- 网名「桃翁」
- 有一个公众号「前端桃园」
- 在杭州、蚂蚁金服体验技术工作。
- 如果你也想来蚂蚁,欢迎投递简历到「[email protected]」
crazylxr / blog Goto Github PK
View Code? Open in Web Editor NEW技术博客记录
Home Page: http://www.taoweng.site
技术博客记录
Home Page: http://www.taoweng.site



























本文只介绍函数式组件特有的性能优化方式,类组件和函数式组件都有的不介绍,比如 key 的使用。另外本文不详细的介绍 API 的使用,后面也许会写,其实想用好 hooks 还是蛮难的。
有过 React 函数式组件的实践,并且对 hooks 有过实践,对 useState、useCallback、useMemo API 至少看过文档,如果你有过对类组件的性能优化经历,那么这篇文章会让你有种熟悉的感觉。
我觉得React 性能优化的理念的主要方向就是这两个:
减少重新 render 的次数。因为在 React 里最重(花时间最长)的一块就是 reconction(简单的可以理解为 diff),如果不 render,就不会 reconction。
减少计算的量。主要是减少重复计算,对于函数式组件来说,每次 render 都会重新从头开始执行函数调用。
在使用类组件的时候,使用的 React 优化 API 主要是:shouldComponentUpdate 和 PureComponent,这两个 API 所提供的解决思路都是为了减少重新 render 的次数,主要是减少父组件更新而子组件也更新的情况,虽然也可以在 state 更新的时候阻止当前组件渲染,如果要这么做的话,证明你这个属性不适合作为 state,而应该作为静态属性或者放在 class 外面作为一个简单的变量 。
但是在函数式组件里面没有声明周期也没有类,那如何来做性能优化呢?
首先要介绍的就是 React.memo,这个 API 可以说是对标类组件里面的 PureComponent,这是可以减少重新 render 的次数的。
举个例子,首先我们看两段代码:
在根目录有一个 index.js,代码如下,实现的东西大概就是:上面一个 title,中间一个 button(点击 button 修改 title),下面一个木偶组件,传递一个 name 进去。
// index.js
import React, { useState } from "react";
import ReactDOM from "react-dom";
import Child from './child'
function App() {
const [title, setTitle] = useState("这是一个 title")
return (
<div className="App">
<h1>{ title }</h1>
<button onClick={() => setTitle("title 已经改变")}>改名字</button>
<Child name="桃桃"></Child>
</div>
);
}
const rootElement = document.getElementById("root");
ReactDOM.render(<App />, rootElement);在同级目录有一个 child.js
// child.js
import React from "react";
function Child(props) {
console.log(props.name)
return <h1>{props.name}</h1>
}
export default Child当首次渲染的时候的效果如下:
并且控制台会打印"桃桃”,证明 Child 组件渲染了。
接下来点击改名字这个 button,页面会变成:
title 已经改变了,而且控制台也打印出"桃桃",可以看到虽然我们改的是父组件的状态,父组件重新渲染了,并且子组件也重新渲染了。你可能会想,传递给 Child 组件的 props 没有变,要是 Child 组件不重新渲染就好了,为什么会这么想呢?
我们假设 Child 组件是一个非常大的组件,渲染一次会消耗很多的性能,那么我们就应该尽量减少这个组件的渲染,否则就容易产生性能问题,所以子组件如果在 props 没有变化的情况下,就算父组件重新渲染了,子组件也不应该渲染。
那么我们怎么才能做到在 props 没有变化的时候,子组件不渲染呢?
答案就是用 React.memo 在给定相同 props 的情况下渲染相同的结果,并且通过记忆组件渲染结果的方式来提高组件的性能表现。
把声明的组件通过React.memo包一层就好了,React.memo其实是一个高阶函数,传递一个组件进去,返回一个可以记忆的组件。
function Component(props) {
/* 使用 props 渲染 */
}
const MyComponent = React.memo(Component);那么上面例子的 Child 组件就可以改成这样:
import React from "react";
function Child(props) {
console.log(props.name)
return <h1>{props.name}</h1>
}
export default React.memo(Child)通过 React.memo 包裹的组件在 props 不变的情况下,这个被包裹的组件是不会重新渲染的,也就是说上面那个例子,在我点击改名字之后,仅仅是 title 会变,但是 Child 组件不会重新渲染(表现出来的效果就是 Child 里面的 log 不会在控制台打印出来),会直接复用最近一次渲染的结果。
这个效果基本跟类组件里面的 PureComponent效果极其类似,只是前者用于函数组件,后者用于类组件。
默认情况下其只会对 props 的复杂对象做浅层对比(浅层对比就是只会对比前后两次 props 对象引用是否相同,不会对比对象里面的内容是否相同),如果你想要控制对比过程,那么请将自定义的比较函数通过第二个参数传入来实现。
function MyComponent(props) {
/* 使用 props 渲染 */
}
function areEqual(prevProps, nextProps) {
/*
如果把 nextProps 传入 render 方法的返回结果与
将 prevProps 传入 render 方法的返回结果一致则返回 true,
否则返回 false
*/
}
export default React.memo(MyComponent, areEqual);此部分来自于 React 官网。
如果你有在类组件里面使用过 shouldComponentUpdate() 这个方法,你会对 React.memo 的第二个参数非常的熟悉,不过值得注意的是,如果 props 相等,areEqual 会返回 true;如果 props 不相等,则返回 false。这与 shouldComponentUpdate 方法的返回值相反。
现在根据上面的例子,再改一下需求,在上面的需求上增加一个副标题,并且有一个修改副标题的 button,然后把修改标题的 button 放到 Child 组件里。
把修改标题的 button 放到 Child 组件的目的是,将修改 title 的事件通过 props 传递给 Child 组件,然后观察这个事件可能会引起性能问题。
首先看代码:
父组件 index.js
// index.js
import React, { useState } from "react";
import ReactDOM from "react-dom";
import Child from "./child";
function App() {
const [title, setTitle] = useState("这是一个 title");
const [subtitle, setSubtitle] = useState("我是一个副标题");
const callback = () => {
setTitle("标题改变了");
};
return (
<div className="App">
<h1>{title}</h1>
<h2>{subtitle}</h2>
<button onClick={() => setSubtitle("副标题改变了")}>改副标题</button>
<Child onClick={callback} name="桃桃" />
</div>
);
}
const rootElement = document.getElementById("root");
ReactDOM.render(<App />, rootElement);子组件 child.js
import React from "react";
function Child(props) {
console.log(props);
return (
<>
<button onClick={props.onClick}>改标题</button>
<h1>{props.name}</h1>
</>
);
}
export default React.memo(Child);首次渲染的效果
这段代码在首次渲染的时候会显示上图的样子,并且控制台会打印出桃桃。
然后当我点击改副标题这个 button 之后,副标题会变为「副标题改变了」,并且控制台会再次打印出桃桃,这就证明了子组件又重新渲染了,但是子组件没有任何变化,那么这次 Child 组件的重新渲染就是多余的,那么如何避免掉这个多余的渲染呢?
我们在解决问题的之前,首先要知道这个问题是什么原因导致的?
咱们来分析,一个组件重新重新渲染,一般三种情况:
要么是组件自己的状态改变
要么是父组件重新渲染,导致子组件重新渲染,但是父组件的 props 没有改版
要么是父组件重新渲染,导致子组件重新渲染,但是父组件传递的 props 改变
接下来用排除法查出是什么原因导致的:
第一种很明显就排除了,当点击改副标题 的时候并没有去改变 Child 组件的状态;
第二种情况好好想一下,是不是就是在介绍 React.memo 的时候情况,父组件重新渲染了,父组件传递给子组件的 props 没有改变,但是子组件重新渲染了,我们这个时候用 React.memo 来解决了这个问题,所以这种情况也排除。
那么就是第三种情况了,当父组件重新渲染的时候,传递给子组件的 props 发生了改变,再看传递给 Child 组件的就两个属性,一个是 name,一个是 onClick ,name 是传递的常量,不会变,变的就是 onClick 了,为什么传递给 onClick 的 callback 函数会发生改变呢?在文章的开头就已经说过了,在函数式组件里每次重新渲染,函数组件都会重头开始重新执行,那么这两次创建的 callback 函数肯定发生了改变,所以导致了子组件重新渲染。
找到问题的原因了,那么解决办法就是在函数没有改变的时候,重新渲染的时候保持两个函数的引用一致,这个时候就要用到 useCallback 这个 API 了。
const callback = () => {
doSomething(a, b);
}
const memoizedCallback = useCallback(callback, [a, b])把函数以及依赖项作为参数传入 useCallback,它将返回该回调函数的 memoized 版本,这个 memoizedCallback 只有在依赖项有变化的时候才会更新。
那么可以将 index.js 修改为这样:
// index.js
import React, { useState, useCallback } from "react";
import ReactDOM from "react-dom";
import Child from "./child";
function App() {
const [title, setTitle] = useState("这是一个 title");
const [subtitle, setSubtitle] = useState("我是一个副标题");
const callback = () => {
setTitle("标题改变了");
};
// 通过 useCallback 进行记忆 callback,并将记忆的 callback 传递给 Child
const memoizedCallback = useCallback(callback, [])
return (
<div className="App">
<h1>{title}</h1>
<h2>{subtitle}</h2>
<button onClick={() => setSubtitle("副标题改变了")}>改副标题</button>
<Child onClick={memoizedCallback} name="桃桃" />
</div>
);
}
const rootElement = document.getElementById("root");
ReactDOM.render(<App />, rootElement);这样我们就可以看到只会在首次渲染的时候打印出桃桃,当点击改副标题和改标题的时候是不会打印桃桃的。
如果我们的 callback 传递了参数,当参数变化的时候需要让它重新添加一个缓存,可以将参数放在 useCallback 第二个参数的数组中,作为依赖的形式,使用方式跟 useEffect 类似。
在文章的开头就已经介绍了,React 的性能优化方向主要是两个:一个是减少重新 render 的次数(或者说减少不必要的渲染),另一个是减少计算的量。
前面介绍的 React.memo 和 useCallback 都是为了减少重新 render 的次数。对于如何减少计算的量,就是 useMemo 来做的,接下来我们看例子。
function App() {
const [num, setNum] = useState(0);
// 一个非常耗时的一个计算函数
// result 最后返回的值是 49995000
function expensiveFn() {
let result = 0;
for (let i = 0; i < 10000; i++) {
result += i;
}
console.log(result) // 49995000
return result;
}
const base = expensiveFn();
return (
<div className="App">
<h1>count:{num}</h1>
<button onClick={() => setNum(num + base)}>+1</button>
</div>
);
}首次渲染的效果如下:
这个例子功能很简单,就是点击 +1 按钮,然后会将现在的值(num) 与 计算函数 (expensiveFn) 调用后的值相加,然后将和设置给 num 并显示出来,在控制台会输出 49995000。
就算是一个看起来很简单的组件,也有可能产生性能问题,通过这个最简单的例子来看看还有什么值得优化的地方。
首先我们把 expensiveFn 函数当做一个计算量很大的函数(比如你可以把 i 换成 10000000),然后当我们每次点击 +1 按钮的时候,都会重新渲染组件,而且都会调用 expensiveFn 函数并输出 49995000。由于每次调用 expensiveFn 所返回的值都一样,所以我们可以想办法将计算出来的值缓存起来,每次调用函数直接返回缓存的值,这样就可以做一些性能优化。
针对上面产生的问题,就可以用 useMemo 来缓存 expensiveFn 函数执行后的值。
首先介绍一下 useMemo 的基本的使用方法,详细的使用方法可见官网:
function computeExpensiveValue() {
// 计算量很大的代码
return xxx
}
const memoizedValue = useMemo(computeExpensiveValue, [a, b]);useMemo 的第一个参数就是一个函数,这个函数返回的值会被缓存起来,同时这个值会作为 useMemo 的返回值,第二个参数是一个数组依赖,如果数组里面的值有变化,那么就会重新去执行第一个参数里面的函数,并将函数返回的值缓存起来并作为 useMemo 的返回值 。
了解了 useMemo 的使用方法,然后就可以对上面的例子进行优化,优化代码如下:
function App() {
const [num, setNum] = useState(0);
function expensiveFn() {
let result = 0;
for (let i = 0; i < 10000; i++) {
result += i;
}
console.log(result)
return result;
}
const base = useMemo(expensiveFn, []);
return (
<div className="App">
<h1>count:{num}</h1>
<button onClick={() => setNum(num + base)}>+1</button>
</div>
);
}执行上面的代码,然后现在可以观察无论我们点击 +1多少次,只会输出一次 49995000,这就代表 expensiveFn 只执行了一次,达到了我们想要的效果。
useMemo 的使用场景主要是用来缓存计算量比较大的函数结果,可以避免不必要的重复计算,有过 vue 的使用经历同学可能会觉得跟 Vue 里面的计算属性有异曲同工的作用。
不过另外提醒两点
一、如果没有提供依赖项数组,
useMemo在每次渲染时都会计算新的值;二、计算量如果很小的计算函数,也可以选择不使用 useMemo,因为这点优化并不会作为性能瓶颈的要点,反而可能使用错误还会引起一些性能问题。
对于性能瓶颈可能对于小项目遇到的比较少,毕竟计算量小、业务逻辑也不复杂,但是对于大项目,很可能是会遇到性能瓶颈的,但是对于性能优化有很多方面:网络、关键路径渲染、打包、图片、缓存等等方面,具体应该去优化哪方面还得自己去排查,本文只介绍了性能优化中的冰山一角:运行过程中 React 的优化。
合理拆分组件还有很多其他好处,比如好维护,而且这是学习组件化**的第一步,合理的拆分组件又是一门艺术了,如果拆分得不合理,就有可能导致状态混乱,多敲代码多思考。
我这里只介绍了函数式组件的优化方式,更多的 React 优化技巧可以阅读下面的文章:
我是桃翁,一个爱思考的前端er,想了解关于更多的前端相关的,请关注我的公号:「前端桃园」,如果想加入交流群关注公众号后回复「微信」拉你进群
欢迎访问个人站点
一个模块只不过是一个写在文件中的 JavaScript 代码块。
模块中的函数或变量不可用,除非模块文件导出它们。
简单地说,这些模块可以帮助你在你的模块中编写代码,并且只公开应该被你的代码的其他部分访问的代码部分。
导出模块所用的命令是 export。
前面也提到一个模块就是一个 javascript 文件,在这个模块中定义的变量,外部是无法获取到的,只有通过 export 导出的变量其他模块才可以用
最简单的导出方式就是在声明的变量、函数、类前面加一个 export
// export1.js
// 导出变量
export let name = '桃翁';
// 导出函数
export function print() {
console.log("欢迎关注公众号:前端桃园");
}
// 导出类
export class Person {
constructor(name) {
this.name = name;
}
}
// 私有函数
function privateFunction () {
console.log('我是私有函数,外部访问不了我');
}注意:
1. 被导出的函数或者类,都必须要有名称,意思就是说不能用这种方式导出匿名函数或者匿名类。
2. privateFunction 函数,没有加 export 命令,被当做这个模块的私有变量,其他模块是访问不到的。
除了上面那种导出方式,还有另外一种
// export2.js
// 导出变量
let name = '桃翁';
// 导出函数
function print() {
return '欢迎关注公众号:前端桃园';
}
// 导出类
class Person {
constructor(name) {
this.name = name;
}
}
// 私有函数
function privateFunction () {
return '我是私有函数,外部访问不了我';
}
export { name, print, Person }上面这种写法导入一组变量,与 export1.js 是等价的。
导入的模块可以理解为是生产者(或者服务的提供者),而使用导入的模块的模块就是消费者。
导入模块的命令是 import, import 的基本形式如下:
import { var1, var2 } from './example.js'import 语句包含两部分:一是导入需要的标识符,二是模块的来源。
注意:浏览器中模块来源要以「/」或者 「./」 或者 「../」开头 或者 url 形式,不然会报错。
例如我们导入 export1.js 模块,可以这么导入
// import1.js
import { name, print, Person } from './export1.js';
console.log(name); // 桃翁
console.log(print()); // 欢迎关注公众号:前端桃园
// 报错, 不能定义相同名字变量
let name = 2333;
// 报错,不能重新赋值
name = "小猪";可以看到导入绑定(这里不理解绑定,文章后面会解释)时,形式类似于对象解构,但实际上并无关联。
当导入绑定的时候,绑定类似于使用了 const 定义,意味着不能定义相同的变量名,但是没有暂时性死区特性(但是在 深入理解ES6 这本书里面说是有暂时性死区限制,我在 chrome 上测试了的,读者希望也去试下,到底受不受限制)。
let name = 2333;上面这行代码会报错。
这种导入方式是把整个生产者模块当做单一对象导入,所有的导出被当做对象的属性。
// import2.js
import * as namespace from './export1.js'
console.log(namespace.name); // 桃翁
console.log(namespace.print()); // 欢迎关注公众号:前端桃园
有时候你并不想导出变量的原名称,需要重新命名,这个时候只需要使用 as 关键字来制定新的名字即可。
// export3.js
function print() {
return '欢迎关注公众号:前端桃园';
}
export { print as advertising }拿上面导出的举例子
// import3.js
import { advertising as print } from './export3.js'
console.log(typeof advertising); // "undefined"
console.log(print()); // 欢迎关注公众号:前端桃园 此代码导入 advertising 函数并重命名为了 print ,这意味着此模块中 advertising 标识符不存在了。
default 关键字是用来做默认导入导出的。
// defaultExport.js
// 第一种默认导出方式
export default function print() {
return '欢迎关注公众号:前端桃园';
}
// 第二种默认导出方式
function print() {
return '欢迎关注公众号:前端桃园';
}
export default print;
// 第三种默认导出方式
function print() {
return '欢迎关注公众号:前端桃园';
}
export { print as default }default 这个关键字在 JS 中具有特殊含义,既可以作为同命名导出,又标明了模块需要使用默认值。
注意: 一个模块中只能有一个默认导出。
默认导入和一般的导入不同之处就是不需要写大括号了,看起来更简洁。
把上面 defaultExport.js 模块导出的作为例子
import print from './defaultExport.js'
console.log(print()); // 欢迎关注公众号:前端桃园 那如果既有默认的又有非默认的怎么导入呢?看例子就明白了
// defaultImport1.js
let name = '桃翁';
function print() {
return '欢迎关注公众号:前端桃园';
}
export { name, print as default }// defaultImport2.js
import print, { name } from './defaultImport1.js'
console.log(print()); // 欢迎关注公众号:前端桃园
console.log(name); // 桃翁混合导入需要把默认导入的名称放在最前面,然后用逗号和后面非默认导出的分割开。
思考了很久是否应该加上进阶内容,本来是想写入门级系列的,但是想了想,还是都写进来吧,入门的看入门前面基础,深入理解的看进阶。
进阶部分主要介绍 模块的几个特性
所谓静态执行其实就是在编译阶段就需要确定模块的依赖关系,那么就会出现 import 命令会优先于模块其他内容的执行,会提前到编译阶段执行。
// static1.js
console.log('佩奇');
import { nouse } from './static2.js'
// static2.js
export function nouse() {
return '我是不需要的';
}
console.log('小猪');可以看到最后输出的应该是「小猪」先输出,而「佩奇」后输出,可以得出虽然 static2.js 在后面引入,但是会被提升到模块的最前面先执行。
这也是我前面所说的不受暂时性死区原因之一,在这里可以写一个例子试试:
// static3.js
console.log(nouse());
import { nouse } from './static2.js'
// 结果:
