bingoohuang / weekly Goto Github PK
View Code? Open in Web Editor NEWweekly
License: MIT License
weekly
License: MIT License











如果我只能给其他程序员一个建议,那就是编写小的代码块,你要多写小方法、小功能、小程序。
我自己写C#时,当函数接近15或20行代码时,我会感到不舒服。我的限制是,一个函数最多最多就是24行代码,因为传统终端就是24行一屏。


风高秋日,Java大师在搅扰中醒来。他起身独自游走,以清除杂念。
大师走到三石庙;在此,尚有人练习ANSI C之道。一博学修士在把门。
大师问,“void之本性,何也?”
“void本无性”,修士答。“无口之犬,其所叼之木;无意之手,其所指之处。void者,无值之至也。”
大师心想,“三石庙无需把守。其中必无有价之物。”
随即,大师走到白石天庙;在此,仅有理论学者,仅许用ML。荒芜的花园中,一修女在尘中写匿名函数。
大师问,“void之本性,何也?”
“void,天之色泽,雾之斤两”,修女答。“叩之,其声如新月躲入云中。取空碗一只,其中void尽可取也。”
大师心想,“伊未言谎,亦未言实”。
再行,见一庄园;在此,一婆婆在修剪树篱。
大师问,“void之本性,何也?”
婆婆一行礼,一言未发,接着修剪树篱。
大师心想,“此为大智,亦或为大愚”。
天色渐暗,大师来到无人的墓地。
大师问,“void之本性,何也?”
院落静悄悄,没有回答。
Java大师便满意了。
简单来说就是要有逻辑、条理(《阿里工程师自我修养》——逻辑+套路),智力不是关键,普通人的智力差不多,思路、套路(路径、方法)才是提高效率的关键。整理自1
四种组织思维的逻辑顺序:
“大前提、小前提、结论”的演绎推理方式就是演绎顺序。
比如,经典三段论:所有人都要死,苏格拉底是人,苏格拉底要死
“第一、第二、第三”
“首先、然后、再者”
很多的时 间顺序同时也是因果顺序
“前端、后端、数据”,
“波士顿、纽约、华盛顿”,化整为 零(将整体分解为部分)等都是空间顺序
比如“最重要、次重要、不重要”
套路是解决问题的方法论(没有金刚钻别揽瓷器活——金刚钻啊),非常重要。 5W2H 分析法,就是一个帮助我们分析问题的非常好的“套路”,如下图:

