Βλάχος Άγγελος ΑΕΜ : 9087
Τριαρίδης Κωνσταντίνος ΑΕΜ : 9159
- Καταγραφή αποτελεσμάτων benchmarks για default τιμές
- Εύρεση στοιχείων για default υποσύστημα μνήμης από αρχείο config.ini
- Αλλαγή ρολογιού στα 1GHz και σύγκριση χρόνου εκτέλεσης
- Κριτική Εργασίας
Από [system.cpu.dcache] L1 Data cache : size 64KB 2-way-associative
size=65536
assoc=2Από [system.cpu.icache] L1 Instruction cache : size 32KB 2-way-associative
size=32768
assoc=2Από [system.l2] L2 cache : size 2MB 8-way-associative
size=2097152
assoc=8Από [system] cache line size : 64B
cache_line_size=64| bzip | mcf | hmmer | sjeng | libm | |
|---|---|---|---|---|---|
| Execution time(ms) | 83.982 | 64.955 | 59.396 | 513.528 | 174.671 |
| CPI | 1.6797 | 1.2991 | 1.1879 | 10.2706 | 3.4934 |
| L1 icache missrate(%) | 0.0077 | 2.3612 | 0.0221 | 0.0020 | 0.0094 |
| L1 dcache missrate(%) | 1.4798 | 0.2108 | 0.1637 | 12.1831 | 6.0972 |
| L2 cache missrate(%) | 28.2163 | 5.5046 | 7.7760 | 99.9972 | 99.9944 |





Μειώνοντας το ρολόι στο μισό περιμένω να δω διπλασιασμό του χρόνου εκτέλεσης δηλαδή επιτάχυνση από 1 σε 2 GHz περίπου 100%.
Σε κάποια benchmarks παρατηρείται αυτό ενώ σε άλλα όχι :
| bzip | mcf | hmmer | sjeng | libm | |
|---|---|---|---|---|---|
| Χρόνος εκτέλεσης στα 2GHz(ms) | 83.982 | 64.955 | 59.396 | 513.528 | 174.671 |
| Χρόνος εκτέλεσης στα 1GHz(ms) | 161.025 | 127.942 | 118.530 | 704.056 | 262.327 |
| Επιτάχυνση από 1 σε 2 GHz(%) | 91.7 | 96.9 | 99.5 | 37.1 | 50.1 |

Αλλάζω τιμές των παραμέτρων και παρατηρώ την αλλαγή στην απόδοση του προγράμματος(μέσω της αλλαγής των CPI):
- L1 icache size
- L1 icache associativity
- L1 dcache size
- L1 dcache associativity
- L2 cache size
- L2 cache associativity
- Cache line size
Όλα τα benchmarks εκτός από το mcf είχαν αρχικά πολύ χαμηλό L1 icache miss rate οπότε περιμένουμε να υπάρχει ουσιαστική αλλαγή μόνο στην απόδοση του mcf
 Πράγματι παρατηρείται 10% επιτάχυνση στην περίπτωση του mcf ενώ στα υπόλοιπα η αλλαγή δεν είναι καθόλου σημαντική. Η παρατήρηση αυτή μπορεί να εξηγηθεί στην περίπτωση που το mcf περιέχει ένα πολύ μεγάλο for loop ,που επαναλαμβάνεται πολλές φορές, το οποίο δεν χωρούσε να φορτωθεί ολόκληρο στην icache και με το που αυξήθηκε το μέγεθος αυτής χωράει. Πράγματι παρατηρώ πλέον πολύ χαμηλό icache miss rate και στο mcf, αντίστοιχο με τα άλλα benchmarks.
Πράγματι παρατηρείται 10% επιτάχυνση στην περίπτωση του mcf ενώ στα υπόλοιπα η αλλαγή δεν είναι καθόλου σημαντική. Η παρατήρηση αυτή μπορεί να εξηγηθεί στην περίπτωση που το mcf περιέχει ένα πολύ μεγάλο for loop ,που επαναλαμβάνεται πολλές φορές, το οποίο δεν χωρούσε να φορτωθεί ολόκληρο στην icache και με το που αυξήθηκε το μέγεθος αυτής χωράει. Πράγματι παρατηρώ πλέον πολύ χαμηλό icache miss rate και στο mcf, αντίστοιχο με τα άλλα benchmarks.