// 小猪
// 我是不需要的经检验确实是可以在 import 之前使用导入的绑定。
静态执行还会导致一个问题,那就是不能动态导入模块。
// 报错
if (flag) {
import { nouse } from './static3.js'
}
// 报错
import { 'no' + 'use' } from './static3.js'因为 import 是静态执行的,所以在静态(词法)分析阶段,是没法得到表达式或者变量的值的。
但是为了解决这个问题,因为了 import() 这个函数,这个算扩展内容吧,写太多了我怕没人看完了,后面会有扩展阅读链接。
所谓的动态关联,其实就是一种绑定关系, 这是 ES6 非常重要的特性,一定仔细阅读。
在 ES6 的模块中,输出的不是对象的拷贝,不管是引用类型还是基本类型, 都是动态关联模块中的值,。
// dynamic1.js
export let name = '桃翁';
export function setName(name) {
name = name;
}
// dynamic2.js
import { name, setName } from './dynamic1.js'
console.log(name); // 桃翁
setName('不要脸');
console.log(name); // 不要脸奇迹般的发现在 dynamic2.js 模块中可以修改 dynamic1.js 模块里面的值, 并且反应到 name 绑定上(这个是重点,这个反应到了消费者模块), 所以我们把导入的变量叫做绑定。
在生产者模块导出的变量与消费者模块导入的变量会有一个绑定关系,无论前者或者后者发生改变,都会互相影响。
注意区分在一个文件或模块中基本类型的赋值,两者是互不影响的。
这个特性比较好理解,就是如果从一个生产者模块中分别导入绑定,而不是一次性导入,生产者模块不会执行多次。
// noRepeat1.js
export let name = '桃翁';
export let age = '22';
console.log('我正在执行。。。');
// noRepeat2.js
import { name } from './noRepeat1.js';
import { age } from './noRepeat1.js';
console.log(name);
console.log(age);
// 结果
// 我正在执行。。。
// 桃翁
// 22虽然导入了两次,但是 noRepeat1.js 只有执行一次。若同一个应用(注意是同一个应用不是模块)中导入同一个模块,则那些模块都会使用一个模块实例,意思就是说是一个单例。
码字不易,写技术文章是真的累,作者花的时间至少是读者读的时间的十倍。在此想到阮老师写了那么多文章,不知道是花了多少时间,竟然还有人这么恨他,攻击他的网站。
我在文章中给我公众号打了很多广告,在此抱个歉,刚运营的公众号,需要拉点粉丝,不喜欢的注重内容就好。
该系列文章不是针对前端新手,需要有一定的编程经验,而且了解 JavaScript 里面作用域,闭包等概念
组合是一种为软件的行为,进行清晰建模的一种简单、优雅而富于表现力的方式。通过组合小的、确定性的函数,来创建更大的软件组件和功能的过程,会生成更容易组织、理解、调试、扩展、测试和维护的软件。
对于组合,我觉得是函数式编程里面最精髓的地方之一,所以我迫不及待的把这个概念拿出来先介绍,因为在整个学习函数式编程里,所遇到的基本上都是以组合的方式来编写代码,这也是改变你从一个面向对象,或者结构化编程**的一个关键点。
我这里也不去证明组合比继承好,也不说组合的方式写代码有多好,我希望你看了这篇文章能知道以组合的方式去抽象代码,这会扩展你的视野,在你想重构你的代码,或者想写出更易于维护的代码的时候,提供一种思路。
组合的概念是非常直观的,并不是函数式编程独有的,在我们生活中或者前端开发中处处可见。
比如我们现在流行的 SPA (单页面应用),都会有组件的概念,为什么要有组件的概念呢,因为它的目的就是想让你把一些通用的功能或者元素组合抽象成可重用的组件,就算不通用,你在构建一个复杂页面的时候也可以拆分成一个个具有简单功能的组件,然后再组合成你满足各种需求的页面。
其实我们函数式编程里面的组合也是类似,函数组合就是一种将已被分解的简单任务组织成复杂的整体过程。
现在我们有这样一个需求:给你一个字符串,将这个字符串转化成大写,然后逆序。
你可能会这么写。
// 例 1.1
var str = 'function program'
// 一行代码搞定
function oneLine(str) {
var res = str.toUpperCase().split('').reverse().join('')
return res;
}
// 或者 按要求一步一步来,先转成大写,然后逆序
function multiLine(str) {
var upperStr = str.toUpperCase()
var res = upperStr.split('').reverse().join('')
return res;
}
console.log(oneLine(str)) // MARGORP NOITCNUF
console.log(multiLine(str)) // MARGORP NOITCNUF可能看到这里你并没有觉得有什么不对的,但是现在产品又突发奇想,改了下需求,把字符串大写之后,把每个字符拆开之后组装成一个数组,比如 ’aaa‘ 最终会变成 [A, A, A]。
那么这个时候我们就需要更改我们之前我们封装的函数。这就修改了以前封装的代码,其实在设计模式里面就是破坏了开闭原则。
那么我们如果把最开始的需求代码写成这个样子,以函数式编程的方式来写。
// 例 1.2
var str = 'function program'
function stringToUpper(str) {
return str.toUpperCase()
}
function stringReverse(str) {
return str.split('').reverse().join('')
}
var toUpperAndReverse = 组合(stringReverse, stringToUpper)
var res = toUpperAndReverse(str)那么当我们需求变化的时候,我们根本不需要修改之前封装过的东西。
// 例 2
var str = 'function program'
function stringToUpper(str) {
return str.toUpperCase()
}
function stringReverse(str) {
return str.split('').reverse().join('')
}
// var toUpperAndReverse = 组合(stringReverse, stringToUpper)
// var res = toUpperAndReverse(str)
function stringToArray(str) {
return str.split('')
}
var toUpperAndArray = 组合(stringToArray, stringToUpper)
toUpperAndArray(str)可以看到当变更需求的时候,我们没有打破以前封装的代码,只是新增了函数功能,然后把函数进行重新组合。
这里可能会有人说,需求修改,肯定要更改代码呀,你这不是也删除了以前的代码么,也不是算破坏了开闭原则么。我这里声明一下,开闭原则是指一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。是针对我们封装,抽象出来的代码,而不是调用的逻辑代码。所以这样写并不算破坏开闭原则。
突然产品又灵光一闪,又想改一下需求,把字符串大写之后,再翻转,再转成数组。
要是你按照以前的思考,没有进行抽象,你肯定心理一万只草泥马在奔腾,但是如果你抽象了,你完全可以不慌。
// 例 3
var str = 'function program'
function stringToUpper(str) {
return str.toUpperCase()
}
function stringReverse(str) {
return str.split('').reverse().join('')
}
function stringToArray(str) {
return str.split('')
}
var strUpperAndReverseAndArray = 组合(stringToArray, stringReverse, stringToUpper)
strUpperAndReverseAndArray(str)发现并没有更换你之前封装的代码,只是更换了函数的组合方式。可以看到,组合的方式是真的就是抽象单一功能的函数,然后再组成复杂功能。这种方式既锻炼了你的抽象能力,也给维护带来巨大的方便。
但是上面的组合我只是用汉字来代替的,我们应该如何去实现这个组合呢。首先我们可以知道,这是一个函数,同时参数也是函数,返回值也是函数。
我们看到例 2, 怎么将两个函数进行组合呢,根据上面说的,参数和返回值都是函数,那么我们可以确定函数的基本结构如下(顺便把组合换成英文的 compose)。
function twoFuntionCompose(fn1, fn2) {
return function() {
// code
}
}我们再思考一下,如果我们不用 compose 这个函数,在例 2 中怎么将两个函数合成呢,我们是不是也可以这么做来达到组合的目的。
var res = stringReverse(stringToUpper(str))那么按照这个逻辑是不是我们就可以写出 twoFuntonCompose 的实现了,就是
function twoFuntonCompose(fn1, fn2) {
return function(arg) {
return fn1(fn2(arg))
}
}同理我们也可以写出三个函数的组合函数,四个函数的组合函数,无非就是一直嵌套多层嘛,变成:
function multiFuntionCompose(fn1, fn2, .., fnn) {
return function(arg) {
return fnn(...(fn1(fn2(arg))))
}
}这种恶心的方式很显然不是我们程序员应该做的,然后我们也可以看到一些规律,无非就是把前一个函数的返回值作为后一个返回值的参数,当直接到最后一个函数的时候,就返回。
所以按照正常的思维就会这么写。
function aCompose(...args) {
let length = args.length
let count = length - 1
let result
return function f1 (...arg1) {
result = args[count].apply(this, arg1)
if (count <= 0) {
count = length - 1
return result
}
count--
return f1.call(null, result)
}
}这样写没问题,underscore 也是这么写的,不过里面还有很多健壮性的处理,核心大概就是这样。
但是作为一个函数式爱好者,尽量还是以函数式的方式去思考,所以就用 reduceRight 写出如下代码。
function compose(...args) {
return (result) => {
return args.reduceRight((result, fn) => {
return fn(result)
}, result)
}
}当然对于 compose 的实现还有很多种方式,在这篇实现 compose 的五种思路中还给出了另外脑洞大开的实现方式,在我看这篇文章之前,另外三种我是没想到的,不过感觉也不是太有用,但是可以扩展我们的思路,有兴趣的同学可以看一看。
注意:要传给 compose 函数是有规范的,首先函数的执行是从最后一个参数开始执行,一直执行到第一个,而且对于传给 compose 作为参数的函数也是有要求的,必须只有一个形参,而且函数的返回值是下一个函数的实参。
对于 compose 从最后一个函数开始求值的方式如果你不是很适应的话,你可以通过 pipe 函数来从左到右的方式。
function pipe(...args) {
return (result) => {
return args.reduce((result, fn) => {
return fn(result)
}, result)
}
}实现跟 compose 差不多,只是把参数的遍历方式从右到左(reduceRight)改为从左到右(reduce)。
之前是不是看过很多文章写过如何实现 compose,或者柯里化,部分应用等函数,但是你可能不知道是用来干啥的,也没用过,所以记了又忘,忘了又记,看了这篇文章之后我希望这些你都可以轻松实现。后面会继续讲到柯里化和部分应用的实现。
在函数式编程的世界中,有这样一种很流行的编程风格。这种风格被称为 tacit programming,也被称作为 point-free,point 表示的就是形参,意思大概就是没有形参的编程风格。
// 这就是有参的,因为 word 这个形参
var snakeCase = word => word.toLowerCase().replace(/\s+/ig, '_');
// 这是 pointfree,没有任何形参
var snakeCase = compose(replace(/\s+/ig, '_'), toLowerCase);有参的函数的目的是得到一个数据,而 pointfree 的函数的目的是得到另一个函数。
那这 pointfree 有什么用? 它可以让我们把注意力集中在函数上,参数命名的麻烦肯定是省了,代码也更简洁优雅。 需要注意的是,一个 pointfree 的函数可能是由众多非 pointfree 的函数组成的,也就是说底层的基础函数大都是有参的,pointfree 体现在用基础函数组合而成的高级函数上,这些高级函数往往可以作为我们的业务函数,通过组合不同的基础函数构成我们的复制的业务逻辑。
可以说 pointfree 使我们的编程看起来更美,更具有声明式,这种风格算是函数式编程里面的一种追求,一种标准,我们可以尽量的写成 pointfree,但是不要过度的使用,任何模式的过度使用都是不对的。
另外可以看到通过 compose 组合而成的基础函数都是只有一个参数的,但是往往我们的基础函数参数很可能不止一个,这个时候就会用到一个神奇的函数(柯里化函数)。
在维基百科里面是这么定义柯里化的:
在计算机科学,柯里化(英语:Currying),又译为卡瑞化或加里化,是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。
在定义中获取两个比较重要的信息:
这两个要点不是 compose 函数参数的要求么,而且可以将多个参数的函数转换成接受单一参数的函数,岂不是可以解决我们再上面提到的基础函数如果是多个参数不能用的问题,所以这就很清楚了柯里化函数的作用了。
柯里化函数可以使我们更好的去追求 pointfree,让我们代码写得更优美!
接下来我们具体看一个例子来理解柯里化吧:
比如你有一间士多店并且你想给你优惠的顾客给个 10% 的折扣(即打九折):
function discount(price, discount) {
return price * discount
}当一位优惠的顾客买了一间价值$500的物品,你给他打折:
const price = discount(500, 0.10); // $50 你可以预见,从长远来看,我们会发现自己每天都在计算 10% 的折扣:
const price = discount(1500,0.10); // $150
const price = discount(2000,0.10); // $200
// ... 等等很多我们可以将 discount 函数柯里化,这样我们就不用总是每次增加这 0.10 的折扣。
// 这个就是一个柯里化函数,将本来两个参数的 discount ,转化为每次接收单个参数完成求职
function discountCurry(discount) {
return (price) => {
return price * discount;
}
}
const tenPercentDiscount = discountCurry(0.1);现在,我们可以只计算你的顾客买的物品都价格了:
tenPercentDiscount(500); // $50同样地,有些优惠顾客比一些优惠顾客更重要-让我们称之为超级客户。并且我们想给这些超级客户提供 20% 的折扣。
可以使用我们的柯里化的discount函数:
const twentyPercentDiscount = discountCurry(0.2);我们通过这个柯里化的 discount 函数折扣调为 0.2(即20%),给我们的超级客户配置了一个新的函数。
返回的函数 twentyPercentDiscount 将用于计算我们的超级客户的折扣:
twentyPercentDiscount(500); // 100我相信通过上面的 **discountCurry **你已经对柯里化有点感觉了,这篇文章是谈的柯里化在函数式编程里面的应用,所以我们再来看看在函数式里面怎么应用。
现在我们有这么一个需求:给定的一个字符串,先翻转,然后转大写,找是否有TAOWENG,如果有那么就输出 yes,否则就输出 no。
function stringToUpper(str) {
return str.toUpperCase()
}
function stringReverse(str) {
return str.split('').reverse().join('')
}
function find(str, targetStr) {
return str.includes(targetStr)
}
function judge(is) {
console.log(is ? 'yes' : 'no')
}我们很容易就写出了这四个函数,前面两个是上面就已经写过的,然后 find 函数也很简单,现在我们想通过 compose 的方式来实现 pointfree,但是我们的 find 函数要接受两个参数,不符合 compose 参数的规定,这个时候我们像前面一个例子一样,把 find 函数柯里化一下,然后再进行组合:
// 柯里化 find 函数
function findCurry(targetStr) {
return str => str.includes(targetStr)
}
const findTaoweng = findCurry('TAOWENG')
const result = compose(judge, findTaoweng, stringReverse, stringToUpper)看到这里是不是可以看到柯里化在达到 pointfree 是非常的有用,较少参数,一步一步的实现我们的组合。
但是通过上面那种方式柯里化需要去修改以前封装好的函数,这也是破坏了开闭原则,而且对于一些基础函数去把源码修改了,其他地方用了可能就会有问题,所以我们应该写一个函数来手动柯里化。
根据定义之前对柯里化的定义,以及前面两个柯里化函数,我们可以写一个二元(参数个数为 2)的通用柯里化函数:
function twoCurry(fn) {
return function(firstArg) { // 第一次调用获得第一个参数
return function(secondArg) { // 第二次调用获得第二个参数
return fn(firstArg, secondArg) // 将两个参数应用到函数 fn 上
}
}
}所以上面的 findCurry 就可以通过 twoCurry 来得到:
const findCurry = twoCurry(find)这样我们就可以不更改封装好的函数,也可以使用柯里化,然后进行函数组合。不过我们这里只实现了二元函数的柯里化,要是三元,四元是不是我们又要要写三元柯里化函数,四元柯里化函数呢,其实我们可以写一个通用的 n 元柯里化。
function currying(fn, ...args) {
if (args.length >= fn.length) {
return fn(...args)
}
return function (...args2) {
return currying(fn, ...args, ...args2)
}
}我这里采用的是递归的思路,当获取的参数个数大于或者等于 fn 的参数个数的时候,就证明参数已经获取完毕,所以直接执行 fn 了,如果没有获取完,就继续递归获取参数。
可以看到其实一个通用的柯里化函数核心**是非常的简单,代码也非常简洁,而且还支持在一次调用的时候可以传多个参数(但是这种传递多个参数跟柯里化的定义不是很合,所以可以作为一种柯里化的变种)。
我这里重点不是讲柯里化的实现,所以没有写得很健壮,更强大的柯里化函数可见羽讶的:JavaScript专题之函数柯里化。
部分应用是一种通过将函数的不可变参数子集,初始化为固定值来创建更小元数函数的操作。简单来说,如果存在一个具有五个参数的函数,给出三个参数后,就会得到一个、两个参数的函数。
看到上面的定义可能你会觉得这跟柯里化很相似,都是用来缩短函数参数的长度,所以如果理解了柯里化,理解部分应用是非常的简单:
function debug(type, firstArg, secondArg) {
if(type === 'log') {
console.log(firstArg, secondArg)
} else if(type === 'info') {
console.info(firstArg, secondArg)
} else if(type === 'warn') {
console.warn(firstArg, secondArg)
} else {
console.error(firstArg, secondArg)
}
}
const logDebug = 部分应用(debug, 'log')
const infoDebug = 部分应用(debug, 'info')
const warnDebug = 部分应用(debug, 'warn')
const errDebug = 部分应用(debug, 'error')
logDebug('log:', '测试部分应用')
infoDebug('info:', '测试部分应用')
warnDebug('warn:', '测试部分应用')
errDebug('error:', '测试部分应用')debug方法封装了我们平时用 console 对象调试的时候各种方法,本来是要传三个参数,我们通过部分应用的封装之后,我们只需要根据需要调用不同的方法,传必须的参数就可以了。
我这个例子可能你会觉得没必要这么封装,根本没有减少什么工作量,但是如果我们在 debug 的时候不仅是要打印到控制台,还要把调试信息保存到数据库,或者做点其他的,那是不是这个封装就有用了。
因为部分应用也可以减少参数,所以他在我们进行编写组合函数的时候也占有一席之地,而且可以更快传递需要的参数,留下为了 compose 传递的参数,这里是跟柯里化比较,因为柯里化按照定义的话,一次函数调用只能传一个参数,如果有四五个参数就需要:
function add(a, b, c, d) {
return a + b + c +d
}
// 使用柯里化方式来使 add 转化为一个一元函数
let addPreThreeCurry = currying(add)(1)(2)(3)
addPreThree(4) // 10这种连续调用(这里所说的柯里化是按照定义的柯里化,而不是我们写的柯里化变种),但是用部分应用就可以:
// 使用部分应用的方式使 add 转化为一个一元函数
const addPreThreePartial = 部分应用(add, 1, 2, 3)
addPreThree(4) // 10既然我们现在已经明白了部分应用这个函数的作用了,那么还是来实现一个吧,真的是非常的简单:
// 通用的部分应用函数的核心实现
function partial(fn, ...args) {
return (..._arg) => {
return fn(...args, ..._arg);
}
}另外不知道你有没有发现,这个部分应用跟 JavaScript 里面的 bind 函数很相似,都是把第一次穿进去的参数通过闭包存在函数里,等到再次调用的时候再把另外的参数传给函数,只是部分应用不用指定 this,所以也可以用 bind 来实现一个部分应用函数。
// 通用的部分应用函数的核心实现
function partial(fn, ...args) {
return fn.bind(null, ...args)
}另外可以看到实际上柯里化和部分应用确实很相似,所以这两种技术很容易被混淆。它们主要的区别在于参数传递的内部机制与控制:
在这篇文章里我重点想介绍的是函数以组合的方式来完成我们的需求,另外介绍了一种函数式编程风格:pointfree,让我们在函数式编程里面有了一个最佳实践,尽量写成 pointfree 形式(尽量,不是都要),然后介绍了通过柯里化或者部分应用来减少函数参数,符合 compose 或者 pipe 的参数要求。
所以这种文章的重点是理解我们如何去组合函数,如何去抽象复杂的函数为颗粒度更小,功能单一的函数。这将使我们的代码更容易维护,更具声明式的特点。
对于这篇文章里面提到的其他概念:闭包、作用域,然后柯里化的其他用途我希望是在番外篇里面更深入的去理解,而这篇文章主要掌握函数组合就行了。
文章首发于自己的个人网站桃园,另外也可以在 github blog 上找到。
如果有兴趣,也可以关注我的个人公众号:「前端桃园」
桃翁桃翁,问个问题呢,据说 js 里面有个执行上下文,这个概念是个什么东东哦?据说挺重要的,给我科普科普呗。
Emm… 这个概念非常的抽象,简单来说呢,就是 JS 在执行某段代码的时候做的一些事情。
具体做的事情就是定义了变量或函数有权访问的其他数据决定了它们各自的行为(作用域链)。每个执行环境都有一个与之关联的变量对象(variable object),环境中定义的所有变量和函数都保存在这个对象中(变量包括 this、arguments)。虽然我们编写的代码无法访问这个对象,但解析器在处理数据时会在后台使用它。
哇,还是好抽象啊,你能不能画个图举个栗子呢?
