- Reinforcement Learning Fundamentals
- Math of Reinforcement Learning (planned)
- Classic Algorithms and Notebooks (planned)
- Reinforcement in Real World
- Projects/Case Studies
Reinforcement Learning is about learning to make good decisions under uncertainty.
This can be seen as an Optimization problem where our aim is to cumulate as much reward as possible (while learning how the world works) i.e goal is to find an optimal way to make decisions
Mathematically goal is to maximize expected sum of discounted rewardsand Everything happens in a MDP setting.
We can model many problems as a Markov Decision Process or POMDP. We define a reward function that captures out goals and we then find a policy that maximuses the sum of future rewards. This is similar to Operations Research techniques focused on selecting the best element from a set of available alternatives to maximize a utility function.
Its based on the reward Hypothesis which says:
That all of what we mean by goals and purposes can be well thought of as maximization of the expected value of the cumulative sum of a received scalar signal (reward).
A value function is an estimate of expected cumulative future reward, usually as a function of state or state-action pair. The reward may be discounted, with lesser weight being given to delayed reward, or it may be cumulative only within individual episodes of interaction with the environment. Finally, in the average-reward case, the values are all relative to the mean reward received when following the current policy.
The value-function hypothesis:
all efficient methods for solving sequential decision-making pro blems compute, as an intermediate step, an estimate for each state of the long-term cumulative reward that follows that state (a value function). People are eternally proposing that value functions aren’t necessary, that policies can be found directly, as in “policy search” methods (don’t ask me what this means), but in the end the systems that perform the best always use values. And not just relative values (of actions from each state, which are essentially a policy), but absolute values giving an genuine absolute estimate of the expected cumulative future reward.
Goal of RL(and exploration) algorithm is to perform well across a family of environments
Generalizing between tasks remains difficult for state of the art deep reinforcement learning (RL) algorithms. Although trained agents can solve complex tasks, they struggle to transfer their experience to new environments. Agents that have mastered ten levels in a video game often fail catastrophically when first encountering the eleventh. Humans can seamlessly generalize across such similar tasks, but this ability is largely absent in RL agents. In short, agents become overly specialized to the environments encountered during training.
"if we don’t generalizations we can’t solve problems of scale, we need exploration with generalization” — ian osbond
In RL, How can an agent discover high-reward strategies that require a temporally extended sequence of complex behaviours that, individually, are not rewarding? One of the reasons it is challenging is because, online decision-making involves a fundamental choice:
Exploitation: Make the best decision given current information Exploration: Gather more information The best long-term strategy may involve short-term sacrifices Gather enough information to make the best overall decisions
