cog-imperial / omlt Goto Github PK
View Code? Open in Web Editor NEWRepresent trained machine learning models as Pyomo optimization formulations
License: Other
Represent trained machine learning models as Pyomo optimization formulations
License: Other






















































































































The ONNX reader requires ONNX and the Keras reader needs tensorflow.keras. We need better and more descriptive error handling to manage this.
There are a couple of small issues on the OMLT package page
If the user does not provide bounds to load_keras_sequential, we get an error when we build the formulation that is difficult to debug.
Dear sir, I change the ANN model to keras_linear_131_relu_output_activation(or keras_linear_131_relu), I get the KeyError: 'relu' error. How to fix it? I checked the utils.py file, relu function was not included in pyomo_activations dictionary variable.
EDIT:
I use formulation = ReLUBigMFormulation(net) , It works.
Originally posted by SaM-92 May 13, 2022
Hello,
Thank you for this nice library. I'd want to ask a question about adding a time index to the model. Can we add time (t) to the model and then modify the input variable for each (t) and receive the forecast from NN for each (t), then maximum the objective function for the summing over 24 hours?
I put it in the equation as below. So, basically what I want to do is solving the same problem over a period of let's say 24 hours.
Thanks so much in advance! :)

Currently, 2D convolutional layers can be read into OMLT. To better support CNNs, the following layers should also be accommodated:
These additions would enable the use of typical 1D and 2D CNNs (maybe 3D if desired...).
Hello,
I've been trying to make the mnist_example_convolutional and mnist_example_dense notebooks work. However, right after executing the imports, I consistently received the error message: "The Kernel crashed while executing code in the current cell or a previous cell. Please review the code in the cell(s) to identify a possible cause of the failure." Surprisingly, altering the order of the imports resolved the issue. For context, I'm using a MacBook Pro with an Apple M1 chip, 16 GB of RAM, and Python version 3.9.13. I'd like to know if anyone has insights into what the issue is here or how the change of import orders solves the problem.
I appreciate any help on this!
We should discuss the import structure. For example, what objects should be at the main level of OMLT, and what sub-modules do we want.
It seems strange right now that OffsetScaling is at the main omlt level while other things are not.
Hello,
While working with the 'Linear Tree Formulations' notebook, I always encounter the error: "ModuleNotFoundError: No module named 'omlt.linear_tree'". The module is visible in the directory structure. My environment is a MacBook Pro with an Apple M1 chip, 16 GB RAM, running Python version 3.9.13. Any assistance or solutions regarding this 'Linear Tree Formulations' error would be appreciated.
I am confused about what format of input bounds should be passed with an onnx model to omlt.
Trying a list or a dictionary:
lb = np.maximum(0, image - epsilon_infty)
ub = np.minimum(1, image + epsilon_infty)
input_bounds = [(float(l), float(u)) for l, u in zip(lb[0], ub[0])]
or
input_bounds = {}
for i in range(28*28):
input_bounds[i] = (float(lb[0][i]), float(ub[0][i]))
Attempting to create the omlt model with either:
write_onnx_model_with_bounds(f.name, None, input_bounds)
network_definition = load_onnx_neural_network_with_bounds(f.name)
formulation = NeuralNetworkFormulation(network_definition)
m = pyo.ConcreteModel()
m.nn = OmltBlock()
m.nn.build_formulation(formulation)
Results in: ValueError: Variable 'bounds' keyword must be a tuple or function
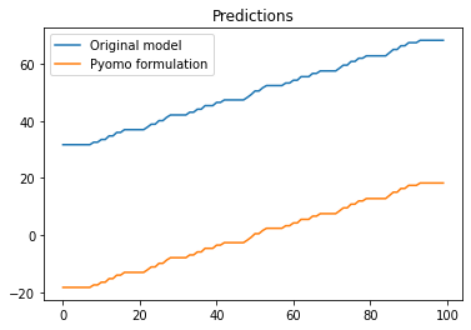
Hi!
I have an issue with the GradientBoostingRegressor not outputing the expcted values after being formulated as part of my pyomo model. The deviation seems to be a static offset, not random.
I'm pretty new to both pyomo and omlt, so this might be human error. I've also been looking for a list of supported models without luck, but I guess that could also be the issue.