在之前说的执行上下文就是解释器在执行 JS 某段代码的时候做的一些事,那么首先我们把代码分个类。
看到这个图相信现在分清楚各种类型的代码,每种类型代码会都会产生执行上下文,我们把 Global 代码产生的执行环境叫**「全局执行上下文」,把 Function 代码产生的执行环境叫「执行上下文」**吧,Eval 代码不考虑。
那我看这个图似乎有很多执行上下文(execution context),这个具体是怎么来的呢?
全局执行上下文只有一个,而执行环境的话是每次函数调用都会产生一个执行上下文。注意要调用才会产生哦,不调用是不会产生的。
那这个执行上下文基本知道是个什么东西了,那执行上下文栈又是啥呢?
见名知意,执行上下文栈就是执行上下文(包含全局执行上下文)形成的栈嘛。
那为什么要有这个执行上下文栈呢?
浏览器中 JavaScript 解释器是单线程的,这就是说同一时间代码只会做一件事,那么创建这么多执行上下文,又不能同一时间执行多个上下文,所以就必须要有个顺序,这个顺序就是就是先进后出,这很明显就是一个栈结构嘛。
那我就疑惑了,为啥要先进后出,不先进先出呢?
我们分析一下图一的代码,结合上图,首先我们看图 1,解释代码的时候首先创建的就是全局上下文,然后再创建 person 的执行上下文,然后再创建 firstName 的上下文,然后再执行完毕 firstName ,就把 firstName 的上下文弹出,再 创建 lastName 的上下文,然后执行完毕,再弹出 lastName 的上下文,然后执行完 person 的上下文,再弹出 person 的上下文,再执行全局上下文,然后全局上下文弹出。
如下是一张经典的执行上下文栈的图。
默认进入全局上下文。如果你的全局代码中调用了一个函数,那么程序将会进入这个被调用函数的上下文,创建一个新的执行上下文,并把当前上下文放到栈顶。浏览器总是会把当前执行上下文放到栈的顶部,一旦函数执行完成,这个执行上下文就会从栈中移除,返回到栈中的下一个上下文。
这些大概明白了,不过你说在创建执行上下文做的那些事儿,我还是有点迷糊,能再详细说说吗?
那我们首先看点代码:
// 例1
console.log(a); // 报错,a is not defined// 例2
console.log(a); // undefined
var a;// 例 3
console.log(a); // undefined
var a = 666;
// 例 4
console.log(this); // window 对象// 例 5
function foo(x) {
console.log(arguments); // [666]
console.log(x); // 666
}
foo(666);
// 例 6
// 函数表达式
console.log(foo); // undefined
var foo = function foo() {}// 例 7
// 函数声明
console.log(foo); // function() {}
function foo() {}这 7 个例子相信大家对这些答案都是没有疑惑的,最基础的东西,例 1 报错,a 未定义,很正常。例 2、例 3 输出都是 undefined,说明浏览器在执行 console.log(a) 时,已经知道了 a 是 undefined,但却不知道 a 是 666(例 3)。
看例 4 就知道,当执行这条语句的时候 this 已经被赋值了。
在例 5 中展示了在函数体的语句执行之前,arguments 变量和函数的参数都已经被赋值。从这里可以看出,函数每被调用一次,都会产生一个新的执行上下文环境。因为不同的调用可能就会有不同的参数。
然后就是例 6,例 7 中可以看出函数表达式跟变量声明一样,只是给变量赋值成 undefined,而函数声明会将会把函数整个赋值了。
总结在执行上下文做的赋值事情
执行上下文就介绍到这里,如果你对相关知识还是感到迷惑,比如当在创建执行上下文的时候还有作用域,以及变量对象等概念,后面再一一介绍,不要担心,跟着我的文章走,这块一定能啃动。
预告一下,下一篇是《变量对象和活动对象》的介绍。
文章首发于个人博客
2016 年都已经透露出来的概念,这都 9102 年了,我才开始写 Fiber 的文章,表示惭愧呀。不过现在好的是关于 Fiber 的资料已经很丰富了,在写文章的时候参考资料比较多,比较容易深刻的理解。
React 作为我最喜欢的框架,没有之一,我愿意花很多时间来好好的学习他,我发现对于学习一门框架会有四种感受,刚开始没使用过,可能有一种很神奇的感觉;然后接触了,遇到了不熟悉的语法,感觉这是什么垃圾东西,这不是反人类么;然后当你熟悉了之后,真香,设计得挺好的,这个时候它已经改变了你编程的思维方式了;再到后来,看过他的源码,理解他的设计之后,设计得确实好,感觉自己也能写一个的样子。
所以我今年(对,没错,就是一年)就是想完全的学透 React,所以开了一个 Deep In React 的系列,把一些新手在使用 API 的时候不知道为什么的点,以及一些为什么有些东西要这么设计写出来,与大家共同探讨 React 的奥秘。
我的思路是自上而下的介绍,先理解整体的 Fiber 架构,然后再细挖每一个点,所以这篇文章主要是谈 Fiber 架构的。
在详细介绍 Fiber 之前,先了解一下 Fiber 是什么,以及为什么 React 团队要话两年时间重构协调算法。
内存中维护一颗虚拟DOM树,数据变化时(setState),自动更新虚拟 DOM,得到一颗新树,然后 Diff 新老虚拟 DOM 树,找到有变化的部分,得到一个 Change(Patch),将这个 Patch 加入队列,最终批量更新这些 Patch 到 DOM 中。
首先我们了解一下 React 的工作过程,当我们通过render() 和 setState() 进行组件渲染和更新的时候,React 主要有两个阶段:
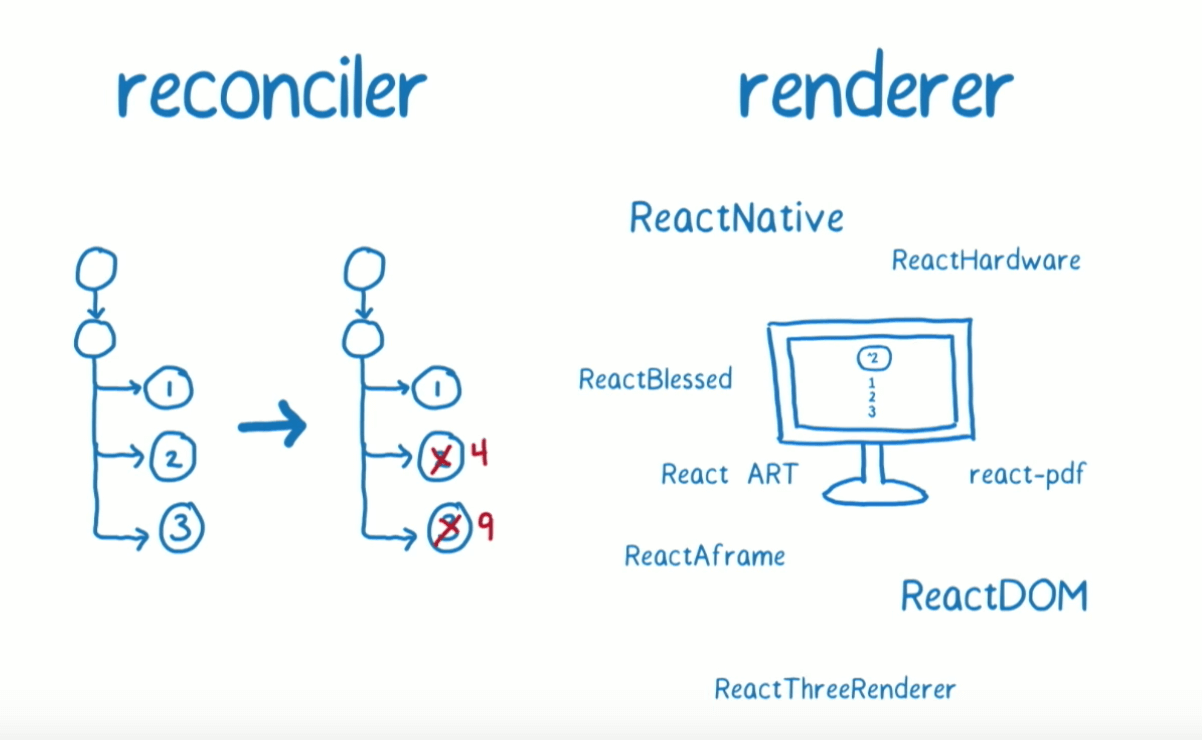
调和阶段(Reconciler):官方解释。React 会自顶向下通过递归,遍历新数据生成新的 Virtual DOM,然后通过 Diff 算法,找到需要变更的元素(Patch),放到更新队列里面去。
渲染阶段(Renderer):遍历更新队列,通过调用宿主环境的API,实际更新渲染对应元素。宿主环境,比如 DOM、Native、WebGL 等。
在协调阶段阶段,由于是采用的递归的遍历方式,这种也被成为 Stack Reconciler,主要是为了区别 Fiber Reconciler 取的一个名字。这种方式有一个特点:一旦任务开始进行,就无法中断,那么 js 将一直占用主线程, 一直要等到整棵 Virtual DOM 树计算完成之后,才能把执行权交给渲染引擎,那么这就会导致一些用户交互、动画等任务无法立即得到处理,就会有卡顿,非常的影响用户体验。
之前的问题主要的问题是任务一旦执行,就无法中断,js 线程一直占用主线程,导致卡顿。
可能有些接触前端不久的不是特别理解上面为什么 js 一直占用主线程就会卡顿,我这里还是简单的普及一下。
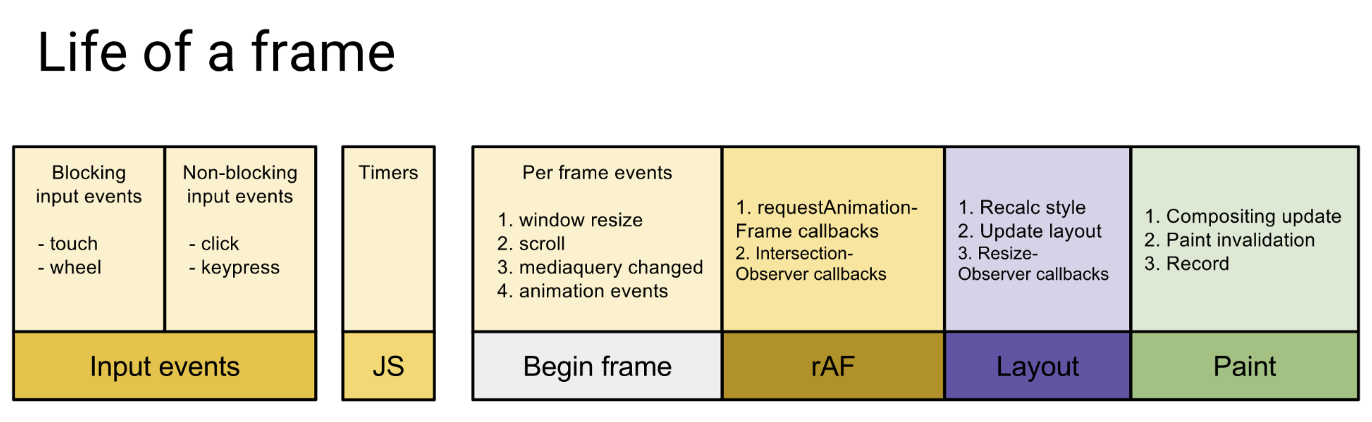
页面是一帧一帧绘制出来的,当每秒绘制的帧数(FPS)达到 60 时,页面是流畅的,小于这个值时,用户会感觉到卡顿。
1s 60 帧,所以每一帧分到的时间是 1000/60 ≈ 16 ms。所以我们书写代码时力求不让一帧的工作量超过 16ms。
浏览器一帧内的工作
通过上图可看到,一帧内需要完成如下六个步骤的任务:
如果这六个步骤中,任意一个步骤所占用的时间过长,总时间超过 16ms 了之后,用户也许就能看到卡顿。
而在上一小节提到的调和阶段花的时间过长,也就是 js 执行的时间过长,那么就有可能在用户有交互的时候,本来应该是渲染下一帧了,但是在当前一帧里还在执行 JS,就导致用户交互不能麻烦得到反馈,从而产生卡顿感。
**把渲染更新过程拆分成多个子任务,每次只做一小部分,做完看是否还有剩余时间,如果有继续下一个任务;如果没有,挂起当前任务,将时间控制权交给主线程,等主线程不忙的时候在继续执行。**这种策略叫做 Cooperative Scheduling(合作式调度),操作系统常用任务调度策略之一。
补充知识,操作系统常用任务调度策略:先来先服务(FCFS)调度算法、短作业(进程)优先调度算法(SJ/PF)、最高优先权优先调度算法(FPF)、高响应比优先调度算法(HRN)、时间片轮转法(RR)、多级队列反馈法。
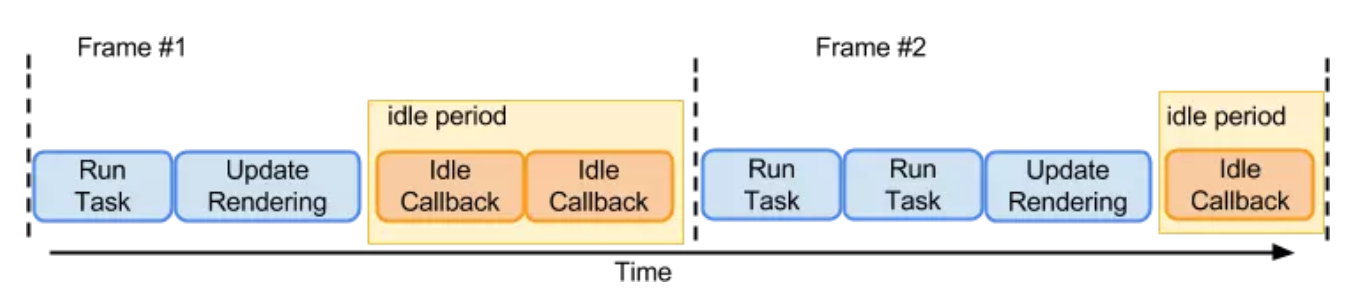
合作式调度主要就是用来分配任务的,当有更新任务来的时候,不会马上去做 Diff 操作,而是先把当前的更新送入一个 Update Queue 中,然后交给 Scheduler 去处理,Scheduler 会根据当前主线程的使用情况去处理这次 Update。为了实现这种特性,使用了requestIdelCallbackAPI。对于不支持这个API 的浏览器,React 会加上 pollyfill。
在上面我们已经知道浏览器是一帧一帧执行的,在两个执行帧之间,主线程通常会有一小段空闲时间,requestIdleCallback可以在这个空闲期(Idle Period)调用空闲期回调(Idle Callback),执行一些任务。
requestIdleCallback处理;requestAnimationFrame处理;requestIdleCallback 可以在多个空闲期调用空闲期回调,执行任务;requestIdleCallback 方法提供 deadline,即任务执行限制时间,以切分任务,避免长时间执行,阻塞UI渲染而导致掉帧;这个方案看似确实不错,但是怎么实现可能会遇到几个问题:
接下里整个 Fiber 架构就是来解决这些问题的。
为了解决之前提到解决方案遇到的问题,提出了以下几个目标:
为了做到这些,我们首先需要一种方法将任务分解为单元。从某种意义上说,这就是 Fiber,Fiber 代表一种工作单元。
但是仅仅是分解为单元也无法做到中断任务,因为函数调用栈就是这样,每个函数为一个工作,每个工作被称为堆栈帧,它会一直工作,直到堆栈为空,无法中断。
所以我们需要一种增量渲染的调度,那么就需要重新实现一个堆栈帧的调度,这个堆栈帧可以按照自己的调度算法执行他们。另外由于这些堆栈是可以自己控制的,所以可以加入并发或者错误边界等功能。
因此 Fiber 就是重新实现的堆栈帧,本质上 Fiber 也可以理解为是一个虚拟的堆栈帧,将可中断的任务拆分成多个子任务,通过按照优先级来自由调度子任务,分段更新,从而将之前的同步渲染改为异步渲染。
所以我们可以说 Fiber 是一种数据结构(堆栈帧),也可以说是一种解决可中断的调用任务的一种解决方案,它的特性就是时间分片(time slicing)和暂停(supense)。
如果了解协程的可能会觉得 Fiber 的这种解决方案,跟协程有点像(区别还是很大的),是可以中断的,可以控制执行顺序。在 JS 里的 generator 其实就是一种协程的使用方式,不过颗粒度更小,可以控制函数里面的代码调用的顺序,也可以中断。
ReactDOM.render() 和 setState 的时候开始创建更新。下面是一个详细的执行过程图:
ReactDOM.render() 方法开始,把接收的 React Element 转换为 Fiber 节点,并为其设置优先级,创建 Update,加入到更新队列,这部分主要是做一些初始数据的准备。scheduleWork、requestWork、performWork,即安排工作、申请工作、正式工作三部曲,React 16 新增的异步调用的功能则在这部分实现,这部分就是 Schedule 阶段,前面介绍的 Cooperative Scheduling 就是在这个阶段,只有在这个解决获取到可执行的时间片,第三部分才会继续执行。具体是如何调度的,后面文章再介绍,这是 React 调度的关键过程。FIber Node,承载了非常关键的上下文信息,可以说是贯彻整个创建和更新的流程,下来分组列了一些重要的 Fiber 字段。
{
...
// 跟当前Fiber相关本地状态(比如浏览器环境就是DOM节点)
stateNode: any,
// 单链表树结构
return: Fiber | null,// 指向他在Fiber节点树中的`parent`,用来在处理完这个节点之后向上返回
child: Fiber | null,// 指向自己的第一个子节点
sibling: Fiber | null, // 指向自己的兄弟结构,兄弟节点的return指向同一个父节点
// 更新相关
pendingProps: any, // 新的变动带来的新的props
memoizedProps: any, // 上一次渲染完成之后的props
updateQueue: UpdateQueue<any> | null, // 该Fiber对应的组件产生的Update会存放在这个队列里面
memoizedState: any, // 上一次渲染的时候的state
// Scheduler 相关
expirationTime: ExpirationTime, // 代表任务在未来的哪个时间点应该被完成,不包括他的子树产生的任务
// 快速确定子树中是否有不在等待的变化
childExpirationTime: ExpirationTime,
// 在Fiber树更新的过程中,每个Fiber都会有一个跟其对应的Fiber
// 我们称他为`current <==> workInProgress`
// 在渲染完成之后他们会交换位置
alternate: Fiber | null,
// Effect 相关的
effectTag: SideEffectTag, // 用来记录Side Effect
nextEffect: Fiber | null, // 单链表用来快速查找下一个side effect
firstEffect: Fiber | null, // 子树中第一个side effect
lastEffect: Fiber | null, // 子树中最后一个side effect
....
