回收,又有什么关系呢?
这些还得看JVM的源码才行,因为决定对象是否需要被回收都是在GC中实现的。
size_t
ReferenceProcessor::process_discovered_reflist(
DiscoveredList refs_lists[],
ReferencePolicy* policy,
bool clear_referent,
BoolObjectClosure* is_alive,
OopClosure* keep_alive,
VoidClosure* complete_gc,
AbstractRefProcTaskExecutor* task_executor)
{
...
//还记得上文提到过的DiscoveredList吗?refs_lists就是DiscoveredList。
//对于DiscoveredList的处理分为几个阶段,SoftReference的处理就在第一阶段
...
for (uint i = 0; i < _max_num_q; i++) {
process_phase1(refs_lists[i], policy,
is_alive, keep_alive, complete_gc);
}
...
}
//该阶段的主要目的就是当内存足够时,将对应的SoftReference从refs_list中移除。
void
ReferenceProcessor::process_phase1(DiscoveredList& refs_list,
ReferencePolicy* policy,
BoolObjectClosure* is_alive,
OopClosure* keep_alive,
VoidClosure* complete_gc) {
DiscoveredListIterator iter(refs_list, keep_alive, is_alive);
// Decide which softly reachable refs should be kept alive.
while (iter.has_next()) {
iter.load_ptrs(DEBUG_ONLY(!discovery_is_atomic() /* allow_null_referent */));
//判断引用的对象是否存活
bool referent_is_dead = (iter.referent() != NULL) && !iter.is_referent_alive();
//如果引用的对象已经不存活了,则会去调用对应的ReferencePolicy判断该对象是不时要被回收
if (referent_is_dead &&
!policy->should_clear_reference(iter.obj(), _soft_ref_timestamp_clock)) {
if (TraceReferenceGC) {
gclog_or_tty->print_cr("Dropping reference (" INTPTR_FORMAT ": %s" ") by policy",
(void *)iter.obj(), iter.obj()->klass()->internal_name());
}
// Remove Reference object from list
iter.remove();
// Make the Reference object active again
iter.make_active();
// keep the referent around
iter.make_referent_alive();
iter.move_to_next();
} else {
iter.next();
}
}
...
}refs_lists中存放了本次GC发现的某种引用类型(虚引用、软引用、弱引用等),而process_discovered_reflist方法的作用就是将不需要被回收的对象从refs_lists移除掉,refs_lists最后剩下的元素全是需要被回收的元素,最后会将其第一个元素赋值给上文提到过的Reference.java#pending字段。
ReferencePolicy一共有4种实现:NeverClearPolicy,AlwaysClearPolicy,LRUCurrentHeapPolicy,LRUMaxHeapPolicy。其中NeverClearPolicy永远返回false,代表永远不回收SoftReference,在JVM中该类没有被使用,AlwaysClearPolicy则永远返回true,在referenceProcessor.hpp#setup方法中中可以设置policy为AlwaysClearPolicy,至于什么时候会用到AlwaysClearPolicy,大家有兴趣可以自行研究。
LRUCurrentHeapPolicy和LRUMaxHeapPolicy的should_clear_reference方法则是完全相同:
bool LRUMaxHeapPolicy::should_clear_reference(oop p,
jlong timestamp_clock) {
jlong interval = timestamp_clock - java_lang_ref_SoftReference::timestamp(p);
assert(interval >= 0, "Sanity check");
// The interval will be zero if the ref was accessed since the last scavenge/gc.
