blue-yonder / tsfresh Goto Github PK
View Code? Open in Web Editor NEWAutomatic extraction of relevant features from time series:
Home Page: http://tsfresh.readthedocs.io
License: MIT License
Automatic extraction of relevant features from time series:
Home Page: http://tsfresh.readthedocs.io
License: MIT License


































































































































































































































tsfresh.examples.robot_execution_failures.download_robot_execution_failures()
got error
"Permission denied: '/usr/local/lib/python2.7/site-packages/tsfresh/examples/data'"
i have to manually sudo mkdir folder and sudo wget http://archive.ics.uci.edu/ml/machine-learning-databases/robotfailure-mld/lp1.data to folder '/usr/local/lib/python2.7/site-packages/tsfresh/examples/data/robotfailure-mld/ " to makedf, y = load_robot_execution_failures() working .
Hi,
I have 400,000 time series, each of length 1,000.
Each time series has a class 0 or 1 (binary classification problem). The dataset is balanced between 0 and 1
I have created my own features (min,max,sd,var,linear regression) on different time length of the time series (50,100,200,300,400,500,600,700,800,900,1000), which cam out to be 900 features.
I have ran the 900 features in grid search with CART (decision tree).
The best accuracy I got was 0.56 or so.
Can tsfresh be used (and hopefully get a much better job). If so, how ?
This is a real life problem, lets see how tsfresh handles it (vs other methods)
in notebook , robot_failure_example.ipynb ,
X_filtered = extract_relevant_features(df, y, column_id='id', column_sort='time')
had error of
"ValueError: Column a__autocorrelation__lag_8 of dataframe must not contain NaN values "
I want to extract features from a rolling window of a table with columns of several timeserieses and do some prediction based on the timeseries in that window.
Currently, as far as I understand the doc. I have to extract the timeseries and tile them like in the example, so there would be a lot of duplicate data because the rolling window and doesn' t seem memory efficient. Is there a rolling window API or better ways to do it?
Thanks!
Currently our test cases only use integer data sets. We should add tests using data sets containing floats, NaNs and +/-Infs as well as data sets of length 1.
The repo description "Automatic extraction of relevant features from time series: http://tsfresh.readthedocs.io. " , there should be a space before the last dot or the url won' t open correctly.
We can use our @set_property( decorator to give the feature calculators objects properties.
This can be for example used to classify fast calculators such as @set_property("minimal", True). We could use such properties to classify our feature calculators even further. For example we could denote calculators that are "time independent" or that are "medium costly" or highly "highly costly".
This issue should be a starting point for a discussion.
When selecting features we assume the classification case only when the target is binary:
target_is_binary = len(set(y)) == 2Otherwise we assume the regression case.
So for a multiclass target the user has to perform a binary one versus rest classification. We should provide an example how to efficiently do that using tsfresh, i.e.:
Can I just confirm that in terms of the DataFrame passed to extract_features, the
DataFrame columns must be named with a string or at least > 0 digit?
The document indeed demonstrates named columns in all the DataFrame examples,
however it does not specifically say that the DataFrame cannot be default
0-indexed and perhaps there is a good reason for that.