};在第二部分,进行 Schedule 完,获取到时间片之后,就开始进行 reconcile。
Fiber Reconciler 是 React 里的调和器,这也是任务调度完成之后,如何去执行每个任务,如何去更新每一个节点的过程,对应上面的第三部分。
reconcile 过程分为2个阶段(phase):
在 reconciliation 阶段的每个工作循环中,每次处理一个 Fiber,处理完可以中断/挂起整个工作循环。通过每个节点更新结束时向上归并 Effect List 来收集任务结果,reconciliation 结束后,根节点的 Effect List里记录了包括 DOM change 在内的所有 Side Effect。
render 阶段可以理解为就是 Diff 的过程,得出 Change(Effect List),会执行声明如下的声明周期方法:
由于 reconciliation 阶段是可中断的,一旦中断之后恢复的时候又会重新执行,所以很可能 reconciliation 阶段的生命周期方法会被多次调用,所以在 reconciliation 阶段的生命周期的方法是不稳定的,我想这也是 React 为什么要废弃 componentWillMount 和 componentWillReceiveProps方法而改为静态方法 getDerivedStateFromProps 的原因吧。
commit 阶段可以理解为就是将 Diff 的结果反映到真实 DOM 的过程。
在 commit 阶段,在 commitRoot 里会根据 effect 的 effectTag,具体 effectTag 见源码 ,进行对应的插入、更新、删除操作,根据 tag 不同,调用不同的更新方法。
commit 阶段会执行如下的声明周期方法:
P.S:注意区别 reconciler、reconcile 和 reconciliation,reconciler 是调和器,是一个名词,可以说是 React 工作的一个模块,协调模块;reconcile 是调和器调和的动作,是一个动词;而 reconciliation 只是 reconcile 过程的第一个阶段。
React 在 render 第一次渲染时,会通过 React.createElement 创建一颗 Element 树,可以称之为 Virtual DOM Tree,由于要记录上下文信息,加入了 Fiber,每一个 Element 会对应一个 Fiber Node,将 Fiber Node 链接起来的结构成为 Fiber Tree。它反映了用于渲染 UI 的应用程序的状态。这棵树通常被称为 current 树(当前树,记录当前页面的状态)。
在后续的更新过程中(setState),每次重新渲染都会重新创建 Element, 但是 Fiber 不会,Fiber 只会使用对应的 Element 中的数据来更新自己必要的属性,
Fiber Tree 一个重要的特点是链表结构,将递归遍历编程循环遍历,然后配合 requestIdleCallback API, 实现任务拆分、中断与恢复。
这个链接的结构是怎么构成的呢,这就要主要到之前 Fiber Node 的节点的这几个字段:
// 单链表树结构
{
return: Fiber | null, // 指向父节点
child: Fiber | null,// 指向自己的第一个子节点
sibling: Fiber | null,// 指向自己的兄弟结构,兄弟节点的return指向同一个父节点
}每一个 Fiber Node 节点与 Virtual Dom 一一对应,所有 Fiber Node 连接起来形成 Fiber tree, 是个单链表树结构,如下图所示:
对照图来看,是不是可以知道 Fiber Node 是如何联系起来的呢,Fiber Tree 就是这样一个单链表。
当 render 的时候有了这么一条单链表,当调用 setState 的时候又是如何 Diff 得到 change 的呢?
采用的是一种叫双缓冲技术(double buffering),这个时候就需要另外一颗树:WorkInProgress Tree,它反映了要刷新到屏幕的未来状态。
WorkInProgress Tree 构造完毕,得到的就是新的 Fiber Tree,然后喜新厌旧(把 current 指针指向WorkInProgress Tree,丢掉旧的 Fiber Tree)就好了。
这样做的好处:
每个 Fiber上都有个alternate属性,也指向一个 Fiber,创建 WorkInProgress 节点时优先取alternate,没有的话就创建一个。
创建 WorkInProgress Tree 的过程也是一个 Diff 的过程,Diff 完成之后会生成一个 Effect List,这个 Effect List 就是最终 Commit 阶段用来处理副作用的阶段。
本开始想一篇文章把 Fiber 讲透的,但是写着写着发现确实太多了,想写详细,估计要写几万字,所以我这篇文章的目的仅仅是在没有涉及到源码的情况下梳理了大致 React 的工作流程,对于细节,比如如何调度异步任务、如何去做 Diff 等等细节将以小节的方式一个个的结合源码进行分析。
说实话,自己不是特别满意这篇,感觉头重脚轻,在讲协调之前写得还挺好的,但是在讲协调这块文字反而变少了,因为我是专门想写一篇文章讲协调的,所以这篇仅仅用来梳理整个流程。
但是梳理整个流程又发现 Schedule 这块基本没什么体现,哎,不想写了,这篇文章拖太久了,请继续后续的文章。
可以关注我的 github:Deep In React
接下来留一些思考题。
我是桃翁,一个爱思考的前端er,想了解关于更多的前端相关的,请关注我的公号:「前端桃园」
我发布了我的第一个 npm 组件,一个基于 react 的 3d 标签云组件。在这途中我也是遇到了很多的坑,花在完善整个发布流程的时间远多于写这个组件本身的时间,所以我记录下我觉得一个正常的 react 组件的发布流程
最后记录这篇文章花的时间比我完成整个组件的时间都多,最终希望能给新手带来帮助
在整个发布组件的过程我做了如下几件事儿:
创建项目文件夹并初始化 npm package ,确保你创建的组件名称没有在 npm 上被使用过, 这里我们用 react-demo 作为示例
mkdir react-demo
cd react-demo
npm initnpm init 是生成初始的 package.json 的命令,在 npm init 的时候,你可以根据你自己的需要进行填写你的组件信息。或者直接使用 npm init -y 采用默认的,后面自己再去修改。
首先安装 react 相关的包:
npm i react react-dom -D采用 babel 编译相关的依赖:
npm i @babel/cli @babel/core @babel/preset-env @babel/preset-react -D
采用 webpack 做构建,webpack-dev-server 作为本地开发服务器,所以需要安装如下依赖:
npm i webpack webpack-cli webpack-dev-server -D
我这里为了简单演示,只安装 babel-loader 用来编译 jsx,其他 loader 安装自己的需要自己安装。
npm i babel-loader -D
另外再安装一个 webpack 插件 html-webpack-plugin ,用来生成 html:
npm i html-webpack-plugin -D然后再添加上常规的 start 和 build 脚本,package.json 如下:
{
"name": "react-demo",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "webpack-dev-server --open development",
"build": "webpack --mode production"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
"@babel/cli": "^7.2.3",
"@babel/core": "^7.2.2",
"@babel/preset-env": "^7.3.1",
"@babel/preset-react": "^7.0.0",
"babel-loader": "^8.0.5",
"html-webpack-plugin": "^3.2.0",
"react": "^16.7.0",
"react-dom": "^16.7.0",
"webpack": "^4.29.0",
"webpack-cli": "^3.2.1",
"webpack-dev-server": "^3.1.14"
},
"dependencies": {}
}当然,你也可以直接把我这个 package.json 复制过去,然后 npm install 进行依赖的安装,也可以一个一个的安装。
一个最基本的组件只需要编译 jsx,所以我这里没有安装 css 以及处理其他的 loader,这篇文章的重点不是讲 webpack 的,所以其他的自行解决,有 webpack 问题可以私聊我。
然后我们再创建如下的目录结构:
├── example // 示例代码,在自己测试的时候可以把测试文件放到 src 里
│ └── src // 示例源代码
│ ├── index.html // 示例 html
│ └── app.js // 添加到 react-dom 的文件
├── package.json
├── src // 组件源代码
│ └── index.js // 组件源代码文件
├── .babelrc
├── .editorconfig // 不必须的,但是建议有
├── .gitignore // 如果要放到 github 上,这个是需要有的
└── webpack.config.js下面我们再创建一个最简单的组件,来进行演示:
/*** src/index.js ***/
import React from 'react';
const ReactDemo = () => (
<h1>这是我的第一个 react npm 组件</h1>
);
export default ReactDemo;接下来添加一个 demo
<!-- examples/src/index.html -->
<html>
<head>
<title>My First React Component</title>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
</head>
<body>
<div id="root"></div>
</body>
</html>/*** examples/src/app.js ***/
import React from 'react'
import { render } from 'react-dom'
import ReactDemo from '../../src'
const App = () => <ReactDemo />
render(<App />, document.getElementById('root'))注意 demo 中的 ReactDemo 是从 ../../src 中导入的
接下来配置非常简单的 webpack, 在项目根路径下创建 webpack.config.js 文件
const path = require('path');
const HtmlWebpackPlugin = require("html-webpack-plugin");
const htmlWebpackPlugin = new HtmlWebpackPlugin({
template: path.join(__dirname, "./example/src/index.html"),
filename: "./index.html"
});
module.exports = {
entry: path.join(__dirname, "./example/src/app.js"),
output: {
path: path.join(__dirname, "example/dist"),
filename: "bundle.js"
},
module: {
rules: [{
test: /\.(js|jsx)$/,
use: "babel-loader",
exclude: /node_modules/
}]
},
plugins: [htmlWebpackPlugin],
resolve: {
extensions: [".js", ".jsx"]
},
devServer: {
port: 3001
}
};Webpack 的配置文件主要做了如下事情:
然后再配置一下 babel,咱们的 babel 主要做两件事,将 jsx 编译成 es5,然后再加一个通用的 env,所以 .babelrc 配置如下:
{
"presets": ["@babel/preset-env", "@babel/preset-react"]
}
可以看到之前的 package.json ,我这里 babel 安装的是 7.x,那么 babel-loader 就应该是 8.x 才行,然后 babel 7.x 相对于之前的配置是不同的,要用这个配置,版本一定要跟我的相同,不然配置可能会不一样。
然后现在执行 npm start,然后再访问 localhost:3001 就可以访问到了。
编写 README,如果你不知道该如何编写,我给你提几点建议,你可以选择你觉得必要的点来写:
当你写完 README 之后,我们将添加一些来自 shields.io 的时髦徽章,让人们知道我们又酷又专业。
想添加什么样的徽章看自己喜欢吧,种类有很多。
可以点击这里看我之前写的 3d 标签云的 README。
现在基本上可以发布了,但是要是能提供一个在线的 demo 让别人在用这个组件的时候可以看到效果就更好了。
发布在线 demo 可以直接用 Github Pages 来帮助我们托管,通过 webpack 构建生产环境版本,然后发到 Github 上去即可。
首先去 Github 创建一个用来存放你组件代码的仓库。
然后把你的项目初始化成 git 项目:
git init再添加远程仓库,将本地仓库和远程仓库关联起来。
git remote add origin [email protected]:crazylxr/react-demo.git接下来我们可以安装 gh-pages 来帮助我们发布到 github pages:
npm i gh-pages -D为了方便记忆,后续能更快的发布,这些命令我们可以写成 npm-scriprt,所以我们增加两个脚本:
{
"name": "@taoweng/react-demo",
"version": "1.0.0",
"description": "react demo",
"main": "lib/index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "webpack-dev-server --open development",
"build": "webpack --mode production",
"deploy": "gh-pages -d examples/dist",
"publish-demo": "npm run build && npm run deploy"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
"@babel/cli": "^7.2.3",
"@babel/core": "^7.2.2",
"@babel/preset-env": "^7.3.1",
"@babel/preset-react": "^7.0.0",
"babel-loader": "^8.0.5",
"gh-pages": "^2.0.1",
"html-webpack-plugin": "^3.2.0",
"react": "^16.7.0",
"react-dom": "^16.7.0",
"webpack": "^4.29.0",
"webpack-cli": "^3.2.1",
"webpack-dev-server": "^3.1.14"
},
"dependencies": {}
}
添加了 deploy 脚本和 publish-demo,以后需要发布 demo 的时候只需要 npm run publish-demo 即可。
然后我们就可以 build 项目之后再将 expamples/dist 发布到 gh-pages 分支:
npm run build
npm run deploy或者直接
npm run publish-demo注意:这里只会将 expample/src 下的文件发布到 ph-pages 分支,master 分支依然没有到 github 上,如果你要把源码放到 github 的 master 或者其他分支上,还是需要自己 push 的。
这个时候,我们可以通过 crazylxr.github.io/react-demo 访问到我们写的 demo。crazylxr 是 github 的 username,react-demo 是仓库名,注意改成你自己的。
我们现在的源码是 jsx 的,所以我们需要通过 babel 把 jsx 编译为正常浏览器能访问的代码。我们可以通过 babel-cli 来编译我们代码,直接编译 src 目录,到 lib 文件夹。更多命令见 babel-cli
npx babel src --out-dir lib执行完这个命令,就把生成一个 lib 文件夹,然后里面的 index.js 就是编译过后的文件,是可以直接发布到 npm 的文件。
然后将这个编译命令写到 script 里,package.json 如下:
{
"name": "@taoweng/react-demo",
"version": "1.0.0",
"description": "react demo",
"main": "lib/index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "webpack-dev-server --open development",
"build": "webpack --mode production",
"compile": "npx babel src --out-dir lib",
"deploy": "gh-pages -d example/dist",
"publish-demo": "npm run build && npm run deploy"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
"@babel/cli": "^7.2.3",
"@babel/core": "^7.2.2",
"@babel/preset-env": "^7.3.1",
"@babel/preset-react": "^7.0.0",
"babel-loader": "^8.0.5",
"gh-pages": "^2.0.1",
"html-webpack-plugin": "^3.2.0",
"react": "^16.7.0",
"react-dom": "^16.7.0",
"webpack": "^4.29.0",
"webpack-cli": "^3.2.1",
"webpack-dev-server": "^3.1.14"
},
"dependencies": {}
}
那么以后要编译 src 下面的代码,只需要执行:
npm run compile
现在我们已经有编译好的代码了,接下来就可以发布到 npm 供其他人使用了。
在发布以前我们是需要一些准备:
注册 npm 账户:
在这里](https://www.npmjs.com/) 注册一个 npm 账号。
登录
在终端输入:
npm adduser也可以用:
npm login然后你会得到一个让你输入username、password 和 **email ** 的提示,把它们填在相应的位置。
关于 package.json 需要注意的点
package.json 里面的配置信息非常重要,我解释一下几个重要的配置。
name: 包名,如果你学习的话建议加一个 scoped,就是我上面的 @taoweng/react-demo 而不是 react-demo,因为 npm 包特别的多,很容易重复。这样这个包就会是私有的,可以通过 npm publish --access=public 将这个包变为共有的包。
description:包的简介。
repository:适合写 Github 地址,建议写成::username/:repository。
license:认证。不知道该用什么的,就写MIT 吧。
main:包的入口文件。就是引入这个包的时候去加载的入口文件。
keywords:添加一些关键词更容易使你的包被搜索到。
更详细的 package.json 配置可见官网。
我这里简单的添加了这些信息:
{
"name": "@taoweng/react-demo",
"version": "1.0.0",
"description": "react demo",
"main": "lib/index.js",
"repository": "crazylxr/react-demo",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start": "webpack-dev-server --open development",
"build": "webpack --mode production",
"compile": "npx babel src --out-dir lib",
"deploy": "gh-pages -d example/dist",
"publish-demo": "npm run build && npm run deploy"
},
"keywords": ["react", "demo"],
"author": "taoweng",
"license": "MIT",
"devDependencies": {
"@babel/cli": "^7.2.3",
"@babel/core": "^7.2.2",
"@babel/preset-env": "^7.3.1",
"@babel/preset-react": "^7.0.0",
"babel-loader": "^8.0.5",
"gh-pages": "^2.0.1",
"html-webpack-plugin": "^3.2.0",
"react": "^16.7.0",
"react-dom": "^16.7.0",
"webpack": "^4.29.0",
"webpack-cli": "^3.2.1",
"webpack-dev-server": "^3.1.14"
},
"dependencies": {}
}
这些配置信息都会在 npm 包的页面显示出来的,所以能填还是填一下:
最后我们在项目中添加 .npmignore 文件,跟 .gitignore 的作用一样,就是在发布 npm 的时候需要忽略的文件和文件夹:
# .npmignore
src
examples
.babelrc
.gitignore
webpack.config.js
这个时候我们就可以发布到 npm 了:
npm publish如果你是私有包,可以这样发布:
npm publish --access=public以后发布新版本的时候,只需要更改一下 package.json 里面的 version 版本号,然后执行 npm publish 和 npm run publish-demo 就可以同步 npm 和 demo。
不过如果想让你的组件在社区里给更多人用,你需要把 README 写得更好一点,然后添加好自动化测试,不然别人不太敢用。
另外在写组件之前可以先了解下有没有类似的组件了,如果有就直接用吧,咱们就站在巨人的肩膀上,把自己宝贵的时间放在创造价值上。
最后整个项目的源代码见 github
在阅读这篇文章之前,我希望你已经了解过 React 的 Fiber 架构,如果还不熟悉,请阅读我的这篇:Deep In React 之浅谈 React Fiber 架构(一)。
在环境搭建上我选择了 Parcel,因为它使用起来非常的简洁,配置少,使用起来方便。
首先通过 npm 安装 Parcel:
npm install -g parcel-bundler创建一个项目目录并且初始化 package.json 文件:
mkdir react-like && cd react-like && npm init -y接下来创建 index.html 和 index.js,在 index.html 里引入 index.js
const title = <h1 className="title"><h2>fetaoyuan</h2><h2>taoweng</h2></h1>;这样的一段 jsx 代码其实对于浏览器来说是一段不合法的 js 代码,本质上,jsx 是 js 的语法糖,比如上面的这段代码会被 babel 转成如下代码:
var title = React.createElement("h1", {
className: "title"
},
React.createElement("h2", null, "fetaoyuan"),
React.createElement("h2", null, "taoweng"));你可以在这里进行在线转换查看转换后的代码
可以看出来转化的逻辑大概是这样:
React.createElement(type, props, child1, child2, child3)清楚了 babel 的转化逻辑,接下来就来实现以下吧。
首先配置一下 .babelrc:
{
"presets": ["@babel/env"],
"plugins": [
["@babel/transform-react-jsx", {
"pragma": "React.createElement"
}]
]
}接下来在 index.js 里写一行代码看是否成功。
document.write('前端桃园')然后让项目跑起来:
parcel index.htmlparcel 是一个非常智能的工具,不需要你去安装 babel 相关的包,会根据你的配置,自动的去安装相关的包,在平时的玩具里面用,还是非常方便的。
然后访问 localhost:1234 就可以看到屏幕输出了前端桃园了。
我们知道在 React 里,children 是作为 props 里面的一个属性,这根 jsx 转化出来的不一样。知道了 babel 转化 jsx 的规则,我们要实现 createElement 就非常的简单了,只需要利用 ES6 的 rest 参数,就可以非常容易的拿到所有的 children。
function createElement(type, config, ...children) {
return {
type,
props: {
...config,
children
}
}
}接下来在进行调试一下:
// index.js
const React = {
createElement
}
function createElement(type, config, ...children) {
return {
type,
props: {
...config,
children
}
}
}
const title = <h1 className="title"><h2>fetaoyuan</h2><h2>taoweng</h2></h1>;
console.log(title)输出的结果如下,是符合我们的期望的。
实际上这个输出出来的,通过 createElement 方法返回的对象记录了这个 DOM 节点我们需要的信息,这个对象就被称为虚拟DOM。
在了解 fiber 架构之后,你就应该知道 fiber 是如何工作的,在初次渲染的时候:
第一步生成虚拟 DOM 上面已经完成了,接下来了解如何通过并发模式来生成 Fiber。
理想情况下,我们应该把 render 拆成更细分的单元,每完成一个单元的工作,允许浏览器打断渲染响应更高优先级的工作,这个过程称为"并发模式(Concurrent Mode)"。
这里用 requestIdleCallback 这个浏览器 API 来实现,这个 API 可以在线程空闲的时候去执行回调函数(执行我们的工作单元)。
由于兼容性的问题,React 目前没有使用这个 API,而是为了这个效果,自己实现了一套方案,但核心思路是类似的。
大致的代码如下:
let nextUnitOfWork; // 下一个执行单元
function workLoop(deadline) {
while(nextUnitOfWork) {
nextUnitOfWork = performUnitWork(nextUnitOfWork)
}
}
function performUnitWork(currentFiber) {
// TODO, 执行单元
}
requestIdleCallback(workLoop)全局遍历 nextUnitOfWork 为下一个执行单元,是一个 Fiber 结构。
我们要知道架构改为 fiber 的一个大的特征就是将结构改为了链表,链表的遍历就是一个一个的, performUnitWork 函数就是执行当前的 Fiber,然后返回下一个 Fiber,这样遍历整棵树。
但是目前的代码是有问题的,因为没有被打断的逻辑,那咱们再加上被打断的逻辑。
let nextUnitOfWork; // 下一个执行单元
// deadline 是还有多少的空闲时间
function workLoop(deadline) {
let shouldYield = false;
while(nextUnitOfWork && !shouldYield) {
nextUnitOfWork = performUnitWork(nextUnitOfWork)
// 回调函数入参 deadline 可以告诉我们在这个渲染周期还剩多少时间可用
// 剩余时间小于1毫秒就被打断,等待浏览器再次空闲
shouldYield = deadline.timeRemaining() < 1;
}
requestIdleCallback(workLoop);
}
function performUnitWork(currentFiber) {
// TODO, 执行单元
}
requestIdleCallback(workLoop)打断的逻辑就在 shouldYield = deadline.timeRemaining() < 1 这行代码里,如果时间片小于 1 毫秒,就被打断,等待浏览器下次空闲的时候再执行。
有没有忽然觉得如此高大上的概念(并发模式),其实原理很简单。