if(interval <= _max_interval) {
return false;
}
return true;
}timestamp_clock就是SoftReference的静态字段clock,java_lang_ref_SoftReference::timestamp(p)对应是字段timestamp。如果上次GC后有调用SoftReference#get,interval值为0,否则为若干次GC之间的时间差。
_max_interval则代表了一个临界值,它的值在LRUCurrentHeapPolicy和LRUMaxHeapPolicy两种策略中有差异。
void LRUCurrentHeapPolicy::setup() {
_max_interval = (Universe::get_heap_free_at_last_gc() / M) * SoftRefLRUPolicyMSPerMB;
assert(_max_interval >= 0,"Sanity check");
}
void LRUMaxHeapPolicy::setup() {
size_t max_heap = MaxHeapSize;
max_heap -= Universe::get_heap_used_at_last_gc();
max_heap /= M;
_max_interval = max_heap * SoftRefLRUPolicyMSPerMB;
assert(_max_interval >= 0,"Sanity check");
}其中SoftRefLRUPolicyMSPerMB默认为1000,前者的计算方法和上次GC后可用堆大小有关,后者计算方法和(堆大小-上次gc时堆使用大小)有关。
看到这里你就知道SoftReference到底什么时候被被回收了,它和使用的策略(默认应该是LRUCurrentHeapPolicy),堆可用大小,该SoftReference上一次调用get方法的时间都有关系。
public class WeakReference<T> extends Reference<T> {
public WeakReference(T referent) {
super(referent);
}
public WeakReference(T referent, ReferenceQueue<? super T> q) {
super(referent, q);
}
}可以看到WeakReference在Java层只是继承了Reference,没有做任何的改动。那referent字段是什么时候被置为null的呢?要搞清楚这个问题我们再看下上文提到过的process_discovered_reflist方法:
size_t
ReferenceProcessor::process_discovered_reflist(
DiscoveredList refs_lists[],
ReferencePolicy* policy,
bool clear_referent,
BoolObjectClosure* is_alive,
OopClosure* keep_alive,
VoidClosure* complete_gc,
AbstractRefProcTaskExecutor* task_executor)
{
...
//Phase 1:将所有不存活但是还不能被回收的软引用从refs_lists中移除(只有refs_lists为软引用的时候,这里policy才不为null)
if (policy != NULL) {
if (mt_processing) {
RefProcPhase1Task phase1(*this, refs_lists, policy, true /*marks_oops_alive*/);
task_executor->execute(phase1);
} else {
for (uint i = 0; i < _max_num_q; i++) {
process_phase1(refs_lists[i], policy,
is_alive, keep_alive, complete_gc);
}
}
} else { // policy == NULL
assert(refs_lists != _discoveredSoftRefs,
"Policy must be specified for soft references.");
}
// Phase 2:
// 移除所有指向对象还存活的引用
if (mt_processing) {
RefProcPhase2Task phase2(*this, refs_lists, !discovery_is_atomic() /*marks_oops_alive*/);
task_executor->execute(phase2);
} else {
for (uint i = 0; i < _max_num_q; i++) {
process_phase2(refs_lists[i], is_alive, keep_alive, complete_gc);
}
}
// Phase 3:
// 根据clear_referent的值决定是否将不存活对象回收
if (mt_processing) {
RefProcPhase3Task phase3(*this, refs_lists, clear_referent, true /*marks_oops_alive*/);
task_executor->execute(phase3);
} else {
for (uint i = 0; i < _max_num_q; i++) {
process_phase3(refs_lists[i], clear_referent,
is_alive, keep_alive, complete_gc);
}
}
return total_list_count;
}
void
ReferenceProcessor::process_phase3(DiscoveredList& refs_list,
bool clear_referent,
BoolObjectClosure* is_alive,
OopClosure* keep_alive,
VoidClosure* complete_gc) {
ResourceMark rm;
DiscoveredListIterator iter(refs_list, keep_alive, is_alive);
while (iter.has_next()) {
iter.update_discovered();
iter.load_ptrs(DEBUG_ONLY(false /* allow_null_referent */));
if (clear_referent) {
// NULL out referent pointer
//将Reference的referent字段置为null,之后会被GC回收
iter.clear_referent();
} else {
// keep the referent around
//标记引用的对象为存活,该对象在这次GC将不会被回收
iter.make_referent_alive();
}
...
}
...
