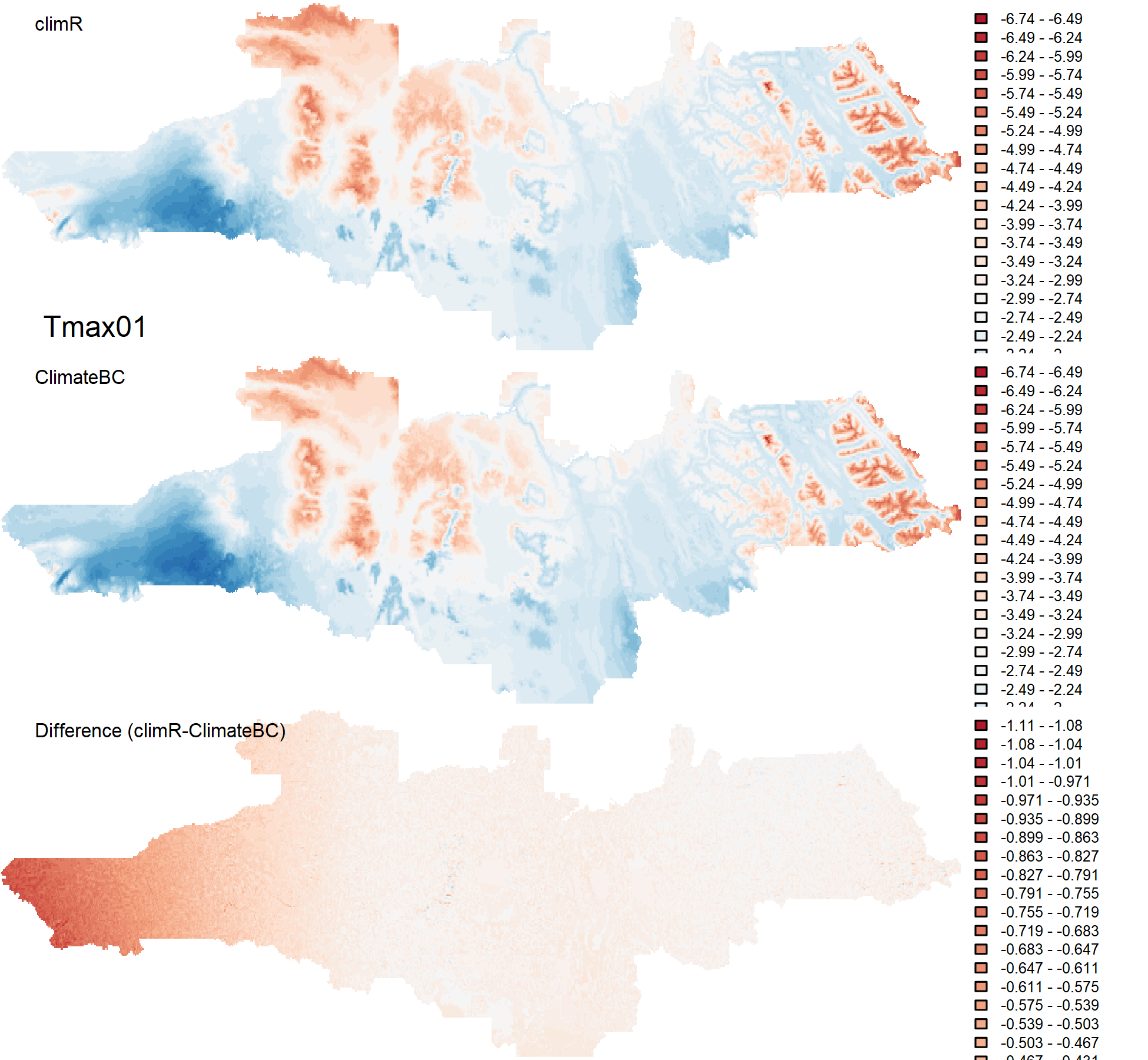
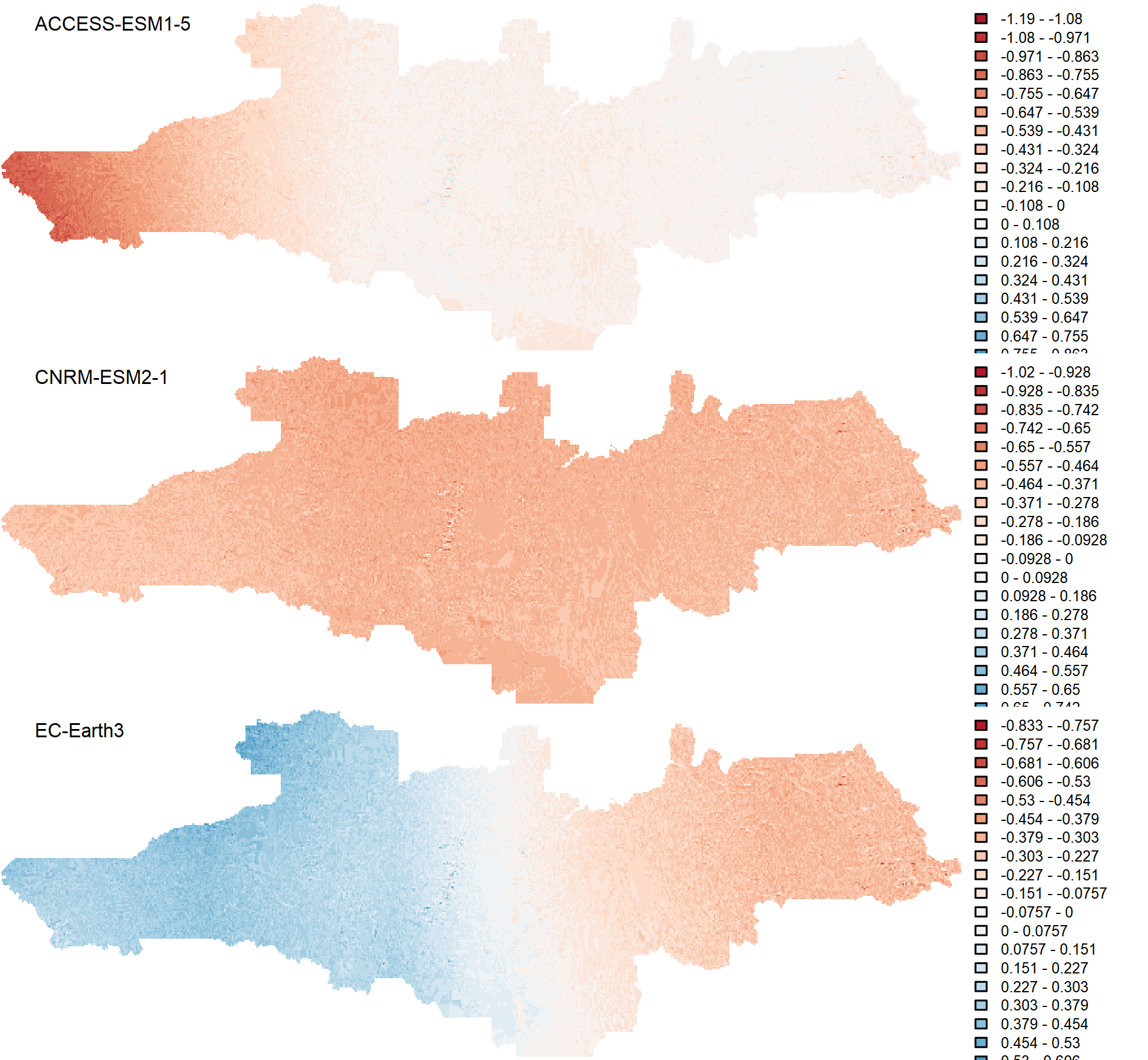
climr is an experimental R package that builds on the downscaling concepts operationalized in the ClimateNA tool (Wang et al. 2016).
It provides downscaling of observational and simulated climate data using change-factor (a.k.a. climate imprint) downscaling, a simple method that adds low-spatial-resolution climate anomalies to a high-spatial-resolution reference climatological map, with additional elevation adjustment for "scale-free" downscaling.
climr is designed to be fast and to minimize local data storage requirements.
To do so, it uses a remote PostGIS database, and optionally caches data locally.
climr provides the following data:
-
Historical observational time series (1902-2022), currently limited to the ClimateNA time series (Wang et al., 2016)
-
Multiple historical (1851-2014) and future (2015-2100) climate model simulations for each of 13 CMIP6 global climate models, in monthly time series and 20-year normals
-
User selection of single or multiple climate variables, with derived variables following the ClimateNA methodology of Wang et al. (2016).
The reference climatologies for British Columbia are the BC PRISM maps provided by Pacific Climate Impacts Consortium. Reference climatologies for North America are the ClimateNA (Wang et al. 2016) mosaics of PRISM (BC, US) and WorldClim (rest of North America). The ClimateNA mosaics are accessed from AdaptWest.
A high resolution composite climatology of BC PRISM, adjusted US PRISM and DAYMET (Alberta and Saskatchewan), is also available for Western Canada and Western US.
Historical observational time series are derived using ClimateNA (Wang et al. 2016).
