d3 / d3-fetch Goto Github PK
View Code? Open in Web Editor NEWConvenient parsing for Fetch.
Home Page: https://d3js.org/d3-fetch
License: ISC License
Convenient parsing for Fetch.
Home Page: https://d3js.org/d3-fetch
License: ISC License
Our project is protected by a HTTP Basic Authentication and we have to enter the username/password on every d3.json() call in Google Chrome.
It seems like in Google Chrome 64 the cached credentials are not transfered to the request, if credentials: 'include' is not set. I haven't found a real documentation for this, but there is a blog post: https://developers.google.com/web/updates/2015/03/introduction-to-fetch#sending_credentials_with_a_fetch_request
Line 7 in d4bfe27
image.js line 3 should read:
var image = new Image();d3.js version 3 (and 4 I think), in the d3.requests module there is a way to hook into the progress of the request using .on("progress", function(...) { ... });, see this block: https://bl.ocks.org/mbostock/3750941
In d3 v5, no such equivalent exists as far as I know in the d3-fetch library, only .then(function(...) { ... });. Is there a plan to implement or a workaround for this feature? Or are the limitations of underlying fetch preventing it from being usable?
Thanks
d3.fetch("file.tsv") could map to d3.tsv, etc. It could arguably even wait until the response headers are returned and look at those.
Hello Mike!
Seems like fetch is not available in IE yet, but it will be a big deal in all d3 projects.
Do you have plans to provide a fallback for IE9+?
or should the browser support be updated to "no IE anymore"?
D3 supports “modern” browsers, which generally means everything except IE8 and older versions. D3 is tested against Firefox, Chrome, Safari, Opera, IE9+, Android and iOS.

When the project is protected by Basic Authentication, each subsequent requests (after the first one which prompt for the Username Password) should use the credentials provided by the user (the token provided by the server to be precise).
XHR request works as expected when NO username / password are provided. The browser take care of handling the authentication token. The developer doesn't have to do anything.
With d3-fetch, every request are sent without login token, which cause "Access denied" error.
The library d3-fetch can't be used as a replacement of d3-request when Basic Authentication is in used.
I have a node application but when I try to use this to use d3.csv, I get ReferenceError: fetch is not defined. I'm simply doing this after npm install d3-fetch (this installed version 1.1.0):
var d3 = require("d3-fetch")
d3.csv("/data/csvs/timeline.csv").then(function (data) {console.log(data)});
I also tried installing fetch as npm install fetch but then the error became TypeError: fetch is not a function
Thanks for your help.
Here's an example from the d3-request readme:
d3.request("/path/to/resource")
.header("X-Requested-With", "XMLHttpRequest")
.header("Content-Type", "application/x-www-form-urlencoded")
.post("a=2&b=3", callback);
But based on the d3-fetch readme, it's unclear if it's possible to post data. Given that the d3-request readme says to use d3-fetch instead, it'd be good to either have "translated" versions of examples that send data or point to other code/libraries with that functionality.
We need a way to load a binary file, like response.arrayBuffer.
Rather than an anonymous boolean, it should be an object that sets properties on the image before setting the src. This way we can set the crossOrigin attribute, and whatever else the browser supports.
d3.image(url, {crossOrigin: "anonymous"})When the webserver sends response with JSON, but status code is other than 200 OK, then the returned JSON is unreachable.
Snipppet:
d3.json(url).then(function(response) {
console.log(response.data);
}).catch(function(err) {
console.log(err.traceback);
});Server responds:
500 Internal server error
{ "traceback": "some traceback here" }
In that case, it is not possible to extract the JSON from the response, because d3 throws error with text constructed from response.status + " " + response.statusText, but original response's body is lost.
Link to problematic line:
Line 2 in daaae61
I was working on a project with @newick and @maiwann using the GIthub API and we used the delete repo endpoint. This endpoint returns an HTTP 204 result on success with an empty body.