This is easily worked around by naming the columns as per all the DataFrame examples and resolves this e.g.:
df.columns = ['metric', 'timestamp', 'value']
df_features = extract_features(df, column_id='metric', column_sort='timestamp', column_kind=None, column_value=None)
But just for clarification, I am constructing a single timeseries Flat DataFrame with just the default
pandas df indexing
0 1 2
0 stats.statsd.bad_lines_seen 1478736060 0.000000
1 stats.statsd.bad_lines_seen 1478736120 0.000000
2 stats.statsd.bad_lines_seen 1478736180 0.000000
And then passing extract_features the following parameters:
df_features = extract_features(df, column_id=0, column_sort=1, column_kind=None, column_value=None)This causes the following error:
ValueError Traceback (most recent call last)
<ipython-input-21-65f3bdeb4c3b> in <module>()
5
6 from tsfresh import extract_features, extract_relevant_features, select_features
----> 7 df_features = extract_features(df, column_id=0, column_sort=1, column_kind=None, column_value=None)
/opt/python_virtualenv/projects/tsfresh-py2712/lib/python2.7/site-packages/tsfresh/feature_extraction/extraction.pyc in extract_features(timeseries_container, feature_extraction_settings, column_id, column_sort, column_kind, column_value)
67 kind_to_df_map, column_id, column_value = \
68 dataframe_functions.normalize_input_to_internal_representation(timeseries_container, column_id, column_sort,
---> 69 column_kind, column_value)
70
71 # Use the standard setting if the user did not supply ones himself.
/opt/python_virtualenv/projects/tsfresh-py2712/lib/python2.7/site-packages/tsfresh/utilities/dataframe_functions.pyc in normalize_input_to_internal_representation(df_or_dict, column_id, column_sort, column_kind, column_value)
260 raise ValueError("You have NaN values in your id column.")
261 else:
--> 262 raise ValueError("You have to set the column_id which contains the ids of the different time series")
263
264 # Either the column for the value must be given...
ValueError: You have to set the column_id which contains the ids of the different time series
And having poked around it is not that simple as utilities/dataframe_functions.py
will always raise ValueError if column_id = 0
>>> column_id = 0
>>> if column_id:
... print(column_id)
... else:
... print('fail')
...
fail
>>>And even if that is changed in utilities/dataframe_functions.py to handle
passing 0 e.g.
# if column_id:
if column_id or column_id == 0:That just raises
--> 259 raise AttributeError("The given column for the id is not present in the data.")
260 elif kind_to_df_map[kind][column_id].isnull().any():
261 raise ValueError("You have NaN values in your id column.")
AttributeError: The given column for the id is not present in the data.
So without having to reverse engineer all the kind_to_df_map stuff, it is easier
for the timebeing to just note in the documentation that the DataFrame columns
should not be 0-indexed?
Or maybe it is just an issue that has not been reported?
Hi,
I reviewed the documentation. There are 2 main things in tsfresh:
I have some general questions:
Especially how to control which features are calculated with setting.name_to_param dictionary.
Currently, travis is starting "setup.py upload" which uploads tsfresh to pypi. This setup py also uses the README.MD as the package description on pypi. However, the documentation looks bad because pypi does not support the github markdown highlighting We should have a separate readme for pypi.
Also, pypi or travis seem to uploaded not only to rtd but also to http://pythonhosted.org/tsfresh/. This seems like a waste of resources, we should only hoste it on rtd (I prefer rtd because you can directly edit the documentation in your browser)
In my DataFrames, I oftentimes find it very reasonable to have quite a few NaN or None values.
In order to run tsfresh, I just set all those values to 0, which is... not ideal. Even imputing missing values would not work particularly well for several of my use cases.
Yet, it seems (from a super naive outsider's perspective), like this is filtering that tsfresh could do relatively easily itself.
When it grabs each time_series, it can simply remove or categorically ignore NaN/None, and compute features on the values that do exist. This makes my life easier when, say, one customer signs up a month after another customer, and thus has missing values for that month.
Again, super naive outsider perspective here, I know this might be impossible. But if it is possible, I'd love to add in that bit of filtering!
At the moment the FeatureExtractionSettingsObject feels clumsy and hard to understand.
Also the naming of some methods do not seem to fit their purpose (I am looking at you, set_default_parameters).
We should rethink our FeatureExtractionSettingsObject API and think about which functionality is still missing. (For example at the moment do_not_calculate is not able to iterate over all kind of time series)
To efficiently handle huge data sets, we could make use of Dask
Currently we calculate the features in a list comprehension:
extracted_features = [_extract_features_for_one_time_series(relevant_time_series, str(kind),
column_id, column_value, feature_extraction_settings)
for kind, relevant_time_series in kind_to_df_map.iteritems()]A first step would be to parallelize this list comprehension with joblib or something similar.
