pgrouter is a lightweight query router that sits in front of two
or more PostgreSQL nodes participating in streaming replication,
and transparently routes queries from clients to the nodes and
back again.
For application developers, pgrouter frees them from having to
explicitly split out their read queries from their write queries.
This enables use of ORMs and other database abstractions that may
not be as aware of the particular needs of a streaming replication
HA PostgreSQL cluster.
For system builders, pgrouter makes it trivially easy to add
high-availability characteristics to previously singleton database
deployments. Since it speaks native PostgreSQL protocol, clients
never know that they aren't just talking to a regular PostgreSQL
database node.
Start with a highly-available PostgreSQL cluster, utilizing native
Streaming Replication. pgrouter sits in front of these
nodes, regularly watching each for changes in status (to pick up
on slave → master promotion), availability (to detect failed
slaves) and replication delay (to detect unsuitable slaves).
Here's a diagram.
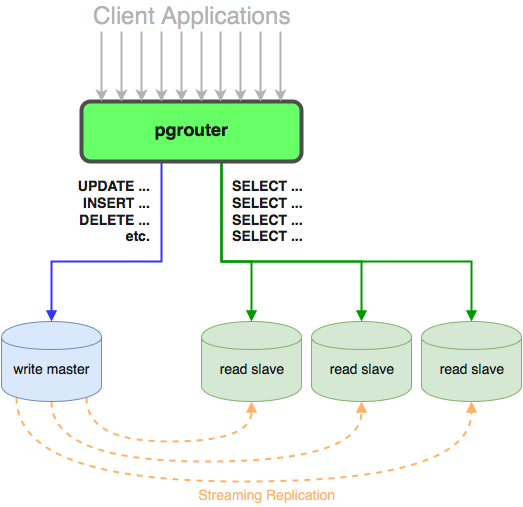
Client applications then connect directly to the pgrouter
process, on the ports it binds, as if it were a regular
PostgreSQL database. pgrouter authenticates the connection and
then opens two connections to the backends, one to the write
master and one to a randomly selected read slave.
Non-destructive queries will be routed to the read slave. All
others will be sent to the write master. pgrouter employs
more than a few tricks to pull this off. Primarily, it attempts
to send all queries to the read slave first. If that PostgreSQL
backend fails because the query is prohibited on read-only
replicas, pgrouter redirects the original query to the write
master. Additionally, since transactions usually perform some
destructive queries, all transactions are forwarded directly to
the write master without bothering the read slave.
To compile from source, just run:
./bootstrap && \
./configure && \
make && \
sudo make install
pgrouter reads its configuration from a file, usually called
something like /etc/pgrouter.conf. It looks a little something
like this:
# pgrouter.conf
listen *:5432
authdb /etc/pgrouter/authdb
log INFO
# health checking configuration
health {
timeout 3s
check 7s
database postgres
username pgrouter
password sekrit
}
# backend configuration
backend default {
lag 200
weight 100
}
backend 10.244.232.2:6432 { }
backend 10.244.232.3:6432 {
lag 50
weight 200
}
backend 10.244.232.4:6432 { }
backend 10.244.232.5:6432 { }
pgrouter aims to be as performant as possible without
sacrificing stability or correctness. I hope to have some actual
benchmarks with graphs and charts and such soon. Until then,
here's two comparative runs of pgbench, running 5 clients
issuing 1000 transactions each, directly against my lab
environment, and transiting pgrouter. The nodes were otherwise
idle.
First, here's what the raw baseline performance is, without
pgrouter in the way:
→ pgbench -U hedgehog -h 10.244.232.2 -p 6432 -t 1000 -c 5
starting vacuum...end.
transaction type: TPC-B (sort of)
scaling factor: 1
query mode: simple
number of clients: 5
number of threads: 1
number of transactions per client: 1000
number of transactions actually processed: 5000/5000
latency average: 0.000 ms
tps = 347.538724 (including connections establishing)
tps = 348.004628 (excluding connections establishing)
Now, adding pgrouter into the mix:
→ pgbench -U hedgehog -h 127.0.0.1 -p 5432 -t 1000 -c 5
starting vacuum...end.
transaction type: TPC-B (sort of)
scaling factor: 1
query mode: simple
number of clients: 5
number of threads: 1
number of transactions per client: 1000
number of transactions actually processed: 5000/5000
latency average: 0.000 ms
tps = 327.116592 (including connections establishing)
tps = 327.280863 (excluding connections establishing)
That works out to about 95% throughput via pgrouter, or a little
over 5% overhead due to the query inspection and rerouting.
pgrouter is, above all things, VERY ALPHA SOFTWARE.
These are the big things that need fixed / done (in some particular order):
- Stress Testing - I'm sure there are combinations of queries
that confound the simple heuristics. I'm sure there are
pathological apps out there doing 700MB
INSERTstatements. These all need tested, and put into a formal regression test suite. - Documentation - It needs to be better and more existent. Needs man pages, example config files (annotated) etc. Comparisons with other tools (pgpool / pgbouncer / pgp) would also be nice.
- TLS - Currently not supported, either on the client side or the PostgreSQL backend side.
- FIXMEs - Scattered throughout - these need fixed.
- Logging - Needs to be smoothed out to ensure that it provides the most value to operators of a pgrouter installation.
- Benchmarks - Need more formal and rigorous testing.
- Long-lived Connections - Currently, we don't handle cases where clients leave connections open for long periods of time and happen to be still-connected when a slave goes away or starts to lag, or gets promoted.
pgrouter is released under the MIT license.