}
不管是弱引用还是其他引用类型,将字段referent置null的操作都发生在process_phase3中,而具体行为是由clear_referent的值决定的。而clear_referent的值则和引用类型相关。
ReferenceProcessorStats ReferenceProcessor::process_discovered_references(
BoolObjectClosure* is_alive,
OopClosure* keep_alive,
VoidClosure* complete_gc,
AbstractRefProcTaskExecutor* task_executor,
GCTimer* gc_timer) {
NOT_PRODUCT(verify_ok_to_handle_reflists());
...
//process_discovered_reflist方法的第3个字段就是clear_referent
// Soft references
size_t soft_count = 0;
{
GCTraceTime tt("SoftReference", trace_time, false, gc_timer);
soft_count =
process_discovered_reflist(_discoveredSoftRefs, _current_soft_ref_policy, true,
is_alive, keep_alive, complete_gc, task_executor);
}
update_soft_ref_master_clock();
// Weak references
size_t weak_count = 0;
{
GCTraceTime tt("WeakReference", trace_time, false, gc_timer);
weak_count =
process_discovered_reflist(_discoveredWeakRefs, NULL, true,
is_alive, keep_alive, complete_gc, task_executor);
}
// Final references
size_t final_count = 0;
{
GCTraceTime tt("FinalReference", trace_time, false, gc_timer);
final_count =
process_discovered_reflist(_discoveredFinalRefs, NULL, false,
is_alive, keep_alive, complete_gc, task_executor);
}
// Phantom references
size_t phantom_count = 0;
{
GCTraceTime tt("PhantomReference", trace_time, false, gc_timer);
phantom_count =
process_discovered_reflist(_discoveredPhantomRefs, NULL, false,
is_alive, keep_alive, complete_gc, task_executor);
}
...
}可以看到,对于Soft references和Weak references clear_referent字段传入的都是true,这也符合我们的预期:对象不可达后,引用字段就会被置为null,然后对象就会被回收(对于软引用来说,如果内存足够的话,在Phase 1,相关的引用就会从refs_list中被移除,到Phase 3时refs_list为空集合)。
但对于Final references和 Phantom references,clear_referent字段传入的是false,也就意味着被这两种引用类型引用的对象,如果没有其他额外处理,只要Reference对象还存活,那引用的对象是不会被回收的。Final references和对象是否重写了finalize方法有关,不在本文分析范围之内,我们接下来看看Phantom references。
public class PhantomReference<T> extends Reference<T> {
public T get() {
return null;
}
public PhantomReference(T referent, ReferenceQueue<? super T> q) {
super(referent, q);
}
}可以看到虚引用的get方法永远返回null,我们看个demo。
public static void demo() throws InterruptedException {
Object obj = new Object();
ReferenceQueue<Object> refQueue =new ReferenceQueue<>();
PhantomReference<Object> phanRef =new PhantomReference<>(obj, refQueue);
Object objg = phanRef.get();
//这里拿到的是null
System.out.println(objg);
//让obj变成垃圾
obj=null;
System.gc();
Thread.sleep(3000);
//gc后会将phanRef加入到refQueue中
Reference<? extends Object> phanRefP = refQueue.remove();
//这里输出true
System.out.println(phanRefP==phanRef);
}从以上代码中可以看到,虚引用能够在指向对象不可达时得到一个'通知'(其实所有继承References的类都有这个功能),需要注意的是GC完成后,phanRef.referent依然指向之前创建Object,也就是说Object对象一直没被回收!
而造成这一现象的原因在上一小节末尾已经说了:对于Final references和 Phantom references,clear_referent字段传入的时false,也就意味着被这两种引用类型引用的对象,如果没有其他额外处理,在GC中是不会被回收的。
对于虚引用来说,从refQueue.remove();得到引用对象后,可以调用clear方法强行解除引用和对象之间的关系,使得对象下次可以GC时可以被回收掉。
针对文章开头提出的几个问题,看完分析,我们已经能给出回答:
1.我们经常在网上看到软引用的介绍是:在内存不足的时候才会回收,那内存不足是怎么定义的?为什么才叫内存不足?