建立中心,明确目标,解决 what、why 的问题,然后才是 how。建立中心两种方式如下:
分析的策略,即按照演绎顺序、时间、空间、重要性四个维度进行分析。其中,空间分析要注意满足 MECE(Mutually Exclusive Collectively Exhaustive,相互独立,完全穷尽)原则。
https://edu.aliyun.com/lesson_1651_13082?spm=5176.10731542.0.0.260b20beuwspD5#_13082
摘要:欢迎大家来到阿里云与 CNCF 共同推出的“云原生”技术公开课。本文整理自云原生技术公开课的课时 2:容器基本概念。本次课程中,阿里巴巴高级开发工程师傅伟为大家介绍了容器与镜像的概念、容器的生命周期、项目架构以及容器与 VM 之间的区别等,精彩不容错过。
本节课程要点
什么是容器与镜像?如何构建容器与镜像
容器的生命周期
容器项目的架构
容器 VS.VM
一、容器与镜像
什么是容器?
在介绍容器的具体概念之前,先简单回顾一下操作系统是如何管理进程的。
首先,当我们登录到操作系统之后,可以通过 ps 等操作看到各式各样的进程,这些进程包括系统自带的服务和用户的应用进程。那么,这些进程都有什么样的特点?
第一,这些进程可以相互看到、相互通信;
第二,它们使用的是同一个文件系统,可以对同一个文件进行读写操作;
第三,这些进程会使用相同的系统资源。
这样的三个特点会带来什么问题呢?
因为这些进程能够相互看到并且进行通信,高级权限的进程可以攻击其他进程;
因为它们使用的是同一个文件系统,因此会带来两个问题:这些进程可以对于已有的数据进行增删改查,具有高级权限的进程可能会将其他进程的数据删除掉,破坏掉其他进程的正常运行;此外,进程与进程之间的依赖可能会存在冲突,如此一来就会给运维带来很大的压力;
因为这些进程使用的是同一个宿主机的资源,应用之间可能会存在资源抢占的问题,当一个应用需要消耗大量 CPU 和内存资源的时候,就可能会破坏其他应用的运行,导致其他应用无法正常地提供服务。
针对上述的三个问题,如何为进程提供一个独立的运行环境呢?
针对不同进程使用同一个文件系统所造成的问题而言,Linux 和 Unix 操作系统可以通过 chroot 系统调用将子目录变成根目录,达到视图级别的隔离;进程在 chroot 的帮助下可以具有独立的文件系统,对于这样的文件系统进行增删改查不会影响到其他进程;
因为进程之间相互可见并且可以相互通信,使用 Namespace 技术来实现进程在资源的视图上进行隔离。在 chroot 和 Namespace 的帮助下,进程就能够运行在一个独立的环境下了;
但在独立的环境下,进程所使用的还是同一个操作系统的资源,一些进程可能会侵蚀掉整个系统的资源。为了减少进程彼此之间的影响,可以通过 Cgroup 来限制其资源使用率,设置其能够使用的 CPU 以及内存量。
那么,应该如何定义这样的进程集合呢?
其实,容器就是一个视图隔离、资源可限制、独立文件系统的进程集合。所谓“视图隔离”就是能够看到部分进程以及具有独立的主机名等;控制资源使用率则是可以对于内存大小以及 CPU 使用个数等进行限制。容器就是一个进程集合,它将系统的其他资源隔离开来,具有自己独立的资源视图。
容器具有一个独立的文件系统,因为使用的是系统的资源,所以在独立的文件系统内不需要具备内核相关的代码或者工具,我们只需要提供容器所需的二进制文件、配置文件以及依赖即可。只要容器运行时所需的文件集合都能够具备,那么这个容器就能够运行起来。
什么是镜像?
综上所述,我们将这些容器运行时所需要的所有的文件集合称之为容器镜像。
那么,一般都是通过什么样的方式来构建镜像的呢?通常情况下,我们会采用 Dockerfile 来构建镜像,这是因为 Dockerfile 提供了非常便利的语法糖,能够帮助我们很好地描述构建的每个步骤。当然,每个构建步骤都会对已有的文件系统进行操作,这样就会带来文件系统内容的变化,我们将这些变化称之为 changeset。当我们把构建步骤所产生的变化依次作用到一个空文件夹上,就能够得到一个完整的镜像。
changeset 的分层以及复用特点能够带来几点优势:
第一,能够提高分发效率,简单试想一下,对于大的镜像而言,如果将其拆分成各个小块就能够提高镜像的分发效率,这是因为镜像拆分之后就可以并行下载这些数据;
第二,因为这些数据是相互共享的,也就意味着当本地存储上包含了一些数据的时候,只需要下载本地没有的数据即可,举个简单的例子就是 golang 镜像是基于 alpine 镜像进行构建的,当本地已经具有了 alpine 镜像之后,在下载 golang 镜像的时候只需要下载本地 alpine 镜像中没有的部分即可;
第三,因为镜像数据是共享的,因此可以节约大量的磁盘空间,简单设想一下,当本地存储具有了 alpine 镜像和 golang 镜像,在没有复用的能力之前,alpine 镜像具有 5M 大小,golang 镜像有 300M 大小,因此就会占用 305M 空间;而当具有了复用能力之后,只需要 300M 空间即可。
如何构建镜像?
如下图所示的 Dockerfile 适用于描述如何构建 golang 应用的。
如图所示:
FROM 行表示以下的构建步骤基于什么镜像进行构建,正如前面所提到的,镜像是可以复用的;
WORKDIR 行表示会把接下来的构建步骤都在哪一个相应的具体目录下进行,其起到的作用类似于 Shell 里面的 cd;
COPY 行表示的是可以将宿主机上的文件拷贝到容器镜像内;
RUN 行表示在具体的文件系统内执行相应的动作。当我们运行完毕之后就可以得到一个应用了;
CMD 行表示使用镜像时的默认程序名字。
当有了 Dockerfile 之后,就可以通过 docker build 命令构建出所需要的应用。构建出的结果存储在本地,一般情况下,镜像构建会在打包机或者其他的隔离环境下完成。
那么,这些镜像如何运行在生产环境或者测试环境上呢?这时候就需要一个中转站或者中心存储,我们称之为 docker registry,也就是镜像仓库,其负责存储所有产生的镜像数据。我们只需要通过 docker push 就能够将本地镜像推动到镜像仓库中,这样一来,就能够在生产环境上或者测试环境上将相应的数据下载下来并运行了。
如何运行容器?
运行一个容器一般情况下分为三步:
第一步:从镜像仓库中将相应的镜像下载下来;
第二步:当镜像下载完成之后就可以通过 docker images 来查看本地镜像,这里会给出一个完整的列表,我们可以在列表中选中想要的镜像;
第三步:当选中镜像之后,就可以通过 docker run 来运行这个镜像得到想要的容器,当然可以通过多次运行得到多个容器。一个镜像就相当于是一个模板,一个容器就像是一个具体的运行实例,因此镜像就具有了一次构建、到处运行的特点。
小结
简单回顾一下,容器就是和系统其它部分隔离开来的进程集合,这里的其他部分包括进程、网络资源以及文件系统等。而镜像就是容器所需要的所有文件集合,其具备一次构建、到处运行的特点。
二、容器的生命周期
容器运行时的生命周期
容器是一组具有隔离特性的进程集合,在使用 docker run 的时候会选择一个镜像来提供独立的文件系统并指定相应的运行程序。这里指定的运行程序称之为 initial 进程,这个 initial 进程启动的时候,容器也会随之启动,当 initial 进程退出的时候,容器也会随之退出。
因此,可以认为容器的生命周期和 initial 进程的生命周期是一致的。当然,因为容器内不只有这样的一个 initial 进程,initial 进程本身也可以产生其他的子进程或者通过 docker exec 产生出来的运维操作,也属于 initial 进程管理的范围内。当 initial 进程退出的时候,所有的子进程也会随之退出,这样也是为了防止资源的泄漏。
但是这样的做法也会存在一些问题,首先应用里面的程序往往是有状态的,其可能会产生一些重要的数据,当一个容器退出被删除之后,数据也就会丢失了,这对于应用方而言是不能接受的,所以需要将容器所产生出来的重要数据持久化下来。容器能够直接将数据持久化到指定的目录上,这个目录就称之为数据卷。
数据卷有一些特点,其中非常明显的就是数据卷的生命周期是独立于容器的生命周期的,也就是说容器的创建、运行、停止、删除等操作都和数据卷没有任何关系,因为它是一个特殊的目录,是用于帮助容器进行持久化的。简单而言,我们会将数据卷挂载到容器内,这样一来容器就能够将数据写入到相应的目录里面了,而且容器的退出并不会导致数据的丢失。
通常情况下,数据卷管理主要有两种方式:
第一种是通过 bind 的方式,直接将宿主机的目录直接挂载到容器内;这种方式比较简单,但是会带来运维成本,因为其依赖于宿主机的目录,需要对于所有的宿主机进行统一管理。
第二种是将目录管理交给运行引擎。
三、容器项目架构
moby 容器引擎架构
moby 是目前最流行的容器管理引擎,moby daemon 会对上提供有关于容器、镜像、网络以及 Volume的管理。moby daemon 所依赖的最重要的组件就是 containerd,containerd 是一个容器运行时管理引擎,其独立于 moby daemon ,可以对上提供容器、镜像的相关管理。
containerd 底层有 containerd shim 模块,其类似于一个守护进程,这样设计的原因有几点:
首先,containerd 需要管理容器生命周期,而容器可能是由不同的容器运行时所创建出来的,因此需要提供一个灵活的插件化管理。而 shim 就是针对于不同的容器运行时所开发的,这样就能够从 containerd 中脱离出来,通过插件的形式进行管理。
其次,因为 shim 插件化的实现,使其能够被 containerd 动态接管。如果不具备这样的能力,当 moby daemon 或者 containerd daemon 意外退出的时候,容器就没人管理了,那么它也会随之消失、退出,这样就会影响到应用的运行。
最后,因为随时可能会对 moby 或者 containerd 进行升级,如果不提供 shim 机制,那么就无法做到原地升级,也无法做到不影响业务的升级,因此 containerd shim 非常重要,它实现了动态接管的能力。
本节课程只是针对于 moby 进行一个大致的介绍,在后续的课程也会详细介绍。
四、容器 VS VM
容器和 VM 之间的差异
VM 利用 Hypervisor 虚拟化技术来模拟 CPU、内存等硬件资源,这样就可以在宿主机上建立一个 Guest OS,这是常说的安装一个虚拟机。
每一个 Guest OS 都有一个独立的内核,比如 Ubuntu、CentOS 甚至是 Windows 等,在这样的 Guest OS 之下,每个应用都是相互独立的,VM 可以提供一个更好的隔离效果。但这样的隔离效果需要付出一定的代价,因为需要把一部分的计算资源交给虚拟化,这样就很难充分利用现有的计算资源,并且每个 Guest OS 都需要占用大量的磁盘空间,比如 Windows 操作系统的安装需要 1030G 的磁盘空间,Ubuntu 也需要 56G,同时这样的方式启动很慢。正是因为虚拟机技术的缺点,催生出了容器技术。
容器是针对于进程而言的,因此无需 Guest OS,只需要一个独立的文件系统提供其所需要文件集合即可。所有的文件隔离都是进程级别的,因此启动时间快于 VM,并且所需的磁盘空间也小于 VM。当然了,进程级别的隔离并没有想象中的那么好,隔离效果相比 VM 要差很多。
总体而言,容器和 VM 相比,各有优劣,因此容器技术也在向着强隔离方向发展。
本节总结
容器是一个进程集合,具有自己独特的视图视角;
镜像是容器所需要的所有文件集合,其具备一次构建、到处运行的特点;
容器的生命周期和 initial 进程的生命周期是一样的;
容器和 VM 相比,各有优劣,容器技术在向着强隔离方向发展。




ECC(Elliptic Curve Cryptography)跟RSA一样,都可以生成公钥和私钥,然后进行加密通信和数字签名操作。ECC在区块链领域有着特殊的地位。因为比特币就是用ECC来生成地址和私钥的。HTTPS也会用到ECC。现代的浏览器也都支持基于椭圆曲线密钥对的认证证书。
ECC从2004年开始才被广泛应用,比RSA要晚很多,它的关键改进就是性能。同样的秘钥长度下,ECC要安全很多(ECC能够对抗量子解密)。ECC和RSA基于的都是正向运算很容易,反向运算很难的单向函数来设计的。运算越难,也就是意味着破解它运算所耗费的能源越多,或者说对应的碳排放量越多。
设计ECC的一套运算标准,就是要选择一条合适的椭圆曲线。一套标准对应的一条曲线,有可能有人暗藏数学机关,造成算法其实是可以通过后门来破解的。目前使用面很广的一套标准是美国国家安全局发布的NSA,被怀疑是有后门的。
基于ECC的各种使用方式,有人申请了很多个专利,而这些专利很多都被黑莓公司所持有。你永远也不知道自己开发一套新的ECC方案,会不会被认为触犯了某个专利。
更多阅读区块链背后的密码学