I've attached an MRE below:
import numpy as np
from sklearn.ensemble import GradientBoostingRegressor
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
import pyomo.environ as pyo
from omlt import OmltBlock
from omlt.gbt import GBTBigMFormulation, GradientBoostedTreeModel
import matplotlib.pyplot as plt
# Train simple model
x = np.array(range(101)).reshape(-1,1)
y = np.array(range(101))
model_gbt = GradientBoostingRegressor(n_estimators=5)
model_gbt.fit(x, y)
# Get predictions directly from model
y_pred = model_gbt.predict(np.array(range(100)).reshape(-1,1))
# Get predictions from pyomo formulation
y_opt = []
for i in range(100):
initial_type = [('float_input', FloatTensorType([None, 1]))]
model_onx = convert_sklearn(model_gbt, initial_types=initial_type)
m = pyo.ConcreteModel('Random GradientBoostingRegressor')
m.gbt = OmltBlock()
input_bounds = {0: (i, i)} # Forces the input to equal the input from the previous prediction
gbt_model = GradientBoostedTreeModel(model_onx, scaled_input_bounds=input_bounds)
formulation = GBTBigMFormulation(gbt_model)
m.gbt.build_formulation(formulation)
m.obj = pyo.Objective(expr=0)
solver = pyo.SolverFactory('cbc')
status = solver.solve(m, tee=False)
y_opt.append(m.gbt.outputs[0].value)
# Plot predictions
plt.plot(y_pred)
plt.plot(y_opt)
plt.title('Predictions')
plt.legend(['Original model', 'Pyomo formulation'])Output
It seems that OMLT doesn't work when using lightgbm with a multiclass classification problem (4 classes). I initialized the lightgbm instance as:
lgb_params = {"learning_rate": 0.05, "num_iterations":200, "early_stopping_round":50, "max_bin": 30, "num_leaves": 30,
"lambda_l1": 0.3, "random_state":42, "force_row_wise":True, "objective":"multiclass",
"metric":['multi_error', 'multi_logloss'], "num_class": 4 }
lgb_model = lgb.LGBMClassifier(**lgb_params)and I used the same code that you can find in docs/notebooks/bo_with_trees.ipynb to get the ONNX model and to build the tree, it returns the following error:
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
Cell In[32], line 13
10 for i in range(x_test_np.shape[1]):
11 input_bounds[i] = (float(lb[i]), float(ub[i]))
---> 13 add_tree_model(opt_model, onnx_model, input_bounds)
Cell In[29], line 8, in add_tree_model(opt_model, onnx_model, input_bounds)
5 def add_tree_model(opt_model, onnx_model, input_bounds):
6 # init omlt block and gbt model based on the onnx format
7 opt_model.gbt = OmltBlock()
----> 8 gbt_model = GradientBoostedTreeModel(onnx_model,
9 scaled_input_bounds=input_bounds)
11 # omlt uses a big-m formulation to encode the tree models
12 formulation = GBTBigMFormulation(gbt_model)
File [...\lib\site-packages\omlt\gbt\model.py:22](file:///.../lib/site-packages/omlt/gbt/model.py:22), in GradientBoostedTreeModel.__init__(self, onnx_model, scaling_object, scaled_input_bounds)
20 self.__model = onnx_model
21 self.__n_inputs = _model_num_inputs(onnx_model)
---> 22 self.__n_outputs = _model_num_outputs(onnx_model)
23 self.__scaling_object = scaling_object
24 self.__scaled_input_bounds = scaled_input_bounds
File [...\lib\site-packages\omlt\gbt\model.py:66](file:///.../lib/site-packages/omlt/gbt/model.py:66), in _model_num_outputs(model)
64 """Returns the number of output variables"""
65 graph = model.graph
---> 66 assert len(graph.output) == 1
67 return _tensor_size(graph.output[0])
AssertionError:that it seems to be related to the number of classes. I solved the problem using a simple PyTorch neural network and OMLT works well in that case, but I was wondering if I did something wrong using the lightgbm model.
The version of lightgbm is 3.3.5 and the omlt version is 1.1.
Thanks for your attention.
Currently, our NetworkDefinition assumes the activation function input is always a scalar. This abstraction does not capture activation functions that require the entire output of a layer such as softmax.
One possibility is to add a mapping in NetworkDefinition to optionally map node indices to layers. Something akin to:
{node_id -> [nodes in layer]}
Then the build_full_space_formulation could do something like the following where we pass in the (possibly empty) layer nodes to the activation functions:
if not skip_activations:
activations = net.activations
block.activation_constraints = pyo.Constraint(block.hidden_output_nodes)
for i in block.hidden_output_nodes:
#check whether the node uses its layer nodes in the activation
if i in net.layer_node_ids:
layer_zhat = [block.zhat[i] for i in net.layer_node_ids[i]]
else:
layer_zhat = ()
if i not in activations or activations[i] is None or activations[i] == 'linear':
block.activation_constraints[i] = block.z[i] == block.zhat[i]
elif type(activations[i]) is str:
afunc = pyomo_activations[activations[i]]
block.activation_constraints[i] = block.z[i] == afunc(block.zhat[i],*layer_zhat)
else:
# better have given us a function that is valid for pyomo expressions
block.activation_constraints[i] = block.z[i] == activations[i](block.zhat[i],*layer_zhat)The utils.py functions would have to be updated to take extra arguments if we go this route.