When calling d3.json, this results in a failing promise with an error indicating a JSON.parse error. This is probably due to trying to parse an empty string (which is not valid JSON)
We did not expect this outcome with a 204 (which is supposed to indicate success)
We solved our problem by using d3.text instead (which does not perform a parsing, so no error), but wondered whether it might make sense to change the behavior of d3.json, hence this issue
I have several pipe delimited text files, that I load and then concatenate before parsing with d3.dsv. I've been loading them asynchronously with d3.queue and d3.text. I've replaced my queue functionality but the new d3.text now does not properly decode these files which it turns out are UTF-16 LE. It worked well before.
There is no example of how to structure the init function but I have tried:
d3.text("/data.csv", { headers: { "Content-Type": "text/html, charset=UTF-16" } }).then(function(text) {
console.log(text);
});
But Im still getting a lot of this: �� and improperly parsed line endings. Did d3.text() lose its decoding abilities? Should the above work?
When d3.xml() is used to download an asset, selection.append(asset.documentElement) returns undefined rather than "a new selection containing the appended elements" (as described in the documentation.
var filename = "assets/game-interface.svg";
var assetLoadedPromise =
d3.xml(filename);
assetLoadedPromise.then( asset => {
// Insert asset
var body = d3.select("body").node();
var insertedAsset = body.append(asset.documentElement);
// Check we have a reference to the inserted element
if (insertedAsset === undefined) {
throw "insertedAsset is undefined";
}
});I seem to be the oddball user running a file-based d3/javascript app, but Chrome does not support fetch() on local file urls, even if --allow-file-access-from-files is set. As a result, 5.0 broke my code that uses d3.xml() to load a local file url. And I presume there's some subset of users who do file-based testing that might also be affected.
There's a Chromium issue open (https://bugs.chromium.org/p/chromium/issues/detail?id=810400) to address this disparity between XHR and Fetch.
By process of elimination, I've determined that an error in I get while running the NVD3 lineChart() example comes from including d3-fetch.v1.js in the same HTML file. The error reported by Safari is "TypeError: d3.svg.axis is not a function. (In 'd3.svg.axis()', 'd3.svg.axis' is undefined)".
This goes away if I don't include d3-fetch, but I need that for…fetching data.
The readme lists functions that take an optional init argument, but never documents it.
When using d3.json in d3 v5, reading in a json file it gives me:
Fetch API cannot load file:///H:/Code/Dashboard/js/jsonOutput.json. URL scheme "file" is not supported.
However when I move back to d3 v4, using the same d3.json code, it works fine and reads the file contents.
I am developing in Adobe Brackets which handles cross origin requests, so it seems d3 is mishandling it somehow.
Now that d3-request is deprecated, can you recommend a replacement for d3.xml()?
A sad high percentage of people work in an (enterprise) environment where they can't install anything and don't have access to a webserver to put (since GDPR considered sensitive) data files on. Maybe for those creating with D3 it's not that high, but for those wanting to SEE the result it certainly is. I know of 2 options:
1: fix content-disposition
A browser-extension to ignore the HTTP-header (https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Content-Disposition) that by default forces files to be downloaded (common in all sorts of enterprise web-GUIs for network file storage of some sort) instead of just handled by the browser. Yes, it's a hack and needs a warning but in many places it's the only way to have D3 working with the flexibility of data-in-its-own-files.
2: The above won't always work for several technical/policy reasons and because too many people still by default send attachments, not links, therefore having the CSV within the HTML is also (again with warning) a useful way.
How is shown in: https://stackoverflow.com/questions/16231266/embedding-csv-in-html-for-use-with-d3-js#16231267
Maybe this could even be used as 'caching': "the data couldn't be loaded from the source, want to see the visualisation based on data saved YYYYMMDD HH:MM:SS?", or actually "To give you an idea of the visualisation BULLSHIT data is used, make sure you get access to the real data, see how at ..."