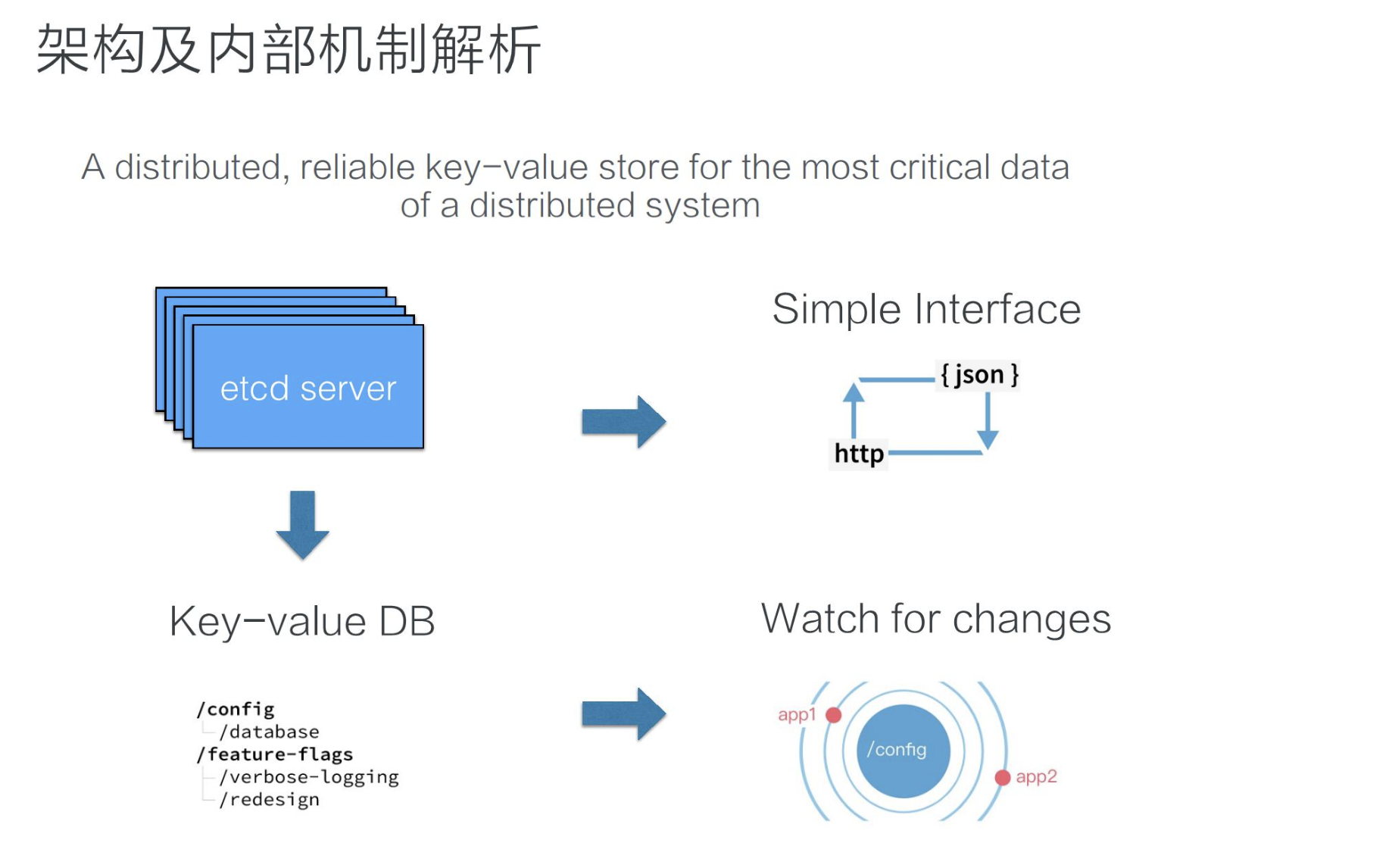
Prometheus 是一个集监控(图表) + 报警 + 时序数据库于一体的开源项目。它采用定期拉取接口的方式来采集需要统计的指标。

图片来自 1
| 组成部分 | 说明 |
|---|---|
| Prometheus Server | 核心组件,只负责数据收集和查询支持,并不直接监控目标服务。它会周期性地从Exporter抓取监控数据 |
| Exporter | 采集组件,一种统称。在目标系统中采集数据,并暴露http接口,供Prometheus Server抓取 |
| Push Gateway | 一个特殊的Exporter。若系统无法支持拉取,可将数据主动Push到一个Push Gateway,其作为一个Exporter供Prometheus Server抓取 |
| Alert Manager | 用于定制报警策略和报警方式 |
| WebUI | 用于查询的交互界面 |
名称 “Ansible” 直接来自科幻小说。Ursula Le Guin 的著作《罗坎农的世界》(Rocannon's World)中, 有一种设备允许即时(比光速更快)通信,它被称为 ansible(从answerable派生)。 Ansible也成为了科幻小说的构成要素,包括在 Orson Scott Card 的《安德的游戏》(Ender's Game)中,该设备远程控制了许多太空飞船。对于控制分布式机器的软件来说,这似乎是一个很好的模型,因此 Ansible 的创建者 Michael DeHaan 借用了这个名字。
Apache 是一个开源的 Web 服务器,最初于 1995 年发布。它是指对原始软件代码修复的补丁,“A-patchy server”(一个补丁服务器)。
Kubernetes 源自希腊语中的“舵手”。该项目创始人 Craig McLuckie 想坚持航海主题,他解释说,技术驱动容器,就像舵手或飞行员驾驶容器船一样。有趣的是,它和英语单词 “governor” 具有相同的词源,与蒸汽机上的机械负反馈装置一样。
CentOS 是 Community Enterprise Operating System(社区企业操作系统)的缩写。
创建于 1993 年 9 月的 Debian Linux,名字来源于创始人 Ian Murdock 和他当时的女友 Debra Lynn。
该名称实际上应该被读作 “EngineX”,指功能强大的 web 服务器,就像引擎(engine)一样。
Python 的创建者 Guido Van Rossum 是喜剧团 Monty Python 的粉丝,Python 的名称也由此而来。

重排序是指编译器和处理器为了优化程序性能而对指令序列进行重新排序的一种手段。
从下图中看一个例子(来源)先,可以repl在线版本跑一下看看实际效果:

在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。重排序分3种类型。
由于指令重排,导致不一样的结果,为了解决因重排出现的不一致问题,可以通过volatile、synchronized、final来防止重排序。
Java编译器在生成指令序列时,插入特定类型的内存屏障(Memory Barriers,Intel称之为Memory Fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序。
插入一个内存屏障,相当于告诉CPU和编译器先于这个命令的必须先执行,后于这个命令的必须后执行。内存屏障另一个作用是强制更新一次不同CPU的缓存。例如,一个写屏障会把这个屏障前写入的数据刷新到主存,这样任何试图读取该数据的线程将得到最新值,而不用考虑到底是被哪个cpu核心或者哪个CPU执行的。
技术负债(英语:Technical debt),也称为设计负债(design debt)、代码负债(code debt),是编程及软件工程中的一个比喻。
指开发人员为了加速软件开发,在应该采用最佳方案时进行了妥协,改用了短期内能加速软件开发的方案,从而在未来给自己带来的额外开发负担。
这种技术上的选择,就像一笔债务一样,虽然眼前看起来可以得到好处,但必须在未来偿还。如果不偿还技术债,则会积聚“利息”,从而导致之后更难以实施更改。 (硬币的另外一面:技术债不一定是一件坏事,有时恰恰需要技术债才能推动项目前进。)
软件工程师必须付出额外的时间和精力持续修复之前的妥协所造成的问题及副作用,或是进行重构,把架构改善为最佳实现方式。