@fracek: Do you know how ONNX handles softmax? My understanding is that the dict-of-dicts is general enough to accomplish CNN, but here it struggles with softmax/normalization.
The neural network formulations have checks that they're given graphs with single inputs and outputs, but these checks are implemented inconsistently in different places.
Hi,
I tried making a simple notebook that optimizes the output of a single-input single-output sklearn gradient boosting model. The output-varieble seems to be ok, but the input variable (decision variable) is not. I've tested it with IPOPT and CBC. I am running this on Linux in Github Codespaces.


It's hard to boil down my code to an MRE, so I've attached the full notebook. It is not that big.
Is it possible to use OMLT in learning to rank? if so , please provide example.
Thanks
When trying to run OMLT in Databricks using the CBC solver, I received a -printingOptions error. -printingOptions may not be an option for the latest CBC?
It appears that OMLT/Pyomo is recognizing the CBC solver. Is this an easy fix to configure this printing option to prevent this error.

We discussed that generating formulations that introduce MIP constraints for ReLU and non-linear constraints for other activations should not be possible. OMLT should throw and exception in this case.
I get the following error when trying to read the attached onnx file:
File "/usr/local/lib/python3.10/site-packages/omlt/neuralnet/activations/relu.py", line 51, in bigm_relu_activation_constraint layer_block.z[output_index].setub(max(0, ub)) TypeError: '>' not supported between instances of 'NoneType' and 'int'
MatMul_Add.onnx.zip
Dear @carldlaird @rmisener ,
We have a question about using OMLT related to some work started by @jalving under DISPATHES last year.
In OMLT v0.3.1, it is possible to use omlt.neuralnet.NetworkDefinition to create an object that can be further processed in OMLT.
https://github.com/jalving/dispatches/blob/prescient_verify/dispatches/workflow/run_surrogate_optimization/rankine_cycle_case/read_scikit_to_omlt.py
In OMLT v1.1, omlt.neuralnet.NetworkDefinition is restructured and this function no longer works.
For OMLT v1.1, if it is possible to build a similar function so that we can read scikit-learn neural networks using OMLT. Who is the best person for us to ask about this?
Best regards,
Xinhe Chen and @adowling2
As far as I can tell from (repo, pypi & actions) the sphinx documentation is not hosted yet. Having the docs hosted on e.g. readthedocs would significantly help adoption.
Hello, I'm new to OMLT and I'm encountering an issue while trying to utilize a pre-trained neural network with a Pyomo model using OMLT. The problem arises when I call the build_formulation function. I have attempted two approaches: one using the load_onnx_neural_network function without input bounds, and the other with input bounds. Unfortunately, both attempts result in errors. I have included the relevant code snippet, the pre-trained neural network in ONNX format, and the error messages. Any guidance or suggestions to resolve this issue and ensure the proper execution of the code would be greatly appreciated.
[
rho.zip
](url)
(All the 4 files mentioned are present in the zipped folder
We are re-evaluating what we should use for our test and integration framework. We initially started with tox, but the configuration is split across many different files and it has been prone to break with various package updates. We should consider implementing a more streamlined workflow.
We currently define the activation functions for neural network nodes in several places:
https://github.com/cog-imperial/OMLT/blob/main/src/omlt/neuralnet/layer.py --> Line 112 - 122
https://github.com/cog-imperial/OMLT/blob/main/src/omlt/neuralnet/activations/smooth.py --> Lines 4 - 43
This is a problem because anyone adding a new activation function (or debugging an existing activation function) will have to add the new activation function twice. Additionally, softplus seems to be missing from one of the two places where we define activation functions (https://github.com/cog-imperial/OMLT/blob/main/src/omlt/neuralnet/layer.py).
Hi,
this is a bit of a long shot: I looked at your example notebook here, and was wondering whether you'd like to share the python script with which you generated the data? The reason is that I'd like to look at the same example process, but I need to export more intermediate values to the csv output, so I thought I might build on your script.
There is some design work to do with the activation functions and constraints to gain more code reuse and expand the list of supported activations.
This issue originally came from a PR comment by @jalving.
add_constraint=True is not used here
net_block and net are also not used in activation methods. we should discuss whether we need them. they might be there for consistency on the calling side.
Originally posted by @jalving in #24 (comment)
Is there interest in adding other readers in addition to ONNX? I have a working sci-kit learn neural network reader.
reminder to finish this test
Originally posted by @jalving in #24 (comment)
Hi @fracek,
I'm having an issue with figuring out whether the input tensor x should be reshaped to the layer's input_size (as opposed to keeping it as the input layer's output shape) before being passed to Layer._eval. Right now this is what happens, in neuralnet/layer.py::90-93 (in Layer.eval). This reshaping also seems to be what is assumed by the dense layer code.