为了便于理解,现在将文件进行拆分一下,将 React.xxx 的 API 放到 react.js 里。
另外我们都知道 react 要进行渲染需要有个 render 函数,这个是在 ReactDOM 下面的 API,所以再建一个 react-dom.js 用来放 render 函数。
对于刚才我们所写的并发模式相关的代码,放到 schedule.js 里。
另外再增加一个 constants.js 的常量文件,用来存放一些特殊常量。
所以现在就有 6 个文件, index.html 、 index.js 、 react.js 、 react-dom.js 、 schedule.js 、constants.js。
index.html 里需要添加一个 react 挂载的节点。
<body>
<div id="root"></div>
<script src="./index.js"></script>
</body>index.js 需要导入 React 和 ReactDOM ,然后调用 render 函数进行渲染。
// index.js
import React from "./react.js";
import ReactDOM from "./react-dom";
const title = (
<h1 className="title">
<h2>fetaoyuan</h2>
<h2>taoweng</h2>
</h1>
);
ReactDOM.render(title, document.getElementById("root"));将 createElement 放到 react.js 里,进行简单的改造,并且创建 constants.js 。
import { ELEMENT_TEXT } from "./constants";
const React = {
createElement,
};
function createElement(type, config, ...children) {
return {
type,
props: {
...config,
children: children.map((child) => {
if (typeof child === "object") {
return child;
} else {
return {
type: ELEMENT_TEXT,
props: {
text: child,
children: [],
},
};
}
}),
},
};
}
export default React;改造的点主要是针对文本节点,如果是文本节点的时候返回一个跟正常的虚拟 DOM 节点一样的结构,而不是直接返回文本,这样做的目的是为了后面方便统一处理。
tip:react 里并没有做这一步,而是直接返回的文本。
constants.js 里存放着节点的一些类型。
// constants.js
// 虚拟DOM 节点类型
export const ELEMENT_TEXT = Symbol.for('ELEMENT_TEXT');
// Fiber 的类型
export const TAG_ROOT = Symbol.for('TAG_ROOT'); // 根节点
export const TAG_HOST = Symbol.for('TAG_HOST'); // host 节点
export const TAG_TEXT = Symbol.for('TAG_TEXT'); // 文本节点
// effect 类型
export const PLACEMENT = Symbol.for('PLACEMENT'); // 增加元素react-dom.js 的 render 函数写成这样:
// react-dom.js
import { TAG_ROOT } from './constants'
import { scheduleRoot } from "./schedule";
function render(element, container) {
let rootFiber = {
tag: TAG_ROOT,
stateNode: container,
props: { children: [element] }
}
scheduleRoot(rootFiber)
return rootFiber
}
export default { render }新建一个 rootFiber 的 fiber,然后通过 scheduleRoot 进行去调度。schedule.js 目前就是这样:
let nextUnitOfWork; // 下一个执行单元
export function scheduleRoot(rootFiber) {
nextUnitOfWork = rootFiber
}
// deadline 是还有多少的空闲时间
function workLoop(deadline) {
let shouldYield = false;
while(nextUnitOfWork && !shouldYield) {
nextUnitOfWork = performUnitWork(nextUnitOfWork)
// 回调函数入参 deadline 可以告诉我们在这个渲染周期还剩多少时间可用
// 剩余时间小于1毫秒就被打断,等待浏览器再次空闲
shouldYield = deadline.timeRemaining() < 1;
}
requestIdleCallback(workLoop);
}
function performUnitWork(currentFiber) {
// TODO, 执行单元
}
requestIdleCallback(workLoop)scheduleRoot 所要做的事情就是将 nextUnitOfWork 赋值为 rootFiber ,这样 requestIdleCallback 调用的时候 workLoop 里才有值。
**performUnitOfWork** 是如何去遍历整棵树的逻辑的函数,同时也会返回下一个要完成的 fiber。
Fiber 架构遍历是采用的深度优先遍历,会先遍历子节点,如果子节点没有,再遍历兄弟节点,如果没有兄弟节点,就返回到父节点。
TODO:这里应该把 react 如何遍历一棵树的原理讲出来。
所以 performUnitOfWork 的代码如下:
// schedule.js
function performUnitWork(currentFiber) {
// 把子元素变成子 fiber
beginWork(currentFiber)
// 如果有子节点就返回以第一个子节点
if(currentFiber.child) {
return currentFiber.child
}
while (currentFiber) {
// 没有子节点就代表当前节点已经完成了调和工作,
// 就可以结束 fiber 的调和,进入收集副作用的步骤(completeUnitOfWork)
completeUnitOfWork(currentFiber);
if (currentFiber.sibling) {
return currentFiber.sibling;
}
currentFiber = currentFiber.return;
}
}
// complete的工作就是收集副作用
function completeUnitOfWork(currentFiber) {}type Fiber = {
//标记不同的组件类型
tag: WorkTag,
// ReactElement.type,也就是我们调用`createElement`的第一个参数
elementType: any,
// 跟当前Fiber相关本地状态(比如浏览器环境就是DOM节点)
stateNode: any,
// 指向他在Fiber节点树中的`parent`,用来在处理完这个节点之后向上返回
return: Fiber | null,
// 新的变动带来的新的props
pendingProps: any,
// 上一次渲染完成之后的props
memoizedProps: any,
// 单链表树结构
// 指向自己的第一个子节点
child: Fiber | null,
// 指向自己的兄弟结构
// 兄弟节点的return指向同一个父节点
sibling: Fiber | null,
// Effect
// 用来记录Side Effect
effectTag: SideEffectTag,
// 单链表用来快速查找下一个side effect
nextEffect: Fiber | null,
// 子树中第一个side effect
firstEffect: Fiber | null,
// 子树中最后一个side effect
lastEffect: Fiber | null,
}如果你是了解 fiber 架构的,那么对于 Fiber 是这么一个结构应该不陌生。其中 tag 和 effectTag 放在 constans.js 里,具体的常量的值我这里保持跟 React 里一样,首次更新的也不多,所以 constans.js 增加的常量有:
// WorkTag
export const HostRoot = 3; // 根节点
export const HostComponent = 5; // 一般的 host 节点
export const HostText = 6; // 文本节点
// SideEffectTag
export const Placement = 0b00000000010;将子元素变为 fiber,首先需要判断当前 fiber 的 tag 类型,不同的类型有不同的策略。
function beginWork(currentFiber) {
if (currentFiber.tag === HostRoot) {
updateHostRoot(currentFiber);
} else if (currentFiber.tag === HostText) {
updateHostText(currentFiber)
} else if(currentFiber.tag === HostComponent) {
updateHostComponent(currentFiber);
}
}
function updateHostRoot(currentFiber) {}
function updateHostText(currentFiber) {}
function updateHostComponent(currentFiber) {} 接下来就是重点了,要实现一个 reconcileChildren 的函数,这个函数理论上就是 diff 的过程,但是由于首次渲染,没有 diff 的过程,就直接创建 fiber 了。
咱们先写根节点的时候的更新方法(updateHostRoot)吧。
function updateHostRoot(currentFiber) {
// 拿到当前 fiber 的所有子节点,然后将所有子节点变为 fiber
const children = currentFiber.props.children
reconcileChildren(currentFiber, children)
}接下来实现以下 reconcileChildren 这个函数。
function reconcileChildren(currentFiber, newChildren) {
let newChildIndex = 0; // 新虚拟 DOM 数组索引
let prevSibling; // 上一个兄弟节点
// 循环虚拟DOM数组
while(newChildIndex < newChildren.length) {
let newChild = newChildren[newChildIndex]
// 要根据不同的虚拟 DOM 类型,给到不同的 WorkTag
let tag
if(newChild.type === ELEMENT_TEXT) {
tag = HostText
} else if(typeof newChild.type === 'string') {
tag = HostComponent
}
let newFiber = {
tag,
elementType: newChild.type,
stateNode: null,
return: currentFiber,
pendingProps: newChild.props,
effectTag: Placement, // 首次渲染,一定是增加,所以是 Placement
}
if (newFiber) {
// 第一个会被当做父 fiber 的 child,其他的作为 child 的 sibling
if (newChildIndex === 0) {
currentFiber.child = newFiber;
} else {
prevSibling.sibling = newFiber;
}
}
prevSibling = newFiber;
newChildIndex++
}
}执行完 reconcileChildren 之后,所有的子节点都转化为了 fiber,不过还有一些属性没有添加上去,比如 stateNode 和 nextEffect 。
接下来继续完成 updateHostText 和 updateHostComponent 。
这两步需要进行 dom 的操作,所以先创建一个 dom.js 用来存放 dom 相关的操作。
// dom.js
// 文本节点直接创建 textNode,host 节点创建 element 之后再进行属性的赋值。
export function createDOM(currentFiber) {
if(currentFiber.elementType === ELEMENT_TEXT) {
return document.createTextNode(currentFiber.pendingProps.text)
}
const stateNode = document.createElement(currentFiber.elementType)
setProps(stateNode, {}, currentFiber.pendingProps)
return stateNode
}
// 除了 children 属性,其他的都作为 dom 的 Attribute
export function setProps(elem, oldProps, newProps) {
for (let key in oldProps) {
if (key !== "children") {
if (newProps.hasOwnProperty(key)) {
setProp(elem, key, newProps[key]);
} else {
elem.removeAttribute(key);
}
}
}
for (let key in newProps) {
if (key !== "children") {
setProp(elem, key, newProps[key]);
}
}
}
function setProp(dom, key, value) {
if (/^on/.test(key)) {
dom[key.toLowerCase()] = value;
} else if (key === "style") {
if (value) {
for (let styleName in value) {
if (value.hasOwnProperty(styleName)) {
dom.style[styleName] = value[styleName];
}
}
}
} else {
dom.setAttribute(key, value);
}
return dom;
}关于 dom 操作就不多说了,这应该是基础,不算是 react 的核心。updateHostText 和 updateHostComponent 的代码也不复杂,如下:
// schedule.js
function updateHostText(currentFiber) {
if (!currentFiber.stateNode) {
currentFiber.stateNode = createDOM(currentFiber);//先创建真实的DOM节点
}
}
function updateHostComponent(currentFiber) {
// 由于 fiber 里面是有 elementType 的,
// 所以是可以根据elementType 来创建 dom 节点的,
// 那么 stateNode 就可以先创建
if(!currentFiber.stateNode) {
currentFiber.stateNode = createDOM(currentFiber)
}
const children = currentFiber.pendingProps.children
reconcileChildren(currentFiber, children)
}到这个时候,fiber list 基本构建完毕,如果在 updateHostRoot 的最后一行打印一下 currentFiber 应该就可以看到整个构建的 fiber 链表。
接下来就是完成 effectList 的构建。
effect list 是在 completeUnitOfWork 函数里完成的,具体代码如下:
function completeUnitOfWork(currentFiber) {
const returnFiber = currentFiber.return;
if (returnFiber) {
if (!returnFiber.firstEffect) {
returnFiber.firstEffect = currentFiber.firstEffect;
}
if (!!currentFiber.lastEffect) {
if (!!returnFiber.lastEffect) {
returnFiber.lastEffect.nextEffect = currentFiber.firstEffect;
}
returnFiber.lastEffect = currentFiber.lastEffect;
}
const effectTag = currentFiber.effectTag;
if (effectTag) {
if (!!returnFiber.lastEffect) {
returnFiber.lastEffect.nextEffect = currentFiber;
} else {
returnFiber.firstEffect = currentFiber;
}
returnFiber.lastEffect = currentFiber;
}
}
}构建完 effect list 了就可以开始 commit 了,构建完 effect list 的时机就是没有 nextUnitOfWork 了,就代表已经调和完毕了,到了下一个阶段:commit。
那么在 workLoop 就会有一个判断是否存在下一个执行单元,如果没有就进行提交阶段。
function workLoop(deadline) {
let shouldYield = false;
while (nextUnitOfWork && !shouldYield) {
nextUnitOfWork = performUnitOfWork(nextUnitOfWork);//执行一个任务并返回下一个任务
shouldYield = deadline.timeRemaining() < 1;//如果剩余时间小于1毫秒就说明没有时间了,需要把控制权让给浏览器
}
//如果没有下一个执行单元了,并且当前渲染树存在,则进行提交阶段
if (!nextUnitOfWork && workInProgressRoot) {
commitRoot();
}
requestIdleCallback(workLoop);
}我们在提交的时候就要拿到整颗 fiber 链表的头结点,但是之前的 nextUnitOfWork 已经为空了,所以还需要一个变量来存储当前正在渲染的根 fiber,这个 fiber 就是之前学到的 WorkInProgress Tree 。
所以就需要一个变量: workInProgressRoot 的遍历用来存储当前渲染的 fiber 树,并且在 scheduleRoot 的时候把根 fiber 赋值给它
let nextUnitOfWork; // 下一个执行单元
let workInProgressRoot; // 当前正在工作的树
export function scheduleRoot(rootFiber) {
nextUnitOfWork = rootFiber
workInProgressRoot = rootFiber
}所以 commitRoot 就应该是这样:
function commitRoot() {
let currentFiber = workInProgressRoot.firstEffect
while(currentFiber) {
commitWork(currentFiber)
currentFiber = currentFiber.nextEffect
}
workInProgressRoot = null
}
function commitWork(currentFiber) {
if(!currentFiber) {
return;
}
let returnFiber = currentFiber.return;
const domReturn = returnFiber.stateNode;
if(currentFiber.effectTag === Placement && currentFiber.stateNode != null) {
domReturn.append(currentFiber.stateNode)
}
currentFiber.effectTag = null
}到此,就已经可以渲染出这样的效果了:
撒花,结束,接下来将实现元素的更新以及函数式组件,还有 hooks。
demo 代码在这里:https://github.com/crazylxr/luffy/tree/chapter1
珠峰架构公开课
本文首发于个人博客
看到这个是不是有一种想打人的感觉,垃圾 JavaScript,这特么都什么鬼,相信很多人不管是笔试还是面试,都被 JS 的类型转换难道过,相信认真看完我这篇文章,妈妈再也不用担心类型转换的问题了。
原始值转化为布尔值
所有的假值(undefined、null、0、-0、NaN、””)会被转化为 false,其他都会被转为 true
原始值转化为字符串
都相当于 原始值 + ""
原始值转为数字
+" 66" // 66
+" 6 7 " // NaN
如果作为一元运算符就是转化为数字,常常用来将字符串转化为数字
+"2" // 2
2+false // 0
如果作为二元运算符就有两种转换方式
流程图如下:
[]+[] // ""_1. 首先运算符是 + 运算符而且很明显是二元运算符,并且有对象,所以选择最后一点,操作数是对象,将对象转换为原始值。
_2. 两边对象都是数组,左边的数组先调用 valueOf() 方法无果,然后去调用 toString(), 方法,在 toString() 的转化规则里面有『将数组转化为字符串,用逗号分隔』,由于没有其他元素,所以直接是空字符串 “”。
_3. 因为加号有一边是字符串了,所以另外一边也转为 字符串,所以两边都是空字符串 “”。
_4. 所以加起来也是空字符串 “”。
(! + [] + [] + ![]).length // 9_1. 首先我们会看到挺多一元运算符,「+」、「!」,对于一元运算符是右结合性,所以可以画出以下运算顺序。
_2. 对于+[],数组是会被转化为数字的而不是字符串,可见「+ 运算符如何进行类型转化」的第一条,所以经过第一步就会转化为
(!0 + [] + "false").length
_3. 第二步比较简单,0 转化为布尔值就是 false,所以经过第二步就转化为
(true + [] + "false").length
_4. 第三步中间的 []会转为空字符串,在「+ 运算符如何进行类型转化」第二条的第三点,对象会被转转化为原始值,就是空字符,所以经过第三步之后就会变成
("true" + "false").length
_5. 第五步就比较简单啦,最终就是
"truefalse".length // 9
《JavaScript权威指南》中类型转换表格
欢迎关注我的公号【前端桃园】
ES6允许直接写入变量和函数作为对象的属性和方法。意思就是说允许在对象中只写属性名,不用写属性值。这时,属性值等于属性名称所代表的变量。下面分别举一个例子来说明:
function getPoint(){
var x = 1 ;
var y = 2;
return {x,y}
}
等同于
fucntion getPoint(x,y){
var x = 1 ;
var y = 2;
return {x:x,y:y}
}
测试:
getPoint();//{x:1,y:10}
var obj = {
fun(){
return "simply function";
}
};
等同于
var obj = {
fun: function(){
return "simply function";
}
}
测试:
obj.fun();//simply function
ES6里允许定义对象的时候用表达式作为对象的属性名或者方法名,即把表达式放在方括号里。
let propKey = 'foo';
let obj = {
[propKey] : true,
['a'+'bc'] : 123
}
测试:
obj.propKey; //true
obj.abc ; //123
let obj = {
['h'+'ello'](){
return "hello world";
}
}
测试:
obj.hello();//hello world
属性名表达式与简介表达式不能同时使用。
//错误的
var foo = 'bar';
var bar = 'abc';
var baz = { [foo] };
//正确
var foo = 'bar';
var baz = { [foo] : 'abc'}
这个比较容易理解,直接阐述文字。
函数的name属性返回函数名。对象方法也是函数,因此也有函数名。
Object.is()用来比较两个值yan'ge严格相等。与严格比价运算符(===)的行为基本一致。不同之处只有两个:一是 +0 不等于 -0 ,二是NaN等于自身
+0 === -0 //true
NaN === NaN //false
Object.is(+0,-0);//false
Object.is(NaN,NaN);//true
Object.assign()方法是用于将源对象的可枚举属性复制到目标对象。它至少需要两个参数,第一是目标对象,后面的全是源对象。
demo:
var target = {a:1,b:2};
var source1 = {a:2,c:5};
var source2 = {a:3,d:6};
Object.assign(target,source1,source2);
target//{a:3,b:2,c:5,d:6}
Object.assign可用于处理数组,但是会将其视为对象
Object.assign([1,2,3],[4,5]);
//[4,5,3]
具体例子参考阮一峰的ES6标准入门
对象的没个属性都有一个描述对象(Descriptor),可通过Object.getOwnPropertyDescriptor(object,prop),object表示对象,prop表示对象的里的一个属性,用的时候需要加上引号。描述对象里面有个enumerable(可枚举性)属性,来描述该属性是否可枚举。
ES5中会忽略enumerable为false的属性
ES6新增的操作
ES6中一共有6中方法可以遍历对象的属性。
以上6种方法遍历对象的属性遵守同样的属性遍历次序规则
首先遍历所有属性名为数值的属性,按照数字排序
其次遍历所有属性名为字符串的属性,按照生成时间排序
最后遍历所有属性名为Symbol值的属性,按照生成时间排序
Reflect.ownkeys({[Symbol()]:0,b:0,10:0,2:0,a:0})
//['2','10','b','a',Symbol()]
(前后应该有两个下划线,这里没显示出来)。用来读取或者设置当前对象的prototype对象。但是一般不直接对这个属性进行操作,而是通过Object.setProtortypeOf()(写操作)、Object.getPrototypeOf()(读操作)或者Object.create()(生成操作)代替。
let proto = {};
let obj = { x : 10};
Object.setProtortypeOf(obj,proto);
proto.y = 20;
proto.z = 40;
obj.x //10
obj.y //20
obj.z //40
function Rectangle(){}
var rec = new Rectangle();
Object.getPrototypeOf(rec) === Rectangele.prototype // true
ES7中提案,将rest参数/扩展运算符(...)引入对象。
Rest参数用于从一个对象取值,相当于将所有可遍历尚未被读取的属性,分配到制定的对象上。所有的键及其值都会复制到新对象上。需要注意的是rest参数的复制是浅复制,并且也不会复制继承自原型对象的属性。
简单的demo
let {x,y,...k} = {x:2, y:3,z:4,a:5};
x //2
y //3
k //{z:4,a:5}
扩展运算符用于取出参数对象的所有可遍历属性,复制到当前对象中。
let z = {a:3 ,b:4};
let n = {...z};
n //{a:3,b:4}
扩展运算符还可以合并两个对象。
let a = { c:5,d:6 };
let b = { e:7,f:8 };
let ab = {...a,...b};
ab //{c:5,d:6,e:7,f:7}
扩展运算符还可以自定义属性,会在新对象中覆盖掉原有参数。
let a = {x:1,y:2};
let aWithOverides = {...a,x:3,y:4};
aWithOverides //{x:4,y:4}
最近我发现很多面试题里面都有「如何理解虚拟 DOM」这个题,我觉得这个题应该没有想象中那么好答,因为很多人没有真正理解虚拟 DOM 它的价值所在,我这篇从虚拟 DOM 的诞生过程来引出它的价值以及历史地位,帮助你深入的理解它。
本质上是 JavaScript 对象,这个对象就是更加轻量级的对 DOM 的描述。
对,就是这么简单!