图来自1
渐渐地,我们学会了用技术债当借口。“之前欠了太多债,所以开发慢”、“历史遗留问题,我也没办法”,后来,我们失去了热爱开发的灵魂,只剩下痛苦而缓慢的完成业务的躯壳。
技术债有如冰山没有露出水面的部分,很多问题可能被隐藏了起来

图来自2
开发者 Jonathan Boccara 将技术债比作俄罗斯方块。
游戏初始,需要从一个空白的页面开始进行,就像从什么都没有的编码项目开头一样。
接着,方块开始掉落,每个方块被放置的位置都会影响游戏的其余部分。如果你在没有太多思考的情况下让方块自由滑落,那么接下来的游戏会变得更为艰难。反之,如果设法构建干净、紧凑的结构,在后期将更易于管理。
每个新的修复程序或开发都像一个新的方块一样,需要与现有代码集成。如果以快速而肮脏的方式对其进行破解,就好像在俄罗斯方块结构中留下了漏洞。
若希望少留些空白或漏洞, 则需要花时间设计一个干净的解决方案,来集成修复程序或开发程序。这不太容易实现,但从长远来看会有所回报。
复制-粘贴式开发模式。
技术债的认识感知是有延迟的,就像在高速上超速开车,直到一周后你收到罚单,才知道自己要付出代价。很多团队不顾后果的复制粘贴,直到体会到业务发展缓慢,但是已经来不及了。
“必须马上上线。”
技术界流传最广的三大借口:
首先这些假设从来没被证明过,其次假设“我们时间紧迫,所以必须牺牲质量”成立,但是不代表着“牺牲质量就能赶时间”。最后,在一个必须马上上线的论调充斥的团队中,那些想要做更多重构和更优设计的人会有深深地负罪感,陷入不断创造技术债的怪圈。
“暂时赶下进度,后面再重构”
如果能够经过合理分析,为了短时间赶工做出一定的牺牲,后面再有计划地重构升级,技术债本身并不一定是全是坏事。但是很多时候这句话成了空头支票,最后,就是变成了上一种恶性循环。
“解决问题的最好办法是写代码”
我们最喜欢的一句话就是“用代码改变世界”。但是恰恰相反的是,如果能够不写代码就能解决问题,才是最好办法。我们喜欢崇拜代码量,但是无休止的复制黏贴带来的大量代码不但没有价值,反而带来更大的成本。
内容摘自于3
团队/技术负责人,对技术宅的认知态度
如果团队/技术负责人,不觉得技术债是个问题,那就还“真不是一个问题”
识别技术债,形成列表,暴露出来
根据观察者效应,将问题暴露出来本身就是一种解决问题的办法。人最大的恐惧就是未知,当技术债可说不可见的时候,才是最让人不想解决的时候。
保持团队良好的Code Review的机制
在Code Reivew过程中,对技术债进行跟踪
Git Data Transport Commands

图来自 1

{
"name": "System – Network Mb/s",
"queries": [
{
"query": "SELECT non_negative_derivative(max(\"bytes_recv\"), 1s) / 125000 AS \"rx_megabits_per_second\" FROM \":db:\".\":rp:\".\"net\"",
"groupbys": [],
"wheres": [],
"label": "Mb/s"
},
{
"query": "SELECT non_negative_derivative(max(\"bytes_sent\"), 1s) / 125000 AS \"tx_megabits_per_second\" FROM \":db:\".\":rp:\".\"net\"",
"groupbys": [],
"wheres": []
}
]
}
100Mbps 意味着 12,500 Kilobytes每秒,或者12.5 Megabytes每秒,或者8秒内下载100 Megabyte的文件,或者80秒内下载1 Gigabyte的文件。

总结一下
System – Network Mb/s和label的Mb/s中说明的一样。As title.
https://edu.aliyun.com/lesson_1651_16895?spm=5176.10731542.0.0.7b8820beLNq5Hx#_16895
本文整理自 CNCF 和阿里巴巴联合举办的云原生技术公开课的课时 4:理解 Pod 和容器设计模式。本次课程中,阿阿里巴巴高级技术专家、CNCF 官方大使张磊为大家介绍了为什么我们需要 Pod、Pod 的实现机制以及详解容器设计模式等,精彩不容错过。
本次课程的分享主要围绕以下三个部分:
一、为什么需要 Pod
容器的基本概念

现在来看第一个问题:为什么需要 Pod?我们知道 Pod 是 Kubernetes 项目里面一个非常重要的概念,也是非常重要的一个原子调度单位,但是为什么我们会需要这样一个概念呢?我们在使用容器 Docker 的时候,也没有这个说法。其实如果要理解 Pod,我们首先要理解容器,所以首先来回顾一下容器的概念:
容器的本质实际上是一个进程,是一个视图被隔离,资源受限的进程。
容器里面 PID=1 的进程就是应用本身,这意味着管理虚拟机等于管理基础设施,因为我们是在管理机器,但管理容器却等于直接管理应用本身。这也是之前说过的不可变基础设施的一个最佳体现,这个时候,你的应用就等于你的基础设施,它一定是不可变的。
在以上面的例子为前提的情况下,Kubernetes 又是什么呢?我们知道,很多人都说 Kubernetes 是云时代的操作系统,这个非常有意思,因为如果以此类推,容器镜像就是这个操作系统的软件安装包,它们之间是这样的一个类比关系。
真实操作系统里的例子

如果说 Kubernetes 就是操作系统的话,那么我们不妨看一下真实的操作系统的例子。
例子里面有一个程序叫做 Helloworld,这个 Helloworld 程序实际上是由一组进程组成的,需要注意一下,这里说的进程实际上等同于 Linux 中的线程。
因为 Linux 中的线程是轻量级进程,所以如果从 Linux 系统中去查看 Helloworld 中的 pstree,将会看到这个 Helloworld 实际上是由四个线程组成的,分别是 {api、main、log、compute}。也就是说,四个这样的线程共同协作,共享 Helloworld 程序的资源,组成了 Helloworld 程序的真实工作情况。
这是操作系统里面进程组或者线程组中一个非常真实的例子,以上就是进程组的一个概念。

那么大家不妨思考一下,在真实的操作系统里面,一个程序往往是根据进程组来进行管理的。Kubernetes 把它类比为一个操作系统,比如说 Linux。针对于容器我们前面提到可以类比为进程,就是前面的 Linux 线程。那么 Pod 又是什么呢?实际上 Pod 就是我们刚刚提到的进程组,也就是 Linux 里的线程组。
进程组概念
说到进程组,首先建议大家至少有个概念上的理解,然后我们再详细的解释一下。