For both 1&2: how do you make sure the D3 js files actually load? From outside, from the same system the data is stored on? Some other hack?
I know the above is inelegant to the least, but in enterprise environments where "web" to many means not using the flexibility of the open web, but clicking a link to some black-box lock-in environment that happens to run in a browser, it is at least something. If a few decision makers are then to experience the flexibility of no-install visualisations running on data-in-its-own-files (thereby uncoupling data-entry, viz-making and some IT-'bureaucracy'), steps can be made towards the proper way.
This probably deserves its own page to minimize noise for those working in proper environments.
Fetch / promise aren't supported in older IE / iOS with decent usage. I'm assuming you'll need to add the polyfill or does v5 drop support for these?
https://github.com/d3/d3-fetch/blob/master/src/dsv.js use csvParse and tsvParse from "d3-dsv"
As explained in d3/d3-dsv#65 by @mbostock :
I recommend using parseRows as suggested in the text you pasted from the README and a row function to turn the array of field values into an object.
Using csvParse or tsvParse make it incompatible with CSP without unsafe-eval.
It impact for example plotly/plotly.js#897 (which use the old version of d3 "3.5.17" so "d3-request" and not this package, but "d3-request" has the exact same problem. I didn't opened an issue there as its status is "This module is deprecated as of D3 5.0; please use d3-fetch instead.")
Or is there another API from this package that can be used to avoid that problem?
d3.json("/graph.json", function (error, graph) {
if (error) throw error;
// ...
}The graph object that is passed to the function here is initialised with extra fields like x, y, vx, vy and index. However I want to turn an ordinary Javascript Object that resembles the original JSON file directly into the graph object. How do I do this?
I wrote this code (much of it legally copied, to be fair):
d3.json("./data.json", function (data) {
// Add X axis
var x = d3.scaleLinear()
.domain([0, 13000])
.range([ 0, width]);
svg.append("g")
.attr("transform", "translate(0," + height + ")")
.call(d3.axisBottom(x))
.selectAll("text")
.attr("transform", "translate(-10,0)rotate(-45)")
.style("text-anchor", "end");
// Y axis
var y = d3.scaleBand()
.range([ 0, height ])
.domain(data.map(function(d) { return d.Country; }))
.padding(.1);
svg.append("g")
.call(d3.axisLeft(y));
svg.selectAll("myRect")
.data(data)
.enter();
});But then I had to install @types/d3 because it couldn't find a declaration file, and after that, that first line threw a ts(2559) error, saying: Type '(data: any) => void' has no properties in common with type 'RequestInit'.. This is how every tutorial says it's supposed to be written. What is happening? Thank you.
The fetch function can take an optional init argument, and it would be nice to have the ability to passthrough an init object to most of the methods in this library (e.g., to set headers on the request, or in the future, to abort fetches).
In the case of d3.tsv / d3.csv, we probably want to allow one or both of an init and row accessor, so we’d need to do a typeof test in the two-argument case to disambiguate between them.
Hello! I've been having difficulty getting d3.csv() in D3v5 to work nicely on localhost in Chrome.
I've made a barebones example here that reproduces the error on both my Mac and Windows machines (latest OS version), in Chrome (latest release version).
When I first load the page, it takes some time before the data arrives. When I check the network tab on my dev tools, it shows up as "pending". It finally arrives after about 30-90 seconds.

When I run the same code through Github pages the error doesn't occur and the console.log happens fine. When I run the same code on localhost in Safari on my Mac, or Firefox on my Windows machine, the error doesn't occur and the console.log happens fine.
Don't hesitate to ask if I can do any further testing to help isolate the issue.
Hi, I am using d3 extensively on OpenProcessing.org, and recently upgraded to v5. However, I am trying to understand how to manage the potential fetch errors, which is not much documented in the docs.
