![]()
![]()
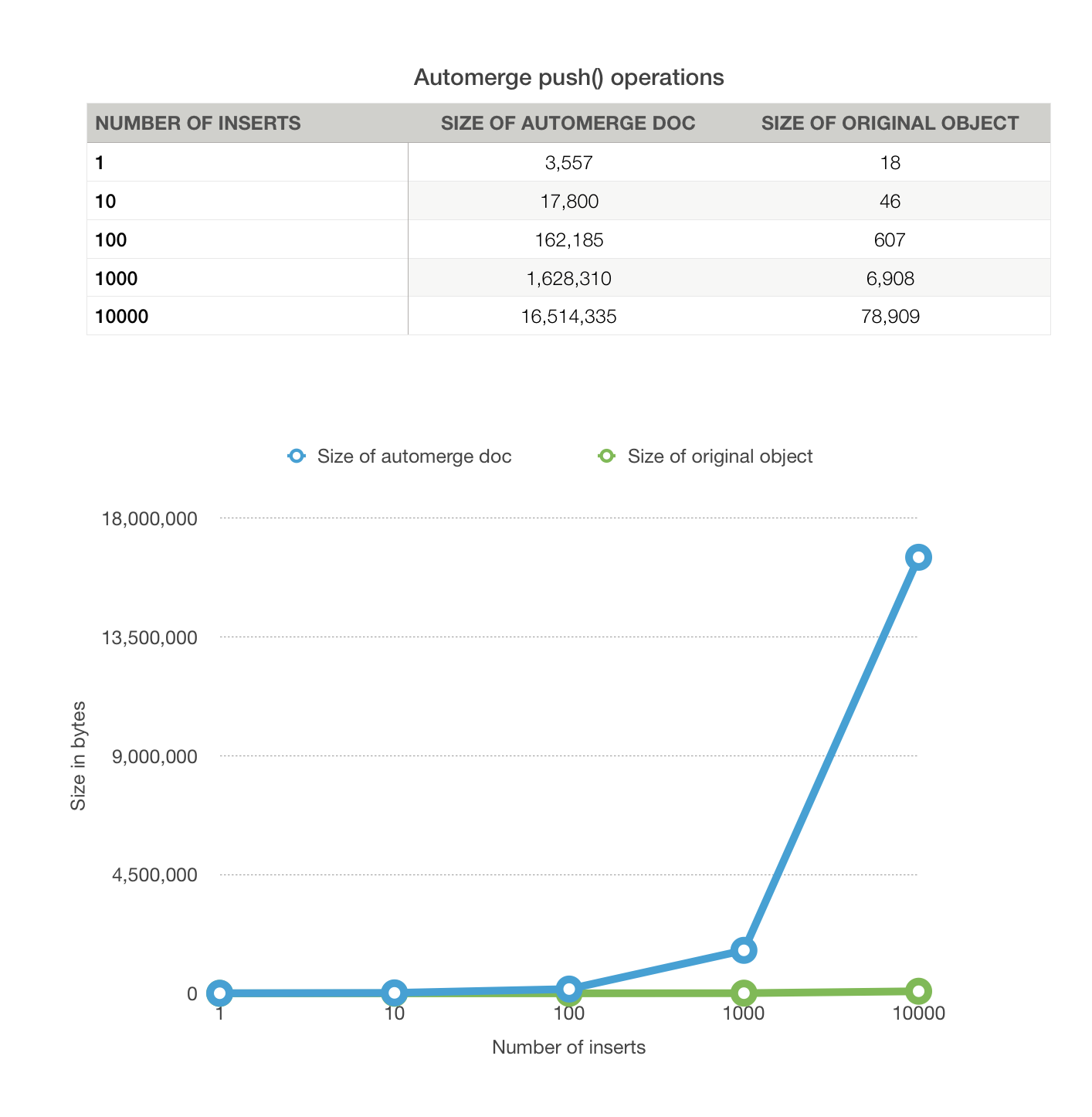
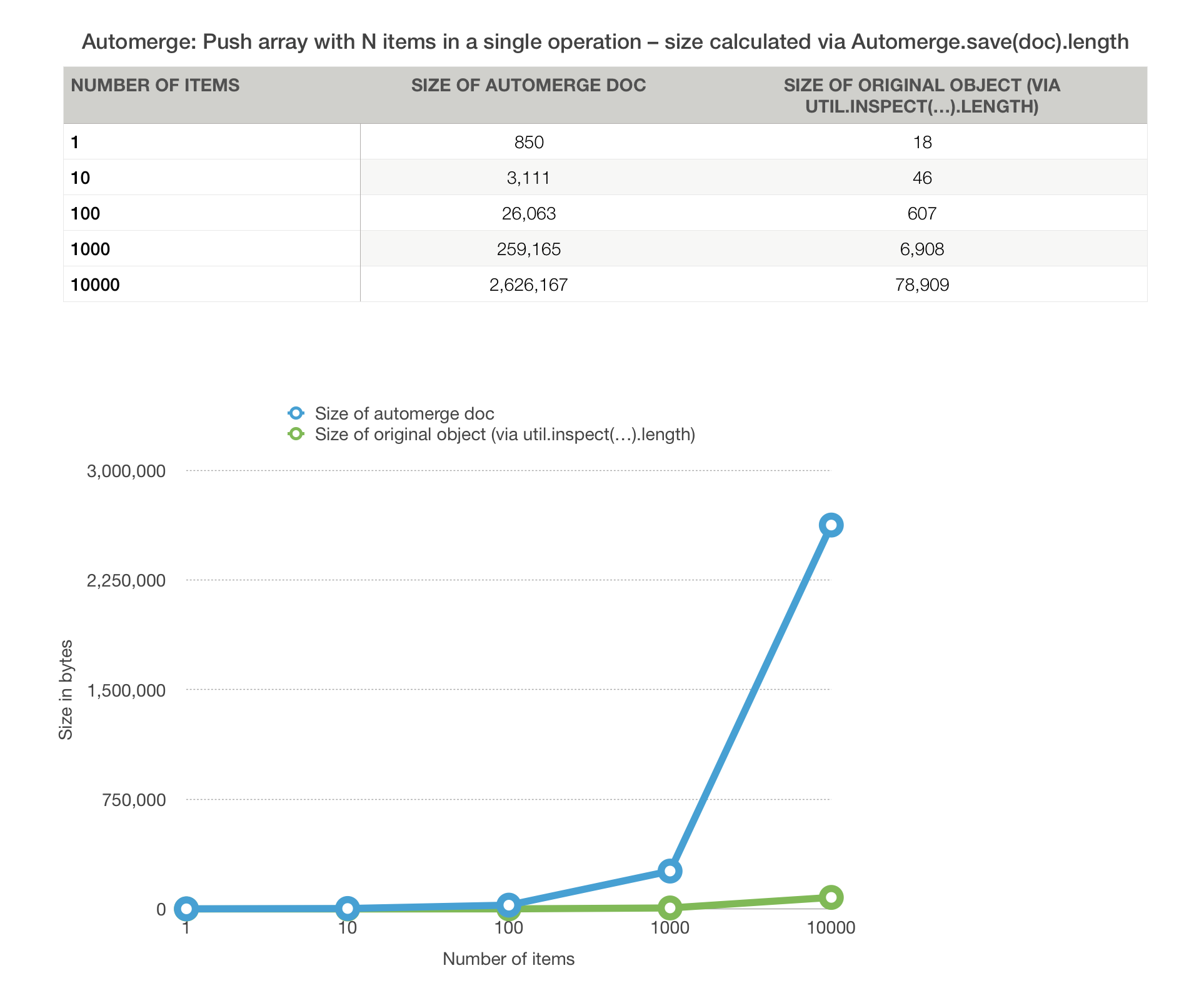
Automerge is a library which provides fast implementations of several different CRDTs, a compact compression format for these CRDTs, and a sync protocol for efficiently transmitting those changes over the network. The objective of the project is to support local-first applications in the same way that relational databases support server applications - by providing mechanisms for persistence which allow application developers to avoid thinking about hard distributed computing problems. Automerge aims to be PostgreSQL for your local-first app.
If you're looking for documentation on the JavaScript implementation take a look
at https://automerge.org/docs/hello/. There are other implementations in both
Rust and C, but they are earlier and don't have documentation yet. You can find
them in rust/automerge and rust/automerge-c if you are comfortable
reading the code and tests to figure out how to use them.
