O apache Kafka é um sistema de mensageria fundado por funcionários do Liknedin, com um foco de conseguir aguendar uma demanda de grande escala de forma distribuída.
Um dos conceitos mais diferenetes para os outros sistemas de mensageria é que ele armazena os dados em disco de uma forma eficiente, não precisando manter tudo em memória e permitindo manter esses dados por um determinado intervalo, e ate mesmo processar novamente.
É um servidor único de Apache Kafka
É um conjuto de sercidores(brokers)
Orquestrador do nosso Cluster, ele organiza quem é o nó principal, qual a saúde dos seus brokers.
Agrupa todas as mensagens do meus tipo, ele é usado para enviar e receber as mensagens.
Subdivisão de um tópico, conceito base usado para conseguir aguentar uma maior carga
Como o Apache Kafka guarda os dados em disco, e precisa que esse consumo e escrita sejam rápidos, ele trabalha com offsets, que básicamente são como indices de um array. Além de usar para uma leitura rápida e organização das mensagens, ele usa o index desse offset para saber em qual posição o consumidor está, para saber qual a próxima que deve mandar.
Todas as instâncias de um tipo de aplicação ficam agrupadas em um consumer group. Quando uma mensagem é disparada para o tópico, apenas uma das aplcações desse consimer group recebe a mensagem, garantindo que a mesma aplicação não vai processar duas vezes a mesma coisa em instâncias diferentes.

Ponto super importante! se no seu grupo de consumidores você tem um número maior de consumidores que o número de partições, um dos seus consumidores vai ficar em processar nada, apenas gantando sua infra, então tome cuidado.
É uma API Rest do Kafka usado para gerenciar os seus schemas, que podem ser em JSON, Apache Avro ou Protobuf(padrão usado no gRPC). Essas infomrações são guardadas diretamente no Apache Kafka. Sobre o Schema, basicamente é um contrato que o producer precisa seguir para poder mandar mensagem para o Kafka, e na hora de enviar a mensagem, é enviados os dados normalmente, e junto desse paylod também é passado qual o Id do Schema que esta sendo usado.
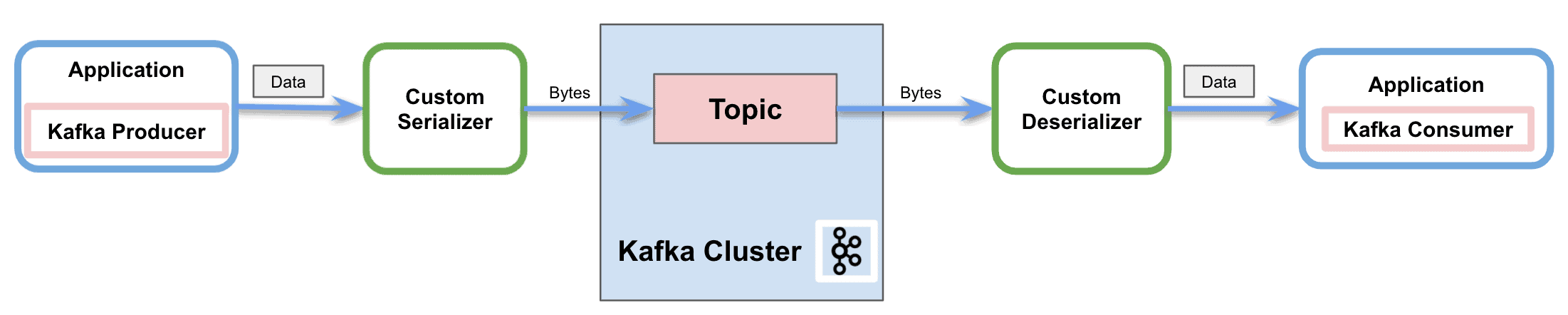
Um conceito bem legal no Kafka são os custom serializer, basicamente tu podes adicionar no producer e no consumer uma forma em comum de serialziar a mensagem, e serialziar pode ser uma um padrão comum como JSON, XML... ou até mesmo para casos onde é necessário o uso de criptografia, de um lado você vai ter um serializer que criptografa e do outro o serializer que descriptografa.