还是前面那个例子:Helloworld 程序由四个进程组成,这些进程之间会共享一些资源和文件。那么现在有一个问题:假如说现在把 Helloworld 程序用容器跑起来,你会怎么去做?
当然,最自然的一个解法就是,我现在就启动一个 Docker 容器,里面运行四个进程。可是这样会有一个问题,这种情况下容器里面 PID=1 的进程该是谁? 比如说,它应该是我的 main 进程,那么问题来了,“谁”又负责去管理剩余的 3 个进程呢?
这个核心问题在于,容器的设计本身是一种“单进程”模型,不是说容器里只能起一个进程,由于容器的应用等于进程,所以只能去管理 PID=1 的这个进程,其他再起来的进程其实是一个托管状态。 所以说服务应用进程本身就具有“进程管理”的能力。
比如说 Helloworld 的程序有 system 的能力,或者直接把容器里 PID=1 的进程直接改成 systemd,否则这个应用,或者是容器是没有办法去管理很多个进程的。因为 PID=1 进程是应用本身,如果现在把这个 PID=1 的进程给 kill 了,或者它自己运行过程中死掉了,那么剩下三个进程的资源就没有人回收了,这个是非常非常严重的一个问题。
而反过来真的把这个应用本身改成了 systemd,或者在容器里面运行了一个 systemd,将会导致另外一个问题:使得管理容器,不再是管理应用本身了,而等于是管理 systemd,这里的问题就非常明显了。比如说我这个容器里面 run 的程序或者进程是 systemd,那么接下来,这个应用是不是退出了?是不是 fail 了?是不是出现异常失败了?实际上是没办法直接知道的,因为容器管理的是 systemd。这就是为什么在容器里面运行一个复杂程序往往比较困难的一个原因。
这里再帮大家梳理一下:由于容器实际上是一个“单进程”模型,所以如果你在容器里启动多个进程,只有一个可以作为 PID=1 的进程,而这时候,如果这个 PID=1 的进程挂了,或者说失败退出了,那么其他三个进程就会自然而然的成为孤儿,没有人能够管理它们,没有人能够回收它们的资源,这是一个非常不好的情况。
注意:Linux 容器的“单进程”模型,指的是容器的生命周期等同于 PID=1 的进程(容器应用进程)的生命周期,而不是说容器里不能创建多进程。当然,一般情况下,容器应用进程并不具备进程管理能力,所以你通过 exec 或者 ssh 在容器里创建的其他进程,一旦异常退出(比如 ssh 终止)是很容易变成孤儿进程的。
反过来,其实可以在容器里面 run 一个 systemd,用它来管理其他所有的进程。这样会产生第二个问题:实际上没办法直接管理我的应用了,因为我的应用被 systemd 给接管了,那么这个时候应用状态的生命周期就不等于容器生命周期。这个管理模型实际上是非常非常复杂的。
Pod = “进程组”
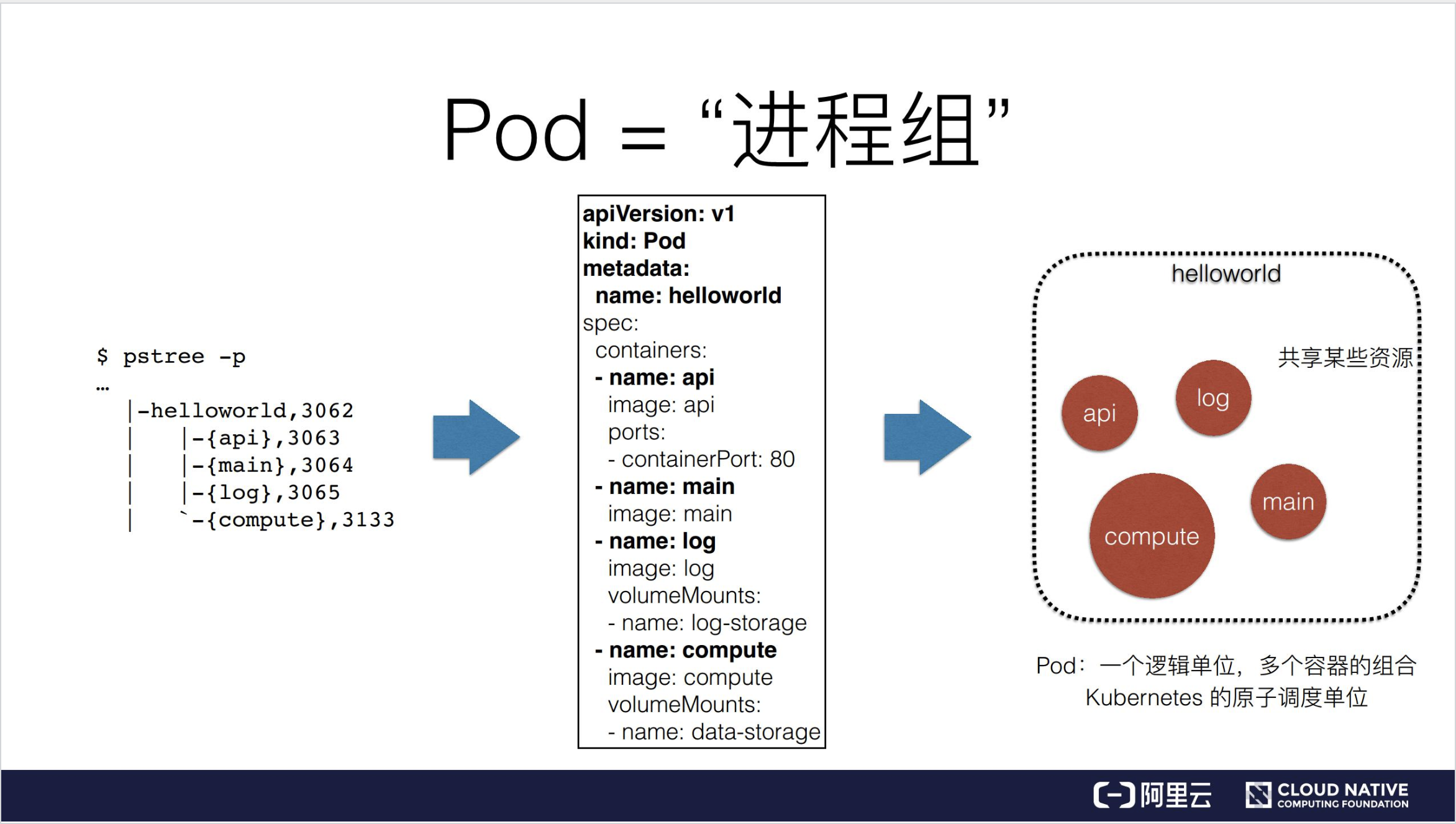
在 kubernetes 里面,Pod 实际上正是 kubernetes 项目为你抽象出来的一个可以类比为进程组的概念。
前面提到的,由四个进程共同组成的一个应用 Helloworld,在 Kubernetes 里面,实际上会被定义为一个拥有四个容器的 Pod,这个概念大家一定要非常仔细的理解。
就是说现在有四个职责不同、相互协作的进程,需要放在容器里去运行,在 Kubernetes 里面并不会把它们放到一个容器里,因为这里会遇到两个问题。那么在 Kubernetes 里会怎么去做呢?它会把四个独立的进程分别用四个独立的容器启动起来,然后把它们定义在一个 Pod 里面。
所以当 Kubernetes 把 Helloworld 给拉起来的时候,你实际上会看到四个容器,它们共享了某些资源,这些资源都属于 Pod,所以我们说 Pod 在 Kubernetes 里面只有一个逻辑单位,没有一个真实的东西对应说这个就是 Pod,不会有的。真正起来在物理上存在的东西,就是四个容器。这四个容器,或者说是多个容器的组合就叫做 Pod。并且还有一个概念一定要非常明确,Pod 是 Kubernetes 分配资源的一个单位,因为里面的容器要共享某些资源,所以 Pod 也是 Kubernetes 的原子调度单位。

上面提到的 Pod 设计,也不是 Kubernetes 项目自己想出来的, 而是早在 Google 研发 Borg 的时候,就已经发现了这样一个问题。这个在 Borg paper 里面有非常非常明确的描述。简单来说 Google 工程师发现在 Borg 下面部署应用时,很多场景下都存在着类似于“进程与进程组”的关系。更具体的是,这些应用之前往往有着密切的协作关系,使得它们必须部署在同一台机器上并且共享某些信息。
以上就是进程组的概念,也是 Pod 的用法。
为什么 Pod 必须是原子调度单位?