If you're familiar with CRDTs and interested in the design of Automerge in particular take a look at https://automerge.org/automerge-binary-format-spec.
Finally, if you want to talk to us about this project please join our Discord server!
This project is formed of a core Rust implementation which is exposed via FFI in javascript+WASM, C, and soon other languages. Alex (@alexjg) is working full time on maintaining automerge, other members of Ink and Switch are also contributing time and there are several other maintainers. The focus is currently on shipping the new JS package. We expect to be iterating the API and adding new features over the next six months so there will likely be several major version bumps in all packages in that time.
In general we try and respect semver.
A stable release of the javascript package is currently available as
@automerge/[email protected] where. pre-release verisions of the 2.0.1 are
available as 2.0.1-alpha.n. 2.0.1* packages are also available for Deno at
https://deno.land/x/automerge
The rust codebase is currently oriented around producing a performant backend for the Javascript wrapper and as such the API for Rust code is low level and not well documented. We will be returning to this over the next few months but for now you will need to be comfortable reading the tests and asking questions to figure out how to use it. If you are looking to build rust applications which use automerge you may want to look into autosurgeon
./rust- the rust rust implementation and also the Rust components of platform specific wrappers (e.g.automerge-wasmfor the WASM API orautomerge-cfor the C FFI bindings)./javascript- The javascript library which usesautomerge-wasminternally but presents a more idiomatic javascript interface./scripts- scripts which are useful to maintenance of the repository. This includes the scripts which are run in CI../img- static assets for use in.mdfiles
To build this codebase you will need:
rustnodeyarncmakecmocka
You will also need to install the following with cargo install
wasm-bindgen-cliwasm-optcargo-deny
And ensure you have added the wasm32-unknown-unknown target for rust cross-compilation.
The various subprojects (the rust code, the wrapper projects) have their own
build instructions, but to run the tests that will be run in CI you can run
./scripts/ci/run.
These instructions worked to build locally on macOS 13.1 (arm64) as of Nov 29th 2022.
# clone the repo
git clone https://github.com/automerge/automerge
cd automerge
# install rustup
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
# install homebrew
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# install cmake, node, cmocka
brew install cmake node cmocka
# install yarn
npm install --global yarn
# install javascript dependencies
yarn --cwd ./javascript
# install rust dependencies
cargo install wasm-bindgen-cli wasm-opt cargo-deny
# get nightly rust to produce optimized automerge-c builds
rustup toolchain install nightly
rustup component add rust-src --toolchain nightly
# add wasm target in addition to current architecture
rustup target add wasm32-unknown-unknown
# Run ci script
./scripts/ci/runIf your build fails to find cmocka.h you may need to teach it about homebrew's
installation location:
export CPATH=/opt/homebrew/include
export LIBRARY_PATH=/opt/homebrew/lib
./scripts/ci/run
Please try and split your changes up into relatively independent commits which
change one subsystem at a time and add good commit messages which describe what
the change is and why you're making it (err on the side of longer commit
messages). git blame should give future maintainers a good idea of why
something is the way it is.
There are four artefacts in this repository which need releasing:
- The
@automerge/automergeNPM package - The
@automerge/automerge-wasmNPM package - The automerge deno crate
- The
automergerust crate
The NPM and Deno packages are all released automatically by CI tooling whenever
the version number in the respective package.json changes. This means that
the process for releasing a new JS version is:
- Bump the version in the
rust/automerge-wasm/package.json(skip this if there are no new changes to the WASM) - Bump the version of
@automerge/automerge-wasmwe depend on injavascript/package.json - Bump the version in
@automerge/automergealso injavascript/package.json
Put all of these bumps in a PR and wait for a clean CI run. Then merge the PR.
The CI tooling will pick up a push to main with a new version and publish it
to NPM. This does depend on an access token available as NPM_TOKEN in the
actions environment, this token is generated with a 30 day expiry date so needs
(manually) refreshing every so often.
This is much easier, but less automatic. The steps to release are:
- Bump the version in
automerge/Cargo.toml - Push a PR and merge once clean
- Tag the release as
rust/automerge@<version> - Push the tag to the repository
- Publish the release with
cargo publish





![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")