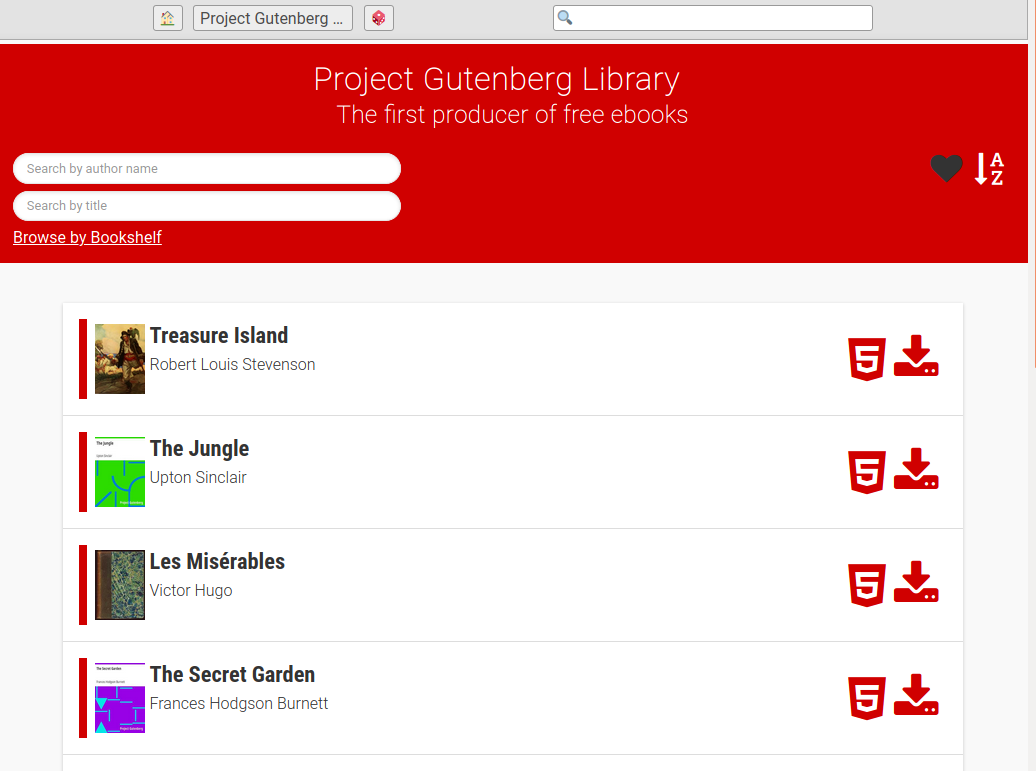
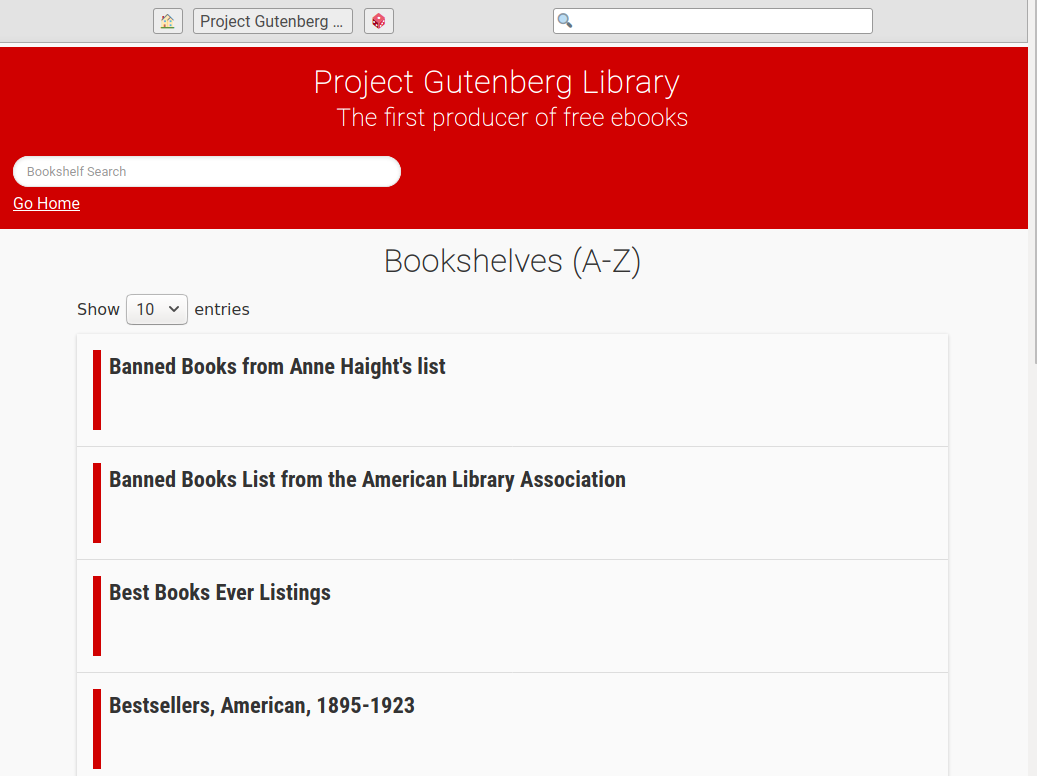
This scraper downloads the whole Project Gutenberg library and puts it in a ZIM file, a clean and user friendly format for storing content for offline usage.


Main coding guidelines comes from the openZIM Wiki
It's recommended that you use virtualenv and py3.6+.
sudo apt-get install python-pip python-dev libxml2-dev libxslt-dev advancecomp jpegoptim pngquant p7zip-full gifsicle curl zip zim-tools
sudo pip install virtualenvsudo easy_install pip
sudo pip install virtualenv
brew install advancecomp jpegoptim pngquant p7zip gifsiclegit clone [email protected]:kiwix/gutenberg.git
cd gutenberg
virtualenv gut-env (or any name you want)
./gut-env/bin/pip install -r requirements.pip- Activate the environment:
source gut-env/bin/activate - Quit the environment:
deactivate
After setting up the whole environment you can just run the main
script gutenberg2zim. It will download, process and export the
content.
./gutenberg2zimYou can also specify parameters to customize the content. Only want books with the Id 100-200? Books only in French? English? Or only those both? No problem! You can also include or exclude book formats. You can add bookshelves and the option to search books by title to enrich your user experince.
./gutenberg2zim -l en,fr -f pdf --books 100-200 --bookshelves --title-searchThis will download books in English and French that have the Id 100 to 200 in the HTML (default) and PDF format.
You can find the full arguments list below:
-h --help Display this help message
