cntchen / cntchen.github.io Goto Github PK
View Code? Open in Web Editor NEWCntChen Blog
Home Page: https://github.com/CntChen/cntchen.github.io/issues
CntChen Blog
Home Page: https://github.com/CntChen/cntchen.github.io/issues























































































































































做个表格对比现在业界现有的配置管理系统.
| 名称 | 语言 / 框架 | 介绍 | 特点 |
|---|---|---|---|
| ACM(阿里云) | 云服务 | 在微服务、DevOps、大数据等场景下极大地减轻配置管理的工作量 | 云服务, 实时推送, 版本管理 |
| Apollo(携程) | Spring Boot 和 Spring Cloud | 分布式配置中心, 适用于微服务配置场景 | 配置实时生效,客户端支持 Java、.Net |
| Disconf(百度) | SpringMvc | Distributed Configuration Management Platform(分布式配置管理平台) | 配置实时生效 |
| Spring Cloud Config | Spring | Spring Cloud Config provides server and client-side support for externalized configuration in a distributed system | Git 来存储配置信息 |
| Etcd(CoreOS) | go | Distributed reliable key-value store for the most critical data of a distributed system | gRPC, Secure |
https://www.aliyun.com/product/acm?spm=5176.8135679.793319.11.22ef5a7eAknOgP
https://help.aliyun.com/document_detail/59957.html?spm=5176.doc59972.6.541.bW7PxM
https://help.aliyun.com/document_detail/59968.html?spm=5176.doc59953.6.543.MnBu6E
前端页面与后台的交互方式一般是在页面解析完成后,使用异步接口请求后台数据,然后根据数据渲染出前端页面.前后端交互的关键在于接口:
前端的特定场景,比如首页,需要不同维度的多种数据,数据需要调用多个接口才能获得,导致前端的请求过多,在移动端这种非健壮性网络下导致页面白屏时间长。所以存在以下矛盾:
另外一方面,在不同场景,希望接口可以返回指定的数据,减少没必要数据的传输。在 RESTful 上的实现,通常是带上查询参数,接口使用场景多了后,接口中的处理逻辑变得复杂和难以维护。
Representational state transfer 是目前主流的客户端和服务端交互方式。REST 服务允许客户端通过预先定义的无状态操作,访问或修改用文本表示的服务端资源.
将后台服务拆分为功能独立的系统,具有业务的独立性和完整性,减少服务间的依赖。微服务可以独立部署,便于负载管理和优化。微服务通过API Gateway 提供 RESTful 的接口。
RESTful 下的接口聚合,服务端的业务复杂度,接口性能不高,并且复用性不高。
query language for APIs - GraphQL
GraphQL 是一种标准语言,类型系统,创建前后端强契约的规范,使得前后端的数据交互处理过程得到简化。客户端可以从服务端的数据集中获取自定义结构的数据.
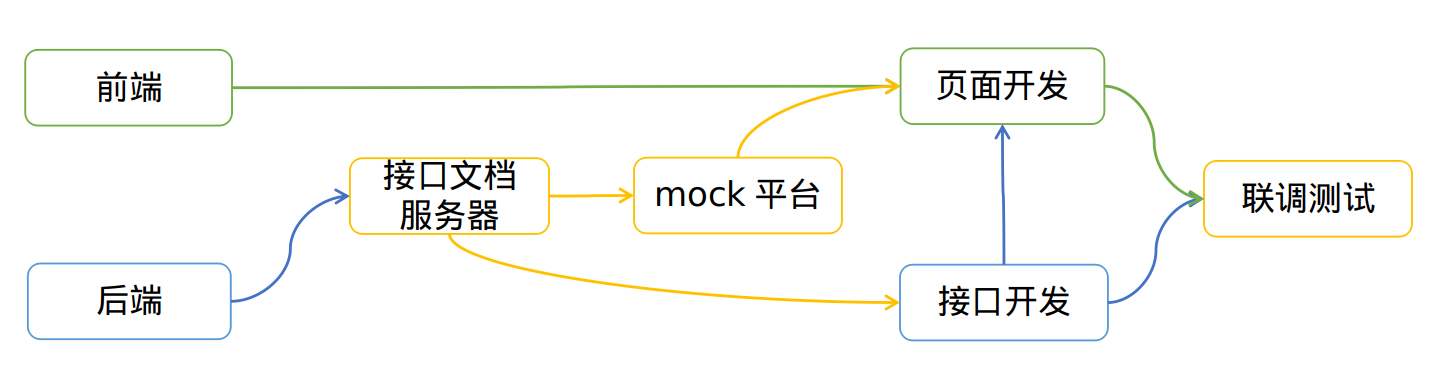
前后端分离 mock AJAX 工作流 前端mock(模拟): 是在项目测试中,对项目外部或不容易获取的对象/接口,用一个虚拟的对象/接口来模拟,以便测试。
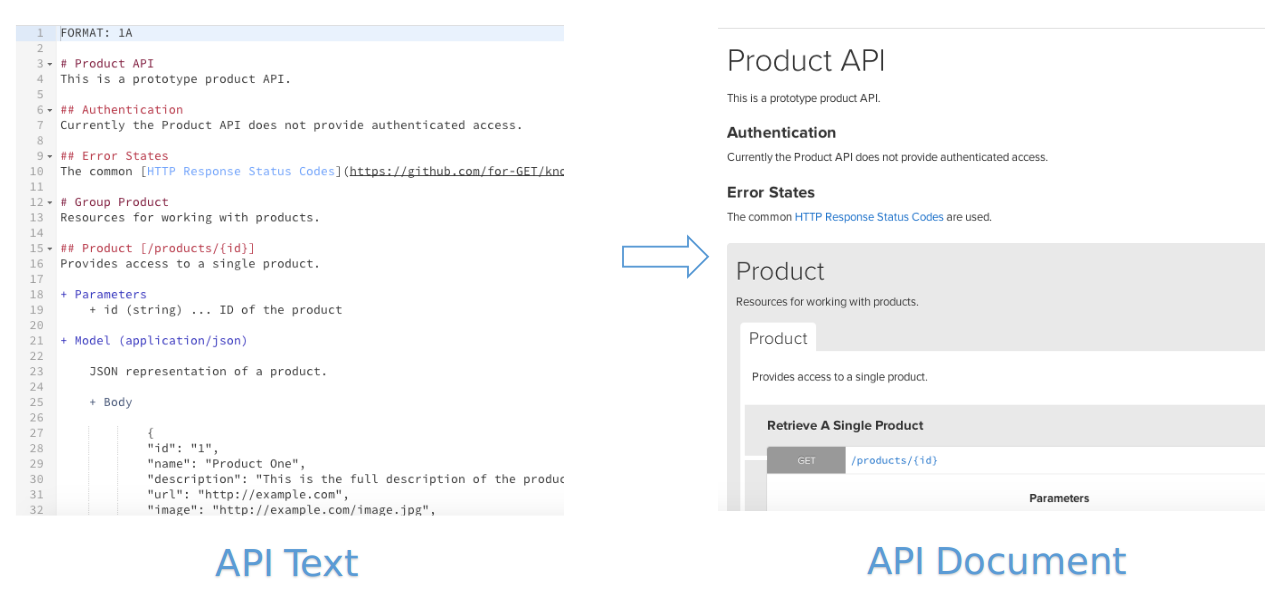
类型1:根据接口描述语法书写接口,并保存为文本文件,然后使用生成工具生成在线接文档(HTML)
-- 也有一些类似 Markdown 的接口文档编辑器,参见:[There Are Four API Design Editors To Choose From Now][There Are Four API Design Editors To Choose From Now]。
类型2:提供在线的接口编辑平台,进行可交互的接口编辑
前端开发过程中,使用 mock 数据来模拟接口的返回,对开发的代码进行业务逻辑测试。解决开发过程中对后台接口的依赖。
将 mock 数据写在代码中。
// $.ajax({
// url: ‘https://cntchen.github.io/userInfo’,
// type: 'GET',
// success: function(dt) {
var dt = {
"isSuccess": true,
"errMsg": "This is error.",
"data": {
"userName": "Cntchen",
"about": "FE"
},
};
if (dt.isSuccess) {
render(dt.data);
} else {
console.log(dt.errMsg);
}
// },
// fail: function() {}
// });hijack(劫持)接口的网络请求,将请求的返回替换为代码中的 mock 数据。
The jQuery Mockjax Plugin provides a simple and extremely flexible interface for mocking or simulating ajax requests and responses
Jquery将 mock 数据保存为本地文件。在前端调试的构建流中,用 node 开本地 mock 服务器,请求接口指向本地 mock 服务器,本地 mock 服务器 response mock 文件。
.mock
├── userInfo.json
├── userStars.json
├── blogs.json
└── following.json
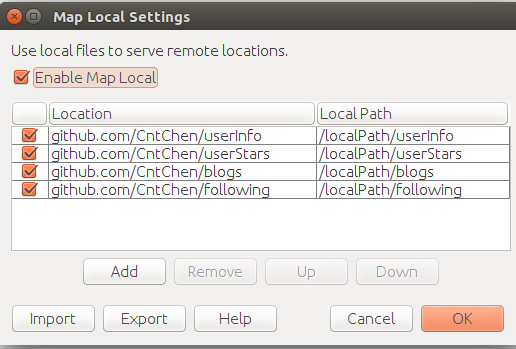
https://github.com/CntChen/userInfo --> localhost:port/userInfo
https://github.com/CntChen/userInfo --> localPath/userInfo
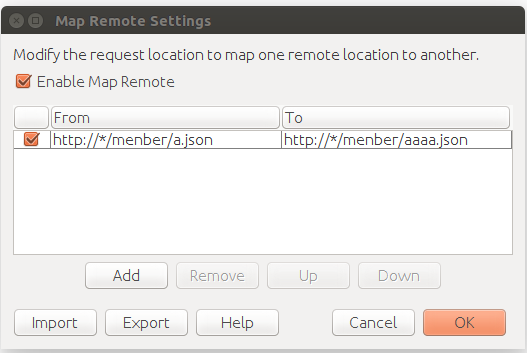
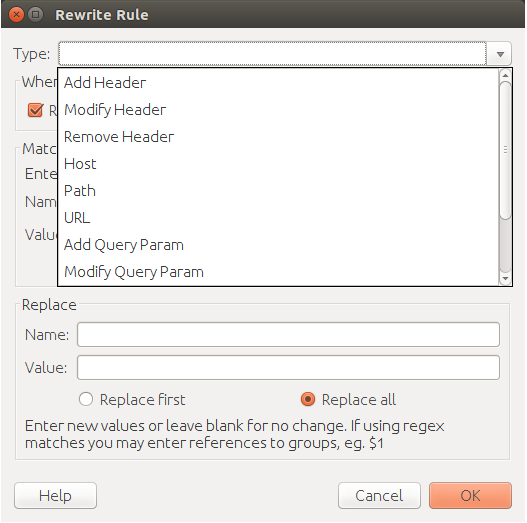
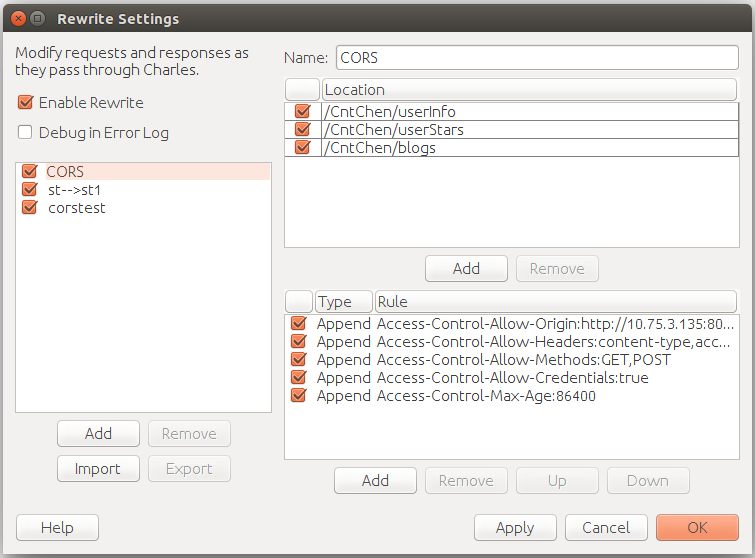
修改接口调用的 request 或 response,添加/删除/修改 HTTP request line/response line/headers/body
解决跨域问题
使用 map 后,接口调用的 response 不带 CORS headers,跨域请求在浏览器端会报错。需要重写接口返回的 header,添加 CORS 的字段。
使用接口文档服务器来定义接口数据结构
mock 服务器根据接口文档自动生成 mock 数据,实现了接口文档即API
没有找到公司级别的框架,除了阿里的 RAP。可能原因:
A powerful high-level API design language for web APIs.
一种使用类markdown语法的接口编写语言,使用[json-schema][json-schema]和[mson][mson]作为接口字段描述。有完善的工具链进行接口文件 Edit,Test,Mock,Parse,Converter等。
Swagger是一种 Rest API 的简单但强大的表示方式,标准的,语言无关,这种表示方式不但人可读,而且机器可读。可以作为 Rest API 的交互式文档,也可以作为 Rest API 的形式化的接口描述,生成客户端和服务端的代码。 --[Swagger:Rest API的描述语言][Swagger:Rest API的描述语言]
定义了一套接口文档编写语法,然后可以自动生成接口文档。相关项目: Swagger Editor ,用于编写 API 文档。Swagger UI restful 接口文档在线自动生成与功能测试软件。点击查看Swagger-UI在线示例。
WireMock is a simulator for HTTP-based APIs. Some might consider it a service virtualization tool or a mock server. It supports testing of edge cases and failure modes that the real API won't reliably produce.
对于前后端分离开发方式,已经有比较成熟的 mock 平台,主要解决了2个问题:
预研时间比较有限,有一些新的 mock 模式或优秀的 mock 平台没有覆盖到,欢迎补充。
笔者所在公司选用的平台是 RAP,后续会整理一篇 RAP 实践方面的文章。
问题来了:你开发中的 mock 方式是什么?
http://yalishizhude.github.io/2016/04/19/front-back-separation/
[图解基于node.js实现前后端分离]:http://yalishizhude.github.io/2016/04/19/front-back-separation/
http://martinfowler.com/bliki/TestDouble.html
[mock 相关的概念]:http://martinfowler.com/bliki/TestDouble.html
https://apievangelist.com/2014/11/21/there-are-four-api-design-editors-to-choose-from-now/
[There Are Four API Design Editors To Choose From Now]:https://apievangelist.com/2014/11/21/there-are-four-api-design-editors-to-choose-from-now/
http://www.ituring.com.cn/article/42460
[联调之痛]:http://www.ituring.com.cn/article/42460
https://zhuanlan.zhihu.com/p/21353795
[Swagger:Rest API的描述语言]:https://zhuanlan.zhihu.com/p/21353795
http://www.cnblogs.com/whitewolf/p/4686154.html
[Swagger - 前后端分离后的契约]:http://www.cnblogs.com/whitewolf/p/4686154.html
http://www.jianshu.com/p/d6626e6bd72c#
[Swagger UI教程 API 文档神器 搭配Node使用]:http://www.jianshu.com/p/d6626e6bd72c#
现在信息太碎片化了,还是要回归书本。
这是我读书的记录,督促自己持续学习。
2016.05 ~ 2017.05.04
读了好久好久,效率非常低,这是需要反省的地方。
这本书让我收获很多,在工作中解决了许多实际问题,也非常推荐软件工程师阅读,前端工程师也合适。
2017.05.4 ~ 未知的未来(2017.08.25)
提高效率看书。
更新: 效率还是比较低,110 天。这本书非常不错,对 CSS 的一些理念有了基本了解。
现在大量使用 flex 布局,以后遇到问题 google 文章应该可以搞定。
2017.08.26 ~ 未知的未来(2018.01.17)
网络是前端工程师拓展外延和了解安全/缓存/web存储的重要一块。系统学习非常有必要。
上一本书看太慢了,这本是大块头,继续坚持。
更新: 坚持不够彻底. 看书遗忘没有关系, 曾经搞懂的东西, 以后再看一下书就可以搞懂.
2018.01.17 ~ 未知的未来
设计模式的书应该是永远不会过时, 以前看过大话设计模式, 现在已经忘光光了. 是时候读书读书啦.
docker - the open-source application container engine
前言: 本篇文章2016年10月就记录了,但是搞丢了,最近重新找回,刚好又要搞 docker 了,重新整理完善.
docker 是比较热门的技术,但是作为一名前端工程师,跟 docker 有工作交集的机会比较少。刚好公司有一个项目,需要自己搭建环境,所以试下 docker.这篇文章是我的学习笔记.
机器: Ubuntu16.10
参考资料 docker 安装手册
$ curl -sSL https://get.docker.com/ | sh
shell 会提示输入 root 的密码,然后开始执行安装过程.
曲折:安装失败.
Err:1 https://apt.dockerproject.org/repo ubuntu-xenial/main amd64 docker-engine amd64 1.12.1-0~xenia
这是因为国外的源不稳定,可以尝试墙内的安装方法:
$ curl -sSL https://get.daocloud.io/docker | sh // 国内的源
$ sudo docker version
$ sudo docker run hello-world
成功标志,以下代码的最后一行:
Unable to find image 'hello-world:latest'
locallylatest: Pulling from library/hello-worldc04b14da8d14:
Pull completeDigest: sha256:0256e8a36e2070f7bf2d0b0763dbabdd67798512411de4cdcf9431a1feb60fd9Status:
Downloaded newer image for hello-world:latest
Hello from Docker!This message shows that your installation appears to be working correctly.
参考资料:docker 入门教程
$ docker search node
曲折:命令执行出错.
Warning: failed to get default registry endpoint from daemon
(Cannot connect to the Docker daemon. Is the docker daemon running on this host?).
Using system default: https://index.docker.io/v1/Cannot connect to the Docker daemon.
Is the docker daemon running on this host?
出错原因:需要 root 账户执行.
解决方法:把当前用户执行权限添加到相应的 docker 用户组里面
$ sudo groupadd docker// groupadd: group 'docker' already exists
// 添加当前用户到docker用户组里,注意这里的yongboy为ubuntu server登录用户名
$ sudo gpasswd -a yongboy docker// Adding user chenhanjie to group docker
// 重启Docker后台监护进程
$ sudo service docker restart# 重启之后,尝试一下,是否生效
$ docker version
// 若还未生效,则系统重启,则生效m,命令:sudo reboot
// from:http://www.wujianjun.org/2016/04/06/docker-install-issue/
// 重启docker服务
$ sudo service docker restart
$ docker search node
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
node Node.js is a JavaScript-based platform for... 3763 [OK]
nodered/node-red-docker Node-RED Docker images. 53 [OK]
strongloop/node StrongLoop, Node.js, and tools. 37 [OK]
kkarczmarczyk/node-yarn Node docker image with yarn package manage... 21 [OK]
bitnami/node Bitnami Node.js Docker Image 18 [OK]
calico/node 14 [OK]
siomiz/node-opencv _/node + node-opencv 10 [OK]
dahlb/alpine-node small node for gitlab ci runner 8 [OK]
$ sudo docker pull node
下载镜像可能会非常缓慢,可以使用国内源:docker下使用daocloud/阿里云镜像加速 .
$ docker run -i -t node
> var a = 1
undefined
> console.log(a)
1
undefined
-i:表示以“交互模式”运行容器,同步容器的 stdin/stdout 到宿主终端-t:表示容器启动后进入其命令行$ docker run -i -t -p 2280:80 -p 28080:8080 rap_v7
-p 28080:8080:参数类似端口映射的功能$ docker run -i -t -d node
1ef49add06ccbb3fbfd47b292707781babc2a72fa15f42148db2ef4017470421
-d:表示 deamon ,以后台启动这个 container$ docker run -i -t ubuntu
root@5b248d962f59:/# ls
bin dev home lib64 mnt proc run srv tmp var
boot etc lib media opt root sbin sys usr
root@5b248d962f59:/# cowsay
bash: cowsay: command not found
root@5b248d962f59:/# apt update && apt install cowsay
执行新程序.
root@5b248d962f59:/# whereis cowsay
cowsay: /usr/games/cowsay /usr/share/cowsay /usr/share/man/man6/cowsay.6.gz
root@5b248d962f59:/# /usr/games/cowsay 'hello'
_______
< hello >
-------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
使用 docker commit 命令来创建新的 docker image.
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2fcf9d176a0f ubuntu "/bin/bash" 10 minutes ago Up 10 minutes romantic_dubinsky
$ docker commit -m 'add cowsay' 2fcf9d176a0f ubuntu-with-cowsay
sha256:ce53d099e30cd453c416561e3919dcb7eaa0b38ebe4fd22b2f9f2ebe0f669ebc
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu-with-cowsay latest ce53d099e30c 3 minutes ago 211.3 MB
rap_v7 latest de72241bf273 8 months ago 1.541 GB
$ docker run -i -t ubuntu-with-cowsay
root@f08dc90c206a:/# /usr/games/cowsay 'hello CntChen'
_______________
< hello CntChen >
---------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
root@f08dc90c206a:/#
使用 kitematic 对 docker image 进行可视化管理。
linux 版本需要自行构建,主要参考:Initial Linux installer。
kitematic 使用 Electron 作为跨平台框架,安装 Electron 过程比较麻烦,反正最后我是安装上了,囧!有机会单独写文章记录安装流程。
// clone
$ git clone https://github.com/docker/kitematic.git
$ cd kitematic$ npm install
// 构建 $ sudo grunk release
// 安装
$ cd dist
$ sudo dpkg -i Kitematic_0.12.1_amd64.deb
安装后报错:

原因好像是:
基于虚拟机,用于mac与windows平台,linux不需要虚拟机直接运行docker
但是,突然国庆长假回来,就好了!!!
然后愉快地使用kitematic。界面非常好看。
没有完成安装,因为 kitematic 已经可以使用了,如果需要应对多个 host 和 container 的场景,这个工具可能会更好.
shipyard 安装参考 .
http://www.docker.org.cn/book/install/supported-platform-17.html
http://www.blogjava.net/yongboy/archive/2013/12/12/407498.html
Chrome: You will die!
IE9: Not today!
搭建公司官网的框架时采用了 vuejs, 使用 history router mode 来做 SEO 优化, 使用 fetch 做网络请求, fetch 用 whatwg-fetch 做 polyfill. 根据百度浏览器市场份额统计, 2017年全年 IE9 的占有率达到 9.50%, 并且 vue 框架也是兼容到 IE9, 所以项目要求兼容到 IE9.
但是 fetch polyfill 并不兼容 IE9, 这篇文章追溯问题原因并提出解决方法.
在 IE9 下打开页面, 发现 fetch 请求报了Unhandled promise rejectionError: 拒绝访问:
IE9

IE11 开 IE9 调试模式

怀疑是 fetch 的兼容问题, 查看一下版本:
$npm list whatwg-fetch
project
└── [email protected] 查看了一下whatwg-fetch 兼容性: 只支持到 IE10. 然后看到 whatwg-fetchv0.11 可以兼容 IE9, 那就降级一下吧:
$ npm uninstall whatwg-fetch
removed 1 package in 4.851s
$ npm install [email protected]
+ [email protected]
added 1 package in 5.96s再试一下, 发现还是一样的问题.
XMLHttpRequest 不支持 CORSfetch 的 polyfill 采用了 XMLHttpRequest 实现, 但是在 IE9 下面, XMLHttpRequest 是不支持跨域请求的. IE10 的 XMLHttpRequest 支持跨域, 而 IE8, IE9 需要使用 XDomainRequest 来实现跨域.
那就用 XDomainRequest 实现异步请求, 代码:
function fetchIe9(url, options = {}) => {
if (window.XDomainRequest) {
// https://developer.mozilla.org/en-US/docs/Web/API/XDomainRequest
// only support GET and POST method
// request and response content type should be JSON
// without response status code
return new Promise((resolve, reject) => {
const method = options.method || 'GET';
const timeout = options.timeout || 30000;
let data = options.body || options.params || {};
if (data instanceof Object) {
data = JSON.stringify(data);
}
const XDR = new XDomainRequest();
XDR.open(method, url);
XDR.timeout = timeout;
XDR.onload = () => {
try {
const json = JSON.parse(XDR.responseText);
return resolve(json.data);
} catch (e) {
reject(e);
}
return reject({});
};
XDR.ontimeout = () => reject('XDomainRequest timeout');
XDR.onerror = () => reject('XDomainRequest error');
XDR.send(data);
});
} else {
// native fetch or polyfill fetch(XMLHttpRequest)
// fetch...
}
}需要注意的是:
XDomainRequest 只支持 GET 和 POST mehtodXDomainRequest 不支持带 cookieXDomainRequest 不能设置 responseType, 通信双方需要约定数据格式XDomainRequest 的响应没有 response status code题外话: whatwg-fetch 一直采用 XMLHttpRequest 来做 polyfill, whatwg-fetch1.0+ 不支持 IE9, 并不是因为没有采用 XDomainRequest, 而是因为 IE9 的状态码不符合 fetch 规范, 而 polyfill 的目标是 polyfill 规范, 而不是做兼容.
写好了代码, 在 IE9 中, 网络请求非常诡异, 经常不行: 请求只持续了不到 1ms, 并且接收数据为 0B, 没有状态码; 但是在少数时候是可以成功请求并获取数据的.
IE9

IE11 开 E9 调试模式
此时 IE11 的 IE9 调试模式是可以的, 看来模拟器还是模拟不到位.