可能到这里大家会有一些问题:虽然了解这个东西是一个进程组,但是为什么要把 Pod 本身作为一个概念抽象出来呢?或者说能不能通过调度把 Pod 这个事情给解决掉呢?为什么 Pod 必须是 Kubernetes 里面的原子调度单位?
下面我们通过一个例子来解释。
假如现在有两个容器,它们是紧密协作的,所以它们应该被部署在一个 Pod 里面。具体来说,第一个容器叫做 App,就是业务容器,它会写日志文件;第二个容器叫做 LogCollector,它会把刚刚 App 容器写的日志文件转发到后端的 ElasticSearch 中。
两个容器的资源需求是这样的:App 容器需要 1G 内存,LogCollector 需要 0.5G 内存,而当前集群环境的可用内存是这样一个情况:Node_A:1.25G 内存,Node_B:2G 内存。
假如说现在没有 Pod 概念,就只有两个容器,这两个容器要紧密协作、运行在一台机器上。可是,如果调度器先把 App 调度到了 Node_A 上面,接下来会怎么样呢?这时你会发现:LogCollector 实际上是没办法调度到 Node_A 上的,因为资源不够。其实此时整个应用本身就已经出问题了,调度已经失败了,必须去重新调度。
以上就是一个非常典型的成组调度失败的例子。英文叫做:Task co-scheduling 问题,这个问题不是说不能解,在很多项目里面,这样的问题都有解法。
比如说在 Mesos 里面,它会做一个事情,叫做资源囤积(resource hoarding):即当所有设置了 Affinity 约束的任务都达到时,才开始统一调度,这是一个非常典型的成组调度的解法。
所以上面提到的“App”和“LogCollector”这两个容器,在 Mesos 里面,他们不会说立刻调度,而是等两个容器都提交完成,才开始统一调度。这样也会带来新的问题,首先调度效率会损失,因为需要等待。由于需要等还会有外一个情况会出现,就是产生死锁,就是互相等待的一个情况。这些机制在 Mesos 里都是需要解决的,也带来了额外的复杂度。
另一种解法是 Google 的解法。它在 Omega 系统(就是 Borg 下一代)里面,做了一个非常复杂且非常厉害的解法,叫做乐观调度。比如说:不管这些冲突的异常情况,先调度,同时设置一个非常精妙的回滚机制,这样经过冲突后,通过回滚来解决问题。这个方式相对来说要更加优雅,也更加高效,但是它的实现机制是非常复杂的。这个有很多人也能理解,就是悲观锁的设置一定比乐观锁要简单。
而像这样的一个 Task co-scheduling 问题,在 Kubernetes 里,就直接通过 Pod 这样一个概念去解决了。因为在 Kubernetes 里,这样的一个 App 容器和 LogCollector 容器一定是属于一个 Pod 的,它们在调度时必然是以一个 Pod 为单位进行调度,所以这个问题是根本不存在的。
再次理解 Pod

在讲了前面这些知识点之后,我们来再次理解一下 Pod,首先 Pod 里面的容器是“超亲密关系”。
这里有个“超”字需要大家理解,正常来说,有一种关系叫做亲密关系,这个亲密关系是一定可以通过调度来解决的。
比如说现在有两个 Pod,它们需要运行在同一台宿主机上,那这样就属于亲密关系,调度器一定是可以帮助去做的。但是对于超亲密关系来说,有一个问题,即它必须通过 Pod 来解决。因为如果超亲密关系赋予不了,那么整个 Pod 或者说是整个应用都无法启动。
什么叫做超亲密关系呢?大概分为以下几类:
比如说两个进程之间会发生文件交换,前面提到的例子就是这样,一个写日志,一个读日志;
两个进程之间需要通过 localhost 或者说是本地的 Socket 去进行通信,这种本地通信也是超亲密关系;
这两个容器或者是微服务之间,需要发生非常频繁的 RPC 调用,出于性能的考虑,也希望它们是超亲密关系;
两个容器或者是应用,它们需要共享某些 Linux Namespace。最简单常见的一个例子,就是我有一个容器需要加入另一个容器的 Network Namespace。这样我就能看到另一个容器的网络设备,和它的网络信息。
像以上几种关系都属于超亲密关系,它们都是在 Kubernetes 中会通过 Pod 的概念去解决的。
现在我们理解了 Pod 这样的概念设计,理解了为什么需要 Pod。它解决了两个问题:
我们怎么去描述超亲密关系;
我们怎么去对超亲密关系的容器或者说是业务去做统一调度,这是 Pod 最主要的一个诉求。
二、Pod 的实现机制
Pod 要解决的问题

像 Pod 这样一个东西,本身是一个逻辑概念。那在机器上,它究竟是怎么实现的呢?这就是我们要解释的第二个问题。
既然说 Pod 要解决这个问题,核心就在于如何让一个 Pod 里的多个容器之间最高效的共享某些资源和数据。
因为容器之间原本是被 Linux Namespace 和 cgroups 隔开的,所以现在实际要解决的是怎么去打破这个隔离,然后共享某些事情和某些信息。这就是 Pod 的设计要解决的核心问题所在。
所以说具体的解法分为两个部分:网络和存储。
1.共享网络

第一个问题是 Pod 里的多个容器怎么去共享网络?下面是个例子:
比如说现在有一个 Pod,其中包含了一个容器 A 和一个容器 B,它们两个就要共享 Network Namespace。在 Kubernetes 里的解法是这样的:它会在每个 Pod 里,额外起一个 Infra container 小容器来共享整个 Pod 的 Network Namespace。
Infra container 是一个非常小的镜像,大概 100~200KB 左右,是一个汇编语言写的、永远处于“暂停”状态的容器。由于有了这样一个 Infra container 之后,其他所有容器都会通过 Join Namespace 的方式加入到 Infra container 的 Network Namespace 中。
所以说一个 Pod 里面的所有容器,它们看到的网络视图是完全一样的。即:它们看到的网络设备、IP地址、Mac地址等等,跟网络相关的信息,其实全是一份,这一份都来自于 Pod 第一次创建的这个 Infra container。这就是 Pod 解决网络共享的一个解法。
在 Pod 里面,一定有一个 IP 地址,是这个 Pod 的 Network Namespace 对应的地址,也是这个 Infra container 的 IP 地址。所以大家看到的都是一份,而其他所有网络资源,都是一个 Pod 一份,并且被 Pod 中的所有容器共享。这就是 Pod 的网络实现方式。
由于需要有一个相当于说中间的容器存在,所以整个 Pod 里面,必然是 Infra container 第一个启动。并且整个 Pod 的生命周期是等同于 Infra container 的生命周期的,与容器 A 和 B 是无关的。这也是为什么在 Kubernetes 里面,它是允许去单独更新 Pod 里的某一个镜像的,即:做这个操作,整个 Pod 不会重建,也不会重启,这是非常重要的一个设计。
2.共享存储
第二问题:Pod 怎么去共享存储?Pod 共享存储就相对比较简单。

比如说现在有两个容器,一个是 Nginx,另外一个是非常普通的容器,在 Nginx 里放一些文件,让我能通过 Nginx 访问到。所以它需要去 share 这个目录。我 share 文件或者是 share 目录在 Pod 里面是非常简单的,实际上就是把 volume 变成了 Pod level。然后所有容器,就是所有同属于一个 Pod 的容器,他们共享所有的 volume。
比如说上图的例子,这个 volume 叫做 shared-data,它是属于 Pod level 的,所以在每一个容器里可以直接声明:要挂载 shared-data 这个 volume,只要你声明了你挂载这个 volume,你在容器里去看这个目录,实际上大家看到的就是同一份。这个就是 Kubernetes 通过 Pod 来给容器共享存储的一个做法。
所以在之前的例子中,应用容器 App 写了日志,只要这个日志是写在一个 volume 中,只要声明挂载了同样的 volume,这个 volume 就可以立刻被另外一个 LogCollector 容器给看到。以上就是 Pod 实现存储的方式。
三、详解容器设计模式
现在我们知道了为什么需要 Pod,也了解了 Pod 这个东西到底是怎么实现的。最后,以此为基础,详细介绍一下 Kubernetes 非常提倡的一个概念,叫做容器设计模式。
举例
接下来将会用一个例子来给大家进行讲解。