就是一个复杂一点的对象而已,没什么好说的,重点是为什么要有这个东西,以及有了这个描述有什么好处才是我们今天要介绍的内容。
再谈为什么要用虚拟 DOM 之前,先来聊一聊 React 是怎么诞生的,毕竟在了解历史背景,再去思考他的诞生,就知道是必然会出现的。
再查了很多关于 React 的历史相关的文章,这篇文章我感觉比较值得令我信服:React 是怎样炼成的。
众所周知,Facebook 是 PHP 大户,所以 React 最开始的灵感就来至于 PHP。
在 2004 年这个时候,大家都还在用 PHP 的字符串拼接来开发网站:
$str = '<ul>';
foreach ($talks as $talk) {
$str += '<li>' . $talk->name . '</li>';
}
$str += '</ul>';这种方式代码写出来不好看不说,还容易造成 XSS 等安全问题。
应对方法是对用户的任何输入都进行转义(Escape)。但是如果对字符串进行多次转义,那么反转义的次数也必须是相同的,否则会无法得到原内容。如果又不小心把 HTML 标签(Markup)给转义了,那么 HTML 标签会直接显示给用户,从而导致很差的用户体验。
到了 2010 年,为了更加高效的编码,同时也避免转义 HTML 标签的错误,Facebook 开发了 XHP 。XHP 是对 PHP 的语法拓展,它允许开发者直接在 PHP 中使用 HTML 标签,而不再使用字符串。
$content = <ul />;
foreach ($talks as $talk) {
$content->appendChild(<li>{$talk->name}</li>);
}
这样的话,所有的 HTML 标签都使用不同于 PHP 的语法,我们可以轻易的分辨哪些需要转义哪些不需要转义。
不久的后来,Facebook 的工程师又发现他们还可以创建自定义标签,而且通过组合自定义标签有助于构建大型应用。
到了 2013 年,前端工程师 Jordan Walke 向他的经理提出了一个大胆的想法:把 XHP 的拓展功能迁移到 JS 中。首要任务是需要一个拓展来让 JS 支持 XML 语法,该拓展称为 JSX。因为当时由于 Node.js 在 Facebook 已经有很多实践,所以很快就实现了 JSX。
可以猜想一下为什么要迁移到 js 中,我猜想应该是前后端分离导致的。
const content = (
<TalkList>
{ talks.map(talk => <Talk talk={talk} />)}
</TalkList>
);在这个时候,就有另外一个很棘手的问题,那就是在进行更新的时候,需要去操作 DOM,传统 DOM API 细节太多,操作复杂,所以就很容易出现 Bug,而且代码难以维护。
然后就想到了 PHP 时代的更新机制,每当有数据改变时,只需要跳到一个由 PHP 全新渲染的新页面即可。
从开发者的角度来看的话,这种方式开发应用是非常简单的,因为它不需要担心变更,且界面上用户数据改变时所有内容都是同步的。
为此 React 提出了一个新的**,即始终整体“刷新”页面
当发生前后状态变化时,React 会自动更新 UI,让我们从复杂的 UI 操作中解放出来,使我们只需关于状态以及最终 UI 长什么样。
下面看看局部刷新和整体刷新的区别。
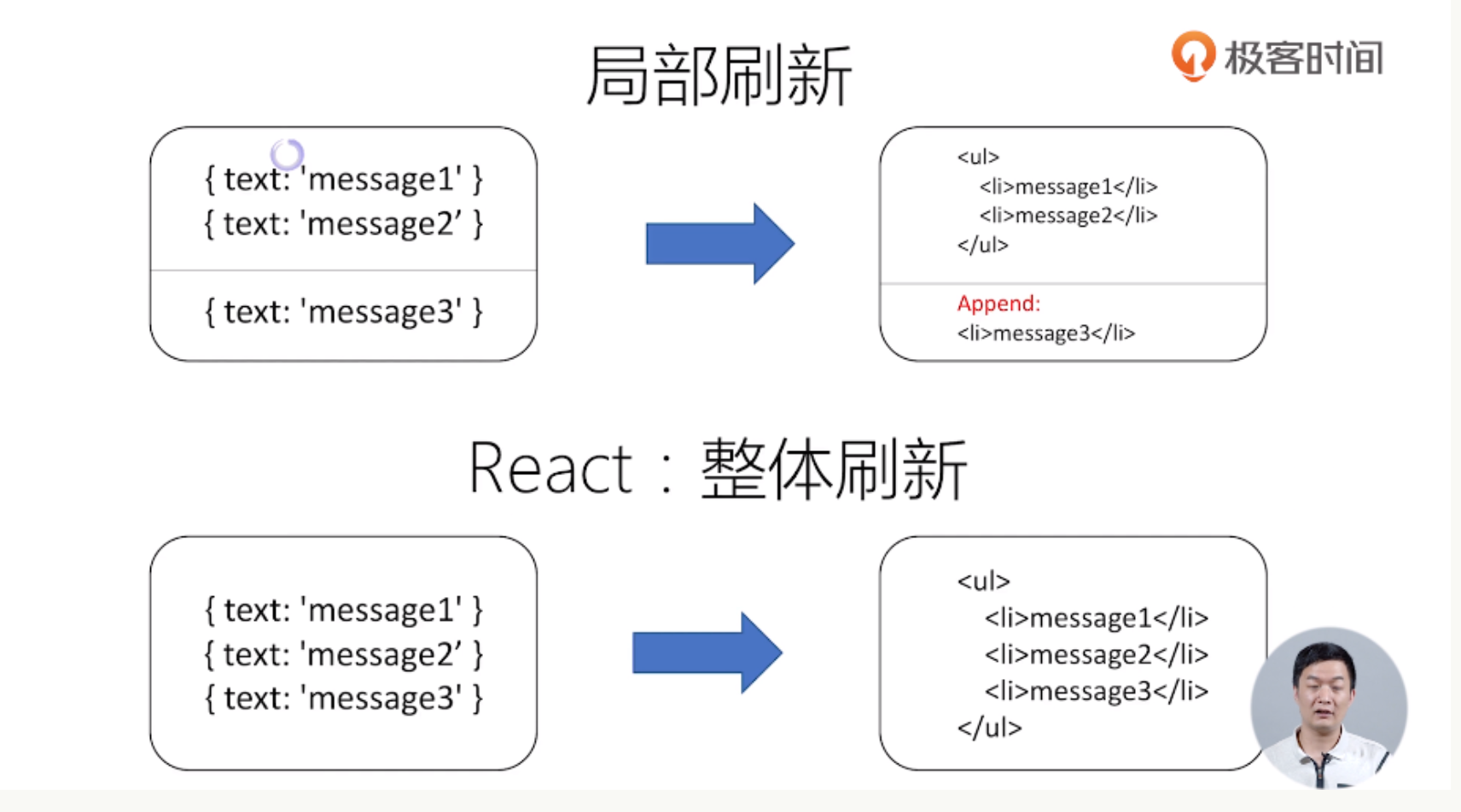
图片来自于极客时间王沛老师的《React进阶与实战》
局部刷新:
// 下面是伪代码
var ul = find(ul) // 先找到 ul
ul.append(`<li>${message3}</li>`) //然后再将message3插到最后
// 想想如果是不插到最后一个,而是插到中间的第n个
var ul = find(ul) // 先找到 ul
var preli = find(li(n-1)) // 再找到 n-1 的一个 li
preli.next(`<li>${message3}</li>`) // 再插入到 n-1 个的后面整体刷新:
UI = f(messages) // 整体刷新 3 条消息,只需要调用 f 函数
// 这个是在初始渲染的时候就定义好的,更新的时候不用去管
function f(messages) {
return <ul>
{messages.map(message => <li>{ message }</li>)}
</ul>
}这个时候,我只需要关系我的状态(数据是什么),以及 UI 长什么样(布局),不再需要关系操作细节。
这种方式虽然简单粗暴,但是很明显的缺点,就是很慢。
另外还有一个问题就是这样无法包含节点的状态。比如它会失去当前聚焦的元素和光标,以及文本选择和页面滚动位置,这些都是页面的当前状态。
为了解决上面说的问题,对于没有改变的 DOM 节点,让它保持原样不动,仅仅创建并替换变更过的 DOM 节点。这种方式实现了 DOM 节点复用(Reuse)。
至此,只要能够识别出哪些节点改变了,那么就可以实现对 DOM 的更新。于是问题就转化为如何比对两个 DOM 的差异。
说道对比差异,可能很容易想到版本控制(git)。
DOM 是树形结构,所以 diff 算法必须是针对树形结构的。目前已知的完整树形结构 diff 算法复杂度为 O(n^3) 。
但是时间复杂度 O(n^3) 太高了,所以Facebook工程师考虑到组件的特殊情况,然后将复杂度降低到了 O(n)。
附:详细的 diff 理解:不可思议的 react diff 。
前面说到,React 其实实现了对 DOM 节点的版本控制。
做过 JS 应用优化的人可能都知道,DOM 是复杂的,对它的操作(尤其是查询和创建)是非常慢非常耗费资源的。看下面的例子,仅创建一个空白的 div,其实例属性就达到 231 个。
// Chrome v63
const div = document.createElement('div');
let m = 0;
for (let k in div) {
m++;
}
console.log(m); // 231对于 DOM 这么多属性,其实大部分属性对于做 Diff 是没有任何用处的,所以如果用更轻量级的 JS 对象来代替复杂的 DOM 节点,然后把对 DOM 的 diff 操作转移到 JS 对象,就可以避免大量对 DOM 的查询操作。这个更轻量级的 JS 对象就称为 Virtual DOM 。
那么现在的过程就是这样:
可以看出,因为要把变更应用到真实 DOM 上,所以还是避免不了要直接操作 DOM ,但是 React 的 diff 算法会把 DOM 改动次数降到最低。
剩下的历史就不谈了,已经引出这篇文章的重点:虚拟 DOM。详细的历史可见:React 是怎样炼成的,文中历史部分内容很多摘抄与此。
传统前端的编程方式是命令式的,直接操纵DOM,告诉浏览器该怎么干。这样的问题就是,大量的代码被用于操作 DOM 元素,且代码可读性差,可维护性低。
React 的出现,将命令式变成了声明式,摒弃了直接操作 DOM 的细节,只关注数据的变动,DOM 操作由框架来完成,从而大幅度提升了代码的可读性和可维护性。
在初期我们可以看到,数据的变动导致整个页面的刷新,这种效率很低,因为可能是局部的数据变化,但是要刷新整个页面,造成了不必要的开销。
所以就有了 Diff 过程,将数据变动前后的 DOM 结构先进行比较,找出两者的不同处,然后再对不同之处进行更新渲染。
但是由于整个 DOM 结构又太大,所以采用了更轻量级的对 DOM 的描述—虚拟 DOM。
不过需要注意的是,虚拟 DOM 和 Diff 算法的出现是为了解决由命令式编程转变为声明式编程、数据驱动后所带来的性能问题的。换句话说,直接操作 DOM 的性能并不会低于虚拟 DOM 和 Diff 算法,甚至还会优于。
这么说的原因是因为 Diff 算法的比较过程,比较是为了找出不同从而有的放矢的更新页面。但是比较也是要消耗性能的。而直接操作 DOM 就是有的放矢,我们知道该更新什么不该更新什么,所以不需要有比较的过程。所以直接操作 DOM 效率可能更高。
React 厉害的地方并不是说它比 DOM 快,而是说不管你数据怎么变化,我都可以以最小的代价来进行更新 DOM。 方法就是我在内存里面用新的数据刷新一个虚拟 DOM 树,然后新旧 DOM 进行比较,找出差异,再更新到 DOM 树上。
框架的意义在于为你掩盖底层的 DOM 操作,让你用更声明式的方式来描述你的目的,从而让你的代码更容易维护。没有任何框架可以比纯手动的优化 DOM 操作更快,因为框架的 DOM 操作层需要应对任何上层 API 可能产生的操作,它的实现必须是普适的。
如果你想了解更多的虚拟 DOM 与性能的关系,请看下面公众号里面的两篇文章和那个知乎话题,会让你对虚拟 DOM 又更深层次的理解。
另外再提一个点,很多人会把 Diff 、数据更新、提升性能等概念绑定起来,但是你想想这个问题:React 由于只触发更新,而不能知道精确变化的数据,所以需要 diff 来找出差异然后 patch 差异队列。Vue 采用数据劫持的手段可以精准拿到变化的数据,为什么还要用虚拟DOM?
要想回答上面那个问题,真的不要仅仅以为虚拟 DOM 或者 React 是来解决性能问题的,好处可还有很多呢。下面我总结了一些虚拟 DOM 好作用。
既然虚拟 DOM 有这么多作用,那么上面的问题,Vue 采用虚拟 DOM 的原因是什么呢?
Vue 2.0 引入 vdom 的主要原因是 vdom 把渲染过程抽象化了,从而使得组件的抽象能力也得到提升,并且可以适配 DOM 以外的渲染目标。 来自尤大文章:Vue 的理念问题
本文在介绍虚拟 DOM 并没有像其他文章一样去解释它的实现以及相关的 Diff 算法,关于 Diff 算法可以看这篇 虚拟 DOM 到底是什么?文中介绍了很多库的 diff 算法,可见其实 React 的 diff 算法并不算太快。
而是通过历史来得出他的价值体现,从历史怎么看大牛们是怎么一步一步的去解决问题,从历史中看为什么别人能做出这么伟大的东西,而我们不能?
每个伟大的产品都会有非常多的背景支持,都是一步一步发展而来的。
另外洗清了一个错误观念:很多人认为虚拟 DOM 最大的优势是 diff 算法,减少 JavaScript 操作真实 DOM 的带来的性能消耗。
虽然这一个虚拟 DOM 带来的一个优势,但并不是全部。虚拟 DOM 最大的优势在于抽象了原本的渲染过程,实现了跨平台的能力,而不仅仅局限于浏览器的 DOM,可以是安卓和 IOS 的原生组件,可以是近期很火热的小程序,也可以是各种 GUI。
最后希望大家多思考,跟随者浪潮站在浪潮之巅。
随着web的发展,网站资源的流量也变得越来越大。据统计,60% 的网站流量均来自网站图片,可见对图片合理优化可以大幅影响网站流量,减小带宽消耗和服务器压力。
有时候你花大力气去配置 webpack 使打包体积减少,不如好好优化几张图片,这篇文章就是让你明白如何选择正确的图片,并且让你明白这么多图片格式,在什么场景下使用什么格式,如果想看答案,那么直接滑到文末看图即可。
在进入正题之前,先聊聊一些图片相关的基本概念。
一张照片(位图)不断放大之后,会看到一个个小格子,这些小格子,叫像素。
一个格子(像素),在计算机中,用二进制来表示,使用的二进制位数越多,像素的色彩就越丰富。
举个🌰,如果一个像素用一位二进制数表示,能有多少种颜色呢?