How can an agent decide whether to attempt new behaviours (to discover ones with higher reward) or continue to do the best thing it knows so far? or Given a long-lived agent (or long-running learning algorithm), how to balance exploration and exploitation to maximize long-term rewards ?
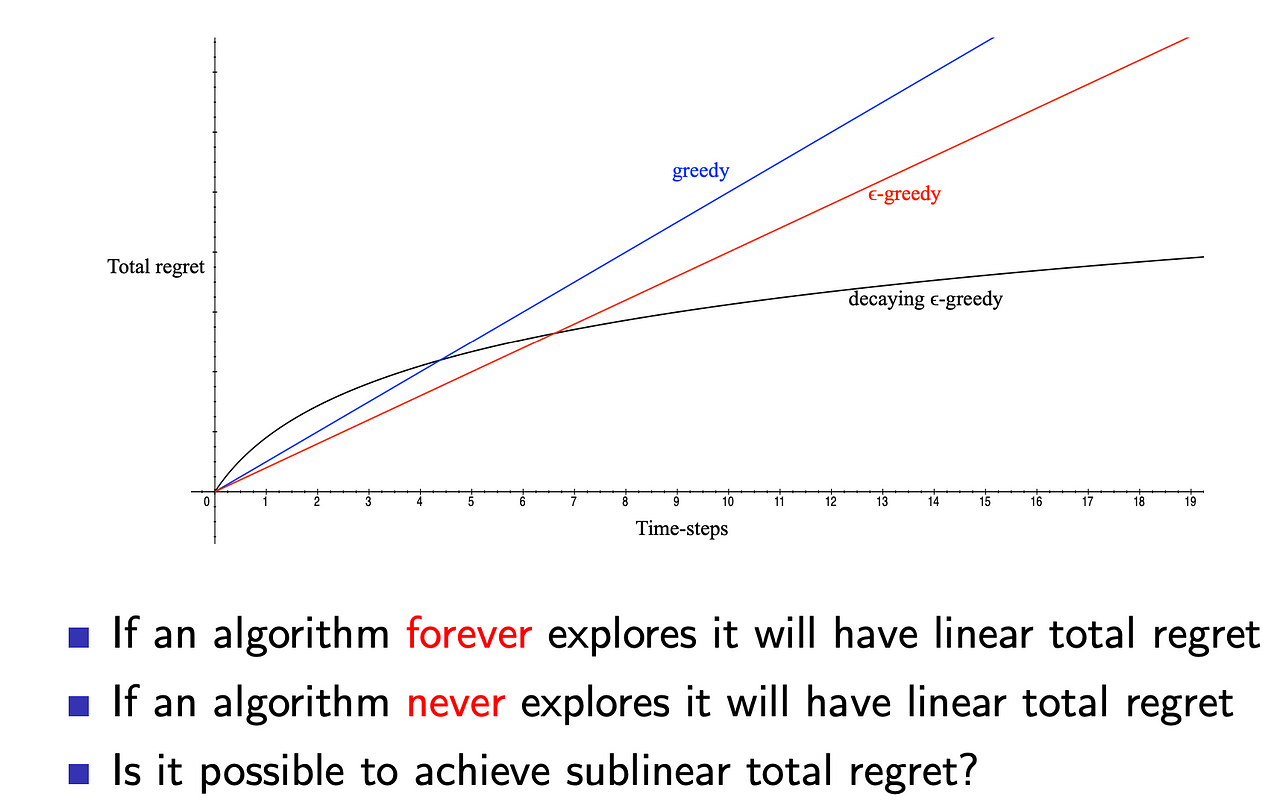
This is know as the Exploration vs Exploitation which has been studied for about 100 years and still remains unsolved in full RL settings.
Techniques: There are a variety of exploration techniques some more principled than others.
-
Naive exploration — greedy methods
-
Optimistic Initialisation — A very simple idea that usually works very well
-
Optimism under uncertainty — prefer actions with uncertain values eg. UCB
-
Probability matching — pick action with largest probability of being optimal eg. Thompson sampling
-
Information state space — construct augmented MDP and solve it, hence directly incorporating the value of information
They are studied for mulit-armed bandits context (because we understand these settings well): I recommend watch this lecture for more details: youtube.com/watch?v=sGuiWX07sKw State of Affairs and Open Problems we look at three questions asked at ERL Workshop @ ICML 2018 panel discussion
In this debate, There are two camps — one thinks exploration is super important and you have to get it right — its hard to build intelligent systems without learning and getting good data is important the other camp thinks there will be so much data that getting the right data doesn’t matter — some exploration will be needed but the technique doesn’t matter.
we take the pendulum example where the task is to balance the pendulum in an upright position.
-
small cost 0.1 for moving
-
reward when its upright and in the middle
state of the art deep RL uses e-greedy exploration takes 1000 episodes and learns to do nothing. which means default exploration doesnt solve the problem. it requires planning in a certain sense or ‘deep exploration’ (branding done by ian osband) techniques gets there and learn to balance by the end of 1000 episodes.
key lesson: exploration is key to learning quickly(off-policy) so its a core component but some problems can be solved without exploration. e.g driverless cars
Exploration is not solved — we don’t have good exploration algorithms for the general RL problem — we need a principled/scaleable approach towards exploration.
Theoretical analysis/tractability becomes harder and harder as we go from top to bottom of the following list
-
multi-armed bandits ( multi-armed bandits with independent arms is mostly solved )
-
contextual bandits
-
small, finite MDPs (exploration in tabular settings is well understood )
-
large, infinite MDPs, continuous spaces

In many real applications such as education, health care, or robotics, asymptotic convergence rates are not a useful metric for comparing reinforcement learning algorithms. we can’t have millions of trails in the real world and we care about convergence and we care about quickly getting there. To achieve good real world performance, we want rapid convergence to good policies, which relies on good, strategic exploration.
other important open research questions:
-
How do we formulate the exploration problem ?
-
How do we explore at different time scales?
-
Safe exploration is an open problem
-
Mechanism is not clear — planning or optimism?
-
Generalisation (identify and group similar states) in exploration?
-
How to incorporate prior knowledge?
