This repo is a combination of utility scripts and services that support the continuous scraping and indexing of public blocks. It powers Blockbuilder's search page.
Blocks are stored as GitHub gists, which are essentially mini git repositories. If a gist has an index.html file, d3 example viewers like blockbuilder.org or bl.ocks.org will render the page contained in the gist. Given a list of users we can query the GitHub API for the latest public gists that each of those users has updated or created.
We can then filter those gists to see only those gists which have an index.html file.
Once we have a list of gists from the API we can download the files from each gist to disk for further processing. Then, we want to index some of those files in Elasticsearch. This allows us to run our own search engine for the files inside of gists that we are interested in.
We also have a script that will output several .json files that can be used to create visualizations such as all the blocks and the ones described in this post.
First create a config.js file. You can copy config.js.example and replace the placeholders tokens with a valid GitHub application token. This token is important because it frees you from GitHub API rate limits you would encounter running these scripts without a token.
config.js is also the place to configure Elasticsearch and the RPC server, if you plan to run them.
There are several files related to users. The most important is data/usables.csv, a list of GitHub users that have at least 1 public gist.
data/usables.csv is kept up-to-date manually via the process below. After each manual update, data/usables.csv is checked in to the blockbuilder-search-index repository.
Only run these scripts if you want to add a batch of users from a new source. It is also possible to manually edit data/user-sources/manually-curated.csv and add a new username to the end of the file.
bl.ocksplorer.org has a user list they maintain that can be downloaded from the bl.ocksplorer.org form results and is automatically pulled in by combine-users.coffee.
These users are combined with data exported from the blockbuilder.org database of logged in users (found in data/user-sources/blockbuilder-users.json. These user data only contains publically available information from a user's GitHub profile.
combine-users.coffee produces the file data/users-combined.csv, which serves as the input to validate-users.coffee which then will query the GitHub API and make a list of everyone who has at least 1 public gist. validate-users.coffee then saves that list to data/usables.csv.
# create new user list if any user sources have been updated
coffee combine-users.coffee
coffee validate-users.coffeeFirst we query the GitHub API for each user to obtain a list of gists that we would like to process.
# generate data/gist-meta.json, the list of all blocks
coffee gist-meta.coffee
# save to a different file
coffee gist-meta.coffee data/latest.json
# only get recent gists
coffee gist-meta.coffee data/latest.json 15min
# only get gists since a date in YYYY-MM-DDTHH:MM:SSZ format
coffee gist-meta.coffee data/latest.json 2015-02-14T00:00:00Z
# get all the gists for new users
coffee gist-meta.coffee data/new.json '' 'new-users'data/gist-meta.json serves as a running index of blocks we have downloaded. Any time you run the gist-meta.coffee command, any new blocks found will be added to gist-meta.json. In our production deployment, cronjobs will create data/latest.json every 15 minutes. Later in the pipeline, we use data/latest.json to index the gists in Elasticsearch.
You can download a recent copy to bootstrap your index here: gist-meta.json
The second step in the process is to download the contents of each gist via a GitHub raw urls and save the files to disk in data/gists-clones/.
The gists for each user are cloned into a folder with their username.
# default, will download all the files found in data/gist-meta.json
coffee gist-cloner.coffee
# specify file with list of gists
coffee gist-cloner.coffee data/latest.json
# TODO: a command/process to pull the latest commits in all the repos
# TODO: a command to clone/pull the latest for a given userdeprecated instructions
Previously, the second step in the process was to download the contents of each gist via a GitHub [raw urls](http://stackoverflow.com/a/4605068/1732222) and save the files to disk in `data/gists-files/`. We now clone because it is a better way to keep our index up to date, and the saved space is negligable. We selectively download files of certain typesif ext in [".html", ".js", ".coffee", ".md", ".json", ".csv", ".tsv", ".css"]This filter-by-file-extension selective download approach consumes 60% less disk space than naively cloning all of the gists.
# default, will download all the files found in data/gist-meta.json
coffee gist-content.coffee
# specify file with list of gists
coffee gist-content.coffee data/latest.json
# skip existing files (saves time, might miss updates)
coffee gist-content.coffee data/gist-meta.json skipWe can generate a series of JSON files that pull out interesting metadata from the downloaded gists.
coffee parse.coffeeThis outputs to data/parsed including data/blocks*.json and data/parsed/apis.json as well as data/parsed/files-blocks.json.
Note: there is code that will clone all the gists to data/gist-clones/ but it needs some extra rate limiting before its robust.
As of 2/11/16 there are about 7k blocks, the data/gist-files/ directory is about 1.1GB while data/gist-clones/ ends up at 3GB.
While big, both of these directory sizes are manageable. The advantage of cloning gists would be that future updates could be run by simply doing a git pull. With this approach, we would be syncing with higher fidelity. It's on the TODO list but not essential to the goal of having a reliable search indexing pipeline.