The CMIP6 global climate model data were downloaded and subsetted to North America by Tongli Wang, Associate Professor at the UBC Department of Forest and Conservation Sciences.
The 13 global climate models selected for climr, and best practices for ensemble analysis, are described in Mahony (2022).
climr is only available on GitHub. To install please use:
remotes::install_github("bcgov/climr")If you want to install the development version:
remotes::install_github("bcgov/climr@devl")See:
-
vignette("vignettes/climr_workflow_beg.Rmd")for a simpleclimrworkflow; -
vignette("vignettes/climr_workflow_int.Rmd")provides a deeper dive intoclimrand more advanced examples of how it can be used; -
vignette("vignettes/climr_with_rasters.Rmd")covers several examples of how to work withclimrusing spatial inputs and outputs, such as raster and vector data.
For an overview of dowscaling methods used in climr see vignette("vignettes/lapse_rates.Rmd")
and vignette("vignettes/methods_downscaling.Rmd")
Copyright 2024 Province of British Columbia
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
climr logo uses icon designed by Freepik, Flaticon.com, available here.
Mahony, Colin. 2022. “Rationale for the ClimateBC/NA 8-Model Ensemble Mean.” http://climatena.ca/downloads/ClimateNA_8ModelRationale_Mahony_07May2022.pdf.
Wang, Tongli, Andreas Hamann, Dave Spittlehouse, and Carlos Carroll. 2016. “Locally Downscaled and Spatially Customizable Climate Data for Historical and Future Periods for North America.” Edited by Inés Álvarez. PLOS ONE 11 (6): e0156720.






![repo-mountie[bot] avatar](https://avatars.githubusercontent.com/in/19327?v=4 "repo-mountie[bot]")