两种,一个二进制位,要不放 0(表示黑色),要不放 1(表示白色)
下图展示了一个像素二进制的位数最多可以展示多少种颜色。
在对图片有了基本的了解之后,接下来对图片进行分下类,有利于理解各种格式图片的特点。
位图,也叫做点阵图,像素图。构成点阵图的最小单位是像素,位图就是由像素阵列的排列来实现其显示效果的,每个像素有自己的颜色信息,在对位图图像进行编辑操作的时候,可操作的对象是每个像素,我们可以改变图像的色相、饱和度、透明度,从而改变图像的显示效果。
前面介绍中的那种不断放大会有小格子的图就是属于位图。
常见的比如:jpg、png、webp等,我们平时遇到的大多数都是位图。
矢量图,也叫做向量图。矢量图并不纪录画面上每一点的信息,而是纪录了元素形状及颜色的算法,当你打开一幅矢量图的时候,软件对图形对应的函数进行运算,将运算结果图形的形状和颜色显示给你看。
无论显示画面是大还是小,画面上的对象对应的算法是不变的,所以,即使对画面进行倍数相当大的缩放,其显示效果仍然相同(不失真)。
常见的就是 svg 格式的。
无压缩的图片格式不对图片数据进行压缩处理,能准确地呈现原图片。BMP 格式就是其中之一。
指在压缩文件大小的过程中,损失了一部分图片的信息,也即降低了图片的质量,并且这种损失是不可逆的,我们不可能从有一个有损压缩过的图片中恢复出原来的图片。
常见的有损压缩手段,是按照一定的算法将临近的像素点进行合并。压缩算法不会对图片所有的数据进行编码压缩,而是在压缩的时候,去除了人眼无法识别的图片细节。因此有损压缩可以在同等图片质量的情况下大幅降低图片的尺寸。其中的代表是 jpg。
在压缩图片的过程中,图片的质量没有任何损耗。我们任何时候都可以从无损压缩过的图片中恢复出原来的信息。
压缩算法对图片的所有的数据进行编码压缩,能在保证图片的质量的同时降低图片的尺寸。
png 是其中的代表。
关键词:无损压缩、索引色、透明、动画
GIF(Graphics Interchange Format) 的原义是“图像互换格式”,是一种基于 LZW 算法连续色调的无损的基于索引色的压缩格式。其压缩率一般在 50% 左右,它不属于任何应用程序所以几乎所有相关软件都支持它,公共领域有大量的软件在使用 GIF 图像文件。
GIF 是一种无损压缩,所以它只是对像素数据进行压缩,其实 LZW 算法只是一个压缩数据的算法,如果你懂哈夫曼算法的话,可能就比较好理解压缩数据是怎么回事儿了。
GIF 的特性是帧动画。
相比古老的bmp格式,尺寸较小,而且支持透明(不支持半透明,因为不支持 Alpha 透明通道 )和动画。
由于采用了 8 位压缩,最多只能处理 256 种颜色,故不宜应用于真彩色(文末的附录有解释)图片。
色彩简单的 logo、icon、线框图、文字输出等
关键词:有损压缩、直接色、适合大图、体积小
JPEG 格式是最常见的一种图像格式,文件后辍名为“.JPEG”或“.jpg”,JPEG 可以说是人们最熟悉的图档格式,相信在数字相机普及的现在,几乎每台数字相机、照相手机都可以(甚至只能)输出 JPEG 格式的图档。
JPEG 是一种很典型的使用有损压缩图像格式,也就是说使用者每次进行 JPEG 的存档动作后,图档的一些内容细节都会遭到永久性的破坏,尤其是使用过高的压缩比例,将使最终解压缩后恢复的图像质量明显降低,如果追求高品质图像,不宜采用过高压缩比例。
JPEG 图片格式的设计目标,是在不影响人类可分辨的图片质量的前提下,尽可能的压缩文件大小。
JPEG 有两种保存方式:Baseline JPEG(标准型)、Progressive JPEG(渐进式)。两种格式有相同尺寸以及图像数据,他们的扩展名也是相同的,唯一的区别是二者显示的方式不同。
Baseline JPEG
Baseline JPEG 文件存储方式是按从上到下的扫描方式,把每一行顺序的保存在 JPEG 文件中。打开这个文件显示它的内容时,数据将按照存储时的顺序从上到下一行一行的被显示出来,直到所有的数据都被读完,就完成了整张图片的显示。如果文件较大或者网络下载速度较慢,那么就会看到图片被一行行加载的效果,这种格式的JPEG没有什么优点,因此,一般都推荐使用Progressive JPEG。
Progressive JPEG
和 Baseline 一遍扫描不同,Progressive JPEG 文件包含多次扫描,这些扫描顺寻的存储在 JPEG 文件中。打开文件过程中,会先显示整个图片的模糊轮廓,随着扫描次数的增加,图片变得越来越清晰。这种格式的主要优点是在网络较慢的情况下,可以看到图片的轮廓知道正在加载的图片大概是什么。在一些网站打开较大图片时,你就会注意到这种技术。
渐进式图片带来的好处是可以让用户在没有下载完图片就可以看到最终图像的大致轮廓,一定程度上可以提升用户体验(瀑布留的网站建议还是使用标准型的)。
更多关于 Baseline JPEG 和 Progressive JPEG 请看这篇文章:使用渐进式JPEG来提升用户体验。
JPG 适用于呈现色彩丰富的图片,在我们日常开发中,JPG 图片经常作为大的背景图、轮播图或 Banner 图出现。
由于 GIF 与 JPEG 有着如此不同的特性,因此我们可以很轻易的选择何时该用哪一种格式来输出我们需要的图档:当图片拥有丰富的色彩时,并且没有明显锐利反差的边缘线条时,选择 JPEG 可以得到最好的输出结果,照片就是最好的例子;当图片是拥有明确边缘的线条图、没有使用太多色彩、甚至可能需要透明背景时,GIF 是很好的选择,档案小、画质又精美。
关键词:无损压缩、索引色、支持透明、体积大
便携式网络图形(简称 PNG,英语全称:Portable Network Graphics)。PNG 能够提供长度比 GIF 小30%的无损压缩图像文件。它同时提供 24 位和 32 位真彩色图像支持以及其他诸多技术性支持。由于PNG 优秀的特点,PNG 格式图片可以称为“网页设计专用格式”。PNG 最初的开发目的是为了作为 GIF 的替代方案的,作为做新开发的影像传输文件格式,PNG 同样使用了无损压缩格式,事实上 PNG 的开发就是因为 GIF 所使用的无损压缩格式专利问题而诞生的。
PNG 有三种形式,下面分别介绍一下他们的区别。
PNG-8 是 PNG 的索引色版本。PNG-8 是无损的、使用索引色的、点阵图。
PNG-8 是非常好的 GIF 替代者,在可能的情况下,应该尽可能的使用 PNG-8 而不是 GIF,因为在相同的图片效果下,PNG-8 具有更小的文件体积。除此之外,PNG-8 还支持透明度的调节,而 GIF 并不支持。 现在,除非需要动画的支持,否则我们没有理由使用 GIF 而不是 PNG-8。
PNG-24 是 PNG 的直接色版本。PNG-24 是无损的、使用直接色的、点阵图。
无损的、使用直接色的点阵图,听起来非常像 BMP,是的,从显示效果上来看,PNG-24 跟 BMP 没有不同。PNG-24 的优点在于,它压缩了图片的数据,使得同样效果的图片,PNG-24 格式的文件大小要比 BMP 小得多。当然,PNG24 的图片还是要比 JPEG、GIF、PNG-8 大得多。
虽然 PNG-24 的一个很大的目标,是替换 JPEG 的使用。但一般而言,PNG-24 的文件大小是 JPEG 的五倍之多,而显示效果则通常只能获得一点点提升。所以,只有在你不在乎图片的文件体积,而想要最好的显示效果时,才应该使用 PNG-24 格式。
另外,PNG-24 是不支持透明的。
理论上来说,当你追求最佳的显示效果、并且不在意文件体积大小时,是推荐使用 PNG-24 的。
实践当中,为了规避体积的问题,我们一般不用PNG去处理较复杂的图像。当我们遇到适合 PNG 的场景时,也会优先选择更为小巧的 PNG-8。
PNG-32 跟 PNG-24 的区别就是多了一个 Alpha 通道,用来支持半透明,其他的跟 PNG-24 基本一样。
呈现小的 Logo、颜色简单且对比强烈的图片或背景等。
PNG 分为两种,一种是 Index,一种是 RGB。Index 记录同一种颜色的值和出现的位置(简单地说,比如一个 2px*2px 的超级小图,从左往右从上往下依次的颜色是红,白,白,红,那么记录的方法就是“红-1,4;白-2,3”);而 RGB 图则把所有像素的色值依次记录下来(即“红,白,白红”)。对于相同的图片,Index 格式的尺寸总是小于 RGB。
其中 PNG-8 就是 Index,称作为索引色,而 PNG-24 和 PNG-32 是 RGB 形式,也可称作为直接色。
因为 PNG 是无损压缩,保留了图片需要的所有信息,所以索引色是可以转化为直接色的。
关键词:年轻、有损、无损、兼容性
WebP 是谷歌开发的一种新图片格式,WebP 是同时支持有损和无损压缩的、使用直接色的、点阵图。
从名字就可以看出来它是为 Web 而生的,什么叫为 Web 而生呢?就是说相同质量的图片,WebP 具有更小的文件体积。现在网站上充满了大量的图片,如果能够降低每一个图片的文件大小,那么将大大减少浏览器和服务器之间的数据传输量,进而降低访问延迟,提升访问体验。
可以看到 WebP 集多种图片文件格式的优点于一身,所以在图片的质量和性能上,WebP 无疑是赢家。
不过 WebP 有有一个缺点,导致还不能大规模使用,那就是兼容性。
这是我 2019 年 5 月截的图,可以看到 IE 和 Safari 所有的版本都是不支持的(这是硬伤), 火狐也是最新的几个版本才开始支持,年轻有年轻的代价。
此外,WebP 与 JPG 相比较,编码速度慢 10 倍,解码速度慢 1.5 倍,而绝大部分的网络应用中,图片都是静态文件,所以对于用户使用只需要关心解码速度即可。但实际上,WebP 虽然会增加额外的解码时间,但是由于减少了文件体积,缩短了加载的时间,实际上文件的渲染速度反而变快了。
**WebP **集多种图片文件格式的优点于一身,所以基本上适合各种场景,但是由于兼容性不好,所以我们如果大规模的适用 WebP,一定要在 Safari 和 IE 里面施行降级。
这是淘宝商品图片是我在 Chrome 打开的例子,可以看到图片的后缀是 .jpg_.webp,如果这张图片在 Safari 打开后缀就变为了 .jpg,这是一种降级方案,其他的方案请读者自行研究,不在本文讨论中。
APNG(Animated Portable Network Graphics)顾名思义是基于 PNG 格式扩展的一种动画格式,增加了对动画图像的支持,同时加入了 24 位图像和 8 位 Alpha 透明度的支持,这意味着动画将拥有更好的质量,其诞生的目的是为了替代老旧的 GIF 格式,但它目前并没有获得 PNG 组织官方的认可。
APNG 第1帧为标准 PNG 图像,剩余的动画和帧速等数据放在 PNG 扩展数据块,因此只支持原版 PNG 的软件会正确显示第 1 帧。
在兼容性方面绝大部分浏览器都还是支持的,如果以前是因为动画的原因用 GIF 的,现在用 APNG 是一个不错的选择,其他的特性是跟 PNG 样的,因为 APNG 只是一个 PNG 的扩展。
更多 APNG 相关的可以看 APNG 那些事
关键词:无损、矢量图、体积小、不失真、兼容性好
**可缩放矢量图形 **英文 Scalable Vector Graphics(SVG),是无损的、矢量图。
SVG是一种用 XML 定义的语言,用来描述二维矢量及矢量/栅格图形。SVG提供了3种类型的图形对象:矢量图形(vectorgraphicshape例如:由直线和曲线组成的路径)、图象(image)、文本(text)。图形对象还可进行分组、添加样式、变换、组合等操作,特征集包括嵌套变换(nestedtransformations)、剪切路径(clippingpaths)、alpha 蒙板(alphamasks)、滤镜效果(filtereffects)、模板对象(templateobjects)和其它扩展(extensibility)。
SVG 跟上面这些图片格式最大的不同,是 SVG 是矢量图。这意味着 SVG 图片由直线和曲线以及绘制它们的方法组成。当你放大一个 SVG 图片的时候,你看到的还是线和曲线,而不会出现像素点。这意味着 SVG 图片在放大时,不会失真,所以它非常适合用来绘制企业 Logo、Icon 等。
1、高保真度复杂矢量文档已是并将继续是 SVG 的最佳点。它非常详细,适用于查看和打印,可以是独立的,也可以嵌入到网页中
2、在WEB项目中的平面图绘制,如需要绘制线,多边形,图片等。
3、数据可视化。
SVG 只是 Web 开发常用的一种矢量图,其实矢量图常见还有几种格式:BW 格式、AI 格式、CDR 格式、ICO 格式。
本文详细的介绍了常见的图片格式:GIF、JPEG、PNG、WebP、APNG、SVG,介绍了他们是什么,有什么用,优点和缺点,以及使用场景。由于图片相关的知识确实太多了,我只是把一些我觉得必要的写出来,下面在网上找到了一个选择图片过程的表格和图,下次不知道选择什么图片格式,直接看图就行。
其中 APNG 和 WebP 格式出现的较晚,尚未被 Web 标准所采纳,只有在特定平台或浏览器环境可以预知的情况下加以采用。图片格式选择过程如下:
| 图片格式 | 支持透明 | 动画支持 | 压缩方式 | 浏览器支持 | 相对原图大小 | 适应场景 |
|---|---|---|---|---|---|---|
| baseline-jpeg | 不支持 | 不支持 | 有损 | 所有 | 由画质决定 | 所有通用场景 |
| progressive-jpeg | 不支持 | 不支持 | 有损 | 所有 | 由画质决定 | 所有通用场景, 渐进式加载 |
| gif | 支持 | 支持 | 无损 | 所有 | 由帧数和每帧图片大小决定 | 简单颜色,动画 |
| png | 支持 | 不支持 | 无损 | 所有 | 由png色值位数决定 | 需要透明时 |
| webp | 支持 | 不支持 | 有损和无损 | 所有(除IE和Safari) | 由压缩率决定 | 复杂颜色及形状,浏览器平台可预知 |
| apng | 支持 | 支持 | 无损 | 所有(除IE 和Opera) | 由每帧图片决定 | 需要半透明效果的动画 |
| svg | 支持 | 支持 | 无损 | 所有(IE8以上) | 由内容和特效复杂度决定 | 简单图形,需要良好的放缩体验,需要动态控制图片特效 |
以下内容大多来自于网络,由于我在写这篇文章的过程中看到了这些,我觉得有必要了解一下,所以我将这些贴出来,跟文章内容关系不大,可以不看。
索引颜色/颜色表
位图常用的一种压缩方法。从位图图片中选择最有代表性的若干种颜色(通常不超过256种)编制成颜色表,然后将图片中原有颜色用颜色表的索引来表示。这样原图片可以被大幅度有损压缩。适合于压缩网页图形等颜色数较少的图形,不适合压缩照片等色彩丰富的图形。
Alpha通道
在原有的图片编码方法基础上,增加像素的透明度信息。图形处理中,通常把 RGB 三种颜色信息称为红通道、绿通道和蓝通道,相应的把透明度称为 Alpha 通道。多数使用颜色表的位图格式都支持 Alpha 通道。
色彩深度
色彩深度又叫色彩位数,即位图中要用多少个二进制位来表示每个点的颜色,是分辨率的一个重要指标。常用有1位(单色),2位(4色,CGA),4位(16色,VGA),8位(256色),16位(增强色),24位(真彩色)和32位等。色深16位以上的位图还可以根据其中分别表示RGB三原色或CMYK四原色(有的还包括Alpha通道)的位数进一步分类,如16位位图图片还可分为R5G6B5,R5G5B5X1(有1位不携带信息),R5G5B5A1,R4G4B4A4等等。
在制作网站页面图片的时候,设计者一般选择 24 位图像。32 位图像虽然质量更好,但同时也带来更大的图像体积(事实上,一般肉眼也很难分辨 24 位图和 32 位图的区别)。此外将原始位图放大与缩小都会使图像效果失真,这是因为它们减小了图像中有效像素的数量或密度的缘故,所以在制作过程中应尽量避免图片被编辑的次数。
描述一幅图像需要使用图像的属性。图像的属性包含分辨率、像素深度、真/伪彩色、图像的表示法和种类等。本节介绍前面三个特性。
搞清真彩色、伪彩色与直接色的含义,对于编写图像显示程序、理解图像文件的存储格式有直接的指导意义,也不会对出现诸如这样的现象感到困惑:本来是用真彩色表示的图像,但在VGA显示器上显示的图像颜色却不是原来图像的颜色。
我这里就不以图形学的方式介绍各种花里胡哨的概念,我就用最简单的,作为一个程序员的角度来理解就行了。
真彩色
真彩色图像是一种用三个或更多字节描述像素的计算机图像存储方式。
一般来说,前三个通道都会各用一个字节表示,如红绿蓝(RGB)或者蓝绿红(BGR)。如果存在第四个字节,则表示该图像采用了 Alpha 通道。然而,实际系统往往用多于 8 位(即1字节)表达一个通道,如一个 48 位的扫描仪等。这样的系统都统称为真彩色系统。
伪彩色
对于伪彩色图像其实可以理解为索引图像,他的每个像素值存储的不是直接的基色强度,而是存储的索引。就跟 js 里面的引用变量一样,变量只是个地址,变量所指向的值才是真正的值。
对于伪彩色图像会有一个颜色表,是一个[3,255] 的数组,分别对应 0~255 个灰度值的RGB值,对照原理如下:
可以看到上图,像素值存储的只是索引号 128,根据索引找到的 RGB 值才是真正的基色强度。
直接色
直接色又称假彩色。它和伪彩色的区别就是,前者的每个基色强度都要通过索引找到真正的基色强度。
小结
直接色系统产生颜色与真彩色系统相比,相同之处是都采用R,G,B分量决定基色强度,不同之处是前者的基色强度直接用R,G,B决定,而后者的基色强度由R,G,B经变换后决定。因而这两种系统产生的颜色就有差别。试验结果表明,使用直接色在显示器上显示的彩色图像看起来真实、很自然。
直接色系统与伪彩色系统相比,相同之处是都采用查找表,不同之处是前者对 R,G,B分量分别进行变换,后者是把整个像素当作查找表的索引值进行彩色变换。
最后欢迎大家关注我的公众号-「前端桃园」,我是桃翁。
// 生成长度为11的随机字母数字字符串
Math.random().toString(36).substring(2);// 获取URL的查询参数
q={};location.search.replace(/([^?&=]+)=([^&]+)/g,(_,k,v)=>q[k]=v);q;获取url里面的参数值或者追加查询字符串,在这之前,我们一般通过正则匹配处理,然而现在有一个新的api,具体详情可以查看这里,可以让我们以很简单的方式去处理url。
假如我们有这样一个url,"?post=1234&action=edit",我们可以这样处理这个url
var urlParams = new URLSearchParams('?post=1234&action=edit');
console.log(urlParams.has('post'));
console.log(urlParams.get('action')); // "edit"
console.log(urlParams.getAll('action')); // ["edit"]
console.log(urlParams.toString()); // "?post=1234&action=edit"
console.log(urlParams.append('active', '1')); // "?post=1234&action=edit&active=1"使用JavaScript简洁代码生成随机十六进制代码
// 生成随机十六进制代码 如:'#c618b2'
'#' + Math.floor(Math.random() * 0xffffff).toString(16).padEnd(6, '0');最开始接触函数式编程的时候是在小米工作的时候,那个时候看老大以前写的代码各种 compose,然后一些 ramda 的一些工具函数,看着很吃力,然后极力吐槽函数式编程,现在回想起来,那个时候的自己真的是见识短浅,只想说,'真香'。
最近在研究函数式编程,真的是在学习的过程中感觉自己的思维提升了很多,抽象能力大大的提高了,让我深深的感受到了函数式编程的魅力。所以我打算后面用 5 到 8 篇的篇幅,详细的介绍一下函数式编程的**,基础、如何设计、测试等。
今天这篇文章主要介绍函数式编程的**。
面向对象编程(OOP)通过封装变化使得代码更易理解。
函数式编程(FP)通过最小化变化使得代码更易理解。
-- Michacel Feathers(Twitter)
总所周知 JavaScript 是一种拥有很多共享状态的动态语言,慢慢的,代码就会积累足够的复杂性,变得笨拙难以维护。面向对象设计能帮我们在一定程度上解决这个问题,但是还不够。
由于有很多的状态,所以处理数据流和变化的传递显得尤为重要,不知道你们知道响应式编程与否,这种编程范式有助于处理 JavaScript 的异步或者事件响应。总之,当我们在设计应用程序的时候,我们应该考虑是否遵守了以下的设计原则。
我这能这么跟你说,一旦你学会了函数式编程,这些问题迎刃而解,本来函数式编程就是这个**,一旦你掌握了函数式,然后你再学习响应式编程那就比较容易懂了,这是我亲身体会的。我之前在学 Rxjs 的时候是真的痛苦,说实话,Rxjs 是我学过最难的库了,没有之一。在经历过痛苦的一两个月之后,有些东西还是不能融会贯通,知道我最近研究函数式编程,才觉得是理所当然。毫无夸张,我也尽量在后面的文章中给大家介绍一下 Rxjs,这个话题我也在公司分享过。
简单来说,函数式编程是一种强调以函数使用为主的软件开发风格。看到这句我想你还是一脸懵逼,不知道函数式编程是啥,不要着急,看到最后我相信你会明白的。
还有一点你要记住,函数式编程的目的是使用函数来抽象作用在数据之上的控制流和操作,从而在系统中消除副作用并减少对状态的改变。
下面我们通过例子来简单的演示一下函数式编程的魅力。
现在的需求就是输出在网页上输出 “Hello World”。
可能初学者会这么写。
document.querySelector('#msg').innerHTML = '<h1>Hello World</h1>'这个程序很简单,但是所有代码都是死的,不能重用,如果想改变消息的格式、内容等就需要重写整个表达式,所以可能有经验的前端开发者会这么写。
function printMessage(elementId, format, message) {
document.querySelector(elementId).innerHTML = `<${format}>${message}</${format}>`
}
printMessage('msg', 'h1', 'Hello World')这样确实有所改进,但是任然不是一段可重用的代码,如果是要将文本写入文件,不是非 HTML,或者我想重复的显示 Hello World。
那么作为一个函数式开发者会怎么写这段代码呢?