In General, we care about algorithms that have nice PAC bounds and regret but they have limitations where expected regret make sense — we should aim to design algorithms with low beysien regret. We know Bayes-optimal is the default way to asset these but that can be computationally intractable so literature on efficient exploration is all about trying to get good beyes regret but also maintain statistical efficiency
But how do we quantify notions of prior knowledge and generalisation? Which is why some experts in the area think its hard to pin down the definition of exploration. i.e when do we know when we will have but its not obvious
At the end of the day, we want intelligent directed exploration which means behaviour should be that of learning to explore . i.e gets better at exploring and there exists a Life long — ciricula of improving.
Real systems, where data collection is costly or constrained by the physical context, call for a focus on statistical efficiency. A key driver of statistical efficiency is how the agent explores its environment.To date, RL’s potential has primarily been assessed through learning in simulated systems, where data generation is relatively unconstrained and algorithms are routinely trained over millions to trillions of episodes. Real systems, where data collection is costly or constrained by the physical context, call for a focus on statistical efficiency. A key driver of statistical efficiency is how the agent explores its environment. The design of reinforcement learning algorithms that efficiently explore intractably large state spaces remains an important challenge. Though a substantial body of work addresses efficient exploration, most of this focusses on tabular representations in which the number of parameters learned and the quantity of data required scale with the number of states. The design and analysis of tabular algorithms has generated valuable insights, but the resultant algorithms are of little practical importance since, for practical problems the state space is typically enormous (due to the curse of dimensionality). Current literature on ‘efficient exploration’ broadly states that only agents that perform deep exploration can expect polynomial sample complexity in learning(By this we mean that the exploration method does not only consider immediate information gain but also the consequences of an action on future learning.) This literature has focused, for the most part, on bounding the scaling properties of particular algorithms in tabular MDPs through analysis. we need to complement this understanding through a series of behavioural experiments that highlight the need for efficient exploration. There is a need for algorithms that generalize across states while exploring intelligently to learn to make effective decisions within a reasonable time frame.
Exploration is about Sample efficient(or smart) data collection — Learn efficiently and reliably. Combining generalisation with exploration(below) is an active area of research e.g see Generalisation and Exploration via randomized Value functions.
An interesting question to ask here is:
Can we Build a rigorous framework for example rooted in information theory for solving MDPs with model uncertainty, One which will helps us reason about the information gain as we visit new states?
The Structure of RL looks at one more problem which is known as credit assignment. Its important that we have to consider effects of our actions beyond a single timestep. i.e How can an agent discover high-reward strategies that require a temporally extended sequence of complex behaviours that, individually, are not rewarding?
“RL researchers (including ourselves) have generally believed that long time horizons would require fundamentally new advances, such as hierarchical reinforcement learning. Our results suggest that we haven’t been giving today’s algorithms enough credit — at least when they’re run at sufficient scale and with a reasonable way of exploring.” — OpenAI
An efficient RL agent must address these above challenges simultaneously.
To summarize we want algorithms that perform optimization, handle delayed consequences, perform intelligent exploration of the environment and generalize well outside of the trained environments. And do all of this statistically and computationally efficiently.

Its not a solved problem:
“Design Algorithms that have generalisation and sample efficiency in learning to make complex decisions in complex environments” — Wen Sun
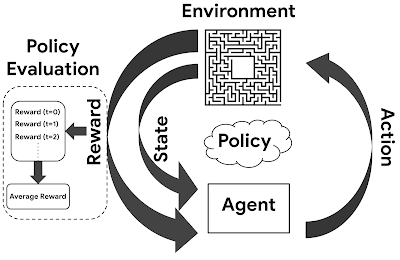
Given a policy we want to compute expected return from a given state by computing the value function the simple idea of monte-carlo is that we compute mean return for many episodes and keep track of the number of times that state is visited using expected law of large numbers and we dont wait till the end — we update step by step(little bit) in the direction of the error i.e we update the value function by computing the difference between the estimated value function and the actual return at the end of each episode
Value function isn’t the only way to solve the RL problem. We have 2 other approaches as well which we will discuss in coming posts, namely model based and policy based. See figure above for the big picture view.

Standard RL offers methods for solving sequential decision making problems (typically formalized by a Markov Decision Process) that involve Maximisation of reward/minimize cost over some time horizon (and where a model of the environment may or may not be known). It assumes an agent that interacts with the environment to learn the optimal behaviour which requires a balance between exploration and exploitation.
