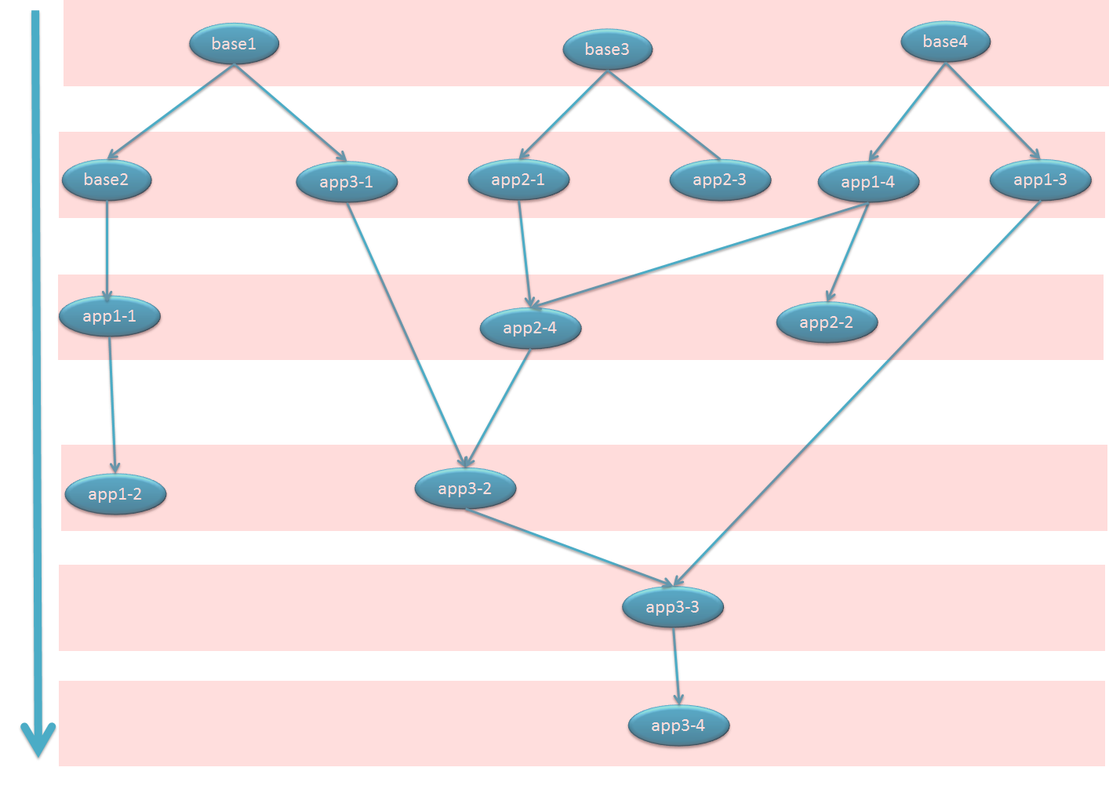
Hello. I am using your library to schedule tasks in directed acyclic graphs (DAGs). I implemented the "shouldExecute" method so that I can choose whether a node is executed based on whether at least one parent node has a success result (ANY) or if all of them have terminated successfully (ALL).
@Override
public boolean shouldExecute(ExecutionResults<String, Boolean> parentResults) {
boolean shouldExecute = true;
if (parentResults.hasAnyResult()) {
List<Boolean> results = parentResults.getAll().stream()
.map(ExecutionResult::getResult)
.collect(Collectors.toList());
if (shouldExecuteConfig.equals(SHOULD_EXECUTE_ALL)) {
// All parents must end with success
shouldExecute = results.stream().allMatch(Boolean.TRUE::equals);
} else if (shouldExecuteConfig.equals(SHOULD_EXECUTE_ANY)) {
// At least one parent must end with success
shouldExecute = results.stream().anyMatch(Boolean.TRUE::equals);
}
}
return shouldExecute;
}By doing that, I encountered an error when executing the next type of DAG:

where stages 1, 2 and 3 are of type ALL and stage final is type ANY.
In this scenario, stage final should be executed when stages 1 2 and 3 finish, when at least one of them finishes with success.
In the case where stage 1 finishes with success and stage 2 with error, stage 3 is skipped and stage final is executed twice, which is wrong.
2024-07-12 11:24:45 INFO Paths:
Path #0
Stage 1[]
Stage 2[Stage 1]
Stage 3[Stage 2]
Stage final[Stage 1, Stage 2, Stage 3]
2024-07-12 11:25:26 INFO Finished with success Stage 1
2024-07-12 11:26:02 ERROR Finished with error Stage 2
2024-07-12 11:26:02 INFO Started Stage final
2024-07-12 11:26:02 INFO Started Stage final
....
A work around to solve this problem is to create another status to the node entity: SUBMITTED. This way a task will only be submitted once to the execution engine.
enum NodeStatus {
SUBMITTED,ERRORED,SKIPPED,SUCCESS,CANCELLED;
}private void doExecute(final Collection<Node<T, R>> nodes, final ExecutionConfig config) {
for (Node<T, R> node : nodes) {
forceStopIfRequired();
if (this.state.shouldProcess(node) && !node.isSubmitted()) { // check is node is already submitted
Task<T, R> task = newTask(config, node);
ExecutionResults<T, R> parentResults = parentResults(task, node);
task.setParentResults(parentResults);
task.setNodeProvider(new DefaultNodeProvider<T, R>(state));
if (node.isNotProcessed() && task.shouldExecute(parentResults)) {
this.state.incrementUnProcessedNodesCount();
logger.debug("Submitting {} node for execution", node.getValue());
this.executionEngine.submit(task);
node.setSubmmitted(); //set node status to submitted
} else if (node.isNotProcessed()){
node.setSkipped();
logger.debug("Execution Skipped for node # {} ", node.getValue());
this.state.markProcessingDone(node);
doExecute(node.getOutGoingNodes(), config);
}
} else {
logger.debug("node {} depends on {}", node.getValue(), node.getInComingNodes());
}
}
}I expect your comments on this solution, or on any other approach that you may think of. Feel free to add this changes to your repo if you feel it is adecuate. Thank you.