比如我现在有一个非常常见的一个诉求:我现在要发布一个应用,这个应用是 JAVA 写的,有一个 WAR 包需要把它放到 Tomcat 的 web APP 目录下面,这样就可以把它启动起来了。可是像这样一个 WAR 包或 Tomcat 这样一个容器的话,怎么去做,怎么去发布?这里面有几种做法。
第一种方式:可以把 WAR 包和 Tomcat 打包放进一个镜像里面。但是这样带来一个问题,就是现在这个镜像实际上揉进了两个东西。那么接下来,无论是我要更新 WAR 包还是说我要更新 Tomcat,都要重新做一个新的镜像,这是比较麻烦的;
第二种方式:就是镜像里面只打包 Tomcat。它就是一个 Tomcat,但是需要使用数据卷的方式,比如说 hostPath,从宿主机上把 WAR 包挂载进我们 Tomcat 容器中,挂到我的 web APP 目录下面,这样把这个容器启用起来之后,里面就能用了。
但是这时会发现一个问题:这种做法一定需要维护一套分布式存储系统。因为这个容器可能第一次启动是在宿主机 A 上面,第二次重新启动就可能跑到 B 上去了,容器它是一个可迁移的东西,它的状态是不保持的。所以必须维护一套分布式存储系统,使容器不管是在 A 还是在 B 上,都可以找到这个 WAR 包,找到这个数据。
注意,即使有了分布式存储系统做 Volume,你还需要负责维护 Volume 里的 WAR 包。比如:你需要单独写一套 Kubernetes Volume 插件,用来在每次 Pod 启动之前,把应用启动所需的 WAR 包下载到这个 Volume 里,然后才能被应用挂载使用到。
这样操作带来的复杂程度还是比较高的,且这个容器本身必须依赖于一套持久化的存储插件(用来管理 Volume 里的 WAR 包内容)。
InitContainer

所以大家有没有考虑过,像这样的组合方式,有没有更加通用的方法?哪怕在本地 Kubernetes 上,没有分布式存储的情况下也能用、能玩、能发布。
实际上方法是有的,在 Kubernetes 里面,像这样的组合方式,叫做 Init Container。
还是同样一个例子:在上图的 yaml 里,首先定义一个 Init Container,它只做一件事情,就是把 WAR 包从镜像里拷贝到一个 Volume 里面,它做完这个操作就退出了,所以 Init Container 会比用户容器先启动,并且严格按照定义顺序来依次执行。
然后,这个关键在于刚刚拷贝到的这样一个目的目录:APP 目录,实际上是一个 Volume。而我们前面提到,一个 Pod 里面的多个容器,它们是可以共享 Volume 的,所以现在这个 Tomcat 容器,只是打包了一个 Tomcat 镜像。但在启动的时候,要声明使用 APP 目录作为我的 Volume,并且要把它们挂载在 Web APP 目录下面。
而这个时候,由于前面已经运行过了一个 Init Container,已经执行完拷贝操作了,所以这个 Volume 里面已经存在了应用的 WAR 包:就是 sample.war,绝对已经存在这个 Volume 里面了。等到第二步执行启动这个 Tomcat 容器的时候,去挂这个 Volume,一定能在里面找到前面拷贝来的 sample.war。
所以可以这样去描述:这个 Pod 就是一个自包含的,可以把这一个 Pod 在全世界任何一个 Kubernetes 上面都顺利启用起来。不用担心没有分布式存储、Volume 不是持久化的,它一定是可以公布的。
所以这是一个通过组合两个不同角色的容器,并且按照这样一些像 Init Container 这样一种编排方式,统一的去打包这样一个应用,把它用 Pod 来去做的非常典型的一个例子。像这样的一个概念,在 Kubernetes 里面就是一个非常经典的容器设计模式,叫做:“Sidecar”。
容器设计模式:Sidecar

什么是 Sidecar?就是说其实在 Pod 里面,可以定义一些专门的容器,来执行主业务容器所需要的一些辅助工作,比如我们前面举的例子,其实就干了一个事儿,这个 Init Container,它就是一个 Sidecar,它只负责把镜像里的 WAR 包拷贝到共享目录里面,以便被 Tomcat 能够用起来。
其它有哪些操作呢?比如说:
原本需要在容器里面执行 SSH 需要干的一些事情,可以写脚本、一些前置的条件,其实都可以通过像 Init Container 或者另外像 Sidecar 的方式去解决;
当然还有一个典型例子就是我的日志收集,日志收集本身是一个进程,是一个小容器,那么就可以把它打包进 Pod 里面去做这个收集工作;
还有一个非常重要的东西就是 Debug 应用,实际上现在 Debug 整个应用都可以在应用 Pod 里面再次定义一个额外的小的 Container,它可以去 exec 应用 pod 的 namespace;
查看其他容器的工作状态,这也是它可以做的事情。不再需要去 SSH 登陆到容器里去看,只要把监控组件装到额外的小容器里面就可以了,然后把它作为一个 Sidecar 启动起来,跟主业务容器进行协作,所以同样业务监控也都可以通过 Sidecar 方式来去做。
这种做法一个非常明显的优势就是在于其实将辅助功能从我的业务容器解耦了,所以我就能够独立发布 Sidecar 容器,并且更重要的是这个能力是可以重用的,即同样的一个监控 Sidecar 或者日志 Sidecar,可以被全公司的人共用的。这就是设计模式的一个威力。
Sidecar:应用与日志收集

接下来,我们再详细细化一下 Sidecar 这样一个模式,它还有一些其他的场景。
比如说前面提到的应用日志收集,业务容器将日志写在一个 Volume 里面,而由于 Volume 在 Pod 里面是被共享的,所以日志容器 —— 即 Sidecar 容器一定可以通过共享该 Volume,直接把日志文件读出来,然后存到远程存储里面,或者转发到另外一个例子。现在业界常用的 Fluentd 日志进程或日志组件,基本上都是这样的工作方式。
Sidecar:代理容器

Sidecar 的第二个用法,可以称作为代理容器 Proxy。什么叫做代理容器呢?
假如现在有个 Pod 需要访问一个外部系统,或者一些外部服务,但是这些外部系统是一个集群,那么这个时候如何通过一个统一的、简单的方式,用一个 IP 地址,就把这些集群都访问到?有一种方法就是:修改代码。因为代码里记录了这些集群的地址;另外还有一种解耦的方法,即通过 Sidecar 代理容器。
简单说,单独写一个这么小的 Proxy,用来处理对接外部的服务集群,它对外暴露出来只有一个 IP 地址就可以了。所以接下来,业务容器主要访问 Proxy,然后由 Proxy 去连接这些服务集群,这里的关键在于 Pod 里面多个容器是通过 localhost 直接通信的,因为它们同属于一个 network Namespace,网络视图都一样,所以它们俩通信 localhost,并没有性能损耗。
所以说代理容器除了做了解耦之外,并不会降低性能,更重要的是,像这样一个代理容器的代码就又可以被全公司重用了。
Sidecar:适配器容器