RL Research community is trying to tackle the following open problem:
- Deep exploration: The design of reinforcement learning algorithms that efficiently explore intractably large - state spaces remains an important open challenge. Here we are interested in answering questions like: How to quickly gather information to learn to make good decisions(how can we efficiently explore the environment ? or What strategies can we use for effective data collection in online settings?). Our solutions must be statistically/computationally efficient in non-tabular settings.
- Environment Modelling (How can learn the environment model? or How can we derive an optimal policy directly considering multiple environments,)
- **Experience Transfer (**how can we generalise, reuse and transfer experiences/knowledge across environments?)
- Abstraction (How can we effectively abstract states and actions? )
But what about real world applications? Interaction with the environment is expensive and sometimes even dangerous in real world settings and such an assumption limits the applicability of RL in real world settings. Furthermore,
The current implementations of the latest advances in this field have mainly been tailored to academia, focusing on fast prototyping and evaluating performance on simulated benchmark environments. Most real world problems on the other hand are not easy to model and we can’t always assume direct access to the environment or high fidelity simulators for learning. The practical success of RL algorithms has built upon a base of theory including gradient descent [7], temporal difference learning [58] and other foundational algorithms. These foundations are particularly poorly-understood for RL with nonlinear function approximation (e.g. via neural network), so-called ‘deep RL’. Which means theory lags practical algorithms which are giving us results. How can we make progress here? For RL to be practical we must acknowledge that solving practical problems in online settings(where agent learns as it interacts with the world) is the elephant in the room - deepRL might be ill equiped to solve problems of online learning nature due to limited data(typically needed for fitting neural nets). Success stories require massive computation offline with lots of data either historical or simulated) and thus it might not a good goal to solve industry problems with classic RL algorithms.
Some of the challenges associated by real world problems have different set of associated challenges. Some of them have been listed by [3]. When Constructing efficient RL algorithms for real world settings we we care about these aspects/properties:
- Training off-line from the fixed logs of an external behaviour policy.
- Learning on the real system from limited samples.
- High-dimensional continuous state and action spaces.
- Safety constraints that should never or at least rarely be violated.
- Tasks that may be partially observable, alternatively viewed as non-stationary or stochastic.
- Reward functions that are unspecified, multi-objective, or risk-sensitive.
- System operators who desire explainable policies and actions.
- Inference that must happen in real-time at the control frequency of the system.
- Large and/or unknown delays in the system actuators, sensors, or rewards
There is a lot of literature that acknowledges these issues but while there has been research focusing on these challenges individually, there has been little research on algorithms that address all of these challenges together. Ultimately we would like reinforcement learning algorithms that simultaneously perform well empirically and have strong theoretical guarantees. Such algorithms are especially important for high stakes domains like health care, education and customer service, where non- expert users demand excellent outcomes.
We cam tackle some of these applied RL challenges by combining ideas and algorithms from existing literature and sub-fields of RL such as inverse RL /learning from demonstration and classic reinforcement learning. Let us discuss a framework for thinking about the various scenarios we might encotuner in the real world based on the kind of data available and associated assumptions.
read more:
‘immitation learning’ aka Demonstration Learning
Inverse Reinforcement Learning:
‘immitation learning’: For example recent work by Hester et al. [1] shows that we can leverage small sets of demonstration data to massively accelerate the learning process even from relatively small amounts of demonstration data
This comes under ‘immitation learning’ and it hold the promise of greatly reducing the amount of data need to learn a good policy. However it assumes that expert policy is available.
Inverse Reinforcement Learning: Similarly work by Ibarz et al. [2] shows that we can improve upon imitation learning by learning reward function (using human feedback in the form of expert demonstrations and trajectory preferences) and optimising it using reinforcement learning.
Most of the traditional RL research assumes that the agent interacts with the environment, receives feedback to learn the optimal behaviour and which also requires a balance between exploration and exploitation. The exploration can be of two types: a) complete Intentional Exploration
b) under safety constraints: In real world we can sometime explore the environment. This problem is studied under: Risk Sensitive RL, Safe RL and Safe Exploration
BatchRL, Counterfactual reasoning: this involves What if reasoning for sequential decision making.