查了好久, 终于看到一篇文章: Internet Explorer Aborting AJAX Requests : FIXED
IE timing out the request even though data is being transmitted.
主要的原因大概是 IE9 会将一个正在传输的请求 timeout 掉.
解决办法是:
onprogress 事件回调, 告知 IE9 这个请求是活动中的, 不要 timeout 掉.function fetchIe9(url, options = {}) => {
if (window.XDomainRequest) {
// https://developer.mozilla.org/en-US/docs/Web/API/XDomainRequest
// only support GET and POST method
// request and response content type should be JSON
// without response status code
return new Promise((resolve, reject) => {
const method = options.method || 'GET';
const timeout = options.timeout || 30000;
let data = options.body || options.params || {};
if (data instanceof Object) {
data = JSON.stringify(data);
}
const XDR = new XDomainRequest();
XDR.open(method, url);
XDR.timeout = timeout;
XDR.onload = () => {
try {
const json = JSON.parse(XDR.responseText);
return resolve(json.data);
} catch (e) {
reject(e);
}
return reject({});
};
// fix random aborting: https://cypressnorth.com/programming/internet-explorer-aborting-ajax-requests-fixed/
XDR.onprogress = () => {};
XDR.ontimeout = () => reject('XDomainRequest timeout');
XDR.onerror = () => reject('XDomainRequest error');
setTimeout(() => {
XDR.send(data);
}, 0);
});
} else {
// native fetch or polyfill fetch(XMLHttpRequest)
// fetch...
}
}XDomainRequest, 因为 IE9 下的 XMLHttpRequest 不支持跨域调用.XDomainRequest 只支持 GET 和 POST method, 并且没有 response status code, 可以说是不完善的 HTTP 异步请求对象.whatwg-fetch1.0+ 不支持 IE9, 是因为 IE9 的状态码不符合 fetch 规范, 而 polyfill 的目标是 polyfill 规范, 而不是做兼容.https://developer.mozilla.org/en-US/docs/Web/API/XDomainRequest
https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest
https://cypressnorth.com/programming/internet-explorer-aborting-ajax-requests-fixed/
Linux OS GRUB 硬盘分区2016年双十一入手了一块500G的 SSD(Solid State Drive,固态硬盘),打算安装到自己的笔记本上。笔记本的 HDD(Hard Disk Drive,机械硬盘)已经跑了 Ubuntu16.10 + Win10 双系统。光驱位的硬盘支架也装好了,一直虚位以待。工作忙一直拖到了2017年。
公司的 PC 机器也是 Ubuntu16.10,并且安装的软件比较齐全,所以计划将 PC 的 Ubuntu16.10 迁移到 SSD 上,然后在笔记本上运行。
该章节是计算机启动和系统加载的一些概念,有助于加深对迁移原理的理解,注重实践的话可以直接跳过。
总结不一定准确,仅作为个人理解。干货可以看这篇文章:uefi-boot-how-does-that-actually-work-then
BIOS(Basic Input/Output System)和 UEFI(Unified Extensible Firmware Interface )是不同的计算机启动固件(Fireware),需要硬件(通常为主板)支持,相互代替的,其中 UEFI 是比较新的方式。
BIOS
经典的启动固件,会调用磁盘的 MBR,然后由 MBR 中的 loader 继续加载操作系统。
UEFI
UEFI 用来代替 BIOS,并克服 BIOS 的缺点,大多数的 UEFI 固件会提供兼容 BIOS 的启动方式。
区别
可以看这篇文章:[UEFI是什么?与BIOS的区别在哪里?][UEFI是什么?与BIOS的区别在哪里]
MBR 与 GPT 用于存储硬盘的分区信息,是不同的硬盘分区表类型。
MBR
MBR 表示 MBR 分区表,MBR 分区表在硬盘开头处存放了特殊的启动分区,称为 MBR(Master Boot Record,主启动记录),包含 Boot Loader 和硬盘逻辑分区。MBR 支持最大约2T的硬盘,最多能划分4个主分区,更多分区需要使用拓展分区实现。
(MBR在行文中可以表示 MBR 分区表和主启动记录两个意思,注意甄别。)
GPT
GPT 表示 GUID(Globally Unique Identifier) 分区表,是 UEFI 规范的一部分,用于替换 MBR 的分区方式。GPT 没有分区数和分区大小限制。
区别
可以看这篇文章:[What’s the Difference Between GPT and MBR When Partitioning a Drive][What’s the Difference Between GPT and MBR When Partitioning a Drive]
File System(文件系统)是存储媒介中文件存储的组织方式。
不同的文件系统类型有不同的速度,灵活性,安全性和占用空间。不同操作系统只支持特定的文件系统类型。
常见的文件系统类型有 FAT16,FAT32,NTFS,EXT3,EXT4,HFS 等。
Wikipedia 上有许多关于磁盘的资料,在磁盘分区上,我猜测的发展脉络是这样的:
If you want to do a ‘BIOS compatibility’ type installation, you probably want to install to an MBR formatted disk.
If you want to do a UEFI native installation, you probably want to install to a GPT formatted disk.
Of course, to make life complicated, many firmwares can boot BIOS-style from a GPT formatted disk.
UEFI firmwares are in fact technically required to be able to boot UEFI-style from an MBR formatted disk.
使用外接硬盘盒,将 SSD 连接到 PC 机上,先查看硬盘状态:
$ sudo fdisk -l
Disk /dev/sda: 465.8 GiB, 500107862016 bytes, 976773168 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disklabel type: dos
Disk identifier: 0xb2708ce0
Device Boot Start End Sectors Size Id Type
/dev/sda1 * 2048 411647 409600 200M 7 HPFS/NTFS/exFAT
/dev/sda2 411648 210126847 209715200 100G 7 HPFS/NTFS/exFAT
/dev/sda3 210128894 913704959 703576066 335.5G f W95 Ext'd (LBA)
/dev/sda5 210128896 703989759 493860864 235.5G 83 Linux
/dev/sda6 703991808 704966655 974848 476M 83 Linux
/dev/sda7 704968704 764067839 59099136 28.2G 83 Linux
/dev/sda8 764069888 771973119 7903232 3.8G 82 Linux swap / Solaris
Partition 3 does not start on physical sector boundary.
Disk /dev/sdb: 489.1 GiB, 525112713216 bytes, 1025610768 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 33553920 bytes其中/dev/sda为 PC 上的硬盘,装有 Ubuntu16.10 + Win7;/dev/sdb为 SSD,当前 SSD 为空盘。
笔记本是 2011 年的机器,主板启动引导好像不支持 UEFI,是用 BIOS。
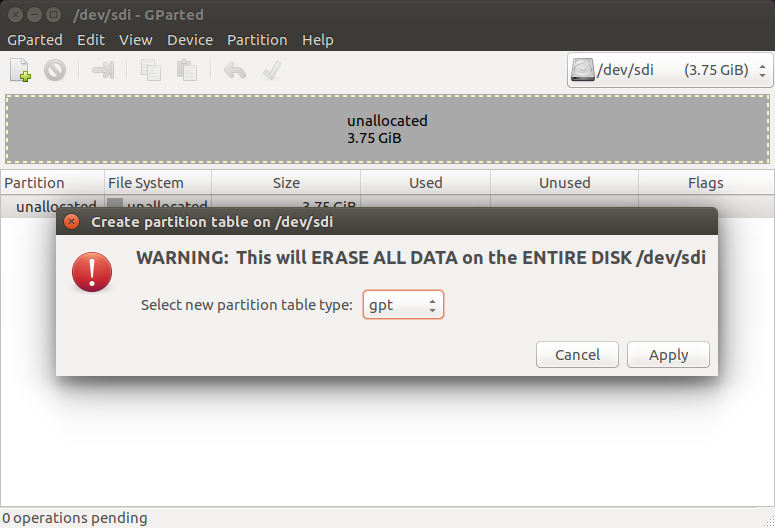
考虑 SSD 的拓展性,分区表选择 GPL,选用的引导方式为 BIOS + GPT。
此时安装 GRUB 引导对分区划分有要求,具体参考接下文的*《GRUB 引导》*章节。
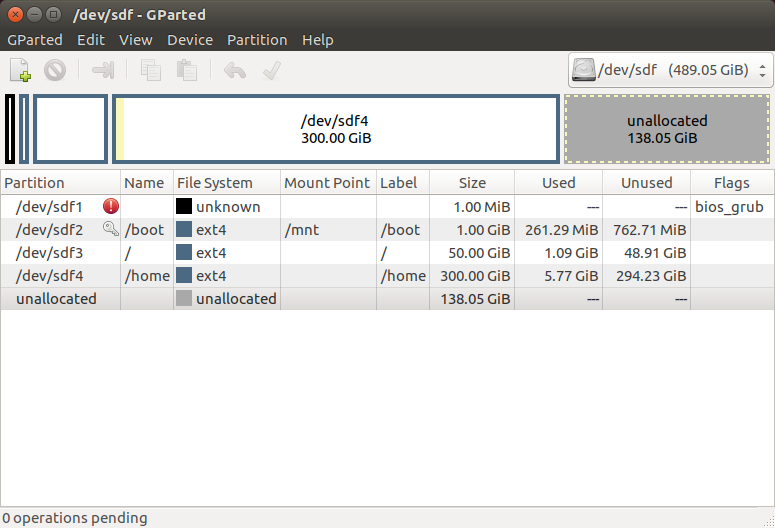
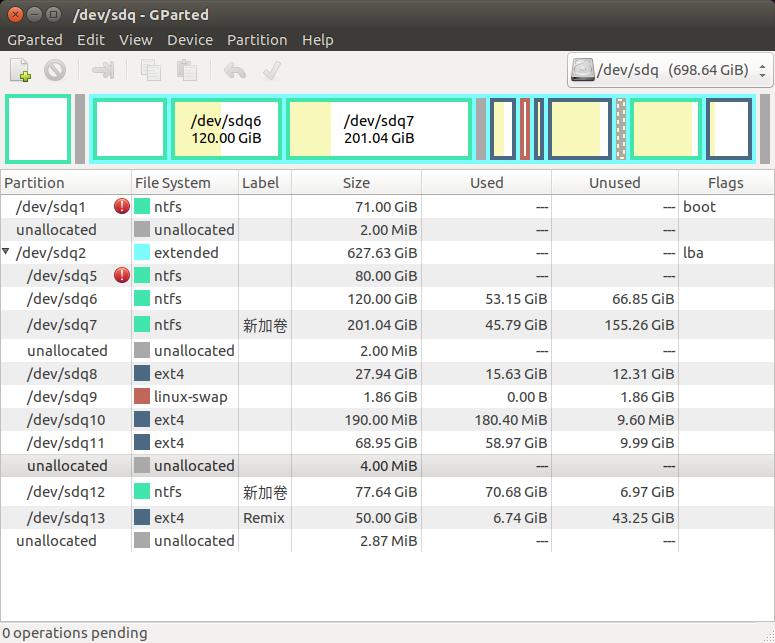
先上分区结果:
(注:前文出现的/dev/sdb1,/dev/sdf1和后面可能出现的/dev/sd#1都为同一个分区,因为多次插拔了 SSD ,所以标识一直按字母序递增)
不建立/swap分区了,因为 Ubuntu17.04也要移除 swap 分区。
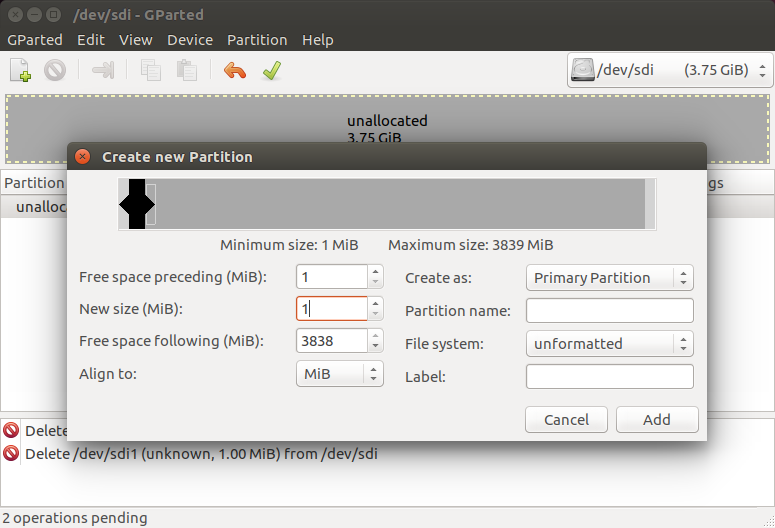
/dev/sdf1分区,建立 GRUB 引导所需分区,大小为 1M,分区文件类型为unformatted,分区 flag 为bios_grub。
/dev/sdf2分区,Linux /boot分区,大小 1G。
/dev/sdf3分区,Linux /分区,大小 50G。
/dev/sdf4分区,Linux /home分区,大小 300G。
分区操作在 Gparted 软件中完成,命令行fdisk和parted也可以操作,但是我不熟悉。
Device --> Created Partition Table。partition tabel type为gpt,然后点击Apply。分区大小为1M,分区类型为unformatted。
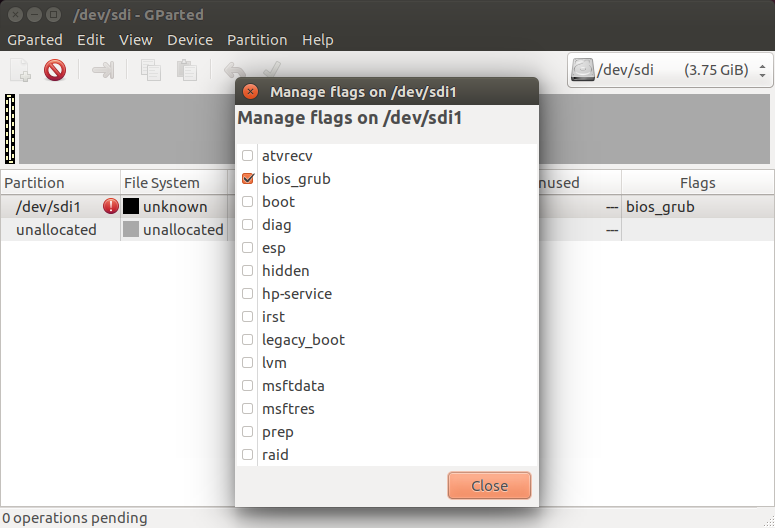
在新建的分区上点击右键,选择managerFlags,然后选中bios_grub选项。
ext4。$ sudo fdisk -l /dev/sdh
Device Start End Sectors Size Type
/dev/sdh1 2048 4095 2048 1M BIOS boot
/dev/sdh2 4096 2101247 2097152 1G Linux filesystem
/dev/sdh3 2101248 106958847 104857600 50G Linux filesystem
/dev/sdh4 106958848 736104447 629145600 300G Linux filesystemGRUB(Grand Unified Boot loader)是硬盘中的软件,引导器(loader)的一种。目前主流版本是 GRUB2,可以看 [GRUB2 中文介绍][GRUB2 中文介绍]。
GRUB 用于从多操作系统的计算机中选择一个系统来启动,或从系统分区中选择特殊的内核配置。
provides a user the choice to boot one of multiple operating systems installed on a computer or select a specific kernel configuration available on a particular operating system's partitions. -- GRUB
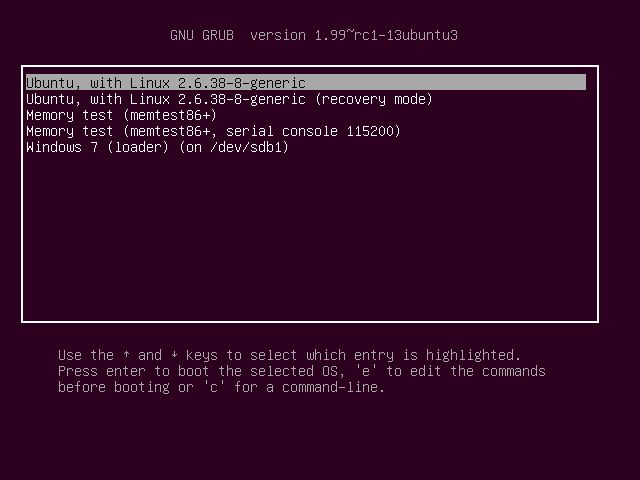
示例:
如图:第一个选项和最后一个选项是选择不同的操作系统;第一个选项和第二个选项是选择不同的内核配置。
其启动代码(boot.img)直接安装在 MBR 中,然后执行 GRUB 内核镜像(core.img),最后从/boot/grub中读取配置和其他功能代码。
BIOS 引导方式中,MBR 分区表和 GPT 分区表的 GRUB 引导文件所放分区不同:
如图,GRUB 的执行顺序为 boot.img --> core.img --> /boot/grub/。
boot.img 和 core.img 都在 MBR 中。MBR 虽然只占用一个扇区(512Byte),但是其所在的磁道是空闲的,不会用于分区,可以放下 core.img。Some MBR code loads additional code for a boot manager from the first track of the disk, which it assumes to be "free" space that is not allocated to any disk partition, and executes it. -- MBR
core.img,需要建一个专门的分区来放,称为BIOS boot partition,该分区的文件类型为unformatted,flag 为BOIS_grub,该 flag 用于标识core.img所要安装到的分区。若果使用 UEFI 引导,GRUB 读取的是 ESP 分区中的数据,不需要 flag 为 BIOS_grub的分区。使用 grup-install 的教程来安装 GRUB 到 SSD 盘。
/boot/boot为 PC Ubuntu 的/mnt,因为我们需要将 GRUB 配置文件放入 SSD 的/boot/grub中。$ sudo mount /dev/sdb2 /mnt
$ sudo grub-install --target=i386-pc --root-directory=/mnt --recheck --debug /dev/sdb
如果看到以下输出,应该就是成功了:
...
Installation finished. No error reported.
此时/mnt目录下,应该有一个./boot/grub的文件夹:
/mnt/boot/grub ⌚ 20:54:33
$ ls
fonts grubenv i386-pc locale
/grub位置/boot,/grub是直接放置在/boot下的:/boot/grub ⌚ 13:30:33
$ ls
fonts gfxblacklist.txt grub.cfg grubenv i386-pc locale unicode.pf2
而grub-install /dev/sdb安装的 GRUB 是/mnt/boot/grub,其中/mnt是 SSD /dev/sdb2分区,从 SSD 启动 Ubuntu 的话,/dev/sdb2会挂载为/boot,此时 GRUB 的位置是/boot/boot/grub。而当grub-install /dev/dsa安装 GRUB 到 PC Ubuntu 启动磁盘时,生成的/grub是在/boot/grub。grub-install的处理逻辑应该是先判断/boot路径是否存在,没有就新建。
所以,要将/mnt/boot/grub移动到/mnt/grub:
$ sudo mv /mnt/boot/grub /mnt/grub
启动电脑后,当 GRUB 无法按照boot.img --> core.img --> /boot/grub/顺序执行时,会看到命令行界面,等待用户输入命令。此时可以通过输入 GRUB 内置的命令来修复 GRUB 引导。
boot.img是写在 MBR 中的,如果不能执行,直接跟 GRUB 引导方式说再见了,所以执行boot.img一般没问题。boot.img不能识别任何文件系统,core.img的位置是硬编码进boot.img的,所以执行boot.img一般没问题。因此,常见的引导问题集中在/boot/grub/,主要有两种,对应有两种引导修复模式:
GRUB Rescue 模式
GRUB Rescue 模式是 GRUB 无法找到/boot分区,也就无法找到/boot/grub/。修复方法可以参考:grub rescue 模式下修复。
GRUB Normal 模式
GRUB Normal 模式是 GRUB 无法找到 GRUB 菜单grub.cfg,无法选择合适的内核或系统来启动。修复方法可以参考:Boot GNU/Linux from GRUB。
该步骤是把 PC 硬盘中几个 Linux 分区的数据拷贝到 SSD 上对应的分区。
(注意:PC Ubuntu 和 SSD Ubuntu 都有/、/boot、/home分区,阅读下文时注意辨别,我有时并没有写得很清晰。)
操作的套路是先将 SSD 的分区使用mount命令挂载为 PC 的/mnt,使用cp命令复制数据,再用umount命令移出这个分区;对下一个分区做同样操作。
// 挂载
$ sudo mount /dev/sdb2 /mnt
// 移出
$ sudo umount /mnt
cp指令要加-r,-f,-a参数,-r表示递归复制,-f表示强制覆盖,-a表示保留原文件的属性(mode,ownership,tiemstamps等)$ sudo cp -rf -a source destination
/boot分区SSD Ubuntu 的/boot从 PC Ubuntu 上看为/dev/sdb2,将/dev/sdb2挂载为 PC Ubuntu 的/mnt。安装 GRUB 之后,/mnt已经有/grub这个文件夹和默认的lost+found文件夹。
使用cp将 PC 的/boot中其他文件复制到/mnt。结果类似:
/mnt/ ⌚ 13:56:06
$ ls | sort
abi-4.8.0-36-generic
config-4.8.0-36-generic
grub
initrd.img-4.8.0-36-generic
lost+found
memtest86+.bin
memtest86+.elf
memtest86+_multiboot.bin
System.map-4.8.0-36-generic
vmlinuz-4.8.0-36-generic/分区SSD Ubuntu 的/分区(根目录)比较特殊:一些子目录挂载了其他分区,并存在“伪目录”,不同子目录有特定的用途。
所以复制/分区是有选择性的,不区分子目录进行复制,可能会提示“权限问题”、“无法访问”等错误。
不需要复制的目录
/boot,/home,/mnt挂载了其他分区
/media /cdrom 挂载可移除的媒体(cdrom 等)
/swap交换分区(不需要交换分区了)
需要复制的目录
主要参考: Linux操作系统备份之二
/bin 系统可执行文件
/etc 系统核心配置文件
/opt 用户程序文件
/root root用户主目录
/sbin 系统可执行文件
/usr 程序安装目录
/var 系统运行目录
需要手动创建的目录
在/mnt中需要给 SSD 的/创建几个空目录。
/dev 主要存放与设备(包括外设)有关的文件
/proc 正在运行的内核信息映射
/sys 硬件设备的驱动程序信息
这几个目录是 Linux 内核启动后由内核来挂载并存放信息的,不能从运行中的 PC Ubuntu 复制过去,但是需要建立空目录,不然内核启动后会报类似错误:
mount: mount point /dev does not exist
创建命令:
$ sudo mkdir dev proc sys
/home分区挂载 SSD Ubuntu/home到 PC Ubuntu /mnt,然后全盘复制:
$ sudo mount /dev/sdb4 /mnt
$ sudo cp -rf -a /home/* /mnt
/home和/boot分区SSD Ubuntu 的/home和/boot需要挂载到/,挂载方法为:修改/ect/fstab。
/dev/sda3为 PC Ubuntu /mntblkid查看 SSD 各分区的 UUID$ sudo blkid
...
/dev/sdb3 UUID="a5eb2b0c-2104-4afe-aa78-93396d3e0986" TYPE="ext4" PARTUUID="b2708ce0-07"
...
fstab文件$ sudo vim /mnt/etc/fatab
fstab文件大概是这样子的:
# /etc/fstab: static file system information.
#
# Use 'blkid' to print the universally unique identifier for a
# device; this may be used with UUID= as a more robust way to name devices
# that works even if disks are added and removed. See fstab(5).
#
# <file system> <mount point> <type> <options> <dump> <pass>
# / was on /dev/sda3 during installation
UUID=a5eb2b0c-2104-4afe-aa78-93396d3e0986 / ext4 errors=remount-ro 0 1
#
# /boot was on /dev/sda2 during installation
UUID=8cba10c6-dff2-4300-a630-ab0e7a4782af /boot ext4 defaults 0 2
#
# /home was on /dev/sda4 during installation
UUID=298ba5ad-d306-4b4a-aaa8-54312590dec6 /home ext4 defaults 0 2将 SSD 通过 USB 插入到笔记本,开机,选择从 USB 启动。此时应该会是看到类似下图的画面。
说明已经进入到 GRUB 引导程序中,但是没有 GRUB 启动选项,无法继续引导了。距离成功仅剩一步:修复 GRUB 引导。
/boot分区和/grub位置*(好像不需要这步,GRUB Rescue 才需要)*// grub> root=hd0,gpt2
// grub> prefix=(hd0,gpt2)/grub
grub> set root=hd0,gpt2
grub> set prefix=(hd0,gpt2)/grub
grub> linux /vmlinuz-4.8.0-36-generic ro root=/dev/sda2
grub> initrd /initrd.img-4.8.0-36-generic
grub> boot
到这一步应该可以启动 SSD 的 Ubuntu,但是下次重新开机,又需要手动指定内核才能启动,通过在 SSD Ubuntu 中重建 GRUB 引导可以解决该问题。
从 SSD 开启 Ubuntu 成功后,执行以下命令:
$ sudo update-grub
$ sudo grub-install /dev/dsa
以上命令更新了 GRUB 可引导的系统/内核列表:/boot/grub/grub.cf,并重新安装了 GRUB。可以参考:Grub2/Installing。
笔记本下次开机,就能看到类似画面:
将 SSD 放入笔记本内置硬盘位,将旧的 HDD 放到光驱位置,开机,完成!(撒花)!
总共花了三天时间搞定这个事情,整理出文章花了N天,查看了很多资料,对计算机开机引导,硬盘分区和 GRUB 算是比较了解了。
现在笔记本有了 SSD + HDD,下一步可能会实践双硬盘的数据备份。
最后放上 HDD 凌乱的分区图,纪念这几年装机折腾的日子。折腾中总有收获。
http://www.ihacksoft.com/uefi.html
[UEFI是什么?与BIOS的区别在哪里]:http://www.ihacksoft.com/uefi.html
http://www.howtogeek.com/193669/whats-the-difference-between-gpt-and-mbr-when-partitioning-a-drive/
[What’s the Difference Between GPT and MBR When Partitioning a Drive]:http://www.howtogeek.com/193669/whats-the-difference-between-gpt-and-mbr-when-partitioning-a-drive/
https://my.oschina.net/guol/blog/37373
[GRUB2 中文介绍]:https://my.oschina.net/guol/blog/37373
已经实现, 分享 slides: 前端配置管理系统从0到1-public, 文件稍大, 慎点.
Node 使用,从大处开始预研,然后从小点切入实践。
先搭建一个 Node 数据配置平台( content service)。
要找一个开源平台,首先需要找对关键字。
https://www.one-tab.com/page/dIcbimsZRR-mGzXN0zZRTA
https://www.one-tab.com/page/HShl4-acSraNThECklqe8w
页面可视化搭建, 是一个历久弥新的话题. 更广义上讲, 页面是 GUI 的一部分, GUI 的拖拉生成在各种开发工具上很常见, 如 Android Studio, Xcode, Visual Studio 等. 前端页面早在十几年前就能用 Dreamweaver, Frontpage 等工具可视化搭建出来.
Dreamweaver 操作页面示例:
但是现在已经很少人使用 Dreamweaver 了, 其主要原因是页面承载的内容已经和页面源码分离, 由后端接口返回再渲染到页面, 静态页面网站无法承载大量的动态内容.
Dreamweaver 死了, 但是页面可视化搭建工具依然广泛需要和使用, 所以这个话题依然值得探讨.
页面可视化搭建的操作对象是页面. 页面是一份 HTML 文档, 不管是静态页面还是动态渲染出来的页面, 在页面上看到的内容, 都是 HTML 文档的一部分.
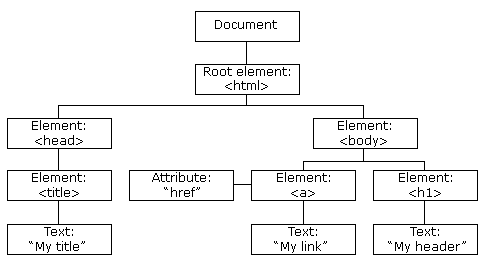
对 HTML 文档的实例化和操作, 通过文档对象模型(DOM)来实现, 也可以说页面是一个 DOM. 本文没有严格区分 HTML 和 DOM 这两个概念, 以下行文都用 HTML 这个概念.
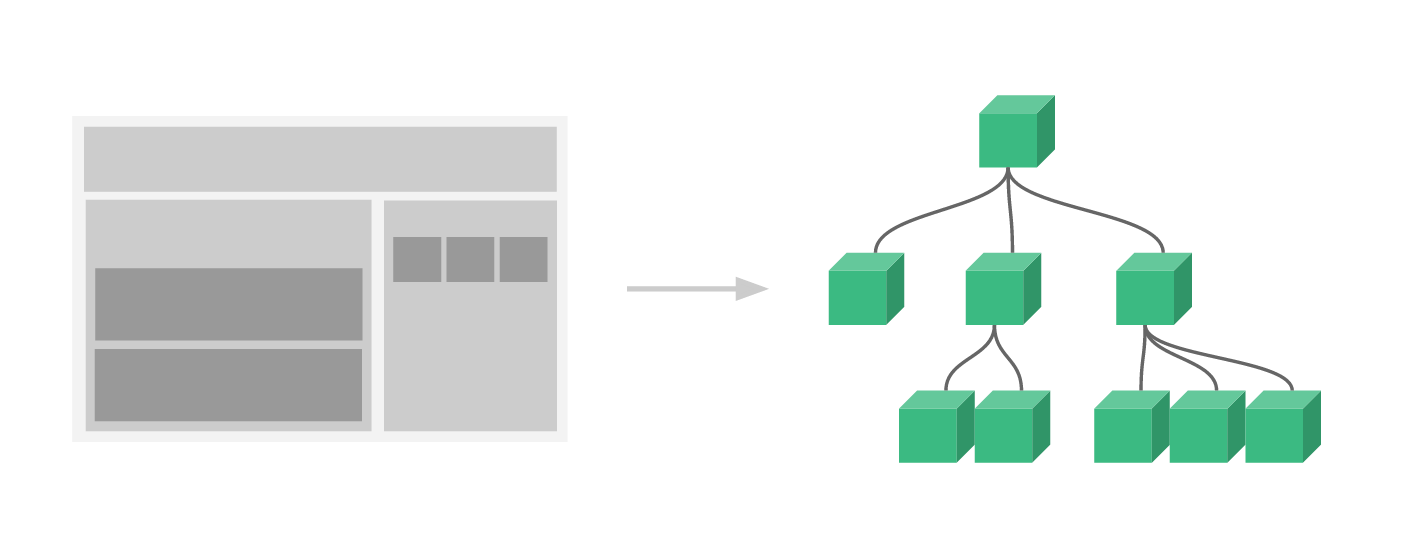
HTML 使用一种树形结构来表示页面, 树的每个节点为一个页面元素或文本节点, 一个页面元素可以包含多个页面元素节点或文本节点. 页面元素通常称为标签, 页面元素类型由 HTML 规范定义.
HTML 结构示例:
HTML Tree + Data从前端开发的角度, 可以认为页面是由 HTML Tree 和 Data 组成, HTML Tree 是页面元素的树形结构, Data 是页面元素的属性或文本节点. 下图中蓝色框所示的节点可以认为是数据.

为什么从前端开发角度会说页面是 HTML Tree + Data? 举一个常见场景来说明: 在开发新页面时, 我们是可以复制已有页面(好吧, 我就是这样的前端工程师), 然后只修改页面 HTML, 或者只修改数据, 或同时修改 HTML 和数据, 从而完成新页面的开发.
上一节说页面的由 HTML Tree 和 Data 组成, 讨论的是静态页面.

浏览器请求静态页面, 网络返回的 HTML 源码就是页面渲染完成后的 HTML. 静态页面的源码和页面渲染结果一致:

当下, 前端页面更多的是有动态逻辑的页面, 在页面中引入和使用动态脚本(Javascript)对页面进行修改和控制.

浏览器请求动态逻辑页面, 网络返回的 HTML 源码与页面渲染完成后的 HTML 有差异. 动态逻辑页面的源码和渲染结果有差异:

页面渲染后是一棵 HTML 元素构成的树, 页面的可编辑粒度为 HTML 规范定义的 HTML 元素.
使用 Web Components 组合 HTML 元素, 实现了功能封装和可复用的页面组件. 在流行的前端框架中, 都提供了组件化的功能, 从前端框架的视角看, 页面是由组件树组成. 这些组件内部维护自身的 HTML 元素结构、样式和功能逻辑, 并通过组件的 props 获取外部传入的数据, 实现了功能封装和复用.
Vue 组件树示例:
在以上的章节中, 我们并没有讨论决定页面样式的 CSS. 因为借助 Javascript 的动态逻辑, CSS 可以归入到 Data 的范围: 通过对页面元素 style attribute 的修改, 或将 CSS 属性动态添加到 <style> 标签中, 可以实现对页面元素样式的修改.
有了对页面组成的认知基础,可以对页面可视化搭建有更多的讨论: 页面可视化搭建是什么? 为什么需要?
如前文所阐述, 动态逻辑页面分解为 HTML Tree, Data 和 Dynamic Logic. 前端开发工程师开发前端页面的过程, 本质上是用编程工具(IDE)对页面的 HTML Tree, Data 和 Dynamic Logic 进行增删和修改.
页面可视化搭建, 是用可视化交互的方式对页面的 HTML Tree, Data 和 Dynamic Logic 进行增删和修改, 从而实现页面的生成. 页面可视化搭建工具是实现页面可视化编辑的软件工具.
用页面可视化搭建工具来搭建页面与前端工程师在页面上搬砖, 都是搭建页面, 区别在于实现页面搭建的方式. 做个简单对比:
| 差异点 | 编程开发页面 | 可视化搭建页面 |
| 技能要求 | 需要编程基础 | 可以没有编程基础 |
| 操作方式 | 在代码编辑器中编写代码 | 在可视化搭建工具中拖拉/填表/编写代码 |
任何工具的存在都是更高效地解决问题. 页面可视化搭建工具, 用于解决页面生成的效率问题.
可能前端工程师会觉得最有效率的页面生成方式是打代码, 但有搭建页面需求的不只是前端工程师. 而可视化页面搭建工具, 恰恰是面向"就缺一个前端工程师"的人员, 用于提升他们生成页面的效率.
我们可以从一些使用场景来窥探页面可视化搭建工具的应用场合.
页面小白不需要任何页面相关的知识, 不需要了解 HTML/JS/CSS 这些概念, 只要像使用 Word 一样在 H5 制作工具上操作, 就可以做出一个挺漂亮的页面. H5 制作工具很多, 其中 百度H5 做很好不错.
如: 小陈女票要生日了, 小陈为女票做了一个有创意的生日祝福页面:

大多数互联网公司需要做许多的活动页面来承载运营业务. 运营活动页面的特点是: 页面功能大同小异、需求急、时间紧、下线快、研发性很比低. 前端工程师无法持续开发无穷无尽的活动页面, 需要采用活动页面可视化搭建工具, 由运营人员/产品人员直接生成活动页面. 研发人员的工作转变为提供满足活动页面业务需要的活动模板.
如: 抽奖活动页面的可视化搭建:

在公司内部, 需要做许多的中后台支持系统, 这些系统的管理端一般用 web 页面承载. 那么问题来了, 中后台系统的前端工程, 怎么保障可用性、可维护性和页面呈现一致性? 这些系统与后台逻辑强关联, 一般由后台开发人员开发; 后台开发人员写代码逻辑是没有问题的, 但是其前端开发能力相对较弱. 所以需要增强他们开发前端页面的能力, 前端开发能力由前端服务化提供.
前端服务化的第一种方式是提供一套组件库, 如 饿了么的 Element.
组件库一般由前端开发人员封装成模板工程, 模板工程提供公共样式和函数库, 并对编写的代码做校验和约束, 一定程度上降低了前端开发难度, 统一后台人员代码风格. 此时后台开发人员的开发方式为: 在代码中用组件拼凑页面, 然后写代码逻辑.
前端服务化的第二种方式, 是提供页面可视化组装系统, 这个系统输出组装后的前端工程源码. 这样的系统比提供组件库和模板工程的方式走得更远: 通过可视化生成模板工程, 后台开发人员不需要在代码中拼凑前端页面, 不需要关注前端组件, 只需要编写代码逻辑.
这种方式可以参考阿里的 ice.
阿里 ice 示例:

前端服务化的终极方式, 是直接提供一个开发的 IDE, 将动态逻辑的书写也在 IDE 中完成.
如 美团外卖前端可视化界面组装平台 —— 乐高, 前端服务化——页面搭建工具的死与生.
美团乐高示例:

更加广泛来说, 为页面小白/运营人员/产品人员提供的页面可视化生成工具, 也是赋予以上人员前端开发的能力. 所以页面可视化搭建, 本质上是前端服务化的一部分. 前端服务化总结, 可以看百度的 前端即服务-通向零成本开发之路.
有了前文对页面的基础认知, 终于进入了本文的正题 -- 页面可视化搭建工具.
前面已经零星讨论过页面可视化搭建工具的定义, 再总结一下: 页面可视化搭建, 是指用可视化交互的方式(对比编写代码的方式), 实现页面的修改或生成; 页面可视化搭建工具, 增强了使用者的前端开发能力, 提升了使用者修改或生成页面的效率.
思考一个更具体的问题: 当我们讨论页面可视化搭建工具时, 怎么进行描述和讨论? 换个角度提问题: 可以从什么维度对页面可视化搭建工具进行描述和区分?
页面可视化搭建工具的区分维度包括:
下文会对页面可视化搭建工具的区分维度做介绍, 并会对每个区分维度提供示例(这些示例不会展开讨论, 且在不同维度下会多次使用同个示例).
页面可视化搭建工具的系统功能是指该工具在解决特定页面可视化搭建问题上提供的核心能力.
页面是由HTML Tree, Data 和 Dynamic Logic 三部分组成, 一个页面可视化搭建工具提供的能力是编辑页面组成部分之一或多部分. 对基于组件的页面, 其可编辑单元为组件, 此时采用 Component Tree 概念取代 HTML Tree.

HTML Tree 编辑这类页面搭建工具专注于可视化地编辑页面 HTML Tree 部分, 一般可以对页面做自由度较高的编辑.
其关键功能在于高自由度: 几乎可以编辑页面可见的所有元素, 能自由修改页面结构、页面元素样式和页面数据, 采用类似 Word, Photoshop 的可视化编辑方式.
这类工具一般只适用于生成逻辑比较简单的页面, 其中原因后续会讲.
常说的 H5 制作工具就是指这类工具.
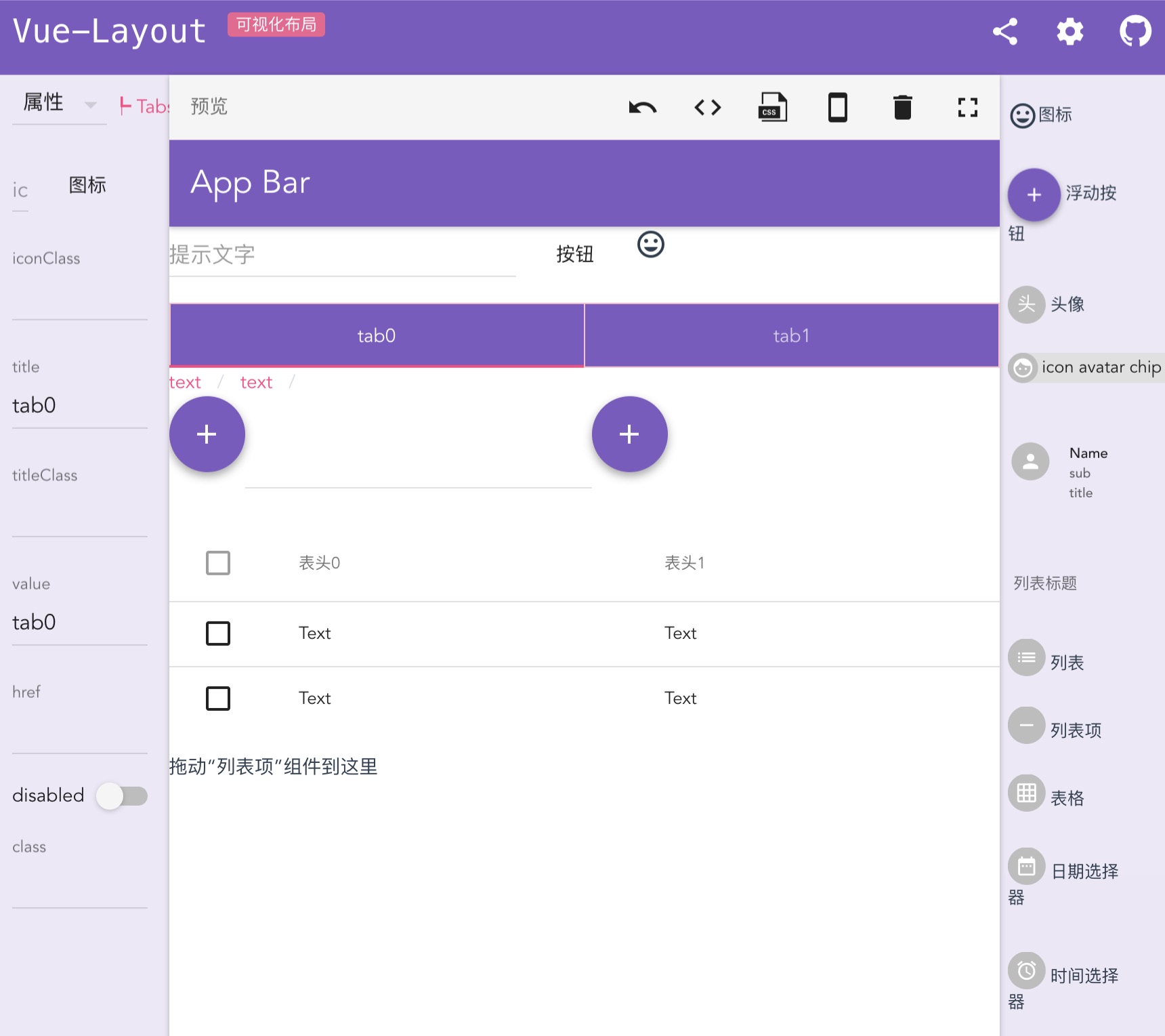
Component Tree 编辑这类页面搭建工具针对组件化的页面, 主要实现 Component Tree 的可视化编辑. 其核心功能在于页面布局设计: 在 UI 组件列表中选择合适的组件, 通过拖拉的方式将组件嵌入到页面中, 生成带布局和样式的页面.
vue-layout 示例:
Data 编辑这类页面搭建工具专注于可视化地编辑页面的 Data 部分, 如图片URL、按钮文本、按钮跳转链接等.
这类搭建工具主要针对 HTML Tree 比较固定、能承载复杂业务逻辑的页面. HTML Tree 固定的常见方式是页面组件化, 只需修改页面组件的 Data 就能快速地生成页面.
其核心功能在于快速搭建承载业务逻辑的页面.
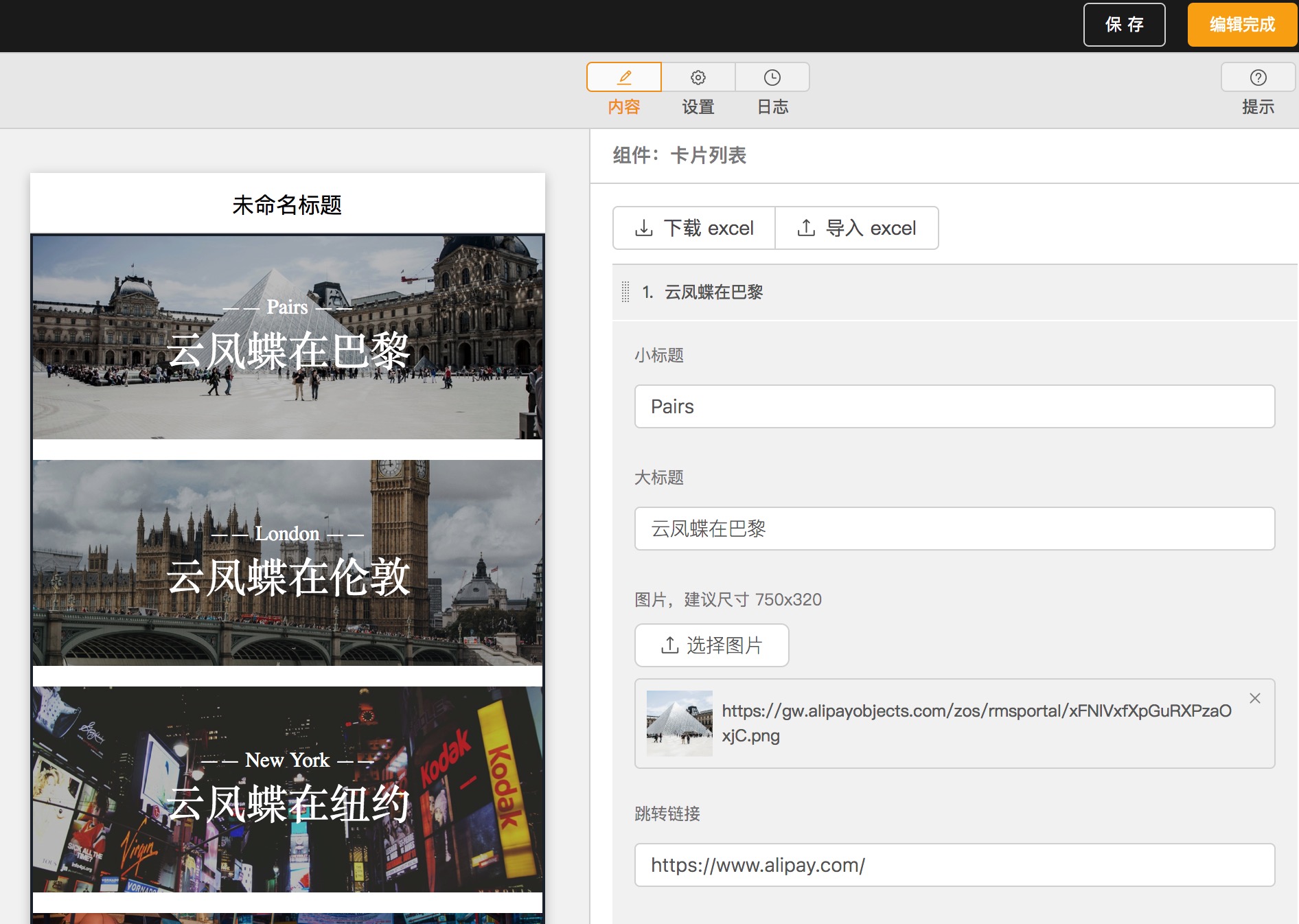
通常营销活动页面就采用这种方式来可视化搭建.
阿里云凤蝶示例:
Dynamic Logic 编辑这类页面搭建工具支持在界面上输入逻辑代码, 实现页面 Dynamic Logic 编辑, 如后台接口请求逻辑, 业务判断逻辑等.
这些逻辑代码需要有合适的插入点, 一般在事件钩子中提供插入点, 如页面 onload、网络请求状态变更、按钮事件、数据变更等.
做到可以支持编辑 Dynamic Logic 是超牛逼的事情, 这类工具对页面的理解最深入, 对开发者的技术能力、前端架构能力和开发能力都要求很高.
还有其他系统功能的组合, 可以综合上面的典型类别来做讨论.
页面可视化搭建工具的面向客群是指工具的使用客群. 不同的使用客群, 其对页面技术的认知程度、搭建页面的诉求有所不同, 所以可以从工具的面向客群来区分不同工具.