软引用会在内存不足时被回收,内存不足的定义和该引用对象get的时间以及当前堆可用内存大小都有关系,计算公式在上文中也已经给出。
2.网上对于虚引用的介绍是:形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。主要用来跟踪对象被垃圾回收器回收的活动。真的是这样吗?
严格的说,虚引用是会影响对象生命周期的,如果不做任何处理,只要虚引用不被回收,那其引用的对象永远不会被回收。所以一般来说,从ReferenceQueue中获得PhantomReference对象后,如果PhantomReference对象不会被回收的话(比如被其他GC ROOT可达的对象引用),需要调用clear方法解除PhantomReference和其引用对象的引用关系。
3.虚引用在Jdk中有哪些场景下用到了呢?
DirectByteBuffer中是用虚引用的子类Cleaner.java来实现堆外内存回收的,后续会写篇文章来说说堆外内存的里里外外。
Ps: 最近一直在找工作,所以半个多月没写文章,本来是想简单写下Java引用的几个点的,但写的时候才发现不把牵连到的知识点说清楚不行,所以又写了这么多。 希望自己能拿到一个满意的offer!
刚做后端开发的时候,最早接触的是基础的spring,为了引用二方包提供bean,还需要在xml中增加对应的包<context:component-scan base-package="xxx" /> 或者增加注解@ComponentScan({ "xxx"})。当时觉得挺urgly的,但也没有去研究有没有更好的方式。
直到接触Spring Boot 后,发现其可以自动引入二方包的bean。不过一直没有看这块的实现原理。直到最近面试的时候被问到。所以就看了下实现逻辑。
更多文章见个人博客:https://github.com/farmerjohngit/myblog
讲原理前先说下使用姿势。
在project A中定义一个bean。
package com.wangzhi;
import org.springframework.stereotype.Service;
@Service
public class Dog {
}并在该project的resources/META-INF/下创建一个叫spring.factories的文件,该文件内容如下
org.springframework.boot.autoconfigure.EnableAutoConfiguration=com.wangzhi.Dog
然后在project B中引用project A的jar包。
projectA代码如下:
package com.wangzhi.springbootdemo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.ConfigurableApplicationContext;
import org.springframework.context.annotation.ComponentScan;
@EnableAutoConfiguration
public class SpringBootDemoApplication {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(SpringBootDemoApplication.class, args);
System.out.println(context.getBean(com.wangzhi.Dog.class));
}
}打印结果:
com.wangzhi.Dog@3148f668
总体分为两个部分:一是收集所有spring.factories中EnableAutoConfiguration相关bean的类,二是将得到的类注册到spring容器中。
在spring容器启动时,会调用到AutoConfigurationImportSelector#getAutoConfigurationEntry
protected AutoConfigurationEntry getAutoConfigurationEntry(
AutoConfigurationMetadata autoConfigurationMetadata,
AnnotationMetadata annotationMetadata) {
if (!isEnabled(annotationMetadata)) {
return EMPTY_ENTRY;
}
// EnableAutoConfiguration注解的属性:exclude,excludeName等
AnnotationAttributes attributes = getAttributes(annotationMetadata);
// 得到所有的Configurations
List<String> configurations = getCandidateConfigurations(annotationMetadata,
attributes);
// 去重
configurations = removeDuplicates(configurations);
// 删除掉exclude中指定的类
Set<String> exclusions = getExclusions(annotationMetadata, attributes);
checkExcludedClasses(configurations, exclusions);
configurations.removeAll(exclusions);
configurations = filter(configurations, autoConfigurationMetadata);
fireAutoConfigurationImportEvents(configurations, exclusions);
return new AutoConfigurationEntry(configurations, exclusions);
}getCandidateConfigurations会调用到方法loadFactoryNames:
public static List<String> loadFactoryNames(Class<?> factoryClass, @Nullable ClassLoader classLoader) {
// factoryClassName为org.springframework.boot.autoconfigure.EnableAutoConfiguration
String factoryClassName = factoryClass.getName();
// 该方法返回的是所有spring.factories文件中key为org.springframework.boot.autoconfigure.EnableAutoConfiguration的类路径
return loadSpringFactories(classLoader).getOrDefault(factoryClassName, Collections.emptyList());
}
public static final String FACTORIES_RESOURCE_LOCATION = "META-INF/spring.factories";
private static Map<String, List<String>> loadSpringFactories(@Nullable ClassLoader classLoader) {
MultiValueMap<String, String> result = cache.get(classLoader);
if (result != null) {
return result;
}
try {
// 找到所有的"META-INF/spring.factories"
Enumeration<URL> urls = (classLoader != null ?