I wanted a script that would take in a list of block URLS and give me a subset of the blocks.json formatted data. It currently depends on the blocks being part of the list, so anonymous blocks won't work right now.
coffee gallery.coffee data/unconf.csv data/out.jsonOnce you have a list of gists (either data/gist-meta.json, data/latest.json or otherwise) and you've downloaded the content to data/gist-files/ you can index the gists to Elasticsearch:
download Elasticsearch 2.3.4
unzip elasticsearch-2.3.4.zip and run a local Elasticsearch instance:
cd ~/Downloads
unzip elasticsearch-2.3.4.zip
cd elasticsearch-2.3.4
bin/elasticsearchthen, run the indexing script from the blockbuilder-search-index directory:
cd blockbuilder-search-index
coffee elasticsearch.coffeeyou can also choose to only index gists listed in a file that you specify, like this:
cd blockbuilder-search-index
# index from a specific file
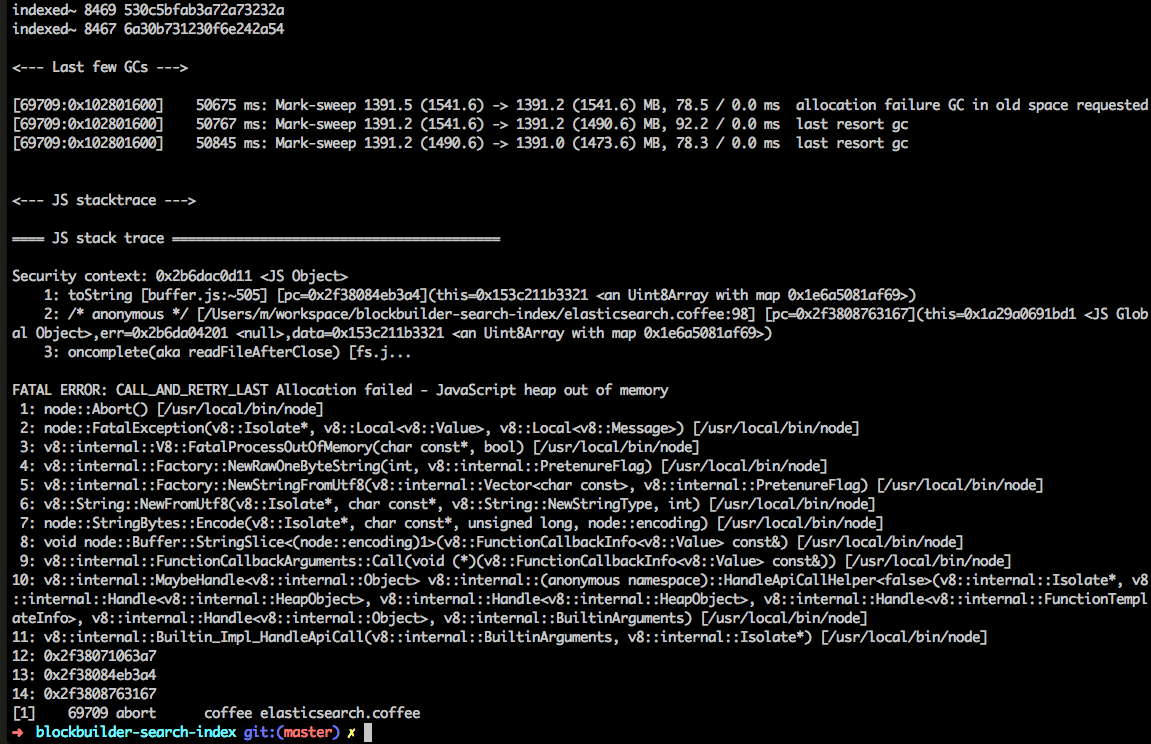
coffee elasticsearch.coffee data/latest.jsonif you see a JavaScript heap out of memory errror, then the nodejs process invoked by Coffeescript ran out of memory. to fix this error and index all of the blocks in one go, increase the amount of memory available to nodejs
with the argument --nodejs --max-old-space-size=12000
if we use this argument, then the whole command becomes:
cd blockbuilder-search-index
coffee --nodejs --max-old-space-size=12000 elasticsearch.coffee
I then deploy this on a server with cronjobs. See the example crontab
I made a very simple REST server that will listen for incoming gists to index them, or an id of a gist to delete from the index. This is used to keep the index immediately up-to-date when a user saves or forks a gist from blockbuilder.org. Currently the save/fork functionality will index if it sees that the gist is public, and it will delete if it sees that the gist is private. This way if you make a previously public gist private and update it via blockbuilder it will be removed from the search index.
I deploy the RPC host to the same server as Elasticsearch, and have security groups setup so that its not publicly accessible (only my blockbuilder server can access it)
node server.js
The server is deployed with this startup script
The mappings used for elasticsearch can be found here. I've been using the Sense app from Elasticsearch to configure and test my setup both locally and deployed. The default url for Sense is http://localhost:5601/app/sense.
The /blockbuilder index is where all the blocks go, the /bbindexer index is where I log the results of each script run (gist-meta.coffee and gist-content.coffee) which is helpful
for keeping up with the status of the cron jobs.