Sidecar 的第三个设计模式 —— 适配器容器 Adapter,什么叫 Adapter 呢?
现在业务暴露出来的 API,比如说有个 API 的一个格式是 A,但是现在有一个外部系统要去访问我的业务容器,它只知道的一种格式是 API B ,所以要做一个工作,就是把业务容器怎么想办法改掉,要去改业务代码。但实际上,你可以通过一个 Adapter 帮你来做这层转换。
现在有个例子:现在业务容器暴露出来的监控接口是 /metrics,访问这个这个容器的 metrics 的这个 URL 就可以拿到了。可是现在,这个监控系统升级了,它访问的 URL 是 /health,我只认得暴露出 health 健康检查的 URL,才能去做监控,metrics 不认识。那这个怎么办?那就需要改代码了,但可以不去改代码,而是额外写一个 Adapter,用来把所有对 health 的这个请求转发给 metrics 就可以了,所以这个 Adapter 对外暴露的是 health 这样一个监控的 URL,这就可以了,你的业务就又可以工作了。
这样的关键还在于 Pod 之中的容器是通过 localhost 直接通信的,所以没有性能损耗,并且这样一个 Adapter 容器可以被全公司重用起来,这些都是设计模式给我们带来的好处。
本节总结
Pod 是 Kubernetes 项目里实现“容器设计模式”的核心机制;
“容器设计模式”是 Google Borg 的大规模容器集群管理最佳实践之一,也是 Kubernetes 进行复杂应用编排的基础依赖之一;
所有“设计模式”的本质都是:解耦和重用。
讲师点评
Pod 与容器设计模式是 Kubernetes 体系里面最重要的一个基础知识点,希望读者能够仔细揣摩和掌握。在这里,我建议你去重新审视一下之前自己公司或者团队里使用 Pod 方式,是不是或多或少采用了所谓“富容器”这种设计呢?这种设计,只是一种过渡形态,会培养出很多非常不好的运维习惯。我强烈建议你逐渐采用容器设计模式的**对富容器进行解耦,将它们拆分成多个容器组成一个 Pod。这也正是当前阿里巴巴“全面上云”战役中正在全力推进的一项重要的工作内容。
来自与bjca李丽霞的对话:
李丽霞: 黄老师,请教个问题,您觉得有没有必要看源代码[捂脸]因为我一直是做业务这一块,写的代码基本是if else所以最近看netty源码,但是netty层层嵌套,我很怀疑看源码是否浪费时间
黄老邪:这个问题非常好,将入选本期“系统架构部周刊”之“到底有必要看源代码么”。我的意见是:1. 有必要,2. 但是需要带着自己的问题去看 3. 从源代码中出来,解决自己的问题。
李丽霞:我现在看netty就是漫无目的,为了看而看,看来我得调整策略了。我平时都不用netty😔。
黄老邪:对啊,看netty,对你现在所从事的工作,实际上没有有效的联系。我掐指一算,你写的代码,基本都是if else,都是crud,都是get set,对吧。
李丽霞: 然后想着看看大师咋写的,结果陷入泥潭🙄
黄老邪:但是嘛,这个东西,我给你讲很多道理,感觉高大上,可能还是解决不了实际问题。所以,我想,还是回到if else怎么写上面去。那么if else有几种写法呢,你能归纳出来么?

图片来自500px
我挺喜欢第一个,就冲着那条可爱的小尾巴。

图片来自“鼠”字太难写了!

2019年10月12日(周六),34岁的肯尼亚人基普乔盖(Eliud Kipchoge)在维也纳只用了1小时59分40秒跑完维也纳马拉松全程42.195公裡。基普乔盖说:"我跑步是为了书写历史。" "我想告诉大家,其实没有极限。"
运动不只锻炼体魄,还是大脑的天然保健品,养成运动习惯能提升我们的记忆力、推理能力等。葡萄牙科学家们还发现,当小鼠跑步速度加快时,小脑联想学习能力竟也跟着变好。2018年4月16日的《自然-神经科学(Nature Neuroscience)》,发表了一篇《运动活动调节小鼠小脑的联想学习》的论文。论文第一作者阿尔贝加里亚(Catarina Albergaria)表示,这证实跑步速度与增强学习间存在因果关系,而不仅仅是相关性:当跑步速度加快,学习能力也变强。根据她的说法,“小脑是一个跨物种的非常保守的结构,有一些跨物种的回路是常见的。” 她推测,基于这些发现的未来研究可以帮助我们更好地理解运动如何影响人类小脑的联想学习。
因此,参与运动可以提高个人的学习能力。
为什么跑得越快,小脑的学习速度就越快?
科学家在小鼠研究中发现:跑越快学习能力越好
黄老邪说,如果没有了老鼠,除了依赖于老鼠的生态链肯定会发生重大“重构”之外,搞IT的也不会有“鼠标”,大**也没有“鼠年”了。记得,看完本期周刊,2020鼠年给女友送一款时尚的好运鼠标。


图片来自500px

以上四个负载工具其中三个公司正在使用,仅Traefik未在产品中正式使用
广东省信息中心二期(统一认证)项目投标,项目要求通过第三方检测机构验证
采用Nginx进行负载性能测试时错误率达0.2%,性能也达不到投标需求
改用Traefik后错误率降为0.001%,性能也达到检测要求
以下从应用场景、性能、稳定性、配置复杂度方面仅提供结论,具体见参考连接:
| 工作网络层 | 应用场景 | 说明 | |
|---|---|---|---|
| LVS | 4 | 热备负载 | 与F5设备相同,流量由linux内核处理,因此没有流量产生 |
| HAProxy | 4和7 | 主要应用于数据库和除web服务的其他服务负载、反向代理 | |
| Nginx | 7 | 热备负载、反向代理 | |
| Traefik | 7 | 热备负载、反向代理 |
LVS > Traefik > Nginx > HAProxy
cpu占用率 Traefik > Nginx (Nginx占用率很低,这点确实厉害)
注:Traefik官方提供的测试结果显示Traefik的性能是Nginx的85%
[ One VM for Traefik (v1.0.0-beta.416) / Nginx (v1.4.6) ]
测试环境为虚拟机,版本号为v1.0的beta版,现Traefik最新版本为v2.1
均通过长期稳定性验证
| 配置复杂度 | 其它 | |
|---|---|---|
| LVS | 高 | linux系统自带 |
| HAProxy | 低 | 采用老黄的工具 |
| Nginx | 一般 | 配置调优较难 |
| traefik | 低 | 自带web配置页面 |
Traefik的logo是这样的(是不是跟golang的logo很像^_^,因为就是go写的)
参考:
https://my.oschina.net/xiaominmin/blog/1598679
https://zhuanlan.zhihu.com/p/41354937
贵州省原副省长王晓光家中堆有4000多瓶茅台,落马前将茅台年份酒倒进家中下水道以销赃。接着又曝出深圳一家国企年会,一晚喝掉16万茅台……
耶鲁大学心理学教授Paul Bloom讲了一个科学实验。这个实验是让品酒人躺在 FMRI(功能核磁共振成像)机器上,嘴里含一根吸管吸酒喝。实验人员换不同的酒,告诉品酒人现在喝的是什么酒(有时候撒谎有时候说真话),同时用 FMRI 对大脑成像来监督味觉体验。如果真的是味道好,大脑成像中某些部位会亮。

这些研究的结果说明,人们说茅台好喝,是真的感觉到了好喝,不是装的。但这有个前提,就是品酒人得知道那是茅台。如果不知道,那就很难喝了,而且也不是装的,是真的难喝。
茅台为什么好喝?因为它贵。我为什么不喝茅台 ,因为我(...)。
说白了,就是神奇的心理作用。正如《功夫熊猫》里鸭爸说的:
只要你相信有秘方,吃起来味道就不同。
所以,要多相信“自己行”、“可以做到”,实际做起来的时候,感觉就是不一样。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.