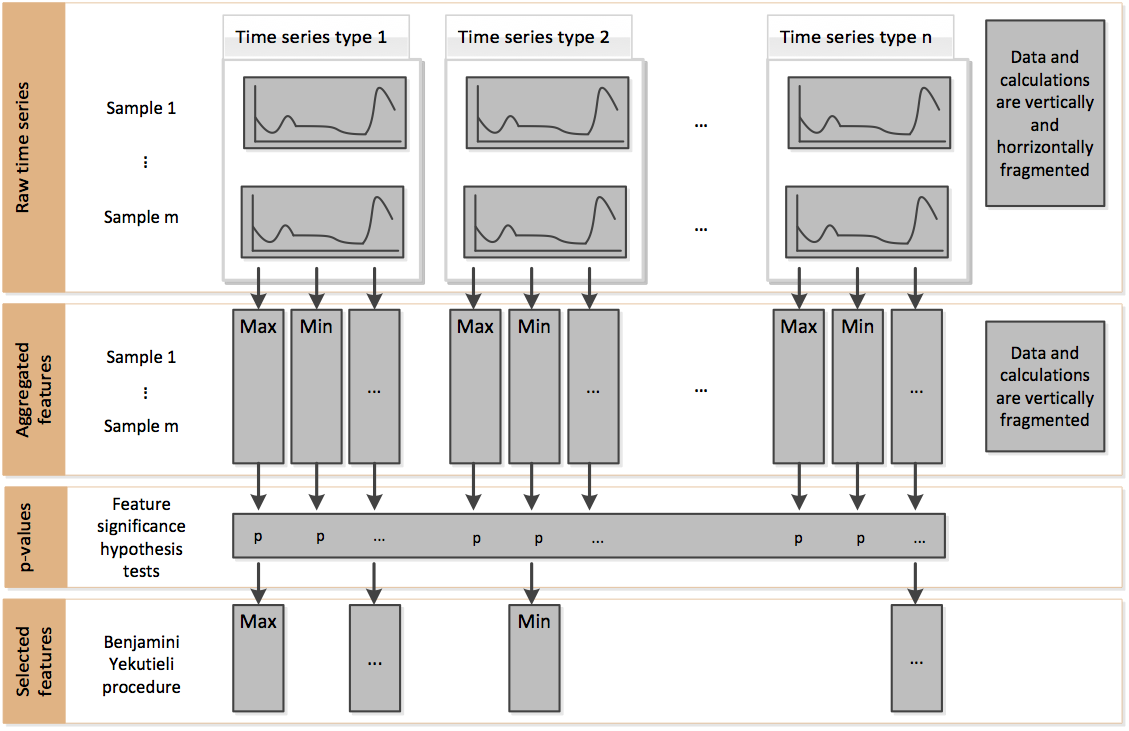
Further, as can be seen here the calculation of features is fragmented both horizontally and vertically. So we can also parallelize on a per sample basis.
At the moment the calculated features are always based on one type of time series.
It would be nice to have features that are based on multiple time series.
We could use something in the line of http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.PolynomialFeatures.html to get feature combinatins.
It would be nice to have an overview in the documentation for which fields (biology, manufactoring line optimization, predictive maintenance, financial data) the application of tsfresh proved to be helpful.
Right now our FeatureExtractionSettings contains many features.
It would be nice to have a smaller FeatureExtractionSettings object that only calculates basic properties such as mean, median, min, max. This would allow to fastly tinker with data and then later calculate the big list of features
I have two time serises with different length and value, and they belong to two different labels, and i transform them into pandas.Dateframe like this

when i use the method extract_relevant_features, and it return an empty list like this

i dont understand the result, does it mean the two serise have no relevant features?
and here i post my code, pitch(picth2)is a list like

my code:
y = [0, 1]
y = np.array(y)
pitch = pitch_analyse.pitch_profile("new001.wav")
pitch2 = pitch_analyse.pitch_profile(r"D:\emotion_new\angry\angry_1_009.wav")
time1 = range(len(pitch))
time2 = range(len(pitch2))
time1.extend(time2)
id_dic = [0]*len(pitch)+[1]*len(pitch2)
pitch.extend(pitch2)
series = {'id': id_dic, 'time': time1,'value': pitch}
series = pd.DataFrame(series)
features_filtered_direct = extract_relevant_features(series, y, column_id='id', column_sort='time')
print features_filtered_directReported by user WickedWicky on r/machinelearning
Following this page http://tsfresh.readthedocs.io/en/latest/text/quick_start.html and I don't know if that is supposed to be up to date but the code blocks don't fit together.