However, the convolutional layer code seems to assume this reshaping should not happen. In neuralnet/layer.py::296 (in ConvLayer._eval), x[index] is used to access elements of the input tensor x, x being the reshaped tensor passed to Layer._eval.
However, index here is yielded from the ConvLayer.kernel_with_input_indexes generator. At neuralnet/layer.py::265, this index is mapped back to an input layer output index. Since this index is used to index x, this would suggest x should not be reshaped, as should remain the input layer output shape.
As a result, the status quo (reshaping x before passing it to Layer._eval) keeps the dense layer code fine but breaks convolutional layer code with index mapping. Not reshaping x fixes this issue but then breaks the dense layer code.
I cannot figure out whether the convolutional layer assumption or the dense layer assumption is the one I should be using, as index mapping is not thoroughly covered by the tests for the input and convolutional layers. Any help would be greatly appreciated! :)
@fracek, we need documentation on write_input_bounds and load_input_bounds (both in https://github.com/cog-imperial/OMLT/blob/main/src/omlt/io/input_bounds.py).
I need to clarify. Does the following make sense and (if it doesn't) would you please suggest an alternative?
For write_input_bounds:
""" Write the specified input bounds to the given file. This input implicitly assumes that all inputs are defined (no indices missing) and all indices are bounded. """
` """
Parameters
----------
input_bounds_filename: file
input_bounds: dict or list
"""`
For load_input_bounds:
""" Read the input bounds from the given file. """
` """
Parameters
----------
input_bounds_filename: file
The file should be a list of tuples with a key (index of the input), lower bound (real number), and upper bound (real number).
"""`
When I call the function net = load_onnx_neural_network(model) with the attached onnx file, I get the following error:
File "/usr/local/lib/python3.10/site-packages/omlt/io/onnx_parser.py", line 235, in _consume_gemm_dense_nodes assert attr["transB"] == 1 AssertionError
MatMul_Add_Sim.onnx.zip
I believe that there is a missing required dependency in the OMLT 1.0 release: onnx is listed as a "testing" dependency, but is required in order to import anything from omlt.io.
% pip install --user omlt
Collecting omlt
Downloading omlt-1.0-py2.py3-none-any.whl (29 kB)
Requirement already satisfied: importlib-metadata in [...] (from omlt) (4.8.1)
Requirement already satisfied: numpy in [...] (from omlt) (1.21.2)
Requirement already satisfied: pyomo in [...] (from omlt) (6.4.3.dev0)
Requirement already satisfied: networkx in [...] (from omlt) (2.6.3)
Requirement already satisfied: typing-extensions>=3.6.4 in [...] (from importlib-metadata->omlt) (3.10.0.2)
Requirement already satisfied: zipp>=0.5 in [...] (from importlib-metadata->omlt) (3.4.0)
Requirement already satisfied: ply in [...] (from pyomo->omlt) (3.11)
Installing collected packages: omlt
Successfully installed omlt-1.0
% python
Python 3.7.12 (default, Nov 10 2021, 15:38:43)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from omlt.io.keras_reader import load_keras_sequential
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "[...]/site-packages/omlt/io/__init__.py", line 1, in <module>
from omlt.io.onnx import load_onnx_neural_network, write_onnx_model_with_bounds, load_onnx_neural_network_with_bounds
File "[...]/site-packages/omlt/io/onnx.py", line 4, in <module>
import onnx
ModuleNotFoundError: No module named 'onnx'
omlt/io/__init__.pyomlt/io/onnx.py (e.g., something like pyomo.common.dependencies.attempt_import())onnx as a required dependencyIndexedVar no longer seems to work when passing to an OptMLBlock.
See the code in: https://github.com/cog-imperial/OptML/blob/dc20370a8d7de3513d1d202e78cbec336bea7a9b/src/optml/utils.py#L11-L19
Does Pyomo no longer support OrderedSet? We can no longer access vars.indexed_set. There is vars.index_set, but it does not have .is_ordered. Does Pyomo assume that IndexVars are always ordered now? If yes, we can just return the values using list(vars.values())
Currently ONNX doesn't support categorical vars which limits the use of tree ensembles in OMLT. By directly interfacing with these libraries, we can add support for categorical vars.
Using Tanh as an activation function returns the following error. Using other activation functions such as sigmoid or relu works fine.