前端小白是不具有前端知识的人群, 他们对页面可视化搭建工具的诉求是交互性越高越好. 最适合他们的工具是像 Word, Powerpoint, Photoshop 等具有丰富交互功能, 且所见即所得的页面搭建工具.
同时他们也不关心页面最后用什么方式托管到互联网上, 页面编辑完成后要帮他们在公网上托管页面, 并提供页面链接, 方便前端小白将页面发给自己的女朋友.
如页面界的 Photoshop:

运营、产品人员没有开发人员页面开发、逻辑编程的能力, 他们的诉求是可以快速搭建活动、产品页面. 活动、产品页面是承载着业务逻辑的: 如包含领取优惠券功能、背景音乐播放功能、产品购买功能等. 运营、产品对页面可视化搭建的另一个诉求是“快速”: 一天好几个活动, 怎么快怎么来.
面向运营、产品的可视化搭建工具, 需要将页面的逻辑功能封装在页面区块内, 支持通过点击来选择区块, 然后在表单中编辑区块所需数据, 只对页面进行少量编辑就完成业务页面搭建.
如领取优惠券的页面, 运营、产品只要在表单中填入优惠券的 ID, 然后就快速生成领取该优惠券的页面, 不需要关心优惠券在页面上如何展示和被领取的具体逻辑.
如, 开源项目 pipeline:

中后台开发人员具有逻辑编程能力, 但其前端开发能力比较弱. 中后台开发人员的诉求是, 在开发中后台系统的 Web 管理端时, 不需要进行重度的前端页面结构和样式开发, 可以专注在逻辑和数据处理上.
这要求页面可视化搭建工具提供页面搭建的区块, 对区块进行可视化组合来输出一个基本的前端页面; 并在页面搭建工具上提供业务逻辑编写的输入点, 或将基本前端页面源码导出到 IDE 中供中后台开发人员进行业务逻辑的开发.
如: ice 阿里飞冰
要啥页面可视化搭建工具, 抓起键盘就开始干.

页面可视化搭建工具的编辑自由度, 是指页面可编辑单元的粒度. 前端页面的可编辑单元为 HTML 元素; 从前端页面组件化的角度, 页面可编辑单元为组件.
不同的编辑自由度的选择, 是可视化搭建工具在不同业务场景下编辑自由度与编辑效率的平衡.

编辑自由度为 HTML 元素(左)与自由度为组件(右)的示例:

编辑自由度为 HTML 元素的页面搭建工具有以下特点: 可编辑的元素丰富、页面结构灵活、可视化编辑效率较低、业务逻辑封装度较低.
这类工具的可编辑单元为 HTML 元素, 可以编辑元素的文本、样式和行为, 可编辑的元素较丰富; 并且可以组合各种 HTML 元素到页面中, 生成的页面结构灵活; 从生成页面的角度, 编辑出一个页面需要从基本的 HTML 元素开始搭建, 可视化编辑的工作量较大; 一个业务功能的实现, 通常需要渲染多个 HTML 元素, 而这类工具可以自由增删业务所需的 HTML 元素, 这导致无法固定地承载业务功能, 所以这类编辑工具生成的页面, 业务逻辑封装程度较低.
vvveb 示例:

编辑自由度为前端框架组件的页面搭建工具有以下特点: 可编辑的元素依赖搭建工具提供的组件, 可视化编辑效率较高、业务逻辑封装度较高.
这类工具的可编辑单元为前端框架的组件, 这些组件需要开发并导入到页面可视化搭建工具中; 组件的渲染结果包含了多个 HTML 元素, 所以从生成页面的角度, 编辑出一个页面只需要组合组件, 可以较快速完成页面生成; 组件本身承载了特定的业务功能, 所以这类编辑器生成的页面, 业务逻辑封装程度较高.
对于嵌套的组件, 需要重点解决组件数据流和组件布局适配.
如: Vue-Layout
vue-layout 示例:
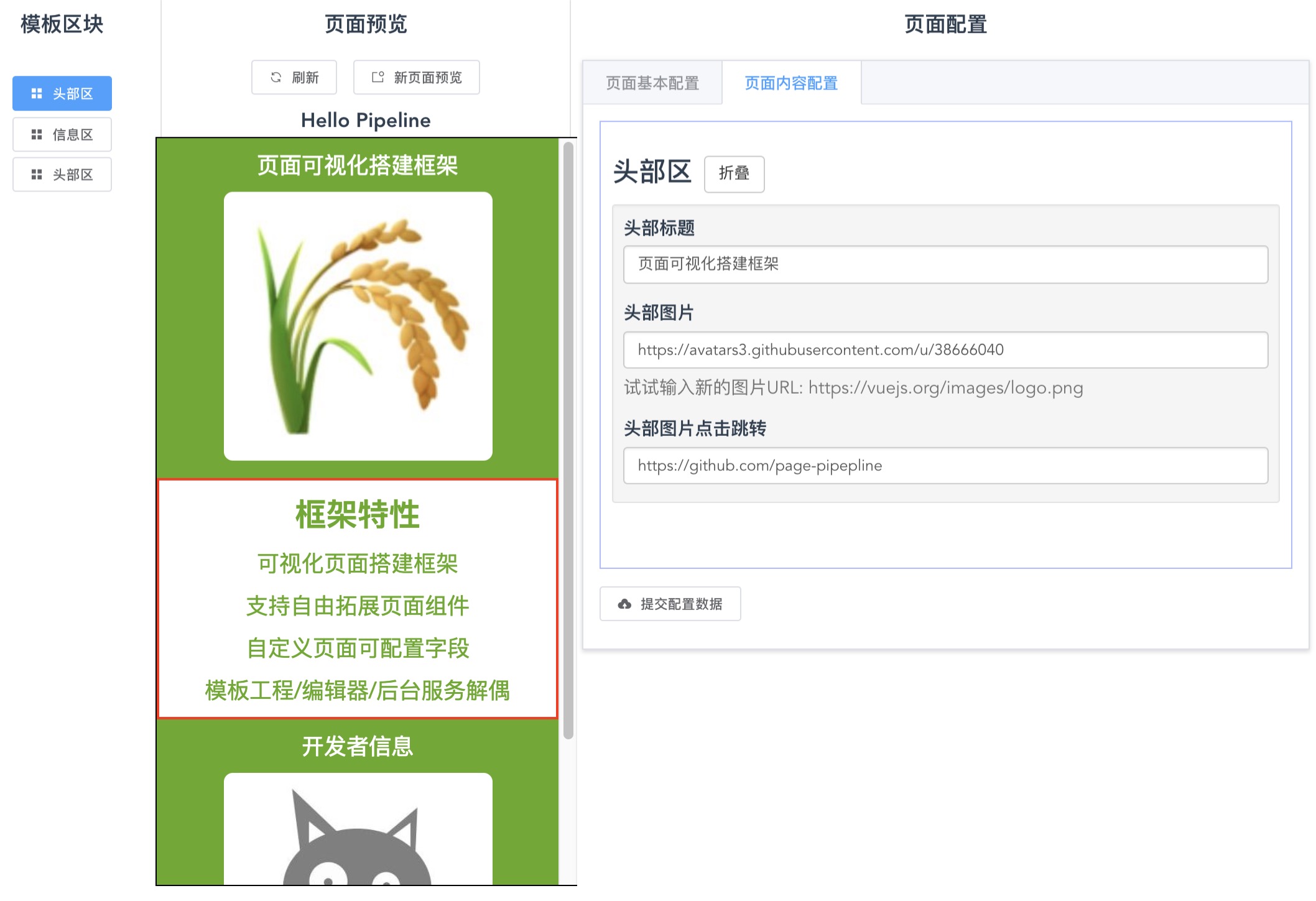
移动端的页面, 常用的布局策略是: 宽度铺满, 高度滚动. 如果前端框架组件都设置为铺满宽度, 页面展示时组件只需在浏览器垂直方向上顺序排列, 则组件组合时候不需要嵌套, 所有组件互为兄弟节点. 这种铺满宽度的组件, 非常适合搭建移动端页面的场景: 在承载页面逻辑的同时, 使得页面的编辑更加简单, 使用者只需要处理组件的顺序, 不需要处理组件的嵌套.
pipeline 示例:
页面可视化搭建工具, 需要对页面做一些约定和约束, 在可视化搭建时遵循工具约定和约束来编辑页面. 更全面讨论页面可视化搭建工具时, 不只是关注工具本身的功能, 还需要关注工具的依赖和约束, 如页面可视化搭建工具的组件化方式、模板组织方式、编辑功能实现方式等. 从工具开发的角度说, 页面可视化搭建工具是需要架构设计的, 不同工具的区分, 其实是不同的页面可视化搭建框架间的差异.
在互联网公司中, 广泛运用页面可视化搭建工具来支持运营活动页面的生成, 本章我们只探讨运营页面搭建工具的理想框架.
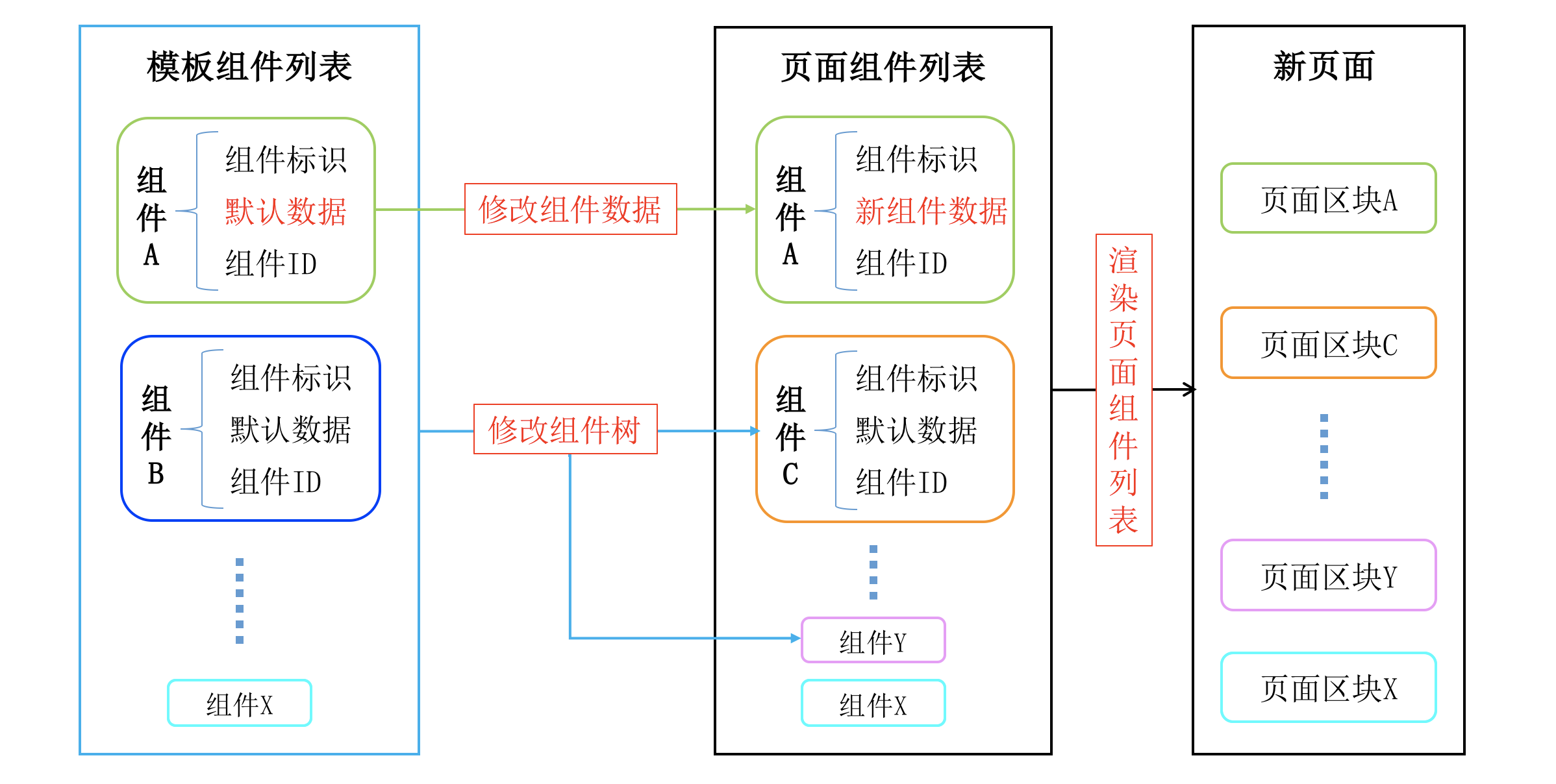
页面可视化搭建框架的核心是实现页面的可视化编辑. 运营页面搭建工具, 声明页面配置数据并提供配置表单, 通过对配置表单的数据填充, 实现基于模板的页面生成. 如图所示:

对页面的可编辑部分, 需要准确描述可编辑部分所需的配置数据; 配置数据是异构的, 不同页面、不同区块的配置数据各不相同. 所以需要对不同页面、不同区块定义各自配置数据的数据结构和字段类型.
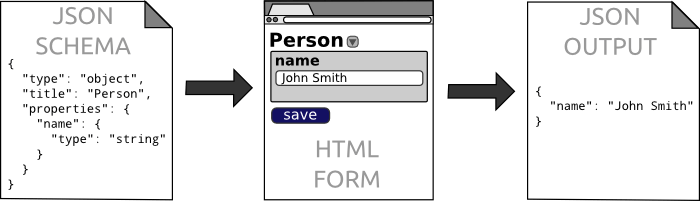
理想的配置数据格式为 JSON, 因为其格式灵活, 前端友好; 理想的配置数据描述格式为 JSON Schema, 因为其支持表单动态生成和数据校验.
采用 JSON Schema, 容易生成配置表单, 只要按照 JSON Schema 对 JSON 数据的描述, 可以动态渲染出配置表单. 并且可以采用 JSON Schema 对编辑后的数据做格式校验, 避免编辑错误.
如配置表单自动生成工具 json-editor:
组件是对 HTML 元素、元素布局和样式、业务逻辑的封装, 通过组件化的方式, 将页面的搭建转化为对组件的组合, 大大减低了运营页面生成的编辑工作量, 实现快速搭建承载业务逻辑的运营页面.
如 pipeline 的页面组件化:

模板是带有默认数据的页面; 对于组件化的页面, 模板是从组件库中选取部分组件, 并带有各个组件的默认数据.
采用模板生成页面, 只需对模板进行少量编辑即可实现页面快速生成.
编辑系统和组件解偶,组件只需要遵循编辑系统的组织约定, 其具体开发过程和承载的逻辑与编辑系统无关, 支持自由拓展页面组件.
编辑系统与模板采用的前端框架解偶, 在遵循编辑系统约定下, 可以选择不同的前端框架.
列举一些页面可视化搭工具, 并附带少量点评.
移动建站平台
Data 编辑, 面向运营、产品人员, 编辑自由度为无嵌套的组件.飞冰 - 让前端开发简单而友好
Component Tree 编辑, 面向中后台开发人员, 编辑自由度为无嵌套的组件.创意,绝不雷同
HTML Tree 编辑, 面向前端小白, 编辑自由度为 HTML 元素.Dynamic Logic 编辑, 面向中后台开发人员, 编辑自由度为可嵌套的组件.Drag vue dynamic components to build your page,generate vue code.
开源项目, 模仿美团点评的乐高.
Design websites in your browser
开源项目.
Component Tree 编辑, 面向中后台开发人员, 编辑自由度为可嵌套的组件.基于UI组件的Vue可视化布局、生成.vue代码的工具。
开源项目.
Component Tree 编辑, 面向中后台开发人员, 编辑自由度为可嵌套的组件.根据接口生成页面,减少重复性工作
列举一些业界在页面可视化搭工具上的实践, 并附带少量点评.
Dynamic Logic 的页面可视化搭建 IDE.Dynamic Logic 的可行性和设计架构.2015年的文章! 完全说到点上.
百度的前端服务化实践, 都在这一篇.
基于组件的页面生成系统-魔方, 采用 npm 管理组件.
内部 ET 平台, 包含活动管理的其他功能.
HTML Tree, Data, Dynamic Login 组成.全文结束, 本文对页面可视化搭建思考和讨论可能还不够完整, 欢迎讨论和补充.
后记: 终于写完了, 历时估计一个月! 写这篇文章的初衷是给我造的页面可视化搭建框架 -- pipeline 写背景, 但思考的点比较多, 所以就独立写了一篇文章. Pipeline 基本对标阿里的云凤蝶, 已经开源, 相关文章还在撰写中. 赶紧点击 Demo 体验吧.
Spring Tomcat Maven Zookeeper Dubbo公司准备上 Node, 初步设想是 Node 使用 RPC 直接调用后台的微服务. 首先需要研究一下可行性. 从我的角度来说, 要做好基础知识的学习, 不能浅尝辄止.
下面对概念的描述并不一定准确,是我到目前为止的理解。
maven java 代码打包工具,匹配前端的 npmspring java 的 servlet 开发框架zookeeper 服务发现,使得服务使用者通过服务发现调用服务提供者的服务,避免直接调用,提升灵活性和实现负载均衡等tomcat , Servlet/JSP container, java 动态服务容器dubbo 阿里推出的一个 rpc 框架,基于 spring 实现.学习记录和代码:
概念
spring 是 java 后台使用的框架, 需要搭建一个进行学习.
介绍
https://docs.spring.io/spring-framework/docs/current/spring-framework-reference/
$ docker pull zookeeper:3.4.10$ docker run --rm --name some-zookeeper -p 2181:2181 -d zookeeper:3.4.10$ netstat -lant | grep 2181
tcp6 0 0 ::1.2181 *.* LISTEN
tcp4 0 0 *.2181 *.* LISTEN $ docker stop `docker ps -f ancestor=zookeeper:3.4.10 -a -q`
$ docker rm `docker ps -f ancestor=zookeeper:3.4.10 -a -q`$ docker exec -it `docker ps -f ancestor=zookeeper:3.4.10 -q` bash$ docker pull tomcat:9.0$ docker run -it --rm -p 8080:8080 tomcat:9.0localhost:8080
$ docker-compose -f docker-compose.yml up --build --force-recreate解决无法打开server status manager app 问题.
学习记录和代码: https://github.com/CntChen/spring-rest-service-test/tree/war-tomcat
使用dubbo 官方 demo, 并添加 zookeeper 注册中心.
学习记录和代码:https://github.com/CntChen/dubbo-demo-test
$ docker run --rm --name some-zookeeper -p 2181:2181 -d zookeeper:3.4.10$ mvn package$ java -jar dubbo-demo-provider/target/dubbo-demo-provider-2.5.6-jar-with-dependencies.jar$ java dubbo-demo-consumer/target/dubbo-demo-consumer-2.5.6-jar-with-dependencies.jarSQL MySQL Terminal Learning公司搭建的接口文档平台 rap 使用了 MySQL 存储数据,后台同事对数据库表做了修改,作为 rap 测试的我在操作 rap 后需要去数据库看数据。
所以学习了一下 SQL 的基本操作。
因为只需要连接远程数据库并修改数据,不需要本地提供 mysql 服务,所以只安装 mysql 客户端。
$ sudo apt install mysql-client$ mysql -h 10.xx.xxx.xxx -u root -p -P 3306
其中:
mysql: 终端中的 MySQL 命令
-h:指定连接的 server host
-u:指定连接的用户名
-p:指定连接的密码,如果没有在命令行中指定,会在该命令执行后询问用户输入,这样可以避免黑客通过查看命令历史获取到 server 的连接密码。
直接输入密码的话:
-pxxxx,不用加空格,可能跟 MySQL 命令解析命令行参数的规则有关。--password=xxxx,完整参数。-P:指定 server 的 port,默认为 3306,所以可以省略
然后输入数据库密码,就可以连接到远程 server,此时终端会等待用户输入 SQL 语句。
Welcome to the MySQL monitor. Commands end with ; or \g.
...
mysql>注意:
数据库语句后面需要加分号才会执行。
数据库的关键字不区分大小写。
显示数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| test_by_chenhanjie |
| bbb |
| ccc |
| ddd |
+--------------------+
4 rows in set (0.00 sec)mysql> use test_by_chenhanjie;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -Amysql> show tables;
+------------------------------+
| Tables_in_test_by_chenhanjie |
+------------------------------+
| persons |
| scores |
| sss |
| test |
+------------------------------+mysql> create database test_by_chenhanjie;
Query OK, 1 row affected (0.03 sec)mysql> create table test ( id int, score int, info text);此处省略一万字。。。
参考资料不是放在最后的吗,怎么出了个大标题?
因为一个一个讲命令没有太大意义,不如系统看下文档。我看的是 w3schools 的教程,顺便强迫自己看英文。
数据库组成
一个数据库服务(RDBMS)包含多个数据库(Database);一个数据库由多个表(Table)组成;一个表由多个记录(Record)组成,一个记录为一行(Row);一个记录有多个字段(Field),一个表中的同一个字段为一列(Row)。
SQL 语法
SQL 语法的关键在于理解关键字和关键字的用法,关键字是基础,对一个 SQL 语句的理解是思维的挑战和提示。
DML 和 DDL
DML 对数据库中的数据进行增删改查操作;DDL 对数据库和表进行操作,用于定义数据库。
数据类型
数据类型是表中字段存储的数据类型,如INT TEXT等。
SQL 函数
SQL 内置的函数可以用于数据的计算,如COUNT NOW等。
数据筛选
数据条件筛选是语句正确执行的关键。
操作符
包括算术操作符,位操作符,比较操作符,复合操作符(Compound Operators)和逻辑操作符。
难点
难点是学习中可能带来疑惑的地方,关键在于理解和实践。我总结的几个点:
联合(Join)
条件查询(Condition Query)
别名(Aliases)
主键(Primary Key)
外键(Foreign Key)
排序(Order)
分组(Group)
空(Null)
操作符(Operator)
索引(Index)
索引可以提高查询速度,但是会减低修改(增删改)的效率,因为需要同时修改索引。
SQL(Structured Query Language)
DML(Database Modify Language)
DDL (Database Define Language)
ANSI(American National Standards Institute)
RDBMS(Relational Database Management System)
ESC (escend)
DESC (descend)
耗时两天,学到很多东西,欢迎批评指正。
浏览器页面在视频播放, 图片浏览, 编辑文本等场景, 会遇到增大页面的可查看和可交互区域的需求.
对于这种场景, 一般做法是提供一个全屏按钮, 用户可以选择点击按钮触发全屏.


本文对实现浏览器全屏进行简单总结:
在了解全屏功能之前, 先了解三个全屏相关概念: 伪全屏, 浏览器全屏 和 元素全屏.
保持页面大小, 将页面中的次要的内容隐藏起来, 把页面空间让给需要突出给用户的内容.
伪全屏并没有改变页面在显示器中的展示面积, 只是优化了页面呈现的内容, 所以称为 伪全屏.

伪全屏是完全由代码控制实现, 不会有兼容性问题.
浏览器全屏时浏览器铺满显示器窗口, 保留标签栏, 地址栏等浏览器组件.
如chrome浏览器全屏:

浏览器全屏通过浏览器菜单或浏览器快捷键触发. 浏览器全屏是操作系统的窗口全屏在浏览器上的实现, 其他桌面软件一般也支持窗口全屏.
IE11浏览器非全屏

IE11浏览器窗口全屏

资源管理器非全屏

资源管理器窗口全屏

control + command + F 切换浏览器全屏F11 切换浏览器全屏元素全屏的元素会铺满显示器全屏, 并将浏览器本身的窗口栏, 标签栏和地址栏都收起来.
腾讯视频网页元素全屏

腾讯视频非全屏

元素全屏是浏览器实现的页面全屏能力, 由 js 代码控制页面中的某个元素进行全屏展示. 相关文档可以看 Guide to the Fullscreen API.
比如: 腾讯视频播放时的全屏, 是对 <video /> 的祖先元素进行了全屏操作.
腾讯视频video元素位置

全屏播放时的全屏元素为 video 的祖先元素

元素全屏能力的浏览器兼容性可以查看官方文档: Fullscreen API.
浏览器元素全屏能力测试: 可以使用元素全屏库 fscreen 的测试页面: http://fscreen.rafrex.com/.

Esc 退出元素全屏测试了 mac 和 windows 系统下的 5 款浏览器.
这些提示是浏览器行为, 无法通过 js 代码禁止.
chrome 会提示 "press Esc to exit full screen"

firefox 会提示 "rafrex.com is now full screen"

IE11会提示"Do you want to view rafrex.com in full screen?...", 可以选择"Allow once", "Always allow", "Deny once"

Edge 会提示"fscreen.rafrex.com switched to full screen(Esc to exit)."

触发元素全屏和退出元素全屏后, firefox 会出现1秒左右的显示器黑屏. fscreen 的测试代码, youtube 的视频全屏播放都存在这个问题.

