The CDRC Semantic Search System is a project designed to enhance the search capabilities of the Centre for Consumer Data Research (CDRC) data catalogue. The goal is to implement a semantic search approach that goes beyond traditional keyword-based searches, providing users with more accurate and relevant results.
-
Semantic Search: Embeds documents using OpenAI which are stored on Pinecone, allowing for semantic querying using cosine similarity.
-
Retrieval Augmented Generation: Generates responses using GPT 3.5 turbo to explain the relevance of retrieved datasets.
The CDRC Semantic Search System follows a standard Retrieval Augmented Generation (RAG) architecture:
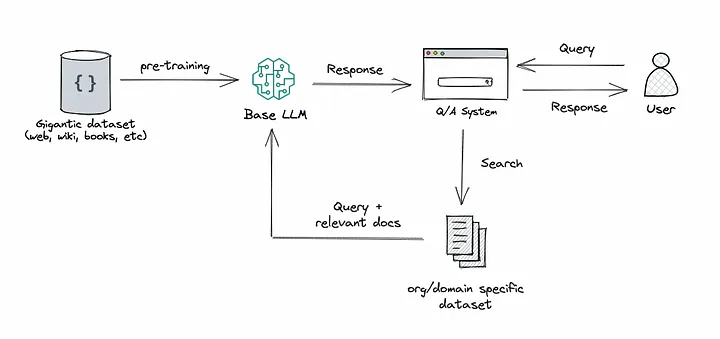
Credit to Heiko Hotz (https://towardsdatascience.com/rag-vs-finetuning-which-is-the-best-tool-to-boost-your-llm-application-94654b1eaba7)
To get started with the CDRC Semantic Search System, follow these steps:
-
Clone the repository:
git clone https://github.com/cjber/cdrc-semantic-search.git
-
Install dependencies:
With pip:
cd cdrc-semantic-search
pip install -r requirements.txtWith pdm:
cd cdrc-semantic-search
pdm install-
Configure the system:
Edit the
config/config.tomlfile to customize settings such as API keys, or model settings. -
Run the system using a DVC pipeline.
dvc repro
NOTE: This requires a Pinecone database and access to the CDRC catalogue.