There is an enormous opportunity to leverage the increasing amounts of data to improve decisions made in healthcare, education, maintenance, and many other applications. Doing so requires what if / counterfactual reasoning, to reason about the potential outcomes should different decisions be made. In practice it mean we come up with policies and evaluate them by utilising existing data logs using counterfactual policy evaluation. A topic of my previous blog post:
Learn more:
I recommend the following talks for learning more about these challenges:
- Efficient Reinforcement Learning When Data is Costly - Emma Brunskill Stanford University
- Reinforcement Learning for the People and or by the People - Emma Brunskill Stanford University
- Towards Generalization and Efficiency in Reinforcement Learning by wen sun at MS research
[1] https://arxiv.org/abs/1704.03732
[2] https://arxiv.org/abs/1811.06521
[3] https://openreview.net/pdf?id=S1xtR52NjN#cite.Mankowitz2016
In the age of big data, we have massive amounts of data available at our disposal and it would nice if we could use some of that to make better decisions in the future. For example in healthcare we are interested in data-drive decision making by developing decision-support systems for clinicians. Such systems take EHRs and real-time data about patient’s physiological information and can recommend treatment (medication types and dosages) and insights to clinicians. The goal here is improve the overall careflow and eventual mortality outcome if the disease is severe.
How might the past have changed if different decisions were made? This question has captured the fascination of people for hundreds of years. By precisely asking, and answering such questions of counterfactual inference, we have the opportunity to both understand the impact of past decisions (has climate change worsened economic inequality?) and inform future choices (can we use historical electronic medical records data about decision made and outcomes, to create better protocols to enhance patient health?). - Emma Brunskill
In this post we discuss some common quantitative approaches to counterfactual reasoning, as well as a few problems and questions that can be addressed through the lens of counterfactual reasoning, including healthcare.
The reinforcement learning (RL) provides a good framework to approach problems of these kind. However, most techniques in RL assume we have an agent that is continually interacting with the world and receiving a reward at each time step. Making use of historically logged data is an interesting problem in RL which has been receiving much attention is recent times. This problem is also important because policies can have real-world impact and some guarantees on their performance prior to deployment is quite desirable. For example in case of healthcare, learning a newly treatment policy and directly executing it would be risky.
One of the problems we face in offline RL is that of evaluating the performance of newly learned policies. i.e we want to estimate the expected reward of a target policy(sometimes known as evaluation policy) and we are given a data log generated by the behaviour policy. Hence we would like to get a reliable estimate without actually executing the policy. Without this capability we would need to launch a number of A/B tests to search for the optimal model and hyperparameters[1].
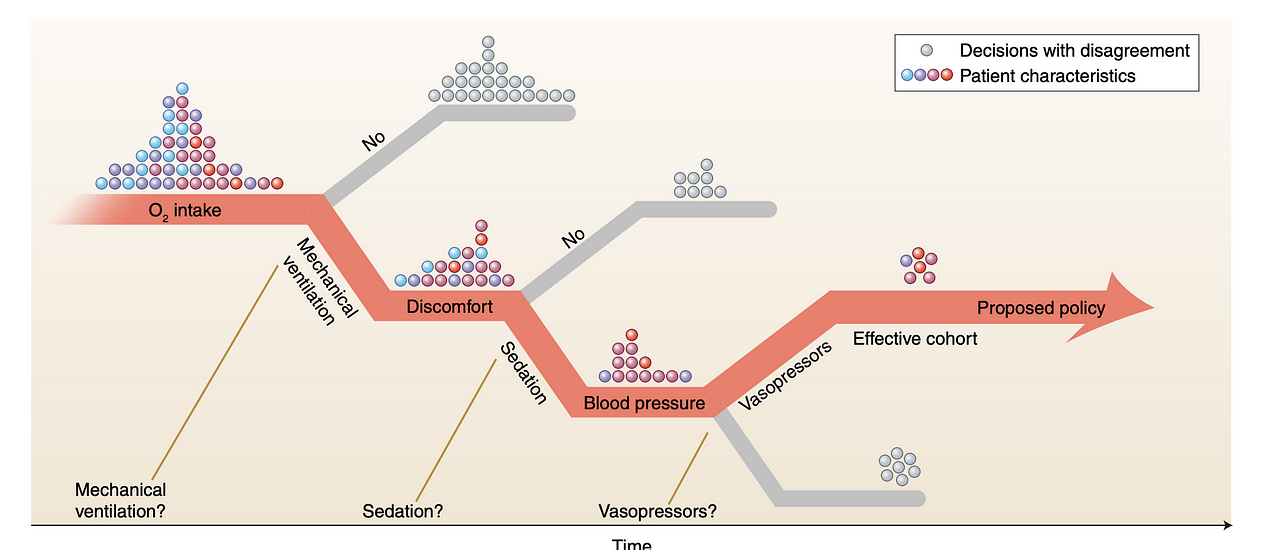
The more decisions that are performed in sequence, the likelier it is that a new policy disagrees with the one that was learned from
This problem is hard because of the mismatch between data distributions. Taking the healthcare example again, Intuitively this means we want to find scenarios where decisions made(actions taken) by the physicians match or nearly match the learned policy. Here We estimate the reward based on the actual outcomes of the treatments that happened in the past. But what makes it challenging is the fact that for a new policy where is no similar history available where we have the actual outcome available for comparison.
