
SVN Dump API
An API for reading, editing, and writing SVN dump files.
Background
SVN dump files are created via the svnadmin dump command, and contain all the
history of an SVN repository. An SVN dump file contains a list of revisions
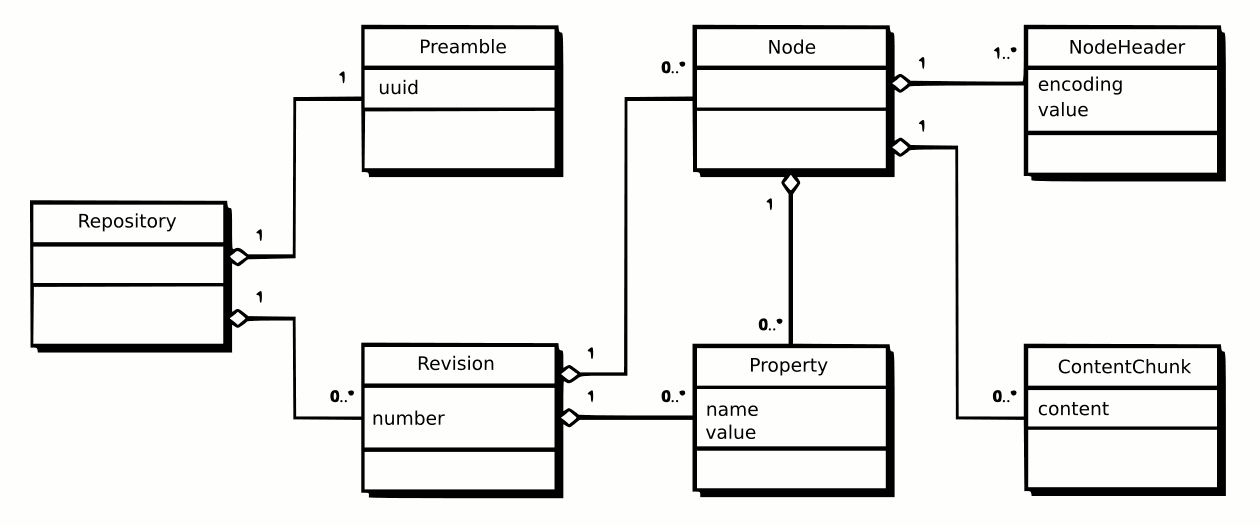
(see Revision), and each
revision contains a list of nodes (see Node).
Revisions can have properties such as author, date, and commit message. Nodes can have properties too, which are maintained on a node by node basis.
Related Work
I'm not the first one to have this idea. Here are some links:
- svndumpfilter: comes with svn, limited functionality
- svndumpmultitool: very similar project to this one, written in Python
Model
SVNDumpFileParser
The SvnDumpFileParser is an auto-generated parser for SVN dump files
(files created with svnadmin dump). It will
parse SVN dump files into a Repository object.
The Repository representation is
meant to be very light-weight and does minimal validation.
The parser is auto-generated using JavaCC (Java Compiler Compiler) from the svndump.jj gramar file.
This grammar generates a parser that is dependenent on the Java interfaces and
classes in this project.
Repository Summary
To get an svn log-like summary of your dump file, you can use the
RepositorySummary (sample output here).
Consumers
A RepositoryConsumer consumes the various pieces of a Repository. Specializations of a consumer are:
RepositoryMutator: changes the Repository in some wayRepositoryValidator: validates the correctness of the Repository in some wayRepositoryWriter: write the Repository in some format
Consumers (and therefore any of its specializations) can be chained together to achieve complex operations on SVN dump files using the continueTo(RepositoryConsumer) method.
Mutators
The API allows for changing of an SVN dump file via
RepositoryMutator implementations.
Some useful mutators are:
ClearRevision- empties a revision (removes all changes, revision is preserved so that references to revision numbers still work)PathChange- updates file/dir pathsNodeRemove- removes an individual file change from a revisionNodeAdd- add some newly crafted change to a specific revisionNodeHeaderChange- change a specific property on an existing SvnNode
To apply multiple mutators in sequence, you can chain them together, using RepositoryConsumer.continueTo(RepositoryConsumer).
Validators
When you start messing with your SVN history via the mutators, you can be left
with an SVN dump file that cannot be imported back into an SVN repository. To
make changing SVN history easier the API has the concept of a
RepositoryValidator.
Validation is done while the data is in memory, which is much faster
than running it through svnadmin load.
Some useful validators:
PathCollisionValidator- checks that file operations are valid (don't delete non-existent files, don't double add files, check that files exist when making copies)
Usage
Command Line Interface
The bin/run-java shell script will run the CliConsumer.
The current usage pattern is to modify the CliConsumer and create your chain programmatically, then do:
mvn clean install dependency:copy-dependencies
cat file.dump | ./bin/run-java > output.dump
or, if your repository is too large for a single file:
mvn clean install dependency:copy-dependencies
svnadmin create /path/to/newrepo
svnadmin dump /path/to/repo | ./bin/run-java | svnadmin load -q /path/to/newrepo
Example: AgreementMaker
To see how all these pieces fit together to allow you to edit SVN history, you can look at a SVN repository cleanup that I did for the AgreementMaker project. All the operations to the SVN dump file are detailed in this test.
Reading an SVN dump file
Parsing an SVN dump file is straight forward. Here's an example that uses a single consumer (writes the SVN dump to STD OUT):
RepositoryInMemory inMemory = new RepositoryInMemory();
InputStream is = new FileInputStream("svn.dump");
SvnDumpFileParser.consume(is, inMemory);
Repository svnRepository = inMemory.getRepo();
See SvnDumpFileParserTest for usage patterns of the parser.
Developing
Coverage Report
To get a JaCoCo coverage report, run the following:
mvn clean test jacoco:report
The coverage report output will be in HTML format in target/site/jacoco/index.html.

![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")