"from tsfresh import select features" should be "from tsfresh import select_features"
and the last block you use 'df' as an argument where you defined it as 'timeseries' earlier.
Currently we calculate the Augmented Dickey-Fuller test statistic as feature. The p-value of the Augmented Dickey-Fuller test might also be a relevant feature.
As the statsmodels function adfuller returns the test statistic as well as the p-value, it would make sense to memoize or buffer the results and add the new feature as a separate function.
A tutorial on how to add new features to tsfresh can be found in our documentation: http://tsfresh.readthedocs.io/en/latest/text/how_to_add_custom_feature.html
I had an idea for a class of features.
as it currently stands, the feature returned by augmented_dickey_fuller is the test statistic. should (1) we return the test statistic feature or (2) a boolean, regarding reject/fail-to-reject hypothesis test?
in conventional analysis, this value is compared with corresponding values at 1%, 5%, 10% significance to test for stationarity (eg if DA statistic > 5% value, then fail to reject hypothesis of non-stationarity).
Hello.
Am I understanding it correctly, that it is recommended to perform PCA on the extracted features to achieve better accuracy in classification?
I saw it in the paper: https://arxiv.org/pdf/1610.07717v1.pdf
In order to follow along on the Quick Start page, in the Dive in section, I believe the method used to load the data should be updated, as the code would not run as is.
from tsfresh.examples.robot_execution_failures import download_robot_execution_failures, load_robot_execution_failures
download_robot_execution_failures()
timeseries, y = load_robot_execution_failures()
User @Huandao0812 reported in issue #22:
Hi Max, I tried to do the same by your example, but my X_new has different number of features than my X_old, my code is here https://github.com/Huandao0812/lstm_exp/blob/master/test_tsfresh.py#L46
can you have a quick look
update: I check the diff of 2 set of columns and this is the difference:
the X_new has 2 more columns than the X_old
diff columns = set(['feature__cwt_coefficients__widths_(2, 5, 10, 20)_coeff_13__w_20', 'feature__cwt_coefficients__widths(2, 5, 10, 20)__coeff_3__w_5'])
I cannot import, the following error appears:
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
<ipython-input-2-0fc1191c9b20> in <module>()
----> 1 from tsfresh import extract_relevant_features
/home/nobody/anaconda3/lib/python3.5/site-packages/tsfresh/__init__.py in <module>()
19
20
---> 21 from tsfresh.convenience.relevant_extraction import extract_relevant_features
22 from tsfresh.feature_extraction import extract_features
23 from tsfresh.feature_selection import select_features
/home/nobody/anaconda3/lib/python3.5/site-packages/tsfresh/convenience/relevant_extraction.py in <module>()
5 from __future__ import absolute_import
6 import pandas as pd
----> 7 from tsfresh.feature_extraction import extract_features
8 from tsfresh.feature_selection import select_features
9 from tsfresh.utilities.dataframe_functions import restrict_input_to_index
/home/nobody/anaconda3/lib/python3.5/site-packages/tsfresh/feature_extraction/__init__.py in <module>()
3 """
4
----> 5 from tsfresh.feature_extraction.extraction import extract_features
6 from tsfresh.feature_extraction.settings import FeatureExtractionSettings
/home/nobody/anaconda3/lib/python3.5/site-packages/tsfresh/feature_extraction/extraction.py in <module>()
9 import pandas as pd
10 import numpy as np
---> 11 from tsfresh.utilities import dataframe_functions, profiling
12 from tsfresh.feature_extraction.settings import FeatureExtractionSettings
13
/home/nobody/anaconda3/lib/python3.5/site-packages/tsfresh/utilities/profiling.py in <module>()
6 """
7
----> 8 import cProfile, pstats, StringIO
9 import logging
10
ImportError: No module named 'StringIO'
A little searching shows that the StringIO module is gone in Python 3 and has been replaced with the io module, from whence io.StringIO should be imported.
Hi,
I tried to run tsfresh on my sample data (2 time series). After calling extract_features I received following matrix:
1003 feature_1 feature_2 ...
