This repo covers the implementation of the following ECCV 2022 paper: "Discriminability-Transferability Trade-Off: An Information-Theoretic Perspective" (Paper)
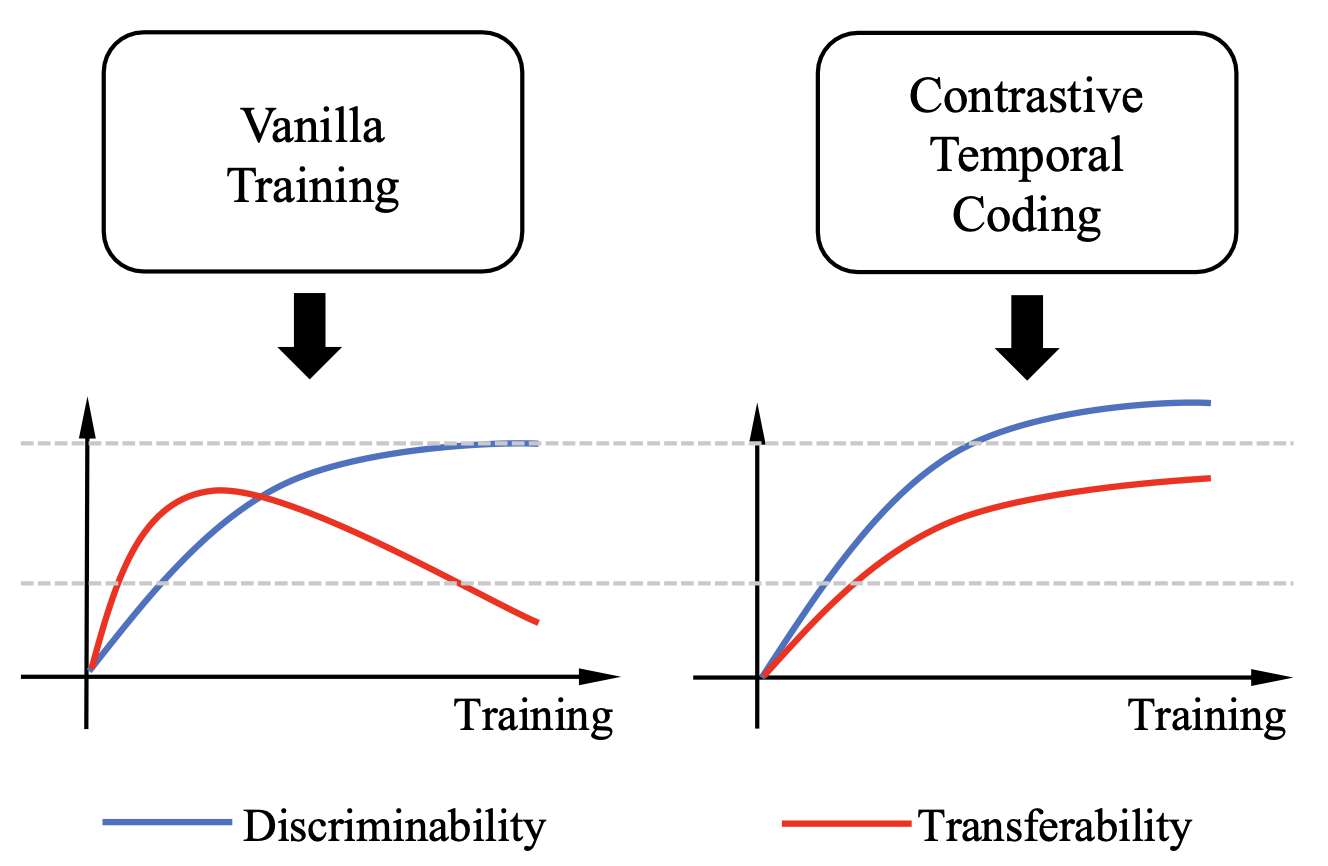
This work simultaneously considers the discriminability and transferability properties of deep representations in the typical supervised learning task, ie, image classification. By a comprehensive temporal analysis, we observe a trade-off between these two properties. The discriminability keeps increasing with the training progressing while the transferability intensely diminishes in the later training period. From the perspective of information-bottleneck theory, we reveal that the incompatibility between discriminability and transferability is attributed to the over-compression of input information. More importantly, we investigate why and how the InfoNCE loss can alleviate the over-compression, and further present a learning framework, named contrastive temporal coding(CTC), to counteract the over-compression and alleviate the incompatibility. Extensive experiments validate that CTC successfully mitigates the incompatibility, yielding discriminative and transferable representations. Noticeable improvements are achieved on the image classification task and challenging transfer learning tasks. We hope that this work will raise the significance of the transferability property in the conventional supervised learning setting.
This repo was tested with Ubuntu 16.04.5 LTS, Python 3.7, PyTorch 1.10.0, and CUDA 11.3.
pip install -r requirements.txt
As the prominent contribution of the paper, we first show how to observe the over-compression phenomenon.
For result stability, we use CIFAR-100 as the source dataset, and CINIC-10 as the target dataset. The download of CIFAR-100 could be complemeted with PyTorch, but the CINIC-10 dataset should be manually downloaded with the following command or the official website or Baidu Pan or Google Drive:
mkdir ./data
cd ./data
wget https://datashare.is.ed.ac.uk/bitstream/handle/10283/3192/CINIC-10.tar.gz
Unzip the CINIC-10 dataset folder in './data/'.
