A Python-based web crawler designed to extract interview data from a popular IT job-hunting website helloworld.rs. The current dataset generated by the crawler includes:
- company names
- positions
- questions
What personally motivated me to do this project was simply learning new Python libraries and utilizing Python for different practical implementations. I also assumed it would be a good way to prepare for upcoming interviews, by having an insight into what companies demand from various positions in the IT field (be it an internship, junior or senior role).
For more information check the notes section.
Web Crawling, also commonly referred to as web scraping, is a technique used to collect and parse raw data from the Web. It plays a crucial role in various applications, from search engines indexing web pages to data extraction for research and analysis.
The history of web crawlers dates back to the early days of the internet when the need arose to index and organize the vast amount of information available online. The first notable crawler, known as the World Wide Web Wanderer, was developed by Matthew Gray in 1993. Since then, search engines like Google have adopted sophisticated crawling algorithms to index the ever-expanding web efficiently.
Web crawlers operate by systematically browsing the internet, starting from a set of seed URLs. The process involves the following steps:
- Seed URLs: Crawlers begin with a list of seed URLs, which are typically high-quality and authoritative websites.
- Page Retrieval: The crawler retrieves the HTML content of a web page from the seed URLs.
- Parsing: The HTML content is parsed to extract relevant information, such as links to other pages.
- URL Frontier: The extracted URLs form a "URL frontier," a queue of links to be visited in subsequent rounds.
- Recursion: The crawler repeats the process, recursively exploring linked pages and adding new URLs to the frontier.
- Politeness and Respect: Crawlers follow politeness rules to avoid overloading servers and respect the terms of service of websites.
For more informations on how web scraping works, and how it's done with Python check out this interesting blog.
Happy scraping!
Before you follow the installation and usage steps, make sure that you have downloaded Python and have installed pip.
To install the web crawler, follow these steps:
- Clone the repository to your local machine:
git clone https://github.com/your-username/your-web-crawler-repo.git
- Open the project in your preferred integrated development environment (IDE).
- Install the required libraries by running the following command in your terminal or command prompt, assuming you have Python and pip installed:
pip install -r requirements.txt
To use the web crawler, follow these steps:
- Navigate to the project directory in your terminal or command prompt.
- Run the main file containing the main method. For example:
python main.py
The program will start crawling the specified number of pages. By default, it crawls all pages (917 pages) on helloworld.rs, but you can customize the number of pages by providing an argument to the scraper.scrape_pages method in the main file.
For example, to crawl the first 100 pages, modify the main.py file as follows:
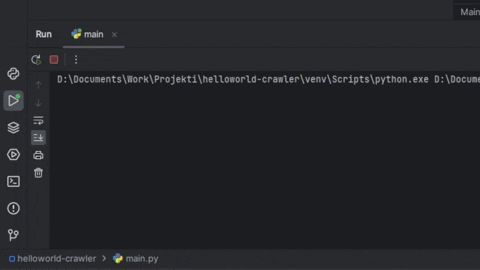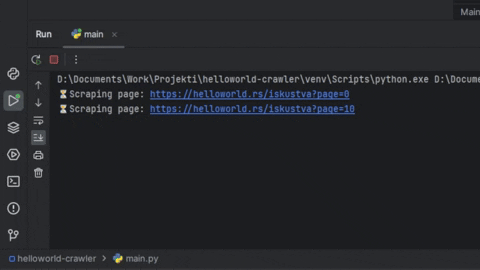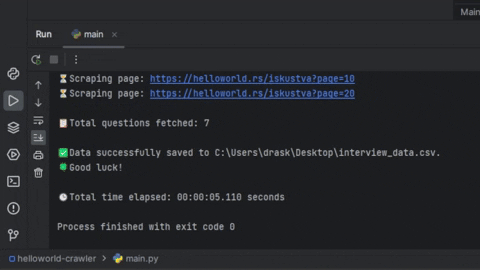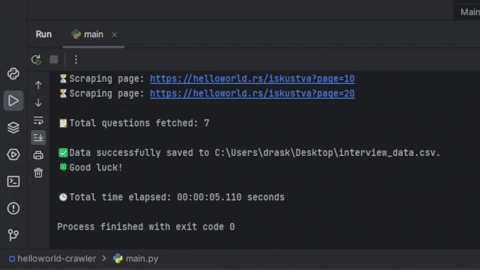
scraper.scrape_pages(0, 100) # Set the desired number of pages; default will be 0, 917After the program executes, a .csv file will be generated in your Desktop folder.
That data can then be used in programs such as MS Excel to easily sort, filter and extract important data. You can also view it inside of IDE's such as PyCharm, either in text format, or table format.
All contributors are welcome!
You know the drill:
- Fork the repository
- Create a new branch for your feature or bug fix:
git checkout -b feature/my-feature - Commit your changes:
git commit -m "appropriate comment" - Push to your branch
git push origin feature/my-feature - Create a pull request explaining your changes and improvements (be as detailed as possible)
This web crawler is designed with a strong commitment to ethical and responsible web scraping practices. It adheres strictly to the rules and guidelines set by the website it crawls, in this case, helloworld.rs.
If, for any reason, the website requests a stoppage of crawling the data, the repository will be removed without questions asked. The collected data, consisting of company names, positions, and interview questions, is utilized for educational and informational purposes. The primary goal is to assist individuals, especially in the IT field, by providing insights into the job market and interview processes. Any personal or sensitive information is handled with the utmost care, and the crawler avoids collecting unnecessary data beyond the scope of its intended purpose.Respecting the policies of the website being crawled is of utmost importance.
The crawler follows the guidelines outlined in the robots.txt file of the website, ensuring that it only accesses and extracts information from areas permitted by the site administrators. It avoids overloading the server with excessive requests, abiding by the principles of web etiquette.