Περιμένουμε ποιοτικά ανάλογα αποτελέσματα με αυτά από την αύξηση του μεγέθους της icache για το mcf αλλά αύξηση του CPI για τα υπόλοιπα
 Πράγματι παρατηρείται ανάλογη(ποιοτικά και ποσοτικά) επιτάχυνση για το mcf με αυτήν από την αύξηση μεγέθους , αποτέλεσμα πολύ σημαντικό για τις σχεδιαστικές μας αποφάσεις αφού η αύξηση του associativity είναι πιο φθηνή διαδικασία από την αύξηση του μεγέθους της μνήμης. Βέβαια παρατηρείται ελάχιστη αύξηση του CPI για τα άλλα benchmarks αφού η αύξηση του associativity σαν διαδικασία αυξάνει την πολυπλοκότητα και το hit-time για την icache.
Πράγματι παρατηρείται ανάλογη(ποιοτικά και ποσοτικά) επιτάχυνση για το mcf με αυτήν από την αύξηση μεγέθους , αποτέλεσμα πολύ σημαντικό για τις σχεδιαστικές μας αποφάσεις αφού η αύξηση του associativity είναι πιο φθηνή διαδικασία από την αύξηση του μεγέθους της μνήμης. Βέβαια παρατηρείται ελάχιστη αύξηση του CPI για τα άλλα benchmarks αφού η αύξηση του associativity σαν διαδικασία αυξάνει την πολυπλοκότητα και το hit-time για την icache.

 Με την αλλαγή στο μέγεθος και το associativity βλέπω επιτάχυνση μόλις πάνω από 1% στο bzip στο οποίο μειώνεται το miss-rate στην dcache. Στα άλλα benchmarks δεν βλέπω καμία αισθητή διαφορά.
Με την αλλαγή στο μέγεθος και το associativity βλέπω επιτάχυνση μόλις πάνω από 1% στο bzip στο οποίο μειώνεται το miss-rate στην dcache. Στα άλλα benchmarks δεν βλέπω καμία αισθητή διαφορά.
 Με την αλλαγή στο μέγεθος της L2 cache βλέπω πάλι επιτάχυνση ~1.7% στο bzip και ταυτόχρονα μείωση του miss rate στην L2 του bzip ενώ στα υπόλοιπα benchmarks πάλι δεν βλέπω κάποια αισθητή διαφορά.
Με την αλλαγή στο μέγεθος της L2 cache βλέπω πάλι επιτάχυνση ~1.7% στο bzip και ταυτόχρονα μείωση του miss rate στην L2 του bzip ενώ στα υπόλοιπα benchmarks πάλι δεν βλέπω κάποια αισθητή διαφορά.
 Με την αύξηση του associativity της L2 σε 16-way η υλοποίηση πλέον είναι πολύ πολύπλοκη οπότε έχω επιβράδυνση σε όλα τα benchmarks. Ξεκάθαρα δεν αξίζει η αύξηση του associativity πάνω από 8-way.
Με την αύξηση του associativity της L2 σε 16-way η υλοποίηση πλέον είναι πολύ πολύπλοκη οπότε έχω επιβράδυνση σε όλα τα benchmarks. Ξεκάθαρα δεν αξίζει η αύξηση του associativity πάνω από 8-way.