I noticed that if I add .catch(function(error){}) to d3.json, all unexpected responses (404, 403, 500...) are actually caught via catch (which is in contrast to the standard fetch API). I think it is great, but "error" only includes a text in the form of "Error: 500 Internal Server Error" at Zo (d3.v5.min.js:2) and not much else. Is there a way to get the original response object, so that I can access response.status, etc.?
Example format I am using is below:
d3.json('url')
.then(function (response) {
//code goes here
}).catch(function (error) {
console.log(error);
});
Hi, is it not possible to use Async/Await with d3-fetch?
i tried doing this:
import * as d3Fetch from "d3-fetch";
async getData() {
const india = await d3Fetch.json('/data/IND.json');
return india;
},
it returned a Promise instead.
PS: currently, i have to save .geojson as .json file format. Feels counter-intuitive? Any plans to add support to read .geojson files?
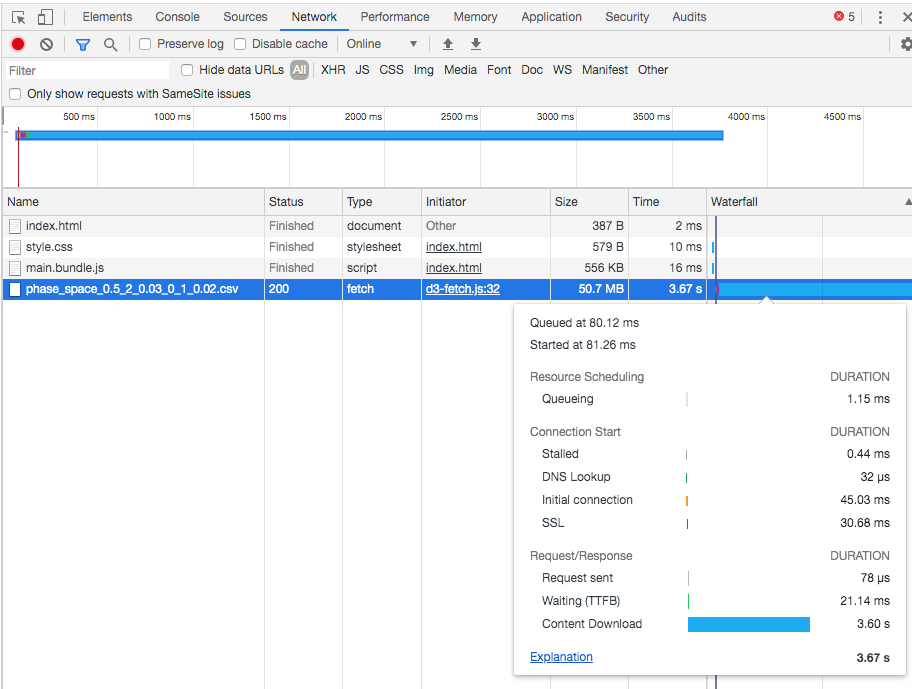
I tried to fetch a relatively large file (200 MiB) for a visualization. However, the fetch request always seems to give up at 50.7 MiB. Below is a screenshot of the situation in Chrome, and a link to the project.
I am not super well versed in the nuances of javascript network requests, but I did notice that "streaming is supported", though I'm not sure if that's used in this case, or how specifically to enable it.
Am I doing something stupid here?
https://github.com/j2kun/harmonic-phase-space
The current d3.json function would not consider a 404 or a 500 an error, but doesn't forward the status code to verify it either. This might lead to hard-to-debug code.
Happy to send a PR if there is consensus
i use this script to open my json file..
function load(){ // <-E
d3.json("data.json", function(error, json){ // <-F
data = data.concat(json);
render(data);
});
when i tried to debug this is success if use D3.js version 3.2.8 but when iam changing to D3.js version 5 is not working. need help to solve this one.
here is the source :
styles.zip
For completeness, we should probably have a d3.dsv(delimiter, url) method which allows you to specify a delimiter, rather than only allowing CSV and TSV.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.