该问题 mac 和 win 都存在. 相关讨论: Black screen for a second when going fullscreen on videos.
mac safari 打开调试工具情况下, 触发浏览器全屏时, 调试工具会黑掉.
IE11 的元素全屏只能由用户操作触发, 不能由键盘事件触发. 相关讨论: IE11 fullscreen triggered from keyboard. 键盘事件触发元素全屏时, 会触发onfullscreenerror(MSFullscreenError) 事件.
QQ浏览器劫持全屏快捷键F11后, 第三次点击F11没有进入键盘事件回调, 直接触发浏览器全屏. 如果第三次点击F11前, 鼠标点击了页面元素, 则问题不会发生.
怀疑是浏览器的坑. 最简测试代码:
let isFullscreen = false;
window.addEventListener('keydown',
function(e) {
console.log('test:', 'keydown', e.key, e.keyCode);
if (e.keyCode === 122) {
console.log('test:', 'F11 clicked');
e.preventDefault();
if (isFullscreen) {
console.log('test:', 'exit fullscreen');
document.webkitExitFullscreen();
} else {
console.log('test:', 'enter fullscreen');
document.body.webkitRequestFullscreen();
}
isFullscreen = !isFullscreen;
}
})
// win7, QQ浏览器10.2(1893), 内核模式: 使用智能内核模式IE10 不支持元素全屏, 可以模拟发送键盘事件触发浏览器全屏. 没实试, 相关讨论: Internet Explorer full screen mode.
公司大前端团队准备上 Node 了,激动人心.所以首先需要预研一下 Node 的应用场景和能力范围,探索 Node 生态跟业务需求结合起来的方式.
Node 是基于 V8 JavaScript 引擎的 JavaScript 执行器. Node 采用事件驱动和非阻塞 I/O 模型达到轻量和高效,并拥有庞大的模块包生态 -- npm.
Node 在高并发轻 CPU 场景性能比 Java 和 PHP 好.
一门编程语言的特性和性能会趋向一致,剩下的就看选择.
阿里的很多 Node 服务,并不是不能用 Java 做,而是前端工程师在自己能力范围内把事情做了,而且做得蛮好的. -- Winter 在 TFC 致词,我听到的大意
使用 Node 技术栈,小团队可以更快把事情做成.
需要一名 Node工程师时,在2年 PHPer 和 2年 FE 间会毫不犹豫选择 PHPer. -- 说明写 Node 服务端, JS 语言不是重点,服务端开发的经验和能力才是
Node 作为 Web 服务器,连接后台数据库/文件系统,接受网络请求,处理业务逻辑,提供静态资源和业务接口.
在服务器(Java/PHP)与浏览器(JS)的中间架一个 Node 中间层.Node 中间层提供直出,接口转发,静态资源等,属于前端范畴,由前端维护.
在前后端接口分离(前后端解耦)情况下,在客户端访问页面时,服务器拉取接口数据,并将数据嵌入页面返回,称为直出.如果返回的是数据和模板,在前端渲染,称为数据直出;如果后端根据数据渲染出页面,直接返回页面,称为页面直出.
Node 中间层代理后台接口,后台接口提供原子 RESTful 接口,前端根据需要组合使用.Node 调用内部接口使用 HTTPS/RPC 等.
参考: 接口聚合的简单研究
关注点在于 Node 的开发和部署方式
关注 Node 层数据的落地,作为其他 Node 层功能的基础支撑.
What companies are using Node.js in production
node.js能开发大型网站吗 -- 国外使用情况
我司没有历史包袱
我们没有直出服务,没有 Node 服务,所以在提升性能,提升用户体验,降低开发成本上,基本可以无痛选择 Node 技术栈.
我司没有积累
Node 服务层的能力是非常强大的,结合我司业务,可以实践的工程还是很多的.以下为头脑风暴结果,具体开展需要做可行性分析,需求评审,架构规划,功能划分,开发计划等等工作.
客户端对接口的访问,先经过 Node 接口中间层,由中间层代理接口服务.
微信商城和 App 的手机专区已经使用了服务端直出,可以保持关注和迭代.
创业团队撸 Node (科普贴,非常有意思)
PayPal 的 Node.js 实践 (Java 和 Node 并行,渐进)
Node.js 在广发证券(介绍架构和微服务)
淘宝前后端分离实践(定义前后端边界)
OpenResty 是 Nginx 的一个 bundle, 添加了许多拓展模块来增强 Nginx 的功能, 其亮点是支持 Lua 脚本, 大大提升了 Nginx 的请求处理能力并降低了配置难度.
刚好有个需求需要 Lua 脚本才能支持, 所以在 Mac 下使用 OpenResty 替换 Nginx.
业界有蛮多对 Nginx 的拓展, 主要的拓展方式有 bundle 和 fork.
Bundle 是基于 Nginx core, 默认提供一些 Nginx 的组件来增强 Nginx 的功能. 如 OpenResty. Bundle 有突出的好处是可以方便地升级 Nginx core, 保持和官方 Nginx 的同步.
Fork 是基于某个版本的 Nginx 做二次开发, 实现各种 Nginx 不支持的功能. 如淘宝的 Tengine. Fork 的好处是提供了 Nginx 及 Nginx 插件无法实现的功能, 但是无法较好保持与官方 Nginx 的同步.
参考官方安装教程, 使用 brew 进行安装:
$ brew install openresty/brew/openresty如果 Nginx 在运行则先停止 Nginx:
$ ps aux | grep nginx
nobody 12129 0.0 0.0 2503864 8 ?? S 5:58PM 0:00.01 nginx: worker process
root 51 0.0 0.0 2502840 8 ?? Ss Thu06PM 0:00.07 nginx: master process /usr/local/opt/nginx/bin/nginx -g daemon off;
$ sudo kill -9 51启动 OpenResty:
$ sudo openrestynginx 命令安装完毕后查看安装路径:
$ which openresty
/usr/local/bin/openresty
$ ls -al /usr/local/bin/openresty
lrwxr-xr-x 1 cntchen admin 42 Jan 3 09:27 /usr/local/bin/openresty -> ../Cellar/openresty/1.13.6.1/bin/openresty查看 nginx 命令路径:
$ which nginx
/usr/local/bin/nginx
$ ls -al /usr/local/bin/nginx
lrwxr-xr-x 1 cntchen admin 32 Oct 25 17:25 /usr/local/bin/nginx -> ../Cellar/nginx/1.12.2/bin/nginx
将 nginx 命令给 OpenResty 使用:
# 保留 nginx 服务命令
$ mv nginx nginx-origin
$ rm nginx
$ ln -s ../Cellar/openresty/1.13.6.1/bin/openresty nginx注意: 如果使用 brew upgrate 对 OpenResty 或 Nginx 进行升级, 会生成指向新版本的默认软链, 所以升级后需要手动处理一下.
OpenResty 配置路径 /usr/local/etc/openresty.
Nginx 配置路径 /usr/local/etc/nginx.
将现有的 nginx 配置复制到 openresty 目录. 然后 reload OpenResty:
$ nginx -s reload访问页面查看是否生效.
https://dchua.com/2017/01/01/supercharge-your-nginx-with-openresty-and-lua/
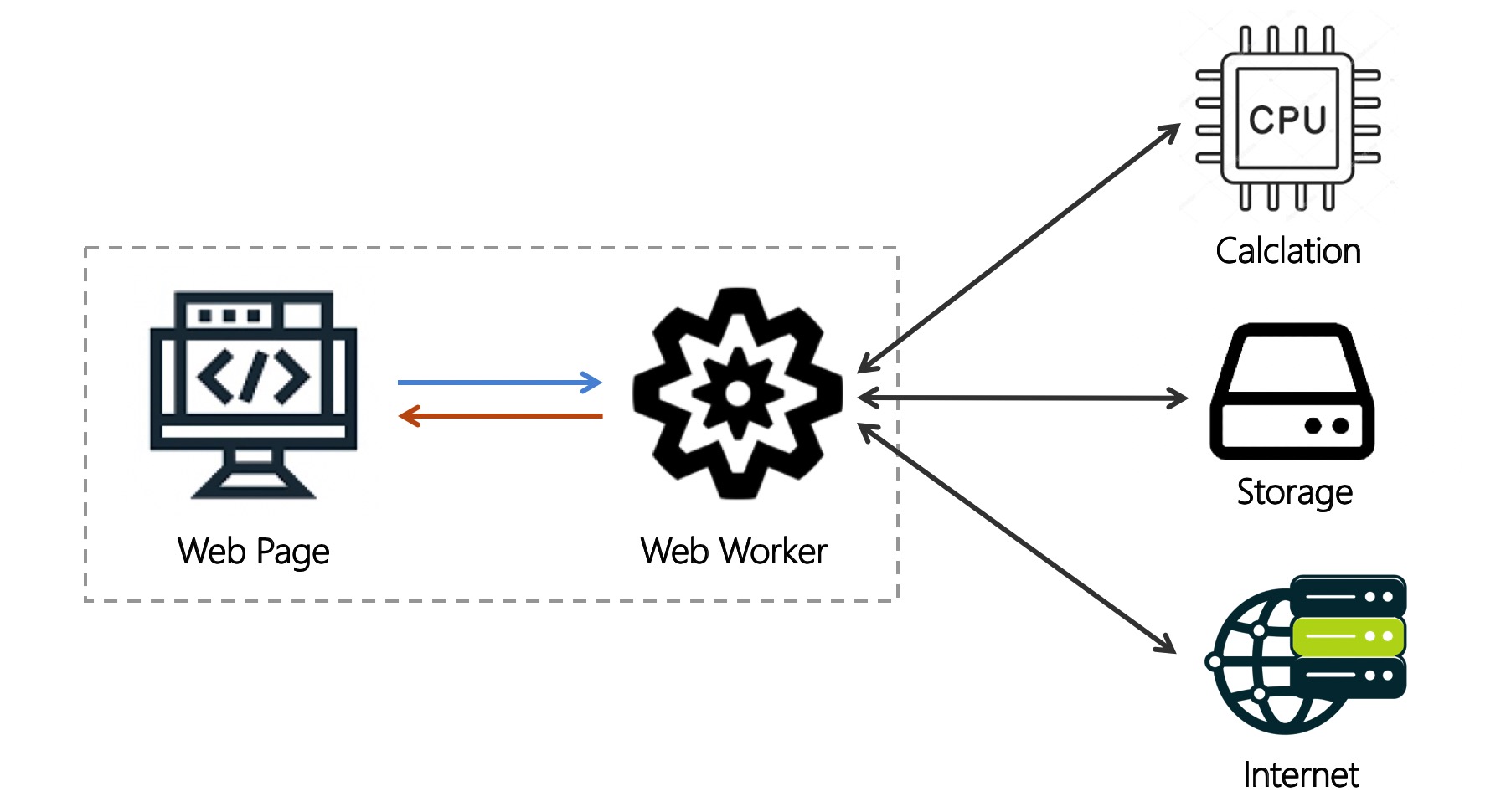
Web Worker 作为浏览器多线程技术, 在页面内容不断丰富, 功能日趋复杂的当下, 成为缓解页面卡顿, 提升应用性能的可选方案.
但她的容颜, 隐藏在边缘试探的科普文章和不知深浅的兼容性背后; 对 JS 单线程面试题倒背如流的前端工程师, 对多线程开发有着天然的陌生感.
⇈图片来源
文献综述(Literature Review)是学术研究领域一个常见概念, 写过毕业论文的同学应该还有印象. 它向读者介绍与主题有关的详细资料、动态、进展、展望以及对以上方面的评述.
近期笔者关注 Web Worker, 并落地到了大型复杂前端项目. 开源了 Worker 通信框架 alloy-worker, 正在写实践总结文章. 其间查阅了相关资料(50+文章, 10+技术演讲), 独立写成这篇综述性文章.
前端同学对 Web Worker 应该不陌生, 即使没有动手实践过, 应该也在社区上看过相关文章. 在介绍和使用上, 官方文档是 MDN 的 Web Workers API. 其对 Web Worker 的表述是:
Web Workers makes it possible to run a script operation in a background thread separate from the main execution thread of a web application.
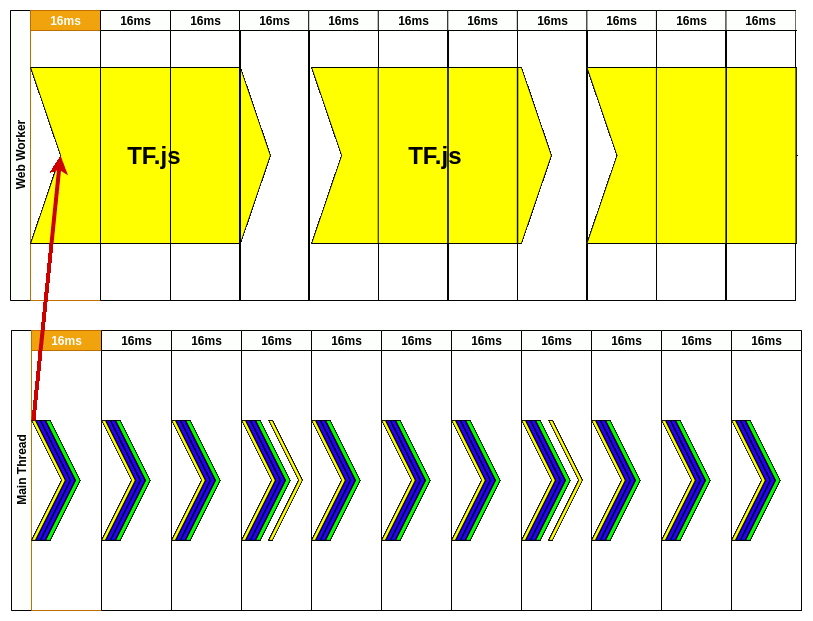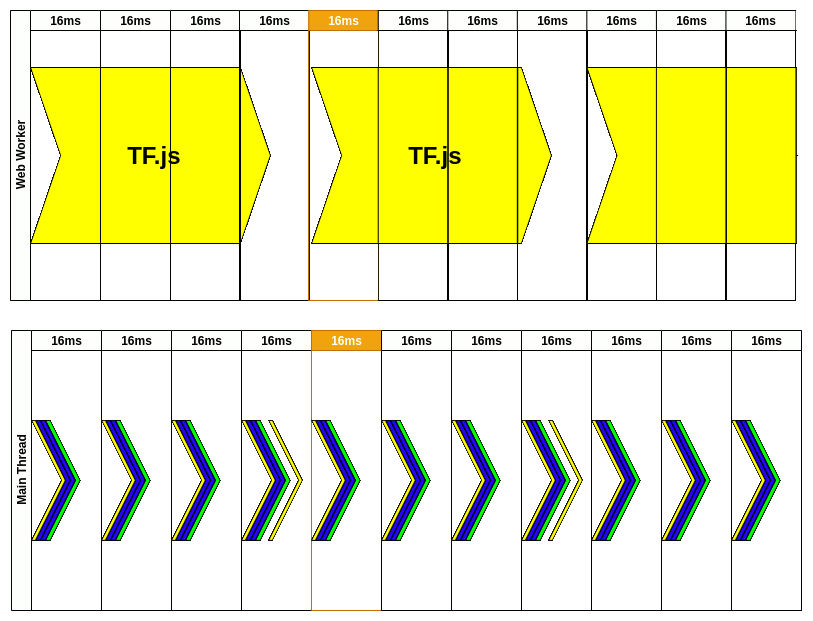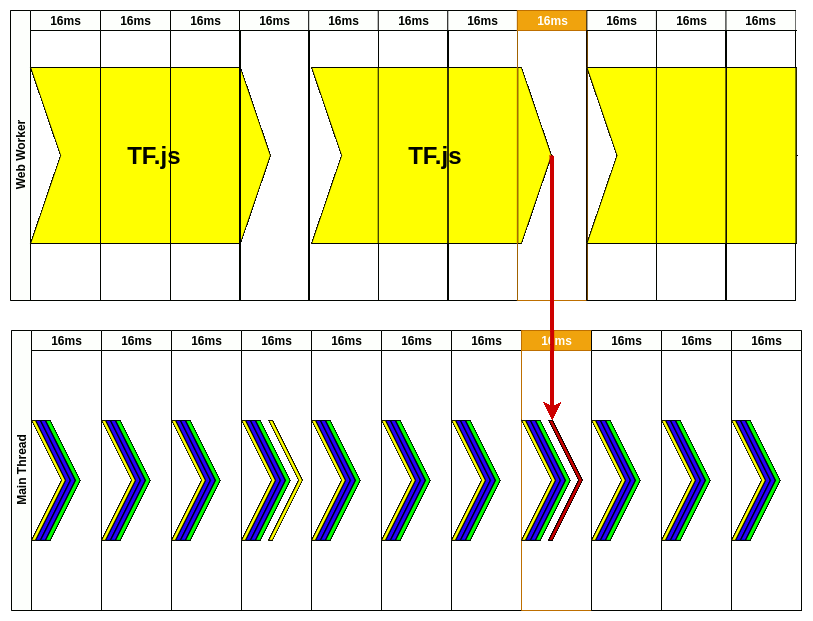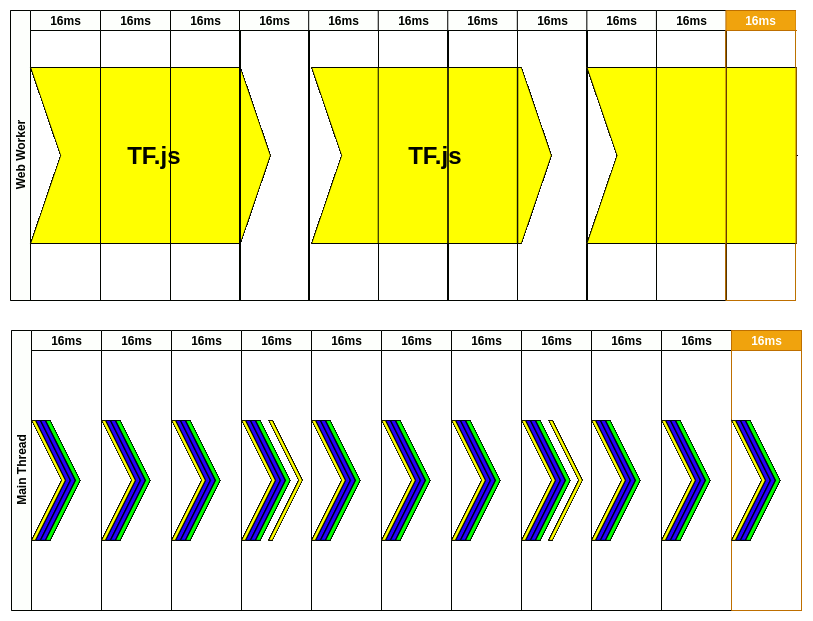
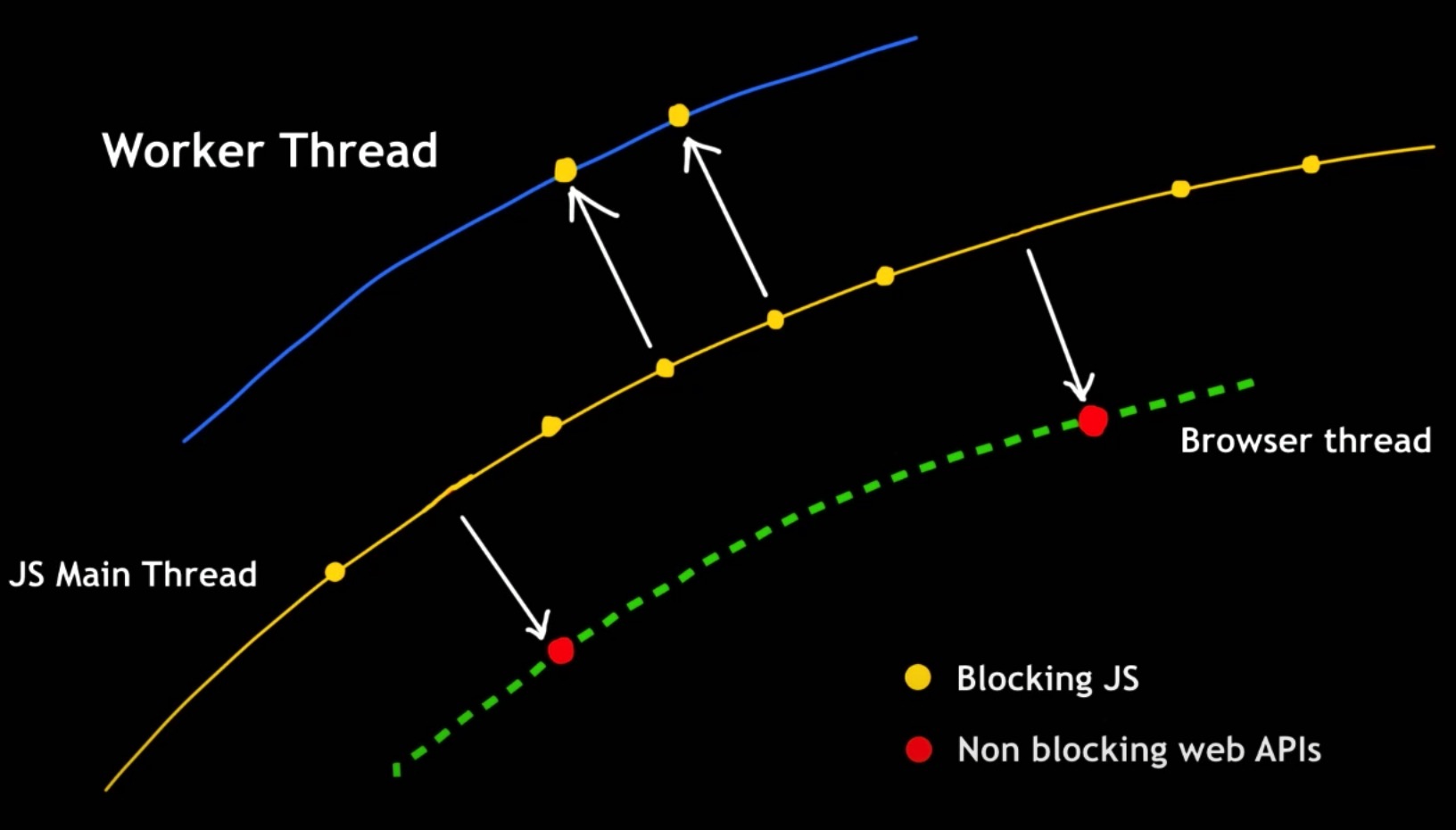
如下图所示, Web Worker 实现了多线程运行 JS 能力. 之前页面更新要先串行(Serial) 做 2 件事情; 使用 Worker 后, 2 件事情可并行(Parallel) 完成.
⇈图片来源
可以直观地联想: 并行可能会提升执行效率; 运行任务拆分能减少页面卡顿. 后面应用场景章节将继续讨论.
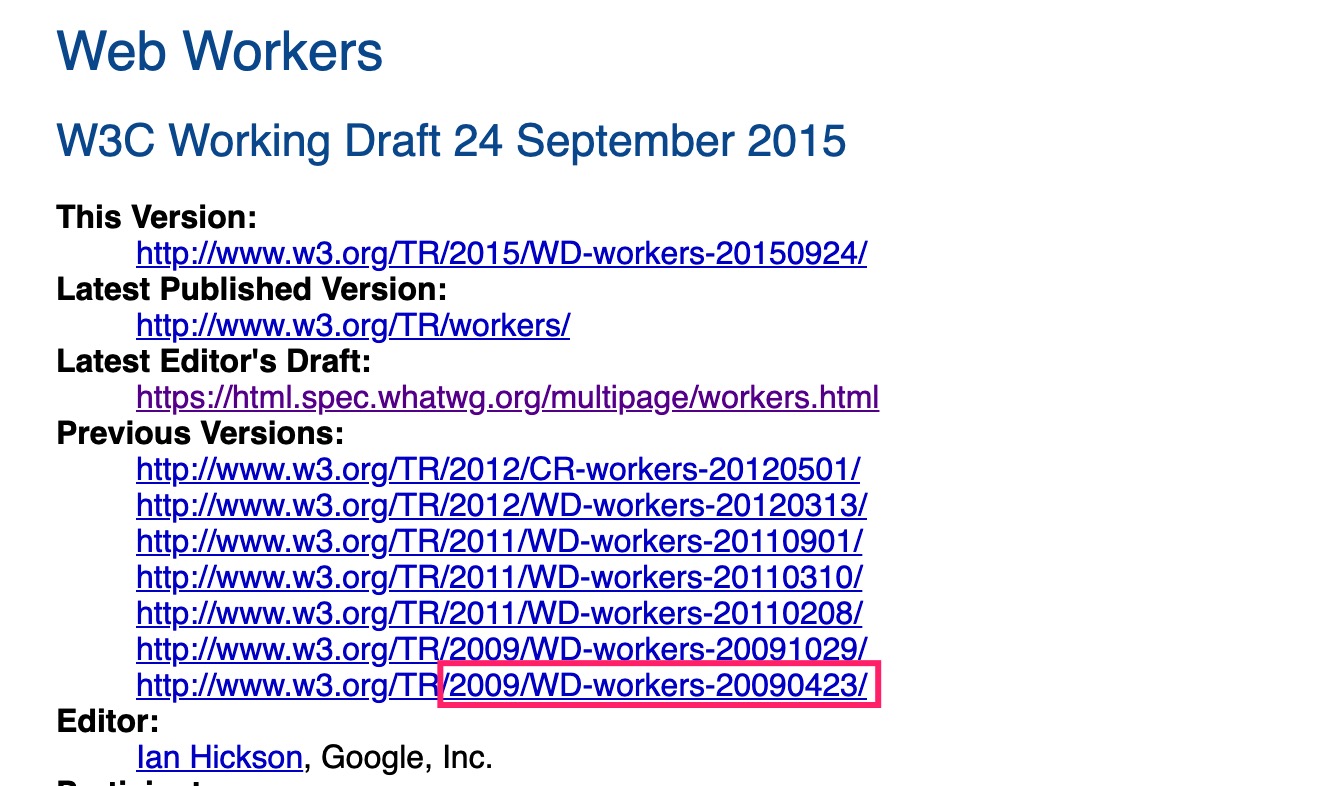
Web Worker 属于 HTML 规范, 规范文档见 Web Workers Working Draft, 有兴趣的同学可以读一读. 而它并不是很新的技术, 如下图所示: 2009 年就提出了草案.
⇈图片来源
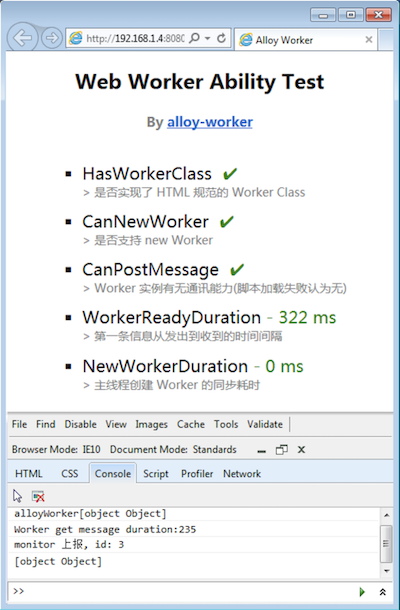
同年在 FireFox3.5 上率先实现, 可以在 using web workers: working smarter, not harder 中看到早期的实践. 2012年发布的 IE10 也实现了 Web Worker, 标志着主流浏览器上的全面支持. IE10 的 Web Worker 能力测试如下图所示:
⇈图片来源
在预研 Worker 方案时, 开发人员会有兼容性顾虑. 这种顾虑的普遍存在, 主要由于业界 Worker 技术实践较少和社区推广不活跃. 单从发展历史看, Worker 从 2012 年起就广泛可用; 后面兼容性章节将继续讨论.
Web Worker 规范中包括: DedicatedWorker 和 SharedWorker; 规范并不包括 Service Worker, 本文也不会展开讨论.
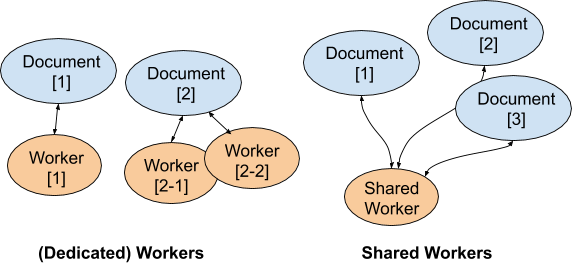
⇈图片来源
如上图所示, DedicatedWorker 简称 Worker, 其线程只能与一个页面渲染进程(Render Process)进行绑定和通信, 不能多 Tab 共享. DedicatedWorker 是最早实现并最广泛支持的 Web Worker 能力.
而 SharedWorker 可以在多个浏览器 Tab 中访问到同一个 Worker 实例, 实现多 Tab 共享数据, 共享 webSocket 连接等. 看起来很美好, 但 safari 放弃了 SharedWorker 支持, 因为 webkit 引擎的技术原因. 如下图所示, 只在 safari 5~6 中短暂支持过.
⇈图片来源
社区也在讨论 是否继续支持 SharedWorker; 多 Tab 共享资源的需求建议在 Service Worker 上寻找方案.
相比之下, DedicatedWorker 有着更广的兼容性和更多业务落地实践, 本文后面讨论中的 Worker 都是特指 DedicatedWorker.
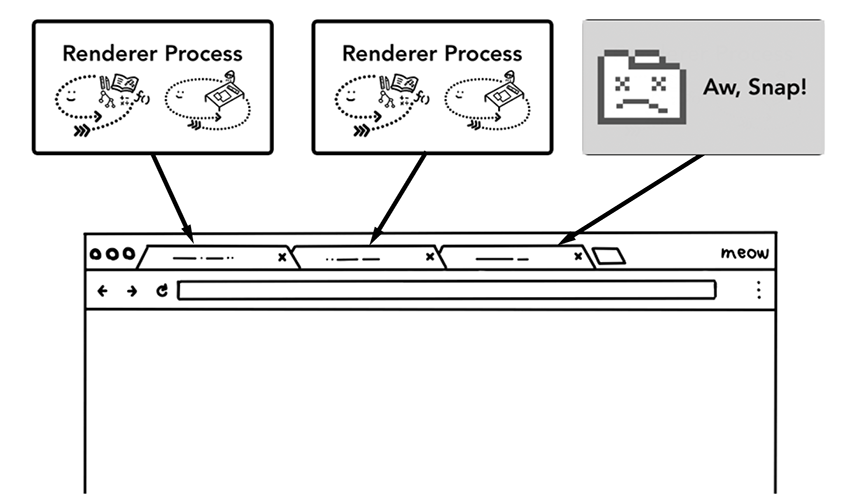
用户使用浏览器一般会打开多个页面(多 Tab), 现代浏览器使用单独的进程(Render Process)渲染每个页面, 以提升页面性能和稳定性, 并进行操作系统级别的内存隔离.
⇈图片来源
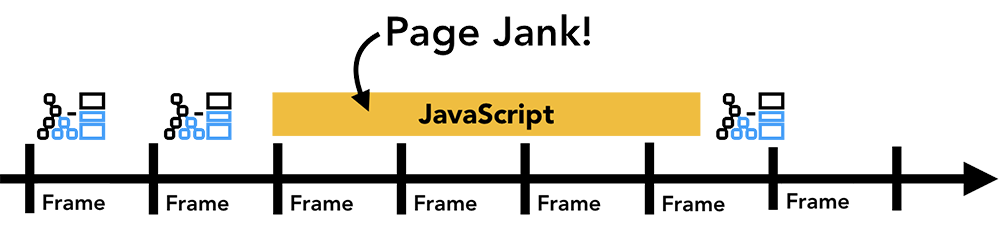
页面内, 内容渲染和用户交互主要由 Render Process 中的主线程进行管理. 主线程渲染页面每一帧(Frame), 如下图所示, 会包含 5 个步骤: JavaScript → Style → Layout → Paint → Composite, 如果 JS 的执行修改了 DOM, 可能还会暂停 JS, 插入并执行 Style 和 Layout.
⇈图片来源
而我们熟知的 JS 单线程和 Event Loop, 是主线程的一部分. JS 单线程执行避免了多线程开发中的复杂场景(如竞态和死锁). 但单线程的主要困扰是: 主线程同步 JS 执行耗时过久时(浏览器理想帧间隔约 16ms), 会阻塞用户交互和页面渲染.
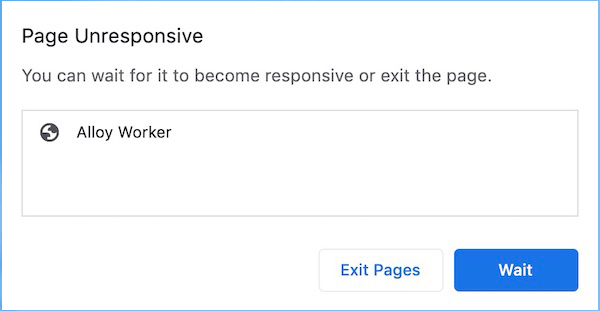
⇈图片来源
如上图所示, 长耗时任务执行时, 页面将无法更新, 也无法响应用户的输入/点击/滚动等操作. 如果卡死太久, 浏览器可能会抛出卡顿的提示. 如下图所示.
Web Worker 会创建操作系统级别的线程.
The Worker interface spawns real OS-level threads. -- MDN
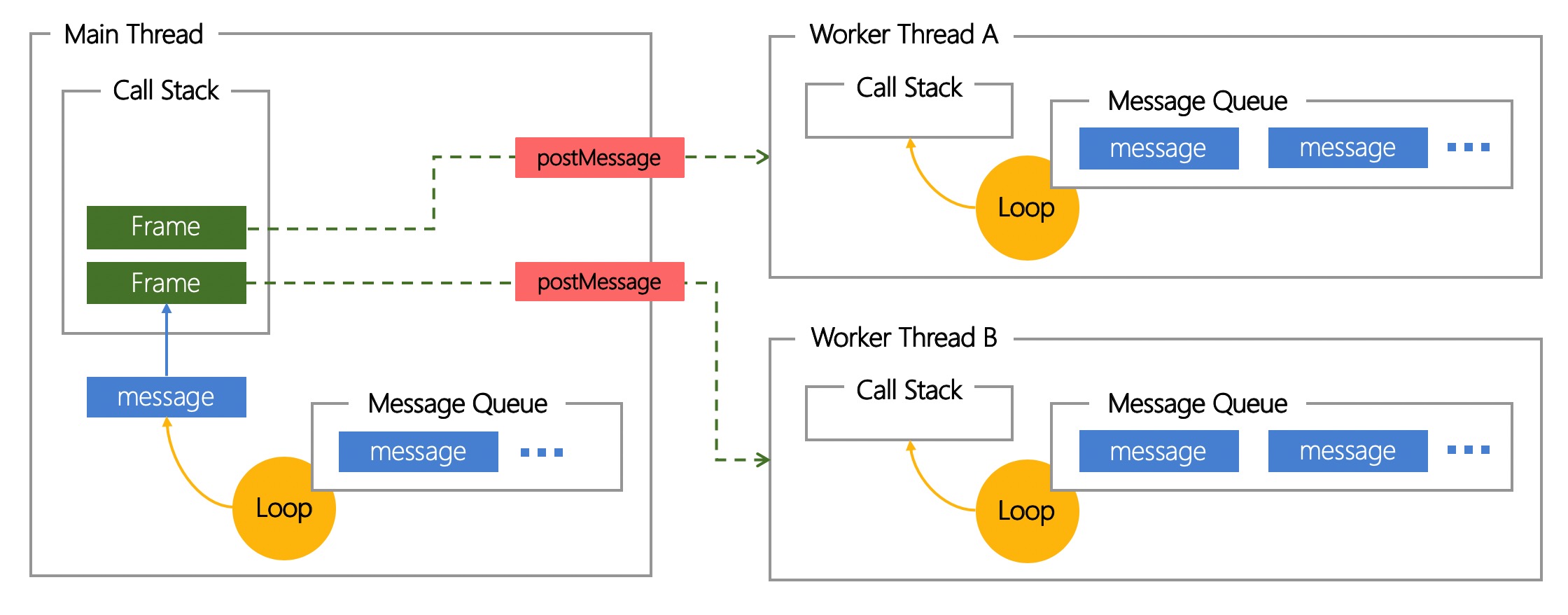
JS 多线程, 是有独立于主线程的 JS 运行环境. 如下图所示: Worker 线程有独立的内存空间, Message Queue, Event Loop, Call Stack 等, 线程间通过 postMessage 通信.
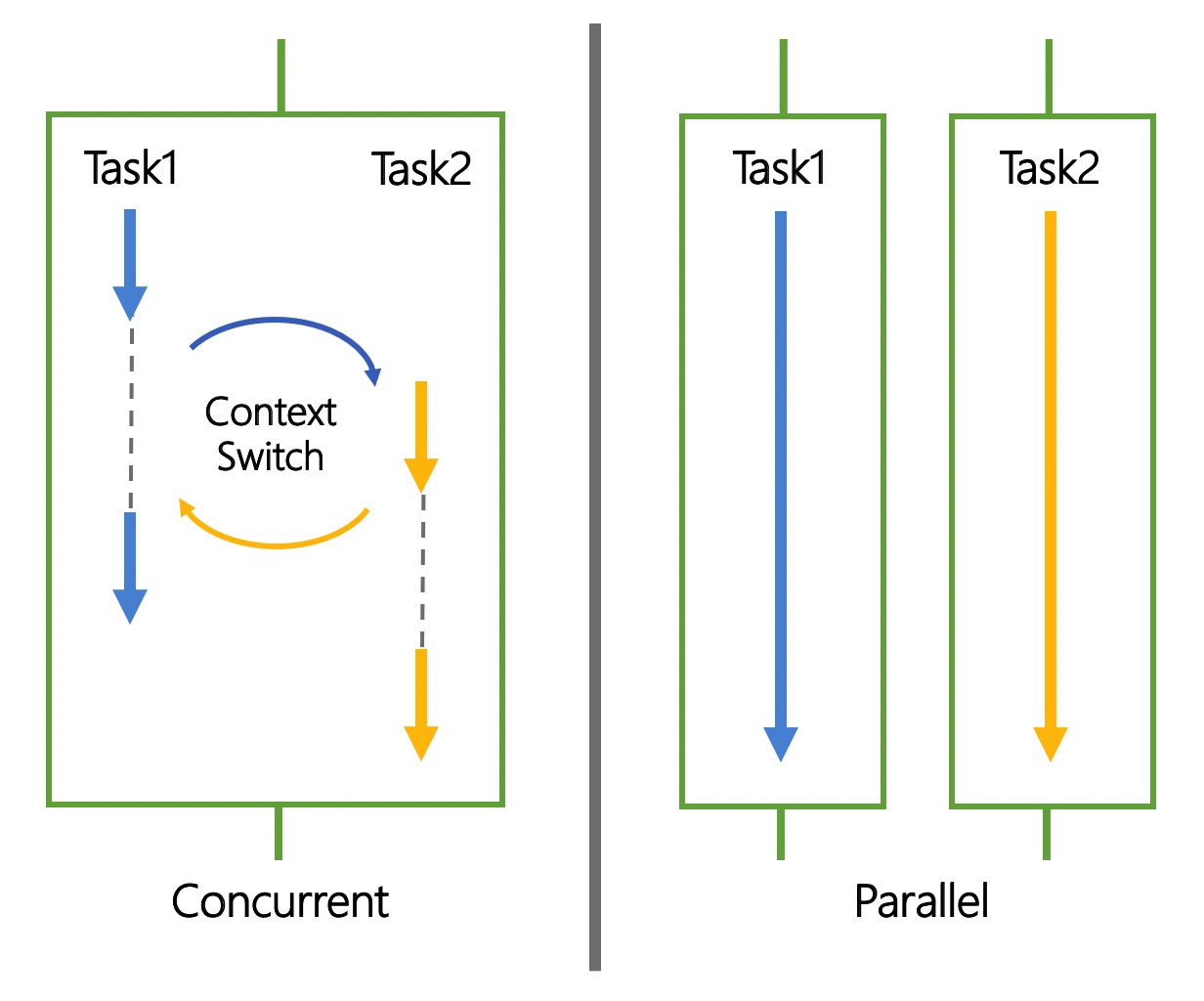
多个线程可以并发运行 JS. 熟悉 JS 异步编程的同学可能会说, setTimeout / Promise.all 不就是并发吗, 我写得可溜了.
JS 单线程中的"并发", 准确来说是 Concurrent. 如下图所示, 运行时只有一个函数调用栈, 通过 Event Loop 实现不同 Task 的上下文切换(Context Switch). 这些 Task 通过 BOM API 调起其他线程为主线程工作, 但回调函数代码逻辑依然由 JS 串行运行.
Web Worker 是 JS 多线程运行技术, 准确来说是 Parallel. 其与 Concurrent 的区别如下图所示: Parallel 有多个函数调用栈, 每个函数调用栈可以独立运行 Task, 互不干扰.
讨论完主线程和多线程, 我们能更好地理解 Worker 多线程的应用场景:
根据 Chrome 团队提出的用户感知性能模型 RAIL, 同步 JS 执行时间不能过长. 量化来说, 播放动画时建议小于 16ms, 用户操作响应建议小于 100ms, 页面打开到开始呈现内容建议小于 1000ms.
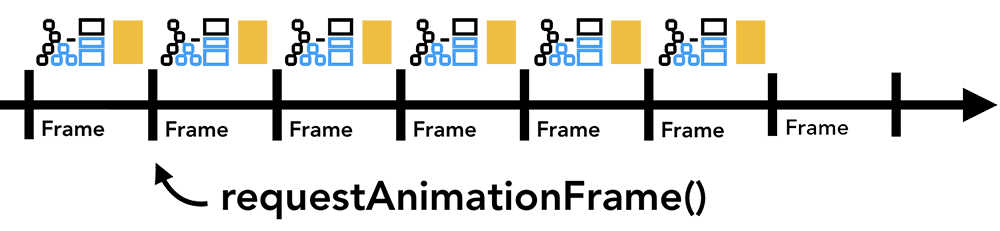
减少主线程卡顿的主要方法为异步化执行, 比如播放动画时, 将同步任务拆分为多个小于 16ms 的子任务, 然后在页面每一帧前通过 requestAnimationFrame 按计划执行一个子任务, 直到全部子任务执行完毕.
⇈图片来源
拆分同步逻辑的异步方案对大部分场景有效果, 但并不是一劳永逸的银弹. 有以下几个问题:
不是所有 JS 逻辑都可拆分. 比如数组排序, 树的递归查找, 图像处理算法等, 执行中需要维护当前状态, 且调用上非线性, 无法轻易地拆分为子任务.
可以拆分的逻辑难以把控粒度. 如下图所示, 拆分的子任务在高性能机器(iphoneX)上可以控制在 16ms 内, 但在性能落后机器(iphone6)上就超过了 deadline. 16ms 的用户感知时间, 并不会因为用户手上机器的差别而变化, Google 给出的建议是再拆小到 3-4ms.
⇈图片来源
Worker 的多线程能力, 使得同步 JS 任务的拆分一步到位: 从宏观上将整个同步 JS 任务异步化. 不需要再去苦苦寻找原子逻辑, 逻辑异步化的设计上也更加简单和可维护.
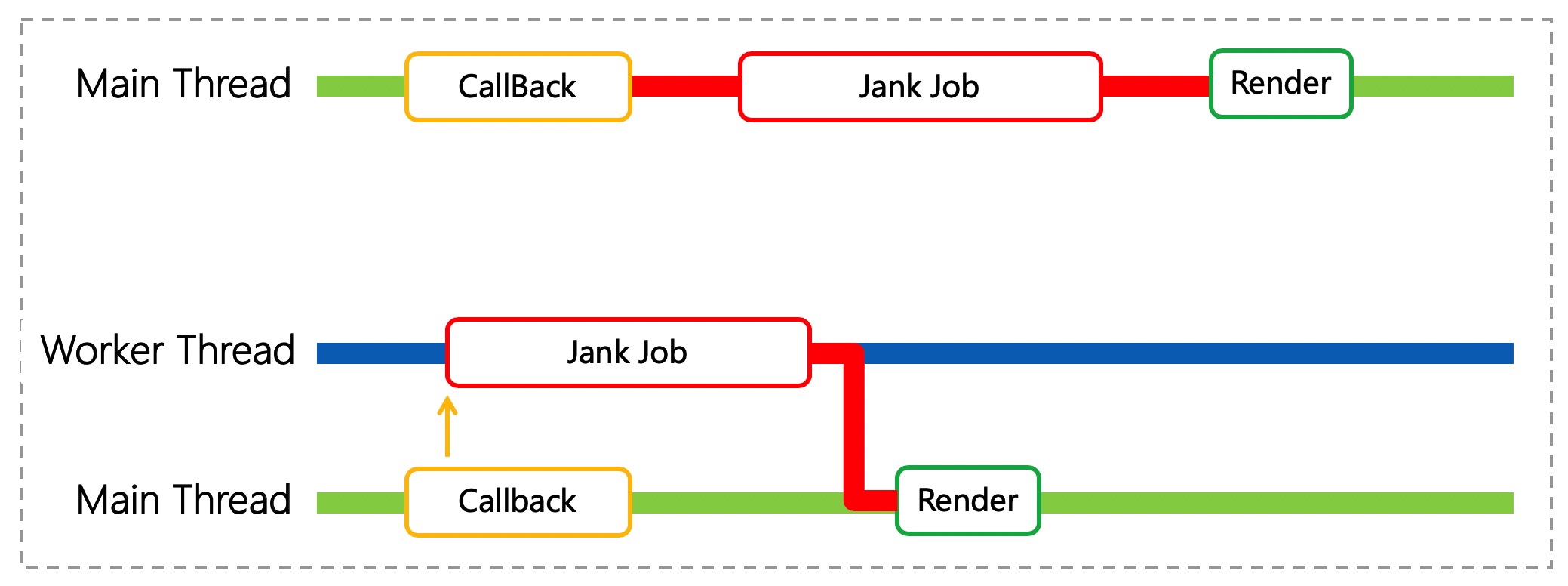
这给我们带来更多的想象空间. 如下图所示, 在浏览器主线程渲染周期内, 将可能阻塞页面渲染的 JS 运行任务(Jank Job)迁移到 Worker 线程中, 进而减少主线程的负担, 缩短渲染间隔, 减少页面卡顿.
Worker 多线程并不会直接带来计算性能的提升, 能否提升与设备 CPU 核数和线程策略有关.