Exception: Unhandled node type TanhONNX version: 1.13.1
OMLT version: 1.1
Pytorch version: 2.0.1
import torch
from torch import nn
from collections import OrderedDict
from omlt.io import write_onnx_model_with_bounds, load_onnx_neural_network_with_bounds
from omlt import OmltBlock, OffsetScaling
from omlt.neuralnet import FullSpaceNNFormulation, NetworkDefinition
import tempfile
if torch.cuda.is_available():
device = torch.device('cuda')
print("Running on GPU")
else:
device = torch.device('cpu')
print("Running on CPU")
class DNN(nn.Module):
def __init__(
self, n_in, n_out, n_neu, n_layers, activ="Tanh"
):
super().__init__()
self.n_in = n_in
self.n_out = n_out
self.n_neu = n_neu
self.n_layers = n_layers
self.activ = getattr(nn, activ)
layer_list =list()
layer_list.append(
('layer_%d' % 0, nn.Linear(self.n_in, self.n_neu))
)
layer_list.append(
('activation_%d' % 0, self.activ())
)
for i in range(1,self.n_layers):
layer_list.append(
('layer_%d' % i,nn.Linear(self.n_neu, self.n_neu))
)
layer_list.append(
('activation_%d' % i, self.activ())
)
layer_list.append(
('layer_%d' % n_layers, nn.Linear(self.n_neu, self.n_out))
)
layerDict = OrderedDict(layer_list)
self.dnn = nn.Sequential(layerDict)
def forward(self, x):
return self.dnn(x)
if __name__=="__main__":
n_in = 2
n_out = 2
n_neu = 5
n_layers = 3
model = DNN(n_in,n_out,n_neu,n_layers,activ="Tanh").to(device)
x = torch.randn(10, n_in, requires_grad=True).to(device)
pytorch_model = None
with tempfile.NamedTemporaryFile(suffix='.onnx', delete=False) as f:
torch.onnx.export(
model,
x,
f,
input_names=['input'],
output_names=['output'],
dynamic_axes={
'input': {0: 'batch_size'},
'output': {0: 'batch_size'}
}
)
input_bounds = [(-1, 1) for _ in range(n_in)]
write_onnx_model_with_bounds(f.name, None, input_bounds)
print(f"Wrote PyTorch model to {f.name}")
pytorch_model = f.name
network_definition = load_onnx_neural_network_with_bounds(pytorch_model)ruff linting revealed the following missing docstrings:
__init____init____init____init____init____init____init____init____init____init____init____init____init____init____init____init__For each of these we should provide a docstring, unless it makes sense to change to private.
For now I've set ruff to ignore these error codes - once the docstrings are completed we should turn that checking back on again.
Hello, I was trying to run the example code provided in the ReadMe and encountered errors when using omlt.io.load_keras_sequential to load the NN into the network definition. It seems that the versioning of TensorFlow changes how some variables are stored and perhaps a version number of TensorFlow needs to be specified in the requires field of setup.cfg.
Here is the error output from the readme example.
Version numbers for the relevant packages, this is running on a windows 10 desktop.
packages:
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
C:\Users\DUSTIN~1.KEN\AppData\Local\Temp/ipykernel_7852/3182238221.py in <module>
34 #multiple formulations of a neural network are possible
35 #this uses the default NeuralNetworkFormulation object
---> 36 formulation = FullSpaceNNFormulation(net)
37
38 #build the formulation on the OMLT block
C:\tools\Anaconda3\envs\new_base\lib\site-packages\omlt\neuralnet\nn_formulation.py in __init__(self, network_structure, layer_constraints, activation_constraints)
68
69 # TODO: Change these to exceptions.
---> 70 network_inputs = list(self.__network_definition.input_nodes)
71 assert len(network_inputs) == 1, 'Multiple input layers are not currently supported.'
72 network_outputs = list(self.__network_definition.output_nodes)
C:\tools\Anaconda3\envs\new_base\lib\site-packages\omlt\neuralnet\network_definition.py in input_layers(self)
68 def input_layers(self):
69 """Return an iterator over the input layers"""
---> 70 for layer_id, in_degree in self.__graph.in_degree():
71 if in_degree == 0:
72 yield self.__layers_by_id[layer_id]
TypeError: cannot unpack non-iterable int objectAt the moment, the documentation copyright is set to me since that's the default used by the template. What should we change that to to give credit to the COG Group, Sandia, and CMU?
Current implementation of convolutional 2D layer assumes (1) no paddings (2) no dilations (3) zero biases.
To add these features, we need:
parameters corresponding to those features in the Layer2D definition: https://github.com/cog-imperial/OMLT/blob/main/src/omlt/neuralnet/layer.py
a bias term in the Layer2D constraints: https://github.com/cog-imperial/OMLT/blob/main/src/omlt/neuralnet/layers/full_space.py
By generalizing function kernel_index_with_input_indexes in line 258 of https://github.com/cog-imperial/OMLT/blob/main/src/omlt/neuralnet/layer.py, it's possible to support more pooling and convolutional layers (e.g., 1D, 3D).
