
An intuitive UI for managing data, for users of all technical skill levels. Built on Postgres.



Website • Docs • Live Demo • Matrix (chat) • Discord • Wiki
Mathesar is a straightforward open source tool that provides a spreadsheet-like interface to a PostgreSQL database. Our web-based interface helps you and your collaborators work with data more independently and comfortably – no technical skills needed.
You can use Mathesar to build data models, enter data, and even build reports. You host your own Mathesar installation, which gives you ownership, privacy, and control of your data.
Table of Contents
- Sponsors
- Status
- Join our community!
- Screenshots
- Live Demo
- Features
- Self-hosting
- Our motivation
- Contributing
- Bugs and troubleshooting
- License
Our top sponsors! Become a sponsor on GitHub or Open Collective.

Thingylabs GmbH |
- Public Alpha: You can install and deploy Mathesar on your server. Go easy on us!
- Public Beta: Stable and feature-rich enough to implement in production
- Public: Production-ready
We are currently in the public alpha stage.
The Mathesar team is on Matrix (chat service). We also have mailing lists and the core team discusses day-to-day work on our developer mailing list.
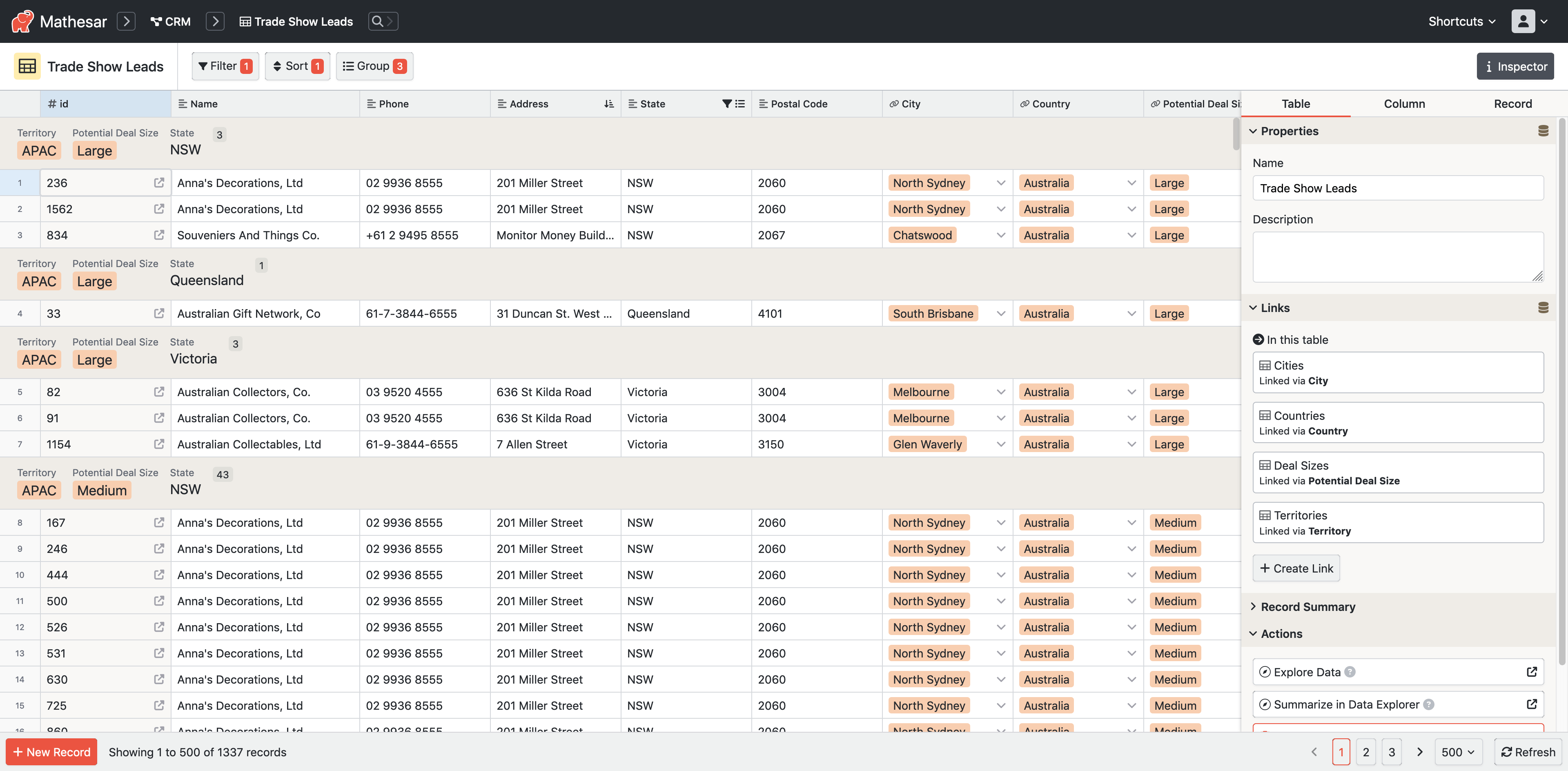
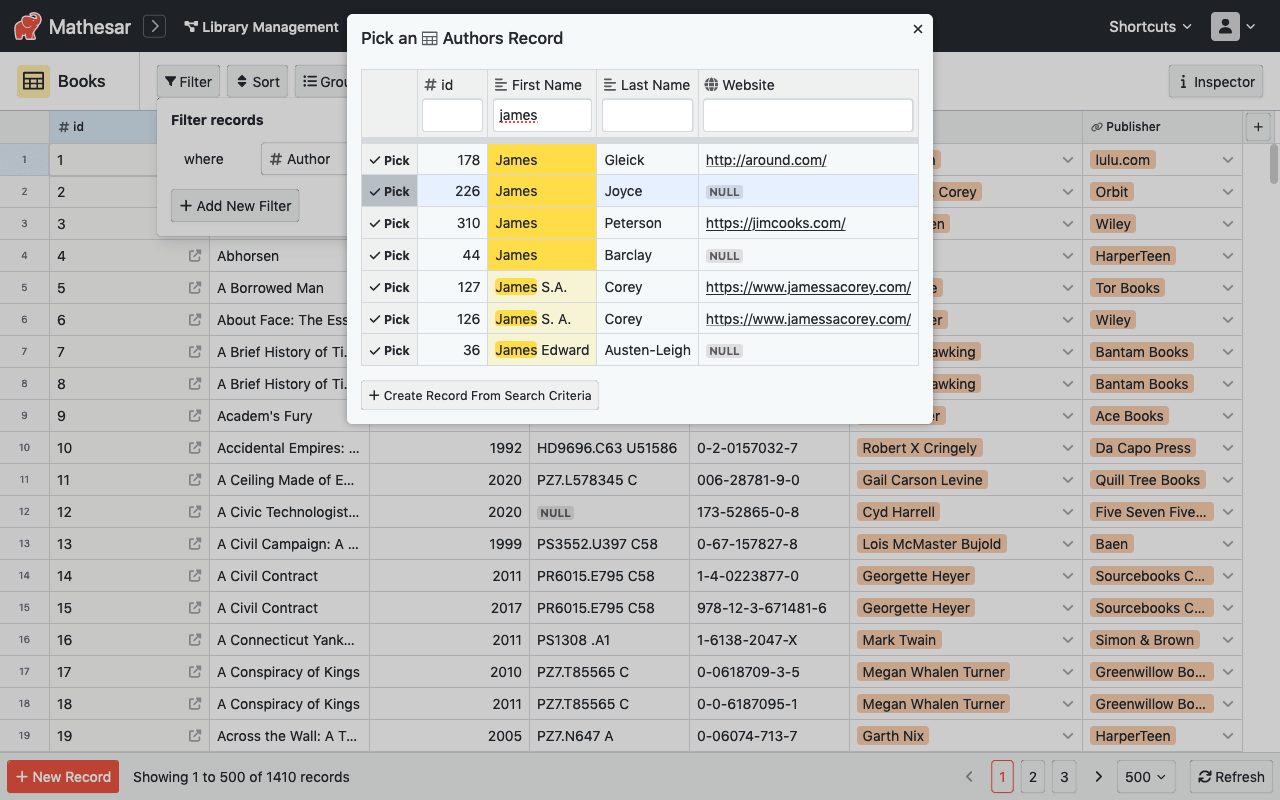

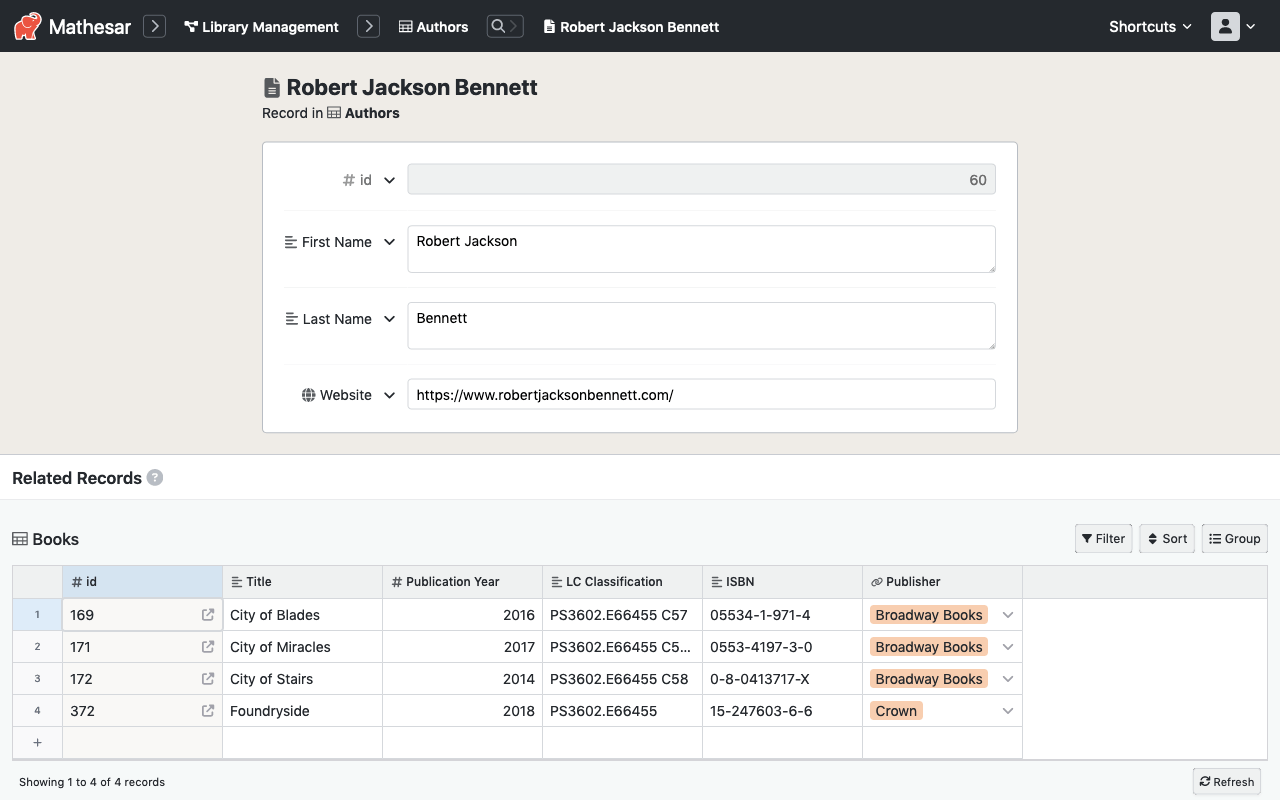
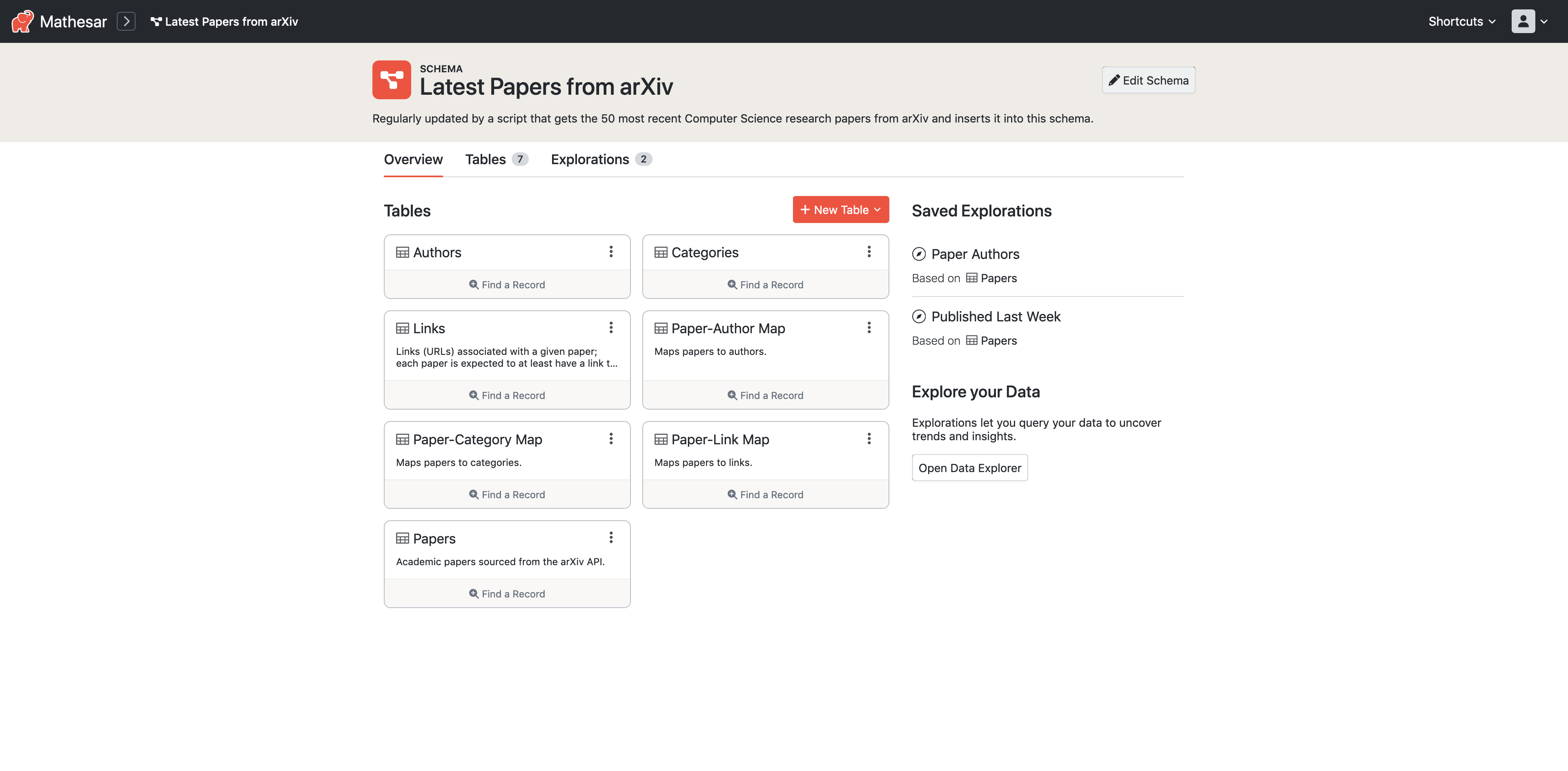