CPU 的单核(Single Core)和多核(Multi Core)离前端似乎有点远了. 但在页面上运用多线程技术时, 核数会影响线程创建策略.
进程是操作系统资源分配的基本单位,线程是操作系统调度 CPU 的基本单位. 操作系统对线程能占用的 CPU 计算资源有复杂的分配策略. 如下图所示:
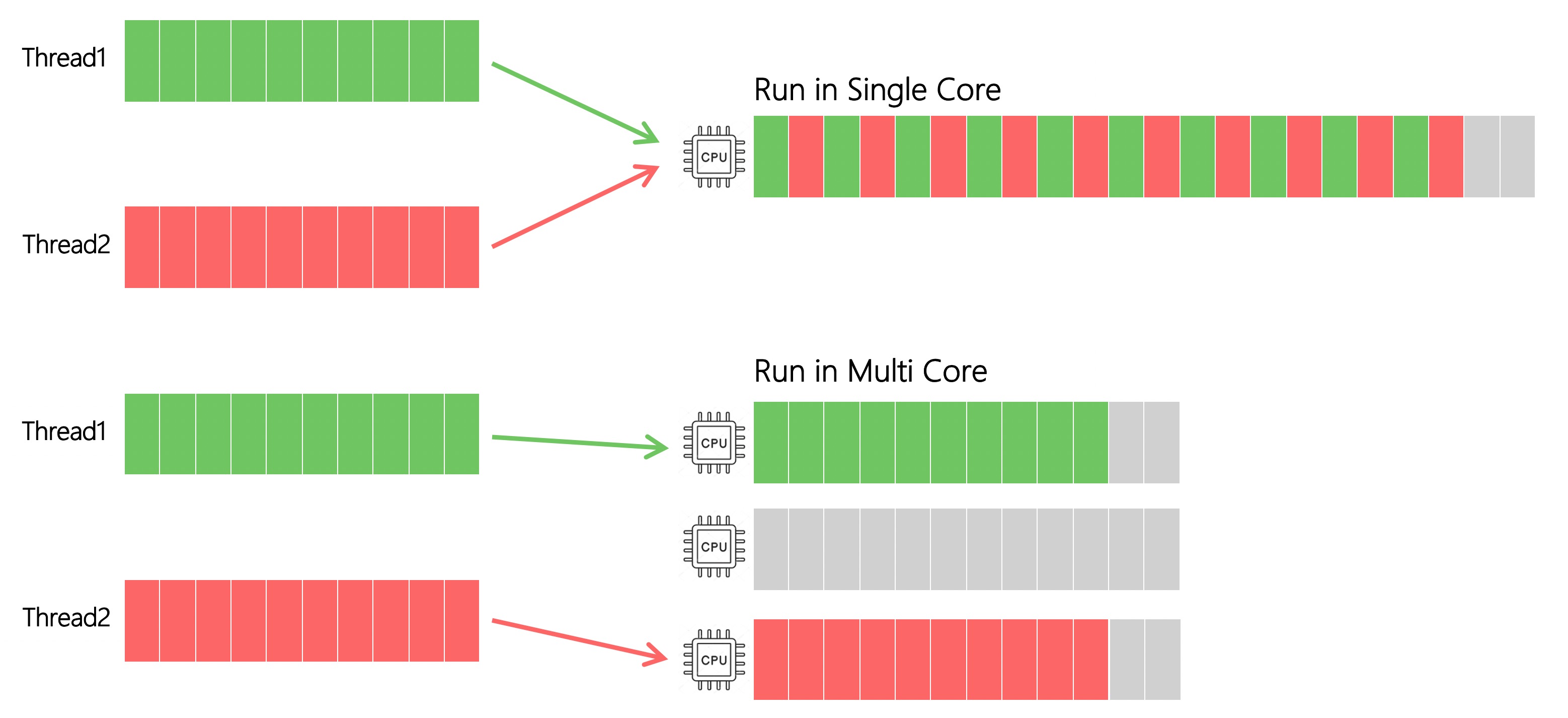
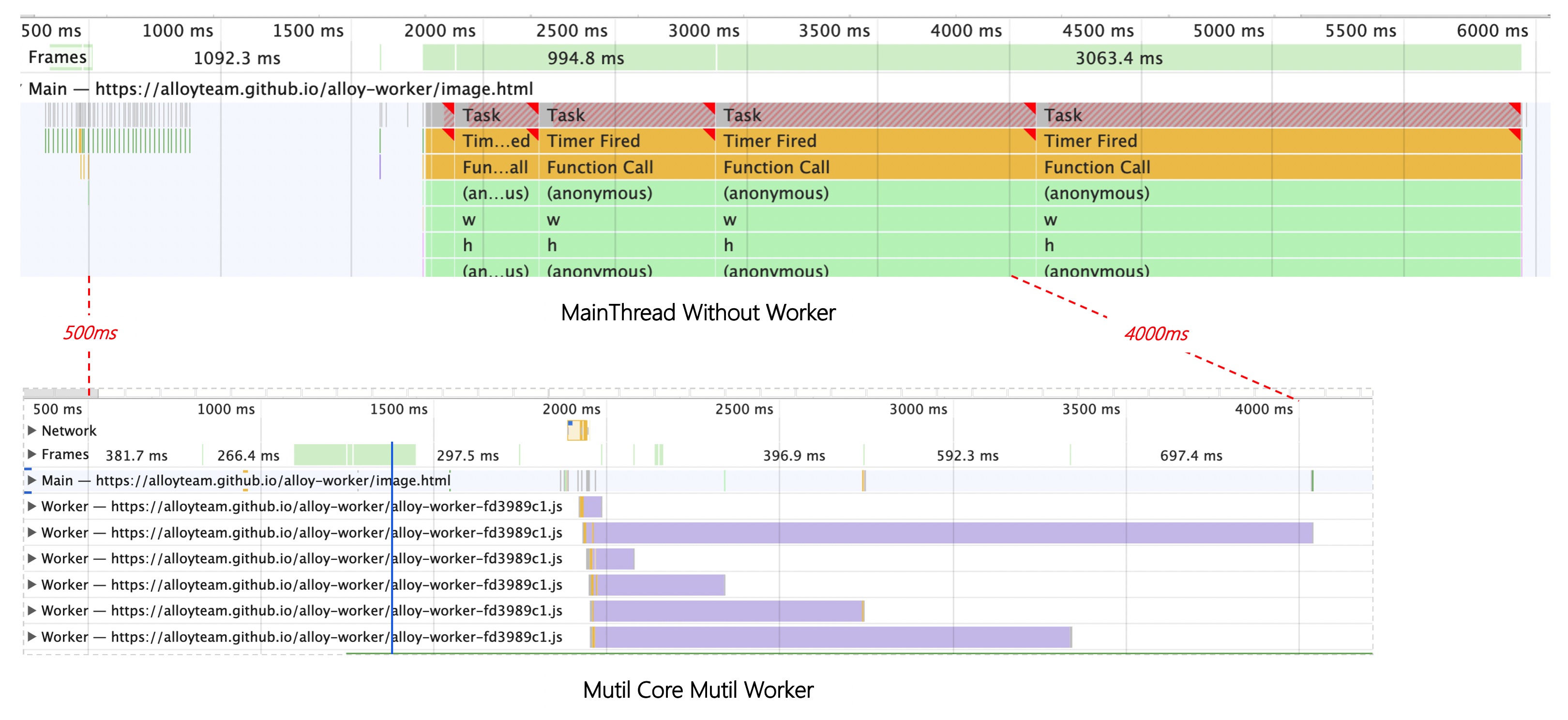
一台设备上相同任务在各线程中运行耗时是一样的. 如下图所示: 我们将主线程 JS 任务交给新建的 Worker 线程, 任务在 Worker 线程上运行并不会比原本主线程更快, 而线程新建消耗和通信开销使得渲染间隔可能变得更久.
⇈图片来源
在单核机器上, 计算资源是内卷的, 新建的 Worker 线程并不能为页面争取到更多的计算资源. 在多核机器上, 新建的 Worker 线程和主线程都能做运算, 页面总计算资源增多, 但对单次任务来说, 在哪个线程上运行耗时是一样的.
真正带来性能提升的是多核多线程并发.
如多个没有依赖关系的同步任务, 在单线程上只能串行执行, 在多核多线程中可以并行执行. 如下图 alloy-worker 的图像处理 demo 所示, 在 iMac 上运行时创建了 6 条 Worker 线程, 图像处理总时间比主线程串行处理快了约 2000ms.
值得注意的是, 目前移动设备的核心数有限. 最新 iPhone Max Pro 上搭载的 A13 芯片 号称 6 核, 也只有 2 个高性能核芯(2.61G), 另外 4 个是低频率的能效核心(0.58G). 所以在创建多条 Worker 线程时, 建议区分场景和设备.
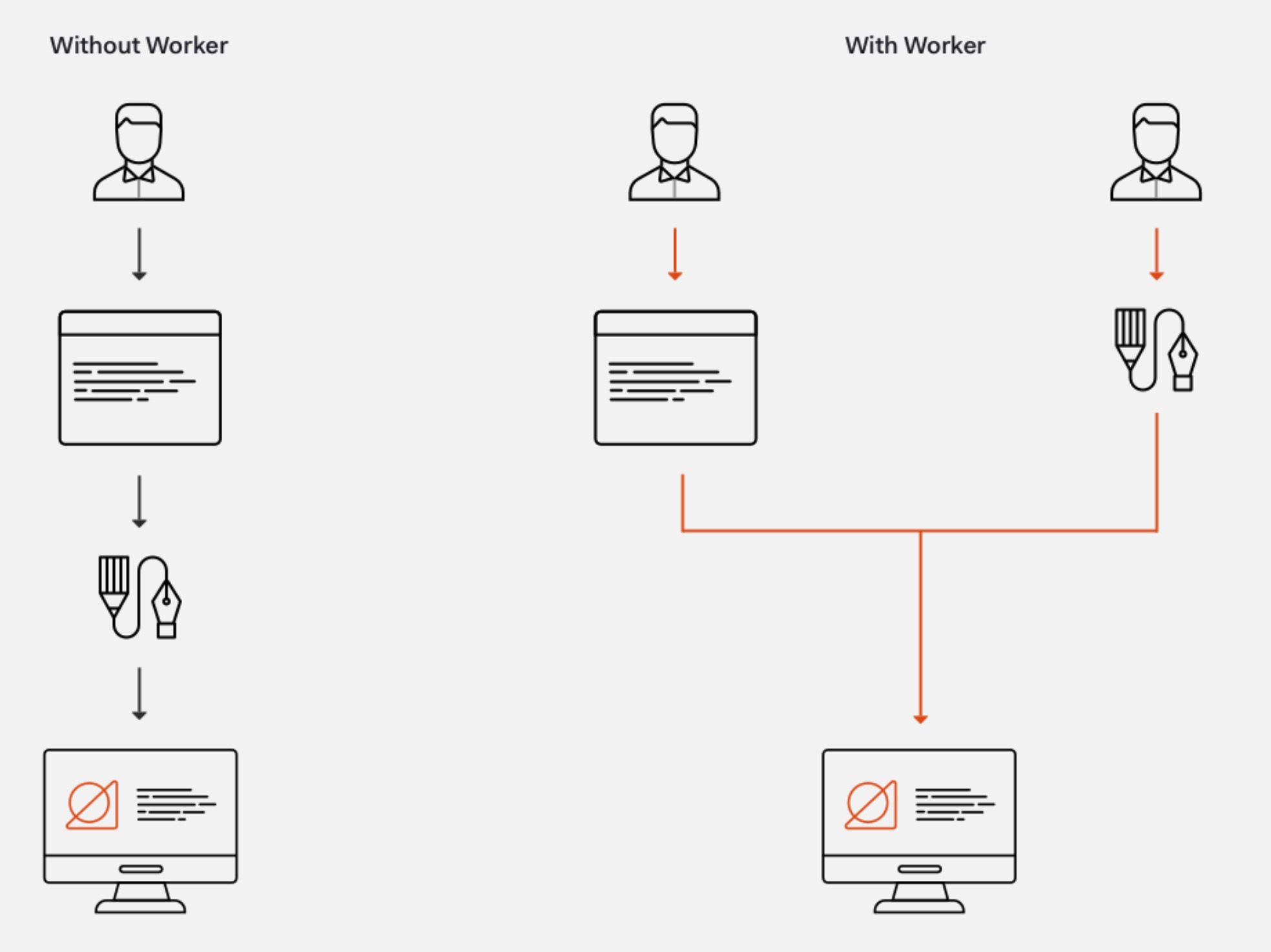
Worker 的应用场景, 本质上是从主线程中剥离逻辑, 让主线程专注于 UI 渲染. 这种架构设计并非 Web 技术上的独创.
Android 和 iOS 的原生开发中, 主线程负责 UI 工作; 前端领域热门的小程序, 实现原理上就是渲染和逻辑的完全分离.
本该如此.
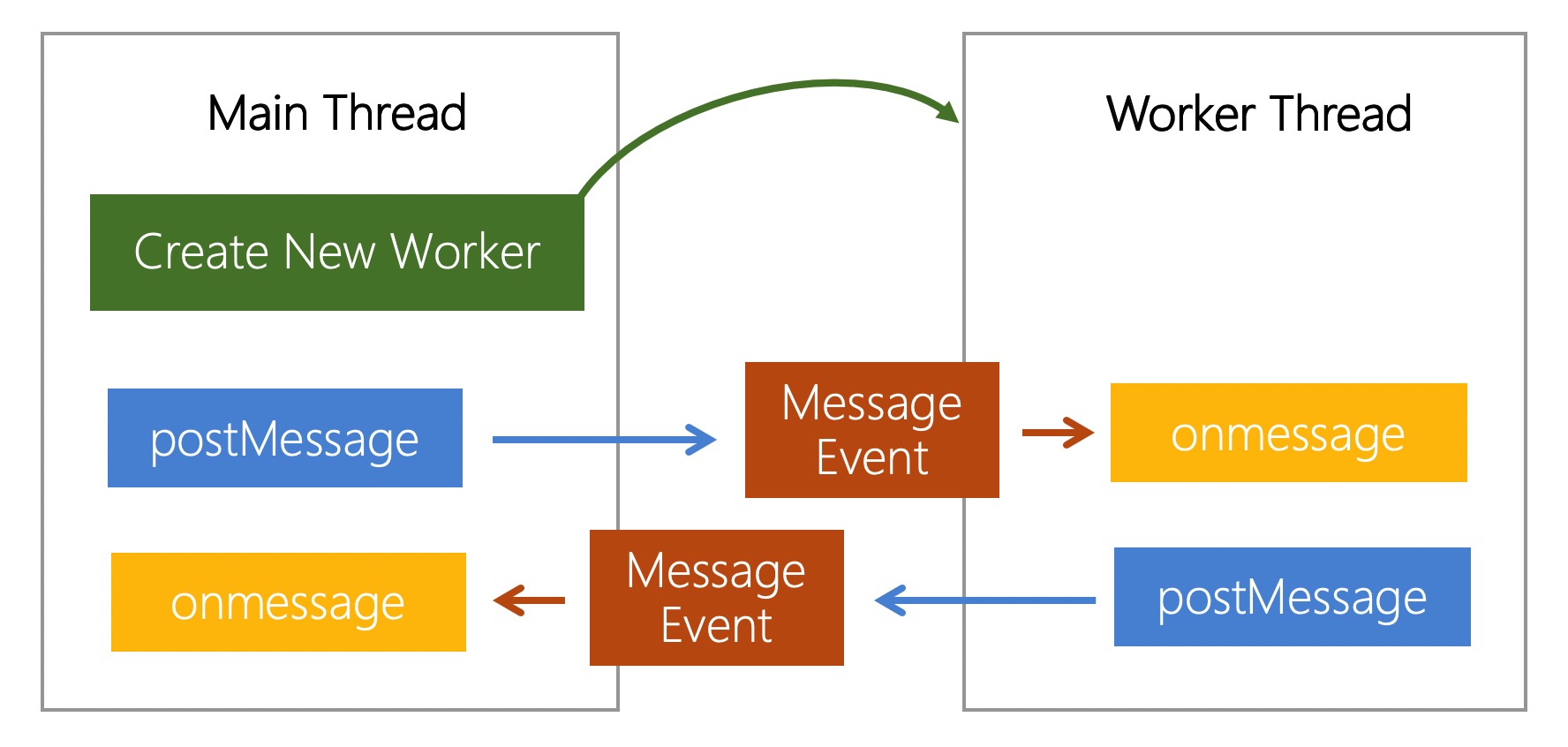
如上图所示的 Worker 通信流程, Worker 通信 API 非常简单. 通俗中文教程可以参考 Web Worker 使用教程. 使用细节建议看官方文档.
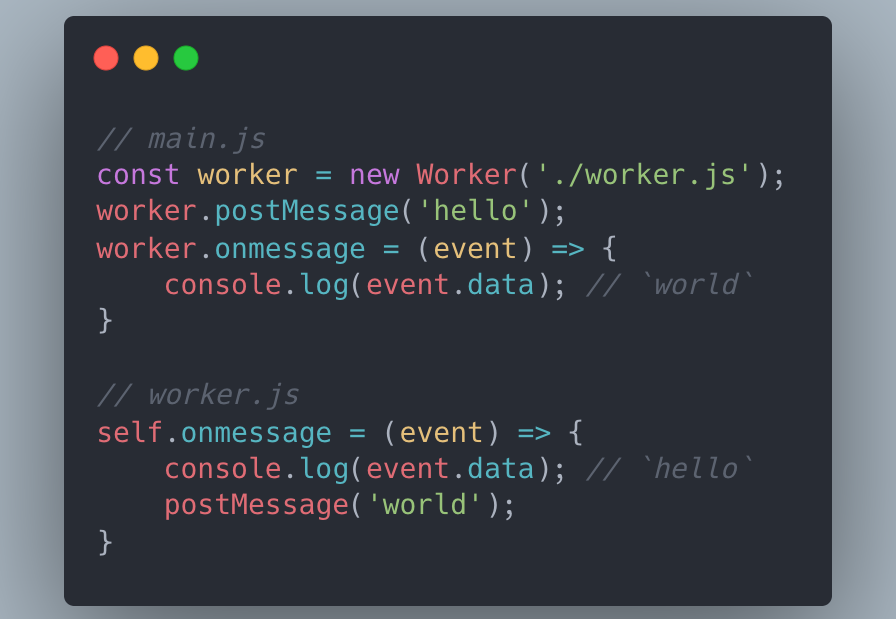
双向通信示例代码如下图所示, 双向通信只需 7 行代码.
主要流程为:
new Worker(url) 创建 Worker 实例, url 为 Worker JS 资源 url.postMessage 发送 hello, 在 onmesssage 中监听 Worker 线程消息.onmessage 中监听主线程消息, 收到主线程的 hello; 通过 postMessage 回复 world.world 信息.postMessage 会在接收线程创建一个 MessageEvent, 传递的数据添加到 event.data, 再触发该事件; MessageEvent 的回调函数进入 Message Queue, 成为待执行的宏任务. 因此 postMessage 顺序发送的信息, 在接收线程中会顺序执行回调函数. 而且我们无需担心实例化 Worker 过程中 postMessage 的信息丢失问题, 对此 Worker 内部机制已经处理.
Worker 事件驱动(postMessage/onmessage) 的通信 API 虽然简洁, 但大多数场景下通信需要等待响应(类似 HTTP 请求的 Request 和 Response), 并且多次同类型通信要匹配到各自的响应. 所以业务使用一般会封装原生 API, 如封装为 Promise 调用. 这也是笔者开发 alloy-worker 的原由之一.
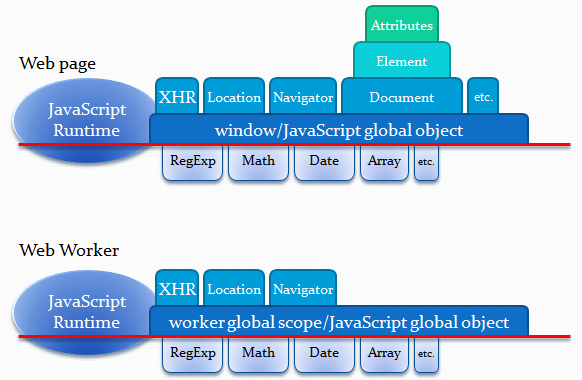
在 Worker 线程中运行 JS, 会创建独立于主线程的 JS 运行环境, 称之为 DedicatedWorkerGlobalScope. 开发者需关注 Worker 环境和主线程环境的异同, 以及 Worker 在不同浏览器上的差异.
Worker 是无 UI 的线程, 无法调用 UI 相关的 DOM/BOM API. Worker 具体支持的 API 可参考 MDN 的 functions and classes available to workers.
⇈图片来源
上图展示了 Worker 线程与主线程的异同点. Worker 运行环境与主线程的共同点主要包括:
Navigator.userAgent 识别浏览器.从共同点上看, Worker 线程其实很强大, 除了利用独立线程执行重度逻辑外, 其网络 I/O 和文件 I/O 能力给业务和技术方案带来很大的想象空间.
另一方面, Worker 线程运行环境和主线程的差异点有:
self.close 自行销毁.从差异点上看, Worker 线程无法染指 UI, 并受主线程控制, 适合默默干活.
各家浏览器实现 Worker 规范有差异, 对比主线程, 部分 API 功能不完备, 如:
好在这种场景并不多. 并且可以在运行时通过错误监控发现问题, 并定位和修复(polyfill).
另一方面, 一些新增的 HTML 规范 API 只在较新的浏览器上实现, Worker 运行环境甚至主线程上没有, 使用 Worker 时需判断和兼容.
Worker 线程不支持 DOM, 这点和 Node.js 非常像. 我们在 Node.js 上做前后端同构的 SSR 时, 经常会遇到调用 BOM/DOM API 导致的报错. 如下图所示:
在开发 Worker 前端项目或迁移已有业务代码到 Worker 中时, 同构代码比例可能很高, 容易调到 BOM/DOM API. 可以通过构建变量区分代码逻辑, 或运行时动态判断所在线程, 实现同构代码在不同线程环境下运行.
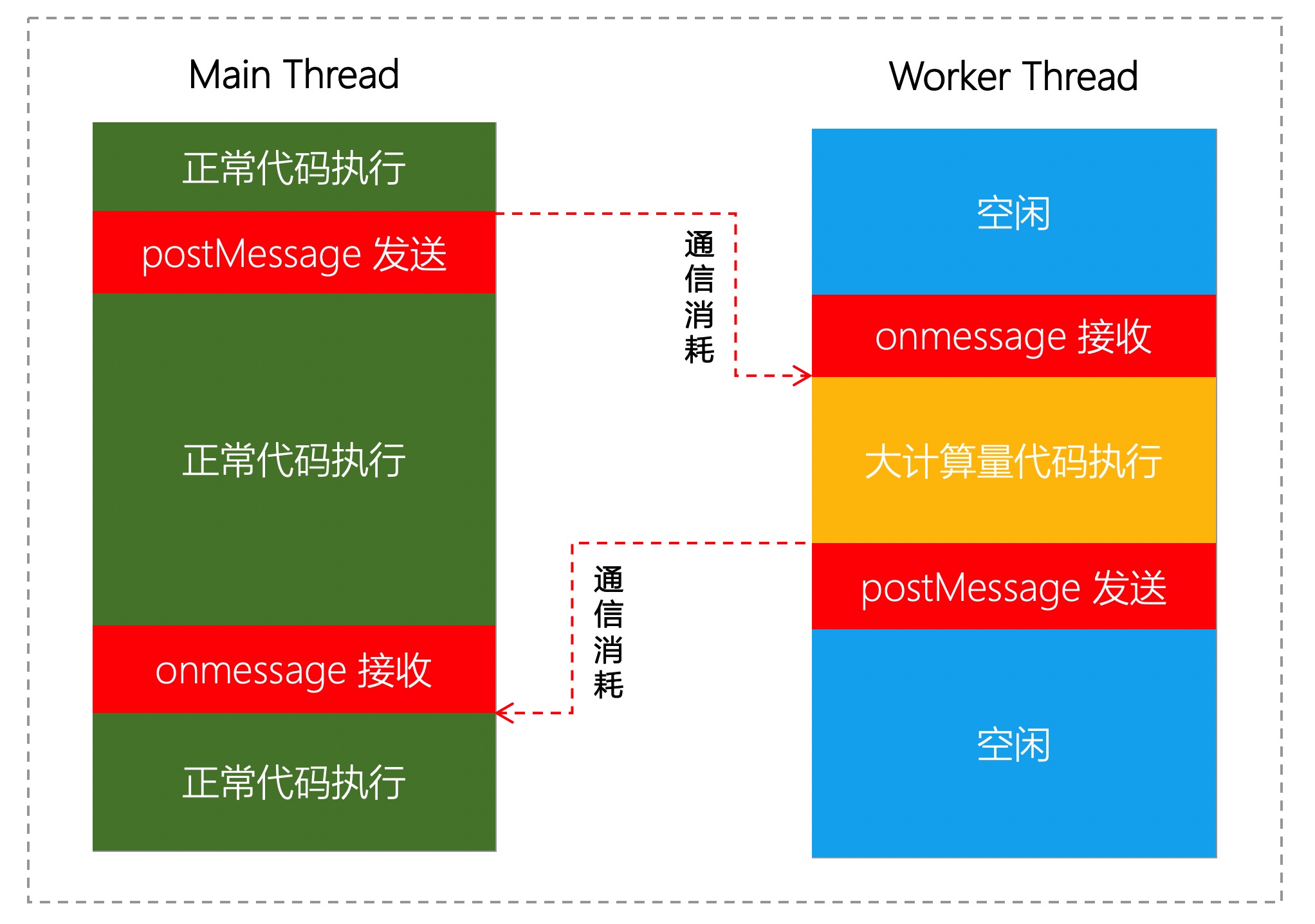
Worker 多线程虽然实现了 JS 任务的并行运行, 也带来额外的通信开销. 如下图所示, 从线程A 调用 postMessage 发送数据到线程B onmessage 接收到数据有时间差, 这段时间差称为通信消耗.
⇈图片来源
提升的性能 = 并行提升的性能 – 通信消耗的性能. 在线程计算能力固定的情况下, 要通过多线程提升更多性能, 需要尽量减少通信消耗.
而且主线程 postMessage 会占用主线程同步执行, 占用时间与数据传输方式和数据规模相关. 要避免多线程通信导致的主线程卡顿, 需选择合适的传输方式, 并控制每个渲染周期内的数据传输规模.
我们先来聊聊主线程和 Worker 线程的数据传输方式. 根据计算机进程模型, 主线程和 Worker 线程属于同一进程, 可以访问和操作进程的内存空间. 但为了降低多线程并发的逻辑复杂度, 部分传输方式直接隔离了线程间的内存, 相当于默认加了锁.
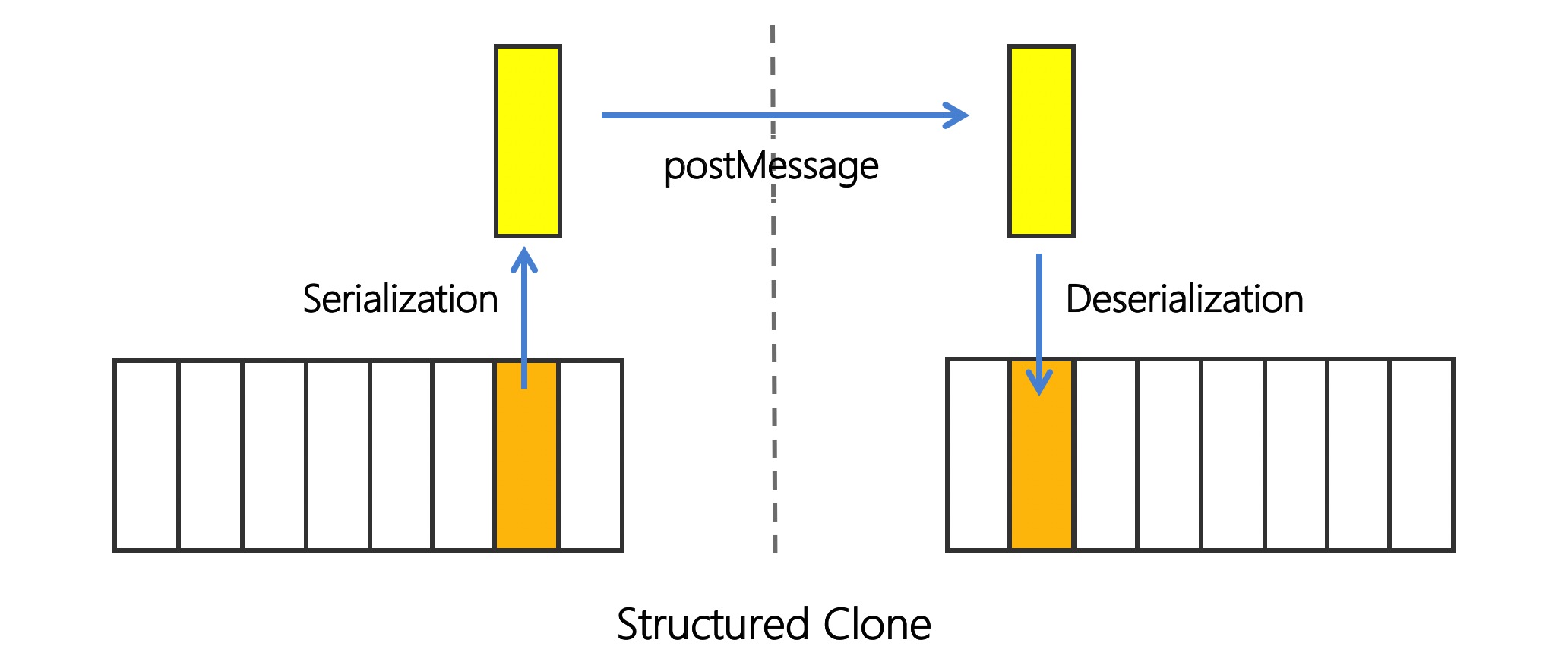
通信方式有 3 种: Structured Clone, Transfer Memory 和 Shared Array Buffer.
Structured Clone 是 postMessage 默认的通信方式. 如下图所示, 复制一份线程A 的 JS Object 内存给到线程B, 线程B 能获取和操作新复制的内存.
Structured Clone 通过复制内存的方式简单有效地隔离不同线程内存, 避免冲突; 且传输的 Object 数据结构很灵活. 但复制过程中, 线程A 要同步执行 Object Serialization, 线程B 要同步执行 Object Deserialization; 如果 Object 规模过大, 会占用大量的线程时间.
Transfer Memory 意为转移内存, 它不需要 Serialization/Deserialization, 能大大减少传输过程占用的线程时间. 如下图所示 , 线程A 将指定内存的所有权和操作权转给线程B, 但转让后线程A 无法再访问这块内存.
Transfer Memory 以失去控制权来换取高效传输, 通过内存独占给多线程并发加锁. 但只能转让 ArrayBuffer 等大小规整的二进制(Raw Binary)数据; 对矩阵数据(如 RGB 图片)比较适用. 实践上也要考虑从 JS Object 生成二进制数据的运算成本.
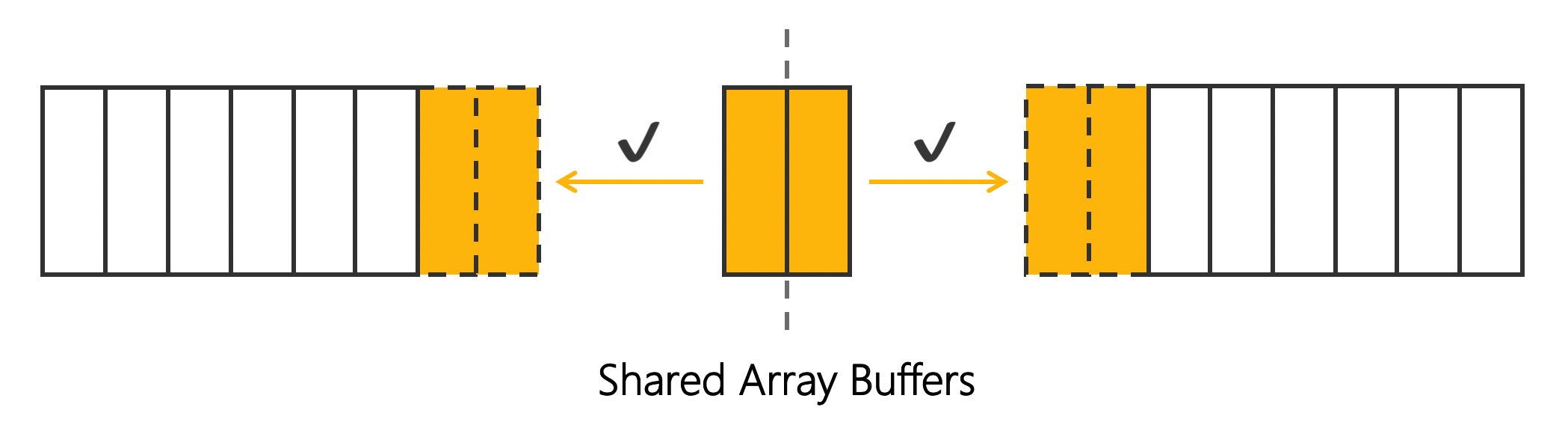
Shared Array Buffer 是共享内存, 线程A 和线程B 可以同时访问和操作同一块内存空间. 数据都共享了, 也就没有传输什么事了.
但多个并行的线程共享内存, 会产生竞争问题(Race Conditions). 不像前 2 种传输方式默认加锁, Shared Array Buffers 把难题抛给开发者, 开发者可以用 Atomics 来维护这块共享的内存. 作为较新的传输方式, 浏览器兼容性可想而知, 目前只有 Chrome 68+ 支持.
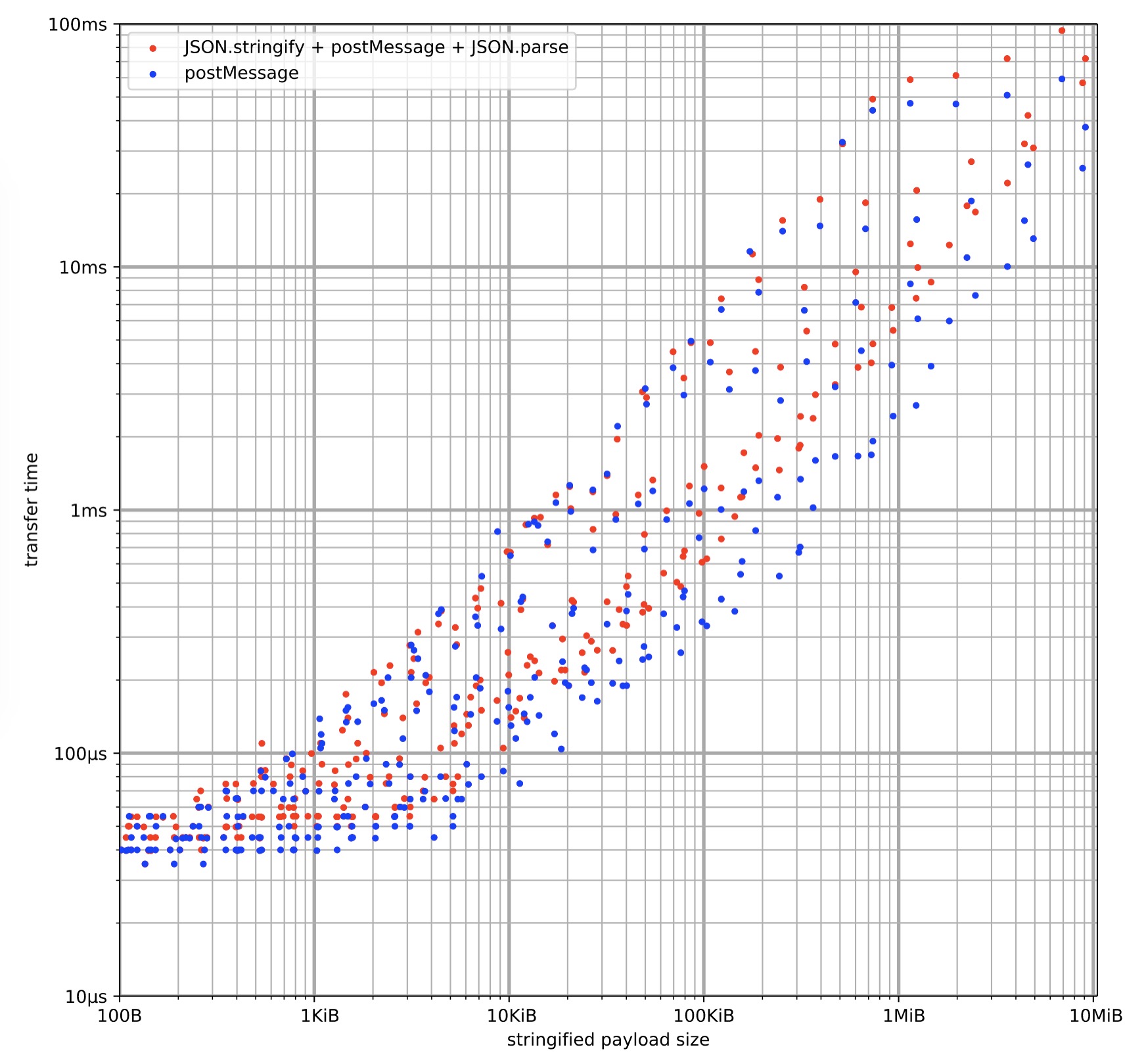
使用 Structured Clone 传输数据时, 有个阴影一直笼罩着我们: postMessage 前要不要对数据 JSON.stringify 一把, 听说那样更快?
2016 年的 High-performance Web Worker messages 进行了测试, 确实如此. 但是文章的测试结果也只能停留在 2016 年. 2019 年 Surma 进行新的测试: 如下图所示, 横轴上相同的数据规模, 直接 postMessage 的传输时间普遍比 JSON.stringify 更少.
⇈图片来源
2020 年的当下, 不需要再使用 JSON.stringify. 其一是 Structured Clone 内置的 serialize/deserialize 比 JSON.stringify 性能更高; 其二是 JSON.stringify 只适合序列化基本数据类型, 而 Structured Clone 还支持复制其他内置数据类型(如 Map, Blob, RegExp 等, 虽然大部分应用场景只用到基本数据类型).
我们再来聊聊 Structured Clone 的数据传输规模. Structured Clone 的 serialize/deserialize 执行耗时主要受数据对象复杂度影响, 这很好理解, 因为 serialize/deserialize 至少要以某种方式遍历对象. 数据对象的复杂度本身难以度量, 可以用序列化后的数据规模(size)作为参考.
2015 年的 How fast are web workers 在中等性能手机上进行了测试: postMessage 发送数组的通信速率为 80KB/ms, 相当于理想渲染周期(16ms)内发送 1300KB.
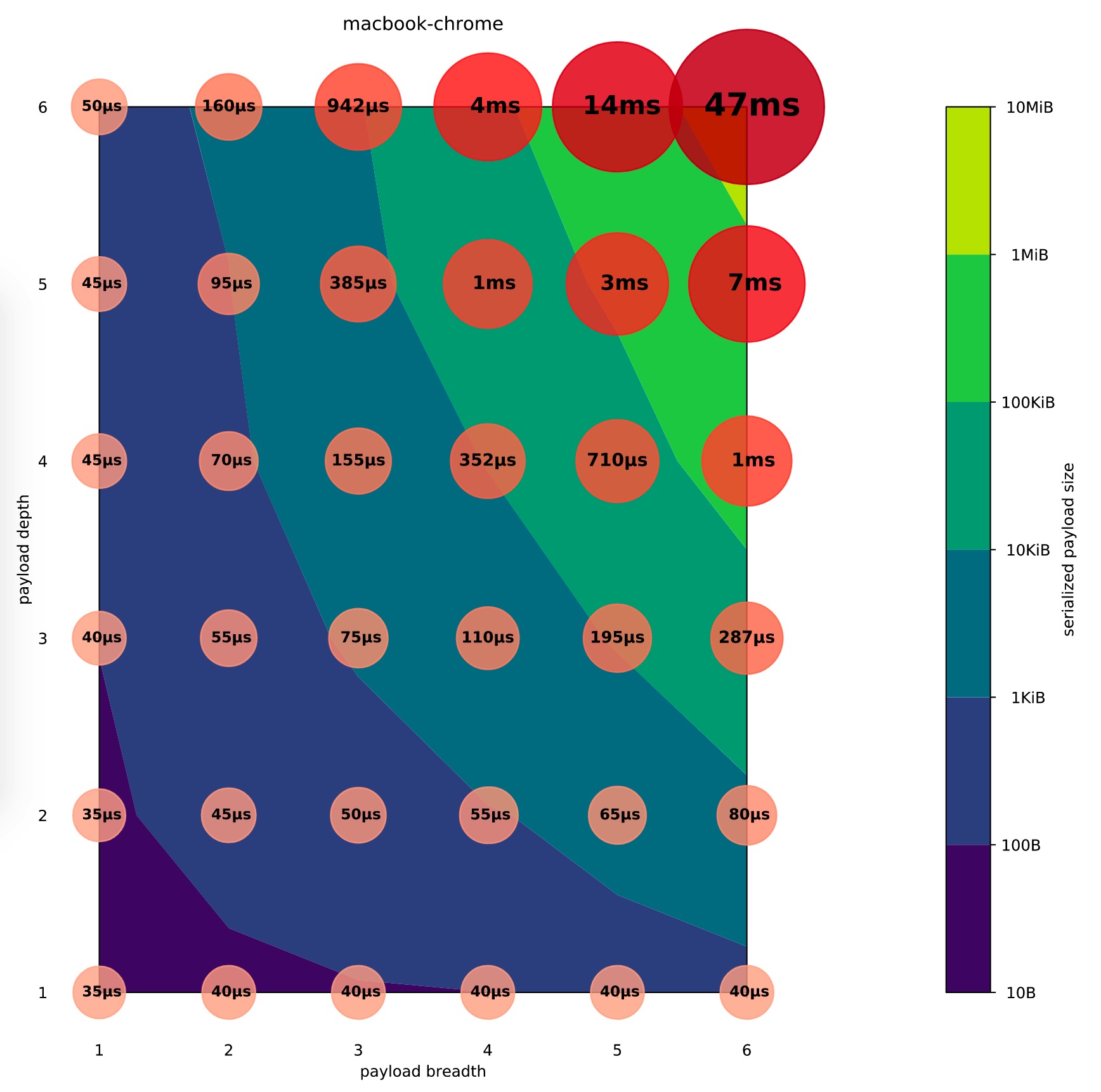
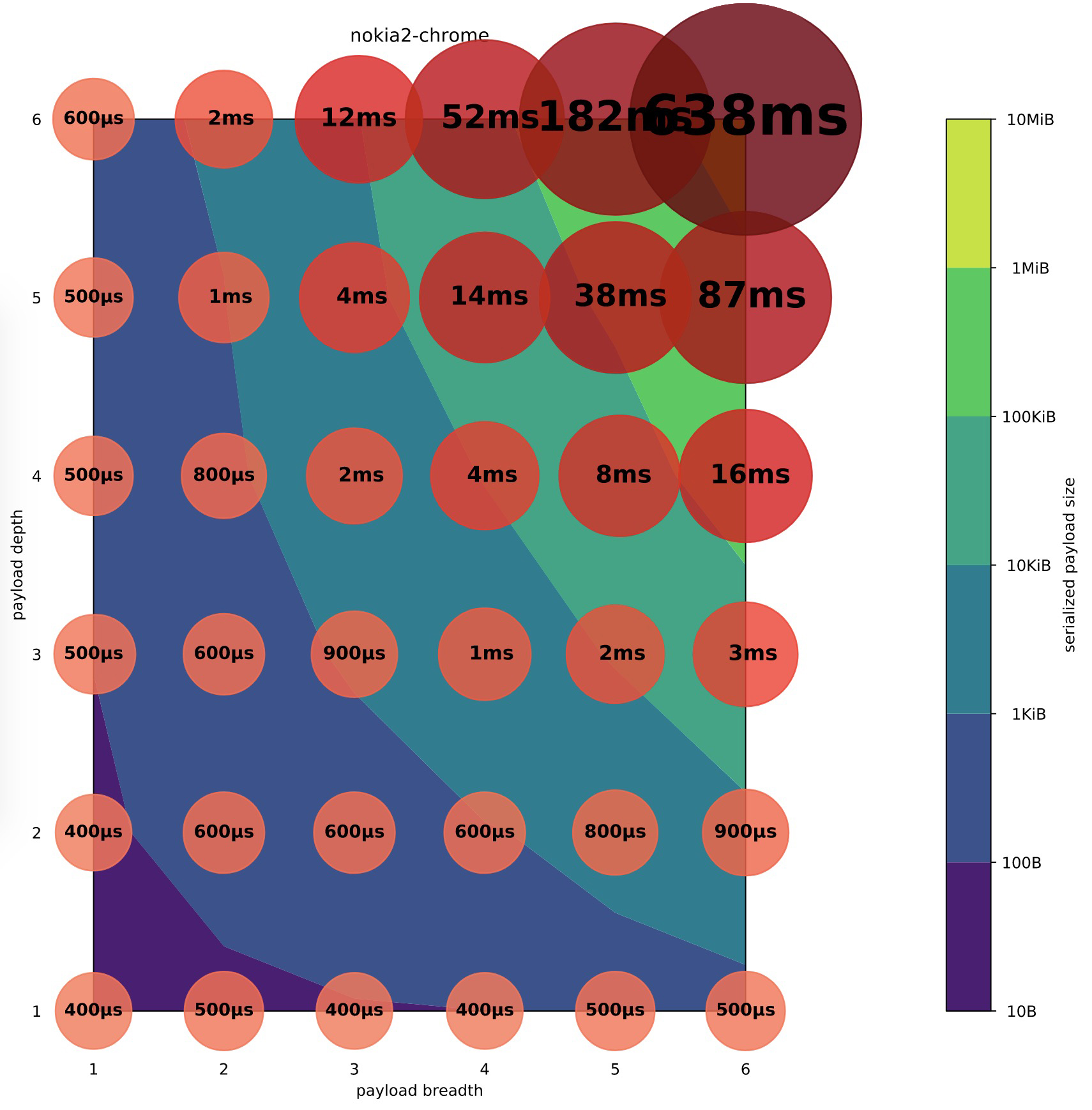
2019 年 Surma 对 postMessage 的数据传输能力进行了更深入研究, 具体见 Is postMessage slow. 高性能机器(macbook) 上的测试结果如下图所示:
⇈图片来源
其中:
低性能机器(nokia2) 上的测试结果如下图所示:
⇈图片来源
其中:
不管用户侧的机器性能如何, 用户对流畅的感受是一致的: 前端同学的老朋友 16ms 和 100ms. Surma 兼顾低性能机型上 postMessage 容易造成主线程卡顿, 提出的数据传输规模建议是:
笔者认为, Surma 给出的建议偏保守, 传输规模可以再大一些.
总之, 数据传输规模并没有最佳实践. 而是充分理解 Worker postMessage 的传输成本, 在实际应用中, 根据业务场景去评估和控制数据规模.
兼容性是前端技术方案评估中需要关注的问题. 对 Web Worker 更是如此, 因为 Worker 的多线程能力, 要么业务场景完全用不上; 要么一用就是重度依赖的基础能力.
从前文 Worker 的历史和 兼容性视图 上看, Worker 的兼容性应该挺好的.
如上图所示, 主流浏览器在几年前就支持 Worker.
PC端:
移动端:
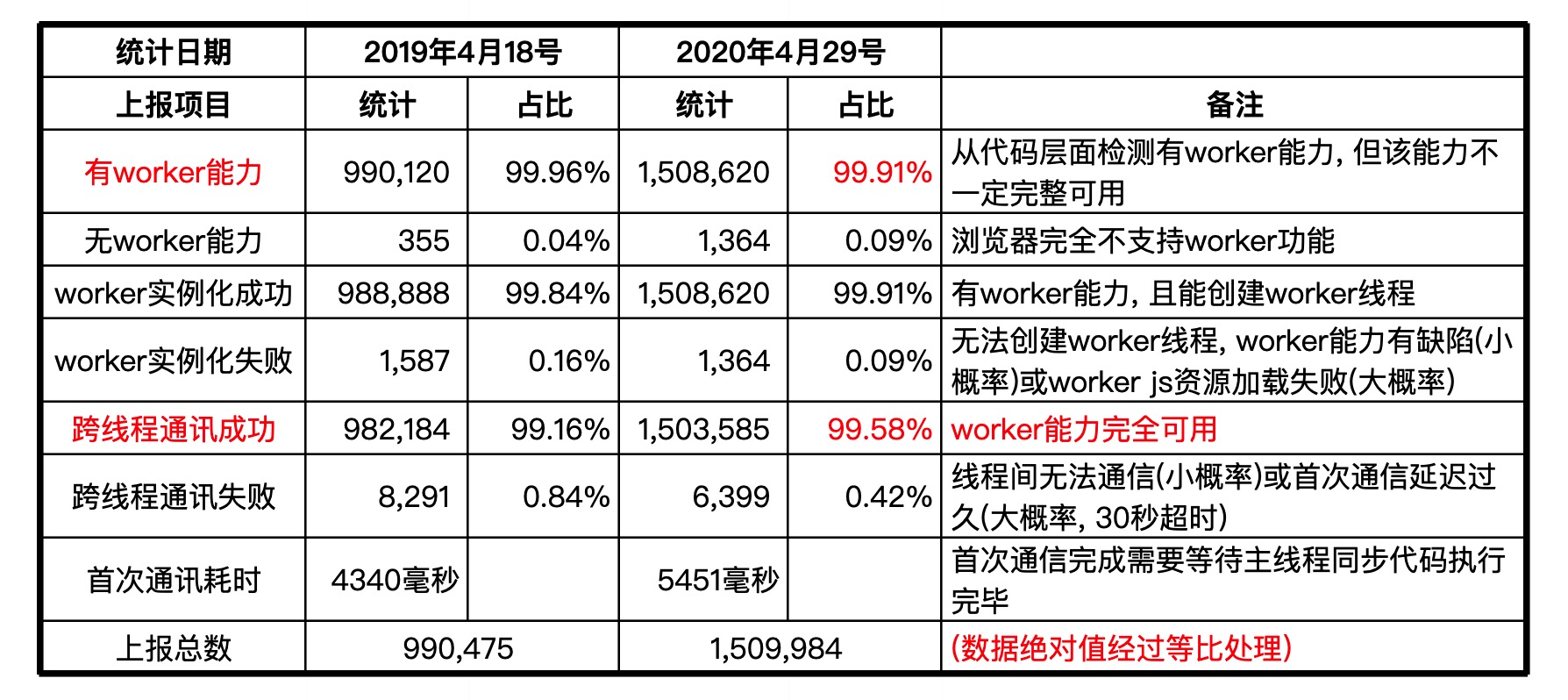
使用 Worker 并不是一锤子买卖, 我们不止关注浏览器 Worker 能力的有或没有; 也关注 Worker 能力是否完备可用. 为此笔者设计了以下几个指标来评估 Worker 可用性:
window.Worker 来判断.new Worker() 是否报错来判断.有了可用性评估指标, 就可以给出量化的兼容性统计数据. 你将看到的, 是开放社区上唯一一份量化数据, 2019~2020 年某大型前端项目(亿级 MAU)的统计结果(By AlloyTeam alloy-worker).
其中:
可见当下浏览器已经较好地支持 Worker, 只要对 0.09% 的不支持浏览器做好回退策略(如展示一个 tip), Worker 可以放心地应用到前端业务中.
前端工程师对 Worker 多线程开发方式比较陌生, 对开发中的 Worker 代码调试也是如此. 本章以 Chrome 和 IE10 为例简单介绍调试工具用法. 示例页面为 https://alloyteam.github.io/alloy-worker, 感兴趣的同学可以打开页面调试一把.
Chrome 已完善支持 Worker 代码调试, 开发者面板中的调试方式与主线程 JS 一致.
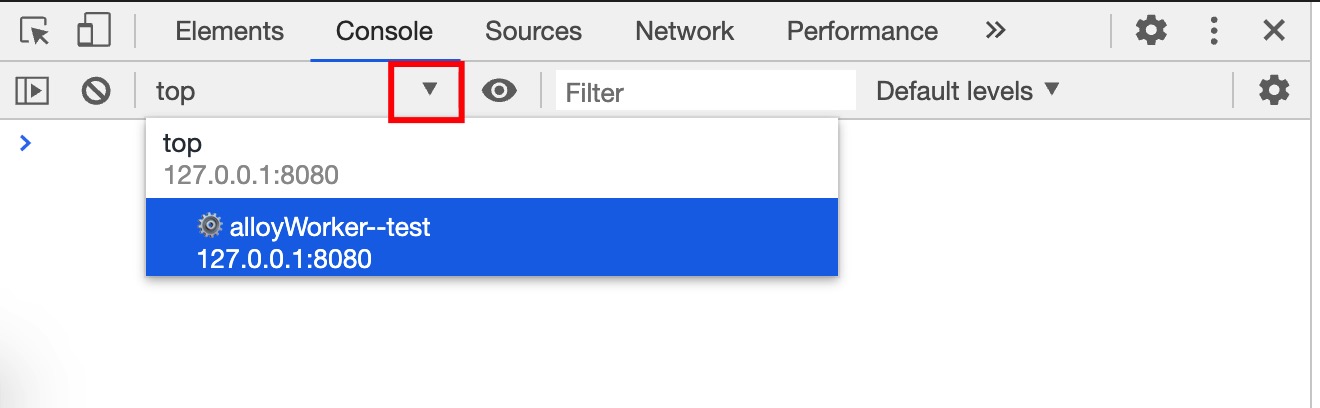
Console Panel 中可以查看页面全部的 JS 运行环境, 并通过下拉框切换调试的当前环境. 如下图所示, 其中 top 表示主线程的 JS 运行环境, alloyWorker--test 表示 Worker 线程的 JS 运行环境.
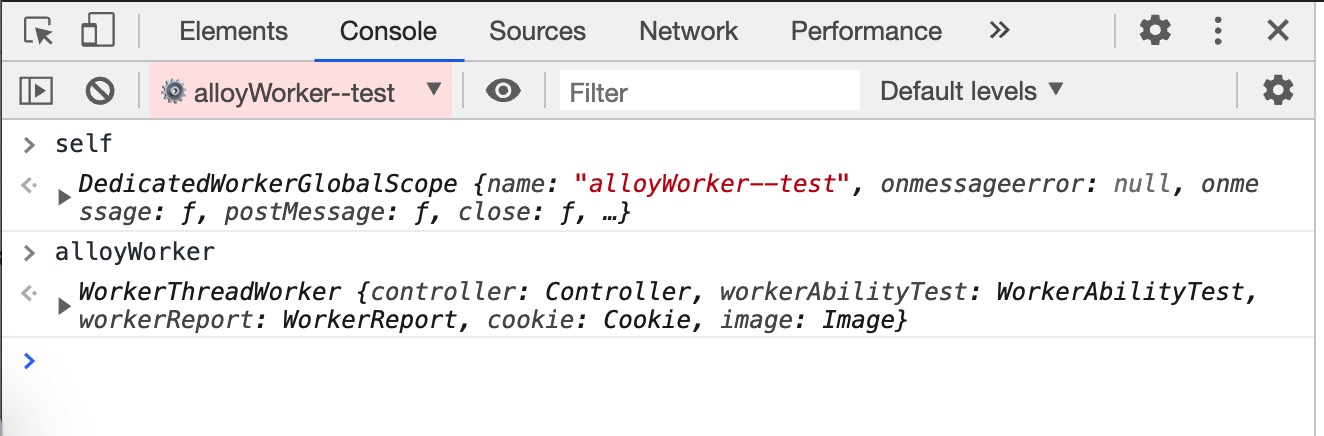
切换到 alloyWorker--test 后, 就可以在 Worker 运行环境中执行调试代码. 如下图所示, Worker 环境的全局对象为 self, 类型为 DedicatedWorkerGlobalScope.
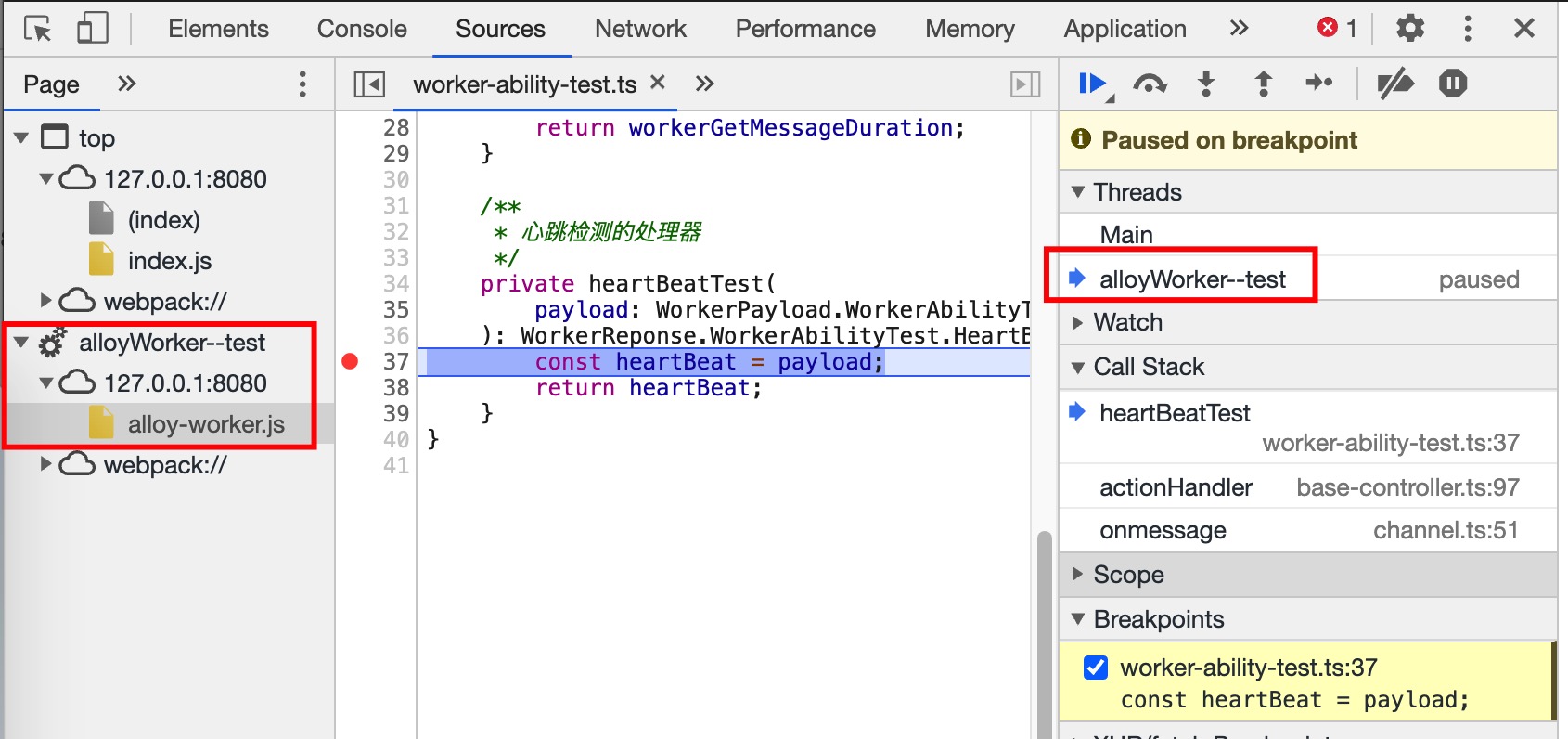
Worker 断点调试方式和主线程一致: 源码中添加 debugger 标识的代码位置会作为断点. 在 Sources Panel 查看页面源码时, 如下图所示, 左侧面板展示 Worker 线程的 alloy-worker.js资源; 运行到 Worker 线程断点时, 右侧的 Threads 提示所在的运行环境是名为 alloyWorker--test 的 Worker 线程.
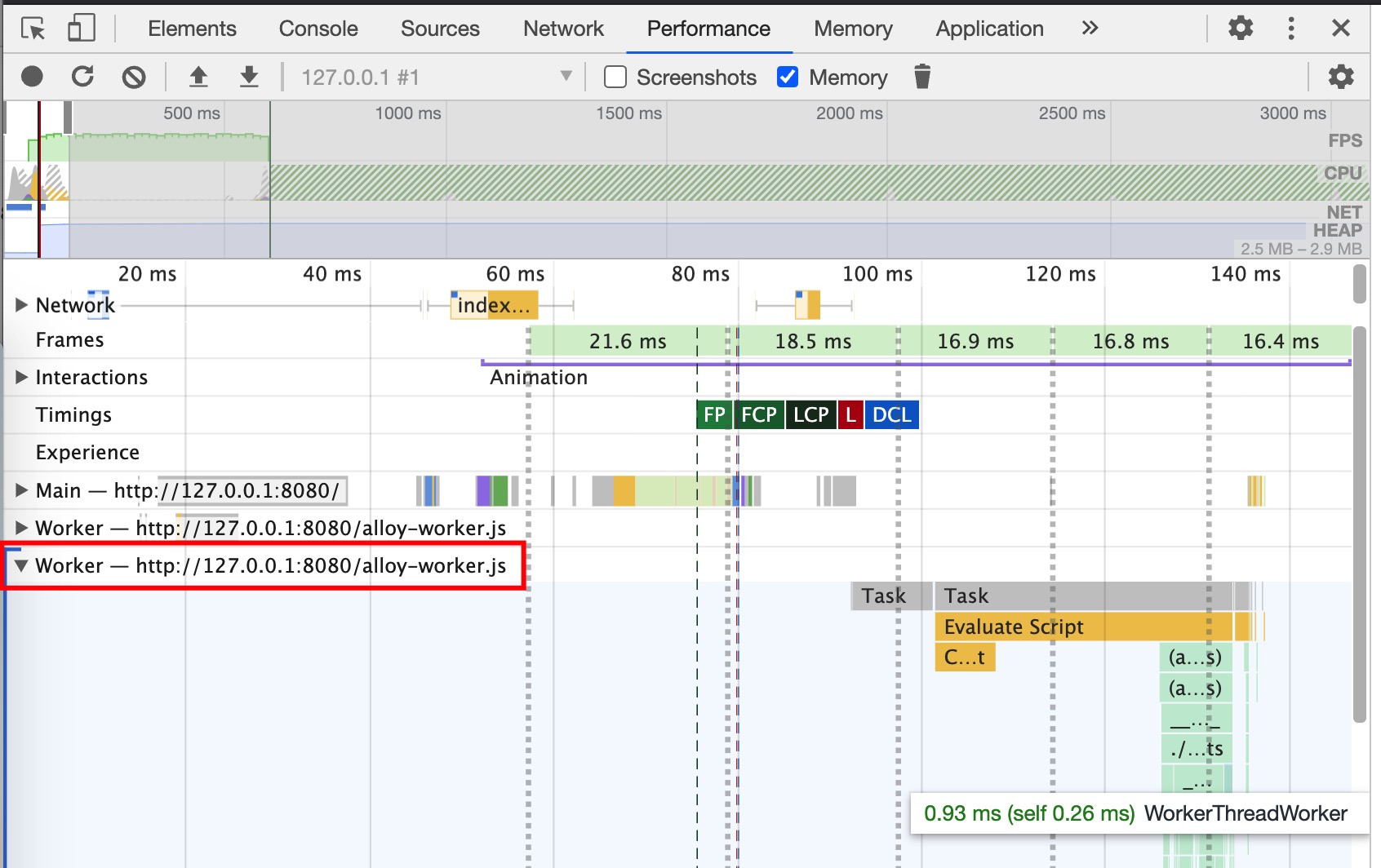
使用 Performance Panel 的录制功能即可. 如下图红框所示, Performance 中也记录了 Worker 线程的运行情况.
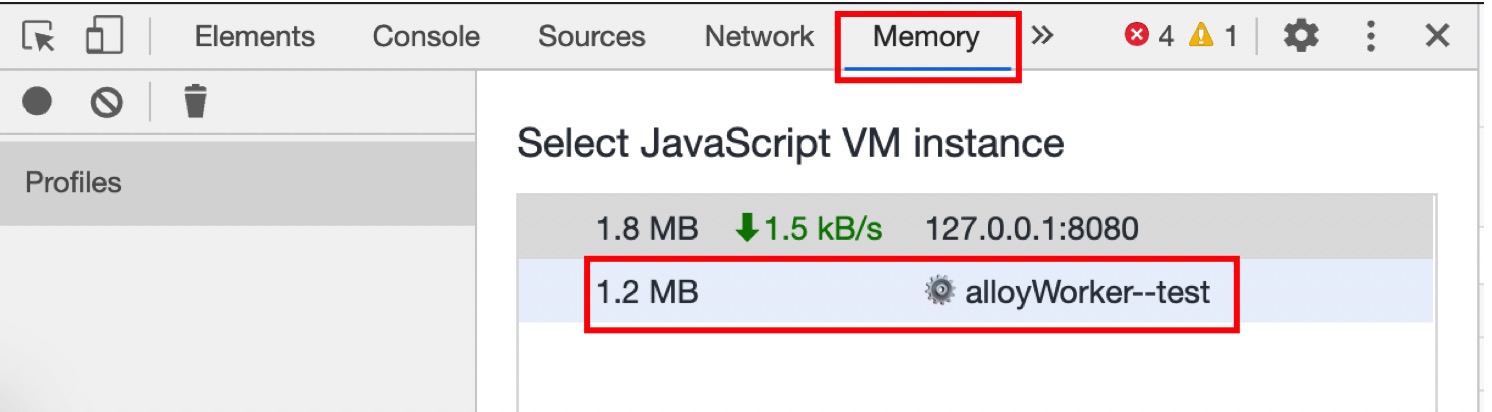
Worker 的使用场景偏向数据和运算, 开发中适时回顾 Worker 线程的内存占用, 避免内存泄露干扰整个 Render Process. 如下图所示, 在 Memory Panel 中 alloyWorker-test 线程占用的内存为 1.2M.
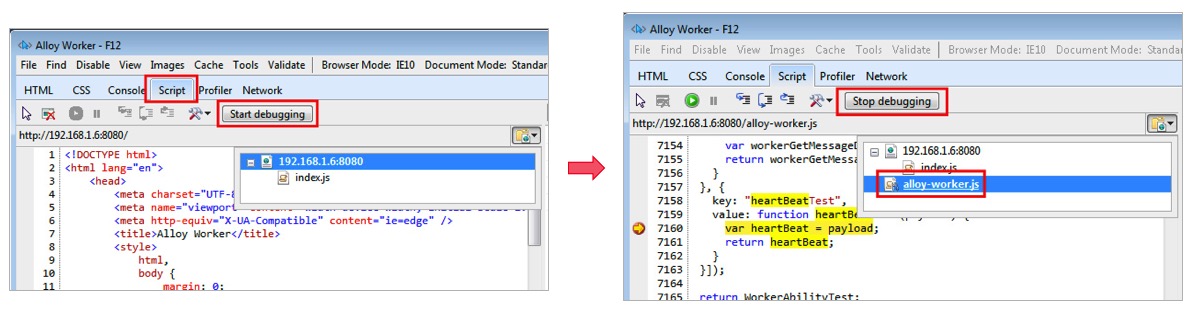
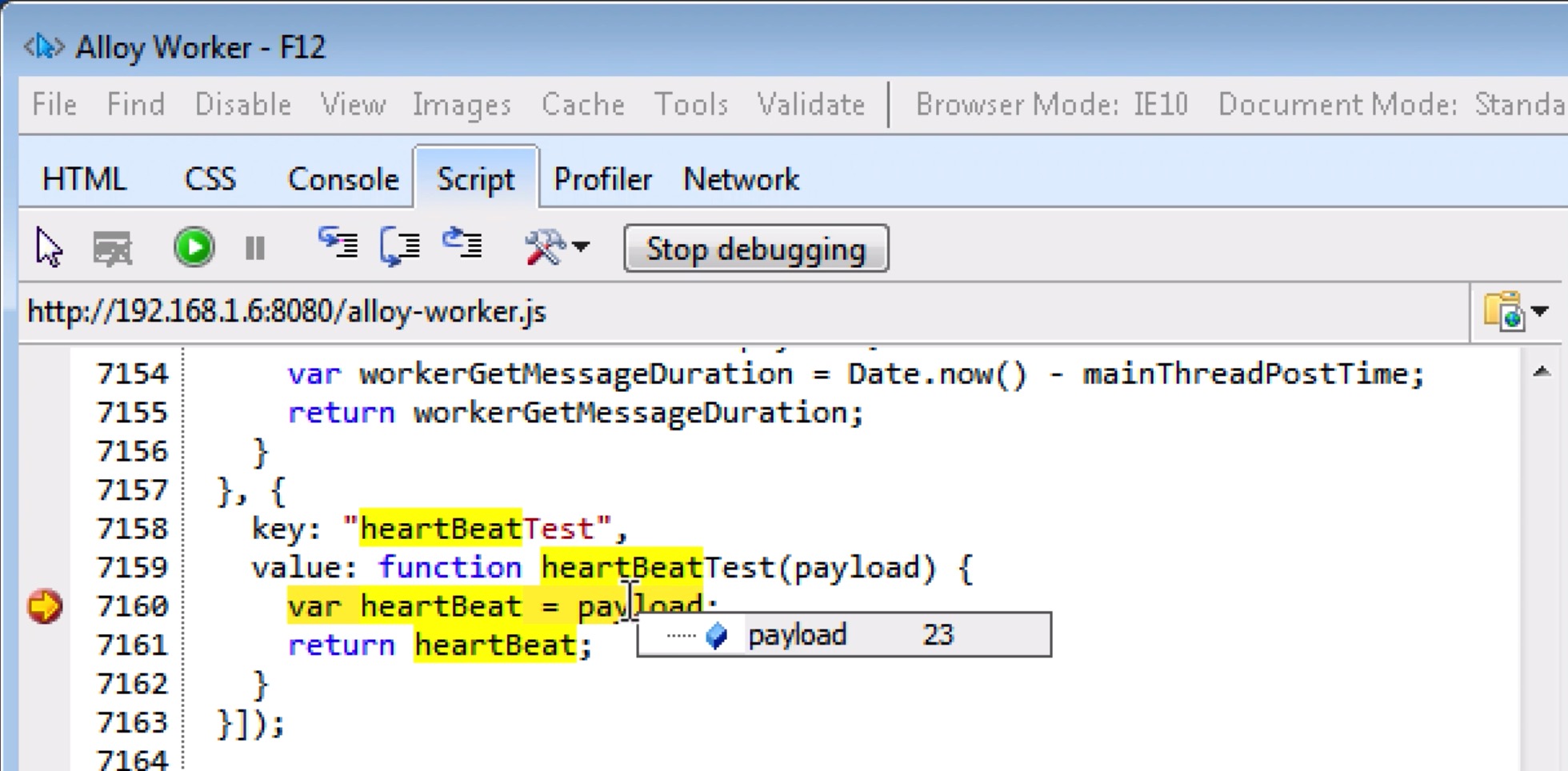
在比较极端的情况下, 我们需要到 IE10 这种老旧的浏览器上定位代码兼容性问题. 好在 IE10 也支持 Worker 源码调试. 可以参考微软官方文档, 具体步骤为:
F12 打开调试工具, 在 Script Panel 中, 开始是看不到 Worker 线程源码的, 点击 Start debugging, 就能看到 Worker 线程的 alloy-worker.js 源码.跨线程通信数据流是开发和调试中比较复杂的部分. 因为页面上可能有多个 Worker 实例; Worker 实例上有不同的数据类型(payload); 而且相同类型的通信可能会多次发起.
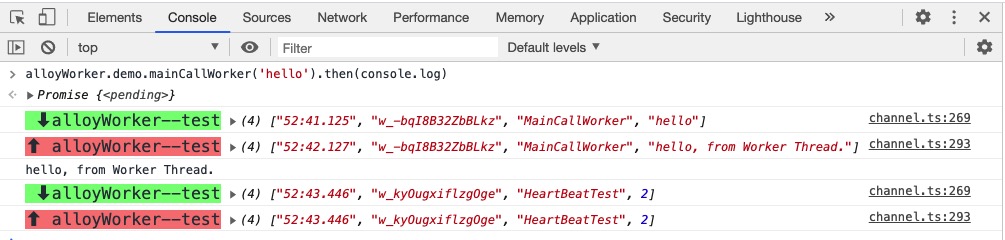
通过 onmessage 回调打 log 调试数据流时, 建议添加当前 Worker 实例名称, 通信类型, 通信负载等信息. 以 alloy-worker 调试模式的 log 为例:
如上图所示:
现代化前端开发都采用模块化的方式组织代码, 使用 Web Worker 需将模块源码构建为单一资源(worker.js). 另一方面, Worker 原生的 postMessage/onmessage 通信 API 在使用上并不顺手, 复杂场景下往往需要进行通信封装和数据约定.
因此, 开源社区提供了相关的配套工具, 主解决 2 个关键问题:
下面介绍社区的一些主要工具, star 数统计时间为 2020.06.
Webpack 官方的 Worker loader. 负责将 Worker 源码打包为单个 chunk; chunk 可以是独立文件, 或 inline 的 Blob 资源.
输出内嵌 new Worker() 的 function, 通过调用该 function 实例化 Worker.
但 worker-loader 没有提供构建后的 Worker 资源 url, 上层业务进行定制有困难. 已有相关 issue 讨论该问题; worker-loader 也不对通信方式做额外处理.
GoogleChromeLabs 提供的 Webpack 构建 plugin.
作为 plugin, 支持 Worker 和 SharedWorker 的构建. 无需入侵源码, 通过解析源码中 new Worker 和 new SharedWorker 语法, 自动完成 JS 资源的构建打包. 也提供 loader 功能: 打包资源并且返回资源 url, 这点比 worker-loader 有优势.