With PR 137 (#137), we reduced coverage from 96% to 92%. The error handling has substantially improved (exceptions rather than asserts), but the code coverage has dropped because exceptions count towards line coverage (assertions don't).
Already PR 137 does include a lot of tests for increasing the code coverage, but any additional tests would always be appreciated. 😀
The CI tests may randomly fail for some notebooks becase Cbc takes too long. We should consider reducing the size of the relu networks. auto-thermal-reformer-relu.ipynb seems to take the longest.
I ran pyomo solve in with omlt and get a bug end with
pyomo.common.errors.DeveloperError: Internal Pyomo implementation error:
"The '_data' dictionary and '_index' attribute are out of sync for indexed Block 'unknown': The None entry in the '_data' dictionary does not map back to this component data object."
Please report this to the Pyomo Developers.
============== Diagnostic Run torch.onnx.export version 2.0.0+cpu ==============
verbose: False, log level: Level.ERROR
======================= 0 NONE 0 NOTE 0 WARNING 0 ERROR ========================
0 InputLayer(input_size=[3], output_size=[3]) linear
1 DenseLayer(input_size=[3], output_size=[128]) sigmoid
2 DenseLayer(input_size=[128], output_size=[128]) sigmoid
3 DenseLayer(input_size=[128], output_size=[128]) sigmoid
4 DenseLayer(input_size=[128], output_size=[1]) linear
============== Diagnostic Run torch.onnx.export version 2.0.0+cpu ==============
verbose: False, log level: Level.ERROR
======================= 0 NONE 0 NOTE 0 WARNING 0 ERROR ========================
0 InputLayer(input_size=[3], output_size=[3]) linear
1 DenseLayer(input_size=[3], output_size=[128]) sigmoid
2 DenseLayer(input_size=[128], output_size=[128]) sigmoid
3 DenseLayer(input_size=[128], output_size=[128]) sigmoid
4 DenseLayer(input_size=[128], output_size=[1]) linear
WARNING (W1002): Setting Var 'neural_net_block0.scaled_inputs[0]' to a numeric
value `0` outside the bounds (0.45, 100).
See also https://pyomo.readthedocs.io/en/stable/errors.html#w1002
WARNING (W1002): Setting Var 'neural_net_block0.scaled_inputs[0]' to a numeric
value `0` outside the bounds (0.45, 100).
See also https://pyomo.readthedocs.io/en/stable/errors.html#w1002
WARNING (W1002): Setting Var 'neural_net_block0.scaled_inputs[1]' to a numeric
value `0` outside the bounds (0.45, 100).
See also https://pyomo.readthedocs.io/en/stable/errors.html#w1002
WARNING (W1002): Setting Var 'neural_net_block1.scaled_inputs[0]' to a numeric
value `0` outside the bounds (0.45, 100).
See also https://pyomo.readthedocs.io/en/stable/errors.html#w1002
WARNING (W1002): Setting Var 'neural_net_block1.scaled_inputs[0]' to a numeric
value `0` outside the bounds (0.45, 100).
See also https://pyomo.readthedocs.io/en/stable/errors.html#w1002
WARNING (W1002): Setting Var 'neural_net_block1.scaled_inputs[1]' to a numeric
value `0` outside the bounds (0.45, 100).
See also https://pyomo.readthedocs.io/en/stable/errors.html#w1002
Traceback (most recent call last):
File "cluster_mange_2.py", line 230, in <module>
tester.main_route()
File "cluster_mange_2.py", line 175, in main_route
self.calculate_next()
File "cluster_mange_2.py", line 141, in calculate_next
self.action,qps,stats = c.sk_baye()
File "/root/k8s_manger/algorithm/modelOptV2.py", line 291, in sk_baye
res = skopt.gp_minimize(self.opt, # the function to minimize
File "/root/mrf_python/lib/python3.8/site-packages/skopt/optimizer/gp.py", line 259, in gp_minimize
return base_minimize(
File "/root/mrf_python/lib/python3.8/site-packages/skopt/optimizer/base.py", line 299, in base_minimize
next_y = func(next_x)
File "/root/k8s_manger/algorithm/modelOptV2.py", line 307, in opt
x,_,cost = self.c.CreatOpt(q)
File "/root/k8s_manger/algorithm/modelOptV2.py", line 405, in CreatOpt
results = opt.solve(m, tee=True)
File "/root/mrf_python/lib/python3.8/site-packages/pyomo/opt/base/solvers.py", line 570, in solve
self._presolve(*args, **kwds)
File "/root/mrf_python/lib/python3.8/site-packages/pyomo/opt/solver/shellcmd.py", line 219, in _presolve
OptSolver._presolve(self, *args, **kwds)
File "/root/mrf_python/lib/python3.8/site-packages/pyomo/opt/base/solvers.py", line 667, in _presolve
self._convert_problem(args,
File "/root/mrf_python/lib/python3.8/site-packages/pyomo/opt/base/solvers.py", line 718, in _convert_problem
return convert_problem(args,
File "/root/mrf_python/lib/python3.8/site-packages/pyomo/opt/base/convert.py", line 101, in convert_problem