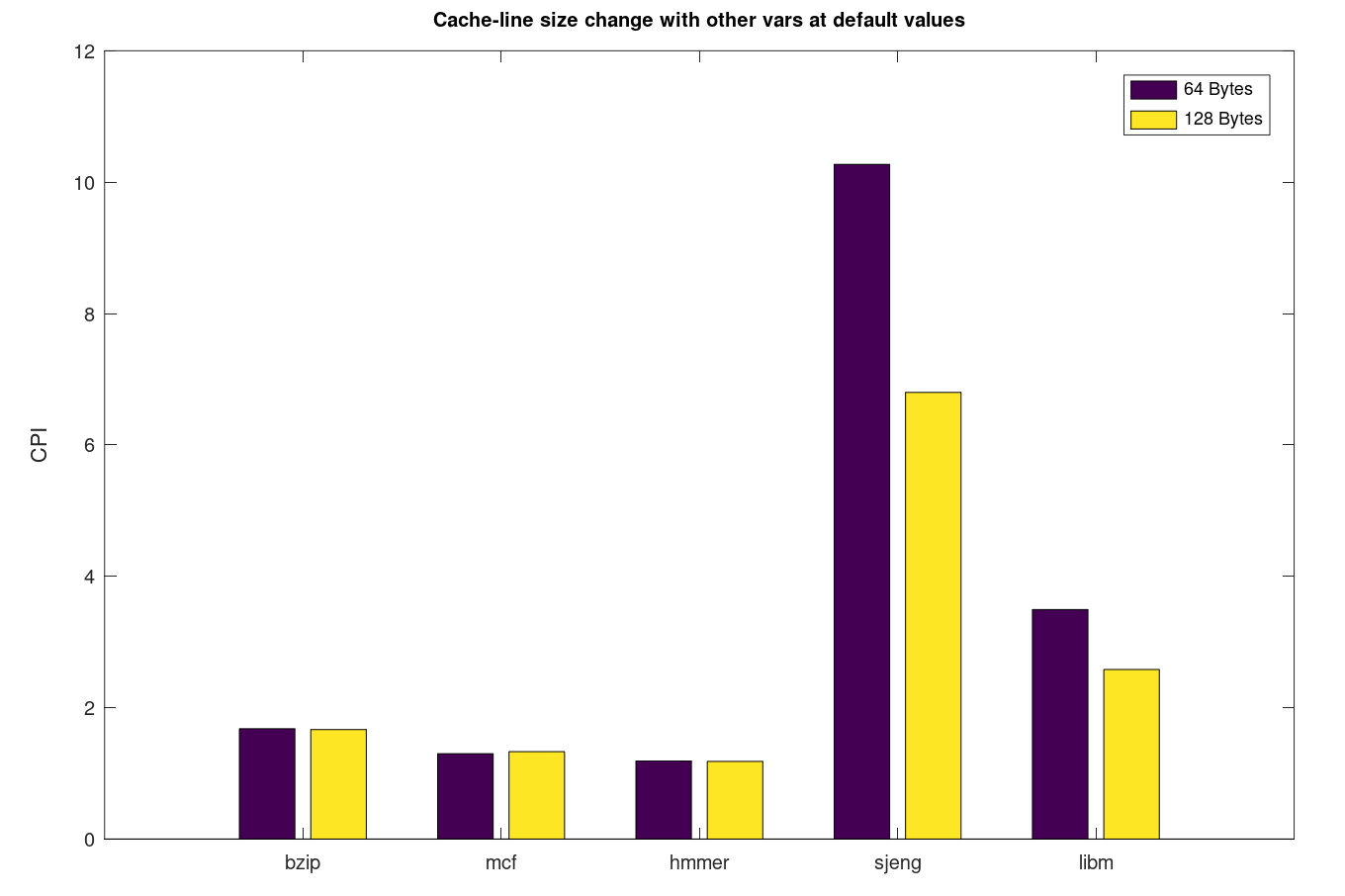 Με την αλλαγή στο μέγεθος γραμμής cache βλέπω πολύ μεγάλη επιτάχυνση στα benchmarks που είχαν πολύ μεγάλο L2 miss-rate(sjeng, libm) καθώς πλέον αυξάνω πολύ την χωρική τοπικότητα στην υλοποίηση μου και σε benchmarks που ασχολούνται με πολύ μεγάλα δεδομένα θα έχω πολύ λιγότερα compulsory misses. Η τεράστια αλλαγή στην απόδοση των 2 benchmarks μας κάνει να πιστεύουμε ότι αυτά έχουν πολύ μεγάλους πίνακες με στοιχεία που χρησιμοποιούνται πολύ λίγες φορές, δηλαδή έχουμε πολύ περισσότερα compulsory από ότι conflict και capacity misses. Αυτό εξηγεί ως ένα βαθμό και το αρχικά πολύ μεγάλο miss rate στην L2 για τα 2 αυτά benchmarks.