也来自 GoogleChromeLabs 团队, 由 Surma 开发. 基于 ES6 的 Proxy 能力, 对 postMessage 进行 RPC
(Remote Procedure Call) 封装, 将跨线程的函数调用封装为 Promise 调用.
但它不涉及 Worker 资源构建打包, 需要其他配套工具. 且 Proxy 在部分浏览器中需要 polyfill, 可 polyfill 程度存疑.
目前社区比较完整, 且兼容性好的方案.
类似 worker-loader + comlink 的合体. 但不是基于 Proxy, 而在构建时根据源码 AST 提取出调用函数名称, 在另一线程内置同名函数; 封装跨线程函数为 RPC 调用.
与 workerize-loader 关联的另一个项目是 workerize (3.8k star). 支持手写文本函数, 内部封装为 RPC; 但手写文本函数实用性不强.
很有趣的项目, 将 Worker 封装为 React Hook. 基本原理是: 将传入 Hook 的函数处理为 BlobUrl 去实例化 Worker. 因为会把函数转为 BlobUrl 的字符串形式, 限制了函数不能有外部依赖, 函数体中也不能调用其他函数.
比较适合一次性使用的纯函数, 函数复杂度受限.
现有的社区工具解决了 Worker 技术应用上的一些难点, 但目前还有些不足:
以上不足促使笔者开源了 alloy-worker, 面向事务的高可用 Web Worker 通信框架.
更加详细的工具讨论, 请查阅 alloy-worker 的业界方案对比.
Web Worker 作为浏览器多线程技术, 在页面内容不断丰富, 功能日趋复杂的当下, 成为缓解页面卡顿, 提升应用性能的可选方案.
2010 年, 文章 The Basics of Web Workers 列举的 Worker 可用场景如下:
2010 年的应用场景主要涉及数据处理, 文本处理, 图像/视频处理, 网络处理等.
2018 年, 文章 Parallel programming in JavaScript using Web Workers 列举的 Worker 可用场景如下:
可见, 近年来 Worker 的场景比 2010 年更丰富, 拓展到了 Canvas drawing(离屏渲染方面), Virtual DOM diffing(前端框架方面), indexedDB(本地存储方面), Webassembly(编译型语言方面)等.
总的来说, Worker 对页面的计算任务/后台任务有用武之地. 接下来笔者将分享的一些具体 case, 并进行简析.
2017 年的文章, 非常好的实践. 在线表格排序是 CPU 密集型场景, 复杂任务原子化和异步化后依然难以消除页面卡顿. 将排序迁移到 Worker 后, 对 2500 行数据的排序操作, Scripting 时间从 9984ms 减少到 3650ms .
2020 年的文章, 使用生动的图例说明 TF.js 在主线程运行造成的掉帧. 以实时摄像头视频的动作检测为例子, 通过 Worker 实现视频动画不卡顿(16ms内); 动作检测耗时 50ms, 但是不阻塞视频, 也有约 15FPS.
笔者撰写文章中, 近期发布.
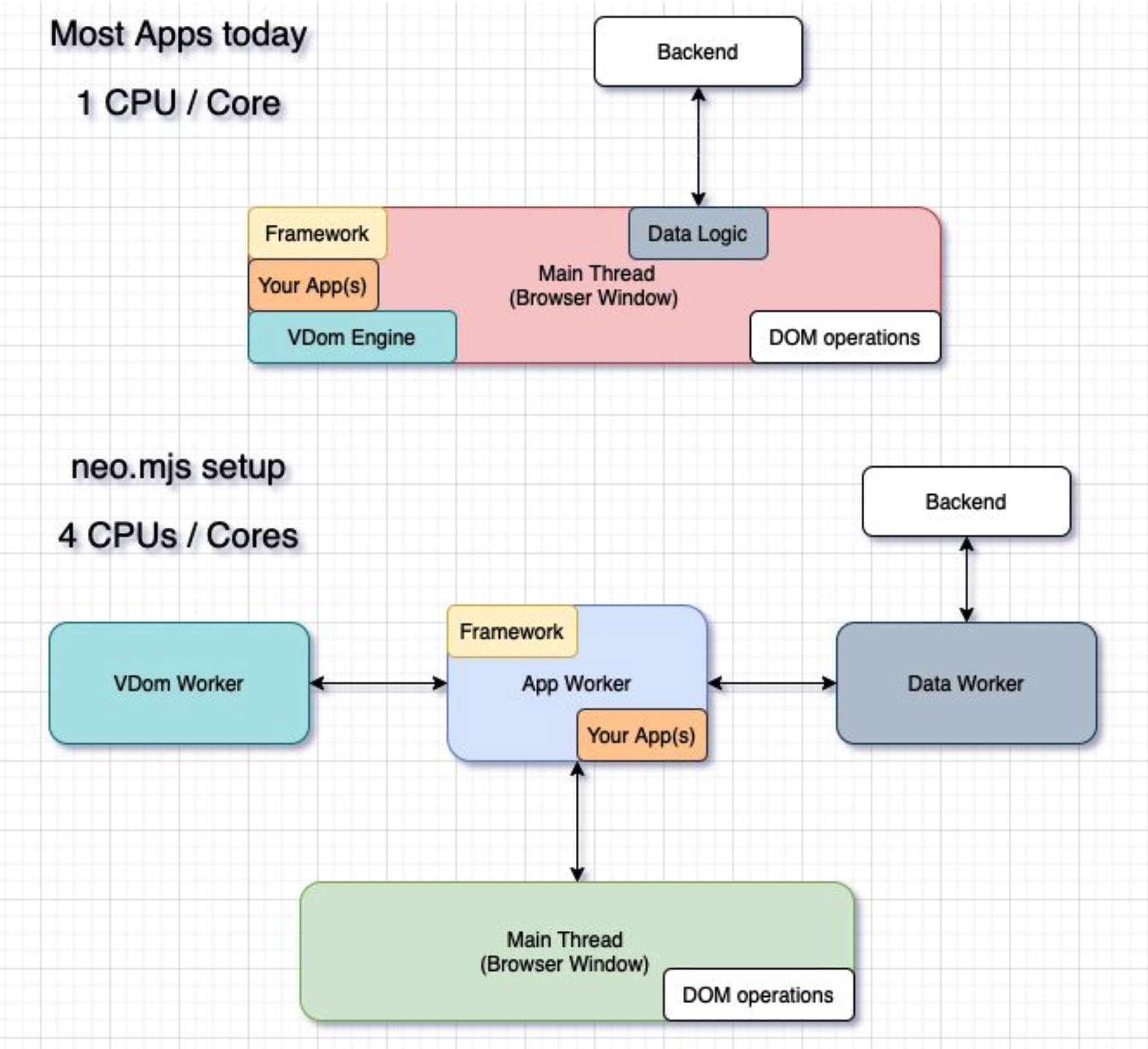
2019 年开源的 Worker 驱动前端框架. 其将前端框架的拆分为 3 个 Worker: App Worker, Data Worker 和 Vdom Worker. 主线程只需要维护 DOM 和代理 DOM 事件到 App Worker 中; Data Worker 负责进行后台请求和托管数据 store; Vdom Worker 将模板字符串转换为虚拟节点, 并对每次变化生成增量去更新.
Google AMP 项目一部分. 在 Worker 中实现 DOM 操作 API 和 DOM 事件监听, 并将 DOM 变化应用到主线程真实 DOM 上. 官方 Demo 在 Worker 中直接引入 React 并实现 render!
Angular8 CLI 支持创建 Web Worker 指令, 并将耗 CPU 计算迁移到 Worker 中; 但是 Angular 本身并不能在 Worker 中运行. 官网 angular.io 也用 Worker 来提升搜索性能.
2019 年的文章. 将 Redux 的 action 部分迁移到 Worker 中, 开源了项目 redux-in-worker.
做了 Worker Redux 的 benchmark: 和主线程相差不大(但是不卡了).
2019 年的文章. 简单分析 UI 线程过载和 Worker 并发能力. 对 Vue 数据流框架 Vuex 进行分解, 发现 action 可以包含异步操作, 适合迁移到 Worker. 实现了 action 的封装函数和质数生成的 demo.
PROXX 是 GoogleChromeLabs 开发的在线扫雷游戏, 其 Worker 能力由 Surma 开发的 Comlink 提供. Surma 特地开发了 Worker 版本和非 Worker 版本: 在高性能机型 Pixel3 和 MacBook 上, 两者差异不大; 但在低性能机型 Nokia2 上, 非 Worker 版本点击动作卡了 6.6s, Worker 版本点击回调需要 48ms.
2013 年的文章. 使用 Worker 将图片处理为复古色调. 在当年先进的 12 核机器上, 使用 4 个 Worker 线程后, 处理时间从 150ms 减低到 80ms; 在当年的双核机器上, 处理时间从 900ms 减低到 500ms.
2020 的文章. 基于 OpenCV 项目, 将项目编译为 webassembly, 并且在 Worker 中动态加载 opencv.js, 实现了图片的灰度处理.
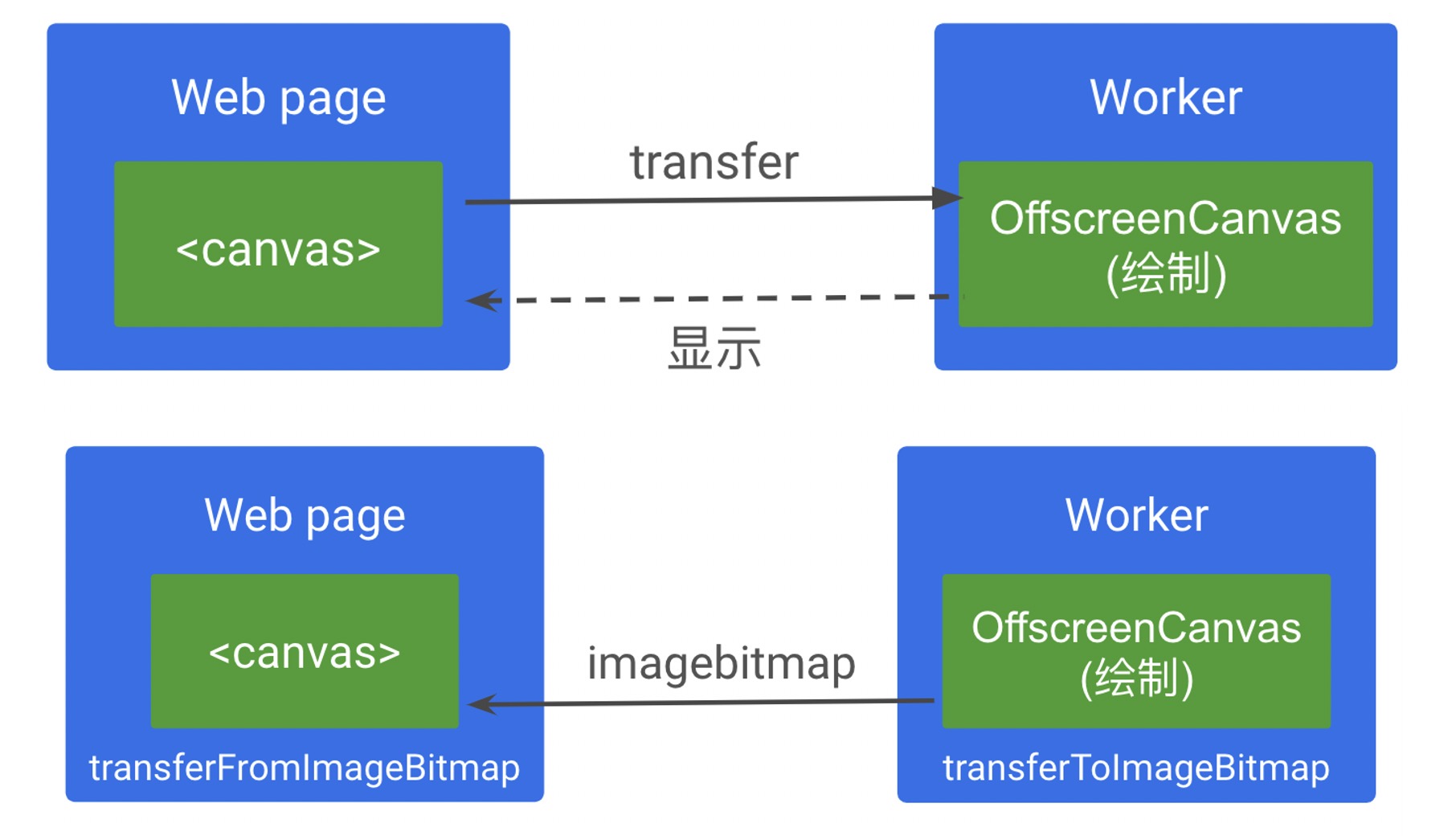
Chrome69+ 支持, 能将主线程 Canvas 的绘制权 transfer 给 Worker 线程的 OffscreenCanvas, 在 Worker 中绘制后渲染直接到页面上; 也支持在 Worker 中新建 Canvas 绘制图形, 通过 imagebitmap transfer 到主线程展示.
hls 是基于 JS 实现的 HTTP 实时流媒体播放库. 其使用 Worker 用于流数据的解复用(demuxer), 使用 Transfer Memory 来最小化传输的消耗.
判断浏览器是否支持 Worker 能力, 有 Worker 能力时将 pdf 文件解析( parsed and interpreted)全部放在 Worker 线程中; Worker 能力不完备则在主线程运行.
2016年的分享 ppt, Pokedex.org 项目在 Web Worker 中进行 Virtual DOM 的更新, 显著提升快速滚动下的渲染效率.
Chrome Dev Summit 2019, 非常精彩的分享, 来自 google 的工程师 Surma. 演讲指出页面主线程工作量过大, 特别是发展**家有大量的低性能设备. 运算在 Worker 慢一点但页面不掉帧优于运算在主线程快一点但卡顿.
同样来自 Surma 的技术访谈. 主要讨论 postMessage 的性能问题. 本文在通信速度部分大量引用 Surma 的研究.
Surma 在 Worker 领域写了多篇文章, 并开源了 Comlink.
2019 年的演讲, 笔者前同事, 曾在 Worker 实践上紧密合作. 演讲讨论 Web Worker 的使用场景; Worker 的注意点和适应多线程的代码改造; 以及实践中遇到的问题和解决方案.
2019 年的演讲, 来自 Netflix 的工程师. 总结使用 Web Worker 遇到的 4 大问题, 并通过引入社区多个配套工具逐一解决.
2018年的演讲, 讲多线程和 postMessage 数据传递部分图很漂亮. 将 Web Worker 应用在他开发的 Web 钢琴弹奏器.
2014年的演讲, 使用生动的图例介绍主线程 Event Loop.
如上文所述, 社区已有许多 Worker 技术的应用实践. 如果你的业务也有使用 Worker 的需求, 以下是几个实践的建议.
使用 Worker 是有成本的: Worker 线程会占用系统资源; 同构代码和异步通信会增加维护成本; 多线程编程会挑战前端仔的思维.
David 的文章指出, 迫切需要 Worker 的场景并不多, 开发者需要考虑投入效益比. 简单来说, 如果页面的某个操作会耗时, 同时不想让用户察觉(转菊花), 那就用 Worker 吧.
虽然 Worker 规范提供了 terminate API 来结束 Worker 线程, 但线程的频繁新建会消耗资源. 大多数场景下, Worker 线程应该用作常驻的线程. 开发中优先复用常驻线程.
这也很好理解, Worker 线程在争取 CPU 计算资源时, 受限于 CPU 的核心数, 过多的线程并不能线性地提升性能, 而每个 Worker 线程会有约 1M 的固有内存消耗.
多线程开发的思维和方式, 是个比较大的话题. 开发者需要控制线程间的通信规模, 减少线程间数据和状态的依赖, 尝试去了解和控制 Worker 线程.
本文试图梳理 2020 年当下 Web Worker 技术的现状和发展.
从现状上看, Worker 已经普遍可用, 业界也有业务和框架上的实践, 但在配套工具上仍有不足.
从发展趋势上看, Worker 的多线程能力有望成为复杂前端项目的标配, 在减少 UI 线程卡顿和压榨计算机性能上有收益. 但目前国内实践较少, 一方面是业务复杂程度未触及; 另一方面是社区缺少科普和实践分享.
前端多线程开发正当时. 笔者维护的 Worker 通信框架 alloy-worker 已经开源, 大型前端项目落地的文章正在路上. 鸡汤和勺子都给了, 加点老干妈, 真香!
https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API
https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Using_web_workers
https://hacks.mozilla.org/2009/07/working-smarter-not-harder/
https://itnext.io/achieving-parallelism-in-javascript-using-web-workers-8f921f2d26db
https://povioremote.com/blog/so-you-want-to-use-a-web-worker/
donedonevue 原理
donePromise
用es5语法实现一个自己的Promise
Proxy
实例解析ES6 Proxy使用场景
done<<高程>>第六章
浏览器渲染
repaint和reflow
done感知性能优化 https://share.weiyun.com/abf5d2140238dc8556ab5ff958b50795
donequerySelectorAll
这一次,彻底弄懂 JavaScript 执行机制
The Node.js Event Loop, Timers, and process.nextTick()
done八大排序算法 http://blog.csdn.net/hguisu/article/details/7776068
设计模式
闭包
Javascript strict mode
页面可视化搭建工具, 是互联网公司中常见的运营工具, 实现了运营人员快速生成和发布页面, 提升页面上线效率; 且无需开发人员介入, 节省开发人力.
页面可视化搭建工具搭建出的页面示例:

