
Gym Trading Env is an Gymnasium environment for simulating stocks and training Reinforcement Learning (RL) trading agents. It was designed to be fast and customizable for easy RL trading algorithms implementation.
| Documentation |
This package aims to greatly simplify the research phase by offering :
- Easy and quick download technical data on several exchanges
- A simple and fast environment for the user and the AI, but which allows complex operations (Short, Margin trading).
- A high performance rendering (can display several hundred thousand candles simultaneously), customizable to visualize the actions of its agent and its results.
- (Coming soon) An easy way to backtest any RL-Agents or any kind
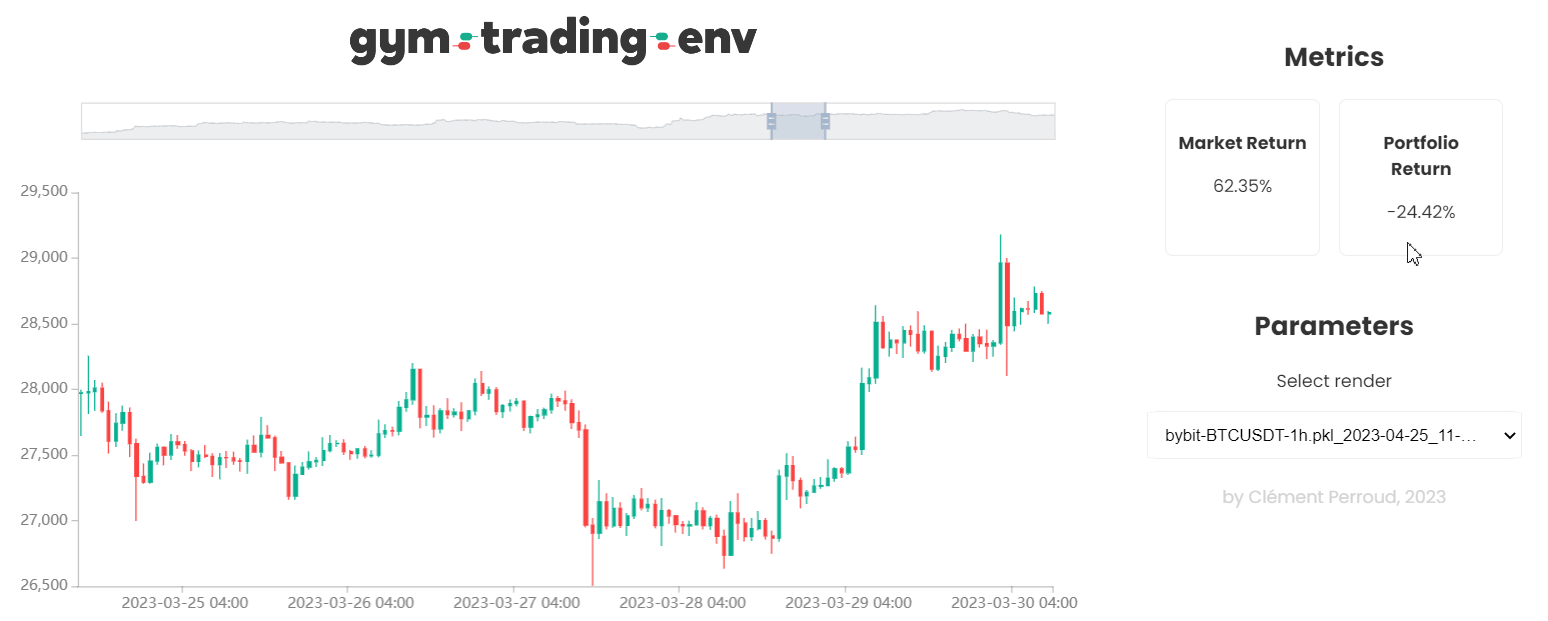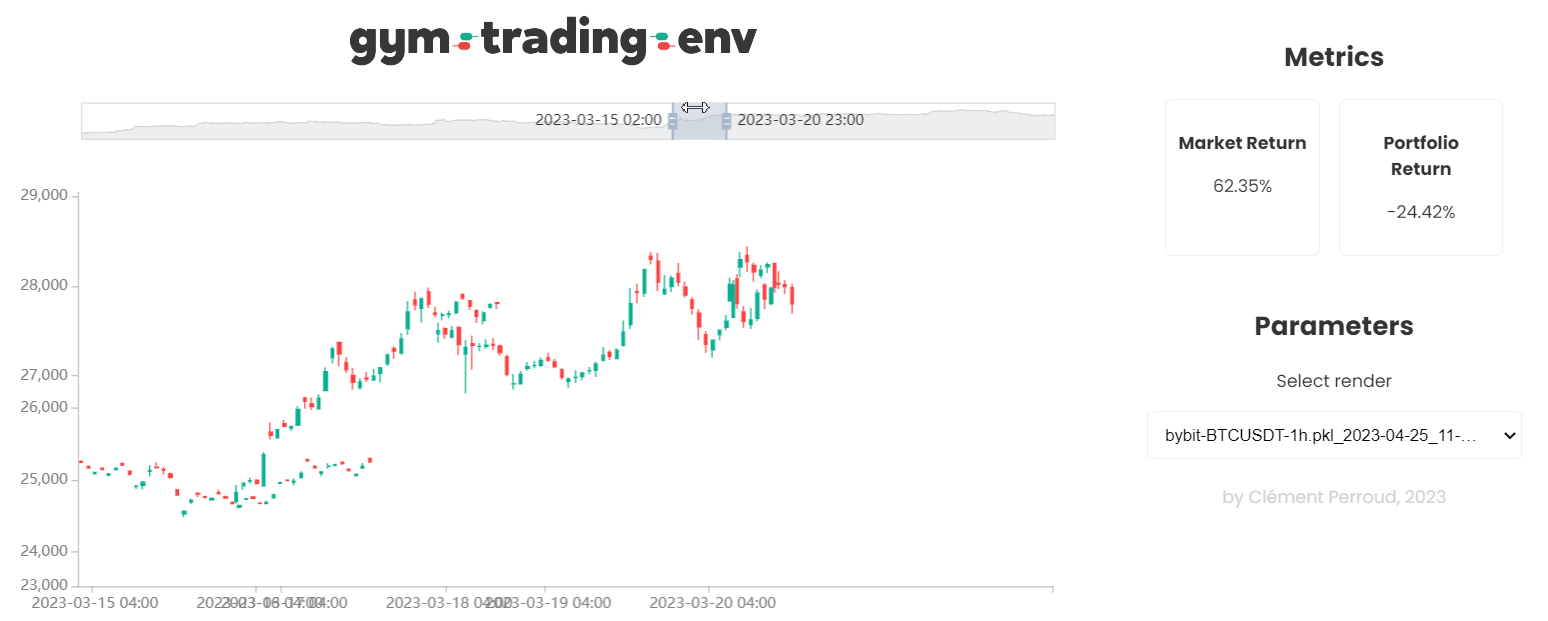