1004 feature_2 feature_3 ...
Then I call select_features like this:
ys = pd.Series([1, 2], index = [1003, 1004], name = 'target')
select_features(features, ys)But all I receive is an empty DataFrame. What I am doing wrong?
I noticed quite a few divide by zero warnings, like below:
/home/preston/.local/lib/python2.7/site-packages/scipy/signal/_peak_finding.py:412: RuntimeWarning: divide by zero encountered in double_scalars
But then, at one point after running for a while, the entire extract_features() process errored out.
Traceback (most recent call last):
File "df_dev_script.py", line 590, in <module>
features = extract_features(combined_df, column_id='store_id', column_sort='created_at_in_local_time')
File "/home/preston/.local/lib/python2.7/site-packages/tsfresh/feature_extraction/extraction.py", line 93, in extract_features
extracted_features = pool.map(partial_extract_features_for_one_time_series, kind_to_df_map.items())
File "/usr/lib/python2.7/multiprocessing/pool.py", line 251, in map
return self.map_async(func, iterable, chunksize).get()
File "/usr/lib/python2.7/multiprocessing/pool.py", line 567, in get
raise self._value
ZeroDivisionError: float division by zero
Should be pretty easy to do safe division that doesn't error.
For our requirements we have to figure out the minimum versions we actually need. Optimizing our requirements increases our compatibility with different package versions and helps us support more environments.
Using a collection of 147 time series with 20 time stamps each, the method extract_features returns 211 features. Some of the features are constant across all 147 IDs but others are not constant.

When the method select_features is applied to the (147,211) DataFrame X, the outcome is and empty DF.

However, there are features whose STD is not zero, X.iloc[:, X.std().values!=0].shape, (147, 165)
This is an example of the correlation between these 165 non-constant features and target

Other attempts were made such as:
extract_relevant_features directly. Resulted in different features but the same empty DF of selected features.extraction_settings.fdr_level = 0.1. Resulted in different features but the same empty DF of selected features. Extracted features were still 211.Questions
For a description of the feature see https://en.wikipedia.org/wiki/Approximate_entropy
A tutorial on how to add new features to tsfresh can be found in our documentation: http://tsfresh.readthedocs.io/en/latest/text/how_to_add_custom_feature.html
Currently we calculate the p-values per feature in a loop:
for feature in df_features['Feature']:
if target_is_binary:
# Decide if the current feature is binary or not
if len(set(X[feature].values)) == 2:
df_features.loc[df_features.Feature == feature, "type"] = "binary"
p_value = target_binary_feature_binary_test(X[feature], y, settings)
else:
df_features.loc[df_features.Feature == feature, "type"] = "real"
p_value = target_binary_feature_real_test(X[feature], y, settings)
else:
# Decide if the current feature is binary or not
if len(set(X[feature].values)) == 2:
df_features.loc[df_features.Feature == feature, "type"] = "binary"
p_value = target_real_feature_binary_test(X[feature], y, settings)
else:
df_features.loc[df_features.Feature == feature, "type"] = "real"
p_value = target_real_feature_real_test(X[feature], y, settings)
# Add p_values to df_features
df_features.loc[df_features['Feature'] == feature, "p_value"] = p_valueThis loop could be parallelized with joblib or something similar.
The feature calculators augmented_dickey_fuller, fft_coefficient, number_cwt_peaks, spkt_welch_density, cwt_coefficients lack unit tests. See feature_calculators.py for their implementations. Stubs for the corresponding tests can be found in test_feature_calculations.py
Does it support different length of time series?
I am interested to use it on audio tasks.
Thanks!
Hello Max and the other contributors,
Great work on this library, It works really well.
Is it possible to save and load extraction calculators that were used in a dataset? For instance, let's say that I have a dataset and I run extract_features and then select_features. As of result, some features are being removed and the standing features were calculated based on a specific calculator. Is there a way to get those calculators?
The reasoning of this option is that I need to run future dataset with the same calculators since my model is being trained on them.
Let me know if this is possible or if am I missing something?
Thank you.
Right now the only progress indicators are the Warning messages.
I know that doing the computation inside an async map call makes this trickier. But even just knowing how many different things it's calculating, and reporting back every once in a while on how many total have been completed, would be really useful. I'm not sure whether to read a quick xkcd comic while waiting, or go home and let this run overnight.