但从零开始设计和开发出这种工具并不简单. 笔者维护的页面可视化搭建框架 pipeline, 提供了页面可视化搭建的核心功能, 免去从零实现页面可视化搭建工具的困难.
本文主要包含以下内容:
前端业务中, 经常需要开发产品介绍页/营销页/活动页/图片展示页等页面. 这类需求有以下几个特点:

对于高频和重复的活动页面开发, 业界一般将页面做成配置化, 配置工作从开发人员交接给产品/运营等需求方; 开发和设计人员只需提供配置化页面支持. 更优的活动页面生成流程依靠页面可视化搭建系统来实现.
现.

流程2.同时, 随着页面可视化搭建系统中的页面模板不断丰富, 新的页面需求对开发人员的依赖逐渐减低, 可由运营/产品直接完成.
更优的活动页面开发流程依靠页面可视化搭建系统实现, 重点是要有页面可视化搭建工具提供技术支持. 页面可视化搭建工具通过填写配置数据表单, 拖拉页面组件等可视化的页面编辑方式, 实现页面的生成或修改.
但从零开始设计和开发出页面可视化搭建工具并不简单, 有几个需要了解和关注的技术点.
从技术角度, 设计和开发一个页面可视化搭建工具时, 需要考虑以下几个技术要点:

页面的基本单元是 HTML 元素, 但是 HTML 元素无法包含业务逻辑, 且由 HTML 元素直接组合出页面, 过于繁杂和低效.

图片来源: https://vuejs.org/images/components.png
页面较好的组织方式是组件化, 如上图所示. 组件是对 HTML 元素、元素布局和样式、业务逻辑的封装. 通过组件封装业务逻辑, 并通过组件属性(Props)向外暴露组件的配置字段. 采用页面组件化, 复杂的页面可视化搭建可以转化为2个较简单的操作:
页面组件化需依靠前端框架来实现. 页面可视化搭建工具的架构方式对页面前端框架有限制: 需选择页面可视化搭建工具支持的前端框架. 如: 页面可视化搭建工具只支持基于 vue 的页面, 那页面组件化的前端框架只能选择 vue.
但是前端技术团队选用的前端框架, 一般已用于支持现有业务, 并沉淀了一定数量的技术组件和业务组件. 如果需要针对页面可视化搭建工具进行前端框架的切换, 成本将会很大.
所以理想的页面可视化搭建工具, 应该和页面的前端框架解偶, 如下图所示. 技术团队在某前端框架中沉淀的技术组件和业务组件, 可在页面可视化搭建工具的页面中复用.

技术难点1:页面可视化搭建工具与页面前端框架解偶.
当然, 前端业务已选用了某前端框架, 开发专门支持该前端框架的页面可视化搭建工具, 也是高效实现目标的选择.
页面模板包含完整的业务逻辑, 有助于快速生成业务页面. 不同的页面模板适用于不同的业务功能, 从模板库中选择合适的页面模板并派生出默认业务页面, 再对默认页面进行可视化编辑, 从而生成目标业务页面.

云凤蝶的页面模板列表:

图片来源: https://www.yunfengdie.com/
模板带有页面的默认数据; 对于组件化的页面, 模板是从组件库中选取部分组件, 并带有各个组件的默认配置数据.

如上图所示, 页面组件库中有组件A, 组件B, 组件C, 组件D, ..., 组件X等. 页面模板一由组件库中的组件A, 组件B和组件C组成, 实现了一个完整的业务功能; 页面模板二由组件库中的组件A, 组件B和组件X组成, 完成另一个完整的业务功能.
页面由页面组件组合而成, 页面的编辑其实是对页面组件进行重新组合, 并编辑各页面组件的内容. 页面编辑包含2个部分: 编辑页面组件和编辑页面内容.
使用组件化的方式来组织页面, 页面可以认为是一棵组件树, 如下图所示, 树中的节点为页面组件, 页面组件可以包含子组件.