problem_files, symbol_map = converter.apply(*tmp, **tmpkw)
File "/root/mrf_python/lib/python3.8/site-packages/pyomo/solvers/plugins/converter/model.py", line 187, in apply
(problem_filename, symbol_map_id) = instance.write(
File "/root/mrf_python/lib/python3.8/site-packages/pyomo/core/base/block.py", line 2016, in write
(filename, smap) = problem_writer(self,
File "/root/mrf_python/lib/python3.8/site-packages/pyomo/repn/plugins/nl_writer.py", line 339, in __call__
info = self.write(model, FILE, ROWFILE, COLFILE, config=config)
File "/root/mrf_python/lib/python3.8/site-packages/pyomo/repn/plugins/nl_writer.py", line 382, in write
return impl.write(model)
File "/root/mrf_python/lib/python3.8/site-packages/pyomo/repn/plugins/nl_writer.py", line 1078, in write
line_1_txt = f"g3 1 1 0\t# problem {model.name}\n"
File "/root/mrf_python/lib/python3.8/site-packages/pyomo/core/base/component.py", line 612, in name
return self.getname(fully_qualified=True)
File "/root/mrf_python/lib/python3.8/site-packages/pyomo/core/base/component.py", line 867, in getname
return base + index_repr(self.index())
File "/root/mrf_python/lib/python3.8/site-packages/pyomo/core/base/component.py", line 797, in index
raise DeveloperError(
pyomo.common.errors.DeveloperError: Internal Pyomo implementation error:
"The '_data' dictionary and '_index' attribute are out of sync for indexed Block 'unknown': The None entry in the '_data' dictionary does not map back to this component data object."
Please report this to the Pyomo Developers.Pyomo version:6.5.0
Python version:3.8.10
Operating system:Ubuntu 20.04 LTS
How Pyomo was installed (PyPI, conda, source):PyPI,
Solver (if applicable):IPOPT
Dear developers,
I am getting the following exception when trying to embed a ReLU network in my optimization model:
Exception has occurred: TypeError
'>' not supported between instances of 'NoneType' and 'int'
This is the piece of code that triggers the error:
model = ConcreteModel()
model.nn = OmltBlock()
keras_model = tf.keras.models.load_model('ip_model_1406S.keras', compile=False)
input = tf.keras.Input(shape = (30,), name = 'IN') # n_scenarios x n_periods*n_products. This command defines an input tensor, but it is not a layer!
fwd_model = tf.keras.Sequential()
fwd_model.add(tf.keras.Input(shape = (30,), name = 'IN'))
fwd_model.add(tf.keras.layers.Dense(units = keras_model.layers[6].units , activation = 'relu', name='H1'))
fwd_model.add(tf.keras.layers.Dense(units = keras_model.layers[7].units , activation = 'relu', name='H2'))
fwd_model.add(tf.keras.layers.Dense(units = keras_model.layers[8].units , activation = 'linear', name='OUT'))
fwd_model.layers[0].set_weights(keras_model.layers[6].get_weights())
fwd_model.layers[1].set_weights(keras_model.layers[7].get_weights())
fwd_model.layers[2].set_weights(keras_model.layers[8].get_weights())
net = load_keras_sequential(fwd_model)
formulation_comp = ReluBigMFormulation(net)
model.nn.build_formulation(formulation_comp)
I'd really appreciate it is someone can explain the error and provide a possible fix.
Thanks in advance!
Our code coverage is generally high, but it's low for CNNs.
@fracek, Could you please submit a PR with the CNN-related tests?
Do we need https://github.com/cog-imperial/OMLT/blob/main/docs/notebooks/gbt.ipynb and https://github.com/cog-imperial/OMLT/blob/main/docs/notebooks/helpers.py, @ThebTron and @fracek? Or can these be deleted?
onnx_parser.py (and possibly keras_reader.py) does not contain checks for unsupported operation types:
=== from PR comment
will this use a linear activation if maybe_node.op_type is not in _ACTIVATION_OP_TYPES? this could lead to an incorrect neural network
Originally posted by @jalving in #24 (comment)
@carldlaird and @jalving have mentioned possible improvements to Pyomo which support named expressions more efficiently. We want to integrate this Pyomo functionality if/when this Pyomo feature becomes available.
Hopefully the reduced space formulations improve as a result.
(We discussed this some months ago, but I only had it as a note to myself, just adding it here for completeness)
We are looking into methods to either read or build formulations for neural networks that are sparse, or approximately sparse. For example, connections that are close to zero (given by some user tolerance) can be ignored during model building. Pyomo should already omit weights that are exactly zero when building expressions, but this can speed up model construction.