classLoader.getResources(FACTORIES_RESOURCE_LOCATION) :
ClassLoader.getSystemResources(FACTORIES_RESOURCE_LOCATION));
result = new LinkedMultiValueMap<>();
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
UrlResource resource = new UrlResource(url);
// 读取文件内容,properties类似于HashMap,包含了属性的key和value
Properties properties = PropertiesLoaderUtils.loadProperties(resource);
for (Map.Entry<?, ?> entry : properties.entrySet()) {
String factoryClassName = ((String) entry.getKey()).trim();
// 属性文件中可以用','分割多个value
for (String factoryName : StringUtils.commaDelimitedListToStringArray((String) entry.getValue())) {
result.add(factoryClassName, factoryName.trim());
}
}
}
cache.put(classLoader, result);
return result;
}
catch (IOException ex) {
throw new IllegalArgumentException("Unable to load factories from location [" +
FACTORIES_RESOURCE_LOCATION + "]", ex);
}
}在上面的流程中得到了所有在spring.factories中指定的bean的类路径,在processGroupImports方法中会以处理@import注解一样的逻辑将其导入进容器。
public void processGroupImports() {
for (DeferredImportSelectorGrouping grouping : this.groupings.values()) {
// getImports即上面得到的所有类路径的封装
grouping.getImports().forEach(entry -> {
ConfigurationClass configurationClass = this.configurationClasses.get(
entry.getMetadata());
try {
// 和处理@Import注解一样
processImports(configurationClass, asSourceClass(configurationClass),
asSourceClasses(entry.getImportClassName()), false);
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to process import candidates for configuration class [" +
configurationClass.getMetadata().getClassName() + "]", ex);
}
});
}
}
private void processImports(ConfigurationClass configClass, SourceClass currentSourceClass,
Collection<SourceClass> importCandidates, boolean checkForCircularImports) {
...
// 遍历收集到的类路径
for (SourceClass candidate : importCandidates) {
...
//如果candidate是ImportSelector或ImportBeanDefinitionRegistrar类型其处理逻辑会不一样,这里不关注
// Candidate class not an ImportSelector or ImportBeanDefinitionRegistrar ->
// process it as an @Configuration class
this.importStack.registerImport(
currentSourceClass.getMetadata(), candidate.getMetadata().getClassName());
// 当作 @Configuration 处理
processConfigurationClass(candidate.asConfigClass(configClass));
...
}
...
