These are the introduction of the paper: Mean Teacher-based Cross-Domain Activity Recognition using WiFi Signals, IEEE Internet of Things Journal, 2023. https://ieeexplore.ieee.org/document/10066505.
WiTeacher aims at recognizing activities for cross-domain scenarios using WiFi Channel State Information (CSI).
@ARTICLE{WiTeacher2023,
author={Xiao, Chunjing and Lei, Yue and Liu, Chun and Wu, Jie},
journal={IEEE Internet of Things Journal},
title={Mean Teacher-based Cross-Domain Activity Recognition using WiFi Signals},
year={2023},
volume={10},
number={14},
pages={12787-12797},
doi={10.1109/JIOT.2023.3256324}
}
The two public datasets used in the paper are shown below.
The data that we extract from raw CSI data for our experiments can be downloaded from Baidu Netdisk or Google Drive:
Data of CSI amplitudes: Data_CsiAmplitudeCut Baidu Netdisk: https://pan.baidu.com/s/12DwlT58PzlVAyBc-lYx1lw (Password: k8yp) or Google Drive: https://drive.google.com/drive/folders/1PLzV6ZWAauMQLf08NUkd5UeKrqyGMHgv
Manually marked Labels for CSI amplitude data: Label_CsiAmplitudeCut Baidu: https://pan.baidu.com/s/1nY5Og4NlLb7VH5oBQ-LH9w (Password: xnra) or Google: https://drive.google.com/drive/folders/1855zX-93QjmAt2wSeJk0rTJRiPaFMGBd (1 boxing; 2 hand swing; 3 picking up; 4 hand raising; 5 running; 6 pushing; 7 squatting; 8 drawing O; 9 walking; 10 drawing X)
Also the raw CSI data we collected can be downloaded via Baidu or Google: Data_RawCSIDat. Note that there is no need to download the raw CSI data for running our experiments. Downloading Data_CsiAmplitudeCut and Label_CsiAmplitudeCut is enough for our experiments. Baidu: https://pan.baidu.com/s/1FpA2u_fzFIh4FuNIcWOPdQ (Password: hhcv) or Google: https://drive.google.com/drive/folders/1vUeJYChsDgBzv7bJbiKDEfAHQje3SW9G
The SignFi dataset comes from the link below: https://github.com/yongsen/SignFi
Despite of significant success of these methods, there still exist some shortages. First, few-shot learning-based methods still need a few labeled samples from the terminal users. But collecting a few labeled samples is still difficult, especially for old terminal users. Second, data augmentation-based methods generally consider all the generated data to possess the same quality. However, GANs are typically unstable and prone to failure, and correspondingly generated samples may exhibit various levels of quality, i.e., some may be like real samples and others may be quite noised. Third, existing methods only consider each sample separately during model training, and ignore the relationships between samples, which can be explored to enhance model robustness.
To address these issues, we present a Mean Teacher-based cross-domain activity recognition framework using WiFi CSI.
In WiTeacher framework, we designed a adaptive label smoothing method to produce proper soft labels for target-like samples generated by StyleGAN. Based on these target-like samples with soft labels, we built a label smoothing-based classification loss to promote the generalization capacity of the model. Further, we presented a sample relation-based consistency regularization term to force the distance of two samples to be consistent with the augmented ones, which can make the model more robust.
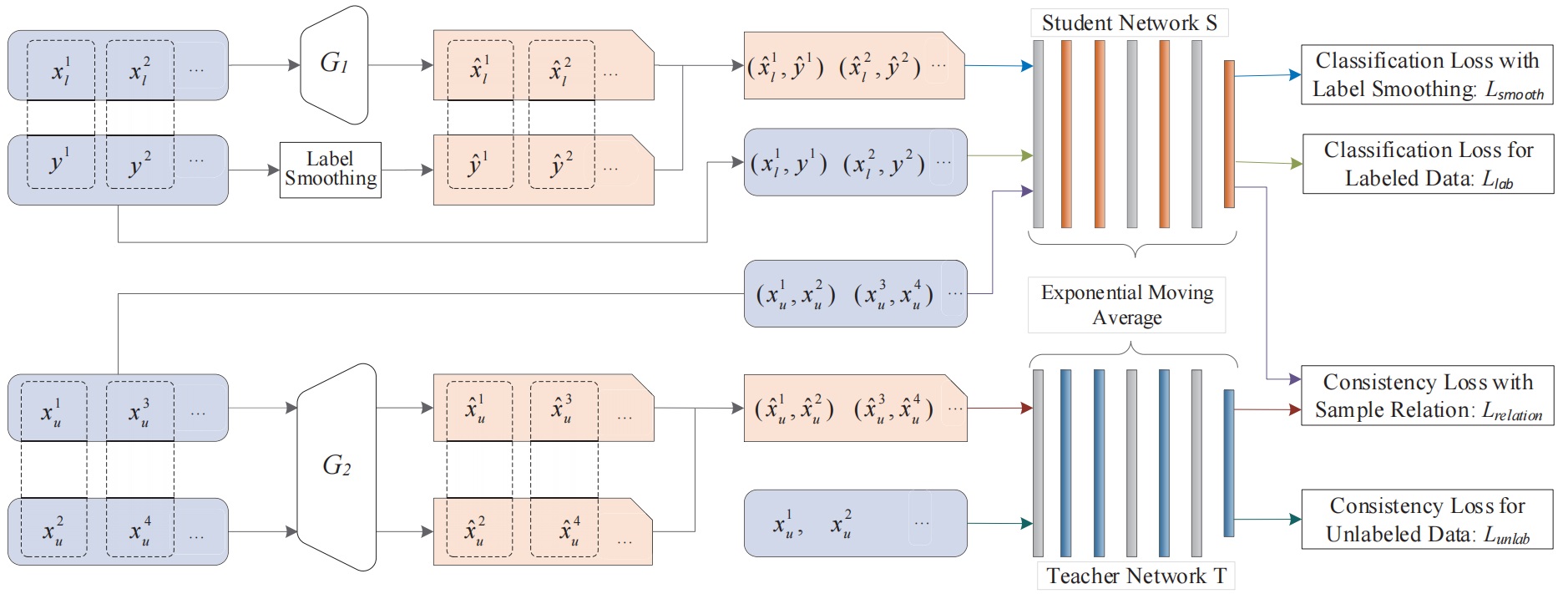
Figure 1. WiTeacher Framework.
Figure 1 presents an illustration of how the proposed framework works.
Here (