Με την αλλαγή στο μέγεθος γραμμής cache βλέπω πολύ μεγάλη επιτάχυνση στα benchmarks που είχαν πολύ μεγάλο L2 miss-rate(sjeng, libm) καθώς πλέον αυξάνω πολύ την χωρική τοπικότητα στην υλοποίηση μου και σε benchmarks που ασχολούνται με πολύ μεγάλα δεδομένα θα έχω πολύ λιγότερα compulsory misses. Η τεράστια αλλαγή στην απόδοση των 2 benchmarks μας κάνει να πιστεύουμε ότι αυτά έχουν πολύ μεγάλους πίνακες με στοιχεία που χρησιμοποιούνται πολύ λίγες φορές, δηλαδή έχουμε πολύ περισσότερα compulsory από ότι conflict και capacity misses. Αυτό εξηγεί ως ένα βαθμό και το αρχικά πολύ μεγάλο miss rate στην L2 για τα 2 αυτά benchmarks.
Αρχικά, και η L1 και η L2 cache είναι κατασκευασμένες από SRAM , βέβαια η L1 είναι optimized ως προς το latency ενώ η L2 ως προς το size οπότε η L1 έχει σημαντικά υψηλότερο κόστος ανα kB. Για αυτό και στις σύγχρονες υλοποιήσεις CPU βλέπουμε τόσο διαφορετικές τάξεις μεγέθους στην L1(κάποια kB) και L2 cache size(κάποια MB). Λόγω έλλειψης επαρκών πηγών και βιβλιογραφίας θεωρούμε αυθαίρετα ότι μια L1 cache κάποια δεκαδες kB κοστίζει περίπου όσο μια L2 cache κάποια MB. Θεωρούμε δηλαδή για τις ανάγκες της συνάρτησης που θα κατασκευάσουμε ότι 64kB L1 cache κοστίζουν 1 μονάδα κόστους ενώ 2MB L2 cache κοστίζουν επίσης 1 μονάδα κόστους.
Όσον αφορά την αλλαγή του μεγέθους , είτε στην L1 είτε στην L2 ,διπλασιασμός του μεγέθους σημαίνει διπλασιασμό του hardware που χρησιμοποιείται άρα και περίπου διπλασιασμό του κόστους, δηλαδή έχω μία σχεδόν γραμμική σχέση μεγέθους-κόστους.
Έχουμε δηλαδή :

Όσον αφορά το associativity , κάθε διπλασιασμός του assosiativity αυξάνει την πολυπλοκότητα και το μέγεθος των ηλεκτρονικών κυκλωμάτων που πρέπει να χρησιμοποιηθούν άρα αυξάνει αρκετά ,αλλά δε διπλασιάζει το συνολικό κόστος.Θεωρώ ότι διπλασιασμός του associativity φέρνει 1,3x κόστος, δηλαδή :

Τέλος όσον αφορά το cache-line size ο διπλασιασμός του για ίδιο συνολικά μεγεθος cache θα έχει ως αποτέλεσμα διπλασιασμό του μεγέθους του buffer, άρα κάποια μικρή αύξηση κόστους , αλλά ταυτόχρονα μειώνει το μέγεθος του κομματιού tag κατά ένα bit άρα επιτρέπει την απλοποίηση και μείωση μεγέθους των κυκλωμάτων που χειρίζονται και αποθηκεύουν το κομμάτι αυτό ,άρα μειώνει και το κόστος αυτό. Συνολικά δηλαδή η αλλαγή του μεγέθους γραμμής cache δεν επηρεάζει σημαντικά το κόστος της υλοποίησης.