在代码编写上, 通过组件标签的组合来声明一棵组件树, 并在打包时生成页面资源, 在运行时加载页面资源渲染出页面.
react 和 vue 的组件树声明示例:

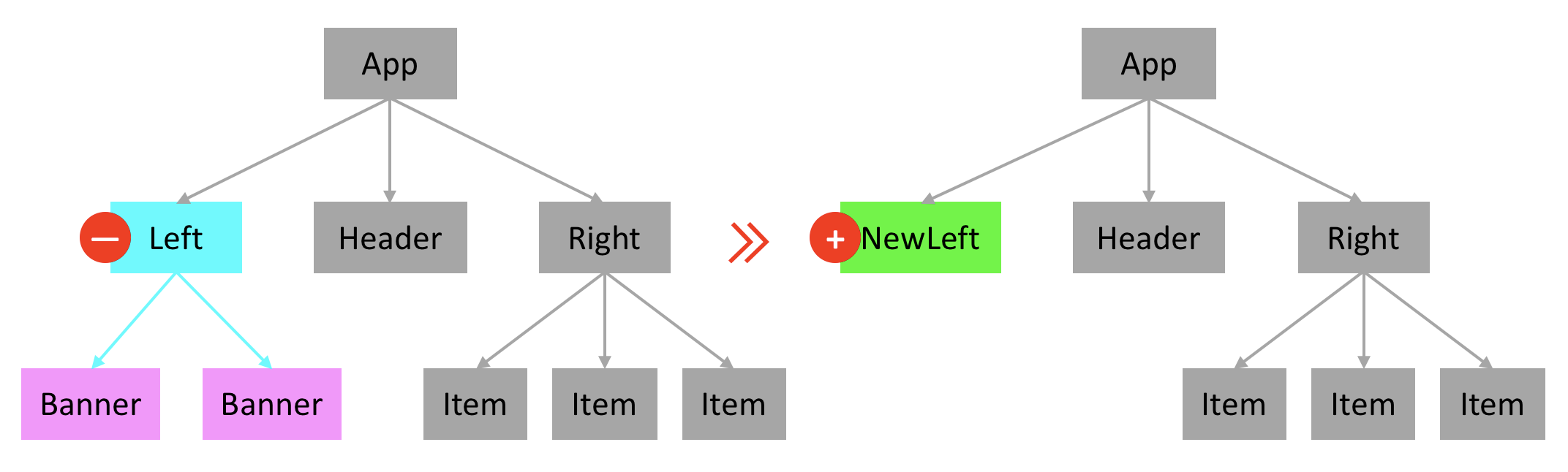
编辑页面组件的一个可行方式是: 动态地给页面源码添加组件, 然后重新打包生成页面. 如通过可视化的方式替换 Left组件 为 NewLeft组件 后, 对源码的组件树声明做替换, 将 Left 标签替换为 NewLeft 标签.

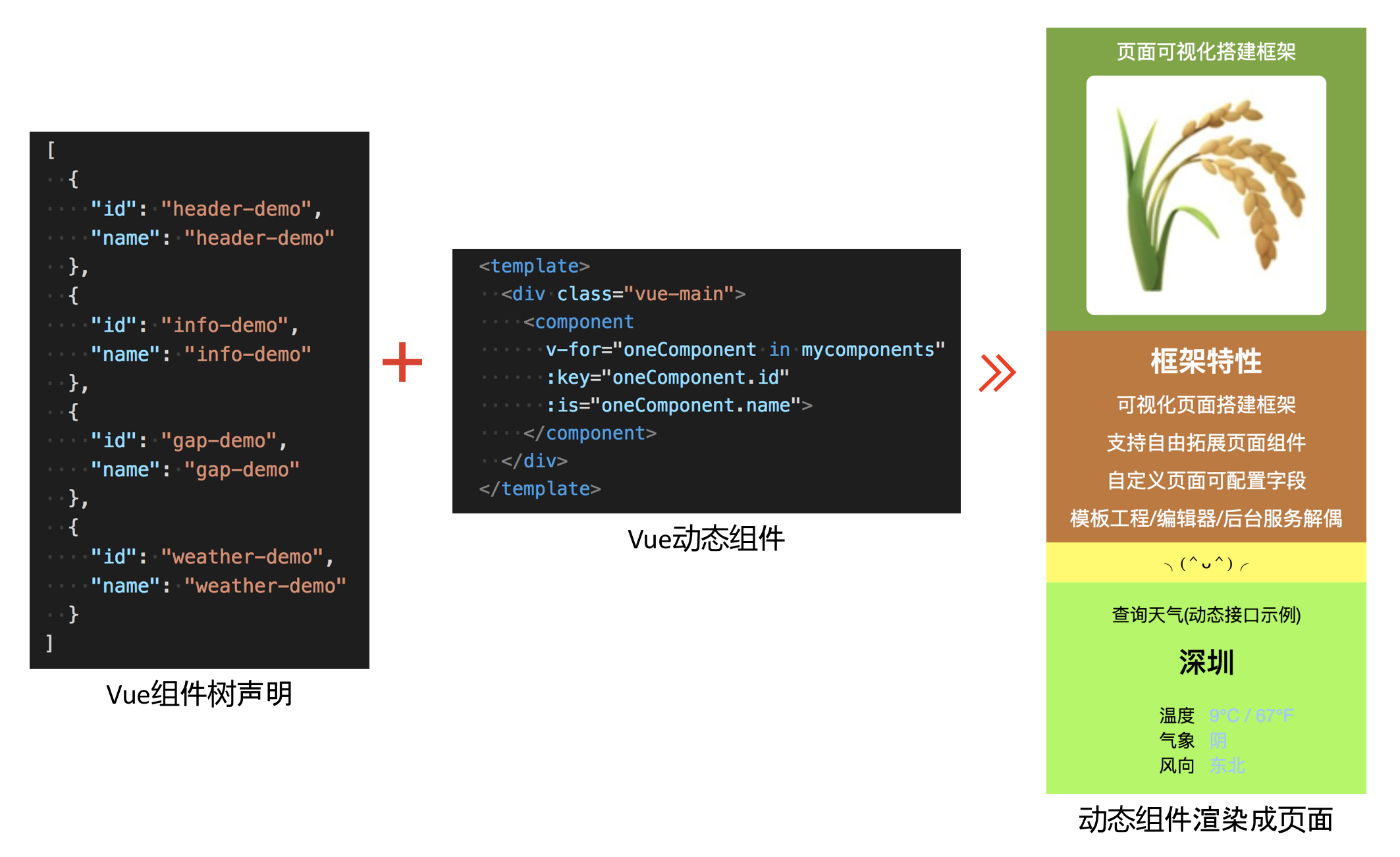
一些前端框架支持动态组件, 可以根据组件树声明动态渲染出组件, 而无需在构建前就定义好页面的组件树结构. 对动态组件页面实现可视化组件编辑时, 可以只编辑组件树声明文件, 然后将组件树声明传入提前打包好的页面中进行渲染. 采用动态组件可以避免重新打包的耗时, 快速生成新页面.
Vue 根据组件树声明动态地渲染组件示例如下图, vue 动态组件使用 compontent 关键字来声明, 并通过 is 属性来决定实例化的具体组件. 对于 react, 组件是一个 js 对象, 直接在 jsx 中按照组件名称返回对应组件就可以了.
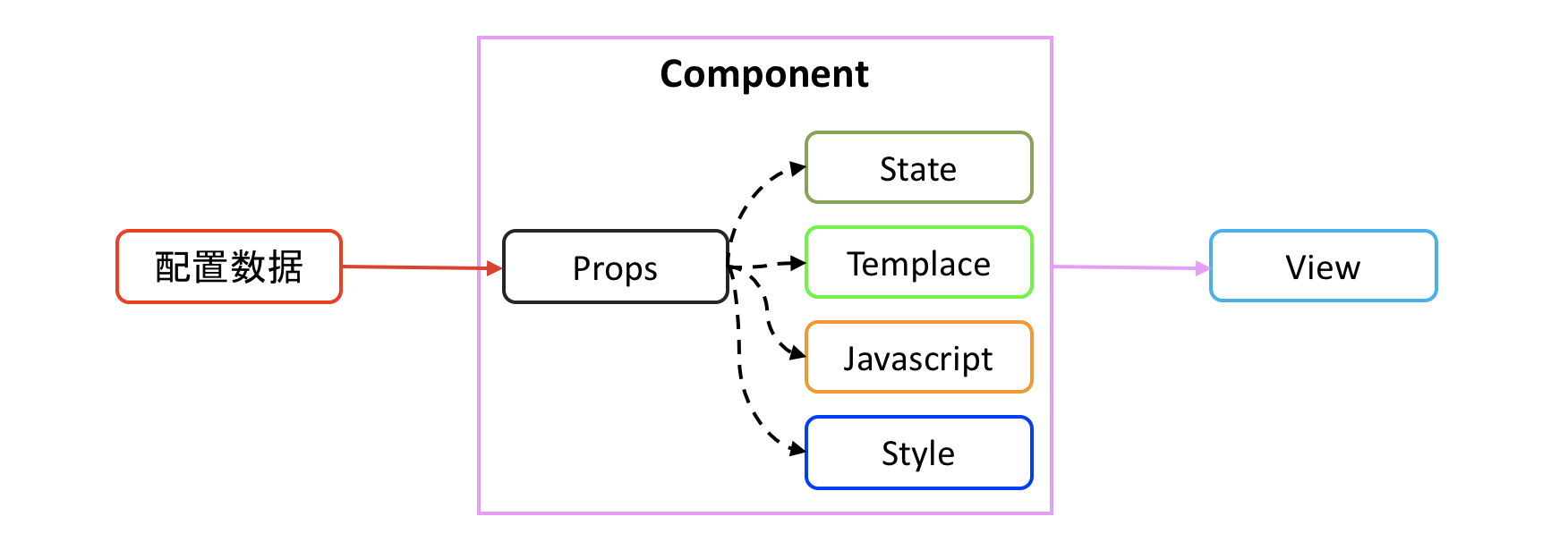
组件化页面的页面内容编辑, 是对页面中各个组件的组件属性(Props)进行配置.
一个组件包含组件属性(Props), 组件状态(State), 组件HTML模板(Template), 组件业务逻辑(Javascript), 组件样式布局(Style)等几个部分.
组件的配置数据通过组件暴露的 Props 注入到组件中, 在组件内部 Props 作为常量分发给 State, Template, Javascript, Style 等其他组件内容, 由组件内容渲染出视图.
组件是业务内容的呈现载体, 不同的业务内容, 封装在不同的业务组件中. 所以页面模板中的组件是差异化的, 差异点体现在组件的 Props, State, Template, Javascript, Style 等组件内容上. 在编辑不同组件内容时, 组件配置数据的数据结构是也是差异化的.
如下图示的页面包含3个组件: 头部组件, 间隔区组件和天气组件. 头部组件的配置数据为头部标题和头部图片等; 间隔去组件的配置数据为间隔提示文本等; 天气组件的配置数据为城市名称. 不同的组件需要不同的配置数据.
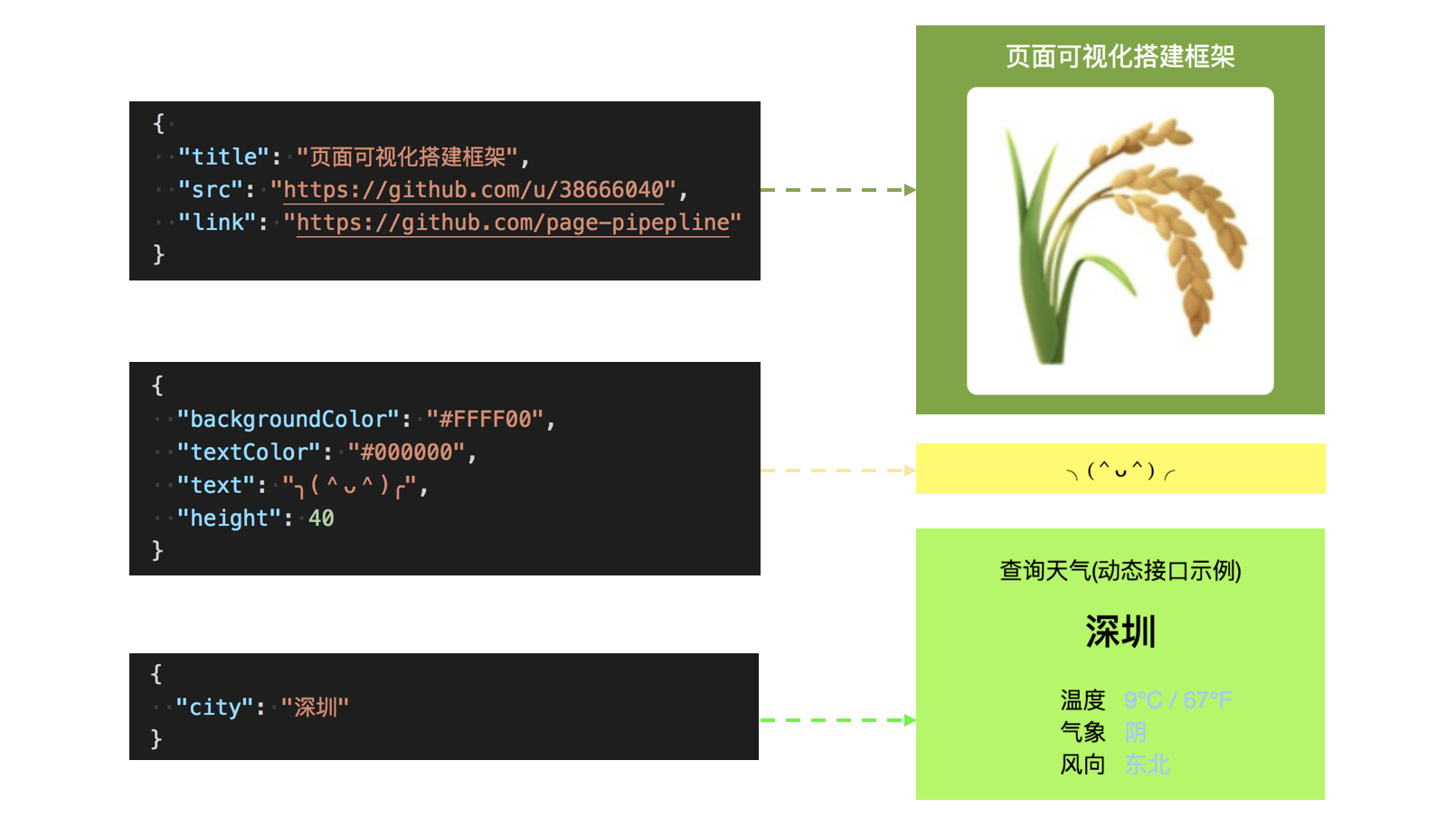
需要为各组件差异化的配置数据定义数据结构和字段类型, 理想的配置数据格式为 JSON, 因为其格式灵活, 支持数据嵌套, 且前端友好.
页面可视化搭建工具的主要使用人员是运营/产品, 如果让运营/产品人员直接编辑文本格式的组件配置数据, 操作不友好并且容易出错. 需提供可视化的编辑方式 -- 使用 Form 表单来填入配置数据. Form 表单是页面中数据交互的基本形式, 非开发人员使用也没有技术门槛. 使用配置表单来填入配置数据有2个好处:

如上图所示, 由于组件配置数据的差异化, 组件配置表单也是差异化的, 需为组件库中的每个组件提供相应的配置表单. 如果为每个组件都编写一个表单页面, 工作量较大; 对于复杂的配置项, 表单页面的编写工作量可能会大于页面组件的开发工作量. 需要重点考虑提供配置表单的方式.
技术难点2: 如何用最简单的方式生成配置数据编辑表单.
组件树定义了组件间父子兄弟的层级关系, 父子组件通过数据流和事件进行关联: 数据从父组件的 State 传递到子组件的 Props; 子组件的变更触发 Event 通知父组件.
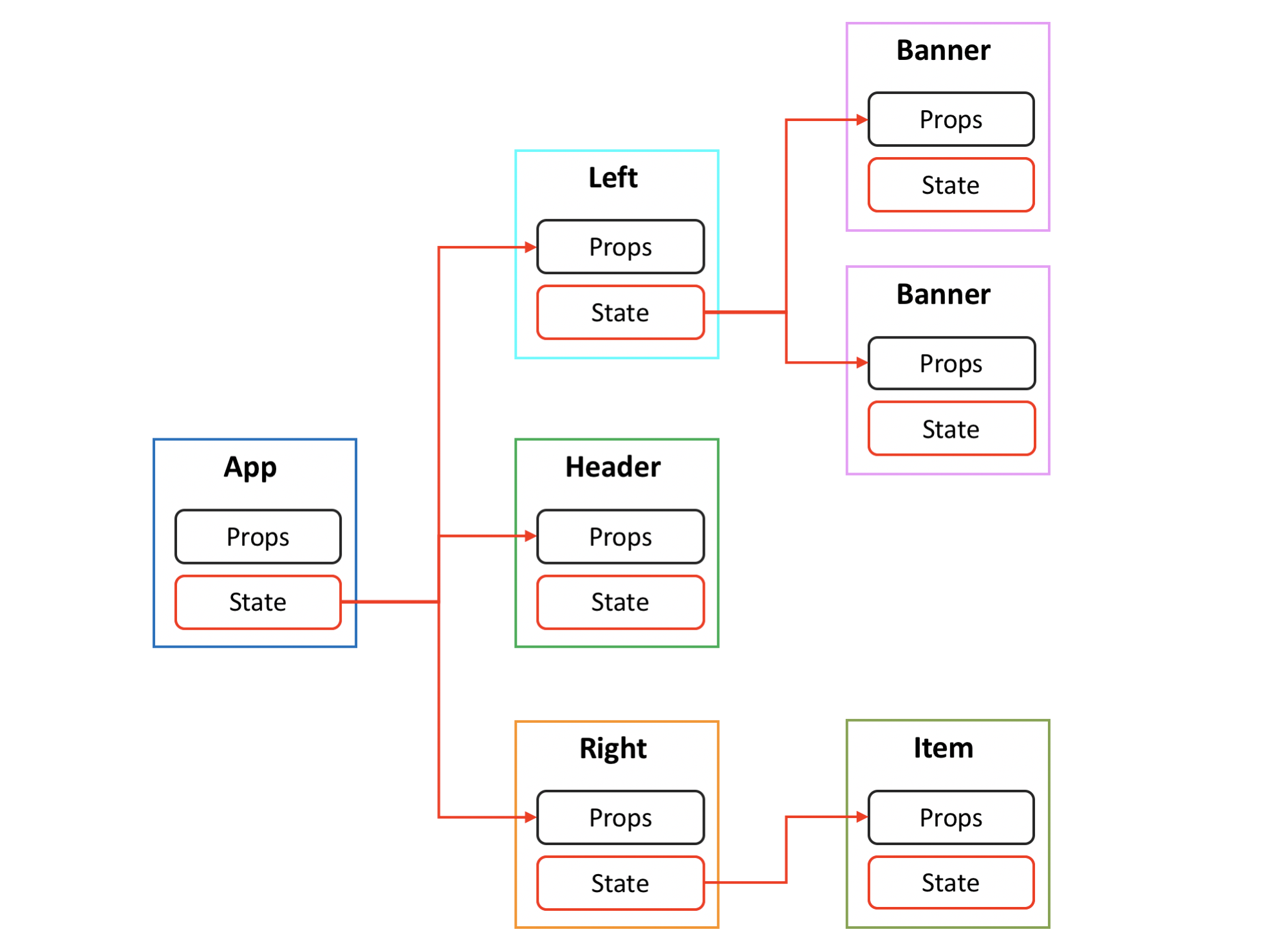
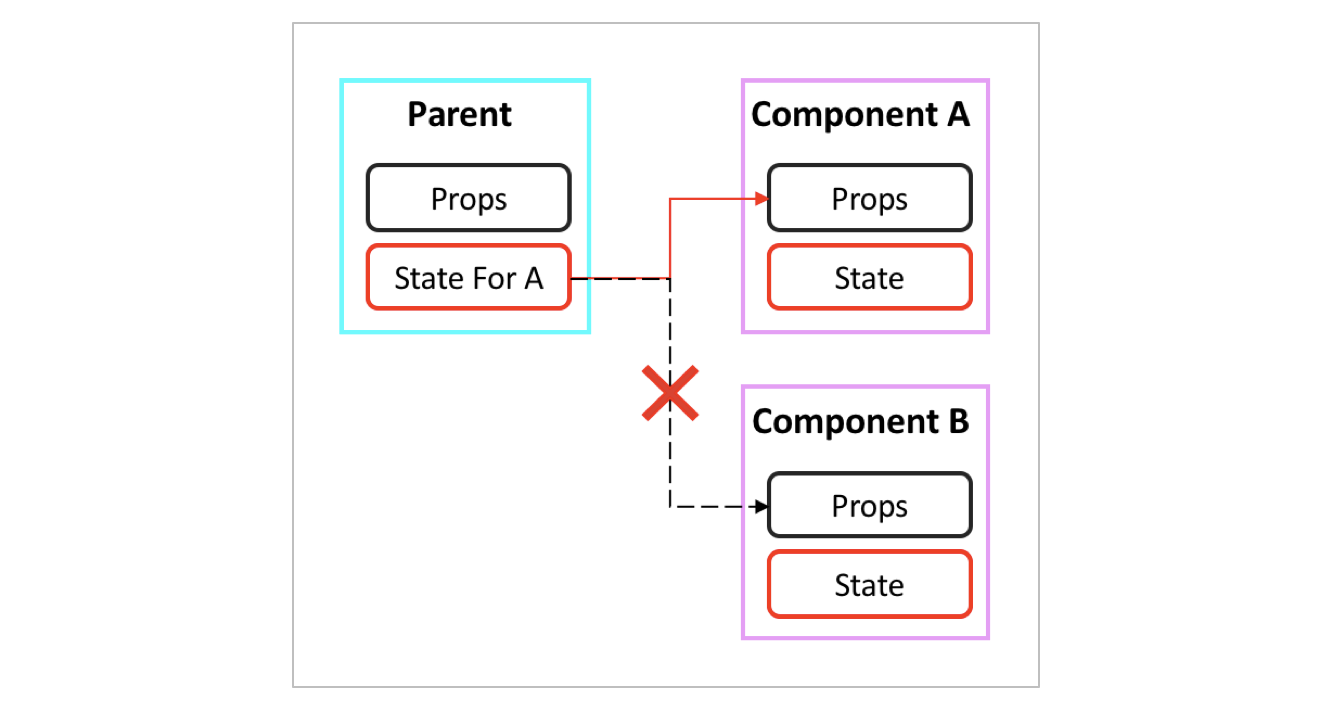
页面可视化搭建工具编辑组件树时, 会修改组件数据流. 而不同组件的 Props 和 State 是异构的, 在编辑组件树时, 需要处理不同组件产生层级关系后对数据流的影响. 如下图, 父组件的 State 只包含子组件A的 Props, 将子组件B挂载为父组件的子组件, 父组件没有子组件B的 Props, 会导致无法渲染子组件B.
同理, 不同的组件有不同的样式布局, 编辑组件树时, 需要处理不同组件产生层级关系后带来的布局影响.

图片来源: https://alligator.io/react/using-this-props-children/
如下图, 一个父组件为行内组件, 给其添加一个块级组件作为子组件, 渲染后可能会导致行内组件被块级组件撑开.

所以设计页面可视化搭建工具的组件树编辑功能时, 需要重点关注组件树的层级关系, 解决组件间数据依赖和组件间布局适配问题. 页面可视化搭建工具需要制订组件嵌套的规则和约束, 通过组件嵌套规则来确保可视化编辑后的组件树正常渲染.
技术难点3: 如何组织页面组件的层级关系.
使用组件嵌套的搭建工具示例:

图片来源: https://github.com/jaweii/Vue-Layout
可以想象, 组件的嵌套会加大页面可视化搭建工具的架构设计和开发难度.
我们注意到, 营销活动的主要平台是移动端, 移动端页面的常用的布局策略是: 宽度铺满, 高度滚动. 如果前端框架组件都设置为铺满宽度, 页面展示时组件只需在浏览器垂直方向上顺序排列, 则组件组合时不需要嵌套 -- 所有组件互为兄弟节点.
这种铺满页面宽度的组件, 非常适合搭建移动端页面的场景: 在承载页面逻辑的同时, 使得页面的编辑更加简单, 使用者只需处理组件的顺序, 无需处理组件的嵌套.
在移动端, 使用非嵌套组件层级规则的页面可视化搭建工具有: 阿里云凤蝶、pipeline 等.
阿里云凤蝶图示:
可视化搭建PC端中后台系统页面的工具, 同样可以采用不嵌套组件层级规则, 如阿里的飞冰:

页面实时预览是页面可视化搭建工具的必要部分, 使用人员可以在通过页面预览来查看和验证可视化编辑的效果.
页面预览示例:
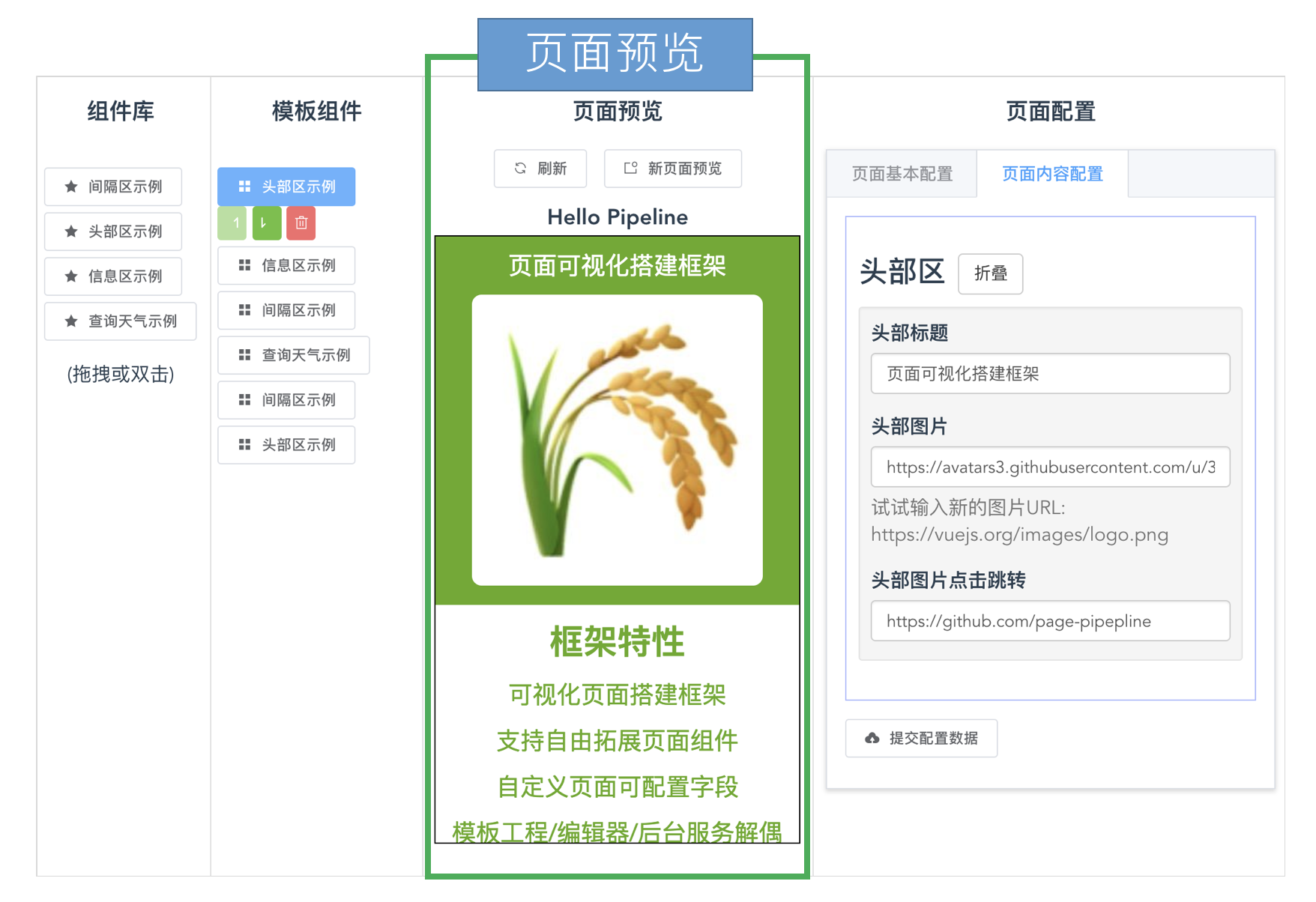
用户的可视化编辑包括修改组件树和修改组件配置数据. 如下图, 用户修改页面后, 需要重新渲染页面组件, 得到新的预览页面.
实现页面预览有两种方式: 页面挂载和后台渲染.
页面挂载指在编辑器前端页面的某个元素节点(div)上渲染出用户编辑的效果. 页面挂载流程图如下:

使用页面挂载的预览方式, 编辑器前端页面需要提供组件库组件渲染环境(组件库前端框架); 为实现前端渲染, 编辑器前端源码需引入组件库组件源码, 后续组件库更新, 编辑器需要同步更新. 页面挂载方式有以下特点:
后台渲染指在后台进行用户编辑结果页面的渲染和生成, 编辑器前端页面通过 iframe 加载和展示结果页面. 后台渲染流程图如下:

使用后台渲染的预览方式, 编辑器前端页面并不需要渲染组件库的组件; 甚至不需要组件源码, 只需知道各个组件的描述信息. 后台渲染有以下特点:
难点4: 如何实现组件库的快速后台渲染, 从而实现编辑器和组件库前端框架的分离.
页面构建是组件化前端源码生成页面资源的必要环节: 在开发时需要进行开发构建来进行页面调试; 在可视化编辑后可能需要重新构建来生成预览页面; 在发布前需要进行生产构建.
在可视化搭建页面时需要“实时”预览, 要求页面页面构建效率高, 实现快速的构建和打包. 更进一步, 后台渲染其实和服务端渲染很像, 能否借鉴服务端渲染的技术思路.
页面可视化搭建工具在业务中的落地, 需要根据不同的业务场景进行业务组件和页面模板的自定义开发. 这对页面可视化搭建工具提出3个要求:
页面可视化搭建工具要支持业务现有的前端框架.
避免后续组件和模板自定义开发时的工作量和割裂感. 我们是希望复用现有前端框架组件, 而不是用另一个前端框架重写一遍.
组件和模板的编写方式需遵循较简单的编写约定, 避免开发人员难上手和写起来不舒服.
自定义模板和组件和在开发模式下进行调试和测试.
页面可视化搭建工具必然会对页面模板和页面组件的编码方式进行限定. 这要求就页面可视化工具在页面模板和页面组件上的约束较少, 减少对前端框架代码组织方式的入侵点.
页面可视化搭建工具, 需要对页面做一些约定和约束, 在可视化搭建时遵循工具约定和约束来编辑页面. 从页面可视化搭建工具的技术要点中, 可以归纳出活动页面可视化搭建工具的理想形态.
页面可视化搭建工具有不同的框架设计和实现方式, 不同的功能有不同的适用场景, 详细分类可以参考笔者以前的文章: 页面可视化搭建工具前生今世.
运营页面搭建工具, 实现基于模板的页面生成; 将页面的逻辑功能封装在组件内, 声明页面配置数据并提供配置表单, 通过对配置表单的数据填充, 进行少量页面编辑就可以完成业务页面搭建.

在编辑自由度的选择上, 选用不嵌套的组件.各组件铺满页面宽度, 在页面高度方向顺序排列.解决组件嵌套带来的数据流问题. 不嵌套的组件如下图各个红框框起来的部分所示.

配置表单的作用是生成和约束 JSON 配置数据, 业界已有对 JSON 进行描述和自动生成表单的方案 -- JSON Schema. 按照 JSON Schema 规范对 JSON 数据进行描述, 可以动态渲染出配置表单; 且 JSON Schema 可以对编辑后的数据做格式校验, 避免编辑错误. 这比编写一个表单页面更加简单和高效.

图片来源: https://github.com/json-editor/json-editor
JSON Schema 的语法并不是很精简, 云凤蝶的 Schema 语法 等方案更简洁, 但是云凤蝶的语法没有开源的表单生成库支持, 在开源实践上还是 JSON Schema 最佳.
Pipeline 是一个开源的页面可视化搭建框架, 主要由笔者在维护. Pipeline 意为流水线, 期望 pipeline 像工厂流水线一样可以高效地组装活动页面.
所谓框架, 是它实现了页面可视化搭建的基本功能, 解决了页面可视化搭建的基本难点, 可以让开发者快速拥有页面搭建的能力, 并支持私有部署和二次开发.
项目信息:

如动图所示, pipeline 的可视化编辑能力有:

如动图所示, pipeline 的组件编辑能力有:
Pipeline 实现了编辑器和页面前端框架的分离, 可以支持不同的前端框架. 所谓支持的前端框架, 就是对某个前端框架按照 pipeline 的约束规则进行组件编辑方式和工程构建方式的改造, 使得前端框架页面可以在 pipeline 中可视化搭建.
目前已经支持 Vue, React, 和 Omi, 理论上可以支持任意前端框架.

阿里云凤蝶 是目前市场上可见中最棒的页面可视化搭建服务, pipeline 的很多方面和云凤蝶相似, 做个简单对比:
| 云凤蝶 | pipeline |
| 商业化解决方案, 直接可用 | 开源系统, 基础的页面搭建框架, 需要自行部署 |
| 生成的页面, 上传的图片等只能托管在阿里, 也限定域名 | 资源落地和周边功能需要自行搭建, 但是可以100%掌控所有资源 |
| 配置表单功能比较完善 | 配置表单比较基础, 需要提升 |
| 使用自定义的组件配置约束规则 | 使用通用的 JSON Schema 规范 |
| 模板前端框架采用 Nunjucks | 前端框架采用没有约束, 已经支持 vue 和 react 等, 业务迁移成本低 |
| 隐藏了模板的构建处理过程, 提供制定的 IDE | 采用 webpack 构建, 模板开发与正常前端项目开发一致 |
| 不支持自定义页面级别的配置项 | 支持自定义页面级别的配置项 |
总的来说: 云凤蝶是完整的商业化页面可视化搭建系统, 适合偏业务运营的公司; pipeline 是开源的页面可视化搭建框架, 适合需要自建页面可视化搭建系统且有技术人员支持的公司.
本文讨论了活动页面开发的痛点, 总结出页可视化搭建工具的7个技术要点和4个技术难点, 并整理出理想的运营页面可视化搭建工具, 最后介绍页面可视化搭建框架 pipeline.
行文仓促, 对页面可视化搭建话题或开源项目 pipeline 感兴趣, 欢迎讨论.
https://www.w3cplus.com/vue/component-data-and-props-part1.html
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.












{kind=link}