In offline RL our goal is to find the best policy possible given the available data.
Offline reinforcement learning can be seen as a variant of standard off policy RL algorithms and usually tend to optimize some form of a Bellman equation or TD difference error[6]. The goal is take the given data and generalize and perform well on future unseen data. This is similar to supervised learning but here the exact answer is not known rather we have data trajectories and some reward signal. If the available These offline- RL algorithms can be surprisingly powerful in terms of exploiting the data to learn a general policy (see Work done by Agarwal et al.). The diversity of data cannot be emphasised enough(which means it is better to use data from many different policies rather than one fixed policy.)
Many Standard libraries have popped up making the process of modeling quite accessible for average Engineers. For example intel coach offers implementations of many state of the art Deep RL algorithms.
Counterfactual policy evaluation:
OPE is the problem of estimating the value of a target policy using only pre-collected historical data generated by another policy. Formally:
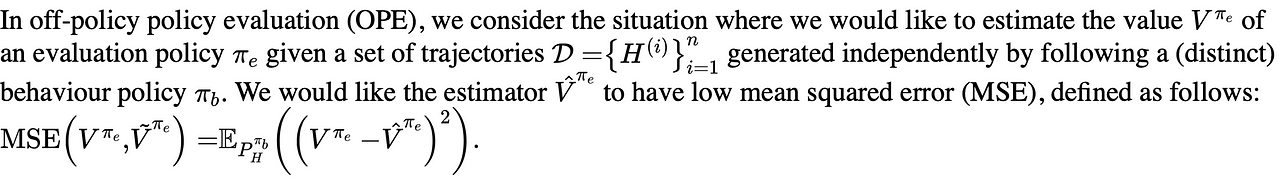

Several well known counterfactual policy evaluation (CPE) methods exist.
we evaluate the quality of Off Policy estimator by evaluating its mean squared error (MSE). Mean square error which is defined as the Difference between Estimate of the Evaluation policy and true Evaluation Policy value. Smaller the error the better the estimator.
These methods can be roughly divided into three classes: importance sampling (IS) methods and doubly robust and hybrid[3]. Each have their own pros and cons in terms of bias and variance trade-off. And there are techniques which have been proposed which try combine the best of both world. Following estimators have proven to be useful in a variety of domains:
- Step-wise importance sampling estimator
- Step-wise direct sampling estimator
- Step-wise doubly-robust estimator (Dudık et al., 2011)
- Sequential doubly-robust estimator (Jiang & Li, 2016)
- MAGIC estimator (Thomas & Brunskill, 2016)
*Model Selection using OPE:* When training models its more useful to evaluate the policy rather than judging the training performance by looking at the scores. Policy describes the actions that model choses and we pick some estimator like for example the MAGIC estimator to evaluate the performance of the newly trained policy. One simple way of choosing between the various trained models is pick one with smallest mean square error estimate[2].

A good estimator returns an accurate estimate by requiring less data compared to sub-optimal one.