Άρα τελικά η συνάρτηση στην οποία καταλήγουμε είναι η εξής :

Με αυτή τη συνάρτηση Βέλτιστες προδιαγραφές κόστους-απόδοσης για κάθε benchmark:
Για το bzip:
- L1 icache size :32 kB
- L1 icache associativity : 2-way
- L1 dcache size :32 kB
- L1 dcache associativity :2-way
- L2 cache size :1 MB
- L2 cache associativity :8-way
- Cache line size :128 B
Για το mcf:
- L1 icache size :32 kB
- L1 icache associativity : 4-way
- L1 dcache size :32 kB
- L1 dcache associativity :2-way
- L2 cache size :1 MB
- L2 cache associativity :8-way
- Cache line size :64 B
Για το hmmer:
- L1 icache size :32 kB
- L1 icache associativity : 2-way
- L1 dcache size :32 kB
- L1 dcache associativity :2-way
- L2 cache size :1 MB
- L2 cache associativity :8-way
- Cache line size :128 B
Για το sjeng:
- L1 icache size :32 kB
- L1 icache associativity : 2-way
- L1 dcache size :32 kB
- L1 dcache associativity :2-way
- L2 cache size :1 MB
- L2 cache associativity :8-way
- Cache line size :128 B
Για το libm:
- L1 icache size :32 kB
- L1 icache associativity : 2-way
- L1 dcache size :32 kB
- L1 dcache associativity :2-way
- L2 cache size :1 MB
- L2 cache associativity :8-way
- Cache line size :128 B
Σε αυτή την εργασία όντας ήδη εξοικειωμένοι με το περιβάλλον του gem 5 , ξοδέψαμε σημαντικά περισσότερο χρόνο στην αναζήτηση βιβλιογραφίας και πηγών για εξήγηση των αποτελεσμάτων μας και δικαιολόγηση συγκεκριμένων σχεδιαστικών επιλογών που κάναμε. Η διαδικασία της αυτοματοποίησης των benchmark μας προέτρεψε να μάθουμε να γράφουμε bash scripts για να γλιτώσουμε αρκετό χρόνο και έτσι επεκτείναμε τις γνώσεις μας στο περιβάλλον unix, γνώση που θα μας φανεί ιδιαίτερα χρήσιμη όχι μόνο στο πλαίσιο του μαθήματος αλλά γενικότερα στην σταδιοδρομία μας ως μηχανικοί υπολογιστών. Συνολικά η εκτέλεση πολλών απανωτών χρονοβόρων benchmark ήταν κάτι που μας δυσκόλεψε ιδιαίτερα σε αυτή την εργασία καθώς δεν είχαμε προσεγγίσει ποτέ κάτι παρόμοιο και δεν μπορούσαμε να προβλέψουμε σωστά το χρόνο που θα χρειαζόμασταν για την εκπόνηση της εργασίας(benchmark total runtime= ~ 15 hours). Βέβαια στο πλαίσιο της εργασίας το εργαστήριο δεν ήταν ιδιαίτερα βοηθητικό αυτή τη φορά διότι δεν υπήρχε χρόνος για εκπόνηση οποιουδήποτε σημαντικού κομματιού της εργασίας και για να κερδίσεις από το εργαστήριο θα έπρεπε να έχεις ήδη ολοκληρώσει όλη την εργασία έτσι ώστε εκείνη την ώρα να λύσει κανείς απορίες όσον αφορά τα αποτελέσματα του. Θα μπορούσε το εργαστήριο να είναι πιο hands-on σε περιπτώσεις όπως αυτής της εργασίας αν και έφταιγε περισσότερο το περιεχόμενο της εργασίας και όχι η οργάνωση του εργαστηρίου.
- Computer Architecture, a quantitative approach
- ARS Technica : Understanding CPU caching and performance
- James R. Goodman, "Using Cache Memory to Reduce Processor-Memory Traffic." 25 Years ISCA: Retrospectives and Reprints 1998: 255-262
- High Performance Embedded Architectures and Compilers : Example Design p. 342-350