The partition-based formulation currently only works for dense neural networks. We would like to extend the partition-based formulation to additionally apply to CNNs.
A research paper describing the partition-based formulation is here: https://proceedings.neurips.cc/paper/2021/hash/17f98ddf040204eda0af36a108cbdea4-Abstract.html
The challenge is to write code equivalent to partition_based.py but with the same careful indexing that had to happen here:
OMLT/src/omlt/neuralnet/layer.py
Line 171 in 683caa7
Even better: generalize the partition-based formulation for both fully-dense NNs and CNNs and thereby avoid having the same tricky indexing in two places.
Originally posted by bspiveyxom October 20, 2023
I tried testing the main OMLT example using a Keras model. The only code I replaced is defining the Keras model "nn".
Loading the Keras model into an OMLT network definition and creating the formulation worked. Then this example fails when calling build_formulation.
Has anyone else tested this and seen this error? Maybe I just need more examples of how to use custom NN models? Help is appreciated to know if this is a bug or need to change the code to use a custom NN model.
ERROR: Rule failed when initializing variable for Var nn.scaled_inputs with
index 1: KeyError: 1
ERROR: Constructing component 'nn.scaled_inputs' from data=None failed:
KeyError: 1
KeyError Traceback (most recent call last)
File :44
41 formulation = FullSpaceNNFormulation(net)
43 #build the formulation on the OMLT block
---> 44 model.nn.build_formulation(formulation)
46 #query inputs and outputs, as well as scaled inputs and outputs
47 model.nn.inputs.display()
File /local_disk0/.ephemeral_nfs/envs/pythonEnv-270249cb-9f79-4e2c-a55c-4f7dd0a7b838/lib/python3.10/site-packages/omlt/block.py:89, in OmltBlockData.build_formulation(self, formulation)
86 self.__formulation._set_block(self)
88 # tell the formulation object to construct the necessary models
---> 89 self.__formulation._build_formulation()
File /local_disk0/.ephemeral_nfs/envs/pythonEnv-270249cb-9f79-4e2c-a55c-4f7dd0a7b838/lib/python3.10/site-packages/omlt/neuralnet/nn_formulation.py:106, in FullSpaceNNFormulation._build_formulation(self)
105 def _build_formulation(self):
--> 106 _setup_scaled_inputs_outputs(
107 self.block, self.__scaling_object, self.__scaled_input_bounds
108 )
110 _build_neural_network_formulation(
import tensorflow as tf
from tensorflow.keras.layers import Dense
from tensorflow.keras.models import Sequential
import pyomo.environ as pyo
from omlt import OmltBlock, OffsetScaling
from omlt.neuralnet import FullSpaceNNFormulation, NetworkDefinition
from omlt.io import load_keras_sequential
# define the Keras model
nn = Sequential()
nn.add(Dense(12, input_shape=(8,), activation='relu'))
nn.add(Dense(8, activation='relu'))
nn.add(Dense(1, activation='sigmoid'))
#create a Pyomo model with an OMLT block
model = pyo.ConcreteModel()
model.nn = OmltBlock()
#the neural net contains one input and one output
model.input = pyo.Var()
model.output = pyo.Var()
#apply simple offset scaling for the input and output
scale_x = (1, 0.5) #(mean,stdev) of the input
scale_y = (-0.25, 0.125) #(mean,stdev) of the output
scaler = OffsetScaling(offset_inputs=[scale_x[0]],
factor_inputs=[scale_x[1]],
offset_outputs=[scale_y[0]],
factor_outputs=[scale_y[1]])
#provide bounds on the input variable (e.g. from training)
scaled_input_bounds = {0:(0,5)}
#load the keras model into a network definition
net = load_keras_sequential(nn,scaler,scaled_input_bounds)
#multiple formulations of a neural network are possible
#this uses the default NeuralNetworkFormulation object
formulation = FullSpaceNNFormulation(net)
#build the formulation on the OMLT block
model.nn.build_formulation(formulation)
#query inputs and outputs, as well as scaled inputs and outputs
model.nn.inputs.display()
model.nn.outputs.display()
model.nn.scaled_inputs.display()
model.nn.scaled_outputs.display()
#connect pyomo model input and output to the neural network
@model.Constraint()
def connect_input(mdl):
return mdl.input == mdl.nn.inputs[0]
@model.Constraint()
def connect_output(mdl):
return mdl.output == mdl.nn.outputs[0]
#solve an inverse problem to find that input that most closely matches the output value of 0.5
model.obj = pyo.Objective(expr=(model.output - 0.5)**2)
status = pyo.SolverFactory('ipopt').solve(model, tee=False)
print(pyo.value(model.input))
print(pyo.value(model.output))`
```</div>
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.