const printMessage = compose(addToDom('msg'), h1, echo)
printMessage('Hello World')解释一下这段代码,其中的 h1 和 echo 都是函数,addToDom 很明显也能看出它是函数,那么我们为什么要写成这样呢?看起来多了很多函数一样。
其实我们是讲程序分解为一些更可重用、更可靠且更易于理解的部分,然后再将他们组合起来,形成一个更易推理的程序整体,这是我们前面谈到的基本原则。
compose 简单解释一下,他会让函数从最后一个参数顺序执行到第一个参数,compose 的每个参数都是函数,不明白的可以查一下,在 redux 的中间件部分这个函数式精华。
可以看到我们是将一个任务拆分成多个最小颗粒的函数,然后通过组合的方式来完成我们的任务,这跟我们组件化的**很类似,将整个页面拆分成若干个组件,然后拼装起来完成我们的整个页面。在函数式编程里面,组合是一个非常非常非常重要的**。
好,我们现在再改变一下需求,现在我们需要将文本重复三遍,打印到控制台。
var printMessaage = compose(console.log, repeat(3), echo)
printMessage(‘Hello World’)可以看到我们更改了需求并没有去修改内部逻辑,只是重组了一下函数而已。
可以看到函数式编程在开发中具有声明模式。为了充分理解函数式编程,我们先来看下几个基本概念。
函数式编程属于声明是编程范式:这种范式会描述一系列的操作,但并不会暴露它们是如何实现的或是数据流如何传过它们。
我们所熟知的 SQL 语句就是一种很典型的声明式编程,它由一个个描述查询结果应该是什么样的断言组成,对数据检索的内部机制进行了抽象。
我们再来看一组代码再来对比一下命令式编程和声明式编程。
// 命令式方式
var array = [0, 1, 2, 3]
for(let i = 0; i < array.length; i++) {
array[i] = Math.pow(array[i], 2)
}
array; // [0, 1, 4, 9]
// 声明式方式
[0, 1, 2, 3].map(num => Math.pow(num, 2))可以看到命令式很具体的告诉计算机如何执行某个任务。
而声明式是将程序的描述与求值分离开来。它关注如何用各种表达式来描述程序逻辑,而不一定要指明其控制流或状态关系的变化。
为什么我们要去掉代码循环呢?循环是一种重要的命令控制结构,但很难重用,并且很难插入其他操作中。而函数式编程旨在尽可能的提高代码的无状态性和不变性。要做到这一点,就要学会使用无副作用的函数--也称纯函数
纯函数指没有副作用的函数。相同的输入有相同的输出,就跟我们上学的函数一样。
常常这些情况会产生副作用。
举一个简单的例子
var counter = 0
function increment() {
return ++counter;
}这个函数就是不纯的,它读取了外部的变量,可能会觉得这段代码没有什么问题,但是我们要知道这种依赖外部变量来进行的计算,计算结果很难预测,你也有可能在其他地方修改了 counter 的值,导致你 increment 出来的值不是你预期的。
对于纯函数有以下性质:
但是在我们平时的开发中,有一些副作用是难以避免的,与外部的存储系统或 DOM 交互等,但是我们可以通过将其从主逻辑中分离出来,使他们易于管理。
现在我们有一个小需求:通过 id 找到学生的记录并渲染在浏览器(在写程序的时候要想到可能也会写到控制台,数据库或者文件,所以要想如何让自己的代码能重用)中。
// 命令式代码
function showStudent(id) {
// 这里假如是同步查询
var student = db.get(id)
if(student !== null) {
// 读取外部的 elementId
document.querySelector(`${elementId}`).innerHTML = `${student.id},${student.name},${student.lastname}`
} else {
throw new Error('not found')
}
}
showStudent('666')
// 函数式代码
// 通过 find 函数找到学生
var find = curry(function(db, id) {
var obj = db.get(id)
if(obj === null) {
throw new Error('not fount')
}
return obj
})
// 将学生对象 format
var csv = (student) => `${student.id},${student.name},${student.lastname}`
// 在屏幕上显示
var append = curry(function(elementId, info) {
document.querySelector(elementId).innerHTML = info
})
var showStudent = compose(append('#student-info'), csv, find(db))
showStudent('666')如果看不懂 curry (柯里化)的先不着急,这是一个对于新手来说比较难理解的一个概念,在函数式编程里面起着至关重要的作用。
可以看到函数式代码通过较少这些函数的长度,将 showStudent 编写为小函数的组合。这个程序还不够完美,但是已经可以展现出相比于命令式的很多优势了。
我们看到纯函数的输出结果是一致的,可预测的,相同的输入会有相同的返回值,这个其实也被称为引用透明。
引用透明是定义一个纯函数较为正确的方法。纯度在这个意义上表面一个函数的参数和返回值之间映射的纯的关系。如果一个函数对于相同的输入始终产生相同的结果,那么我们就说它是引用透明。
这个概念很容易理解,简单的举两个例子就行了。
// 非引用透明
var counter = 0
function increment() {
return ++counter
}
// 引用透明
var increment = (counter) => counter + 1其实对于箭头函数在函数式编程里面有一个高大上的名字,叫 lambda 表达式,对于这种匿名函数在学术上就是叫 lambda 表达式,现在在 Java 里面也是支持的。
不可变数据是指那些创建后不能更改的数据。与许多其他语言一样,JavaScript 里有一些基本类型(String,Number 等)从本质上是不可变的,但是对象就是在任意的地方可变。
考虑一个简单的数组排序代码:
var sortDesc = function(arr) {
return arr.sort(function(a, b) {
return a - b
})
}
var arr = [1, 3, 2]
sortDesc(arr) // [1, 2, 3]
arr // [1, 2, 3]这段代码看似没什么问题,但是会导致在排序的过程中会产生副作用,修改了原始引用,可以看到原始的 arr 变成了 [1, 2, 3]。这是一个语言缺陷,后面会介绍如何克服。
内容来至于《JavaScript函数式编程指南》
欢迎关注个人公众号【前端桃园】,公号更新频率比掘金快。
vim 被誉为『编辑器之神』,与之同时代的 emacs 被誉为『神之编辑器』。可以看得出 vim 在编辑器的地位是很高的,得益于 vim 的指法,敲起代码来如行云流水。特别膜拜创始人创始出这么方便的敲代码的指法,这篇文章就是来带你入坑 vim 指法操作。
在当今前端开发工具百花齐放的时代(VS Code、Sublime、Atom 以及 IDE Webstorm),我为什么还要介绍 20 多年前开发的一个老古董呢?在这里我想说的是出身虽然老,但是所带来的价值并没有减,一旦习惯了 vim 的指法之后,你会觉得不用 vim 操作写代码会觉得很不习惯,甚至不知道怎么操作。然而用在支持 vim 指法的编辑上写代码你会觉得如行云流水,如果再配个机械键盘,简直是享受,特别符合极客的风格。
一旦学会了 vim 的指法,会让你终身受益,至少在你敲代码的年代会收益,毫无夸张, 它会让你摆脱烦人的,在敲代码的时候频繁的移动鼠标,这也是 vim 的设计理念之一 -- 脱离鼠标。
本篇文章比较适合前端开发者,因为我也只是用 vim 在前端领域做过一些开发,其他领域我没有发言权。
Q:你推荐 vim 是要我们完全放弃以前的编辑器而投入 vim 的怀抱吗?
A:当然不是。首先 vim 的学习成本还是很高的,因为他跟平时我们用的编辑器敲代码的方式根本不同,因为它是不用鼠标的,纯键盘操作。你想想如果你在你的 vs code 上不用鼠标操作,你上下左右全靠方向键,那敲代码的速度得有多慢。而且初学者想把 vim 打造成一个自己的 IDE 还是很有难度的。所以我这里推荐的是,不管是你的 vs code、sublime等,装一个 vim 插件。我在 vs code 上试过,很爽,只不过现在投身到 emacs 的怀抱了。
虽然我用 emacs 了,我还是会装 vim 插件(Evil)。如果有兴趣,下次可以推荐一下 spacemacs 。
开题说了这么多,就是想吸引一下大家,觉得 vim 的指法是值得去学习的,接下来进入正题。
vim 上的所有定义的快捷键都是有一定的意义的,在这里我先把常用的一些列出来。
h(左)、l(右)、j(上)、k(下)、f(front)、b(back)、u(up)
d(delete)、i(insert)、a(append)、c(change)、y(copy)、p(paste)
w(word)、s(sentence)
vim 里面有好几种模式,但是因为我这里介绍的是在目前的编辑器里面装 插件,所以像命令模式这种用来保存文件、退出文件的就不介绍了。
当我们记住上面的助记符之后,我们就可以像写英文短语一样操作了。
vim 快捷键语法:[operator][count][motion],例如 删两个单词就是
d2w,operator 和 motion 我已经在前面给出来一些了。
最基本的上下左右移动(跟键盘上下左右的键盘效果相同,但是往往方向键在键盘的右下方,离主键盘区较远,这个也相对比较有优势):
移动属于 motion,所以在前面加上「count」就可以移动多行了,比如向上移动 10 行,就可以 10k。往往编辑器会有行号,定位需要做个加减法,如果采用的是相对行号,用这个就比较方便。不懂相对行号的同学看下图就懂了。
w:光标往前移动一个词
b:光标向后移动一个词
0:移动光标到当前行首
^:移动光标到当前行的第一个字母位置(注意与 0 的区别)
$:移动光标到行尾
fx:移动光标到当前行的下一个 x 处(x为任意字母)
tx:和上面一个命令类似,移动到 x 的左边一个位置
):移动光标到下一个句子
( :移动光标到上一个句子
{:移动光标到上一段
}:移动光标到下一段
在刚才介绍了通过相对行号来进行移动到行的光标,还有采用绝对定位来移动的。那就是 gg。
语法: [num]gg
书签功能:这个功能也是很方便,很少有编辑器有的功能,单独列出来讲,强烈推荐。
Ctrl + b:向上移动一屏(Foward首字母小写)
Ctrl + f:向下移动一屏(Backward首字母小写)
Ctrl + d:向下滚动半屏内容(Down首字母小写)
Ctrl + u:向上滚动半屏内容(Up首字母小写)
在 normal 模式下是没有删除操作的,d 这种删除也是剪切。
以上全是 normal 模式
在前面也说了,进入编辑模式也就变成了「哑巴」vim 了,就跟一般的编辑器没什么区别了。很多人就知道用 i 可以进入,还有很多命令可以让你聪明的进入。
要是前面都学会了,可视模式就比较简单了,而且你将会经常用到这个模式。我会把这个模式称做「选择模式」,接下来我们就来探索一下是如果选择的。
其实也就两个关键的点:v(字符选择)、V(行选择)
在 normal 模式下,按一下 v,然后可以按 l,重复按 l,你会发现右边的在一直被选中(高亮的部分)。同样的操作,按了 v,然后再练习一下按 h、j、k。
选中的目的是什么呢?就是为了进行一些编辑操作,比如删除 d (实质是剪切)、复制 y。
小提示,常常选中之后用 c 也是比较好的选择哦,剪切并进入插入模式。
V 就是选中行,也很简单。按了 V 之后,然后按 j、k,就可以上下选择行了,然后一次性删除 d、复制 y,就比较方便。
这个功能就比较强悍了,很适用,强烈推荐。
先来记公式:operator + i|a + scope
operator 就是我们前面提到的插入(c)、剪切(d)、复制(y)以及选择(v),i 表示 scope 范围内,a 表示包含 scope 标签,scope 就是操作的范围了。
实例:
以下如果将 i 换成 a,则会将符号也包含进去
vib(选中小括号内的内容)
viB(选中大括号内的内容)
vi"(选中双引号内的内容)
vi'(选中单引号内的内容)
vi<(选中尖括号内的内容)
u: 撤回上次操作(效果跟 command + z 效果一样)
/|?xxx:表示在整篇文档中搜索匹配xxx的字符串, / 表示向下查找, ? 表示向上查找.其中xxx可以是正规表达式。查找到以后, 再输入 n 查找下一个匹配处, 输入 N 反方向查找.
:%s/original/replacement:检索第一个 “original” 字符串并将其替换成 “replacement”
:%s/original/replacement/g: 检索并将所有的 “original” 替换为 “replacement”
:%s/original/replacement/gc:检索出所有的 “original” 字符串,但在替换成 “replacement” 前,先询问是否替换
这些操作一般编辑器都自带有很好的快捷键,记不住也没啥。
我写这篇文章的目的不是为了总结什么知识点(其实当你 vim 用熟了,这些命令完全形成肌肉记忆了,根本不用记下来),或者说想发篇文章之类的,仅仅是想给 vim 做一个宣传,让更多的人接触 vim,让更多的开发者在开发上效率更高。如果你觉得这篇文章对你有帮助,请转发给更多的人让他们都了解了解。
最后想提醒的就是,对于这些快捷键,死记是很难记完的,根据我总结的一些语义话的方式去记,有公式的记公式,可能要快一点,然后就是多实践,敲多了自己就记住了。我刚开始学的时候,还不知道有那些助记符,基本完全靠死记硬背,我就是用一张纸,然后把命令手写抄到纸上,放在我的电脑旁,忘了就马上拿来看看,别说,效果还挺好的。
祝你们好运!
大家好,我是桃翁,我为自己代言!
个人微信公众号,以后尽量坚持每周一篇干货
参考文章:
VIM 百度百科
如何用Vim提高开发效率
Symbol 是一种特殊的、不可变的数据类型,可以作为对象属性的标识符使用,表示独一无二的值。Symbol 对象是一个 symbol primitive data type 的隐式对象包装器。它是JavaScript语言的第七种数据类型,前6种分别是:Undefined、Null、Boolean、String、Number、Object。
Symbol([description])
description : 可选的字符串。可用于调试但不访问符号本身的符号的说明。如果不加参数,在控制台打印的都是Symbol,不利于区分。
var s1 = Symbol('symbol1');
s1 //Symbol(symbol1);
因为Symbol函数返回的值都是独一无二的,所以Symbol函数返回的值都是不相等的。
//无参数
var s1 = Symbol();
var s2 = Symbol();
s1 === s2 // false
//有参数
var s1 = Symbol('symbol');
var s2 = Symbol('symbol');
s1 === s2 //false
由于每一个Symbol值都是不相等的,那么作为属性标识符是一种非常好的选择。
let symbolProp = Symbol();
var obj = {};
obj[symbolProp] = 'hello Symbol';
//或者
var obj = {
[symbolProp] : 'hello Symbol';
}
//或者
var obj = {};
Object.defineProperty(obj,symbolProp,{value : 'hello Symbol'});
定义属性的时候只能将Symbol值放在方括号里面,否则属性的键名会当做字符串而不是Symbol值。同理,在访问Symbol属性的时候也不能通过点运算符去访问,点运算符后面总是字符串,不会读取Symbol值作为标识符所指代的值.
常量的使用Symbol值最大的好处就是其他任何值都不可能有相同的值,用来设计switch语句是一种很好的方式。例如:消除魔术字符串(这里留给读者思考,如果有什么疑问,可以给我留言)
对于Symbol.for方法需要记住两点:
Symbol.for('foo') === Symbol.for('foo'); //true
Symbol('foo') === Symbol('foo'); //false
Symbol.keyFor方法返回一个已登记的Symbol类型的值的key。
var s1 = Symbol.for('foo');
Symbol.keyFor(s1) //"foo"
var s2 = Symbol('foo');
Symbol.keyFor(s2);//undefiend
上面的代码中,变量s2属于未登记的Symbol值,所以返回undefined
Symbol作为属性名,虽然不是私有属性,但是在for...in,for...of循环中,Object.keys(),Object.getOwnPropertyNames()都不会获取到。通常通过两种方法达到Symbol属性的遍历。
下面给出一个例子来解释上面所有的。
var obj = {};
var a = Symbol('a');
var b = Symbol('b');
obj[a] = 'hello';
obj[b] = 'world';
//获取不到
for(var i in obj){
console.log(i); //无输出
}
Object.getOwnPropertyNames(obj);//[]
//可以获取
var objectSymbols = Object.getOwnPropertySymbols(obj);
objectSymbols// [Symbol(a), Symbol(b)]
Reflect.ownKeys(obj);//[Symbol(a), Symbol(b)]
以Symbol值作为名称的属性不会被常规方法遍历所得到。我们可以利用这个特性,为对象定义一些非私有但又希望只用于内部的方法。
var size = Symbol('size');
class Collection {
constructor(){
this[size] = 0;
}
add(item){
this[this[size]] = item;
this[size]++;
}
static sizeOf(instance){
return instance[size];
}
}
var x = new Collection();
Collection.sizeOf(x); //0
x.add('foo');
Collection.sizeOf(x); //1
Object.keys(x)//['0']
Object.getOwnPropertyNames(x) //['0']
Object.getOwnPropertySymbols(x) //[Symbol(size)]
上面的代码中,对象x的size属性是一个Symbol值,所以Object.keys(x)、Object.getOwnPropertyNames(x)都无法获取它。这就造成了一种非私有的内部方法的效果。如果对ES6定义类方面还不清楚的,可以先不看这段,或者自己查查资料,后面的文章我也会分享出来,总的来说现在JavaScript的新标准越来越像Java了,比如新增的const、let块级作用域,class定义类等等。
除了自己定义的Symbol值外,JavaScript有一些内置的Symbol表示的内部语言行为不在ECMAScript 5及以前暴露给开发者。这些Symbol可以被访问被下列属性:
返回对象的默认迭代器的方法。被for...of使用
与字符串匹配的方法,也用于判断对象是否可以用作正则表达式.被 String.prototype.match()使用。
一种方法取代匹配字符串的子串。被String.prototype.replace()使用。
返回与正则表达式匹配的字符串内返回索引的方法。被String.prototype.search()使用。
在与正则表达式匹配的索引处拆分字符串的方法。被String.prototype.split()使用.
确定构造函数对象是否将对象作为实例识别的方法。被instanceof使用
一个布尔值,指示对象是否应该被扁平化为数组元素。被Array.prototype.concat()使用.
从关联对象的环境绑定中排除其自身和继承的属性名称的对象值。被with使用
用于创建派生对象的构造函数。
将对象转换为原始值的方法。
用于对象的默认描述的字符串值。被Object.prototype.toString()使用.
我这里没给出具体的例子,针对这11个属性。忘读者自己主动去把这几个属性搞懂,对理解有些方法是非常有用的。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.