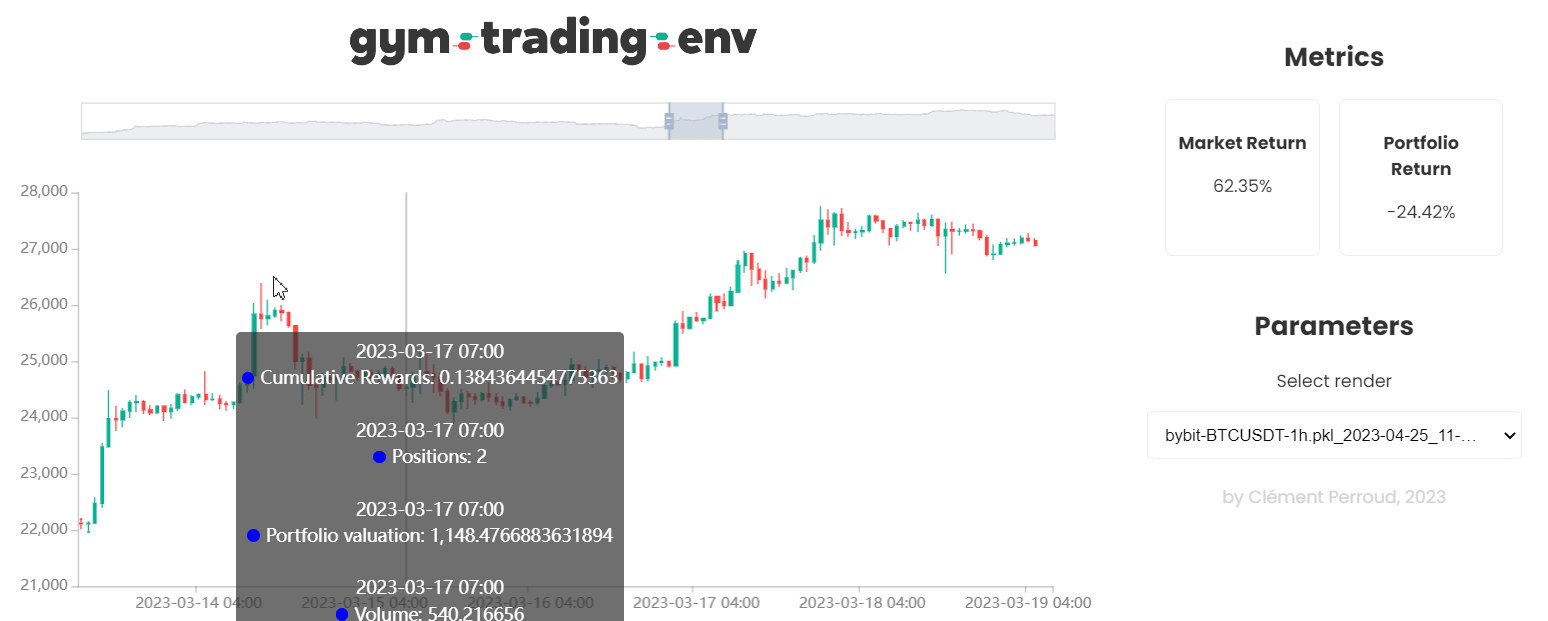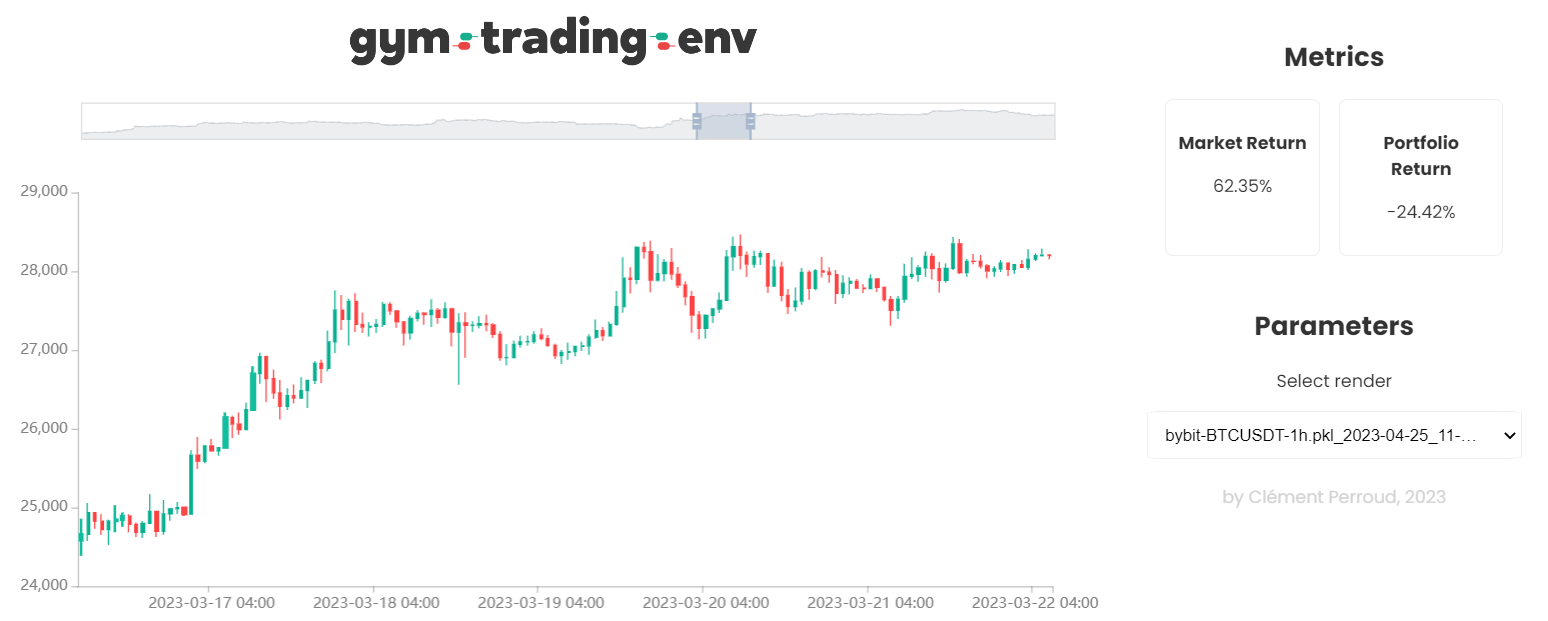
Gym Trading Env supports Python 3.9+ on Windows, Mac, and Linux. You can install it using pip:
pip install gym-trading-envOr using git :
git clone https://github.com/ClementPerroud/Gym-Trading-Env






















































































