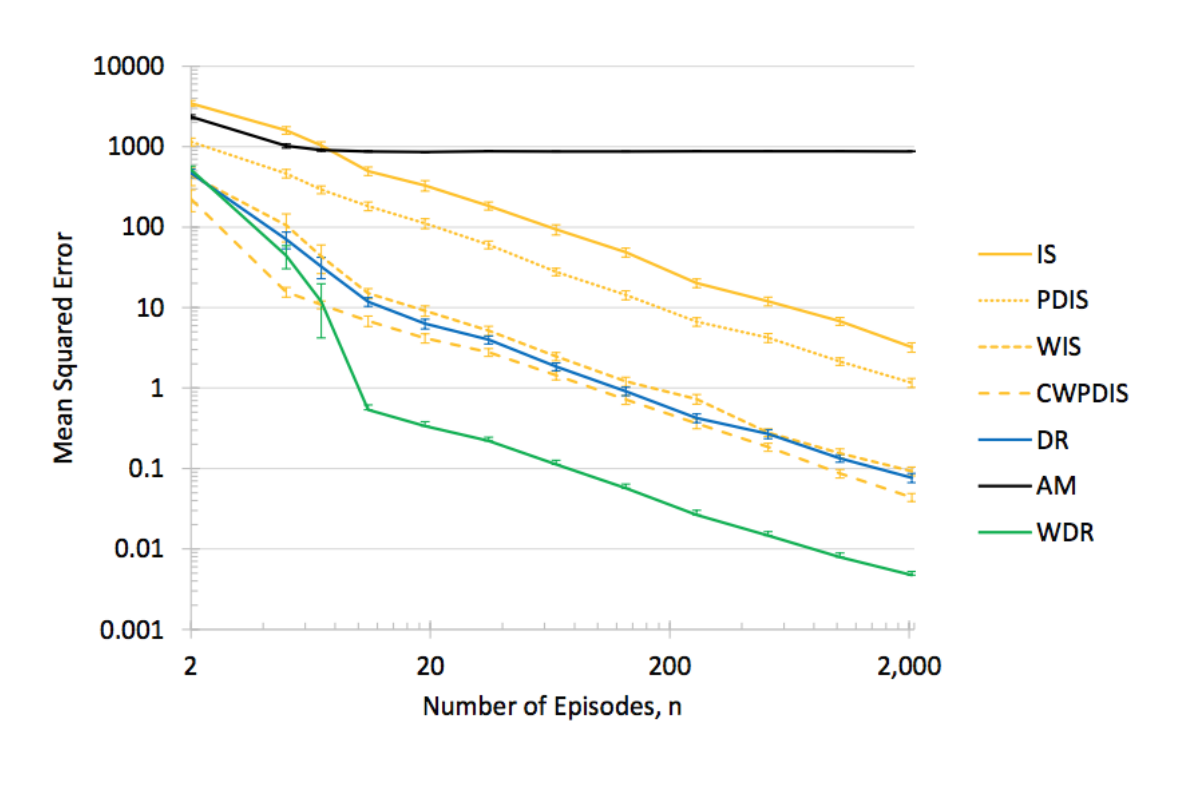
Lastly, We should keep in mind that there is no single estimator method that performs well for all application domains. Voloshin et al. [3] offer guidelines for selecting the appropriate OPE for a given application(see figure below). They have conducted a comprehensive Empirical Study to benchmark various OPEs in a variety of environments.
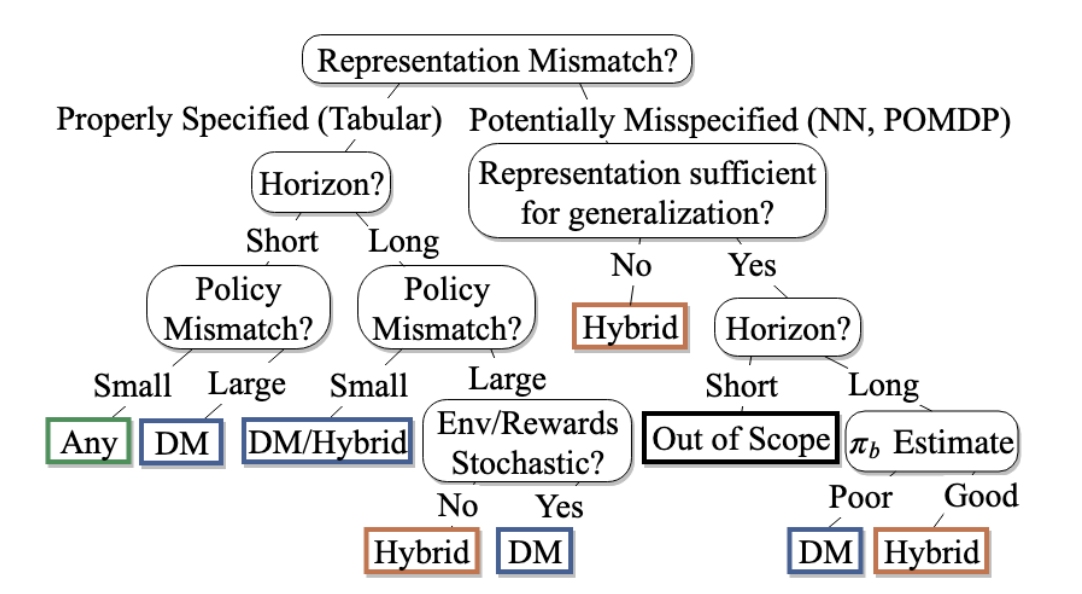
read more:
- Sutton, R. S. & Barto, A. G. Reinforcement Learning: An Introduction. Chapter 5.5.
