cstar_perf is a performance testing platform for Apache Cassandra which focuses on a high level of automation and test consistency.
It handles the following:
- Download and build Cassandra source code.
- Configure and bootstrap nodes on a real cluster.
- Run stress workloads.
- Capture performance metrics.
- Create reports and charts comparing different configs/workloads.
- Webserver frontend for scheduling tests, viewing prior runs, and monitoring test clusters.
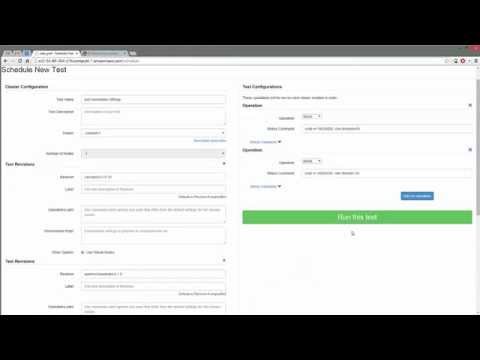
The evolving documentation is available online here.
- Setup a cstar_perf development/demo environment
- Setup cstar_perf.tool
- Setup cstar_perf.frontend
- Running Tests
- Architecture
The source for these docs are contained in the gh-pages branch, please feel free to make pull requests for improvements.
Copyright 2014 DataStax
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.

































































