-y --wipe-db Empty cached book metadata
-F --force Redo step even if target already exist
-l --languages=<list> Comma-separated list of lang codes to filter export to (preferably ISO 639-1, else ISO 639-3)
-f --formats=<list> Comma-separated list of formats to filter export to (epub, html, pdf, all)
-e --static-folder=<folder> Use-as/Write-to this folder static HTML
-z --zim-file=<file> Write ZIM into this file path
-t --zim-title=<title> Set ZIM title
-n --zim-desc=<description> Set ZIM description
-d --dl-folder=<folder> Folder to use/write-to downloaded ebooks
-u --rdf-url=<url> Alternative rdf-files.tar.bz2 URL
-b --books=<ids> Execute the processes for specific books, separated by commas, or dashes for intervals
-c --concurrency=<nb> Number of concurrent process for processing tasks
--dlc=<nb> Number of concurrent *download* process for download (overwrites --concurrency). if server blocks high rate requests
-m --one-language-one-zim=<folder> When more than 1 language, do one zim for each language (and one with all)
--no-index Do NOT create full-text index within ZIM file
--check Check dependencies
--prepare Download rdf-files.tar.bz2
--parse Parse all RDF files and fill-up the DB
--download Download ebooks based on filters
--zim Create a ZIM file
--title-search Add field to search a book by title and directly jump to it
--bookshelves Add bookshelves
--optimization-cache=<url> URL with credentials to S3 bucket for using as optimization cache
--use-any-optimized-version Try to use any optimized version found on optimization cache