- http://tgabel.de/cms/fileadmin/user_upload/documents/Lange_Gabel_EtAl_RL-Book-12.pdf
- https://people.cs.umass.edu/~pthomas/papers/Thomas2015c.pdf
- Survey paper of batch RL to write prev section https://arxiv.org/pdf/2005.01643.pdf
- IS: https://medium.com/@jonathan_hui/rl-importance-sampling-ebfb28b4a8c6
- additional resource: https://danieltakeshi.github.io/2020/06/28/offline-rl/
[Combined notes] (https://paper.dropbox.com/doc/0.-Introduction--BFT_TqCOHWpWkWGTSgv3iWSwAg-8pHcTKBEfCeEqLMswL2w0)
Must know topics:
Vocabulary:
If you’re unfamiliar, Spinning Up ships with an introduction to this material; it’s also worth checking out the RL-Intro from the OpenAI Hackathon, or the exceptional and thorough overview by Lilian Weng.
math of monotonic improvement theory (which forms the basis for advanced policy gradient algorithms)
- vanilla policy gradient (also called REINFORCE)
- DQN
- A2C (the synchronous version of A3C)
- PPO (the variant with the clipped objective)
- DDPG
The simplest versions of all of these can be written in just a few hundred lines of code (ballpark 250-300), and some of them even less (for example, a no-frills version of VPG can be written in about 80 lines). Write single-threaded code before you try writing parallelized versions of these algorithms. (Do try to parallelize at least one.)
- For artificial agents to be considered truly intelligent they should excel at a wide variety of tasks that are considered challenging for humans. Until this point, it had only been possible to create individual algorithms capable of mastering a single specific domain.
- Successfully combining Deep Learning (processing perception) with RL (decision-making) at scale for the first time
- is able to master a diverse range of Atari 2600 games to superhuman level with only the raw pixels and score as inputs.
- Takes the raw inputs and a reward signal (e.g the score) and it has to then figure out everything else. i.e transform a vector of image pixels into a policy for selecting actions
- They leveraged recent breakthroughs in training deep neural networks to show that a novel end-to-end reinforcement learning agent, termed a deep Q-network (DQN) was able to surpass the overall performance of a professional human reference player and all previous agents across a diverse range of 49 game scenarios
- One Key ingredient is experience replay - where by a network stores a subset of the training data in an instance-based way and then replays it offline, learning anew from successes or failures that occurred in the past.
- This work represents the first demonstration of a general-purpose agent that is able to continually adapt its behavior without any human intervention, a major technical step forward in the quest for general AI.
-
Enormous Search Space and impossible to write evaluation function
- Top players use intution and insticts rather than calculuation like in chess Components:
-
Monte Carlo Tree Search (certain variant with PUCT function for tree traversal):https://int8.io/monte-carlo-tree-search-beginners-guide/
- Residual Convolutional Neural Networks – policy and value network(s) used for game evaluation and move prior probability estimation
- Policy Network tries to predict the move that human was going to
-
play by training on 100k human games downloaded from internet - After training it can output probability distribution of possible moves
- we can look at top 5 moves
- trained the second neural network(called the value net) to predict from the current position who is likely to be a winner
- trained on the data produced by first network playing against itself many millions of times
- Reinforcement learning used for training the network(s) via self-plays
- Latest and greatest version of AlphaGo
- Fully automated pipeline - No bootstrapping from human data
- Starts from completely random play with 'zero knowledge'
- plays against itself millions of times
- Learns incrementally from its own mistakes
- Even Stronger, more efficient and more general
- Trained on three perfect information games (chess, shogi and Go)
- Chess engines are highly specialized systems using a whole bag of handcrafted hurrisitics, extensions and domain knowledge
- Alpha Zero replaces all of that with Self-play reinforcement Learning + Self-Play Monte Carlo Tree Search
- No Openbook or endgame database or Heuristics
- Starts from random play
- Same Algorithm with Same hyperparameters for all 3 games
- Proof that system is very general and that learning systems could be better than hand-crafted systems
OpenAI created a bot which beats the world’s top professionals at 1v1 matches of Dota 2 under standard tournament rules. “The bot learned the game from scratch by self-play, and does not use imitation learning or tree search. This is a step towards building AI systems which accomplish well-defined goals in messy, complicated situations involving real humans.” https://blog.openai.com/dota-2/