We use the following script for training a 'ResNext32-16x4d' on the source dataset CIFAR-100 :
python train_vanilla.py --epochs 200 --dataset cifar100 --model resnext32_16x4d \
--weight_decay 0.0005 --momentum 0.9 --learning_rate 0.05 --batch_size 64 --save_freq 2 --note vanilla
We train the model for 200 epochs and save checkpoints for each 2 epochs. After training, the 100 checkpoints could be found in './save/model/{vanilla_folder_in_step2}', and the folder name ends with 'vanilla'. In the following, we observe over-compression based on experiments with the obtained vanilla training checkpoints.
We use the following script to conduct transferring experiments for each checkpoint obtained in Step 2:
python transfer.py --source_dataset cifar100 --target_dataset cinic10 --model resnext32_16x4d \
--ckpt_path {vanilla_folder_in_step2} --start_epoch 2 --skip 2
We conduct the transferring experiments with the obtained vanilla training checkpoints in Step 2. For fast experiment, the `skip' parameter could be larger than 2, but needs to be even.
We use the following scripts to calculate information dynamics on source and target datasets:
- I(X;T) on the source dataset CIFAR-100:
python mine.py --mode xt --model resnext32_16x4d --dataset cifar100 \
--ckpt_path {vanilla_folder_in_step2} --lr 8e-5 --iter_num 1e+4 --start_epoch 2 --skip 2
- I(T;Y) on the source dataset CIFAR-100:
python mine.py --mode ty --model resnext32_16x4d --dataset cifar100 \
--ckpt_path {vanilla_folder_in_step2} --lr 1e-5 --iter_num 2e+4 --start_epoch 2 --skip 2
- I(X;T) on the target dataset CINIC-10:
python mine.py --mode xt --model resnext32_16x4d --dataset cinic10 \
--ckpt_path {vanilla_folder_in_step2} --lr 8e-5 --iter_num 1e+4 --start_epoch 2 --skip 2
- I(T;Y) on the target dataset CINIC-10:
python mine.py --mode ty --model resnext32_16x4d --dataset cinic10 \
--ckpt_path {vanilla_folder_in_step2} --lr 1e-5 --iter_num 2e+4 --start_epoch 2 --skip 2
Then, we detail the training of our proposed Contrastive Temporal Coding (CTC), and prove the transferability improvement.
We could adjust hyper-parameters for emphasizing discriminability or transferability.
-
For emphasizing transferability:
python train_ctc.py --epochs 300 --dataset cifar100 --model resnext32_16x4d \ --momentum 0.9 --learning_rate 0.05 --batch_size 64 --weight_decay 0.0005 --weight_decay_coef 2.0 --stage_two_epoch 200 \ -a 0.5 -b 1.0 --instance_t 0.10 --instance_m 0.9 --nce_t 0.10 --nce_m 0.9 --update_memory_bank \ --save_freq 2 --note ctc -
For emphasizing discriminability:
python train_ctc.py --epochs 300 --dataset cifar100 --model resnext32_16x4d \ --momentum 0.9 --learning_rate 0.05 --batch_size 64 --weight_decay 0.0005 --weight_decay_coef 2.0 --stage_two_epoch 200 \ -a 0.1 -b 1.0 --instance_t 0.50 --instance_m 0.9 --nce_t 0.40 --nce_m 0.9 --update_memory_bank \ --save_freq 2 --note ctc
After training CTC model, checkpoints could be found in './save/model/{ctc_folder_in_step2}', and the folder name ends with 'ctc'.
We use the following script to conduct transferring experiments for each checkpoint obtained in Step 1:
python transfer.py --source_dataset cifar100 --target_dataset cinic10 --model resnext32_16x4d \
--ckpt_path {ctc_folder_in_step2} --start_epoch 2 --skip 2We use the following scripts to calculate information dynamics on source and target datasets:
- I(X;T) on source dataset CIFAR-100:
python mine.py --mode xt --model resnext32_16x4d --dataset cifar100 \
--ckpt_path {ctc_folder_in_step2} --lr 8e-5 --iter_num 1e+4 --start_epoch 2 --skip 2
- I(T;Y) on source dataset CIFAR-100:
python mine.py --mode ty --model resnext32_16x4d --dataset cifar100 \
--ckpt_path {ctc_folder_in_step2} --lr 1e-5 --iter_num 2e+4 --start_epoch 2 --skip 2
- I(X;T) on target dataset CINIC-10:
python mine.py --mode xt --model resnext32_16x4d --dataset cinic10 \
--ckpt_path {ctc_folder_in_step2} --lr 8e-5 --iter_num 1e+4 --start_epoch 2 --skip 2
- I(T;Y) on target dataset CINIC-10:
python mine.py --mode ty --model resnext32_16x4d --dataset cinic10 \
--ckpt_path {ctc_folder_in_step2} --lr 1e-5 --iter_num 2e+4 --start_epoch 2 --skip 2
If you find this repo useful for your research, please consider citing the paper
@inproceedings{cui2022discriminability,
title={Discriminability-Transferability Trade-Off: An Information-Theoretic Perspective},
author={Quan Cui and Bingchen Zhao and Zhao-Min Chen and Borui Zhao and Renjie Song and Jiajun Liang and Boyan Zhou and Osamu Yoshie},
booktitle={ECCV},
year={2022}
}
For any questions, please contact Bingchen Zhao ([email protected]) and Quan Cui ([email protected]).
- Thanks for CRD and MINE. We build this library based on the CRD's codebase and MINE's codebase.