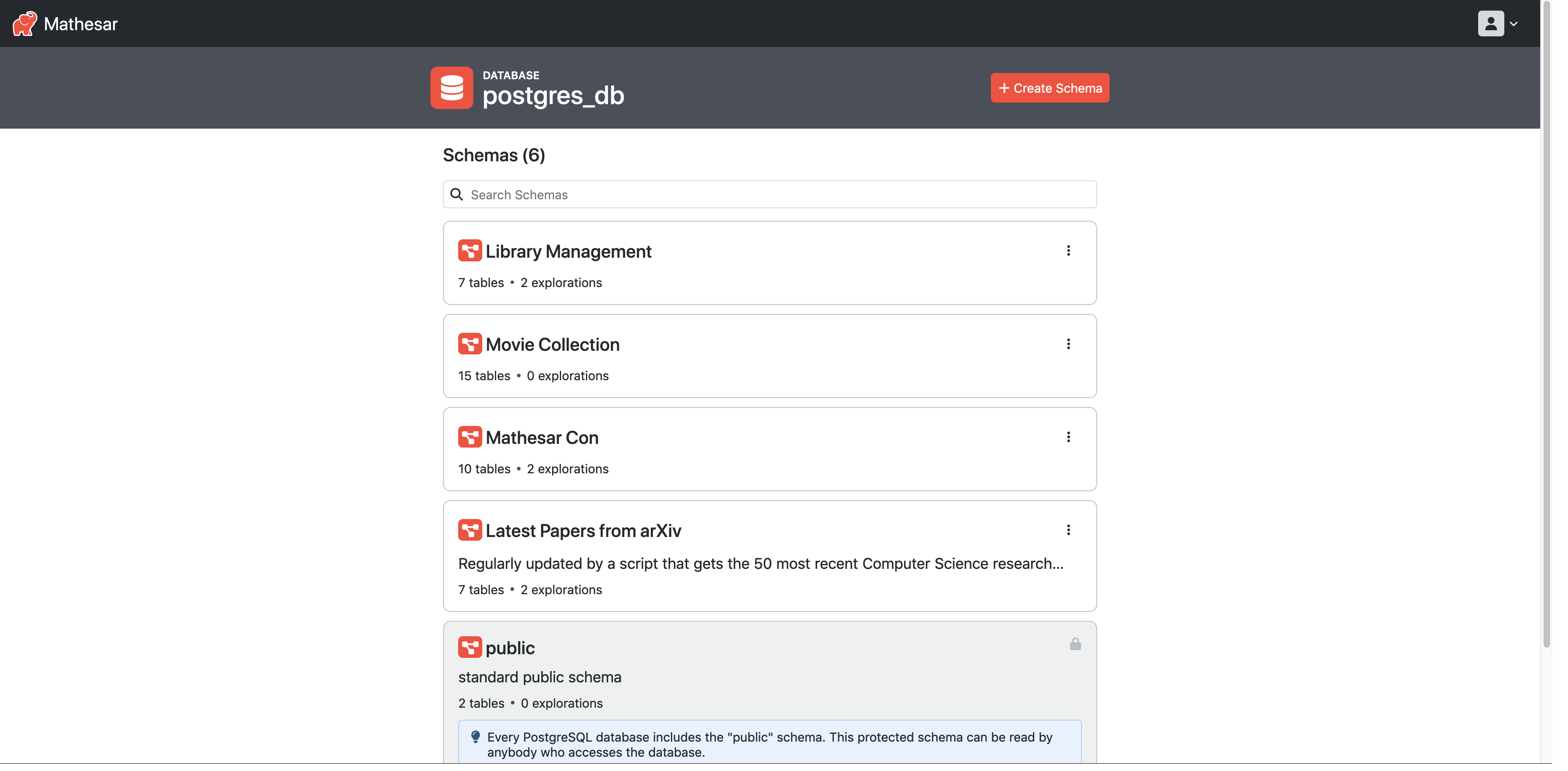
Check out a live demo of Mathesar here!
- Built on Postgres: Connect to an existing Postgres database or set one up from scratch.
- Set up your data models: Easily create and update Postgres schemas and tables.
- Data entry: Use our spreadsheet-like interface to view, create, update, and delete table records.
- Filter, sort, and group: Quickly slice your data in different ways.
- Query builder: Use our Data Explorer to build queries without knowing anything about SQL or joins.
- Schema migrations: Transfer columns between tables in two clicks.
- Uses Postgres features: Mathesar uses and manipulates Postgres schemas, primary keys, foreign keys, constraints and data types. e.g. "Links" in the UI are foreign keys in the database.
- Custom data types: Custom data types for emails and URLs (more coming soon), validated at the database level.
- Basic access control: Users can have Viewer (read-only), Editor (can only edit data, but not data structure), or Manager (can edit both data and its structure) roles.
Please see our documentation for instructions on installing Mathesar on your own server.
Mathesar is a non-profit project. Our goal is to make understanding and working with data easy for everyone.
Databases have been around for a long time and solve common data problems really well. But working with databases often requires custom software. Or complex tooling that people struggle to get their heads around.
We want to make existing database functionality more accessible, for users of all technical skill levels.
We actively encourage contribution! Get started by reading our Contributor Guide.
If you run into problems, refer to our troubleshooting guide.
Mathesar is open source under the GPLv3 license - see LICENSE. It also contains derivatives of third-party open source modules licensed under the MIT license. See the list and respective licenses in THIRDPARTY.































































































