}可以看到,在第一步收集的bean类定义,最终会被以Configuration一样的处理方式注册到容器中。
@EnableAutoConfiguration注解简化了导入了二方包bean的成本。提供一个二方包给其他应用使用,只需要在二方包里将对外暴露的bean定义在spring.factories中就好了。对于不需要的bean,可以在使用方用@EnableAutoConfiguration的exclude属性进行排除。
后端服务的接口都是有访问上限的,如果外部QPS或并发量超过了访问上限会导致应用瘫痪。所以一般都会对接口调用加上限流保护,防止超出预期的请求导致系统故障。
从限流类型来说一般来说分为两种:并发数限流和qps限流,并发数限流就是限制同一时刻的最大并发请求数量,qps限流指的是限制一段时间内发生的请求个数。
从作用范围的层次上来看分单机限流和分布式限流,前者是针对单机的,后者是针对集群的,他们的**都是一样的,只不过是范围不一样,本文分析的都是单机限流。
接下来我们看看并发数限流和QPS限流。
更多文章见个人博客:https://github.com/farmerjohngit/myblog
并发数限流限制的是同一时刻的并发数,所以不考虑线程安全的话,我们只要用一个int变量就能实现,伪代码如下:
int maxRequest=100;
int nowRequest=0;
public void request(){
if(nowRequest>=maxRequest){
return ;
}
nowRequest++;
//调用接口
try{
invokeXXX();
}finally{
nowRequest--;
}
}显然,上述实现会有线程安全的问题,最直接的做法是加锁:
int maxRequest=100;
int nowRequest=0;
public void request(){
if(nowRequest>=maxRequest){
return ;
}
synchronized(this){
if(nowRequest>=maxRequest){
return ;
}
nowRequest++;
}
//调用接口
try{
invokeXXX();
}finally{
synchronized(this){
nowRequest--;
}
}
}当然也可以用AtomicInteger实现:
int maxRequest=100;
AtomicInteger nowRequest=new AtomicInteger(0);
public void request(){
for(;;){
int currentReq=nowRequest.get();
if(currentReq>=maxRequest){
return;
}
if(nowRequest.compareAndSet(currentReq,currentReq+1)){
break;
}
}
//调用接口
try{
invokeXXX();
}finally{
nowRequest.decrementAndGet();
}
}熟悉JDK并发包的同学会说干嘛这么麻烦,这不就是信号量(Semaphore)做的事情吗? 对的,其实最简单的方法就是用信号量来实现:
int maxRequest=100;
Semaphore reqSemaphore = new Semaphore(maxRequest);
public void request(){
if(!reqSemaphore.tryAcquire()){
return ;
}
//调用接口
try{
invokeXXX();
}finally{
reqSemaphore.release();
}
}条条大路通罗马,并发数限流比较简单,一般来说用信号量就好。
QPS限流限制的是一段时间内(一般指1秒)的请求个数。
最简单的做法用一个int型的count变量做计数器:请求前计数器+1,如超过阈值并且与第一个请求的间隔还在1s内,则限流。
伪代码如下:
int maxQps=100;
int count;
long timeStamp=System.currentTimeMillis();
long interval=1000;
public synchronized boolean grant(){
long now=System.currentTimeMillis();
if(now<timeStamp+interval){
count++;
return count<maxQps;
}else{
timeStamp=now;
count=1;
return true;
}
}该种方法实现起来很简单,但其实是有临界问题的,假如在第一秒的后500ms来了100个请求,第2秒的前500ms来了100个请求,那在这1秒内其实最大QPS为200。如下图:
计数器法会有临界问题,主要还是统计的精度太低,这点可以通过滑动窗口算法解决
我们用一个长度为10的数组表示1秒内的QPS请求,数组每个元素对应了相应100ms内的请求数。用一个sum变量代码当前1s的请求数。同时每隔100ms将淘汰过期的值。
伪代码如下:
int maxQps=100;
AtomicInteger[] count=new AtomicInteger[10];
long timeStamp=System.currentTimeMillis();
long interval=1000;
AtomicInteger sum;
volatile int index;
public void init(){
for(int i=0;i<count.length;i++){
count[i]=new AtomicInteger(0);
}