We could provide a stand alone script that runs tsfresh directly on csv files and returns the results as another csv file.
I don't see a list of features to be calculated somewhere, can we add that information into documentation?
It would be good to add a section in how_to_contribute on testing with examples and some information on how the project is tested locally.
I understand that printing all the UserWarnings and RuntimeWarnings is useful while developing on the source code of tsfresh, but as a user, it makes me wonder whether I screwed something up, or if there are bugs in the calculations themselves.
I'm assuming it's all intentional, but that's an assumption I'd rather not have to make, and a not-ideal user experience.
If you're ok with blocking warnings by default, I'm happy to implement that (I do something similar for auto_ml, since I assume it's my responsibility as the project's author to handle these warnings, and that my end users should not have to be bothered by my design choices).
There should be an easy way to obtain a list of all features a FeatureExtractionSettings object is configured to calculate.
@CYHSM mentioned this paper https://www.ncbi.nlm.nih.gov/pubmed/10843903?dopt=Abstract
We should implement the entropy features sample entropy (SampEn)
Currently we only support Python 2. In future releases we want to support both Python 2 and 3. This howto outlines the main steps towards Python 3 support.
I have run this command for installation of tsfresh in windows 10:
"C:\Anaconda2\Scripts\pip.exe" install "C:\Anaconda2\extrapackages\tsfresh-master.zip"
I got the error as:
Processing c:\anaconda2\extrapackages\tsfresh-master.zip
Complete output from command python setup.py egg_info:
Installed c:\users\vinodv\appdata\local\temp\pip-jwysox-build\.eggs\pyscaffold-2.5.6-py2.7.egg
ERROR:root:Error parsing
Traceback (most recent call last):
File "c:\users\vinodv\appdata\local\temp\pip-jwysox-build\.eggs\pyscaffold-2.5.6-py2.7.egg\pyscaffold\contrib\pbr\pbr\core.py", line 111, in pbr
attrs = util.cfg_to_args(path, dist.script_args)
File "c:\users\vinodv\appdata\local\temp\pip-jwysox-build\.eggs\pyscaffold-2.5.6-py2.7.egg\pyscaffold\contrib\pbr\pbr\util.py", line 246, in cfg_to_args
pbr.hooks.setup_hook(config)
File "c:\users\vinodv\appdata\local\temp\pip-jwysox-build\.eggs\pyscaffold-2.5.6-py2.7.egg\pyscaffold\contrib\pbr\pbr\hooks\__init__.py", line 25, in setup_hook
metadata_config.run()
File "c:\users\vinodv\appdata\local\temp\pip-jwysox-build\.eggs\pyscaffold-2.5.6-py2.7.egg\pyscaffold\contrib\pbr\pbr\hooks\base.py", line 27, in run
self.hook()
File "c:\users\vinodv\appdata\local\temp\pip-jwysox-build\.eggs\pyscaffold-2.5.6-py2.7.egg\pyscaffold\contrib\pbr\pbr\hooks\metadata.py", line 26, in hook
self.config['name'], self.config.get('version', None))
File "c:\users\vinodv\appdata\local\temp\pip-jwysox-build\.eggs\pyscaffold-2.5.6-py2.7.egg\pyscaffold\contrib\pbr\pbr\packaging.py", line 710, in get_version
raise Exception("Versioning for this project requires either an sdist"
Exception: Versioning for this project requires either an sdist tarball, or access to an upstream git repository. Are you sure that git is installed?
error in setup command: Error parsing c:\users\vinodv\appdata\local\temp\pip-jwysox-build\setup.cfg: Exception: Versioning for this project requires either an sdist tarball, or access to an upstream git repository. Are you sure that git is installed?
----------------------------------------
I have installed git from git-scm.
In "Path" system variable the "C:\Program Files\Git\cmd" path is present.
user @danjo89 reported an error
https://gist.github.com/danjo89/7db0fc3e145337969cec1f0e08a239fe
we do not have a check if the target y is a pandas Series. In the above case the target was a pandas DataFrame. We can easily add an check for that
Add the following points to FAQ:
We already include type annotations for most functions in their docstrings. mypy offers a comment syntax for annotating types in Python 2. This would help us ensure that these annotations are correct.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}