sum=new AtomicInteger(0);
}
public synchronized boolean grant(){
count[index].incrementAndGet();
return sum.incrementAndGet()<maxQps;
}
//每100ms执行一次
public void run(){
index=(index+1)%count.length;
int val=count[index].getAndSet(0);
sum.addAndGet(-val);
}滑动窗口的窗口越小,则精度越高,相应的资源消耗也更高。
漏桶算法思路是,有一个固定大小的桶,水(请求)忽快忽慢的进入到漏桶里,漏桶以一定的速度出水。当桶满了之后会发生溢出。
在维基百科上可以看到,漏桶算法有两种实现,一种是as a meter,另一种是as a queue。网上大多数文章都没有提到其有两种实现,且对这两种概念混乱。
第一种实现是和令牌桶等价的,只是表述角度不同。
伪代码如下:
long timeStamp=System.currentTimeMillis();//上一次调用grant的时间
int bucketSize=100;//桶大小
int rate=10;//每ms流出多少请求
int count;//目前的水量
public synchronized boolean grant(){
long now = System.currentTimeMillis();
if(now>timeStamp){
count = Math.max(0,count-(now-timeStamp)*rate);
timeStamp = now;
}
if(count+1<=bucketSize){
count++;
return true;
}else{
return false;
}
}该种实现允许一段时间内的突发流量,比如初始时桶中没有水,这时1ms内来了100个请求,这100个请求是不会被限流的,但之后每ms最多只能接受10个请求(比如下1ms又来了100个请求,那其中90个请求是会被限流的)。
其达到的效果和令牌桶一样。
第二种实现是用一个队列实现,当请求到来时如果队列没满则加入到队列中,否则拒绝掉新的请求。同时会以恒定的速率从队列中取出请求执行。
伪代码如下:
Queue<Request> queue=new LinkedBlockingQueue(100);
int gap;
int rate;
public synchronized boolean grant(Request req){
if(!queue.offer(req)){return false;}
}
// 单独线程执行
void consume(){
while(true){
for(int i=0;i<rate;i++){
//执行请求
Request req=queue.poll();
if(req==null){break;}
req.doRequest();
}
Thread.sleep(gap);
}
}对于该种算法,固定的限定了请求的速度,不允许流量突发的情况。
比如初始时桶是空的,这时1ms内来了100个请求,那只有前10个会被接受,其他的会被拒绝掉。注意与上文中as a meter实现的区别。
**不过,当桶的大小等于每个ticket流出的水大小时,第二种漏桶算法和第一种漏桶算法是等价的。**也就是说,as a queue是as a meter的一种特殊实现。如果你没有理解这句话,你可以再看看上面as a meter的伪代码,当bucketSize==rate时,请求速度就是恒定的,不允许突发流量。
令牌桶算法的**就是,桶中最多有N个令牌,会以一定速率往桶中加令牌,每个请求都需要从令牌桶中取出相应的令牌才能放行,如果桶中没有令牌则被限流。
令牌桶算法与上文的漏桶算法as a meter实现是等价的,能够在限制数据的平均传输速率的同时还允许某种程度的突发传输。伪代码:
int token;
int bucketSize;
int rate;
long timeStamp=System.currentTimeMillis();
public synchronized boolean grant(){
long now=System.currentTimeMillis();
if(now>timeStamp){
token=Math.max(bucketSize,token+(timeStamp-now)*rate);
timeStamp=now;
}
if(token>0){
token--;
return true;
}else{
return false;
}
}as a meter的漏桶算法和令牌桶算法是一样的,只是**角度有所不同。
as a queue的漏桶算法能强行限制数据的传输速率,而令牌桶和as a meter漏桶则能够在限制数据的平均传输速率的同时还允许某种程度的突发传输。
一般业界用的比较多的是令牌桶算法,像guava中的RateLimiter就是基于令牌桶算法实现的。当然不同的业务场景会有不同的需要,具体的选择还是要结合场景。
本文介绍了后端系统中常用的限流算法,对于每种算法都有对应的伪代码,结合伪代码理解起来应该不难。但伪代码中只是描述了大致**,对于一些细节和效率问题并没有关注,所以下篇文章将会分析常用限流API:guava的RateLimiter的源码实现,让读者对于限流有个更清晰的认识。
http://blog.zhuxingsheng.com/blog/counter-algorithm.html
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.